On an earlier occasion, I posted up our updated measurement data from Almagre. I’ve been working on this material in preparation for AGU (Dec 14). Today I’m going to show some initial chronology calculations.
In doing these calculations, I’m trying to reconcile exactly to standard methodology while, at the same time, trying to be a little bit reflective about the statistical meaning of their methods (and porting the software to R as much as possible.) I have done runs in Arstan on our data and on Graybill’s co524. I also corresponded with Rob Wilson on this matter. I had trouble reconciling the archived Graybill chronology with Arstan options and Rob kindly identified the precise Arstan option used by Graybll.
Data Sets
In addition to our collection in 2007, there have been two previous measurement data archives for Almagre: Lamarche in 1968 (co071) and Graybill in 1983 (co524). The Graybill archive includes some (but strangely not all) Lamarche cores. According to my best efforts at concordance, Graybill trees with id over 30 were actually collected by Lamarche. Three of our trees (30,33, 47) matched Graybill trees.
For the calculations here, I’ve collated a data set using the “fresh” Graybill measurements, the original (and more complete) Lamarche measurements and, from our update, I’ve excluded the first two sites (Elk Park, Almagre Base) which are not in the same area as the Graybill samples. I don’t believe that the results are particularly sensitive to the exact collation. (I’ve examined some sensitivities but am still doing analysis.)
In a first pass analysis, I’m using all past and present data (strip bark and whole bark) in order to reconcile results to past results as much as possible and will then look at strip bark-whole bark disaggregation.
The resulting data set has 37 trees and 77 cores.
Detrending
Arstan detrending is done by first trying to fit a “generalized” negative exponential to each core. A “generalized” exponential has the shape:

There are some interesting numerical analysis issues pertaining to this sort of non-linear fit. I can substantially replicate Arstan results by doing these fits using the R function nls and even more conveniently using nlsList (in the nlme package). I can often obtain convergence when Arstan converence failed and I suspect that they’ve set their iteration a little low relative to their tolerance. A second Arstan option is a negative sloping line if a neg exponential fit fails and then a line through the mean.
An odd feature in Arstan detrending – and I don’t think that it matters much in this example, but doesn’t seem to make any sense – is that the “age” of each core is determined individually even though another core may have established an earlier date for the tree, This is shown in the example below (which has the most cores of any tree on the site). I’ve plotted the ring width information from each core together with the Arstan fit. For example, the green core is fitted as though it’s a new tree even though the blue core has shown that the tree was already at least 150 years old and no longer juvenile at the commencement of the green core. In solid black, I’ve shown the negative exponential fit using all available data for the tree. This seems far more rational than trying to treat each core separately. At the end of the day, I don’t suppose that the decision makes much difference, but detrending on a tree basis (rather than a core basis) seems a safer approach, especially when one is worried about strip bark potential problems. Dendros have been increasingly moving towards standardization on a more regional basis, and standardization at a tree (rather than a core basis) is at least consistent with that trend.

After fitting a curve, the standard dendro procedure is to divide the measured ring width by the fitted width to produce a dimensionless ratio. There are occasional discussions about whether to use residuals, as would be far more conventional in mainstream statistics, but ratios are well-established. I’ve used ratio approaches here in order not to vary too many things at the same time.
Power Transformations
A second decision in chronology-making is the decision of whether to transform the data to “normalize” it. Ring width data, even after detrending is typically very non-normal and this is the case here. Willis showed a pretty violin plot in the earlier thread and I’ve applied this below in combination with a QQnorm plot to illustrate the distributions. First here is the distribution of “standardized” detrended ring width ratios calculated according to the above procedures. As you can see, this is highly non-normal with a positive skew.
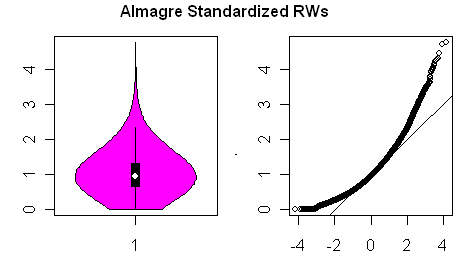
Figure 2. Violin and QQnorm plots of Almagre detrended ring width ratios.
Cook has initiated the use of power transformations to normalize ring width distributions (a technique nearly always used by Rob Wilson in his work) and an excellent idea. I haven’t explored the criteria that they use to select the power transformation index. I experimented with several different transformations starting with k=0.5 and after a couple of attempts used k=0.375. This resulted in the following distribution. Because of the severe non-normality of the Almagre data, I have the impression that some of the variation in the older chronologies is significantly reduced as a result of power transformation reduction of non-normality artefacts.

Reconciliation
First here is a plot comparing a chronology using only updated measurements to a chronology using only Graybill 1983 measurements (excluding Lamarche for now.) This shows a couple of things: that our sampling actually did replicate Graybill’s results (r=0.89 for this period) (I’m not sure whether this is biased upward in the crossdating exclusions, biases from which seem possible to me, but are a large study in themselves). For now, we can say that – whatever interpretation one may put on the final chronology itself, there does seem to be data that can be independently recovered.
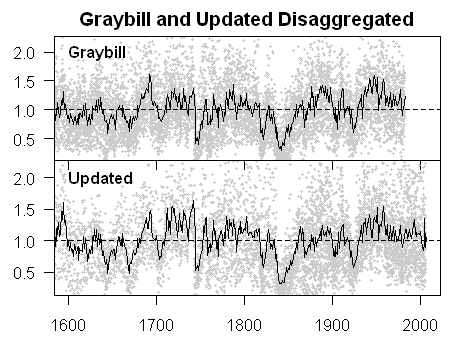
Chronologies
First here is a plot showing the original Lamarche and Graybill chronologies, together with our extension to 2007 (without a power transformation). Values were at high levels in the late 19th century and again in the 1950s and have declined since the 1950s reaching more or less average levels in the 1990s-2000s.
The most notable feature on the recent portion of this graphic (and perhaps the entire graphic) is the severely reduced ring widths in the 1840s. Steve Mosher has linked to some references reporting severe drought in Colorado in the 1840s http://www.ncdc.noaa.gov/paleo/pubs/woodhouse2002/woodhouse2002.html
http://www.sciencedaily.com/releases/2005/02/050218140645.htm
and it’s hard to avoid the iview that the reduced growth in Almagre bristlecones in the 1840s isn’t associated with contemporaneous drought throughout the state – a view which is certainly consistent with the impression of our most knowledgeable botanical observers of moisture limitation at the site.

Here is a blow-up of the same chronology for the 1830-2007 period, covering the low-growth 1840s.

Power Transformation Chronologies
Here is a the power-transformation chronology (k=0.375) for the 1830-2007 period. Much of the variation has been damped down and one is left with an impression of rather limited variation other than for extreme events like the 1840s (the 1920s were also low-growth here).

Power Transform Chronology k=0.375.
Finally for today, here is the power transform chronology for 900-2007 (with an 11-year smooth):
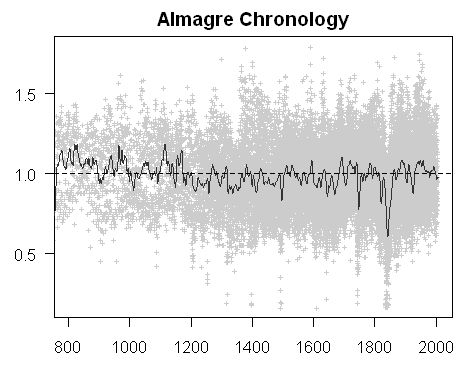
Correlations
The correlation of the ring width chronology to the HadCRU3 grdicell (annual) is 0. The first graph shows the correlation of the chronology to monthly temperatures at the nearest USHCN station (Chessman adjusted). In addition to the usual barplot showing the correlations to the current and preceding year, I’ve shown correlations of the ring width to the temperatures in the following year. The most “significant” correlation is between ring width and April temperature of the following year – a “teleconnection” that is appealingly Mannian.

Despite some evidence that large-scale drought such as the 1840s can affect growth, there is little correlation between statewide precipitation index and ring widths as shown below.

“Reconstruction” of Cheesman Reservoir Temperature
The graphic below shows a “reconstruction” of Cheesman Reservoir July-August temperature done in one of the common dendro ways – by variance matching. The r2 of this “reconstruction” is under 0.01 – not that this precludes a Mannian model. After all, this may teleconnect with temperatures in Bali or Beijing or Rio de Janeiro or Antarctica. 2002 and 2003 were warm summers at Chessman Reservoir, but did not result in exceptional growth.
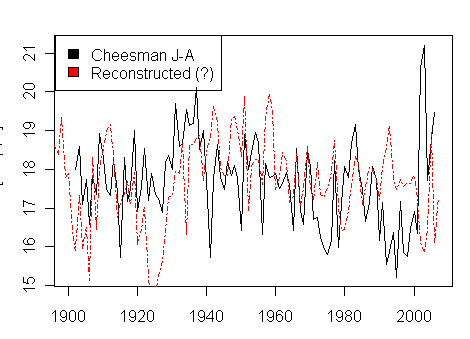





58 Comments
Looking at 1980 – present I have one overbearing thought:
Wot no hockey stick?
Maybe it should be called the Toronto Maple Leaf graph
They don’t do hockey either.
But, I thought it was settled science that BCPs were thermometers, not rain gauges.
From Salzer, M.W. and K.F. Kipfmueller. 2005. Reconstructed temperature and precipitation on a millennial timescale from tree-rings in the southern Colorado Plateau, U.S.A. Climatic Change, 70: 465-487.:
I don’t mean to be a noob on bristlecone pine tree proxies, but on your correlations by month: In what month of the year does a tree ring “begin” and “end?” The way you labeled the months seems to imply a ring matches a calender year, but my understanding was that the inner or first part of a ring was the new spring growth, so the actual year should be april to april or may to may or whatever.
It’s good to see that your 900-2007 chronology closely tracks the others and largely negates the criticism that your methods were non-standard. Something happened with Lamarche from about 1180-1410 though. Congratulations on extending the data 25 years on the recent end and 200 years on the ancient end with a “significant” peak at about 980.
#5. We did not extend the ancient end. The update includes the ancient data and merely overplots it.
I don’t think a state-wide precipitation index means much at high elevations. I would imagine that nowpack amounts and the number of thunderstorms that happen to occur there are especially critical.
#7 Agreed on snowpack.
Steve,
You’ve got yourself confused by a common misuse of the double-negative here, I believe. I think you’re trying to say the reduced growth is associated with the statewide drought, in which case it should be “is” rather than “isn’t” after “1840s”. “Hard to avoid” is essentially the same as “easy to accept”. If you read that sentence using the latter version, it’s hard to avoid the fact that you’ve not used good grammar.
1) They got a hockey stick out of THAT?!?! WTF?
2) Trees make lousy thermometers, apparently.
RE: #7 and 8 – Adding to this, I would say that summer thunderstorms are probably a bit more reliable on the Front Range than in the Whites. Both are of course highly dependent on snow pack persistence as a control on how much moisture is available in July and August. The idea scenario is where winter comes in two surges, one that dumps lots and lots of snow, then, a hiatus in say, March or April, allowing the ground to thaw, followed by a late series of snow events, dumping massively throuth late April and May, atop the now thawed ground. A typical pattern in the Whites, perhaps also common in the Front Range.
You see a similar, albeit smaller dip in 1934. Granted I looked at 1934 for a particular reason.
The rebound in 1935 is remarkable.
The question for the biologists is how rapidly does a tree respond to climate differences
( BCPs aint tomatoes) Anyway, the dip in the 1934 range would seem to be negataively correlated
with temp (assuming no lag in the response) and then 1935 shows a spurt of growth.
Record rainfall 25 miles from colorado springs in 1935. 24 inches in 6 hours. in a region
that sees 16=18 inches/yr
http://books.google.com/books?id=NuP7ATq9nWgC&pg=PA118&lpg=PA118&dq=record+rainfall+colorado+1935&source=web&ots=4J7L2hfCdj&sig=psuDy2xCm2L3oK3PNXTQZNw-imw
Colorado spring rainfall… http://www.crh.noaa.gov/pub/?n=/climate/cospcpn.php
MrPete will comment on the use of colorado springs precip data.
Just to clarify:
Do you mean you think drought was likely widspread across the state?
Also, I was looking for USHCN data for Cheesman Reservoir. The only source that I found for this was this one. I’m curious why the table for Cheesman ends at 1984. If there is a more recent record for this site, could someone link it?
the table for Cheesman ends at 1984
That should read “1994”. Sorry. Same question. What happened the last 13 years?
I’m confused over the grey “cloud” around the chronology graphs. Are these the yearly values with the graphs giving smoothed values?
Can you estimate confidence bands? If the “clouds” are yearly values I’m guessing such bands would be pretty big.
And finally, how do we get from these curves to temperatures?
Should be interesting in San Francisco.
How indeed. There’s no correlation during the calibration period. Which would imply the temperature reconstruction confidence bands are infintely wide.
Teleconnection?
Sorry – the clouds show all the individual measurements.
No idea. When there’s an r2 of 0, it’s about as informative as a Mannian reconstruction.
I love a good crosspost. Independent convergence, as opposed to forced consensus.
#13. My USHCN collation has Cheesman through to 2006.
O.k. Found it.
MattN: That’s just it, they didn’t get a hockeystick out of this kind of data. This kind of data was used to create the flat shaft. The blade was created by splicing on the modern thermometer record to the end of the chart. Locate the record that shows what you want for each time period. Splice them together. Prove anything you want.
“Numbers are like people. Torture them long enough, and they’ll tell you anything you want to hear.”
Steve: There’s more to making the proxy blade than that – as I’ve discussed at length on the blog elsewhere.
#16, 17. I’ve added a dendro-style “reconstruction” of Cheesman Reservoir temperature.
Steve:
Just for clarification purposes, is it accurate to say that the Sheep Mountain (California) BCPs are believed to be the source of the hockey stick, rather than these Colorado BCPs?
Steve: Yes, Sheep Mountain is by far more important. See the Ababneh update though.
So this is the result of the negative exponential fit of each tree, averaged together and with an 11-year smooth through the incredibly noisy data.
Can this whole procedure have any statistical or physical integrity? Does bristlecone tree growth relate to any useful climatic variable?
Steve: Perhaps it is teleconnected.
To any newbies: this is a major development in the so-called “hockey stick debate”, which asks: “are current temperatures ‘unprecedented’ compared to previous tiems, such as the MWP?”. Past studies have relied on data that were 20 years old. These data are new. They illustrate a huge 20th century divergence between the tree-ring record and the instrumental temperature record. i.e. Treering vs. temperature calibrations that appeared to work well up until the 1980s no longer work.
Thanks Steve. I guess I was trying to clarify for the purposes of those posters who are looking for the hockey stick in the Amalgre BCPs. As I understand it, there never was a hockey stick from the Amalgre chronology, only from the telconnected sweet-spot of Sheep Mountain.
Sorry if this is a bit OT for this thread, but have you tried updating the Sheep Mountain data with Abaneh’s data and running it through a psuedo Mann-o-matic, in the same way you did with the tech stocks? I try to keep up with the blog, and if I missed this, I apologize for eating the bandwidth.
Steve, in #24 you say “Perhaps it is teleconnected.” Are you being funny or are you serious? (I personally find this teleconnected idea to be complete nonsense, but I’m not a scientist, and am I right in thinking that even Bender may findit plausible?
Regarding Cheesman temperature record
Perhaps you’ve discussed already: It’s difficult not to speculate on the effect of the Hayman Fire on the 2002 temperature reading. It was Colorado’s largest wildfire. Photo shows Cheesman in the cleft of the northward-spreading fire. The year was 2002, the “tip” of the hockeystick blade, I believe.
I’ve added a comparison of a chronology developed only from our Graybill site measurements and the Graybill 1983 measurements. They match very closely (r=0.89). So the chronology itself appears to be replicable and not merely random. Determining whether or not the chronology is teleconnected to precipitation in Bombay, births in Honduras, wine sales in Australia or the first consonant of Presidential surnames will undoubtedly require “sophisticated” analysis.
#27
He’s being funserious. Let’s have our lecture from JEG on what teleconnection *really* means. Then we can judge. Agnosticism is hard, I know.
Steve, As an engineer, rather than a statistician, I find most information from the graphs rather than the basic numbers, but one thing has been totally baffling me with these rings, apart from the point you make. Just looking at rings from trees cut down in my own garden, the widths vary around the tree, and they don’t vary evenly, so, for instance, one side of the slice has ring,say, 1995 wider than 1996, yet further round the trunk, it’s the other way round. Given variations like this, just how can anything at all be extracted from tree rings? This is shown in post #39 by Willis in the earlier Almagre thread. Some major events do seem to line up, but in other places, the two lines are going in different directions, forgive me, but, huh….?
The subsequent question is how are the detrending equations obtained? Is there some sort of recent calibration, or is this just an educated guess on someone’s part?
Finally, silly question perhaps, but has anyone done a plot of this century’s rings against “global temperature”?
Hope this is not too simplistic, as I really am interested and have been following for quite a while now.
Sorry, I’d intended to quote your # 17, but haven’t quite got the hang of block quotes yet.
You said
Sorry – the clouds show all the individual measurements.
And finally, how do we get from these curves to temperatures?
No idea. When theres an r2 of 0, its about as informative as a Mannian reconstruction.
Re #32:
That is a very good question…
Highlight all of the text you want to quote and hit the B-Quote button. The window will put appropriate tags around your quoted text.
Mark
#28 asks
CA search for “bender” and “teleconnection” leads to:
http://www.climateaudit.org/?p=2400#comment-164463
Short answer: it depends what you mean by “it”. There are several layers to the dendro-teleconnection postulate.
-climate at A is correlated (shares a common low-frequency signal) with climate at B (reasonable; e.g. Tasmania-California via ENSO)
-trees at A respond causally to climate at A (reasonable)
-trees at A spuriously correlate better with climate at B than A (reasonable; given B is detected post-hoc and correlation is a statistic subject to sampling error)
-trees at A appear to respond better to climate at B (reasonable; thinking correlation may imply causation)
-trees at A actually do to respond better to climate at B than A (unreasonable)
Fishing for teleconnective dendro-correlations is prone to logical errors of the type post hoc ergo proctor hoc. Fine for building working hypotheses. But not robust enough to withstand a challenge in court.
The correlation between this analysis and that of Graybill almost a quarter-century ago seems to be very important, and a ringing endorsement of the methodology employed in both cases. It is extraordinary that, on an individual tree level, data is so noisy as to appear almost useless, yet the whole contains a long-term signal that is reproducible.
Aye, there’s the rub. If I have enough ‘proxy’ series and enough temperature series I can find many correlations. It is worse if the series are trending/non-stationary and I don’t adjust appropriately for it. Standard statistics says that about 1 in 20 regressions will show ‘significant’ correlation where there is none — how many regressions do you think researchers run before they fix on the one they publish?
Give me enough data and I will find a pattern in it. A pattern that might even be ex-post rationalisable. But dollars to doughnuts it won’t be a real pattern.
That’s because the “noise” isn’t due to sampling error. It’s the internal complexity of the trees’ response to the environments in which they live. The sampling error on these chronologies is miniscule becasue the populations have been so intensely sampled. Don’t mistake complexity for uselesenss.
Questions and comments:
Confused why the final power transformation chronology, from 900 on, is displayed starting at or before 800?
Be careful about assuming tremendous replication power. Yes, with appropriate smoothing and a small data set, the data largely duplicates Graybill’s over the displayed period. That’s comforting. Is the correlation as nice over a longer period of time, and with other Graybill trees? I dunno.
JS, I (and Kenneth Fritsch) anxiously await JEG’s explanation to the contrary.
32, Tony: I think it goes this way: If you draw, say two or three lines from the center (pith) of the tree perpendicular to the rings to the outside of the tree and measure the ring widths along each line, you will generally see that the relative ratios of the widths along each line are the same, even though the rings vary in width around the diameter of the tree. It’s this ratio that is supposed to be a thermometer. Of course, if the core isn’t taken perpendicular to the pith, you don’t have the proper ratios, so you have measurement errors, and I don’t know how these are dealt with.
Could you graph against sunspot numbers?
I think those trees like lots of sunspots.
Some more hints. USHCN have precip data for cheeseman, canon city, etc. You can get monthly data.
A glance at the data suggest this: Watch the spikes and jolts. Watch the tree ring response when the
rainfall jolts below the mean of 16 in. Basically, look what happens if
1. year X is mean precip (16 in or slight above)
2. Year X+1 is 2-3Sd below it.
Basically what happens if a tree get 16 inches ( mean) one year and 10 the next ( sd = 3)
Its different if the precip falls from 19 to 13.
Years to check, 1923-24, 1933-34, 38-39, 42-43, 77-78.
( eyeballing)
When the rainfall falls a 2 or 3 stdv below the mean, the tree responds.I looks to me.
( i havent looked at all the rings ) but the jolts below the mean precip seem to indicate something.
What;s left when you remove this signal?
Steve M thanks for taking time to explain some of the steps used in reducing the tree ring measurements to more meaningful data. Attempting to understand what tree ring growth means and how it is handled and manipulated would not have been something that I would have thought would be occupying much of my time in retirement. The real life participation in these activities that you and Mr. Pete have reported here would make it difficult not to take an interest.
Am I correct in assuming that your TRW are being measured in exactly the same manner as those used in the original reconstruction? Did they use MXD in conjunction with TRs at that time or is that a more recent development? I seem to recall that a number of Rob Wilsons papers described calibrations that apparently were weighted more heavily by the MXD variable than TRW.
One thing struck me: in standard dendro treatment there seems to be no consideration of non-stationarity. Does anyone know why this is ignored? Annual ring widths would appear to invite time series-based analytical techniques. And things do look non-stationary, meaning that the negative exponential is a bad idea. Am I missing something here? I’ve thought of 2 justifications: Dendros go for the residuals and they are white noise –not sure I believe this and how can these (straight reisudals or these ratios) then reveal a hockey stick (not white noise)? The other theory: when dendro techniques were being developed time series techniques were not easily implemented, apart from trivial examples. I’d love to hear from the dendro folks that drop by here.
#45. MXD wasn’t done in the original bristlecone studies, nor by us.
I’ve done chronologies using ARSTAN but I’ve done fits here using R scripts that I’ve reconciled to ARSTAN. The only slight difference is standardizing on a tree basis rather than for each core. It doesn’t really make any difference. For consistency’s sake, I’ll archive an ARSTAN version as well. I have a secondary interest in showing dendros that you can make chronologies using a statistical technique known off the Island.
Will we see this soon?
#46
Hey, I look at it and think that it looks like a massive panel data set. With enough samples you can estimate year dummies and age dummies across the entire stand. No need to impose any structure on the data or growth patterns of trees. You could parameterise it if you felt the need – but that wouldn’t be necessary with enough data. You might have some identification problems for really ancient dates but that may not be a significant problem depending on the objective. Take the year dummies and you have your ‘climate’ signal. Although you will still have the problem of interpreting that climate signal, your normalisation should be better than what you would get with a tightly parameterised and restrictive funcitonal form as is used in the standard detrending procedure.
The techniques are the same as are used to estimate interesing effects in, say, the PSID (Panel Study of Income Dynamics) and the statistical properties are well established. (Like, for example, separating cohort effects from age effects.)
I’ve estimated chronologies using some settings in the nlme package in R. You have to estimate cross factors and it’s a little tricky.
For this particular data set, where the cores are often long, the detrending doesn’t have as much impact as one would think. The juvenile portion wears off after about 50 years and is flat thereafter. My suspicion is that there is some bias introduced with these series, since they usually don’t hit the pith and the juvenile bias could simply be a decline from a high quasi-cycle. A ring width average looks very similar.
…and a followup speculation.
If the trees reliably go stripbark at an advanced age, then the age dummies would pick that up (on average) and you would have a novel way of partialling out that particular confounding influence. The big panel data approach would identify the strip-bark growth pulse with age not year. Maybe I’ll fire up Stata and poke around in the data set when I don’t have anything better to do.
Of chronologies archived at the ITRDB that go back to AD1000, it looks like Almagre is the highest!
Correlations
Steve, a year ago I expressed reservations about using mid-level correlation coefficients, preferring r^2 above 0.9. I am pleased our thoughts are converging and that we both agree that a correlation coefficient of zero has significant interpretative confidence.
Re # 32 Tony Edwards
Graphs are ok, but have a closer look at Steve’s graph “Grabill & Updated…” The two curves do look well correlated, but when you do a count you find that the eye sees mainly about 25 peaks in this 400 year term, marching in step. It is not uncommon in many fields of science that the devil is in the detail, requiring an excellent statistician (which I am not) to extract the max from the data. But you’d know this. It’s part of the reason why the hockey stick had so much public impact.
Steve – Re “detrending” exponential correction. I presume this is used because the ring width is a greater part of the diameter when the tree is young, then it evens out somewhat in midlife. However, towards death, the ring width should thin (relatively) as its function and load decreases. I have not specifically searched recent papers for a more sophisticated curve, but did work through the maths of this with foresters 20 years ago. We also did live weight vs. time curves for plantation trees to predict best harvest time, this possibly related to ring growth measurements.
Looking forward to the final conclusions from your stay in Calif. Fascinating numbers.
SteveM are all the cores used in the plot shown above, both cores for each tree? If so, then as well as the strip bark-whole bark disaggregation, it would be interesting to see that data compared.
I had asked in the previous thread how the dendros do it … Steve Mc, many thanks for explaining how they do it.
However, it seems to me that the standard method, with or without a power transformation, throws away a lot of information. I would respectfully submit that my method preserves that information.
I had looked for a method that would preserve the pattern, minimize single-year jumps, and have a relatively normal distribution. The derivative, or “first difference”, was the obvious choice. However, the normal (discrete) first difference definition of (Y(t) – Y(t-1))/(X(t) – X(t-1)) doesn’t work because a ring width change of 1 mm on a 2 mm ring is very different from a 1 mm change on a 5 mm ring. To equalize the effects of wide and narrow rings, it is better to use a percentage change. (Using the median of percentage change, curiously, will also remove most of the “early fast growth” bias which the dendros remove with ARSTAN.)
I initially used a straight percentage of increase, Y(t) / Y(t-1) – 1. This does not give a normal distribution. A better form is logarithmic, ln( Y(t) / Y(t-1) ). This can be restated as ln(Y(t)) – ln(Y(t-1)), and is not too far from normality. (The normality only matters for the error calculation.)
Then I took the median of the individual tree changes for each year. I used the median to minimize the “one-year jump” error. Finally, I inverted the original logarithmic transformation to yield the reconstructed dataset.
To understand why this transformation is better than the ARSTAN==>average transformation, we can consider a much simpler question. What is the most accurate way to estimate a given single year’s change in the record?
Now, we can average year t and year t-1, and subtract one from the other, that’s one way. The problem is that it doesn’t deal well with single-year jumps. If a couple of the trees took big single-year jumps last year, it will skew the record. It may make a year of declining ring width look like a year of increasing ring width. And unfortunately, it will skew the record for as long as it does not return to its former position. Taking the median of the first difference (as a percentage) avoids or greatly minimizes those problems.
In addition, I’m nervous about ARSTAN. I get nervous in general when you fit a line to a bunch of natural data and say “ceteris paribus, it would should be like this” …
Ringwidth = A + B exp(-C*age)For starters, it assumes that you know the tree’s age. Given that in this species, the location of the heart is often anyone’s guess, does a core reveal the age of the tree? I would think in many cases, no.
Steve is pointing in the right direction with detrending on the basis of the whole tree or the stand, rather than the individual core. But this still does not deal with the one-year jump problem … and it still requires that we know the age of the tree. The core with the green crosses illustrates the problem perfectly. If we didn’t have the longer core, we would ARSTAN detrend that whole tree totally incorrectly.
The result of this incorrect detrending is that it removes good information from the dataset, and replaces it with wrong information. Does this make a difference? I don’t know. I also don’t like the idea that some trees get detrended with a straight line with a negative slope … and when you are looking for a trend in data, that doesn’t seem like a good plan.
This is a particularly insidious error, because (as in the green cross data in Fig. 1) the un-detrended change may represent valid data. The insidious part is, under ARSTAN, it sometimes will fit a line or a curve with an erroneous negative slope, but it will never fit a line or curve with an erroneous positive slope. This has the potential of introducing an erroneous positive bias in the results, because some valid negative trends will have been removed.
As I said, I don’t know whether this is a problem, or how to quantify it. I point it out as a potential hazard of ARSTAN detrending. I suspect that some broader average, based on Steve M’s “grassplots” or the like, applied only to the trees where it is clear that there is a real need based on some statistical evidence, would do a better job.
Finally, I like my method better than the dendro method because it is conceptually much simpler. I am calculating the integral of the median of the first derivative. This avoids fitted curves, and allows the inversion of the final result back into the units we started with (ring width).
Anyhow, gotta run, work calls. I’ll look further at these questions and report back.
w.
I wondered if someone could explain something I could not grasp from the intro: Where did the 900 – 1100 data come from?
I’ve always been baffled by the normalization of the raw data. (The step where you fit an exponential curve to the data and subtract off the exponential trend.)
As I understand it, this step removes the trend from the data. How then can you use the detrended data to say anything about the trend in the data, i.e., that it is warmer in later years than in earlier years? Don’t the results we are interested in depend critically on the curve used to detremd the data?
And even if some information manages to survive the detrending, don’t the confidence intervals explode because the detrending process itself introduces noise into the results?
Given that the Team can, with a straight face, use the confidence intervals from the calibration period in the backcasted period, I would be astonished if the Team has even thought of this, but has anyone thought of it?
A bit hard to find the right slot for this, but it’s about CO2 fertilization of tree growth and possible effects on tree ring analysis. It’s about FACE, a method where free air CO2 enrichment is given to growing systems. It’s typically coordinated by Oak Ridge National Laboratories, who commonly tag the added CO2 with isotopes to follow its path.
On Unthreaded #32 @ 150 I posted on March 20 2008 that the preamble to some FACE work (for oceans) had ideological preconceptions and I gave this excerpt:
Now on to trees and compounds of forest with high CO2 added.
http://www.anl.gov/Media_Center/News/2005/news051220.html
A minor derivation from this press release is that maybe reduction of atmospheric CO2 can be done by adding more CO2 to the atmosphere.
Note, however, that no promises are given that the new carbon will stay in the soil forever. Other agricultural studies suggest it will be temporary, otherwise soils would soon turn to coal or similar.
The reason I raise FACE here is to show you CA maths people the power of meta-analysis. The sought effect was not found until meta-analysis was done. Why have you not informed and educated the rest of us before of the power of this method/ (He asks sarcastically).
Finally, another CA contributor has noted an absence of reported temperature measurements, so that tree ring analysis in the future, from these trees, might be difficult to interpret.
Is FACE worth a separate thread?