OK, folks. We finally extracted enough information from Martin Juckes to be able to replicate SI Figure 1. I’ll show here how one gets from point A to point B, which will help understand us understand exactly why Juckes did this the way he did. One more time, here is Juckes’ Figure 1 with its legend.

Fig. 1. Proxy principal components: the first principal component of the North American ITRDB network of Mann et al., 1998. (1) Using the normalisation as in Mann et al. 1998, (2) as (1), but using full variance for normalisation rather than detrended
variance, (3) normalised and centred on the whole series, (4) centred only (5) as archived by MBH1998. 21-year running means.
Here is where I started from: a plot of the 70-series AD1400 network with the Mannian, covariance (cen) and correlation (std) PCs scaled by their standard deviation over 1400-1980 and centered over 1856-1980 (instead of 1902-1980). When Mann re-scaled series for his regression step (not that such re-scaling is necessary) , Mann re-scaled by dividing by the standard deviation over the calibration period.

Figure 2. 70 series AD1400 NOAMER network. Scaled by standard deviation 1400-1980; centered on 1856-1980. All 3 PCs are here flipped from the versions archived by Juckes (series 16, 22, 24).
I note in passing that these 3 series centered on 1400-1980 are used in Juckes’ Comment on EE Figure 2, in the form shown below.

Figure 3: As Juckes Comment figure 1, but using the grey curve is generated using the “princomp” function instead of the “svd” function, so that the data is automatically centred. Also shown is the PC generated when the data is also standardised (grey dashed curve). As in figure 1, the PCs have been smoothed using a 21 year block average instead of Gaussian
smoothing. Here the curves have also been normalised to unit variance. All these curves have, by construction, zero mean (prior to smoothing). [The curves have been end-padded with 10 years of the closing value].
In response to persistent questioning here, Juckes said that he used rms normalization in his SI Figure 1 – something nowhere mentioned in the article. the standard deviation is obtained from the sum of the squared distance from the mean; the rms is calculated similarly except using the squared distance from 0. In a quick google, I saw this technique used in electrical circuits where there is a natural 0 in alternating circuits. I have never seen this method used in multiproxy climate studies. You’d have thought that this is something that Juckes should have mentioned in an article that dwells on normalization and standardization issues. Even more – justifying its use. Where else did he use this method? Did he sometimes use standard deviation and sometimes rms?
Anyway, applying rms to the same network yielded the following figure. It didn’t change the scale of the covariance (cen) and correlation (std) PCs very much, but it sharply reduced the scale of the Mannian PC1. Is this a good thing or a bad thing? Who knows? Wegman said that the Mannian PC1 was an incorrect methodology – a point that I agree with. So I’m not sure why anyone cares about different procedures for re-scaling it. There is endless talk in paleoclimate about how to re-scale things – shouldn’t this innovation by Juckes have been mentioned and justified? The main function of dividing by the rms in spaghetti graph terms is that Juckes makes the Mannian PC1 appear less of an outlier than it appears when scaled by its standard deviation.

Figure 4. 70 series AD1400 NOAMER network. Scaled by rms 1400-1980; centered on 1856-1980. All 3 PCs are here flipped from the versions archived by Juckes (series 16, 22, 24).
Now this figure still doesn’t replicate SI Figure 1 very well. However it is an exact replication of Juckes SI Figure 2 as shown below. All 3 PCs are here flipped from the versions archived by Juckes (series 16, 22, 24). I’m going to discuss orientation of PC1s on another occasion in connection with Juckes’ comment on EE Figure 1. The salient point here is that we’ve exactly replicated Juckes’ SI Figure 2 up to and including PC1 orientation.

Figure 5. Juckes SI Fig. 2 Caption: As Fig. S1, except allowing padding of up to 10 years data, so that the proxy network is 70
instead of 56 trees (see section 2 of this document for lists of proxies).
So the next step should be pretty easy: apply the same algorithm to the 56 site network, the sites which do not require extension in the 1970s (the PCs from which are PCs 1-15 in the 30-series archived network). We’ll ask later why Juckes has done a separate analysis on a 56-site network.

Figure 6. 56 series AD1400 NOAMER network. Scaled by rms 1400-1980; centered on 1856-1980. All 3 PCs here have been assigned the same sign as the corresponding series in SI Figure 2.
OK, the orientations don’t work. So let’s see what happens when the signs of two series are changed. We now nearly have Juckes SI Figure 1. There’s still something in the centering.

Figure 7. 56 series AD1400 NOAMER network. Scaled by rms 1400-1980; centered on 1856-1980. All 3 PCs here have been oriented to match the corresponding series in SI Figure 2.
So:
There’s still a loose end in the centering. Again what is the purpose of these guessing games? Juckes’ refusal to provide a coherent description of his scaling and centering procedures is intolerable.
More substantively, there are some important differences between the 56-site network and the 70-site network. The covariance PC from the 56-site network has more of an uptick than the covariance PC from the 70-site network. I looked at the sites and the reason is simple – 12 of the 14 sites that make up the difference are non-bristlecones. So the dominance of bristlecones in the 56-site network is greater than the 70-site network and this increases bristlecone weight in the PC1 however calculated. (In MM05 EE, we observed that all the PC1s in the AD1000 network had a HS shape because of there were so many bristlecones – without the need for any mathematical artifice. In this context, we observed that the reliance on bristlecones was the elephant in the room within all these arcane discussions of PC methods. The Team never likes to discuss bristlecones and Juckes pointedly does not do any sensitivity analyses on presence/absence of bristlecones – a point that I’ll return to.)
In the rest of Juckes’ study, now I’m wondering when he used standard deviations and when he used rms. Does one have to guess at every step? I wonder if he’ll tell us.





77 Comments
was there an evanescent version of this post posted last night ?
confused
per
Yes there was. I needed to change some things and then accidentally overwrote the graphics that I used. So I scrubbed it; it was late so I re-did it this morning when I was fresh.
Steve- If I were looking at Juckes’ blue squiggle and your blue squiggle on an oscilloscope, I would conclude that your squiggle was a bandwidth limited version of Juckes’ squiggle – that is, the high frequency content is more smoothed in your squiggle. I would suggest that by playing with the filter values, you could get a better match.
Presumably, the greater the “decentring” effect on a series, the larger the RMS value should be, so using the RMS will reduce the weight of the series most affected by the decentring routine.
If the decentred series has excessive weight, surely the most logical way to deal with this is to use the centred series? Surely Occam’s razor should tell us that the idea of decentring and then trying to fiddle the weights to be “better” over and above just plain centring should be deposited firmly in the cylindrical filing cabinet.
#4. I’m not sure that rms-rescaling of the Mannian PC1 has any impact later in the process. I haven’t determined exactly what Juckes does downstream. In Mannian methodology, I don’t think that it would make any difference as (I’m 99.99% sure) the two regression stages would simply use the shape and be indifferent to the re-scaling. So the rms re-scaling would simply be a rhetorical method of de-fusing the extreme look of the Mannian PC1.
#5, I follow now, I had been reading a bit between the lines – so the rms rescaling appears (at this stage) to be primarily a piece of chartmanship (I had incorrectly assumed it was being applied prior to the NOAMER PCA).
I think “cute” sums that one up.
RE: #6 – I just blurt it out, Jukes et al are cooking the books, so to speak.
RMS rescaling on non-periodic data? What’s the justification for that? I think that “chartmanship” is being generous in this case.
#5. I checked the calculation of the CVM (Series #7), which I was able to replicate almost exactly in the usual CVM method – scaling each series by its standard deviation – no rms stuff. In this particular example, rms re-scaling didn’t make a whole lot of difference, but the replication was less exact and it’s definite that rms re-scaling was not used. So for sure, it seems to be just an ad hoc unreported rhetorical device in these figures.
RMS is used in electrical circuits because it can be used in power calculations to treat alternating current sources as if they were direct current: The standard power equation, P = V**2/R, works for both AC and DC if the AC values are RMS. So RMS is used in electrical circuits for convenience.
Hello Stephen, sorry to be slow to answer some questions, I didn’t realise your commiment to keep things on one thread would evaporate so quickly.
First, to return to a number of issues that have been raised over the past few days:
Could you provide me with:
c:/climate/data/mann/pc.tab
c:/climate/data/mann/eof.ordermann.tab
c:/climate/data/mann/tpca-eigenvals.tab
c:/climate/data/mann/weights1.tab
c:/climate/data/mann/gridpoints.tab
c:/climate/data/mann/gridcell.stdev.ordermann.tab
c:/climate/data/mann/mask.edited.tab
c:/climate/data/mann/nhmann.tab
c:/climate/data/mann/treepc.byregion.count.SI.2004.txt
c:/climate/data/mann/treepc.byregion.directory.SI.2004.txt
These are all required by the code for your Energy and Environment (2005) paper, which you kindly provided last week.
Secondly: I notice on that on page 888 you are having trouble interpreting mr_mbh_1000_cvm_nht_01.02.001_pc: This figure could be interpreted as a coding error or as an illustration of the pitfalls of combining the use of proxy PCs and the composite approach. The problem is the arbitrary sign of the PCs. If this is not adjusted the composite is likely to be meaningless because of the arbitrariness, if it is adjusted estimates of significance can be compromised. Some such reconstructions (using adjusted PCs) are included in the discussion for comparison purposes, but for the main conclusions we avoid proxy PCs so as to avoid this problem. The curve you show on page 888 has an unadjusted PC, so it is basically meaningless.
Thirdly: you ask on page 894 about which proxies are used for each reconstruction: in the netcdf file containing the reconstructions, each reconstruction has an attribute “proxy_list” which lists the proxies.
Fourthly: Are you suggesting that any data which is in your possession should be considered as published? It is an interesting idea, and would certainly cut down all the hassle of peer review etc. But seriously, if you can stop posting extended discussion of your problems coming to grips with trivia long enough to say anything serious, do you have any authorative information about the Indigirka data in your possession which would justify its use as a proxy? If so I think it would be really useful if you could write it up and get it published.
Fifthly: Concerning your efforts to reproduce figure 1 of the supplement: your ability to create endless confusion out of a simple problem is amazing. The scaling of the curves in supplement figure 1 was not described in great detail because its irrelevant, the scaling used in the composites is described because its relevant.
re: #11
No offence, Dr. Juckes, but do you have any authorative information about any bristlecone pine data in your possession which would justify its use as a temperature proxy?
Dr. Juckes,
Steve set up the “omnibus” thread for your back-and-forth with him. His committment was to provide you with a quiet space where you would not be interrupted by chatter and noise. Ergo no evaporation.
The other threads “Juckes and the …” are for general commentary by anyone. The purpose of having your name in the post title is just his way of keeping track of his research by theme. He’s not trying to keep you off balance by using your name in multiple places; he does this with everyone, including bender, Willis, and Dano.
Re #12: No offence, but I do. Stephen believes that bristlecones are heavily influence by CO2 fertilization. As far as I can tell, his view on this is based on Graybill and Idso (1993) who say, in their conclusions, “Out research supports the hypothesis that atmospheric CO2 fertilization of natural tree has been occurring from at least the mid- to late- 19th century”. So they do not interpret their evidence as proof. Let’s look a bit closer at their evidence: a study of strip-bark orange trees and a statistical analysis of correlations between pine trees and climate records. It has been discussed elsewhere on this blog, and appears to be agreed, that using statistical links, or absence of them, between proxies and temperature is not a valid means of selecting proxies for a study such as ours. So, to be consistent, the statistical analysis of Graybill and Idso should not be used in the selection of proxies. The experimental results from strip-bark orange trees, are, on the other hand, valid prior information. The trouble here is that they were not only looking at another species but it is also noted in Graybill and Idso that such results are not obtained, with any species, where nutrients are a limiting factor.
The bristlecones don’t correlate with local temperature changes, so they shouldn’t be used in proxy reconstructions. The reasons for the lack of correlation don’t matter.
Similarly any other proxy that doesn’t correlate with local temperatures should not be used for reconstructions. Teleconnection proxies such as the one in the Red Sea should be avoided as well. These are valid criteria for rejecting proxies.
re: #14
Thank you for your reply. While I expect Steve will have a response at some point, I do want to point out that your analysis has a problem. You’re begging the question when you say skeptics claim,
and that this disproves their objections to BCPs as proxies.
I asked you for the reason you thought Bristlecones were a good temperature proxy and you’ve essentially said “well, using the skeptics logic, they can’t prove CO2 fertilization.” Even if this were true it wouldn’t validate BCPs. Essentially you’re saying that if CO2 fertilization isn’t proven then BCPs must be valid proxies simply because they roughly match the instrumental record in most of the 20th century. But of course what they match is the global temperature and not the local temperature. And the degrees of freedom of the match is essentially 0. I.e. they have larger rings and the instrumental record shows an increase.
Further, there have been a number of discussions on this site about other possible reasons for larger rings in BCPs, including dust from nearby lakes which have dried up providing trace mineral fertilization and human emissions of things like NO2 or SO2 which could also provide fertilization. Not to mention an increase in precipitation which could be a side effect of global warming but still isn’t a temperature proxy per se.
Finally there’s the “divergence problem” which you’ve not addressed here. Of course if we had updated BCP results it would be helpful in seeing just how much of a problem it is, but if moving beyond the calibration period results in discrepencies the question is if the calibration period results were simply a result of spurious correlation in the first place.
Re #15,16: The reason for using Bristlecone is not because of temperature correlations: they are used because they are long-lived trees living in a marginal environment which is expected to make them respond to temperature variations. There is a good discussion of this (in a general sense, not specific to Bristlecones) in “Paleoclimatology: Reconstructing climates of the Quarternary” by R.S. Bradley.
Re #17
But they don’t!
That’s like saying we use blood-letting because it is expected to make people better – regardless of whether it does or not. When you work out that blood-letting doesn’t make people better you don’t persist with it for old times sake!
re: #17 Dr. Juckes,
Actually we’ve had several discussions here on precisely the theory you outline. The trouble is that it’s rather a wishful theory. I’d be nice if the only/primary limit on the growth of treerings on trees in such an environment were temperature, but when you set and think about it you realize that that’s not likely to be the case, especially over the entire lifespan of a Bristlecone Pine. During warmer periods, for instance, what’s to prevent precipitation from becoming the limiting factor? And in cold periods, snowfall accumulation is likely to be limiting, at least in some areas, by changing the period of time when the trees can have access to unfrozen ground.
Then there’s the problem of lack of nutrients in the soil and the possible effect of dust fertilization in addition to nitrogen oxides or sulfur oxides in the atmosphere not to mention the question of CO2 fertilization. This last would mostly concern the industrial period, but if it’s confused with being a proxy for rising temperatures, it can thereby attenuate the signal from the earlier periods, explaining, perhaps, the relative reduction in the signals for the MWP and LIA in reconstructions which rely on BCPs for their temperature signal.
Re #18, 19: It would “be nice if the only/primary limit on the growth of treerings on trees in such an environment were temperature”, but it is not necessary. We assume that there is a temperature signal which is tcoherent among the proxy collection and that other factors are not coherent. We do not assume that the signal to noise ratio in any one proxy is greater than unity, so we do not require the signal to be detectable in individual proxies.
But temperature varies throughout the globe. Some places get cooler, others warmer. So how do you know that your large growth rings actually come from trees in regions that have warmed? Shouldn’t the calibration be done for each proxy based on ring width vs local temperature?
Also, wouldn’t a CO2-fertilization signal be coherent among the proxy collection?
Re 20:
A lot of assumptions in a very vaguely writen response”¢’¬?at least to this man-in-the-street layman. Any proof that there’s a coherent temperature signal? Any proof that the other factors aren’t coherent? If none, then why the assumption? Appears arbitrary and without any basis.
WRT to SNR, does your nonassumption mean that you assume the SNR’s less than unity? If so, why?
If there isn’t any detectable signal in an individual proxy (I assume that you’re referring to a temperature signal), then what proof do you have that there’s a detectable signal in multiple proxies?
Re 20, 21: If the signal to noise ratio in each individual proxy was good enough you could extract local temperatures, but it isn’t. A CO2 signal would not be present in the non tree-ring proxies, and there is no clear evidence that it would be present in the tree-rings.
Re 22: there is more in the paper, I wasn’t trying to reproduce the paper in my last post. Not assuming SNR is less than one does not mean assuming it is greater than one. We use a standard statistical technique to estimate the statistical significance of the temperature signal in the proxy, as described in the paper.
If the proxy signal to noise ratio is not good enough to extract local temperature, how can any conglomeration of these non-temperature proxies be of any value in extracting global temperature?
nanny, you say above that:
ASSUMING that 1) the individual proxies all contain some version of the same signal, and 2) that the noise is white noise, averaging them will increase the signal to noise ration (SNR). This is because the noise is uncorrelated, and will tend to cancel out, while the signals in the proxies are correlated, and will not cancel out.
The problem, of course is in the assumptions. You can’t just assume them, you have to demonstrate that they are each individually true. The Team has not done that.
See Steve M’s post here on the subject.
w.
Willis / Martin,
I understand that this is an assmption, but isn’t the point of collecting multiple samples (ex. ring widths) in one area to find the signal from the noise of individual trees?
Re 18:
That’s like saying we use blood-letting because it is expected to make people better – regardless of whether it does or not.
Too funny in the context of AGW. Blood-letting was used for centuries with no evidence of efficacy.
Re 22:
Didn’t ask you to. In #20 you stated:
I asked, in #22, WRT to SNR, does your nonassumption mean that you assume the SNR’s less than unity? If so, why?
And you respond with something that’s nonsensical:
Also, you didn’t answer these other questions, WRT to your statements:
Any proof that there’s a coherent temperature signal?
Any proof that the other factors aren’t coherent? If none, then why the assumption? Appears arbitrary and without any basis.
If there isn’t any detectable signal in an individual proxy (I assume that you’re referring to a temperature signal), then what proof do you have that there’s a detectable signal in multiple proxies?
Re 28: Which part is the question? Have you tried reading the paper? The composite has a correlation with temperature which is extremely unlikely to happen by chance. That is the result.
Did you already update your Table 3 with corrected simulations? As I told you (don’t know if it is showing now due to the blog problems), you have to flip your simulated series such that the signs of correlations are matching those of proxies. Otherwise you are comparing apples to oranges.
Also, have you by now already figured out the assumed noise correlations in your paper? How about exact rules for standardisation? Zero mean and unit variance in calibration period, no flipping according to positive correlation? And most importantly, under what conditions and in which sense the LS estimator $latex \hat{\beta}[\tex] on p. 1028 l.10 is not optimal and the correction on l. 13 should be used? And no Martin, these conditions are not stated in your paper, and yes, I have read your paper several times.
I think I buy the concept of amplifying a signal by combining proxies. But I still have a great deal of trouble understanding why the results are so dependent on a very few tree ring series. If the concept is correct, why is the reconstruction so sensitive to the inclusion of bristlecones?
I have always beleived that the more data, the better. Small populations create statistical problems that you do not have with large populations.
If you only see a temperature signal in a sub-set of the proxies, did you ever consider the fact that:
1. The signal may be significantly influences by something other than temperature?
or
2. The signal is a product of the method?
Re:#28
John,
He’s just saying that he doesn’t assume either characteristic in any one proxy. His later answer is elliptical, but not nonsensical; it boils down to an answer of “no”.
#29. Martin, the failed Durbin-Watson statistic indicates that the correlation is spurious, as this term is used in Granger and Newbold 1974,
#17 dr juckes, you said:
The reason for using Bristlecone is not because of temperature correlations: they are used because they are long-lived trees living in a marginal environment which is expected to make them respond to temperature variations
so, bristlecones are not used because of temperature correlations…but…because they are “expected” to respond to temperature variations?
really? could you please explain the difference?
#29
Failed cointegration tests also seem to indicate that the results are spurious. (In the context of an Engel-Granger (1987) two-step procedure with the interpretation given by Blough (1992) so you can avoid philosophical discussion about whether temperature is I(1) or not – you just need to treat it that way to conduct correct inference.)
#31 Jae
It is the weighting of the proxies that worries me. Also are these in fact proxies for temperature at all?
The problem is one can find lots of things that have some kind of correlation with instrumental temperature, but that does not mean that they are proxies for temperature.
CO2 by itself correlates positively pre 1930 and post 1970, negatively between the two.
Mark
But isn’t each proxy a composite of individual measurements (ex. of tree rings) in a certain area?
So, shouldn’t an average of these measurements (i.e. the proxy itself) give us the supposed “signal” for the local climate?
Let me re-write that for you:
OK – so what? I could say the same thing about global population, cumulative rainfall, world GDP, the divorce rate and many other series to boot.
May I commend an article by the well-known econometrician Hendry, entitled Econometrics- Alchemy or Science. online here , discussed at CA here
I’ve provided some nice quotes at the earlier thread. It’s hard to pick one, but since Juckes has emphasized that his results are “99.98% significant” perhaps this one for now:
Do read the thread and article.
Martin, I’m now convinced that you are absolutely right when you say:
Guess what happened! I came across these wonderful Wiener proxies and the composite gives stats comparable to those of Union CVM! These proxies are very usuful: Dr. Wiener had archieved infinitely of them to my Matlab! The best of all, they are sampled throughout the history: in a second I can reconstruct the temperature history of the whole Holoscene! Anyhow, I took 10000 of these magic proxy sets, and the average r was 0.65, detrended r 0.32 and \sigma 0.15. I think these results must be at least 99.98% significant!
Here’s the code:
% Wiener CVMproxies=18;
years=1000:1980;
samples=length(years);
calib=years>=1856 & years
#42 (contd) The rest of the code:
% MITRIE instrumentaljuckes=load('juckes_instr.txt');
instr=juckes(1:end-25,2);
% Wiener proxies
proxy=filter(1,[1 -1],randn(samples,proxies));
% "standardise"
proxy=proxy-repmat(mean(proxy(calib,:)),samples,1);
proxy=proxy./repmat(std(proxy(calib,:)),samples,1);
proxy=repmat(sign(instr'*proxy(calib,:)),samples,1).*proxy;
% CVM
CVM=mean(proxy,2);
CVM=CVM*std(instr)/std(CVM(calib));
% stats
rr=corrcoef(CVM(calib),instr);
rd=corrcoef(detrend(CVM(calib)),detrend(instr));
sigma=sqrt(mean((CVM(calib)-instr).^2));
disp([rr(2) rd(2) sigma]);
(#42) This is hard today, the last line in #42 should be:
calib=years>=1856 & yearsSeems like the code tag is cutting, lets try without it:
calib=years>=1856 & years
Ok, I give up. The line should end: less or equal to 1980;
Re#42 Is the Weiner proxy link correct?
Here’s an R version of Jean S’s script . I also got a mean correlation of 0.645 using Juckes’ method on Wiener processes.
Steve: it looks like you only used 1000 magic proxies, whereas jean s used 10,000, yet you still got the same correlation coefficient.
Since we now know that random walk has such a great predicting power on temperature, this has to open great new opportunities. Think about it, most of standard mathematical finance is almost directly applicable … maybe in the future weather is predicting according to Black-Scholes-Juckes formula 😉
#49: jae, Steve used 1000 (I did 10000) times 18 proxies. This the best part of these magic proxies: there is plenty of them available. Every time you need another proxy collection, your computer gives you one in an instant. No more dirty field trips!
Congratulations JeanS, you broke the code.
re: #48
I got 0.6475893 when I ran it. Should we have a contest for who can get the highest number from Steve / Jean S’s code? Let’s see what I get in a second run… Only 0.646667 this time. It does take 3-4 minutes to run on my computer which is gettin a bit slow these days compared to newer ones.
Perhaps this is another application of the old stockmarket axiom “The trend is your friend”.
That’s certainly worthy of posting at CoP. It’s not that his existing Monte Carlo results are wrong – they are just irrelevant and he is drawing conclusions from them that can not be sustained by the actual evidence presented. “On the basis of the correlation statistics presented we can not reject the hypothesis that the Union reconstruction is a random walk and, thus, conclude that the correlation with temperature is highly likely to have occurred by chance. That is the result.”
I think there should be a licensing scheme for people dealing with integrated variables – they really are dangerous in untrained hands.
Rather than doing a regression on Juckes data to see if there is a temperature signal, simply add them together(subract the series mean first). If the signal is coherent across the series, the signal will add but the noise will decrease as sqrt[number of series]. If there are enough series available the signal will eventually appear out of the noise, without having to assume anything about the signal. If it’s all just noise, the summed series will slowly disappear with the usual statistical fluctuations along the way.
Unfortunately, directly summing series to determine the actual signal only works if they all
have the same relative signal strength to begin with. One purpose of regression, or any other
adaptive method, is to weight each according to its relative strength. Unfortunately number 2,
this then requires some knowledge of what each “signal” represents after processing, before any
summing can be made. The HT approach seems to be of the sort “this correlates with temperature
during the calibration period (arbitrarily chosen to artificially produce said correlation)
therefore it must be temperature.” That they may also correlate with CO2 itself, or solar
activity (or any of a number of other factors) seems lost on the team.
Mark
I still do not understand exactly what I kind of Monte Carlo simulation Juckes ran. From what’s in the paper, I cannot understand what is being done. What is being randomly generated, out of what distribution? How many different seeds were used?
Were all 10,000 replications done using a single pseudo-random series (that is, with the same seed?) What was the random number generator they used? Did they use the stock Python RNG?
If someone understands what they did, could you explain in plain English?
Sinan, I don’t understand it completely, either. However, the thing what gives him (and is plain wrong) such a low correlations for CVM is that he is not “flipping” his random series. He did flip some of his proxies, and the same should be done for the noise series. At least he should have equivalent amount of positively and negatively correlated (with instrumental series) series, which in practice means that they are almost all positively correlated.
Assuming your proxies are uncorrelated, the correlation for CVM is just mean of individual correlations. This tells you exactly why the sign of correlation matters so much, and why Juckes’ simulation series get so low r values.
Re #57
My best guess is that in the AR(1) version he does:
Step 1: Run regression Union(t)=rho*Union(t-1)+epsilon(t)
Step 2: Generate 10,000 series as Synthetic(t)=rho*Synthetic(t-1)+mu(t) where mu(t)=N(0,sigma) with sigma obtained from step 1.
Step 3: Replicate this procedure for temperature to generate a synthetic temperature series.
Step 4: Calculate the distribution of correlation coefficients between the two synthetic series to determine significance levels.
They focus, however, on the results from a process where they match the ‘full autocorrelation structure’ of the two series. I don’t have access to the reference they point to but it seems like they run an AR(70) at Step 1. (I would be gobsmacked if they are fitting anything other than noise with most of those AR terms – but they could be doing an MA(70), it’s not clear, but those are pretty much equivalent anyway.)
It is also not clear how the temperature and Union synthetic series are paired. But I think they are generating two random series for each iteration of the Monte Carlo. Jukes reported that it didn’t make any difference just using the actual temperature series so I think Step 3 seems to be a pointless exercise that just serves to obfuscate what’s going on.
I really doubt that any features of the pseudo-random numbers they are generating matter. But maybe they are sampling from the actual residuals from Step 1 – that might matter.
If the code were available it would clarify all these ambiguities but I haven’t seen it. Does anyone know if the code is available?
…oh, missed a constant in those equations. Please assume its existence or assume demeaned data.
Check also his Figure 6. Three observations:
1) The instrumental temperature is a clear outlier
2) Is any of these proxy set really well-modeled with AR(1) noise??!
3) See (especially the MSH and the Union collection) the form of the proxy autocorrelations. For a reference, plot the autocorrelation function from a lognormal sample.
Jean S.
Thank you for the explanation (and don’t worry about the constant term 😉 You are right, the technicalities of the RNG don’t matter at this point, but I still like to know those things.
Thank you for pointing out Figure 6. I had forgotten about that.
Anyway, thanks to you I have a better understanding of what is going on, but can’t help ask why 🙂
PS: I teach my students that the significance level of a test is the probability with which they are comfortable of making a Type I error, declaring a difference/relationship when there is none. If the p-value, that is, the probability of observing what we observed conditional on the null hypothesis being true is smaller, then we declare statistical significance. Now, read that sentence for a significance level of 99.98%!
#56
No, it still works. What will cause problems and slow the convergence is if the noise has a different rms amplitude from series to series.
4) Y-Label is the same as in Figs 1,3,4,5 and 7.
wrt 1), they probably applied non-robust red-noise analysis 😉
#56 Paul is correct here under the assumption of linearity that the HT make. You don’t even have to do any normalization on the proxies. If you have a series of equations of the form.
You have a series of n proxies Pi with individual measurements Pij and you assume that.
Pij = Ai Tj + Bi Nij + Ci
Where Tj is the temperature signal that you are looking for, Nij is your white noise function and Ai, Bi and Ci are unknown constants and inverted series are flipped so that all Ai are positive.
If you sum the proxies over i and divide by n, you will get a signal multiplied by a constant, a noise component multiplied by a constant and a constant offset. As n increases, the noise component will decrease. This decrease may be slower, as Paul says, because of the constant multiplier but it will still happen.
This will also work if P is some function of T that can be written in the form.
Pi = Ai f(T) + Bi Ni + Ci
Where f(T) is monotonic.
As has been discussed in several threads, this is a pretty heroic assumption but if it is true and we sum the proxies, a signal should emerge.
#42
Magic! I tried CVM with dataall.txt, more is not better. http://www.geocities.com/uc_edit/cvm.html
#66
Of course not, this is why you need a specialist from the HT to (cherry) pick the “temperature sensitive” subset 😉
#65: Chris, yes in theory. However, if you have (spurious) correlation with the temperature series, your flipping may be incorrect and you get wrong signs to Ai’s. This is why, even if you make the “heroic assumption” :), and unlike Juckes is claiming, the SNR of your proxies really matters. If it is high, you probably flip them right, if it is low, then…
Also, to be honest, there should be no “blind” flipping of the series. One should know (from physical considerations) if each proxy is responding positively or negatively to the temperature. Realizing that these guys have not even studied which of their series really are linear in temperature , this knowledge if far too much to ask and we have to resort to the second best option.
corrigendum:
Corrected my CVM computations and included past climate reconstruction using univariate classical calibration estimator. same url http://www.geocities.com/uc_edit/cvm.html
None of my errors affect my previously published (#66) results.
Williams (1969) A Note on Regression Methods in Calibration, Technometrics Vol. 11, No. 9:
That was 1969, but now we are much more advanced 🙂
#68 Yes I should have been careful about using the word flipped. I meant flips based on physical arguments prior to data analysis.
I should have dropped the last three sentences because this argument is incomplete. Instead, I should have added that finding a signal is neccassary but not sufficient. You still need to demonstrate that this model has some sort of validity.
Jean S, if it’s a beauty contest between cherry picking and flippping, I’d put more weight on cherry picking as a Team technique. Using Yamal rather than Polar Urals Update or Yakutia/Indigirka is more characteristic of Team CVM methods, as opposed to flipping the Chesapeake series, which is a bit of a one-off. Although as soon as I say this, I think about the G Bulloides coldwater series. Had the percentage of coldwater diatoms declined in the 20th century, yielding an upside down HS, would the Team have used this as evidence of warming? and inverted the graphic? Of course they would.
#62
Sinan, in signal processing Decision Theory is known (for historical reasons) as Detection Theory. Much of the terminology comes from the radar engineering (think airplane in a radar). The null hypothesis is that the signal is absent from the data (noise only), and the probability of a Type I error (level of significance) is called “false alarm probability” 😉
And to all nitpickers out there: I do understand that the intended meaning of Juckes’ “99.98% significant” is 1 minus the ordinary meaning of significant.
My world as dictated by “Detection, Estimation and Modulation Theory, Part I” by Harry L. VanTrees.
Man that was a tough class. The third in his series is for radar, btw. 😉
Mark
#69 cont.
model
proxy=A(local_temp+noise)
i.i.d (spatial and temporal) Gaussian noise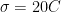 , would explain the last figure, A is the unknown scale.
, would explain the last figure, A is the unknown scale.
Maybe I should try to say it differently:
Our recent findings show that the equivalent local-level proxy noise variance is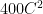 , or even more. This level of SNR appears unprecedented in the context of at least the past 2000 scientific publications. This anomalous finding can only be explained by modern anthropogenic forcing of subjective human-induced components into the research results. Unless urgent and strenuous mitigation actions are taken immediately, a whole branch of science will lose its credibility for decades ahead.
, or even more. This level of SNR appears unprecedented in the context of at least the past 2000 scientific publications. This anomalous finding can only be explained by modern anthropogenic forcing of subjective human-induced components into the research results. Unless urgent and strenuous mitigation actions are taken immediately, a whole branch of science will lose its credibility for decades ahead.
(Sorry, just trying to learn how to write like a pro scientist;) )
One Trackback
[…] (Decoding Juckes SI Figure 1) […]