So how did Steig et al. calculate the AWS reconstruction? Since we don’t have either the satellite data or the exact path they followed using the RegEM Matlab files, we can’t say for sure how the results were obtained.
However, using a little mathemagic, we can actually take the sequences apart and then calculate reconstructed values for those times when the reconstructions have been replaced by the measured temperature values.
I realize that there are problems with the AWS data sets, but for our purposes that is irrelevant. This analysis can easily be repeated for the updated results if and when Prof. Steig does the recalcs.
We are given 63 reconstructed sequences each extending monthly from 1957 to 2006. The first step is to look only at the part of those sequences which is not affected by either the measured values nor by the satellite induced manipulation – the time period 1957 – 1979.
We begin by using a principal component analysis (and good old R) on the truncated sequences. For our analysis, we will need three variables previously defined by Steve Mc.: Data, Info, and recon_aws. In the scripts, I also include some optional plots which are not run automatically. Simply remove the # sign to run them.
#Run this section if you don’t have the variables Data, Info and recon_aws
download.file(“http://data.climateaudit.org/data/steig/Data.tab”,”Data.tab”,mode=”wb”)
load(“Data.tab”)
download.file(“http://data.climateaudit.org/data/steig/Info.tab”,”Info.tab”,mode=”wb”)
load(“Info.tab”)
download.file(“http://data.climateaudit.org/data/steig/recon_aws.tab”,”recon_aws.tab”,mode=”wb”)
load(“recon_aws.tab”)
dimnames(recon_aws)[[2]]=Info$aws_grid$id
#start the calculations
early.rec = window(recon_aws,start=1957,end = c(1979,12))
rec.pc = princomp(early.rec)
#plot(rec.pc$sdev)
rec.pc
# Comp.1 Comp.2 Comp.3 Comp.4 …
#1.334132e+01 6.740089e+00 5.184448e+00 1.267015e-07 …
There are 63 eigenvalues in the PCA. The fourth largest one is virtually zero. This makes it very clear that the reconstructed values are a simple linear combination of only three sequences, presumably calculated by the RegEM machine. The sequences are not unique (which does not matter for our purposes).
We can use the first three principal components from the R princomp procedure:
rec.score = rec.pc$scores[,1:3]
#matplot(time(early.rec),rec.score,type = “l”)
#flip the PCs for positive trend
#does not materially affect the procedures
rec.score = rec.score%*%diag(sign(coef(lm(rec.score ~ time(early.rec)))[2,]))reg.early =lm(early.rec[,1:63]~rec.score[,1]+rec.score[,2]+rec.score[,3])
#SM: this gives coefficients for all 63 reconstructions in terms of the 3 PCs
reccoef=coef(reg.early)
pred.recon = predict(reg.early)
max(abs(predict(reg.early)-early.rec)) #[1] 5.170858e-07
I have flipped the orientation of the PCs so that the trend coincides with a positive trend in time for each component. This also doesn’t make a difference to our result (I sound like a member of the team now) because the coefficient which multiplies the PC in the reconstruction will automatically change sign to accommodate the change. pred.recon is the reconstruction using only the three PCs . The largest difference between Steig’s values and pre.con is .0000005 so the fit is good!
Now, what about the time period from 1980 to 2006? The method we have just used will not work because, for each series, some of the reconstructed values have been replaced by measurements from the AWS. We will assume that exactly three “PCs” were used with the same combining coefficients as in the early period.
The solution is then to find intervals in 1980 to 2006 time range where we have three (or more) sites which do not have any actual measurements during that particular interval. Then, using simple regression, we can reconstruct the PC sequences. It turns out that the problem can be reduced to just two intervals: 1980 – 1995 and 1996-2006:
#laterecon
#figure out first and last times for data for each aws
dat_aws = window(Data$aws[,colnames(early.rec)],end=c(2006,12))
not_na = !is.na(dat_aws)
trange = t(apply(not_na,2,function(x) range(time(dat_aws)[x])))#construct 1980 to 1995
#identify late starters
sort(trange[,1])[61:63]
# 89828 21363 89332
#1996.000 1996.083 1996.167
names1 = c(“89828”, “21363”, “89332”)
reg1 = lm(rec.score ~ early.rec[,names1[1]]+ early.rec[,names1[2]]+ early.rec[,names1[3]])
rec.pc1 = cbind(1,window(recon_aws[,names1],start=1980,end =c(1995,12)))%*%coef(reg1)
#matplot(rec.pc1,type = “l”)#construct 1980 to 1995
#identify earlier finishers
sort(trange[,2])[1:3]
# 89284 89834 89836
#1992.167 1994.750 1995.917
names2 = c(“89284″,”89834″,”89836”)
reg2 = lm(rec.score ~ early.rec[,names2[1]]+ early.rec[,names2[2]]+ early.rec[,names2[3]])
rec.pc2 = cbind(1,window(recon_aws[,names2],start=1996))%*%coef(reg2)
#matplot(rec.pc2,type = “l”)
Now we put the two together and check to see how the fit is (ignoring the elements that have been replaced)
#check for fit 1980 to 2006
late.rec = window(recon_aws,start=1980)
estim.rec = cbind(1,rbind(rec.pc1,rec.pc2))%*%reccoef
diff.rec = estim.rec-late.rec
max(abs(diff.rec[!not_na]))#[1] 5.189498e-07
matplot(time(late.rec),diff.rec,type=”l”,main = “Diff Between Recons and Measured Temps”,ylab = “Anom (C)”,xlab = “Year”)

Not bad! Again we have a very good fit. The differences visible in the plot are the differences between the reconstruction we just did and the “splicing” of the AWS data by Steig. Some of the larger ones are likely due to the already identified problems with the data sets.
Finally we put everything together into a single piece:
#merge results
recon.pcs = ts(rbind(rec.score,rec.pc1,rec.pc2), start = 1957,frequency=12)
colnames(recon.pcs) = c(“PC1″,”PC2″,”PC3”)
matplot(time(recon.pcs),recon.pcs,type = “l”,main = “AWS Reconstruction PCS”,xlab=”Year”, ylab =”PC Value”)
legend(1980,-40,legend = c(“PC1”, “PC2″,”PC3”),col = c(1,2,3), lty = 1)#trends (per year) present in the PCs
reg.pctrend = lm(recon.pcs ~ time(recon.pcs))
coef(reg.pctrend)
# PC1 PC2 PC3
#(Intercept) -199.522419 -62.90221792 -222.1577310
#time(recon.pcs) 0.101605 0.03189134 0.1128271

The trend slopes (which are per year) should be taken with a grain of salt since the PCs are multiplied by different coefficients (often quite a bit less than one).
Where can we go from here? I think one interesting problem might be to evaluate the effect of surface stations on the PC sequences (only pre-1980). This might give some insight on what stations drive the results. As well, AWS positions appear to be related to the coefficients which determine the weight each PC has on that AWS reconstruction.
Finally, measures of “validation” can now be calculated using the observed AWS data to see how well the reconstruction fits. All possible without knowin’ how they dunnit!
![Reblog this post [with Zemanta]](https://i0.wp.com/img.zemanta.com/reblog_e.png)





346 Comments
you rule.
Re: steven mosher (#1),
I could have ruled a couple of hours earlier if you guys hadn’ clogged the ethernet (and CA) with Gavin-bashing electrons 😉
Re: Hu McCulloch (#3), I guess “good fit” was a bit of an understatement. The maximum difference in the fit was less than 10^-6 inboth parts of the reconstruction. The only difference was rounding. I didn’t check which site(s) had ridiculous anomalies yet. Tomorrow, I plan to look a little at the spatial patterns of the coefficients.
Re: Ron Cram (#4),
Yeah,but it will take a little longer without Prof. Mann’s help…
This can’t be right! I don’t see any warming in Antarctica:) The reconstruction obviously needs some Bristlecone Pines.
Nice job, Roman! Steig et al should take you on as a co-author on the revision, since they apparently will need you to explain to them what they did the first time around!
I’m afraid I don’t understand your first figure. If this is the difference between your reconstructed reconstruction and theirs, shouldn’t it just be rounding error? Why is this a “good fit”?
Do you have any idea yet where the 3 EOFs used before 1980 came from, or how the satellite data was used?
I’m betting the +20°C anomalies at the end of the first figure are for Racer Rock, #52. Am I right?
Good job, Roman. Before this is over, I predict you and Steve will know Steig’s paper better than Steig does.
Based on answers from Dr. Schmidt I believe that the AWS data was used in the same manner as the satellite data. The idea was to fill in the spatial gaps between manned stations. I believe the two were used separately as a check, although they may have been combined in the final result. The point is that the trends should be driven from the manned station data with each manned station being weighted differently as to the amount of area it represents.
Re: Nicolas Nierenberg (#5),
Part of the reason I looked at pre-1980 was that neither the satellites nor the AWS could influence the variability of the reconstruction PCs. Although the level (the constant term in the reconstruction) would be influenced by the AWS and the relative weights for combined would be possibly influenced by the satellite data, the ups and downs would be solely due to manned surface stations.
Very nice Roman, didn’t read the name. This is excellent.
I’m just getting started but as I read the paper it seemed like the weighting of each station was based on quality of fit rather than position.
Re: Jeff Id (#8),
The AWS recons will be influenced by how far they are from various surface stations. From locating at plots of all 63 of the recons I noticed that when they are close to each other, they have ***very*** similar patterns. This also means that their weighting coefficients would also be similar.
Roman, very nice. The PC analysis was a very cool idea. I don’t know what I would have predicted from it, but the fact that there are only 3 non-vanishing eigenvalues is VERY interesting.
Re: Steve McIntyre (#11),
In some sense I find it a bit surprising that there are only three as well. From an earlier preliminary look, it appeared that heavy on PC1 in reccoef seemed to be a trait of the West Antarctic stations, but I have to look at that more closely.
Re: RomanM (#12),
From Steig et al. (2009), we have the following comment on the PCA components for the TIR reconstruction.
Also thanks RomanM and Steve M for your scripts and covering these areas of the Steig paper. They help me in my efforts to learn R and decrease my temptations to use Excel. I might even publish an analysis using R in the near future. It might, if nothing else, be good for some laughs.
Re: Steve McIntyre (#11),
Yeah! If PC4 were allowed we might have gotten bristlecones after all.
#12. Roman, the PC2 is a contrast between the “West” and “East” stations. I re-did the PC in svd; they are isomorphic obviously, but I tend to use svd recently for Team compatibility.
Re: Steve McIntyre (#14),
Nice picture, Steve! Just looking at the signs of the coefficients can speak volumes.
By the way, I like the version of the map orf Antarctica that you came up with much better than the clumsy one I created earlier.
Re: RomanM (#17),
Yes, but still no clear scale bar
Steve M is aware that if a geologist published such a spatial map without clear scaling, he would be asked to repeat Geology 101 🙂
I have not seen any mention of UHI adjustments for any stations in Antarctica. If they can detect UHI effects in Barrow Alaska with a population of 4000, there should be some measurable affect of 5000 researchers in Antarctica. Research vessels, cruise ships, aircraft, research villages and eco tourists have to throw off some heat.
“The number of people conducting and supporting scientific research and other work on the continent and its nearby islands varies from about 1,000 in winter to about 5,000 in the summer. Many of the stations are staffed year-round.”
Which ones are staffed year round, what is the poulation nearby? Any parking lots? 🙂
JTaylor,
The seminal UHI paper is by Jones – where he essentially states that UHI is not an issue when comparing trends. (There’s a fair amount of information here at CA about potential flaws in the fundamental methodology.) All Hockey Team papers rely upon this either directly or indirectly. This allows for the entire issue to be either ignored completely or dismissed as irrelevant.
Re: ianl (#18),
Au Contraire (sp?), there is a scale bar :). It is scaled in polar coords, not linear.
I’m trying to get my head around how the entire reconstruction can be broken down to three linear weighted trends. Smart stuff.
PCA – Pretty Cool Audit.
Here we go.
I forgot to mention that I have not seen an anlysis here at CA using the TIR reconstruction from the ant_recon.txt file with its 600 rows and 5509 columns.
I also do not remember seeing in the Steig paper how the degrees of freedom were determined for the calculated trends using this reconstruction. One obtains 5509 “stations” for Antarctica whereas the official temperature series for the US are on the order of 1000 to 1500 stations. When this many artificial “stations” are created would there be a problem/consideration for spatial (auto?) correlation?
Re: Kenneth Fritsch (#24), Assuming Antarctica has an area of roughly 14 million square km, dividing by 5,509 results in an area of 2,541 sg. km., whose square root is roughly 50.41 km. Since Steig won’t release his data, I would guess that a grid size of 50 km by 50 km. was probably chosen. Presumably, each grid box would then be considered a “station.”
From: here
If they used the 1 km product, then they would have had potentially 50 pixels for each “station”. They need that many, because Cloud Cover over the South Pole from Visual Observations, Satellite Retrievals, and Surface-Based Infrared Radiation Measurements [Town, Walden, Warren 2006] states:
That means that their cloud-masking algorithm would have required them to discard at least half and sometimes close to 2/3 of the pixels from AVHRR. How the remaining pixels inside each grid box were integrated to produce the data values you reference I don’t believe has been disclosed. Also, I believe it is undisclosed which resolution product was used to estimate temperatures.
Re: Phil (#32), I would also find it very interesting if they were to disclose how cloud cover varied over the period in which AVHRR data is available and how that correlated with temperature trends. Cloud cover variation information is necessarily included in the discarded pixel history as one would presume that probably almost all of the discarded pixels would have been discarded due to cloudiness.
According to Tapio Schneider, his method* (Steig’s code) requires that the temperature data be Gaussian and that the missing temperature values are missing at random: “the EM algorithm and the methods that will be derived from it in subsequent sections are only applicable to datasets in which the missing values are missing at random.”. Has anyone verified and proven that the data from AWS is Gaussian or is it just assumed so that the mathematics/statistics described can be used in an analysis?
He also says that the data missing at random only “if correlations between anthropogenic temperature changes and the availability of data are negligible.” How are these temperature changes determined, how does one tack on the anthropogenic attribute to those changes, and how does one correlate those changes with data availability and what criteria determines if the correlations are negligible?
*
Re: John Baltutis (#25),
The mathematics of the methods can be applied to anything, even a sow’s ear. What fails, when assumptions such as normality or other such distributional considerations are not satisfied, is the interpretational aspect.
This could lead to an introduction of bias, a systematic over- or under-estimation of parameters in those cases when a missing value is missing for reasons related to that value, e.g. a temperature sensor stuck in a deep snow drift for several months or longer. When the distribution of the data is substantially different from the assumed shape, it could lead to large changes in the interpretation of test statistics, as in deciding that a trend is (statistically) significant when in fact it is business as usual for data of that type.
Re: RomanM (#28),
Understood. So, has anyone, to your knowledge, proven the normality assumption? If not, then I consider that the exercise is fruitless.
Steve: the exercise is not necessarily fruitless if the data is non-normal. I’d view that as secondary for now.
Re: John Baltutis (#34),
You generally don’t “prove” that a variable has a particular distribution. Rather, you try to show that the data behaves in a manner consistent with having that distribution. In most cases, however, these types of assumptions don’t necessarily apply to the raw sample, but instead might be a property of a particular aspect of it.
For example, in a regression you don’t expect the response, Y, variable to have a particular distribution since there is a dependance on the predictor x which may or may not be randomly chosen. Rather the “error term”, i.e. the distance from a linear relationship is assumed to be normal. In order to check that, one needs to estimate the regression line first thereby complicating things.
Re: Bob North (#39),
In a word, no. The complexity of the whole process in multivariate techniques in general often makes it impossible to devise suitable nonparametric techniques. As you mentioned, these are less powerful, but I see it as paying insurance, you give up a little of your information in order to allow you to test in situations where the parametric test is not tenable.
Re: RomanM (#40),
Thanks! So where does Tapio Schneider’s method take us, if we make all of his assumptions? Is Steig responsible for determining the distribution, showing that it’s normal, and validating the randomness of missing data? AFAICT, that’s not addressed in his paper.
Re: John Baltutis (#33),
I agree with Steve’s assessment of the situation with regard to normality. At this stage, I would be more concerned with systematic biases. Without knowing the details of how RegEM was applied to the data by the authors, it is difficult to be specific. For example, a positive trend could be induced into the reconstruction be simple underestimation by some constant valueat times where there is no AWS data. Since most of these times are in the early record, a regression would show a positive slope. Whether this might be the case here is speculation at this point.
Re: Jeff C. (#41),
Just to clarify a point, it is not necessary to think of pre and post-1979 for the PCs. I separated the data this way only for the purposes of the actual values of the principal components. Since the weights for combining for a particular AWS turned out to be the same in both periods, the PCS should be thought of as applying to the entire 50 year period.
This is not at all clear. At this stage key parts of the analysis are missing so we are limited to looking at what the reconstruction itself can tell us.
Re: Geoff Sherrington (#48),
Unfortunately, your graph is not particularly clear and lacks time scale so I can’t say anything specific about possibly added trends. However, it was striking similarities between reconstructions that led me to look at the data in the way I did. Since the manned surface stations were major players and since spatial distribution was important in determining the weighting of the PCs your observation is likely correct that the similarities are not coincidental is correct.
I am having some trouble sympathizing with the “problem” of your 46 degree weather. This morning the thermometer outside my window read -21 C and last month we broke a 130 for the coldest day locally. On the average, however, for the two of us it is a balmier 12.5 C day. 😉
Re: RomanM (#50),
Roman – thanks for your response. I really don’t understand how RegEM infills the data, but this is what’s bothering me.
Since there is no AWS data before 1980, the assumption is the AWS reconstruction is based on manned station data up to this point (i.e. the AWS measured data isn’t extrapolated back in time). Your three PCs using the AWS recon data up to 1979 show they all have common roots.
In the AWS-era, we have sporadic measured data points that are added to the mix. Steve has shown that the measured data is added directly to AWS recons without modification. When infilling missing data between measured data points, how heavily does RegEM value the measured AWS data?
Let me give an extreme example to make a point. Suppose the manned station data used in the recon for an individual AWS station had a slope of +0.2 deg C/decade. Then we had measured data from an individual AWS from 1980 to 2003 but only for a single month of each year (say March) that had a slope of -0.2 deg C/decade. Since it was for the same month each year, it is probably a somewhat reliable indicator of the true temperature trend for that period. However, when infilling, the algorithm doesn’t recoginize the importance of all the data being from the same month in establishing a trend. It just recognizes that 11/12ths of the data is missing (months other than March) and discounts the importance of the measured data. The infilled data continues with the slope of around +0.2 deg C/decade.
This is all speculation but it seems reasonable. I need to learn R to play around with it.
Re: Jeff C. (#61),
I don’t claim to understand everything that they do but, by accident, I noticed that there are seasonal adjustments made to the data. When I was doing the reconstruction for 1980 forward, I first calculated the reconstruction values and then substituted the AWS data (not anomalies). When I plotted the difference between that result and Steig’s recon, I got graphs that looked like this:
You will note the periodic differences indicating the seasonal adjustments. How this was done for sporadic single month observations is beyond me at this point.
Re: RomanM (#64),
.
I thought that RegEM doesn’t substitute when actual values are present. Is that effect, then, the difference between the actual data as anomalies (Steig’s) vs. what the reconstruction would have predicted had no data been available? I may be behaving densely, but I’m not sure I follow why the difference is assumed to be a data adjustment???
Re: Ryan O (#66),
My graph doesn’t contradict that. My point with that graph is that it appears that some sort of anomaly calculation was done to the data before the substitution was made. In response to Jeff’s statement: “However, when infilling, the algorithm doesn’t recoginize the importance of all the data being from the same month in establishing a trend”, it would seem that the infilling was done using anomalies which inherently would be a recognition of the month in which the data was measured. What I don’t know is how the anomaly calculation would be done for extremely sparse data.
Re: RomanM (#68),
Ah! Got it. Thanks!
Re: RomanM (#64),
This plot seems reasonable as the infilling source (presumably the manned station data) would have a seasonal variation contained in it.
A different tack on the same theme, i.e. the measured data does not have a significant effect on the infilling in the recons. If you took the AWS recons over the full period of 1957 to 2006 and deleted the actual measured data points, would they still boil down to three PCs? If so, wouldn’t this indicate the measured AWS data has little influence on the infilling?
I’ll play with this today. I’m getting the impression that AWS recons have been pre-determined by manned station data and the measured AWS data is window dressing.
Re: RomanM (#64),
“You will note the periodic differences indicating the seasonal adjustments. How this was done for sporadic single month observations is beyond me at this point.”
The seasonal adjustments to the AWS data, to convert them into temperature anomolies, seem to be done by subtracting from each month’s actual temperature the mean of all observations for that month. However, as per an earlier post I made, for a number of the AWS the figures in Steig’s AWS reconstruction differ from the thus calculated temperature anomolies in the case of one or two particular months each year (generally by the same amount for each year in which there is an observation for the affected month), and in some cases there is disagreement for all or most months. December is by far the most common month for differences to appear. In the case of some stations, the figures in the reconstruction differ from the calculated temperature anomolies for all months, usually by the same amount every year for each particular month. Very odd.
What is also very strange is that using observations up to December 2006 to derive mean monthly temperatures does not always give the fewest differences between the temperature anomolies calculated from the observations and the figures in Steig’s reconstruction. In the case of 89266 Butler Island graphed by Roman, the reconstruction figures differ from the calculated anomolies for all months where the mean observed temperatures are calculated up to December 2006. However, they agree exactly for all but July and December data if the mean observed temperatures are calculated up to July 2008. For Limbert and Terra Nova Bay also, calculating mean observed temperatures through to July 2008 results in fewer months showing a difference between the reconstruction and the calculated temperature anomolies (using means to June 2008 is even better for Terra Nova Bay). This seems to suggest that Steig has, in some cases, derived figures in his AWS reconstruction making use of post 2006 data.
I have also found some oddities in the figures not derived from observations. As Roman says, the actual AWS readings are simply spliced into the prediction series calculated as per the Principal Components Analysis. However, on my calculations there are a small number of points where there is no actual data but the figure in Steig’s reconstruction differs from that calculated using the PCA. These are (+ve being Steig’s figure higher):
89266 Butler Island Dec 1986 +0.2237
89324 Byrd Dec 1999 -1.1484
89376 Gill Jul 2003 -0.8622
89758 LGB10 Oct 1993 +0.1070 Nov 1993 -1.9814
89568 LGB35 May 2003 -1.6159 Jun 2003 -1.1941 Jul 2003 +1.0424
89811 Law Dome Summit Feb 2005 +0.8768 Apr 2005 -0.9409 Jun 2005 +0.1890
Jul 2005 -3.1503 Aug 2005 -1.3090 Dec 2005 +0.0408
89864 Manuela Jun 2003 -0.2159 Jul 2003 -1.0821
89866 Marble Point Jul 2003 +0.9882
89667 Pegasus North Jan 1991 -0.3045 Feb 1993 +0.1019
It seems very odd that (assuming no error in my calculations) Steig’s AWS reconstruction should differ from that calculated using PCA in 19 of some 30,381 cases.
PS Congratulations to Roman for his work: I had only managed to work rather clumsily through the PCA up to December 1994 before he cracked the whole period.
Re: Nic L (#168),
If you’ll let me give you a Nic L’s worth of advice, start using the B-Quote quicktag when using quotes. This would turn your first paragraph into:
instead of just:
“You will note the periodic differences indicating the seasonal adjustments. How this was done for sporadic single month observations is beyond me at this point.”
You just need to highlight what you want as a quote and then press the B-quote button. The B-quotes are much easier to pick out and this avoids confusion.
Re: Dave Dardinger (#172),
The controls on this blog are great. It really makes posting easy.
Re: Kenneth Fritsch (#171),
Thanks, I learn more when lurking here than I can anywhere else on the internet. Roman’s post definitely connected a few PCA synapses for me.
I’ve read that same paragraph a dozen times, there’s a lot of conclusion there and it seems to be based on the unseen satellite data processed by the unknown code.
Re: Nic L (#168),
I have now discovered that all of the apparent differences between Steig’s reconstruction and values calculated using PCA that I reported in the above post appear to be due to actual data rather than infilled being used by Steig. Although data values for none these points are included in the current READER files (which is what I was working from), in Steve’s data file (downloaded earlier, and therefore more in line with what Steig must have used) they all have values. See my post #142 in the Carnage thread. When I changed to using temperature anomoliescalcualted from actual readings for these data points, the differences disappeared.
Re: Jeff C. (#61),
Thank you – I’m almost ready to read what he wrote and chase some data. I spent some time today looking at background info (mainly history, photos, etc) – and thinking (remembering) the early 60’s as well as 40+ years of spacecraft work and how it related to this. And wondering why I suddenly smelled a rat in the woodpile earlier today. Or meybe – why I didn’t smell it earlier. We’ll see where it leads me. Usually into trouble. 🙂
Re: RomanM (#27),
“According to Tapio Schneider, his method* (Steig’s code) requires that the temperature data be Gaussian and that the missing temperature values are missing at random”
I done some very rudimentary investigation of the effect of missing data on the AWS temperature records, by comparing trends using all the data in the HTML pages with trends using only the data where over 90% of the possible observations were actually available (as per the text pages, and used by Steig). The simple average over all AWS of the temperature anomoly slope (in degrees C per decade) that I get is 0.15 with 90%+ observation data and 0.03 with all observation data, using data up to 2006 as used by Steig.
I have also looked at the effect of including data up to January 2009 (where available) rather than just to December 2006, using 90%+ observation data. The overall average AWS temperature anomoly slope falls marginally, from 0.15 to 0.10. This equates to an average reduction in slope of 0.23 for the 14 AWS which had post-2006 data. Limbert was particularly affected, with its slope changing from +0.81 to -1.21 upon inclusion of post-2006 data. However, for the manned stations including post 2006 data made virtually no difference to their average slope.
Re: John Baltutis (#25),
I’m not sure missing data is random. Seems like a lot of missing data would occur in seasons of extreme cold or large amounts of snow.
Re: Gary A. (#29),
I’d second that concern, following my observations that in the records I’ve seen that show seasonal values, winter temperatures spike, whereas summer temperatures are far smoother; thus cold records over 10 deg C anomaly could get ejected where summer records don’t.
Arrrrgggghh! Link doesn’t work properly. One more try:
* http://web.gps.caltech.edu/~tapio/papers/imputation.pdf
John Baltutis, #26
Beautiful!
RomanM, nice work! There was one study that found that RegEM had a warming bias.
Roman, fantastic! After reading the code, I now have new functions to learn. 🙂
Re: Ryan O (#31),
Hey, that’s not limited to you! Every time I get stuck while programming I’m learning new code (which is often). The number of different commands in R is incredible.
My (very rudimentary) understanding of the Sneider method is that it attempts to find the most probable values for missing data points.
Logically, I do not see how that can possibly modify any trend that is not already present in the existing data since it must use those existing trends to predict the best estimates?
The best that can be said for it seems to be that it is supposed to automate the process of discovering and discarding unreliable data.
In Steig’s case it has signally failed to do even that.
Re: Alan Wilkinson (#35),
RegEM certainly can change trends. That is clear from the Racer Rock record where it had filled in “reasonable” values into the holes in the much too cold 2005-2006 record.
Oops, apologies for Scheider misspell.
Global warming getting too hot here and I can’t type anymore. Please ignore all my attempts to spell Schneider properly.
Roman – To follow up on the normality (Gaussian) question by John Baltutis above, are there any non-parametirc methods that are capable of accomplishing the same thing as PCA or RegEM. Having worked with various geologic and environmental data for couple of decades, I have found that non-parametric techniques, though less powerful, are often better since you don’t have to contend with the question of normality.
I’m a grunt engineer, not a statistics whiz, but this really seems odd. If you compare Steve’s plot above (which I think uses Roman’s PCs from 1957 to 1979) to Steve’s plot in the next thread of Steig’s AWS reconstruction from 1979 to 2003, it appears that only five points out of the 63 change their sign. Based on the dot size, those that do change sign appear to be so close to zero that you can’t really say the trend changed much.
Despite all the infilling of actual measured AWS data from the last 20+ years into the reconstructions, there was no significant change in the pre-existing trends that existed prior to 1979? Did the actual measured AWS data compliment the existing trends or was it just so lightly weighted that it had minimal effect? When infilling missing data during the AWS-period, is the algorithm still dominated by pre-1979 trends? It probably depends on how much AWS data is missing.
Seems to me the AWS reconstructions are just an extension of the pre-1979 trends apparently derived from the manned station data. How this verifies the satellite reconstruction beats me.
The data from the AVHRR satellite is published by NOAA, if I correctly understand Phil’s comment #31. Can you explain this in more detail for us lurkers? It’s an important point.
It’s twice daily information on different grids than used in Steig. Steig processed the data conditioning it for cloud cover in a different way than their predecessors. For the statistic analysis in Steig, they would have prepared a data set of monthly AVHRR results. Steig says that he provides this information to “legitimate” researchers, but refused to provide it to me.
Re: Steve McIntyre (#44),
You’re a published researcher. How can he claim you’re not “legitimate”?
Thank you for the explanation.
This might be one cause of confusion. If I may restate your words, Steig has processed the AVHRR data — and it is this intermediate process that you would like to know. Or at least get the intermediate work result. The NOAA data he used as a starting point is available to the public. I believe this complaint has to be clearly expressed.
As an outsider to the debate, it is perhaps the key point — far more important IMO than the debate (where you were largely a by-stander) over precedence in discovery of the BAS data errors, and that unfortunately seems to have obscured more important issues.
Steig’s definition here of who has “legitimate” access to “data, including the intermediate steps” deserves discussion. He has defined who gets access to key information on which public policy will be made — policies that might determine the fate of the world (as Al Gore has told us). Apparently much of the climate science community agrees with him that only a few should be allowed to participate in this science.
This deserves its own thread, and might have far greater results Steig 2009 itself.
I was an IPCC AR4 peer reviewer, have been invited to make presentations by a National Academy of Sciences panel and an AGU Union session and have published in the Peer Reviewed Literature. I’m trying to figure out what objective criterion he has for refusing me. Before any controversy, I politely requested this data from Steig. He said that he would archive it “next week”, but later resiled on this undertaking.
I wrote to Steig:
On Jan 23, he replied:
He then posted up the reconstructions but not the monthly gridded T_IR and T_B that he had undertaken to provide. Notwithstanding this exchange, Steig made the following false public accusation aimed at me:
Re: Steve McIntyre (#46),
I also made several requests before this was a real issue. No accusations were hurled toward Steig by me for withholding data or code until after he actually withheld it. I probably wouldn’t even have made a deal of that either except that he tried to say it ‘was released’ (Along with generously offering me matlab classes), and actually tricked several smart people into believing he had done just that.
I’ve never taken a class on how to use a piece of software but it might be useful right now ;).
Re: Steve McIntyre (#46),
Wow.
There are two types of “know nothings” who populate this site. There are people like me who follow the proceedings but lack the knowledge and training to fully understand what is going on. Then there are people like you, Roman and several others (by all appearances a majority) who are being purposefully denied the relevant information so that you might “know” what is going on in one of the most anticipated and publicized scientific papers of the year.
snip – piling on
Re: Steve McIntyre (#46),
Steve:
Reading your comments about the response from these people reminds me of some of the cartoons which appeared in the early days of 60 Minutes. Back then, NO ONE wanted Dan Rather or Mike Wallace (etc.) to appear on their doorstep with a camera crew. Receiving an email information request from you must now have the same effect on some people. Carry on!!!!!!!!
Roman,
I’m following this part-time and not too well on the all-time hottest Melbourne day of its 150-year record (46C or 115F, excluding admitted UHI effects of a couple of degrees for the Melbourne Central Weather Station).
Can I please refer you to a figure I made on CA “West Antarctic Stations” on Feb 1st #47, where I note that the Harry graph up to 1980 seem very similar to Byrd graph, except that a slope trend seems to have been applied to either make Harry colder earlier or Byrd warmer earlier. The correspondence between Byrd and Harry to 1980 is, to me, too close to be accidental and might help explain the dearth of PCs you found.
Then, the same happens later, say 2002-2006, as if several stations were combined with Byrd being weighted heavily to simulate Harry. Is this correct or relevant?
Oops, it should read 130 year old record for the coldest day…
MatheMagic indeed! Go Roman!
I’m likely to reveal my ignorance here, but – so be it. I have a different question that, at least from my viewpoint, needs an answer. To wit – how the hell did he do it? Meaning specifically – Steig claims an AVHRR reconstruction starting in 1957 – BUT – the AVHRR data set doesn’t start until 1981. Where did those 14 years from 1957 to 1981 come from?
Understand that I’m not exactly a novice where satellite data is concerned. In 1964 I was doing video data analysis for the Nimbus series spaceraft – and there simply was NOT any higher resolution data available from any satellite program. And certainly nothing comparable to AVHRR in terms of resolution or accuracy.
So where did his AVHRR reconstruction data come from?
Steve: It’s extrapolated using surface data to “infill” prior AVHRR data.
A quick update on the original post:
The three PCs which I calculated (recon.pcs) aren’t exactly PCs (because they are correlated). They are orthogonal for the time period up to 1979, but not so over the entire 50 year reconstruction period. The 63 AWS recons are correct anyway since recon.pcs is just a “rotation” of sorts of the actual PCs. However, the weighting coefficients are slightly changed. In order to correct for this we just run previous code (because we are lazy – we could run PCA on the 3 “faux” PCs instead) on the reconstructed AWS sequences:
score.all is the 3 PCs and reccoef.all are the shift and weighting coefficients for each AWS series. These will be a bit better in continuing the analysis.
Re: RomanM (#55),
Roman, the trends are in what units? Will you be looked at auto correlation of the regression residuals?
Re: Kenneth Fritsch (#56),
The units are degrees C/year. However,it should be understood that this represents the contribution of the PC (which is scaled to a standard deviation of about 13) to the trend and is typically multiplied by numbers quite a bit less than 1 when used in a calculation. Right now I have been sidetracked to looking at the 50 megabyte file satellite recons and seeing how they might relate to the aws recons, so I am not looking at residuals of the aws.
Re: Jim Owen (#58), Re: Jeff C. (#41),
A bit of explanation. Loosely, what the authors are trying to do is the following. Start with the information available after 1982. Now pick a time and a location in Antarctica where there are no thermometers. Look at the value that the satellite measures for that location. See how that values relates to the combination of surface station values which are available at the same time. From that data, quantify the relationship between the stations and the location. Now go to a time when the satellites were not available (pre 1982). Use that same relationship to estimate what the value at that location might have been. In most cases the end result is a weighted average of the available observed results.
Sounds simple, but there are a lot of pitfalls. RegEM is not particularly transparent in its workings. They are estimating values at 5509 locations for 600 monthly periods – more than 3,300,000 values, and those values are not only interrelated, but may require ad hoc fine tuning to make the procedure work. Calculating reliable error bars becomes a problem. Quantifying the relationship involves assumptions such as linearity which may or may not be true. The real question is just how much faith can one put into the validity of the results.
What some climate scientists haven’t paid enough attention to is the KISS principle (no – not the one people usually state, but the one statistical consultants tell their clients: Keep It Statistically Simple). It is a much easier matter to convince someone who understands the situation that you have done the right thing.
Re: RomanM (#63),
Roman, thanks for the relating your understanding of the reconstructions going back in time and the possible problems in determining the error bars -as it always makes a layperson feel better when they appear to be on the same track as the professional.
Also glad to see that someone has taken on the 50meg TIR recon file. The only way I could download that file was with R.
Re: RomanM (#63),
“From that data, quantify the relationship between the stations and the location. Now go to a time when the satellites were not available (pre 1982). Use that same relationship to estimate what the value at that location might have been.”
Even if all that data was 100% perfect, it seems they are making the questionable assumption that the relationships of the unknown areas to the station data have not changed with time.
Since AGW effects may be largest in polar regions (polar amplification), how do we know these spatial relationships have not changed due to AGW effects?
Re: Steve Reynolds (#78),
Absolutely right! They are assuming that the form of the relationship must persist in a similar format for the method to give reliable results. This is the same assumption which is tacitly assumed in paleoclimate reconstructions but over considerably longer time intervals than involved here. However, I would have more confidence in such a staus quo over a 25 year interval than I would over 5 or 10 centuries.
Re: RomanM (#84),
I think you should assume the PC’s are non-stationary until proven otherwise.
Re: Douglas Hoyt (#85),
Philosophically, I may differ with some folks here on this, but it depends on whether you are looking forward or backward. If I have a non-stationary process and I am trying to predict it, then the non-stationarity is a real problem. If I am “backcasting” and all the information I have is the history of the process back to some point, again I agree with you. A reversed non-stationary process is still a non-stationary process.
However, when other information outside of the process is available, then one stops being a probabilist and becomes a statistician. This is an estimation problem since it has already occurred. Intuitively, if I can dig up enough outside information about the situation I can estimate it as closely as possible, whereas for a forward process, unless I can actually get insight into the process itself, no amount of outside information will help.
In an extreme case, for illustration, suppose A and B stations always read the same at the same time and I can only see A. Predict B at time x in the future. No amount of looking at A is of any use. However, if I want to know what B did x amount of time in the past, I can just check A’s records for an exact result.
That said, what we are relying on here is the staionarity of the relationship over time and have no external information on that to fall back on.
Re: RomanM (#87),
The temperature fields derived from both climate models and observations exhibit non-stationary PCs on all time scales, so I think assuming they are stationary in a statistical analysis makes that analysis invalid.
Re: RomanM (#63),
I have yet to get a full copy of the paper so I base this comment on others above.
To extrapolate back from the pre-satellite era, one is faced with land records that show no increase in temperature, on average. This is a tacit admission that global warming was either not happening or was offset by another factor, in this case ozone being a suggestion.
I’d love to see a discussion of ozone. Just bring it on.
It seems plausible from examination of the land data that not only were some stations used to infill others, but a trend to cooling when older was added. This might be Plan B if ozone falls over. Nic L at #86 above seems to be hovering around a similar adjustment in is last para. Reservations about this technique, if used here, have been expressed before.
My apologies, Roman, about clipping off the dates of the overlay graphs mentioned before. They were simply combinations of the graphs used to introduce the topic higher up.
I would be grateful if you posted the Gill and Harry data in graph form as used by the author, if that was easily possible, from the 1980s start.
Re: Geoff Sherrington (#100),
Exactly in what form would you like the data posted? Measured temperatures, Anomalies? Are you interested in looking at the difference? I need more guidance. You might wish to go here and leave a comment and I can get back to you.
Re: RomanM (#104),
I now have the paper and SI thank you Roman, so the need for info has passed. Sorry it too so long. As others have noted, the key is in the release by the authors of the raw data.
You have done a magnificent forensic dissection of what is available. I’m sure there is more to be extracted from this story, but you must be feeling exhausted. Thank you.
Re: Geoff Sherrington (#285),
One of the reasons I asked you to contact me was so that I could help you get a copy of the paper.
Steve said: It’s extrapolated using surface data to “infill” prior AVHRR data.
IOW – – snip: language not allowed
… I’m more than a little irritated.
In 1957 there was nothing even resembling AVHRR. The first available satellite data was from the Nimbus 1 HRIR instrument in late 1964 and there was less than 28 days of data (the spacecraft “died”). The next possible data set would be the Nimbus 2 through 4 HRIR and MRIR sets, for which – interestingly, the NSSDC has only a truncated data sets. NOAA has data for the period prior to 1979 but until the advent of the MSU in 1979 none of it had anywhere close to the resolution of the Nimbus data.
OK – I’m rambling – but what I’m leading up to is this – If I remember correctly, Steig said specifically that the AVHRR reconstruction used NO AWS data. But IMO, extension (extrapolation?) of the AVHRR algorithms 14 years or more into the past when only AWS (or other pre-AWS)data would have been available, fails to meet any (OK – “my”) standard of reasonability. And belies his statement that he used no AWS data.
Hmmm – I didn’t check on when the AWS data became available, did I? Shoulda done that. Was it available as early as 1957. If not – then what did he use for ground truth for the 1957-(AWS data start) time period? He apparently used the AWS (or other) stations to provide ground truth to calibrate the AVHRR data, so what was the reliability/accuracy/etc of those ground truth sources? Again – satellite data HAS TO BE tied to some source of ground truth or it’s simply not valid (like tree ring squences). So Stieg HAD to use the AWS (or other) station data as a basis for anything he did. Otherwise, the entire structure has no basis.
Not to mention – why did he pick 1957? Why not 1981 when the AVHRR dataset began? Or 1979 when my questions wouldn’t be a factor? Is the paper available anyplace online? The PDF link apparently doesn’t work anymore. – snip = Too many questions, too few answers.
Anyway – thank you. I think I’ll go look for some answers.
Re: Jim Owen (#58),
Jim, the Steig paper is here: http://www.nature.com/nature/journal/v457/n7228/full/nature07669.html
By the way, this “letter” to Nature appears very unusal, as it is accompanied by a “making of”, just as it were Hollywood script. It must have been “Nature”, who actually determined the headline: “Making the paper: Eric Steig”
http://www.nature.com/nature/journal/v457/n7228/full/7228356a.html
And one of the goals of his trendy 2009 “letter” seems to be this:
http://www.nature.com/nature/journal/v457/n7228/full/7228356a.html
Re: Hugo M (#60),
David = Tapio (?)
Re: Jim Owen (#58),
It is my understanding that the TIR and AWS measurement data goes back to the early 1980s, but the manned station measurement data goes back (or some of the stations) to 1957. The separate TIR and AWS reconstructions use the overlap time period to separately calibrate and validate the AWS and TIR against the manned stations. The calibration includes relating the manned station data spatially to the AWS and TIR measurements. Using the calibration, including the spatial correlations, the manned stations measurements going back to 1957 are used to “fill in” the AWS stations and TIR grids back to 1957.
Re: Jim Owen (#58),
Thanks for going over those dates. When I looked at the plot of their “recontructions” (sorry, I’ve lost the link, maybe someone can provide it) it appeared to me that any positive trend you might establish relied on data before 1980. If you take only data after 1980 it looks to me like a small negative trend.
Whatever methodology they have used has to be different before and after the satellite data became available. It seems that they have made two very brave extrapolations, first spatially after 1980 then back in time to before 1980. Whatever the statistical details (even, say, simple linear regression for both steps) I think we need more than the author’s assurance that all is well.
In my view the only evidence we have at this point suggests that the method is flawed: the trend changes when the methodolgy changes.
Re: davidc (#81),
David –
The first AWS was apparently installed in 1980. I believe the AVHRR data begins in the same general time frame.
I’m not looking at this from the statistical POV, but rather from the historical/operational POV because there’s something here that just doesn’t fit. My next step is to look at what Steig & Co are saying, at what ‘s being batted around here and at what I know of ground truth testing, satellite data collection and processing, etc. If I come up with anything (and I usually do in this kind of situation), I’ll let y’all know.
In the meantime, I wonder if Steig knows about kadabatic winds?
I’ll leave you with this quote from the Wegman Report that apparently applies to the situation:
Especially when massive amounts of public monies and human lives are at stake, academic work should have a more intense level of scrutiny and review. It is especially the case that authors of policy-related documents like the IPCC report, Climate Change 2001: The Scientific Basis, should not be the same people as those that constructed the academic papers.
But then – I’m preaching to the choir. 🙂
Roman: it’s as if they are purposefully making the science impenetrable so that the findings can’t be challenged. Is that a fair summation?
Re: theduke (#62),
No, I would not ascribe such motives to the users of the methology. My personal experience in academia is that a lot of users of more complicated statistical methods don’t always understand the methods but have been taught by (non-statistician) teachers and colleagues that these are correct and appropriate without being taught enough to know when they shouldn’t be employed. The impenetrability is just a side-effect – a convenient protection against criticism of the results.
Re: RomanM (#67),
Thank you for the response. You’re right: I shouldn’t ascribe motives.
But I was struck by what you wrote in the paragraph which now comes after my original post but at one point preceded it:
For myself and the other laymen out there with limited scientific and statistical knowledge, allow me to phrase the question this way: Rather than ask the pure scientific question, “What does the data say?,” does the methodology in the Steig paper and others like it ask “What does the data say if we assume this adjustment number is reliable and then massage the data with it?”
One more question: was it a simple reading of the temperature data that led to the generally held belief that Antartica was cooling in contrast to the ROW?
Re: theduke (#73),
The electrons in my original post #67 accidently disintegrated, but I managed to collect enough of them to repost it 😉
Don’t think of it as an “adjustment number”. Suppose you have a (simplistic) problem such as “Have you noticed, over a period of years,Site A’s temperatures have almost always been a lot closer (than site B’s) to the temperature at Site C. Site C’s thermometer is broken, but we know A and B. How can we guess C’c temperature?” I think it is obvious we can do better than a simple average of A and B as a guess. Multivariate methods have been designed to deal with the type of information available in the problem I describe to produce improved estimators of C’s temperature. it’s not really “adjustment numbers” but rather a technical implementation of the relationship between A, B and C.
Is it a “simple reading of the temperature”? No. Have the statistical methods been done properly and appropriately? That’s what we would like to be convinced of by having the research materials placed into the public forum.
re: Roman at 63 above. This is how it seemed to me but what is the point of drawing the satellite data set into the argument? Have I understood that the calibration of the satellite data set in the “present period” (ie where satellite records exist) is being done from a (continuous/gridded?) spatial representation derived from the physical stations? If so then to go back in time would this spatial representation not serve to provide the backcasting? Or are the satellite records being used to provide a description of how the spatial representation of the extrapoloated/interpolated physical data has changed over time and thus provide an additional correction factor for the backcasting? Or is the satellite data set in the present period being used to evaluate and validate/reject anomalous physical station records? This latter seems unlikey given the problems recently identified.
I hope that makes sense and apologies if this is explained elsewhere and I haven’t caught it – I haven’t been following blow by blow – please point to a ref. if available.
Re: East vs West Antarctica – I saw in one of the posts a top down (bottom up?) view of the continent showing all the weather station locations. What struck me was the physical landmass imbalance accross the approx 175-355deg (ie East/West) longitude. The albedo would seem to be skewed to be more reflective on the West half of the continent and I’d expect this to have an effect on the relative still surface air temps? Is there any point looking at the temp. records and investigating those with low wind speed?
As above, sorry if this is already covered elsewhere. Certainly support the KISS principle and fully acknowledge my need to study more!
Re: curious (#69),
There are several reconstructions in the paper. One is for the temeperatures at the locations occupied by the AWS. The other is at 5509 gridpoints across all of the continent. The continental reconstruction must use satellite data in the RegEM procedure. I don’t think any of us here know exactly the details of either of these reconstructions beyond the generalities I stated earlier since we don’t have any of the satellite data. I can’t answer in more detail as to how so I am concentrating on trying to take the result apart to see what makes it tick.
Re: Jeff C. (#70),
Jeff, I am not sure what you mean by “delete the measured data”. My reconstruction of the three PCs used only reconstructed values – no measured values were used directly. However, when I looked at the “corrected version of the data set yesterday, I was a bit surprised to see that there were some changes in the new PCs (which translates into changes in all of the other AWS besides the two series whose data was corrected).
Re: RomanM (#74),
Roman, I apologize as I realize I’m not making myself clear. Let me try another explanation. I may be completely off base, but I’m suspecting the AWS reconstructions were generated using the following method:
1) Manned station data alone from 1957 to 2006 used to generate 3 PCs (methodology TBD).
2) 3 PCs used to generate AWS reconstructions from 1957 to 2006 for each AWS location.
3) Where available, measured AWS data is plugged into recons replacing data generated using the 3 PCs.
Steig’s seems to imply this on page 3 of the SI.
This would explain why the AWS measured data is unchanged in the AWS reconstructions as it was added after the fact and was not manipulated by the algorithm. This would also explain why the Harry/Gill mashup had a significant effect on the reconstruction for that site as it would have had a large percentage of measured data plugged in due to the large number of measured data points. Most of the other sites have a small number of measured AWS data points and have little effect on the overall trend generated by the 3 PCs.
By “delete the measured data” I mean the following:
1) Start with the AWS recons for all 63 sites from 1957 to 2006.
2) Wherever measured data exists for a given AWS location (as shown in the BAS records) replace the value in the recon with (null)
3) Calculate the PCs on the AWS recons with the real, measured data missing (as produced in step 2)
4) If only 3 PCs are non-zero, then the measured data had no significant effect on the reconstuction except where the measured data points were plugged in. If more than 3 PCs are non-zero, then the measured data (or something else) was affecting the reconstruction.
I realize it is a lot of work. Steve mentioned he scraped the BAS data awhile back. Does anyone know if it is available in a format comparable to the AWS recons?
Re: Jeff C. (#77),
“If only 3 PCs are non-zero, then the measured data had no significant effect on the reconstuction except where the measured data points were plugged in.”
I meant if only three eigenvalues are non-zero. College stats was 25 plus years ago for me. Senior moment.
#77, Jeff, I’ve been experimenting a little with this. Roman’s technique, as you observed, is really very brilliant as, among other things, it yields the “fitted” values the RegEM output writes over.
By recovering the “fitted” values that RegEM overwrites, it’s possible to develop some comprehensible statistics on the fitted portion. The idea behind RegEM for fitting things isn’t crazy; but the lack of proper exposition of why things are doing what they do is disquieting. I know that all they’re interested in is the “answer”, but some people actually care about how you get the answer.
Jeff, the compilation Data.tab has column ids compatible with recon_aws.
Re: Steve McIntyre (#83),
Thanks Steve, I have not had a chance to process it yet. My wife claims I earlier called my son David “Data”. Sure sign that is time to take a break.
I’m starting to get a really bad feeling about this.
I think Steig gives it away on page 3 of the SI:
“We apply the same method as for the TIR-based reconstruction to the AWS-data, using RegEM with k = 3 and using the READER occupied weather station temperature data to produce a reconstruction of temperature at each AWS site for the period 1957-2006.”
1) Steig says the same method is used for the satellite recons and AWS recons and that the basis is the manned station data.
2) The RegEM with k=3 is analogous to Roman’s 3 PCs that he dug out of the AWS recons.
3) Based on Roman’s work and some supposition, the AWS recons appear to actually be the 3 PCs from the manned station data sprinkled with some measured data to give it an air of “independence” (those of us that actually design and build things for a living know it should be exactly the opposite).
4) The satellite recons may(?) use the same 3 PCs from the manned station data for their adjustments. (Remember how Gavin said the AWS and satellite recons agreed better (to his satisfaction – snort) after the Harry/Gill mixup was corrected? Makes sense as the corrected Harry had less independent data than the repaired Harry. Repaired Harry had more data points from the 3 PCs.)
5) The key to the entire paper is how were the 3 PCs derived from the manned station data and how are they applied to different physical locations in Antarctica (either satellite or AWS). The West Antartica warming is some artifact from the manned station data. If I had to guess it would be a misapplication of the peninsula warming.
I may be completely wrong, but this is starting to have an MBH feel to it.
Re: Jeff C. (#88),
Arrgg…my #4 above should say:
“Makes sense as the corrected Harry had less independent data than the *PRE*-repaired Harry. Repaired Harry had more data points from the 3 PCs.
Re: Jeff C. (#88),
According to Guillaume Dargaud,
Probably most antarctic stations are occupied only during antarctic summer, and are eventually falling back to AWS mode after the staff has left. This would introduce sort of a credibility transfer for all the time the station’s pyhsical conditions are actually not watched by anyone. Further this could explain, why two stations, a manned (=occupied) one and an AWS at least in one instance shared the same ARGOS ID (I don’t remember it’s name for the moment)
Re: Roman at 87. Sorry if this is nitpicking and/or showing ignorance but I don’t think this works:
You still need to know about the relationship between A and B in order to draw conclusions about past B from looking at past A. The fact they have tracked each other for a period of time does not mean they always did, or as you say, always will. Lets say A was installed 10 years before B (which could be more or less remote), then B is installed and then they track each other for ten years – would n’t it be stretching it a bit to say you can give an exact value for B say 15 years ago? Surely there would still be a qualifying level of confidence associated to this value – this is what you appear to be saying in reply 84? And wouldn’t this level of confidence be influenced by the amount of knowledge of the physical situation/relation as well as the numerical record? The ten year equivalence period could just be a transitory phenomenon? This is what I was trying to understand with the satellite record in comment 69 (thanks re: response) and seems to be what Douglas in 85 is querying?
Or are saying, for example, that they were both installed 20 years ago and they have tracked each other since, then you lose contact with B and check A’s record to find out what B said 15years ago? This is ok but only possible because you’d already had the evidence of direct equivalence?
Sorry if this is factor 10 dim – feel as if I’m showing a lack of stats. knowledge!
Roman, #76: thank you for the response. I learned something.
And while I am in no position to judge, I suspect Steve Mosher’s comment in #1 regarding your work here is warranted. :>)
re: me at 92 above. Sorry Roman – just reread your last line of 87. I think we are in agreement and my query is is whether this relationship over time can be/is being clarified by use of the satellite records to calibrate the surface station records.
If you’re interested, I tried Roman’s analysis on the Briffa RegEm infilled data in M08. It didn’t break down as well.
Standard deviations:
Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6
1.476147e+00 1.179788e+00 9.743212e-01 8.467065e-01 7.061957e-01 6.532276e-01
Comp.7 Comp.8 Comp.9 Comp.10 Comp.11 Comp.12
5.507370e-01 5.221837e-01 4.794592e-01 4.367229e-01 4.086026e-01 3.207884e-01
Comp.13 Comp.14 Comp.15 Comp.16 Comp.17 Comp.18
2.964651e-01 2.878016e-01 2.671150e-01 2.494141e-01 2.148621e-01 2.058160e-01
Comp.19 Comp.20 Comp.21 Comp.22 Comp.23 Comp.24
1.867056e-01 1.657067e-01 1.553564e-01 1.343227e-01 1.188218e-01 1.162435e-01
Comp.25 Comp.26 Comp.27 Comp.28 Comp.29 Comp.30
1.089920e-01 8.713525e-02 7.935963e-02 7.311353e-02 6.544345e-02 5.484138e-02
Comp.31 Comp.32 Comp.33 Comp.34 Comp.35 Comp.36
4.850883e-02 4.461025e-02 3.949616e-02 3.302591e-02 2.020060e-02 1.891998e-02
Comp.37 Comp.38 Comp.39
1.429577e-02 8.153046e-03 3.157659e-09
You might have these figures, but Australian data gathering in the Antarctic can be tabulated approximately as:
ID (Aust) NAME START END LAT LONG
300000 DAVIS Jan-57 -68.577 77.9725
300001 MAWSON Jan-54 -67.6014 62.8731
300002 TAYLOR ROOKERY Jan-57 Dec-58 -67.45 60.8667
300003 WILKES Jan-59 Dec-69 -66.25 110.5833
300006 CASEY (TUNNEL) Jan-69 Jan-89 -66.2833 110.5333
300007 MOUNT CRESSWELL Jan-72 Feb-03 -72.7333 64.3833
300008 MAWSON (MOORE) Jan-72 Dec-84 -70.3 65.1
300009 MAWSON (KNUCKEY) Jan-75 Dec-84 -67.8 53.5
300010 MAWSON (MT KING) Jan-75 Dec-84 -67.1 52.5
300011 CASEY (LANYON) Jan-83 Dec-87 -66.3 110.8667
300015 LAW BASE Jan-87 Feb-92 -69.4167 76.5
300016 PRINCE CHARLES Jan-88 Dec-92 -70.2333 65.85
300017 CASEY Feb-89 -66.2792 110.5356
Has anyone here attempted to contact “Nature” to see what sort of transparency they would be interested in providing, now that their cover story has proven to be so contentious? Surely the uncovering of bogus surface data, however insignificant Steig et al insist that is, has`raised some eyebrows over there. I assume Steig had to provide “the works” to get his article published.
Steve: “the works” – my guess is that we presently have more material to work with than the Nature referees (the supplementary information presently at Steig’s website would be very unlikely to have been available to Nature referees)
Re: wmanny (#101),
snip at will … but I did this:
Mr. Philip Campbell
NPG Editor-in-Chief
The Macmillan Building
4 Crinan Street
London N1 9XW
United Kingdom
Subject: Verification and Validation of Computer Codes used as Basis for Paper Submittals
Dear Mr. Campbell:
Paper submittals the basis of which are calculations with computer software continue to be important sources of publications in your NPG journals. Some of these papers might at some time be used as audit/checkpoints/benchmarks for other calculations, and others of these papers might become part of the basis for public policy decisions. The software used for these papers needs to be Verified and Validated for the applications to which they are applied. Papers for which the software has not been Verified should not be accepted for publication in archival journals such as those published by NPG.
The first crucial aspect of such papers should be the status of the Verification of the software. Verification is the process of determining that the coded equations are correctly solved. Several engineering societies and their journal editorial boards have put into place technical requirements on the Verification of the software before the paper can be considered for publication. If the requirements have not been met the paper will not be published; in some cases the paper will be rejected out-of-hand and not be sent out for review. Papers for which the basis is a single calculation on a single grid with no investigations of convergence and other stopping criteria are typically sent back to the authors.
Some of these professional organizations and associated journals include: The American Society of Mechanical Engineers (ASME) Journal of Heat Transfer and Journal of Fluids Engineering; The American Institute of Aerospace and Astronautics (AIAA) Journal of Spacecraft and Rockets; and the International Journal of Numerical Methods for Fluid Flow. Other professional societies and journals are sure to follow the lead of these.
References for the editorial polices for these journals are as follows.
The ASME Journal of Heat Transfer:
Editorial Board, “Journal of Heat Transfer Editorial Policy Statement on Numerical Accuracy,” ASME Journal of Heat Transfer, Vol. 116, pp. 797-798, 1994.
The ASME Journal of Fluids Engineering:
C. J. Freitas, “Editorial Policy Statement on the Control of Numerical Accuracy,” ASME J. Fluids Eng., 115, pp. 339–340, 1993. http://tinyurl.com/9fsb98. and J. Fluids Eng. 130, 2008. http://tinyurl.com/8phpar
The AIAA Journal of Spacecraft and Rockets:
AIAA, Editorial Policy Statement on Numerical Accuracy and Experimental Uncertainty, AIAA Journal, Vol. 32, No. 1, p. 3, 1994.
The International Journal of Numerical Methods in Fluids:
P. M. Gresho and C. Taylor, “Editorial,” International Journal of Numerical Methods in Fluids, Vol. 19, p. iii, 1994.
Complete and detailed discussion of all aspects of Verification, Validation and Software Quality Assurance for scientific and engineering software are given by Roache in the book, “Verification and Validation in Computational Science and Engineering,” published by Hermosa Press and a paper by Oberkampf, et al., “Verification, Validation, and Predictive Capability in Computational Engineering and Physics,” Sandia National Laboratories Report SAND 2003-3769, http://www.prod.sandia. gov/cgi-bin/techlib/access control.pl/2002/023769.pdf, 2003. These publications contain extensive reference citations to the published literature on these subjects.
Papers for which data analysis is the primary focus, in contrast to massive calculations with massive computer programs, also need to be Verified; procedures generally called Verification of a calculation. In this case, the input data for the analysis should be verified independently of the authors of the paper. And the calculational aspects of the analysis, which in this case would play the role of the equations and their solution, independently Verified. These activities, of course, should precede publication of the paper.
I have been unsuccessful in locating an editorial policy for NPG journals on this important issue. If one exists will you kindly let me know how I can access it. If a policy does not exist do you have plans to address this issue?
In light of the large potential for uninformed applications of calculated results reported by NPG, especially applications that might impact public policy, I suggest that the editorial board initiate discussions of these issues and begin planning for implementation of a sound basis for review and acceptance of papers the basis of which are numerical calculations with computer software.
Thank you for your attention to this matter. Please do not hesitate to contact me if you need additional information on these subjects.
Sincerely,
Dan Hughes
Schmidt has offered up a new thread on RC in defense of non-transparency (or at least I think it’s a defense — the paper he wrote to attempt to refute two others was transparent, as were the others). I wonder if Ross McKitrick will comment there or here.
I much enjoy these analyses/audits/deconstructions of papers that are performed here at CA and that has been particularly so with Steig et al. (2009) even when realizing that the analyses are far from exhaustive. Having said that, I judge the claims in Steig to be an exercise in overreaching and under-detailing based on the following results of a simple-minded analysis of my own – and with R script.
Below I provide R script for regressions of the monthly temperature anomalies from the Steig reconstruction with AWS (downloaded at approximately 10:00 AM February 7, 2009) for the time periods 1957-2006 and 1965-2006. Below I report the summary of those time period result along with the regressions from 1970-2006 and 1980-2006 for which the R script is not posted since the procedure can be readily adapted from the first two scripts. 1957-2006 regression is adjusted for lag 1 auto correlation of the regression residuals while the other time period regressions are not. The p value below is the probability of the trend not being 0 by chance. TS is the trend slope (in degress C per decade) and CI is the 95% confidence intervals for the trend slope.
1957-2006: Adj R^2= 0.02; p= 0.00; TS = 0.138, CI = 0.046 to 0.230
1965-2006: Adj R^2= 0.00; p= 0.30; TS = 0.052, CI = -0.046 to 0.149
1970-2006: Adj R^2= 0.00; p= 0.93; TS = 0.006 CI = -0.120 to 0.131
1980-2006: Adj R^2= 0.00; p= 0.54; TS = -0.057, CI = -0.239 to 0.126
What these calculations show me is that given accurate measurements, adjustments and RegEM procedures in Steig, the conclusion of a warming Antarctica can be made only when going back to 1957 and that going forward in the starting time of the series (and not very far) the warming/cooling trends can be shown to be statistically very uncertain.
I think the combining these calculations with the following statement from RC about 1935-1945 being the warmest decade of the 20th century makes any conclusions about long term trends in the Antarctica and potential effects of AGW even more tenuous.
http://www.realclimate.org/index.php/archives/2009/01/state-of-antarctica-red-or-blue/
Download file from Steig site and calculate 1957-2006 monthly trends AWS:
Calculate 1965-2006 monthly trends AWS:
Re: Kenneth Fritsch (#105),
I hesitated to offer improvements for fear of discouraging Kenneth on his first effort, but hey…
You can avoid all of this:
with this
I’m not sure why it is a bit different. Maybe the data has changed on the website again.
The value can then be incorporated into the script that follows without having to retype it.
Check out ?lag and ?acf for more info on autocorrelation and lagging of sequences.
Re: RomanM (#107),
Thanks, Roman for your help – again. I know that I am often too hesitant to ask for help, but solicited or unsolicited help with R is always welcome. I can already see where R is much more efficient than Excel (and I think I know Excel well)- even with my clumsy programming.
That ?command asking R for help has worked well for me as has searching the internet. Your example points to just how efficient R can be when one learns most of the best commands.
Thanks, again.
Re: RomanM (#107),
The two acf calculations do give different results and not because the data has changed on the website. I reproduced both Kenneth and Roman’s values so there is either an algorithmic or precision difference in the two methods.
As a complete R novice that’s all I can contribute.
Re: Alan Wilkinson (#137),
Alan, as an incomplete R novice, I agree that the difference is not due to the input data changing, but not to worry, as I am going with Roman’s procedure in the future.
Re: Alan Wilkinson (#137),
I did some experimentation by exporting Ken’s data to a statistics program called Minitab. Interestingly enough, it gave me the identical two results that R did. There must be a difference in the way the correlations are calculated for ACF. Offhand, I don’t know what that difference is.
Re: bernie (#150),
Because of the complexity of the procedure, who knows what happens with Regem. Rotating the PCs does not affect the reconstructions, but it changes the three (in this case) pieces that are added together in the reconstructions. If a rotation would cause two of the coefficients for say, for a given AWS, to be close to zero, then the remaining PC has the same pattern of variation as the AWS. If other AWS’s have a similar configuration of coefficients for that rotation, one might consider that PC as identifying the group (e.g. close in distance or from a particular region). I doubt that it would pick out particular individual AWS’s.
Re: RomanM (#155),
I wondered (lying awake in bed – shouldn’t do that!) if the difference is because the acf calculation is doing a multivariate correlation whereas Kenneth was looking at a single lag? So the single variable regression soaks up some of the extra trend that gets allocated to higher order lags in the acf calculation?
Re: Alan Wilkinson (#156),
Re: Bernie (#157),
Hey! Don’t badmouth Minitab. It’s in version 15 and pretty good now – a lot easier to teach in an elementary course.
Alan, take a sleeping pill. No, a correlation is a correlation. Something is different in the calculation, but I’m not sure what since I haven’t worried about how modern programs do these things. Other people have already done the worrying. There might be some sort of adjustment because the “sample sizes” are different for the various lags: n-1 for lag 1, n-2 for lag 2, etc.
Re: RomanM (#158),
Final comment on the acf correlation. Got it figured out. When Ken did the correlation by hand, for the denominator, his formula used the square root of the product of the variances of the shortened (599 point)original sequence and the variance of the (599 point) lagged sequence. The formula for acf replaces each of these with variance of the complete 600 point sequence. That is the difference.
Re: RomanM (#161),
Well done!
Re: bender (#162),
Got the clue from here. 🙂
#105. Hey, Kenneth, your own R script. Well done. Pretty soon you’ll never use Excel again (it’s OK for some forms of editing tables, but I don’t use it otherwise.) 🙂
And when one leaves off the $acf[n]in the above command one obtains a neat/cool graph showing all the lag correlations from 0 through 25. Lag12 comes in second highest to lag1 at something like 0.14, as I recall.
Re: Kenneth Fritsch (#109),
Cool..
Recall that above Roman generated his 63 estimated 1980-2006 AWS reconstructions using a few series that had overlaps of no measured station data. When he subtracted his estimated reconstruction from the Steig aws reconstruction, he got the first chart in his post. He speculated that the spikes were from the actual measured data that was spliced in the reconstructions.
I took Roman’s estimated recon and replaced elements in the time series with the corresponding element from Steig’s recon ONLY at points where the BAS data shows that real, measured data exists (from Steve’s data.tab file). I then subtracted the two and got this, the difference is virtually zero.
[IMG]http://i404.photobucket.com/albums/pp127/jeffc1728/diff_plot.jpg[/IMG]
Note the scale on the left. The biggest difference between the two is 5.189498e-07.
What does this mean? Here is my take, some of this I said earlier in the thread, but now I am much more confident.
1) Roman’s methodolgy nailed the basis of the aws recons.
2) The AWS recons aren’t really reconstructions (to my way of thinking at least). They are products of the 3 PCs with the real, measured data sprinkled in almost as an afterthought. In my opinion, a true AWS recon would have used to measured AWS data as part of the infilling algorithm. It doesn’t use it at all. Regardless of the trend in the measured AWS data, the infilling is solely based on the 3 PCs.
3) On page of the SI, Steig says the same methodology was used for the AWS data as the satellite data. My strong suspicion is that he used these same 3 PCs for the satellite recons, and then spliced in satellite measurements that passed some cloud masking test. Presumably the AWS recon coeficients for each AWS site are determined from on lat/long or the distance/direction to some fixed position. The satellite recon would use the same method to determine their coeficients for each gridcell.
4) Steig talks of how the satellite recons and AWS recons “agree very well”. Not surpising if the roots of both are the same 3 PCs. Gavin stated that fixing the Harry/Gill mixup made the satellite and AWS agreement improve. Makes sense. Although Harry/Gill was corrupted, it had more independent data (data from other than the 3 PCs). Once Harry was fixed, more of its data came from the 3 PCs than before, hence better agreement.
5) It all comes down to the source of the 3 PCs. Steig seems to say it comes from the manned station data on page 3 of the SI. In comment 14 above, Steve notes that PC2 causes the “contrast” between West and East Antarctica. (Note, if running Steve’s code in #14, comment out line 4 (x=rec.svd$v[,3]) or it gives you PC3 instead.) If we can figure out how the manned station data was used to get these, this thing breaks wide open.
I’ll put the code in a follow-up comment.
I knew I wouldn’t be able to get the plot embedded correctly. Click on the link to see it.
How do I tag to embed plots? Thanks.
Roman’s decomposition of the AWS recon is very cool. Maybe some of the people who are complaining about the blog could spend some time with this analysis.
Here are a few supplementary notes on what the RegEM “is” in terms understood off the Island.
Roman has shown that the RegEM reconstruction can be written as follows”
Then they (in effect) substitute actual values for fitted values, making a splice of fitted and real data.
By overwriting fitted data with actual data, they get a “perfect” fit to observations and thereby make it impossible to evaluate things.
But Roman’s methods enable the fitted data to be reverse engineered (in this case) and the calculation of things that you expect to see in statistical analyses – like residuals. Things that are never mentioned in Mannian studies.
I’ve also applied Roman’s method to pre- and post-Harry results and will report on this tomorrow probably (unless, of course, Gavin beats me to it.)
A question here: over at RC, an AWS reconstruction is in this figure:
I haven’t seen any information on how they go from the AWS reconstruction of the 63 stations to an Antarctic recon. Has anyone seen any info?
Re: Steve McIntyre (#113),
Yes, being able to get “under” the replaced values was in fact the part I was happiest with in the analysis. The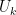 can of course be orthogonalized in the entire period which is what I did in #55 although that is not crucial to the reconstruction. It can help to do so when looking at averages of trebds from the different reconstructed series.
can of course be orthogonalized in the entire period which is what I did in #55 although that is not crucial to the reconstruction. It can help to do so when looking at averages of trebds from the different reconstructed series.
Re: Jeff C. (#111),
I agree with most of your comments hoowever, I have the feeling that the aws reconstruction itself does use the observed data beyond the simple replacement. I may not have dug deep enough, but the all the reconstructions appeared to change somewhat in the “corrected” data set posted on Steig’s website.
I spent time today looking at ant_recon.txt. I am happy to report that in fact the 5509 series in that file are ALL reconstructed from a single set of 3 PCs. With only 600 values in each series there is a heck of a lot of colinearity in these series. I ended up having to use svd since princomp (which gives more statistical content in the output) refuses to do the calculations when the number of variables exceeds the length of the series. I am not quite finished with the analysis and I will post relevant scripts, probably tomorrow afternoon. The data set is large. With all of the 5509 complete regressions. etc, I ended up saving a 250 MB RData workspace! I’d like to see Ken do that in Excel.
By the way, the few places where I compared the sat recon to the AWS recon did not look all that close to me. Of course, I didn’t smooth everything first with a 40 year filter.
More tomorrow on this.
Re: RomanM (#114),
Roman – yes it does seem as something is going on there. In the SI on page 3 Steig says:
This is an interesting sentence as it seems to say that the satellite and AWS reconstructions use the same methodology and that the basis for the recons (your 3 PCs) are the “READER occupied weather station temperature data” (i.e. the manned station data, not the AWS data).
However, up in comment #95 Hugo M notes:
The thinking being that many of the manned stations are deserted during the Winter. Perhaps what Steig refers to above as “READER occupied weather station temperature data” actually contains some AWS data to supplement the winter months.
Thus the 3 PCs are affected by changes in some AWS data series resulting in a small change in ALL of the recons. However, changes in a specific AWS series does not affect ONLY its infilling as that is governed strictly by the 3 PCs.
Hope that makes sense. When I replaced the the elements in your recons with the actual measured data, the difference between it and Steig’s recons was virtually zero (5.18e-07 worst case for ANY point in any series.) If the measured data from individual AWS sites was used to in its reconstruction (other than affecting the 3 PCs), there would have been non-zero outliers.
Things sure move fast around here.
Re: Jeff C. (#127),
Yes, what surprised me was that corrections to Harry (and presumably Racer) produced differences in all of the AWS recons before 1980 when the only existing information was the surface stations. In RegEM every variable (surface or aws or satellite) can have an effect on every other variable at every time in the infilling process.
Re: Steve McIntyre (#128),
That’s odd. The large blue dot overlapping with a somewhat smaller red dot in the upper left of PC1 is strange. I realize that the trends for the two could still both have the same sign, but the pattern involving the three PCs is different. If the PCs were physically meaningful, there would have to be some explanation for this.
Re: RomanM (#133),
The authors of Steig state that the AWS and TIR reconstructions are totally independent and therefore the interactions should only be AWS stations with manned stations and TIR grid data with manned stations and never AWS stations with TIR grid data.
Is that your understanding also.
Re: Kenneth Fritsch (#139),
My statement applies to all of the variables that are used in a particular analysis. From the Steig SI pdf:
I would interpret that as saying that the AWS and satellites were not usen in the same analysis.
Re: Kenneth Fritsch (#136),
I could do it in one line even incorporating unequal weights for the months (which I didn’t do in my quick analysis of the graph that Steve’s post contained). When I programm in R, I generally try to avoid giving names to variables if I won’t use that variable anywhere other than that specific calculations. It reduces clutter in the workspace. To calculate the variable y in the script in your post, (assuming no missing values in matws) I might do something like
The first two lines could be combined, but there is no gain in doing that and you might end up spending 10 minutes figuring out why you parentheses didn’t match up. In the process only one variable y was formed.
Re: RomanM (#143),
From the methods section.
Aside from Einstein’s interpretation, I believe the space-time matrix A may be the 3 pc’s from satellite which divide the space according to the trend, Steve’s plot of trend #14 smakes me think that. I’m really not sure what’s going on exactly but I don’t believe location of individual stations was incorporated into the analysis except by correlation to the 3 pc’s in the RegEm analysis.
You probably have a much better handle on RegEm than myself but it looks like the TTLS method incorporates an additional input matrix, I haven’t quite figured out yet how to implement it in matlab. I’ve spent a few hours this weekend pushing matrices at it, I’m getting some errors still. If A is another input (not even sure where that goes in matlab), it would be how the satellite trend was incorporated into the AWS measurement.
If someone has thoughts on this I’m all ears.
Wish we had the code.
Re: jeff Id (#144),
From the Methods Summary section on the last page of the paper (bold mine)
In my interpretation, this is using stations with TIR in one analysis and stations with AWS in the other.
I interpret the “space-time” matrix differently. I think that space-time is used gratuitously to be impressive here when a more straightforward description is more informative. From T. Schneider’s 2001 paper:
Without going through the matlab programs, my take is that in the Tir and station recon, p would be 5509 + the number of stations used (I believe they did both the case of all and stations and also using only some smaller selected number) and n =600 months. RegEM infills all the missing values (in this case close to half of the values in the matrix are missing since there are no satellite values prior to 1982). In the AWS construction, p = number of manned stations + number of AWS, and again, n = 600. In this case, n is larger than p, but the AWS data is extremely sparse. Presumably the data could be either raw data or anomalies although, I suspect that the former might lead to some problems with the assumptions of the analysis.
Re: RomanM (#146),
Thanks Roman, I think that will help.
Re: RomanM (#143),
I checked your quick analysis with and without using the weights for the months and the trend slope and stdev of the trend slope differ very little. Actually to be more concise, we have to adjust for leap years (do that in one line).
Seriously this has been a good learning opportunity/experience for me. I have actually been keeping notes.
Re: Steve McIntyre (#113),
It appears that this is a plot of the simple annual means of all aws.
(a one line program, great shades of APL!) creates:
which is a perfect match… except for the fact that it is about .25 degrees lower than the one in the RC graph. Hmmm…
Re: RomanM (#120),
Roman, I just finished my script for doing the AWS annual trends. Can you really do most of what I did below in one line? Does it weight the monthly means for the different number of days in the months. I am going to try your script tonight or tomorrow AM.
Anyway the summary of what I found was the following with the 1957-2006 AWS trend in degrees c per decade.
Adj R^2= 0.09, Trend Slope= 0.139, p= 0.02, Lag1Corr= 0.27, Adj CI of Trend Slope= -0.009 to 0.287
What I find of interest here is that the lag1 auto correlation of the regression residuals is larger than the corresponding correlation was for the regression using monthly data. Not that I have done that many time series regressions but it has been my experience that the reverse is usually true, i.e. the monthly larger than the corresponding annual.
Also when the CI limits are adjusted for the lag1 auto correlation the lower limit is less than 0 indicating that we cannot be confident that the trend slope is not 0.
Roman, to simplify the comparison of pre- and post-Harry, I’ve made your script into a function. For Ken and others, the function shows a nice feature of R – you can make a list of odds and ends done in the calculation so that when you want to compare pre- and post-, you have easy nomenclature. I’ll show below.
Here’s the function implementing Roman’s decomposition of Steig’s recon_aws
Now here’s the base case (uncorrected). Download info.
Now do the base case calc:
Now downloaded new Steig recon and new Harry, R Rock versions:
Now calc new results:
If you want to say compare the pre- and post- PC1, then do this (the lists have kept track of the different things in a consistent nomenclature).
Just a heads-up for our statistical gurus.
Amundsen surface and clean_air AWS are located at the same place. Amundsen data is 1957-2008 and clean_air is 1986-2002. Clean_air doesn’t have sufficient data to create an annual temperature for 1986-87 so here is a comparison of the yearly temperature anomalies from 1988-2002.
Clean_air 1990 is missing Sep thru Nov data. There is also missing data Oct 93 thru Jan 94. This second group seems to correlate with a step change between 1993-94. Maybe a relocation or sensor change? I used the Giss metANN clean_air values since the monthly data in both reader and Giss are identical though missing the same months.
There are a few minor differences in the monthly data for Amundsen, but it is complete during the time frame. I calculated the metANN temperatures from the reader data.
I wonder if the Steig paper compensates for the anomalous trend differences. +1.5C is quite a bit different than -0.5C over 15 years.
Clean Air 1994 Service History
Here are plots of the difference between the pseudo-PCs pre- and post- Harry/RR. There is a noticeable 1979-2003 trend difference between the “PC1″s, but not the others. Exactly why a difference of this size doesn’t “matter” to the Steig recon remains an intriguing question as it looks noticeable.
A very important knock-on point for the “AWS Recon”. This is going to be a linear combination of the reconstructions. When we find out how this was done, then it will be easy to determine the weights of each of the PCs in the reconstruction and then see what the replacement of actuals does.)
I’ve done a reverse engineering style regression (of the type that UC, Jean S and I have done extensively in trying to get footholds on the Mann corpus) and will report on that in a minute or so.
Re: Steve McIntyre (#118),
I’ve been playing with the data sets, trying to evaluate just how much the changes to Harry and RR affected the overall reconstructions. As has been mentioned above, the Harry/RR corrections changed the three PCs thus affecting the reconstruction of every AWS site. However, it turns out that Harry and RR are affected far more than any of the other AWS sites in the reconstruction.
First, here is the difference between the Steig AWS recon and the corrected Steig AWS recon:
Lots of changes in Harry and RR, but the large magnitude differences are from the corrections to the spliced in READER data. I removed the spliced in data from both data sets (set them to NA) and then replotted the difference.
This is the changes to the 63 recons solely caused by the change in the 3 PCs. (It would be more accurate if I replaced the spliced in values with reconstructed values instead of NA, but I haven’t gotten that far yet.) You can see that Harry and RR still seem to have much larger changes than the others. To quantify the amount of change to each AWS time series, I calculated the std deviation for each AWS site difference set (set na.rm = TRUE in R so the missing points are ignored).
You can see that the std devs for Harry and RR are much larger than all the others (0.5 to 0.6 vs less than 0.1 deg C for the others). I mapped the std deviations to see if the magnitude of the std devs was correlated to proximity to Harry or RR.
There does seem to be a small difference between West and East Antarctica, but I was suprised that the larger std devs AWS sites were not clustered around Harry and RR.
It appears that the AWS data is used in the generation of the 3 PCs as we have speculated. However, their impact in the reconstructions seems to be largely limited to themselves. Impact on the other AWS sites looks like it is close to the statistical noise level.
LINK
Re: Gary A. (#119), thanks for that information. I thought there must be a reason.
Wish they had included information about the previous location. It would be nice to know how far they moved it and if the elevation changed.
The mean of the annualsequence was -.172. Shifting it up makes them pretty even.
I did a reverse engineering regression of the “PC1” in the pre-1980 period. An r^2 of 0.97.
Here’s a derivation:
A=anom(Data$surface,index=1970:2000)
A=window(A,start=1957,end=c(1979,12))
count=apply(!is.na(A),2,sum)
A=A[,count>=200] #276 24
K=ncol(A)
B=window(roman1$pcs,start=1957,end=c(1979,12));dim(B)
fm=lm(B~A)
name0=Info$surface$name[match(dimnames(A)[[2]],Info$surface$id)];name0
j=1;
GDD(file=paste(“d:/climate/images/2009/steig/rev.eng.PC”,j,”_coef.gif”,sep=””),type=”gif”,w=380,h=300)
par(mar=c(7,3,2,1))
barplot(fm$coef[2:(K+1),j],col=”grey80″,las=3,ylim=c(-3,3),names.arg=name0)
title(paste(“Reverse Engineer PC”,j,” (Roman)Coefficients”,sep=””))
dev.off()
Steve McIntyre:
“Roman has shown that the RegEM reconstruction can be written as follows
… where k=3.”
does this mean, there are only 3 trends and all measurements can be represented by a superposition of these ? One trend would be the yearly seasonal cycle and the other 2 ?
I doubt that it has anything to do with seasonal because the data has been deseasonalized by subtracting some sort of monthly mean from each month. In the AWS reconstruction, presumably manned surface stations were used so that if there is some sort of interpretability to the PCs, it is much more likely that it would be geographical in nature.
#124. Not three “trends”, but Roman’s three “PCs” which may or may not prove to have any plausible interpretation.
Here are reverse engineering plots of the coefficients of the “PC1” and “PC3” against surface stations 1957-1979. What does it mean, if anything? Dunno. Right now, and this is still stumbling in the dark a bit, it doesn’t appear that the coefficients of the PC1 in this period have any intelligible meaning. One really wishes the RegEM jockeys did mundane things like report coefficients and residuals, before they held press conferences.
Jeff:
Interesting insight. Does that mean that one validity check Steig needs to do is too look at a subset of the data for when the surface stations are actually occupied. Is that one way of controlling for possibly AWS-based infilling of the surface station data?
With all of the 5509 complete regressions. etc, I ended up saving a 250 MB RData workspace! I’d like to see Ken do that in Excel.
I couldn’t and that is why I am using R, though is not 250MB the R limit.
With all of the 5509 complete regressions. etc, I ended up saving a 250 MB RData workspace! I’d like to see Ken do that in Excel.
I couldn’t and that is why I am using R, though is not 250MB the R limit?
#127. Jeff, I don’t think so, tho I know where you’re coming from. However, the pre- and post-Harry AWS recons are different for every station – some more than others. So HArry is used in the AWS reconstruction somehow.
The Harry error is pretty neat for reverse engineering since it gives two recons with only Harry and RR varied. It’s worthwhile comparing them. There are a lot of differences between pre- and post- Harry recons in detail that should help the reverse engineering.
Re: Steve McIntyre (#132),
LOL. I can’t help but see the similarities with the codebreakers trying to decipher messages from the Enigma electronic encrypting machine during World War 2. They were always looking for two encrypted messages with similar content.
Re: Steve McIntyre (#132),
Steve said:
Nots sure if anyone has done it yet, but it may be interesting to use Roman’s recons of the original data and the the post-Harry/RR revised data (i.e. recons without the real, measured data spliced in) and plot the change in trend for each AWS location on the Antarctica map. Since there would be no measured data affecting the results, the change would be entirely based on the presumed “feedback” into the creation of the 3 PCs. Magnitude of changes and proximity to Harry and RR may give some insight into how the data is used.
It might also be interesting to use the same method to plot the change in the 3 PC coefficients between the two recons for all the same sights. Presumably the coefficients are related to some physical attribute of the AWS locations (lat, long, altitude, distance to coast, etc.) but who knows.
I’ll try to do this when I get to work (on my break, of course!)
Re: Jeff C. (#151),
On second thought, scratch that second paragraph. If the coefficient are related to physical attributes, they are fixed, it’s the PCs that change. I need coffee.
#133. Roman, while you derived them as PCs, you’re working in reverse. Presumably any 3 linear combinations of the ‘PCs’ would “work” as well. At this point, any interpretation is likely to be post hoc anyway.
Correlations in Mann’s proxy work tend to be entirely opportunistic/data mining and I would assume that this is happening here somewhere – not necessarily intentionally, but certainly without much introspection.
Re: Steve McIntyre (#135),
You’re very right about that. When I was looking at the satellite data, initially, rather than do svd on the 5509 x 600 data matrix, I took smaller subsets of the data (anywhere from 10 to 50 columns) and did princomp on the data. All of the analyses gave me three components, but the three eigenvalues corresponding to one set were not in the same ratios with each other as in the other sets. All set of three PCs could reconstruct the entire 5509 column data set virtually exactly. Each set of PCs was a transformation of any other set which preserved orthogonality.
I finally did svd on the whole set on the premise that the RegEM would have calculated their PCs from the same matrix.
Jason Smerdon has a new article on RegEM here . He states:
This is the sort of thing that reviewers can attend to. I guess the Nature reviewers either didn’t know or didn’t care.
Re: Steve McIntyre (#140),
Well, I guess my query WRT to random missing data is answered in Smerdon, et al:
With the ultimate conclusion:
Re: John Baltutis (#142),
In other words RegEM is an interpolator, not an extrapolator. To use it for extrapolation is either foolish or devious.
Re: bender (#152),
That’s my understanding as well. Just like ICE in the calibration exercises we’ve worked with in here. CCE can extrapolate, but this property comes with a price tag, very wide CI.
I am one of the very many bystanders, watching with fascination the nimble footwork of the main actors. This is extemely valuable work in my opinion. I am no expert on climate but my instinct is to be very sceptical of complex statistics based on uncertain data! I am an old physics professor and have refereed numerous physics papers over the years. As a referee you try to apply your experience and judgement to evaluate the soundness of a paper and you criticise obscure procedures(!) but it is extremely rare that a referee goes into the kind of detail displayed on this thread. It seems safe to assume that it has not been done in this case either.
I have a small suggestion: In order to get to an interpretation of the three principal components it might be an idea to make an orthogonal transformation with the requirement that the negative weights become as small as possible. If you had just two stations, it would be more transparent to have the independent measurements as a basis rather than their sum and difference.
Re: Jens Andersen (#141),
This is an excellent suggestion. Criteria for the rotation of factors (both, orthogonal and oblique) have been developed for exactly this sort of purpose in Factor Analysis.
For those not familiar with that type of analysis, a dataset is expressed as a linear combination of unseen “factors” (which are sort of like infilled variables with no prior observations). Sometimes, the factors (which are not unique) can be “rotated (i.e. linearly transformed)so that the coefficients for adding the factors together exhibit “interpretable” characteristics. There are a number of methods developed, but factor rotation is basically an ad hoc procedure open to “cherry picking” when determining the type and amount of rotation.
If I were an author of the original paper, this might be one way to get some insight into understanding the results of the original RegEM analysis. However, here, while we are still in the process of deconstructing the data, I think it would be of more limited value.
Re: RomanM (#145), But wouldn’t it also potentially highlight stations that have been spliced or somehow contaminated? After all isn’t that part of the case against the BCPs?
RomanM:
Minitab! Jeepers that was around in 1971!! I still have a manual somewhere.
RomanM:
I wasn’t, honest! I actually have fond memories of it – though it must have been a main frame version of some kind.
Kenneth Fritsch (#105 2/8/9) ran regressions from Steig’s reconstructions and the adjusted R^2’s approaches zero.
What do the very low R^2’s mean?
I looked at the trends for the TIR reconstruction with the monthly data and compared the regression summaries in the table below to those of the AWS reconstruction. I selected the 4 time periods used previously in an attempt to show the effect of start time on the trend and the uncertainty of those later starting trends. The R script for the TIR regressions is listed below.
The table is headed by the adjusted R^2, the trend slope (TS), the standard error of the trend slope (StdErrTS), the probability of the trend slope being different than zero by chance, the lag auto correlation of regression residuals (CorrLag1) and the confidence intervals that were adjusted using Nychka procedure as applied in Santer et al. (2008).
Both reconstructions show that once the starting point moves forward from 1957, the trends become more uncertain and generally more negative. The TIR reconstruction trends differ from AWS in the higher AR1 values and showing a more positive trend in the later trends – although those trends are not significantly different than 0.
Those very small R^2 values bother me as it apparently does Robert (Rabbie?) Burns in the post above. The statistics in the case of 1957-2006 have a low R^2, but the p value says that the chances of the trend being zero are very low. In the other time periods, the trend cannot be shown to be different than zero. Recall that when I did the trend statistics on the annual data for AWS 1957-2006, the p value was greater than 0.05.
Regress TIR Recon Monthly 1957-2006:
Regress TIR Recon Monthly 1965-2006:
Regress TIR Recon Monthly 1970-2006:
Regress TIR Recon Monthly 1980-2006:
Divide and conquer. Split the large problem into smaller chunks. If it’s not the covariances in the numerator it must be the variances in the denominator.
As a general comment, it’s pleasing to drop in periodically and see the growth in the number of skilled users of R. Statistics is the Achilles heel of climate science. (That’s why real climatologists aspire to keep real statisticians away from their precious greenhouse models.)
I was able to get the AWS RegEm redonstruction to run last night.
It’s interesting what happens to the upslope when you use higher order TTLS truncation paramaters. I could use the help of some of you stats experts in moving forward.
Re: jeff Id (#166),
Good work jeff. Keep ploughing ahead, but don’t neglect your day job 😉 .
One question, are you working with the original AWS data or the corrected? Is there a version of Data$aws floating around with all of the updates?
Re: RomanM (#167),
I’m using the one off CA directory with two AWS series removed. – from 65 to 63, I can’t remember the numbers but Matlab won’t converge with them in Data.
Re: jeff Id (#166),
Jeff, your analysis was the cat’s pajamas/neat/cool. The case for the number of PCs to include in the PCA has always been here at CA a matter of relating the selected PCs to some natural occurrence or phenomenon. What your analysis shows is that the conclusions from the Antarctica reconstructions, i.e. the 1957-2006 temperature trends could be susceptible to cherry picking of the PCs. The excerpt listed below from Steig et al. (2009) gives a glimpse of the rationale for the first 2 of the 3 PCs selected, but without much detail.
I have enjoyed this thread and could not help but learn from participating/observing here.
You know the reconstruction was very sensitive, I think it needed to be done on anomaly data to be more reasonable. There isn’t a lot of data in the matrix though.
I tried to leave a comment at RC but it doesn’t even say awaiting moderation, I think I may have experienced a service upgrade.
Does anyone here know what correct values for the truncation parameter should be?
Re: Jeff Id (#170),
The anomaly data as used by Steig is available from his reconstruction by replacing the places where there is no AWS with NAs. Using the variables from my script in the lead post:
Try the RegEM using these anomalies.
Re: Nic L (#168),
It’s tough sledding trying to figure out the details of what is claimed to be an obvious turnkey operation! I thought it might be a little easier to do if we had a script to check the consistency of their anomaly adjustments (continuing from the script above):
monthlies is a 63 x 12 matrix of the monthly adjustments made by Steig to calculate anomalies when done consistently for the station. If the value is an NA, then at least two different values were used for that month in different years. In you want to know the ranges for a given aws: e.g. for station 4, use check.range(diff.recon[,4])$maxmin . Some of the NAs could be no months available at all for that aws.
Re: RomanM (#174),
I saw your earlier post and I’ll try that soon. It seemed possible to me that this anomaly was calculated after the fact because of this in the SI:
This was not the case in the Tir data where they clearly state they used anomaly but since so much data is missing in the AWS record I wasn’t sure. I put another question into RC on this but no answer yet. From what I’ve read about RegEm, cyclic errors need to be treated differently.
Re: Jeff Id (#175),
I would think that you would get convergence faster in the RegEM algorithm be removing the cyclicities (which are of differing amplitudes at the various locations). It can’t hurt to try.
Re: RomanM (#176),
I think you’re right, I’ll give it a try. I’m thinking about pasting the ends on a bunch of Briffa data too. Who knew the implications of imputation could be so implacably interesting? sorry.
Re: RomanM (#174),
Thanks for the neat script, Roman, that is much more elegant than my efforts. Your results are different from mine for some stations, however. This may well be due to my making errors, but in some cases it could be that there are differences in the basic AWS data. I am investigating further.
Re: Nic L (#199), Nic & Roman, I was confused a bit by how Steig calculated the anomalies as well. He doesn’t use all available data in all cases. So what I did was subtract the recon from READER and find the mode of each month, then used that value to convert READER to anomalies:
.
“temp” is the READER data.
.
After doing this, even Bonaparte Point lies on the zero line . . . except for all the values they didn’t use. 🙂 There were 31 stations where at least 1 READER month was not used – I’m assuming to increase their verification scores – but it’s pretty obvious that they did not use the READER data “as-is”.
I’ve been trying to wrap my mind around this puzzle, and thought I’d summarize what I think I know. I apologize if this stuff is obvious, but I’m an engineer, not a statistician and a fair amount of the discussion has been over my head.
Known:
1) The satellite and AWS reconstruction use the same methodology (Steig SI page 3)
2) The satellite and AWS recons both use the 42 READER occupied sites data as the basis of the recons (SI page 3 and page 4)
3) The AWS data is spliced into the recons exactly as measured without alteration (Steve’s comparisons of the READER data to Steig’s recons)
4) The AWS recons from 1957-2006 are constructed soley from 3 PCs (origin TBD) with the AWS data spliced in. (Roman’s work)
5) When changes are made to the AWS data, the 3 PCs used in the AWS recons change (comparison of original AWS recon vs. Harry/RR corrected recon)
6) The AWS corrections (Harry/RR) did not affect the satellite recons and the AWS data is not used at all in the satellite recons (Steig’s explanation of the corrected AWS recons)
.
I have drawn these conclusions from the five points above (quite possibly in error):
– Both the AWS and satellite recons each use two input data sets. Data set A (the 42 READER occupied stations data) is common to both recons. Data set B (the AWS data for the AWS recon, and the satellite data for the satellite recon) are different between the two recons.
– Data set B is used as a splice in the recons (known for the AWS recon, presumed for the satellite recon). Data set B appears to also be used by the reconstruction algorithm in the generation of the 3 PCs, but it’s weighting is TBD.
– Since the AWS data is sparse and spliced ito it’s recon, the satellite data is probably also spliced in a sparse fashion. Presumably, satellite data that passes the cloud masking test (Steig SI page 1) is used as data set B for the satellite recon. This data is spliced into the satellite recon and also used to some unknown extent to generate the 3 PCs used in the satellite recon.
– Since data set B is different for the satellite and AWS recons, the 3 PCs used in the two recons are different.
.
Any feedback is appreciated. Much of the discussion has been to deep for this state college graduate, but it has been fascinating to follow.
Re: Jeff C. (#178),
Your six statements are pretty accurate. With regard to statement 1, they also claim to have done a “conventional PCA” whose result appears in Figure S4c, however the plot is barely pink and wouldn’t make a good cover so they don’t push the point.
With regard to your conclusions so far I only disgree with
Yesterday, while driving into town for some chores, I had one of those “AHA!” moments when I twigged to that same statement. I thought “Wow, we actually have the (summarized) satellite data we wanted to get”! It took a couple of minutes to realize that, alas, it is almost certainly not true.
If you do a PC on the reconstructed data including the spliced data (in this case I happen to be using the “corrected” values, but the result is very close to that using the earlier version) the largest eigenvalues (of 63 all together)look like:
You will notice they they don’t suddenly drop down to (virtually) zero after the first three. This is because the spliced data are not that highly correlated and the first three PCs can’t capture their complete relationship. More PCs are needed.
However, when you do a PC analysis of the reconstructed gridded sat values in the file ant_recon.txt (5509 grid points!), the fit using three PCs to ALL the data points (5509 x 600) is virually perfect to a tolerance 10^-6. You wouldn’t get that if splicing had taken place. So, no splicing is indicated for the satellite data.
However, after I realized that the aws WAS spliced and satellite data wasn’t, I asked myself, “Why NOT”? It isn’t clear to me that splicing is good or bad, but why would you do it in one case, but not the other? I don’t have an answer.
Re: RomanM (#179),
Roman, thanks for the response. I understand exactly what you are saying as I also ran the PCA on the Steig recon and noted that the eigenvalues didn’t drop off after three. In fact, they were still rather large all the way out to the 63rd eigenvalue. Makes sense with the recon being spliced. If the satellite recon eigenvalues dropped off after three, they almost certainly were not spliced.
Why splice one and not the other? Why splice the AWS recon at all? At the risk of violating blog policy, perhaps it was since the BAS data was freely available to the public, the authors knew it would be cross-checked against the AWS recons. Not much of a concern with the satellite data.
Re: Jeff C. (#181),
For sure Roman and you are right, no splice.
It’s a claim of the paper that after 3 pc’s for the satellite data, the rest aren’t important. This is hard to for me to imagine just by natural variation in the data. What determined the PC threshold? It’s not like using more PC’s would have taxed the computer. That key is hidden in the missing code along with the masking technique.
Re: RomanM (#179),
I was speculating in an earlier comment that by splicing the measured READER data into the AWS recon, one couldn’t tell how far off the recon was from the READER data (perhaps by design).
Roman’s code allows us to know what the recon data would have been if the splice had not happened. I used Roman’s code to reconstruct 1980 to 2006, I then substituted NA for any value where measured data did not exist. I did a likewise NA substitution in Steig’s AWS recon. I subtracted the two to leave me with a table of “errors” in the reconstruction wherever measured data was available. The plot of the std deviations of the errors is below.
Harry and Racer Rock are the worst and that is not surprising as I am using the original, uncorrected recon and we know the READER data had discontinuities for these sites. However, all of the other sites have fairly large std deviations, some as large as 2.3 deg C. This means where we have measured data, the recon using the 3 PCs would have generated data with fairly large errors. Presumabaly all the points where we don’t have measured data have similar errors.
I’ll see if I can clean up that plot as it’s not showing up real clearly. I’m also going to look at how the 3 PC recon may have changed trends in the measured data.
Code is below, I’m new to R and could use some help in simplifying the brute force substitution for future refernce.
Re: RomanM (#179),
This might help explain that. This is what the map looks like if you splice the manned data back in – centered of course.
.
.
It’s more interesting if you also splice in the data from the AWS recon.
.
Why would you splice the data in at all? RegEm with enough freedom should fit the curves well enough that you don’t need splicing. I can’t wait to see the sat data. The three PC’s are probably the key to what happened in this paper, along with the processing algorithms for cloud masking.
I also have been thinking about the final averaging, in the case of sat data they have a good grid. In the AWS data the spacing is all over the place. I don’t recall any mention of area weighting prior to averaging.
Re: Jeff Id (#180),
I was thinking more that the data would be in there from the beginning.
The EM algorithm does not in way change the existing data. It should alternate between infilling data and recalculating the estimate of the covariance matrix until the values settle down. The Reg (regularized) part is used because there are more missing values than you have information to guess them with. Ad hoc conditions are added to allow for a solution (which depends on those conditions. That shouldn’t change any of the values either. In this case, you should end up with with a covariance matrix and infilled missing values. But that doesn’t seem to be the case in the satellite recon. They must have done things differently in the two situations… for a reason?
Re: RomanM (#182), Your right again someday you’ll get tired of that. What was I thinking? Reg Em only infill’s missing values. How could the sat data have 100% of the values infilled? Now that is interesting….
What if the PCA analysis got mixed around with regem in the output.
From your PCA analysis did the 4th PC drop all the way to 0?
Re: jeff Id (#184),
It looks to me that this result wasn’t a mixup. I think it was mann-made.
Re: jeff Id (#184),
I think we are looking at this backwards. The only infilling that seems to happening is with the measured AWS data into the 3 PC-generated reconstruction. Since the satellite recon can be described by three PCs, there is no true, measured data in the result. There is no infilling of missing values, the entire reconstruction is mathematically-derived.
Re: Jeff C. (#187),
You seem to be right. The RegEm software looks for NaN values and infill’s them. The satellite recon would have some imputed data if it had been processed through RegEm but not many values should be missing. They claim the satellite data can be represented by 3 pc’s, not presenting the data and replace the whole bit with fake data. They then run a bunch of verification stats which capture more short term variation in the r values than long and state a good fit.
Re: jeff Id (#188),
I’m coming to a similar conclusion, but after thinking about it for awhile, there might be an alternative explanation to consider. The AWS data are actual measured temperature values, no post-processing or massaging required. The satellite temperature data isn’t, but is a post-processed result of a temperature proxy (I believe). Could the fact that the satellite data can be described by three PCs be an artifact of that post-processing (i.e all the satellite “measurements” are correlated)?
I don’t think so as Roman said in #179:
I don’t think it would be that clean with a mishmash of both the recon and satellite data. Although the satellite measurements might be correlated to each other, they wouldn’t be correlated to the reconstructed data points.
Re: RomanM (#182),
Not sure if anyone has done this, but it would be interesting to see how well the AWS measured data (that spliced in) agrees with the AWS recon for the same dates (using Romans estimated recon). Roman’s first plot in the original post gives a visual representation of the difference between the two from 1980-2006 and it looks like there are quite a few large deltas. The stats on the differences might be surprising.
Since the BAS data is public, this comparison could have been made easily if the recons didn’t have the measured AWS data spliced in. Splice in the data, now the comparison can’t be made. Or at least that is what one would have thought, Roman figuring out the basis for the recons changed that.
The sat sensor is an IR brightness sensor, I bet my own state college engineering degree that typical post processing of sat data itself doesn’t create 3 pc’s. Without looking it up, there was a reference to a paper on haw the cloud removal was done, I wonder if that is the process creates the effect.
We need ALL the code and All of the data.
Re: jeff Id (#190), An Improved In Situ and Satellite SST Analysis for Climate, Reynolds, et al 2002 is the paper that apparently is referenced for cloud removal. However, I did not see a very clear and detailed explanation of the cloud removal procedure in that paper. Maybe I missed something. From page 2 of the reference:
Although the quoted section and this reference are concerned with estimating sea surface temperatures, it raises the question of whether the air surface temperatures for Antarctica were also derived using an algorithm “tuned” to available surface station data. If so, then the satellite “temperatures” and the surface station temps would no longer be exactly independent, would they? Maybe I’m wrong. It is just a thought.
Re: Phil (#195),
Are the visible channels capable of distinguishing cloud from snow/ice adequately enough to be useful in Antarctica even in daytime? I would guess not since Antarctic white-outs are a well-known phenomenon amongst pilots.
Re: Alan Wilkinson (#198),
Variability and Trends in Antarctic Surface Temperatures from In Situ and Satellite Infrared Measurements, Comiso 1999 I believe is the paper that Steig, et al referenced regarding cloud masking. I mistakently referenced a different paper in Phil (#195). From Comiso 1999, page 6:
Figure 4 on page 7 of the paper shows color images of both day and night masking. More importantly, Comiso concludes:
IIRC, Steig et al 2009 doesn’t specifically mention that their satellite data (which was calculated by co-author Comiso) was any more accurate than 3°C.
Re: Phil (#207),
So Channels 3,4,5 are the IR data and their variations seem to be the main discriminants used for cloud detection in the polar region. The comment isn’t very explanatory to say the least – it’s far from clear why night data is harder to analyze. Presumably winter data is then also harder to analyze?
Re: Alan Wilkinson (#208), Yes, I think you are correct.
Re: Geoff Sherrington (#213),
I haven’t seen any mention of what is done under the clouds in anything I have been able to find (I might have missed somthing, though), with one exception. The exception involves a NOAA product called the Cloud and Surface Parameter Retrieval (CASPR) system. From the main page:
I do not know if CASPR was used by Comiso in calculating the satellite data, but maybe many of the same cautions would apply to whatever method he did use. Sorry I couldn’t be more helpful.
Re: Phil (#250),
Thank you for the clarification and reference. In concept, to me it is akin to taking an average temperature by multiplying the maximum by 2 and then dividing it by 2. You have to have some basis better than guessing for distinguishing under-cloud temps from cloudless temps.
Another possibly relevant point is emerging from some work on Australian high quality rural stations. The “warming trend” (a linear least aquares over the period 1968-2008) falls into two groups, being those below altitude 50m asl and those 50-600m, the highest, asl. By choice and coincidence, this also separates the sites by the seaside from those inland. The Antarctic is ringed by weather stations near sea level, but has a high plateau interior with inland staions.
Now, in the Australian example the inland trend line is commonly 3 to 5 times the coastal one. Not the temperature, but the trend 1968-2008. This is a huge difference. It is almost certainly not UHI. Why should this be so, and does it happen in the Antarctic? I don’t have easy access to analytical facilities but I hope that some of you can examine this separation to see if it exists for Antarctica. In Australia, there might be a complication with a switch from daily recording to half-hourly and perhaps different instruments and housings.
Re: RomanM (#222),
Your map should be on the Front page with equal prominence to the earlier one. It makes a hugh impact when Joan & John Citizen can look at 2 pictures and say “Wow! These are rather different. There is some funny business here.”
And it is the Joan and John Citizens who need to look at the evidence.
I just had a someone call my attention to this.
trunc = min([options.regpar, n-1, p]);
This parameter is then passed as dummy variable r into pttls.m:
% [Xr, Sr, rho, eta] = PTTLS(V, d, colA, colB, r) computes the
% minimum-norm solution Xr of the TLS problem, truncated at rank r
The truncation parameter is equal to the rank of the least squares method used. In my post this means we only see strong positive slopes with rank 1 TTLS.
I should know more about the pedigree of the satellite data as I’m a systems engineer for a satellite contractor. In my defense, we didn’t build it and I’m a comm systems guy, never dabbled in remote sensing.
I agree we need all the code/data, but if your thoughts in #188 are correct, I doubt we’ll get it anytime soon.
Speaking of obscure state colleges, Go Matadors!
Re: Jeff C. (#192),
Estimating near-surface air temperature with NOAA AVHRR James P. Riddering and LLoyd P. Queen, Can. J. Remote Sensing, Vol. 32, No. 1, pp. 33–43, 2006 has one description of how temperatures are estimated from AVHRR data. Please note the flowchart on page 4 and the 2 empirical formulas on page 3. What is interesting is that, in this study, the satellite temperature reconstructions (they are not direct measurements) are compared to gridded air temperature measurements from weather station observations. Obviously, I don’t know if this is similar to or very different from how air temperature reconstructions were calculated for Antarctica, but it is the most illustrative study I have been able to find so far. What strikes me is that the satellite air temperature reconstructions are rather indirect. Although not as indirect as estimating temperatures from tree rings or isotopes, it does not appear to be as direct as an actual thermometer. I would suspect that most people would assume that satellite measurement of temperature would be more direct than this, but until the actual method is disclosed we are just guessing as to how they came up with their satellite “temperatures.” Also worth pointing out are the scatterplots of air temperature estimates compared to ground estimates shown in Figure 3 on page 6, in Figures 4 and 5 on page 7 and in Figure 6 on page 8.
Re: Phil (#194),
Phil – thanks for the link. Looks like interesting reading.
Last one tonight. For those of us who don’t live with stats, a very cool version of the truncation parameter in ttls.
Click to access Sima.pdf
Just to verify what Roman wrote in #179, I ran the PCA on the satellite reconstruction (ant_recon.txt from http://faculty.washington.edu/steig/nature09data/data/) using prcomp (prcomp uses svd) in R. The eigenvalues are:
Roman is exactly right (no suprise), the satellite measured data can’t have been spliced into the recon as the fourth value drops to 9.73e-08. As Roman mentioned, the eigenvalues for the AWS recons were:
with PC 63 still as large as 0.0939. Clearly the spliced in measured AWS data is not well correlated with the reconstructed values.
I then downloaded the satellite reconstruction using conventional PCA (ant_recon_pca.txt). Steig discusses this on page 4 of the SI:
I performed prcomp on it, the eigenvalues are:
Again, it clearly seems that there is no spliced in data in the reconstruction as the fourth value is close to zero.
Note above that Steig discusses how missing data was infilled in the PCA recon using mean monthly climatology. He doesn’t discuss this at all in the RegEM description because it infills the missing data. Note that the infilling he is talking about is to the input to algorithm (the READER data) not the output (the reconstruction). I think this is significant as the satellite reconstructions appear to be entirely mathematically mathematically derived.
Why then does the AWS recon use the spliced in data? I keep coming back to the same answer, they didn’t want people comparing the measured AWS values (readily available from BAS) to the reconstructed AWS values. Roman’s code allows us to do that, the plot at the top of the post shows lots of deltas in the +/-5 degree range.
Sorry. Added comments.
I worked on an anomaly calculation from the raw data, I think after last night that it isn’t as straightforward as you would expect from the lack of data. If you have only got one data point for a particular month, your anomaly becomes zero Steig et al may have substituted a reasonable NaN for that point. I wonder if that’s what Ryan was seeing.
I don’t have time to run the script now to check it out.
Re: Jeff Id (#202), Yes, I noticed that, too, but there were other issues as well. If you calculate the anomalies for Butler Island just using monthly means, you get offsets for each month, some of which are almost a whole degree C. All of those months have many points present, so the single data point observation does not apply. For some reason, Steig calculated the anomalies using about the first half of Butler Island data. He then included all of the data. At present, I’m mystified as to why he would do this. I hosted plots of this here: http://rankexploits.com/musings/2009/steigs-antarctica-part-two/ .
Re: Ryan O (#203),
Thanks Ryan, I read it quick and it looks like a nice post, I really don’t have enough time unfortunately to study this in detail until tonight. I have one question which is still bothering me that you may be able to answer. From what you’ve done with the anomaly, does it seem seem possible that the anomaly data was calculated after RegEm was implemented with the full set of data or has that possibility been eliminated by some of your calculations? In other words, how well can you replicate any of the anomalies?
The quote in 175 above above should say anomaly not temp. It seems to make more sense to use anomaly, I’m just not sure that’s what actually happened.
Re: Jeff Id (#204), Most of the anomalies are replicated exactly from the original data. The only ones that weren’t were where a) the data set had changed (like Bonaparte Point); b) original data was not used by Steig (like D_47); or c) all of the original data was used in the reconstruction, but for some reason, the anomalies were calculated using only portions of it (Butler Island). Because of the existence of c) my guess is that the entering argument into RegEM was anomalies, not temperatures.
.
If this is true, then it would be interesting to see how the base periods for the manned stations match up to the base periods of the AWS data (1980-2006 with some oddities). A mismatch in base periods could produce some interesting results. 🙂
As I have maybe stated on this blog before, I’m a physicist so I tend to look at things from a very basic perspective first. I can’t comment as yet on the stuff Roman is doing but I wanted to comment from a general point of view that some of the engineers and physicists here maybe appreciate.
From reading over on RC, the RegEM method fills in data using a method that essentially works using the assumption that the spatial and temporal variation of data set 1 (say satelite estimates of surface temperature) can be used to fill in data (best estimate) of data set 2(surface temp taken by thermometers). The assumption being that as the two are measuring the same quantity more or less, then data set 1 can be used as a proxy indicator of variation, so to speak, to reconstruct or interpolate holes in data set 2. So in principle this is not a bad thing.
Now taking the simplest approach and understanding that there may well exist a fancy maths short-cut, a person could also by hand overlay the relevant satelite data to each surface station and produce an initial estimate of how the two relate, including estimation errors. They would get a feeling for the data distributions and possible errors and uncertainties. If this produces erroneous results then it follows that there’s not much hope for RegEM.
However it appears that the satelite data isn’t freely available and that seems a bit disappointing.
Re: MC (#206),
I did approximately this with the aggregated data from West Antartic and East Antarctic. There is some rather good evidence that they are offset (lagged) by some 10 months for reasons that might be related to weather circulation. Or particularites of ground stations in West and East.Re: Kenneth Fritsch (#171), This has a quote about rotation of climate. The last sentence in the blue box is
My main question has been how the satellite data are corrected for cloud cover. So far as I can see (and I am probably wrong) the satellites can measure surface temp only when there is no cloud, so surface temp under cloud is inferred. This is a bit shakey if we are looking for an average of very small temperature differences.
We interrupt this work for an update from Realclimate:
It appears that the folks at RealClimate have no consistent definition of “data.” The latest spin about Steig 2009 is as follows:
(Note in this and the previous reply no name is given for the editor).
OK, you have your orders. Relax. The authors will release this vital information when they are good and ready to do so. OK, back to the regular ClimateAudit program of reverse-engineering…
Question: will you complete your work before Steig et al release the “processed data”? Or will they wait until you finish, and immediately release the it? I’ll be for the latter.
Re: Fabius Maximus (#209),
Aren’t these two questions exactly the same? In both cases Steve has to go first…
For comparison I present below the graphs for the trends of AWS and TIR annual temperature anomalies for the period 1957-2006and the ARn correlations for AWS and TIR for the time periods 1957-2006 and 1965-2006. The R code is listed below.
The annual trend for the AWS reconstruction becomes flat sooner than the TIR trend. What I find unusual is the high values for the ARn correlations with larger n values. The TIR reconstruction shows this effect to a greater degree than the AWS reconstruction. Any ideas what can cause this type of regression autocorrelations?
Regression AWS Annual 1957-2006:
Regression AWS Annual 1965-2006:
Regression TIR Annual 1957-2006:
Regression TIR Annual 1965-2006:
Re: Kenneth Fritsch (#211),
Kenneth, break up your periods into 1957-1980 and 1980-2006. You will see wholly different results between the AWS and TIR reconstructions. The reasonable match between the two sets breaks down. AWS is essentially flat from 1980-2006, while the warming in the TIR reconstruction accelerates during the same period. In the times where there is no actual AWS or TIR information, the match is good (because they’re both using surface stations). In the area where you have actual AWS or TIR information, the match is very poor – and it’s especially poor when you match the AWS station to the closest TIR gridpoint.
.
Additionally, if you do autocorrelations on just the TIR data (so 1982-2006), you’ll find that the TIR data alone is more highly autocorrelated than either the 1957-1980 manned surface station data or the 1980-2006 period in the AWS data, and the TIR data has a noticeable peak in the autocorrelation at lag=36 months. I posted some of this at lucia’s blog (rankexploits.com).
Re: Ryan O (#214),
Ryan, I have done a break down of the monthly and annual data for the periods 1957-2006, 1965-2007, 1970-2006 and 1980-2006 for both the AWS and TIR reconstructions. I obtain statistically significant trends (trend slope different than 0 with p less than 0.05) for the monthly AWS and TIR 1965-2006 period and the annual TIR 1965-2006 period. All the other periods for AWS and TIR have no statistically significant trends. My point has been that even with no errors in the Steig et al. (2009) paper analysis it becomes obvious to me why the authors were intent on stretching the “warming” period back to 1957 – go forward a few years and no trend warming or cooling. I think they thought saying the Antarctica has been warming over 50 years as a very important statment to make. The RC quote I gave in an earlier post above stating that the 1935-1945 decade was the warmest of the 20th century for West Antarctica and not including that in the paper or a detailed discussion of trends coming forward is problematic for me.
Re: Kenneth Fritsch (#217), Ah, we were looking at different things. I was comparing the trends at each station with the corresponding gridpoint in the TIR reconstruction – to see how well they matched on a point-by-point basis. They do not match after 1980.
Re: Ryan O (#214),
I have been looking at the trends of the AWS reconstruction as well. I wrote a program (scavenging bits and pieces of code from Steve Mc et al) which will calculate the decadal trends from Steig’s reconstruction (original or corrected) and display them on a map of Antarctica. Beginning and end times can be chosen in the format c(yr,mon), e.g., c(1980,1) is Jan 1980. To include all of the year, the variable en should be specified as c(year,12). I ran this for the period 1980 to 2006 with the corrected data:
Despite the fact that this is based on only 27 years (3 years shy of Tamino and RC’s standard of a minimum of 30 years is necessary to determine climate trends 😉 ), it is pretty clear that Steig’s own reconstruction shows little (if any) warming trend after 1980. If the “Western Antarctic” has warmed since 1957, it would seem that either almost all of that warming must have taken place before 1980 or took place on the peninsula. From this graph, one might be given to conclude that Steig’s stated results are “true”, but somewhat misleading. Maybe they could put this as a picture on the back cover of Nature…
Re: RomanM (#222),
You joke, but this is a valuable contribution to science that readers of Nature would find interesting. My advice is to submit a 250-word correspondence clarifying the localized nature of Steig’s “continental”, “multidecadal” pattern.
Re: bender (#223),
Where am I going to find the other 31 co-authors?
Anyway, there’s probably bigger fish left in the barrel…
Re: RomanM (#229), May I humbly question your priorities? Maybe you should draft Steve M to help with the writing. It would take less than one day. Don’t underestimate the impact. Everyone’s busy. This is good stuff.
Re: RomanM (#222),
100km different because the TIR reconstruction doesn’t actually cover the entire area where there are AWS stations. But the vast majority are within 50km, and most are within 30km.
.
http://rankexploits.com/musings/wp-content/uploads/2009/02/ant_recon_names1.txt
Re: RomanM (#222),
🙂 I had a chuckle . . .
The map is cool. I will have to play with that. I printed out a map and hand-marked dots to get an idea where things were when I was playing with the AWS trends by location. Not so much elegant. Haha.
If you look at the TIR reconstruction for the same gridpoints in the same way, you see a wholly different picture of Antarctica post-1980. Way different. If Steig’s goal was to use the AWS recon as a reality check on the TIR recon, it fails.
Don’t know if this helps or not, but here’s a text file with the AWS station, the corresponding gridpoint in the TIR reconstruction, and the distance to that gridpoint in km. A couple are > 100km different because the TIR reconstruction doesn’t actually cover the entire area where there are AWS stations. But the vast majority are within 50km, and most are within 30km.
http://rankexploits.com/musings/wp-content/uploads/2009/02/ant_recon_names1.txt
Re: Kenneth Fritsch (#211),
Ken, the series are non-stationary in trend. Also, they are short (hence the wide Bartlett bands). The AR coefficients are virtually meaningless, especially the higher ones. They bounce up and down at the high end because the series contain jagged trends. Note that they do not exceed the Bartlett bands, so they are not significantly different from zero. Don’t waste your time trying to interpret things that aren’t there.
The AR(1) coefficient is close to non-zero, and this is probably all trend. Try removing the trend and check the acf of the residuals. AR(1) should be ~0 if it’s white noise.
Non-stationary series can be tricky to work with. You actually have second-order non-stationarity as well, in that the variance diminshes near the tapering end. That also affects your ability to correctly estimate acf – because the variance is heteroskedastic.
Welcome to the dangers of using classical time-series methods with short, noisy, maddeningly trendy, heteroskedastic climate data. Keep going. Gavin might learn something from you about “weather noise” and “internal climste variability”.
Re: bender (#215),
Bender, thanks for your comments on ARn and AR1 as they are much appreciated by a novice in dealing with time series. I will follow up with your suggested analysis and those from Ryan.
Re: Kenneth Fritsch (#218),
.
Not sure how great my suggestions are. I am more novice than you . . . 🙂 Not only did I download R little more than 3 weeks ago, but the only statistics I actually know with any reasonable level of competence are those used in manufacturing for process control and reliability testing (sequential life testing, DOEs, Ppk, etc.).
Wow! This has become an R hotbed! It helps to have a lot of eyes looking at the data from many angles. Way to go Ken!
Lost a couple of comments in mid-stream because of two power outages (freezing rain here today – where is GW when you need it? 😉
). I switched to my laptop and wireless and put the internet connection on a back-up power source so will try again.
Jeff C. (#212), what you are doing is somewhat related to the RE and CE statistics that the hockey
team is so fond of. Your code can be simplified – with practice (and a little experience) you can use more of what R was designed
to do well.
For example, you have
which can be done as
although the second line is not necessary for your calculations of diff0.sd.
You can extract the anomalies without a lot of work (and without Data$aws) in a very simple fashion:
This gives the anomalies embedded in the 1957 to 2006 time frame and calcuatesthe SD’s. You can use this to derive the anomalies in the corrected data set as well without knowing what corrections they may have made to the AWS data set. There is a very small chance (about 1 in a million) of an actual anomaly being flagged as a recon value, not enough to worry about.
Re: RomanM (#216),
Roman, my hammeR is seeing nothing but statistical nails. I may soon seek intervention.
Re: RomanM (#216),
Roman – thanks for your help in understanding how to simply this. I need to work on breaking my bad Visual Basic habits. Regarding your map plot, I generated something similar and also saw the negative trends on most sites. Since I’m new to R, I figured I must have made a mistake in coding it because it just couldn’t be right.
Re: Jeff C. (#232),
The other side of reporting bias. Disbelief leading to failure to report.
Do it today!
I’m having trouble accessing BAS data right now. I was trying to re-scrape and it’s hanging up all over the place.
I did a linear detrend of the annual AWS and TIR reconstructions for the period 1957-2006. I have attached the ARn graphs below. I have only listed the R code I used for AWS since TIR follows on it directly.
Does R have detrend and Durbin Watson functions?
AWS detrended:
TIR detrended:
ARn AWS 1957-2006:
Re: Kenneth Fritsch (#234),
Rather than answer your question directly, let me suggest how you can do wider searches in R. This may not apply to some lower numbered versions but works in R2.8.0 which I am using. You can search R help for general words usning fuzzy matching (simlar to Clicking Help => Search help …) by typing ?? followed without a space by the word you are looking for. If you want to search for a phrase, it should be put in quotes. Examples of such searches are ??Durbin or ??”nonlinear regression” .
Sometimes the search produces answers which include procedures in other libraries. For instance, one of the results produced by ??durbin looks like car::durbin.watson . This means that the function durbin.watson is in the car library and to get more information (without loading the library), you can type ?car::durbin.watson . I am not sure whether it produces results only from the libraries that you have on your computer or from a broader database.
Re: RomanM (#235),
Roman, I have R version 2.8.1 and I was aware of the fuzzy searching technique (you had provided me with it and other searching techniques previously and they have been helpful). I attempted your suggested enteries with no success. I have seen the function online using durbin.watson and I was quite sure its was with R. It may, as you suggest, be part of a library I do not have loaded – although I thought at the time of the downloading of R I took the comprehensive options.
Re: Kenneth Fritsch (#245),
One more piece of information and then the professor hat is off. Old habits are hard to break.
I haven’t used it much nor do I know how well it works, but when in doubt try
http://www.rseek.org/
..but that’s all… no more advice … I know when to quit …
Re: RomanM (#247),
Roman, you do remind me of my graduate school professor, but then he was twenty years my senior and I think I am a few years yours. Anyway thanks for the link as it listed all the regression statistics and the packages in which the statistics resides. I downloaded the package car and now have durbin.watson in R. I also loaded the package stats (which I thought was already available) and that should provide me with dwtest.
I made a minor change in Roman’s trend plot code to allow changing the start and end points. It is interesting to look at different time periods.
Here are the AWS trends from the entire record of 1957-2006
Here are the trends using only the 1957 to 1979 portion (prior to AWS or satellite data)
Here is the 1980 to 2006 trends (same as Roman’s plot above):
I’m going to try putting this in some surface plotting software to see if I can get some Nature-like charts.
Re: Jeff C. (#236),
You didn’t need to make any “minor changes” in my code. The numbers in the line
are there as default values so you don’t have to put in every value every time you use the function. If you want to plot from 1970 to 1980, just type trend.plot(1970, c(1980,12)). You don’t need to redefine the function to change any of values. Just replace them with your own. You can change one of the later variables by specifying the change. For example, trend.plot(size=4) would run with the others all at default, but make the dots larger.
By the way, I ran the same other two as you did. They reinforce the notion that any overall warming came early .
This is interesting. Look what happens if you extend the AWS recon trends back only four years from 1976 to 2006. Compare this to the 1980 to 2006 plot above. Remember how the paper and the SI referred to strange time ranges (i.e. 1979 to 2003 or 1969 to 2000)? Turns out that including or excluding a few years off either end makes a huge difference in the trends.
Roman – I apologize as it is painfully obvious you know *much* more about this that I do. I didn’t redefine the function each time, but the minor change was changing this line in the function:
To this:
I couldn’t get the end date to change without that modification. I’m probably missing something here.
Re: Jeff C. (#239),
My bad! Good change! All that explanation for nothing. I noticed the change of the default value of st to 1957 in your script and thought that was the change that you were referring to. The change you made was needed. Sorry about that.
Re: Jeff C. (#239), and Re: RomanM (#238),
BTW, that wasn’t meant to sound snarky as I am clearly out of my depth here. I appreciate the patient assistance you and the others have shown over the last week as I learn this stuff.
Below are the plots of the auto correlations for the regression residuals for the AWS and TIR monthly reconstructions after detrending for the period 1957-2006. These plots show more ARn’s apPEARing outside the Bartlett boundaries than was the case for annual reconstructions over the same period. The R code follows on that used for the annual detrended auto correlations.
Re: Kenneth Fritsch (#241),
My plots in the post above should have been labeled. The top one is for AWS and the bottom for TIR. The Bartlett limits should have shown at approximately plus and minus 0.075 for the TIR plot (same as the AWS plot).
I was reading some of RyanO’s work and he had some good questions. Since I did not know the answer I though to ask over at RC.
I guess I was not polite enough or they did not like hearing that the AWS data does not support the paper.
Looking at the AWS maps, it seems that one could make a pretty good case that temperatures in Antarctica (except for the Peninsula) varies in opposition to the rest of the World. Temperatures rose from the fifties up to about 1980 while the rest of the world was cooling, then after 1980 when the rest of the World was warming, temperatures in Antarctica flattened or declined. I wonder, has temperatures in Antarctica started rising again in the last decade, when they have gone flat in the rest of the World?
READER AWS today has the following sites with noticeable amounts of “new” data.
Bonaparte_Point – 54
Byrd – 5
Casey_New_Airstrip – 22
Hi_Priestley_Gl – 9
Pegasus_North – 27
As a sort of validation exercise, maybe someone could see how the original recon stands up compared to the “withheld” data. I’ll do it if no one else does.
Just quickly “eyeballing” reader and comparing with Russian data set there seem to be mismatches at Bellingshausen station.
Temporal plots and trends are here http://south.aari.nw.ru/default_en.html
Go to summary tables with yellow icon.
Reader summary here http://www.antarctica.ac.uk/met/gjma/temps.html
Slightly different geographic coordinates as well.
This is very odd. I modified Roman’s AWS recon plotting routine to plot the grid cells for the satellite reconstruction. Here is 1957 to 2006:
Note how are there are virtually no blue dots. I think there actually are a few, but they are so limited you can’t see them. I found this hard to beleive, so I recalculated the trends in Excel to see if I still got an overwhelming number of positive trends. Same thing.
Here is 1980 to 2006, you still see almost zero blue dots.
It is not until you plot the trends for shorter periods that you start to see large quantities of blue. Here is 1980 to 1990.
I’m still finding this hard to believe so if anyone wants to check my code I would appreciate it. Thanks.
Hm . . . not sure what I’m doing wrong, but when I try to run Steve’s mapping script, I get:
.
Do I need to install something besides just the mapproj library?
Nevermind. So much for not clearing the workspace. I had previously defined a function I called “map”. Doh.
Jeff C,
the reason you get those results are AVHRR shows warming from 1980 – 2006 and AWS shows no warming (basically flat) from 1980 – 2006. The only way to get the AVHRR and AWS trends to be similar is to use RegEM to backfill the 1856 – 1980 and since the same source is used to back fill both of them, you get similar trends from 1956 – 2006.
Re: Vernon (#255),
Yes, I agree and I understand the differences in the trends. My surprise was that for the 1957 to 2006 period, out of 5509 gridsells, 5508 had a positive trend and only one had a negative trend. For the 1980 to 2006 period, 5490 had a positive trend and 19 had a negative trend. This despite the fact the split was roughly 20 pos/43 neg for the AWS recon trends of 1980 to 2006.
I simplictically viewing the 5509 gridcells as akin to 5509 little thermometers each as a somewhat independent measurement. Since the recon was derived from measured, satellite data I had expected to see at least some regions that have cooled. We know cooling has taken place at some locations based on the READER surface and AWS measurements. Yet from 1980 to 2006, 99.6% of the satellite recon gridcells show warming. I call BS.
Re: Jeff C. (#259),
From Comiso 1999, page 18 (Comiso 1999 is reference 8 in Steig, et al 2009 and Comiso did the satellite reconstructions and was a co-author in Steig 2009):
Comiso goes on to say:
Figures 17c and 17d are on page 21 of Comiso 1999. Figure 17c is the complete yearly average per pixel of 1992 minus 1979. Figure 17d is the trend result per pixel using the Jan and Jul monthly average data from 1979 to 1998. It really is striking to look at how well the 2 figures match up. I suppose this was a way of validating trends computed from just two months per year vs. doing whole years. Figures 17c and 17d show a very different spatial distribution than that shown in your post above. Specifically, compare the third figure in Jeff C. (#251) (decadal trends 1980 to 1990) to Figure 17c in Comiso 1999 (1992 minus 1979), where Comiso 1999 shows strong cooling in the peninsula.
It would be interesting to hear an explanation of these differences from Comiso himself.
Re: Phil (#260), The superscript tags aren’t working. Please subsitute yr^(-1) in the above for yr-1.
Re: Phil (#260),
On page 1 of the SI they seem to dismiss the earlier Comiso data set due to inadequacies in the cloud masking algorithm he used.
They go on to say:
It would be interesting to have an explanation. In the main text acknowledgments it says “J.C.C. (Josefino C. Comiso) performed the cloud-masking calculations and provided the updated satellite data set”. Apparently, he agrees with the new conclusions and methodology.
Riddle me this, batman:
.
Gavin says at RC:
.
To me, this means that the surface station data should remain untouched by the infilling and the satellite data provides the spatial map to help RegEM fill in the areas without data. Someone correct me if I’m already off the rails . . .
.
So if I were to do something totally crazy – like find the gridpoints in the TIR recon that match the station locations – and subtract the ACTUAL data from the TIR recon, I should get a flat line with zero slope and a y-intercept corresponding to the difference between my base period and Steig’s for anomalies, right?
.
Here’s the results of said craziness (red indicates TIR trend is GREATER than the actual data for that time period, blue means the opposite):
.
.
.
.
The results are almost identical to the TIR vs. AWS recon. TIR shows warming since 1980, actual ground observations do not. And the reconstructed information at the gridpoints corresponding to the manned stations does NOT appear to be actual data – it appears to be infilled.
Re: Ryan O (#257),
Ryan, from my reading and understanding of Steig et al. (2009), I would have agreed with the Schmidt excerpt in your post. The problem becomes then of reconcilling what you found with that excerpt/understanding.
We know that the AWS and TIR measurements only go back to approximately 1980 and therefore the reconstruction calibration in the over lap period of 1980-2006 (with the manned stations) is used to in-fill all the missing data for TIR and AWS in their respective reconstructions using the manned station data with the calibration in 1957-1980 period.
Therefore, it is clear that for the period 1957-1980 the AWS reconstruction is based exclusively on the in-filled AWS station data using the relationship/calibration of AWS with the manned stations in the 1980-2006 overlap period. Only the AWS stations are used during that period and not the manned or any of the TIR data. The same would apply in a similar fashion for the TIR 1957-1980 in-filled data.
What does all the foregoing say about your findings for the difference between the TIR Recon and the manned station data? It would say to me that the relationship of the TIR to manned station data changed at the local level from the calibration period 1980-2006 to the “reconstruction” period 1957-1980. Giving Steig the benefit of the doubt, one might want to see if the overall trend for the manned stations is different than the overall trend for the corresponding TIR grids. Your map would indicate that the overall trends will be different. What you have found, in my mind and at this point in the analysis, does not bode well for the Steig calibration as applied over time.
Looking at the comparison for 1980-2006 makes me wonder whether we are missing something in this analysis, since this is the calibration and validation period. The overall trends for the manned stations and TIR reconstruction appear from the map color sizes to be different also. One would think that we would see a better agreement if the TIR data was calibrated to the manned station data during this period. Perhaps the TIR data for this period is simply the measured data and then we are looking at difference between TIR and manned station raw measurements.
I would suggest that you recheck your premises and results. If they hold up, you would appear to be on to something pending an explanation that would put those results in better agreement with Schmidt’s excerpted comment.
I do not know how difficult it would be, but you might want to estimate whether the correlations Steig reports could be compatible with your difference findings.
Re: Kenneth Fritsch (#264), As I am prone to error, I am doing as you suggest – checking and second-checking. So far it doesn’t look good for Gavin’s explanation. I will try to post something tonight with some actual statistics attached instead of just pretty graphs.
.
Right now, there is one big thing that makes me believe the recon cannot possibly have been done as Gavin described:
.
Using the mode of ACTUAL – RECON for each month, I can find no values that repeat for anomaly determination. In other words, there is no series of constants that can the subtracted from each month of the ACTUAL data to yield anomaly values that are the same as the RECON values. None.
Re: Ryan O (#266),
Ryan, Gavin’s explanation is very much in line with what the Steig paper states and what makes sense on carefully studying what the authors did and determining what makes sense.
I seldom doubt, after verifying, what people like Schmidt say, my problem is with what they don’t say.
Re: Kenneth Fritsch (#267), Yep. My read of the paper led me to a slightly different (albeit similar) take on what was done than Gavin . . . but what I see from the data so far doesn’t mesh with either.
Argh. It’s late. This sentence:
should read:
Here’s plots of AVHRR RECON – GROUND STATION ACTUAL at the closest gridpoint to the station for those stations with essentially complate information over the recon period. None match. To me, it looks as if there is no actual ground station information in the recon – it’s all imputed.
.
The column number in the full recon is at the bottom left; the distance from the station (based on the coordinates provided by BAS) is in the bottom right.
.
Re: Ryan O (#262),
Ryan – go back and read Roman’s comment at (#179). He did a PCA on the satellite recon and there were only 3 eigenvalues that weren’t virtually zero. I think this demonstrates that there is no actual measured data spliced into the satellite recon as the measured data wouldn’t be well correlalated with the reconstruction. This is unlike the AWS recon which certainly does have measured AWS data spliced in.
It is a mystery why they are different.
Jeff,
I may have misunderstood the implications of Roman’s comment and the ensuing discussion. I took it to mean that either:
.
a) The station data was completely present (from 1957-2006) and the satellite data was used simply to get the post-1982 variation between sites; or,
b) The satellite data was used in lieu of the station data
.
I was attempting to see if the case was a) or b). It definitely looks like b) (Gavin’s comments on RC notwithstanding). My question, then, is if the recon were done using the satellite information simply to get the spatial variation of temperature BETWEEN actual ground sites – meaning no direct use of the satellite temperatures (as Gavin claims) – then would it be possible to have the recon essentially completely described by only the three PCs?
.
There is always a statistically significant probability that I am utterly confused. 🙂
Re: Ryan O (#265),
Ok, I understand and agree it seems to certainly be b). My takeaway from #179 is that the satellite recon doesn’t have *any* measured data in it, either from the satellite or station data. It is entirely derived mathematically from the 3 PCs (and the 3PCs came from some combination of the satellite and manned station data).
I guess what I’m trying to say is that the satellite recon isn’t real measured data that has been infilled. Even if we had the actual satellite measurements, they won’t agree with the recon because they aren’t the same.
I may be way off base, but this is my take on what’s happening:
Versus this
Re: Jeff C. (#269),
Thanks for the explanation. I’m not terribly familiar with PCA, so whether something is described by 3 principle components or 100 has no instant meaning to me except insofar as it is a measure of the relative complexity of the relationships between the data.
.
On the recon methodology you give . . . something doesn’t feel right about it for reasons I can’t really put my finger on. I would have assumed they had done something like this:
It doesn’t make sense to me at the moment why you would infill the missing manned station data independently, then use that to infill missing AWS, then re-generate the whole thing using the resulting PCs, and finally toss the actual data back in. This is a question to anyone; I clearly don’t know the answer.
.
For the satellite recon, my (uneducated) first guess differs only subtly:
.
I would be interested in anyone else’s assessment of this.
According to Ryan O (#257),
Gavin says at RC:
Ryan O says:
Gavin would be more or less correct in what he says. According to the Steig paper, one reconstruction used the AWS stations and the manned surface stations in one recon and the second used the TIR satellites and the same surface stations. In the first case , the data from the AWS was “spliced” into the recon. In the second, the results have NO actual measurements from anywhere in any of the series. The fit from the 3 pieces is just too good. One would expect a relationship between the manned surface stations and the satellite recon, more so in the pre 1982 time period, because that is the sole source of information used in extending the recon back to 1957. The relationship will extend to other grid points other than just the one in which the station is located. But no “flat line” because it ain’t actual station data!
Re: RomanM (#270),
Thanks. That’s part of what I was trying to find out. As mentioned in the post above, PCA is unfamiliar territory for me, so how many PCs something has does not have intrinsic meaning to me.
.
As far as the second part of what I was trying to find out – how different the recon is from the actual data – I’ll have more tonight. For the moment, they look to be in a similar boat as the AWS data – warming to about 1970 or so and flat thereafter. This contrasts sharply with the satellite recon, which warms throughout. In other words . . . no match.
When I said:
Re: RomanM (#270),
Roman’s, post above puts this piece of the puzzle to rest for me. The TIR reconstruction data contains no actual measurements over the entire 1957-2006 period, while the AWS does for the 1982-2006 time period and it is spliced to the reconstructed values for the 1957-1981 period.
So can we agree on Roman’s accounting of the reconstructions and on that basis determine whether Ryan’s analysis is compatible with Steigs calibrations. Those colored dots appear to indicate big differences but we need to put numbers on them and do some statistical analyses as Ryan suggests.
I’ll try again. I’m having the same luck getting past the automated spam filter here as I have at RC. This might be more pertinent to the new thread but it doesn’t matter.
I have redone the AWS RegEM Calcs with similar results to Steig.
There is a step in my version when compared to the papers AWS reconstruction that I can’t explain yet but otherwise is quite similar.
Well, because of the AWS reconstruction, we all knew it was getting warmer in Antaractica, but until I looked at the satellite reconstruction, I didn’t know that it is getting worse. The trends of the warming are increasing!
How did I find this out? I looked at the trends in the 5509 recons and calculated the trends pre and post 1982, the year in which the satellite observations began. Vitually all the trends were positive. That this was true for the post 1982 throughout the entire continent was certainly a surprise. But a larger one was to come. In a bit more than 45% of the grid points, the decadal trends in the warming after 1982 were larger than they were before 1982 .
The script for calculating this is
The line in the plot is not a regression line but simply a reference line where the two trends are equal.
You can see from the graph that there are some interesting patterns in the plots and I suspect that it is related to the 3PC reconstruction. It also has a relationship to the relative variabilities (Pre and Post) of each of the 5509 series and I will likely put something up on that in a day or so.
However, we aren’t finished here yet. So how does this relate to the location of the grid points? Taking the plotting done by Jeff C. (#251), and adapting it to my purposes:
You can see that it is mainly in West Antarctica where my plot of the AWS station reconstruction in #222, showed cooling in parts of that area after 1980. Combining that with Jeff’s posts in #236, that would indicate considerable disagreement between the two reconstructions. This seems to contradict the statement by Steig at al.: “Results from our AWS-based reconstruction agree well with those from the TIR data (Fig. 2).” I guess it just depends on how you look at the data…
Re: RomanM (#275),
Roman, your anlysis is more descriptive in pinpointing differences, but do not we know that there are (visual) differences in trends between AWS and TIR and over the split in time periods by inspection of the trend lines for both. Using the Steig results for AWS and TIR, we know it is getting warmer in the Anarctica starting when? I think the answer is sometime before 1965 as the latter time period trends are not statistically significant and that is the case for both AWS and TIR reconstructions.
Could one do differences between AWS and TIR reconstruction data and determine if that difference is statistically significant?
Re: Kenneth Fritsch (#276),
Ken, the two graphs that I have put up are for the TIR reconstruction only, not the AWS. What they show is that about 45% of the grid points supposedly had a LARGER amount of warming in the last 25 years (from 1982-2006) than they did in the first 25 years (1957-1981). This is the opposite of the pattern evident in most of the AWS reconstruction. This would not only indicate that it is continuing to warm, but at an increasing rate. Did we know this already? For the individual grid points?
Re: RomanM (#275), Roman and others…thanks very much for all the work you’ve been putting in on this. I confess it’s a bit difficult to follow, mainly becuase it’s spread out over a couple of threads and several hundred posts.
Any chance you could give us the Reader’s Digest condensed version? Sort of what we know so far, what still needs to be checked, etc.?
Thanks.
Re: RomanM (#275),
I agree that your graphs detail some surprising differences. I guess I was just attempting to segway in some of my own observations.
In a word, no.
I’ll try this from home. I was spam blocked from commenting at work. This has been one of my favorite threads.
I have taken another shot at replicating the RegEm process. It looks pretty close except for a step at 1980.
I looked at the Durbin-Watson statistic for lag 1 through lag 25 autocorrelations of the regression residuals to determine the statistically significant lags for the regression residuals for the AWS and TIR reconstructions over the period 1957-2006 for the monthly and annual data. The results are listed below for those lags with p equal to or less than 0.05 along with the R script for the AWS annual calculation.
I plan next to look at the autocorrelation of the residuals for other temperature anomaly time series in order to determine whether these reconstructions have unusual residual autocorrelations.
Monthly AWS: lag1 =0.00; lag2= 0.00; lag4 = 0.01; lag5 = 0.02; lag 11 = 0.00
Monthly TIR: lag1 = 0.00; lag2 = 0.00; lag4 = 0.04; lag10 =0.02; lag11 = 0.00, lag23=0.02; lag24 = 0.00; lag25 =0.01
Annual AWS: lag1 =0.00; lag12 =0.01
Annual TIR: lag3 =0.03
Durbin-Watson AWS Annual 1957-2006:
Here is what is really bothering me about this. Page I of the SI has plots of the decadal trends using AVHRR data that has been processed using various cloud masking algorithms.
Steig mentions their improvements to the cloud masking algorithm in the SI:
The first figure are the trends using the cloud masking technique from Comiso (ref 8) from 1982 to 1999. The third figure shows the trends using the “improved” cloud masking techniques used in Steig 2009 over the same time period (1982-1999).
Yet when you look at the decadal trend in the satellite reconstruction from 1982 to 1999 (compare to figure C), it looks like this:
What happened to that large area of cooling in the East Antarctica interior? They state that their cloud masked AVHRR data is that shown in figure C. Figure C is supposed to be the trends from the real, measured satellite data after it has been cleaned up from clouds, the largest error source according to Comiso. Yet the satellite recon replaces virtually the entire cooling area with warming.
No wonder they won’t release the satellite measured data, although figure C gives us an insight into what is in it.
Steve – I hope the graphics aren’t slowing the server. If so, just say so and I’ll stop putting them in the comments.
That should say Comiso (ref 8). Not sure why that smiley face showed up.
I’ve been trying to post today several times. Since Steve is out having fun or something on a Friday (good for him) there’s nobody to fix it.
I’ve made an attempt to run the AWS reconstruction again.
It’s pretty close, if my comment makes it through this time there’s more to say.
My other stuff made it through, I didn’t see it. thanks.
Re: Jeff C. (#283),
I’m really surprised the sat data didn’t fit better than that.
The RegEm data doesn’t fit either. I’m pretty sure I’ve done everything right but the uptrend I found is greater than the reconstruction. Visually the basic shape of the data is correct though.
If the basic sat trends don’t match, it makes me wonder if the RegEm result I found isn’t also correct. Is it possible that there was some kind of GISS corrected anomaly used? Anyway, after some time looking at the data it looks to me as simple as the pre-1980 surface station data pasted on AWS.
A bit belated, but here’s the point-by-point comparison with uncertainties for recon gridpoints to actual station data. The method is pretty simple: I find the mean of the common points between 1982-1990 to form the baseline. The reason is that there are the most stations with data available during that time (27), so it allows me to keep the same baseline for a good number of stations. Here’s that:
Red are peninsula stations, blue are west Antarctica, and black are east Antarctica.
.
So now let’s look at 1957-1981:
To me, that looks pretty poor. The recon does a poor job matching stations backwards in time. In general, just like for the AWS recon, the peninsula warming is OVERSTATED in the early period, east looks okay, and there just isn’t much west data, unfortunately.
.
Now 1982-2006:
Looks a little better than the early period. With the exception of one station, the west stations don’t show any statistically significant difference (though they’re all above zero). Of the 27 stations, only 6 fall below the zero line, and all of the ones outside the confidence intervals are above zero.
.
The picture gets even uglier when you break everything up into 8-year blocks. I’ll put these one right after each other so you can see the progression:
.
.
Qualitatively, the actual data from the manned stations is the same as AWS: Except for the peninsula, no statistically significant warming after 1969. The satellite recon, however, significantly understates the peninsula warming trend (by more than a degree C over the analysis period) and overstates the east/west Antarctica warming.
.
In the 1957-1981 period, more of the recon data falls OUTSIDE the 95% confidence level than within. After 1982, about a third of them are out, over half would be out using a 90% confidence level, and most are out on the high side.
.
Script:
Pics didn’t work. Carbon error. Steve, please feel free to snip out or delete the above post. Here it is again:
.
A bit belated, but here’s the point-by-point comparison with uncertainties for recon gridpoints to actual station data. The method is pretty simple: I find the mean of the common points between 1982-1990 to form the baseline. The reason is that there are the most stations with data available during that time (27), so it allows me to keep the same baseline for a good number of stations. Here’s that:
Red are peninsula stations, blue are west Antarctica, and black are east Antarctica.
.
So now let’s look at 1957-1981:
To me, that looks pretty poor. The recon does a poor job matching stations backwards in time. In general, just like for the AWS recon, the peninsula warming is OVERSTATED in the early period, east looks okay, and there just isn’t much west data, unfortunately.
.
Now 1982-2006:
Looks a little better than the early period. With the exception of one station, the west stations don’t show any statistically significant difference (though they’re all above zero). Of the 27 stations, only 6 fall below the zero line, and all of the ones outside the confidence intervals are above zero.
.
The picture gets even uglier when you break everything up into 8-year blocks. I’ll put these one right after each other so you can see the progression:
.
.
Qualitatively, the actual data from the manned stations is the same as AWS: Except for the peninsula, no statistically significant warming after 1969. The satellite recon, however, significantly understates the peninsula warming trend (by more than a degree C over the analysis period) and overstates the east/west Antarctica warming.
.
In the 1957-1981 period, more of the recon data falls OUTSIDE the 95% confidence level than within. After 1982, about a third of them are out, over half would be out using a 90% confidence level, and most are out on the high side.
Did the same thing with the AWS (corrected) recon vs. the full recon:
.
Similar effect as above: AVHRR has a smaller warming trend from 1957-1980, but a larger warming trend from 1980-2006. For the moment, that’s all for the in-process graphs . . . I need to read up on graphing in R so I can put these into 2 or 3 graphs succinctly.
.
Next I think I’ll combine the geographical areas (peninsula, west, east) and see what pops out . . .
Re: Ryan O (#291), Hmmm. I haven’t had a chance to really delve into this but I was under the impression that the AVHRR data was used to provide spatial and temporal distribtution information so as to create an interpolated grid of data between AWS stations in the 1982 to 2006 period. Gavin made reference to ‘Bayesian priors’ and I’m hoping that he meant that the trends in the two should be similar if they are measuring the same thing hence the use of one data set to bolster the other. It doesn’t look like this is the case and it appears some explanation i.e. actual satelite overlaid to station data, is needed.
Geoff I know you mentioned this earlier Re: Geoff Sherrington (#213), , but is such data readily available?
Below the trend results of the 64S to 90S GISS annual temperature anomaly data are compared to the Steig et al. (2009) AWS and TIR reconstruction trends for the Antarctica. I also did a Durbin-Watson analysis of the lag n regression auto correlations for the GISS data to compare with the Steig counterparts. I chose the periods 1957-2006, 1965-2006, 1970-2006 and 1980-2006 for the comparison as those were the periods I used in looking at the AWS and TIR trends previously.
The generic R script that I used is listed below. I was unable to use either read.table or the scan commands successfully due the interjection of non data lines in the table. I used readLines to get the GISS table into R where I cleaned out all but the required data. My problem then was that R saw the each line as an element and thus I had many rows but only one column. I was unable to get R to break the rows into 17 elements and thus copied the data to notepad and called it back with read.table.
Below are listed the temperature trend slopes (TS) in degrees C per decade and the p values (p) for the probability of slope being different than zero by chance. I do not list the results of the GISS Durbin-Watson results but only note that the GISS data had no statistically significant lag n auto correlations of the regression residuals as contrasted with AWS and TIR which did.
While the results below show differences in the four time period trends between the AWS, TIR and GISS data, all three series show that as the start date is moved forward from 1957 the trends are not significantly different than zero. When combining those trends with the observations that 1935-1945 was probably the warmest of the century for West Antarctica I fail to see what the a warming from a 1957 start date means in the bigger picture of natural cyclical trends.
I do want to look at the differences in temperature anomalies and trends between the 3 time series.
1957:2006: AWS TS =0.139; TIR TS = 0.118; GISS TS = 0.114
AWS p = 0.02; TIR p = 0.02; GISS p = 0.00
1965:2006: AWS TS =0.053; TIR TS = 0.086; GISS TS = 0.048
AWS p = 0.46; TIR p = 0.20; GISS p = 0.29
1970:2006: AWS TS =-0.009; TIR TS = 0.064; GISS TS = 0.020
AWS p = 0.91; TIR p = 0.45; GISS p = 0.73
1980:2006: AWS TS =0.-051; TIR TS = 0.112; GISS TS = 0.023
AWS p = 0.60; TIR p = 0.44; GISS p = 0.81
Beautiful.
I need to correct the comparisons for AWS, TIR and GISS that I did in the previous post on this thread. Note that in the previous post the GISS R script shows that I calculated the GISS trend from 1957-2008 and not 1957-2006 as I did for the AWS and TIR data. Indeed that is what I did – and demonstrates the importance of R documentation.
Below are the adjusted GISS values along with the previously reported AWS and TIR results. The conclusion on the trends not being different than zero coming forward from 1957 does not change. The trends for GISS do approach the AWS trends.
My error does show that the end points can have a significant affect on the calculated trend value. Again, my next step will be determining whether a statistically significant difference exists between the temperature anomalies for these temperature time series.
1957:2006: AWS TS =0.139; TIR TS = 0.118; GISS TS = 0.101
AWS p = 0.02; TIR p = 0.02; GISS p = 0.02
1965:2006: AWS TS =0.053; TIR TS = 0.086; GISS TS = 0.022
AWS p = 0.46; TIR p = 0.20; GISS p = 0.64
1970:2006: AWS TS =-0.009; TIR TS = 0.064; GISS TS = -0.017
AWS p = 0.91; TIR p = 0.45; GISS p = 0.73
1980:2006: AWS TS =0.-051; TIR TS = 0.112; GISS TS = -0.044
AWS p = 0.60; TIR p = 0.44; GISS p = 0.67
Below are the results of regressions of the reconstruction anomalies (annual) for TIR minus AWS over several time periods. Typical R script is shown below. The trend slopes of the differences (TS) and probability (p) of these slopes being different than zero by chance are listed.
As the trends are moved forward in time from the 1957 start, the TIR-AWS differences become more significant, i.e. p gets smaller while difference trend slope becomes larger. One can see that the 1982-2006 period shows a difference trend that has a p = 0.07. That time period was selected as 1982 was the year the TIR measurements were initiated (AWS started in 1979). Actually coming forward one more year gives a p = 0.01 for the trend slope for the TIR-AWS difference over the period 1983-2006.
Regressing TIR-AWS difference over 1957-2006: TS = -0.02: p = 0.58
Regressing TIR-AWS difference over 1970-2006: TS = 0.074: p = 0.26
Regressing TIR-AWS difference over 1980-2006: TS = 0.169: p = 0.11
Regressing TIR-AWS difference over 1982-2006: TS = 0.223: p = 0.07
Regressing TIR-AWS difference over 1983-2006: TS = 0.318: p = 0.01
I judge that in putting Steig et al. (2009) in perspective that the 1935-1845 warming in West Antarctica cannot be emphasized enough and particularly so when going forward (using Steig’s data) from 1957 shows no statistically significant trend. In fact, it is Steig who points to the warm 1935-1945 episode here in the link and excerpt below.
http://www.pnas.org/content/105/34/12154.abstract
Look at how Steig et al. (2009) warming is described/interpreted here at Climate Progress in the lead-in piece and then pay careful attention to how a poster is handled who attempts to put all the trends together including that for 1935-1945.
http://climateprogress.org/2009/01/21/antarctica-has-warmed-significantly-over-past-50-years-revisited/
Here are graphs of the temporal evolution of the means of the AVHRR reconstruction vs. manned station data. A little explanation here:
.
The way Steig calculates his verification statistics excludes time as a factor. It’s a simple point-by-point comparison. So as long as the series he’s comparing sort of start at the same point and end at the same point, the verification statistics look plausible. This is fine if you’re determining if there is a difference in mean temperature over a time period, but it is not fine if you are looking for temperature trends. They allow you to pass verification even though the trends within the series could be rejected by an appropriate test. This is critical to Steig’s conclusions. Because his verification statistics are insensitive to trends within the data, by choosing the correct starting and ending dates, the satellite reconstruction shows strong warming. Others have already noted the apparent cherry-picking of dates.
.
To show that his trends can be statistically rejected, a test is needed that is sensitive to trends between arbitrary times. The simplest way I can think of to do this is to compare how the difference in means between the ACTUAL data and the RECON data at a common grid point evolves temporally. From there, I can generate a confidence interval for each point and plot that with respect to time.
.
The plots below are generated in the following manner:
.
1. Paired Wilcoxon test (so a non-normal distribution is okay) between the ACTUAL and RECON data for +/- 48 months (time frame doesn’t really matter – the results are pretty much the same whether you use 24-96 months . . . just changes how smooth it is).
2. Normalize the difference in means to the 95% confidence interval (allows multiple series on the same plot).
3. Repeat for every point in the series.
.
Now you have a time series showing where the rolling +/-x months means are as a ratio of the 95% confidence interval. If any points exceed +/- 1.0, the null hypothesis that the +/-x month means are the same at that point in time is rejected at a 95% confidence level.
.
Just to give Steig the best possible chance of passing this test, I added a step to center the ACTUAL and RECON means for the whole series using only common points. I think a more appropriate way would have been to set the means equal at the beginning or end of the series, but even giving Steig this benefit of the doubt doesn’t let him pass. I then grouped the series by location and ran the test for all stations with about 30+ years of data. The results are not good for Mr. Steig.
.
.
Probably the most striking is the understatement of the peninsula warming – the range on most of those series is 2.5 times the 95% confidence interval . . . which means there is an infinitesimal chance of them being correct. You can also see the reason the 1979-1982 start dates are important, as the AVHRR means tend to be outside the lower 95% confidence interval at those times.
.
I am in the process of grouping and plotting the results from the AWS recon vs. the AVHRR recon. They are similar. The null hypothesis that the means temporally evolve in the same way (and, hence, that the derived trends are valid) is rejected at a 95% confidence level.
.
Apologies in advance to Mr. Steig for being blunt, but his AVHRR reconstruction is utter bunk.
.
.
.
Script (be forewarned – running this takes a LONG time. If you do all the stations and the AWS recon at once like I did, you’re doing 600,000 paired Wilcoxon tests on +/-48 months of data apiece):
Dammit. Not sure why I can’t get pics to work…they work on the preview.
.
Oh good God . ..
.
Here’s the same analysis comparing the corrected AWS reconstruction to the satellite. In some of these, the AVHRR means spend more time OUTSIDE the 95% confidence intervals than inside them. Every single series exceeds the intervals at least once.
.
Ryan, from my layperson’s perspective I judge that your analysis does an excellent job of informing and detailing where differences between TIR and manned stations and AWS and TIR occur. I am curious whether you determined that the paired differences did not have a normal distribution.
I am sure no disrespect was intended on your part, but I would think your reference to Eric Steig should either be Steig or Dr. Steig or Eric Steig.
I think that while your analysis, which shows differences at individual stations and areas in the Antarctica, provides a more complete picture than that reported in Steig et al. (2009), the authors of that paper are going to focus on the overall trends from the accumulated reconstructed stations. They apparently judge that it is important to be able to state that 1957-2006 trends show a warming Antarctica and they will point to those trends (and differences) as a measure of the accumulation of stations and not individual stations.
What I have been repeating ad infinitum here is that given the authors’ perceived intent, I would have to point to the sensitivity of the starting date to trends and view their conclusions in context as either adding nothing new to the science (outside the exploitation and application of the RegEM methodology to these data along with their own unique cloud masking algorithm for adjusting the TIR measurements) or being rather disingenuous about the selection of a starting date. It turns out, of course, that the 1957 start coincides with a number of manned stations temperature measurement starts and thus the start date can be posed as not so arbitrary. But then I would think the authors are obligated even more to talk about the sensitivity of trends to start dates.
Re: Kenneth Fritsch (#302),
Yes . . . you are correct. I think I will use “Dr.” going forward. 🙂
.
Normal distribution: I ran this first using t-tests instead of Wilcoxon tests. The results are very similar except during periods where one time series moves suddenly relative to another. In those times, the differences do not have a normal distribution. When the series do not move suddenly relative to each other, the differences are fairly normally distributed. To avoid any potential problems, though, it made sense just to abandon the assumption of normality and use Wilcoxon. (Oh – I have an extra “0” above – it’s 60,000 paired tests, not 600,000. Haha!)
.
As far as the conclusions in the paper go, nothing here seems to debate the 1957-present trend, and I think the 1957 start date is a reasonable choice. It’s the starting point for decently reliable data that is somewhat continuous. If we had such data back to the 1930s then I might question the choice of 1957, but since we do not, I can see no reason why an analysis should not start there.
.
The dissection of the reconstructions, I think, highlights a gross conceptual error in the paper that is more important and fundamental than drawing a straight line from 1957 to present and glossing over the fact that the most recent 30+ years shows a flat trend. The error the authors make is switching the dependent and independent variables. Because of this, I think their conclusions do not add anything to the science; rather, they subtract from the science via confusion.
.
1. To make the AVHRR reconstruction, they process satellite information in a manner that has not been validated to produce physical results. This is okay – you have to start somewhere. No issue here.
.
2. They apply the processed data to the continent along with the manned station data and perform a calibration. Again, okay.
.
3. Using the combination of the two data sets, they calculate 3 PCs for analysis. So far so good.
.
4. Using the 3 PCs, they infill everything over the entire analysis period and call this the “reconstruction.”
.
In my opinion, #4 is where they went off the rails. That is where the dependent variable (the PCs) suddenly becomes the independent variable and the independent variables (actual temperature information) become dependent. In a physical sense, what they are saying is PC causes temperature. They have reversed the cause-and-effect.
.
The error does not end there, however. They are fully aware that the method of parsing the satellite data is unproven, so they generate separate reconstructions using the AWS stations to attempt to show that the results are equivalent. They generate verification statistics that indicate no significant difference between the other reconstructions and the AVHRR reconstruction. Unfortunately:
.
1. The reconstructions do not constitute a valid reality check because all of the reconstructions are generated using RegEM or PCA with unproven assumptions. In both cases, the unstated (and unproveable in the absence of actual data) assumptions are a) the spatial variance does not change with time; b) the distribution of the missing values with respect to time does not change the results; and c) the distribution of the missing values with respect to location does not change the results. However, in order to show a), you must first show b) and c). They cannot show b) and c) because that information does not exist. In other words, even if the reconstructions were consistent with each other, the only thing you have shown is that they are consistent with each other. That fact confers zero ability to show that they are consistent with reality unless a), b), and c) can be shown – and nothing the authors have done in any way indicates that a), b), and c) hold.
.
2. Not only does showing agreement between reconstructions NOT demonstrate agreement with reality, but the reconstructions do not even agree. The mismatch between the AWS and AVHRR trends post-1980 is significant – especially since the trends in the peninsula, west Antarctica, and the coastline east of the bay go in opposite directions.
.
3. The verification statistics used are not appropriate tests if subsets of the data are later going to be used for trend analysis. The RE/CE numbers they show are insensitive to how the data changes with time. I feel any test to validate the use of subsets of data must also evaluate the temporal evolution of the data. Time must be explicitly included.
.
4. The only real data present – the ground station data – is not consistent with the reconstruction. The one piece of information they have that is actual data has a statistically significant difference in trend.
.
To me, this paper is not good science at all. Its conclusions are not supported by the data provided, and the assumptions required to assume that the AVHRR reconstruction reflects actual conditions are both unstated and unproveable. The manner in which the AVHRR reconstruction is presented and discussed confuses cause-and-effect. The method of verification is not sufficient to allow the data to be subsetted for trend analysis.
.
Bender had made a comment earlier that this paper deserves a response in the literature, and I find myself agreeing with him. Whether Antarctica is actually warming is not the issue. The issue is that the method used to determine the trend is decidedly erroneous.
Re: Ryan O (#303),
Ryan, thanks for your comprehensive reply. I am in essential agreement with what you have stated and do not see where it conflicts with the sermon that I continue to preach.
Re: Kenneth Fritsch (#305), And I wholeheartedly agree with said sermon. 🙂
.
Re: MC (#304), I agree. In the effort to get to #5, the authors glazed over 2-4. #5 isn’t where the science is, really. The real science is in 2-4. That’s where the real learning would take place. But this paper seems to have short-circuited that.
Re: Ryan O (#303),
Well put. Take a look at my comment in (#283). They showed just a peak at their hand with figures C and D with respect to the satellite data. Setting aside whether or not the cloud masking was done correctly, this is supposedly the satellite data pre-RegEM/3 PC reconstruction. It looks nothing like the reconstruction for the same period. They didn’t infill, they replaced, and then used the dubious AWS stats to bolster it.
Regarding a response, go for it. Who knows, maybe you can join Steve in the select club who have had their methods called “bizarre” by the Team. It’s a badge of honor. Gavin called my post on distance weighting the input to RegEM, “not worthy of reading on the slowest of days”. He may have been right, but it still felt good.
Re: Jeff C. (#307), I had forgotten about that one! Yah, that’s a good one, too . . . I was mystified as to how the recon looked so different from that figure until you and Roman, et. al., explained that the recon had no actual data – a possibility that up to that point had never even occurred to me. 🙂
Ryan I’ll go one further. In my mind PCs are good at spotting characteristics but like you say they are the dependent variables. What I would have done is this:
1) Process AWS data and AVHRR and characterise each station in the 1982 to 2006 period (it is 2006 isn’t it?)
2) Describe the characteristics and propose a possible model/simulation with inputs from other measured parameters and physics. End paper.
3) Someone then runs the model, matches the calibration period then extrapolates into the past using the available data as reference tests
4) We see what works and what doesn’t and maybe we all learn something.
5) Then we do the trend analysis
RE Ryan O., #290,
Do you know what definition Steig uses for “East Ant.” and “West Ant.”? The paper and the SI don’t seem to say, yet you provide graphs for both. Are you just guessing, or is it indicated somewhere?
I was thinking of using something like 60W-180W down to 85S, plus 50-60W down to 75S, for W. Ant. Does this make sense?
Re: Hu McCulloch (#309),
try
WA=data.frame( lat=-c( 79, 85, 85, 85, 85, 85, 85, 60, 60, 65, 65, 65, 65, 79, 79 ),
long=c(162,162,178,-150,-120,-90,-56, -56, -56, -90,-120,-150, 178,178,162) )
Re: Hu McCulloch (#309), That would get you close, but I ended up doing a finer sort based on the shape of the curve. This does result in a geographic correlation, but it’s not as clean as simple lat/lons. It’s more like blobs, where stations within that particular blob showed a similar evolution of temperature with time. I really need to relabel the plots and provide the stations that I used so others can replicate. I will do that tomorrow. 🙂
Re: Hu McCulloch (#309),
Here’s my grouping. I did the grouping entirely by curve shape. The border between east and lower east was a little hazy – I had to switch 2 stations to clean up the regions. “Upper East / Central” corresponds to my earlier “North/Central” and “Lower East” corresponds to my earlier “South East”. The north/south descriptors aren’t very accurate. 🙂
.
The interesting thing is, after I did the grouping, there was only one outlier: D_47. It’s the yellow guy down at the bottom. I had it grouped into the “Upper East/Central” one. Its shape is identical to the south pole AWSs and very dissimilar to the AWSs around it. I contacted BAS and UofW to ask if the listed lat/lon was incorrect. BAS responded that they do not know; their info comes from UofW. I haven’t heard back from UofW yet.
.
If you bind the manned stations into columns 1-37 and the AWS ones into 38-100, you can use the following definitions:
.
Why infill if your sole purpose is to estimate a trend? What regression algorithm nowadays can’t handle missing observations? I don’t get it.
Re: bender (#313), I don’t think their sole purpose was to estimate a trend.
Re: bender (#313), Re: Ryan O (#314),
I think in the end that being able to state that 1957-2006 has a warming trend was the major and perhaps sole intent of the paper.
When I used the GISS zonal temperature series for 64S-90S it matched well with the AWS reconstruction over the entire 1957-2006 time period. I think most of the paper amounts to something on the order of saying that: look we can use these impressive methodologies PCA and RegEM to derive trends that are nearly the same as those that could be derived by simplier methods.
Their analyses do allow them to point to trends in smaller areas of the Antarctica and to rationalize those differences, but, using their methods, I think as the scale is reduced the uncertainty increases. Is not that what your analyses show, Ryan?
Re: Kenneth Fritsch (#315), My opinion is that they wanted to show that the warming is continuing and it is continent-wide. You can’t get those 2 conclusions using just the surface data available, which is why they opted to reconstruct the whole thing.
Re: Ryan O (#317),
Ryan, you are losing me here. I have used Steig’s reconstruction data (AWS and TIR) to show that one cannot show statistically significant trends different than zero when the starting time changes from 1957 to 1965 or any of the other time periods coming forward in time. I can show that same uncertainty also using the GISS surface data.
I am not sure what kind of picture one can get out of the GISS grid data for the Antarctica but it might be interesting to look. The grid resolution will not match that of the 5509 “grids” derived from the TIR data but that fine of a resolution is not needed to make the Steig conclusions.
We need to go back to the Steve M thread where he throw up the Steig reference of others doing back-of-the envelop estimates of what is happening in the Antarctica as opposed to Steig sophisticated methods into the face of Hansen and what Hanson has done with the GISS series.
I suspect that Steve M hit a nail on the head early with implications that Steig was merely putting a pretty face on what Hansen (GISS) had already done.
Steve: that wasn’t really my first observation – which was that HAnsen used the same data set as Steig, including AWS, – so Steig’s reproaches to earlier observers included Hansen and GISTEMP and that I’d like to see a better exposition of why their answers were different.
Re: Kenneth Fritsch (#318),
.
I added the bold. I am in agreement with you that these trends are not statistically significant based on the p-values. However, p-values don’t appear on the maps they give in their paper – maps that are largely red. The TIR values are higher than GISS and the AWS values because in the 1970-1985 range, most of the TIR reconstruction is below the 95% confidence interval, and by 2006 many of the individual series are above the 95% confidence level with respect to the actual data present.
.
Their abstract:
Re: Ryan O (#319),
Whoah. Does the rate of increase NOT exceed zero when you consider 95% confidence intervals? Are you telling me that the 0.1°C/10y figure is non-significant? What’s the standard error on the slope estimate (SEE)?
Re: bender (#326),
If you look from 1957-present, yes, there is statistically significant warming. But all of this takes place between 1957-1969 and everyone already knew that. From 1969-2006, no, the warming is not statistically significant. Here’s the results from the West Antarctica stations from the AWS recon and two manned surface stations (actual data). The AWS raw data is not long enough to generate trends.
.
Only 1 station (Theresa) shows a non-zero trend at a 5% significance level. Erin is close. Everybody else is far from significant, and 3 stations are negative. The only complete actual data set (McMurdo) shows a zero trend. The average of all the stations shows a zero trend.
.
I am in the process of collating the differences between what these show and what the satellite recon shows. They are very different.
Re: Ryan O (#327),
That’s news that Nature should know about. Jason (from the other thread), you listening?
Re: Ryan O (#327),
Ryan, I was planning to calculate, as an R exercise and for my own curiosity, the trends and p values over several time periods for the Antarctica peninsula, West Antarctica (separate from the peninsula) and East Antarctica. The Steig authors, besides making the 50 year warming trend claim for all of Antarctica are also implying that over some time period the peninsula warming is spreading to West Antarctica. What I see you doing is presenting trends for individual stations and then summing to get an overall picture. There are many advantages to doing it your way as it would immediately flag outliers or stations/areas with great leverage. Since, however, Steig et al. talks about general trends, I would like to see those calculated over time. If you have the overall trends and p’s for these areas I would only do mine as an exercise.
Re: Kenneth Fritsch (#331), I have not done that, and I wasn’t planning to do so. I was going to focus next on the total temperature delta for various timespans for each series in the AWS recon and the manned stations and compare that to the temperature deltas from the satellite recon. The normalized confidence interval plots are not directly convertible to temperatures, so I have to do that separately. I would be interested in what you find. 🙂
Ryan, I know what Steig authors have said/implied, but one needs to look deeper to see what they are really saying, i.e. what they would say they said/concluded under tough questioning at a later date.
Here is the link to the Steve M comparison for GISS gridded versus the Steig recon (appearing as a graph in the Steig paper) for 1979-2003 in the thread titled Steig versus Hansen.
http://www.climateaudit.org/?p=5027#comments
Re: Kenneth Fritsch (#320), One last thing . . . based on the Steig vs. Hansen figure . . . they claim that 1) they replicate that cooling for that period, but 2) that the overall trend is positive. The satellite recon clearly shows a positive trend from 1970-2006 (keeping with the idea that the warming is continuing in recent decades) – albeit the trend for the whole continent has a poor p-value.
.
I also don’t agree that what is important is what they say under later questioning. Most people won’t hear that or care. What is important is what they both claim and imply in the paper.
Accidentally hit submit.
.
Note that they start out by saying “in recent decades”. They then go on to explain what they find is different. The implication in their abstract is that the warming is continent wide – not just isolated to the peninsula – and that there is enhanced warming in West Antarctica – and this is relative to recent decades, not just from 1957.
.
That means the trends need to be broken down by region to address their claims. They achieve the enhanced warming in West Antarctica because their satellite recon is outside the confidence intervals of the actual data. I have not done so yet, but I bet if I just regress the West and Bay regions in the TIR recon, I will find statistically significant trends since 1980.
.
They also claim the continent-wide trend is positive. According to the limited surface station data, it is not. And the context for all of this (for most readers, anyway) is the first sentence: in recent decades.
.
Their Figure 2 in the text clearly implies the trend is continuing:
.
http://www.nature.com/nature/journal/v457/n7228/fig_tab/nature07669_F2.html#figure-title
.
As does the sea ice loss rate shown in Figure 4:
.
http://www.nature.com/nature/journal/v457/n7228/fig_tab/nature07669_F4.html#figure-title
.
You do not show a figure correlating sea-ice loss to temperature trends from 1979 – 2003 unless you are implying that the temperature trends are the cause.
Meanwhile … back in the Artic, NSIDC reports
“As some of our readers have already noticed, there was a significant problem with the daily sea ice data images on February 16. The problem arose from a malfunction of the satellite sensor we use for our daily sea ice products. Upon further investigation, we discovered that starting around early January, an error known as sensor drift caused a slowly growing underestimation of Arctic sea ice extent. The underestimation reached approximately 500,000 square kilometers (193,000 square miles) by mid-February. Sensor drift, although infrequent, does occasionally occur and it is one of the things that we account for during quality control measures prior to archiving the data. See below for more details.”
Ryan, I think we are in reasonably good agreement on what the authors imply and what the astute analyzer can obtain from the authors evidence and the two are the same.
I have read enough papers like Steig et al. (2009) to immediately look at what the authors present as evidence and what they conclude. I am not looking for actual inconsistencies between the two but rather how the casual reader and media types might interpret it and how the authors, under close scrutiny as scientists, and not policy advocates, would be required to answer. I look for deniability and see lots of it in this paper. I am particularly wary when I do not see the authors give confidence intervals and in this case CIs for trends. Their keeping to the mantra of warming over the last 50 years is also a red flag for me.
Meanwhile I will watch with interest as the analyses of the details of the reconstructions continue here at CA
Re: Kenneth Fritsch (#324), Cool. I think maybe we were just looking at it from different angles. I was looking at if from the perspective that there eventually should be something in the literature to show not only the errors in what is actually explicitly claimed but also to show errors in what was implied – without necessarily attributing the implication specifically to Dr. Steig.
Here’s the satellite recon. Average trend is 0.16 deg C/decade with a standard error of 0.05.
.
Yet the authors claim good correspondence between the 2 recons.
Re: Ryan O (#328),
Thank you for the stats. Should have been in Steig’s SI.
“Good correspondence”?! More like NO correspondence – at least in the low frequency domain.
Whilst it is very easy to compute linear trends in climate data I still worry about such calculations when simple plotting of the data shows that such a model is often completely inadequate as a compact description if applied over the sorts of time periods that are routinely discussed. Of course, as a start, one must work with “deseasonalised” data. If raw data are used any putative trend will be completely disguised and lost amongst the relatively huge month to month changes that happen everywhere. Thus I submit that the statistics displayed by Ryan O (#327 and #328), whilst illustrating very nicely the points he wants to make may not be based on the most appropriate model. Unless there is a technically plausible hypothesis that a linear trend underlies the observations it may not be the most fruitful way of describing the observations.
It has been my experience over the last 15 years that very abrupt steps in climate can be detected for individual stations over wide geographic ranges and on many time scales. Thus I think that our investigations might be more fruitful if this step behaviour were to be taken into account when examining hard-won observational data. How such step changes are to be detected is another matter (I have a suggestion!) but the techniques of time series analysis might be a good starting point. It is important to note that we are dealing with historical data, and that we have (presumably) no interest in forecasting until a viable model has been identified. My opinion, for what it’s worth – not much perhaps- is that forecasting climate is almost certainly doomed to failure unless we attempt to explain and reproduce some of the features that have occurred in the past. As far as I’m aware current climate models are not good at this.
Robin
Re: Robinedwards (#333), You should look at these, then. I think you will find this more to your liking:
Ryan O (#300)
Ryan O (#301)
The linear trends were to answer bender’s question. 😉
Re #334, Ryan O.
Well, yes I have looked at those, and others, and some of them are exactly what makes me worry about fitting simple linear trends over longish time periods! Without going into detail it is evident that some of those plots (most?) are of the saw-tooth variety with fairly consistent grand scale slopes, often of about zero. I don’t have to hand the data in the ASCII format that I can work with to check the details so can’t quote the precise statistics. Some do indeed look like long-term linear sequences. And so on a smaller scale do the saw teeth themselves. They are remarkably linear in many cases for periods of some years and then terminate in a step change in both senses.
This is what I find so remarkable. What underlies these linear periods, and what brings about the abrupt step?
This kind of thing happens with a great deal of “climate” data – real temperature observations, tree ring widths, lake deposits, ice core proxies and others.
Does no-one else find these abrupt changes interesting or worthy of technical pursuit?
Re: Robinedwards (#336), Those aren’t plots of temperature. They’re plots of the difference in means normalized to the 95% confidence level – in other words, they show how the satellite reconstruction differs from the ground data. The strange sharpness of the plots is due to the normalization process.
.
For example, let’s say that the satellite mean and ground mean differ by 0.5 degrees for a point in 1970, and the 95% confidence interval happens to be +/- 0.6 degrees. This would plot as a “0.833”, because 0.5 degrees does not exceed the 95% confidence interval.
.
Now let’s say the means differ by 0.4 degrees in 1980, but the confidence interval is +/- 0.2 degrees. This would plot as a “2.000” because 0.4 degrees is outside the confidence interval.
.
This is what gives those graphs their peculiar shapes.
Re: Robinedwards (#336),
We have discussed change points in time series previously here at CA. I have looked at some for global zonal temperature series with methods to statistically determine the change points. There have been papers discussed where change points were determined for the global anomalies going back into the late 1800s. I recall that 4 change points can be distinguished. The problem then becomes, to what does one attribute those change points. I would think some a priori rationale would be preferable, like, for example, with the Antarctica trends measured from the Steig data and looking at the 1957-1980 periods and the 1981-2006 period.
I plan on eventually looking at change points in the Antarctica data (by way of Steig), but my upfront guess would be that that data is too noisy to find change points. In lieu of that analysis I think looking at the trends going forward as I have attempted here at least gives a reasonable picture of the sensitivity of the trend to start dates.
The reasoning, as I have heard it, for calculating long term trends in temperature series is that a priori the observation that CO2 levels in the atmosphere have been increasing over those time periods. As a layperson I am not at all sure how change points and/or the use of change points are viewed by professional statisticians.
Here’s 2 more plots that show the differences in the trends for actual/AWS vs. satellite for 1957-2006 and 1969-2006:
.
.
The peninsula is striking.
Just for comparison, I think it would be helpful to see either another map with all of the relevant station types posted in close proximity, or perhaps a thin circle/box around each station so that we can see which stations match as well as the ones that don’t.
In the Table below, I have summarized the trends (in degrees C per decade) using the Steig TIR monthly reconstruction data for Antarctica divided into the areas East, West minus the Peninsula and the Peninsula. I calculated trends for the periods 1957-2006, 1965-2006, 1970-2006 and 1980-2006 and included the trend slope (TS), the adjusted lower and upper 95% confidence intervals (CIs), the AR1 correlation that was used in adjusting the CIs for the trend slopes using the Nychka adjustment as applied in Santer et al. (2008), p the probability that the unadjusted trend slope is different than zero by chance and the adjusted R^2 for the temperature anomalies regressed over time.
The basic R script used for the calculations is listed below.
I selected the 3 divided areas of the Antarctica for my own convenience by dividing East and West Antarctica at 0 to 180 longitude for the East and 180 to 360 for the West. The Peninsula was separated from West Antarctica using the longitude from 285 to 330 and latitude greater than -76. I believe that East and West Antarctica are separated by the mountain range running down the continent of Antarctica which does not correspond exactly with my designation, but for my purposes I do not judge that the difference is important.
The adjusted trend CIs show that the trends are not significant (include zero in the interval) for all time periods for East Antarctica and not significant for West Antarctica minus the peninsula for the periods 1970-2006 and 1980-2006. The Peninsula trends were larger than those of the East and West minus the Peninsula and significant for all four time periods. My divisions of the Antarctica allotted the 5509 TIR “grids” as follows: East = 3558, West minus Peninsula = 1730 and the Peninsula = 221. It can be seen that the East trends will dominant the overall Antarctica trend.
I am not at all sure that the Steig authors implicitly made these distinctions of areas and time periods clear in their paper. I will be doing a similar analysis next using the AWS reconstruction data.
The AR1 correlations were all statistically significant. (I also do not judge that the regression residuals from trending data necessarily need the trend data detrended). I should have done a Durbin-Watson auto correlation calculation and will do it later. These regression data from TIR showed some rather persistent and significant auto correlations into higher orders.
Below are the results of the AWS reconstruction data broken down into the areas and analyzed in the exact same manner as was done and reported in my previous post on this thread using the TIR reconstruction data.
AWS, like the TIR reconstruction analysis of trends, shows that going forward from 1957 the uncertainty of the data does not allow determining either cooling or warming trends in East and West Antarctica areas. The nominal trends for East and West Antarctica show more cooling for the AWS versus the TIR reconstruction. The Antarctica Peninsula shows warming that is statistically significant in all time periods. The warming trends are nominally higher in the AWS versus the TIR reconstructions – opposite to the AWS versus TIR relationship shown for East and West Antarctica comparisons.
A major difference between the AWS and TIR area relationships are that the TIR reconstruction might allow the implication of the Steig authors that the West Antarctica temperature trends have increased since 1980 in step with increases in the Peninsula. Using the AWS breakdown of those areas would indicate something of the opposite, i.e. that West Antarctica has nominally cooled since 1980 while the Peninsula has continued on nearly the same warming trend value over all the periods 1957-2006, 1965-2006,1970-2006 and 1980-2006.
The breakdown of AWS station assignments by way of my area designations was as follows: East Antarctica = 42; West Antarctica minus the Peninsula = 14 and the Peninsula = 7. My crude calculation to approximate percent of these 3 areas (per my designation) to the total of Antarctica is: East = 64%, West minus the Peninsula= 30% and the Peninsula = 6%. The percent breakdown for the AWS stations is: East = 67%, West minus the Peninsula= 22% and the Peninsula = 11%. The breakdown for grid areas for the TIR reconstruction is: East = 65%, West minus the Peninsula= 31% and the Peninsula = 4%.
The story emerging here is that are some critical technical issues regarding AWS vs TIR that Steig et al. failed to address. Their publication was clearly premature.
Re: bender (#343),
Nope, sorry bender, you have exposed your complete lack of understanding of The Scientific Process. This is Science in Action. Right before our very eyes. This is How Science Works.
Certified Climate Scientists Peer-Review Publish, in the Select and Exclusive Certified Climatological Journals having The Highest Impact Factors, their zeroth-order EWAGs, failing to check even the simple arithmetic.
Mere mortals then correct the mistakes.
Science at work, it’s a beautiful thing.
Re: Dan Hughes (#344),
Although this has come to be the way that climate science is conducted, it is NOT the way science works best. The ideal situation is when you have opposing views competing by trying to determine the objective truth. Instead what you have are competing views trying to establish a position. That may be how law has come to operate, but it is not how science should work. Science done that way is very, very expensive.
Re: bender (#343),
In my mind the paper is not so much premature as it is incomplete. That is a general complaint I would lodge against a number of climate related papers that have been analyzed here at CA, i.e. it is not what they say, it is what they do not say.
Re 337 (Ryan O). Thanks for setting me straight on the plots 301, 302. Reading the label script at 90 degrees from my rather still neck direction was causing me some trouble :-)) .
Having been away briefly I returned to an unreachable CA, for reasons now explained. Severe withdrawal symptoms now abating, thank goodness.
I am still fascinated by the strange shapes of your difference curves, in particular those of the saw tooth variety. Is there a convincing explanation for their occurrence? Can’t help feeling that something interesting has been going on but I can not propose anything. Perhaps some very careful assessment of the two elements of the subtraction sums is called for. Not being an R user I’ll have to do this in a rather simple way, but /will/ have a go, but it will take time.
Robin
Re 347, for “still” please read “stiff” !
Robin
3 Trackbacks
[…] Deconstructing the Steig AWS Reconstruction […]
[…] I was mystified, other, more intelligent folk (Roman M, Jeff C, and Jeff Id) over at CA and the Air Vent had already figured out what had been done. Here’s the CliffsNotes […]
[…] Email from co-author Eric Steig to Steve McIntyre on January 23 (source): “I have always intended to provide all the material on line; I wasn’t allowed to do […]