I’ve discussed “mixed effects” methods from time to time in paleoclimate contexts, observing that this statistical method known off the Island can provide a context for some paleoclimate recipes, e.g. in making tree ring chronologies. This would make a pretty good article.
Another interesting example of this technique, which would also make a pretty good article, is placing Hansen’s rather ad hoc “reference” period method in a statistical framework using a mixed effect method. I’ve done an experiment on the gridcell containing Wellington NZ with interesting results.
The details of Hansen’s “reference method” is not fully described in Hansen et al 1999, 2001, but should be decodable from code placed online in the past year (though there are details of the code that remain still impenetrable to me, but I’m chipping away at them.)
For this particular gridcell calculation with 250 km smoothing, there are 4 contributing stations in which the starting point is 4 monthly adjusted station series. Let’s stipulate the adjustments for the purposes of the present calculations, though the urban adjustments are themselves questionable. Hansen’s “recipe” for his reference period is to start with the longest series, then arrange the other series in descending length. For the second series, in the overlap period where both series have values, he calculates the average difference by month in the overlap period, which is called “bias”. The “bias” is subtracted from the second series and a weighted average of the two series is made according to their weights (the distance from the gridcell center), using whatever values are available. This process is repeated and then the final series is converted to an anomaly centered on 1951-1980.
At the end of the day, they have, in effect, estimated 48 deltas (4 stations x 12 months) plus an anomaly for each year. Hansen argues that this “reference period” method is a better utilization of available data than requiring a fixed anomaly period as in the CRU method.
Now watch the following calculation, about which I’ll comment more at the end. First we import the test data: the 4 stations and the Hansen’s gridded data (all excerpted from Hansen data).
chron=read.table(“http://data.climateaudit.org/data/giss/step3/step3_test.dat”,sep=”\t”,header=TRUE)
chron=ts(chron,start=c(chron[1,1],1),freq=12)
Z0=data.frame(chron)
Next, I make a data frame that is more organized for statistical analysis – a “long” array in which each row contains the date in decimal years (1955.42), the station id, the month (as a factor) and the adjusted temperature. Each measurement goes on its own row.
chron=chron[,3:6]
N=nrow(chron);M=ncol(chron);year=c(time(chron));month=rep(1:12,N/12);name0=dimnames(chron)[[2]]
Network=data.frame ( c(t(array( rep(name0,N),dim=c(M,N)))), rep(year,M), month,c(chron))
names(Network)=c(“id”,”year”,”month”,”chron”)
Network$month=factor(Network$month)
This dataset will look something like this:
id year month chron
1 X507934360010 1938.000 1 NA
2 X507934360010 1938.083 2 NA
3 X507934360010 1938.167 3 NA
4 X507934360010 1938.250 4 NA
….
Now for an important trick. To do the sort of analysis that I wish to do, we have to create a nested factor for each of the 12 months for each station. This can be done as follows (a technique noted in Bates 2005 article in R-News):
Network$IM=with(Network,id:month)[drop=TRUE]
Now the data frame looks like this – the IM factor becomes very useful:
id year month chron IM
1 X507934360010 1938.000 1 NA X507934360010:1
2 X507934360010 1938.083 2 NA X507934360010:2
3 X507934360010 1938.167 3 NA X507934360010:3
4 X507934360010 1938.250 4 NA X507934360010:4
Now we can calculate a statistical model doing everything that Hansen does in pages in one line – only better – as follows using the lme4 package (also loaded here):
library(lme4)
fm.month = lmer(chron~(1|id)+(1|IM)+(1|year),data=Network)
The object fm.month contains random effects for both the station:month combinations and for each time period, all calculated according to an algorithm known off the Island. The values in ranef(fm.month)$year compare to the Hansen gridded anomalies as shown in the graphic below (the scale of the difference in the thrid panel differs from the upper two panels). The lmer random effect and the Hansen reference-method anomaly have a 0.975 correlation (which is about as high as I’ve been able to do with any actual emulation of Hansen’s method BTW. In this particular case, the Hansen reference method turns out to increase the trend by 0.05 deg C/decade or about 0.25 deg C over the 50 years shown here. I don’t know whether this occurs in other gridcells; it’s the sort of thing that might be worth returning on some occasion. (The urban adjustment to the Wellington NZ series had also caused an increase in the trend.)
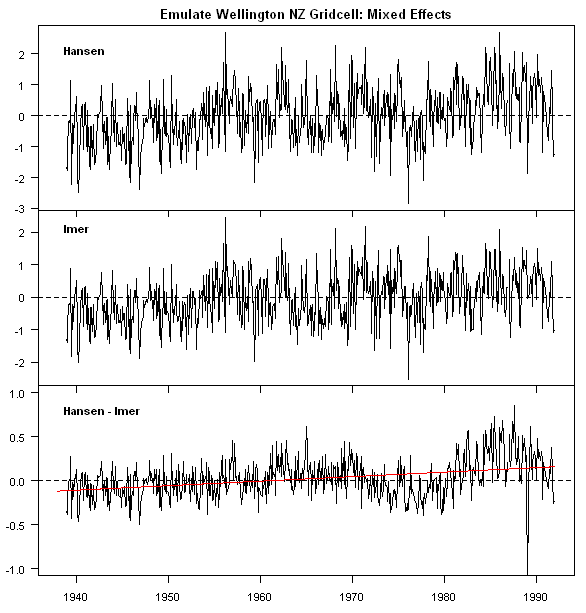
I know that some critics have been screeching about the pointlessness of examining what Hansen actually does and urging me to study other “more important” problems. In my opinion, before making suggestions, it’s a good idea to understand what people are doing or trying to do. In this particular step, Hansen’s reference period method can be construed as a way of constructing estimates of the various quantities estimated through the above method (all neatly packaged in the lmer-object fm.month). In this particular case, Hansen’s calculations, viewed as statistical estimates, do not coincide with the maximum-likelihood estimates, which are arrived at in the lmer calculation. At the present time, it’s hard to tell whether the Hansen method would tend to cause the introduction of an upward trend relative to the maximum-likelihood calculation (as in the above case) or whether the trend differences from maximum likelihood estimates are randomly distributed between positive and negative values.
However, I think that the above example is sufficient to show that the Hansen “reference period” method does not yield a maximum likelihood estimate. Once the issue is framed in a proper statistical format, it’s hard to think of any particular reason for using the Hansen “reference” method. As noted above, it’s possible that errors introduced by this method are random and cancel out, but that would be sheer good luck and not a justification of the method.





26 Comments
To determine if there is upward bias, would you have to do this for each of the 8000 grid cells?
Are you also saying that in Hansen 1999, 2001 or any other place you have been able to look, that you have been unable to find a detailed justification/explanation of this “reference period” method that you can agree or disagree with?
Maybe I misread something, but this:
suggests that sites closer to the center of a grid are weighed more than those away from the center. If so, why does is this done? Wouldn’t all areas of a grid be equally weighted?
Steve:
You appear to be somewhat understating the importance of the Hansen reference period and its potential for upward bias. Fine, I understand your caution. I assume (bad practice I know) however, that you are planning similar analysis for other grid areas.
Plodding work indeed, but necessary given the influence of Dr. Hansen and of his numbers in calibrating climate models.
Thanks again for your hard work. I look forward to seeing the results.
I agree that your approach is quite justifiable. Certainly, since GISS temperature data and Hansen has great practical authority with politicians and the public, the actual “raw” data and the methods used to “reduce” it must be thoroughly reviewed by someone. Apparently, you are one of the very few independent people investing the enormous time required to be comprehensive in that regard. As such, you are performing a service for humanity.
If you can pursue this study of the “Hansen method” to the end, there are at least three possible worthwhile outcomes:
First, and unlikely to me, you may show that the “Hanson Method” is actually quite sound and represents the best way to look at the existing data. Or, you may show that it is unsound — but happens to give the “right answer” for temperatures. Or, you may find that it is biased, perhaps unintentionally, towards indicating increasing temperatures (“global warming”) — a “blockbuster” to be sure if done by objective reproducible means.
In the mean time, I shall continue to visit your site as I am trying to get my mind “up to speed” on the details of “global warming” predictions — and do some bush league predictions of my own (as I enjoy “computer modeling” real systems, whether I am good at it or not). Your site is one that digs deep enough and communicates enough (both your reporting and the responders’ comments) to make a real difference to my minuscule efforts.
Steve, great work. Some how I suspect we are headed toward Hockey Stick 2. If, I repeat, if, it should happen again, then this whole Global temperature story may be shown as a worse house of cards than Mann’s. Between Watts’ and your work it is getting really hard to believe any temperature projections from the historical datasets.
CoRev, editor
http://globalwarmingclearinghouse.blogspot.com
“First, and unlikely to me, you may show that the “Hanson Method” is actually quite sound and represents the best way to look at the existing data.”
Oh yes! The existing data…..
Steve, terminology confusion for this occasional reader. What do you mean by 250 km smoothing when the 3 comparison stations for Wellington NZ (Chatham Is etc)that you have used before are all more than 250 km away? Is this another, closer set of stations within a 5 x 5 minute gridcell?
BTW, I disagree strongly with those “critics (who) have been screeching about the pointlessness of examining what Hansen actually does”. You continue to show that doubt is thrown on the past surface temperature record, with example after example. If the accepted century of temperature records eventually adjusts to inconsequential change through a process of death by 1,000 cuts, then 1,000 cuts are needed. Yours is the most promising approach I have seen to valid auditing of the GHG AGW assumption via land surface temperatures.
“…Once the issue is framed in a proper statistical format, it’s hard to think of any particular reason for using the Hansen “reference” method…”
This is an important result of your work.
Another outcome is, that given Mr. Hansen’s scientific record (http://www.climate-skeptic.com/2008/06/gret-moments-in.html), the poor or missing science behind his temperature “adjustments”, the poor programming abilities against NASA standards and the reluctance to disclose, he is, in my view, intellectually not suited for his position.
Please forgive my presumption to comment here. I am a retired physicist, having spent most of my working life in industry working with complex system codes. I have recently been following this website and that of Anthony Watts with great interest.
My work in industry was controlled using quality assurance procedures, which governed every aspect of the work, and we were externally audited regularly to ensure compliance and accreditation. Everything was open to audit. For computer codes we had software development plans and needed software description documents, user manuals, user guidelines, input and output manuals, verification and validation documents, configuration control procedures and documents etc etc. This applied not just to the system codes but also to data manipulation codes and graphics codes etc. All usage of the software was strictly controlled, requiring independent verification and approval before publication of any results. Records of all work was archived so that it could be retrieved and independently audited.
Am I being naive here? Do not similar quality assurance procedures apply to the work of government laboratories and university research departments? If not, why not?
Does any independent organisation audit government laboratories and university research departments?
Phillip,
I’m a retired NASA Project Manager/Project Scientist/System Architect who managed “in house” (hands on) projects. We (teams and I) have had successful experimental equipment on Spacelab and in the crates to go to the ISS (any year now 🙂 ). As an Engineering Scientist I’m a “Jack of all trades, and master of none” — but I enjoyed software engineering and computer modeling my designs the most. With that background, I can make these comments:
NASA has created technical “guidelines” (in various forms) for just about everything. Some make excellent sense (honestly, some I would approach differently). Unfortunately, some excellent guidelines are not followed by everyone — particularly software development guidelines when non-flight quality software is involved.
Formal reviews at the project level are frequent for flight projects — but are rare for non-flight projects such as Hansen’s. Nonetheless, how well the “details” were reviewed depended on the interest and competency of the reviewers. Few reviewers went to any depth (basically they would spend a day or two on a review) — and none to the depth needed here.
The good project managers tried to get the best people to review of their projects in depth. Arrogant people and people with “things to hide” tried to downplay reviews — again, this is easy to do in a non-flight project — and easier to do if one is the manager of a NASA facility not located at one of the major NASA centers.
Thus, all the “inferences” that Hansen and his ilk and their work have been “superficially reviewed” in so-called “peer review” by close associates rings true to me. Moreover, poor programming practices and critical mistakes in non-flight software have been commonplace — particularly in the 80s and 90s when Hansen et al were gaining recognition — so, he would not be unique if his software had serious issues. Also, its true that a lot of code was probably developed by a “river” of graduate students flowing into and out of the project (rather than Hansen himself) — this is the kiss of death, usually (but, maybe they did better in this case).
I would be “pleasantly” surprised if there were no serious errors in Hansen’s methods (“pleasantly” because I am NASA), but I expect a deep enough review will find them. Heck, when I reviewed a project, I did so in depth, and I virtually always found some serious (often showstopping) errors.
So, keep up your detective work, Steve. I am betting it will pay off.
I don’t know what gets used at NASA, but everyone else uses DO-178B for flight software. NASA was represented on SC-190 (which wrote it).
Based on the process artifacts I’ve seen (or lack thereof), it appears to me that Hansen is using assurance level “E” – no effort required.
To my mind, the failure modes effects analysis says that getting it wrong could result in 20% excess mortality or worse. This would put the Design Assurance Level at “A – Catastrophic”. There should be huge piles of artifacts documenting the process as Allen noted above.
For levels D and above, a skilled programmer should be able to work from the design documents and come up with functionally identical code.
Re; 10 and 11
From your comments, I would infer that no one has done an FMEA on Hansen’s software.
Steve,
Great work!
I guess it’s long overdue for him stand up and say, “Hi, I’m James Hansen, and I am not a statistician.”
In answer to #7 there are a number of other statistically “good” sites with long records within 250km of Wellington around that could be used to check the data quality. There are the lighthouses at Baring Head (where CO2 samples are collected in southerlies) Brothers, Stevens and Castlepoin. Then there are the stations at Ohakea and Kaikoura.
There is a very good reason these aren’t used. They don’t show the trends that the dataminers want.
re: #9 and 10
My primary conclusion, based on many attempts to engage GISS/NASA’s Real Climate on V&V and SQA topics are as follows.
The world seems to be divided into two parts; (1) Those who know about the procedures and processes, have used them in their careers, know that it can be done, at reasonable costs, for a wide variety of software, and know that successful applications of them do improve many critical aspects of software, and (2) those who have not used them (they may or may not know they exist) and state that it can’t be done for ‘my software’.
Then usually I hear rationalizations that peer-review of papers for publication in Science Journals, comparisons of results from other software, and a couple of other softballs provide more than sufficient alternative assurance that there are no problems in my software. The very best one of all is the claim, which was written by a very respected Science Historian and colleagues, and has appeared in a peer-reviewed Science Journal, is that models/methods/codes/applications that involve Natural physical phenomena and processes can be neither verified or validated.
I do not know of any other areas of software applications (not a single one), the results of which might affect the health and safety of the public, for which this approach and these rationalizations are accepted.
Look around CA and you’ll find many threads and comments on these subjects.
Looking at the NASA Quality Assurance Standard, NASA-STD-8739.8, Appendix A.4, “Potential for impact to equipment, facility, or environment:”, threshold for “Full/High” is “Greater than $100M”.
#15 quoted models/methods/codes/applications that involve Natural physical phenomena and processes can be neither verified or validated.
“I do not think that word means what you think it means.”
I would agree that GISTEMP (and Hansen’s work in general) can neither be verified nor validated. That’s not exactly a ringing endorsement, though.
Re: Philip Bratby
I can be more succinct than most.
Answers in order:
1. No, you’re not being naive. You have a realistic expectation that, for the mega-dollars involved, there would be at least the same levels of quality control that you experienced. And you would be extremely disappointed.
2. In theory they should, but while Congress strains over the gnats of the space exploration budget, the rampant camel-swallowing of bad science in NOAA continues.
3. If there are, we have yet to hear about them, except in areas directly related to public health like the EPA or the Office of Scientific Integrity.
I would encourage you to check out claims made in climate models to see whether they make any physical sense.
Philip Bratby, thanks for your comment. You say:
The answers respectively are yes, no, “We doan gotta show you no steenkin’ badges”, and not that I know of.
It is valuable in this regard to distinguish between what I call “research grade” computer models and “industrial grade” models. Research grade models are the usual models made by scientists and engineers, of a wide range of complexity and purpose. They are generally investigative in nature and ad hoc in construction. All too often they are opaquely coded, inadequately commented, are generally far from bug-free, and are not validated or verified in any meaningful way. However, they are generally adequate for the job they are usually asked to do, in an environment where errors are low-cost (e.g. A projection of income levels in 2025 for a scholarly paper doesn’t cost anyone much money if it is wrong).
Industrial grade models are for projects where 1) lives and/or 2) big money and/or 3) unique opportunity are involved. If there’s big money or lives riding on it, it gets tested. Tests don’t find every flaw … but they find lots of them. V&V testing and SQA procedures are routine and required for industrial grade models, from software running things as diverse as elevators to subways to submarines to seven-forty-sevens to space probes.
The modelers are asking us to bet big money, huge money, on unvalidated, unverified research grade models. Sorry, I don’t buy it, particularly when the different model responses can be coded with so few parameters (as in the “model of models” used by the IPCC to simulate the GCMs).
Please don’t get me wrong. There’s no conspiracy. It’s just that the science of climate science is largely computer-based computation … Steve’s work in finally replicating Hansen’s algorithm is crucial in this regard. Steve, another outstanding piece of work, my congratulations.
Hansen’s method may prove to be error-free, or self-canceling … although the first site analyzed is hardly encouraging. My main problem is the laziness of the investigators. There is no method that can replace a human being reading the metadata for each station and giving it some kind of a rating. Hat tip to Anthony Watts, you will indeed eventually cover the globe.
w.
Steve:
Would it be possible for you to either link a description of what the lmer calculation does, or better, to post an explanation of it?
I find the problems with Hansen’s ad hoc method to be illustrative. We have a small,tightly knit and perhaps even insular community that everybody is relying on for accurate information on how the Earth’s climate is changing over time, and what influence human activity is having on it, yet there appears to be little of self-auditing activity in that field, but rather, if anything, more of a wagon-circling going on…
They are anything but lazy. A growing body of evidence indicates the AGW climate modelers and the dendro-climatologists are actually dedicated, productive artisans in lab coats who are using the computational sciences as productivity-enhancing tools in sculpting raw, unpolished data sets into pretty curves which fit their artistically-motivated ideas as to what they want to communicate to their artisan peers and eventually to the public.
Supplying a user manual which documents in good detail how the computational tools are actually being employed would expose these data sculpting methods for what they actually are.
This means we are not likely ever to see the AGW modelers willingly adopt any kind of self-policing software quality assurance ethic. If they ever did so, they would be voluntarily telling us what it is they are actually doing.
Supplying this kind of information could ultimately prove fatal to their careers as AGW data artisans, assuming some group of economically and politically influential people ever began taking the low-level details of their work seriously enough to challenge it.
Readers may want to ask whether there is any connection between:
1) The reticence to allow outside questioning of climate analysis/adjustment methods and software (and the related push to communicate that ‘the science is settled, and deniers should be ____’)
and
2) Policy PR recommendations, such as published here:
I do NOT want to hijack this thread into context of politics or marketing.
However, it seems worth at least noting that certain arenas of scientific work today just possibly may be influenced by marketing PR, and not purely emerging from the available data.
When considering the quality of work done, perhaps we can best compare what we’re seeing to the kind of analysis that supports marketing of a new automobile** rather than a trillion dollar investment in the future of the planet.
**Apocryphal story: when the Chevy Nova didn’t sell in Latin America, who was harmed but a few shareholders? Who woulda thunk that “No Va” means “Doesn’t Go” in Spanish? (It’s actually not true… but perhaps that’s the point. AGW research is no laughing matter, folks…)
#19. lmer is a function that does a linear mixed effects model. There is a discussion here of the function here http://cran.r-project.org/doc/Rnews/Rnews_2005-1.pdf which links to the Pinheiro-Bates. There is a large literature.
In this case, picture it as the following model:
where i is station, m is month, t is time
 is the mean for month m at station i
is the mean for month m at station i
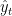 is the anomaly for time t
is the anomaly for time t
Mixed effects is a standard and effective way of estimating models like that. Now your inclination is to probably say, well, duhhh, so what. What’s so hard about that? And you’d be right. But this simple point seems to have eluded a lot of people so far.
This rather reminds me of the SE versus SEM discussion. While both are rather meaningless in a certain context, both go to show two sides of the same coin; one is almost impossibly difficult to pass, the ther is almost impossibly difficult to fail. When you get 14 +/- 2.5, with squiggles purposely set to match other squiggles as far as looks, it takes some amount of art to convince anyone of anything related to the squiggly lines. And yet, entire economic systems are supposed to rest upon these visually similar lines.
How is an elephant like a gazelle like a lion like a human? Yes, they all have four limbs, two eyes, and a mouth.
Gee whiz.
Nice work Steve! Now you just need to do a “multiple regression mixed model”, using also solar inputs, compensation for urban effects/%forested/%agriculture within buffer areas, and whatever other variables are appropriate in addition to the CO2 variable for predicting tempertature.
And so what happens if the same method is applied to the rest of the data? I gave that one a shot and came up with a fairly good correlation with the published “global” GISSTEMP anomalies. (R-squared = 0.72)
Using groups for urban/suburban/rural, altitude band, latitude band, station id, and year in the R Project lmer function applied to the giss.dset0 annual temperature data. It nicely shows the effects of each of the above factors. The details and graphs are here. From raw data to unbiased results in one R command! No doubt there are better ways do this, but these results are not bad. Changing the model formula around and using various different groups, didn’t seem to make much difference to the random effects calculated for time. I’ve done the same for giss.dset1 data and got much the same results.
A post that begins with “As Steve McIntyre has so brilliantly shown…” can’t be all bad.
Steve: Nice analysis. I’ll take a closer look at your methodology sometime soon. The term that I’ve frequently used for Team statistical methods is “artisanal” – the term doesn’t mean that the methods are “wrong”. The purpose of trying to place artisanal methods in a statistical context is to simplify analysis of things like UHI by having an algorithm that can be understood. The battleground issue in station data is UHI. My objection to Hansen’s methods is that the purported UHI adjustment isn’t one. Simply doing a mixed-effects style average of dset0 station data doesn’t do a UHI adjustment either. But the algorithm style looks like a very nice enhancement of what I did in the old post. Nicely done.
Continuing on with the data mining of the GISSTEMP material, I have been looking for evidence of a heat island effect, and my conclusion is that it won’t be found in this data.
Since my initial analysis didn’t show a robust HIE, I looked bias in the dset1 data.
Details here:
http://sextant.blogspot.com/2010/01/seeking-heat-island-effect.html
2 Trackbacks
Wikio’s Science Blog Rankings…
This post may sound a bit ungracious, and possibly even egotistical, but I have a real gripe with the new list of the Top 100 science blogs on Wikio at the moment. Others are very happy with it – Greg Laden celebrated getting to number 9 (which curious…
[…] framework: tree ring chronologies here and Hansen’s “reference” method here. Let me start with a very standard boxplot from a standard mixed effects (random effects) program, […]