Yesterday I described the work done to the surface station records in Hansen Step 2 in preparation for adjusting urban stations to match the trend of nearby rural stations. The basic substeps are
- Deciding which stations are rural and which are urban. The methodology used for most of North America differs from that applied to the rest of the world.
- Sorting the rural stations by record length
- Identifying rural stations that are near the urban station, where near is defined to be any station within 500km. Failing that, near can be extended to 1000km, or about the distance from New York City to Indianapolis, IN.
- After the nearby stations are identified, they are combined into a single series, beginning with the series that has the longest record.
- The urban series is subtracted from the combined rural series.
The overlap period of this new series is passed to a FORTRAN program called getfit. The purpose of getfit is to find a fit using regression analysis of a line with a break in slope somewhere in the middle (referred to as the knee). The slopes of the two lines are returned along with the coordinates of the knee. The following image is an example of what this program is trying to do.
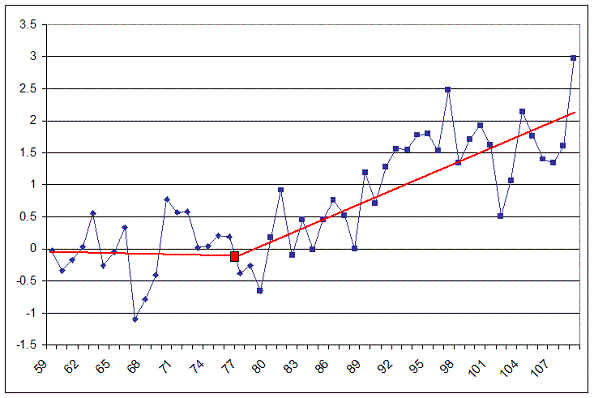
The algorithm iterates through all but the first five years and last five years of overlap, selecting each year as the knee in it’s search for the best broken-line fit to the curve.
Each knee is processed through the fitting algorithm, which returns the two line slopes, the temperature value of the knee (y-value), and an RMS value for the fit. If the resulting RMS is smaller than the previous smallest RMS, the old slopes and knee are discarded in favor of the new values. At the end of the iteration process, the best knee and slopes will have been selected for this particular curve.
The two slopes returned are the left slope (ml) and the right slope (mr). During the calculations, the hinge point is considered to be a part of the “left-side”data. The formulas for calculating the slopes are:
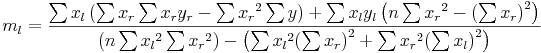
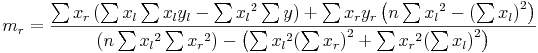
where:
- x is a year in the overlap period.
- y is the temperature value for the year x.
- n is the count of years in the overlap period with valid y values.
- Variables with a subscript l represent data to the left of, or including, the knee. A subscript r represents data to the right of the knee.
The y-value of the knee, yk, is found using the following:

RMS is calculated using yk:
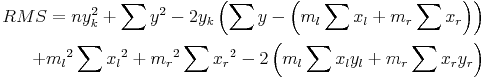
The left and right slopes are now used to adjust the urban record. The years of overlap between the urban and combined rural records are iterated. For years less than and including the “knee year” the adjustment to the urban record (rounded to the nearest integer) is:

For years greater than the “knee year” the adjustment to the urban record (rounded to the nearest integer) is
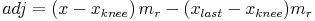
Finally, the adjustment is added to the urban record, producing the homogenized urban record. One would therefore expect the adjustment values to be largely negative in order to remove the UHI effect.
For each year that an adjustment is applied, it is done so from December of the previous year through November of the current year. This is in line with GISS reporting annual temperatures on a winter through fall seasonal cycle.
There is a special case that seems to extend the range of years that can be adjusted more broadly than the period of overlap. I do not fully understand what is going on yet, nor do I know if it is a case that will ever actually happen. Right now I believe the above fairly summarizes the general case.
If I am able to determine what is going on in the special case I will post the results here. Understanding things is complicated by the fact that the case is considered across several programs, and the variable names are not only unclear, they are inconsistent.
Right now, however, I intend to take a fresh look at Cedarville to try and understand what is happening in that urban, one stop-light town.
Steve: It’s worth comparing John’s above analysis to http://www.climateaudit.org/?p=2095





93 Comments
So there is only one possible knee per series? This assumes the effects of urbanization as a linear process?
Oh. I see…. Sorta like a triage station for injured temperature data? … Gets fitted with a false leg so it can stand up to scrutiny? ; )
Did they apply a Chow test?
But such a procedure is bound to produce an underestimation of urban heat island effects if such effects are reasonably well correlated to economic activity. Growth of economic activity in cities are an exponential function which the above fits to a straight line, which in turn is bound to underestimate the temperature effect in recent years. There must be something more to this algorithm? (It is hard to believe science at NASA being this sloppy….)
The idea that everything fits a linear trend of one sort or another must be a sign of the true faith in climate science.
John, a passing comment from part I where you note in #21
The situation has similarities to interpolation of mineral grades between samples in drill holes. Here, considerable trouble is taken to define a search shape that can be moved over the study area, (in this case analagous to finding and weighting rural to correct urban). The assumption of a 2D circle is naive, as are the (conflicting) assumptions about its radius of influence as is linear weighting with distance. The approach you describe is kindergarten stuff.
In mineral work, there is derived a 3-D search body whose dimensions are calculated according to semivariograms and whose principal 3 axes are commonly of different length. The weighting function is derived from drill holes (often at different attitudes), so that one has a better estimate of whether a point has predictive capability for another.
I would imageine that even in the USA, search ellipsoids would have different properties at least around the Rockies compared to the central plains; and that in a proper analysis, there might be several dozen areas defined, each with its own search shape.
But I’m sure you know this. What is worse, the mineral body is stationary. Weather rolls over the countryside. Do they correct the urban-rural distance for the time taken for weather systems to move from one to the other?
One does not know which past temperature reconstruction to use as one suspects all to contain errors of adjustment.
This is truly amazing. Trying to fit whether Rural or Urban stations with use of such a simplistic algorithm is shear madness. One only has to take a look at all the case samples of surface stations investigated by Anthony Watts to know this is futile.
That shows how nonsensical the methodology is. Even a congressman/congresswoman with no scientific background can grasp how ridiculous that is.
Re Bob B says:
June 10th, 2008 at 5:53 am
No, it’s sheer madness. Trying to tell the temperature of the upper troposphere by measuring varying windspeeds at 10k up in the air is shear madness…. (sorry, sorry….)
JF
The horror! The horror!
Is there any indication that the method “mines” for upward trends in the circumstances in which it is applied?
What happens when there is more than one change in direction of trends?
#11 No, I see no indication that the method would favor upward trends. If there is more than one change in direction, I think it just means the fit is less ideal.
#10 ?
Re:11 It appears to me that the answer is “yes”. In the example given there seems to be a clear second knee at about point 98 that returns to a flatter slope, and that is ignored. The algorithm probably mines simply becau it the program has no provision for a change to a flatter slope. Murray
John G: “selecting each year as the knee in it’s search for the best broken-line fit to the curve.”
Something seems very wrong with that sentence. (No, more than just the incorrect apostrophe in its.)
Michael J: “That shows how nonsensical the methodology is.”
What do you have against the distance between New York City and Indianapolis?
Julian F: “windspeeds at 10k up in the air”
Anything having to do with wind is shear madness.
Hmmm. Do you think the shear rate has had a homogeneity adjustment? If it hasn’t, it might be deformed.
10 (JC) Excellent, the route to the dark heart of climate science is tortuous and torturous, but I don’t think Steve will become corrupted.
=============================================
500 or even 1000 kilometers?! Why not use the whole country? Seriously.
snip – resist the temptation to vent
If rural stations are going to be used to modify the climate data for an urban site, what happens if you swing an arc of 500kms and find several rural stations and then work the problem separately for each rural-urban pair? Do the same for all rural stations within 1000km. Is the “best” pair picks for drawing conclusions?
I just wonder, how it is possible to make homogenizations without checking the individual data and station metadata. I’ve read a PhD Thesis of Petr Stepanek (quoted it already here at CA) about homogenizations of Czech long temperature series and it seemed to me, that it is quite a lot of work, to get it all right, no automatical slapping of comparisons with something somewhere in the radius 500-1000 km. Here is a shorter version in English.
Some quotes:
It seems like buckets/inlets/hulls all over again, this time in terrestrial version…
On reflection, if there had been a general leveling off of temperature anomalies since 2001, as Lucia seems to have found, then the algorithm, by excluding the last 5 years is going to present an out of date picture (ie understate any recent level or downward trend).
Also. if the effective end period of data happens to have, for normal cyclical reasons, an upward trend, then the cyclical effect is going to take a long time to unwind. How could one isolate a cylical trend from an UHI trend?
Is there no method of including the last 5 years data? I’m not suggesting the Mannian dodgy endpoint method.
Example of removing cyclical effects:
http://news.bbc.co.uk/2/hi/science/nature/7423527.stm
I just have to say that what Steve has done–figuring out what a bunch of undocumented Fortran does–is nothing short of heroic. He must have an exceptional attention span.
Steve: This particular post is by John Goetz and so I don’t deserve credit for it. However, I have in fact also waded through this particlar undocumented Fortran and discussed it on other occasions – so John Goetz and I are fellow soldiers here.
Craig. I’m sure you meant John Goetz? Or am I making an Ar$e of myself again?
The New York to Indianapolis analogy does not convey the full climate impact because of the east-west vector. How about NYC to Charlotte, North Carolina.
Imagine applying a UHI correction for NYC based on a “rural” station in the Smokies…
I was thinking of someplace west of Charlotte, up in the mountains (I know Charlotte isn’t in the smokies).
Seeing what the plonkers have done is certainly good for a chuckle. Have they ever attempted a justification for this absurd rigmarole?
John Goetz or others:
I’m looking for a project to brush up on my Matlab/Octave skills. Would you be interested in helping out with a port of GISTEMP? I would want to design it with configuration options to allow for different algorithms at each stage. Help with coding, architecture, or testing would be useful.
# 12 John,
Think about how the paint problem that Anthony identified would fit into this algorithm .
It’s worth comparing John’s above analysis to http://www.climateaudit.org/?p=2095. I got some way towards writing a knee-fitting function. However, this was bottlenecked at the time by everyone’s inability to get Hansen Step 2 to compile. If someone has got Step 2 to compile, I’d like them to archive some benchmark cases of individual stations. If that’s done, we can make an emulation of the algorithm in R in short order and this will enable a much better assessment of what he’s really doing.
It might be instructive to sort through the all the stations in GISS and determine which stations adjust which.
JohnV, I’d be happy to help with testing and perhaps looking through the code. My software skills are very rusty. Reading is one thing, writing is another.
Okay, this is probably too simple, but since the purpose of these data is to determine a trend of regional/global temperatures, doesn’t it seem reasonable to use only rural sites that meet quality control specifications? Wouldn’t the sampling be sufficient rather than trying to adjust the whole population of data through some contortionist calculations? Since the heat island effect is well understood, using readings affected by that and then trying to correct them with data from sites that may be geographically quite different seems a colossal waste of time.
It would be far better to keep urban data as recorded over time and simply identify the period for each site when urban encroachment began. If the rural averages show no trend increases while the urbanized locations do as encroachment occurs, then the data are both useful and untouched. Of course, if the sites themselves are faulty, then that is another matter.
I think you guys are all missing the utility of converting regional urbanization into a linear trend. The dollar value of reliably projecting growth for city planners, utilities, marketing firms, distributors, highway planners, and businesses of all kinds cannot be underestimated.
No wonder they tried to keep the code secret. It’s a goldmine!
Steve, JohnV, I think the complicating factor is figuring out what the special cases are and how they are handled. They get obfuscated by the constant reading and writing of files in differing formats, switching between use of months and years and back and forth, cryptic variable names, changing variable names, etc. etc. For example, wkkruse in another post noted that if only one rural station is used to adjust an urban station it is done so at full strength (not weighted). However, if the basic pieces are put in place identifying the special cases and correcting for them might not be so difficult as trying to figure out what they are in advance.
A simple question to ask here is how the process is verified. It is a methodology that takes raw data and makes a prediction; namely some notion of regional temperature. How is this tested? If I had an alternative process, how would I verify the results?
I wonder if Hansen himself understands the code…
Remember, this code was written a long time ago, and I’d be willing to bet it started as a research project or experiment trying to answer the question “I wonder …”. There were probably limitations imposed by the computing systems they used which forced them to break files up, reformat things to view intermediate results, etc. I doubt they ever expected it to grow in importance as it has done (i.e. – the output is used to justify policy decisions).
So, while I wanted to claw my eyes out when trying to decode what was going on, I can understand why it is what it is. At this point in time, though, it seems like they could hire a summer college intern to write a C++ or R version with the specific task of making it more readable and supportable.
That it’s never been done might lead one to believe they don’t care about reproducability. Especially given that mess before the code was freed; ‘why don’t you write a new program instead of trying to see how ours works’.
re 37. you can tell by reading it that it was written in the days when tapes had to be loaded.
The problme with legacy code is nobody wants to touch it and you are almost forbidden to.
However, note the python stuff that has been glommed onto it.
John Goetz: apologies for missing that this was your post. Habit. Kudos and i know about the “clawing your eyes out” part–I’ve spent time doing this sort of thing also.
I sure this has been discussed ad nauseum, but I have been tried to see which/where Canadian Surface Station data is used in GISTemp. And it looks like there are many partial records…but few current records, a very precious few. And of those precious few, many are very incomplete. So I am really not sure how GISS gets any usable information at all for most of the Canadian region, even if the smoothing is out to 1000kms.
5. The urban series is subtracted from the combined rural series.
The overlap period of this new series is passed to a FORTRAN program called getfit. The purpose of getfit is to find a fit using regression analysis of a line with a break in slope somewhere in the middle (referred to as the knee).
I don’t understand this. Why is “the urban series … subtracted from the combined[summed?] rural series” and what is the point of the two-line fit. Is fit supposed to be the final adustment to the urban series. Maybe, I just need to see/think about the math on this.
That it’s never been done might lead one to believe they don’t care about reproducability. Especially given that mess before the code was freed; ‘why don’t you write a new program instead of trying to see how ours works’.
The fact that this is in fortran, using flat files, and not hosted in a modern database, using modern front-end linAlg-processing software is insane. I don’t want this to come out the wrong way, but everything thing I’ve read of the general behavior in various posts here is almost trivial to implement in modern software and databases. Yeah, there might be some special cases that are (obviously) hard to track down in this spaghetti. But, this is really sad.
Why is “the urban series … subtracted from the combined[summed?] rural series”
Whoops, summed -> weighted sum/average.
James Smyth:
Agreed. Are you interested in contributing to a modern port? As I said above, I’d like to do it in Matlab/Octave. Admittedly, it may not be the optimal language but it is convenient for me right now. The syntax is also very C-like so it could be easily re-ported to C++, C#, Java, etc.
Before anyone else volunteers to rewrite the original code, it might behoove someone who has excellent FORTRAN skills to flowchart the whole thing first. Once that has been done, then it becomes a simple matter for some modern programmer to port it into a modern programming language.
If nobody else comes forward, I might be able to convince my husband to flowchart it. It would cost me a lot of banana nut bread, though (his favorite).
re 42. james sometimes we come off very hard on the guys at nasa for this old legacy code. I have. It really is abysmal. I gave up on it. so John G gets mad props for working through it.
A matlab version as JohnV suggests would be nice, anything that was structured orgnaized and documented.
re 45. put it though a CASE tool and reverse engineer it. that would be a start.
Agreed. Are you interested in contributing to a modern port? As I said above, I’d like to do it in Matlab/Octave. Admittedly, it may not be the optimal language but it is convenient for me right now. The syntax is also very C-like so it could be easily re-ported to C++, C#, Java, etc.
Absolutely. I looked at some of this Fortan stuff a few months ago and gave up in disgust, so I’m glad to see you’ve made so much headway.
Just thinking out loud here (and I apologize if this stuff has been hashed out around here or something like the ‘R’ language referenced around here suffices), but you want to get this data into a real database, at a minimum for sorting, searching, etc. Additionally, (and I understand that Matlab is a top notch matrix/vector processing languange), I would at least investigate the opensource community for open source database designed for matrix vector operations, etc. And I know that Oracle 10g added a vector operations package, but I don’t know how sophisticated it is, or whether it’s in the free versions. But, I might, uh, know someone w/ access to Enterprise versions.
My Matlab is going to be rusty, but I was once real comfortable w/ that. Have you looked into any other open-source math packages as options?
And Java would be least recommended from the list above.
Who is supplying the grant money? I jest.
Steve: R is brilliant at handling matrices and vectors. I would be surprised if you can do things in Matlab that can’t be done just as well or better in R. I
Oracle 10g added a vector operations package
Huh, turns out its just a PL/SQL ront-end into LAPACK.
But, still that would be pretty nice, assuming it supports the complete LAPACK operation suite.
48 James Smyth
I hate java. Yuk.
James Smyth:
It was actually the other John (Goetz) who’s made progress. I haven’t even looked at the GISTEMP code yet, but I did put together a simple program with a similar goal last fall. SteveMc doesn’t like me talking about it though. 🙂
The vector operations for the GISTEMP algorithm are extremely simple. I don’t think it even has any matrix ops. A database would be useful but it’s primarily batch processing — the overhead of inserting and retrieving from a database is overkill for a few sequential passes through a time series. I can see writing the final results to a database for post-processing and visualization.
I am tempted to use f2c to convert to C, manually move it to C#, and use the refactoring tools of Visual Studio. My motivation for using Matlab/Octave is purely selfish (I want to chase some Matlab consulting work), but I think it’s a good choice. R is also a good choice but it’s syntax is pretty opaque to my eyes.
Steve: You can talk about this all you want but you should at least make an effort to note the caveats – that the US history is different than the ROW, that the US methods are different from the ROW, that the US experience shows that CRN classes matter, that if you have a strong rural framework, that the surface stations evidence suggests that the GISS adjustment provides a more reasonable estimate than CRU or NOAA which omit such adjustments and that there is not necessarily any strong rural network in the ROW. I didn’;t find the US results particularly surprising; however, it was useful to be able to see that there was an objective difference in histories from different CRN classes. My objection is that you tend to provide an incomplete survey of results, which then get interpreted by others as vindicating methodologies that are far from vindicated. But we’ve been over this before and I don’t wish to debate it again.
Steve McIntyre:
I guess you missed the smiley face.
On the other hand, you tend to provide an incomplete survey of results, which then get interpreted by others as invalidating methodologies that are far from invalidated.
It’s all a matter of perspective I suppose. Remember that my original work with OpenTemp was only in response to speculation on this site that the USA48 temperature history was significantly wrong.
I agree.
Do you have any suggestions for porting and modernizing GISTEMP?
Steve: Right now, the main requirement is to be able to be able to have some station data at the beginning and end of Step 2. IF we have some before and after station data, it will be pretty easy to emulate the calculations. Ordinarily I’d try to work through the code transliterating into R, but, in this case, as others have observed, there is an unbelievable amount of useless garbage in the code and my judgement is that it’s pointless to try to port the code as is. It’s disgusting. As noted, I spent some time on Step 2 last fall and got quite a bit done, but lacked any intermediate station info to benchmark and verify. So the most useful contribution right now would be just to get some station results and intermediate information from Step 2 from a frozen Step 1 version (a frozen version because Hansen rewrites history all the time and it would be convenient to freeze one version).
Careful of JohnV’s bearing gifts.
Did you hear about the climate scientist guy who was insulated from his data?
More seriously, I have difficulties following some of this because in past experiences we looked for anomalous results. With this brand of climate science the game seems to be to remove anomalies. Also, I guess my data had more contrast, but not always.
Question: I realise the main, first objective here is to retrieve a clean data set as the foundation for reconstruction. But is it the intention to use the same official algorithms, or to look at past surface temperatures with a clean whiteboard and then devise better ways to adjust, where adjustment is deemed needed?
He got a lung disease from asbestos exposure.
In my past career as an application programmer, I have encountered legacy systems that had three of four different coding styles superimposed on top of each other as a result of several factors including changes in personnel, the evolution of coding methods towards a modular design approach, and last but not least, the addition of significant functionality which the original coders never envisioned as part of the application.
I have to wonder if over the course of this code’s evolutionary history, the twin concepts of “climate signal” and “teleconnection” have crept into its foundational requirements as a justifcation for taking the approach that it takes.
Check out this comparison of the difference between 250KM and 1200KM Radius.
And this is regardless of its CRN rating?
The computation John Goetz describes in the post seems to essentially just replace the trend in an “Urban” series with an average of the trends in the adjoining “Rural” series, so as far as the global trend goes, the “Urban” series may just as well have been disregarded entirely, and the “Rural” series given bigger weights in the average. Retaining the adjusted “Urban” series does allow them to impact year-to-year changes in the global average a little, but as far as the climate trend goes, it just gives the illusion that a larger number of stations are being used than really are.
I don’t see that the piecewise linear trend causes any particular bias to the adjustment. However, it may introduce an unnecessary wild card if it is used outside the overlap period from which the curve was fit to adjust the “Urban” series, since regression forecast standard errors tend to increase rapidly as you move out of sample.
John doesn’t actually say what is done with the predicted Y values, but I would assume that if Y is defined as R-U, where R is the average rural anomaly and U is the urban anomaly, and Yhat is the prediction of the piecewise linear regression of Y on time X, then the “adjusted” Urban series is Uadj = U + Yhat.
The curve that is being fit can be regarded as a first degree “spline”, with a “knotpoint” at the “knee”. It can be fit with just a few commands in a language like GAUSS or MATLAB (or R, I presume): If XK is the selected “knotpoint” or “knee”, define
XX = (X-XK)*(X>XK),
where (X>XK) is interpreted in these languages as a Boolean operation, ie 1 if true and 0 if false. Then just regress Y on a constant, X, and XX by OLS, asking for the predicted values and the SSR. No special coding is required.
There is no particular reason to expect Y = R – U to be piecewise linear like this, but evidently Hansen or whoever had in mind that these “Urban” stations used to be not so urban, so that if one goes back before XK, the difference will be fairly constant, as captured by the first leg of the line, whereas since XK, the UHI effect has steadily grown, as captured by the second leg of the line. But whether or not this is true, if R is your standard of what U “would” look like in the absence of UHI, you should just toss U and use R! (as many commenters have already noted here)
Re Lotte, #3, A “Chow test” tests for a complete break in the regression line, with no constraint that the two legs joint up continuously at the “knee” or “knotpoint”, and so wouldn’t be appropriate here. If you did want to test whether the slope undergoes significant change at a pre-determined “knee”, this can be done just be looking at the t-statistic on “XX” in the regression above, since its coefficient is just the change in slope.
Since the “knee” is in fact not pre-determined, but found by a search for the best fit, the t distribution no longer governs the t-stat on the change in slope. A similar problem arises with the Chow test: If the breakpoint is pre-determined, the Chow test is just an F statistic with the usual F distribution. But if the breakpoint is found by searching for the best fit, the F distribution is no longer valid. This is what is known as the “Goldfeld-Quandt” test, which basically just uses modified critical values for the best-fitting Chow test. Something similar would be valid here, but since it’s not important whether the curve kinks or not, I don’t think it’s an issue in this case.
Hu, one of the quirks of GISS adjustment outside the US – see discussions last fall – is that there are about as many negative urban adjustments as positive urban adjustments. Many, if not most, of the “rural” stations are not “rural” in a USHCN sense. OFten they are quite urban – they are just smaller cities than GISS-urban.
This is ultimately the issue with the ROW GISS adjustment – can one find any firm ground?
58.
One other thing to note is that every month the knee point will be recalcalated.
That is, as new data comes in the “knee point” calculation is redone, so the past
gets readjusted potentially.
#58
Hu, thank you for pointing out that I never said what happens to the adjustment. You correctly surmise that it is added to the original urban record. I have edited the post to make this clear.
#61. John G, when someone makes a suggestion, it makes sense to me to do exactly what you’ve done here – edit the text for clarification, noting it in a comment as you’ve done. In similar cases, like you, I saw no more purpose in keeping the old text than publishing a journal article as a redlined version complete with chicken-scratch of changes from the original draft. I don’t change text after an initial “review period” other than to sometimes insert a clearly marked “Update”.
I don’t know whether you’ve noticed that this has sometimes set off wild accusations in blog-world. I’ve been shrilly criticized for this as somehow being inconsistent with having an “audit trail” – needless to say, by people who aren’t bothered by the lack of archived data in major data sets. Or I’ve been accused of doing so to try to make myself “look good” as opposed to making sensible edits to deal with comments, just as people do every day elsewhere.
However, readers like Phil have sneered at me for doing what undoubtedly seemed pretty innocuous to you. Strange world.
#58
That is essentially my point in #32.
As to Steve’s point about rural stations really being smaller urban stations, perhaps a study of the lat/long results in Google Maps could lead to a list of locations that aptly fit the description of a rural station.
Why not group stations according to their deltas/data issues and then investigate each group one station at time?
Get one station right then get a group right, then move on to the next, building protocols that can be expanded as needed.
The stations with continuity, rural, and no moves would be the first and easiest and most useful to work on.
Then work down the group list until the data is useless or tedious due to various issues.
#62 Steve
Yes, I’ve noticed. My usual response is “good grief” as I advance to then next comment. The “audit” trail as you point out is right there in the attached comments.
Is the assumption of linearity of UHI trends true? Imagine Chicago as it grew out into corn fields where a weather station was at a post office next to fields. As it became urban, rapid UHI, but after a point it ceases to get warmer because it is surrounded by miles and miles of city. This creates an asymptotic effect not properly captured by the algorithm. Next, with more time one can get lots of trees growing up around the station, cooling it, or densification if apartments and offices go in nearby. It could go up more or down after some decades (pos or neg UHI relative to before). All of this is without the monkey business of moving stations close to buildings for the automated sampler electrical cords. Net effect: unpredictable without study.
The audit trail is cached all over the Internet! Say for example the “wayback machine”:
http://web.archive.org/web/*hh_/www.climateaudit.org/
Just a few there to go back and look at…… 😀
Results 1 – 10 of about 4209 Previous 1 2 3 4 5 6 7 8 9 10 Next
So the complaint is invalid.
I know that this must be a stupid question but anyway —
Doesn’t the use of this calculation indicate that UHI is making a difference on urban trends even though I have read that other researchers discount this?
Also another question
-Wouldn’t UHI reach a saturation level? If an area becomes completely built up wouldn’t the increase in the UHI anomaly cease. Wouldn’t this cause a second breakpoint at which the UHI trend would flatten again?
Craig: “Net effect: unpredictable without study.”
Exactly. Eventually you hit a population/technology level where you wouldn’t expect a change like before the build out. But then again, the larger the area (and surrounding suburbs and roads and farms) the more the UHI would affect the weather farther and farther away.
As you mentioned, the Chicago metropolitan area
And of course, the NASA study on UHI and weather. at the earth obsevatory site.
The assumed plateau in UHI effect seems appropriate when looking at the direct impact of UHI. However it seems to me that the indirect impact of surrounding UHI will be felt and reflected in the observed urban temperature.
Suppose urban development ceased in Anthropolis in 1950, while the surrounding communities continued to grow. Further suppose that the immediate urban heat effect in the city core hasn’t changed over the last 58 years. In my hypothesized community the daily heat increase due to pavement, albedo, excess heat, etc remains the same now as it did back in 1950, for the core of the city.
Now suppose that over time the surrounding communities have increased in size, population density, urbanization, etc., so that by 2008 you have an urban area that is 5 times what it was in 1950. Now you have the same daily increase in heat over 5 times the area. How will it refelect in the observed temperatures?
In 1950 when you had winds bringing air from the surrounding communities into the Anthropolis the air from the surrounding communities was much cooler, say 5 degrees F. Now the air from those surrounding communities is the same temperature. I would think that the observed temperatures would continue to show an effect from the growth of the surrounding communities, even though growth ceased downtown. The evening lows will likely be warmer than they were 58 years ago. At what point is the urban area so large that the center ceases to see any effect from continued expansion at the perimeter? Beats me, I would wager that this thought experiement is more accurate an assessment of UHI than Parker’s work.
re 66. In a previous version of GISS the knee was fixed at 1950, as I recall
The most inportant point is HU’s I think. By using the rural to adjust the urban you just get a false sense of increasing N.
#71 — “By using the rural to adjust the urban you just get a false sense of increasing N.”
Interesting, too, that when one falsely increases N, one falsely diminishes the statistical uncertainty SD.
#71. Steve Mosher, I notice that you’ve been discussing Hurst with one of Hansen’s bulldog service providers, who said that he didn’t know about available routines to calculate the Hurst exponent. I would expect a bulldog service provider to know such things: the fracdiff package in R has a very easy-to-use function. You might pass this on to Hansen’s Chihuahua.
Earle #70: “I would wager that this thought experiement is more accurate an assessment of UHI than Parker’s work.”
One would think so, given the empirical evidence.
Steve #73: “You might pass this on to Hansen’s Chihuahua.”
One might imagine it’s a female Chihuahua, perhaps?
#71 Steve
That may be. The following lines of code are found in PApars:
But that is it. The array X is not referenced anywhere else in PApars or padjust. It is one of a number of seeming dead-ends I found throughout these routines.
SteveMc. I was happy he took the topic up! So I count the blessings.
It struck me as odd that he would do posts on hydrology and not mention Hurst,
even if to dismiss him.
WRT to R’s package for fracdiff. I will note this. some people like to reivent the wheel. they cannot be stopped. hopefully it will roll.
Crap.
Now I am the ambassador to tammy town?
I’m an instigator on the ice guys.
On a light note, this global warming has to be pinned down. A friend in UK has a daughter who was told by her teacher that global warming would cause an asteroid to hit Earth. Has this been factored into UHI adjustments?
The main fundamental source of noise I see for reconstructions is the time at which a weather station ceased to be rural and started to turn urban ( a gradual process more often than a kee bend). Usually, there is no reason to put a weather station in a place where no people come to settle, so there is a lack of persistently rural stations. Australia might be able to help here because of records kept at isolated cattle properties and small mining towns, some of which continued to live after the ore ran out. There were quite a few small mining towns built in the 1870-1910 era, so there is a chance of long records with external factors scarcely changing. Ditto cattle properties.
It would be interesting to see the record of station(s) that were urban and became rural.
Problem is, if town is abandoned the weather station will probably be dismantled too, so I imagine that those stations would be exceedingly rare.
There is one more category of station that is almost always permanently and totally rural, and that is lighthouses. I don’t know about the rest of the World, but in northern Europe there are quite a few of these that have weather stations. One drawback is that they are all coastal, of course.
Another, though smaller, group would be isolated islands where there is essentially nothing except a weather station, places like Jan Mayen, Björnöya (Bear Island) and Hopen. Incidentally, and remarkably, none of these is in GISTEMP, though all three have easily accessible records that go way back and would fill out those 1200-km arctic extrapolations very nicely.
Crawfordsville, IN, is a station that today is treated as rural by GISS, but when one looks at the station history it is clear it was once located in town for a very long period of time and therefore should have been treated as urban. In fact, if bright lights were not used to classify the station, GISS would treat it as non-rural (the flag is “S”, for small city).
From 1885 to 1925 it was located somewhere near Wabash College (may have been at several locations). From 1925 to 1982 it was located at the Power Plant in town, next to the Wabash River. From 1982 to 1991 it was located at a radio station just outside of town. It looks somewhat rural, but I believe it was pretty close to a large parking lot. Since 1991 it has been located on a farm way outside of town.
In February I was able to compile STEPS 0,1,2,3, and 5 of GISTEMP. (I haven’t worked out STEP4.) I ran it and saved all the results with and without “periurban” adjustments. Is this the kind of benchmark you would like, Steve?
This collection of code and output is downloadable here. The zip file is a little under 400 MB.
Steve: Arthur, can you subdivide the zip file into smaller bites?
Bruce(#32):
I agree with you completely about the absurdity of “homogenizing” UHI-corrupted records. Cross-spectrum analysis reveals that very low-frequency components are quite incoherent at station separations over 100 km. Having compiled simple averages of relatively uncorrupted records from USA, Europe, and the globe between the polar circles on a consistent geographic sampling density (necessarily sparse), I find no meaningful secular trend during the 20th century, but a sharp cooling swing to below -.6C in the mid-70’s, followed by a sharp warming, which peaked near +.6C in 1998. The trend seen in GISS and HADCRUT “global anomalies” is provably the product of using UHI-corrupted records.
#82. Arthur, can you get the program to write out in ASCII instead of binary. Alternatively can someone decode the binary files?
Re: Julian Flood says:
June 10th, 2008 at 7:23 am
Methinks you have far too much faith in our elected representatives.
Hoystory says: June 12th, 2008 at 11:01 pm
‘Julian Flood’
Not me, vicar. I’m the ‘global warming is caused by oil/surfactant altering CCN numbers and thus modulating low level albedo’ fruitcake — I have no knowledge of USian politics.
JF
RE #82 and #84. Here are STEPs 0-3 in individual zip files. I’m not sure how to deal with the binary outputs at this point.
STEP0, 70 MB
STEP1, 94 MB
STEP2, 33 MB
STEP3, 127 MB
#71,72 On increasing N.
Wouldn’t the large N be necessary to be able to claim significant temperature increases for the past century with the confidence expressed by IPCC and others?
re 88. it goes to their stated error bars.
The odd thing is that they spend some much clusmy effort on adjusting the US which is a miniscual portion of the entire global.
odd
#89 Odd or necessary?
Sorry for this being off the topic but I didn’t know where else to post it.
Here at Climate Audit a wide range of data and theories are investigated and audited that have influence on climate policy.
But, the basic cornerstone of AGW theory, thesis that rise in CO2 concentrations is man-made is not studied much in depth. I have in mind peer reviewed works of Zbignjev Jaworowski or Tom Segalstad (see http://www.co2web.info/, or in recent times some very interesting blog posts by Roy Spencer (see here and here) that all assert that much larger portion of CO2 rise is due to the natural factors that IPCC admits, and that temperature reconstructions from ice cores are unreliable (and thus iconic statement of 280 ppm v of preindustrial CO2). As I laymen-economist I am not familiar with all scientific details of the debate, but as a taxpayer interested in what theories and data supports expansive cap-and-trade programs of energy rationing, I would like to see analysis of that problem from some highly competent climate auditors. In one previous occasion, you Steve defended your decision not to touch in this sensitive issue by arguing that your time is scarce. But, you can put in charge some other competent climate auditor to write a post and moderate discussion.
Additionally, you probably would agree that issue whether rise in CO2 content of atmosphere is entirely man-made or not is for overall evaluation of official IPCC AGW theories (your main proclaimed task) much more important than whether Jim Hansen inflated temperature rise by one additional tenth of degree C of dubious adjustment (which is not by itself unimportant issue or one not deserving to be audited). But, if serious work exist that challenge most basic tenet of AGW, isn’t your duty as Climate Audit, best science blog in the world, to address this issue, to give every pro et con, and to conclude whatever your conclusion will be, eg. that Segalstad, Jaworowski or Spencer are fools. But, let’s first investigate their arguments and prove they are wrong, and why they are wrong (or right).
One point I do not quite understand is that once the trend lines are established, they then get shifted so as to ensure the adjustment for the final year is zero (set x=xlast in the final equation to see).
If this is purely presentational then why do it? It causes confusion as the distant past can get revised each year by approximately the difference between the last two years’ urban-rural temperature differences. If there is a genuine right hand slope then this across the board change in the adjustment is biased (i.e. has a non-zero expectation).
If it is not purely presentational and there is some theoretical justification then it may be the wrong methodology. Recalculating the mean square error using the shifted trend lines will produce a higher figure than could be achieved by fixing the final point to zero before doing the minimisation.
On top of these issues, rounding the adjustments to integers for individual years will probably introduce unnecessary rounding artifacts.
Steve et al:
As a lay person I admire your efforts to Figure out and correct Mr. Hansen’s data, analyses, syntheses, and conclusions. However, I believe it to be empirically and logically impossible to adjust “urban” surface instrument data points or time series to remove a heat island effect – by using rural data points or times series. I see no conceptual basis for doing so.
I agree with Bruce Hall. The best scientific (and political) approach is to select “rural station” (aka from environments not much affected by man) data from rural stations so numerous and geographically dispersed and representative, that it would be difficult to maintain that the temps measured do not represent a reasonable picture of temperature change caused by changes to the greenhouse while excuding changes to the ground in “urban” areas.