CA readers have followed some of the interesting reviews at Climate of the Past, where some of the exchanges have been lively (although most papers don’t seem to attract much comment.) Two reviews are in on Bürger’s most recent submission and a 3rd reviewer has been invited to give an opinion. However, he’s slow about these things. (CPD reviewers are allowed to identify themselves – Joel Guiot has submitted a review under his own name, and the third reviewer will as well.) The third reviewer is sometimes distracted by interesting by-ways in an article and this is no exception. So I thought that I’d explore some of these by-ways on CA for him. It’s possible that Reviewer #3 will draw on some of this material, although it’s too lengthy and ambling for a review.
Bürger discusses the topic of RE significance – a topic which I think is important and one which is in a very unsettled state, as Bürger observes, noting that MM05a and MM Reply to Huybers had reported that very high RE values could be generated from red noise treated in an MBH manner resulting in a 95% benchmark of over 0.5 (he expressed it differently), while MBH and Huybers had argued for a benchmark of 0. He didn’t discuss Ammann and Wahl 2007 arguing for and using 0.0 as a benchmark (based on their rejected GRL submission). I’ll discuss this further, but first I got intrigued by a point made by Referee #2 about Bürger’s use of the term “skill” which had echoes, in my opinion, of a broader issue.
Referee #2 observed that the paper was “difficult to read”, an observation that TCO would doubtless have agreed with and I agree with. I’ve spent a lot of time on the paper and it’s taken me an unduly long time to understand what he’s doing. One more reason for archiving code. If I could read his code, I could sort out what was explained poorly. Anyway Referee #2 observed:
in this paper, the term “skill” is never clearly defined.
The term “skill” is not incidental. Bürger uses the term “skill” 50 times – 8 times in his abstract, 16 times in his introduction and 9 times in his conclusion. Indeed, his main conclusions are about “skill” – he argues that MBH claims of skill in the range of 50% are over-estimates and that “more realistic estimates” of MBH98 skill are about 25%. Thus, without ever defining skill, Bürger nonetheless manages to estimate it. You can sort of figure out what he means in any given context, but he moves rather fluidly from a colloquial understanding of the term to its use to denote a very particular statistic/skill score. Referee #2 illustrated the fluid usage through the following sentence (just one possible example):
“Calibrating is done,…, by optimizing the model skill for a selected sample (the calibration set) and is almost affected by the presence of sampling noise. This renders the model imperfect, and its true skill is bound to shrink. But it is this skill that is relevant when independent data are to be predicted”.
The referee observed (correctly in my opinion):
The expression “by optimizing the model skill” is rather puzzling because (1) there is no “the skill” but “a” skill among many possible skills, and (2) the parameters of a given statistical model are estimated by optimizing a given criterion (Mean Squared Error, likelihood function, etc) that can be very different for a chosen skill score that has been calculated after the parameter estimation step.
The referee then proceeds to make sensible observations about the need to carefully define terms citing Thornes and Stephenson 2001 as an example of how skill measures can be clearly defined. Instead of responding to the referee’s concern about the failure to define the term “skill” and his concern about the fluidity of its use, in my opinion, Bürger missed the point about the fluid use of terms, choosing instead to debate incidental aspects of how the referee illustrated the point. Bürger:
1. (“skill”): – For the introductory statements, “skill” was intentionally used in a more colloquial and general sense. For any skill score measuring the correspondence of a modeled quantity to observations the following is almost axiomatic: If a model, calibrated by whatever method, is applied to independent data the skill is expected to shrink. I should be very surprised if the rev disagrees on this point. (If he/she is able to provide a counterexample it will of course be considered accordingly.) The actual law of shrinkage certainly depends on the chosen model and score. Eq. (4), for example, applies to cross validity, Rc, for model estimates based on least-squares. The scores mentioned by the rev, such as odds ratio (ORSS) and Peirce (PSS), are binary and as such not really appropriate for climate reconstructions.
I didn’t think that the referee was contesting the argument that the value of a statistic will typically decline in a verification sample, but Bürger’s use of the phrase “model skill” in the context of “optimizing the model skill”. Similarly the referee also didn’t propose the Odds Ratio as a specific test, but merely illustrated that there can be many ways to measure skill. While Bürger studied RE and CE statistics in an MBH context (and the results expressed narrowly are of interest), I think that Bürger’s fluid terminology has allowed him to reify the colloquial idea of skill with a particular statistic without properly distinguishing the two.
The concern over fluid use of the term “skill” reminded me of two interesting exchanges about the topic – one at the House Energy and Committee hearings last summer; the other at the blogs of Pielke Sr and James Annan about a year ago.
House Energy and Commerce Committee Hearings
Oddly enough, the House Energy and Commerce Committee hearings had a very illuminating exchange involving Wegman and Mann, illustrating a communication problem between statistical and meteorological communities.
Wegman testified:
when I read the paper [MBH98] originally, it took me probably 10 times to read it to really understand what he was trying to say. He uses phrases that are not standard in the literature I am familiar with. He uses, for example, the phrase “statistical skill” and I floated that phrase by a lot of my statistical colleagues and nobody had ever heard of that phrase, statistical skill. He uses measures of quality of fit that are not focused on the kind of things typically we do.
Of course, as Mann observed at the NAS Panel hearings, he is “not a statistician”. Mann later had an opportunity to comment on Wegman’s point and stated:
That was another very odd statement on his part, and I found his lack of familiarity with that term somewhat astonishing. The American Meteorological Society considers it such an important term in the context of statistical weather forecasting verification that they specifically define that term on their website and in their official literature. And in fact it is defined by the American Meteorological Society in the following manner: “A statistical evaluation of the accuracy of forecasts or the effectiveness of detection techniques.” Several simple formulations are commonly used in meteorology. The skill score is useful for evaluating predictions of temperatures, pressures, et cetera, et cetera, so I was very surprised by that statement.
Mann’s observation about the American Meteorological Society can be confirmed, as it does indeed define skill as follows:
“A statistical evaluation of the accuracy of forecasts or the effectiveness of detection techniques.” Several simple formulations are commonly used in meteorology. The skill score (SS) is useful for evaluating predictions of temperatures, pressures, or the numerical values of other parameters. It compares a forecaster’s root-mean-squared or mean-absolute prediction errors, Ef, over a period of time, with those of a reference technique, Erefr, such as forecasts based entirely on climatology or persistence, which involve no analysis of synoptic weather conditions: If SS > 0, the forecaster or technique is deemed to possess some skill compared to the reference technique.
To which, Wegman later replied:
My own sense is that if you look at, for example, this matter of statistical skill, it doesn’t matter that the American Meteorological Society says what statistical skill is. Statisticians do not recognize that term. I went around to a whole dozen or so of my statisticians network and asked them if they knew what they were talking about. It is my contention that there is a gulf between the meteorological community and the statistical community.
We examined, for example, this committee that is on probability and statistics of the American Meteorological Society. We found only two of the nine people in that committee are actually members of the American Statistical Association, and in fact one of those people is an assistant professor in the medical school whose specialty is bio-statistics The assertion I have been making is that although this community, the meteorological community in general and the paleoclimate community in particular, used statistical methods. They are substantially isolated.
Pielke and Annan
While the exchange between Wegman and Mann illustrates, at a minimum, a communication problem, it doesn’t exclude the possibility that the two communities might be doing similar things using different terminology. Econometricians use somewhat different language than signal processors for multivariate analyses, but one can often identify common features under the terminology.
Light is shed on the AMS definition through discussions took place last year at Roger Pielke Sr’s blog here and at James Annan’s blog here
Pielke Sr comment defined “skill” in terms of how closely the model fir observations.
I interpret skill as an absolute measure of forecast error with respect to observed data. I agree that skill of different models can be compared with each other, as long as observed data is the reference.
James Annan argued vehemently against “skill” being appropriately measured against actual data as opposed to against a reference point both in terms of the logic and in terms of the AMS definition:
In saying “I interpret skill as an absolute measure of forecast error with respect to observed data”, you are demonstrating that your use of the term “skill” differs from the AMS reference which you cited and other similar references…They all explicitly define skill as a comparative measure in which the data are used to determine which of two competing hypotheses (generally a model forecast and a simple reference such as persistence) is more accurate. as I said previously, using your own idiosyncratic definition is liable to mislead your readers. Your measure is simply not “skill” as understood in the forecasting field.
and again here at his own blog:
Incredibly, it turns out that Roger is claiming it is appropriate to use the data themselves as the reference technique! If the model fails to predict the trend, or variability, or nonlinear transitions, shown by the data (to within the uncertainty of the data themselves) then in his opinion it has no skill. …I repeat again my challenge to Roger, or anyone else, to find any example from the peer-reviewed literature where the target data has been used as the reference hypothesis for the purposes of determining whether a forecast has skill.
After this exchange, Henk Tennekes observed:
To both of you, I suggest that your quest for an objective and universally valid metric for the measurement of skill is unlikely to succeed. Skill, however defined, is ultimately a qualitative judgment, not a quantitative one. More precisely, it is a judgment, not a calculation. Being an old man, I want to remind you that I have written more than once about the added value of human skills. You might wish to delve into my Illusions paper, and into Michael McIntyre’s response (Weather 43, 294-298, 1988).
Apart from that I want to apologize for the loose way I fooled around with the skill concept in my blog and in earlier speeches and opinion pieces. Flowery language has its own problems, unfortunately.
The last sentence here closes the circle back to Bürger’s article – “flowery language has its own problems”. Quite so.
Annan’s challenge, to find a peer-reviewed article, any article, in which the “target data has been used as the reference hypothesis for the purposes of determining whether a forecast has skill” contrasts rather sharply with the routine use of actual data in hindcasts to claim “skill”. Whether meteorological forecasting terminology involving, as Annan says, a comparison to a reference forecast, should be applied to hindcasting reconstructions, is, I think, an open question.
Prior Paleoclimate Usage of the Term “Skill”
I also became a bit intrigued at exactly when the term “skill” started being used in paleoclimate literature. All the current dendrochronological verification tests except the CE statistic are described in Fritts 1976, which uses the term Reduction of Error (RE). The CE statistic seems to have entered tree ring literature with Briffa et al 1988 (cited by Bürger). About the RE statistic, Fritts 1976 merely says:
any positive value indicates that there is some information in the reconstruction. (p.24)…
Jacoby et al 1985 say:
Although not very well known outside the atmospheric science literature, the RE statistic is rigorous estimate of statistical estimates. An RE greater than 0 is regarded as proof that the estimates are an improvement over using just the mean (Gordon and Leduc, 1981
The term skill is used in Preisendorfer 1988 uses the term “skill”, who uses the term “hindcast skill”, where, as I read his equation 9.48, it is equivalent to what we would call the calibration r2 statistic. Preisendorfer, in his usual interesting bibliographic notes, discusses linear regression going back to Wiener and, in a meteorological context, refers to a couple of articles by Davis in the mid-1970s which use the term “skill”.
The transfer of the term “skill” to dendroclimatology seems to have been done by Jacoby and D’Arrigo in connection with their NH temperature reconstruction in the late 1980s. Jacoby and D’Arrigo Clim Chg 1989 substantially increases the properties attributed to the RE statistic from the earlier publications (even though no new statistical texts demonstrated the upgrade):
The reduction of error is a rigorous method of testing significance (Gordon and Leduc 1981). Any value above 0 indicates significant predictive skill. (p 47)
Fritts 1991 uses the term skill with less forcefulness as follows:
Any positive value of RE indicates that the regression model, on the average, has some skill and that the reconstruction made with the particular model is of some value..
D’Arrigo and Jacoby, 1992 (Climate since 1500). made a similar claim with the first hint of potential problems resulting from the presence of trends:
Any positive RE value shows that there is considerable skill in the verification period estimates as compared to the calibration period mean (Gordon and LeDuc 1981). The strength of the RE in this case may however partly reflect a difference in the mean of the calibration and verification periods (Gordon and LeDuc 1981).
The influential study Cook et al 1994 re-stated the various Fritts’ tests, together with the CE statistic. About the RE statistic, they observed:
Thus RE>0 indicates that the reconstruction is better than the calibration period mean. However there is no way of testing the RE for statistical significance. Note that x in the denominator will not produce the true corrected sum-of-squares unless it is identical to the verification period mean. Consequently a large difference in the calibration and verification means can lead to an RE greater than the square of the product-moment correlation coefficient. This occasional odd behaviour suggests that they should be interpreted cautiously when the data contains trends or are highly autocorrelated.
I’ll check this reference for its use of the term “skill” (but can’t find the article right now – it’s somewhere here).
The RE statistic got discussed in the context of MBH98 claims about the verification r2 statistic (together with actual values of ~0 for the verification r2 statistic.)
Back to Bürger
Let’s grant Bürger a little license for terminological inconsistency and then examine actual usage to see if there are some distinct usages that we can follow. He cites a number of articles from psychometric literature (Raju et al 1997; Cattin 1980) in which he says:
skill is accordingly being referred to as crossvalidity
In examining the underlying references, “cross-validity” in Raju et al is equivalent to what we would call “verification r2”. Bürger’s equation (4) says that the verification r2 in a multiple regression study is necessarily less than the calibration r2. He goes on to say:
Equation (4) applies to models estimated by ordinary least squares and thus to all reconstructions (“predictions”) that are based on some form of multiple regression.
I suspect that this is true, but there are differences between Partial Least Squares Regression and OLS regression. You shouldn’t just say this sort of thing, unless you have a citation. However, the salient thing here is that “skill” is said to be defined by a statistic that is equivalent to a verification r2 statistic. This however is the last we hear of this statistic, as Bürger moves into a lengthy series of RE and CE calculations for MBH98 flavors. These calculations are by far the most focused part of the paper. As a referee, I’m not sure whether I should be saying what should be in or out of a paper – I find many referee suggestions of this type to be annoying – but, in this case, as a blogger, I think that Bürger should ditch most of the theoretical stuff and focus on simply reporting the flavor calculations, staying away from metaphors and unfocused terminology.
After doing hundreds of RE and CE calculations under various permutations, Bürger proposes that these simulations enable him to estimate the skill of the MBH98 reconstruction, which he places at 25%, less than MBH claims of about 50%.
Here there is an interesting difference between how he handles the RE statistic and how a statistician would view it. The viewpoint of a statistician is always that one is using a statistic (verification r2, RE, or for that matter, Durbin-Watson or more exotic statistics) against a null hypothesis. On the other hand, Bürger’s viewpoint is that “skill scores” are estimates of the “skill” of the model, with the term “skill” somewhere morphing into an identification with percentage explained variance (with RE, CE two variants). One quickly gets into deep epistemological waters here.
It seems to me that the problem is almost identical to what we saw with Juckes’ attempts to claim 99.99% significance. In my comment on Juckes, I observed:
There is a large economics literature on the topic of “spurious” or “nonsense” correlations between unrelated series [Yule 1926; Granger and Newbold 1974; Hendry 1980; Phillips 1986 and a large literature]. Yule’s classic example of spurious correlation was between alcoholism and Church of England marriages. Hendry showed a spurious correlation between rainfall and inflation. The simulations performed in Juckes et al have virtually no “power” (in the statistical sense) as a test against possible spurious correlation between the Union reconstruction and temperature. A common, but not especially demanding, test is the Durbin-Watson test [Granger and Newbold 1974], whose use was encouraged by the NRC Panel (p. 87). According to my calculations, the Union Reconstruction failed even this test (see http://www.climateaudit.org/?p=945 ).
I also observed that it was trivial to develop an alternative chronology with different medieval-modern relationships that was also 99.99% significant through slight variations in proxy selection. Obviously both reconstructions could not be 99.99% significant — a point which seems interesting to me, but which Juckes chose not to respond to.
IMHO the problem with Juckes’ simulations is that, in null hypothesis terms, they simply tested the Union reconstruction against a null hypothesis of randomly generated AR1 red noise. I agree that the time series properties of the Union reconstruction are inconsistent with it being randomly selected AR1 noise. The trouble is that that is not the issue: the issue for these reconstructions is twofold: (1) do “key” proxies contain non-climatic trends, which have a spurious correlation with temperature in the calibration period? (2) has the selection of proxies into subsets been biased towards the inclusion of HS-shaped proxies (regardless of whether the reasons are “good”)?
Despite all of Bürger’s work, he doesn’t seem to have grasped either nettle. In particular, he doesn’t mention bristlecone pines. The $64 question for MBH98 is whether there is a spurious relationship with bristlecones in a complicated multivariate setting with other proxies functioning as white noise or low-order red noise – very much the viewpoint of MM05b and our Reply to Huybers (MM05 EE curiously is not cited by Bürger, although he makes many citations to us and not disparagingly). I don’t know how you can do a statistical evaluation of MBH98 without taking note of the non-robustness of its results to the presence/absence of bristlecones. Thus, doing thousands of simulations on the basis that bristlecones are a valid proxy and hoping that this will shed some light on the “skill” of MBH98 seems a pointless exercise to me.
Having said that, Bürger is a thoughtful guy and there’s interesting material in the article. I didn’t enjoy reviewing it at all. I’;ve only written up about half my notes here. At every step, I wanted to act as a friendly editor and send a cleaned-up version to him focusing and what is salvageable, rather than criticizing things. In this case, I think that would be more constructive and save a long song-and-dance. On the other hand, Referee #1 (Joel Guiot), an editor of CP, liked the article as it is.





43 Comments
God, am I glad the “skill” point has been cleared up. I also had never heard of it in reference to statistics previously and it seemed to refer to such a fundamental property I was feeling mightily embarrassed. Now it turns out that it is a term peculiar to meterologists. The lesson is I should have asked earlier. It seems that in this field nothing is as simple as it could be and people display a penchant for talking knowingly among themselves.
I wouldn’t be so bold as to say the point is “cleared up”. I’m merely turning over a stone.
Steve:
More precisely you have lessened my embarrassment by pointing out that the “skill” term is (a) particular to meterologists and (b) apparently means different things to different meterologists!!
What am I missing? Wegman says neither he nor statisticians he’s asked have ever heard the phrase “statistical skill.” The AMS quote does not address this – “skill” and “skill score” are not the phrase in question. Obviously, from the AMS quote, the term “skill” is statistical in meaning, and we can tell from this what Mann means…but this makes the invention/use of a phrase “statistical skill” redundant, non-AMS-standard, and potentially confusing.
I do find it amusing, however, that Mann resorts to the AMS to defend himself. I see a lot of criticism about meteorologists “not being climate scientists,” often used to discredit folks such as Dr. William Gray.
I can’t be the only person who thinks that the flowery language combined with confusing (and sometimes deceptive) uses of terms like “skill” is used to mask the absolute banality of what they are doing.
No-one wants to say “we used least squares regression” or “we copied the method used by other people in the field because we don’t know any better”.
On the Internet there’s something called the “Post-Modernism Generator“, a computer script which will create an essay, complete with citations, that is logical gibberish. I’m sure that Steve could produce a similar “write your own dendroclimatology paper” which would look identical but mean nothing.
In politics, you’d call this “sexing up the dossier”
This really resonated with me. The term “skill” has been bothering me for a long time.
I am not a statistician but I have studies statistics (both in the context of econometric models and the rather more straightforward kind we use in experimental economics.
In my interactions both within the field of economics as well as with people who work in psychology, sociology and evolutionary biology, we realize that sometimes we call the same things by different names. On the other hand, we all know enough standard statistics to be able to define any concept in terms that others with similar statistical and mathematical background can understand.
Thank you, Steve, for this exposition, yet I am still confused about this magic term, “skill”, which I had never heard before stumbling upon the climate reconstruction literature 😉
Somewhat related:
In my Intro Stats class, we are just at the point where I try to get across to students the fundamental principle that hypotheses are not supposed to be formed based on observed patterns in the data set against which they are going to be tested. This is always the most fun and challenging part as the world is full of people who “succeed” by doing just that.
Sinan
I think the third reviewer dissected the skill issue with great skill!
I am struck by Mann’s reference to the AMS definition of skill, which refers entirely to forecasting skill, wherere predictions of measurable quantities can be compared to the later actual measurements. I can’t see how this has much of anything to do with reconstructions, where the whole point is to try to come up with values in the absence of real measurements.
Ok, color me confused. I am a geologist who doesn’t particularly like to deal with statistics and am lucky enough to work in a portion of the field where when I need to work on statistical issues, I can ask somebody else to help me with it. As such, when it comes to discussing what a particular statistical test means, I tend to look at the bottom line instead of the multiparagraph explanation with equations involved.So when I read Amman getting worked up because Pielke dared to suggest measuring the skil of a forecast by comparing it to actual data, I about lost it.
Lets stop with “the flowery language” and talk about what the point of trying to demonstrate “skill” is. What everybody is saying…using a wide variety of terminology…is that they want their model/forecast to be as close to reality as possible. The AMS definition is based off of comparing their forecast to other forecast methodolgies…why? Juckes wanted to compare his reconstruction to noise…why? Why not take actual data and then compare the ability of the model to match that data? In know in some cases the real data isn’t available, but in alot of cases it is. So why measure your model against something other than reality?
Maybe I am being way too simplistic about this, but it seems like the ideal way to examine a given reconstruction would be to take the portion of that reconstruction for which actual data are available and compare it to the real data to see if it matches up. For multi-proxy methods, this would require examining each series to see if it matched local conditions. If the reconstruction can’t match the real data, you don’t have any business relying on it as evidence of past conditions. At that point, the “skill” of the reconstruction is really a meaningless term because it isn’t predicting reality.
If I am missing something, please let me know, but I just don’t see why these reconstructions should be evaluated any other way before they are evaluated against the real word
They do this, actually. That’s how Mann, et. al. have determined that their proxies are viable back in time. They perform the reconstruction and compare it to temperature, getting reasonable correlations. Unfortunately for them, the statistical properties of the “signals” change over time, so what correlates well during their so-called calibration period, is of little use beyond that range. Also, the correlations probably work rather well against CO2 change, rather than temperature change (PCA does not attach a little white flag to the result that says “I’m temperature” or “I’m CO2”). The correlation also apparently falls apart in recent time, which is known as “the divergence problem.” Yeah, it’s a problem alright.
Mark
#9. Bill – you should read some of my old posts on Briffa’s “explanation” of the divergence problem -maybe google Briffa cargo cult. Maybe someone will link to them.
Re: Bill F
Bill, your post presents a good opportunity to address a number of issues.
First, some notes on the nature of Statistics.
Most commonly used statistical techniques assume that the data set one is working with is a random sample of independent observations from a larger population. The properties of estimates and tests are derived on the basis of being able to repeatedly randomly and independently sample out of this population. Since, with any given data set, we are looking at a random subset of all possible observations, there will be some variation in the values of statistics that we compute from data. This is, in a nutshell, what is called “sampling error”.
On the other hand, in a lot of contexts (examples abound in economics), we just do not have that option. One particular case is when the researcher is dealing with historical data. The fact that there is one and only one history and it is not the result of a controlled properly randomized experiment cannot be stressed enough.
Now, think about the history of temperature measurements at a particular location. There is only one such series. It is not possible to go back and sample another sequence of temperature measurements with another set of controlled conditions. The history of temperature measurements is immutable.
So, suppose now, I fit some curve using some method to this series of historical observations. Suppose that the curve I fit matches the behavior of what I have observed thus far perfectly. (That is, its within sample behavior is excellent). Can I confidently extrapolate from this? Can I predict what future temperatures will be based on this beautiful fit?
A favorite quotation of mine (I don’t remember who said it) goes like this:
So, sometimes you are lucky and if the road behind you is straight, the road ahead is also straight. But, occasionally, there is that sharp curve on the hillside. You will definitely find out about the curve, but only after you have fallen off of it. That is, we cannot tell what the future holds based on the past.
So far, I have said nothing about temperature reconstructions. From what I can understand, the methodology goes something like this:
There is a period of time where we have both historical temperature measurements and measurements on some other variables which we believe to be influenced by temperatures (say, tree ring widths). Can we construct the relationship between these proxies and temperature today, and say something about temperatures in the past? How can we say we have come up with a good description of the relationship between temperatures and tree ring widths?
Clearly, at any given point in time, temperatures cause some of the variation in tree ring widths. (It is also possible that the growth rate of trees today cause some of the temperature variation today and tomorrow). In most normal formulations, therefore, temperature is an explanatory variable and tree ring width is a response variable.
In climate reconstruction, things are the other way around: In such constructions, tree ring width becomes the explanatory variable and temperature becomes the response variable (because the researcher wants to say something about the temperature in time periods for which we have tree ring width observations but no temperature observations).
This, I think, they refer to as “inverse regression”. While one can find quite a few scholarly articles on this topic, I believe reversing the roles of variables from the actual processes that generate the observations is to be avoided. Anyway, I digress.
So, temperature reconstructions regress temperatures from the recent periods on tree ring widths in the same period. That gives them an equation into which they can plug in a tree ring width and get back a temperature estimate.
How good is this equation? Well, there are two ways to answer this. One way, which all of this stuff about “skill” focuses on is to look at how well it fits the data in the last 150 or so years. The other way, is to test the reconstruction with data that is out of sample.
This is where Steve M.’s mantra about updating the proxies comes in. We cannot go back in the past and see how well the equation performs at estimating the temperature because we do not, will never, know the temperature in a particular location in 1543.
On the other hand, we are measuring temperatures daily. So, it is possible to take modern tree ring widths, plug it into the equation we came up with, predict temperature and compare it to reality. This is a far stronger test of how good proxies are than their ability to match the actual relationship between tree rings and temperature.
What meteorologists do is exactly this. They predict key variables in advance, and a comparison between that prediction and the actual observation allows us to compare how good they are at predicting. On the other hand, a good fit within sample tells us nothing about the ability of a model to predict out of sample observations.
At the time of the HS, IIRC, MBH used proxies that came up to 1980. That means we now ought to have, for each proxy, 27 data points, out of the original sample, which we can use to evaluate the performance of these reconstructions. This is the only test that we can do that actually matters.
Whether goodness-of-fit within sample is measure using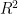 or RE or something else is almost entirely irrelevant because those measures of fit give us no real information about how well the proxies predict temperatures in the time periods in which we have absolutely no idea what the real temperatures were.
or RE or something else is almost entirely irrelevant because those measures of fit give us no real information about how well the proxies predict temperatures in the time periods in which we have absolutely no idea what the real temperatures were.
I have oversimplified some things to keep the post from getting very long (and it is already too long, apologies).
Sinan
Re: 12
Correction:
What I had meant to type was:
This is a far stronger test of how good proxies are and their ability to match the actual relationship between tree rings and temperature.
Sinan
Sinan:
I hope you get a reaction from those who have been working this issue because your very clear statement is exactly the way I have been thinking about it. The added caveats are that all models assume essentially – all other climate variables and variable impacting the width of tree rings being equal and that we actually can agree on the key variable, namely, the temperature. Even so, you are right we should first test the simplest model by checking the newest set of tree ring widths.
Re: 14
Thanks Bernie. As Steve M. has pointed many times in the past, economists face these and other kinds of issues all the time (both the non-experimental nature of most of our data as well as various endogeneity problems. For example, how does one estimate returns to college education when people who go to college choose to go to college because they expect to be better off by making that choice?
How does one deduce temperature sensitivity based on trees which have survived through temperature fluctuations over hundreds of years when the more sensitive trees might have died and not made it to 20th century?
I don’t pretend to have any answers to the latter question, but, at least in the case of returns to education, any economics paper that did not address the inherent bias in the selection process would be ripped to shreds at the working paper stage and I just to not see the same high standards applied to research in the climate reconstruction studies.
I am afraid I have strayed off-topic here so I will shut up 🙂
Thanks Sinan,
With the AMS process, I understand that they take their forecast, and compare it to forecasts from other methods, such as using past climate data from the same period of time…i.e. the model-based prediction for high temperatures on March 28th compared to the average high temperatures for the past 30 march 28ths at the same location. That is their way of saying is our forecast method better (or more “skillful”) than looking out the rear window of the car?
In other words, they aren’t telling you how well they actually predict the weather in an absolute sense…they could be wrong 95% of the time, and they would still be considered “skillful” if the other method was wrong 98% of the time. I would rather see them evaluate skill in an absolute sense, by comparing their forecast to the actual conditions that occur during the forecast period and then telling us how often they were right. That is what I mean by judging skill against real data.
Lets say you and I were each asked to predict the color of the sky before walking out the door, and you said red and I said green. Just because the wavelength of my color was closer to blue than yours wouldn’t mean my prediction was more skillful, because we are both still wrong.
Now I think part of the problem with comparing “forecast skill” to tree-ring based temperature reconstructions is that a reconstruction isn’t really a forecast. You aren’t predicting anything so much as showing that your method of reading the rings is valid and that the ring width is a function of temperature. We already have plenty of temperature data for at least a portion of the time period covered by many tree ring series. Where I disagree with you is where you say we only have one data set. We have at least two. We can have an instrumental set from a nearby station, and we have a set from the trees growing there.
So why can’t the dendroclimatologists first look at the tree rings from say 1900 to 1940 and compare them to the instrumental record to develop a “prediction” of the tree’s response to temperature. Then use the data from 1940 to 1980 or whenever the series ends to test the “skill” of the prediction against the actual instrumental data for that period? If the “prediction” does not accurately predict the actual data, then how can you have any confidence in the ability of it to backforecast to time periods where we have no data? If the tree ring based temperature forecast for any given series doesn’t match the real data where they are growing, how can you say that they will then turn around and accurately show a “global temperature signal” with any level of “skill”? It really seems to be more of a case of taking a random signal and torturing it until you get the shape you want at that point.
It seems like Steve does a great job delving deep into the statistical methodology and going back and showing how random noise series can be input and used to create the same statistical parameters with some of these constructions. But I was really struck by Juckes’ claim that his proxies did not have to match the local records in order to be used in his reconstruction. For me, that shocker points to a far more basic and fundamental problem than how these guys are doing their statistics. It seems to me that if the proxy data doesn’t match the local instrumental data, then it is dead from the start and no amount of statistical manipulation can turn it into a meaningful representation of anything. I appreciate the urge to “update the proxies” and think it is a good idea on the whole, but for lots of locations, there is already nearby real world data to compare the existing proxy data to and apparently guys like Juckes don’t care whether it matches or not. What good will updating the proxy do if they already don’t match the local data and are bing used anyway?
#15 Sinan,
I totally agree with you about the problems with confounding variables that are essentially unmeasurable. I think I drive my wife crazy when we are riding in the car and a report about a new study comes on the radio. I end up spending several minutes dissecting all of the other possible variables that were not considered as a part of the study.
My favorite one to consider is the idea of telephone opinion polls. Think about how much gets done based on public opinion…and for so long, random dial telephone polling was the standard means to do find out what the public’s opinion was. But if you only called during the day, you were then restricting your view of the public to “people who are home during the day”. Which meant that most likely your subset was made up mostly of four groups…stay at home moms, unemployed people, people who work nights, and kids. But of those subsets, the kids were unlikely to take the poll and the people who worked nights would be trying to sleep and would either not answer the phone or would not take the poll. So most of the polls would really only reflect the opinion of a very tiny subset of the population that was either a stay at home mom or unemployed. Even now that they do more calling at night, they are still only going to get a response from people who are willing to take the time to answer the poll…which to me would likely represent a very specific set of personality types that would assumably bias their survey towards the opinions of people with those particular personality types. If you really sit and puzzle on it long enough, you eventually reach the conclusion that even if you can find a statistically representative number of people willing to take your survey, the bias inherent in the methods alone should cause a great deal of uncertainty in whether the poll actual reflects the opinions of the population it is supposed to represent. I doubt that tree-ring proxies have any lower degree of uncertainty…
Mark,
My understanding of what the hockey team was doing was taking groups of proxies and comparing them with a glabal data set of temperatures. I was not aware that they ever tried to evaluate the individual proxies against local temperature data before accepting them as valid. I think Steve even specifically pointed out some of their series which were bing used by others as precipitation or ocean current proxies instead of temperature.
Bill F (#17): In case you have not heard of it, a favorite example of a poorly designed telephone poll.
Re: 16
Bill, we agree on most points. In fact, one can go one step further. Do the construction using first half of the data set, then predict temperatures using the tree ring widths from the second, and then do a construction using the second half, and predict temperatures using tree ring width data from the first half.
As for your comment:
It is true that one can randomly sample among stations but one cannot randomly sample among temperature observations for a given station. It is in that sense that the data are fixed.
Now, it would be a useful experiment to do the temperature reconstruction using a subset of temperature data and see how much success one has in predicting temperature changes in the other subset.
Potential difficulties (both in concept and implementation) arise from the fairly non-random distribution of where humans have chosen to measure temperature.
A significant problem with these temperature reconstructions is that the sparsity in the most famous literature of any consideration of how their constructions might be falsified.
Sinan
Dear Steve,
that’s a very detailed and comprehensive study on the topic of “skill” from the viewpoint of comparative literature. If you forgive me, 😉 I wouldn’t criticize Burger myself.
It is nice to have exact definitions of objects, but on the other hand, it is not always the key physical requirement. Skill is not an objective physical observable: it is a useful concept that helps in your strategy to find the answers to scientific questions and the right theories. Burger clearly wanted to say some universal statements that are independent of the partially cultural details of the exact definition of a skill.
Skill just measures how much more accurate prediction you get from a formula, theory, or model in comparison with a supernaive model such as a constant average. Whether it is worth at all to go to a more complex model. Even if you get some skill, the new complicated model can still be a bad step because the amount of parameters can be too expensive for the small increase in accuracy; the notion of “skill” doesn’t save you from models with too many parameters – do I understand well? The phrase “higher skill” just means “more accurate agreement with the data”.
I don’t quite understand the discussions about the skill of the predictions. Of course that a model has either a low skill or a high skill for its predictions but I think that you can only know what the answer is after the future comes and the predictions can be compared with reality. Or do I misunderstand something?
While I think that Burger doesn’t rely on details of the definition, I think that at various places, they had offered some definitions – so did you, in fact. So if Burger talks about the skill claims by MBH, I think that it is expected that he should use a definition that is as similar to the MBH definition as possible – while obvious errors in it are corrected – and before you find an actual error in his statement, it doesn’t seem justified to criticize him.
Let me return to the first point. I do think that the notion is generally a fluid notion, and if you call for this notion not to be fluid, you contradict one of its basic characteristics. There is no God-given universal skill usable in all situations, but there are still qualitative statements that one can do independently of having an exact definition. People using different conventions should still be able to read the paper which is why I think that a more fluid qualitative treatment of the notion is better.
Of course, the sentences about it must be supported quantitatively, but I think that Burger’s sentences with the word “skill” are qualitative.
BTW the blog page says that there is a 15 minute delay due to caching. I think I know how to circumvent it. Just add some extra arguments to the URL such as … ?p=1301¬hing=000. 😉
All the best
Lubos
They do actually do that to a certain extent.
A problem with that approach is that it is very hard to resist peeking at the other data – and once you’ve peeked or done this once the value of the ‘withheld’ data set is gone from a statistical point of view. Thus, for example, there were many studies of money demand in the economics literature that claimed to find robust relationships between activity and money and used exactly the procedure described above. Unfortunately, these all broke down when truly out of sample data became available. In the case of these equations a big problem was the ‘all other things equal’ assumption that turned out to be spectacularly wrong during the financial deregulation of the 1980s.
With respect to tree rings you have similar problems. And these are problems that are inherent in the statistical process. In an ideal world you would run one regression (with the fist half of the data), test it and then publish. In reality people run hundreds of regressions until they find one that works. This is not a problem that is unique to dendroclimatologists. But it means that the only true demonstration of skill is when entirely new data is used to test a hypothesis – regardless of what procedures the researcher claims to have followed with their initial data set. Thus, you need to wait a while and gather additional time series, or go somewhere else and gather new tree rings. But you have to use data that was unavailable to the original researcher – you just can’t help peeking, it’s human nature.
#22. The form of split samples is observed in many studies; Juckes is rather an exception. I agree 1000% with John S on the problems with knowing the data sets. People know what the data look like in advance. I successfully predicted over 80% of the proxies selected in Hegerl et al because I expected them to use almost the same proxies as Osborn and Briffa 2006, which they did. I made a prediction in advance of the paper being released, which is up at the blog.
Because many of the tree ring sites were taken up to only 1980, there is actually an ideal opportunity to see how they perform out of sample. That’s why I’m attentive to new data – to see if the ring widths reflect recent warm temperatures. However, there is much evidence that they don’t – hence the “divergence factor”. In any other field , the “divergence” problem would be held to falsify the hypothesis of a linear relatinoship between ring widths and temperature above a threshold – as one would expect from the upside-down quadratic growth curves in botanical studies. One sees data being truncated at 1960 to avoid facing up to this. Briffa’s handling of the divergence problem is a marvel and bears repeating over and over:
Of course, when I make these quotes, the tree ring people think I’m being mean to them. I did a detailed report on this issue in http://www.climateaudit.org/?p=529 and showed a wonderful truncation of the Briffa record in IPCC TAR here http://www.climateaudit.org/?p=194 .
Re: 22
John S., note that my first post (#12) in this thread pointed out the need for genuine out of sample verification by extending proxies.
Sinan
SS is a heuristic, not a statistic. Wegman is a statistician, not a heuristician.
Sinan,
Not arguing with anything you’ve said – just emphasising a point that I think bears repeating.
Dear bender #25, the rather rigorous definition of SS in your comment combined with the opinion that it is just a “heuristic” just don’t seem to fit together too well.
It is perfectly plausible that the statistical community doesn’t use certain semi-scientific semi-conventional measures of validity of a model but this fact itself doesn’t imply that these methods are scientifically flawed.
I am sure that many other fields are using statistical methods that are unfamiliar to 99+ percent of statisticians. My guess is that the statistical machines used to evaluate data from experimental particle physics or the WMAP variations would sound unfamiliar to most statisticians in many respects, and these statisticians would struggle for some time before they could accept them.
And if I can be frank, I think that experimental particle physicists who deal with the events are way better statisticians than statisticians.
But anyway, these methods work and allow physicists to test standard theories and sometimes find new phenomena. Statisticians are just not experienced with certain kinds of tasks even though their nature is statistical. I would discourage everyone from criticizing others for using certain methods just because you’re not used to these methods unless you are able to prove that they lead to wrong conclusions or results.
Re #27, Lubos
What do you mean by “statistical machines” ?
And surely the experimental particle physicists have written up and justified any new techniques they might have developed ?
#27
That is true. But often those methods are flawed, specially if the experiments cannot be controlled / repeated, and the observed responses are barely detectable. ‘we must be able to explain it all’ mentality kicks in, and statistics are exploited.
I don’t think so. Very often they suffer i.i.d syndrome 🙂
I agree. Quite often the methods are the very same methods that statisticians use, but with different terminology.
Re #27
Generally speaking, the expermiental sciences don’t need to deal with leading-edge statistics. They can construct their experiments to provide good quality data where external factors are held constant and proper sampling can be done. It’s the non-experimental sciences – with economics being the prime example – where you need to be really careful with your statistics and a lot of statistical innovation happens. If your data is crappy (statistically speaking) and you can’t get better data, you do the best you can with that data – econometrics excels at identifying the robust conclusions that can be made from poor quality data. In the expermiental sciences you try to get better data – in economics you have to get better statistics.
Re #29, UC
I agree with this bit :
I don’t like this bit :
which sounds a bit Mannian.
The interim step needs to be a detailed justification of the new method, I would have thought.
Bill F,
Regarding phone polls, people who don’t have a landline (ie, cellphones only) don’t get polled at all.
Lubos
I agree but with the following caveat. Researchers should be free to choose the statistical methods that reflect the nature of the data that is being analyzed and the question being asked. I think the common ground needs to be using methods that have well defined assumptions and well defined limitations that are articulated in a statistics/methods reference (as opposed to simply citing another “successful” user of the same techniques). I noted with interest Steve picking up on a statistical point in Burger and arguing that the point needed appropriate citations. The challenge in fields like climatology is that those interested in the results come from a wide array of fields and, therefore, there is a responsibility on the part of climatologists to provide references for what might appear to be SOP statistical practices in the field but which are in fact discipline specific procedures. Highly specialized fields like particle physics may well “get away with” evolving their own statistical tools until it comes to the point where their conclusions require public policy decisions. Then they will have the responsibility of making their methods and tools more transparent to “skilled” laymen. It is the price of relevance and/or notoriety.
Yet another reason for having statisticians review articles that involve statistical analysis.
Lubos, your posts are always thought provoking. However, I must respectfully disagree when you say:
This is Alice in Wonderland science.
The onus is not on us to believe six new statistical methods before breakfast, or to show that some novel, unusual statistical procedure doesn’t work. The onus is on the dendrochrologists to show that it does work, that is some theoretical justification for the procedure, and their conclusions should be discarded until such substantiation is forthcoming.
w.
Heuristics can be complex and they can be “rigorous” in their definition. That doesn’t mean a network of statisticians is likely to have heard of them. I’m not dismissing SS, or any heuristic. I’m explaining how gaps in knowledge between disciplines can arise. Creativity in isolation is how it happens. And this is the mark of art, not science.
Dear fFreddy, by statistical machines, I mean a whole framework of statistical concepts, algorithms, conventions, exceptions, rules how to choose which sub-method should be used, and criteria to determine whether the results are trustworthy.
I just think you wouldn’t be satisfied. The colliders, for example, deal with a huge number of events (colissions that produce new particles with particular properties) per second and it is impossible to store data about each of them. Most of them must be thrown away. The events that are used to deduce physics are only an “interesting subset”. The discarded events are “uninteresting” and they are counted as following a boring background. Quite clearly, there is a lot of conventions one must pick in dividing the events into the interesting and uninteresting ones in the first place, and understanding physics is a key to do it right.
After you do it, you end up with the interesting events but there is no 100% reliable way to reconstruct what happened in a particular event. (In fact, this question can’t be answered even in principle because amplitudes from all possible processes with the same initial and final state contribute to a given event.) Many different types of events – e.g. with new intermediate particles – have signals that overlap with each other but give different patterns of signals, hopefully. Some of the signals are known, some of them are not because they are “new physics”. One must be able to choose a cut that defines the number of jets in an event – a jet is a stream of many particles going in a “similar” (…) direction, resulting from a quark or gluon that was in the middle.
There is no canonical method to do these things. In fact, there are many systems of conventions and approaches. Also, there are many event simulators, and they differ in profound technical details. You can’t justify one over the other by a universal argument. You must allow them to co-exist and only if one of them turns out to give systematically more useful and accurate results, it will be preferred. Everything must be allowed to compete: not only experimental teams and theories but also statistical strategies. Which of the event simulator strategies will be the winner in the future doesn’t depend on statistics only. It depends on the laws of physics, and some of them are not yet known or not yet properly understood as far as their consequences go.
I am sure you must have heard this from many alarmists already, but I certainly agree with whoever has said that science is not just statistics, and the best choice of statistical methods to study Nature may depend on the laws of physics, not just some universal statistical rules and dogmas.
It is also untrue that statisticians are necessarily guaranteed to be the best people for everything that has the word “statistics” in it, just like climatologists are not necessarily the best choice to solve anything with the word “climate” in it. The expectation whether someone does things right and takes the most important things into account depends on the intelligence and training of the person, and similarity to other tasks he has solved in the past.
I am really sorry to say the same thing as Mann but it’s true. 😉 Now, Mann was almost certainly wrong in most of his statements about the past hockey climate, which makes the work unusable, but you can’t prove he was wrong just because he is not a statistician. The whole concept of competing professions who have the right to keep ownership over their topics is completely silly. If someone else does things better than a “clique” in a field, he is just doing it better.
If string theorists become better in predicting nuclear scattering experiments than the people who learned nuclear physics for decades, what can you do about it? 😉 It is pretty likely that it is going to happen. There are many examples like that. Outsiders with sufficient talents and hard work can do things that the insiders can’t. They can be patent clerks or mining consultants and their way of talking about scientific questions doesn’t have to fit the box of a horde mentality, but this itself doesn’t prove that they’re wrong.
Dear Willis #34, I completely agree that in order for a method to have any value, one must show that it works. I don’t know why you think I disagree. 😉 But before you prove that it works, you must try whether it works. 🙂
Bender #35, this is just terminological issue but you’re just wrong if you say that heuristics can be rigorous. Internally they can be rigorous but they’re certainly not rigorous as a description what they want to describe, by definition. Heuristics are tools to direct our attention in the hopefully right direction. And again, I don’t think that the observations “network of statisticians hasn’t heard about XY” proves that XY is wrong.
OK, let me mention one more thing about this general question of presumption of innocence. I actually disagree with the rule that we must always assume that everything is wrong unless it is rigorously proven, or something like that.
Another word to describe this approach is bias it and can’t be used consistently with the laws of logic. If a person writes a non-rigorous paper asserting “A”, someone else can write a non-rigorous paper asserting “non A”. You can’t assume that both of these papers are wrong just because you should always assume that non-rigorous papers are wrong – because it would be logically inconsistent.
I think that the only scientific approach is to admit “I don’t know” at the beginning and judge various statements fairly regardless whether they are formulated as “positive” statements or “negative” statements – which is a matter of presentation not science, after all. Saying that one must always assume something about a certain result formulated in a certain way is bad. Assuming that a paper must be wrong is as irrational as assuming that a paper must be right.
Of course that until sufficient evidence is given for a statement or a paper, a rational person won’t take it seriously. A rational person will continue to think that “we don’t know”. But saying that it must be wrong just because it appears in a paper that is not rigorous is simply irrational. Even non-rigorous work can lead to a systematic improvement of our knowledge, and in most fields it does as long as the signal is stronger than the noise where noise includes not only uncontrollable fluctuations but also fraud and ideologically-driven selection bias.
I think that, for the most part, most of us are on the same page here, although we may be expressing it in different ways. My instinct when I see discussions of “statistical skill” is to see if that is isomorphic to some statistical concept with which I (or Wegman) might be familiar – in the same way that I don’t throw up my hands because someone calls what I would call an “eigenvector” an “empirical orthogonal function” or “principal mode” or something like that.
Von Storch has observed to me quite fairly that most statisticians don’t really bring much to the party as they typically arrive with i.i.d. baggage and try to force the problems into a mold that doesn’t apply. I thnk that econometricians and even business statisticians are, in some ways, more useful because they are used to autocorrelated series and have different instincts than an i.i.d. statistician.
When one is dealing with the Team, I get the sense of people using big words pompously or people trying to fit the facts to the policy without inquiring into what could be wrong with their model rather than practical people soberly viewing their data.
Let’s suppose that we grant weather forecasters their use of “skill” as a useful concept in eveluating weather forecasting systems. The question then is whether this vocabulary with its metaphorical baggage is a more useful way of approaching paleoclimate reconstructions. Thinking some more about it, I see one huge difference – the weather forecasting models are physics-based, even if there is a lot of parameterization in them and they actually do get tested on out-of-sample data. So one can see how the term “skill” can have real meaning in a practical sense. When one is making a climate reconstruction from dendro site chronologies, we do not have a physics-based link between ring widths and temperature – we have curve fitting in a calibration period. I think that the enterprise is much more in the style of statistical modeling than it is to weather forecasting.
Thinking about it a little more,
I like that .
Actually I even think that the more complex a field is the more chance an outsider has to shed some light in it because he is still able to ask simple , relevant questions .
I have a friend who is expert in the string theory and he told me that the guy who will find one day the way out of this mess will almost certainly be somebody who has not a clue in string theory and who will ask the right question about the gravity and quantum mechanics .
Somebody I forgot has said that it is better to bring wrong answers to relevant questions than to bring right answers to irrelevant questions .
Tom:
Sounds like Feynmann!!
Re: #38
You have summarized my thoughts on the subject nearly exactly. Without out-of-sample results be careful of what and how you conclude, be very careful. Heck, you should even be careful of how you conclude using out-of-sample results.
And a statistic used more or less exclusively in your community or invented in your community should not be considered merely a convenient term for community discussions, it should either have statistical rigor or be redefined as a part of your community terminology and without statistical implications.
Interestingly, the concept of “modes” is rather common in the signal processing community. At least, the SIGINT guy I used to work with (before I got this shiny new job) referred to eigenvalue decompositions as dominant mode analysis. I was explaining the Gram-Schmidt process I was working with (uh, a sort of PCA method, btw) and he kept mentioning that I was “finding the dominant modes” (he also kept bringing up “Householder rotations”). It was a term I was unfamiliar with, but nevertheless meant exactly what I was addressing.
Mark
O.K. This might sound a bit odd, but has anyone ever looked at the tree rings in Central Park, NY or other Parks where mature trees have been MOVED. Large living trees have been moved from all over in Parks in the US and UK. There will be records of where the trees were dug up from and when they were moved and planted.
What happens to tree ring growth whene you move it into the center of a heat Island? The trees in Cental Park will be a lot warmer than almost anywhere in 200 miles, surely that should give you some signal.