The position at ClimateAudit is that error bars in MBH98 are incorrectly calculated and “pseudo science” and that no one knows how the error bars in MBH99 were calculated (not just Me, Jean S, UC but also von Storch) and these error bars are also “pseudo science”. Notwithstanding this view, UC has posted up MBH98-style error bars for the Loehle reconstruction as shown here:


UC comments:
We have a trade-off here, no error bars or wrong error bars. Not a good situation, no indication of accuracy or false indication of accuracy (which leads to discussion about reliability, or consistency in some fields). Here are the MBH98-style CIs for Loehle’s reconstruction Jean sent me:
Jean S had previously written:
I personally do not believe the Mannian error analysis is worth anything. However, since JEG seems to be insisting on those, I calculated the Mannian CIs for the Loehle reconstruction the following way:
1) I took the HadCRU global instrumental series and 30-year run mean filtered it (in order the target series to match the Loehle reconstruction)
2) stardardized the both series to the mean of 1864-1980
3) calculated RMSE (over the overlap 1864-1980) between the series (which gives the Mannian CI sigma).I sent my files to UC for double checking, but here are the preliminary results:
RMSE=0.067, so that gives Mannian CIs as 2*sigma=0.13! BTW, R2=0.73 and the series are remarkably similar using the Mannian terminology.Theres some skill for you, JEG. Have fun!
I suspect that I speak for Jean S and UC (both statistics professionals in respected universities) as well as myself when I say that the apparent inability of climate scientists to recognize and reject the pseudo-science of MBH error bars – worse, their embracing of these calculations as an advance in their science – does not increase our confidence in their judgment when we are asked to accept their judgment in other areas that we have not studied.





283 Comments
Bravo .
So now let’s all try to get the correct confidence intervals, so that the field moves from pseudo-science to real science, by everyone’s standards.
We can do this.
Jean S, UC, please advise.
But, JEG, before we get too carried away playing science, shouldn’t we advise IPCC re: AR4 ch. 6?
JEG?
Speaking a little bit of the future, what will happen if the “proper” error bars look like this?
Re #4
If that were to occur, one would hope that that would be the graphic included in the next IPCC, AR5. i.e. “We don’t know where we stand today, but the models tell us CO2 is driving temperature up.”
So what exactly are the error bars for the Loehle reconstruction saying about one section of the curve compared to another and about the source data?
Steve: they don’t say anything. Mannian confidence intervals are completely meaningless. UC has merely shown them here as an exercise demonstrating that one can make the Loehle reconstruction as pseudo-scientific as the Mann reconstruction.
JEG, fair question although I’m not sure that we can give you an answer. Can you do some homework for us on this topic. If you read this post, you can see that we’ve tried very hard to understand MBH99 confidence interval calculations and have not succeeded. Allowing for the possibility that Mann may actually have discovered a valid approach, I would like to do a similar calculation MBH99-style, which might also contribute to the answer. Can you obtain from your collaborator a statistical reference for the calculation and either a description of the methodology according to the standards that you think should apply to publications or even source code if no such description exists (as is likely). You’ll probably get your head bitten off, but you seem pretty confident. I’m not suggesting this to be obtuse, but because I would like to understand an approach developed within the field before making prescriptions.
The calculation of “honest confidence intervals” is an issue that is not limited to climate science, although the practices within the field probably make such estimation impossible (not least because of the extensive recycling of data about which the selectors know the properties – this is a problem that econometricians have reflected on without resolving.)
Although Mann talks about the inappropriateness of verification r2 (and I’ll post about this some time), if you have a reconstruction with a verification r2 of ~0, then I don’t see how you’re going to be able to establish confidence intervals less than natural variability – whatever that is. UC has a chart showing confidence intervals a mile wide both perfectly horizontal as being his view on what has been established to date from these studies.
Thinking out loud for a moment, perhaps the most fundamental problem with these reconstructions (and this is a topic that I’ve written about extensively at this blog) is that trivial variations in proxy selection can lead to reconstruction variants that are virtually identical in the calibration and verification periods but diverge widely in the MWP. Typical verification statistics for the two variants tend to be statistically indistinguishable. Loehle is another example of this – being in a sense a Moberg variation. How can one assign any confidence in Moberg’s version as opposed to Loehle’s version?
There is one angle that may be worth thinking about. I think that Loehle’s exclusive use of calibrated proxies is possibly a useful avenue. I’m not sure that he even did this intentionally, but sometimes you do sensible things when you’re fresh.
You snickered at Loehle’s overly simplistic approach to calculating a temperature composite, but the irony is that a simplistic approach like this might actually open up the possibility of a more structured approach to estimation. While not all the authors attach confidence intervals to their estimates, some do. DeMenocal attaches confidence intervals to his reconstruction of 1.3 deg C or something like that. One could probably work up some sort of calculation – I’m not sure what it would mean, but it would have better chance of meaning something that the obviously wrong MBH approach.
#6
They’re not real error bars so they don’t tell you anything. If they WERE real error bars then, crudely, because the error envelopes on CWP & MWP overlap (ever so slightly) you could not conclude that the higher mean of the MWP is significantly different from the lower mean of the CWP; there’s too much uncertainty given the imprecision of the proxies. i.e. It is likely the means are equivalent within the degree of resolving power afforded by that sample size.
That could change if you could reduce the error bars, by increased sampling, by using better proxies, and so on.
Well now that seems like a simple request. And it could move the whole field forward…
🙂
Steve: It is a simple request but the chances of any response are negligible.
Of course Mann discovered a valid approach. We’re just too stupid to identify and understand it.
Just how were these error bars computed? And why are they wrong? Just saying they are computed as in MBH98 doesn’t help much, since a) MBH98 used a much more complicated sequence of calculations, and b) they weren’t very explicit about where their estimates, let alone their error bands, came from.
It occurs to me now that my earlier concerns about heteroskedasticity across series could be solved simply by first estimating (across time) a variance for each series about the time-specific means, and then using these at each point in time to construct a variance for the mean, as follows:
Let Xit be the observation on series i at time t (after Craig’s 30-year rolling mean), Mt be Craig’s mean for time t, nt be the number of smoothed series observed at time t, and Ni be the number of (smoothed) observations on series i. Then Vi, the variance for series i can be estimated as
Vi = Sum [(Xit – Mt)^2 * nt/(nt-1)]/Ni,
where the sum is over times with observations on series i. Also, vt, the variance of mt may then be estimated by
vt = (Sum Vi) / nt^2 ,
where the sum is over series observed at time t. The standard error of mt is then st = sqrt(vt), and confidence intervals can be constructed using t critical values for n DOF, where n is the average number of smoothed observations available. This is still only approximate, but it is a lot better than just appealing to asymptotics to get around the heteroskedasticity.
This method would yield a constant vt if all 18 series were always observed. When some are missing, vt will increase depending on the information in the omitted series.
In some future study, the Vi’s could be used to estimate the mean more efficiently by Weighted Least Squares (WLS), but for the moment, Craig’s published estimates are OLS, so they need confidence intervals.
Looking at the graphs (Lohle Proxies #2), the frequency of some of the series changes abruptly, causing their unsmoothed variances to change. However, the smoothed series (not graphed) would show much more constant variance. Can we see graphs of the smoothed series?
I’m off to shop for sweet potatoes before they run out. Cheers!
Steve: I’ve added in Jean S’ explanation of the error bar calculation using MBH methods.
#1: I have a faint idea what one should do with locally calibrated reconstructions: determine CI:s for each series and combine those taking into account the sampling issues. Not an easy job. Since CI:s depend from the calibration method (i.e., the assumed model for a proxy) and no CIs (to my knowledge) has been calculated to those series (used e.g. in the Loehle reconstruction), this spells a lot of work, even if the sampling uncertainty could be satisfactorily solved.
Having said that, I have to confess that I do not have an idea what to do with those globally calibrated multiproxy studies. This is probably because I’m one of those who
That is, I do not apparently understand teleconnections. I though I did, but I guess I was wrong. To be specific, I can not understand how a variable (proxy) can be uncorrelated with another variable (local temperature), but still can explain something useful about a third variable (global temperature), which is essentially an average over variables of the second kind.
Bender (#8) wrote,
Assuming independence, the standard error of the difference is not the sum of the standard errors, but the root sum of the squared standard errors, a necessarily smaller number. So if the CWP and MWP 95% confidence intervals just touch, or even if they overlap just a little, you can definitely reject equality at the 5% test size or even smaller. (Because of the smoothing, adjacent years are not independent, but beyond Craig’s 30-year moving average independence may be reasonable to assume, depending on how the underlying series were constructed.)
Hu, we were able to figure out how MBH errors were calculated see http://www.climateaudit.org/?p=647.
How Mann got to his reconstruction was not considered in his calculation. He just calculated the residuals in the calibration period and doubled the standard error. We know exactly what he did and there’s no obstacle to doing the same thing with Loehle. It doesn’t mean anything either, but it puts the recons on the same footing.
BTW this methodology – 2 times the calibration period residuals – continues to be used all the time in climate science. It’s probably latent in IPCC AR4, so Loehle could dress this method up with “high” recent authority.
In #11, I misspoke:
I should have said n-1 DOF, where n is the average number of smoothed observations available. Since n is about 17.5 (?), n-1 would be about 16.5. This can either be rounded off to the nearest integer, or, just to be fancy, the t distribution with fractional DOF can be used.
Jean, do you think my proposal in #11 has any merit? Ideally, one would delve into the source papers to find their standard error estimates, but my method allows one to infer their measurement error along with the idiosyncratic error just from Craig’s data, using only the assumption that the underlying errors are (roughly) constant over time.
http://www.climateaudit.org/?p=2388#comment-163289
You mean that you actually believe that the world average (30 year mean) temperature can be bracketed with 18 proxies within 0.26C interval with about 95% certainty?
RE Jean, #16,
If these are independent draws on world temperature, and the confidence intervals are computed correctly (eg with my formula at #11?), and this is the result, then yes. No draws are completely independent, but these seem to have a fairly good geographical distribution. On the other hand, I have no clue how UC computed these, other than by an MBH procedure that everyone here thinks must be wrong, so the second “if” condition may have serious problems.
Future studies with denser proxies will have to address the spatial autocorrelation more explictly, however. I suppose this can be done by positing that the correlation is a declining, one-parameter function of great circle angular distance, and then estimating that parameter by ML, and global temperature by GLS.
No way, no how. Not now, not ever. And $100 in the CA tip jar says neither does JEG. (That’s why he’s here at CA, trolling for gray matter, code & data. He’s ambitious, wants to make a name for himself, wants to answer the question, knows it could go either way.)
I’ve added in JEan S’ first comment on this: Jean S had previously written:
To me, until the CI of data collected is accounted for, the rest of this is meaningless statistical shenanigans.
Somehow, it “feels” like the old saw in the software business: it’s 10x harder to remove bugs each step down the path. Kill bugs as early as possible.
In the case of dendro proxies, we’re demonstrating that intra-tree sample variability can exceed the “signal” by several *hundred* percent. I’ve not seen such variability accounted for.
Seems “plausible” that many other proxy types might have similar hidden variability issues.
it is rather obvious, that you got the “proper” error bars right.
people on this site will still attack the small error bars at the end of the 20th century and will continue to ignore/excuse the huge ones around MWP.
Steve: that’s a very unfair comment. I’ve never taken a position on the relative MWP-modern position; there’s evidence both ways. My objection is to the pseudo-science of Team studies which uses poor statistics to make unwarranted conclusions. I don’t think that the data here justifies the opposite position any more than the Team has proved their position.
IPCC AR4 says:
I’m 99% sure that this is just MBH98-style calibration period two-standard error bars. So this would mean that the error bars shown here are calculated according to IPCC AR4 standards. Even if we at CA think that this calculation is incorrectly done, surely no one can cavil at a chart implementing the IPCC AR4 “consensus” method.
RE 17:
“If” indeed. Problem is they are not. If I understand correctly, they are (somewhat) independent draws of measurements that to a greater or lesser degree covary with local temperature.
However, I entirely agree that it would be great to see the error bars you propose in 11. They’ll be much wider, and much closer to the truth (which $100 in the tip jar says is like #4).
sod,
“It is rather obvious” that you’ve got it backwards. People on this site know the relatively small error bars in the 20th century for an instrumental record would make sense. It’s the lunacy of the error bars 500-1000+ yrs ago being small that makes little sense.
The “huge ones around MWP” in #4, which you claim to be “obviously right,” would make it impossible to say with any certainty whether or not 20th century temps are warmest in the last several hundred years.
You mean that you actually believe that the world average (30 year mean) temperature can be bracketed with 18 proxies within 0.26C interval with about 95% certainty?
I don’t believe tomorrow’s world average temperature can be, let alone 1000 years ago!!
Tomorrow’s 30-year world average is almost identical today’s, and therefore known with 99.9999% certainty. Mind your time scales.
Steve,
I just put $100 in tip jar in support of your great work. But I agree with MrPete in 20. In my past engineering work I have observed mathematicians happily calculating equations to five significant digits when the source of the numbers was junk. This thread is beginning to look a bit like that. I suggest your work on the source data for the proxies is more valuable at this time than trying to stir around the junk to see if there is a pearl in there somewhere.
But I am not a mathematician so I will be observing with interest to see if those who contribute here can really establish the CI for a collection of data of unknown and variable CI.
i was mostly speaking about the comment section.
but let me rephrase:
you did not forcefully attack (or even dismiss) Loehle for the lack of error bars.
you do forcefully attack (and let others do so) errors and error bars on modern temperature measurements and in other reconstructions.
i am aware of that. but the comparison of modern and medieval temperatures would become much more easy any way. and it would seriously damage claims that MWP was warmer than late 20th century.
PS: Steve, thanks a lot for erasing the “cathedrals” comment. i was just typing a reply, starting with asking you why you don t erase such nonsense…
all who read it (and the poster) might want to follow these two links:
http://en.wikipedia.org/wiki/Aachen_Cathedral
http://en.wikipedia.org/wiki/Ulm_M%C3%BCnster
Steve: yous say: “you did not forcefully attack (or even dismiss) Loehle for the lack of error bars. …you do forcefully attack (and let others do so) errors and error bars on modern temperature measurements and in other reconstructions.”
If you think about it, you’ll have a hard time finding any comment from me attacking things for lack of error bars. Maybe you think that I’ve done so because many other people have done so. But it’s a mantra that others use, but not really me. I’ve spent time trying to figure out how error bars were calculated in individual papers; I’ve criticized MBH calculations for being pseudo-science. Personally I don’t know how you would go about calculating error bars on these reconstructions or even if you can; so I’d be more inclined to be critical of pseudo-scientific calculations than simply being silent on the matter.
JEG’s criticism on the absence of error bars that no one knows how to calculate seems only that Loehle was insufficiently pseudo-scientific as compared to the Team – a deficiency that is readily corrected by merely including the pseudo-scientifc calculation done here by UC/Jean S applying the “best” IPCC AR4 methodology.
#4 Geoff Olynyk says:
“Speaking a little bit of the future, what will happen if the proper error bars look like this?”
I would conclude that a great deal more work needs to be done before temperature reconstructions provide any useful information. I would therefore leave all of them out of the IPCC and would certainly not make any statements regarding whether current temperature anomolies are unusual.
#22
AR4, my emph
Often means that one bootstrap CI widens the 2000-end so that instrumental fits in. Just partly kidding.
Scaling errors are not discussed. I’ll try to explain that (re #1 ), takes some time. .
No, it would make such a comparison more difficult, if not impossible. The greater the error/uncertainty, the more difficult it is to compare. Forget about statistics – just use common sense.
You can spend a lot of time outside today and get a good idea of the local weather, right?
(A) Let’s say you had done the same thing last Wednesday. Maybe it was a really memorable day because you don’t get out much, because it was a special occasion, because you took notes, etc. Whatever. You could compare the two days seemingly well – which one was warmer, which one was windier, which one was sunnier, which one was wetter, etc.
(B) But let’s say you weren’t in town last Wednesday. Or maybe you were in bed sick all day. Or in business meetings. Or maybe you just can’t match up the days of the week to the weather enough to remember what you thought about last Wednesday.
So in which case can you better compare the local weather of this Wednesday and last Wednesday – case (A) where there is little uncertainly in last week’s weather, or case (B) where you’re not very sure.
sod The Mannian error bars are obviously [incorrect] The simple fact that the number of data points is drastically reduced going back in time must increase the possible error. Any error bars that don’t show that charateristic are [incorrect]
Simple eg. If the number of samples or data points were 1000 in 1950, but out of these there were only 100 in 1550, and out of those only 10 in 550, then error bars must be correspondingly wider. Wouldn’t they?
#32
Careful. Mann computes 2*stds for each step.
#32, “If the number of samples or data points were 1000 in 1950, but out of these there were only 100 in 1550, and out of those only 10 in 550, then error bars must be correspondingly wider. Wouldnt they?”
You are assuming that teleconnections only occur across space. If they also occur across time that would account for Mann’s counter-intuitive error bars.
28 sod says:
November 21st, 2007 at 12:47 pm
“you did not forcefully attack (or even dismiss) Loehle for the lack of error bars.”
I am not sure what you have been reading, but the comments seemed very clear that the lack of error bars or was and significance testing was a major problem in Loehle’s study. SteveM has been very consistent on that point and it is indeed unfair to imply he has not been.
PS Further regarding error bars. When I was at college (a long time ago) they said that for a population with a standard distribution, if the population were a certain size, then a certain smaller number of sample measurements would give the characteristics of the population as a whole, but only within certain levels of confidence. For example, 100 samples out of a population of 1000 may give a 99% confidence level, but 10 samples out of 1000 may only give 60% confidence (say), and these percentages are expressed as Standard Deviations from the mean (average).
My question is, for these temperature proxy samples, what are the confidence limits saying? Are they saying that from a sample of tree rings we can tell what what all the trees of a particular type on a particular site are likely to measure, within a percentage error? If so it would seem that the number of samples is very small for each proxy type group. A few dozen trees from the bristlecone pine population on Sheep Mountain is in my view far too small a sample to give any reliable approximation of the characteristics of all the trees on Sheep mountain, especially in view of the unusually diverse growth characteristics of the trees in question. So are enough sample being taken in the first place to give any meaningful result? Is one borehole, a statistically meaningful sample?
Quick check, since you’ve been going over all of this for a lot longer.
1st. Did Mann et al., 1998; Briffa et al., 2001; Jones et al., 2001; Gerber et al., 2003; Mann and Jones, 2003; Rutherford et al., 2005; DArrigo et al., 2006 actually show their results with the “2-standard-error range at the multi-decadal time scale” and “calculated on the basis of analyses of regression residuals” like they say?
2nd. Within this second group (Briffa and Osborn, 1999; Esper et al., 2002; Bradley et al., 2003b; Osborn and Briffa, 2006), do they all have a common proxy (BCP’s, I’ll bet).
#33 UC. You ARE joking, aren’t you?
Just a quick out-loud thought on the whole notion of “getting the right confidence limits.” What it really boils down to is
1) Setting out exactly which statistic is being calculated, and then
2) Getting the variance of that statistic right
After doing that, confidence intervals are trivial.
As Steve mentioned earlier, one of the advantages of Loehle’s approach is that its simplicity makes these two tasks much easier. I gather that with many of the proxy studies completed in the past 10 years, even step 1 is quite difficult, and even when completed, the complexity of the estimatiors make derivation of the variance virtually impossible.
Another way to get at variances of even complex proxies in a way that may be non-controversial is with bootstrapping techniques. It is simple, it is easy to apply, and a standardized approach can be developed to use on any proxy study, no matter how the proxies are composed.
Here is the Wikipedia reference:
Here is a reference from Stanford:
Here is an example of how bootstrap can be applied:
If I ask you what 2+2 is and you do one of the following, you’re not really helping your case.
1) RTFR
2) If you take the following into account, and validate the….
3) Um, well, the thing of it is….
4) I didn’t do that sort of study in school, so I’m not really qualified to answer that at the present time.
5) The time scales at which the retreat of the icebergs exhibits is totally incoherent as far as the lapse rate of outgassing in the tree ring proxies.
Here’s what impresses me.
1) 4
2) I don’t know. Ask Jim Dunnigan, I think he knows that.
3) “7” “No, that’s not it” “I could be wrong about that, but as far as I know it’s the answer.”
4) It’s 7 minus 3…. 🙂
Five for large values of two
#32,
It won’t necessarily make that much difference. At least in the iid case, the convergence of an empirical estimate of variance (ie, an estimate of the error) to the true variance is exponential in the number of samples. So the “variance of the error estimate” is pretty small once you have a few tens of samples – going to a few hundred won’t make a lot of difference.
Here is a source link on the GRIP core
Click to access icecores_palaeoclimate.pdf
It goes back thousands of years and there are war, periods in the Holocene that make the MWP look like a blip. Makes you wonder why Greenland didn’t collapse into the sea, and why Antarctica never melted?
Nice plot. It musta been a lot of work to knock that out so quickly.
But if you’re trying to get to the truth, I just don’t understand why you didn’t add more temperature proxy records that actually HAVE been archived. -Cause you ain’t scared to get your hands dirty!
And what happens if you use Dye 3 instead of GRIP? And what about including Antarctica temp records? Last time I checked, it was on earth. Northern Hemisphere records dominate the Loehle 2007 plot…
Of course NH dominates.
Ref 1 JEG, Should the confidence level be based on each proxy or the final reconstruction? The comparison of the individual proxies included in the reconstruction indicates a level of confidence in the reconstruction. Confidence in each peer reviewed series used in the reconstruction is a different matter, I would think.
How would you rate the confidence level of say Bristle Cone Pine temperature reconstructions? I just want to learn.
Why 2 times? Where did the number 2 come from? Just plucked out of the air? I knew it was bizzare, but I didn’t realize that it was actually this simple and crazy.
Steve: Be careful. It’s not crazy for the simplistic reason you’re assuming. In a normal distribution, two times the standard deviation gives you 95% confidence intervals. That’s not the beef. The beef is with using overfitted residuals – compare this to one of my posts on Wahl and Ammann where I get good fits using their methodology with noise.
Jimmy, DYE 3 is nearly identical to GRIP. Check out the link I provided in 43. There was also an interesting comment in the article I linked,
I have never found a good graph of the Law Dome borehole, however.
Uh, sure enough, I finally find the Law Dome plot, here on CA
http://www.climateaudit.org/?p=1602
There’s your MWP in the SH. Hmmm…
Steve: That’s a dO18 plot not a borehole plot. The NAS panel mentioned an Antarctic borehole in their press conference, but it’s never been published and the author, Gary Clow of USGS, would not release the data.
Let me ask you something. If I’m plotting some data and I don’t know the precise margins of error, am I able to … well… fabricate the error bars? 😉
A second question: Am I able to control in my graphs the margins of errors?
A last question: When calibrating proxies am I able to move the gauge up or down to make it appears as accurate as I pretended it to be?
Instead of trying to estimate the errors wouldn’t it be possible to directly test the hypothesis “current temperatures are the highest in 2000 years” with each proxy an individual “observation” (eg YES/NO)
Yorick – Dye 3 has much warmer temperatures for the last few decades. Look in the link you provided. It will change the shape of the Loehle 2007 reconstruction.
As for Antarctica, these two links provide temperature estimates:
Vostok: ftp://ftp.ncdc.noaa.gov/pub/data/paleo/icecore/antarctica/vostok/deutnat.txt
EPICA Dome C: ftp://ftp.ncdc.noaa.gov/pub/data/paleo/icecore/antarctica/epica_domec/edc3deuttemp2007.txt
There are also marine sediment core SST records (using Mg/Ca) that could be added.
I’m just wondering why only 18 proxy series were used when more data is out there (as in not being sat on by the data-hoarders).
Jimmy,
To answer your question, read carefully here and ask yourself, why only treerings proxies? 😉
Re: 49, Steve, etc.
Re: isotope/temp
For what it’s worth I found this page
http://www2.umaine.edu/itase/content/Science/strategies.html
containing this pic of nine Antarctic graphs
Eyeballing the graphs I see no MWP, LIA, recent warming, nada. But I’m better at eyeballing verbal inconsistencies in IPCC texts…
Nasif- not quite sure what your point was…
Maybe I wasn’t too clear. I was saying that there are additional *non-tree-ring temperature proxy records* that could have been used in the Loehle 2007 reconstruction.
They should be added in b/c they are available. Don’t really see a reason why they ain’t????
MarkR
No kidding, MBH98
See also http://www.climateaudit.org/?p=647, and I have verified this quite accurately ( http://www.climateaudit.org/?p=2326#comment-160325 , 1650 step data missing). Mann uses variance matching for RPCs, so these error bars expand very moderately, and they even have upper bound.. Note that Loehle’s network is not increasingly sparse.
Re # 51 D Cutler
I agree. There is some confusion of the old terms “precision” and “accuracy” on which I have written before.
It is more important to have confidence that the method under study produces results which are close to the right results, whatever ways are available to estimate their accuracy.
Precision is of somewhat lesser importance, since there are stats ways to estimate it, smooth it, etc.
I worked in geochemistry, where sometimes we would have a dozen different elements and compounds measured in many places around a geological anomaly or an ore deposit. By analogy, compare the different elements to the 18 different methods Craig used. By all means, do replicate analysis on each sample to estimate its error envelope, the path to precision calculations.
In geochem, when all of the various elemental concentration show even visually similar expected distribution patterns about the anomaly centre, one starts to get an increased confidence that the anomaly is real, that it is supported by more than one type of measurement. When virtually all of the elements follow quite similar patterns in space (as opposed to time for Craig), then one is dealing with evidence-based science which probably has predictive possibilities. (e.g. If you see the pattern in another place, it’s worth investigation).
I care less about the confidence limits in Craig’s data at this stage. There will be scatters about the means. To me, the importance of the paper is that sans tree ring counts, the many remaining estimators show such similar patterns. That is, there is prima facie evidence of actuality.
The counter possibility is that the pattern of all of the proxies is disturbed by one or more events as yet unrecognised or wrongly quantified. Given the diversity of methods, this is unlikely unless there is a systematic error in the measurement of time or the relation of each proxy to temperature. I reserve doubts about these, as a prudent person.
The graph could look a heck of a lot less convincing than it does. It’s highly unscientific of me to say so, but it looks to be in good order.
Steve, If you may attempt to contact the authors of the article linked in #43, as they reference the Law Dome borehole data, though they don’t publish it. They may have access to it, or at least explain why nobody can have it.
I think the way to go here is to take a network of proxies where the original peer-reviewed work reveals the functional relationship wrt temperature. Then apply basic error propagation (likley in combination with time series bootstrap) to come up with some sort of CI. But the bootstrap needs to work for nonstationary series and that is still a not quite unresolved issue. Intuitively I would expect something like the graphic Geoff Olynyk posted above. And I am unsure how many papers show the details of calibrating their proxy to temperature…
ok, Christopher – so you think there is no hope… but if there is none, then why do so many people spend their time talking about all of this???
Craig Loehle took a nice step in the right direction. His work does not include the tree-ring proxies that have been beat up lately. Nice move.
But my point is – amid all of the back-slapping on Loehle – why are only 18 records included? Why not include ALL the records that are available? No fruit-picking. Put ’em all in. ***And no complaining about the ones that are being sat on. Or complaining about Mann. Or some detailed statistical no-no.
Put them all in. Then turn the crack and see what comes out.
That ain’t been done yet. By nobody.
my bad for #60. make that “crank” not “crack” in the next last sentence…
“Put them all in. Then turn the craNk and see what comes out.”
guess i should have said crank means…. by crizznanck I mean simple average.
Jimmy,
Craig Loehle is headed in the right direction because he is willing to learn to walk before he runs. Taking his lumps on Climate Audit, he has already learned how to take his next faster steps. Don’t complain, this is the way science is suppose to work.
If you want instant answers, look to Mann and company. Its not science, but they have all the answers.
Cliff
Re # 60 Jimmy
A careful person would not add more data sets to the existing. A prudent person would look for points in common between proxy groups (such as all those with delta O18 basis) and separate them even further for further comparison.
I have scepticism about the “throw it all into a meta study” approach.
#62 – I was trying to help out with the next step.
#63 – So you’re 100% positive that those 18 records are the only non-tree-ring datasets that reconstruct temperature for the last 2000 years?
Overall, I am kind of taken aback about how many people on this site believe that the Loehle 2007 reconstruction is global and proves that the MWP was global…
I think most people are still considering the flaws and hoping for a new version, and withholding judgement on what it infers until seeing the final product.
Don’t assume too quickly.
That said, certainly it would be worthwhile to ensure all available proxies fitting the selection criteria are used. Yes some may have been missed. And I’m sure if evidence came to light that Craig ‘cherry-picked’ and excluded such valid proxies for nefarious reasons, he would be drummed off this site very fast. I don’t have any reason to believe that yet though.
#64. I, for one, don’t think that. I don’t know how one can place error bars on this or similar calculations, but my judgement is that that error bars are large enough that they do not preclude the modern warm period form being warmer than MWP – just as I have argued that Mann’s method did not permit him to argue the opposite.
I’ve produced many calculations showing that slight variations of the canonical multiproxy studies produce warm MWPs just as the Loehle study has, but my interest was primarily in demonstrating the non-robustness of the canonical studies.
I’ve also been concerned that some of the canonical studies (Moberg, Esper in particular) had MWPs whose peaks were remarkably close to but just under the modern peaks. In business when you see knife-edge accounting profits, one wonders what charges might have been deferred to yield the knife-edge profits. So it’s interesting that when a non-Team calculation using the same sort of materials shows a different medieval-modern relationship.
IS there any objective sense in which one can say that Moberg’s network is more representative than Loehle’s varied and expanded version of Moberg’s network – Moberg being a NAture article and widely cited. It’s not at all obvious to me.
THere are some things in Loehle’s presentation that can be prettied up, producing statistics that people look for, however meaningless they may be. In this respect, JEG’s complaint seems to me, not that Loehle was pseudo-scientific, but that he was insufficiently pseudo-scientific.
Will the resulting reconstruction be as legitimate as any of the Team reconstructions? I can’t see why it wouldn’t be.
#64. As to candidate series, I’ll make a thread (And this is something Craig asked for) in which people can suggest candidate millennial proxies. I’m pretty sure that the Richey Pigmy Basin SST reconstruction meets the criteria; I don’t know whether the Black CAriaco Mg-CA SST is long enough.
The development of Mg-Ca SST measurements is an important new development. These studies are hot off the press and have not been multi-proxied. The oceanographic authors are terrifically cooperative. I’ve received very cordial and informative responses to inquiries from Lowell Stott, William Curry, Konrad Hughen very large names in their fields. David Black’s archiving of Cariaco data was concurrent with publication and the other guys are almost equally prompt.
64:
Well, maybe we can’t know for sure, but when you add Loehle’s work with all these studies, and read history books, you certainly have to agree that it’s possible the MWP. If it is possible
64, cont. Hit wrong key. If it is possible, then we simply cannot conclude that the modern warming is not a natural phenomonen.
There will soon be a richer academic field correlating history, anthropology, archeology, and climate reconstructions, as the temperature record becomes more clear. I hope I’m not belaboring the obvious.
=============================================================
Thank the Team for choosing “hottest in a thousand years” as the marketing slogan for the Mannomatic Hockey Stick Replicator attachment to the Mannomatic Spurious Correlation Generator (with 4-barrel enHansenizer, at no extra cost). You can thank them for “global” (rather than hemispheric or regional) while you are at it. Oh, and don’t forget “Anthropogenic” as well. That’s all marketing – and damn good marketing to boot. Sales to the credulous have been phenomenal and they haven’t even had to toss in a set of Ginsu knives.
[snip]
RE 64. I assume nothing about the MWP. or whether it was global.
What kind of sampling do we need to assure that our results are “global”. You can
make your teleconnection arguments later. I want to know, absent teleconnections,
how many sites do you need to charaterize a global temp? Some ( gavin) have suggested
that 60 sites will do. This figure is for THERMOMETERS. Lets accept that on its face.
Now, what about proxies? Prima facia it would appear that actual thermometers record
temps better than proxies. OTHERWISE, we would calibrate thermometers to proxies.
So, if a minimum of 60 pristine thermometers are required to characterize the “ave” temp of
the globe, then the number of proxies should be???
A. Higher
B. Lower
The global issue is a nice one. To prove that the MWP was global, how many sites do you need?
To prove it was regional how many sites do you need?
I like proxies. I think every 30 years or so we should go look at mud, and ice, and wood, and
shells and THEN decide whether the world has gotten warmer.
Jimmy says:
With your permission, I’d like to modify your statement:
Overall, I am kind of taken aback about how many people on other sites believe that the Mann 99 reconstruction is global and proves that the MWP doesn’t exist
#’s 66,67 – Mg/Ca is relatively new. The first papers on Mg/Ca of forams being used for SST only came out in 1995. New records are coming out every month it seems.
#’s 68-72 – You all raise good points. Especially #72. How many records does it take to get a global average? (not to be confused with how many licks does it take to get to the center of a tootsie pop, mind you…)
The idea in post #67 is a good idea. I think there are a lot more than just 18 records that fit the bill of 1) covering the last 1000-2000 years, 2) Are NOT tree rings, 3) have adequate temporal resolution. There is also the sticky issue of calibrating with instrumental data too…
A more useful idea than a global average though is to draw a line on the globe around the region that shows evidence for a century or more of warmer conditions around 1000AD. This rudementary mapping technique would be a little more robust than a slew of statistical tests.
#64 Jimmy:
Jimmy, I don’t know how old you are, or what your background is (not that either of those necessarily matter), but please allow me to thing things in perspective from my point of view.
Due to a particular assignment(job assignment, not school) I had in 1981, I was in enrolled in some fairly extensive geology training.
Three 16 week sessions, 8 hours a day. Field trips, lectures, the whole nine yards. Part of the training was walking through Earth’s history from on a geologic time scale. Recent events were things like most recent glacial cycles (~100,000 years per), and “yesterday’s news” was the MWP and the LIA, both well established events.
Along comes a couple of papers in the late ’90’s, and not only does the MWP disappear, but so does the LIA (look at the original hockey stick graphs). So I was skeptical from the get go. Learning of the extraordinary flaws in the papers proved that my skepticism was justified. Seeing the emergence of the frenzied politico/academic/cultural phenomenon know as AGW, only deepened my skepticism.
Am I willing to accept Loehle’s reconstructions at face value simply because they fit they framework I was taught 25 years ago? No. But he is cooperating in efforts to improve what he’s done, and has been open with his data and methods. Can the same be said of the Hockey Team?
Jimmy (#60) writes,
There is a valid statistical no-no against including every proxy available: If a given proxy has a variance that is approximately twice the average variance of the other proxies used to compute the mean, then it contributes more noise than news to the unweighted mean and so should be excluded from it.
Suppose, as in my comment #11 above, that the variance of proxy i about global temeperature at time t, as estimated across time, is Vi. Then with n proxies, the variance of their equally-weighted average is Sum(Vi)/n^2. If proxy n is omitted, the variance of the average is the same sum, taken to n-1, and divided by (n-1)^2. The former is greater than the latter iff Vi is greater than (2n-1)/(n-1) times the average of the first n-1 variances. This factor is approximately 2 for largish values of n (more precisely 2.06 for n = 18 as when all of Craig’s proxies are active).
If the mean is instead estimated by WLS as discussed at #11 above, every proxy, appropriately weighted in inverse proportion to its variance, will reduce the variance of the weighted mean, at least a little. But for Craig’s keep-it-simple unweighted average, there is actually a valid reason to exclude the most imprecise proxies.
#76 – I thought that was one of the positive aspects of the Loehle construction: all the records were converted to temperature – so if there is larger variance in one of the records, then it’s b/c the temperature changed more there.
So are you 100% certain that there are no other records out there that have the same characteristics as the 18 Loehle 2007 records?
-adequate temporal resolution
-are recording temperature for the last 2000 years
*AND* close-to-equal variances
Steve: there are some other records. I’ve posted on a few. And Craig is interested in suggestions. His inventory of long (at least to MWP) temperature-calibrated series is larger than Moberg, Mann, etc, so any potshots applied to him apply to the articles published in Nature and Science as well.
Re Jimmy #77 (and #76), I was overstating it a little to say that “There is a valid statistical no-no against including every proxy available ” A softer and truer statement would be “There is sometimes a valid statistical justification for not including every proxy available.”
And then in my post #76, instead of “If a given proxy has a variance that is approximately twice the average variance of the other proxies used to compute the mean, then it contributes more noise than news to the unweighted mean and so should be excluded from it,” a more precise conclusion would have been, “… and so may legitimately be excluded from it.” One is not required to exclude such variables when computing the unweighted mean as Craig did, but one would have an entirely valid justification for doing so.
If one is going to do WLS instead, the noisy series always improve the answer, but only very slightly, so that at some point is just isn’t worth the trouble to try to include them.
Jimmy goes on to ask, “So are you 100% certain that there are no other records out there that have the same characteristics as the 18 Loehle 2007 records?” I assume this was directed to the group in general, as I never made such a claim. I suppose there are a few that Craig overlooked. I do think his criterion of peer review is a very useful one. Peer review is neither necessary nor sufficient to guarantee quality, but it narrows the field to a manageable number of series that have at least some plausibility going for them, and is also the very flag that Mann et al hide behind. If there are some good series that haven’t been so published, they could still be included, but only in a separate calculation.
Thanks, Steve, for reposting Jean S’s explanation of “MBH-Style error bars” in #19. I did see that go by in an earlier thread, but didn’t make the connection.
It appears that MBH are confusing the standard error of the residuals of their calibration equation with the standard error of their “forecast” of pre-calibration temperatures. The SEs of the parameter estimates and the forecasts are all proportional to the SE of the residuals, but these are very different numbers. They have done step one, but omitted steps 2 and 3.
In MBH99, there is an additional step in which a hand-crafted adjustment is added to a temperature series that is obtained from an underlying regression (of sorts). This adjustment, arbitrarily adding the difference in trends between the Northern Treeline series and their PC1 estimates since 1700, as discussed here on a Nov. 13 thread, is done under the pretext of adjusting for CO2, but in fact the CO2 series is not included in any regression, either linearly or nonlinearly as they suggest would be appropriate. In fact the role of this adjustment is merely to make the final estimate have a desired shape, with a cool LIA preceded by a not too warm MWP, while retaining the higher frequency 20th century stripbark surge imbedded in PC1. There is no statistical method for computing error bars for hand-selected coefficients, so it would be futile to try to compute correct error bars for the 1999 paper.
(Had the difference in trends between the two series since 1700 been added as an additional explanatory variable, its coefficient could have been estimated and given a standard error, but then the forecasts would in all probability have fallen apart, which would not have served MBH’s purposes.)
Steve — Dang, you’re prolific! I’m just getting around to this problem and you’re already 8 posts ahead of me!
Steve: Hu, see http://www.climateaudit.org/?p=2367 on this “adjustment”. I’ll move this comment later today to the other thread.
JEG says at his blog re Loehle:
As best as I can understand what JEG is saying, his position is that manifestly incorrect error bars are scientific – something that I would regard as pseudo-scientific. In this respect, his objection to Loehle is that he is insufficiently pseudo-scientific if I may put it that way. Had Loehle included MBH-style error bars according to the pseudo-scientific conventions of the trade, I guess that would have removed one obstacles.
The Hegerl et al error bars, referred to here approvingly, were of course a minor classic even in Mannian terms, as in some cases the lower bound exceeded the upper bound.
I guess that Judith Curry mis-spoke when she said that she and JEG was interested in discussing Mann et al 2007.
RE 80.
Steve Judith and Jeg were playing a game well known in grad school.
The game is called “have you read?”
HYR
When you are losing an argument or at a point where you need to score some points
or change the subject: HYR.
This works in the seminar setting or the class setting . The student asks an uncomfortable
question and the professor says “have you read” It’s almost always a bluff. Citing
something fresh, citing “personal communication” citing something arcane, citing something
“in press”
I loved your response to the Mann2007 challenge. Throw the BS flag.
sory, but i have t disagree. any sort of error bar, however “false” is good in comparison to no error bar.
had Loehle added any error bar, we would immediately see that his claim that MWP is warmer than the end of 20th century is nonsense.
had he added a reasonable error bar, taking into account his lack of proxies at the end of the 20th century, the problem would be even more obvious.
sorry, but this simply is not what happened.
Sod:
sory, but i have t disagree. any sort of error bar, however false is good in comparison to no error bar.
Or… “It is better to lie than to say ‘I don’t know!'”
#82,84. The number of Loehle proxies in the 20th century at all times exceeds the number of proxies in the closely related Moberg low-frequency network. If someone wants to throw Loehle out because of 20th century proxies, then Moberg has to go as well (and the other studies as well.)
I’m OK with all of them being thrown out. What I don’t understand and ‘m trying to be objective here – is an actual defect that Loehle has that is not also shared by Moberg or Mann (or one that can’t be cured by making a pseudo-scientific calculation like calculation period residuals calculated above by Jean S/UC. Surely a study doesn’t become scientific by making an incorrect calculation. Having said that, Loehle could cosmetically do the calculation and I don’t see what differences then remain between his effort and Moberg and the others.
In his shoes, I would couch the MWP observations in more nuanced terms – not that these results were “right” – but that the proxy selections and calculation were as reasonable as the closely linked Team studies and showed a MWP warmer than the 20th century with equal certainty or lack of certainty as that claimed by Moberg or Mann.
I would also argue the point in terms of refuting the following Moberg claim:
His network would seem to provide “some evidence” to the contrary, though it hardly proves the point.
Given the lack of proxies for recent decades, is there any reason why the instrumental temperature record should not be used? It could easily be shifted to match the proxy reconstruction for the late-1800s. It may have issues, but it is surely at least as good as the indirect temperature/precipitation proxies.
Steve McIntyre:
You seem to be defending the Loehle reconstruction by arguing that it is no worse than others. Yet you have been relentless in tearing apart the others. Is “no worse” a high-enough criteria? Why does Loehle get an easier reception?
Note:
I have never attempted to defend any of the other reconstructions as I am not familiar with them. I am just curious why you defend Loehle while attacking most (all?) of the others.
thanks for the graph steve, you are very fast!
(what proxy is dropping out in the 16th century though? error?)
i missed the majority of the Moberg discussion. is he using simple averages as well? or does a “wavelet transform” behave differently, when proxies are dropped? (what is it anyway?)
http://tinyurl.com/2lpf42
if both use averages, then the important number is the PERCENTAGE of proxies, that still provide data. and we could limit ourselfs to the 20th century.
(total number is ratehr irrelevant, when a serious percentage turns flat, or am i wrong?)
can someone do it? (Steve has alot to do. someone else got the power?)
thanks. i would be more careful about claims about the end of the 20th century as well.
and i would prefer some of the Mann claims to be phrased more carefully.
Steve: I discussed the application of Moberg’s method to Loehle’s data here http://www.climateaudit.org/?p=2403 . Loehle’s network holds up proportionally with Moberg’s. I think that you’ve got a red herring here as Loehle’s network holds up OK compared to the others. Obviously I believe in bringing proxies up to date, though some ocean sediment series have low resolution – but some don’t.
The early ending series is MD95-2011 which is a piston core where the top was lost. There’s a box core covering the other portion- it’s a very interesting core BTW on which I mean to post some time. The alkenone measurements don’t seem to have been done on the box core though, but there are dO18 values which show a HOlocene Optimum. The box core comes up to the 1990s with a resolution of a couple of years. It’s good stuff.
BTW I think that Moberg goofed on one of his proxies (Lauritzen) which ends in the 19th century in the original publication but in the 1930s in Moberg – one of those things that the Team hates admitting. (Moberg also used one bristlecone pine series twice by mistake, one in an old version, one in a new version, but hasn’t talked much about that.)
#85. This comes up with tree rings all the time. There’s no problem in updating tree ring proxies and some have been (and remain unreported). The problem is whether the tree rings record warm temperatures. If they don’t record the warm 1990s and 2000s, how do we know that would have recorded warm 1010s? One can splice an instrumental temperature onto a possibly meaningless shaft but does it mean anything?
The SST guys purport to calibrate temperature according to a physical relationship rather than correlations which is all that the tree ring guys have. Whether their calibration is any better is another day’s topic. If we were satisfied that these proxies would record warm temperatures and had proof of this, then one might look more favorably on what you propose.
I would like to see more high-resolution SST proxy work (and it’s being actively done.)
#88 Steve McIntyre:
I realize there are problems with proxy temperature reconstructions and I am aware of your opinions regarding updating the proxies (and tree rings in particular). However, given that they have not been updated and given that Loehle2007 does not use tree rings, is there any reason why the instrumental record should not be spliced onto Loehle2007 for the last century?
Without speaking of the quality of the reconstruction prior to 1900, I am concerned by the divergence between Loehle2007 and CRU or GISTEMP in the 20th century. The divergence could be an artifact of the small number of proxies available for the 20th century. For that reason, the instrumental record may be a better indicator.
FWIW, the Loehle2007 MWP would still be warmer than the last decade when using the instrumental record, although not by as much.
John V,
Hopefully you are not suggesting comparing annually resolved records to decadally (or worse) resolved records.
thanks for the answer.
but let me repeat what i said above: if both methods come down to frming some sort of average, the TOTAL number at the end will be irrelevant. on the other hand, the percentage of “active” proxies will be the important thing to look at.
so a graph with only the 20th century and the percentage of proxies that still provide data would be very valauble.
it should be easy to do, but i don t have the Moberg numbers.
here are the Loehle numbers again:
http://www.climateaudit.org/?p=2382#comment-162999
if we were both measuring some water that is being heated, and i use 10 thermometers, while you use 20.
we average the temperature on our thermometers and some of them stop working at a certain moment, keeping their last temperature.
then the total number of active thermometers is irrelevant, but the percentage of working thermometers is important. and whoever has the highest percentage number at the latest time gets the best result..
I don’t see that at all John V. Steve’s made comments on Craig’s work, but does he need to say the same thing bender and our visiting team member said over again?
Commenting on the criticisms being leveled as applying to other papers too doesn’t seem to me to be giving anyonee a break, but rather they should be leveled equally. I see that as two separate issues, the criticisms themselves and the applicability of the criticisms.
And at least Craig admits his paper has some issues he should take care of and is going to fix them….
#90 bender:
I don’t understand your concern with merging series with different temporal resolution. The Loehle2007 proxies have temporal resolutions ranging from years to multiple decades.
I posted last week that I re-generated the Loehle results by interpolating between his data points and using what I consider a better method of combining records. My question now is whether it’s reasonable to append the yearly instrumental record to the end of the yearly-interpolated Loehle2007 results.
The Scafetta and West paper that SteveMc promoted to the front page today merges CRU onto Moberg2005. I also see that SteveMc has compared Moberg2005 to CRU in earlier posts. I get the feeling that it’s a reasonable thing to do despite your objections.
RE 90. No Bender, John has already done the splice or he would not ask the question.
JohnV. I love you man, but get some game.
In the end the ClimateAudit position will likely be this: We find no statistically valid
evidence that the MWP was any warmer or any cooler than the present period.
LOST IN THE NOISE.
basically, folks dont get to claim “warmest in a millenium” . But John YOU KNEW THAT.
You knew that a tree ring could not resolve a temperature to 1C accuracy. You knew that.
Why pretend otherwise?
#94 steven mosher:
I actually haven’t done the splice — I’ve only eyeballed it. I don’t have the time that I did a couple of months ago.
I see it this way. Everything is a temperature proxy — including the instrumental record. Why should it not be included in all reconstructions? It’s an honest question.
John V, it is colder today in California than it was during November 2005. What is wrong with this comparison?
#96 bender:
All proxy reconstructions use proxies with different temporal resolutions. By your argument, Loehle2007 would have to be thrown out since it uses proxies with resolutions varying from 1 year to 60+ years.
For proxies, I believe that if there is a data point available every 10 years, the convention is to treat it as an average for the period. In my analysis I used linear interpolation between data points. So, the appropriate comparison is “the 30 days preceding today were colder than the 30 days of November 2005”.
Do you have a legitimate complaint with using the yearly instrumental record as opposed to using the yearly GRIP borehole (Dahl-Jensen et al, 1998), Conroy Lake pollen (Gajewski, 1988), Chesapeake Bay Mg/Ca (Cronin et al 2003), or the other yearly series in Loehle2007?
RE 95. We all eyeballed it.
Analyze this. Pikes peak area. 1933 temps. 1934 temps.
Also, remember this is dust bowl era.
we have around 30 cores. 29 of those 30 cores indicate that HOTTER temps result
in smaller rings.
29 of 30. John, is ring width correlated with Temp? or Drought? Think?
1935. Colorado experiences record level rainfalls. Huge rainfall. record rainfall.
Same 30 cores. From 1934 to 1935 do you think they responded to the rain?
50%? 75%? 95%? Take a guess. Dont look. guess.
The BCP do not record temp. Maybe something else does. Game over. thank you for playing.
#98 steven mosher:
I’m not arguing against Loehle. (I previously had a concern with his method of merging series. I looked into that and posted last week that my concern was unfounded). I’m not arguing for tree rings. I never mentioned bristle-cone pines. I’ve never defended any of the other reconstructions. (Other than to ask why they are treated differently than Loehle2007). I have previously posted that I do not believe tree rings are a very good temperature proxy.
I’m asking a simple question — is there any reason why the instrumental record should not be included for the 20th century? Why are you being evasive? Why bring up bristle-cone pines?
Sheesh. It’s tough to get a simple answer around here.
JohnV:
What temperature record do you propose using for your splice?
Based on earlier analysis, it appears that GISS might be OK for the contiguous USA. But what would you use for the Rest Of the World?
re 95
Danger Danger answer from a layman Danger Danger
Isn’t that the question that temperature reconstruction are trying to determine. If the proxies used in a reconstruction are not accurate and so cannot predict past temperatures, what is the point of splicing the reconstruction to an instrumental record? Comparing the instrumental record with a reconstruction of the current period form the proxies would indicate how much credence should be given to the reconstruction of long ago periods. The divergence issue brings this into question.
re 95
Gore in “An Inconvenient Truth” shows the Mann/IPCCC hockey stick (which he incorrectly describes as coming from Thompson) together with a plot of the historical C02 concentration. He points out (paraphrasing) that the shaft of the hockey stick is flat and that temperature follows the shape of the flat portion of the C02 curve. The important part of the hockey stick is not the blade but the flat shaft. If there was a global MWP them the usefulness of the hockey stick would be called into question. So another reason for not grafting the instrumental record onto a reconstruction is that it misses the point.
I’ll give you a couple of reasons not to use the temperature record. (Or maybe the same reason put multiple ways…..)
1. It’s not a proxy but an actual measured quantity. The only reason you use proxies is because you don’t have the temperatures.
2. The proxies have a diferent time-scale and resolution than multiple daily direct measurements and are not the same thing, why put them together?
3. While a proxy may give you a pretty good idea what things are like over a long period of time, the thermometer measurements seem to have gotten more accurate over time, which ‘could’ explain the rise they give. But you can’t muck about with what the climate was like over 100 years in a proxy, just on the aplicability of it to using it to measure temperature.
4. What does putting them both together tell us? Why further cloud the issue by blending them? What is the benefit from doing so?
John V is essentially asking “why not?” Yet he won’t answer my #96. John V, this is classic dodge & weave. Redeem yourself. Answer my question and I’ll answer yours.
Sure, you can ask “why” or “why not” but I can’t think of any valid compelling reasons to answer “Why”. It doesn’t get us any more real knowledge of either the past or the present or the future.
It’s like searching for a quarter someplace other than where you dropped it because the light is better where you’re looking now. What greater understanding do we get from grafting proxy to thermometer data?
(That’s taking it for granted that everything involved is meaningful and accurate, but hey, you have to take certain things for granted to answer certain questions.)
“What if” can be a helpful thing that leads to greater understanding.
John V — 99:
I’m not bender. I’m not a statistician. But why do you think that question has a simple answer?
If I understand correctly, the tree / thermometer data is collected over a temperature range that does not capture the current global average temperatures.
That means that if past global temperatures matched current temperatures, tree data would be applied outside the range of calibration. Extrapolation may work, or it may not.
If extrapolation does not work, then patching the pinecone data will give a flawed visual image and distort our understanding.
If it turns out we are lucky and extrapolation does work, then patching will work out fine. That will be luck.
So…. is it ok to patch? That depends. What question are you trying to answer? If the question is “Was the a Medieval Warm Period global and equal to the current temperature excursion”, I’d say patching might be very deceptive.
For some other question, maybe it would be ok.
I’m eager to see the Almagre data.
sod,
You keep harping on when the series in Loehle’s work end, yet you’ve posted a link to Buntgen et al (2005) a number of times. In that work, only 2 of those 5 series continue past the 1995 year you don’t think is recent enough on Loehle, 1 of the 5 series ends in 1914, and only 2 of the 5 series – which carry repeated caveats from the authors themselves – suggest the temperatures in the alps in the 20th century were high.
Additionally, why not look at the dates of the series used in MBH98, MBH99, Mann and Jones (2003)?
Because either sod doesn’t understand this subject or he’s trying to mislead by muddying the waters on what the subject is. This is the primary reason the point is made “Yes, that’s all well and fine in this paper, but it’s not okay in this other one?” becomes some other esoteric issue. I think that’s called hand-waving. This is why so many questions get no clear answer. Whatever the reason.
#103 Sam Urbinto:
My reason for putting them together is that the proxies are not up to date. The instrumental record is presumably used to calibrate the proxies, so it is therefore implicitly used as the true temperature. Proxies are used when the true temperature has not been measured.
If the goal is the most accurate temperature history, then the most accurate data should be used for every time period. For the 20th century, the instrumental record is the best available data.
=====
Bender:
Rather than answer your invalid question, I explained why it was invalid. You asked if comparing a single day’s temperature to a monthly average was appropriate. The answer is no.
Now to my questions (repeated here):
Do you have a legitimate complaint with using the yearly instrumental record as opposed to using the yearly GRIP borehole (Dahl-Jensen et al, 1998), Conroy Lake pollen (Gajewski, 1988), Chesapeake Bay Mg/Ca (Cronin et al 2003), or the other yearly series in Loehle2007?
Note that proxy studies already use proxies with different temporal resolutions. You are semingly ok with that. What’s the difference with the instrumental temperature record?
And why is the answer “no”, John V?
JohnV: even if you sense there is a big cat stalking you, I think you should answer the question. It’s called the Socratic method.
bender:
Enough with the condescending questions. Just tell me why I can’t compare today to November 2005 and then answer my question why yearly proxies can be merged with multi-decadal proxies but yearly instrumental data can not. Be sure to explain why your day-vs-month analogy applies to instrumental data but not to proxy data.
I asked an honest question. I await an honest answer.
You replied “no”. You must have a reason?
@John V said–
And the reasons to not put them together include
a) the measurements by two different ‘instruments’ (trees vs. thermometers) may not be the same thing for a variety of reasons.
b) putting them together may be deceptive for a variety of reasons
Or, putting them together might be just fine.
So where does that put us?
If you want to put them together, put them together and advance your best shot giving a full argument. What’s with asking isolated questions as though there really is an absolute answer to ‘can we slap these to things together’? The answer can’t be given without additional information.
Why, oh why, does this line of questioning remind me of a what I called “pre-grading” on the part of students. If you have an honest straight-forward question ask it. If you just want someone to grade your paper, give it back to you and re-work it it it’s wrong (so as to escape the need for actually identifying what you know and trying to understand) …. well.. sheesh!
As far as the statistical issue goes, I think we are in the region of high beta error. It’s difficult to learn anything. Deal! The best course is to get more data. Yes, I know that’s difficult.
I’m interested in the Almagre data and anything else that might come along. . .
From CA pae 179 here is a splice of Moberg to satellite – note the purple on the right side. A Loehle splice would be even more so. There’s more than one possible way of splicing – as I recall . Moberg ended in 1979 about the same time time as satellit started and I think that I just spliced at 1979.
Legend: blue – Moberg; purple- satellite; red – Jones. Please see original post for details.
Note: this is not meant to legitimize splicing – merely to show the effect of Moberg+ Satellite as opposed to Mann + Jones instrumental – in a format more or less consistent with the IPCC TAR graphic.
#115 Steve McIntyre:
Thanks. I gather that splicing is therefore a reasonable.
I understand that Blue is Moberg2005 and red is satellite. What’s the purple?
=====
#113 bender:
I’m not playing your game, because I know how it works: I answer your question. You find a small problem with my answer. Then we’re arguing about *your* analogy instead of *my* question.
If you have a reason why including instrumental data in temperature reconstructions is a bad idea, then share it with the rest of us. If there is a reason why single-year resolution instrumental data is bad while single-year proxy data is ok, then share it with the rest of us.
=====
#114 lucia:
In the past I’ve made graphs and posted them without asking questions first. That invariably leads to lots of attention and flames, but little worthwhile discussion. This time I had the idea and thought I’d ask about it first. It was my attempt at being non-confrontational. So much for that approach.
Steve: John V – this was just an exercise to show what it looked like. The problem that you are failing to understand is the Divergence Problem and proxies. If you have Divergence between proxies and temperature in the 1990s (And there’s been much discussion of this on the blog), then you have no way of knowing whether past warm periods might have been concealed by similar divergence. It’s pretty basic. You shouldn’t include instrumental temperature data in a recon because you had no instrumental measurements in the MWP. Mann uses instrumental data from 12 sites as “proxies” and gooses his reported correlations that way.
Wrong. My “game” is to have you answer your own question. You see, this way you not only get your answer, I also get to learn how you think.
Why do you think Mann wanted to make it abundantly clear that “no climatologist had ever spliced a proxy and instrumental record together” [paraphrase]? Why did he seem to think it was a bad idea?
But JohnV– I’m not bender, have no idea what ultimate idea what you might be driving at and I thought up quite a few reasons why splicing can be error prone.
I answered your question– but you seem to want to ignore that. So, even assuming you got bender to say he thought splicing was ok, you still wouldn’t be clear. After all, I reserve judgement until you ask a question that contains enough details to permit anyone to give a real answer!
In my opinion, no one can answer the question you asked without more information from you. It may be sad and unfortunate, but yes, sometimes you go down a path, it takes quite a bit of explanation, and only then does the problem with a technique become clear.
This isn’t like following a recipe to bake pie and having the pie come out a pie. Steps sometimes don’t work.
Quite honestly: I think AGW is probably correct. I also think for better or worse we are in a situation where we can rarely show any individual thing to within 95% confidence without there being some deficiencies in the empirical proof of a individual hypothesis. But, by the same token, we get a lot of data that strongly suggests AGW.
The problem: failure to prove something to 95% confidence doesn’t mean the theory is wrong. It might be wrong– but it also might mean there is not enough good data to pick out a signal from the noise.
You can bang your head against the wall for ages arguing about splicing or you can try to get more or better data.
Steve has funded the Almagre data out of his own pocket. If you really believe in BP’s and also in AGW, feel confident the Almagre data will bear you out. Or, if you doubt, tremble. Either way, the issue of splicing goes away.
But what’s the point of trying to get bender to answer questions that can’t be answered? Wait a month. Your question to bender may be irrelevant!
“Splicing” is not the issue; you can do anything you like on a graphic and no one is going to hang you for it. It’s the inference you’re trying to draw from the splice that is the issue. So: what is the inference you are trying to draw from the splice? And do the uncertainty levels around each piece allow you to safely make the inference you wish to make. (I’ve said this once before. Why do you make me say it again?)
As for my first question – do you intend to compare a pre-instrumental record subject to both reconstruction error (y-axis) and dating error (x-axis) to a precise instrumental record free of dating error? – the problem is the unequal level of uncertainty in the two records.
Who has more money: you or the average neighbor on your block? You know your salary with absolute precision. But your neighbors’ salaries is only a guess. Do you have enough information to make a decision? Their car, their house, their clothes, these are proxies for wealth. But what is their level of debt? You can’t know for certain without more data.
This is quite aside from the issue of how crappy the proxies may perform during the MWP – Steve’s bolded reply in #116. An effect that yields not only more uncertainty, but a potential source of bias toward underestimated warmth.
as John V said above, this sort of defence is very weak. if other papers have a similar problem, then that is a bad thing. but it is very much irrelvenat to this dicussion.
i keep quoting Buntgen, because i got linked to him by one of you guys on this page. you think his data is fine in the MWP. you think it has huge problems at the end of the 20th century. strange.
i keep quoting him, because the same fals claim is repeated in this comments over and over again: the hockey stick is dead, because of Steves work on the Bristlecone. the Buntgen paper shows that there is plenty of work left for Steve.
final point:
the value of the number of proxies used to determine the end of the 20th century, masiively depends on the METHOD used to combine them.
i didn t look deeply into the methods of other papers. but the Loehle method of averaging is masiively skewed by proxies dropping out early.
i am pretty sure i understand the problem. Steve gave an excellent graoph in #84. but the conclusion he is drawing is absolutely false:
again: the total number of proxies used is irrelevant.
an important thesis in climate science postulates a massive change in temperature at the end of the 20th century.
Loehles reconstruction of this period is to 6% based on a number from the 16th century, a time called “LITTLE ICE AGE” over here.
20% of the reconstruction is by proxies from the 19th century or earlier, 50% of his proxies don t have data beyond 1950.
the method of averaging, applauded for its simplicity on this page, makes this lack of proxies devestating for his results at the end of the 20th century.
other methods, in other papers, might do better.
ps: temperature measurement is obviously the best proxy we have for the 20th century. if reconstructions don t fit to the temperature, important questions need to be asked. it is not the other way round!
sod, the buntgen recon is not global. It is “composed of larch data from four Alpine valleys in Switzerland and pine data from the western Austrian Alps”.
sod, the buntegen recon is contaminated by the effect of insect outbreaks:
Where is their proof of the assertion of effective minimization of non-climatic effects?
Sorry, the stick is broken.
Are my eyes lying or do I see 3 colors in Steve’s graph in 115? Blue – Moberg’s recon; Red – NH temp; Purple – satellite data.
I assume that if Steve meant that red is satellite temps then he would have written so. But, as I said before maybe my eyes are lying.
sod, what do you think of buntgen’s efforts to control for the effects of moisture in those larch trees growing at high elevation? Were they adequate? By what measure?
We’re a bit off track talking about buntgen in this thread, sod. My suggestion is that you nicely ask Steve M to set up a thread for that paper, as I don’t believe it’s been discussed yet. Let’s try to keep our the discussion well-threaded.
In other words, the Divergence Problem.
It’s not a defense of Loehle, it’s a legit question for you. If you can defend a paper you’ve brought-up repeatedly, then you’ll be satisfied when it comes to the same issues with Loehle.
Wow, so according to Buentgen, there are two tree series (out of the 5 they studied) in the Alps which suggest the late 20th century temps might be historically warm? Amazing. How well does that represent the entire world? And what do Buentgen’s error bars look like so that we may make a true comparison of the 20th century vs MWP for these series? Even the authors themselves (at least 3 times I saw in my perusal) warned about putting too much stock in the recent data. We also don’t see annual data, but smoothed…and padded at the critical endpoint.
a thought struck me last night- in these reconstructions, all the proxies records are added together to get one temperature record.
*Has that ever been done for modern instrumental data by adding both global temperature and global SST’s anomalies together? Is there any reason why it should be??? …as the oceans absorb a lot of heat from the atmosphere.
Steve: that’s precisely what the HadCRU and similar temperatuer histories do. The SST portion of these records is much under-analyzed.
JohnV sorry about the BCP diversion, I thought I was on a different thread. Carry on
sod wrote:
As I understand it, what is claimed is not a “massive” increase but an unprecedented increase. The hope of the AGW advocates is to match one clearly and undeniably unprecedented event — the emergence of industrial technology and the resulting release of CO2 — with an unprecedented increase in temperature. The simultaneous emergence of two unprecedented phenomena is a correlation that one can reasonably argue must be causal in nature.
To me, the importance of Loehle is not what it says directly about the twentieth century. Its importance is its support of the existence of the MWP and the LIA. If those two phenomena actually occurred, then tree ring data is (evidently) useless as a temperature proxy and the hockey stick does not prove that late twentieth century temperatures are unprecedented. The fact that much of Loehle’s data terminates before the end of the twentieth century seems largely irrelevant.
#116 Steve McIntyre:
I actually understand that problem, but that was not what I was suggesting. (Re-reading my posts I can see how I gave the impression that was my intention). My original concern was the divergence between Loehle2007 and the instrumental record in the late-20th century.
Presuming that the instrumental record is correct, doesn’t the divergence in Loehle2007 raise some red flags? (As it does for the MBH and Moberg reconstructions). I wonder if the divergence would be reduced by using only instruments that are close to the proxy sites.
=====
#118 lucia:
Why are you still asking about bristlecone pines? I was asking about splicing the instrumental record onto the Loehle2007 reconstruction to extend the Loehle2007 reconstruction from the 1970s to present day. That’s it.
=====
#119 bender:
I understand that there are large uncertainties in the proxies and smaller uncertainties in the instrumental record. The problem is that using Loehle2007 alone, there is infinite uncertainty for the last three decades. Is it not better to splice the instrumental trend (normalizing to the period of overlap with the Loehle trend) than to have nothing?
The temperature and temporal resolutions of each proxy are also different. Yet they can still be merged to generate a proxy reconstruction. If one of the proxy series was much better than the others but ended in 1800, would you suggest not using it? Why?
i did NOT bring up Buentgen.
instead i told you, that bringing other papers up is a weak defense.
let me try to explain what is wrong with the Loehle paper, and what might be different in other papers:
1. Loehle does not have strong proxies for the end of the 20th century.
my main problem with this poin is, that he did not address it at all in his paper.
2. the simple method he is using (averages, flat line approximation), which was applauded by you, is INCREASING the problem of the missing proxies.
if i look at the graph that Steve did, using the Moberg method on the Loehle paper, a different method changes the end of the 20th century significantly.
http://www.climateaudit.org/?p=2403
3. Loehle is making rather strong claims about the (most important) period. (end of 20th century)
at first look, i would say neuther Moberg nor Buentgen make similar strong claims.
4. the Loehle results (as they stand) are not in line with the most precise data (temperature measurement) at the end of the 20th century.
i see how you will not like this point.
before bringing up other papers, please check whether they have ALL of these problesm as well (or at least other problems of similar significance, that can be easily checked).
John V. you seem to understand:
1. The uncertainty inequality problem.
But you ask:
Unask the question. It is best to wait for the approximately correct confidence intervals to be calculated by Loehle & JEG. Short of that, it is probably best to not make any inference either way. Given the size of the uncertainty likely to come out of Loehle & JEG’s collaboration, you open yourself up to a possible incorrect inference: CWP warmer than MWP – the same mistake the alarmists keep making over and over.
There are two other problems associated with making an inference based on such a splice.
2. The resolution problem: a coarse-resolution proxy (or smoothed, well-resolved proxy) will have much of the interannual variability ironed out of it; whereas the instrumental record will have all of it intact. It is completely unfair to compare a single cherry-picked year, say 1998, to a three hundred year period, such as Lamb’s MWP. Alarmists make this logical error all the time. The fair comparison is a three-hundred year average back then to a three hundred year average now. Or a year then to a year now. Mixing timescales and cherry picking from the highly resolved series will cause you to make a seriously incorrect inference with very high probability. The tacit assumption you are making is that 1998, say, is representative of the next 300 years. How likely is that? (Not clear why you do not see this when you do see that it is unfair to compare today’s daily temperature to last year’s mean for the month. Statistically, it is the same process.)
3. The divergence problem: If you don’t really understand this issue, you are missing the boat. Read every post at CA on it. If the proxies diverge from the instrumental record now (and they do!) then what’s to prevent them from diverging even worse during warmer times in the past? Nothing! I repeat: nonlinear temperature proxies may seriously underestimate the MWP. [Michael Moore (American filmmaker) would ask: “why is this question not being discussed in the literature? Isn’t it sort of damning?”]
John V, bender does not play games for the sake of winning arguments. Good luck in your work. Be careful in your reasoning.
#120 “i keep quoting Buntgen”
#131 “i did NOT bring up Buentgen”
The problem, sod, is you keep repeating yourself over and over (between posts and now within), with text getting louder and louder, and you don’t seem to be learning anything from what other people are saying. What’s next? ALL CAPS? Then ALL CAPS bold? The more you do that, the more you will be ignored. It’s called a tantrum. And the solution is to let you wail away in isolation.
The goal of reconstruction is to reconstruct past temperatures, not temperatures during the modern instrumental period. If you have problems with the canonical literature employed by Loehle (2007), why not discuss those papers that trouble you most? You seem to be blaming Loehle for the shortcomings of the proxies, which makes no sense.
Loehle is working on calculating robust confidence intervals – a major improvement over your beloved hockey stick studies that are juiced up on drought-limited bcps and bug-ridden swiss larch. Patience.
Looking at any number of divergent proxies, I doubt it. But I’ve never quite understood why this isn’t always attempted.
Of course, this would eliminate any “teleconnections.”
#132 bender:
If you review my posts, you will see that I have been strongly against cherry-picking single years. You state that “alarmists make this logical error all the time” while conveniently ignoring the 1934-vs-1998 USA48 comparison that contrarians use all the time. (BTW, you should avoid using “alarmist” as I avoid the word “denier”). I can assure you that I will never make a comparison of 1998 to any year are range of years. Loehle2007 made the error you describe when calling the MWP warmer than CWP without any error bars and while truncating CWP. I believe you called him on that error, but curiously few others had any problem with it.
You state that “nonlinear temperature proxies may seriously underestimate the MWP” — could they not also seriously over-estimate MWP?
The divergence problem seems to be a major downfall of the Loehle2007 reconstruction. The reconstructed 20th century is very different than the instrumental record. Much more so than Moberg2005 (from SteveMc’s post above).
Finally, I don’t really care about MWP vs CWP. My primary concern is the divergence between temperature and non-AGW influences in the last 30 years. I asked an academic question about using the best-available data for a given time period. Apparently it was a touchy subject.
sod, read up on the divergence problem. That’s what you are describing, and it appears to be a problem in all tree-ring based reconstructions too. It’s been discussed many times at CA. One tires of spoonfeeding the links. Save yourself some embarrassment and read.
John V, biting the hand that feeds. This why I asked your intent, so that I could better answer your question. And now I am accused of conveniently ignoring data. bender disagrees with all bad statistical analysis – on both sides of the debate. And if YOU were to review MY posts you would know that.
Again, good luck in your work. You will need it.
#13. You’ve completely misconstrued my Moberg-style calculation. In my Moberg calculation, I used Moberg’s tree ring proxies as well. Although Loehle’s rationale emphasized that he didn’t use tree ring proxies, my hunch was that the difference was in the low-frequency selections and not in the tree ring proxies. The calculation that you refer to showed that he could have included Moberg’s tree ring proxies and reached the same conclusion.
With the tree rings included and using Moberg’s wavelet method, the 20th century looks different but the MWP-modern relationship of Loehleis preserved.
I guess the ultimate question in all of this is: is there any objective reason why the Loehle recon should not be included in spaghetti graphs? Or would there be any if a Supplementary Information was created that contained the statistics and pseudo-confidence intervals desired by JEG?
#138 bender:
I missed you asking my intent. You asked about comparing a day to a month. You assumed my intent incorrectly.
I did not accuse you of “conveniently ignoring data”. I said that you ignored the fact that contrarians compare 1934 to 1998 in the USA48 all the time, while stating that “alarmists make this logical error all the time”. I also acknowledged that *you* called Loehle2007 on statistical issues (while others did not).
Anyways, this was much ado about nothing. We both could have saved a lot of time and effort if you stated your objections clearly at the beginning.
You, sir, should have answered my initial question about whether you were intending to make an inference involving a comparison between a coarse-resolution proxy record and high-res instrumental record. But for some reason you did not want to dislose your intent. And so it went …
bender, I like the phrase that I just used – “pseudo confidence intervals”. What has been helpful for me in the exchange with JEG has been some of his choice of words, which I find useful. His concern with Loehle 2007 is that it is “pseudo science”. I’ve never used the word “pseudo science” in my discussion of MBH and the Team. However, it’s obvious that any Team article meets all of the JEG criteria for “pseudo science”, whether JEG cares to admit it or not. But the word “pseudo science” is an excellent one in this regard. IT captures nicely the point that the method has to be right as well as the answer.
Extending that, I think that the term “pseudo confidence intervals” describes the typical Team calculations. They are not real confidence intervals and I’d be hesitant to present them on that basis. But I think that I could present a “pseudo confidence interval”, even if it was a meaningless calculation provided that one clearly identified it as such.
That IS the question, and the answer is: NO. The true uncertainty on all these recons is floor to ceiling. And if folks would plot the error bars honestly, Loehle’s recon would slot right inside that envelope. Instead, because they don’t, Loehle’s recon appears to be an outlier. But it’s not. It’s just one of the million flavors that an honest bootstrap resampling method would come up with.
The spaghetti graphs are an attempt to be inclusive. Exclusion of any one series must be strongly justified on a sound rational basis – something distinctly lacking in certain rookie accusations of “pseudoscience”.
Let me try it:
I’m pseudoconfident that CWP is unprecedented.
I’m pseudoconfident that MWP did not exist or was not global.
I’m pseudoconfident in the AGW hypothesis.
Seems to work.
I’m pseudoconfident that JEG’s new secret method will be an improvement on the pseudoscience that passes as science in the literature these days.
The spaghetti graphs can be called “Pseuds’ Corner” – which one used to hear in Britain about 35 years ago.
Are pseudo-scientists pseudo-salaried?
#141 bender:
I finally understand what you were really asking. I thought you had a problem with the concept of merging data sets with different temporal resolutions. You thought my intent was to compare 1998 to the entire MWP. We argued right past each other and we were both right. What a waste of time.
As I said before, the confusion could have been avoided if you asked your question or stated your objection clearly from the start.
Correct me if I’m wrong, but shouldn’t any linear combination method that derives its weighting from a minimization of mean square error produce identical error results (though not necessarily unique solutions)? PCA, RegEM, etc., all derive results from 2nd order statistics, correct?
Mark
I’m gonna buy my x-mas LCD TV with pseudo-Benjamins. Wonder what Circuity City will say?
Mark
@130–
Sorry– confused about which proxy data. My comments would be the same regardless of the specific proxy used for the past. If proxies are used in the past, and you want to slap on new better data at the front end, you need to be very, very careful. It’s not clear you can just slice data without a huge amount of care.
So, the answer to your simple sounding initial question: “can you just splice data” can’t just be “yes” or “no”. The answer is a this question: “Could you describe the two data sets in more detail, and how you plan to splice and what phenomena you are trying to detect”. You need to answer a whole bunch of questions like: “Will splicing involve significant overlap?” etc.
If you don’t answer stuff like that, no one can really hazard a good answer. (Certainly, no one can say “yes”. But they might not want to say the answer is absolutely positively always no. It’s usually impossible to splice without introducing significant uncertainty. But maybe there is a case in which the uncertainty can be resolved.)
When you ask this:
The problem is that using Loehle2007 alone, there is infinite uncertainty for the last three decades. Is it not better to splice the instrumental trend (normalizing to the period of overlap with the Loehle trend) than to have nothing?
The answer is: It’s probably better to admit you have infinite uncertainty that to splice and still have a huge amount of uncertainty. But, more precisely: before you can get a better answer out of someone, describe how you plan to normalize, and then explain the uncertainties introduced into the phenomena you want to observe by normalizing.
For the question being asked, is it important to have the proxies line extended up to 2007? Is it sufficiently important to introduce uncertainty in the earlier period?
JEG’s ability to turn smart phrases while verbally tap dancing his way around this blog is most appreciated and an unexpected bonus coming from what one might expect to be a rather matter-of-fact climate scientist. His approach, while smart-alecky in context, does allow one to take a personal broadside and still chuckle at his remarks.
My question remains: after this flamboyant display of JEG, the erudite, and the urbane, will we be privileged with the presence of JEG, the serious climate scientist, here to answer rudimentary questions (and particular those posed by JEG, the viewer of misconceptions by CA participants) like, for example, a simple explanation of how teleconnections have been validly applied to a temperature proxy.
missquote. let me complete the prases:
#120 i keep quoting Buntgen on discussions about the destruction of the hockey stick.
#131 i did NOT bring up Buentgen on this topic. Michael did. (#107)
if i don t answer, i get accused of dodging. #126
if i do answer, i get accused of derailing the topic. #124
so i kept my answer short. and i told you that i think it is irrelevant to this topic.
i was linked from this comment section to the paper over at CO2 science. please discuss problems with the paper with the guys over there first.
http://www.co2science.org/scripts/CO2ScienceB2C/articles/V10/N11/C2.jsp
if you think so, please tell Loehle. he is making some wild claims about the end of the 20th century. why not stick to MWP and LIA?
i said this at least 10 times now: i know about problems with proxies. it is their use in the Loehle paper, that i disagree with.
why doesn t he call it a reconstruction till 1950, drop the remarks about the end of the 20th century and mention the problem with the 3 early drop outs among his proxies? that would settle the case for me.
Loehle is using a too simple method with bad proxies. he should be more patient in drawing his conclusions.
no need for fancy words or major reading. the Loehle paper has a bad method stretching bad proxies to their limits problem.
i am not suprised that it does not reconstruct reality.
i would start by fixing the obvious short commings (do you consider a 15th century proxy a good guess for estimating 1995 temperature?) or by limiting the ambition of the project.
sorry Steve, i missed that. i had just read what you wrote when you posted the link:
so i assumed that you had just used the wavelet method on the Loehle data.
so two questions remain for me:
1. would the Moberg wavelet method handle the early dropping out of proxies better, than an average does?
2. anyone around who can replot the graph from #84 in a way, that shows the percentage of “active proxies” in both studies over time during the 20th century? do you guys at leat agree that this percentage is important, when using the Loehle method?
As I said before, I did not know if there was a basis for objecting to anything. That’s why I started by asking what you were planning on doing with your splice. There are many comparisons you might have been planning. How am I to guess? That is why you should have answered the question. Last post. Go ahead, get in your last word.
I think I said something like this, but let me do some paraphrasing of both lucia and bender:
Comparing a coarse-resolution proxy record and high-res instrumental record is not valid.
Putting them together is deceptive for a variety of reasons
No inferences drawn from such an exercise can be expressed with any kind of confidence — unless valid reasons for the inference can be demonstrated.
Lastly, there are valid criticisms of Loehle 2007. Involving methods of combining the proxies, having proxies that are not specifically of temperature, and other such things. These may or may not be present in other combinations of proxies in other papers. All that means is that if a criticism of Loehle 2007 is valid, it’s valid to apply it to anyone that has done the same thing. Not to excuse him, but to point out that it’s rather selective to complain about him now and not others previously.
What’s not really valid is criticising Craig for the data itself, that belongs aimed at the place the data is from. All Craig did is take these non-tree-ring peer-reviewed proxy papers and combine them.
John V: NO SPLICING. Is that clear enough? Even Mann thinks it’s a bad idea, and he’s “not a statistician”.
#153. you see changing populations of proxies all the time in these studies. CPS has exactly the same issues as does Mannian methods.
You’re misconstruing what Moberg’s wavelets do. All they are is a smoothing mechanism -sort of high-falutin alternative to Loehle’s 30-year running mean. Does anything much turn on one versus the other – I don’t think so. Moberg uses high-frequency from tree rings only.
After Moberg smoothing, he average the records – same as Loehle and then rescales like CPS.
There’s nothing in the Moberg methodology that will enable him to avoid any problem that you attribute to Loehle. Because Loehle’s network is at all times larger than the Moberg network, I don’t think that a valid criticism ofone relative to the other lies here.
The main difference, as I’ve said repeatedly, is not due to things like a depleted 20th century population (Moberg has the same) but to the non-use of the two uncalibrated Moberg series: G Bulloides and Agassis, neither of which were calibrated to temperature and both of which had huge nonlinear responses to whatever they were responding to. I’ve criticized the G Bullodies proxy on multiple grounds. Those are the reasons for the differences not what you’re talking about.
bender:
As I said, I misunderstood your question. Reading your #90 again, I now understand what you were asking. We were arguing past each other.
I’m not sure what to make of two of your statements:
Anyways, this is obviously an emotional issue for you so I’ll leave it alone now.
Perhaps what should be done instead is look at the residuals between Loehle and the instrumental record (appropriately smoothed). I’d appreciate any pointers about how that should be done. Should I use only instrumental data in the same geographic areas as the proxies?
Re153 (sod),
I guess he figured there was enough information in the other proxies post-1950. I find this comment interesting considering your initial wrath that the reconstruction “conveniently” didn’t get more recent than 1995.
Is “3 early drop outs” out of 18 really a problem? At what point does “early drop outs” become a problem – 3 (17%), 2 (11%), or 1 (6%)? In any case, someone better tell GISS. Their instrumental record should’ve stopped in the early 1970s, with all of the “early drop outs” there http://data.giss.nasa.gov/gistemp/station_data/ . It looks like you’ve just eliminated a highly-regarded record of unusual late 20th century warming. The GISS record would end in the cool 1970s, before the PDO and in the midst of some “global cooling” hype. Congrats.
Your wording gives this sentence any number of meanings, so please clarify. How/where is a 15th century proxy used to “guess” 1995 temperature in Loehle 2007?
Ok, sod. Maybe that explains why you don’t understand the issue – that all the proxy methods suffer from a 20th century divergence problem: (a) the proxies diverge from the instrumental record, and (b) individual proxy samples frequently diverge from one another. Is “divergence” too fancy a word for you? What would you prefer?
Please refrain, if possible, from repeating yourself. We all agree that robust confidence intervals are required to make correct inferences vis a via 20th century. What else is there to concede? Nothing. So please stop derailing the discussion with wasted bandwidth. You’ve made your excellent point, and it’s already been conceded. Good show.
The problem for your argument that Loehle should be dismissed is that one ought to apply the criterion for dismissal evenly across the board. ALL proxy-based recons need robustly estimated confidence intervals (as opposed to pseudoconfidence intervals). What’s good for Loehle is good for MBH, Moberg, Buntgen, etc. You see: you want to dismiss Loehle for one problem (poor sampling resolution in the modern era), but accept the others despite their problems (underestimation biases during the MWP, non-robust pseudoconfidence intervals). You are inconsistent in your judgement. And your vehemence is starting to suggest a bias.
If the proxies are so poorly resolved during the instrumental era that the calibrations are unreliable, then that is not Loehle’s problem, it is eveyone’s problem, including Moberg’s.
Last post to you, sir.
John V
I try to make things simple, for simple people.
Overlay curves on one graph: ok
Color them the same and pretend they’re one single dataset: not ok
Make inference between series without considering uncertianty on curves: not ok
Use the word “splice” ambiguously: not ok
Good?
Good rule of thumb; apply criticism accross the board, up and down, past and future. An issue is an issue is an issue.
John V, I make of it is that you can do anything in a graph you’d like, but that just spicing course and fine probably isn’t going to get you a graph that has any meaning. Or if it has meaning, it’s inconclusive at best.
Subtracting apples from oranges: not ok
John V
unceasing bad science, bad statistics, obfuscation, graphical trickery, rhetorical dodge-and-weave makes bender “emotional”: yes
Apologies to CA.
Now I understand. John V wants to produce a graph somewhere and pretend to be an authority on its interpretation when in reality he doesn’t understand how to reason about stochastic time-series subject to different, unknown sampling biases and huge uncertainty. So he’s trying to probe CA to figure out where the line is, but not actually wanting to know how the line is drawn. Because he’s in a rush to promote his particular interpretation without caring whether it’s actually correct or not. So this is what mosher was referring to. mosher smart. My bad.
#164 bender:
Take a deep breath. Calm down.
I asked if it was ok to do something. You’ve made it clear that it isn’t. Thanks.
I can’t see how you make the jump from my question to accusing me of “bad science, bad statistics, obfuscation, graphical trickery, or rhetorical dodge-and-weave”.
Here is another question with no ulterior motives:
How does one quantify the divergence problem if not from the difference between the instrumental record and a proxy reconstruction?
#165 bender:
Seriously, calm down.
I asked a question. We argued past each other. Now you’ve blown a gasket.
As I said before, I was trying to be non-confrontational by asking and learning first.
I did not accuse you. I accuse those who make the very mistake that you were contemplating making. For the reason that you know it is wrong, but can not say why.
I’m calm. I get it. You wish to play at authority, but are not qualified. Good luck. Read statistics books.
@JohnV–
I don’t know. How does one? And could you define what you mean by “difference”? Difference in the mean at one point? Different statistical moments? (which?)
I think that’s the issue here. You can’t really quantify it. Unless I missed something. The point is that as soon as they diverge in the present, then the line of thought goes to if they’re diverging now, what makes it a good proxy? Since it could have diverged (probably did diverge) in the past also.
Seems too uncertain to bother with much. And/or the resolution isn’t really good enough to be meaningful anyway, especially given all the other factors that are associated with tree growth.)
The question is ill-posed, but I suppose I should get used to that. As before, it makes presumptions. More information is required before it is possible to determine that you understand what you are asking. (For context, can I presume you have read the papers by Wilson and by Wilmking on the issue as it pertains to tree rings.) What do you mean “quantify the divergence problem”? Where are you coming from?
1. The problem has to be qualified before it can be quantified. What is its cause? That is a mystery. All we know right now is that it exists.
2. What do you mean by “the”? There are many divergence problems. Quantifying “the” problem implies quantifying all the sub-problems.
3. “Divergence” and poor fit are different, but related issues. Your assay measures degree of fit, not degree of divergence. Broad-sense “divergence” is out-of-sample/future observations departing (or diverging) from a sample-based expectation, yielding poor fit. Narrow-sense divergence is poor fit resulting from opposing systematic trends that ultimately stem from some oversight in the causal relationship between temperature and proxy datum. The first challenge is determining whether departing observations really are sustained trends.
4. The only way to solve the narrow-sense divergence problem is to resolve the true relationship between temperature and proxy datum through careful study, i.e. manipulative experimentation. This is the only way to correctly calibrate a reponse. All other methods are approximations.
[snip]
Here’s the question that started this huge waste of time:
“Given the lack of proxies for recent decades, is there any reason why the instrumental temperature record should not be used? It could easily be shifted to match the proxy reconstruction for the late-1800s. It may have issues, but it is surely at least as good as the indirect temperature/precipitation proxies.”
I think a lot of this comes from this part:
“It may have issues, but it is surely at least as good as the indirect temperature/precipitation proxies.
They aren’t the same thing, any more than adding a quarter and a penny gets you 26 pennies or 1 and 1/25th quarters. Why surely? Why come to that conclusion? Why assume that’s true?
It also defies explanation how anyone can accurately quantify a divergence from an instrumental record which is known to have a significant non-quantified range of inaccuracies.
You force me to guess your intent in comparing the two series and then complain that I make guesses at your intent? Talk about not making sense.
Guess what I’m thinking.
WRONG!
@John V–173.
Yes. There are many reasons they should not be used. (This answer was provided by many people above.)
Yes. Ink can always be shifted so that two endpoints match. Ink can be splattered on paper in arbitrary ways. Many true things can be said of ink.
At least as good for what purpose? Shifting the ink line to match end points is usually very, very bad if you wish to learn anything from the data. Such a graph is almost surely worse than one without extra data slapped on.
People have been asking you to answer a) shift ink for what purpose? b) how will you decide how far to shift the ink.
Only if you answer these, can anyone answer you.
The answer to your most recent question involves (b). I’m under the impression that the correct answer to (b) involves research involving linear algebra and likely, calculus. Someone, someday, may do this. They may even find an answer– or not. Meanwhile, no one knows how to correctly shift the ink in a general problem.
You attempted to get approval of whatever it is you’re up to, which you’re not willing to disclose. No wonder you started a fight.
lucia:
Thank you for the direct and clear answer to my original question. I have a few concerns with some of the details of your answer, but way too much time and space has been wasted on this already. I won’t even attempt to overlay the instrumental record on Loehle2007.
bender:
As I have said multiple times, I *misunderstood* your question. The way I understood it did not make sense, so I tried to explain why it did not make sense, and asked you some questions to clarify. And then the whole thing blew up. That’s typical around here.
====
Wait a minute…
What’s that red-line on the graph that starts this thread? I hope it’s not the instrumental record.
The topic of the thread is the absence of proper error bars or other valid indicators of the range of confidence there may be in the accuracy of the data points used in the graph. The red line is not an error bar or comparable indicator of error range/s, so it is not the immediate topic of discussion in the thread.
I will close by pointing out that this is NOT a “waste a time”. This symbolizes precisely what is wrong – with the media people repackaging what the policy people have repackaged from the climate scientists who have repackaged what they were taught in statistics in graduate school. Broken telephones, bad connections, corrupt signals.
Re #180: #161
You need it to calc “Mannian CIs.” It’s not simply a matter of “overlay” or “shifting.”
#166 replies to #164, so he probably never even read #161. Too busy looking for an argument.
I am forced to repeat: there’s nothing wrong with plotting the instrumental data on a second y-axis, scaled however you like. The problem is the interpretation of the graph. Can one possibly be any clearer?
Read before choosing to argue!
again:
the method of Loehle is, to form an average of all proxies. those that don t have any data in the year, are considered to have the closests data that they have.
so more and more of his proxies turn flat and taint the remaining proxies.
that few proxies reach up to 1995 is a related problem. Loehle is talking about the end of the 20th century. we would expect him to have data reaching up to the end.
you are right. so IF the NASA was using the Loehle method: simply average all stations. abandoned stations keep the last measured temperature in every following year.
THEN their data would not show hockey stick form.
fortunetly NASA does NOT use the Loehle method.
i still can t believe it as well. Steve provided a graph in post #84.
http://www.climateaudit.org/?p=2405#comment-167079
first Loehle proxy ends in 1500.
i am curious: will you (or anyone else?) comment on this fact?
i simply wouldn t use a term like “divergence problem” for the specific Loehle case.
it is a problem, if the majority of the “divergence” is difficult to explain/remove.
in this case that is easy:
just ignnore everything beyond 1950 and you significantly reduced your “problem”. Steve has even done most of the work already:
http://www.climateaudit.org/?p=2405#comment-167279
no. most of the problems are a speciality of Loehle alone. please take a look at the percentage of proxies dropping out early! (Steve´s graph above)
i did an experiment: i created my own (weird) hockey stick. a constant increase of 0.01°C per year, all over the 20th century, from 0°C to 1°C.
i did copy paste this data 18 times and attacked it with the Loehle method:
all 18 proxies go flat after the last year of data. (3 proxies have a 0°C data from start to finish)
then i calculate averages for every year and plot the graph till 1980.
no hockeys stick. and guess what remains of the 1°C temperature increase.
you can easily do the same with GISS data.
reading your comments to John V, i can t say that I will miss your replies.
John V. – I have a suggestion that may make everyone equally unhappy: why not take the 8 series from Loehle that go through 1985 or later, compute a temperature anomaly for each series from a baseline period (doesn’t really matter when, you might try a 300-500 year period between the MWP and the LIA), and calculate decadal averages for the 8 series of anomalies.
A plot of the decadal averages and a centered 100 year moving average ought to be of some value, no? Of course there are limitations (spacial distribution, etc.), but at least it gets around your concerns regarding the paucity of data in recent decades.
The 8 series would be (in Loehle’s archive):
Farmer
Holmgren
Dahl-Jensen
Ge
Cronin
Kim
Yang
Tan
I’d love to see you post a plot of this here at ClimateAudit.
(Please don’t interpret this as me giving you an “assignment.” I’m trying to help address your concerns.)
Bender. There is actually a fun game here treat thermometers as proxies. ( actually did this a while back)
basically I turned thermometers into proxies by removing data
So a proxy site only records may june july, for example, like a tree recording a growth season.
Reconstructing the past US temp data from a limited number of Proxy thermometers was not very effective.
Its not sod is a cross: Kentucky bluegrass, featherbed bent and norCal sensimia.
Canonball!
#188 Let’s see you use 4/12 months. I would guess your pseudoproxy r2 is only 0.33. Do you recall what you got?
0.33 would leave a *ton* of room for warm winter and shoulder-season anomalies. How do dendro recons account for this? Ans: They don’t. They do a little hand waving exercise, lip service to “limitations in interpreting the data”. And once you’ve paid lip service, you’re free to speculate.
But I’m pseudoconfident that JEG will address this issue.
Grammatical error. Meant to type:
“Lets see … you use 4/12 months.”
@John V-180 wrote:
“I have a few concerns with some of the details of your answer, but way too much time and space has been wasted on this already.”
I agree much time has been wasted. It’s too bad after posting that observation, you continued to debate the issue you introduced but now call a waste of time by bringing up the red line. 🙂
So, though I fear wasting your time by addressing issues you raise, I’ll observe that, whatever the red line might be, if you squint at the graph, you will see that the red line is clearly not spliced. The red line is also not “shifted to match the proxy reconstruction for the late-1800s”. Had it been shifted to match and/or spliced, it would match the proxy.
So, it is not an example of what you proposed could be done, and which many of us– including bender– all told you could not be done. It is, in fact, and example of what bender said could be done, long, long ago.
Re #188 Has anyone ever explicitly attempted a summer vs winter temp recon? How skillful are the recons and how well do they covary?
What would a monthly graph of traffic on a network with an average traffic rate of 1 bps tell you?
bless you lucia
Loehle doesn’t do this. (Mann does this for the 1970-1980 period but it doesn’t have a big impact on his results.) Like Moberg, Loehle simply uses the available proxies (all standardized).
lucia, bender, et al:
It’s not that I proposed anything could be done. I asked if it could be done.
My choice of words ignited a flame war (inadvertently), but basically the red line above is what I was asking about. I would guess the line was overlaid by averaging the difference between the CRU instrumental record and the Loehle reconstruction for the years of overlap.
=====
Mike B:
Thanks for the suggestion, but there’s no way I’m touching that in this thread.
#188/#193 Wouldn’t that be interesting if MWP was marked by exceptionally moderate mediterrenean/maritime climate: slightly cooler summers, much warmer winters. Then (assuming linear response) the tree proxies would give you a flattened MWP, while the ice proxies might give you a higher MWP.
Comments from the paleo people?
sod,
I would agree that such a method of extending series for a long period of time using simply the last available value in the series would be a farce. But in perusing Loehle, I came to this step in his methods (bottom of p.1051):
“When missing values were encountered, means were computed for the sites having data.”
That is far different from the method you have suggested was done. Where are you reading that proxies which end prior to 1995 are given a fixed value for the remainder of the reconstruction?
(1) if you are going to claim that “most of the problems are a speciality of Loehle alone,” it would help if you could substantiate it in some way. Just saying it doesn’t make it so.
(2) “Steve’s graph above” which you referred to – in direct response to someone specifically mentioning the same “problem” occurs with Moberg – clearly shows that Moberg suffers from the same problem of “proxies dropping out early!” So you referred to a graph which directly refutes your claims in (1). And as many folks here have tried to tell you, the same thing happens in other proxy reconstructions. This is NOT a “speciality of Loehle alone.” I’ve referenced you to MBH98, MBH99, Mann and Jones (2003), and that swearword Buentgen et al to show you that this is TYPICAL and not a “speciality of Loehle alone.”
hm. this means that i was very wrong.
i can t access pdf from this computer and don t have the time to dig up the discussion that mislead me. sorry if i caused a lot of confusion.
i remember he is smoothing the points over the periods without data. wouldn t series with more data outweigth series with few by a lot?
#197 Give it up already! I started by asking what the intent of doing that might be and you didn’t answer! It’s all about intent vis a vis intepretation. Please read #161 and #185 for clear answers to your question regarding graphics.
thanks, that explains a lot. looks like i was very wrong.
Steve: Thanks for gracefully acknowledging this. It’s good to clear up factual things.
RE 191.
I did a bunch of recons.. 1 month 3 month, 6 month R^2 were all around the range you suggested.
The method I used was pretty crude (OLS) I was just curious.
I actually used the entire 1221 network. Temp reconstruction seemed very senstive to “missing data”
or dating error.. same issue different cause.
basically if a thermometer that only records a “season” cannot reconstruct it’s continents temp,
Then a tree that records a growing seasons climate cannot either! DUH!
Also
Reconstructing a red noise process with dating error?
Anyway I thought it an instructive excercise in reconstruction.
Irony. People whine about surafce stations wanting to clean up the sites ( say 200 stations out of 1221)
As if 1221 wasnt an oversampling. Yet, on the other hand they argue that 20 or so proxies can pin down
the golbal temp 1000 years ago.
Boggles me mind.
@John V-
Oh stop!
Examine the structure of your “question” — which you requoted in its full three statement form. Though the first sentence ends with a question mark, it is followed by your own two sentence answer.
This is the structure of the “rhetorical question/ answer” combination. The way English works, you were making a declarative statement which you used to support the suggestion you made in the two sentences that followed.
Maybe you aren’t aware of what you were doing. If not, then consider yourself informed.
#205: Interesting. If only he’d used the ‘point d’ironie’ to indicate his question was rhetorical.
This might be better worded. What is the only thing a monthly graph showing network traffic at an average rate of 1 bps tells you, assuming “a month” is the last 30 days?
#207 Without knowing the distribution and without having some measure of its deviance, you might have had many many bits in one very short interval, or you might have had 1bps every single second of the month. If you’re planning a robust network, the distribution of traffic matters.
RE 206
Yup. Long while back I surmised that perhaps JohnV had already done the splicing. Why else ask
permission? Makes no sense. Hell, I’d do the splice and let bender beat me like a rented mule.
Learn me a good lesson it would. That’s a good thing. In this forum there is only one reason
to ask permission.
Now, JohnV said that he only “eyeballed” the splice. I take him at his word. But why not
just do the splice and take a beating?
Being wrong has it’s rewards.
… at the expense of Steve M’s bandwidth. Why don’t we each put $20 in the CA tip jar (tuition fees) and call it a draw?
#211 steven mosher:
I was simply asking if splicing/overlaying would be valid.
I had previously read concerns with doing so on this site. I was confirming, playing nice, trying to be non-confrontational.
For some reason, I am no longer able to ask honest questions around here.
Is it because I’m from the “other side”?
That’s a rhetorical question.
bender, #209 Yes, that’s all true, we don’t know the distribution nor distribution. We don’t know the sampling interval or any of the averaging periods or how bursty/steady the network is, nor its patterns. But what do we know ‘for certain’ about what that graph is showing, stated as a qualifed absolute (there’s one variable/qualifier there)?
RE 214. JohnV Why ask? Why? Splicing/Overlaying it is a 5 mintute job. Just do it.
Dont ask permission. That’s the part I dont get. Seriously. . that is why I’m trying to figure out
why you would ask. Now if the task were some large ass bootstrapping excercise, then I would ask.
Otherwise just post the splice and watch the fireworks. Sometimes I am wrong on purpose just to
watch the scramble.
We’ve wasted more time on asking permission
than the task takes. Do the splice. Post it. and then ask “is this kind of splicing valid or not.”
Just cause you do the splice doesnt mean you endorse it. Do it as an excercise an illustration
a thought experiement. THEN watch the dust fly.
Crap. do the splice send it to me and I’ll pretend I did it. Let Bender kick my sorry butt.
it’s no skin off my nose ( bad metaphor mix )
Bottom line you confused me with this asking permission thing.. So I read beyond the words.
Wont happen again
Exactly. 😉
skeptical bender vs Al:
RE 213… you gave me a nose enema.
From how Jean S. explained it in the original post and the excerpt here, and what UC said, the red line is HadCRU statistically treated to compare to the Loehle reconstruction by standardizing them both with each other. Simply in order to calculate the “Mannian confidence interval” from the root mean square deviation.
CI=.13 R^2=.73
Perhaps somebody can explain the importance of that simply for us, if I have it correctly, but I take it to be the CI is not very good for that particular CI method.
This leads back to my question. The only thing a monthly graph of traffic with a 1 bps average tells us is that over the last 2592000 seconds, whatever and whereever was being measured saw 2592000 bits of traffic in total.
You’d have to ask more questions to know this graph only showed one switch port, saw all that traffic over 10 minutes and then was unplugged, where 5 second samples were divided by 5 and then those seconds averaged into minutes into hours into days into weeks into months. (60 60 24 7 4)
You can image the graphs of each time period (1 minute, 1 day, 1 week, etc) aren’t very similar. But it’s all the same data, so it shouldn’t matter, right? 😀
#211 mosh pit
Here’s what’s going on:
1) Torture the data until it confesses
2) Passive/Aggressive vague rhetorical question/answer to get “permission” for torture technique from someone at CA
3) Trimuphantly present confession, along with CA “permission” for torture technique
4) Return to RC for back-slaps and high-fives from “real” scientists
5) Move on…
RE 216. That was my INITIAL take, But JohnV denies it. I do not like looking at motives.
I made a mistake doing this. I will take JohnV at his word and suggest that we DROP IT. If he says
he asked an honest question, then he asked an honest question. END OF STORY. No scientific point
in anymore discussion of this aspect of the problem.
RE 192. I’ll go look at the work I did.. or maybe redo it. But I first Tried to recon from the winter
months and that didnt work so well.. Basically the first 3 months dont predict the year too well.
I think the june july august worked better.. again it was very crude more of a thought experiment.
It might however make a nice instruction piece on the dangers and pitfalls of reconstructions.
sod re #199,
The way I read it, the series are smoothed individually and converted to a anomoly, and then the normalized anomaly is averaged over the series which have available data.
Look at it this way: I take a temperature reading every day at noon for 365 days on my side of town. You take a temperature reading once a month at noon in yours (but maybe don’t keep track of which day of the month you take it on, either). How do we try our best to get things apples-to-apples in order to combine our readings and calculate an annual average across the entire town? I average all of my readings over 365, and you average all of yours over 12. The fact I have 365 readings doesn’t outweight yours just because you only have 12.
Mike B:
I’ve never even posted at Real Climate. I can assure you I’m not going to run over there now.
=====
steven mosher:
I was trying to learn something but my supposed motives (with your help) and misunderstanding of bender’s question made that impossible. Next time I’ll be more deferential with any questions.
=====
Hey, what happened to bender’s accusations based on where I live? Steve McIntyre, sometimes I think it would be better for the posts that cross the line to remain. It’s informative about those who write them.
Re #218
More than that, mosh, the four-month to twelve-month correlation tells you precisely how much white noise needs to be added in a bootstrap resampling approach to make sure the confidence intervals on the summer proxy signal are sufficiently wide enough to apply to inferences on a twelve-month temperature input.
SOD (#153) raises a valid question,
Since Craig’s sparser proxies come in and out, even after his 30-year MA, the number of active proxies should often be less than 18. Yet Steve McI’s graph @ #84 shows a long run of 18’s from about 200 AD to 1500 AD. This can’t be right.
By the formula I proposed (long, long ago) at #11, temporarily missing proxies will increase the correctly computed standard error bars according to the information in the missing series. In particular, the late 20th century will have a big standard error as the proxies drop off. This is just the nature of his series.
It is of course interesting to overlay modern instrumental series to see how well Craig’s series compares in the early 20th century, and where it would lead, if instrumental, in the late 20th century. However, it misses the point to ask him to include modern instrumental data as one of his proxies, since this data does not go back into the period he is trying to measure.
Furthermore, since his series is heavily smoothed by his 30-yr MA, there is no point in trying to match annual instrumental data to it on a year-by-year basis. There are only 2 or 3 non-overlapping estimates in his series to compare to the instrumental data, and any comparison should take this into account.
Would it be possible to directly test the hypothesis that it’s currently the hottest ever (or some equivalent),
using each proxy as a single “observation”. That would avoid many of the statistical problems
discussed here.
how?
Statistics is not a hoop to be jumped through, or gotten around. It is a tool for achieving robust inferences.
Bender, John V, et al… I’m bemused reviewing this thread of conversation.
I see two key challenges facing us as a community:
1) The “curse of knowledge.” This is well described in the Heath brother’s excellent book Made to Stick.** Essentially, those with specialized knowledge find it very difficult to imagine what it’s like to not know. Basic experiment: think of a tune, tap it out on a tabletop for a friend–it is highly unlikely they’ll be able to guess the tune on the first try.
2) We’re all well trained in working well with information; few of us are well experienced in working well with people either face to face or screen to screen. Platitudes such as “speak with care, listen with grace” and “let go of offense” come to mind.
Because AGW has become a hot political/policy topic, a lot of baggage has “leaked” into the math/science sphere on this topic… and “skeptic” truth-lovers outside the supposed consensus have been taking a severe beating from powers-that-be, often without justification. Likewise, “proactive” truth-lovers inside the supposed consensus have been lionized by those same powers-that-be, often without justification. And people with little or no understanding take sides on the basis of silly charicatures.
The result: lots of mistrust, lots of offense taken at strawmen magnified by media and politicians (and from which real scientists simply have little energy to continually refute/correct/humbly demure.)
If we’re ever to see resolution on some of these issues, I sense two things are needed:
1) Newer participants need (and need constant reminder) to have a lot of patience, and a lot of “speak carefully, listen gracefully.” The true experts here are only human, have limited time, emotional energy, and have good reason to be cautious about motives.
2) Longer term expert participants need (and need constant reminder) to also “speak carefully, listen gracefully” but even more, need to go the extra mile to explain carefully and clearly their points. Reminds me of the Manhattan Project quote (attributed to Bohr?) — “To resolve this, those of us with more specialized knowledge need to cross over, to think like the others. In this case, physicists need to learn to think like engineers.”
FWIW,
MrPete
** If I had the bucks, I’d give this book to every professional I know who works with information. The book is about crafting memorable messages, and doing so with integrity.
“He uses statistics as a drunken man uses lamp-posts… for support rather than illumination.” – Andrew Lang (1844-1912)
#226: additional advice
-Vague questions are not answerable questions. Be clear if you can, but defintiely be prepared to clarify.
-Graphics vs. inference (based on graphics) are separate (but related) issues. They are related by intent.
-Clarity of purpose is essential. If purpose is unclear, advice will be bad and advice-giver will be on the hook.
-CC is a serious issue. Not prepared to do some learning? Consider getting lost.
ok, i did some reading. Craig`s method obviously makes much more sense now.
call me stupid, but i still don t fully understand what he is doing.
here is the post that i misread:
http://www.climateaudit.org/?p=2380#comment-162896
as he writes in the paper that he doesn t interpolate, i assumed the use of step functions. (i thought i remembered a discussion about step functions meeting in the mddle, but i couldn t localise it. so perhaps i dreamed about it or someone other than Craig brought it up.)
here is his description of the methodology:
http://www.ncasi.org/publications/Detail.aspx?id=3025
the way i read it, the smoothing of the individual proxies will spread a single data point in a century out over 30 years. (and not as i falsely assumed from the 15th or 19th century till 1995)
does he mean that every of those 30 years has the same data after this smoothing? (with only a single point in 30 year reach)
when means are calculated over all proxies, that single data point will be factored in over 30 years. in the remaining 70 years of that century, this proxy will be ignored.
if i get this right, a single data point will have less influence than i thought it would have. but it stills makes the number, position and values from data points in each proxy in the late 20th century crucial.
i asked about these things in the very first comment i made about the Loehle paper.
http://www.climateaudit.org/?p=2380#comment-162122
i think i understand your example, but i am not sure that this is what Loehle does. the average wouldn t be different, if i would stretch my monthly data over an entire month? (“step function”)
RE Sod, #29, that’s the way I read Loehle’s paper — if he has a series with only one observation every 100 years, each point will be stretched 15 years or so in each direction, and then there will be a gap of 70 years until the next stretched point. The 30-year window is a little arbitrary, but that is what he did. As a consequence, there should often be less than 18 series active, contrary to Steve’s graph at #84, as I already noted at #222.
Also, someone (Sod again, I think) asked how it was that Steve has the number of series dropping permanently from 18 to 17 around 1500, even though every series has observations until at least 1810 (see Sod’s #91). Is this an error, Steve?
The formula I give in #11 will given an increase in the standard error bar for the simple mean when a series drops out, unless the average variance of the dropped series about the time-specific means of all the series is more than approximately twice the average of the variances of the included series. But as I pointed out earlier, in that case it would have been legitimate to have used this objective criterion to omit the noisy series altogether.
The late 20th century will have a rapidly increasing standard error bar as the number of included series, even after stretching, declines, so there won’t be much to compare to instrumental readings in the late 20th century.
If I had a spreadsheet or ASCII file with all the series in one format, both raw and with Craig’s rolling mean, I could easily compute the standard errors in my #11. Neither UC nor Jean S, both statisticians I gather, has objected to my formula, so it must be valid! ;=) But I’m too lazy to try to parse the source files whose URLs have been posted here. (If Craig doesn’t want to distribute other people’s raw data, all I really need is his smoothed version of each series, with “missings” indicated somehow.)
Steve: The series are in the directory http://data.climateaudit.org/data/loehle and a version collated by interpolation (not necessarily what Loehle did) is at http://data.climateaudit.org/data/loehle/loehle.interpolated.dat .
In my attempt at emulating Loehle, in the Viau example of 100-year spaced values (And it’s a bit of an oddball), I interpolated all values linearly – hence the even count. Whether or not Loehle did it this way, this would be a plausible way of implementing what he has in mind. In practical terms, I think that it makes much more sense to establish search criteria that require series to have greater than one per 100 years resolution. I’ve coirresponded with him to clarify this and am still a little confused on the matter.
The series ending in the 16th century is MD95-2011,a Norwegian sea sediment series, which does end in the 16th century. It is a piston core where the top was lost. There is a box core at the same site that comes to 1998 or so at 2-3 year resolution. These are pretty interesting cores as they have very high resolution for a sediment series – a few years. I’ve got most of the material for an interesting post. While the box core has dO18 measurements on it, it doesn’t have alkenone SST measurements to be consistent with MD95-2011. Doing alkenone SST on the box core is much to be desired.
My size up is that this doesn’t affect the general shape very much.
#228 bender:
Let’s go back to your original clarifying question to end this:
“Hopefully you are not suggesting comparing annually resolved records to decadally (or worse) resolved records.”
I originally interpreted this as meaning that you had a problem with including yearly-resolved and decadally-resolved records in the same reconstruction. My interpretation was wrong.
In post #148 I realized what your question really meant. You thought I would compare a single hot year from the instrumental record against the MWP. Let me state unequivocally that I was never going to do that. I have already said as much many times in this thread but my answer seems to have been missed in the confusion. Going back over this “conversation”, it seems to me the whole problem has been that I misunderstood your clarifying question.
=====
lucia:
I did not fully parse your early comments because they were referring to tree rings (probably because of steven mosher’s accidental foray into bristlecone pines).
#232 I DO like a happy ending. Cheers.
@bender 233. 🙂
RE Steve McI @ #231,
Is the Norwegian MD95-2011 the one Sod refers to as a “Finnish Lake”? (close enough for me!)
I agree that interpolation (as in the graphs you posted on an earlier thread) wouldn’t make much difference, but since Craig’s published series uses his 30-year step function with missing gaps, it’s important to establish error bars for his actual calculation. If all one wants to do is compare the alleged MWP and LIA to the early 20th century, a series with only one observation per century could be just as valuable as one with annual observations, so it could be unwise to reject it altogether. His choice of 30 years is arbitrary, but reasonable.
One problem with this approach is that you then end up trying to compare a fairly long historical interval with sparse observations to a fairly short instrumental period rich in observations. This plays into the hand of the argument that the MWP “did not exist” or “was not global” because your historical interval is so long you end up bringing in many values that probably are not indicative of peak MWP temperatures. To answer “how warm might the MWP have been?”, you want high precision over as small an interval as possible at that point where you think temperatures were highest. THAT (as long as the CI’s are robustly estimated) is an apples-apples comparison to the CWP.
Empirically, your optimal sampling strategy for a field program would be to cherry-pick pick your MWP peak (based on ALL proxies, not a cherry-picked proxy) and sample the heck out of all the proxies that yield data in that interval.
There are limits to what you will be able to squeeze out of the existing proxies. Know that limit.
Cherry-picking the peak MWP date in #326 is legitimate, by the way, because it is comparable to the cognitive bias that causes us to frame the question in terms of temperatures occurring *this* decade (as opposed to the cooler 1970s, or 2010s?, for example).
A.k.a. aliasing.
Mark
Aliasing? I will look up the etymology.
Aliasing results from a sample rate that is not at least twice your highest frequency component. If you choose only one point, you may pick a valley, rather than a peak, in short.
Signal processing concept (look up “Nyquist” for more information).
Mark
Thank you. Skeptics need to be wary of the aliasing problem, which warmers try to use to advance the argument that CWP is “unprecedented” and MWP was “nonexistent”. Correct for the aliasing bias inherent in paleo records, and then we’ll see.
It should be intuitive that you can’t know frequencies above the sampling frequency, but it’s less obvious what that means for proxies with low temporal resolution. It means that there’s a limit to how high the derivative can be, regardless of what actually happened in history.
You’d think so, Larry, but your initial education is probably similar to mine and that’s one of the first fundamental concepts we were both taught, so our opinions are likely biased. 🙂
Btw, bender, it’s more than just a problem of picking a valley over a peak. The when higher frequency terms are “aliased” to lower frequency locations, they are indistinguishable from true lower frequency terms.
Mark
thanks. that is how i understand it as well.
that paper was the one missing in the list i kept quoting. i am not sure whether i ever mentioned it under any name.
would stretching the smoothing period from 30 to 50 years lead to smaller error bars?
i thought we were simply comparing “warmest” periods?
thanks, it will be interesting to know. as it looks like i am not the only one who misinterpreted this part, Craig might want to add in another sentence or two on this subject.
i agree. but it might affect the end of the 20th century quite a little. it would be nice to know more about this.
looking at this topic (error bars?) the effet of the 30 years “flat” aproximation from some of the proxies should be interesting as well.
looking at the paper, i think Craig should mention, that some proxies outweight others by factor 3.
#242
In practice the sampling frequency is not fixed over time – the Nyquist frequency is a global time-series parameter that may not apply in any one time interval. There are clusters of times when there are more records than others, so there is a legitimate temptation to average them and assume that the mean is representative of the whole time period.
What is intuitive to the theoretician is counter-intuitive to the empiricist longing for a quick and dirty, easy answer.
This creates other problems, even more difficult to disentangle.
Mark
RE 245. The engineers who post here will naturally run for Nyquist. That’s because
they are working in systems where the freq of the source is KNOWN. or if it is not known
you can guess and test.
Nature is not so accomadating. What’s her frequency?
Mark T, Maybe I’ll ask you to clarify #243 (bottom) and #246 if and when you have the time and inclination.
42
247, the issue here is the “frequency” of the samples, i.e. the temporal resolution. It’s not so much about nature as it is about the lab methods, although back mixing of the materials in the sediments will also screw up high frequency response.
Kenneth?
Steve M, I wonder if the post title should be changed to “MBH-style error bars (i.e. pseudo-confidence intervals) for Loehle” to make it clear that these “error bars” are not actually error bars in the strict, formal sense of the term.
Steve: And who said we didn’t learn anything from JEG – he helped our vocabulary.
That’s the entire point here; what is the data? What does it look like? How has it been processed, if at all?
I like that Pete, ” those with specialized knowledge find it very difficult to imagine what its like to not know.” Exactly. I like to put it the other way, you don’t know what you don’t know. And you don’t know what the other person doesn’t know, either.
Good example Mark. I knew what you meant, but others? Yep. So, it was good of you to explain it. I’d explain it this way. If you sample a 10 V P-P 60 Hz sine wave once a second, all you’re going to get in reality is a DC voltage spike (or 0) once a second. Sample it at 90 degrees (http://www.sfu.ca/sonic-studio/handbook/Sine_Wave.html for picture), a chart would show +5 V DC based upon the sampled value. Fill in a database with 0 for the other 59 1/60ths, you get a chart with a blip 1/60 of the chart wide and an average of 83.3 mv. Samples at 0 90 180 and 270 would get you a square wave. That wave (or a database with 0 for the non sampled 56) averages 0 (lol, what if you sampled it 6 times a second at a start point of 0 degrees versus 5 versus 10 versus 15…?) 🙂
If you increased the number of samples to 10, then 20, then 30… You start getting closer (and the start point less important). The more you sample it, the more it looks like the original (the smoother it gets) but past a certain point, you can’t get any more resolution out of the samples then you had with the original wave.
bender, that was the point of my question earlier; the only thing you know about a 1 bps 30 day average is that where and what was measured had a total of 2.592 Mbps. But you do know that at least. Sure, it tells you nothing about what was being measured (how many things?), what the traffic looked like (all at once or spread out over multiple periods), how it was being sampled (every nanosecond then combined, once per hour then divided by 3600, etc), or even anything about the network at all in the slightest, not even if the device(s) were hooked up the entire month.
The interesting thing is the way you answered it. You didn’t answer it directly and exactly (“All you know is a total of 2,592,000 bits was measured where it was measured”) And you added extra information I didn’t ask for (instead of asking for more information).
Certainly both are valid (telling versus asking), but you more commented on (and/or expanded upon) my question, rather than gave me an answer to the specific question.
I guess I need to be more specific myself, too, don’t I! My purpose was as a thinking exercise about how the discussion was going. Too bad it didn’t work…. Unless of course you knew what I was trying to accomplish! 😀
ah, now i found it. sometimes i should read what i quote 🙂
big excuse to both countries 🙂
re 235, 238 etc
First we need to know how the proxy – temperature relation works. Snapshot from years 1000, 1100, 1200 (leads to aliasing) or downsampled from annual data ( one example, monthly temperature averaged to annual record, downsampling with 1/12 ratio). Former is not valuable, latter is. Here’s example, AR1 ‘signal’ in blue, ‘snapshot’ re-sampled back to annual series (red), and re-sampling with anti-aliasing (green). Different results.
Note how the green line oscillates, some climate scientists would say that signal does not exhibit long-term memory of its phase. And then they’d try to separate this oscillation from red noise. Even when it is generated from red noise. Funny.
Frank D, Esper J, Cook ER. 2007. Adjustment for proxy number and coherence in a large-scale temperature reconstruction. GEOPHYSICAL RESEARCH LETTERS 34 (16): Art. No. L16709 AUG 29 2007
See Figs 1E and 3B
JEG, where are you ?
As a Frenchman, I’m suprised a “grande gueule” compatriot like you has shut up so rapidly after he can’t put up.
Man, I would love to see an exchange between a putative scholar and the CA’s cowboy who doesn’t like ones pisses on his boots while telling him it’s raining (CA regulars know who).
re 249 & 251. I’d Rather not laugh, but you two made me do it
How does one obtain error bars for the type of data I have? Responding to some suggestions here from statisticians, I propose the following:
IF the proxy data (before conversion to temperature) were all annual and measured without appreciable error, we could do the following:
1) take the regression equations which give temperature from proxy value, and get an error function from them for each data set:
T(t)=f(P(t))+eps(m)
Where T is temp, P is proxy value at time t, eps is error function due to the model m.
2) Use monte carlo sampling of eps for each series at each time, compute 1000 such data sets, and at each time compute the 95% confidence intervals. This will move the error though the interpolation and/or smoothing (in a crude but not quite correct manner).
BUT: the proxies are NOT measured accurately. There is considerable sampling error (even ignoring dating error for now). The problem now becomes:
T(t)=f(Pprime(t)+eps(s))+eps(m)
Where eps(s) is error due to sampling and Pprime is the true proxy value that we dont know. This would be like doing a diet study where the peoples weight was guessed by a third party. Since the errors at t are normal (or whatever) around Pprime but not around P (which is our sampled value), we cant do monte carlo sampling.
Any suggestions on how to cut this Gordian knot?
Craig, could you please tell us whether we understand the way you are stretching single data points right?
http://www.climateaudit.org/?p=2405#comment-169394
Craig # 259 —
Neither of our statisticians here, UC and Jean S, has nixed the method I proposed in #11, so I’m assuming it’s OK. This method cuts your Gordian knot with an admittedly unsubtle blow of the proverbial sword (or ice axe?).
I figure that each study has been calibrated to local (or even global) temperature with some measurement error that depends on the accuracy with which the proxy itself has been measured, and then also the accuracy of that proxy for measuring local (or global) temperature, however calibrated. This temperature measurement error may or may not have been correctly estimated in the study itself, or even be estimable from the information provided in the study, but no matter!
I assume that the true local temperature the proxy has been calibrated to measures global temperature with some idiosyncratic locality-specific error. Each study’s temperature estimate therefore measures global temperature with the sum of two errors — the study’s measurement error plus the locality’s specific error. Assuming that errors are uncorrelated across studies, all that matters for the variance of the average of the proxy-generated temperatures are the study-specific variances of the sums of these two errors, and these variances can be estimated by averaging together the annual DOF-adjusted mean squared errors (about the annual means for each series), as I suggested in #11.
This method has the virtue of not requiring one to delve into how each study calibrated its temperature estimates. Instead, it just takes them as given but noisy, and then estimates the variance of that noise by comparing each one to the average of the others.
My approach does assume that each study-specific variance is constant over time. This clearly isn’t true when your raw data has a drastic change in frequency, but after your 30-year MA it probably isn’t too bad.
Steve (#230) posted the link to his tabulation of your raw data, in convenient identical formats. (Thanks, Steve!) I still haven’t gotten around to trying to combine these into a master table of annual observations on your 30-year running mean, but after I do I can compute the se’s quickly. — Day job, you know! ;=( You don’t happen to have an ASCII file or spread sheet with all of your ducks in a row that you can send me, do you? (mcculloch(dot)2 (at) osu(dot)edu).
In any event, how did you stretch a single point to 30 years? 14 years back and 15 years forward? Or 15 back and 14 forward? Or 15 years in each direction, making in fact 31 years in all counting the raw datum? Also, did you round fractional years to the nearest integer, or just truncate to the next lower integer? These details won’t change the big picture, but could prevent an exact fit to your summary series.
Anyway, congratulations on publishing a very stimulating paper!
re: 260 “RE Sod, #29, that’s the way I read Loehle’s paper “ if he has a series with only one observation every 100 years, each point will be stretched 15 years or so in each direction, and then there will be a gap of 70 years until the next stretched point. ”
That is correct. I did not feel that points estimated every 100 yrs should be stretched infinitely, so that is as far as I stretched them.
sorry: for year x, it is 15 forward and 15 back, plus the x yr for 31 total
Hu has proposed the following:
“It occurs to me now that my earlier concerns about heteroskedasticity across series could be solved simply by first estimating (across time) a variance for each series about the time-specific means, and then using these at each point in time to construct a variance for the mean, as follows:
Let Xit be the observation on series i at time t (after Craigs 30-year rolling mean), Mt be Craigs mean for time t, nt be the number of smoothed series observed at time t, and Ni be the number of (smoothed) observations on series i. Then Vi, the variance for series i can be estimated as
Vi = Sum [(Xit – Mt)^2 * nt/(nt-1)]/Ni,
where the sum is over times with observations on series i. Also, vt, the variance of mt may then be estimated by
vt = (Sum Vi) / nt^2 ,
where the sum is over series observed at time t. The standard error of mt is then st = sqrt(vt), and confidence intervals can be constructed using t critical values for n DOF, where n is the average number of smoothed observations available. This is still only approximate, but it is a lot better than just appealing to asymptotics to get around the heteroskedasticity.
This method would yield a constant vt if all 18 series were always observed. When some are missing, vt will increase depending on the information in the omitted series. ”
One of the issues that JEG had was that the c.i. should reflect how well the series were calibrated to temperature. This is not addressed by Hus idea, and is what I was attempting above. Also not addressed by Hu is that the data at any one point in time may be more variable than at others.
How about simple confidence intervals on the mean computed from the data at each point in time? If the data at year t were vary variable, the c.i. would be wider, which is what you want.
Craig, my opinion would be that if you’re using already finished peer-reviewed published studies, why would you need error bars? The data is already perfect. 🙂
Seriously, I would think that what UC and Jean S. have already done is fine. Or that the task is either a) impossible or b) not needed. Or both.
I think I posted this in another thread But I think you need to look at error propagation based on how each proxy was calibrated to temperature. I assume, perhaps incorrectly, that such information will be in the original papers that gave rise to the datasets you used. That, to me, has to be the first step. You need a closed form equation as to how the calibration errors propagate right down to the 30 yr MA. That would give you some sense of error. I think a time series bootstrap could be a useful tool to take that error and get to CIs. Perhaps too vague but if you can point to a paper that has calibration equations in it I (or someone else) can take a run at it.
#266 Christopher the papers I cite mostly have the equations in them, but usually not with true confidence intervals on the regression. Usually just R2. Would it not be the case that garbage temperature equations should give very wide error bars on the resulting set of estimates at each time? That is, maybe the quality of the temperature models is already baked into the cake?
Re #11 and Loehle07 Fig. 3,
for some reason I think that we are pulling on our own bootstraps 😉 JEG deserves something better.
Maybe start with a model (before going to the spatial-temporal sampling / low-pass response issues)
where is local reconstruction (i=1:18),
is local reconstruction (i=1:18), 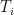 is local temperature,
is local temperature, 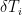 is scaling error term (
is scaling error term (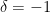 for non-sense proxy recon), and
for non-sense proxy recon), and 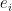 is local noise term, hopefully not very red and hopefully independent of other
is local noise term, hopefully not very red and hopefully independent of other  s. Just an idea, though.. Who knows, maybe we’ll never find finite-length CIs for JEG.
s. Just an idea, though.. Who knows, maybe we’ll never find finite-length CIs for JEG.
I thought JEG had worked this problem out using his Monte Carlo scheme? I’m not lifting a finger until he reports back about what he found. I suppose JEG & Mann are going to try to pre-empt us – the way Mann & Emanuel did last year on the hurricane story. Good thing CA is such a rich source of research ideas for those in need.
Don’t be bitter; just so long as the science advances.
================================
#270 Exactly. If audit raises the standard for transparency, replicability, and honesty in interpreting statistics, that’s good enough.
RE#201:
“When missing values were encountered, means were computed for the sites having data.
thanks, that explains a lot. looks like i was very wrong.
Steve: Thanks for gracefully acknowledging this. Its good to clear up factual things.”
Except of course that it does no such thing! The comment about ‘missing values’ was preceded by the following:
“Data in each series had different degrees of temporal coverage. For example, the
pollen-based reconstruction of Viau et al. (2006) has data at 100-year intervals. Other
sites had data at irregular intervals. This data was taken as is without interpolation.
Data in each series were smoothed with a 30-year running mean. This should help
remove noise due to dating and temperature estimation error. If data occurred every
100 years, each point would be stretched by the smoothing to cover 30 years.”
The latter point is I’m sure what Sod was referring to concerning sparse data being stretched out?
What exactly does a 30 yr running mean of 100 yr data look like?
Re#5
“Re #4
If that were to occur, one would hope that that would be the graphic included in the next IPCC, AR5. i.e. We dont know where we stand today, but the models tell us CO2 is driving temperature up.”
Actually a more reasonable interpretation would be “We know where we stand today and are reasonably confident about the last century but we don’t have much of a clue before that”.
In order to do error analysis Id need the functional form with coefficient values and their standard errors. R2 is not enough. The idea is to form CIs for all these coefficients and propagate that through every single computational step you do in your paper until you get to your ensemble proxy. Do any of the original papers for the proxies have such information?
Craig wrote in # 264,
As I tried to make clear in #261, the method I proposed back in #11 does not require one to know in advance how well each series was calibrated, since that error just shows up in Vi along with the error of the locality’s true temperature’s ability to measure global temperature. The time series of residuals will tell you the combined effect, provided Vi is constant over time.
Admittedly, but as I already noted, your 30-year smoothing will make them much more homoskedastic than they appear in the plots of your raw data that Steve posted on an earlier thread. If this is still a concern, one could fit a GARCH model to each study’s residuals and still have lots of DOF to spare. But some structure has to be imposed, and as a first cut I think constancy is better than no CIs at all.
This works if you’re willing to assume that all studies have equal variances (or known variances), both with respect to their ability to measure local temperature, and with respect to their locality’s ability to measure global temperature. I think that’s a lot worse than just saying they’re unknown and unequal but constant over time.
Sam Urbinto (#265):
Even UC admits that the CI’s he computed were all wrong — they were just intended to be an illustration of how bad Mannian CI’s would have been in this context. And Jean S never computed an alternative that I am aware of.
Hu, it’s been fairly clear to me (at least I thought it was…) that the exercise was in how pointless (???) doing it was. I don’t know enough to comment on your #11 It seems that Jean S. did the inital work and UC confirmed it and graphed it. I believe they had both already said it was meaningless crap, leading me to believe trying to do a “real one” was similarly meaningless.
Did you try your method and post the results? If you did, I missed it (or didn’t understand it).
I’m just an agnostic bystander, although I do at least semi-understand the basic stuff like confidence intervals and standard deviation, at least as far as normal distribution goes. Beyond that, I get lost. In order to do error bars at all, don’t you need to know or be able to calculate the +/-?
Let’s not make conclusions yet, this is a young thread 😉 MBH98 CIs are clearly meaningless crap (we know the method).
For Loehle07, we haven’t even tried yet. #11 and Loehle07 Fig. 3 are OK starting points, but both methods provide finite CIs for any input data. Next step is to read the original publications. If the original reconstruction errors can be shown to be independent of target temperature, we can come back to the global scale. If not, then there’s more work to do..
Valid CIs for Loehle Global Temperature
by Hu McCulloch
(Perhaps Steve might want to start a fresh thread on this)
I have now constructed valid CIs for Craig Loehle’s unweighted average global temperature series, using the method I described at #11 above (in the 11/21 thread #2405). The exact standard errors vary with the number and identity of the proxies that are included at any point in time, but generally are around 0.16 dC. A plot of a 95% CI (+/- 2se) about Craig’s series is linked at http://www.econ.ohio-state.edu/jhm/AGW/Loehle/OLSCI.gif and should appear below:
The MWP is significantly above the bimillennial average during approximately 850-1050. There is also a significantly below-average LIA approximately 1450-1750.
Detailed graphs of the individual series etc are in a (still very preliminary) note at http://www.econ.ohio-state.edu/jhm/AGW/Loehle/LoehleGraphs.doc. As discussed there, the variances of the 18 series differ considerably. Two of them, #3 Cronin and #10 deMenocal, have such high variances that they are actually detrimental to the variance of the unweighted average of the series. Two others, #6 Korhola and #13 Viao, have very low variances about the mean and so are very informative.
Because of the unequal variances, Weighted Least Squares (WLS) estimates that weight each series in inverse proportion to its variance are more efficient. The standard errors are generally around 0.10 dC, a considerable improvement over the unweighted Ordinary Least Squares (OLS) estimates above. The WLS estimates with a 95% CI are linked at http://www.econ.ohio-state.edu/jhm/AGW/Loehle/WLSCI.gif and should appear below:
The significant portions of the MWP and LIA are about the same with WLS as for OLS, so thanks to Craig’s data set, the MWP is alive and well. (The little bump in the late 20th century at the right end of the graphs must be Al Gore!)
Only rarely were all 18 series active. Usually 14-16 were availble, though occasionally the number fell as low as 12. If there is popular request, I could post the graph of this that appears in the paper linked above.
I was able to replicate Craig’s series from the raw data Steve posted to within an average absolute difference of 0.0018 dC and a max abs difference of 0.0919 dC, but only by using a 29-year rolling mean rather than 30 as indicated in the paper or 31 as Craig says he in fact used in #263 above. The average abs difference was 0.0105 dC and the max abs difference 0.203 dC using a 31-year centered rolling mean, and comparably bad with a 30-year rolling mean, whether 14/1/15 or 15/1/14. I take this to mean that he in fact used a 29-year rolling mean.
#278,
Interesting work! Note that you are using mean of the data as a reference, not the true global mean temperature. That reminded me of Baron Munchausen (bootstrap in English version, in German version he draws himself up by his own hair (?)).
Our search for scientific CIs is progressing, though. Let me try the same method with Mann’s network..
Much better. Now to audit the method.
Interesting work, Hu.
UC,
Good point, I would nuance it slightly differently though (and this adds to the changing of number of proxies or the use of weighted means): the CIs presented are not for the global mean, but for the average of the 18 locations (which may be slightly different), or for the average of the 16 locations if we remove some on S/N grounds. Furthermore, if we weight to reduce the variance, this may increase the disparity between the mean of the locations and global mean.
To get the best estimate of global mean, I suspect, requires a balancing act between:
* Geographical representation (most area covered)
* Weighted mean (to get the best S/N for the given locations)
* Relationship between this and the global mean (perhaps derived by relating limited numbers of weather station data to complete networks?)
I would have thought, given an arbitrary set of proxies and a S/N estimate for each, it should be possible to derive an “optimal” set of weights to minimise CIs for the global mean on this basis.
I believe someone already did a plot similar to this in an earlier thread (limited number of stations vs. full network).
Spence —
Thanks. A more ambitious future study would utilize only
studies that reported confidence intervals, and then use this information
in addition to their conformity to the consensus to establish weights
and to compute CI’s for the consensus. Craig has found such CIs for
#11 (Holmgren), but I doubt that all the others were so careful.
UC —
The choice of a reference period is admitedly arbitrary, but Craig’s choice of the bimillennial average is quite reasonable for this data set.
#279 :
Isn’t the true global mean unknown, otherwise sampling were unnecessary? A CI, according to my books, should bracket the respective population parameter with the specified probability. It is necessarily spread around the sample mean, the best estimate available for the true mean. Did I get something wrong ?