Judith Curry and JEG have expressed an interest in talking about Mann et al 2007, Robustness of proxy-based climate field reconstruction methods, JGR pdf. This is successor article to Mann et al, 2005, Testing the Fidelity of Methods Used in Proxy-Based Reconstructions of Past Climate, pdf.
Looking past the annoying and amusing faults, here are some thoughts about the substance of the article. There are two sorts of results in Mann et al 2007: results on the MBH98 network and pseudoproxy results.
The pseudoproxy results are much weakened because they only consider results from one quirky and idiosyncratic multivariate method (RegEM TTLS) in a very tame pseudoproxy network without
(a) comparing results from the method to other methods other than their own equallty quirky RegEM Ridge, or
(b) examining results from networks that are flawed and, in particular, flawed in ways that may potentially compromise MBH. I’ve posted on both these issues and will review some thoughts on this.
It is somewhat surprising to see another lengthy effort to rehabilitate the MBH98 network, which is analysed complete with original (incorrect) PC series without conceding a comma to the NAS panel or Wegman reports or even mentioning the bristlecone problem. Mann shows that he can recover the bristlecone shape using RegEM if we spot him the PC1 or raw bristlecone series. This was never in doubt – see MM (EE 2005) and, other than for polemical reasons, it’s hard to see any purpose or interest in the application of RegEM to this flawed network.
MBH98 Network
The main properties of the MBH98 network have been known for some time. MM (EE 2005) and Wahl and Ammann (2007), despite the claims made in the latter, agree on virtually every specific calculation, as is unsurprising since our codes matched. If you do an MBH98-type calculation with 2 NOAMER covariance PCs, the bristlecones get downweighted and you don’t get a HS; if you increase the number of covariance PC2 to 5, you include the bristlecones and you get a HS. If you use correlation PCs, the bristlecones dominate the PC2, which is attenuated a little, and you get a HS; if you do a calculation without bristlecones, you don’t get a HS regardless of method. If you do a calculation without a PC analysis and without bristlecones, you don’t get a HS; if you do a calculation with bristlecones and without a PC analysis, you get a HS. The incorrect Mann method promoted bristlecones into the PC1 of the AD1400 network and made the HS shape of the bristlecones appear to be the “dominant component of variance” as opposed to a local phenomenon (and very reliant on chronologies done by Graybill.)
Where does RegEM fit into this dispute? It really has nothing to do with it. After the construction of their PC-proxy network, Mann carried out an “inverse regression” analysis – described in the most overblown and uninformative terms imaginable. I’ve worked through the linear algebra of this and confirmed (as have UC and Jean S) that, in the early AD1400 and AD1000 steps where only one temperature PC is reconstructed, that the weights of each proxy are in direct proportion to their correlation with the temperature PC1. This is a form of Partial Least Squares regression (one-stage) – a method used in chemometrics.
In the Mann et al 2007 proxy section, they use RegEM (Total Least Squares version) instead of Partial Least Squares regression. They say that the process is non-linear and that they are unable to calculate weights for each proxy – a claim also made for MBH98, which proved untrue. Their network is based on the identical MBH98 network – warts and all, including the incorrect PC series, criticized by both the NAS Panel and Wegman, which seems pretty insolent towards other climate scientists and rather weak reviewing by JGR.
Using RegEM, they “get” a NH reconstruction that is said to be pretty similar to the MBH98 reconstruction and I don’t doubt that this is true. What I don’t “get” is exactly what this proves in the scheme of things. My instinct is that RegEM (TTLS) is generating coefficients somewhere (or is approximated by this) and that the weights are more or less approximated by the weights from Mannian inverse regression.
In MM (EE 2005), we discussed the situation where Mannian inverse regression was done with no PCs; in this circumstance, because there are a lot of Graybill bristlecones, they dominate the network without PC analysis – but any pretense of geographic balance was sacrificed in the process, one of the warranties of MBH that led to its acceptance. So the fact that RegEM leads to a similar result in a case where the network is dominated by bristlecones is a nothing and has been known since 2004 and a response given in MM (EE 2005).
Mann et al 2007 do not mention the word “bristlecone” even once – a remarkable omission since they still continue to imprint his results. Indeed, one might argue that Mann’s major innovation was his introduction of the known-to-be-problematic bristlecone chronologies into multiproxy reconstructions – a temptation resisted by Bradley and Jones 2003 and Jones et al 1998 (but perhaps anticipated in Hughes and Diaz 1994).
Pseudoproxy Results
Mann et al 2007 report a lot of RE, r2 and CE statistics for different reconstructions using pseudoproxies. I think that these sort of pseudoproxy studies can be quite useful, although I don’t think that scientists in the field have necessarily got the hang of these studies yet or that Mann et al have given a very broad survey of results that need to be examined. Zorita’s results are the most reliable.
A couple of my more interesting posts have reported my pseudoproxy results, one using Echo-G runs (kindly provided to me by Eduardo Zorita) and one using pseudoproxy networks constructed to emulate the MBH98 network (Huybers #2 and Reply to Huybers) also here and I’ll try to tie these three different studies together.
In Mann et al 2007, he only considers results from RegEM (TTLS) under different noise scenarios. In Benchmarking from VZ Proxies, I tested the effect of a broader range of methods on attenuation of low frequency response, comparing the impact of OLS regression, PLS (Mannian inverse) regression with and without detrending, CPS and principal components (PC1). OLS regression had the “best” fit in the calibration period but the poorest low frequency recovery; in the circumstances of this very “tame” setup where an equal amount of noise was added to each proxy, the PC1 and simple average had the best recovery of low-frequency variance, with Mannian inverse regression in the middle, as shown below:

Spaghetti graph of selected multivariate methods. The blow-up is not because of intrinsic interest to the period, but just to show detail a little better in a different scale.
I then compared verification statistics for the different reconstructions as shown below. OLS yielded much the “best” fit in the calibration period, but the worst fit in the verification period. I think that this is a useful perspective on what’s going on with more “sophisticated” multivariate methods, as they will fit somewhere on this graphic (and there is no free lunch.) You’ll notice that these reconstructions all have good calibration r2, RE and verification r2 (other than OLS). In this particular case, the one example with a verification r2 failure (OLS) is the one with the worst performance in terms of signal recovery – suggesting that this particular statistic is definitely worth looking at.
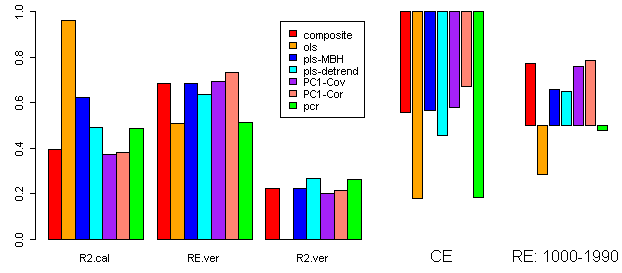
Another interesting image in the earlier post was the image showing the regression coefficients (the “Fourier” space if you will) for the different methods – and this is a tame network with an equal amount of noise. The best models were the ones with the most balanced weights and the worst models were the ones with the most tailored weights. The mathematics of this are trivial once you think about it: because equal amounts of noise are being added to a signal, the noise cancels out most effectively if the weights are equal. If some of the series are turned upside down as happens in OLS, then the noise reduction cancellation is diminished. IF you think about it, you’ll see why.

One of the morals for me from the adverse impact of flipping series is that anyone starting a temperature reconstruction needs to know the sign of the expected relationship to temperature in advance and specify it in advance. This is one of the hidden strengths of the simple average, that can get overturned in a noisy network.
If we put Mann et al 2007 results in this context, we find that RegEM methods, like all other methods, will generally yield high calibration r2, RE and verification r2 scores in a tame network with known and equally distributed noise additions. There are a couple of cases (j,x) in which the RegEM method fails to achieve a good r2 in the verification period and my guess is that it’s ended up overfitting the model somehow – along the lines of the OLS failure shown in my example. It’s just a guess.
“Wild” Networks
In these pseudoproxy studies, the noise is all very “tame” – it’s white noise of equal amount or low-order red noise of the same type. However, if you plot the residuals for each proxy in the MBH AD1400 network, that’s not what you get. The residuals for the NOAMER PC1 and Gaspé are fantastically autocorrelated. Actually autocorrelation doesn’t really describe the mis-specification at all: the residuals for the NOAMER PC1 relative to the recon are hockey stick shaped – something that doesn’t fit very well into autocorrelation vocabulary or techniques. The reason is that the PC1 is a super hockey stick that overshoots the NH reconstruction. So the residual is itself also a HS. This of course renders assumptions about white and low order red noise completely moot. I’ll try to post up a graphic illustrating this point – I probably have one already somewhere.
There is also another notable gap in the Mann et al 2007 pseudoproxy study. They only deal with how the system works on a network where a signal is guaranteed. What happens when you move into networks where there is no common signal? What happens then? Now you’re getting into the pseudoproxy networks of our Reply to Huybers and my post Huybers #2 and Wahl and Ammann #2. In those cases, I constructed synthetic hockey sticks from red noise (or alternatively from stock price indices), blended in a network of 21 white noise series and pressed it into the Mannomatic.
What happened? You get “reconstructions” that were functionally equivalent to MBH as shown below: high calibration r2, high verification RE and negligible verification r2 : same as MBH98 in the AD1400 network. Virtually all of the MBH proxies can be replaced with white noise with no impact whatever on the reconstruction. However there are a few “active ingredients” – in the AD1400 network, they are the Graybill bristlecone pine PC1 and the problematic Jacoby Gaspé series. See this post for a derivation of the graphic below.
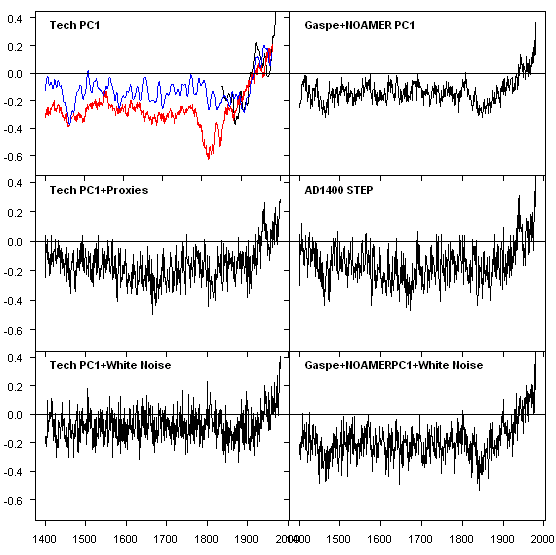
Left – Tech stocks; right – MBH. Top left – Tech PC1 (red), MBH recon (smoothed- blue). Top- Tech PC1 and Gaspé-NOAMER PC1 blend; Middle – plus network of actual proxies; Bottom – plus network of white noise.
So from a mathematical point of view, this very different type of pseudoproxy situation has to be incorporated into the testing universe. There is no evidence that the MBH proxies contain a common signal along the lines of the Mann et al 2007 pseudoproxy test. If anything, the MBH proxies are remarkably orthogonal. Because they are “near orthogonal”, you end up with an interesting mathematical situation in which the matrix that rotates PLS coefficients to OLS coefficients is near-orthogonal and thus Mannian situation can end up being much closer to an OLS overfit than one would like.
One of the obstacles to understanding the situation is that people are used to regressions from cause to effect as Ross pointed out, where collinearity is a problem. Here you actually want collinearity and orthogonality is the problem. Mannian inverse regression is actually an improvement on OLS which is not “optimal” at all, but in a case where the proxies are near orthogonal, it may revert back to having OLS problems.
If you don’t know much about the proxies other than their sign, I think that there’s something to be said for quite simple averaging procedures. You may leave something on the table but you’re less likely to screw up. As for re-scaling after averaging – both UC and Jean S recoil at this step: it’s a different kettle of fish and deserves a lot more thought than has been given to it. It’s not a given that it’s a good technique and I’ll discuss this another day. That’s one reason why the Loehle method – the simple average so scorned by JEG – is intriguing: it avoids the potentially problematic re-scaling step. It may have other problems but it avoids that one.
One of the things that I’d be interested in seeing from the various Mann networks is a barplot of the coefficients along the lines of the plot shown here for the VZ network. Yeah, I know that they say that it’s impossible, but I suspect that they can be extricated somehow. Maybe JEG can figure out how.





24 Comments
uhhh, does “Tech Stocks” mean NASDAQ?
There is no definition of it in the post….
#2. See http://www.climateaudit.org/?p=370 for a derivation of the graphic. I took 16 or so tech stock prices histories during a period of rising prices and substituted the tech stock prices for bristlecone pine chronologies, otherwise leaving the other tree ring chronologies unchanged. Then I calculated MAnnian PCs and did a Mannomatic inverse regression. It outperformed MBH as a temperature reconstruction.
Is this going to be a conversation? Now that you posted what you think, have Judy or JEG posted their thoughts on the paper at their blogs?
Steve, this is general to proxies, but I hope is appropriate here. I can understand and accept that, for instance, dO18 can be measured in recent times and the relationship between values and temperature noted to give a degree of calibration, but to revert to one of your favourites, tree rings, it appears that this, if done similarly, produces no serious co-relation to any one of several possible factors. So how is a tree ring calibrated to temperature in historic times with such amazing accuracy? BTW, how are your samples from the Starbucks trip coming along?
Steve: Got the measurements this week and will post up. I got involved in thinking about pseudoproxies.
Like the inconvenient MVP before it, there must be a proxy in this data that shows that Wegman, NAS, and Steve McIntyre don’t exist!
The regularized EM algorithm estimates a linear regression model (only the estimation procedure is nonlinear). The estimate of the matrix of regression coefficients you are looking for is determined by the estimated covariance matrix of the data and the residual covariance matrix. In the code regem.m, the matrix of regression coefficients is the matrix B. You can make a plot of the regression coefficients from the entries of B after the last iteration.
Tapio, thank you for a comment. I’d be pleased if you could comment also the issue here.
#6. Tapio, thanks very much.
If anyone can get this thing to run, I would like it if you could collect the regression coefficients. Then we can do a couple of things – compare the coefficients to the coefficients from other methods including Mannian inverse regression.
Also we should then be able to collect terms in the linear algebra as I did previously for the Mann process, thereby showing NH temperature as a weighted average of the individual proxies. RegEM TTLS is then (as I surmised) simply another method of assigning weights to the proxies for computation of this average.
In this particular case, it would seem to be simply be one more method of imprinting the Graybill bristlecone chronologies as the NH temperature.
Jean S: I have not followed in sufficient detail how regularized EM algorithms have been used to be able to comment on specific implementations. However, estimating a covariance matrix as a sample second moment matrix when data are not centered would obviously be problematic.
Here are two other issues that I have pointed out to several people working with regularized EM algorithms and that may be of broader interest. The first may account for the differences seen between using truncated total least squares and ridge regression (Tikhonov regularization). My impression is that where TTLS performs better than ridge regression, the regression models linking proxies to instrumental data do not provide much information beyond the (temporal) mean. When ridge regression is used, the regularization parameters chosen are so large that all principal components except perhaps parts of the first or first few are effectively filtered out by the ridge regression. Since ridge regression filters principal components with a Wiener filter, it will already filter the first or the first few principal components strongly for relatively large regularization parameters. For example, if the regularization parameter (h) is comparable with the square root (lamdba) of the largest eigenvalue of the covariance matrix, the weight already of the first principal component will be only 1/2, with lower weights for higher principal components [see Eq. (19) in Schneider (2001)]. TTLS may then perform better because at least the first (or first few) principal components (now of the total covariance matrix, rather than of the covariance matrix of only the available data for a given year) would be completely retained, without the damping that a Wiener filter would imply for them. This may be a reason for the sensitivities seen with respect to the choice of regression method in some applications of regularized EM algorithms.
The second issue pertains to the scaling of variables. Both ridge regression and truncated total least squares can be viewed as errors-in-variables methods that are still appropriate if there are errors in predictors (see Golub, Hansen, and O’Leary, SIMAX 1999), as is generally the case in the estimation of climate data from proxies. In the code here, the methods are implemented in standard form, that is, they operate on correlation matrices. This is only adequate if the variances of the errors (observational, measurement, etc) in the variables relative to the variances of the variables themselves are approximately homogeneous. If the relative error variances are inhomogeneous, as will likely be the case when different kinds of paleo-proxies are used, a different scaling should be used (see Golub et al. 1999).
I would be interested in seeing systematic tests with actual data and with pseudo-proxies investigating the extent to which these two issues affect results.
#8 Steve M, I have gotten mbhstepwisehighrecon.m to run and also mbhstepwiselowrecon.m to run after making some fixes as it was broken. In your Feb 3, 2006 post on Rutherford et al [2005] Collation Errors, I posted comments #1, #3, and #15. Comment #15 was about line 158 where it appears that the true value of nproxies gets stepped on by nproxies = 112. nproxies is used again in line 215 and 216 to assign weights but not sure of impact. Given that the matlab script to combine the results (NH and G temps) is not provided and the “center” issue, not sure about the usefulness. Can do if interested.
The program takes forever to run if I remember correctly. The lack of identation in the “for end” loops makes it tough to follow.
Phil B.
In the MATLAB text editor, the key sequence Ctrl-A, Ctrl-I works wonders 😉
#11, Thanks Spence, didn’t know that and will give it a try. Perhaps, should also pay attention to the spell checker. Phil B.
The editor for version 7.1 and later is much more useful in this respect, btw. I highly recommend the upgrade as it is the most significant I’ve seen in years (most importantly, support for 64-bit processors with winders).
Mark
Re:3
lucia
Discussion about what, pray tell?
Is the earth flat; somewhat flat; considerably less flat than before; possibly not all that flat after all; upon full consideration and for all intents and purposes, is best accepted as being a globe?
When did “this has been proven wrong” go out of fashion in science?
When at last notice, did we do away with the fundamental concept that once falsified, a hypothesis and whatever it postulates is history?
Pls enlighten us.
St. Mac:
Well, there’s red snow. There’s white snow. And then there’s the snow where the huskies go!
Tapio:
Yes, it is exactly what is happening in Rutherford et al (2005) as you can see from the link I provided (Steve’s post also has a link to a backup of the original code, if you want to check yourself). IMO, this is not only “problematic”, it practically destroys the algorithm. Notice also that the mean parameter is directly affected. This is what I wanted to have your opinion about. After all, bad reputation of Rutherford et al (which is claimed and understood as being an application of the RegEM algorithm) affects directly the reputation of your RegEM algorithm.
Thank you also for the indsider’s comment on the RegEM algorithm and interesting reference. Just a quick question: have you (or anyone) considered using RegEM on integrated climate data as it seems to be relatively nonstationary?
@Tetris–14
Sorry I wasn’t clear. At the beginning of his main post, Steve says
Judith Curry and JEG have expressed an interest in talking about Mann et al 2007.
So, evidently Steve accepted their invitation to talk about it. Having expressed an interest to talk about Mann et al 2007, are Judy and JEG going to give their points of view on Mann 2007 somewhere now? If they did , those of us not entirely up to speed on these statistical issues could read what Judy and JEG think.
It appears the discussions would require more than a comment after Steve’s post, so I wondered if Judy or JEG would post at a blog, web page etc.
Re: #17
If past reactions are predicitive in these matters, I suspect that a reply from Judy and/or JEG will concentrate on Steve M’s critique of the paper without concluding, in any detail, much about the paper’s results and conclusions.
Steve: I disagree. If past reactions are predictive, this is usually the point where real climate scientists disappear.
@18: Kenneth.
If so, anyone who can’t assess Mann on its own merits will not be able to learn what’s good about Mann from someone who thinks it makes a contribution to knowledge about climate.
Since peer reviewers are generally anonymous, the public will have little information other than “It was published in a reputable journal”. That would be sort of a shame — particularly if the paper does contain useful interesting information. (And it well may. Most papers contain some useful information even if that information is not definitive or may be flawed.)
Past reactions are predictive except at tipping points.
=================================
Re: #19
Lucia, I would have to say that Steve M’s notation on my reply is valid for any number of visiting real climate scientists that I have observed here, but before departing they frequently key on critiquing those critiquing the Hockey Team papers without revealing much in the way of judgments on the critiqued papers. The follow on to this departure can sometimes come from other visiting real climate scientists stopping in to implore the participants here to be more polite to these visitors in the future or do without their potential contributions to the knowledge base here. These exhortations run counter to my blogging experiences where I have found those visitors (often with a counter POV to that of the majority of the blog participants) who come to inform avoid general comments on the participants or their POVs like the plague.
Since in my view, JEG is more aggressive in these regards than other visiting climate scientists and his web site indicates he wants to teach the world about AGW and its repercussions, he might remain a bit longer. I, however, do not see these more politically oriented climate scientists doing much critiquing of papers providing evidence for AGW. I think the problem there lies in the split personalities of the scientist and policy advocate and hearing the policy dominated personality, not the scientist, making the decisions of what and what not to critique at least on a blog such as CA.
By the way, I think that the attempts by Mann et al. to do a comprehensive reconstruction of historical temperatures from proxies were somewhat original and admirable, or at least a strong push of past attempts, in providing real world support for the climate computer models. The lack of proper statistical guidance, the authors hurry to get their message out on what they saw as a critical problem needing immediate attention and the advocates of immediate AGW mitigation suspending normal judgments of the works because it fit their needs so well are what I see as being problematic for this sequence of events.
If OLS is equivalent to ICE, it actually finds the best fit (minimizes calibration residuals), and in proxy-temperature case makes the most obvious overfit. Let me try to get an understanding of the methods applied. As we know, core of MBH9x is the double pseudoinverse, in Matlab
RPC=P*pinv(pinv(TPC(1:79,T_select))*P(903:end,:));
where P is standardized (calibration mean to zero, calibration de-trended std to 1) proxy matrix, TPC target (temperature PCs) and T_select is that odd selector of target PCs. After this, RPCs are variance matched to TPCs, and brought back to temperatures via matrix multiplication. As you can see, I can replicate MBH99 reconstruction almost exactly with this method:
Differences in 1400-1499 are related problems with archived data, and in 1650-1699 they are due to unreported step in MBH procedure. Steve and Jean S have noted these independently, so I’m quite confident that my algorithm is correct.
I’ve considered this method as a variation of classical calibration estimator (CCE) and Steve’s made a point that this is one form of PLS. These statements are not necessarily in conflict. Original CCE is (with standardized target)
where matrices and
and 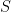 are ML estimates of
are ML estimates of  and
and 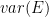 , obtained from the calibration experiment with a model
, obtained from the calibration experiment with a model
By setting , I get exactly the same result as with double pinv. Which verifies my observation that MBH9x is CCE with special assumption about proxy noise and with incorrect variance matching step after this classical estimation.
, I get exactly the same result as with double pinv. Which verifies my observation that MBH9x is CCE with special assumption about proxy noise and with incorrect variance matching step after this classical estimation.
Back to OLS (ICE) estimate, which is obtained by regressing directly X on Y,
this is justified only with a special prior distribution for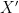 , which we don’t have. Thus OLS is out of the question. Yet, it is interesting to observe that OLS is actually a matrix weighted average between CCE and zero-matrix (Brown82, Eq 2.21) :
, which we don’t have. Thus OLS is out of the question. Yet, it is interesting to observe that OLS is actually a matrix weighted average between CCE and zero-matrix (Brown82, Eq 2.21) :
It would be interesting to compute MBH99 results with real CCE, but S does not have inverse for AD1700 and later steps. But results for up to AD1700 are here, CCE:
ICE:
As you can see, variability of ICE is lower, as it is weighted towards zero. But hey, where did that hockeystick go ?
Agreed. It was premature to take the paper and run with it the way people did. It’s truly unfortunate. In the normal course of things, perhaps others would try to replicate the results, would find problems, would question the use of proxies, methods, etc. and the science would move towards some better certainty about the issues. The paleo recons could then be viewed with better confidence as saying something useful about past climate change and ultimately, about current.
Steve: There was nothing original about the idea of a proxy reconstruction. Bradley and Jones 1993 had done one and Jones et al 1998 somewhat preceded MBH98. Even Groveman and Landsberg 1979 – discussed previously. Mann’s key innovations (and this is from a Bradley interview) were 1) his mathematical methods for extracting a faint signal (which turn out to be Mannian PCs); 2) and this is perhaps due to Hughes, the introduction of BCPs into climate reconstructions, which previous people had steered clear of. Of course the Team quickly got addicted to crack once Mann legitimized the use of BCPs.
My point was not to congratulate Mann in any way. There’s been more than enough of that elsewhere. It was to lament what happened to the paper and science as a result of politicization and the policy process regarding global warming. Had this been an obscure corner of the science world and not part of a global debate about climate change, the MBH reconstructions would likely have been treated the way any other paper and method, conclusions, etc. would be treated in the normal course of things. Other scientist would eventually try to replicate the research, would find flaws, and the MBH innovations, for what they are worth, would either be left in the dustbin or improved. That didn’t happen and this is an exemplar of what happens to science and policy when the stakes of the policy debate and its outcomes are so high.