A few days ago, I showed that a trivial variation to the Moberg CVM reconstruction led to a very different medieval-modern relationship. Juckes has reported that the Moberg CVM reconstruction is "99.98% significant" – not quite the most significant in a milllll-yun years, but VERY, VERY significant. I thought it would be interesting to see if my variation was also significant and, if so, ponder what that meant for these calculations.
Let’s review what Juckes did. His significance test more or less follows the methodology of a certain Michael Mann in MBH98 by performing a univariate test without considering prior selections or processing. Juckes:
The significance of the correlations between these six proxy data samples and the instrumental temperature data during the calibration period (1856–1980) has been evaluated using a Monte-Carlo simulation with (1) a first order Markov model (e.g. Grinstead and Snell, 1997) with the same 1-year lag correlation as the data samples and (2) random time series which reproduces the lag correlation structure of the data samples (see Appendix B2)….

Table 3. R values for six CVM composites evaluated using the Northern Hemisphere mean temperature (1856 to 1980).
Columns 2 and 3 show R values for the 95% significance levels, evaluated using a Monte Carlo simulation with 10 000 realisations. In columns 2, 7 and 8 the full lag-correlation structure of the data is used, in column 3 a first order Markov approach is used, based on the lag one auto-correlation. Column 4 shows the R value obtained from the data and column 5 shows the same using detrended data. Column 6 shows the standard error (root-mean-square residual) from the calibration period. Columns 7 and 8 show significance levels, estimated using Monte Carlo simulations as in column 2, for the full and detrended R values. The HCA detrended significance is low because the proxies have been smoothed, removing high frequency information.
Now let’s consider the variation of the Moberg CVM obtained by using Yakutia/Indigirka instead of stereotyped Yamal and the Sargasso Sea SST reconstruction (an actual SST proxy) rather than a proxy for Arabian Sea coldwater upwelling (BTW this proxy probably got into circulation in Team-world through a graphic by coauthor Overpeck overlaying the Arabian G bulloides against the HS). As you see, the reconstructions are pretty similar in the 1856-1980 instrumental period, but the medieval-modern relationships are quite different. The correlation for one series is 0.58 and the other is 0.57. So both reconstructions are "99.98% significant" under Juckes’ test, but they are different – and materially different in the MWP.

Left – Juckes CVM; right – CVM with Sargasso Sea and Yakutia/Indigirka instead of Arabian Sea G bulloides and Yamal/
How can they both be 99.98% significant? It doesn’t seem to me that they can. So whatever Juckes has done to benchmark significance, the calculations can’t be right. One of Wegman’s recommendations to climate scientists was that they involve statisticians. Nanne Weber said that Juckes was their statistician; a quick look at Juckes’ publications shows that he has very substantial background and experience in atmospheric turbulence.
How should one establish significance for these reconstructions? Given that two equally plausible reconstructions diverge substantially, I’m not sure that you can. The NAS Panel concluded that you couldn’t establish statistical significance for these things. They also recommended that you use verification period residuals for estimating confidence intervals.
Speaking of which, let’s note that Juckes did NOT reserve a verification period. No RE, no verification r2. In my own experimenting with reconstructions that would be similar to the Juckes CVMs (see for example my AGU05 presentation), the reconstructions have high calibration r2; negligible verification r2. Juckes only used an 1856-1980 calibration period. It’s hard to imagine that he didn’t start with a Mannian 1902-1980 calibration period and 1856-1901 verification. My guess is that his CVMs fail such tests. I’ll take a look at that some time.





186 Comments
This would be a very good field for someone to introduce Bayesian Model Averaging. If you have a model with k potential variables and no strong priors about which to include or not include, that makes 2^k possible models; not to mention the methodological variants beyond simple linear models. Let’s say there are 30 potential regression variables, that’s over 1 billion models. BMA runs them all, then uses a posterior statistic to quantify the support each model gets from the data, with appropriate penalties for overfitting. From this you get robust posterior point estimates and confidence intervals. The alternative is the classical Model Selection approach where you pick a model, hope it’s right, and apply it, but then you might run into this kind of situation where 2 models each get the same support from the data, yet yield contradictory conclusions. If there’s a robust effect in the data then BMA will find it, but if the results wander all over based on small model respecifications BMA will strip away illusory results like 99.98% significance etc.
“My guess is that his CVMs fail such tests. ”
If that’s true then we have not only the cherry-picking of data, but the cherry-picking of results. Does Juckes, too, have a CENSORED directory, where the found-wanting are cast into eternal silence?
Re #1
Now THAT’s an interesting idea. Any applications of this method in the literature?
I have asked Juckes about his methods for calculating significance here, and I am awaiting his response. My results had nothing resembling their results, but perhaps my methods are flawed … who knows.
Using normalized 1850-1980 datasets, I calculated the mean, and the standard error of the mean, of the squared residuals (Union – instrumental)^2.
Square root of the mean is the rms error. Square root of the s.e.m is the error of the rms value. This gave a 95% confidence interval rms value of 0.77 ± 0.66 sd.
This value totally encompasses the value that I got for red noise vs. instrumental (rms = 0.99 sd) and approaches that for white noise (rms = 1.41 sd).
Finally, at the location cited earlier in this post, Juckes says:
I don’t understand this, and hope it is a mistake. He says his test consists of correlating random series based on the Union, not with the instrumental temperature, but with random series based on the temperature. Does this make sense to anyone?
w.
Re #4
He is talking about a Monte Carlo experiment of some sort. The gist of his experiment is that he can reject that the actual data come from a population (or populations) that looks like his synthetic red noise series (with some statistics that match those of the Union series and the temperature series). It is a fairly standard approach when the distributions are complicated and exact analytical results can’t be calculated. I’d have to read the paper to work out more than that but it sounds like he is calculating critical values based on the distribution of correlation statistics for two red noise series notionally called ‘temperature’ and ‘Union’ – as you surmised.
The literal interpretation of the result is that he can reject the joint hypothesis that Union and temperature are both generated by the synthetic series as described in his Monte Carlo experiment. It doesn’t really tell you anything more than that – the correlation is not really the point. He could have calculated the mean difference between the two series, the difference between the 56th observation of the ‘Union’ series and the 12th observation of the ‘temperature’ series, or the cube root of the geometric mean of the series that results from interleaving the growth rates of the two series – all that matters is that whatever he uses has some power to distinguish between populations and reject his H0 distributional assumption. The immediate comeback would be that his characterisation of the Union or temperature series is inadequate in some way (I don’t know if this is the case, just that this is the assumption that the validity of the test and conclusions rests upon).
Willis, I don’t get your calculation for the distribution of the RMS error – in particlar how you calculate a standard deviation for the distribution of the red noise RMS. Could you set out your calcs in baby steps.
I haven’t thought this through and have only done a couple of quick calcs, which I don’t vouch for but my impression is that the expected RMS error for red noise will be similar to the expected RMS error for white noise – it’s just that the wings are broader. In some simulations with red noise, I found that you generate more low rms error values, but nothing like you’re suggesting.
The main problem is simply that, when there’s been data snooping, all statistical tests fail.
But even if you let that pass, his significance tests don’t model the pick-and-average methodology. He doesn’t have a univariate series generation. He’s non-randomly picked 18 series from a larger universe, then averaged them. So you have to test for significance in a more sophisticated way.
But none of this touches on the fact that two differently generated series appear equally “significant”. Thinking out loud, the sought-for test is not really against a red-noise hypothesis but against an apple-picking alternative. How does he (or anyone) show that a CVM of cherry-picked proxies is significant relative to a CVM of apple-picked proxies? Or vice versa. It’s harder than against red noise.
Well, since I’m working in Excel, I ran small samples, a hundred at a time. I generated red noise samples using the autocorrelation structure of the Union reconstruction, and calculated the rms error for each one. I took the standard deviation of the resulting rms errors, and calculated the standard error as .
.
Seems to me that for any given means used to generate red noise, or for white noise in general, the standard error is purely a function of n.
w.
To tie my point in with Steve’s – with data snooping his Monte Carlo experiment is inadequate because it doesn’t include the selection process so his characterisation of the series is inadequate. In that case you could, for example, generate 100 random series and then select the 10 most ‘interesting’ from that population and then calculate correlation statistics to give a better representation of the process of generating the correlation statistic that is being tested and for which you are trying to find critical values.
Hmmm… I seem to remember reading a paper like that somewhere… I wonder where that was? No, please, don’t help me, I’m sure it will come to me soon.
Data snooping here: http://www.climateaudit.org/?p=801 . I’ve collected some economics papers on it. There’s one beautiful discussion that concludes that sometimes all you can do to test a hypothesis that’s already been snooped is to wait for time to pass. Ergo, since so many proxies end ~1980, testing of the hypothesis that these 18 proxies can measure world temperature is really easy: all one has to do is,…. update the proxies. Oh, wait a minute, Hughes already updated Sheep Mountain in 2002. He’s just not telling anyone the answer.
Re: 10
Like any reasonable person, I agree these proxies should be updated. Since no one in the academic community appears willing to do this for whatever reason, why don’t we just take up a collection and get it done? Does anyone have any idea how much this would cost? I’ll bet the money could be raised within a year or less, the actual work done by some grad students in the space of a few months, and the results analyzed by the CA community in a few weeks or less. I’m doubtless being hopelessly naive, but it just doesn’t seem like an overly complex exercise. Seems to me the most difficult aspect would be finding qualified people near the relevant sites to collect the data. As a lover of good science, I for one would be happy to contribute to such a cause. Comments?
Re: #10
I would think the lack of effort in doing this updating says something about the current state of climatology. It would be difficult, in my judgment, to conclude that these people are ignorant of implications of data snooping, but, on the other hand, I have seen first hand here that some of the participants have no shame when it comes to rationalizing their data selections or not even an interest in explaining the selections without first being confronted.
Re #11
You get the permissions all squared away at your end and I’ll do the Sheep Mtn bcps at my own expense. Once you’ve got the official permissions documents all ready, send them to Steve M.
#5
yes. Next question: how would you interpret MBH98 figure 7 significance levels? Quite similar method used in there..
#8
Got same conclusion from short Monte Carlo simulation. I used N=79 (1902-1980), average of 2*RMSE was 0.57 C and std 0.1 C (see
http://www.climateaudit.org/?p=896#comments #53 ). i.e. compared two independent AR1 series after CVM, temperature was simulated AR1 p=0.7.
“99.98% significance!”, I laugh and throw my head back and fall off my chair.
“Brad,” the wife yells, “Brad, what’s wrong with you?”
The para-medics arrive, “Now, sir, just calm down, what’s wrong?”
“99.98% significance! Juckes is a statistical god! Who would have thought!”, I laugh so hard, I start convulsing.
“He’s gone,” say the medics, “Get him into the ambulance and take him to the psych ward.
“99.98%!”, I jabber, as they take me away.
Moral of the story: all AGW’ers are absolutely certain of themselves and all skeptics are (now) crazy.
Re #5, John S., thank you for your explanation. I still don’t understand why he is testing red noise with “Union” characteristics against red noise with “instrumental” characteristics.
Seems like he’d want to see if his Union reconstruction does significantly better than red noise at predicting the actual instrumental record, not other red noise.
No?
w.
I think that in this case it doesn’t change the results. Red noise or the actual NH Temp against Union, no difference.
Steve’s question
is a good one. (CO2 , NHTemp) after CVM is also 99.98 % significant. And (Solar, NHTemp), etc.. Just choose any series with similar shape as NHTemp has. I like this CVM.
Isn’t this just a fallacy of the excluded middle? They are showing that
H0: selected proxies are just red noise
is not true, and conclude that
Ha: selected proxies represent global temperature with high accuracy
is thus true.
? Don’t worry Willis, you are not the only one who is confused 😉
Re #13, bender
What are these permissions ? Who issues them ? How long does it take ? Is there a cost involved ?
Are you comfortable with the loss of anonymity for publication purposes ? Are you familiar enough with procedures to be able to fully document such a sampling, so that it could not realistically be contested by those it offends?
NB Please don’t take offence at the above – I think it is a terrific idea and I am just trying to think it through.
SteveM: I commented earlier on Juckes test approach (here). I agree there is nothing wrong with using Monte Carlo results to determine statistical significance, but it does require that the simulated test statistics be computed from the right population — one corresponding to the real data. I doubt that was done.
If I understand correctly, Juckes tried to generate samples from (maybe?) an MA(70) stochastic process, then computed his test statistic for each of 10000 simulated samples, and then computed the “rank” of his real statistic in the context of the 10000 simulated test statistics.
In response to your question about why Juckes did not get a “milllll-yun years,” I think it is because he only conducted 10000 Monte Carlo experiments. A p-value of 0.02% is as small as you can get, assuming he did a 2-sided test (by convention, that’s what you do in this case). That would require the statistic corresponding to all simulated samples be less extreme than the “real” result. IMHO, if nothing else, he should have run enough samples so that we he could see how extreme the result really is — i.e., enough so that the real test statistics would rank 100 or greater among the simulated statistics. This is not necessary; but it would have been nice.
More to the point, I wonder what would result if Spearman’s rho (a rank-based, nonparametric test; also Mann-Kendall would work), rather than Pearson’s, test were used. His results might be due to mis-specification of the distributional form of the errors. This does not seem all that likely, but it is worth checking.
However, the obvious thing to check is the time-series model. How, precisely, were those 10000 samples generated? I am not sure I understand what was done. It is clear to me that Hosking’s approach, though cited, was ignored. I am confident that what was done was odd, but I have yet to figure out the details.
Along these lines — I should know the answer to this, and I apologize — are the data that were used to compute the statistics available on the web somewhere? If so, I would be interested in trying to check the results.
If the weighting of the samples in each group is determined by the correlation to the instrumental calibration period, then is it not natural, indeed inevitable that the samples (as reweighted) will have a high correlation to the instrumental/calibration period? I’m 99.98% certain.
The reconstructions are in two locations mitrie_new_reconstructions_v01.csv and mitrie_new_reconstructions_v01.nc. THe union reconstruction is #1 in the first set and #67 in the second set. The proxy versions are also in the SI. I’ve made short collation scripts and will post them up.
I think that any of these CVM reconstructions, including the Union reconstruction, are going to be “significant” although I’m a bit dubious about 99.98% significant. I did 100 simulations using ARMA(1,1) simulations and got a couple of results that were just as “good”. These simulations spread out the results from the AR1 results – and, as you’ve pointed out, it’s impossible to tell how he did his “hosking” results.
#21 in the CVM method, the samples are all evenly weighted (but have been pre-selected). In the INVR method (i.e. partial least squares regression as known in the rest-of-the-world), which is also used, you’re right. In previous incarnations of these reconstructions with calibration-verification periods, the verification r2 breaks down. Juckes avoids this by not reserving a verification period.
Re: #23
Does this mean that Juckes has created his tests in such a way as to avoid checking for spuriously high statistical significance?
Re # 17, UC, thanks for the post. I had said
You replied:
I got to thinking about that, and I’m not sure it’s true. Suppose we create some red noise based on the autocorrelation of the Union record. Now, let’s divide them into say six groups depending on their general appearance. Let the groups be say, “upward sloped”, “downward sloped”, “U-shaped”, “upside-down U-shaped”, “sigmoid”, and “inverted sigmoid”.
Are all of these shapes equally probable? Although I have no numbers to prove it, my gut says no. The question is very important, because the correlation between the red noise and any given dataset depends on the shape of the dataset. This is why I would say that it does matter whether we compare the red noise to the instrumental data or to other red noise.
And this, in turn, brought up another related idea for me, regarding Monte Carlo red noise. This was, how do we establish that the red noise that we have generated contains, or encompasses, or adequately represents, a given dataset?
If we have a sigmoidially shaped dataset, for example, how do we prove that
1) our red noise is somehow a superset of that dataset, and
2) our sigmoidially shaped dataset is neither over-represented nor under-represented in the red noise?
I ask this second question because of my experience in generating the red noise to compare to the instrumental record. I used a variety of methods to generate it, from making noise that is slightly pink (mostly white noise with a bit of lag 1 correlation) to noise that had a long-term autocorrelation structure that was similar to the “Union” reconstruction, mixed with just a bit of white noise. As might be expected, they performed differently, with the slightly pink noise giving results more like white noise (rms ~1.4), and the redder noise giving results (rms = ~1.0) nearer to the Union reconstruction [rms = 0.77 ± 0.66 (2 sd)]. I was quite surprised at the sensitivity of the red noise results to the exact autocorrelation values used, as well as to the size of the random noise component.
Obviously, the better the red noise emulates the underlying structure of the Union reconstruction, the smaller the difference in rms between Union and red noise … but what, if anything, does a finding that the Union reconstruction outperforms a given run of red noise prove?
It may just prove that we have done a poor job in the creation of our red noise, perhaps something as trivial as a coding error … it may prove that our red noise only rarely produces shapes like the Union reconstruction … it may prove that we have a small difference in the autocorrelation that makes a big difference in the results … it may prove that the earth’s temperature is not really an ARIMA process, although it is convenient to treat it as one …
Before I put much belief in the Monte Carlo method, I’d have to see some proof that it works as advertised. Otherwise, just like in Monte Carlo … the roulette wheel might be crooked …
In particular, I’d want to see a formal proof that the red noise being tested adequately represents the Union reconstruction. But it seems like this is a circular process. The better the red noise reproduces the Union reconstruction, the smaller the difference in rms error between the Union reconstruction and the red noise … with the limit of the process being red noise that is exactly centered around the Union reconstruction, and with no difference in the two rms errors.
But what would any of that prove, particularly to a “99.98%” confidence level?
w.
To Mr Juckes:
Will you PLEASE explain to these people what you have done. Allowing the discussion to continue like this brings further doubt to the efforts of climate scientists, which following the efforts of Mr Mann, seem increasingly to be held in low regard.
My concern, unlike the sceptics, is that I am convinced that there is a problem, and we need urgent action to deal with the problem. Unfortunately this controversy is damaging our case. We need climate scientists to put forward strong arguments supported by sound statistics.
Those of us who are gravely concerned for our children’s future need climate scientists to lift their game so that the science supporting taking action is as credible as it can be. Unfortunately, the net effect of people like you engaging, and then retreating hurt, is that it gives the impression that the sceptics are winning.
#26. I heard a report that Ed Wegman of the Wegman Report has addressed standing-room only crowds at the American Statistical Association conference and a couple of other conferences in the past 2 months and their collective jaws reportedly basically dropped to the floor when they heard when the Team was doing.
I’d also repeat once again that I believe that climate is a serious issue , otherwise I wouldn’t bother with this. I do not claim that discussions of proxy issues has any direct bearing on arguments from physics. But I do believe that people should be meticulous in their methodology and should be completely open about what they are doing.
In Juckes’ case, for example, he says that he will archive their code after it’s published. Why not before, so it’s easy to see what he did for review purposes?
Re #26, Concerned of Berkeley
Why ? You seem to recognise that the statistical approaches are being shown to be garbage. So what evidence has convinced you ?
Re#23 Does not pre selection on the selection bases Juckes uses amounts to the same thing as weighting to the instrumental calibration period? ie He appears quite happy to use non temperature proxies as long as they have a rising trend in the instrumental calibration period, but discards known temperature proxies for whatever random reason he can find.
If I have been following this properly, Juckes takes a number of the Hockey Teams papers, purports to test them, but in doing so discards some of their proxies, and substitutes different ones, he then
as you say
So he cherry picked already published papers, picking those purported temperature proxies with the best match to the recent instrumental record, rescaled them to match the instrumental/calibration period, and then tested them for significance, against the same instrumental calibration period.
PS I’m afraid I don’t know what the CVM is. Is it possible to have a link to a description of it?
#26, COB
I’d love to think that the sceptics (like myself) were winning but sadly, at the moment, were are most certainly not. In the UK there is a long long way to go yet before the voice of reason is even allowed to be heard. I however convinced that once it is allowed to be heard and policy is allowed to be based on sound science rather than eco-theologically inspired alarmism, then common sense will once more prevail.
COB, in respect of global warming there is no reason for you to be concerned about the future of your children. In respect to your children’s future there are many other things that you should be far more concerned about than global warming. For example, will they be able to get a job? If they luckily enough to get a job, will they be able live with the increasing level of taxes which we are now expected to pay inorder to fund the ever increasing number of bureaucrats that decide what we can and cannot do? Will they be able to find somewhere to live of their own? Will you be in a position to be able to pass on any of your harded earned wealth on to them rather than the taxman? Will they be able to find a life partner with whom they can settle down and perhaps have their own children? These are all things which as a parent of five children give me sleepless nights, not global warming.
KevinUK
#29. CVM is a simple way of constructing an index from a subset of proxies. You:
1) scale the proxies (i.e. center and divide by s.d; hopefully using s.d. over the max period
2) average
3) re-scale the average to match s.d of target
Hidden is step 0 – pick the proxies.
Kevin #29
wrt to hope that voice of reason will be heard, it’s worthwhile noting that AGW/Climate change is not the only field of endeavour where “science” is being distorted. We have some issues which are clearly systemic
A quick glance by someone such as yourself with a keen eye for modelling at http://www.warmwell.com and search that site for David King, Roy Anderson, Margaret Beckett will be quite revealing.(more gigo modelling)
There’s quite a lot of info. I can probably guide you quickly to some of the most relevant.
You can e-mail me at brent_ns AT hotmail.com if you would like
cheers
brent
Its my guess that Concerned of Berkely (#26 above) is engaging in irony to make a point to Mr Juckes and the RC crowd.
It’s my guess that Concerned of Berkeley is serious, and just doesn’t realize that the same crap science behind overfitted multiproxy reconstruction models underlies the GCMs. It’s my guess is CoB hasn’t read the Wegman report and doesn’t understand why Wegman is making jaws drop. It’s not what Wegman is saying. It’s what he’s stumbled across. Junk science.
Re #31, Steve M., you say:
A caveat here. Most temperature proxies are autocorrelated to some degree. Because of this, the normalization must be done using the s.d.
Near as I can tell, both Juckes and Hegerl omitted this part …
This also affects the standard error of the mean, widening it considerably. The standard deviation is larger due to the autocorrelation, because the effective “n” is reduced. This affects both the numerator and the denominator of the s.e.m. calculation, which is .
.
w.
#35. I agree with your point but I think that it is a secondary issue. If you use Yamal and Arabian Sea rather than (say) Indigirka/Yakutia and Sargasso Sea, you’ll get higher modern than MWP under a variety of weighting systems and vice versa.
Actually we raised a related point in our Reply to Huybers where we showed that PC series in the North American network had different results when standardized with a type of autocorrelation-consistent standard deviation – although all of these variations are just greater or lesser weights to bristlecones/foxtails.
Re 36, you’re right, Steve M., it’s not a major issue regarding the weighting. However, it is more important regarding such things as the 95% confidence interval of the rms error, used by Juckes in his claim of statistical significance.
w.
No wonder we are failing to find new world class ore-bodies.
It’s the 99.99% confidence level we need to examine.
Re: #27
Yes, Steve, I’ve noted this POV from you a number of times in the past and it interests me.
I don’t want to put words into your mouth, but my take on your position seems to be that: (a) things are warming up; and (b) we can’t be excluded as the cause of it.
You try very hard to pass no judgments as to whether we’re the primary reason, or whether what we’re doing is a cause for concern. Nevertheless, sometimes you insert an, “I’m not sure,” comment.
I find this curious. I’m not sure whether it is genuine, or merely your personal mechanism to try and maintain an “open mind”.
Unless I’m mistaken, there are two main “culprits” which the AGW’ers argue are the imminent cause of our demise: carbon; and CO2.
Carbon is what we and all other living things are primarily made from. CO2 is what ensures all plant life thrives. In turn, it increases O2 in the atmosphere, which ensures that animal life thrives.
In the past, all evidence points to eonic timeframes where things were either colder or hotter than today. As regards the so-called “polluting” effects of carboniferous contamination of the atmosphere, there have been highly volcanic periods in the Earth’s past where the world was bathed in far higher levels of the same kinds of “pollutants” which we are so concerned about now (we burn fossil fuels – volcanoes do, too!).
Anyway, Carl Sagan’s quote that, “Extraordinary claims require extraordinary evidence,” is trite these days. All of your investigations show that the foundations of doomsday climate science is fundamentally flawed. It’s the Hockey-Stick, Stupid. Yet, you seem to think there’s some underlying worry about this particular period of warming. Where’s your proof, Steve?
Surely, the starting hypothesis must be: temperature fluctuates, naturally. Surely, one must hove to that point of view, unless they are presented with credible evidence otherwise.
Are you in possession of evidence to the contrary, Steve? Or, are you just hedging your bets? [Or, are you just being polite?]
You understand odds. You understand software-based “future-machines”, not only in climate science, but in horse racing and stock markets. This is why I find your apparent concern about man-made warming curious, to say the least.
There is no proof. There is only a theory which fails every time anyone looks at it, because it attempts to predict the future…and everyone should know that you can’t do that.
#39
Brad, a small correction to your analysis.
While the plant kingdom does produce O2, the amount actually it does, compared to what is in the air we breathe, is not an issue.
Otherwise your points are accepted.
Re:#40
Fair point, Louis.
#39. Brad H, I’ve by no means shown that “the foundations of doomsday climate science is fundamentally flawed”. I’m convinced that the HS arguments are flawed, but that is different from proving that the MWP was warmer than the modern period. I’m inclined to think that it was, but proving it is a different issue.
The main arguments for concern about increased CO2 are the obvious ones: 1) CO2 levels are increasing materially; 2) CO2 has an important role in greenhouse warming; 3) increased CO2 levels will tend to increase temperature by some amount. How much is the $64 question. Unfortunately IPCC has never bothered providing interested readers and policy makers with an intermediate level complexity description of the underlying physics and the key issues in iumproving the understanding of the physics. This may seem like an astonishing claim, but I’ve parsed the 3 reports and am convinced it’s true. They go from one-sentence explications to reporting GCM results. But just because IPCC explained it badly or not at all doesn’t mean that there isn’t a problem. I don’t know whether there is or isn’t – I’m not trying to obfuscate – I just don’t know. In this particular case, the whole enterprise has become entangled with POV and politics, so I don’t trust pronouncements from people who, under normal circumstances, could reasonably be regarded as authoratitive. That doesn’t mean that they are wrong or that political leaders can afford not to rely on such pronouncements – that’s a separate matter.
#32, brent
Thanks for the link. I’m a keen visitor to Numberwatch and so I’m well up on the BSE debarcle. You are quite right to point out that we have a systemic problem in the UK. As you know part of this problem is our wonderful scientifically precise (NOT!!) DEFRA. It shouldn’t come as a surprise to anyone who visitors this blog to find out that DEFRA has behind both the BSE alarmism that led to the unnecessary slaughter of millions of animals in the UK and is currently the main government department that funds all the current AGW propaganda. It appears according to Chris Monckton that they are also funding all the ‘science’ within the IPCC.
For those non-UK residents on this forum here are some examples of what we have to put up with in the UK from the ‘players’ mentioned by Brent
Sir David King – Greenpeace Busines slecture in October 2004
(Slight aside I think that its ironic that the Greenpeace web site uses ColdFusion for rendering its web pages)
Prof. Roy M Anderson – doesn’t mind jusifying the mass slaughter of animals and whales at the behest of politicians
Margaret Beckett the UK’s current Foreign Secretary but former Secretary of State for DEFRA. As a firm supporter (previously funder) of AGW propaganda she clearly isn’t concerned about the effects air travel may have on global warming having between 2002 and 2005 taken 134 flights on ministerial business flying some 103 thousand miles. Again ironically she may well be my neighbour shortly now that I have accepted a new job in the city (Derby) for which she is an MP.
KevinUK
Re:# 42
Fair enough, Steve. [I do get on my high horse sometimes, don’t I.]
#25
Maybe so. My Monte Carlo run was short, some 300 samples. I’ll rephrase: Red noise or the actual NH Temp (1902-1980) against Union, no significant difference. (Can’t open mitrie_instrumental_v01.nc , any advice? )
I don’t think that Monte Carlo method is the problem here. For me, it is the meaning of ‘99.98 significance’ in this context. I assume that 99.98 was obtained this way: 10 000 simulations, for 2 of those R exceeded 0.535 (MBH case). Does not prove anything to me, quite easy to find ‘reconstructions’ that are as significant (or even more..), like in #17.
Actually, for the ‘first order Markov approach’ we can obtain variance for R without Monte Carlo. In Spurious Regressions in Econometrics, C.W.J Granger and P. Newbold, Journal of Econometrics 2 (1974), there is a related example of two independent first order autoregressive progress. Variance of sample R for those is given as
(p1 and p2 are the one-lag autocorrelations) i.e. redness matters. Thus, my conclusion in #14 is not valid.
UC, a question. If the process is ARMA(1,1), do you have the equivalent formula?
Don’t forget the very high significance levels obtained by Hendry for the relationship between U.K. inflation and cumulative rainfall discussed here http://www.climateaudit.org/?p=744. The Hendry equations could readily be reversed with U.K. inflation (or some such economic indicator) serving as a predictor of global temperature.
#2 – a good example of BMA in action is This paper by Koop and Tole, which appeared in the Journal of Env Economics and Mgt (a high-ranked journal in our field) in 2003. They re-examined the claim about modern air pollution being a major cause of mortality. Gary Koop’s textbook is here and includes some supplementary on-line materials.
Re: #48 Thank you for the references. This method – BMA – appears to have wide applicability in the earth sciences. One wonders why it is not used more frequently. (I have my guesses … )
(#45)
It seems that all relevant papers are already discussed here, Granger -74 in here: http://www.climateaudit.org/?p=317
#46 Not aware of such formula, but finding the original Kendall 1954 might help. I’ll try to find it.
Re #42:
Steve hits upon a key issue here…we have a high-stakes “game” here however you come at it. Climate and climate change IS a serious issue, or why does this site exist? Even the premise that our activities could affect future generations in a dramatic and inequitably spread fashion deserves a conscientious response. Whatever disagreements we might have on the details, I will give credit to Steve for respect to the seriousness of the issue.
The fact is that we may not know all the detail we want before some action is prudent. I suspect from the comments I have seen that Steve also thinks likewise, and I would be interested to hear him directly address this. If there is a serious risk of harmful climate change and there are already actions open to us that will have minimal cost and will help position us more flexibly while we learn more of the details of climate impact then why would we NOT pursue them?
The problem is we don’t have a clue as to what part of warming is caused naturally or by CO2, solar, land use changes, or what ever other things you can think of. It would be foolish to pick an item to attempt to control, until you can determine how the ratio of causes break out. If you can’t be sure of even those, the investment will more likely than not be wasted.
Maybe if there were firm ratios of the effects of the major causes, it might be worth doing something. To my knowledge those figures are all disputed at this time. Does anyone really know the portion of warming caused naturally? Put an accurate percentage on it and maybe there is something to discuss.
It would be a hell of a thing spend enormous sums controlling CO2 and find that we are naturally going into a cooling phase. I’m of the opinion that natural forces swamp anything we might do. Anyone think bringing on an ice age sooner is a good idea? Like I used to tell my kids. If you don’t know what your doing, and it’s expensive to be wrong, you observe. But keep your hands off.
#46
ARMA(1,1) case, here’s how I think it should be derived:
Bartlett, M. S. An introduction to stochastic processes with special reference to methods and applications (1960) gives
Using this I can derive the given AR1 case, so I think it is the correct equation:
And ARMA(1,1) case is obtained by changing the i=-1,1 terms accordingly.
BradH said…
[.You understand odds. You understand software-based “future-machines”, not only in climate science, but in horse racing and stock markets. This is why I find your apparent concern about man-made warming curious, to say the least.]
BradH ,
It doesn’t matter whether you do horse racing predictions , stock markets analysis or climate change modelling, if you know the language of numerical computing, and that is all you need which is regardless of your background. As I understand Steve’s background , he is an economists with statistical emphasis. I do develop software mainly in numerical computing similar to what Steve is doing, from Computational Finance, Feedback Control Systems, Embedded DSP (Digital Signal Processing), Digital Image Processing, Pattern Recognitions, Data Mining, Non-linear Dynamics, Machine Learning, etc… Once someone understands the art of numerical computing (numerical analysis), then he/she can model anything which involves mathematical modeling. I am not a climate scientist or have done any modelling in this area before, however I can read those peer review papers that are available from different related journals in climate science, because most of the models are mathematical (numerical), which I already fully understood. The mathematics are the same except that the domain is different.
I am aware that some difficulties climate scientists in their current models are climate systems feedbacks which are very complex , highly non-linear and very difficult to model. This is my domain area of expertise in modeling & development of large scale industrial dynamical feedback control systems mainly in the process manufacturing industries. Until I see some progress in both linear & non-linear ‘climate feedback dynamical control systems’ modeling, being published and verified by climate scientists, then I will remain a skeptic. As mentioned above, that I have seen the complexity of modeling dynamical systems for me to dismiss anything simplistic (which mostly what those models described in the IPCC report) to portray that the human civilization is doomed by rising temperature (man-made).
You must read the following page and try to understand the problems described there, about how difficult to model ‘coupling’ climate feedback systems. If you have not understood the analysis methods in dynamical systems feedback control, then follow the second link , which give you a good introduction. You can learn about the concept of process feedback transfer function. Michael Mann mentioned ‘transfer function’ in his hockey stick paper but gave none at all. I couldn’t understand why he mentioned that at all. If you want to dig deep into the theory of non-linear control, there are some books at Amazon available on the subject.
“WORKSHOP ON CLIMATE SYSTEM FEEDBACKS”
http://grp.giss.nasa.gov/reports/feedback.workshop.report.html
“Control theory”
http://en.wikipedia.org/wiki/Control_theory
Enjoy your reading.
RE: #54 – It would be interesting to see how Mann would handle Control Loops, active filters and other things typically covered in systems engineering courses.
Re #54
“Transfer function” in dendroclimatology is specialist jargon for the inverse function to that which describes tree ring response to climatic input. i.e. It is the entire reconstructive step, whether a mathematical “function” or an algorithmic computational “procedure”.
sione, I sympathize with your view when you say:
Given your experience in process control of nonlinear feedback driven systems, what do you make of the “cloudy Earth” argument – that watery Earth can handle anything that CO2 throws at it, by virtue of negative nonlinear feedback from cloud formation? I know you’re not a climate scientist, but is this argument logically sound in your view? Have you looked at any of these GCMs, to see if the negative feedbacks are overly-linearized, when they should really be nonlinear? I ask because that’s the kind of trick that is used all the time to make complex models analytically tractable. I’m wondering if the warming predicted by these models is an artifact of linearizations that are not all that drastic under current conditions, but are terribly problematic under futuristic scenarios.
I’ve not seen this question asked anywhere yet in the public domain. (I should have asked Isaac Held when he was here.)
bender,
I think this is referred to as the “linearity assumption” by the modellers. Some seem to think that this should be tested somehow, and others believe it can’t be tested at all. That is just one of the reasons I can’t take the GCMs seriously. They may be interesting lab experiments, but that’s all.
Posted by Steve #27 I heard a report that Ed Wegman of the Wegman Report has addressed standing-room only crowds at the American Statistical Association conference and a couple of other conferences in the past 2 months and their collective jaws reportedly basically dropped to the floor when they heard when the Team was doing.
Now this is very interesting. Do you have more information on this? It would be extremely beneficial to the debate if the American Statistical Association or the media would elaborate on this some more.
#58
Jeff, you can find this on this blog with the Search function on the top right of the main page. An example here: Edward Wegman Testimony
Re #27: wrong again McIntyre: the code is published and the review process is happening. I guess it is a little confusing, having a two stage publication process with on-line journals.
Re #26: It took McIntyre the best part of a week to understand how to plot a couple of curves from a data file. Against that background, you’ve got to expect that it will take some time.
Re #4: I’ve just re-run the Monte-Carlo tests using the actual temperature series: the significance is 99.89% for the Union reconstruction. This means that we can reject the null-hypothesis that the reconstruction series is correlated with temperature by pure chance. The Monte-Carlo approach avoids having to estimate degrees of freedom by generating random series with correlation statistics consistent with the null-hypothesis.
Re #42: How about: CO2 in the atmosphere acts as an insulating layer, absorbing infra-red radiation emitted from the Earth’s surface. More insulation (i.e. more CO2) causes the temperature of the surface to rise. [[NB: this is not intended to be complete, it is a response to McIntyre’s request for a simple explanation.]
#60. When you say that the code is published, it would have been helpful if you had provided a URL to the code rather than your usual guessing game. The You might considering amending the online SI, which says: “The software (in the `python’ language) used to generate the reconstructions presented in the manuscript will be made available on http://mitrie.badc.rl.ac.uk when the manuscript is published.”
At the website, I was unable to locate ate a link to the software from the webpage. However, my going to a file and scrolling up – the procedure which you said was too hard for you to do at climate2003.com – I identified a software file called http://home.badc.rl.ac.uk/mjuckes/mitrie_files/software/mitrie_python.tar. Is this what you mean? I notice that this file does not include a readable script in any way comparable to the scripts that I provided for my articles. The code contains no commentary. Perhaps the rms-normalization can be discerned somewhere in the python code, but really, people should not have to wade through your python code to learn things like that.As far as I can tell, the script does not include code for how you did your reconstructions.
As you say, after a considerable amount of time and effort, I was unable to guess that you had used rms-normalization in your figure. You seem to think that proves something about me – I think not. Your refusal to provide an immediate clarification about what you did says something about you.
#60 I had said in #42:
In response to this, MArtin replied:
With all respect, I didn’t ask for Martin’s “simple explanation”. I asked for an intermediate-level complexity exposition from IPCC, in which a chapter or two were devoted to the topic. Instead, IPCC 4AR includes self-indulgent fluff like a history of climate science.
I’ve edited a couple of comments as I’d like Martin to talk about proxies rather than changing the topic.
The following are the session descriptions from the ASA’s Joint Statistical Meeting held in August. Climate analysis is obviously a big deal to a number of these statisticians. There is no excuse for their absence in the analytic process. It would be fun to try a lure a couple of these Stats to this happy hunting ground.
Ah, to have been a fly on the wall…….
354 CC-400
Late-Breaking Session #2: What Is the Role of
Statistics in Public Policy Debates about Climate
Change?”¢’¬?Other
The ASA, ENAR, IMS, SSC, WNAR
Organizer(s): Edward Wegman, George Mason University; Richard L.
Smith, h e University of North Carolina at Chapel Hill
Chair(s): Douglas W. Nychka, National Center for Atmospheric Research
8:40 a.m. The Kyoto Accord, the 2001 IPCC Third
Assessment Report, and the Academic Papers
Underpinning Them”¢’¬?Edward Wegman,
George Mason University
9:05 a.m. National Research Council Report on the “Hockey
Stick Controversy'”¢’¬?J. Michael Wallace,
University of Washington
9:30 a.m. The CCSP Report on Temperature Trends in the
Lower Atmosphere”¢’¬?Richard L. Smith, h e
University of North Carolina at Chapel Hill
9:55 a.m. Floor Discussion
ALSO OF INTEREST
3:05 p.m. On Nonparametric Smoothing Methods
for Assessing Climate Change”¢’¬?Patricia
Menendez Galvan, Swiss Federal Research
Institute WSL/ETHZ; Sucharita Ghosh, Swiss
Federal Research Institute WSL
9:25 a.m. Statistical and Computational Issues in
Climate Research”¢’¬?Invited
Section on Statistical Computing, Section on Physical and Engineering
Sciences, Section on Statistical Graphics
Organizer(s): Donald B. Percival, University of Washington
Chair(s): Donald B. Percival, University of Washington
8:35 a.m. Statistical Analysis of Spatial Patterns of Climate
Variability”¢’¬?J. Michael Wallace, University of
Washington
9:00 a.m. Interpreting Recent Climate Change”¢’¬?Francis
W. Zwiers, Canadian Centre for Climate
Modelling and Analysis
9:25 a.m. Statistical Problems in Climate Change
and Geophysical Fluids”¢’¬?Carl Wunsch,
Massachusetts Institute of Technology
9:50 a.m. Disc: Richard L. Smith, h e University of North
Carolina at Chapel Hill
10:10 a.m. Floor Discussion
179 CC-613
Statistical Methods in Climate Modeling
and Seismology”¢’¬?Invited
WNAR, Section on Physical and Engineering Sciences, Section on Bayesian
Statistical Science, Section on Statistics and the Environment
Organizer(s): Gabriel Huerta, University of New Mexico
Chair(s): Gabriel Huerta, University of New Mexico
2:05 p.m. Probabilistic Projections of Climate Change:
Bayesian Models for Analyzing Ensembles of
Global Climate Models”¢’¬?
Claudia Tebaldi,
National Center for Atmospheric Research;
Richard L. Smith, h e University of North
Carolina at Chapel Hill; Douglas W. Nychka,
National Center for Atmospheric Research;
Linda O. Mearns, National Center for
Atmospheric Research
2:35 p.m. Uncertainty Estimation in Geophysics”¢’¬??Mrinal
K. Sen, h e University of Texas at Austin
3:05 p.m. Estimating Parametric Uncertainties of the
Community Atmospheric Model (CAM3) and
Processes Controlling Global Climate Change”¢’¬?
Charles S. Jackson, h e University of Texas at
Austin
3:35 p.m. Floor Discussion
235 CC-214
Climate, Weather, and Spatial-Temporal
Models”¢’¬?Topic-Contributed
Section on Statistics and the Environment, Section on Statisticians in Defense
and National Security, Section on Bayesian Statistical Science, WNAR
Organizer(s): Stephan Sain, University of Colorado at Denver and
Health Sciences Center
Chair(s): Douglas W. Nychka, National Center for Atmospheric Research
8:35 a.m. Models for Multivariate Spatial Lattice Data
and Assessing Climate Change”¢’¬?
?Stephan Sain,
University of Colorado at Denver and Health
Sciences Center
8:55 a.m. Spatial Patterns of Global Climate Change
Fields”¢’¬??Reinhard Furrer, Colorado School
of Mines; Reto Knutti, National Center for
Atmospheric Research
9:15 a.m. Modeling Precipitation Network Data When
Station Reporting Times Are Misaligned”¢’¬?
Jarrett Barber, Montana State University;
Alan E. Gelfand, Duke University; Douglas
W. Nychka, National Center for Atmospheric
Research
9:35 a.m. Spatial and Temporal Models for Evaluating IPCC
?Mikyoung Jun, Texas
Climate Model Outputs”¢’¬?
A&M University; Douglas W. Nychka, National
Center for Atmospheric Research; Reto Knutti,
National Center for Atmospheric Research
9:55 a.m. A Hierarchical Bayesian Spatio-Temporal Model
for Tropospheric Carbon Monoxide”¢’¬??Anders
Malmberg, National Center for Atmospheric
Research
10:15 a.m. Floor Discussion
THERE ARE MORE, here is the link!
Click to access ProgramBook_Full.pdf
Dr. Juckes, you are not fooling anybody. May the truth of that haunt your dreams because it’s not getting through to you in your waking moments it seems! I am not a scientist, but my husband is and if he treated or responded to anybody questioning his work like you are, he’d be fired. I for one am shocked at your behavior, fudging, and lack of fellowship in the spirit of truth, and even though that seems to be the way climate “scientists” think they can operate these days; it is still hard to understand as reality.
We watched the television show “Cosmos” with Carl Sagan the other day. His subject of discussion touched on this as well-how famous ancient Greek thinkers-although considered brilliant in their day (and they felt that way of each other too) when pondering the universe-did find flaws in their thinking and observations-but would not share many of those flaws with the “peasents”, so they would remain in their elite positions. They also adopted ideas or theory from people not belonging to their “club” and failed to cite them as sources for that information.
So there goes progress.
Apologies SteveM if I put this comment in the wrong place.
#60
Yes, that was already mentioned in #45. But then I applied CVM to reconstruct NH temp using Solar (i.e. http://www.nature.com/nature/journal/v430/n6995/extref/nature02478-s1.htm , fig7-solar.txt vs. nhmean.txt), years 1902-1980. And the resulting R=0.81. How significant is that?
RE: #60 – CO2 is present with the morphology of a specific layer? That is news to me. I have not seen any cross sections of the atmosphere depicting a CO2 layer, unlike the Ozone layer. Where is this CO2 layer? Does it really exist? Or, are the CO2 molecules more or less distributed widely, in accordance with their proportion of the overall atmospheric ratio?
Steve S.
I think it’s especially important in this thread to pay attention to the wording used. Whatever failings in tone and content there are in Dr. Juckes’ posts, he didn’t indicate that CO2 is present as a specific layer. He said CO2 “acts as an insulating layer”; in any case, since that comment was either the result of a misunderstanding or non-responsive, it’s not worth pursuing further.
Re #60
You can reject that the reconstruction series is generated by the process you use in the Monte Carlo simulation. That is a bit of a distance from saying that you can reject that the correlation with temperature is pure chance or indeed causal. There are an infinite number of other generating processes for the reconstruction that still imply no meaningful correlation with temperature.
A quick question, how likely was the Union reconstruction to have been generated by your Monte Carlo characterisation of it? Does it actually sit close to the 50th percentile?
Re #61: The page you had trouble with contains the sentence “NEW:: Our work is now published in a Climate of the Past Discussion paper. Software used for this paper can be downloaded here, the data used is provide in the supplementary material.” — With a link to the code in the obvious place. Does your browser not show link the link on the word “here”? The code does all the reconstructions, as described in the README file. The language is widely used and documentation is freely available.
You were not able to “guess” that rms normalisation was used in figure 1 of the supplement, you were told.
Re #62: Sorry, I can see its not quite what you asked for, but perhaps it is not a bad thing to start at the simple level. Re 67,68: Yes, CO2 is more or less well mixed in the atmosphere. To be more precise, we should perhaps say that the atmosphere acts as an insulating layer because of the CO2 and other infra-red absorbing molecules it contains (especially water vapour). An important point here is that O2 and N2 do not absorb infra-red radiation, so even though the CO2 is a small proportion of the atmosphere by mass it is still a major factor in determining the insulating properties.
Re #65: The absorbing properties of CO2 have been directly measured in great detail and can be explained by well understood physics of molecular structure.
re #66: You can’t determine the significance from the R value alone, it depends on the correlation structure of the data (or, form a different perspective, on the number of degrees of freedom).
re #69: I think there is a detail missing: you ask how likely the Union construction is to come out of the Monte-Carlo approach: an exact match, as in the curves lining up exactly, won’t come out of the Monte-Carlo approach. The R coefficient of the Union reconstruction lies in the 99th percentile of those evaluated from the Monte-Carlo simulation, that is what the significance level means.
Re #65,70: Sorry, just realised that “well understood” is not a good phrase here: the kind of physical theory needed is undergraduate level physics, which is clearly not understood by a lot of people. But understanding properties of atoms and molecules has been a major success of 19th/20th century science, and the absorbing properties of CO2 are a relatively simple part of that achievement.
Yes, that is true. And with the known correlation structure, the variance of R can be obtained using equations shown in #53. (But need to remember that the distribution of R is not Gaussian, and not necessarily unimodal).
Correction to #66: I was comparing nh-reconstruction (and Figure 7 version of it..) and solar. For nh instrumental R=0.7 or would be closer. But even R=0.7 is much larger than R=0.535, so I think solar vs. nh_temp is more significant than Union vs. NH temp. Need to check it though, takes time, slow computer, sorry.
Doh, R=0.535 was from MBH99 not Union.. Anyway, I’ll run the 10000 and let’s see..
#70
Result of a simple AR1 test, simulated Instrumental NH temp and Solar (p1=0.7, p2=0.98), N=10000: max(R_sim)= 0.65. Now is this more significant than the Union, because R of (NH, Solar) is 0.72? Residual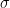 for this ‘reconstruction’ is 0.147. Detrended R is 0.4.
for this ‘reconstruction’ is 0.147. Detrended R is 0.4.
Please don’t take offence, I’d just like to know where’s the mistake..
#70 and #71 Martin
“Re #65: The absorbing properties of CO2 have been directly measured in great detail and can be explained by well understood physics of molecular structure.”
“Re #65,70: Sorry, just realised that “well understood” is not a good phrase here: the kind of physical theory needed is undergraduate level physics, which is clearly not understood by a lot of people.”
I think its time for you to leave this debate as its now obvious that you have lost it. Resorting to insulting the intelligence of visitors (many of whom like myself are physicists) to this blog by saying that they are not capable of understanding the basic physical processes that underpin the GHG effect, I think, more than adequately demonstrates that you are now desperate. You can’t win the debate by discussing the science so instead as with your fellow HT members you resort to arguing from your claimed level of authority.
Since you claim to be arguing from authority Martin, then lets take a look at your authority. This will require some questions to be asked so here goes. I understand that you work at CCLRC RAL? Besides proxy temperature reconstructions what else do you do during your day job? According to this link you are an atmospheric scientist. Are you involved in any of the work on particle physics that is funded by the CCLRC or the ISIS facility i.e. do you have day to day contact with any physicists at RAL? If so do you ever discuss quantum mechanics with them and in particular its relevance to the GHG effect and global warming? Do any of them believe (as you do) that CO2 is the primary GHG or do they know that the primary GHG is water vapour? As an atmospheric scientist in the space science and technology department do you have any day to day dealings with your colleagues in the solar terrestial physics field? If so, how may of them think that CO2 (along with positive feedback from water vapour) is the primary cause of global warming? As an atmospherc scientist do you have any dealings with Isaac Held or Brian Soden? Are you directly involved in climate modelling i.e. do you perform climate simulations? If so then with whom do you interact with in this respect? As an ‘atmospheric scientist’ I am puzzled as to why you are involved in temperature re-contructions and why are you the lead author for this report?
KevinUK
Kevin,
I think you’re being a bit too harsh on Dr. Juckes. But you’re right that he’s trying to duck the hard questions by focusing on the weakest links in the chain.
Actually I had a better response to his “blanket” remarks than those presently here but Steve “edited = removed” it (see #63) in a futile attempt to keep things on topic. The point is that the “blanket” metaphor is badly flawed since that isn’t how CO2 warming works. But such “undergraduate” analogies are just begging for drawing out those who haven’t studied the actual physics and that appears to be Dr. Juckes intention.
I’m afraid that the AGW proponents have a rather off-base opinion of the intellectual and educational attainments of the skeptics and this means that they generally come here expecting to talk to people who don’t know what they’re talking about and become flustered when faced with real and serious questions. So they end up trying to argue with those who are confused and then can feel satisfied when they run back to their peers and say that all they found here were yahoos.
Re #70: I don’t know what your p1 and p2 mean: how well does your AR1 process match the correlation structure of your proxy?
Re #75: The fact that a lot of people do understand it doesn’t alter the fact that a lot of people don’t. ISIS is not going to add a lot to our knowledge of the infra-red absorbing properties of CO2. Quantum mechanics is necessary to explain the radiative properties of atmospheric gasses. I’m lead author on the report because I wrote it. What are you angry about?
Re #60 (Martin):
Oh dear, here we go again… How hard is it to you to understand the simple thing that you are measuring a fit against a series you have already fitted your proxies?!?! This has been described even here several times, including the fifth line in this very post and again in the last paragraph, but you still don’t seem get it. What’s wrong with you? Please keep reading this until you understand it. Maybe then we can really “move on”.
I don’t have time to teach you basic under-grad statistics, but here is a try to improve your understanding. Cut and paste the following Matlab code and play with it. Maybe then you understand. You may apply “my method” to your Union proxies (and use your full NH series). Let’s call the reconstruction MJMBR (=”Martin & Jean Mannian BSt Reconstruction”). Please report your r values and “significance”. I’m sure it’s going to beat your reconstructions!
Here’s the script:
% "Mann Optimal" Tempererature Reconstruction from Pseudo Proxies
% Jean S/17.11.2006
clear all; close all;
% Instrumental record. I'm using MBH99 version:
% ftp://ftp.ncdc.noaa.gov/pub/data/paleo/paleocean/by_contributor/mann1999/recons/nhem-raw.dat
inst=load('nhem-raw.dat');
[n_inst,m]=size(inst);
% Any start year before first instrumental year will do!
years=666:inst(end,1);
n_years=length(years);
% The number of pseudo proxies
% Experience has shown that for the best results one should have
% around n_inst+1 proxies ;) But any number will do.
N=n_inst-47;
% Visually nice proxies:
P=filter(1,[1,-0.8],randn(n_years,N));
% But we can use any (random) proxies you wish.
% Uncomment for white noise:
%P=randn(n_years,N);
% Now (LS) _optimal_ estimation of the proxy weights:
weight=pinv([P(end-n_inst+1:end,:) ones(n_inst,1)])*inst(:,2);
% NH tempereture reconstruction
T=P*weight(1:end-1)+weight(end);
% Some statistics
RE=1-mean((T(end-n_inst+1:end)-inst(:,2)).^2)/mean((inst(:,2)- ...
mean(inst(:,2))).^2);
r=corrcoef(T(end-n_inst+1:end),inst(:,2));
% Plot
subplot(2,1,1);
plot(years,T,'b');
hold on;
plot(inst(:,1),inst(:,2),'r');
title(['With ' num2str(N) ' proxies']);
legend('Reconstruction','MBH99 Instrumental',0);
xlabel('Year');
ylabel('Temp');
axis tight;
subplot(2,1,2);
plot(years(end-n_inst+1:end),T(end-n_inst+1:end),'b');
hold on;
plot(inst(:,1),inst(:,2),'r');
title(['RE=' num2str(RE) ', r=' num2str(r(2))]);
legend('Reconstruction','MBH99 Instrumental',0);
xlabel('Year');
ylabel('Temp');
axis tight;
UC, please, could you produce a few figures with the above code (with different parameter values) to your page for people to see?
Here you go. I have a long version of .m CVM simulator, but let’s continue step by step..
p1,p2 are the one-lag autocorrelations I used in the simulation. I think 0.98 is quite good estimate of the one-lag autocorrelation of Solar. First equation in #53 would help to analyze the effect of more complicated models. Nothing significant though, I believe..
Jean S,
now let’s be careful, your code does direct regression, right? Then there are INVR and CVM, and Table 3. is about CVM results. And MBH99 is quite close to CVM+INV, but I need to consult Steve to find out whether this hypothesis is true..
re #79: Thanks… there is something strange though… extra red line from 1980 on plus my reconstructions (with the same values) on my machine look slightly better?!?
re #80: It finds the best least squares fit of the proxies to the instrumental record under the affine linear model P*A+c. All the HT reconstructions are fundamentally affine linear, so I don’t expect any of them to beat mine under Mannian (Juckes) “optimality” criterion.
Re #78: The testing is done on the significance of the R statistic precisely because the fitting process does not affect the R statistic. What is being tested is how well the shape of the unfitted composite matches the shape of the temperature series. I’ll have a look at your code next week. (No comment on UC’s calculations because it is currently not showing — a temporary problem I think).
81,83
My nhem-raw was corrupted. Uploaded new jpgs, but it seems that we are famous, data transfer limit exceeded…
The code is turnkey. I’ve run it myself. It took 10 seconds to download the file, type in the local file name, and run the code. Next week?
#77, martin
“Re #75: The fact that a lot of people do understand it doesn’t alter the fact that a lot of people don’t. ISIS is not going to add a lot to our knowledge of the infra-red absorbing properties of CO2. Quantum mechanics is necessary to explain the radiative properties of atmospheric gasses. I’m lead author on the report because I wrote it. What are you angry about?”
Martin you claim to better understand how quantum mechanics determines the radiative absorption properties of CO2 than others on this blog. Good, I’m glad you do understand quamtum mechanics well as given that you claim to be an ‘atmospheric scientist’ I wouldn’t expect any less. I’m not an atmospheric scientist but I also understand how quantum mechanics determines the radiative absoption properties of gases e.g. CO2. As you didn’t answer the question I asked I assume therefore that you’ve never discussed quantum mechanics (and its relevance to the GW debate) with your particle physics colleagues at RAL? Would you care to discuss this subject with a non-climate expert like myself as it is fundamental to the whole debate on global warming, particularly the issue of positive feedback from water vapour? I’d like that very much as sadly Issac Held didn’t stay around for too long to discuss it. Perhaps after we’ve finished our debate we can then educate Gavin S over at RC about black body radiation.
Now you answered my question as to why you are the lead author with an obvious answer but that’s not what I was asking. What I want to know is why is an atmospheric scientist from the space science and technology dept at RAL writing a paper on temperature re-constructions? Who funded the writing of this paper? In asking these questions let me make it clear that I am not questioning your motives, but rather as a UK taxpayer I wish to know why RAL (through the CCLRC?) are involved in paleoclimatology?
KevinUK
re #83:
But you did “standardize” your proxies, didn’t you?
Also, my comment in #78 was by no means specific to this “Table 3 thing” … hopefully you get the point “next week”.
re #84: Maybe you should put some ads to your page to get some money from the downloads 😉
BTW, few days back I noticed that you had done something with MBH99 AD1000 proxies (could not find the post again), my question is, what proxies did you use? Are they available somewhere?
#88
Hey, no oil money involved, u know 😉
Anyway, I think you are referring to Weblog update imminent # 87:
No time to clean my code (hey, where’s all that oil money??) but here is shortly my impression of INVR, CVM and ‘direct LSQ’
% NPro whole period
% NCal calibration period
% P raw proxy matrix
% T = (NH) instrumental temperature
% Ps(:,i)=(P(:,i)-mean(P(:,i)))/std(P(:,i)); standardized P
meanT=mean(T(1:NCal));
Tr=T(1:NCal)-meanT;
%% direct regression (my term (?))
Xd=[P(1:NCal,:) ones(NCal,1)];
bha=(Xd’*Xd)\Xd’*Tr;
pha=[P ones(NPro,1)]*bha+meanT;
%% inverse regression
X=Ps(1:NCal,:);
Bh=((Tr’*Tr)\Tr’*X)’;
ph=(Bh’*Bh)\Bh’*Ps’;
INV=ph-mean(ph(1:NCal))+meanT;
% CVM
xk_=mean(Ps,2);
CVM=xk_*std(Tr)/std(xk_(1:NCal));
CVMs=CVM-mean(CVM(1:NCal))+meanT;
Re #70
To answer my own question. The likelihood that the Union reconstruction has the AR(n) DGP that you specify for your Monte Carlo experiment is 0.02%. Thus, you can reject H0 that the DGP for the Union reconstruction is the AR(n) process you use to generate your distribution of R statistics. OK – so what is its DGP?
Rejecting H0 does not mean that Union=f(temp). There is a rather wide universe of alternative DGPs for the Union reconstruction that implies no causal correlation with temperature. Jean has apparently specified one above by taking account of the pre-selection of the proxies used in the reconstruction with the raw DGP for the reconstruction still not having a relationship with temperature.
Your statement “This means that we can reject the null-hypothesis that the reconstruction series is correlated with temperature by pure chance. ” is not supported by your evidence – because that is not your H0, you have specified an incredibly broad and compound statement as being your H0 in that sentence. For example, can you reject that Union=f(rainfall) on the basis of your experiment? Union=F(population)? The statement, the Union reconstruction is not a simple AR(n) process is supported because that is your actual H0.
Re: 86
This doesn’t seem unreasonable to me. I’d prefer Dr. Juckes to respond to the substantial questions about the methodology in the article, such as the recent ones by John S and Jean S.
#91, Armand
I’m asking these questions of Martin, because like Martin is now, I used to be in a government funded job – literally next door to where Martin works. I use dto work close to Martin’s sister laboratory at Darebury and until very recently I shared an office with people who are in the same ‘space science’ business as Martin. I just want Martin to admit that his funding most likely comes from the Natural Environment Research centre (NERC), as does Peter Cox’s the inventor of the ‘Day of the Triffids’ model that when incorporated into GCMs predicts increases in mean global surface temperature of over 10C and predicts the extinction of thousands of species and the Amazonian rain forest. Now it might not seem unusual in the US for an organisation like NASA (GISS) to be involved in climate modelling but it is unusual in the UK for an organisation like RAL to be involved in paleoclimatology. As a UK taxpayer I want to know why Martin as head of the Atmospheric Science Group of SSTD, RAL is involved in paleoclimatology studies. Its a reasonable question to ask and I’m sure Martin won’t mind answering it. I also hope (given that on his own admission he ‘understands the physics’ which visitors to this blog don’t) that he won’t mind having a debate on quantum mechanics and its relevance to global warming. I’m sure we’ll all learn a lot from the debate.
KevinUK
#92
sorry ‘centre’ should have been ‘Council’. Must re-read before clicking that submit button.
KevinUK
Re #19 fFreddy, I have no idea what’s involved in getting the permissions. That’s why I want to make it *your* new job!
Re #91 It is as reasonable a question as “who is the botanist on this team?” Which I asked several weeks ago while investigating the possibility of a mis-specified growth response model.
In fact, talking with a PhD botanist today who has many years experience with experimental (not just survey-style) tree-line conifer work, he indicated that many dendroclimatologists consider treeline conifer growth as a proxy for evapotranspiration, not temperature. So much for that part of the “consensus”. His work will be published soon.
Now THAT makes sense! I can identify with the trees in this respect, since I have precisely the same problem at high altitudes/latitudes!
Re #95 It makes sense to me too. When you consider how that Norby et al paper* cited by Idso explained the CO2 “fertilization” effect as largely an increase in water-use efficiency, this makes even more sense. CO2 affects evapotranspiration in the same way that wind exposure does. And when you consider the strip bark form is a product of cambium dieback … well, is that not evapotranspiration driven – just like needle dieback, twig dieback, root dieback?
*Wullschleger S. D., T. J. Tschaplinski, and R. J. Norby. 2002. Plant water relations at elevated CO2–implications for water-limited environments. Plant Cell & Environment 25: 319-331.
I want to know what Juckes et al. make of this work. Are they avoiding the issue? I keep asking to the point that I am clogging up Steve M’s blog. But I think it is important to know how they defend their proxy in light of this work. It appears the team has NOT moved on. But the tree physiologists HAVE. Am I being unfair?
Here are some other papers by the Richard Norby group showing how plants grow under variable/extreme environmental conditions. These guys really know what they are doing. Maybe dendroclimatologists should be forced to include a botanist and a statistician on their writing teams?
Re: #92
I don’t think funding issues have any relevance to the correctness/completeness of the work in this paper. At the least, they are better discussed in a separate thread, leaving this for scientific issues.
Certainly, your proposed quantum mechanics discussion would be better in its own thread.
96: Yeah, and this mechanism may well explain the “divergence problem.” If temperatures go up and moisture stays the same, the trees get stressed. If there is not enough moisture, increased CO2 will not help. Most treeline areas have very poor soil, poor water retention.
In fact I talked to a second botanist today, this one from Sweden, and she pointed out *exactly* what you have said here, jae. These are not crackpots, folks. These are academic PhD scientsts who disagree with the dendroclimatological “consensus”.
Maybe I should go hang out with maksimovich and the Russian solar physicists. See what they’re willing to say about GCMs, off the record.
#100 — If you do, Bender, please ask them why no one has propagated the parameter uncertainties and measurement errors through a GCM to determine a confidence limit. If their response includes cynical laughter I’d sure like to know, and why. Maybe my question is hopelessly naive, scientifically.
Fritts 1969 ss a very detailed study relating bristlecone pine growth to evapotranspiration. Fritts was one of the coauthors of Lamarcge et al 1984 proposing CO2 fertilization in connection with Sheep Mountain (a study generalized in Graybill and Idso)
Re #101 Naive? Not at all. That’s one of the questions I want answered too.
Re #102 If your point is that it’s been known for a long time that the bcps are unsuitable as a temp proxy, I would agree. But the fact is some have chosen to ignore that “POV”. That’s why I list the Norby references in #97. It’s easy to ignore a 1969 paper. It’s easy to dismiss Idso. But how do you dismiss all these other, more recent papers? I want to know what Dr. Juckes thinks of them.
#92 “I just want Martin to admit that his funding most likely comes from the Natural Environment Research centre (NERC), as does Peter Cox’s the inventor of the “Day of the Triffids’ model…” – KevinUK
That’s right. If Juckes is funded by the *very same* Council as a (presumably) dodgy piece of work, then QED, his work must be dodgy too. I love this place! Now explain why paleoclimatologists must have a thorough grasp of QM.
It seems a bit unfair that people like Steve McIntyre can be attacked for his source(s) of funding but climate scientists, who are clearly as white as the driven snow (except for not reporting adverse results, inaccurate descriptions of methods, withholding of data, etc. etc.) can’t have their funding questioned in any way.
FWIW I don’t particularly care where the funding for a given paper comes from, only if the science is solid or not, but this particular complaint just seems so hypocritical.
#105 McIntyre can be criticised for a number of things, but as far as I know, his funding isn’t one of them because he has no funding.
That doesn’t stop people trying…
Thankfully that does not include you, it would seem.
But would you agree, Mick, that it’s not valid to attack anyone’s science based on where the funding for it comes from, even if that funding source is an oil company or similar? The science is what’s at issue here, not who pays for it. If you want to show that it’s flawed you have to point out where the logic has gone wrong. Agreed? I think we should be fair to all parties on this issue.
Re #105. 106, 107 – You guys should get on line (if not in Canada) and pick up the last Fifth Estate program on the “Denial Machine” and watch them attack people and not the science. If you are in Canada they will continue to rub it in sevaral times this weekend on CBC Newsworld. But a Warning first – Sit on the floor or a very low chair (avoids falling off) and make sure you have one of those bags you may have saved from an airplane seat in front of you.
re 108
Teh CBC has an omsbudsman who takes complaints. They also seem to be very
sensitve to charges of bias. So a number of letters pointing out the slant
exhibited by this program would proably be efficacious. Remmber what happened
to the CBC after “The Valour and The Horror”. They are very sensitive to the
the possibility of budget cuts.
I seldom watch the CBC. What did the “Denial Machine” program say?
http://www.cbc.ca/fifth/denialmachine/index.html
Re #106
Such as?
Re # 110 You can get to the link here:
http://www.cbc.ca/fifth/denialmachine/index.html
Here is a summary:
The Denial Machine investigates the roots of the campaign to negate the science and the threat of global warming. It tracks the activities of a group of scientists, some of whom previously consulted for for Big Tobacco, and who are now receiving donations from major coal and oil companies.
Who is keeping the debate of global warming alive?
The documentary shows how fossil fuel corporations have kept the global warming debate alive long after most scientists believed that global warming was real and had potentially catastrophic consequences. It shows that companies such as Exxon Mobil are working with top public relations firms and using many of the same tactics and personnel as those employed by Phillip Morris and RJ Reynolds to dispute the cigarette-cancer link in the 1990s. Exxon Mobil sought out those willing to question the science behind climate change, providing funding for some of them, their organizations and their studies.
The Denial Machine also explores how the arguments supported by oil companies were adopted by policy makers in both Canada and the U.S. and helped form government policy.
#112 How about:
1. Failure to publish. If he thinks he has important things to say there really is no excuse for refusing to write them up and get them into the international scientific literature. Here, he’s just playing to the gallery. Few regular posters have the maths background to check out what he says, but more than a few give the strong impression that they will cheer for anything that suggests AGW is a conspiracy by wicked scientists and/or the UN. No doubt this is vey satisfying for his ego, but since very few climate scientists bother to post here his claims go largley unchallenged.
2. Prima Donna behaviour – e.g., thread titles such as “Is Gavin Schmidt Honest?” or “Possible Academic Misconduct By…”. How old is this guy? At times he behaves like a stroppy teenager. If he could just calm down sometimes and restrict himself to a cool presentation of facts he would be so, so much more effective. And please, don’t say that similar behaviour by others in the field excuses him. It doesn’t. I wouldn’t accept that as an excuse from a child so I won’t accept it from him either.
Mick
#104
Martin is an atmospheric scientist NOT a paleoclimatologist. See here. As an atmospheric scientist I’d expect him to be well versed in quantum mechanics as it is after all fundamental to the physics (radiative absorption) of the atmosphere. He doesn’t appear to have ever discussed quantum mechanics and its relevance to global warming with any of his fellow physicists at RAL so I’ve suggested that as an expert that he discuss it with me and others on this blog who he claimed do not understand it very well. Are you a UK taxpayer? I am, hence why I want to know why the NERC is funding an atmospheric scientist to conduct paleoclimatology (specifically proxy temperature re-construction) studies?
#114
Do you haave a twin who goe sby the name of TCO by any chance? Steve will publish when he’s good and ready and not before. Can I ask when was the last time that you were called to give testimony before a US congressional committee? Can I also ask that if you think Steve is a ‘prima donna’ then what do you think Michael Mann, Gavin Schmidt and Billy (wiki) Connelly are?
KevinUK
re 113:
LOL Exxon-Mobil please contact me, you owe me some money for being a sceptic.
RE: #114,115
note that steve has published twice in E&E, once in GRL. These have given him an important platform, and his published work has definitely made an impact; it was accepted by the NAS and Wegman reports.
Having said that, it would be great to see more such publications. There are some details; you can’t just publish the details of how difficult it is to replicate X different papers. So how to write it up as a coherent package ? And how to deal with the issue that prior publication (i.e. on a blog) will disqualify from publication ?
But it is important to dwell on the importance of publication. I am sure no-one misses this.
per
#113
So the centrepiece of this programme is a certain Saint Frank Luntz who has now been struck down on the road to Damascus and has come to see the light. He now acknowledges that global warming is a reality. Well thats good because that means that he’s joined the rest of us who also think that global warming is a reality – a reality that has existed for decades, centuries, millenia along with global cooling. What I noticed about this programme is that there was vitually no mention of MAN-MADE global warming and for some reason it seems to claim the the ‘denial machine’ invented the term climate change so that it could be used instead of the phrase global warming. I think someone should therefore tell the UN that the IPCC has been mis-named and that they should now be called the IPGW.
KevinUK
Indeed if we get a winter like 1963 in Europe, be prepared for a standstill and serious economical damage. Gas shortages, people freezing to death, fuel riots etc. So yes, global warming is good for you. IPCC doesn’t consider the benefits of mild winters.
And please don’t fall for the scaremakers that increasing CO2 means stronger winters as well, because it doesn’t.
Re #114 – **but since very few climate scientists bother to post here his claims go largley unchallenged.**
There are a growing number of competent scientists reading and posting here.
It is not that *his claims go unchallenged*, but how do you challenge something that is correct? That is why he is unchallenged and the “climate scientists aka statisticians” will not engage him in a debate, but resort to printing statements such as “has been refuted”. Look at the high levels where his claims found agreement – NAS and Dr. Wegman.
Re #116 I wonder if Exxon will send a check to lukewarmers like me. Lukewarmers ought to get at least some free gas.
Wasn’t the remark relating quantum mechanics to the understanding of carbon dioxide effects on climate pretty much a throw away line? It has been a while since I have read the current literature, but I would assume our knowledge of carbon dioxide absorption and emission of electromagnetic radiation is derived from direct measurement (and well known and understood) and not from the exact analytical solutions of the Schrodinger wave equations for carbon dioxde.
I think it best we keep Martin Juckes on line to answer the direct questions about his proxy paper. I can get past the very human tendency to spar a bit and do not see it as an impediment to anyone who really wants to engage and answer questions in a search for the truth — but I judge that it is a bit more efficient, in his case, to stay completely on topic.
#117 — “There are some details; you can’t just publish the details of how difficult it is to replicate X different papers.”
But Per one can write a critical review. Critical reviews have a very important and honored place in research publications. They establish the position of the field and show what has worked and what has not, and why in each case. Often, suggestions for improvements are made, and fruitful directions for future research are assessed. These sorts of reviews are the teaching tools of new generations and in constant reference by working scientists. Steve M. is in a perfect position to write such a review. It would be a killer and an absolute classic. It would be cited for 100 years; first as the way to rigor in the field, and later by historians of climatology or science as the fulcrum on which the field turned. After a critical review by Steve M. plus whoever else came aboard, dendroclimatology would never be the same. And it should never be the same.
#123 – I totally agree. So why won’t he write a review of stats methods for paleoclimatology?
#124. Mick, when I started this, I was astonished that no one had ever verified the work behind such a famous article and had a limited goal of simply verifying what was done. I’ve reported on these problems. I’ve also been upgrading my own skills in theoretical issues with autocorrelated series etc. Trying to write a review of stats methods for paleoclimatology is a very large undertaking. I agree that it should be done. It would take me a very long time to do.
# 78
Here is another m-file, includes CVM, INVR and INVR+CVM (#89). Should be turnkey (simulates temperature as well).
Re #124 It is not necessary to be an authority to prove the authorities wrong.
#124 Mick, try reading the Wegman report by a top statistician, and peer reviewed. Not as comprehensive as SteveM, but still makes some of the points loud and clear.
bio
PS JohnA, should there be a link to Wegman on the Sidebar?
re #78: This code creates a “reconstruction” by direct regression, so that the reconstruction is fitted to the temperature record. It is clearly, as you say, incorrect to test the significance of this using a Monte Carlo simulation with a null hypothesis assuming independence of the reconstruction and the temperature record. A meaningful Monte Carlo simulation could be carried out by taking as a null hypothesis: “the proxy records are independent of temperature”. In the CVM method this is equivalent to the null hypothesis I have taken, because the composite is just a sum of the proxies.
In your code, replace:
T=P*weight(1:end-1)+weight(end);
with:
T= sum(P,2)/N;
and you will be simulating what we have done, apart from scaling of T.
Re various posts by KevinUK: I certainly didn’t claim to know more about quantum mechanics than all the people who write here, but I know enough to understand the basics of radiative absorbtion in the atmosphere. People over at ISIS obviously have a far greater knowledge of quantum mechanics, but in my work I have never needed anything I can’t find in text book.
Concerning funding: NERC has put a lot of effort into developing climate models. This work is aimed at improving understanding of past climate variability to aid both to aid development of climate models and to aid policy makers.
#129
Yes, that example doesn’t bring CVM-based Rs down, just direct (and inverse) regression based Rs. In addition to the match-with-Solar question, I have another CVM-question: in Table 3. none of the coefficients of correlation is 1. It means that there is noise in the reconstructions, right? So, before the CVM step, we have a proxy-based vector:
and R(T,P)=0.535 (MBH case).CVM won’t change this. Now, CVM includes a step where P is divided by the standard deviation of P. But standard deviation of P includes the effect of n. Doesn’t this mean that T will be always scaled down?
(Sorry if this is a stupid question, I’m a CVM-newbie..)
Mick,
I find your criticism of Steve McIntyre’s “failing” to publish to be idiotic. First, he has no obligation to anybody to publish anything. Second, he is unfunded and doing all this in his spare time. The same is true for Ross and a few others that have been working with him. This blog even goes way beyond what could reasonably be expected of anyone in this situation. You want him to publish, then fine, put your money where your mouth is and write him a check.
I find it incredible that he has accomplished as much as he has; most people would not put this kind of effort into something they are not being paid to do. I keep expecting him to get fed up with the whole thing and just drop it, but he persists, often in the face of viscious attacks on his character. I wonder if you were in his place, Mick, if you wouldn’t get a bit surly at times too; I’m not so sure I could do any better under similar circumstances. So even when I sometimes find his comments a bit too ascerbic, I cut him some slack. I’d suggest you do the same. Alternatively you could walk a mile in Steve’s shoes and undertake your own analysis of these issues and start your own blog to discuss them.
re #129: Good Martin, you are starting to get the point. Now, I reformulate my question from #87, which you chose not to answer:
did you “standardize” your proxies (essentially using the temperature as the reference) or not?
This point was even understood in MBHx, although they did not practise it… that’s why they have the reference and the calibration periods. You can take this idea (using the calib and ref periods) even further by arbitrarily changing the calibration and verification periods. This was done in the Burger and Cubash-paper submitted to the very same journal as your paper. Amazingly, the paper got rejected. I bet the politics had nothing to do with it.
Also for a further reference (I’m planning a post here so I want to have the facts straight):
do you still stand by your claim that the correlation (instead of covariance) based PCA is the right way to do with these proxies? Related to this, which of the following are assumed to be valid for proxies:
1) linearity with respect to the temperature
2) spatial whiteness of the noise
3) temporal whiteness of the noise
4) Gaussianity of the noise
To clarify my point in #130, change the code linked in #126 :
p_prox=0.0; % white proxy noise
w_prox_s=2; % std 2
w_sample_s=0;
CVM result is in here http://www.geocities.com/uc_edit/ex1.jpg
cfCVM =
0.5092
I think Bender is after the same issue in
http://www.climateaudit.org/?p=894#comment-69280 (?)
re #133: Yes, I think Bender is also after the same thing, so am I in the correlation part of #132 🙂 It’s all about SNR…
Re 132: the proxies are standardised to unit standard deviation. A composite is then formed. The significance of the correlation between the composite and the temperature is tested. The composite is scaled to get the reconstruction. Re your 4 assumptions, see appendix B.
Re 130: This is dealt with in appendix B. Variance Matching (the “VM” of CVM) means that the variance of the reconstruction matches the variance of the measured temperature in the calibration period. This means that there should be no bias towards higher or lower variance in the reconstruction. The reconstruction does rely on a degree of stationarity.
Then I’m doing something wrong.. My version of CVM (and INVR, BTW) underestimates the simulated ‘MWP’.
Can you be more specific?
re #135: Martin, first, try to answer the questions instead of annoying replies like “see appendix B”. I’m no baby. I do know how to read. I also have a PhD in related issues, so I may understand something about these maths. If I ask you something, it’s very likely that I was not able to completely understand (or was not sure) what you meant in your paper. In #135 you refer to appendix B twice, it does not contain answer to either of the questions.
So you standardize your proxies to unit sample variance. Yes, but over what period? How about mean? It is not said in the beginning of your Appendix A, ans I could not find it from anywhere else either. Am I supposed go to check the code? Appendix A only says “standardized” proxies. In my field, this type of use of completely ambiguous language is not acceptible. Why are you in purpose making readers’ life hard? Wouldn’t it be fair for the poor reader to just say everything plain and clear? Or are you misleading in purpose?
Here’s again a code. Try it and tell if the “standardization” matters to your correlations. Notice that the noise is Gaussian, and both spatially and temporaly white.
n=18;
I=900:1000;
N=randn(1000,n);
T=filter(1,[1 -1],randn(1000,1));
P=T*randn(1,n)+N;
P1=mean(P,2);
P2=mean(P./repmat(std(P),1000,1),2);
P3=mean(P./repmat(std(P(I,:)),1000,1),2);
corrcoef([P1(I) T(I)])
corrcoef([P2(I) T(I)])
corrcoef([P3(I) T(I)])
No, your Appendix B does not have a single word about assumptions on proxies. Is it so hard to list the numbers from #132?
No it is not either. Neither it is in Appendix A. Your CVM estimator depends directly on the variance of x, which, on the other hand, depends from the noise variance. So depending from the noise variance of your proxies, you get either “under” or “over” estimates.
BTW, you claim on p.1028 l.11 that y^* is not an optimal estimate. However, as far as I can see, the estimator is the ordinal LS estimator, which indeed is optimal under various criteria. So assuming your model, under what criterion it is not optimal and your CVM is?
Is this suppose to mean something specific?
#135
Let me guess. You assume that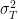 is very close to
is very close to 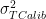 . i.e. calibration data variance represents well the whole data set variance. IOW, there was no MWP. Well, of course this would be silly, I’m just motivating you to answer 😉
. i.e. calibration data variance represents well the whole data set variance. IOW, there was no MWP. Well, of course this would be silly, I’m just motivating you to answer 😉
#135
In appendix A there is a statistical model
and it is said that
I’m quite confused with bars and hats here, but to me it looks like the square root term is less than one. Underestimate of y is corrected by underestimating it more?
Dumb question (because I know you know what you’re doing): you’re sure you’re not confusing symbology for parameters from normal & inverse regression? (I probably should not ask without reading Appendix B.)
Juckes said:
Unfortunately, Martin, in playing his usual guessing games, didn’t provide UC with the periods involved. I’ve experimented a little and here’s what I think are the applicable periods for the Esper CVM :
– he zero-ed his instrumental target series on 1856-1980
– he scaled the proxy series on the period 1000-1980. I had to experiment a little as there are other possibilities, but I eventually guessed this.
– the scaled proxies were average. I have an exact correlation at this step.
– the composite was re-scaled to the mean and sd of the target in 1856-1990 period. Here I used the instr series archived by Juckes. There is a slight discrepancy in the final calculation The 1856-1980 standard deviation of the archived Esper CVM version is 0.1799047 as compared to 0.1805515 for the target. The mean of the Esper CVM in 1856-1980 is -0.000639 as compared to the target 0.000000 .
This results in a slight discrepancy of up to +- 0.02.
IT’s hard to say what accounts for these slight remaining difference. Perhaps there’s a different instrumental target series used somewhere. Perhaps the target sd is a slightly different period.
Steve M, you say above that:
Was the standard deviation adjusted for autocorrelation? And if not … why not?
Many thanks,
w.
Maybe I’m missing something here, but doesn’t this have a direct solution without using a Monte Carlo method? Can’t we use the Quenouille formula?
Using that on the Union and the instrumental data gives us p = 0.08, which is both not significant and is a looooong way from 99.98% significant ….
What’s wrong with this approach?
w.
The issue with any significance test is exactly what alternative is being analyzed. For example, aside from autocorrelation, consider Yule’s type spurious regression of alcoholism levels against Church of England marriages. They have a correlation that is 99.98% “significant”, as do many other unrelated series – South African wine sales against Honduran births, that sort of stuff. A 99.98% “significant” correlation has negligible power as a test against that sort of mis-specification, or against more subtle forms of mis-specification: e.g. perhaps bristlecones and/or foxtails ring width being a function T+P+CO2 with interaction terms; ot nonlinearity or multiple other issues. It really makes you wonder as to the qualifications of the Euro Team to carry out this sort of study, especially in light of Wegman’s observations about how paleoclimatologists do statistics.
Concerned in Berkeley,
Food of various kinds can be grown under water. Very little food grows under ice.
I’m very concerned about my children’s future.
Please tell me how we can avoid another ice age.
I’d also like to know how to prevent volcano erruptions. I am told these can lead to global cooling and inadequate cropos. Something needs to be done.
Climate change can take decades to centuries. Volcanos can erupt in a day.
#140
Just read Appendix A2.
I think I understand why CVM underestimates past temperatures, but I’m not sure why INVR (my version of it, I use P2 of #137) does the same. (Sorry for being provocative)
I have tested all three estimators (direct regression, inverse regression and CVM) with pseudo-proxies in climate simulations, and I find that all three are biased, even in a control run simulation. The least biased in CVM, which proves to be quite robust under different levels of noise and network size. But so far, there is no perfect method.
I think the reason is that in a shot calibration period, the methods cannot capture well the relationship between pseudo-proxies and temperature at centennial scales. In all three methods, increasing the amount of noise and shortening the calibration period increases the bias. On the contrary, reducing the noise and lengthening the calibration period reduces the bias. The bias is always in the direction of underestimating the deviations from the mean, i.e. warm bias for colder periods and cold bias for warmer periods than the calibration mean.
The estimation of the variance in the CVM step is indeed biased when the series display autocorrelation. To estimate this bias one needs a model for the process itself, i.e. AR-1 or similar. For an AR-1 process the underestimation of the standard deviation is of the order of 10% when the ar-1 coefficient is 0.9. For lower autocorrelations the bias is very small. The NHT may have a 1-lag autocorrelation of this order. However, the autcorrelation of the all-proxy composite depends on the proxies used and on the number of proxies used, but I would say it will tend to be smaller (although one can construct counterexamples). In this conditions the error in this step of CVM will be small, unless the AR-1 model for the processes is really wrong- which may be the case. If the process happens to be for the NHT and the proxies-composite, then there is no bias in the re-scaling step in CVM.
The problem will be that one can perhaps specify a process for the proxies composite, since the data are available, but not for the NHT, for which only a short record is available.
I think the question of the significance of the correlation with autcorrelated-process is indeed relevant, but I have not checked that in this particular case. Perhaps the approach indicated by Willis is feasible, but we will encounter the problem of estimating the autocorrelationm structure, Due to the short record, the long lags autocorrelatiosn will not be estimated well. Other approach could be to assume a underlaying processes for NHT and the proxies-composite, which is also burdened with problems
#130
The expression P=alpha T +n ( I think the parenthesis are wrong in 130, is just a model for a proxy, which will not be fulfilled in reality.
I do not underastand what do you mean by “T will be always scaled down”. Alpha is just a parameter to convert units from the dimensionless proxy composite to temperature. The reconstructed T is proportional to the proxy-composite, so it will remain above or below the calibration-period mean regardless of the the value of alpha. This issue is therefore not important for the question whether the reconstructed MWP was warmer or colder than today. Which proxies are used, of course, may be important.
However, the amount of noise present in the proxies and the number of proxies does influence the CVM output. If this number is low , the proxy-composite will not be able to filter-out this noise and the alpha will in effect re-scale noise to temperature, which is an undesired effect. Again this would affect only the amplitude of the reconstructed variations around the calibration mean.
Ideally one would want to have many independent proxies, but the number available proxies are limited.
Perhaps I should renew my question for Martin or Eduardo from #90 in light of Steve’s comment at #144. So the Union reconstruction is not an AR(n) – on what basis can you claim that it is anything else?
I might also comment that it looks like an AR(70) (or more) is being estimated. Is that really the length of the AR process that is estimated for the Union reconstruction Monte Carlo? I would be surprised if there was any significance beyond 5-10 terms and the rest would just be modelling noise.
Eduardo, I agree with your comments. I did a post on this a while ago (which you commented on at the time). It’s one of many things that would be worth writing up. One interesting to think about in your pseudoproxy networks is this – under what circumstances does a lower-order PC contain a relevant temperature signal? In my experiments with your pseudoproxies, any large-scale signal was in the PC1. Any lower PCs in pseudoproxies were local oscillations (covariance or correlation). So based on the pseudoproxies, there’s no basis for using any PCs lower than the PC1 and this whole faux argument trying to justify the bristlecones based on Preisendorfer’s Rule N draws no support from your pseudoproxies.
Eduardo, good to hear from you again. In #147 you say:
I believe this is not only incorrect, it is way, way incorrect.
According to Nychka, an unbiased estimator of the effective number of data points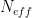 in an autocorrelated series is:
in an autocorrelated series is:
where “r” is the lag-1 autocorrelation of the series after detrending. Also, Nychka notes that if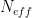 is less than 6, estimates of uncertainties and confidence intervals is likely to be unreliable because the effective N is so small.
is less than 6, estimates of uncertainties and confidence intervals is likely to be unreliable because the effective N is so small.
Standard deviation is a function with the form of:
and the standard deviation, adjusted for autocorrelation, is
This yields the relationship
Now, for a temperature series 1850-1979 inclusive, N = 130. Let’s use that N for a typical sample size. Substituting N = 130 and r = 0.9 into Equation 1 gives us an effective N for the hypothetical series of only 2.67.
Substituting this into Equation 2 gives us an adjusted standard deviation that is 8.8 times the unadjusted standard deviation! Obviously, this is a long ways from your “10% greater” figure. (It is also unreliable because the effective N is less than 6, as Nychka noted).
Using real numbers, let us take the Union reconstruction 1850-1979 inclusive. The lag-1 autocorrelation of the detrended Union reconstruction is 0.6, N = 130, and from Equation 1,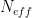 = 26.5. Subtituting that into Equation 2 gives us an adjusted standard deviation which is 2.25 times the unadjusted standard deviation, viz:
= 26.5. Subtituting that into Equation 2 gives us an adjusted standard deviation which is 2.25 times the unadjusted standard deviation, viz:
Union SD = 0.18
Union adjusted SD = 0.40
At least, that’s how I figure it … I’d be very interested in the opinions of the statistical heavyweights on this board.
My best to you,
w.
Willis,
I think I am not wrong in this case, but surely I can be convinced otherwise. I say this because I have tested it with Montecarlo series.
My estimation is based on the paper by Bellhouse and Sutradhar
Variance estimation for systematic sampling when autocorrelation is present, The statistician 37, 327 (1988).
I am not sure in which context the estimation by Nychka is valid, as I do not have the source. perhaps for the estimation of correlation? In any case the concept of effective degrees of freedom may be not very well defined and may differ from application to application. I think also that the series of NHT, modelled or observed, in the last 130 years has certainly many more than just 2 or 3 degrees of freedom. But try to construct Montecarlo series with a .9 lag-1 autocorrelation and estimate the variance with the standard formula for uncorrelated process.
eduardo
#149
I am not claiming that the Union recon is an AR-1 process. I have just stated that, if I have made no error, for the estimation of the bias in the variance, the influence would be minor. The important factor is something proportional to the sum of the autocorrelation for all lags. I think that, unless the process has a very long memory, with substatial autocorrelation at long lags, the bias will probably be not very large. If both series, the reconstruction and the NHT obey the same process, then there is no bias in this particular step, although the confidence intervals may become large
#150
Yes, I would also say that the pseudo-proxies would not support a NHT signal in lower-order EOFs. I can imagine, however, some constructed situations in the real world which could lead to such a result. For instance, if a non-climatic regional forcing is responsible for most of the growth variability. In any case, even then, I would expect the large-scale temperature signal to be in the second EOF, not in the fourth. I think this is indeed awkward. I underline, however, that my knowledge of dendro proxies is quite limited, but I would sleep much better if reconstructions were not too strongly dependent on the bcp.
eduardo
Re #153
My point was that all the Monte Carlo experiment can show is that the Union reconstruction is not a simple AR process. Using it as proof of anything else – as seems to be what is being done in the paper – is not supported by the evidence. Thus, no conclusion about the “significance” of the correlation can be drawn as seems to be done in the following sentences from the paper:
Not sure what happened to the second half of my comment there, second time lucky…
My point was that all the Monte Carlo experiment can show is that the Union reconstruction is not a simple AR process. Using it as proof of anything else – as seems to be what is being done in the paper – is not supported by the evidence. Thus, no conclusion about the “significance” of the correlation can be drawn as seems to be done in the following sentences from the paper:
Aaargh! Ditch the blockquote tags.
My point was that all the Monte Carlo experiment can show is that the Union reconstruction is not a simple AR process. Using it as proof of anything else – as seems to be what is being done in the paper – is not supported by the evidence. Thus, no conclusion about the “significance” of the correlation can be drawn as seems to be done in the following sentences from the paper:
I’m sorry about the duplication. Hopefully I’ve got it this time and the failed posts can be deleted. They all looked fine in preview.
My point was that all the Monte Carlo experiment can show is that the Union reconstruction is not a simple AR process. Using it as proof of anything else – as seems to be what is being done in the paper – is not supported by the evidence. Thus, no conclusion about the “significance” of the correlation can be drawn as seems to be done in the following sentences from the paper:
The 99.98% statistics are proof of what the Union reconstruction is not (they show that there is only a 0.02% chance – using the converse of the evaluation statistic – that the Union reconstruction is an AR(n) series). They are not proof of what it is or proof of any significance to the correlation with temperature as seems to be claimed. You can not evaluate the significance of the correlations using this kind of Monte Carlo technique. It is like saying, “This unknown animal is not a cat, therefore it is a dog.” – do you see the flaw in the logic there? Do you understand my point now?
#154. Eduardo, then how can you therefore stand by and acquiesce in presenting a reconstruction that includes not one but two foxtail chronologies – let alone as “independent” sites that are only a few km apart?
Echoing comments of others and myself, the relevant test is one that would be a test against an unrelated trend, not against an AR1 process. I think that Juckes’ failure to report results for calibration-verification periods are symptomatic here. He gave what purported to be a reason on an earlier occasion. But it’s inconceievable that he didn’t try a calibration-verification test first. If he did, he’ll have run into results like I reported at AGU last year – seeimingly plausible calibration r2, danger-indicated in the calibraiton DWs and failure in the verificaiton r2. Either Juckes did the calculations and didn’t report them; or he neglected to do the calculations. You tell me which is worse.
Eduardo, I appreciate your response in #152. You say:
As I mentioned above, the effective N for the Union reconstruction, 1850-1980 is 26.5. The corresponding figure for the NHT in the last 130 years is 30.7. So while there are “more than just 2 or three degrees of freedom”, there are not “many more”.
I will take a look at your reference and see what it says. In the meantime, let me pose the following question for you.
You have used a “Monte Carlo” method to determine the significance of the Union”¢’¬?NHT match. But before you can do that, you have to determine whether the red noise that you are generating actually makes red noise that is similar to your Union dataset. How have you verified that?
Finally, what I believe to be an unasked question. The CVM method contains an implicit assumption, which is that the variance is fairly constant throughout the period of record (stationarity). Or, failing that, that the modern period is fairly typical of the record regarding variance. However, this is not the case for your reconstruction:
As you can see, the modern period has among the highest variance in the record. How does your method adjust for that, if at all?
Best of life to you,
w.
Eduardo, further discussion of the Nychka equation for N_eff can be found here. The formula as shown above is a refinement of earlier work by Nychka, discussed here.
I am unable to access the Journal you mentioned, so I cannot comment on your method. Perhaps you could give us a digest of the method you used, as I have done above, or provide code that explains the method.
Best to you,
w.
#160. Willis, I routinely look at differences between modern and historical variances in CVM composites. In the underlying proxies, it is very rare for 20th century proxies to have a difference in variance as marked as the Union CVM. However if you think about the formula for variance of an average, it includes covariance terms. If you have biased picking, then the covariance between the proxies in the 20th century will be greater than in a prior period leading to an observable difference in variance. I’ve mulled over whether this can be worked up into a diagnostic for potential cherrypicking – I think that it might be possible.
Willis and EDuardo, here’s a previous post http://www.climateaudit.org/?p=342 on calculating variance of autocorrelated processes based on Pericval
#147
That is, reconstruction errors are a function of temperature when those methods are used. Calibration period -based error estimates are thus not valid. (Steve has shown that MBH9x method is essentially INVR).
#148
…
Let’s find the important part of your message:
..this would affect only the amplitude.. And it will scale it down,
as shown in this example: http://www.geocities.com/uc_edit/ex1.jpg .
This was my point in #130.
Willis,
First of all, I want to clarify that I am here only trying to discuss the issue of the estimation of variance of an autocorrelated process, and not the issue of the significance of the correlation between autcorrelated process. I knwo it is also relevant for the Juckes et al, but let us try to mix up things.
I do not understand completely the aprocah of the effective number of degrees of freedom. I would see thatne estimate this number and then sample the process at a suffcient long lag and apply the standard estimation for an uncorrelated process. But the expression you posted previously involving the square roots of the sample size is only valid for uncorrelated process , and not for autocorrelated processes. I am not sure, but I think, you are mixing two different things here.
Unfortunately I am not programming in R, but I can explain what I did. You can relatively easy derive analitically an an expression for the result of the standard estimator of the variance:
Sum {y_i – 1/n Sum {y_k}}^2
in the case of a AR-1 process. Then you see that this standard estimator is indeed biased, and you have to correct it included a factor that involves
Sum rho_k for all k’s.
This is indeed similar to the formula you suggest to estimate the correlation between autocorrelated process For an AR-1 process, this sum is easy to compute, for other process it is not so straihgtforwardd. For an AR-1 process, this term becomes large for lag-1 autocrrelation of 0.9 and higher, which is consistent with the paper by Parcival. The bias is not to increase the variance, as I think you wrote somehere else. A positive autocorrelation will deflate the true variance (if you are sampling artificially close samples you are not grasping the full variance) and inflate the true variancence if the autocorrelation is negative.
A more easy thing to do is simulate Montecarlo AR-1 processes. One can calculate theretically the variance of such processes. One can also estimate the variance with the standard estimator. by comparing both, you can see that the bias is indeed large when the 1-lag autocorrelation to construct the Montecarlo series is above 0.9. I think this is the easiest and quickest way to see this. You can try and we can then re-check our results.
You can also try with those Montecarlo surrogates to estimate the sample lag-1 correlation. It also shows large variations, so this could explain in part the variations in time you see in the sample lag-1 autcorrelation of the Union. I am not asserting that the Union nor NHT is a AR-1 processes, only that some of the effcets you are describing are also, al least partially, present in AR-1 processes as well.
A similar think can be said of your suggestions of using the formula of the correlation between autocorrelated processes. There is, however, one problem, also presented in the Percival paper (Three curiosities..). The estimation of the long-lags autocorrelations is always not correct, as the sum of the estimated sample lag-correlations must be zero. So, one has to assume an underlying process, in which the autcorrelation can be calcuated analytically, or ba some other trick, e.g. assuming that long-lags autocorrelations are zero.
In any case, I find this discussion quite useful and I am learning a couple of new things. not surprising as I am not a statistical heavyweight. Actually, I try to loose weight all the time.
I think that the main problems with CVM and with the other methods lies somewhere else, namely in the contamination by a level of long term-noise that for me is quite difficult to estimate.
eduardo
#164 UC
yes, you are right. The true amplitude will be underestimated as one is substituting noise for temperature signal. As I said, in my opinion this is the main potential problem, but it is difficult to say how large the problem is.
Hegerl et al tried another approach to bypass this, namley a total least qsuare regression between the composite and NHT, but unfortunately with only few samples. That was the rationale of that step, just to estimate an unbiased scaling factor.
any other ideas are of course welcome
#166
I’m glad that you agree. In my opinion this is very large problem. It makes
this standard error completely useless. In addition, as it seems that INVR behaves similarly, so MBH9x CIs are useless as well.
1) Take spatial sampling error seriously. First do a reconstruction with 18 thermometers, and see how well those 18 thermometers reconstruct global temperature. Don’t use INVR of CVM in this reconstruction.
2) Take proxy noise seriously. Compare proxy to local instrumental temperature and try to estimate the noise this way.
3) Accept the fact that 2-sigma levels will increase to 1.5-2 K, or even more.
A more visual approach to express my suggestion in here
UC, thank you for your interest.
Well, the fact that reconstructions by MBHxx method underestimate the amplitude was published 2 years ago. Some people do not still agree, but many do agree with this. CVM suffers probably of qualitatively similar problems, but this underestimation is much less than for MBHxx. Also, test of how well a few timeseries can replicate the NHT have been also done a few time ago, and are being done now. For instance these tests I am refeering to are made with a large proxy network, say 100, and with a small one, say 15.
How would you estimate proxy noise? At interannual timescales, I agree that one can get a reasonable estimation by comparing with the local temperature, but what about centennial timescales, which are the relevant here? how do you know how much of the centennial trends are temperature related and how much is non-climatic? I take the issue of noise seriously, and we have been discussing this problem here for quite along time. remember the bad apples..
I would not be sure that sigma levels are of the order of 2K (at which timescales, centennial?) since even the NHT variations in the past millennium have probably not been that large. or are you referring to local temperatures?
Thank you for listening 😉
I believe you refer to Storch et al Science 04 paper. Well, repetition is not bad thing in science.
You can leave the word probably out. And we should forget MBHxx now, it is not enough to impress me if some method underestimates less than MBHxx.
Suggestion: Let’s start from interannual timescales, and after that decide should we even further. If we can’t estimate the proxy noise, we can’t use proxies at all. (and let’s not use error measures that are upper-bounded by calibration temperature variance, please.. )
I think that the objective of all this reconstruction stuff is to see if variations in the past have been large. So it is better not to assume anything beforehand. And sigma levels depend on the proxy noise, so before estimating the proxy noise there is no upper limit for 2-sigmas.
Martin Juckes, #135:
Eduardo Zorita, #166
Any plans to solve this disagreement? And where I go wrong in #139?
#171
Martin and I are referring to different aspects, I think.
In the case of a stationary signal and stationary noise: one the variance is matched in a calibration period, under stationarity asumptions, its is matched in all periods. I think this is what Martin meant.
I was writing about tests in in climate model simulations as surrogate reality, in which the shortness of calibration period does not allow to capture the low-frequency variance. In this case, if the spectral characteristics of the noise are different than those of the signal (e.g. the temperature spectrum is more red than the noise), then a bias arises. However, as I said, in these tests the CVM is the one with smallest bias and yields quite reasonable results, something like retrieving 80% of the centennial variability.
I think this is an open and interesting problem, and again any *constructive* suggestions are welcome. Perhaps other areas have experienced similar probems
Eduardo, you can be on that. I can think of several methods that would probably work for your pseudo-proxies. IMO, state-space modelling, e.g. Kalman filter, might work. However, the real problem I see is that I don’t think (at least) tree-ring proxies follow a linear model. So IMO, the real thing to concentrate is to derive a functional form for the (annual/full season) temperature respond. You linked a while ago to a paper with a model of a tree growth with respect to different characteristics. Extending/approximating that model in annual bases might be a good start.
#172
It is still matching the signal with signal+noise .. And this stationary signal assumption is very interesting in this context. Let’s assume 1000-1980 temperature was stationary so we can use proxies. Then let’s compare these results to 1980-2005 instrumental and conclude that recent warming is something that never happened before..
Without specifying proxy noise, how can you obtain such values?
If #167 won’t do then I’m out of ideas.
#174. Eduardo’s pseudoproxies assume that the pseudoproxy is a gridcell temperature plus a uniform mixture of white noise. Under such circumstances, an unweighted average of scaled proxies is a pretty sensible way to go. If you plot the residuals for each individual pseudoproxy, you get a white nois-ish residual.
I just question whether this is a very realistic model. For example, the statistical propoerties of the Mann network are much better modeled by 1) pre-processing red noise series to make a HS-shaped series e.g. through Mann’s PC method, but cherry-picking would probably work as well; 2) filling up the network with low-order noise; 3) Mannian inverse regression with re-scaling.
Re #172
Well, in most circumstances when the statistics do not permit a robust inference the scientist will use cautious language, taking care to avoid over-interpreting the results. Instead, what we have in climate science is a rush to over-interpret the results because there is a premium for making alarmist statements in the literature. We are told, by some, that this is the “precautionary principle” at work. It may be precautionary from one constituent’s POV, but it is, scientifically speaking, the antithesis of “precautionary”. My constructive suggestion is to accept the limitations inherent in the data, and to resist the urge toward alarmist language (e.g. “unprecedented” warming, etc.).
Fine and dandy to construct new models as we try to work out the statistics. Meanwhile, let’s not play gambling games with our credibility when it comes to uncertain propositions about which we are under-educated.
#173-176
Ok, I think this is a reasonable suggestion. I will try to have a look at how Kalman filter methodology can be applied here . There are not many models of tree-ring growth that I am aware of. In that paper they reach the conclusion that the model produces growth series that are correlated with the true series with correlations that are not higher thn those obtained directly to local temperature, so some progress is still needed.
the pseuso-proxies do not neccesarily assume white noise. You can put whatever noise you think it is reasonable. So far I have tried with red noise and long-term persistence (LPT, Hurst series) noise, and assuming different levels of noise contamination. In all cases the CVM method is the best of all three, and it is quite robust to all these different parameters. However, it is indeed not perfect.
I have already commented somewhere else here about alarmist langauge, and others have also published on this in other media.
You will still need measurement noise model (specially the R matrix). And we are again back in #167. I’m afraid that there are no shortcuts.
#173-178
In my field (feedback control systems) my colleagues who have used Kalman filters say they can work well when you have a good (linear) model of the system, even in the face of changes in the system and noise parameters (the whole point of KF), but if you don’t have a decent model, it quickly goes all to hell, and produces worse results than much simpler techniques. Caveat emptor!
When I was in grad school, virtually every lecture I got on techniques such as this started with the sentence, “First, we assume a Gaussian noise distribution…” Then after an hour of math, they never got back to examining the validity of the assumption. In the real world, I have virtually never run into noise distributions in my field that were remotely Gaussian.
I read a little while back that the Black-Scholes economic model that won these guys the Nobel Memorial Prize for Economics and that was the basis for the techniques of the Long Term Capital Management hedge fund was all based on assumptions of Gaussian distribution of the magnitude of economic “disturbances”. Evidently, it was well known by the time they got the prize that this assumption was completely invalid, that the distributions had far “fatter” tails than Gaussian, and that this is what led to the downfall of LTCM.
#179
With respect to LTCM: Not exactly.
It’s not really about leptokurtosis. It’s about making bets bigger than you can afford to carry until they pay off. The Wikipedia article gives a nice summary with the key quote “The market can stay irrational longer than you can stay solvent”.
Kalman Filter works well when the assumptions are satisfied (applied optimal estimation is something HT should look into, BTW). But in the climate case, only 1000 years or so, it is easier to compute everything in batch mode. I don’t think recursive solutions are needed. In addition to the noise model problem (..HT can’t admit that proxy noise variance is close to ..) But another problem is the dynamic model for global temperature process. Underestimation of autocorrelation leads to underestimation of temperature variability, as shown in here:
..) But another problem is the dynamic model for global temperature process. Underestimation of autocorrelation leads to underestimation of temperature variability, as shown in here:
http://www.geocities.com/uc_edit/ar1/estimation.html
I originally thought this was the problem of Mann’s reconstructions. But here I have learned that it is not the dynamic model, but general overfitting using multivariate calibration and additional scaling steps.
Fat-tail distributions are very challenging indeed. The estimator can be BLUE and still the designer needs some additional outlier-search procedure..
Re #180, John S
Why does everyone call it leptokurtosis ? Lepto usually means small – you would have thought high values would be called baryokurtosis or some such.
Love the Keynes quote.
It’s true that LTCM did produce some bogus “value-at-risk” numbers based on a bogus data model. But that is NOT what led to their demise. In their determination to take ever larger positions, they got into markets that they did not understand with very slim margins. I believe it was human nature that blew them up, not a bad data model.
I am glad that this discussion has moved towards demanding an explicit description and justification of the HT’s data model. The HT’s opaque statistical maipulations are certainly suspicious, but I think the discussion should focus on making them justify that what they are doing develops the true signal. Scientists should have an obligation to do nothing less.
I was looking for an appropriate spot to pose my query of proxy temperature reconstructions with the intent not to disturb too much a discussion that might be a ways ahead of my comprehension of all the statistics involved. I have gained some better insights into the analysis involved from these discussions and this one in particular. From a layman’s view I can appreciate the subtle and important effects on these analysis of such statistical features as AR, ARMA, ARIMA, stationarity, detrending, filtering and some of the even more sophisticated methods of detecting a signal from a noisy environment.
First and foremost, and obviously from a less sophisticated understanding of time series analysis, what I see are correlations reported for many of these reconstructions from the calibration period of around 0.45, and without further analysis and adjustment of this number, we are looking at regressions where temperature explains approximately 20% of the proxy’s measured response. That means that we have approximately 80% variation in response that is unexplained. Now it is simple matter for me to understand that if this other 80% is like unvarying white noise and continues that way back into the entire proxy estimation period, we can obtain a reasonable estimation of historical temperatures, providing further that the response of the proxy remains the same for temperatures over the entire range of real reconstruction temperatures. One need be more concerned, I would image, the greater the amount of unexplained proxy response comes out of the calibration process and 80% seems at lot to me.
The next step is that of verification, which to my understanding is important, if for no other reason than the one Steve M often mentions, and that it is to indicate whether the selection of proxies for the calibration was over fit, i.e. the regression will perform in the period from which it was selected, but no so well in other periods where no prior fitting was done. When these regressions show significantly lower R^2 values in the verification process than in the calibration process, as apparently they do in many cases in the reconstructions, that in my view is a show stopper right there. I guess my question at this point is why argue the more sophisticated statistical analytical points when the lower level stuff says stop?
The Hockey Team puts forth, in my view anyway, rather esoteric rationalizations and much effort at this point with references to lower frequency responses from the proxies that the regression R^2 misses, the use of CVM to average out white and other noises, using even unexplained, much less unsubstantiated, teleconnections of temperatures away from local responses towards extended regional ones and even resorting to computer calculations with pseudo-proxies to justify results that still do not overcome the original assumptions about the unexplained noises that must cancel/average out, or at least tend to, over numerous proxies.
Would not a less hurried Hockey team concentrate efforts on a better understanding of all that noise in the signal and a basic biological/physical understanding of the proxy responses to temperature and other potentially involved variables? Add to my puzzle the residual graphs that Steve M recently published at CA showing a less than random, or even recognizable pattern, in the residuals (noise) between the instrumental and proxy temperature responses in the Union reconstructions, and I have to ask whether I am missing some more subtle aspects of the analyses of these reconstructions (from my less than sophisticated comprehension of the analyses) that might not change my view of the results, but at least explain more of the direction that the Hockey Team has taken.
Also I must ask whether econometric analyses, both good and bad, could be presented here to show more acceptable (in comparison to the reconstructions by the HT) statistical analyses of time series and critique the less than optimum approaches?
#184, good post. Some thoughts:
If the conventional statistical analysis gives RE of -18, you have to invent something better. (even though RE is HT accuracy measure, not conventional (IMO))
CVM does not average out the noise, it scales the noise so it looks like signal. Sorry, I’m provocative and maybe even cynical now.
There is a fascinating talk about statistics online here. It should be required listening for all proxy folks …
w.