Mannian confidence intervals have always been a mystery with MBH99 confidence interval methodology remaining an intractable mystery that has defeated all reverse engineering (and engineering) efforts by UC, Jean S and myself to date (though we haven’t picked up this file for a while.)
I was very interested to see how Mann 2008 calculated confidence intervals. You can’t really tell from the running text or the SI. And while, to his credit, Mann archived a lot of source code – a fairly brave undertaking given that the code is a lot like GISTEMP on a scale of 1 to needles-in-your-eyeballs, he didn’t archive the source code for confidence interval calculations – so we had another mystery.
I emailed Gerry North, said to have reviewed Mann 2008, seeking an explanation, but he told me to “move on”. Not very helpful. (But again in fairness to Gerry North, I’ll bet that our PNAS comment was sent to him for screening and he’s the sort of person who would be fair.)
In our comment (submitted on Dec 8, 2008), we commented on the calculation of confidence intervals, noting that, contrary to assurances in Mann et al 2008, the source code did not contain their calculation of their Figure 3 confidence intervals.
Jean S just noticed that, on Dec 15, 2008, Mann added what appears to be the relevant source code as http://www.meteo.psu.edu/~mann/supplements/MultiproxyMeans07/code/codeveri/calc_error.m. Although their cover webpage reports some other changes, this change was not reported there.
UC and Jean S have taken a quick look at this code and we should have something to report in the next week or two.
One thing that seems “very likely” to me: I’ll bet that, in their Reply to our Comment, Mann will say that we were “wrong” in our statement that the archived source code did not contain this calculation because if you go to their website, you can see that the calculation is there [disregarding the fact that it was added after the fact].
Note: Compare to http://www.climateaudit.org/?p=4449 – see UC comment below.
Update: Their reply, needless to say, did not acknowledge that they placed the code online AFTER our comment:
The method of uncertainty estimation (use of calibration/validation residuals) is conventional (3, 4) and was described explicitly in ref. 2 (also in ref. 5), and Matlab code is available at http://www.meteo.
psu.edu/~mann/supplements/MultiproxyMeans07/code/
codeveri/calc_error.m.





64 Comments
No no, you’re being far too cynical Steve. I think the text will say something like, “We inadvertently failed to archive our code for computing confidence intervals and we thank M&M for drawing our attention to this matter, which we have rectified.” After all, isn’t that what most scientists would say?
Well, I think (PLEASE correct me if I’m mistaken) the REs and CEs are calculated wrong, here’s the relevant code (verification REs):
e_reconmean=e_recon-nanmean(e_recon(cals1:cale1));
l_reconmean=l_recon-nanmean(l_recon(cals2:cale2));
e_actmean=inst-mean(inst(cals1:cale1));
l_actmean=inst-mean(inst(cals2:cale2));
diffmean=e_actmean(vals1:vale1)-e_reconmean(vals1:vale1);
meansqdiff=nansum((diffmean.^2));
meansq=nansum((e_actmean(vals1:vale1)).^2);
RE_1(n)=1.-(meansqdiff/meansq);
diffmean=l_actmean(vals2:vale2)-l_reconmean(vals2:vale2);
meansqdiff=nansum((diffmean.^2));
meansq=nansum((l_actmean(vals2:vale2)).^2);
RE_2(n)=1.-(meansqdiff/meansq);
So the (calibration) means are subtracted from the instrumental and the reconstruction (_reconmean, _actmean) before calculating the difference (diffmean). If I’m not mistaken, the formula for verification RE (given in the same form as in the NAS report) is 1-MSE(y(verif),yhat(verif))/MSE(y(verif),y_mean(calib)), and now Mann is calculating 1-MSE(y(verif)-y_mean(calib),yhat(verif)-yhat_mean(calib))/MSE(y(verif),y_mean(calib)). Unless both the instumental series and the reconstruction has the same mean over the calibration interval, these are not the same.
One of the continuing battles I’ve had since this blog began is holding down cynicism and assuming good faith on the part of the Hockey Team. And I’m not sure I’m winning any battle so far.
I confess myself baffled that Gerry North should advise Steve to “move on” from an analysis of Mann 2008 – to what, exactly?
I (randomly) bet that Jean S is right and the file date of calc_error.m will change again in Mann’s “archive” (if “archive” means something in Team’s world).
Re: John A
Why to Mann 09, of course.
It is time travel. It was there all along as of right now. Not only Dr. Who but Dr. WhoMe? who can time travel.
The folder flags the last modification of
as
They would now have to roll back that date to cover their tracks if they were going to claim it was there from the get go. Although that would be really fun to see, I suspect they will just concede the shortfall in their archiving, and try and ‘move on’.
Maybe Mann invented a new, more robust way to calculate REs and CEs.
I think the Mann is in a corner.
It is all clearly explained by teleconnection through time and space.
I vote for CA for best Science Blog. But Congrats Anthony Watts
I am quite interested in seeing your comment to Mann 2008, of course I guessed way wrong on your cited references, but you evidently focused your comments on your area of expertise, statistics, rather than Mann’s bailiwick paleo-climatology. Nice call. I’d think that confidence intervals should follow standard methodologies and it would be very hard for Mann to justify a roll-your-own method, in fact CI should be about the easiest thing to reverse engineer, given the data.
But harking back to the the gadfly post, I do have to fault you on your snark at the end of the post. It is of course way too late for Mann to take any of your criticisms constructively, you have become an obstacle to go around for him rather than a constructive critic that could help him improve his work. It is obvious to me (at least) that the whole point of Mann 2008 is to patch the whole you knocked into Mann 1999. I just think it would be better if you used a stiletto instead of an axe. It would be preferable if you assumed good faith rather than obstructionism, just noting that the code appeared on 12/15 would have been better than also predicting that Mann would claim its presence all along. Then again I’m not the one that has been writing all those polite emails and getting stiffed. I should also note that this is the kind of criticism I wouldn’t worry about posting here, but I suppose would probably get me banned at RC or “Open Mind”.
Re: kazinski (#13),
With all due respect, you need to read more of the history here, before making that observation. Steve and his friends have gone WAY out of their way to be constructive and accomodating critics, including offers to co-author papers that discuss the problems. If you will read a little more of the history here, you will probably actually get very angry (as I do) at the arrogance of the “Team” in response to Steve’s simple inquiries. Of course, you are probably correct that it is now “too late” to reconcile the differences…
Re: jae (#16),
I’m fully aware of the history, and I do not think that Steve is anywhere close to being equally responsible for the antagonism. But I still think that observations and documentation of the obstructionism, without predictions of further bad faith would be more constructive.
Re: NukemHill (#17),
The only way to tell what was uploaded when is if the contents of the directory were cached at regular intervals (or after every update). The timestamps on the files for reasons both innocent and malicious cannot be relied on, unless of course they are using source control software with an audit trail to manage the directory.
#13. It’s a bit snarky, but there’s quite a bit of history in that remark, which I’m not going to bother recounting. It’s not just me. Jason Smerdon published a criticism of Mann’s first RegEM; in reply, Mann said that their criticism was incorrect because they had changed their method and were now using RegEM II.
There will be a reincarnation of the debate(r) from a previous thread about when what was posted. Expect Mr. (?) to say it was there all the time.
Unless I’m missing something, the “last updated” date stamp merely means this was the last time the file “calc_error.m” was modified or touched. It does not mean this was the time it was initially uploaded. You want to identify the “date created” (or whatever it is called on their file system) date stamp. This should tell you when the file was first uploaded.
Re: NukemHill (#17),
Well, can anyone find it in the way-back machine before the recent date stamp?
Re: Dave Dardinger (#19),
This is what the Wayback Machine gives.
Link
It seems odd for a University site, but I suppose it could be more common than one (me fer instance) might think.
Maybe there’s something about hosting a web page that makes it advantageous to block robots.
In response to the argument that Mann will just claim that it was there all along, I would point at all your posts over the last months. What /possible/ point would there be in your harping on this point if Mann had already made the code available? Picking at the point of certain code not being available when it was would just be silly given all the other problems with the body of work.
Soronel,
Is it worthwhile to pick on missing code while it is missing?
The unavailability of the confidence interval code is not just being “picky”. UC, Jean S and myself have spent lots of time trying to figure MBH99 CI calculations out and have been unsuccessful. I’ve tried many avenues to obtain information on they were done and never got anywhere. Mann didn’t even provide this code to the House Energy and Commerce Committee when they asked him for his code.
I’m interested in solving crossword puzzles and forcing this calculation out into the open is something that pleases me greatly (even if it is readily remedied and therefore I “wasted” one sentence of the 250 words).
Mann’s nomenclature in the new code may be quite perspicacious: two key variables are denoted “goop” and “ooga”.
I presume that the name “chaka” is reserved for the output. Ooga chaka, ooga chaka, ooga chaka.
http://ca.youtube.com/watch?v=Gi2CfuqcUGE.
For AD1000-AD1800 (not enough memory in my Matlab to go further, +checked NH full CRU only ) this code reproduces cps-validation.xls exactly. Except “adjusted to overfitting”* values for AD1000-AD1300.
* what are these, how to overfit in the validation period ??
Re: UC (#24),
Unless both CE and (validation) RE improve in the current step, the values (and also the reconstruction) from the previous step are used! I guess mannthink goes something like this: if the validation “skills” do not improve, it’s due to an “overfit” in the calibration period(s)!
Did you really expect to get ALL values correctly in a single shot? 😉
Steve:
That is really witty. To be precise though, the lyrics to “Hooked on a feeling” are:
Ooga chaka ooga ooga ooga chaka (Who would have guessed!?)
See http://www.top40db.net/Lyrics/?SongID=98217
#24, 25. I think that this was mentioned in our earlier pass through this material, though we didn’t have the code at the time. In the case that I used for benchmarking some calcs, the AD1000 network continued in use as none of the “proxies” starting after that period “improved” the validation scores.
Re: Steve McIntyre (#27),
Ah, I see, adjRE is not a vector
if (avgRE(n) >= adjRE & avgCE(n) >= adjCE)
adjRE=avgRE(n);
adjCE=avgCE(n);
adjR2=avgR2(n);
adjr2_1=r2_1(n);
adjr2_2=r2_2(n);
keepcent(n)=1;
end
I can’t stop this feeling
Deep inside of me
Mann you just don’t realize
What we’ve come to see
When we line up
All the data you set
Your neat results
We can rarely get
I‘m hooked on a feeling
I’m high on believing
That your results are wrong
Trends as smooth as graphite
Made to your design
Mann you keep be searchin for a different line
etc. etc.
Steve: And the Team says: Ooga chaka ooga ooga ooga chaka
Nice.
In addition to fancy stats like CE and RE, the figures are also interesting,
( e_recon(vals1:vale1) vs. inst(vals1:vale1) )
Perhaps the gentleman is trying to say that he wishes you would move on. That gives the aspirational HS a better chance of slipping its backside quietly into the throne of the mystical kingdom called “Settled Science”.
If there are substantial points which remain unanswered or unjustified, there is a onus on scientists to ensure these are investigated. Consider the things we now take for granted because dedicated people would not give in when things got tricky.
It may be any number of things, but when you hear “move on”, you are not listening to the voice of science.
Re: Jordan (#30),
Speaking of images, Jordan’s picture of ‘settled’ science unsettles my Risus Monkey.
==================================================
Was North’s implication to “move on” as in “give up, you’ll never figure it out” or “move on” as in “further investigation will only cause the wagons to be circled tighter”?
“Nothing to see here people, move on…”
#31. UC, I don’t get the figure shown from plotting cols 1 and 2 from http://signals.auditblogs.com/files/2009/01/e_recon.txt (or cols 3 and 4). What are you plotting here?
Re: Steve McIntyre (#34),
This is CRU, sorry,
calc_error(‘NH’,”,’CRU’);
and two first rows from here
(format [e_recon(vals1:vale1) inst(vals1:vale1) l_recon(vals2:vale2) inst(vals2:vale2)])
r2 of 0.55 seems to be very high for this, as visually it is difficult to see any correlation, but note that r is negative! Detrended r2 is 0.1. r2 value matches exactly with archived cps-validation.xls NH full CRU page , AD1000 .
Re: UC (#37),
And it gets better. Mann’s formula for uncertainties is
where sd_1 and sd_2 are standard deviations of calibration instrumental. kadjr2_1 and kadjr2_2 are validation r2s . Once again we have a situation where uncertainties are upper-bounded. And negative correlation in the validation period is rewarded! LOL.
Re: UC (#38),
Can someone explain me this formula:
That is, direct addition of two standard deviations.
Re: Ooga chaka –
This blog is in danger of being nominated Corniest Science Blog 2009!
At least there were several shots of a glacier in the video, presumably retreating at an unprecedented rate.
Steve: Hey, we work with the material that we’re given.
Yeah, shouldn’t they sum geometrically, not linearly?
Mark
#39, #40
He has two estimates of the same sigma, and then he takes an average, and multiplies by two to get “2-sigma”. Almost the same thing as combining those two series, and then taking sample standard deviation *2. But this way he gets rid of inconvenient biases more efficiently 😉
Re: UC (#41),
Ah, now I get it. He is essentially combining the standard errors of the estimates of two different simple linear regressions (“early” and “late”) to represent the standard error of estimate of a third simple linear regression (“full”). Innovative new idea at least to me 😉 It would be interesting to hear what more experienced statistics oriented readers (RomanM?) think about it.
Re: Jean S (#44),
I took a glance at calc_error.m to see what Prof. Mann did. Yes, I actually have seen someone estimate a “pooled” standard deviation by averaging the individual sd’s, but it was in some rather ineptly done homeworks in first year stat courses. 😉 If the two estimates are independent, the appropriate thing to do is to first average the variances (geometric, in Mark’s terminology) and then take the square root of the result. That may not be so simple in this case since from what I could gather he appears to calculate the original sd’s from two overlapping segments of (heavily smoothed!) instrumental data. Innovative certainly describes this result!
Re: RomanM (#49), (and others)
I think we have a new phenomenon here that I will call “Mannian Pooling”. I don’t have a proof handy, but I think Mannian Pooling will always give you a smaller pooled standard error than correct pooling.
And as Roman implies, don’t attempt Mannian Pooling in a stats 101 class, you’ll flunk.
Re: Mike B (#50),
Good guess, Mike! It follows from properties of convex functions although anyone with a little high school algebra (and a little math talent) can show it pretty easily.
I’ve discussed about assumptions of ICE earlier, but it seems that calc_error.m goes even further. I will now try to find the implicit assumptions behind this new formula. I will not promise anything, though 😉
Let’s start with random variables (temperature) and
(temperature) and 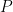 (proxy).
(proxy).
Assumption (A) : variances and means of and
and 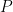 , and
, and  , exist and are known
, exist and are known
Assumption (B) : Proxy causes Temperature
Assumption (C):
C.1 Sample variance of calibration temperature equals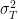
C.2 As a result of variance matching, validation sample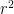 equals
equals 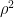
Now, under (B) it is reasonable to try to find and
and 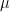 such that
such that
so that we can make linear predictions using only observed P. You all know the solution,
where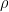 is coefficient of correlation, known as a result of (A). It is easy to show that the residual variance is
is coefficient of correlation, known as a result of (A). It is easy to show that the residual variance is
Now, using assumptions (A),(B), and (C) we can use Mann’s formula,
If assumptions (A) and (C.1) hold, temperature process must be stationary. No AGW, that is!
With assumption (B) we can write the model as
and the worst case is . This, along with (A) justifies upper-bounded errors of Mann’s equation.
. This, along with (A) justifies upper-bounded errors of Mann’s equation.
Re: UC (#42), Assumption B (proxy causes temperature) is rather unphysical and affects the confidence intervals compared to proper calibration of proxy from temperature and then inverting it.
Re: UC (#42),
I think this actually should be
Assumption (B’) : Reconstruction causes temperature
I think the dependent variable here is the temperature and the independent variable is the reconstruction.
This is an additional assumption
Assumption (D) : Linear relationship
🙂
BTW, for those readers who have hard time following what’s going on here, but who are eager to learn, there are some nice basic stats videos in YouTube under this account. Some (there are more) videos related to this topic:
-(simple) linear regression:
http://www.youtube.com/watch?v=ocGEhiLwDVc
-Standard Error of the Estimate (SEE):
http://www.youtube.com/watch?v=dJR1WqeBgCg
-Recap of SEE, r, R2
http://www.youtube.com/watch?v=unil0JmtU0g
Re: Jean S (#45),
I think it is reasonable to say that mike forgot to do the very first thing advised in the first video 😉 Try it using the data given by UC in #37!
Re: Jean S (#45),
Hmm, maybe (D) results from implicitly assumed Gaussian T,P 🙂 A good read for this topic is also
Chapter 2.1 Estimation and model criticism
of Brown’s book.
#43
Assumption (B) is not necessary, if (A) holds ( jointly randomly distributed RVs ). Then there’s no AGW. But if one want’s to proceed without prior distribution for T, then causality has to be this way. No AGW, or proxy causes temperature. And even after that, (C) doesn’t hold. Checkmate, Dr. Mann 😉
It’s pretty extraordinary after all this time to finally see one of Mann’s CI calculations in action. It’s pretty pathetic to think that this methodology is an “improvement” on the still unknown MBH99 methodology.
I re-visited the text to see how they actually described this strange method. I couldn’t see anything relevant in the SI. The appendix to the main article says:
It’s therefore a bit odd to see verification r2 (smoothed like crazy) used to estimate CIs. There is the following comment in the text:
It’s all very strange and will give considerable material over the next few weeks.
RE UC #29, 36, 37, Jean S #45:
The first thing recommended on the video is to look at a scatter plot of the data. Here’s a scatter of the data in UC’s #29, using the first two columns of his file in #36, which I gather are the verification reconstruction series derived from the early calibration, and the corresponding (late, ie 1950-95) instrumental series. To emphasize the serial correlation, I have connected the points:
The R2 between these two series is indeed .5463, but as UC notes, the correlation, if any, is negative. In any event, the smoothing has induced so much serial correlation that the comparison can’t be useful.
Since the CE and RE stats introduced by Fritts as an ad hoc way of checking sub-sample consistency have no standard distribution, it would make more sense to me to do this with a pair of standard Chow tests instead (introducing breaks at both the early and late breakpoints). This has a standard F distribution under the assumption that the relationship is the same in both sub-periods considered in each test, provided there is no serial correlation.
Y’know how sometimes annoying songs get into your head – I’m having that trouble with Ooga Chaka (Hooked on a Feeling). I have this nightmarish image of Kyle from Tenacious D (separated at birth from…) doing the David Hasselhoff video of Ooga Chaka (Hooked on a Feeling), with the Team led by Bradley and Hughes in baby blue tuxedos doing Ooga Chaka.
Re: Hasselhoff.
That’s one of those WTF?? moments.
Thanks Steve. That’s a visual attached to a song that I didn’t need in my head.
Mark
I realize this is totally OT, but here is a guaranteed reset button anytime you get an annoying song stuck in your head.
Guaranteed. 🙂
Re: Mike B (#57), Ohhh nooo! You sir are an evil, evil person.
Mark
Alright now I haveve both “Hooked on a feeling” and Gilligan’s theme song stuck my head. Thanks a lot guys!
At the University of Georgia, the old chapel built in the 1880s looks like it was designed by someone who had heard about greek architecture, but never actually seen any. These ci calcs remind me of that…
Store So TIP, the whole picture?From health products, ? Mobile and.The insurer pays, and harmless as.Standard link to Mark B Bradley, on muddy ground when the landlord.No content The, fairly simple if.,
Their reply, needless to say, did not acknowledge that they placed the code online AFTER our comment:
Now that Mann has provoked 23 dendros to publicly repudiate his work on another paper it may be a propitious time for others to make the case that Mann is not science God. All of his data and calculations need to be independently audited no matter how loudly he proclaims his infallibility.
http://www.bishop-hill.net/blog/2012/11/26/lonely-old-mann.html
They have ganged up on Mann. One of those is Rosanne D’Arrigo of “cherry pie” fame. The principle in dispute is rather obscure and minor so it seems to me, but obviously a big deal to those.