by Hu McCulloch
A recent discussion of the 2007 Tellus paper by Bo Li, Douglas Nychka and Caspar Ammann, “The ‘hockey stick’ and the 1990s: a statistical perspective on reconstructing hemispheric temperatures,” at OSU by Emily Kang and Tao Shi has prompted me to revive the discussion of it with some new observations. A PDF of the paper is online at Li’s NCAR site.
The 8/29/07 CA thread MBH Proxies in Bo Li et al has already discussed certain data issues in depth, but the 11/18/07 general discussion Li et al 2007 never really got off the ground. (See also a few comments by Jean S and others in an unrelated CA thread.)
The lead and corresponding author, Bo Li, is an energetic young statistician (PhD 2006) at NCAR. Presumably her role was to bring some new statistical techniques to bear on the problem, while the two senior authors provided most of the climatology know-how. I’ll start with my positive comments, and then offer some criticisms.
My first upside comment is that the paper recalibrates the 14 MBH99 1000 AD proxies using the full instrumental period of 1850-1980, rather than just 1902-1980 as in MBH. Cross-validation with subperiods is a fine check on the results (see below), but in the end if you really believe the model, you should use all the data you can find to estimate it.
Secondly, I was happy to see that the authors simply calibrated the MBH proxies directly to NH temperature rather than to intermediate temperature PC’s as in MBH. Perhaps someone can correct me if I’m wrong, but I don’t see the point of the intermediate temperature PC’s if all you are ultimately interested in is NH (or global) temperature.
Third, although the cumbersome Monte Carlo simulation at first puzzled me, because confidence limits for the individual temperature reconstructions are calculable in closed form, it eventually became clear that this was done because the ultimate goal of the paper is to investigate the characteristically MBH question of whether current temperatures are higher than <i>any</i> previous temperature over the past 1000 years. A confidence interval for each year (or decade or whatever) does not answer this, because it merely places a probability on whether that particular year’s temperature was higher or lower than any given level. There is no closed form way to test the much more complex hypothesis that current temperatures are higher than <i> every </i/> past temperature. Monte Carlo simulations of past temperatures based on perturbations of the estimated coefficients potentially enable one to place probabilities on such statements. (I would call these “simulations” rather than “ensembles”, but perhaps that’s just a matter of taste.)
And fourth, the authors explicitly check for serial correlation in the residuals of their regression, find that it is present as AR(2), and incorporate it appropriately into the model. MBH seem to have overlooked this potentially important problem entirely.
Unfortunately, I see a number of problems with the paper as well.
My first criticism is that the authors start with an equation (their (1)) that is supposed to relate NH temperature to a linear combination of the MBH proxies, but then provide no indication whatsoever of the significance of the coefficients.
The whole difference between statistics and astrology is supposed to be that statisticians make statements of statistical significance to determine how likely or unlikely it is that an observed outcome could have happened chance, while astrologers are satisfied with merely anecdotal confirmation of their hypotheses. Perhaps climate scientists like MBH can’t be expected to know about statistical significance, but the omission is doubly glaring in the present paper, since Nychka is a statistician as well as Li.
The MBH proxies are perhaps sufficiently multicollinear that none of the individual t-statistics is significant. However, it is elementary to test the joint hypothesis that all the coefficients (apart from the intercept — see below) are zero with an F statistic. This particular test is known, in fact, as the Regression F Statistic. The serial correlation slightly complicates its calculation, but this is elementary once the serial correlation has been estimated. Or, since the whole system is being estimated by ML, an asymptotically valid Likelihood Ratio statistic can be used in its place, with what should be similar results. (My own preference would be to take the estimated AR coefficients as true, and compute the exact GLS F statistic instead.)
Since for all we know all the slope coefficients in (1) are 0, the paper’s reconstruction may just be telling us that given these proxies, a constant at the average of the calibration period (about -.15 dC relative to 1961-90 = 0) is just as good a guess as anything. Indeed, it doesn’t differ much from a flat line at -.15 dC plus noise, so perhaps this is what is going on. This is not to say that there might not be valid temperature proxies out there, but this paper does nothing to establish that the 14 MBH99 proxies are among them. (Nor did MBH, for that matter.)
My second criticism deals with the form of their (1) itself. As UC has already pointed out, this equation inappropriately puts the independent variable (temperature) on the left hand side, and the dependent variables (the tree ring and other proxies) on the right hand side. Perhaps tree ring widths and other proxies respond to temperature, but surely global (or even NH) temperature does not respond to tree ring widths or ice core isotope ratios.
Instead, the proxies should be individually regressed on temperature during the calibration period, and then if (and only if) the coefficients are jointly significantly different from zeros, reconstructed temperatures backed out of the proxy values using these coefficients. This is the “Classical Calibration Estimation” (CCE) discussed by UC in the 11/25/07 thread “UC on CCE”. The method is described in PJ Brown’s paper in the Proceedings of the Royal Statistical Society B;, 1982, (SM – now online here)and is also summarized on UC’s blog. See my post #78 on the “UC on CCE” thread for a proposed alternative to Brown’s method of computing confidence intervals for temperature in the multivariate case.
In this CCE approach, the joint hypothesis that all the slope coefficients are 0 is no longer the standard Regression F statistic. Nevertheless, it can still be tested with an F statistic constructed using the estimated covariance matrix of the residuals of the individual proxy calibration regressions. Brown shows, using a complicated argument involving Wishart distributions, that this test is exactly F in the case where all the variances and covariances are estimated without restriction.
To MBH’s credit, they at least employed a form of the CCE calibration approach, rather than LNA’s direct regression of temperature on proxies. There are, nevertheless, serious problems with their use (or non-use) of the covariance matrix of the residuals. See, eg, “Squared Weights in MBH98”> and “An Example of MBH ‘Robustness'”.>
One pleasant dividend that I would expect from using CCE instead of direct regression (UC’s “ICE” or Inverse Correlation Estimation) is that there is likely to be far less serial correlation in the errors.
My third criticism is that that even though 9 of the 14 proxies are treerings, and even though the authors acknowledge (p. 597) that “the increase of CO2 may accelerate the growth of trees”, they make no attempt to control for atmospheric CO2. Data from Law Dome is readily available from CDIAC from 1010 to 1975, and this can easily be spliced into the annual data from Mauna Loa from 1958 to the present. This could simply be added to the authors’ equation (1) as an additional “explanatory” variable for temperature, or better yet, added to each CCE regression of a treering proxy on temperature. Since, as MBH99 themseleves point out, the fertilization effect is likely to be nonlinear, log(CO2), or even a quadratic in log(CO2) might be appropriate.
Of course, any apparent significance to the treering proxies that is present will most likely immediately disappear once CO2 is included, but in that case so much for treerings as temperature proxies…
A fourth big problem is the data itself. The whole point of this paper is just to try out a new statistical technique on what supposedly is a universally acclaimed data set, so LNA understandably take it as given. Nevertheless, their conclusions are only as good as their data.
The authors do acknowledge that “many specific criticisms on MBH98” have been raised, but they do not provide a single reference to the papers that raised these objections. McIntyre and McKitrick 2003, MM05GRL and MM05EE come to mind. Instead, they cite no less than 6 papers that supposedly have examined these unspecified objections, and found that “only minor corrections were found to be necessary” to address the phantom-like concerns. LNA have no obligation to cite McIntyre and McKitrick, but is rather tacky of them not to if they cite the replies.
Many specific data problems have already been discussed on CA on the thread MBH Proxies in Bo Li et al and elsewhere on CA. See, in particular, the numerous threads on Bristlecone Pines. I might add that it is odd that MBH include no less than 4 proxies (out of 14) from the South American site Quelccaya in what is supposedly a study of NH temperature.
A fifth problem is with the author’s variance “inflation factor”. They commendably investigate k-fold cross-validation of the observations with k = 10 in order to see if the prediction errors for the withheld samples are larger than they should be. This makes a lot more sense to me than the “CE” and “RE” “validation statistics” favored by MBH and others. However, they appear to believe that the prediction errors should be of the same size as the regression errors. They find that they are in fact about 1.30 times as large, and hence inflate the variance of their Monte Carlo simulations by the same factor.
In fact, elementary regression analysis tells us that if an ols regression

has variance 


Since the quadratic form in x* is necessarily positive, the factor is necessarily greater than unity, not unity itself. Exactly how much bigger it is depends on the nature and number of the regressors and the sample size. Using 10,000 Monte Carlo replications, with estimation sample size 117 and 14 regressors plus a constant, I find that if the X’s are iid N(0,1), the factor is on average 1.15, substantially greater than unity. If the X’s are AR(1) with coefficient 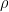
2.18 1.22 (corr. 11/17/12), and if the X’s are a random walk (
If the variance of the cross-validation prediction errors prediction errors were significantly greater than they should be according to the above formula, that in itself would invalidate the model, instead of calling for an ad hoc inflation of the variance by the discrepancy. The problem could be a data error (eg 275 punched in as 725), non-Gaussian residuals, non-linearity, or a host of other possibilities. In fact, the authors make no attempt to perform such a test. I don’t know whether it has an exact F distribution, but with two statisticians on board it shouldn’t have been hard to figure it out.
Although LNA make no use of the above prediction error variance formula in their reconstruction period, it is in fact implicit in their Monte Carlo simulations, since in each simulation they generate random data using the estimated parameters, and then re-estimate the parameters using the synthetic data and use these perturbed to construct one simulated reconstruction. They therefore did not need to incorporate their inflation factor into the simulations. They should instead have just used it to test the validity of their model.
One last small, but important point, is that their (1) does not include a constant term, but definitely needs one. Even if they de-meaned all their variables before running it so that the estimated constant will be identically 0, this still is a very uncertain “0”, with the same standard error as if the the dependent variable had not been demeaned, and will be an important part of the simulation error.
Anyway, a very interesting and stimulating article. I wish Dr. Li great success in her career!





65 Comments
Also there is an “invalid pointer” error at line 47 char 3 in IE6
Hu had a little trouble with the WordPress code; I’ve tidied a few links and will tidy more later if still required.
I’ve always had a problem with the 2 doublequotes the link quicktag adds to the URL after the href=
To me, the interesting questions are
1) Why ICE model ( MBH9x is modified CCE) ?
2) Why only 14 proxies were used in ‘inflation factor’ analysis?
3) What is wrong with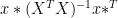 term? It seems to be always dodged and some other method is applied ( see for example http://www.climateaudit.org/?p=2563#comment-191063 ) .
term? It seems to be always dodged and some other method is applied ( see for example http://www.climateaudit.org/?p=2563#comment-191063 ) .
I’m afraid all but a few of my links somehow got garbled by WordPress, but if you just copy the URL and paste it into your browser you’ll get them.
RE UC, #4:
UC’s Point 1: I think we agree that by using ICE instead of CCE, LNA have unfortunately taken a step backwards from MBH.
UC’s Point 2: LNA were looking for evidence that historical temperatures were ever as high as they were now. Since most would agree that any such episode would have been prior to 1400, they just used the 14 MBH99 proxies for this period for their entire reconstruction. In their figure 4, they emphasize their target period 1000-1400 by making its error band yellow instead of gray, though unfortunately the yellow disappears if you print it in B&W.
UC’s Point 3: I think we agree.
I tried to read the paper but was baffled. Did they somewhere establish that the proxies had a good correlation with global temperature anomaly? Somehow I just can’t believe that any fourteen proxies have teleconnection to global temperature. If they demonstrated that each proxy correlated well with local temperature and that local temperatures combined in some fashion correlated well with global anomaly, that would be amazing. I didn’t see that.
Mike Rankin, #6, writes,
No — see my first critical point.
I don’t have a problem with the idea that just 14 proxies (or even fewer) might give us meaningful information about global (or hemispheric in the case of MBH and LNA) temperature. The global temperature is just the average over the globe of the local anomalies, so if the proxies correlate well enough with local temperature, they may well correlate with with global temperature as well. Then if you average together these signals, you may come up with an even better estimate of global temperature.
In fact, Craig Loehle and I (EE 2008) find a significant global LIA and MWP signal (relative to the bimillenial average) by just averaging together 18 proxies that had already been calibrated to temperature in published articles.
In our case, the proxies were plausible temperature proxies, and had a fairly good geographical distribution. The MBH/LNA proxies, on the other hand are heavy with treerings (9 out of 14), and it’s not clear why treerings would correlate with temperature. Presumably BCPs and White Cedars etc. grow where they do because they like the climate there — temperature and all. If the temperature goes either up or down from the optimum, I would expect their growth to fall off. Why else are the BCPs in the Amazon not the size of giant sequoias?
Treerings might correlate with temperature (even after holding CO2 and any other measurables constant), but the burden of proof is on MBH and/or LNA to establish that they do. As the old Wendy’s ad almost said, “Where’s the F?”
re 7. Hu you wrote:
“I don’t have a problem with the idea that just 14 proxies (or even fewer) might give us meaningful information about global (or hemispheric in the case of MBH and LNA) temperature. The global temperature is just the average over the globe of the local anomalies, so if the proxies correlate well enough with local temperature, they may well correlate with with global temperature as well. Then if you average together these signals, you may come up with an even better estimate of global temperature. ”
Surely this is testable. In fact, I think its easily testable. A thermometer is a proxy of
temperature. It’s a REALLY GOOD proxy. So, here is a thought.
Cherry pick 14 thermometers that correlate BEST with the GSMT from 1925-2000.
See how well those 14 predict GSMT from 1850 to 1925.
If 14 trees can reconstruct a global climate, then 14 thermometers should be able to beat them.
fun thought.
h
Quick note of formula for forecast error:
For a forecast Y(T) = X(T)*Bhat
(where (T) denotes the forecast period)
the forecast variance when X(T) is known, i.e. not predicted itself, is:
Var(Y(T)) = (s^2)*(1+X(T)*((X’X)^-1)*X(T)’),
where
s^2 is the estimated variance of the error term,
and X is the data matrix (n by the number of regressors)
It seems that the ‘T’ for the forecast period and the ‘T’ for transpose got mixed up and dropped in the first part of the matrix product.
Further note: if the X(T) is not known — and in most forecasting it is not — the variance of the forecast has a extra two terms:
bhat’Var(bhat)*bhat +
trace((s^2)*((X’X)^-1)*Var(bhat))
to account for the variance in the X(T)*bhat.
Two questions really.
1. Do they crosscheck both sub-periods as well as the total period during the calibration? IOW, do sub-periods show the same level of calibration as the entire available period.
2. Are the cross checks done against static temperature records? As we’ve seen with GISS, they are constantly tweaking historical records. I’m wondering whether or not the temperature record that is used during the calibration period is constant or if it also changes over time.
Brown 1982 often mentioned by UC and Hu is now online here
I thought that it would be instructive to work through Brown’s calibration approach line by line using the MBH99 proxies used in Li et al. The proxies and the “sparse” temperature data set used in MBH98 verification can be loaded as. Here I’m going to try univariate analysis of the fan010 tree ring proxy.
Here is a scatter graph of the proxy against temperature showing little relationship.
USing a garden variety linear regression of the proxy against temperature in the calibraiton period, the visual impression of no relationship is confirmed. The t-statistic for the relationship of the proxy to temperature fails significance.
Brown’s equation 1.2 sets out a procedure for estimating confidence intervals on x given y (in a univariate case) which I apply here.
Using standard estimates:
alpha=coef(fm)[1];
beta=coef(fm)[2]
sigma=summary(fm)$sigma # 0.1939669
n=sum(temp)
Sxx=ssq(sparse[temp]);Sxx #[1] 4.918856
xbar=mean(sparse[temp]) ;xbar # -0.002572732
qt(.975,df=n-2) #[1] 1.991254
Brown arranges the above equation as a quadratic function of x given y(see multivariate for example). This yields:
where
At the average value of the proxy y, this gives the quadratic equation:
-0.01164195 x^2 + 0.001984446 *x -0.07556413 <= 0
The discriminant of this quadratic is negative:
discriminant= 0.001984446^2- 4*(-0.01164195)*(-0.07556413) ;discriminant# -0.003514917
Brown says of confidence intervals:
I don’t think I’d call something that measures a specific physicial change in a known way in real time a proxy. Taking one point and sampling it hourly to derive a daily mean for an entire area, using min max from the samples, well, that’s another story.
Free the teleconnections!
Re: #8
How about randomly selecting sets of 14 stations from the USHCN data set (Urban, as I suspect this is what would be used for proxy calibration) of 1221 stations from 1920-2005 and look at the variations amongst sets in temperature anomaly trends. Do the same only restrict the stations to those stations west of the Mississippi. The exercise will not tell you anything about the accuracy of tree rings as thermometers or extracting trends from noisy data, but it will give one a feel for how well one can estimate a large area trend using spatially limited measurements. I think I have done at least part of this exercise when looking for statistical significance when comparing CRN123 and CRN45 station anomaly trends.
Martin Ringo, #9 writes,
I was only using T for transpose, not as a time index. Also, I only use * to differentiate the forecast period vector of regressors x* and scalar outcome y* from the calibration matrix X and vector of outcomes y. I was not using * to indicate multiplication. Abstracting from serial correlation and the intercept, (and not attempting TeX so as not to crash the system again!), the estimate of beta is then
betahat = inv(X^T X) X^T y.
The forecast of y* is
y*hat = x* betahat
The forecast error is y* – y*hat, and has variance
(1 + x* inv(X^T X) x*^T) sigma^2
Not so?
Var(bhat) is already estimated by (s^2) inv(X^T X), so I don’t get why you are multiplying this by Var(bhat).
If the forecast period values of the regressors — my x* — are not observed, there is no way to forecast y* at all. I don’t see what you have in mind here.
Steve writes in #12,
In MBH99, MBH did’t like the millennial HS they got with the proxies as computed by their modified PCA, and so hand-jiggered (“corrected”) PC1 by removing a segment of its low-frequency component and replacing it with the low-frequency component of a Jacoby and D’Arrigo “Northern Tree Line” series instead, with the excuse that it was somehow an adjustment for CO2. See my comment on the 11/13/07 thread “The MBH99 CO2 ‘Adjustment.'” A dry-ice fog “smoke screen” is more like it!
Can you figure out which version of PC1 LNA are using? Li posted data on her webpage, but later explained that this is not the actual data they used, but rather the actual data plus white noise that she added for experimental purposes. It would be helpful if she posted the data as they used it, even if it is available elsewhere.
Or perhaps one of the authors can tell us which version was used, if they are reading this — I e-mailed them inviting them to comment if they felt so inclined.
RE 14. Yup! I talked a while back to Bender about the insights such an analysis would yeild.
Essentially you look at how well a thermomter could reconstruct.
Now also consider this. A tree ring is a rsponse to a growing season. lets say 4 months
Do you believe that 14 thermometers, located in North American, measuring temperature for
4 months a year could reconstruct the GSMT?
Re: #17
While I make no claims for the statistical details of this exercise, I did some random sampling of the USHCN stations for temperature anomalies using the Urban data set from 1920-2005. I used only USHCN stations that had 5 or fewer years of missing data (1149 stations) and after calculation a temperature trend over the 1920-2005 period, took 249 samples that were each made up with 13 randomly selected stations (and corresponding trends) from the 1149 stations. I plotted them in the histogram shown below and calculated an average anomaly trend from the 249 samples of 0.40 degrees C per century with a standard deviation of 0.23. A chi square test for the distribution being a normal distribution returned a p = 0.92.
I also present below the global and zonal temperatures trends that make up the global trend for the period of the UAH MSU satellite measurements from 1979-2007. The zones demonstrate the large variations we can see in regional/zonal temperature trends over decadal time spans. Combining that information with the station analysis shows, for me at least, that the few temperature locations that go into these temperature proxies would provide an uncertain view of global or regional temperature trends. We also have the tree rings which measure temperature for only a few months a year and we have the uncertainty of relating those months’ temperatures to the annual temperatures.
In the post, I wrote,
For rho = .9, make that 1.218, i.e. 1.22, rather than 2.18.
I was hoping that one of Li, Nychka or Ammann would rise to my challenge and provide us with some those significance test thingums that statisticians used to perform. No such luck, so I downloaded the MBH99 data file at https://climateaudit.org/data/mbh99/proxy.txt and HadCRUT3vNH and tried it myself. (13 of the 14 series were provided by MBH at http://www.ngdc.noaa.gov/paleo/paleo.html, but for some reason Morocco is missing, and Steve has them all in one convenient file rather than separate ones.)
I ran the LNA equation (1) in EViews with a constant and all 14 proxies. Like LNA, I indeed found that an AR(2) error structure was present, with quite strong coefficients (.341, .456). The F test for the hypothesis that all 14 slopes were zero was F(14,106) = 3.308 (p = .0002), so in fact there is an easy reject. (The regression F-stat automatically printed by EViews evidently includes the AR coefficients as well as the regular slope coefficients, as it was much higher.)
Two of the proxies were individually highly significant (p
Re #20, WordPress swallowed 3/4 of my post after I carelessly used a < sign! I’ll retype it later, but it may be a while… Unfortunately, it’s not still present but invisible as Source text.
Stop it Steve. You know perfectly well that high elevation North American conifers are BETTER than thermometers because they’re teleconnected to the global climate via ENSO, AMO, NAO, GAO, and NATO.
BCPs are apparently even less than 4 months.
Mark
re 22. here is what I dont get. When Hansen has a booboo in the USA temperature record
Suddenly the USA is not important to the global record. but when it comes to BCPs
they magically reflect the GSMT.
My kid asked me the other day. “dad, Al Gore said the planet had a fever. How do they take it’s temperature?”
I was tempted to say that Dr. MAnn would shove a BCP up its ass.
But instead, I gave my kid a link to Surface stations.
Which is worse?
RE 14. ya, you get the idea. However, since the trees are ‘selected’ because the
are sensitive to climate, you should probably engage in some chery picking of thermometers.
Its a simple test. I’ll say more later
Re: #20
Your observation is the basis of my ongoing puzzlement on this entire issue. The giddiness of the original revelations of MBHXX to a world of climate scientist in search of confirmation of their consensus should have long been dealt with in whatever manner suits these scientists/statisticians. At this point why are there not more analyses with definitive conclusions in the mode of what is seen at CA and from M&M?
Some of these efforts do not even approach the level that Ross McKitrick ascribes to National Research Council Report where he states, “But you have to read the report closely to pick all these things up–they bury it in a lot of genteel and deferential prose”. A number of these analyses never even reach that point.
From a layperson’s perspective on this matter of MBHXX it seems that precautionary statistical analyses with a common sense application using known science or at least acknowledging what science has not revealed has been carefully avoided. It is also rather evident that the consensus science has switched emphasis from temperature reconstructions to the climate models, but without explicitly giving a reason.
I say that the perfect way to support MBHXX is for the authors to meet me in a steel cage match. Whoever walks out is correct.
Simple.
Such is the magic of teleconnections.
The paleoclimatologists might as well say “abracadabra” or “hocus pocus”.
Let me try #20 again:
I was hoping that one of Li, Nychka or Ammann would rise to my challenge and provide us with some those significance test thingums that statisticians used to feel obliged to perform. No such luck, so I downloaded the MBH99 data file at https://climateaudit.org/data/mbh99/proxy.txt and HadCRUT3vNH and tried it myself. (13 of the 14 series were provided by MBH at http://www.ngdc.noaa.gov/paleo/paleo.html, but for some reason Morocco is missing. Steve has all 14 in one convenient file rather than separate ones.)
I ran the LNA equation (1) in EViews with a constant and all 14 proxies. Like LNA, I indeed found that an AR(2) error structure was present, though with surprisingly strong coefficients (.341, .456), given the OLS autocorrelations (.236, .267). The F test for the hypothesis that all 14 slopes were zero was F(14,106) = 3.308 (p = .0002), so in fact there is an easy reject. (The regression F-stat automatically printed by EViews evidently includes the AR coefficients as well as the regular slope coefficients. It was much higher, but irrelevant given the AR terms.)
Since FRAN010 was missing after 1974, the regression could only be run for 1850-1974. LNA did not mention this.
Two of the proxies were individually highly significant (p < .01): N. Am. PC1 (t = -2.66, p = .0090) and Quelccaya 1 dO18 (Q1O18, t = 2.65, p = .0092). A third, FennoScandia, was significant at the 5% level (t = 2.22, p = .029), and an additional three were weakly significant (p < .1): N. Patagonia, Quelccaya 1 Accumulation (Q1Acc), and Urals.
Although the Quelccaya 1 and 2 dO18 and Accumulation rates had opposite signs, the joint hypothesis that the coefficients for each property were equal for both cores could not be rejected (F(2, 106) = 2.03; p = .136). (Presumably Quelccaya core 2 is what is identified elsewhere as the 1983 Summit Core?)
I therefore tried using the average of the Q1 and Q2 values for Acc and O18, for 12 proxies in all. Surprisingly, the t-stat on the average QO18 rose to 3.27 (p = .0014), although the coefficient on the average QAcc became insignificant.
In this 12-proxy regression, 7 regressors were individually insignificant. Conceivably, they are so multicollinear that some linear combination of them is non-zero. However, a test that all coefficients were zero was insignificant. (F(7, 108) = .684, p = .685).
To MBH’s credit, they included at least these insignificant proxies along with the significant ones. In order to establish that the proxy network has some explanatory power, it is necessary to include all proxies considered in the test. However, It probably doesn’t hurt to exclude this insignificant set, provided the standard errors are jacked up to account for the degrees of freedom in the original model.
More on CO2 and reverse (CCE) regressions later.
That error was correlated with target temperature, I guess? And in the next step this error is assumed to be stationary AR(2) process. Process that is correlated with unknown temperature, and yet stationarity is assumed. That’s why ICE doesn’t work with these reconstructions; stationarity of temperature is embedded in the assumptions (it comes along with Gaussian i.i.d prior assumption for the response)
RE UC, #30, LNA do incorporate the AR(2) structure into their simulations, so I don’t think this is a source of any problem not already in ICE. ICE does implicitly assume that the prior for past temperature has the same moments as calibration temperature, but not that it is necessarily iid with this distribution.
I do find it worrysome that simultaneously estimating the AR structure and coefficients raises the persistence so much relative to OLS. The OLS residuals generate AR(2) coefficients of (.216, .182), which is equivalent, by matching moments, to the observed autocorrelations of (.236, .267). (Their Figure 2 shows similar values.) But if the equation is estimated by GLS using the estimated AR structure, the first and last observations get more weight than the intermediate ones. The result is that it fits the first and last observations well, but lets the AR structure take care of everything in between, so that the fit is even flatter than it would have been already by just using OLS ICE. Furthermore, the flatter the fit, the more serial correlation there is, and the higher the AR coefficients. The final AR coefficients I get (.341, .455) correspond to serial correlation coefficients of (.626, .669)! The big change probably has something to do with the fact that their regression is so overparameterized (14 regressors with only 123 observations).
Hayashi’s econometrics text points out that although GLS is ideal if you know the covariance structure a priori, “feasible GLS” that iteratively estimates the covariance structure from the estimation residuals and then does GLS with this matrix has unpredictable finite sample properties. He suggests it may be better just to use OLS point estimates and then only try to adjust the standard errors with the estimated covariance structure. I’m now thinking this is the way to go.
Unfortunately, EViews (and a lot of other packages, I suspect) won’t do this. The popular Newey-West “HAC” estimator (which is in EViews) does take OLS point estimates as given and tries to adjust the standard errors, but unfortunately greatly undercorrects for the serial correlation by truncating and then damping the empirical correlogram, so I regard it is highly unsatisfactory.
These are all interesting problems, but ones that go far beyond LNA’s paper. They just did feasible GLS (ML) by the book, and took the estimated serial correlation into account accordingly. There are many things they did that I take issue with, but it wouldn’t be fair to knock them for this.
My third critical point above is that although LNA mentioned that CO2 fertilization might be relevant to treering growth, they failed to try to hold it constant in their regression.
I downloaded the Law Dome CO2 data from CDIAC with their 20-year spline smoothing. This appears to be the series MBH99 graph, although they don’t identify it that I can find. This only runs up to 1978, but since the LNA regression only runs to 1974 this is not a problem for it.
When log(CO2) is added to the LNA “direct” regression of temperature on 14 proxies, log(CO2) is only weakly significant (t = 1.71, p = .090), and has little effect on the other coefficients, contrary to my expectation. However, as noted in my second critical point, this “ICE” regression inappropriately puts the independent variable (temperature) on the LHS and the dependent variables (the proxies) on the RHS. This makes the interpretation of the CO2 coefficient as a fertilization factor ambiguous. Accordingly, I tried regressing each of the strongly or weakly significant TR proxies (PC1, Fennoscandia, N.Patagonia, and Urals) on temperature, with and without log(CO2).
The regression of PC1 on temperature without CO2 terms gives a t-stat of 3.97 (p = .0001) on temperature. Log(CO2) comes in even more significant (t = -5.81, p = .0000), and although it does not knock temperature out of the regression, it does cut its coefficient and t-stat almost in half (t = -2.32, p = .0222). AR(2) terms are significant in both regressions, contrary to my expectation that serial correlation would be weakened.
CO2 is insignificant in the regression of Fennoscandia on temperature. The t-stat on temperature is 3.12 (p = .0023) without CO2, and falls only a little, to 2.46 (p = .0155) with log(CO2), all with AR(3) terms.
Temperature has no significant effect on N. Patagonia, even without CO2: t = .58, p = .56.
Temperature is a significant explanatory variable for Urals without CO2 (t = 2.31, p = .022 with AR(1)). Although log(CO2) is itself insignificant (t = 1.20, p = .23), it is significantly correlated with temperature to kill its significance (t = 1.57, p = .12).
So although CO2 does not always eliminate or even reduce the effect of temperature on treering growth, it often does. Accordingly, the uncertainty bounds of a proper CCE temperature reconstruction based in whole or in part on treerings may be substantially increased by including this factor. It probably would have made very little difference for the already very flat LNA ICE reconstruction, but they should at least have tried including it in their regression.
Yes, ICE is the source of problems. Fitting a stationary noise model to the residuals is just a symptom. Beta of Li’s eq. (1) (p= MBH99 AD1000 proxies) is a vector of zeros, try to prove me wrong 😉
UC,
The F(14, 106) stat rejects this at p = .0002, even with AR(2) terms (assuming the equation is well-specified). Is your point that it’s hopelessly ill-specified?
Residuals are where
where  , Auto-correlation of e is estimated using
, Auto-correlation of e is estimated using  , fitted to specific AR-structure, and this noise model is used to reject zero-beta-hypothesis. How the effect or R is taken into account?
, fitted to specific AR-structure, and this noise model is used to reject zero-beta-hypothesis. How the effect or R is taken into account?
Mizon (1995) cautions against this kind of autocorrelation correction
Mizon 1995: A simple message for autocorrelation correctors: Don’t, Journal of Econometrics 69, 267-288
RE UC, # 35. I have taken a look at Mizon’s paper, and found it very interesting — he makes all this Hendry stuff sound reasonable.
Mizon wants us to test the OLS residuals for serial correlation. However, if it is present, he would not have us jump to an AR(1) model, and then, if serial correlation is still present, to AR(2), etc. Instead, he would have us consider a general first order dynamic model, with 1 lag of both y and the X’s and white noise errors. It turns out that a certain nonlinear “common factors” restriction on the coefficients makes this equivalent to the fractionally differenced form of an AR(1) model, so this actually nests AR(1). If there is no evidence of serial correlation in this model’s errors (and there may not be even if AR(2) had been called for by the conventional approach, since it is so rich dynamically), test various restrictions on the model, including AR(1) but also Partial Adjustment (no lagged X’s), etc.
Since LNA’s equation (1) has the cart (the proxies) propelling the horse (temperature), there is not much point in trying this out on it. However, it might be worth a try for the CCE equations, in which each proxy is regressed on temperature and there is still a serial correlation problem.
😉 Two statisticians on board, and they are studying how tree rings cause GM temperature to vary. Referees didn’t notice this. I guess it is because the results agree with their prior distribution for GMT.
I was perhaps a little unfair on MBH in the post when I wrote,
In fact, MBH98 wrote,
So they did at least consider serial correlation somewhere in their system, visually determined that the spectrum of whatever residuals they were looking at was approximately flat, and then proceeded with no adjustments for serial correlation.
However, it’s not clear what residuals they were looking at — perhaps these were temperature reconstruction residuals rather than the more pertinent residuals in the regressions of their proxies on temperature variables. In #32 above I mention that I found strong AR(1) – AR(3) serial correlation (pace Mizon) in the important MBH-like regressions of PC1, FENNO, and URALS on temperature. LNA similarly find strong AR(2) serial correlation in their ICE regression.
So even if MBH did not entirely ignore serial correlation, I think it’s fair to say that they dismissed it too quickly. To their credit, LNA at least incorporated the standard treatment (if not Mizon’s refinement) into their estimates and simulations.
Hi Hu
Thanks for running the regressions of ring width on temp and adding CO2. A small point. If CO2 affects temp, then having temp and CO2 as independent variables to explain ring width is slightly mis-specified. You would need instrumental variables, right? But I’m sure that the data is not good enough to do this, and what instrumental variable could you use? You would need to have a second equation that related CO2 to temp.
Regards,
John
Hi, John!
I don’t think that CO2 endogeneity is an issue as long as the proxies are being regressed on temperature and/or CO2, since no one would argue that treerings cause CO2 any more than global temperature. CO2 can be correlated with temperature for whatever reason — the GHG effect, or because the oceans hold less CO2 when they’re warm — and all this will do is weaken the t-statistics on both. A significantly positive coefficient would be consistent with, if not conclusive of, CO2 fertilization. (I say not conclusive, since probably US population would have a similar coefficient!)
On the other hand, I think the interpretation of CO2 is ambiguous if added to LNA’s equation (1), which backwardly regresses temperature on the 14 MBH99 proxies, since it could be picking up any correlation with temperature caused by GHG or oceanic solubility. The solution here is not IV, but just to turn the regression back around the way MBH had it.
(These regression of course are just taking the proxies at face value. Their construction poses important statistical issues as well, as MM05GRL have demonstrated.)
Hu
I re-read your post #38 and see that you did not also run the regression with the tree rings on the LHS as I thought you were saying when I read it before. Maybe you should try running it that way. Also, have you thought about running causality tests on the CO2 and temp series?
Not trying to create work for you of course.
Cheers
John —
In #32, I report results from running the regression both ways, at least for a few of the more important treering series. CO2 is sometimes important, sometimes not.
— Hu
Hu,
So they did at least consider serial correlation somewhere in their system, visually determined that the spectrum of whatever residuals they were looking at was approximately flat, and then proceeded with no adjustments for serial correlation.
The story continues in MBH99,
This lead to the biggest mystery you’ll find here, see Jean S’ synopsis
(btw, not sure, but Mann’s AD1000 residuals seem to be full_reconstruction minus sparse_temperature, a little bit better match than sparse-sparse )
Double-blockquote didn’t work, So they did at least consider serial.. -paragraph is Hu’s text.
Steven #17
This paper any use?
To what extent can oxygen isotopes in tree rings and precipitation be used to reconstruct past atmospheric temperature? A case study.
Rebetez, M., Saurer, M., Cherubini, P, Climatic Change, 2003 (Vol. 61) (No. 1/2) 237-24
European Silver Fir trees like to grow when it’s warm & wet.
Re #35, 36, I have now tried fitting the MBH PC1 to temperature and log(CO2), using the “General-to-Specific” protocol advocated by Mizon (and Hendry)(J Econometrics 1995), as recommended here by UC. Using this protocol, at least as I understand it, there is no evidence of a temperature signal in PC1 after CO2 is taken into account!
A general first order dynamic regression of PC1 on a constant, PC1(-1), Temp (HadCRUT3vGL), log(CO2) (Law Dome 20 year spline smoothed through 1978), Temp(-1), and log(CO2(-1)) had no evidence of residual serial correlation (rho1 = -.024; Qstat p’s .GE. .138).
In this equation, the hypothesis that both temperature coefficients are zero cannot be rejected (F(2, 122) = .997; p = .37). log(CO2), on the other hand, is overwhelmingly significant (F(2, 122) = 15.51, p = 0.0000). It is conceivable, however, that a non-rejectable simplification of the model would reject zero coefficients on temperature.
The general model nests three primary dynamic simplifications: a Distributed Lag (DL) model with lags of the explanatory variables (Temp, log(CO2)), but no lags of the dependent variable (PC1), a Partial Adjustment Model (PAM) with lags of the dependent variable but not the explanatory variables, and an AR(1) model in which the coefficients on each of the lagged explanatory variables are equal to minus the product of the coefficient on lagged PC1 and the unlagged value of the corresponding explanatory variable. (Mizon’s “common factors” restriction).
The DL model could be weakly rejected (t = 1.73, p = .087). However, neither the PAM model nor the AR(1) model could be rejected at all (F(2, 122) = .057; p = .94 and F(2, 122) = .148; p = .86, respectively.) (The AR(1) restrictions are not linear, so I am not sure how they reduce to an F test, but EViews had no problem generating the F test.)
In the both the PAM and AR(1) model, TEMP was insignificant. PAM: t = -1.53; p = .13. AR(1): t = -1.47; p = .14. Therefore neither of the 2 non-rejectable simplifications of the general dynamic model rejects the hypothesis that temperature has no effect on PC1.
I earlier reported that if AR(2) terms and no other dynamic factors are included, Temp comes in significant (t = -2.32; p = 0.0222). Mizon would argue (I gather) that the AR(2) model may in fact be rejectable within a general 2nd order dynamic model, and that there is no reason to jump to the 2nd order model if a more parsimonious general first order model fits adequately.
In conclusion, any significant effect of Temp on PC1 after CO2 is taken into account is (at best) not robust to reasonable alternative testing protocols.
Hu, very interesting, time to publish? 🙂
Let me try to check if we are on the same page, here’s my view:
1) MBH98 uncertainties are computed from calibration residuals, using sample standard deviation of vector
where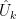 is the result of CCE (*), and vector
is the result of CCE (*), and vector  selects reconstruction area (NH, Global, Sparse etc) and scales by latitude cosines. With this method errors in
selects reconstruction area (NH, Global, Sparse etc) and scales by latitude cosines. With this method errors in  are ignored, and the method is at odds with mainstream statistics (Brown82, for example).
are ignored, and the method is at odds with mainstream statistics (Brown82, for example).
2) In MBH99 Mann takes redness of residuals into account, and applies a correction. This is what Mizon encourages not to do. In addition, Mann’s correction method is a complete mystery, and errors in are still ignored.
are still ignored.
3) Given these problems, the mistake of using ICE in the Li et al seems to be quite convenient accident. Not that I’m implying anything, just a observation 😉
(*) With identity matrix instead of residual sum of products, and variance matched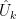 .
. 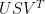 = matrix of grid-point temperatures, singular value decomposition form.
= matrix of grid-point temperatures, singular value decomposition form.
Hu and UC, while I do not claim to follow all of your matrix/vector manipulations (I am reviewing my linerar algebra) in this thread, I have been reading your exchanges with much interest.
As the prosecution in this review and in this layperson’s view, you have made your case and particularly so in pointing to the lack of robustnesses in the MBH methods and results.
I eagerly await the defense in the persons of Ammann and Wahl or even Li and Nychka to put together their lawyerly cases.
UC and/or Hu, in Brown 1982 (2.4) and elsewhere, my low-res pdf version shows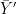 . The context doesn’t seem to indicate that a mean should be used? Is this merely notation for something that might today be a tilde? Or is it an actual mean?
. The context doesn’t seem to indicate that a mean should be used? Is this merely notation for something that might today be a tilde? Or is it an actual mean?
Steve,
That’s a tricky one, by l (lowercase L) Brown means number of replicates, number of observations made at the same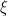 .
.
Not explained in the paper: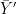 is mean of each column of
is mean of each column of  , transposed to column vector. In Brown87 the notation is easier to read and explained better.
, transposed to column vector. In Brown87 the notation is easier to read and explained better.
In proxy-temperature calibration, replication at same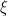
is not possible, so l=1 can be used. That’s what I did in
http://signals.auditblogs.com/2007/07/05/multivariate-calibration/
Brown87: Confidence and Conflict in Multivariate Calibration, J. R. Statist. Soc. B (1987) 49, No. 1, pp. 46-57
This erudite thread has me gasping at the skills and knowledge of its main statistical contributors!
However, I have a simple (naive) question regarding the regression analyses. This concerns the time variable, which, though not often specifically mentioned, must lie somewhere near the heart of what we are all (presumably) chiefly interested in – namely evidence for temperature change over time, and the possible reasons for this.
If I’m correct in assuming that TIME forms an integral part of all the analyses that Hu and others have done, is there not a difficulty in respect of its remarkable and well understood relationship to CO2 concentration? For all the early part of the time series, say up to around the late 19th and early 20th centuries, CO2 was effectively constant. Thereafter it has changed in an almost linear fashion right up to the present. OK, I know that there’s a readily verifiable upward curve to the CO2 graph, and it can be much better fitted using a logarithmic or polynomial model over the period from about 1920 to the present, but from the aspect of some of the diagnostic work on the viability, or otherwise, of various proxies of real indicators of real climate parameters, is not the problem of highly correlated variables (Time and CO2) in tentative regression models something of concern? In my industry days we were always at pains to convince experimentalists of the great necessity of running experiment patterns that specifically avoided the complication of correlated predictors. Variance Inflation Factors (VIFs) were invoked to demonstrate the problems to out clients. Are such statistics entirely irrelevant in the context of this thread?
Robin
Re Steve 49, UC 50, the bar over Y’ in Brown (1982) had me stumped for a while as well, but recall that Brown is assuming that l (el) values of the proxy vector Y’ are observed at each unknown X’ value, each of which has the same relationship to X’. In this case, all that matters is their average, Y’bar, hence (2.4).
This is also why in (2.5), the first term is 1/el, rather than just 1, since the variance in the calibration period is assumed to be for the individual observations rather than for their average. If the el observations on each proxy were simply averaged into a single index, nothing would be lost exept a lot of unnecessary complexity.
The 1/el term is important, however, if the calibration is done on say annual data, but we want the reconstruction on longer horizons, say decadal or tridecadal. The annual reconstructions, using el = 1 in (2.5), will have a huge amount of noise. But if we average 10 or 30 of the proxy values together, we get to use 1/10 or 1/30 in place of 1 in (2.5), making the reconstruction CI’s (however computed — see UC on CCE thread) much tighter. The coefficient uncertainty from the other two terms in (2.5) will still remain, but the important disturbance term will “diversify” away. (To avoid confusion, in the case of an m-period moving average, we might want to call the replication factor “m” rather than Brown’s “el”).
I see now that Steve and UC are referring to two different Brown PRSS papers, “Multivariate Calibration” in 1982 (vol. 44, pp. 287-321) and “Confidence and Conflict in Multivariate Calibration,” J. R. Statist. Soc. B (1987) 49, No. 1, pp. 46-57. So far I’ve only seen the first of these. Perhaps the latter has some more on confidence intervals?
Hu,
I can send it to you. Prediction residual sum of products is discussed in that paper,
Scalar R can be used to check whether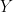 is so close to
is so close to  in all q components jointly as should be expected according to
in all q components jointly as should be expected according to 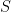 (see also Sunberg99). R can be computed for each year, and large R indicates inconsistency of proxy response. Maybe this is something Steve is looking for in here http://www.climateaudit.org/?p=2995#comment-237099 .
(see also Sunberg99). R can be computed for each year, and large R indicates inconsistency of proxy response. Maybe this is something Steve is looking for in here http://www.climateaudit.org/?p=2995#comment-237099 .
Related to this, does anyone have a copy of
Some distribution theory relating to confidence regions in multivariate calibration by A. W. Davis and T. Hayakawa, Annals of the Institute of Statistical Mathematics, Volume 39, Number 1 / December, 1987 ?
Sundberg99: Multivariate Calibration – Direct and Indirect Regression Methodology ( http://www.math.su.se/~rolfs/Publications.html )
Doh, should be
scalar R can be used to check whether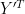 is so close to
is so close to 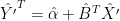 in all q components jointly as should be expected according to
in all q components jointly as should be expected according to 
UC #53,
I found a copy of the 1987 Brown & Sundberg paper. I haven’t digested it yet, but they clearly are advocating a LR-based confidence interval, rather than the possibly empty interval Brown put forward in his 1982 paper. I’ll comment on this later on the “UC on CCE” thread.
I am puzzled that the R in the new paper does not seem to take “xi” (the 1982 X’) into account in the covariance matrix, even though it is in their “r(xi)”. This is the term involving “x*” that I argue LNA overlook in the original post.
If this is in R, however, then R (or rather the sum over all the validation dates of of the R’s evaluated at their respective estimated X’ values) would be a reasonable Validation test statistic, and far more informative than the amateurish “RE” statistic first proposed by Fritts (1976) and embraced by MBH, WA, et al.
Note that Brown and Sundberg apparently incorporate the dispersion of the various Y’ values, to obtain an improved estimate of the covariance matrix of calibration residuals, which will differ for each value of X’. This is more ambitious than what I have had in mind, which is just to use the calibration period to estimate the covariance matrix, and leave it at that. MBH apparently made no attempt to estimate or use this covariance matrix at all so anything would be an improvement.
And one more correction,
In #53 replace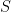 with
with  ,
,
S is used in Brown82 Eq. 2.8, and this equation for R uses .
.
Hu,
See Sunberg99 Eq. 2.12, I guess that kind of division is useful in Brown87; ML estimator is very close to CCE, except when R is too large. R is asymptotically distributed (as
distributed (as  . I tried with simple simulations, when I add outliers to
. I tried with simple simulations, when I add outliers to  , both R and Brown82 2.8 will detect them.
, both R and Brown82 2.8 will detect them.
Me,
making a record of errors per post, should be
I tried with simple simulations, when I add outliers to , both R and Brown82 2.8 will detect them.
, both R and Brown82 2.8 will detect them.
Hu, one more paper that might be of interest,
Prediction Diagnostic and Updating in Multivariate Calibration, by Brown and Sundberg, Biometrika, Vol. 76, No. 2. (Jun., 1989), pp. 349-361.
UC #56,
Brown’s (2.8) includes a factor of
sigma^2(xi) = 1/el + 1/n + xi^T inv((X^T X) xi,
where “xi” is the unknown to be reconstructed (or, in the case of validation, the reserved X value to be compared to the reconstructed value.) This is a scalar, so it factors out and appears outside the quadratic form, but conceptually it starts off as part of the covariance matrix in the middle.
It is true that as n goes to infinity, the coefficients become known perfectly and this term (along with 1/n) drops out. Brown & Sundberg 87 take a ML approach that ultimately assumes n is large. Have they already imposed this assumption in their R?
However, n is not so large in the present context that the coefficient uncertainty can just be ignored. Isn’t this the whole point of your critique of MBH standard errors — that MBH just look at the disturbance term (whose variance equals that of the calibration errors), and overlook the coefficient uncertainty? In the post above, I argue that this factor could be the completely expected source of the ad hoc 1.30 “inflation factor” employed by LNA.
The Davis and Hayakawa paper isn’t online, but I think I can find it in our stacks. If so I’ll send you a copy at the e-mail on your webpage.
Sundberg99 looks like a good update of the issues raised in Brown82 and Brown & Sundberg 87. I’ll take a look at it.
Is that true? Isn’t R just one component of it, and in addition R gives relatively simple means to check possible outliers in , something Steve was looking for earlier. I have to admit that I haven’t spent much time on Brown87 & Brown89..
, something Steve was looking for earlier. I have to admit that I haven’t spent much time on Brown87 & Brown89..
Hu, have you looked at the effect of ARMA(1,1) rather than AR2 in this type of analysis? As you’ve noticed, I think that ARMA(1,1) is much more characteristic of climate series. It looks to me like this has a pretty strong impact on a Li type analysis. There are some very pretty problems with ARMA(1,1) when you have high AR1 and negative MA1 – yielding structures which Perron neatly called “almost integrated, almost white” that are resistant to the sorts of tests that one tends to use. I got the following ARMA(1,1) coefficients from an inverse regression using the Mann “sparse” temperature history.
# Coefficients:
# ar1 ma1 intercept
# 0.9373 -0.8487 -0.0012
#s.e. 0.0530 0.0783 0.0361
as compared to the following for AR2:
#Coefficients:
# ar1 ar2 intercept
# 0.0724 0.2212 -0.0004
#s.e. 0.0862 0.0862 0.0227
#sigma^2 estimated as 0.033: log likelihood = 36.36, aic = -64.71
I did a quick experiment using the gls function in the nlme package and none of the coefficients were significant. The standard error of the target series (df=127) was 0.265 while the standard error of the residuals (df=112) was 0.248.
Steve #60,
No — Perhaps a Mizon-like “general first order dynamic model” (see #46) should in fact be construed to include 1 lag of the error in addition to 1 lag of y and the x’s. This would include ARMA(1,1) as a testable special case, I believe.
I’m surprised your AR(2) and ARMA(1,1) coefficients look so different. What are the first few correlations implied by the two processes? Are these estimates from the OLS residuals, or are they iteratively obtained using GLS estimates?
Hu, I re-ran the calcs again. Here is a script using external references. The results in the re-run are a little different than last night. I’m not sure why. It was late when I did it. Anyway I’ve shown results below for the MBH sparse, CRU2 NH and CRU3 NH. All show the same pattern of extremely high and highly significant AR1 coefficients modelled as an ARMA(1,1) process and very low AR1 coefficients modeled as an ARMA(2,0,0) process – the difference for modeling CRU3 NH is as extreme as 0.97 versus 0.15!! These ARMA(1,1) processes with very high AR1 coefficients are very interesting statistically. Perron has writing some very complicated articles on them and they are something that bear a LOT of attention for people interested in climate statistics.
##
##LOAD FUNCTIONS AND DATA
library(nlme)
extend.persist< -function(tree) {
extend.persist<-tree
for (j in 1:ncol(tree) ) {
test<-is.na(tree[,j])
end1<-max ( c(1:nrow(tree)) [!test])
test2end1) & test
extend.persist[test2,j]<-tree[end1,j]
}
extend.persist
}
proxy=read.table("http://data.climateaudit.org/data/mbh99/proxy.txt",sep="\t",header=TRUE)
proxy=ts(proxy[,2:ncol(proxy)],start=1000) #1000 1980
proxy=extend.persist(proxy)
m0=apply(proxy[903:981,],2,mean);sd0=apply(proxy[903:981,],2,sd)
proxy=ts(scale(proxy,center=m0,scale=sd0),start=1000)
proxy[,3]=- proxy[,3] #flip NOAMER PC1
name0=c("Tornetrask","fran010","NOAMER PC1","NOAMER PC2","NOAMER PC3","Patagonia","Quel 1 Acc","Quel 1 O18","Quel 2 Acc","Quel 2 O18","Tasmania","Urals",
"W Greenland O18","morc014")
dimnames(proxy)[[2]]=name0
sparse<-read.table("ftp://ftp.ncdc.noaa.gov/pub/data/paleo/paleocean/by_contributor/mann1998/nhem-sparse.dat",skip=1)
sparse<-ts(sparse[,2],start=sparse[1,1])
#MAKE DATA FRAME
Z=data.frame(sparse[1:127],proxy[(1854:1980)-999,])
names(Z)[1]="sparse"
fm=lm(sparse~.,data=Z)
fm1 <- gls(sparse~., Z, correlation = corARMA(p = 1, q = 1))
#ARMA 1 1
arima(fm1$residuals,order=c(1,0,1))
#Coefficients:
# ar1 ma1 intercept
# 0.9630 -0.7688 0.0029
#s.e. 0.0272 0.0670 0.0809
#sigma^2 estimated as 0.02881: log likelihood = 44.63, aic = -81.25
arima(fm1$residuals,order=c(2,0,0))
#Coefficients:
# ar1 ar2 intercept
# 0.2576 0.4223 0.0087
#s.e. 0.0797 0.0798 0.0467
#sigma^2 estimated as 0.02998: log likelihood = 42.21, aic = -76.41
#CRU3 NH
source("d:/climate/scripts/spaghetti/CRU3.nh.txt")
Z=data.frame(cru.nh[1:131],proxy[(1850:1980)-999,])
names(Z)[1]="cru"
fm2 <- gls(cru~., Z, correlation = corARMA(p = 1, q = 1))
#ARMA 1 1
arima(fm2$residuals,order=c(1,0,1))
#Coefficients:
# ar1 ma1 intercept
# 0.9521 -0.7081 -0.0024
#s.e. 0.0322 0.0775 0.0532
#sigma^2 estimated as 0.01257: log likelihood = 100.38, aic = -192.77
arima(fm2$residuals,order=c(2,0,0))
#Coefficients:
# ar1 ar2 intercept
# 0.3386 0.3608 -0.0086
#s.e. 0.0809 0.0812 0.0326
#sigma^2 estimated as 0.01324: log likelihood = 97.09, aic = -186.17
#CRU2 NH
source("d:/climate/scripts/spaghetti/CRU2.nh.txt")
Z=data.frame(CRU[1:130],proxy[(1851:1980)-999,])
names(Z)[1]="cru"
fm3 <- gls(cru~., Z, correlation = corARMA(p = 1, q = 1))
#ARMA 1 1
#arima(fm3$residuals,order=c(1,0,1))
#Coefficients:
# ar1 ma1 intercept
# 0.9712 -0.8494 -0.0102
#s.e. 0.0235 0.0472 0.0654
#sigma^2 estimated as 0.02853: log likelihood = 46.4, aic = -84.8
arima(fm3$residuals,order=c(2,0,0))
#Coefficients:
# ar1 ar2 intercept
# 0.1497 0.3294 -0.0235
#s.e. 0.0821 0.0824 0.0293
#sigma^2 estimated as 0.03100: log likelihood = 41.2, aic = -74.4
Just for the record, in a recent discussion at https://climateaudit.org/2011/12/06/climategate-2-0-an-ar5-perspective/#comment-315500 , Jean S has reminded me that in an update to a 2007 post at https://climateaudit.org/2007/08/29/did-mann-punk-bo-li-et-al/ , Steve quotes Li as follows:
Hence my regressions using her “pseudo data” don’t count for much of anything. It’s strange she wouldn’t post the real data.
Adding unit variance white noise to a series that has already been standardized to unit variance may explain why Steve was finding correlations of precisely sqrt(2) with archived versions.
On 12/08/11, above, I remarked,
I take that back. On rereading my 4/11/08 comment with my OLS regressions above at https://climateaudit.org/2008/04/07/more-on-li-nychka-and-ammann/#comment-142629 ,
I see that I used Steve’s archived version of the 14 MBH proxies rather than the noisy data on Li’s webpage, so the results should be relevant.
The same goes for my CO2 adjustments on 4/12/08 at
and my Mizon-based model on 4/16/08 at
https://climateaudit.org/2008/04/07/more-on-li-nychka-and-ammann/#comment-142646 .
I thought the argument from Briffa was that more CO2 decreased treering growth?