Hans Erren has digitized the Ababneh Sheep Mountain version and I’m going to show some extremely interesting knock-on results both on MBH98-99 and Mann and Jones 2003. I started in on Mann and Jones 2003, partly for a little variety and partly because the Sheep Mountain impact was particularly strong on this network.
Before I get to analyzing the impact of the Ababneh version on this network, there are some baffling adjustments to the Mannian PC1 that I’ve been unable to figure out and maybe readers can help. I’ve posted up all the relevant materials and some analysis script.
Mann archived the Mann and Jones PC1 in the Jones and Mann 2004 archive here. They state that they used 6 chronologies, but do not state which ones. Within the MBH99 network, there are exactly 6 series that start in AD200 or earlier. I then calculated the (erroneous) Mannomatic PC1 and compared it to the archived PC1 – it was a pretty close match, but not exact. By experimenting with it – and I hate to say how much time these experiments take – I deduced that there was a correlation of more than 0.9999 between values up to 1700 and a much lower correlation after that. This confirmed that I’d spotted the correct 6 chronologies and that the JM04 PC1 was a re-scaled re-centered version of the Mannomatic PC1 up to 1700 and was a splice of some other series after 1700.
Needless to say, there’s no account of the splicing in Mann and Jones 2003, but by now I can sometimes anticipate Mannian ad hockeries. I tried the MBH99 “fixed” PC1 in the AD1000 network (“fixed” implies a rational process; let’s use the term “adjusted” instead) since there is no evidence that the PC1 is in any sense “fixed”. The “adjusted” and raw AD1000 PC1 were formerly available at Virginia Mann’s FTP site, but with the evolution of PennState Mann, this archive is no longer available. I saved it in Nov 2003 when it was first made public and I’ve posted up the PC1s from that network here. Experimenting some more, I determined that the correlation of the AD1000 PC1 fixed adjusted had a correlation of more than 0.999 with the JM04 archived PC1 for the period after 1700, showing that it had been re-scaled and re-centered somehow to yield the JM04 version.
There was some evidence on the re-scaling and re-centering of the AD1000 fixed adjusted PC1. Jones and Mann 2004 (though not Mann and Jones 2003) Figure 4 caption said that the series had been standardized on 1750-1950. This yielded an emulation of the archived PC1 that was pretty close – it was a bit more than rounding but not a lot more. See the top panel of Figure 1 below showing the discrepancies between the trial rescaling of the AD1000 fixed adjusted PC1 and the JM04 archived version – there is a relatively good match after 1700 and poor match prior to 1700.. So far so good.
Now another problem arose – and this is one that I’ve not been able to figure out at all. One’s first assumption is that the AD200 PC1 would be rescaled and recentered in the same way (on 1750-1950). This proved not to be the case as shown in the graphic below -see the middle panel. The second panel shows the discrepancies between the AD200 PC1 re-scaled in the same way and the archived PC1. Neither the centering nor the scaling match.

Figure 1. Discrepancies between trial adjustments to PC1s and Jones and Mann 2004 Archived PC1
The third panel shows my best attempt to re-scale using actual periods. While the match is pretty good, the scaling and centering rationale that I’ve found necessary to achieve this make no sense at all.
In order to get the right centering, I found that it was necessary to re-center on a subperiod of 1000-1700. Re-centering with later values was substantially off in the same way as the middle panel (subperiod 1600-1950). Experimenting, I found that the mean discrepancy in 1000-1700 was reduced to much smaller positive value using 1000-1700 as a base period; with 1000-1600 as a base period, the mean discrepancy was negative. So interpolating, I tried a base period of 1000-1650 and got a mean discrepancy close to zero. So for now I’m guessing that the AD200 PC1 was re-centered on 1000-1650 – 1650 is a date that emerges inexplicably in the MBH98 archive – although it is date not mentioned in any MBH98 periodization. Why this period (if indeed this guess is correct)? I have no idea.
However scaling on 1000-1650 didn’t work. It didn’t reduce the amplitude quite enough. Again through much experimentation, I concluded that the re-scaling period had to include values from the 20th century in order to get enough amplitude reduction. If the period ended in 1980, the length required to get the right amplitude was implausibly short. 1950 is a date used elsewhere and only a few periods ending 1950 yield an appropriate amplitude reduction – most of which were not round periods. One such round period started in 1600. Using 1600-1950 to re-scale, I got a pretty decent re-scaling. The bottom panel shows the match scaling on 1600-1950 and centering on 1000-1650. Does this make any sense? Of course not.
Perhaps there’s a simpler and more plausible system for rescaling and recentering, but there’s no hint in Mann and Jones 2003 that anything of this sort is even going on, much less any hints on how he did it. I’ve posted up a script showing some of my experiments and downloaded the various relevant time series.





72 Comments
‘Mannian ad hockeries”
That’s a keeper.
Naive question from a newbie follows….
Ask Michael Mann how he did it? Assuming he is a scientist, he will believe in the scientific method, and as far as I know, this requires verifiability – or am I wrong?
Steve: I’ve been trying for years to get information about Mannian calculations and am stonewalled not just by Mann, but by his funders and journals. I’ve made persistent efforts to obtain information without success.
Ross:
Mann would just as well have Steve Mc. fall off the face of the earth. You’ve made some bad assumptions! 🙂
And they call those of us that wish to understand their means and methods before we accept their condlusions. I wonder if they would let me control their check book with out having the right of verification? It sure seems they want control of my check book without my being able to verify.
Makes one wonder.
Bill
Ross, Bill… this is just the tip of the iceberg (so to speak). Normally, one would expect that these “details” would not only be available, but would have been part of the original publication and verified in peer review.
Upon discovering that this (and more) not only happens but is quite common in real climate science today… aren’t many of us going through a grief process? Shock and denial, anger and frustration, despair and pain, hope. “Sad” doesn’t begin to express the response of those of us who care about the truth. Perhaps I’m just a pollyanna optimist, but I really do have hope for the future.
Ross, as you will discover if you read some of the archives here, the obfuscation and lack of cooperation by some of the famous climate scientists is simply shocking.
1650, huh?
Damn, this is going to ruin my Sunday.
Looking at those panels, I can almost see something clawing its way out, waving its scaly arms at me, yelling, “Don’t you see me? I’m right here!”
I hate that.
no, it isn t.
trying to reproduce a graph, as Steve does in this topic is helpful.
pointing out that axis are named in a false way at the end is not.
Am I correct to read the third panel as suggesting global cooling? Thus Erren’s work would make a case that if we applied the MBH rules of analysis in the most consistent and statistically reasonable fashion we’d assume the earth is cooling?
Steve it would sure help me and I think many readers to have some “lay articles” about these topics on a side panel. ie a few paragraphs where you lay out your basic, simple take on Hockey Stick, Ice Cores, etc. Alternatively just a page of links for that – e.g. a link to Wegman for his easy to read treatment of hockey stick stuff.
Sod says: ” … trying to reproduce a graph, as Steve does in this topic is helpful. pointing out that axis are named in a false way at the end is not.”
I am sure that when Mann was forced to include a correction to Nature Steve had produced something to science. Mann still did not show his data or methods. Steve did show that you cannot rely on Mann although media use his results. Steve has published something really relevant to science.
noT helpfuL – foR whoM? thE publiC? otheR researcherS? thE publiC?
i jusT don’T geT thaT sorT oF ‘reversE’ logiC I guesS … identifyiG a ‘falsE’ issuE unlesS iT iS iraQ …
RE 24.
Yes. I saw the same thing with Eli Rabbett and Kristen here on CA.
When Kristin made a simple mistake a college professor piled on.
Tough guys. I suppose.
Gore made a movie. he talked to gavin, mann and hansen. They were advisors.
Now, when a court in England found some problems with AIT… MANN and GAVIN
lept to his defense. The defense was : IT’S A MOVIE not science. GORE IS ALLOWED
some minor mis statements. My favorite.
Gore claimed that Island nations HAD BEEN
evacuted.
The truth: One island nation asked New Zeeland to make plans in case they
has to be evacuated.
GORE: Island nations HAVE BEEN evacuated.
TRUTH: one island nation asked New zeeland to make plans.
MANN: gore was right and perhaps he made a mistake in verb TENSE
Now. A editorialist in NOWHERE NEVADA makes a bone headed mistke in converting
C to F. Pennstate Mann cannot resist the urge to correct a dirt simple error
while he IGNORES his own.
I’d overlooked/forgotten that “the man” was a principal(sic) component over at RC. I’d gotten used to Gavin shilling for Hansen. The hockey stick is likely made from Unobtainium which makes it impossible to be bent after fabrication. The “Error in Ely” dustup just goes to show that Mann is a correction diode (half rectifier?).
Was there an effort to systematically log the results of the Where’s Waldo game? Given that the PC lexicon still heavily weights the word and concept of “Global”, it might be useful to keep a running figure of merit/table/World Map on just how global all of this change in measurements is turning out to be.
Enough about Mannian tantrums, does anyone see any reason why Steve’s graph centering attempt didn’t work? Mosh, what’s that factoid thing that clawing to get out?
I’ll use my electronics skills here.
Rescaled AD200 PC1 looks like it is “dc coupled” where Center 1000-1650 looks like an AC coupled signal. It looks like the DC offset was removed to show only the AC component of the signal.
Using that sort of analogy, maybe something similar occurred in Mann/Jones original PC1. But it’s hard to tell without the original PC1 graph to look at side by side for comparison. Steve, could you post the target next to your attempts so that those of us with visual signal analysis skills can compare? Steve I know you know what you seek, but sometimes you have to spell it out for us so we get the whole picture. Your caption says: Figure 1. Discrepancies between trial adjustments to PC1s and Jones and Mann 2004 Archived PC1 but your top panel label says “2003 PC1” so I really don’t know what I’m looking at here. Maybe that top panel “is” the original Mann/Jones PC1 and I’m just a bit confused. If it is, the only thing that makes any sense is a short circuit.
When I troubleshoot electronics signals, having a storage oscilloscope to show signal “A” and “B” next to each other does wonders for figured out what’s happened to signal “B” derived from “A”.
Steve: I’ve posted the relevant series at http:/www.climateaudit.org/data/mann.jones.2003/pcversions.dat. There are 5 columns described in the readme: col 1- is the Jones and Mann 2004 archived “target”; col2 is the AD200 mannomatic; col 3 is the AD1000 fixed/adjusted PC1; col4 is the AD1000 mannomatic PC1; col5 is Mann’s AD1000 PC1 adjustment.
Since the correction up to 1650 works but don’t necessarily make sense, why not just assume that the correction used in the first 1/3 plot was applied to the data after 1650. –> flat line –> no problem. Once something doesn’t make sense, why stop there? It’s Climate Science afterall.
People seem to be a bit confused here (maybe I am too!) but Steve’s plots are not the original PC1’s themselves, but the difference between the PC1 used in MJ03 and Steve’s various attempts at replicating it – when the two match, we should just see a big black line across “0.0”.
It looks like two different versions of the data have been spliced – one version post 1650, the other pre 1650, with differing centring and scaling. I think Steve’s question is – can anyone come up with a single explanation, or does it really look like they’ve just spliced a bunch of arbitrary versions together. The sections look to match too well to just be chance?
The whole approach of the team to versioning and control is just bizarre. The trouble with having so many grey versions is the ability of the experimenter to pick and choose the versions which give the best results, just another degree of freedom.
I’m re-visiting Mann’s adjustment to the AD1000 PC1. I’m going to do a post on this on some notes from a couple of years ago, where I got stuck and maybe some people can help there as well. Something that I’m wondering about: it’s very unlike Mann to voluntarily tone down a HS shaped series as he did with the AD1000 PC1 – which he called his CO2 adjustment. In some of the AD1400 experiments, you got bad RE statistics sometimes when the HS was too big: it overshot the verification period. I’m wondering whether the MBH99 CO2 adjustment – which seems ridiculous as a CO2 adjustment – is merely a fudge which cuts back the AD1000 PC1 in order to get a good RE statistic. IT will take a couple of days work: mostly documenting the adjustment which is hard to decode even by Mannian standards.
I’m looking forward to something on the MBH99 CO2 adjustment. I’ve never been able to get my head around that one.
I’ve been resisting that explanation since I first saw it, but so far cannot come up with a better one.
Remember, da Mann said no splicing.
Could it be a trap? Some wacky but remotely justifiable system of adjustments that looks like a splice, and he’s hoping someone will accuse him of it?
“Remember, da Mann said no splicing”
Think of it more as a bilinear adjustemnt and all will be well.
“Fixed” can also mean manipulated to advantage. e.g. a fixed horse race.
Steve in #41:
Very unMannly?
I’m going to move a lot of comments to Unthreaded.
For we who visit from time to time, we are now being overwhelmed by the versions of data and their acronyms and their histories. Would it be possible to do a short chronology starting with raw data and adding a brief explanation as to how this became the next version? I have horrible thoughts about people with less familiarity than you doing nice analytical stats on data sets that have been mucked around and deriving conclusions about Man, not Nature. Just covering the USA is hard enough, the ROW is for the bewildered like me.
Steve,
Not sure if I got this right, but I don’t think that the “correction” changes RE values, it just levels 1000-1399 reconstruction up some 0.1 degrees:
Zoomed:
UC:
I think you got it right (I got the same a while back). I’m also speculating that you got also the reason correctly: try plotting the trend line 1000-1850 as in the original (Fig3a/MBH99; use the reconstruction for post 1400, i.e. not the step AD1000 for that period). I think Mann was not ready to give up LIA.
The sole purpose of MBH99 was to get rid off MWP. This comes out plain and clear from the MBH99 submission version. From abstract:
From intro:
Finally, from the main text (essentially the same text also in the final version except for the Bradley reference which is crucial for the point I’m making):
Thus LIA was well-established (co-author Bradley has publications on that). So when getting rid off the MWP, you have to be careful not also to get rid of LIA. Hence the “adjustment”.
This can’t be true.. Here we go, with fixed PC1:
Here we have long-term cooling period prior to industrialization, -0.02 C/ century. But without this Mann-made effect, we have:
with long-term cooling of only -0.004 C/ century!
Off topic, but CA has been named co-winner with BA for bes science blog. The oting site was vague as to the problems leading to the declaration of the tie.
Congrats Steve!
#29: Yes, beautiful 🙂 As I’ve said earlier, it’s wrong to think that MBH9X was poorly done: every piece of it seems to be carefully hand-crafted. Future generations may view the hockey stick as what it truly is: a masterpiece of twisted art.
MBH – the gift that keeps on giving.
Well done, UC.
Well done UC.
Oops. Well done Jean S and UC.
I prefer to think of it as the bad meal that keeps on repeating.
#34: Thanks James! UC and me agreed to have few beers for this CO2-adjusted long term cooling. Of course, we expect the Big Oil to sponsor the event (still waiting for the cheque) 😉
It may just be me, but I’m afraid I don’t get what the problem was, or what the solution was.
Perhaps this has something to do with the fact that I don’t see how to do PCA with an unbalanced panel of data, with some series not going all the way back. The standard discussions assume a balanced panel.
Suppose we had several chronologies of tree rings or whatever back to 1500, and progressively smaller numbers back to 1400, 1300, etc., and wanted to reconstruct temperature from them. My (perhaps misguided) approach would be to start with the fullest chronology (back to 1500), estimate PCs from it, then regress instrumental temperature T on these during the instrumental calibration period, say 1850 – present. If some of these turned out significant after correction for serial correlation and using mining-adjusted critical values, retain these and use them to predict T back to 1500, and to compute forecast standard errors.
Then take the next longest set, back to 1400 say, and repeat the whole process, using only these chronologies. This will give forecasted temperatures from the present back to 1400, but the new forecasts back to 1500 will be preempted by the presumably superior full-data forecasts. However, the new forecasts will look pretty much like the original forecasts in the overlap period, because the data is pretty much the same. The spliced series will show a small discontinuity in 1500, and probably larger confidence intervals before 1500 because of the reduced data quality. The longest period(s) may not have any significant PCs at all, and therefore no forecast.
The result will be a spliced series with small jumps and a confidence interval that grows with distance into the past, that may or may not purport tell us something about past temperature. The PCs themselves are worth looking at and contemplating, but may or may retain a discernible identity at the breakpoints. Does this have something to do with the obviously fragmentary PCs in Steve’s original post?
Regressing T on the PCs rather than the PCs on T seems a little backwards, given that T is exogenous and the PCs respond to it. However, since we are just trying to predict T conditional on the PCs, rather than trying to model tree growth, regressing T on the PCs makes sense to me. (In a simple regression, the t-stats and R^2 are identical either way, though the product of the two slopes will be R^2 rather than unity as one might expect from algebra. This phenomenon, which I call “reverse regression”, may relate to the “inverse regression” that has been mentioned in the Proxy discussion.)
For better or worse, PCA has become a growth industry in econometrics, given the interest in it expressed recently by Ben Bernanke and Rick Mishkin. Mark Watson gave an interesting plenary talk on it at this summer’s Econometric Society meetings at Duke, that I could almost understand. He addressed the important issue of which PC’s one should retain, given that their nature is entirely empirical. The month before I had heard another plenary talk by Serena Ng at the CEF meetings in Montreal, that I didn’t understand at all at the time. It was only when I heard Watson speak that I realized they talking about the same thing!
Hu, I have a problem on understanding what you are talking about? The topic of Steve’s post? The result in #29? Or MBH methodology in general? The first two do not really have anything to do with PCA, and for the third one:
That is not how it was done in MBH:
1) Mannian “PCA” was used for some proxies
2) Not all proxies were handled with “Mannian PCA”
3) The regression was not done with temperature, but “temperature PCs”
4) The caliberation period was much shorter
5) No significance testing and retaining was done (and I suppose if you did it correctly the way you described you would have nothing to use for forecasting; why do you expect a spatially limited proxy to have significant correlation with hemispheric temperature?)
Plus all the other problems with the quality of proxies etc.
So until you specify a little more carefully what you are after, it is quite hard to give any better answer than this.
What would be the purpose of choosing PCA in this case?
When:
see http://www.statistics.com/resources/glossary/p/pca.php
AFAIK There is not a large number of variables in any of the Proxy reconstructions.
39, I second that. For us non-statisticians, it’s far from evident that that’s the correct tool. A simple explanation of when you typically use PCA would be helpful; none of the statistics sites do a good job of explaining that.
#39: Mark, there is a large number (compared to the length of the calib period) of variables in the original proxy set. So it does make sense to reduce the number. However, IMO, this should be done the way Hu is suggesting: apply PCA to ALL proxies. As far as I have understood, the supposed reason for using “PCA” in MBH on some proxy sets is the balance in the spatial coverage.
Can I second what larry said without sounding like Moe or Curly.
Maybe we need a kindergarten class in PCA. or a good link so we can RTFM.
If I were to use tree rings as thermometers, I would use PCA only to extract a common tree ring signal from an area not larger than 500 km diameter. I then would calibrate the PCA’s to regional temperature anomalies, and continue with these derived temperatures to construct a hemispheric anomaly.
IMHO using one tree ring PCA for entire North America doesn’t make sense at all.
#40: Let me try: you can always fit N series to N sample points perfectly. So when the number of variables (weights of your proxies) is high, you can fit anything (or as UC put it; you can fit an elephant). Thus you want to get the number of you variables down. This is when you use PCA, which essentially tries to collect the “useful information” to as few series as possible, before you do your fitting. Thereby reducing the risk of “overfitting”, i.e., you can not fit an elephant unless your original series really contained an elephant.
This is also the reason why it is for me so hard to understand why people do not to seem to get the thing that “Mannian PCA” is not really any PCA at all: it does not do what it is supposed to do (“collect the useful informations/signals”).
#43: Hans, yes that is the generic way I would try to do it also (but not sure if it even possible that way). But ASSUMING (see also the comment in 5) in my answer to Hu) you could calibrate your proxies to hemispheric temperature, it makes sense to reduce the number of ALL proxies with PCA.
#37. Your point about PCA with an unbalanced panel goes back to an issue that cropped up in our first effort at replicating MBH. Undoubtedly the most common procedure for PCA with missing data is simply to do PCA using the available data. How to deal with missing data was a puzzle back in 2003 – no protocol was stated in MBH: they just said that they used “conventional” PCA and Mann did not provide details when requested – this was prior to any controversy. So in MM2003, we calculated PCs over the longest available record.
Mann had actually calculated PCs in steps changing the number of retained PCs by step. How the steps were determined is a mystery as is the method for determining the number of retained PCs.
This caused a lot of controversy at the time, as Mann and his acolytes argued that our failing in MM2003 to implement his undisclosed stepwise procedure amounted to “throwing out” vast quantities of tree ring data [although they never faced up to the fact their claims to “robustness” to presence/absence of all dendro data meant that one should be able to “throw out” dendro data and get a similar result.]
Of course, this issue was layered with the more fundamental problem with Mannian principal components and ultimately boiled down to weightings given to bristlecone pine.
For historical reasons, there are a lot of bristlecone pine chronologies – nearly all by one author, Donald Graybill, which is an issue that’s not been attended to sufficiently. THe older the network, the greater the bristlecone proportion. While Mannian PCs dramatically highlighted and overweighted bristlecones, any PC method is going to pick out this pattern. If one is trying to develop some kind of index for tree growth as a whole, you’d have to assess regional and species weights in a more rational way than historical accident.
There are some interesting differences in multivariate objectives between “signal extraction” and usual regression methods. In regression, you don’t want collinearity. While in signal extraction, you actually want collinearity. One of the big problems in MBH is that the MBH proxies contain virtually no common signal. Thus his regression methodology (which I’ve characterized as one-stage PArtial Least Squares as practiced in chemometrics) becomes more or less equivalent to an ordinary multiple regression. The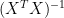 matrix which rotates the PLS coefficients to OLS coefficients is close to the identity matrix. Since this is the case and OLS, about which we know a lot, approximates PLS, we can apply some of our OLS intuitions to understand the PLS situation. The OLS situation is that the calibration period regression (and this is a distinct issue from principal components ) is in the AD1400 case with PCs a regression against 22 close to orthogonal predictors, of which one is a classical univariate spurious regression and the others are white noise, over a short calibration of 79 years.
matrix which rotates the PLS coefficients to OLS coefficients is close to the identity matrix. Since this is the case and OLS, about which we know a lot, approximates PLS, we can apply some of our OLS intuitions to understand the PLS situation. The OLS situation is that the calibration period regression (and this is a distinct issue from principal components ) is in the AD1400 case with PCs a regression against 22 close to orthogonal predictors, of which one is a classical univariate spurious regression and the others are white noise, over a short calibration of 79 years.
The Wahl and Ammann no-PC reconstruction, widely hailed in the climate science community, is even wilder: a 79-year calibration regressing against 90 predictors. There’s enough collinearity that it’s not a perfect fit, but it’s wildly and amusingly overfit. I predict that, once understood, it will become a statistical classic (as how not to).
ahhh…. this must be the great ‘breakthrough’ and ‘paradigm’ shifting work of new AGU Fellow Michael Mann…. has anyone yet vindicated his methods and papers, or has the field merely moved on?
We haven’t even dug into the horrors that await in the “new” method known as “Regularized Expectation Maximization,” which, as I recall, Jean first pointed out a few of its oddities when it was first published.
Mark
Hu, here are a couple of posts in which I describe experiments with PCA and other forms of signal extraction. The second post has some good experiments using pseudoproxy data from the von Stoch -Zorita model: something that I should have worked up into a paper. The third post (together with some earlier linked posts) describes the PLS structure of MBH – UC and I are on the same page in our methods, although we each use different terminology to relate the method back to statistical procedures known to statisticians.
http://www.climateaudit.org/?p=609
http://www.climateaudit.org/?p=733
http://www.climateaudit.org/?p=707
UC, Re #27, #29
Just to help my understanding of these plots: are these the complete reconstructions (i.e. stepwise spliced) or are they the complete plot for the AD1000 step only?
(Hope that question is clear!)
#42: Try this: http://www.cs.mcgill.ca/~sqrt/dimr/dimreduction.html
#49: Spence, AFAIK, #27 is AD1000 step only and #29 is the complete reconstruction (both with varyng AD1000 step with fixed/not fixed NOAMER “PC1”).
Re #51
Thanks Jean S, shortly after posting #49 I read your #28 more carefully and the pieces fell into place. Everything takes a little longer on a Monday 😉 Thanks for confirming, all makes good sense now!
#47: Mark, I suppose you have not noticed this:
I think the calibration was not the only thing that needed “revision”. 🙂
Jean S (#38) says,
Primarily the topic of Steve’s post, which is about the Mann-Jones PC1, and then shows what appear to be sub-period-specific PC’s, which I thought might perhaps be related to the necessarily unbalanced panel of data in these studies.
Personally I would be very surprised if the PCs had a significant correlation with hemispheric temperature, given the weakness of the signal, but that is what MBH etc purport to find. There are obviously many things beside hemispheric temperature that affect tree rings — precipitation, sunshine per se (net of volcanic ash, clouds etc), larch budmoth infestations, competition from other trees, local temperature, etc, etc. So one would expect that most of the PCs would be insignificant, and hope that maybe one of them is (if only weakly) picking up the NH signal. In particular, I would be astonished if PC1 happened to correlate, unless, that is, a whole orchard of cherry trees went into the databank….
Mark (#39) writes,
The title of the recent Bernanke and Mishkin paper was, as I recall, “Econometrics in a Data-Rich Environment”. Their problem was, how do you forecast inflation, say, when you have only 200 observations on it but 1000 candidate explanatory variables. Their solution is you boil the 1000 variables down to maybe 10 principal components, which maybe pick up the labor market, the housing market, the foreign sector, etc., and then run your 200 observations on these to see which if any have explanatory power. In this case, only 200 PCs would be identified, while the remaining 800 eigenvalues would all be 0, with eigenvectors spanning the 800-dimensional space orthogonal to the identified PCs. But that doesn’t keep you from looking at the first 10 or whatever PCs.
These proxy studies presumably are based on thousands of trees, grouped perhaps into hundreds of chronologies. If you only have 79 observations on T, you can’t just regress it on all of them, so you use PCA instead. But if you’ve already grouped the trees into say 5 megachronologies based on what you know about their similarities, you may as well just regress T directly on those to make your forecasts.
Hans (43) writes,
MBH98 does apparently disaggregate the T data in this manner, so as to obtain local T forecasts, and then aggregates these back into NH and global T estimates However, I don’t see the point of the intermediate step if all you are interested in, in the end, is NH or global T.
It does greatly complicate the article, however, thereby discouraging all but the most intent from even attempting to replicate it. (I haven’t looked at MBH99 yet, since I’m assuming it just extends the approach of MBH98.)
If only 1 PC turns out to be significant, and it happens to be PC1, then so be it. But I would never have expected this to occur naturally.
Of course, the search for significant PCs should not just correct for serial correlation by conventional means, but should also be on the lookout for spurious regression (ie a unit root in the regression errors not detectable by older methods) when the autocorrelation is strong.
#56 Hu
I think that would agree with Hans on this one. It makes sense if the intent of the reconstruction is to predict the global temperature as measured (calculated) from the global stations. Unless you assume the existence of some global climate consciousness which manifests itself through tele-connection with the proxies, the response of the proxy can only be to physical effects which are actually present at the site. If these effects include increased or decreased precipitation, CO2 variation, etc., then you are no longer talking about response to temperature, but must start separating proxy response due to those different unmeasured factors. In this context, it makes sense to calibrate proxies to local temperature conditions. As part of the calibration process, one could e.g. conceivably use PCs to combine multiple proxy records at the same site.
The second stage should be to calibrate the actual (not the proxy-estimated) temperature records from these sites with the global (or NH or SH) temperature being reconstructed. In the simplest case, this might be done through a regression procedure or through a set of PCs. It also has the advantage of providing estimates from each of the two sources of error (as in a cluster sampling situation): the ability of the proxy to measure the measure at the site and the ability of the different sites from which the proxies are chosen to reflect the global climate. This would likely provide more realistic (and probably a lot bigger) error bounds for the reconstructed estimates than the PCs calculated from the raw proxy data fitted to the same temperature signal. As a bonus, it may reduce the amount of cherry-picking of proxies which fit the desired end result, but are unable to sense local temperature variation.
re 45:
Jean S, could you explain – in layman’s terms – what the benefit is of Principal Component Analysis over simple stacking (just adding all signals and taking the average)? Does PC1 mean anything if PC2 is also big?
Here is the european Hockeystick by Luterbacher compared with grape harvest dates
What is apparent that in the early part (before 1750) of the sequence the tree ring based Luterbacher series completely looses fidelity, compared to the single harvest proxy. Is this a key property of PC1?
#43 Hans Erren wrote: “If I were to use tree rings as thermometers, I would use PCA only to extract a common tree ring signal…”
Hans, PCA extracts no physical signal. PCA is a numerical construct, and each principal component is only numerically orthogonal. It is not physically orthogonal. Physically, any PC is an admixture of signals. The only way to extract one signal from the physical mixture of signals that is any PCA, is by application of a quantitative physical theory.
This seems to be a common error of thinking in climate science, and it can’t be repeated often enough. PCA as such does not extract or orthogonalize physical signals.
It emphatically cannot be used to extract temperature signals from tree rings series taken from trees only qualitatively judged to be temperature-limited.
#42: Steve Mo, I did some googling and IMO this seems to be pretty good: http://www.snl.salk.edu/~shlens/pub/notes/pca.pdf
#58: Hans, when you do “simple stacking mean” you are actually doing a projection of the original signals, that is, you take a certain linear combination of the original signals. “Simple stacking mean”-projection is fixed a priori (before seeing the data), therefore, the question “how well it describes” your original data depends completely on what your original signals were. Suppose the extreme case: your signals are P1=T and P2=-T (T is any signal of your choice) and then the mean is simply the zero signal (i.e., tells nothing about your original data). In PCA, the projections are chosen based on the data such that they “describe the original data the best”.
See the above paper for better explanations…
#58: Hans, hopefully I can field this one well enough to be of help. Principal components are simply linear combinations of predictive variables. For example, you can predict Y (temperature) with variables {x1,x2….x200}, or you can predict it with a linear combination of them, i.e. PC1 = ax1 + bx2+ cx3…. When we say that PC1 is heavily loading on bristlecones, it could mean this: Given bristlecone proxies being x2, x5, and x7, and other proxies for x1-x8, PC1 = .02×1 + .43×2 – .12×3 + .22×4 + .51×5 – .04×6 + .3×7
+ .08×8. If x2, x5, or x7 are high values, it has a large effect on PC1 whereas the other variables do not have nearly the same effect. N.B. these coefficients should square and add to 1.
The construction of PC1 is accomplished by explaining the maximal amount of variance that is possible with such a linear combination. [A simple example is to try and predict points Zi on a graph using X and Y. Suppose that you have Z1 = (1,1), Z2 = (2,2), Z3 = (3,3), which requires two variables to describe and is the same as Y = X. A linear combination of Xs and Ys will rotate this line along the X-axis and able to be described by Z1 = (1), Z2 =(2), instead of (1,1), (2,2), and thus reduces the dimensionality of the problem.] The next largest amount of variance that can be explained by another linear combination (with different coefficients {a,b,c..}) is PC2. And so on.
The primary advantage of doing PCA is that you gain degrees of freedom in predicting the target variable; 10 highly correlated variables can have a large amount of their variance contained within a couple (1,2,3?) principal components, depending on the data. This helps to prevent spurious modeled relationships when 200 vars are used as predictors for
#60 (Pat): What do you mean by “physical signal”? Could you also explain this (emphasis mine):
I can think several ways (depending on assumptions) of extracting signals from a mixture (other than “quantitative physical theory”).
#59: The example equation got mucked up, here it is hopefully:
When we say that PC1 is heavily loading on bristlecones, it could mean this: Given bristlecone proxies being x2, x5, and x7, and other proxies for x1-x8, PC1 = .02*x1 + .43*x2 – .12*x3 + .22*x4 + .51*x5 – .04*x6 + .3*x7
+ .08*x8. If x2, x5, or x7 are high values, it has a large effect on PC1 whereas the other variables do not have nearly the same effect.
RE thanks Jean. I’l go sit in the stacks for a bit
Slide Show from a commercial site.
I can see how the data is grouped now. Are the Principal Components recalculated and weighted for graphing?
Also, it seems to me that if Proxies as a group were originally chosen because they provided a good representation for temperature, why would one need to look for a “signal” in amongst the noise?
And how does one know that the signal found is for the required variable, eg temp?
Indeed when it is described as mulitivariate, I can see only two factors, growth anomaly and temperature. I don’t see any data for water, or CO2 etc being used.
And how does one deal with Benders point that the variables are not stationary over time? eg Trees may be Temp limited or they may be water, or CO2 limited at different times.
Seems to me that this choice of data manipulation merely disguises the fact that the “Proxies” chosen do not correlate well with each other in the first place. So they can’t all be temperature Proxies, if in fact any of them are.
Looking at the example application in the link slide show above it appears to be a one dimensional problem.
In summary PCA seems to be useful when you are looking for patterns in dat with multiple variables. Not when the the whole purpose of the exercise is based on the assumption that the data has only one variable, and you already know it is temperature.
Oops this link takes you to the first page of the slide show.
#66: Mark, good questions. But all of you, try to separate in your discussions when you talk about the real PCA and its hypothetical use for proxies from the discussion of MBH and its cousins.
Some points:
-Yes, there are several variables in proxies and PCA does not fully separate them. It simply “condenses” your variables into few signals (assuming that variables are linearily related, which might be already too much assumed). It is not the purpose of PCA in this tree ring proxy thing to fully “extract” temperature signal, not even in MBH.
-In MBH, the “temperature extraction” is supposed to happen (it does not) in the final regression phase (the calibration). Keep in mind that MBH proxies contain also intrumental data, precipitaion proxies etc.
-PCA in general might be usuful even it does not separate the variables. This was indicated already by Hu (#37): one should test which PCs are best for forecasting (i.e. which contain most “temperature signal”). I do not believe it would work for tree rings and hemispheric temperature, but in principle it is a working idea.
-And once again: Mannin PCA is not PCA at all. It does not have any properties the true PCA has. What Mannian PCA does is that it projects proxies such that those proxies with highest difference in the calibration and overall mean get rewarded. The only purpose I can see for it, is that it guarantees the overfit in the final phase of the MBH algorithm even in the case only few proxies are used.
#63
I take this to be the common observation that PCs have no inherent meaning. They are a mathematical construct that finds the orthogonal vectors that explains the most variance in your data. What that projection means is then a matter for philosophers to debate. Mann’s PC1 could be a temperature signal, a CO2 signal, a signal related to the albedo of my nether regions or some combination of all or none of the above.
If you want to attach some meaning to it you need to do a lot more work. A physical theory is one way, a good (non-spurious) regression might be another. But talking about Mann’s PC1 as “the” temperature component is just wishful thinking.
…or at least that is my take on it. And you seem to have said more or less that at #68 while I was typing.
Mark R writes, (#66)
We wouldn’t know that any of the tree ring PC’s indicated temperature until we regressed T on the PC’s and found some of them to be significant (after correcting for serial correlation and spurious regression and adjusting critical values for data mining).
There is no guarantee that any of them would be significant,
no reason they couldn’t be.
CO2 is very relevant, since it arguably fertilizes trees, and since CO2 has increaed a lot in the past 50 years, correlating with the recent growth spike in many of the series. Also, we have a resonable measure of it over the past 1000 years or more from ice cores. This spike may be also due to temperature, or to tree-specific factors like injuries that leave it in a “stripbark” condition. Since the stripbark is visible, one can simply avoid those trees for this purpose as recommended by NAS, compute PC’s from the remaining trees, then regress Temp on the PC’s and CO2 during the last 79 years or whatever. Then if anything is significant, use these coefficients to construct pre-instrumental T estimates from the PC and CO2 data.
These estimates will of course have a big se, and are meaningless unless the se is reported alongside them. For this purpose, it is sufficient to use what I call the “coefficient forecast se” based only on the uncertainty of the coefficients, and not the “total forecast se” which also incorporates the variance of the regression error that will accompany the actual Temp value. Unfortunately, EViews automatically give you the total forecast se if you ask for the “forecast se”, so you have to remember to back the coefficient forecast se out of it, using @SE to recover the se of the regression errors along with the Pythagorean theorem. (If you’re using EViews, that is…)
According to Steve in the Almagre discussion, Graybill was originally looking for this CO2 fertilization effect when he cored his trees, but it turned out not to be very strong. Nevertheless, it can’t hurt to try adjusting for it. It can always be left out if it is insignificant.
One problem with adjusting for CO2 in this manner is that it might automatically erase any evidence of a causal link from CO2 to Temp, which after all is what this discussion is all about. Perhaps the AGW people have come up with a way around this. Have they?
Many thanks to all who have responded to the issues I raised. For some reason I am left with a nagging question mark as to why no-one from outside the Hockey Team has attempted a truly independent construction using only bona fide temperature proxies for which data is publicly available?
Also, I would be very interested to see a reconstruction calibrated against world temp, US temp, and unfudged satellite temp. Using the R statistical package, which is open to anyone. A sort of Open Millenial Temperature Reconstruction.
I can understand there may be good reasons why SteveM has chosen not to do it, but I don’t understand why everyone else seems to be avoiding it. It is after all probably the most important issue at this time.
Re: #61
Jean S., thanks much for your reference explaining PCA and the time you have taken to explain the nuances of this analytical tool and its applications in the Mann publications. It makes the time spent at this blog well worth the effort and a great learning experience.
One Trackback
[…] American PC1 shown on a top of Eos Figure 2 (“Western US”), and discussed by Steve here. This series is a splice of Mannomatic PC1 of six chronologies extending back to AD200 (up to 1700) […]