Juckes has much to say about several MM articles, none of it favorable and little of it accurate. Juckes, like the rest of the Team, seldom quotes our articles – instead, he typically paraphrases what we said, often creating a straw man, which he prefers to deal with. It’s a wearisome task disentangling the many mischaracterizations of our work.
I’ll discuss a few points. Although he spends a great deal of time discussing standardization prior to PC calculations, astonishingly he does not discuss or even cite the Huybers Comment or the Reply to Huybers, the NAS panel or the Wegman panel.
In our published articles, we dwelled almost entirely on MBH98. This is not to say that there are not important things to say about MBH99, but we didn’t get to that in our published articles. We’ve had discussion on the blog of some puzzling features of MBH99, including the impenetrable calculation of confidence intervals in MBH99 – an important outstanding issue which Juckes (like Wahl and Ammann before him) simply avoided.
Our principal published reference to MBH99 was in MM05 (EE), where we pointed out that bristlecones were prominent in the MBH99 PC1 regardless of methodological artifice simply because of the dominance of bristlecones in long American tree ring chronologies. We observed this as forcefully as we could as follows:
Although considerable publicity has attached to our demonstration that the PC methods used in MBH98 nearly always produce hockey sticks, we are equally concerned about the validity of series so selected for over-weighting as temperature proxies. While our attention was drawn to bristlecone pines (and to Gaspé cedars) by methodological artifices in MBH98, ultimately, the more important issue is the validity of the proxies themselves. This applies particularly for the 1000–1399 extension of MBH98 contained in Mann et al. [1999]. In this case, because of the reduction in the number of sites, the majority of sites in the AD1000 network end up being bristlecone pine sites, which dominate the PC1 in Mann et al. [1999] simply because of their longevity, not through a mathematical artifice (as in MBH98).
Given the pivotal dependence of MBH98 results on bristlecone pines and Gaspé cedars, one would have thought that there would be copious literature proving the validity of these indicators as temperature proxies. Instead the specialist literature only raises questions about each indicator which need to be resolved prior to using them as temperature proxies at all, let alone considering them as uniquely accurate stenographs of the world’s temperature history.
In contrast to MBH99 where the bristlecones dominated merely through longevity, the dominance of bristlecones in the MBH98 AD1400 PC1 was achieved through a mathematical artifice – the Mannian “principal components” method. We observed that the characteristic hockey stick shape of Graybill’s bristlecone and foxtail chronologies falls to the PC4 using covariance PCs and to the PC2 using correlation PCs – but in neither case was the characteristic (bristlecone) hockey stick the “dominant component of variance” as Mann had claimed.
In MM05 (EE), we also observed that the MBH reconstruction using correlation PCs for the North American network was about halfway between the results using covariance PCs and Mannian PCs. (In passing, despite this explicit reporting of results using correlation PCs, Juckes, following Wahl and Ammann, accused us of “omitting” the consideration of what happens when chronologies are divided by their standard deviation. This accusation is false, since using correlation PCs is precisely equivalent to PCs using chronologies divided by their standard deviation. I’ll return to this point in more detail on another occasion.
For now let’s examine how Juckes goes about constructing one of his straw men. He states:
MM2005 argue that the way in which the stage (1) principal component analysis is carried out in MBH generates an artificial bias towards a high “hockey-stick index” and that the statistical significance of the MBH results may be lower than originally estimated.
As always, you have to watch the pea under the thimble with the Team. Yes, we said that the Mannian PC method was “biased”. But we did not say that MBH statistical significance was “lower than originally estimated“. We said that MBH results had no statistical significance. We stated categorically that the AD1400 step of the MBH98 reconstruction failed one of the statistical tests (verification r2) that Mann said had been used. Of course, Mann has subsequently said that the test was not used (that would be a “foolish and incorrect thing” to do, but readers of this blog know that he did calculate the statistic, obtained adverse results which were not reported and that he’s dodged a bullet in not being held accountable.)
The point here is that it’s not a matter of being “lower”; it’s a matter of there being no statistical significance. We stated that the seeming “significance” of the MBH RE statistic was due to inappropriate benchmarking of statistical significance in the context of biased methodology. If I were re-stating this argument today, I would place more attention on high RE statistics from the classical spurious regressions – Yule’s type case of alcoholism versus Church of England marriages has a very high RE statistic and a very high correlation statistic – one that is undoubtedly 99.98% significant in Juckes’ terminology.
But look carefully at what Juckes left out of his summary of MM2005 – bristlecones. The third leg of our abstract was that the biased methodology interacted with proxies whose validity had been questioned by the relevant specialists. Juckes leaves this leg of the argument out and you’ll see how this contributes to the sleight-of-hand below. Juckes mentions bristlecones later (see below) but avoids any sort of systematic discussion of an issue that is surely central in any supposed “evaluation” of miullennial reconstructions.
As to our argument about the “bias” in MBH methodology, this was upheld by both the NAS panel and the Wegman panel. We used the term “bias” carefully – we did not say that the MBH method was the “only” way to get a HS or that it was the only potential form of “bias” (low-tech cherry-picking and data snooping is another source of bias). However, for a study that had been so widely cited for obtaining a HS-shaped result, it was remarkable that it used a methodology that was so seriously “biased”.
We connected the bias to statistical significance through simulations on red noise, originally in MM05 (GRL) and re-stated in Reply to Huybers, in which we argued that MBH failed to account for the bias of their methodology in calculating the statistical significance of their RE statistic. The NAS panel also endorsed our concerns about statistical significance of MBH, stating that our concerns about statistical significance were one of the factors in their withdrawing claims to statistical skill prior to 1600.
However, Juckes completely fails to cite either the NAS Panel or the Wegman report on the issues of bias or statistical significance. Instead, he cites a study by Mann’s sometime coauthors, Wahl and Ammann as follows:
This [sic] issue has been investigated at length by Wahl and Ammann (2006) in the context of the MBH1998 reconstruction (back to AD 1400).
Now this assertion is also false. Wahl and Ammann 2006 is a long article, but it does not contain an “investigation at length” of the issues as presented here: our criticisms of bias in the PC methodology or inappropriate benchmarking of statistical significance. Wahl and Ammann (Climatic Change 2006) cited Ammann and Wahl (GRL, under review) for their results on bias and statistical significance. However, Ammann and Wahl (GRL, under review) was rejected a few days after their Climatic Change article was accepted (although it is still not in print).
If you download Wahl and Ammann 2006 and search on “review”, you will get 12 occurrences of the term “review”. If you then parse through each of the citations, you will readily observe that Wahl and Ammann (Clim Chg 2006) relies on the rejected Ammann and Wahl (GRL 2006) for its claims about bias and statistical signfiicance. Wahl and Ammann 2006 merely re-states (and relies on) results from the rejected paper, but is not an “investigation at length” of these particular issues as claimed by Juckes.
Perhaps Juckes is merely a victim of previous academic check-kiting by Wah and Ammann. The original check-kiting was an issue raised by a peer reviewer in the first review of the article – since Wahl and Ammann’s submission to GRL was originally rejected in May 2005 (it was later re-submitted when a new GRL editor was appointed.) Wahl and Ammann withheld the news of this rejection from the editor of Climatic Change and even cited the already rejected article in response to the reviewer. The reviewer advised the editor of Climatic Change that Wahl and Ammann should not use results from the rejected article. Instead of the Climatic Change editor following this logical advice, the reviewer was terminated.
In any event, Wahl and Ammann knew of the second rejection of their re-submitted GRL article in early March. Since the Climatic Change had not been printed – it still hasn’t appeared in print -in my opinion, Wahl and Ammann had an obligation to amend their Climatic Change article to remove reliance on the rejected article. Of course, they did no such thing and the version presently online is completely unchanged and still cites the GRL article as :under review”. Juckes is now passing the bad check on to more innocent parties.
Juckes goes on to say:
The problem identified by MM2005 relates to the “standardisation” of the proxy time series prior to the EOF decomposition. Figure 3 assess the impact of different standardisations on the reconstruction back to AD 1000, using only the proxy data used in MBH1999 for their reconstruction from AD 1000….This figure shows that there is considerable sensitivity to the adjustment of the first proxy PC, but little sensitivity either to the way in which the principal components are calculated or to the omission of data filled by MBH1999. Thus, the concerns about the latter two points raised by MM2005 do not appear to be relevant here, though the sensitivity to adjustments of principal component may be a cause for concern.
His Figure 3 shows “Reconstructions back to 1000, calibrated on 1856 to 1980 northern hemisphere temperature, using the MBH1999 proxy data collection” with various permutations and combinations.
One straw man here is Juckes’ seeming concern about the impact of closing extrapolations as supposedly expressed in MM2005 [ the “omission of data filled by MBH99”]. The issue of closing extrapolations is simply not an issue in MM2005; I’m 99.9% sure that it’s not even mentioned in either article. Yet no fewer than half of Juckes’ archived PCs pertain to this particular case, which was not at issue.
What’s the background to this? In MM03, we observed that many MBH98 series were extrapolated (“filled”) from end dates in the 1970s to 1980. Because the MBH98 proxy data as originally archived (a version now deleted) included erroneous collation of most of their PC series – which resulted in numerous PC series having identical values – this left a surprising number of 1980 values in the original data set either being erroneous or filled. It now looks like the data set as originally archived was a version developed by Rutherford for Rutherford et al 2005 (which contains a characteristic and am,using collation error as well) and that a different version was used in MBH98 (which materialized only in November 2003 after the publicity from MM03).
In his Nature correspondence and in a rejected submission to Climatic Change, Mann argued that the closing fills made little difference and it was not an issue that we pursued in the MM2005 articles. However, MM05 (EE) contained a lengthy discussion of the undisclosed and unique extrapolation of the Gaspé series, an extrapolation which appears to have had no function other than to get a HS-shaped series into the AD1400 network. (BTW see the discussion elsewhere on Jacoby’s refusal to release an update of the Gaspé cedar series which does not have a HS-shape.)
It was hard to see why Juckes spent so much time on the issue of closing fills, since it simply wasn’t an issue in play. However, Hockey Team curiosities are seldom without a purpose. In the AD1400 network, 14 out of 70 series contain closing fills. These are mostly not bristlecones. By reducing the network to 56 series, the bristlecone impact in the AD1400 network increases and this seemingly unrelated criterion becomes a handy way for the Team to “data snoop” – in this case, use a seemingly unrelated criterion as a way of enhancing bristlecone weighting.
It is also curious to observe such seeming concern over complying with MM03 issues. MM03 also sharply criticized the use of obsolete (and grey) versions of proxies. We illustrated the problem with the TTHH series. An updated version shows a sharp decline in the 1980s – virtually a type case of the divergence problem (And discussed by D’Arrigo in a subsequent paper).
However, there’s a much more important bait-and-switch, where you really have to watch the pea under the thimble. Let’s go back to the MM05 (EE) quote at the beginning. We said that different forms of standardization were not an issue in MBH99 – in MBH99, the issue boiled down to the validity of bristlecone ring width chronologies as a unique measurement system for world temperature plain and simple. We explicitly said that mathematical artifice was in issue in MBH98, but was not a key issue in MBH99. (There are some intersting issue in connection with the “fixing” of the PC1 in MBH99 which bear careful consideration and upon which Jean S and I have been recently corresponding.)
So in connection with MBH99, the “problem” was not “standardization” methods, but the validity of bristlecones. Juckes once again has mis-characterized very explicit statements and then proceeded to a lengthy exposition of a straw man. I’ve tried to point out as forcefully as I can that there is an interaction between the flawed methodology and the flawed proxies (bristlecones) – we determined the connection by seeing what the flawed method did. But a responsible scientist, on becoming aware of the issue with the flawed proxies, cannot simply ignore the problem, as the Team seems hell-bent on doing.
I mentioned above that Juckes considered bristlecones in passing. Here’s what he says:
Briffa and Osborn (1999) and MM2005c suggest that rising CO2 levels may have contributed significantly to the 19th and 20th century increase in growth rate in some trees, particularly the bristlecone pines, but though CO2 fertilisation has been measured in saplings and strip-bark orange trees (which were well watered and fertilised) (Graybill and Idso, 1993, and references therein) efforts to reproduce the effect in controlled experiments with mature forest trees in natural conditions (KàÆàner et al., 2005) have not produced positive results. MM20005c and Wahl and Ammann (2006) both find that excluding the north American bristlecone pine data from the proxy data base removes the skill from the 15th century reconstructions.
As usual, Juckes has not directly quoted us and mis-characterized what we said. I agree that an MBH98-style rconstruction without bristlecones has no skill, but we deny that it is the exclusion of bristlecones that “removes” the skill. We deny that reconstructions with bristlecones have “skill”. Yes, we agree that reconstructions with bristlecones have a seemingly high RE statistic, but we argued that the seeming significance of the RE statistic was an illusion (“spurious significance”) and that the catastrophic verification r2 failure showed a lack of statistical skill even with bristlecones.
As to CO2 fertilization, we were very careful not to take a position on whether CO2 fertilization was or was not responsible for the 20th century growth pulse that Hughes and Funkhouser 2003 characterized as a “mystery”. If anything, our position would be that of Hughes and Funkhouser – the growth pulse is a “mystery”. We argued that, if bristlecone growth was to be used as a unique measure of world temperature, it was, to say the least, highly disssatisfying that MBH co-author Hughes, when talking to specialists in specialist journals, should describe 20th century bristlecone growth as a “mystery”, while at the same time, MBH98-99 results depended on bristlecones.
We noted that Graybill and Idso has posited CO2 fertilization as an explanation but did not rely on it. We also noted that other authors had identified potential nitrate fertilization; that 19th century sheep grazing had caused a pulse in growth in some American Southwest tree species; and that bristlecones competed with big sagebrush, suggesting at least the possibility of an important interaction between precipitation and temperature – an interaction strongly emphasized by Graumlich in connection with foxtails, although Graumlich’s arguments were not explicitly canvassed in MM05 (EE).
We’ve discussed bristlecone growth on the blog on many occasions and new information and thoughts continue to percolate. Recently Louis Scideri, a prominent author in the field, has visited with more interesting comments. As of today, I’m inclined to think that each of temperature, precipitation and fertilization have an impact, with important interaction effects (most marked on strip-bark, but probably present in all forms).
The time is long overdue for a fresh analysis of bristlecones and foxtails. Hughes apparently made a new collection of bristlecones at Sheep Mountain in 2002. It is very unfortunate that these results have neither been published nor archived. However, based on my knowledge of mineral exploration stocks, I feel confident that, had bristlecone ring widths at Sheep Mountain been off the charts due ot warmth in the 1990s and 200s, we’d have heard about it. This is a dog that it is not barking.
As to Juckes, it amazes me how someone can purport to do an “evaluation” of millennial reconstructions and discuss our work at length and then totally fail to analyse the impact of presence/absence of bristlecones on the MBH reconstruction?
But hey, it’s the Team.





185 Comments
Steve M., you criticize Juckes for not citing Wegman et al. Yet even Al Gore seems to have forgotten about the Wegman report—despite Wegman saying at the hearings (under oath!) that he voted for Gore in 2000. Gratitude?? I wonder how Wegman feels about that….
Sara, none of them want to discuss Wegman, although he’s very eminent – Chairman of the NAS Committee on Theoretical and Applied Statistics. And Wegman was a lot more indpendent than Nychka who is thanked by Wahl and Ammann. It’s even more surprising that he didn’t even discuss the NAS panel. I thought that academic articles were supposed to deal with relevant up-to-date literature. The NAS panel published in June; Juckes didn’t submit until late September. Lots of time to consider their remarks. But it’s ridiculous that he didn’t discuss the Huybers comment and our Reply which are both on point. It’s quite bizarre.
“But hey, it’s the Team.” etc.
McIntyre – why not stick to a cool presentation of the facts and let them speak for themselves? Cheap snide comments are becomming a trademark of yours.
OK. Mick, I’m tired of dealing with misrepresentations and mischaracterizations. Do you agree that Juckes has misrepresented and/or mischaracterized the matter? Do you agree that it’s ridiculous for him to purport to do an “evaluation” and then dodge the bristlecones? You might weigh in with a comment on the statistics from time to time.
Steve, wouldn’t the definitive way of dealing with this matter be to produce your own reconstruction of the period in question – apologies in advance if you’ve already dealt with this suggestion.
In addition to the spurious RE and zero r2 scores there are the negative CE scores even when the bristlecones are in the pot, which Juckes ought to acknowledge. The NAS panel noted “Reconstructions that have poor validation statistics (i.e., low CE) will have correspondingly wide uncertainty bounds, and so can be seen to be unreliable in an objective way. Moreover, a CE statistic close to zero or negative suggests that the reconstruction is no better than the mean, and so its skill for time averages shorter than the validation period will be low.” (p 91)
The NAS text then does the elliptical two-step around criticizing Mann by diverting this finding onto Wahl and Ammann: “Some recent results reported in Table 1S of Wahl and Ammann (in press) indicate that their reconstruction, which uses the same procedure and full set of proxies used by Mann et al. (1999), gives CE values ranging from 0.103 to –0.215, depending on how far back in time the reconstruction is carried.” But of course their circuitous wording can’t disguise the fact that the NAS was admitting that the hockey stick fails the verification tests across much of its length, and is “unreliable.”
Proxy,
In regards to you comment #5. This suggestion has been made a number of times. The problem is that if one feels the use of proxy data cannot validly be used to reconstruct temperature trends then one cannot use them to reconstruct a temperature trend.
Once again, all I can say is: amazing and unbelievable!
Nice summary, Steve M. You saved me a bundle of time. Now I don’t have to answer Juckes’ latest question on “Omnibus”.
I can’t wait to get out to the field with Dr. Scuderi next summer. He seems like a very conscientious field biologist. It pays to know your system if you want to make grand claims in the highest journals. I suspect those bcps are going tell us quite a story!
#3 — Mick says, “Cheap snide comments are becomming a trademark of yours.”
That’s no cheap snide comment, Mick. Over the lifetime of CimateAudit, Steve M. has had to deal with one misrepresentation of his work after another by HTeam members, as well as one seemingly incredible failure after another of HTeam analyses to come to grips with some central issue of proxy calculation. Eventually, the pattern becomes too obvious and too repetitive to ignore. HTeam members are all very intelligent people. The scientific lacunae they oversee just cannot be accidental. Under those circumstances, and given the attacks Steve M. has had to absorb, his cynicism is entirely justified and commendably understated.
Re #10: I support Pat’s comments in spades!
I might add here that when I made my presentation at KNMI, I met at length with Juckes coauthor Nanne Weber and I made the identical offer to the Euro Team that I made to Wahl and Ammann: that there was little interest in further controversy, that we make an attempt to make a statement of what we agreed on and what we disagreed on. Like Wahl and Ammann before them, the Euro Team elected to engage in controversy, rather than try to resolve things. I think that the Euro Team, like Wahl and Ammann, are behaving very inappropriately, but I did what I could to try to pre-empt the controversy, that Juckes and the other 8 members of the Euro Team have chosen to initiate, after being lavishly funded by the Dutch government to do so,
Re 12.
‘after being lavishly funded by the Dutch government’
???
You mentioned that they received about 90000 euro for this work. That is just sufficient to finance one man year of research (travel, conference costs etc. excluded). It is not at all a big project but rarther a small one. So don’t exaggerate.
Re: 13, GB,
Granted that 90K Euro is one man year of research, but let’s put things into perspective. Do you believe that the quality of the work justifies this expense? If not, then it would be lavish funnding even if the amount were much smaller.
How lavishly do you think the Dutch government has funded Steve M.’s work to correct the misrepresentations in their funded work?
gb, thank you for your post. You say:
Travel and conferences excluded? Man, I gotta get me a grant. What travel and conferences were required to do a half-assed rehash of previous bad work? Did they have to go to Kenya to attend the Kyoto fiasco? Have they heard of email?
And why on earth would it take a man-year to do what they have done? Half a dozen of us on this blog have put in maybe a week each and blown their report apart. That adds up to maybe 1.5 man-months, we’ll call it two to be generous. If I had paid a hundred grand US for their “analysis” of the climate reconstructions, they’d be fired on the spot.
“So don’t exaggerate,” to quote a previous post.
w.
Good post, I noticed a few small mistakes. Feel free to delete this comment.
typo: “previous academic check-kiting by Wah and Ammann”
what’s an “and am”?: “(which contains a characteristic and am,using collation error as well)”
typo: “I agree that an MBH98-style rconstruction without bristlecones has no skill”
Another (funded) investigation of “exceptionally” warm November 06 weather is announced by the KNMI. One keeps itself busy this way…
Hello McIntyre, wondered where you had got to. I answered some of these points on a different thread on wednesday
(http://www.climateaudit.org/?p=894, comment 36).
Have you worked out why your disclosed code for the McIntyre and McKitrick (2003) paper does not reproduce the results presented in that paper yet? Surely it is easy enough just to make the code you used available?
Dr. Juckes,
I’m sure you think you are being clever in implying that McIntyre and McKitrick have not fully disclosed their methods and code, however to me it just appears childish, especially when compared to the practices of your peers. I expected more from a professional than a school-yard taunt.
#18.
Martin, I re-ran the code and replicated the original figures (although there is a very slight difference in layout). Here are clips from what was published in MM03 and a run from climate2003 code from a fresh R re-boot:
As to what you might have done differently in obtaining http://home.badc.rl.ac.uk/mjuckes/tmp/fig6_mm2003_recalc.eps and
here: http://home.badc.rl.ac.uk/mjuckes/tmp/fig7_mm2003_recalc.eps , it’s hard to say. You say that you copied data files as you were unable to read the files from R. This doesn’t make sense to me. My computer reads directly from http://www.climate2003.com without any trouble. You shouldn’t have any trouble either. Why don’t you try it without the step in which you copy files to your computer. Perhaps you did something in the copy step. It’s hard to say.
Re 20: I can’t see how copying a text file from one computer to another can make any difference. I can;t read directly with R. It handles data from eclogite.geo.umass.edu OK apart from: ftp://eclogite.geo.umass.edu/pub/mann/MANNETAL98/EIGENVECTORS/tpca-eigenvals.out. This file contains some numbers of the form 2.3176329210401D-02, which cause my version of R [2.3.1 (2006-06-01)] to crash, what does your R installation do with these numbers?
I’ve read this directly from R in many different R versions without any trouble so the problem is somewhere on your end.
Re 22: Correct — the problem is that running your code does not produce the figures you say it should. Is there some undisclosed machine specific sensitivity in the code?
Well, I used a different computer to produce the versions just now as compared to the computer used in the original article. While MBH98-type results are very non-robust as Burger and Cubasch have confirmed, I don’t think that they are so non-robust as to be machine-specific. If you want to send me digital text files of various intermediates, I could try at some point to see what you’re doing but I won’t have time for a few days to attend to you. In the meantime, maybe you could turn your attention to answering some questions that we’ve asked you.
Steve, have any of our regulars here tried to replicate this themselves? If they are able to do it then it would be clearly something in how Dr. Junkes is doing it and if they can’t then it must be something in your computer setup which isn’t in the R code itself; perhaps some sort of R add-in you didn’t realize was necessary.
I’m using a new computer with a fresh R installation and everything’s on my d: drive now, not my c: drive so old calls to my own directories that I might not be noticing shouldn’t be a problem. You’d think that Juckes would turn a little attention to running Mann’s inoperable code produced for the House committee. Oh, I forgot, they’re the Hockey Team.
Re #25
Would be happy to run a test. Anyone have a url handy?
Dr Juckes, certainly you know from experience that getting some programs to work immediately, even on same-type machines/OSs, can be problematic. The simplist thing can muck things up.
Alittle patience, and maybe alittle help from your assistants, and I’m confident you’ll get it working.
The script
http://climate2003.com/scripts/MM03/redo.mann.txt
Runs turnkey and produces the result Steve M describes, namely the bottom Fig. in comment #20.
I’m using R 2.0.0 on a Windows PC.
OK, I had a go at this. I’ve never used R before so I had to download and install it. (I usually use MATLAB so a bit of a learning curve for me)
I’m running under MS-Windows and using R version 2.4.0 downloaded from the University of Bristol mirror.
I can report the script from http://www.climate2003.org ran without modification and downloaded data directly from the website.
The result of the run can be found here.
I’ll try posting an image though this might not work!:
Ignorance to enlightenment in 40 minutes (including a coffee break while code was running). See how advantageous it is for independent researchers to share turnkey code? Dr. Mann, take note.
Re #30
Yes, that’s what I got as output too.
Hmm, finger trouble with the above it would seem
Firstly, I downloaded from http://www.climate2003.com, not .org!
Secondly, it seems I’m not quite getting the image tags right. One more try…
So here’s how Juckes expressed the matter – in his usual gracious style:
and again:
Do despite Juckes’ complaints, we now have two other people replicating the figure from the code with no babysitting. I wonder if we’ll hear back from Juckes on this.
Re 34: OK, I’ll try again with the version of code archived at http://www.climate2003.com on Nov 24th. But I’ll be away for the next couple of days.
For reference, I amended the code slightly today as there was an internal reference to a set of gridcell standard deviations calculated from HadCRU2 that I used in MM03 (since they were then unavailable from Mann.) In his submission to Climatic Change in 2004, Mann called use of this gridcell standard deviations a “grievous error”. I uploaded this data in April 2006. To run the April code, you would have had to change a read file from a c: directory to the climate2003.com/data/MM03 directory. I noted this and left the earlier version on file. This doesn’t seem relevant to Martin’s problem.
running R 1.9.1 I get the same result as spenceUK
(in approx 3 minutes on XP 2.2 GHz 1GB)
three minutes
I normally dislike ad hom comments, but does does anyone else find this example of the technical competence of a member of the Hockey Team mildly disturbing?
And remember, it is Juckes (is that pronounced “Jokes” in the original Dutch?) work that will be the credible expose of the obvious and grevious shortcomings of MM’s criticisms of MBH, because that is “peer reviewed” and this is just a blog of bluffers, right?
It’s pretty amusing that no one except Juckes seems to have trouble replicating this graphic. Juckes made some very strong accusations, not just once, but a couple of times, with taunting. It makes one wonder about his motives.
Probably what happened is he had an old version of the code (pre April 2006) and didn’t bother to check if it was up to date. Complain first, check later. Pretty irresponsible. (I admit: I’ve done that before. But I have always apologized after realizing my error, and tried to make up for it.)
Dear readers, go re-read #23. It sounds funny now. Pssst, McIntyre’s trying to mislead us all with faulty codes that have hidden machine-specific dependencies in them.
Yes, that *must* be it. LOL.
Well, I think at least we should give Juckes some credit. He was dying to publish a paper that could kill off MM05 and restore the HS to the centre of the field.
Was it hubris that led him here to gloat about his amazing discovery, or did he want to find the answer to an apparent conundrum? Since he is supposed to be a scientit so I would hope it was the latter. However, given that he let fly in his paper with this whopper without first asking Steve about it makes me fear it was the latter.
I suppose the question Matin needs to come here and answer now is; soue he plan to remove the reference in his paper to a “lack of full disclosure” on the part of M&M? And a sincere apology might be approporaite as well if this sorry little episode isn’t to be logged as a new low for the Hockey Team.
And maybe a postscript message for the Team. You really need to be giving each other some better professional council, as this blooper shows.
#41. I didn’t notice Mick weighing on the tone of Juckes’ remarks either online here or in his paper.
I was surprised at Dr. Juckes imperious tone and lack of technical expertise. By displaying his lack of ability with such a simple technical task, he risks losing whatever respect he might have had.
That seems to be part of the problem with many other members of the Hockey Team–lack of technical ability. I don’t expect someone like Al Gore to have any actual expertise bearing on the science of climate. Prestigious and well-compensated members of the Hockey Team are a different matter.
I don’t want to be accused of cheer-leading; but clearly, Steve M knows what he’s doing when it comes to this issue of multiproxy reconstruction. I’m in no position to judge how much of an expert he is, but clearly he is an expert. I think Dr Juckes is just starting to appreciate that now. Hopefully other team members are not far behind.
In the future the teams will argue that improvements in statistical methods were already “in the pipe”, that Steve M & Wegman had nothing to do with the revitalization of the field. That would be nonsense. Steve M is a prime mover.
I read a few posts yesterday afternoon in between video game playing with my 11 year old. I figured it was his time and I shouldn’t let myself get rerouted trying to learn how to download R, learn how to run it, and see if Steve M’s level of frustration is justified. I saved that for this morning. I have no prior experience with R. I had one College statistics class over 20 years ago. I do like data though, thus I have been reading this website, as well as competing views, since June. I started an hour ago finding R and downloading it from the Berkeley mirror. I got positive results within 20 minutes getting the two stick picture at the end of the run. I spent another 20 minutes running it another 3 or 4 times before I learned how to use CTRL R to step through each line in the script file and then save the 4 stick graphic before it got replaced with the two stick version.
I have both files now, they look like the above graphics, and I concur that Steve’s frustration with this issue is justified.
John Norris –
Inspired by your example, I spent a little time this morning replicating your efforts – and I mean a very little time. From finding R to finished graphs: 21 minutes. I am not a professor, nor a practicing scientist. I do know my way around computers and data; having made my living that way for the past several decades. Nonetheless, this replication exercise is about as turnkey as its possible to be.
I have to say – based on Dr. Jukes comments here – that the apparent gap between his patronizing, agressive attitude and his skill (sic) in an elementry task such as this is risible.
No more like Dutch for “itching”…
If you have R already installed on your machine, you can get the graphic in question merely by inserting the following command in R:
source(“http://www.climate2003.com/scripts/MM03/redo.mann.txt”)
It took about 2 minutes on my computer while it runs around and downloads data from various places. The emulation in this particular code is not what I currently use – this is from 2003 and is simply what I used then – a lot more information has become available since then so that I’ve modified our emulation of MBH and the current version exactly reconciles to Wahl and Ammann. The other codes are all about as easy to run. The GRL code has a lot of simulations and takes a long time. I didn’t make tghem totally turnkey as I was archiving them for documentaiton, but it’s easy to make them turnkey and would have been a nice feature earlier.
If you want to install R, go to http://www.r-project.org. Anyone that’s interested in statistics should use R (IMHO).
I think it’s pretty cool how Steve M is making the science available to just about anyone to replicate. Down with the ivory towers!
Steve,
it took about 20 minutes including the installation of R language version 2.4.0 (I am on 256 kbit line) and I was able to reproduce the graph. It is really great piece of work and hopefuly sets new standard on the science that aims to influence political decisions.
#51 The HT attitude towards data analysis reminds me of the disclaimer sometimes seen during especially vigorous TV car adverts. Their version would be something like: “Warning – Restricted data manipulated by professional scientists. Do not attempt!”
I mean geez… couldn’t Dr. Jukes find some neighborhood kid to help him run Steve M’s script?
Dr Juckes should now demand also a turnkey application from MBH.
What’s all this about Hockey Sticks and — whoops! I just created the two-chart graphic. 2 minutes or so. Once I figured out that Steve’s fancy quote marks in #50 have to be replaced with simple double quotes.
Re #50,
Steve, downloaded R this morning and played around with some of the commands, very interesting, even if it was my 10th+ computer language to learn (although this is different, as it is not a general-purpose language)… But need to go to learn more about modern statistics (my last course was some 40 years ago…).
Used your source command:
source(“http://www.climate2003.com/scripts/MM03/redo.mann.txt”) but needed to replace the ” ” with straight quotes " ", as WordPress replaces the straight quotes which are needed for R.
It took my computer only 4 minutes to grab the commands and data from the net and produce the graphs, even while it was very busy by making a backup of the main hard disk to a portable one…
About 5 minutes to download,verify and install R, and around 4 minutes to replicate the data…
Well, I feel like Mr Juckes must be feeling right now, namely pretty dumb. I decided to jump on the bandwagon and install R myself. Successfully installed R 2.4.0 and after having replaced the double single quotes with single double quotes got it the turnkey solution to run … almost. I get the following error message:
> source(“http://www.climate2003.com/scripts/MM03/redo.mann.txt”)
Error in file(file, “r”) : unable to open connection
Onar, are you logged on to the internet? That statement gets the info from the web …
w.
Onar, you might want to try putting that URL into a browser and see what happens. Perhaps the climate2003.com web site is having an issue right now, or your internet connection isn’t quite 100% and unable to reach that server for some reason.
Willis,
I am indeed on the web — as these posts of mine are proof of. I have, as Nicholas suggested, already put the URLs of each and every file reference URL into the browser and checked them. All of them are working for me.
Dunno … sounds like your computer isn’t letting R communicate with the web. Me, I drive a Mac and have never seen this problem. Maybe some PC folks might have an idea … works for me on the Mac.
w.
Onar àÆ”¬⥭,
It looks as though the command you used uses different quotation marks to what R expects. If you copy/paste the following line into R it should work:
source(“http://www.climate2003.com/scripts/MM03/redo.mann.txt”)
This is what I typed in and the results:
Note that the first command was a copy/paste from your post and the quotation marks are different
Onar
Step 1: Open the script at http://climate2003.com/scripts/MM03/redo.mann.txt
Step 2: Save the opened script as a (default) .txt file on your local drive.
Step 3: Open the saved file and paste contents into the R window.
Step 4: Run the script in R
No changing of quotes or anything else is necessary – it is completely turnkey.
Good luck!
It is the quotes. I’m not sure why, but copy-and-paste produces quote symbols on my machine that R can’t parse. I change the quotes and it works.
This has gone beyond interesting but I just installed and ran this test in a couple of minutes. I copied and pasted the command line from #63 and got
Error: syntax error in “source(“”
so I deleted and retyped the double quotes and everything ran perfectly. Seems like a strange translation/character set feature with this web site and quotes!
Thanks to Martin Juckes for finally prompting me to install R and stop making do with Open Office!
Well, how about that! Since I was the one who originally suggested some of the regulars try reproducing the figures, I was feeling a bit guilty I hadn’t done it myself. Since I’d already installed R2.1.1, I just clicked on Stevan N’s link in post 64 above and then copied and pasted the code into the R console and it automatically ran and in a couple of minutes there was the graph.
Now, has anyone tried the older code Steve says he’s left there to see if it explains why Dr. Juckes had trouble? Not that he shouldn’t have been able to figure it out most likely if he’d tried. But it’d be nice to know what could have gone wrong.
#67. Yes, I ran the old code. After my recent computer crash, all my files are on my d: drive. The old code had a reference to a file on my c: drive (and also online). When it tried to read the file from my c: drive (which it found before), it issued a diagnostic as to a read failure. So the logical thing that I would have done is to try to locate the file in question – I would have noticed the call to the c: directory, recognized that it was a relic of the original code and looked in the file http://www.climate2003.com/data/MM03 to see if there was an online version of the data file (which there was.) That’s what I did when I re-tested the code. Again this is not the present version of our Mann emulation and there are numerous changes since then. But it gave enough of an emulation of Mann’s method that we could do some sensitivity testing.
I got this error:
source(“http://www.climate2003.com/scripts/MM03/redo.mann.txt”)
Error in scan(file = loc1, n = 1082 * 4, skip = 0) :
scan() expected ‘a real’, got ‘1.0474342107773D-01’
that’s a diagnositc in reading the format at Mann’s old website at UMass. The read works for other people (and for me), but not for you. I don’t know why – maybe one of the computer specialists can advise. It’s the line reading the eclogite files which are in a D format.
In general:
– the change in quotes is what WordPress does when it translates what you type as comment on this page to what you see in the preview and the final result. can be circumvented by replacing the (straight) quotes in the text into the html equivalent ‘& quot ;’, but without the spaces. The end ‘;’ seems not necessary in WordPress, but is normally obliged in html.
– there may be an issue with a a firewall program, which blocks the access of R to the net. The first time I ran the R-script, the (Symantec) firewall software on my PC asked if I would allow R to access the Internet. Something similar may happen with corporate/university networks, which don’t allow access to the outside world, without specific access permission (either for the program or the specific PC) from the network administrator.
Some question: while I can follow most of the statistic issues here (but can’t comment), I want to learn more about the different statistic items under discussion. Does anyone know some good introduction pages on the Internet for statistics? Nice positive result of the discussion with Juckes: it triggers someone’s curiosity to know more!
Re #58
Onar, I wonder if you have successfully tried to run the following command on R:
> source(“http://www.climate2003.com/scripts/MM03/redo.mann.txt”)
I have tried (replacing the double quotes as everyone has suggested) and get the same error message as you:
Error in file(file, “r”) : unable to open connection
Stevan (#64), I have also tried following your suggestion but with no better results. I suspect there may be a problem with R accessing the internet from my home PC. I’ll try at work tomorrow.
Like Ferdinand, my interest has been piqued and hopefully my statistical understanding will improve
Paul and Onar, could you do me a favor. Could you go the URL and paste it into your computers and report the exact step where the read failure occurs. I’ve successfully read the UMAss data, but it might make sense for me to re-archive a version of the data is identical but easily read on all computers, unlike what Mann archived.
It seems as good a time to post this query: If any of you know of a grad student proficient in R and needing a few bucks on the side, please let me know. I need tutoring!
I have spent any number of whole days beating my head against my desk, only to end up with 2 lines of code.
It does NOT help to be learning statistics at the same time, but that’s my fault. Though I may ask the odd statistics question or two, most questions will be about “getting stuff done” in R.
$20,25,30 per hour? No idea, but my forehead is bleeding.
BTW, the name “R” is really cute but for searching with google I wish it were something else. I had no idea how many people’s names have the middle initial “R”.
jam [at] wellfunction.com
TIA
“R” is no worse than “S”.
Joel,
I have used the introduction pages at http://wiener.math.csi.cuny.edu/Statistics/R/simpleR/ which gives a good overview of the first steps to get R working.
But there are many more at http://cran.r-project.org/other-docs.html
Re #73
Steve, I’ve done as you’ve suggested and here is the first read failure:
> #LOAD MBH DATA #this collates and may require a minute or so
> source(“http://www.climate2003.com/scripts/MM03/read.mann.txt”)
Error in file(file, “r”) : unable to open connection
I’m sure the problem is with ‘R’ accessing the web. There are plenty of other error messages but these are more than likely due to the fact that I’ve not managed to download any data!
Paul, try going to the URL and then copying the webpae at the url into your R onsole.
Re #73,
Steve,
I tried this and it fails every line where it tries to access the web from the code. (subsequently it also fails to make calculations which rely on these connections.) The problem does not seem to be at your end, but some quirk with R and/or my specific machine. When I paste the URLs into IE I succeed in downloading the script and all the data.
re #78, 79
Steve, like Onar I’ve gone to the URL, downloaded and saved it as a .txt file before copying it into the R console. R is just failing to access the web from my home PC and internet connection. I’ll try again tomorrow from the lab and see if things are any better.
I’m convinced the problem is at my end and nothing to do with the file you have posted at the URL.
Thanks for trying to help.
I downloaded “R”, saved the txt file and used Notepad to copy and paste into the console of “R.” I’m using Win XP and the Firefox browser.
I obtained the same graphs as Spence_UK.
Onar, Paul,
If you have a program like Norton Internet Security working on your computer, you can check in that program under “status”, “personal firewall”, “configuration”, “programs” if R (or any other program on your computer) is allowed to have access to the Internet. Other similar programs like McAfee may be the cause of the same problem.
I blocked R from access to the net and received similar messages as you have:
After restoring the status for R’s internet access to “all allowed”, everything worked fine again…
I notice that rwnj in message 69 is reporting the same error that Juckes reported.
Re #83 / #69
It would be useful to know:
– what version of R are you using ?
– what OS are you using ?
– what browser are you using ?
– what encoding is your browser using ?
– are you behind a firewall ?
– Any virus protection; if so – what is it ?
Thanks…
I’m using R 2.2.1 on Gentoo Linux AMD64. I got this:
> source("http://www.climate2003.com/scripts/MM03/redo.mann.txt")
Error in scan(file = loc1, n = 1082 * 4, skip = 0) :
scan() expected 'a real', got '1.0474342107773D-01'
I’ll try a newer version of R.
So some people here now are getting errors of the exact same form as what Juckes reported, and there is no clear immediate answer as to what the issue is. And yet, y’all went off on his supposed technical incompetence when he reported that error.
I’d say y’all owe him an apology.
I got a similar error with R 2.4.0
> source("http://www.climate2003.com/scripts/MM03/redo.mann.txt")
Error in scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings, :
scan() expected 'a real', got '1.0474342107773D-01'
I had a look at the file ftp://eclogite.geo.umass.edu/pub/mann/MANNETAL98/EIGENVECTORS/tpca-eigenvals.out and I think the problem is at the end:
1050 0.10625100880861 1.22395E-08 0.99999986015136
1051 1.0474342107773D-01 1.18946E-08 0.99999987204598
1052 1.0183728486300D-01 1.12437E-08 0.99999988328971
I’ve never seen that D-xx notation before and R doesn’t seem to be able to interpret it. How is it different from the E-xx notation?
I’m going to look at how R is compiled and see if the problem is a missing option.
#86. Lee, you’re completely offbase and your total bias shows. Juckes showed a completely different graphic and threw around baseless accusations. Lots of people have replicated the result. That some people have trouble reading internet files is due to their configuration and not due to the program. Your bias is just palpable.
#87. Nicholas, I and others have read the file successfully so it’s not R per se.
For example, if I use the command (watch for the Word-press quotation marks) scan(“ftp://eclogite.geo.umass.edu/pub/mann/MANNETAL98/EIGENVECTORS/tpca-eigenvals.out”) it reads instantly.
The error is obviously a format issue with the downloaded redo.mann.txt file on certain Linux distros.
Steve, Juckes was ridiculed ON THIS SPECIFIC ISSUE. Whether t=or nto the problem is with R per se, it exists, it is real, it is keeping people on this board for being able to replicate your results, it is not trivial, and it has not been solved yet by people on this board, and it is identical to the issue on which he asked for help.
The ridicule aimed at him ON THIS SPECIFIC ISSUE was, at least, unjustified. I accept that there are other issues – I didn’t comment on those. I have to say that the readiness with which contempt was heaped his direction on this issue doesn’t dispose one toward careful examination of your side on the other issues.
Nor does the fact that my one post pointing this out drew a heated response from you, while the piles of abuse aimed at him went unchecked.
Back to the science – does anyone have a solution to this data problem?
I have an idea what is going on.
R is programmed partially in Fortran. When I install it, it uses the GNU Fortran compiler I have installed (gfortran 4.1.1) to compile part of R.
After some searching I found out that the E-xx format is used for single precision numbers and the D-xx format is used for double precision numbers. However I’m not sure if it’s standard Fortran syntax to write them out to a file in that format. So, I’m guessing the problem is that gfortran is generating parsing code that does not expect the D-xx format numbers.
The R program you’re using in Windows was presumably compiled with a different Fortran compiler which does understand those type of numbers. I don’t know the explanation for why mine can’t handle them.
Perhaps the best solution would be for you to download that file, replace D with E, and then point your script at your copy of the file? I know it’s a pain but it should mean better compatibility.
> scan("ftp://eclogite.geo.umass.edu/pub/mann/MANNETAL98/EIGENVECTORS/tpca-eigenvals.out")
Error in scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings, :
scan() expected 'a real', got '1.0474342107773D-01'
Lee, I’m 100% sure I can solve this problem easily if I were at all serious about it. I have a day job and should be doing that right now, instead of fiddling with R.
What I would do is this:
* download that file
* replace D with E in the last few lines
* download Steve’s script
* replace the URL with my local file path
Voila.. it should work.. this isn’t brain surgery. I just thought I’d point it out to Steve so he could fix it so that nobody else has to go through these problems. The problem is in fact an R/Fortran problem. Unfortunately, Fortran being what it is, these sort of small issues are common. I think Steve has done a terrific job with archiving this code and making it as turnkey as possible. Where’s the code for MBH98 and 99 I can download and run with one small fix like this?
Nicholas, I don’t disagree with you. I am simply and frequently surprised by the vehement contempt shown against ‘disagree-ers’ here. The initial disagreement was unpleasant on both sides. But the specific issue he reported and asked for help with, and which he was trashed for, was this specific one, and he was vilified over it – and it turns out that it took some specific expertise to narrow down the issue, it was not readily apparent, and that your solution shows that the statements that it will just run with that data – an the insults agaisnt his technical competence based on those statements – were wrong.
In any event, I’d recommend anyone experiencing the ‘quotes’ problem to download the latest version [2.4.0]. In the What’s New page the following fixes are noted:
Not sure if this is the problem (having no aquaintance with R until yesterday morning) but it looks likely… Note that the fix applies to non-Windows OS – Linux, etc.
I haven’t seen any reports here with problems from those using Windows with current versions of R.
Drat – I botched the link. This is the Berkeley What’s New mirror.
There are also fixes relating to real number interpretation but I can’t suss them out yet…
I downloaded the redo.mann.txt, read.mann.txt and tpca-eigenvals.out files and made the appropriate changes to the scripts and data (replacing D-XX by E-XX in the .out file) and it ran just fine on WinXP as expected.
Re:#94
Lee, rather than creating a strawman to get offended about, please reread the relevent posts in this thread:
In post 18, Dr. Juckes said
Do you really think that is an appropriate way to ask for help?
It’s clear from Dr. Juckes’ post 21 that he correctly identified the issue (which was in fact trivial, as Nicholas pointed out in post 93). If he was unable to solve it, that would suggest the ridicule was justified. If he was able to solve it (as I expect), I would have expected him to post at least a quick note of acknowledgement.
YMMV (Your manners may vary)
Arman, that is not what I was taking the CA’ers to task for. As I said, there was plenty of unpleasantness on both sides on several issues, that was one of them.
But Juckes was accused of technical incompetence, gleefully and repeatedly, for not being able to run that data set. And yet, when a couple of posters found that they had the same problem, it took some time to find the solution, it was NOT true that the data set would simply run, and Juckes himself in asking about that specific error has said that he would look again when he got back, was was not going to be around for a while. And in fact, his initial ‘guess’ a machine-specific difference, was reasonably close – it seems from the comments above to be a problem with compiling R on some linux installations.
The gleeful trashing of his technical competence on this basis was simply unfounded. And poorly done – very poorly done.
To be fair it it wasn’t clear what Martin Juckes meant by “not reproducing the results” – his initial comments implied the graph wasn’t being reproduced, not that there were errors running “R” .
Hopefully Steve M. will replace the eigenvalue data with something that the Linux “R” version won’t spit out.
Lee, Juckes has made a variety of unfounded allegations. You’re completely out of line here. Juckes didn’t just say that he had a read failure at the UMass FTP site, but that he got different figures and accused us of providing false code. Juckes:
Or again:
My response was far more gracious than Juckes deserved:
Upon which a variety of people immediately replicated the results with no trouble. Some people who replicated the results mentioned their operating systems (Windows). Maybe a Linux system would account for the read error, but they don’t explain the different graphic.
The reaction was primarily to Juckes’ accusations of malfeasance in what was archived – accusations that were readily refuted by people simply reproducing the results. For Juckes to have made accusations in such a tone, he should have been sure of what he was saying; he ran off half-cocked and commentators are entitled to snicker at him in my opinion.
#100. Remember that the troublesome files are not my files, but Mann’s. Any files that I save are in readable ascii formats, not weird Mannian formats. I am certainly prepared to save the recalcitrant Mann files in a more readable format. The purpose was primarily to document the calculations, not to be a turnkey installation across multiple platforms – but to repeat, the read problems derive from Mann, not from me. Although I’m sure that I can figure out a way of reading even Mann’s files so that Linux machines can read them as well.
Lee, when you say that the initial disagreement was “unpleasant on both sides”, I refer you to my repsonse to Juckes which,despite Juckes’ unpleasant accusations, was quite restrained:
Steve, this works for me:
connSurely there is a way to parse that string into a list without having to write it out to a temporary file first, but I don't know what it is. This works:
strsplit(gsub("^[ \t]+|[ \t]+$", "", data, perl = TRUE), "[ \t]+")
except that the elements of the list are strings, not numbers, and I don’t know how to get R to convert them. Perhaps you do? That would be cleaner. I’d be curious to know how to do that.
Gah, sorry, that was cut off, I’ll try again:
conn <- url("ftp://eclogite.geo.umass.edu/pub/mann/MANNETAL98/EIGENVECTORS/tpca-eigenvals.out")
data <- gsub("(\\d+\.\\d+)D([+-]\\d+)", "\\1E\\2", readLines(conn), perl = TRUE)
close(conn)
cat(data, file="temp.tmp")
list <- scan("temp.tmp")
unlink("temp.tmp")
list
strsplit(gsub("^[ \t]+|[ \t]+$+", "", data, perl = TRUE), "[ \t]")
re #78, 82
Steve,
I’ve just run the script at http://www.climate2003.com/scripts/MM03/redo.mann.txt from the PC in my office (Internet Explorer, Windows XP Pro) with absolutely no problems. Reproduces your graphs perfectly.
Ferdinand I think you must be right and will now look at the settings on my internet security at home!
#86 Lee, I spent 20 seconds on this problem and have never used R before.
#84 R v. 2.2.0
Apple OSX Tiger
Safari
Don’t know the encoding; firewall and virus protection are whatever comes in the Apple box.
Lee has too much free time, is being ridiculous. Let us answer Dr Juckes #23:
Answer: No. There are apparently some machine dependencies in R (no surprise, given the number of flavors of computing devices out there), but the code itself is universal.
I hasten to point out that (1) there was nothing here for Steve M to “disclose”; (2) The use of the term “disclose” is set in the context of another disclosure issue, this one a little more serious. (Do a text search on “discos” and you’ll see how Juckes manages to twist the argument from one of data disclosure by Team Euro to one of code disclosure by Steve M.)
Lee has time enough to write, but not to read. And that is the problem with peas under thimbles. Blink, and you’ve missed it. Lee blinked, and now he’s in the wrong. Never blink when the team is at work.
Does anyone know how to read (or whether) you can read zipped directories directly in R without manually unzipping the files? I’ve experimented with zip.file.extract, unz and gsfile with no success? In such cases, I’ve done the manual unzipping but I was thinking of posting up a couple of codes that would be more turnkey if the zipped directories could be read directly.
Just a belated note to confirm that after copying and pasting the code at the URL Steve gave into R 2.3.1 GUI window, it took less than 90 seconds to produce the graphs (including download time).
Re: #89
Steve, I tried this command too, and the result:
> scan(“ftp://eclogite.geo.umass.edu/pub/mann/MANNETAL98/EIGENVECTORS/tpca-eigenvals.out”)
Error in file(file, “r”) : unable to open connection
This pretty much confirms that the problem is not at your end, but with my machine/internet connection. I will try to install R on my work computer to see if I get the same problem there. In any case, it’s nice to see that with a few blog entries, technical issues can be identified very quickly.
Re #106
Hmmm, you could do that. Or you could try a text search on “disclos”.
RE 99 Lee says:
Lee, I think you’re just angry because Dr Juckes’ himself is demonstrating incompetence (among other things) here in public, at least on some specific issues, and you know it.
Re above: As noted in various comments there are problems with running the code on Linux. Thanks to Spence_UK for answering the question about operating systems. The first problem on Linux was the crash on reading “tpca-eigenvals.out”. After I’d corrected this I got the figures I referred to above. Now I’ve got in running on windows, producing the correct results as noted above, I’ve traced this back to the reading of MANNETAL98/EIGENVECTORS/pc01.out etc. These also contain numbers which the linux distro of R cannot handle — but in this case rather than crashing the program appears to insert incorrect numbers and carry on.
“… and so I sincerely apologize to Steve M for implying in #23 he had something to disclose.”
Excellent. On to the next issue.
bender, Juckes lived up to the over/under on whether he would apologize, didn’t he?
Martin, BTW, as I mentioned elsewhere, Wahl and Ammann cited the MM05(EE) supplementary information in Wahl and Ammann 2006 (which you cite) the first draft of which was in May 2005, also containing the citation. So it turns out that I actually had archived the MM05(EE) source code on a timely basis and a citation to it had actually occurred in a source known to and cited by you.
“… and so I sincerely apologize to Steve M for that false accusation too.”
See how easy it is to apologize? You just type the words, and out they come. Then you press “submit”. And we all move on.
Mr. McIntyre, I believe this does what you want:
Archive: test.zip
Length Method Size Ratio Date Time CRC-32 Name
––––––– –––––– ––––––– ––––– –––– –––– –––––– ––––
0 Stored 0 0% 11-28-06 10:49 00000000 a/
0 Stored 0 0% 11-28-06 10:49 00000000 a/b/
20 Stored 20 0% 11-28-06 10:49 6883b30c a/b/c
–––––––– ––––––– ––– –––––––
20 20 0% 3 files
$ cat a/b/c
1 2 3
4 5 6
7 8 9.3
R
> zipfile <- unz("test.zip", "a/b/c", "r")
> scan(zipfile, what = list(0.0, 0.0, 0.0))
Read 3 records
[[1]]
[1] 1 4 7
[[2]]
[1] 2 5 8
[[3]]
[1] 3.0 6.0 9.3
close(zipfile);
I think this will work in Windows, although I haven’t tested it. The forward slashes should be understood by unz, despite Windows using back slashes for path separators.
I hope this helps. Downloading & reading a zip file will likely be much faster than downloading a number of individual files.
D’oh, that was all nicely formatted in the preview in a PRE block but it got stripped out when I posted it. I hope you can still understand it.
Additional note: I suppose the limitation of this method is that, for efficiency’s sake, if the zip file is located on the internet you’ll need to download it to the local disk before reading the files inside the zip. Otherwise, if you put a URL inside the unz command, I don’t know if it’s going to download the zip file once for each internal file you read. It probably isn’t smart enough to cache it locally. However, I don’t think downloading a zip file to the local disk, reading the files inside it one at a time, and then deleting the zip file is going to be too difficult. If you want me to provide you with some code to do that too I’ll be glad to oblige.
Nicholas, can you directly read Juckes’ files from
http://www.clim-past-discuss.net/2/1001/2006/cpd-2-1001-2006-supplement.zip ? If you can, could you post up the ocde? Some of the tables are in ncdf format. These can be read by R using hte ncdf package. There are some csv files that can be read with read.csv, though the collation is little bit fiddly. OR for that matter a script to read the zipped file form a local directory.
I’ll attempt to write some code to directly parse those files from that URL. It should be possible. Give me 30-60 minutes or so and hopefully I’ll have something to show. (I hadn’t used R before yesterday.)
Mr. McIntyre, hopefully this is what you were after:
script
Each variable created in that script (e.g. http://x256.org/~hb/download_juckes.r) is a list of four items. They are name, long name, units, and data. The data may be “rotated” relative to the way you like it – I have each row being the data from a single proxy/instrumental series/reconstruction. If you’d rather they were organized in columns I assume there’s an easy way for you to rotate them.
Where possible I have tried to pad the data so that the index is in fact the year. Maybe this is not what you want, but I figure it’s less likely to lead to a mistake this way. If you don’t like it I can remove that feature.
If this doesn’t do what you want, please let me know and I can modify it.
Oops, paste error, I meant to say (e.g. mitrie_cited_reconstructions_v01)
You’ll see what I mean if you run the script then examine:
mitrie_cited_reconstructions_v01[[1]]
mitrie_cited_reconstructions_v01[[2]]
mitrie_cited_reconstructions_v01[[3]]
mitrie_cited_reconstructions_v01[[4]][[1]]
mitrie_cited_reconstructions_v01[[4]][[2]]
etc.
And I forgot to add that I haven’t bothered touching the CSV files at all, since they seem to just be duplicates of some of the ncdf files. Since some data was ncdf-only, I had to write the script to parse them anyway.
I re-uploaded the script since I noticed I was not creating the matricies properly. If you downloaded it, please re-download it. Sorry about that.
Now that it’s fixed, this works:
plot(1:1993, mitrie_cited_reconstructions_v01[[4]][[2]])
Sorry for all these posts.
I made a futher update to the script so that the first row of each data matrix contains the x-axis “label” values (typically, the year) for each value in the corresponding data rows.
I realized this was necessary since some of the data seems to have mis-specified array locations. For example, the instrumental data starts ca. 1850, but the data file starts at 1000, for some reason. Now that the year values are stored too, it’s a bit less confusing. You can do:
plot(mitrie_instrumental_v01[[4]][[1]], mitrie_instrumental_v01[[4]][[2]])
and you get a reasonable result.
Nicholas,
I clicked on the script link in #193 and the code appeared which I copied to my R Console. It then read the first line and gave an error message:
It then tried downloading the zip file
But then when it tried creating the various reconstructions I got this sort of message:
So what am I doing wrong, or more likely not doing at all?
Dave,
Firstly for my script to work you need to install the ncdf plug-in for R. The data in that zip file is mostly in ncdf binary format so you need it to be able to parse the data at all.
I guess I was wrong that the Windows zip decoder could handle forward-slashes. Give me a few minutes and I’ll try to work out a way to detect which type of slash should be used for the platform you are running the script on.
P.S. I also added a function called “vector_2d_to_matrix” to the script, so that you can do this:
inst <- vector_to_matrix(mitrie_instrumental_v01[[4]]);
plot(inst, type="l")
and if you want you can also do
transposed_inst <- t(inst);
which might come in handy depending on how you want to use the data.
OK, I have updated the script. Hopefully it will fix the problem running on Windows, as I’m using file.path to generate the zip file paths, rather than hardcoding the / character in them. I also fixed a small bug and put the matrix conversion into use, and stuck a plot command on the end so you get a demo graph when you run it.
Hope that helps! Let me know if there are any more problems.
It took some searching, here are the Windows ncdf plug-ins for R:
For Linux, I had to install the “netcdf” package in my OS (in Gentoo I did “emerge netcdf”). Then I ran R as root and did:
install.packages(“ncdf”)
Dr. Juckes,
Thank you for inspiring me to download and install the R statistical software package. Like many others here, I was able to download and install the software and run the script in a matter of minutes.
I am also glad to see that the CA crew were able to identify and solve the problem that you had on your computer, the resolution of which was beyond your capabilities. Should you encounter any additional roadblocks in your efforts to find the one true proxy, I am sure that the CA crew will again come to your aid.
Tongue firmly in cheek,
Earle
Re 115: All I said was that it was undisclosed, and as far as I’m aware it was not. This doesn’t mean it was anyones fault.
Re 116, 117: But why wasn’t it made available on publication, and why did you continue to declare it was unavailable on your web site?
Re 131: Yes, the problem is that it doesn’t run on Linux without modification. As McIntyre points out, the problem is that the fortran format in many of Mann et al.’s data files is incompatible with the Linux R distribution (as the package says, “R is free software and comes with ABSOLUTELY NO WARRANTY”). After reformatting the affected files the code runs without problem.
Then you should have said “undiscovered”, or “unknown”.
“Undisclosed” implies that someone is hiding something.
Re 133: On this site I think “undisclosed” usually means McIntyre has misunderstood something. He certainly uses it frequently where there is no reason to think anyone is hiding anything.
When I read, these posts, I can’t help but be reminded of Oscar Wilde’s story.
As most of us know, Oscar was a famous playright around the turn of the 20th century. He was also famously bisexual. Unfortunately for him, that was illegal at the time. Also, unfortunately for him, the father of one of his partners “outed” Oscar. He then sued the self-same father.
However, it seems that Oscar’s proclivities were well known and readily provable. In fact, his law suit brought legal attention to something which had just been a matter for the society pages, until then.
Old Oscar was promptly put in jail, which led to a plummet in both his career and his finances. If the stories are to be believed, the public repugnance he encountered was far more damaging to him than the actual prison sentence.
[Mind you, his legal cause wasn’t helped by the fact that the man whose son he’d been shagging was the Marquess of Queensbury – a somewhat well connected gent.]
Anyway, why does this story always come to mind when I read these Euro Hockey Team threads?
Because of the moral: If you’re going to accuse a person of something, you’d better have your facts straight, your preparation meticulous and your proof watertight. The M of Q knew that, but Oscar had bad advice.
I would suggest that Steve and Ross know the moral of this story. Do the Euro Team?
re: #134 Dr. Juckes,
Could you give us an example of where Steve has a) been given adequate information and b) misunderstood it and c) said that the information was “undisclosed” either before or after he did finally understand it?
The normal process is that he asks about a given proxy or procedure and is either refused the information or given partial information. He then goes through several iterations of trying harder to get the information and only then claims the information is “undisclosed.” In your case you’ve asked once and then felt free to use the term (or other similar ones) to denegrate Steve. There are many threads which Steve has posted up here which illustrate the process he goes through, including the actual e-mail or other correspondence. So far as I know nobody has ever claimed that Steve has made up his correspondence or failed to include pertinent correspondence. So, I’m afraid I have to respectfully disagree with your claim.
No, “undisclosed” means “undisclosed” and does not attribute motive. As you can see, Martin has seized on your usage to make an unwarranted rhetorical claim.
Martin Juckes says:
” On this site I think “undisclosed” usually means McIntyre has misunderstood something. ”
To Martin Juckes undisclosed usually means that when Steve McIntyre asks for data which have been used by Hockey Stick members in articles in Nature or Science then Steve has misunderstood the case because when the articles have been published then the authors have no obligation to disclose data any more.
Do you think perhaps Dr. Juckes is milking the remaining project budget for “additional research time spent” with all this back and forth stuff here?
I am joking but at this point nothing would surprise me.
Martin, you’ve made another accusation. Let’s work through an example – which is probably the one that’s been the most prominent. I originally said that the MBH reconstruction had adverse verification r2 results for the AD1400 step and that Mann failed to disclose the adverse results. You’ve made the accusaiton that this is just my “misunderstanding”. What have I misunderstood?
Sorry if I’m not on the ball here: have we got to the stage where Martin J has been able to replicate the necessary graphs?
re #141: #132 implies to me that he is now running the code with the correct result.
James,
When someone accuses you of not disclosing something it is reasonable to assume that they believe you have the information but are not releasing it for some reason. After all, it would not be reasonable to expect someone to disclose the unknown/unknowable. This does not imply motivation on the accuser’s part (why they did it), but clearly they have implied that you have been less than honest. This is especially true given the subject at hand (full disclosure of data and code) and the person accused (Steve McIntyre).
Instead of simply reporting his problem, Dr. Juckes took the opportunity to make a back-handed insult to Steve McIntyre, implying that he was a hypocrite for not disclosing the “real” code or some machine dependancy. Obviously Steve didn’t know anything about the obscure problem with the Unix port of R. He deserves an apology, but somehow I don’t think he’ll get one. I think it’s telling that Dr. Juckes is engaging in word games and insults instead of debating the substansive issues raised here about his new paper.
Re 140: see for example comment 15 on page 888: “Now there has to be some still undisclosed re-weighting.”
Also note that “You’ve made the accusaiton that this is just my “misunderstanding”” is clearly untrue.
re: #144
So, Dr. Juckes, still at your patent evasions? I went and looked at 888-15 and while Steve indeed used the phrase quoted, A) you didn’t reply, and B) certainly didn’t show that the differences between what you’d published and what Steve had shown was due to any misunderstanding on his part.
Now Steve said in #140 above:
You now have responded:
For this to make any sense this must mean that your accept that Steve’s analysis that:
must be correct. Either that or you’re directly claiming that Steve purposely made a false claim. I hope that that last is not the case. In any case, you’ve yet to provide an example where it can be shown that Steve has indeed “misunderstood” any properly disclosed information. Therefore your claim that that’s what “undisclosed” usually means around here is looking rather dubious.
#144.
In #134, Juckes said:
In #140: I stated:
In #144, Martin said:
:et’s see – Martin says that this site “”undisclosed” usually means McIntyre has misunderstood something.” “Usually” obviously doesn’t mean “always” and obviously doesn’t mean “on a single occasion” although it would certainly require that happen on more than one occasion.
Now I thought that I’d try to see if Martin had any examples to back up his latest accusation and started with Mann’s failure to disclose the adverse verification r2 statistic. Now Martin didn’t specifically say that this particular case was an example where I misunderstood the situation. Indeed, Martin now appears to have disassociated himself from suggesting that this is a case where I have not misunderstood the situation. I take it then that Martin agrees that Mann failed to disclose the adverse verification r2 statistics and that this is not aa case where I misunderstood the situation. So we’ve got one example – frequently used at this site – that goes against MArtin’s claim that this is what the term “usually” means.
Martin has provided a single example to support his claim of “usually” and it is an odd example, which I will discuss over at page 888 where the example is in front of us. It’s a very strange example as in this particular case I’m pretty sure that I’ve not “misunderstood” anything – the problem is that Juckes’ reported methodology is inaccurate on two different counts.
Martin, you keep wondering around here just throwing out accusations, and not answering any questions. I’ve made you several stricly scientific questions (mainly regarding your paper), and I’m tired of waiting for the answer. You have clearly read them and choose not to answer. As you are the lead author of the paper, from now on I take your neglect to answer my questions to represent all of the authors. To you, and to your co-authors, here are my main unanswered questions repeated for your convinence:
1) CVM proxy “standardization” consists of three steps: a) zero mean in the calibration period b) unit variance
in the calibration period and c) positive correlation with instrumental data. Is this right? If so,
why in the Union reconstruction the Chesapeake series is flipped but Quelcaya 2 [accum] is not?
If my proposed rules are not correct, what were the exact rules and why some of the negatively correlated series
were flipped?
2) What is your exact model for proxies? In particular, are you assuming spatial and temporalily white noise?
How about equal SNR?
3) Your clearly used flipping in the CVM-MBH constructions and in the CVM-Union. Did you use it also in your Monte-Carlo
simulations (Table 3)? If you did not, you have to correct your Table 3. It is not enough to claim that 1c)
is not part of the procedure: in that case the statistics of your simulatated proxies do not present
the real proxies as most (almost all) real proxies respond positively to the temperature (i.e., the correlation
with the instrumental data should be nonnegative). Please provide also a direct link to simulation codes,
as I’m unable reproduce the low values present in Table 3.
4) You claim in Appendix A that the (univariate) LS estimator is not optimal (after you have already averaged the standardized proxies) for reconstructing the temperature series. Instead you claim that a “correction” should be applied (“variance matching”). Under what conditions is this true?
Re 146: This is drivel. Are you saying that unreported is the same as undisclosed?
Re 147: More drivel: you keep starting up threads, so the discussion is disorganised and disjointed. This obviously suits your purpose. If you want answers, ask your questions coherently and stop mixing them up with insults. Mind you, there is some insight mixed in with the drivel. The Chesapeake bay series should not have been flipped — that was an error. (2) We are doing a composite, which does not require an exact model because we do not have an exact model. We are assuming equal information content.
(3) I have provided a link to the code. Are you running the python code, or have you tried to convert it to R?
See above: I’ll remove the flipping from the Union reconstruction.
(4) Under the conditions stated in the appendix.
Don’t worry, and no hurry. We’ll collect these and there will be more formal questionnaire later.
Linear model in which the errors have expectation zero and are uncorrelated and have equal variances?
#148. “drivel” – Martin, you really are such a tease. No I’m not sure what you’re sayig is “drivel” – are you saying that it’s “drivel” that Mann failed to disclose the adverse verification r2 statistics? Are you saying that he did disclose them? C’mon, Martin, stop pulling our legs.
Look, Martin: Mann didn’t disclose the adverse verification r2 statistics. It wasn’t that these adverse statistics were reported in MBH98 and I “misunderstood” them. The adverse verification r2 statistics were not disclosed. Mann calculated the verification r2 statistics – it’s observable in his code – and didn’t disclose the adverse results. In fact, he misrepresented the situation by saying that the verification r2 statistic was considered. IPCC TAR continued the misrepresentation by asserting that MBH98 had “skill” in verification statistics.
Re 150: I was referring to your post, 146, as drivel. Why are you so fixated on MBH98?
No wonder the number of science graduates here in the UK is dwindling 😦
There are enough obfuscations in Juckes’ responses to keep the layman well-and-truly away from these important debates.
What “Page 888” is he referring to?
RE: #152 – Here:
http://www.climateaudit.org/?p=888
re #153 – cheers.
re 148:
I haven’t started a single thread. I’ve been asking these questions in maybe three different threads, where there have been your commentary. You also have commented these threads later, so obviously you’ve seen the comments.
(1) & (3): So flipping is not part of the process except for PCs, correct? In what part of your code the Chesapeake bay series was flipped? I’m not fluent in Python, and I could not locate that.
No, I’m doing my tests with Matlab, I’m not fluent with R either. I have experience from several programming languages, so I can pretty much READ the python code. However, this takes a lot of time. That’s why asked you to point me directly to your code where the _simulations_ (table 3) are done. But your policy seems to give thesse nonanswers like ” I have provided a link to the code”. Thanks a lot.
You do not again answer about flipping of your random series. I assume you did not do it, which is an obvious mistake.
(2) & (4): Assuming “equal information content” does not tell anything specific. Again you force me guessing, so I take that as you assume equal SNR to your proxies. Which, of course, is invalidated even within the tree ring indecies, not to speak about different type of proxies.
You do not specify the conditions in your Appendix. That’s why I am asking that. Until you specify your conditions, you can not claim any type of optimality. You do claim optimality, so I’m asking under what conditions? More importantly, assuming the model on p. 1028 l.9 such that N is Gaussian, gives that given on the very next line is the ML estimator (see, e.g., Rao&Toutenburg: “Linear models – Least Squares and Alternatives”, 2nd edition, Springer 2002, Theorem 3.14). So again, under what conditions is CVM optimal and in which sense (and should be given preference over the ML estimator on the very same page)?
given on the very next line is the ML estimator (see, e.g., Rao&Toutenburg: “Linear models – Least Squares and Alternatives”, 2nd edition, Springer 2002, Theorem 3.14). So again, under what conditions is CVM optimal and in which sense (and should be given preference over the ML estimator on the very same page)?
Jean S and others: Seems to me that your questions of Dr Juckes are highly pertinent, and necessary. But shouldn’t these questions be posed on the Climate of the Past Discussion Board as well?
Bruce, there is no discussion there. Willis will collect all these issues in a week or two, and post them there. So everything will be on the record.
But now I’m asking these questions as they are not explained in the paper. If they were, I would not need to be asking. If this would be my own review in my own field, I would not have bothered: the clarity of a paper is one issue, and this paper clearly fails it. So under my normal review, I would have just marked REJECT with an explenation that the paper can not be followed, do not conatin all the relevant information and has a lot of ambiquous statements.
Re: 151
Martin,
The MBH98 “Hockey Stick” graph is almost the cornerstone of the IPCC’s TAR. In addition, it has been referenced and shown in articles in the press and scientific journals as well as Gore’s movie. In addition, many of the proxies have been used in other studies. If there is a problem with the methodology of MBH98, then the effect is much more than repudiation of a single paper.
You clearly are intelligent, and therefore you already know this. Why, therefore, did you ask this question?
#158. Brooks, in this particular case, I was just responding to Martin’s claim that “On this site I think “undisclosed” usually means McIntyre has misunderstood something.” I was merely trying to see if MArtin had ANY examples to support this claim. I started with the disclosure example that has probably been most discussed. Martin first denied that he claimed that I “misunderstood something” in this particular example. Then he said that he didn’t want to talk about it.
His “example” of a case where I supposedly “misunderstood something” is an example where he said that he used an unadjusted PC1, but used an adjusted PC1; said that it had been oriented to correlate to NH temperature, but had been used in reverse orientation – as I described. So it was rather an infelicitous example of my supposed “misunderstanding” as present evidence indicates that I understood the matter precisely, it is the article that described it incorrectly.
So MArtin has still not provided any example – let alone support for the claim “usually” in his wild claim that: “On this site I think “undisclosed” usually means McIntyre has misunderstood something.”.
#155
Optimality of CVM is indeed an interesting topic. Line 11 tells that is not an optimal estimate of
is not an optimal estimate of  . Actually, I think this was argued in 68-71 by Krutchkoff and Williams and others in Technometrics. The other option was not CVM, but Inverse Regression. The above eq. is actually classical calibration estimator,
. Actually, I think this was argued in 68-71 by Krutchkoff and Williams and others in Technometrics. The other option was not CVM, but Inverse Regression. The above eq. is actually classical calibration estimator,
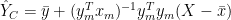
and the inverse calibration estimator is
(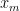 = centered x). But seems to me that the latter is very biased when 1) N is large and 2) Y deviates significantly from its mean in the verification period.
= centered x). But seems to me that the latter is very biased when 1) N is large and 2) Y deviates significantly from its mean in the verification period.
Refs:
Krutchkoff (1967) Classical and Inverse Regression Methods of Calibration, Technometrics Vol. 9, No. 3
Williams (1969) A Note on Regression Methods in Calibration, Technometrics Vol. 11, No. 9
Krutchkoff (1969) Classical and Inverse Regression Methods of Calibration in Extrapolation, Technometrics Vol. 11, No. 3
BTW,OT,etc., Williams mentions something about the signs :
re #160. Thanks for the references.
The book by C.R. Rao (Yes, THE Rao) and H. Toutenburg is an excellent buy if you want an uptodate account of the linear models. It is interesting to follow the work of the Team from this 400+ page book: Hegerl 2006 (total least squares, p. 70) is slightly more advanced (in terms of page numbers) than MBH (partial least squares, p. 65). Judging from that the next attempt will be minimax estimation (p. 72) or censored regression/LAD estimators (p. 80). 😉
re 155: Really sorry, I somehow mistook you for McIntyre. I think it was the use of bold font which threw me. What was that about?
Could you be a little clearer about your difficulties with the appendix?
Re 158: “The MBH98 “Hockey Stick” graph is almost the cornerstone of the IPCC’s TAR”: is this a joke, or are you seriously deluded?
#162 Martin
Brooks Hurd is not seriously deluded. If anyone is then you are. As you know full well sinc eyoua re being paid by ME and other UK taxpayers, the MBH98 ‘Hockey Stick’ is the poster child of the IPCC TAR. It is constantly regurgitated and presented in media as proof of ‘unprecented (within the last thousand years)global mean surface tempertures in the 90s’. Steve (and Ross) have meticulously shown that it is based on ‘junk science’. Their findings have been confirmed by the NAS panel and subsequently by Edward Wegman and yet people like yourself continue to deny and refuse to acknowledge the significance and importance of these findings. As a UK taxpayer, I’m being asked to pay additional taxes to fund further studies (like you own) that use the same proxies and variations on the same dubious statistical methods that have been shown by Steve and Ross, the NAS Panel and Edward Wegman to be unsound. I’m sorry but I’m not going to do this. I want my hard earned taxes to be spent on solving real problems likely poverty, urban regeneration etc and not on bolstering self-promoting politicised academic communities like the Tyndall Centre.
As you are active today posting on this blog, may I draw your attention to the Juckes Omnibus thread and the questions I have asked you there.
KevinUK
re #162:
Oh dear! Sorry for all the UK readers but my appreciation of UK university degrees is starting to get below acceptable levels.
The bold text in #147 was about the fact that despite all the effort you had completely ignored my questions. So I just stated that up to that point I had taken your ignoring as a personal behaviour of yours, but from that point on, you are the representative of the whole paper for me. I know some of your co-authors are also reading this blog, and that was my way of telling them that what you are doing here is now affecting also their reputation in my eyes.
I do not know how I can be any clearer. Let’s try to review my post #147 and the bidding afterwards.
(1) Your appendix A2 (CVM) does not specify how the proxies are handeled from the raw data up to that point. Assuming the notation is same as in the appendix A1, we get to know that the variables represent “stardardised” proxies. However, the is an ambiguous statement and does not tell exactly what to do. After several attempts from me and several others (especially UC), we still had not obtained a clear answer from you how the stardardisation should be performed. The replication efforts showed that proxies should be scaled to a) zero sample mean in the calibration period (1856-1980) and b) to unit sample variance. Also, you flipped some of PCs elsewhere, and the Chesapeake bay series in the Union CVM reconstruction. So I further assumed that also c) flipping of the negatively correlated seris is a part of the standardisation. Then I asked you if these were rules how your standardisation is done, if they are not, what are the exact rules.
are handeled from the raw data up to that point. Assuming the notation is same as in the appendix A1, we get to know that the variables represent “stardardised” proxies. However, the is an ambiguous statement and does not tell exactly what to do. After several attempts from me and several others (especially UC), we still had not obtained a clear answer from you how the stardardisation should be performed. The replication efforts showed that proxies should be scaled to a) zero sample mean in the calibration period (1856-1980) and b) to unit sample variance. Also, you flipped some of PCs elsewhere, and the Chesapeake bay series in the Union CVM reconstruction. So I further assumed that also c) flipping of the negatively correlated seris is a part of the standardisation. Then I asked you if these were rules how your standardisation is done, if they are not, what are the exact rules.
Then I pointed out that there is a negatively correlated series in the Union CVM which is not flipped, and asked for the clarification for the fact.
Now your answer in #148 tells that flipping is not part of the stardardisation, and that the flipping of the Chesapeake bay series was a mistake. Fine, but this leads to two things:
i) (see here) All your figures and statistics involving the Union reconstruction are now wrong in the manuscript. Are you going to submit a correction to the CPD? [Also in this part of world where I’m living it is customary to say something like “thanks” for pointing out mistakes not “drivel”]
ii) As I say in #155 I was unable to locate the flipping of the Cheasapeake series from your code, and asked for the location where it was done. If the flipping is not done is your public code, how are we supposed, even in theory, to replicate your results?
2) In your appendix A2 you do not specify your model beyond that (after summing) it is linear in temperature. Assuming again that the proxy model given in your appendix A1 holds for this also, we know additionally that the noise process is independent between the proxies (essentially spatially white). However, there is no specification about temporal structure of the noise nor there is any specified distribution attached to your noise series. This is what I’m asking (and have been asking at least twice before #147).
Now from your answer in #148 I take it that you say that the SNR is the proxies is equal. This is clearly not true (so the assumption is invalid) as stated in #155. Your answer does not clarify anything conserning the temporal structure of your noise (and the distribution).
3) Here I’m asking about the flipping. Since at that point I assumed that the flipping is part of the standardisation, so I asked if you’ve done that also for your noise proxies. I also point out that weather the flipping is part of the CVM procedure or not, you should flip your simulated proxies as the true proxies almost always have positive correlation. This is a simple thing of comparing apples to apples. Also, as I was unable to replicate your Table 3, I asked for the direct reference to the code so I could check why my results are so different from yours. You nicely answered “I have provided a link to the code.”
4) This is (again) asking about your statement in Appendix A2, p. 1028, l. 10-12:
You claim that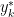 is not optimal. As explicitly pointed out to you in #155, you can not claim any optimality unless you specify your model (see 2)) and you specify in what sense the optimality is claimed. Again, as pointed out to you several times,
is not optimal. As explicitly pointed out to you in #155, you can not claim any optimality unless you specify your model (see 2)) and you specify in what sense the optimality is claimed. Again, as pointed out to you several times, 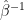 is the ordinary univariate LS estimator. As I explicitly point out in #155, this estimator is, under the assumption that your noise is Gaussian, optimal in ML-sense. As UC kindly points out in #160, there are other conditions where the LS estimator is not optimal. However, I’m unaware of the situation where your CVM estimator would be optimal, or even preferrable to the LS estimator or IR methods of UC’s post. So I’m still asking under what conditions the above statement holds. I would be very pleased to see also a proof of that fact.
is the ordinary univariate LS estimator. As I explicitly point out in #155, this estimator is, under the assumption that your noise is Gaussian, optimal in ML-sense. As UC kindly points out in #160, there are other conditions where the LS estimator is not optimal. However, I’m unaware of the situation where your CVM estimator would be optimal, or even preferrable to the LS estimator or IR methods of UC’s post. So I’m still asking under what conditions the above statement holds. I would be very pleased to see also a proof of that fact.
Can some native English speaker tell if my English in #164 is understandable? Just to make sure that Martin gets finally my concerns correctly. I can further clarify parts which are not understandable.
Good enough English for me to understand Jean. Of course, you and I apparently speak the
same language in the end (uh, signal processing, hehe.)
Gaussian noise would imply the estimator is also optimal in the MMSE and MAP sense as well,
correct?
Mark
Jean,
Your text was certainly clear to me. I must say that you are continually tightening the noose on Martin, but I’m not at all certain he will let it continue. Though it’s nice he’s continued here even after being given rather a hard time, that can change in an instant. He picks and chooses what questions he will deign to answer anyway, so your technical one are unlikely to be ones that will draw his attention, unless of course, you have an error somewhere.
This brings up a possible scenario from chess strategy. Perhaps you or Steve or someone can offer a gambit. I.e. something which appears to be a mistake on your part but which is actually a trap designed to have Martin commit himself in a certain area. For some reason it seems that Martin isn’t much concerned with the fact that what he says here is public record and he will have to deal with it in the future, and perhaps in venues where he can’t just refuse to answer; at least not without adverse consequences.
Good luck finding anything in that code. I’ve been a software engineer for over 20 years, and I can’t say that’s the worst code I’ve ever seen, however it is certianly some of the worst. Put aside the fact that Python is not the best language to use for this kind of task, the code is just poorly written and totally undocumented. I guess they come from the school of “it was hard to write so it should be hard to read”. I can’t think of a single job I’ve had where I wouldn’t get repremanded for turning out code like that.
RE: #168 – Spaghetti code – for some, it is mere incompetence,
Rather than people accessing code wouldn’t it be wiser for each party to provide the procedure – or pseudo-code – needed to carry out the calculation? This would allow others to see what is needed to emulate the various plots.
#170. I think that actual code is much better than pseudo code. The trouble here is how Juckes codes.
Martin Juckes,
Why in the hell are you agreeing to discuss this here, where there are multiple crossing threads and piecemeal evolving attacks from multiple people, with little or no organization, and additionally confused by additional absurd comments from onlookers with no expertise?
Isn’t there a forum specifically for disciplined critique and review of your submitted paper, at the journal site? Let McIntyre put together a reasoned presentation of this set of criticisms, and then dispute it in the place set aside for that dispute.
Lee, which part of my #157/164 you did not understand?
Lee,
You were absent when these threads developed, so naturally they appear confusing to you. Evolution is a messy process leading to the most unlikely structures. The fact is Dr Juckes asked for “Juckes omnibus” but then proceeded to comment all over this blog wherever his name appeared (which is not a public information tool, but Steve M’s laboratory notebook). That is, in part, why the threads are convoluted. Because Dr Juckes was trying too hard to defend his reputation instead of just focusing on the methods of his science.
When you jump in the middle of something it is bound to look more complex than someone who has been here awhile. You lack the patience, it seems, to disentangle the complexity.
bender, I am “criticising,” in a sense, both sides, and pointing out that proceeding this way is unlikely to lead to resolution with any clarity.
If this process has sharpened the questions or clarified potential answers, fine. But this isn’t the place – if for no other reason, given the kinds of onlooker insults being bandied way too often – to tie it together.
But there is another reason – comments here are not part of the formal review process, and if they are that significant, they should be.
BOTH sides, ti seems to me, have good reason to want this debate sharpened and brought back to where it should be.
I understand how it might look that way from the outside. Not to worry; things will come back into focus. Remember: this blog is a lab notebook. The sharpening comes later. That was exactly Jean S’s point.
re #175:
Come on Lee. The discussion here, robust as it has been, has resulted in more real discussion of the specific issues (and flaws) of Dr Juckes’ work, which, if he were to adopt a Richard Feynman attitude, he should welcome as a positive contribution from his “reviewers”. It is possible, even likely, that Dr Juckes can defend his position on some of the points, but it is also evident to us lurkers that there are some areas where he is clearly struggling.
I understand that Willis is going to pull together a coherent summary of the points raised here, and submit these to COP in due course. That submission will probably be a fine piece of reviewer comment, and enhance COP’s approach of exposing papers to wider peer review.
At this point, it might actually be strategic to let Juckes et al off the hook. Let the CoPD paper be published as is, warts and all, and then demolish it with a counter-publication. Having a paper solidly refuted is far more embarrassing than having a manuscript rejected. The optimal choice depends on how much time you have for preparing a counter-pub and whether you think you can actually get it published.
Re: #172
I think perhaps what you are seeing is those regular posters (and Steve M) who know the details of the methodologies of these reconstructions and their associated histories sufficiently well to ask questions of Dr. Juckes and follow-up questions without having to painstakingly go back for time consuming searches of literature references as apparently Dr. Juckes does or at least prefers to do. This leads to frustration and impatience on all parties and boys being boys and blogs being blogs leads to some peripheral squabbling that I find well worth the effort sorting through for the more substantial parts of the discussion.
I know in the past that you have been super sensitive to this blogs demeanor, while participating not exactly like a shrinking violet yourself, but would you agree that we can learn from these exchanges and perhaps in ways not afforded by the published literature or some other more formal (and even perhaps highly censored) forum? I would also doubt that Dr. Juckes needs a TCO (for giving advice) any more than Steve M does.
RE: #170, #171 – Pseudo code is a good tool to help facilitate an in depth review of QA and design compliance. It depicts the thinking and logic (or lack thereof) of the developer. Where time allows, I strongly recommend it.
#172, Lee
“Why in the hell are you agreeing to discuss this here, where there are multiple crossing threads and piecemeal evolving attacks from multiple people, with little or no organization, and additionally confused by additional absurd comments from onlookers with no expertise?”
What’s your expertise? I suspect there are many of us here who are far more expert in certain aspects of climatology than you are. On this blog unlike RC, we respect and acknowledge peoples lack of expertise and encourage them to contribute. Referring to some of us as ‘onlookers with no expertise’ that make ‘absurd comments’ is an insult. Some of us here are more expert in certain technical areas than the claimed experts. For example, Martyn has declined twice at least now my offer to discuss quantum mechanics and its relevance to the physics of the GHG effect. He has admitted himself that he has never discussed this topic with his particle physics colleagues at RAL who are clearly more expert in this area than he is. IMO Steve M is far more of an expert in proxy temperature reconstructions than Martyn is. This comes as no surprise to me because Martyn is in fact an atmospheric scientist and not paleoclimatologist who for whom reseaon, which so far he will not explain, has carried out a paleoclimatology study in support of the Euro HT.
KevinUK
RE: #179 – Let me be neither the first nor the last to tell you that you are basically full of animal droppings. I am speaking of what I do for a living. I have seen the very things I mentioned in that post. The fact it bothers you says much about both your own ethics as well as about your lack of ability to witness the sort of heat that sends fools, briggands and ne’er do wells out of the kitchen.
Hehe, the irony of this statement is amusing.
Mark
You certainly spend a good deal of space painting yourself as the victim here and at times it seems to interfere with productive dialogue. I think that attitude is what makes your appearances at this blog somewhat suspect to some of the other posters here. If one were truly interested in engaging in a strict discussion of facts and theories here, I doubt that your concluding remark above of “..internally reinforcing the community of believers here” would be considered necessary. That tends to make me believe that you are here more to give your opinion/judgment of the people posting here than sticking to ideas. I have had internet experience as a contrarian poster and discussing issues with contrarian posters without getting all tied up in personalities — so I know it can be done if that is one’s primary purpose.
Re: 162,
Dear Martin,
This thread was unavailable yesterday, therefore, here is my answer to your post.
Believe me, I have been called worse things in the past, however what you are doing is nothing more than using a logical fallacy known as an ad hominem argument.
When I said that the “Hockey Stick” is almost the cornerstone of the IPCC TAR, it is because the Summary for Policymakers is what most people in the press, and government would read. The TAR itself is quite large and it is highly unlikely that busy reporters or elected officials would get very far beyond the Summary for Policymakers. I do not think that the title of this dosument can be any clearer.
There are two graphs on this document: Jones’ instrument data, and the hockey stick from MBH98. In the text of the summary it says:
This comes right out of MBH98. Figure 1b is the hockey stick.
MBH99 states in the conclusions:
On page 3 of the summary, under the topic There is new and stronger evidence that most of the warming observed over the last 50 years is attributable to human activities, the hockey stick is referenced again:
If any policymakers would go beyond their summary, they might read the Technical Summary, the Scientific Basis. On page 1 of the Technical Summary under the topic of Surface temperatures during the pre-instrumental period from the proxy record we see the hockey stick once again labeled as Figure 5. The second sentence of this section states:
In the body of the TAR, the hockey stick is labeled Figure 2.20. Figure 2.21 on the same page is is a spaghetti graph with the hockey stick and other reconstructions. From 2.3.2.2 Multi-proxy synthesis of recent temperature change
The next page of the TAR is 2.3.3 Was there a “Little Ice Age” and a “Medieval Warm Period”? The conclusions of this page as posited by the section title can be found in paragraph 5:
This conveniently supports the temperature reconstructions in MBH98 and MBH99.
Although I could continue, I think that this post goes a long way toward making my point that the hockey stick is essentially the cornerstone of the TAR, at least in the area of pre-instrumental temperatures. Without MBH98 and MBH99, what would the temperature history in the TAR have been based upon? Phil Jones’ instrument record? Two centuries would hardly have been as persuasive as the ten century graph and quotes from MBH98 and MBH99.