Myles Allen, a declared supporter of open data archives, has, in blog comments here, proposed “name and shame” as a first tactic against data obstructionists (as opposed to FOI).
Journal editors can and should enforce a simple “disclose or retract” policy if a result is challenged, and almost all of them do: if any don’t, then the solution is to name and shame them, not set up a parallel enforcement system.
I partly agree with this; I’ve used FOI primarily as a last resort. And in the case of climate scientists and journals that withhold data unashamedly, I believe that it remains a valuable tool of last resort. Obviously I’ve not been shy about naming data obstructionists at Climate Audit, though this longstanding effort has typically encountered resentment rather than encouragement from the community. Perhaps Allen will add his voice in more direct communications with editors rather than just at blog comments. Regardless, it’s nice to get even some moral support, since, for the most part, the community has united in solidarity behind data obstructionists.
By coincidence, Myles’ comments come in the midst of another data non-archiving incident that I haven’t reported on.
Real Climate recently praised a new multiproxy study (Gergis et al 2012). Gergis et al is the fourth or so multiproxy article co-authored primarily by Raphael Neukom and Joelle Gergis. Several articles in this corpus are cited prominently in AR5.
 One of the coauthors, Ailie Gallant, was a featured performer in the recent We Are Climate Scientists anthem, with her cameos occurring during the memorable declaration:
One of the coauthors, Ailie Gallant, was a featured performer in the recent We Are Climate Scientists anthem, with her cameos occurring during the memorable declaration:
We’re climate scientists. What we speak is true. Unlike Andrew Bolt, our work is peer reviewed. Haaaa…
None of the data for the earlier articles was archived. Or, more accurately, it was archived in a secret Swiss databank only accessible to the illuminati. CA readers will recall that I requested data for an earlier article from co-author Neukom and was blown off ( see CA post here.)
Gergis et al 2012 and the “Screening Fallacy”
CA readers will recall the long-standing blog criticism of the “Screening Fallacy”, not just here, but at other technical blogs as well. Not understanding the problem is almost the litmus test of being a professional climate scientist.
The error is committed once again by Gergis et al. They described the selection of 27 proxies from a network of 62 as follows:
Our temperature proxy network was drawn from a broader Australasian domain (90E–140W, 10N–80S) containing 62 monthly–annually resolved climate proxies from approximately 50 sites (see details provided in Neukom and Gergis, 2011)…
Only records that were significantly (p<0.05) correlated with the detrended instrumental target over the 1921–1990 period were selected for analysis. This process identified 27 temperature-sensitive predictors for the SONDJF warm season (Figure 1 and Table 1) 228 henceforth referred to as R27.
On the surface, screening a network of proxies for correlation to temperature seems to “make sense”. But the problem is this: if you carry out a similar procedure on autocorrelated red noise, you get hockey sticks. If you think that a class of proxy is a valid temperature proxy, then you have to define the class ahead of time and take it all. No after the fact “screening”. [Note – June 1] Gergis et al 2012 say that their screening is done on de-trended series. This measure might mitigate the screening fallacy – but this is something that would need to be checked carefully. I haven’t yet checked on the other papers in this series. (Update 2: Despite the above statement in their article, Gergis et al did not screen on detrended data after all. The article is presently removed from the Journal of Climate website and “on hold” – see other posts in this sequence)
I discussed the screening fallacy (not by that name) in early CA posts e.g. here, as a criticism of Jacoby’s selection of the 10 “most temperature sensitive” sites from a network of 36. (Jacoby compounded the problem by refusing to provide data from the “other 26 sites” when requested, a refusal supported by the journal (Climatic Change) and the U.S. National Science Foundation.
David Stockwell wrote about the fallacy in 2006 – blog post here, article in AIG News here. Ross and I wryly cited Stockwell, 2006 (AIG News) in our PNAS Comment on Mann et al 2008; Mann et al fulminated against the temerity of citing AIG News but did not refute the point.
Mann et al 2008, better known for the Upside-Down Tiljander problem that also baffles climate scientists, also committed the screening fallacy. (Mann et al 2008, like his earlier article, is a laboratory of statistical horrors.) Jeff Id, then a new blogger, wrote two excellent blog posts in Sept 2008 here here commenting on this error in Mann et al 2008. Lubos Motl’s follow-up article here is a further demonstration of the phenomenon.
Lucia re-visited the problem in October 2009 (on the eve of Climategate), pondering why it so befuddled climate scientists. See her clear exposition, aptly entitled Tricking Yourself into Cherry Picking.
Archiving
Unlike their earlier articles, Gergis et al at least archived the 27 “temperature-sensitive predictors”. But like Jacoby, they did not archive the 35 “climate proxies” that they didn’t use. I asked them for these other proxies. While I was at it, I also asked them for digital versions of the proxy networks used in Neukom and Gergis 2011 (Holocene), Neukom et al 2011 (Clim Dyn) and Neukom et al (2010).
None of my requests have thus far been acknowledged by the authors.
I also sent these requests to editors of the four journals, urging them to require the authors to archive their data, and, if the authors were unwilling or unable to do so, require the retraction of the article – a remedy that Myles Allen seems willing to support.
I also wrote to Valerie Masson-Delmotte, CLA of the paleoclimate chapter of AR5, notifying her of the data archiving issue for articles cited in AR5. (I met her at AGU one year and talked to her for a while and got a good impression of her.)
John Matthews of Swansea Univesity, editor of The Holocene, responded promptly saying that The Holocene does not require authors to archive data, that the article satisfied the referees and that was that.
The Holocene does not have a policy of requiring its authors to archive their data sets. We offer the facility of publishing Supplementary Material on-line. It is up to the authors whether or not they archive their data sets. Authors are expected to describe their data sources and methods adequately, which in this Research Review was done in detail and to the satisfaction of our referees. There is, in my view, no case for retraction.
I forwarded Matthews’ refusal to Masson-Delmotte, urging that IPCC accordingly de-certify The Holocene as an eligible citation in AR5.
As Dr Matthews says in his letter, the journal Holocene does not have an adequate or indeed any policy of requiring authors to archive data. Unless it establishes such a policy, I suggest that IPCC not permit the citation of articles from Holocene in the forthcoming assessment report.
Perhaps Myles Allen can encourage Matthews of the merits of adopting a data policy.
I next heard from Anthony Broccoli, editor of Journal of Climate. (Broccoli had acted as editor of O’Donnell et al 2010 and had required us to make major revisions and resubmissions to accommodate Eric Steig, aka the anonymous Reviewer A.) Broccoli unresponsively told us to contact the authors – even though the reason for contacting Broccoli had been the past uncooperativeness of the authors and the authors had not responded to the present email:
Thank you for your inquiry. Please communicate directly with the authors regarding access to their data.
Lest a ball remain in my court, I emailed Neukom and Gergis one more time, including an extra pretty please this time (literally):
Gergis et al 2012 states:
Our temperature proxy network was drawn from a broader Australasian domain (90E–140 W, 10N–80S) containing 62 monthly–annually resolved climate proxies from approximately 50 sites (see details provided in Neukom and Gergis, 2011).
You’ve archived the 27 series that you screened from the 62, but have not archived the original population of 62 series that entered into the analysis. Could you please provide me with a copy of this data.
Pretty please with sugar on it,
Despite using these magic words, I haven’t heard back from the authors.
I did hear back from Valerie Masson-Delmotte, whose response was somewhat positive about ensuring that the Second Draft would be constructed around publicly available data:
I thank you for your concern about the IPCC AR5 assessment, and the references cited in the first order draft. The IPCC First Order Draft review process would have been a standardized way to send your comments and suggestions to all Chapter 5 authors. It is our duty to make this assessment as transparent as possible, following IPCC guidelines and IAC recommendations. We are aware that not all funding agencies or publishers follow a consistent strategy with regard to the public release of data associated with published articles. Regarding your specific concerns, we are confident that the next draft of our chapter will be based on new publications associated with publicly available datasets.
This is encouraging.
Update: June 1 12>30 am:
Joelle Gergis has responded blowing off my request (cc to David Karoly, Valeria Masson-Delmotte (AR5 CLA) and the editor of Journal of Climate). She says that I should try to get the unarchived data from the original authors, saying snottily that this is “commonly called ‘research'” and that they “will not be entertaining further correspondence” on the matter.
Mr McIntyre
We have already archived all the records needed to replicate the analysis presented in our Journal of Climate paper with NOAA’s World Data Center for Palaeoclimatology:
http://www.ncdc.noaa.gov/paleo/recons.html
While the vast majority of the records contained in the full Australasian network are already lodged with NOAA, some records are not yet publically available. Some groups are still publishing their work, others have only released their data for use in a particular study and so on.
The compilation of this database represents years of our research effort based on the development of our professional networks. We risk damaging our work relationships by releasing other people’s records against their wishes. Clearly this is something that we are not prepared to do.
We have, however, provided an extensive contact list of all data contributors in the supplementary section of our recent study ‘Southern Hemisphere high-resolution palaeoclimate records of the last 2000 years’ published in The Holocene (Table S3):
http://hol.sagepub.com/content/early/2011/12/16/0959683611427335
This list allows any researcher who wants to access non publically available records to follow the appropriate protocol of contacting the original authors to obtain the necessary permission to use the record, take the time needed to process the data into a format suitable for data analysis etc, just as we have done. This is commonly referred to as ‘research’.
We will not be entertaining any further correspondence on the matter.
Regards
Joelle
—
Dr Joelle Gergis
Climate Research Fellow
UPDATE: For the record, I have had totally the opposite experience with Fredrik Ljungqvist. I’ve contacted him in the past and re-contacted him today. He has been promptly helpful and consistently cordial.





341 Comments
You have a positive reply from her. Now will she get out-voted by the “consensus?
A good initiative.
Myles Allen shames his own name at the Bish’s.
===============
By picking just proxies you like
That aligns with the putative spike
In the temps as they sit
Well, your network will fit
And you get this effect the first strike!
But if temperature records adjust
To correct them — and I think they must
Then by pre-screening quirk
A quite different network
Gets selected; the old one’s a bust.
Thank you sir, for the work that you do!
The statistical tinkering crew
Can confuse folks, but here
You do much to make clear:
The Team should be team-mates with you!
===|==============/ Keith DeHavelle
“By picking just proxies you like”
That is just the second selection. The first is deciding which data equal “climate proxies.” So it appears there is a double culling. The process of the first culling are not specified, to my sight.
I cannot think of another reason why “climate” and “temperature” are differentially deployed in one paragraph, except to indicate difference.
The ‘screening problem’ you mention is epidemic. The problem appears to occur *whereever* there is an ‘almost known’, or ‘expected’ set of findings on one side and an array of noisy datasets on the other.
Fishing for patterns in noise in fMRI neuroimaging studies (http://www.nature.com/news/2009/090427/full/4581087a.html):
Re: the music video you linked.
Actually not a bad Rap. Catchy, good rhythm / intonation / enunciation for the genre, and reasonably clever / literate lyrics (sorry, but the very best Rap has literate lyrics, where literate has nothing to do with the classics).
The video is funny for a couple of reasons.
1) Argument from authority in it’s purest form: “We’re climate scientists. What we speak is true.”
2) The climate scientists in it are lip syncing to the somewhat talented actual performer. Is this “The trick to hide that climate scientists can’t Rap”? Even though one of the posts for this video claims they can (can’t find the link again, but it had horrible orange links on a black background)?
Steve: I discussed the video here https://climateaudit.org/2011/05/12/mo-money-mo-problems/, linkinh inter alia to Jones (Kim) et al 1996. http://www.youtube.com/watch?v=YpRfpk311NU
Who took the c out of rap? Beats me but I sure know now who put Big C back into rap.
Steve got me, as expected.
My premise was pre-dissected.
He sees things, way before me
That you, and I, just don’t see
Rappers do art, just like you
Graphs, and charts, and doo doo doo
Steve had asked, don’t just OINK
Just be cool, post on point
— Point taken. We’re out 🙂
Yeah, not exactly nullius in verba is it?
Couldn’t find the first one I saw claiming Climate Scientists can Rap, but here is a different one:
http://globalwarmingisreal.com/tag/dan-ilic/
Joelle Gergis writes:
I wonder if Myles will sit idly by or whether he will write to the journal or the university to “name and shame”.
Sigh, seems there is no end to this nightmare. I wonder if in 2020 we will still be getting these responses, with the only difference of them slightly increasing in their snarkiness’o’meter.
Climatologists like Gergis and Neukom fall under the rubric of what Feynman called “advertising” rather than science. Unless one is “leaning over backwards” (Feynman) to ensure maximum rigor and unbiased scrutiny of data and methods, it is always too easy to lapse toward “cargo cult science”. This is what too many climatologists risk doing, whether or not their results are ultimately sound. They are not displaying the integrity as Feynman defined it of always striving to subject their work to the most scrupulous possible checks and review (brief excerpt, full talk at link):
“But there is one
feature I notice that is generally missing in cargo cult science…. It’s a kind of scientific integrity, a principle of scientific thought that corresponds to a kind of utter honesty–a kind of leaning over backwards….
“In summary, the idea is to try to give all of the information to
help others to judge the value of your contribution; not just the
information that leads to judgment in one particular direction or
another.”
[Richard Feynman, 1974 CalTech Commencement Address, “Cargo Cult Science”]
Dr Gergis,
You write “We will not be entertaining any further correspondence on the matter”. As you reject the so-called ‘screening fallacy’ may I infer that likewise you will not be entertaining any further?
Regards,
I’ll bet a cooperative reply would have taken less time and fewer bytes on the internet.
Speaking as someone who does technical auditing, and also receives audits of my technical work, I can understand the fear of sunlight. Ultimately though, you have to show your work or you just end up looking the fool.
I just note in passing that the Aus2K Project were involved in this work (http://www.pages-igbp.org/workinggroups/aus2k). This is part of PAGES “a core project of the International Geosphere-Biosphere Programme (IGBP) and is funded by the U.S. and Swiss National Science Foundations, and the National Oceanic and Atmospheric Administration (NOAA). It is overseen by a Scientific Steering Committee (SSC) comprised of members chosen to be representative of the major techniques, disciplines and geographic regions that contribute to paleoscience” (http://www.pages-igbp.org/about/general-overview). The SSC membership is http://www.pages-igbp.org/people/scientific-steering-committee-ssc and “[t]he authority for all PAGES policy and activities resides with the PAGES SSC”.
Perhaps give Prof. Alan C. Mix, Oregon State University, or Prof. Hubertus Fischer, Bern, the SSC co-chairs a yell.
Neukon and Gergis are at U of Melbourne. Maybe someone in Australia can submit an FOI for the 35 data sets considered in the screening process but not archived: http://www.unimelb.edu.au/unisec/foi.html.
David Karoly, a prominent IPCC-er, is a coauthor.
Hmmm… why is it I get the feeling these climate scientists are much like a past Queensland Premier and peanut farmer(truly), who while presiding for years via a clear gerrymander, when asked any probing or impertinent questions would reply- ‘Don’t you worry about that!’and carry right on.
He used to refer to press conferences and doorstop interviews as ‘Feeding the chooks!’.
Steve,
As an alumnus of Melbourne Uni, I intend to put in an FOI request.
Research is not truly replicable if the proxies aren’t appropriately archived for all comers.
Regards
Michael, I’m in Melbourne too but a U of Q grad. Pleased to help. sherro1 at optusnet dot com dot au
The coral records that weren’t used appear to be at NCDC. It’s the tree ring data that isn’t archived – chronologies considered but screened out; and measurement data for chronologies that are available.
You call it Screening Fallacy, I call it “Then A Miracle Occurs”
http://omnologos.com/agw-missing-step-two/
Or as they would say on Blue Peter, “Here’s one I prepared earlier”
I would say to Dr Joelle, she is perfectly free to refuse to show her workings, but until she does, I am perfectly free to disregard anything she might have to say to me as a tax payer based on them.
Steve is diligently doing something that is clearly already missing from the IPCC process and holding it to the highest standards that would improve its standing.
Why do these authors think that forcing people to “research” and pick up the traces of each of their own steps, which they should have properly to hand and documented, adds to their own credibility?
I suspect that they don’t see this as obstruction but some sort of battle hardened response to a well known “enemy”. Concealing any ability to retrace their silent steps e.g. everything that fell by the wayside and was not used and that led to to the selected conclusions, seems to be a normal pathological practice in paleoclimate further justified by the “war” status.
This I think illustrates the general problem – it’s not what climatologists are telling us about, but what they are not telling us about.
Myles Allen focussing on the temperature record fits this pattern.
How about a new Ballad of the Climatologists:
Now you beign unfair the data exist, only they lost it in house move and you now how messy those can be!
But, but – the proxies which were not used in the study are not part of the “data”, you see, and therefore does not have to be archived.
Someone should tell Joelle Gergis that others being able to reproduce your work is called ‘science’. They sound like a true follower of ‘Mann’ complete with the need for a massive ego and a belief that for special people like them the standard scientific approach of ‘critical review ‘ is not needed .
Re: KNR (Jun 1 03:30),
I am irresistibly reminded of a possibly clever, but definitely over-indulged, four-year old who has taken too much fizzy pop and been allowed to stay up well past her bedtime.
Is this the same Myles Allen who penned this polemic at “Bishop Hill”?
I do think it is sad for democracy that so much energy in the debate on climate change has been expended on pseudo-debates about the science, leaving no room for public debate about the policy response. In the run-up to Copenhagen, public discussion of effective alternatives to a global cap-and-trade regime (which I would personally view with as much scepticism as most of the readers of this blog) was remarkably absent. It still is, and it always will be as long as the public are kept distracted by a debate over the Medieval Warm Period, which has only ever featured in one of the lines of evidence for human influence on climate (and not, in my view, a particularly strong one). The data we primarily rely upon is the instrumental temperature record, which, as I explained in the talk, emerged from the CRU e-mail affair pretty much unscathed (and I stand by the assertion that one would not have got this impression from media coverage of the issue).
snip – editorializing on policy
Tony Mach, fyi, those are not Don’s words, that is a quotation from Myles Allen writing at Bishop Hill, but Don omitted the quotation marks. Full quotation can be found here:
Myles Allen quotation at Bishop Hill
@Don Keiller
One more thing: Can I take it from your words that you do understand and acknowledge that the “Screening Fallacy” is a big problem that might invalidate many climate reconstructions? And do you imply that climate reconstructions are overrated when it comes to making policy decisions?
Tony, you have obviously got hold of the wrong end of the stick here.
What I’m saying is that Myles Allen seems to be trying to have it both ways
1) He wants relevant information released
2) Yet he also defends CRU/Phil Jones when they don’t release data.
FYI I am of the camp that;
1) Believes temperatures have risen
2) is not at all convinced that CO2 has more than a marginal effect
3) and is appalled by the post-hoc cherry-picking and circular arguments of much of climate “science”
FYFI I was the one (along with Professor Jonathan Jones of Oxford) who used FOI to force CRU to release the CRUTEM dataset.
I Also took CRU and the ICO and their lawyers on in Court and won to get covering emails released.
I’m sorry, I misunderstood what you said and got the wrong impression – my bad.
No problem, Tony.
Missed out the quotations.
My bad.
I understand how Gergis could be irritated if someone wants to suddenly grab the data and methods which have been years in the making. There is also an argument that their study used data collected by others and that they are not the custodians of these data and therefore don’t have the right to give it away. It is, however, a poor argument. There are only limited circumstances in which data can be considered to be the property of the scientists. One such example is my own field, collider physics. Large collaborations spend up to 20 years building an experiment and then sign up to spending a lot of their time maintaining the experiment and showing that the data can be understood. If data and analysis methods were to be given away the moment they become available there would be no incentive for anyone to do the hard work in the first place and these long-term experiments would likely not take place. Furthermore, the sheer volume of data makes public availability a problem (we’re designing the WWW successor to deal with the problem of distributed analysis). To prevent bias we have independent experiments trying to prove each other wrong. An ultimate aim is to make the data public but only at the end of the experiment, which I think is a fair approach. Furthermore, and critically, our work does not directly inform public policy. Also, we have a track record of getting things right and winning Nobel prizes. Even when we get things wrong, something which is unavoidable in research, eg superluminal neutrinos, we’re careful to emphasise the caveats and the possibility of a mistake being made. We also took care to correct the record when the key mistake was found in the neutrino work.
Gergis’ made quite a splash with their work. It will be used by politicians to justify making sets of laws. It will be waved around as the Mann hockey stick was (it even turned up in my wife’s driving instructor class!). It is wholly unacceptable that it is not open for complete reproduction and study by anyone with sufficient interest and time to do this.
I started off having some sympathy for Mann’s position when dealing with Steve. However, my stance was based on the assumption that peer review was working in climatology as it does in my field and that different groups were actively competing to pick faults in each other’s work (which is how it should be – if work survives competent attempts to kill it, it is probably good).
Nowadays, I look with despair at the ineptitude of the climate community in the way they deal with critics. They have a bunker and tribal mentality which represents the very antithesis of how a research environment should operate. One shouldn’t have to fight for openness in science – it should be a given. Its a tragedy that we’re in this situation. I assume that the more perceptive among the climatologists now realise that their community’s behaviour is as much responsible as the critics for promoting the case to be sceptical. One can only hope that as old guard retires the younger folk will take the appropriate steps to fix the problem.
“An ultimate aim is to make the data public but only at the end of the experiment, which I think is a fair approach”
… and then publish? Or do you do as UEA does, and continue to publish little bits of it for years and years and say “the rest is secret because we’re still working on it”?
Sorry, to me there is no excuse possible. To get published, it should be an absolute requirement that ALL the data is archived and available BEFORE SUBMISSION!. And that of course includes excluded data which is PART of the input.
There would be no need for FOI and all these requests/rejections is they simply behaved like scientists should.
Steveta
I explained the rationale behind our data policy. If an experiment takes twenty years to build and those who build it then have to spend a substantial fraction of their time maintaining and making sure that the data (when they finally arrive) are understandable then why shouldn’t they have exclusive access to it during the lifetime of the experiment ? Experiments aren’t contracted out by physicists, we do the lot from start to finish, and this has proven to be a highly successful model of working. Issues of bias are dealt with by having competing experiments (genuine competition, that is). If data were made available as soon as they were ready then groups would simply not bother to do all of the hard work in building and maintaining the things. I can’t see how your demand that all data should be immediately free would benefit scientific research in this case since there wouldn’t be any data to go around. Babies and bathwater spring to mind.
Roger,
If experiments take 20 years, and releasing data before the experiment is over can’t be done, then policy decisions too should not be made until the experiment is done.
Seems simple to me – scientists on the public purse who hold onto “their” data should be summarily sacked.
Roger here outlines a ‘free rider’ problem with data. The idea seems to be that if those who do the hard work getting it are made to share it, lots of people will just wait for someone else to get it.
So what ? It’s all paid for by the public isn’t it? And this didn’t seem to trouble BEST did it?
Sony
There are no public policy decisions informed by the results of particle physics experiments (at least not for 20-30 year periods).
Batedbreath
I’ve outlined clearly the data availability policy at a large experiment and the rationale behind it. Do you have a specific issue with the reasoning ? If so, perhaps you can let me know what this is instead of calling for me to be sacked.
Eroica
Who would invest the ca 20 years in building the experiment and then large amounts afterwards in understanding the experiment if they could instead just wait and get the data for free ?
You mentioned BEST. However, the volume and complexity of data at a collider experiment are many orders of magnitude greater than for BEST. That’s why several thousand people need to be persuaded to collaborate on the building and operation of an experiment. How would you persuade them to do this if they though they could, instead, wait for the data to arrive ?
Roger, your argument sounds perilously close to the well known quote
“We have 25 or so years invested in the work. Why should I make the data available to you, when your aim is to try and find something wrong with it.”
Of course, those who do the research get to write the paper first. But after publication (we can quibble about exactly when) it makes sense that it should be available – which is pretty much what you said originally.
If physics experiments need 30 years, then we expect to wait 30 years before making huge policy decisions bases on it. Quite right. (Did this apply to the Manhattan project I wonder?). Not so climatology – its models are nowhere near reliable or useful, yet the whole world is asked to accept a huge hike in energy costs on the back of them.
How do you persuade scientists to produce data if they’ll be made to share it? Pay them, with public money.
Roger >> There are no public policy decisions informed by the results of particle physics experiments (at least not for 20-30 year periods).
—–
Is this the myopia typical of academics? Pray tell us if down your way particle accelerators grow on trees?
Roger:
I can excuse you wanting to wait until the initial data are published before releasing code and data. That’s a common maximum period for delaying release of data and code. Not minimum.
I cannot in any fashion condone the withholding the data associated with your publication because you might reuse it in a future publication. (Spare me the parsing of words to make what you are doing sound like something different than what you are doing.)
The excuse (and it is just that) that you will in the future augment this data set with further data collection has more holes in it than ___________ <- insert favorite expression.
The fact is you damage the scientific process with this practice in so many ways, that it is difficult to enumerate them all.
clt510
You’ve chosen to condemn.I imagine you also consider yourself to be a sceptic. Please therefore motivate your condemnation by ologically refuting the specific points I’ve made (repeatedly here) concerning data availability.
Isn’t the simple point that there is a difference between owning a dataset (i.e. copyright is yours) and allowing others to use under specific circumstances. Oxford dictionaries run quite a successful business using this model.
Even if you don’t feel easy about allowing others to see it, but you want your results to be taken seriously, there are quite straightforward techniques for organising independent audits under very tightly controlled circumstances so that you can present your results with credibility.
If results are to be used for public policy it would not be unusual for the government to have the results independently reviewed under appropriate confidentiality arrangements.
HAS
In our field we expect our results to be taken seriously by having a wholly independent reproduction with a different dataset taken under identical conditions by a different experiment using a different detector. Rather ironically, if particle physics were to be “slimmed down” to a system of producers+users and users then this reproduction-by-independent-experiment approach may not be possible in the future… Pity, since its far more likely to catch a mistake than if people would do their checks using one dataset handled in one specific way.
Roger,
you’ve talked a lot about your field. The results in your field are not being used in IPCC or used to develop public policy. I prefer to think about data availability in a “common law” approach rather than a “Napoleonic code”. On the cases in hand, the data should be archived. I am not opining on some other case.
In the end it is guaranteeing the system’s integrity that counts. People will judge the quality of the outputs based on their assessment of that overall system.
What you describe in particle physics is one approach to the problem, but I think you simplified a little in your original comment. My point is that demonstrating system’s integrity doesn’t necessary entail that the data be “given away the moment they become available”.
HAS
We must have read two different discussions then. I have consistently explained and defended on this page, and in quite some detail, the rationale for the data policies used in particle physics experiments. The opposition to this has largely been of the “the data are public, end of story”-type. I’m baffled that my arguments are the ones deemed to be oversimplified.
Sure, one or two phrases could have been more precisely worded and a few more caveats added but those wouldn’t change anything of substance.
Roger I’m not a “skeptic”, other than in the classic physicist sense (not the misused way it gets applied in climate science).
We regularly generate large data sets and make them available to the community before publishing. In fact we’re in the middle of putting together the archive of the data we’ve collected over a three week period, using instruments that we spent 10 years developing (as I mentioned below I was team-lead on the instrument development).
I see no benefit to withholding data or methods, because it reduces the amount of outside scrutiny of your work and leads to mistakes like superluminal neutrinos.
The possibility of a “scoop” is an issue, but practically with large datasets it doesn’t happen. I can’t imagine anybody delving into a large detectors dataset without the help of the people in the group. One of the conditions we have when people use our data is joint authorship of any publications (I never said you had to surrender the intellectual rights to your work). It’s like free publications for your curriculum vita when it happens (which as I said is very rarely).
I’d be a lot more worried about it if I had a data set of 100 respondents to a questionnaire. Of course I would with-hold the results of the survey until I had published in that case, but then I would make the instrument (the questionnaire) as well as the data available. Since I’d be using standardized techniques, I’d provide e.g. a matlab script to replicate the results as published. Even if I were to expand the data set with more survey results later, I believe ability of others to replicate my results (which protects my a$$ as well as their’s) supersedes any intellectual claim I might have from “we’re still adding to our data set”.
I have a similar experience to what you were describing. We were doing a survey type analysis (collecting events if you want). When we had enough to publish, we published, but we kept adding new events to the data set after publishing. The original data set is online. The extended version (which hasn’t been published yet) still is proprietary.
If I understand your reasoning, you claim it’s OK to withhold the published data because you’re augmenting it, so the “full” data set still isn’t complete.
My reasoning is responsible conduct in research demands that you release all of the data you reported on in your initial manuscript (including data you rejected because it failed some threshold test). You don’t have to include any new data you’ve collected since publication, but I think it doesn’t meet the bar of ethical conduct to withhold data that are published.
You might be aware that there is a growing movement to require people who receive federal funding in the US to become certified via a course on responsible conduct.
So in a sense what you are saying is becoming no longer true—there are standards that are being established. NOAA already has them, NSF and NIH are in the works to establish newer, tighter regulations on their data. Yes there is Bayh-Dole, but ownership hierarchy is the funding institution, then the university/research institute. If the university feels there is commercial intellectual value associated with the data, they can request that the ownership of the data be handed over to them for commercial exploitation, but the funding agency can always say “no” (I’ve seen that happen).
My sensors are an example of the successful use of Bayh-Dole… certain technical aspects of my sensor design are considered intellectual property of the university and we have a license agreement in place with a manufacturer to sell them. But that had to go to all of the funding agencies over the 10-years they were developed before the rights were transferred to and now held exclusively by the university.
Steve
I’ve talked a lot about my field because I don’t like dogma, and most of the posts arguing against a part of my first post were dogmatic. Its not a bad thing to be aware that different fields can do things in different ways, the reasons why that is the case, and how one can ensure reproducibility.
Understood. I think that you’ve made your point about your field. Again, I’m not extrapolating from climate to your field, but equally I think that the specific circumstances of climate require archiving of paleolclimate data cited by IPCC.
There is another factor to consider , it the situation is as urgent and if the science is a ‘settled as claimed far from hiding data for the good of humanity you would expect them, to be ramming this data down peoples throats as there is no time to lose . And yet time and gain its ducking and diving which is seen and largely because the ‘settled’ and ‘urgent’ claims turn out to be BS .
Climate scientists act more like bad children how can never admit to their lies even when their caught red handed, their first instinct is to keep on lying . The sold public trust down the river for the price of gravy train research funded and political influence. They have no one to blame for that but themselves.
“Roger
I understand how Gergis could be irritated if someone wants to suddenly grab the data and methods which have been years in the making”
Really? When we write methods papers we are delighted when people use our method and then cite our work.
If one produces a crystal structure of a protein one sticks it in the database (along with the original electron density so that anyone can derive their own structure). Many people then upload the structure and use it to determine what will happen in vitro, for instance when one uses site directed mutanogenesis.
As soon as data is published it is public.
End of story.
If you don’t believe me ask the Patent Office; if you publish before gain a IP disclosure or filed for Patent Protection, then you can’t file later. We were burned 18 months ago when a Journal placed our manuscript on line (in the ASAP page) on a Thursday, instead of the following Monday.
This constituted a public disclosure.
So the rule is, and should be, print = public. Warts and all.
Why are you surprised that somebody would be irritated by such a request ? Its quite often the case that one plans a series of papers based on a lot of preparatory work. Its only human to want a clear field for a short period of time when you do this especially if the later papers in the planned series would compete against papers which could only have happened because of the first paper and all the preparatory work you put in it.
Also, why are you lecturing me about these data not being made public ? Did you bother to read my whole post or just the first few lines ?
Re: Roger (Jun 1 07:30),
They get irritated?
Poor dears. How tiresome it must be for them to be fed and watered and cosseted in a nice university building at public expense and then for the public to have the effrontery to want to see what they’ve been doing for two or three or five years. What uppittiness…what temerity!
How dare the public be so unpleasant? Surely only climate scientists are subjected to such humiliation? Nobody anywhere else is expected to justify their existence or explain their decisions in such a cavalier way.
The public must understand that their role is to pay the bills and shut up. Ours is to do whatever we do behind tightly closed doors. When we have something to tell you we will give you just as much as you need to read and obey. But until we’re good and ready, we absolutely refuse to answer any questions or accept any other interventions.
Latimer
Why are you so upset that someone could be irritated ? I expect a lot more from climate scientists than they currently give but I’m not sure I can expect them to stop having human emotions. The terseness of a mail is neither here nor there.
Re: Roger (Jun 1 07:30),
@Roger
As should be pretty obvious by now, I am not an academic. I have many friends who stayed in that field, but I went off to do other things thirty odd years ago….industry and commerce and consultancy and stuff.
And when I now look at the academic world, my conclusion (influenced by my experiences elsewhere) is that academics in general, and climatologists in particular, frequently behave like a bunch of spoilt kids. Both collectively and individually.
I have very little sympathy for their silly conventions and customs, which mostly seem designed to provide maximum ego-boost to the individual at minimum benefit to the public as a whole. And Ms Gergis’s reply to Mr McIntyre seems to emphasises all that is wrong in the system as is.
It also raises the wider question of who represents the public interest in all these debates about Freedom of Information? The individual academics clearly do not….they only give up their data when legal penalties are suggested…and then through gritted teeth. The academic institutions – composed of academics – do not ..witness UEA’s complete stonewalling over many years. And I guess the funding councils, themselves also composed largely of academics or ex-academics or those with close past or possibly future ties to academe aren’t going to rock the boat too much.
So effectively my role, as Joe Sixpack, is to pay the bills and leave the academics to play their own little academic games in their won little way. And then, when the results achieved are disappointing or dubious to shut up and pony up some more cash.
I find this state of affairs very poor. Hence my commentary here and elsewhere. And my lack of sympathy when academics get irritated about stuff that anywhere outside of their own world is just a part of life.
And finally, a semi-rhetorical question. If you were given the job of trying to really understand the complex system called ‘climate’, one of your first tasks would be to design an organisation that would best achieve this. And then to staff and support it with the best people you could.
With that in mind, would today’s organisation..based on mall university departments and papers published in journals and all that goes with them be your optimum organisation of choice? Or academics, with all that goes into an academic training and personality type be your staff profile of choice?
Mine wouldn’t be. If yours would, I’d be interested to know why.
Latimer
I think its certainly the case that academics can be highly strung and rude. However, its also appropriate to note that these characteristics are not restricted to the academic world.
If I was made the boss of all things climate the very first thing I would do would be to order a review of the key results and conclusions. This implies getting senior (and active i.e. no politicos) scientists with no dog in this fight together. I’d give them a generous budget to employ postdocs and students and give them five years to do the work with updates required every year. Their remit would be to find mistakes and problems since this is how science should be done i.e. you attack work and if it survives then its likely good science. I’d also have at least two of these teams working independently. Let first rate statisticians have a go at the hockey stick, ditto modellers etc. The overall cost of this would be negligible in real terms.
Regarding organisation if the whole thing were to be set up from scratch, I’d insist on larger collaborations (its much much harder to fool yourself if 50 other people are ready to point out errors). I’d also invest in getting up-to-date proxies. In general, the university system works well in most fields and I’m a little surprised at how poorly it functions here. I rather suspect that this is due to the people (unfortunately). Often, all it takes is 5 or 6 key people in positions of influence and group think sets in.
Re: Roger (Jun 1 07:30),
Roger I think your “boss of all things” proposal is eminently reasonable. To highlight, I’ve bullet-pointed the proposals. Many of these proposals have been taking place via the blogosphere (CA, Lucia, Jeff, etc)…
“Roger
Why are you surprised that somebody would be irritated by such a request ? Its quite often the case that one plans a series of papers based on a lot of preparatory work”
It is data we are talking about, if you publish a result based on the data, then the data has to be presented. No one can replicate or falsify a finding if they do not have access to the data.
Moreover, scientists have a duty to communicate to people, anybody really, because the work is funded by the taxpayer.
Roger,
Considerable overlap with your thoughts, comprehended, fine in theory, not so good in practice.
You write “the very first thing I would do would be to order a review of the key results and conclusions”
Practical question: What if the reponse to you was “We are not going to give key results and conclusions to you”?
I was working with Warwick Hughes in 1992 or so on the project that resulted in the “Why should I give you my data …” response from Phil Jones, so I’m not talking from theory.
Geoff
If key conclusions weren’t given then the independent groups would note this clearly. These wouldn’t be whitewash committees.
One could also add that governments could commit to accept the findings of the independent groups. Even if they refused to do this it would create a very large stink, far larger than climategate, especially if the groups contained high profile names (eg a Nobel prize winner).
Paul
We certainly make all of the data in the papers after the publication. However, each study represents a stripped down set of data. If someone wants all the data from the Ca 1000 billion collision events which were eventually whittled down to, say, 10 interesting events from, say, possible Higgs boson decays then they will have to wait. We won’t release those until the experiment is over and there is anyway the practicalities of making such data available (we have already had to develop the WWW successor to deal with this type of thing).
The issue of potential bias is addressed by having two independent experiments using different technologies and a mandate to disprove one another.
None of the above means we’re perfect or that there are no biases. However, the situation is a bit more complicated than the “free the data!” cry shouted by many here would suggest.
No it isn’t. Just ensure that you only ever put publicly funded data where the public can see it. You then won’t need go through the trouble of ‘releasing’ data, since it was never hidden in the first place.
Punksta
In view of your comment that the situation isn’t complicated, can you specifically address the following concerns I raised regarding data availability at collider experiments:
(1) Given the ca 20 years required to build and the huge subsequent investment in operating and understanding a detector (eg one part of a typical detector can have ca 100 million read out channels) how will you persuade physicists to actually undertake this effort in the first place given that, under your proposal, they could get it for free as soon as it is available ?
(2) The data storage and access issues are huge. For example, datasets are of the order of 150 petabytes. Where is this all to be stored for easy access by the public ?
(1) It’s their job, isn’t it?
(2) I don’t think the data in climate science is anywhere as large.
Punksta
(1) The point is that they wouldn’t do their job if they could get it for free. The problem is then that nobody would do it. There is no incentive to do the hard work if the reward is the same if you skip the hard work.
(2) Climate science is indeed very different, which is the theme of my posts. I’m simply pointing out that things aren’t black and white and that different fields can legitimately have policies in which data access is restricted for a time. Things aren’t black and white.
Re: Punksta (Jun 1 07:59),
Re your point 2. Where is the data stored now? How difficult is it to write a front-end that allows public access?
And don’t forget that part of the reason that we, the public, want access to the data is to help to keep the researchers honest.
Companies I work for want to see some or all of receipts for my expense claims, independently verified timesheets for my ‘by the hour’ invoices and logs for all phone and written work that I do on their behalf.
Is it because they don’t trust me? I hope not me an individual, but not every one who has ever been employed by them has been scrupulously honest. So they ask everyone to do the same. Maybe they check them all, maybe none, or maybe just a random sample, But if I were ever tempted to be dishonest (so far I have never succumbed) that those checks could be applied is a strong disincentive to misbehave.
Same with data access for academics. Especially climatologists – some of whom give the very strong impression that integrity and probity are not always at the very forefront of their motivations.
‘doveryai, no proveryai’…Trust, but Verify
Yes I see the “free rider” problem you allude to. But if a scientist’s job is to get XYZ data, then that’s what he must do. If he doesn’t do this well enough, then, like anyone else who doesn’t do his job, he needs to be released. We are after all talking about public money here, not private money, and public money is supposed to be for the public good.
And saying that it’s technically or economicially difficult to archive data, really has nothing to do with deliberately hiding publically-funded data for personal academic advantage.
Compare that to tree ring: If a group collects tree ring data, they should be the first to use the data and publish their findings/studies based on that data. As long as no studies have been published, they don’t need to publish their data. *) But once a study using the data is published (regardless by whom), the underlying data (in its entirety) should be available. I think Roger is arguing for nothing else.
*) Unless it is publicly funded, then there should be a time-out after which the data has to be published – published study or not.
Punksta
I think you’ve missed the point. My point is that scientists would go away and do other research which doesn’t need a 20 year run-in if there was no benefit to all this preparatory work. If another scientist (or group of scientists, and it would be a group) could perform the same research with no preparatory work then the first scientist would see little or no benefit to his/her investment and would choose to push other research without the long run-in time.
Its perfectly valid to point out the logistic challenge of storing and making available data. The full dataset isn’t even available routinely to the scientists on these experiments owing to the sheer size of it and difficulties in providing adequate software to access it. Instead they use skimmed datasets. One would have to provide quite some extra resources into making these data generally available.
Throw your rhetoric as much as you want (“hiding publicly funded data” etc) but please explain how the successful research (eg Nobel prizes) going on today could still carry on if nobody would be prepared to put the work in to make it happen.
And one more thought: These problems are not unique to climate sciences, in clinical trials there is a tendency to hide inconvenient data as well. The solution? All clinical trials must be announced. Want to collect tree-rings/ice-cores/ocean-sediments/whatever? Fine, but announce it before you start – that would be a tested solution.
(On the other hand, physics stays exciting, regardless whether a higgs boson is found or not – in both cases there will be enough exciting work in the future. Granted, some people are married to their ideas, but I haven’t seen anything quite like climate science in that regards)
The “it’s their job” response is completely off the mark. Academic research is more like entrepreneurship–raising grant money and betting that one’s idea will “pay off” in results that will satisfy curiosity and receive recognition. The public would not be willing to pay enough salary to get people to do the kind of painstaking innovative work Roger is talking about absent these “profits.” But in climate science, where the policy stakes are higher and the research costs lower, it should be possible to pay people enough to get data released, with the researchers foregoing some of this recognition “profit.”
stevepostrel
If academic high-flyers would not do the painstaking work of getting the data without being allowed to hide it (even fr a while), perhaps the job should be farmed out to professionals in the area.
Roger
Sheer quantity of data
(Doesn’t seem to apply to climate science as it does to physics; but, for the sake of the argument, let’s imagine it does)
Am I correct in assuming the data is stored on a computer disk rather than scraps of paper? Then how difficult would it be to have this disk seen – and made available by – an ftp server? Nothing fancy, just the basics would be a huge improvement over nothing at all.
Free riding on data
Why would any scientist or group do the spadework of generating data, if others could have access to to before the creators of the data had published? Everyone would just wait for someone else to do generate the data, and the net result would be noone would do it, and science would be the worse. Similar argument to patent and copyright.
This assumes government funding agencies are behaving much like private entities, ie acting in their own interests. But surely the whole purpose of government funding of science, is to commission work that is beneficial to society as a whole. If funding agencies are not doing this, they are not doing their job, and need to be replaced or reformed. Once funding agency does commission some data research work, it will surely not be a problem finding some scientists to carry out the work.
Punkasta
You don’t store 150 petabytes of data on a ftp server. The distributed analysis model developed for participating physicists has involved developing the WWW successor (the GRID). To make this all universal is further development work. Furthermore, the documentation of these data is (run-by-run databases concerning the response of the millions of channels of a particular subsystem) is also problematic. There is no way that making this all universally accessible and up-to-date for the whole world would not be a significant expenditure. The LHC experiments are probably the most complex scientific endeavours in history. One can’t just shove the data onto a disk (especially not with 150 petabytes) and say “there you go”.
Regarding free riding,the funding agencies don’t come up with a strategy, the scientists do. They form collaborations and go to the funding agencies to beg and sell their idea and they fight off other researchers who also want to get a slice of the pie. As pointed out, you need several thousand scientists to get together to do this. They must all be supported by their universities etc. Under your scheme you may not get those several thousand scientists to do this since many would prefer to avoid the hard preparatory work and focus on other more short term research in the meantime. Furthermore, some universities would prefer this as their staff would get more immediate returns (and the uni would improve its league table rankings). Like everything in life, its complicated and proposing changes to successful working practices is rarely a good idea unless it is absolutely necessary.
On another note, it is extremely unlikely that someone like Steve could come in and do with LHC data what he did with climate data. It is simply too complicated and one typically needs a run-in time of around a year. Furthermore, even with the code, he would need powerful computers to process and strip the data. I assume that you don’t want to insist that the universities also open up all their computers to anyone who wants to use them ?
Roger
Data
Yes I do take on board hugeness, complexity, need for documentation, etc. But as a starter idea, nothing says all the data needs to be on one single ftp server. And you wouldn’t need to ‘shove’ data onto disks seen by ftp servers, if that was their normal abode.
Free riding
“the funding agencies don’t come up with a strategy, the scientists do”
OK, that’s a clear problem. A basic reform we need then is to get some strategists employed by funding agencies, who then put out some jobs that scientists tender for. A bit of a role-reversal, akin to senior public prosecutors and lawyers becoming judges later in their careers.
Punksta
Data
You haven’t addressed the point of the cost of such a highly complex system.
Free riding
With your proposal you are violating a fundamental principle of how science is done i.e. it is bottom up. In the UK, this is known as the Haldane principle. Those who do the science get to decide what is important work and what’s not. They then have to persuade the funding agency/politicians that this is a good idea. This model has worked fantastically well in particle physics. Changing it to commission-led science wouldn’t be a good idea. The best strategies are usually those developed by people who know what they’re talking about and are doing the research.
An example of a consequence is that the funding agencies (usually staffed by politico scientists) decide that lots of research into carbon capture is the most important way to spend the “energy research” budget. Scientists on the ground disagree but have less (or no) power to put forward their own strategy.
As I’ve mentioned a few times, this is all complicated and its usually unwise to touch things which work unless its strictly necessary. In collider particle physics, a successful field with two wholly independent experiments reproducing each other’s work, I don’t see the necessity.
Roger
Cost
Would running a number of ftp servers on the machines where the data already exists, really impose a significant cost?
Strategy
Yes ok, bottom up, those with the knowledge less likely to be political. Except look at the IPCC cadre – could anyone be more political ? I think the relevant difference with particle physics here, is that it doesn’t have an obvious political implication (wouldn’t serve to justify eg a new Higgs or Buckyball tax).
Are scientists looking to their own careers (and ideologies) any better guardians of the common interest than policos on the funding agencies?
And too you haven’t addressed the idea of some experienced, senior scientists moving into funding agencies.
Yes, it’s complicated. But nowhere near as complicated as the science underneath surely. And yes, if it ain’t broke, don’t fix it. But it is (somewhat) broke.
For LHC experiments the cost would be large. Making data available for the scientists (via distributed worldwide computing) already account a significant amount of our resources. To make this all universally available and well documented is far from being trivial.
Regarding the IPCC , this is my point. This field has become horribly political and the research results are feeding directly into the law making process. The usual rule of “let the scientists decide how to manage their research communities” can’t hold in this case, especially since Steve M. and others have exposed a number of mistakes. These mistakes may well be minor in the great scheme of things (I simply don’t know) but the fact they haven’t been acknowledged by the community, even when faced with evidence such as the Wegman report, is more worrying to me than the fact these mistakes exist. In this case, at the very least, no result should find its way into the IPCC report unless it is fully reproducible. Furthermore, there is no argument that data management issues are in any way an obstacle in this case. The datasets are comparatively tiny and easy to work with. I don’t see any legitimate argument stopping data release here.
The fact is, CERN throws 99% of their data away. I just saw this today:
http://www.theregister.co.uk/2012/06/14/cern_cloud_helix_nebula/
Quote – Bob Jones, head of openlab at CERN:
The four major experiments at LHC – Atlas, LHCb, ALICE (A Large Ion Collider Experiment) and Compact Muon Solenoid – generate 1 petabyte of raw data per second, Jones said.
“We don’t record all that. Ninety-nine per cent is data we’ve seen before and we throw it away; the [other] 1 per cent and knowing which 1 per cent [it is] is IT’s job,” he added.
Despite binning so much of the data, CERN still ends up with around 15 million GB of data a year…
Sam
Do you have a serious point other than writing “boo hoo” ?
I thought this was a serious site.
Re: Roger (Jun 1 08:48),
Sam makes an admirably succinct point that in a work climate where many do not know when or from where their next pay cheque will arrive, academics whinging that they have such a hard life of twenty years regular employment are unlikely to gain a lot of sympathy.
That was his serious point.
Most scientists spend around a decade wondering whether or not they’ll be in a job in a year’s time.
Roger:
That’s why it’s critical to make contributions that the community finds indispensable. Making data publicly available is one of those… personal experience on that one.
But I feel your pain on this though… it’s not that different than working for industry (where your section can get shut down at the whim of a manager), except the pay here is much worse.
For the non-technicals here – “screening” means excluding inconvenient data ?
No, cherry picking the outliers that give the biggest eeffect.
Eroica, If you want a comment to appear right at the end, go to the very last comment and do a Reply. As a test I’ve just done this on
– clt510 Posted Jun 2, 2012 at 12:13 PM.
Seems silly, but let’s see if it works.
The rule I was taught in grad school was that data could only be used for one publication. Once published, data could not be ‘mined’ for multiple publications. Obviously, this does not hold for climate science.
I’m surprised your grad school taught you that. Its perfectly appropriate to use a dataset for a number of publications. It depends how closely related they are and the time scales needed to perform the research.
“Its perfectly appropriate to use a dataset for a number of publications”
Not in any journal I have published in.
This is PNAS ItA, pretty typical
“Journal Policies
(i) Articles are considered provided they have not been Published Previously or concurrently submitted for publication elsewhere. Related manuscripts that are in press or submitted elsewhere must be included with a PNAS submission.”
“(x) Materials and Data Availability. To allow others to replicate and build on work published in PNAS, authors must make materials, data, and associated protocols available to readers. Authors must disclose upon submission of the manuscript any restrictions on the availability of materials or information. Data not shown and personal communications cannot be used to support claims in the work. Authors are encouraged to use SI to show all necessary data. Authors are encouraged to deposit as much of their data as possible in publicly accessible databases. Such deposition may facilitate access to data during the review process and postpublication. Fossils or other rare specimens must be deposited in a museum or repository and be made available to qualified researchers for examination.
Authors must make Unique Materials (e.g., cloned DNAs; antibodies; bacterial, animal, or plant cells; viruses; and algorithms and computer codes) promptly available on request by qualified researchers for their own use. Failure to comply will preclude future publication in the journal. It is reasonable for authors to charge a modest amount to cover the cost of preparing and shipping the requested material. Contact pnas@nas.edu if you have difficulty obtaining materials.”
So if I genetically alter a cell line to generate a humanized antibody to a cancer cells surface receptor I MUST provide it to qualified researchers for their own use.
Pretty standard boiler plate for biological sciences. Normally you can email anyone for tips/cell lines and cDNA.
Some people charge for tissue arrays, which are tricky to generate and take quite a lot of work to properly type each of all the samples, and normally get authorship.
Doc Martyn
You’d better send a mail to the LHC experiments and make complaint .They have typically published over 100 papers so far on one dataset taken in 2011. They were published in top journals as well.
Different fields have different publishing needs depending on the complexity and aims of the publication and the size and type of the base dataset.
You ought not to extrapolate from your understanding of one field and try to prescribe how others should act, not least if others have proven to be highly successful.
Even if you choose to view it in a distant black-and-white way, the situation is complicated.
Roger, I understand the case your making, and it is an argument with merit. However, I do find flaw in the key assertion you are making, namely that experimental physicists are primarily motivated by exclusive access to data.
I’ve never known someone like this. Every physicist I’ve ever met working on particle physics, going back to my first encounters in the early 80s while a student at UC Davis, spending a summer at SLAC helping with data crunching, through the present, have never mentioned this as a motivation.
Rather, everyone has been motivated by first their wonder of the universe and thirst to understand it better, the “coolness factor” of working on an accelerator project, the prestige, the community, and for some, teaching.
I’m not implying that your concern over motivation is meaningless — as I said above, it certainly has merit. The question though, is, were data required to be made public upon publication of the principle’s analysis, theory, and conclusions, would that be sufficiently demotivating to, as you assert, cause scientists to abandon these efforts?
I claim no, it would not — I’ll assert that more strongly and say that I doubt anyone — including you — would move on to non-experimental pursuits or even some other career. My experience with experimentalists is the things I list above drive their passions first and foremost, not the data exclusivity you are concerned about.
I try to imagine any of the thousands of people working on the LHC abandoning the effort when told a new standard would be in place requiring full disclosure of all data up publication after the experiments have run. Frankly, I find the idea laughable. Whatever small fraction might be so sensitive and quit, would be swiftly replaced by equally competent scientists eager to join the experiment that, for whatever reason, weren’t involved to start with.
My 2cents.
Dave, I must agree. No experimental physicist worth his/her salt would be deterred by this – as you say, it’s the intrinsic interest and worth of the work, plus a competitive desire to be associated with it and to publish it with their name on it that drives them.
If the prospect of too much hard work deters them, they are in the wrong game.
Having had a lot to do with academics over the years – mainly research types but also working stiffs – both socially and professionally, I must agree that many (by no means all) are incredibly precious and socially inept. They labour under the delusion that because they are academics they are smarter than everyone else, and that those who entered other fields of endeavour should humbly defer to their wisdom, which is demonstrably untrue.
When I was at the ANU in the 1970s, quite a few of those who remained to do PhDs and become academics would frankly be almost unemployable anywhere else, something that even their undeveloped social antennae may have detected at the time. It is true that some of them were exceptionally bright, but some of them were pretty ordinary except for an aptitude for playing the game required to get a foot on the ladder.
Gergis’ ill-mannered and arrogant response to Steve’s request is not a sign of intellectual merit. For a so-called scientist, her suggestion that no-one has the right to look at how she put together her publicly (she can’t spell, either!) funded research displays a breathtaking lack of comprehension of the scientific method. “Run away and do your own research” is not an acceptable response to a polite query about your data sources in any circumstances, let alone where so much public policy depends on its veracity.
Johanna
Would you write that type of post about people of different ethnicities or is it just academics who deserve your lazy generalisations ?
Roger, your arguments have been based on a mixture of special pleading and generalisations from the get go. You have claimed that experimental physicists wouldn’t do certain work if they were required to publish their taxpayer funded data with the papers that rest on it. My response is, if they are not prepared to do this, make way for someone who will.
You whine about the corrosive effect of job insecurity on scientists, as if the vast majority of the workforce doesn’t live with it every single day, or alternatively that academic scientists should be protected from it in a way that their colleagues in the world of commerce are not, for reasons that are never articulated because they do not stand up to scrutiny.
As someone who has sat through many an excruciating dinner party with academics playing the same tired tune, and who has worked in a government grant agency ditto, it is familiar ground for me. There is a sense of entitlement which pervades this narrative which is less than compelling, especially to long suffering taxpayers.
As I said in my post, not all academics, scientifically oriented or not, are like this. But, there are lots of touchy, insecure prima donnas among them, very often the least able, whose life mission is becoming insulated from impartial criticism and securing tenure, both of which they feel they richly deserve.
I had dinner the other night with an old friend who has just secured a research post in a team at the ANU after 25 years in a high pressure, unforgiving job. She is gobsmacked at the leisurely and disorganised work mode there. She has a nice office with a good view, though, something that never came her way in her previous life, so there are consolations. 🙂
DaveW
Thanks for your post.
With the new proposed model that the experiments give away the data asap then one can still be inspired by the wish to understand the universe and do number crunching etc and do great physics (if the data are there, that is). It would, in principle, be even easier to spend time looking for the signal of the Higgs in a mass of background data if one didn’t have also to spend time calibrating and maintaining the detector. The LHC experiments have (and need) several thousand physicists. It only takes a small loss of essential skills and manpower contributions to weaken or make such projects untenable. Even those who wanted to be the ones building the experiment and analysing data would still have to go to their universities and funding agencies and deal with the argument from the funders that they can still become world leading Higgs specialists by getting the data free. Eg Uni X doesn’t spend a lot of money building, Uni Y thinks this could also be a great way to economise.
Sadly, much of this whole discussion has been led by dogma and its more than a little disappointing. Because of stone walling and poor conduct by climate scientists some folk here are now arguing that a different (and so far highly successful) research field should fundamentally change the way it works. The vast majority of people commenting have zero knowledge of my field and its complexities and consequently see any posts which point these things out as therefore being largely irrelevant. Add to that other fallacies (eg employment conditions of scientists – most scientists have lived on short term contracts and are forced to move away “for experience” for up to a decade) – and the whole thing becomes rather depressing. The irony is that most folk here would consider themselves sceptics yet seem wholly unable to realise that scepticism also implies avoiding drawing firm, hasty conclusions from a weak or non-existent knowledge base.
Finally, as mentioned, it would anyway be quite a challenge to make these data publicly available. It would take a lot of manpower (my guess, based on the manpower used to distribute the data for physicists to access) is that one would need around 2 people working full time, such is the size of the dataset. More people would be needed to design and implement the archive system in the first place. Keeping all documentation continuously up to date so that someone could have the same data understanding as someone on the experiment probably requires at least another person. The hardware (we need storage and universal access of 150 petabytes of data) would require more investment. “Public money” seems to be the cry here. Its hard to see how the public gets value for money in this case. Our policy of making data available at the end of the experiment in a simplified format (eg give the calibrated energy from a calorimeter and not the output of a million channels) and which is well understood is hardly a daft one.
We have two people associated with data archiving and collection in our group. 100% of one guys job is just that. I’m the other guy (as well as the chief designer for the instruments for our work). I wouldn’t advocate making the petrabyte archive copyable, but it might be cool if there were tools where researchers (yes I used that word) could set up their own
We find it more useful to provide source code and (limited) consulting help to people that to constantly keep documentation updated (which we find people rarely read carefully anyway).
I think part of the value added to any experiment is the data itself, rather than the interpretations put on it by any one person.
It’s my impression the drive for more openness comes from non-publically funded studies, such as major drug studies funded privately by drug companies. So the argument for openness isn’t just a “the public paid for it so they deserve a copy of the work”, it’s “if this work has a public impact, it is the duty of the scientists to publish their work in a manner where their methods and assumptions can be scrutinized.”
By the way, I used to do High Energy Physics, so I do understand the culture and understand some of the issues.
It’s not as neat and tidy as you make things sound…you have to understand a lot about the instrument (acceptances etc), about how to perform monte carlo studies, data formats and a lot of other things before you could publish. In practice, if you released your archive today, it might take a couple of years before a competitor could reach the level you are at today.
In my area, it’s pretty common to release the data once it’s been error tested, this can be months before our first publication. The data sizes typically are in the 10s to 100s of GB. Same dealio for us–there is little to seriously concern one self with that somebody else who isn’t intimately familiar with the experiment is going to write a paper ahead of us.
(But we do like the extra sets of eyes this brings to the table, we feel that our data products are improved by more people scrutinizing it.)
Here’s the header and a selection of proxy/contact information from Joelle Gergis’ Table S3 (I hope it comes out):
+++++++++++++++++
2. Proxy data sources
Table S3: List of palaeoclimate data sources. To seek permission to use non-publicly available records, please contact the original authors directly. For composite series, the sources of the subchronologies are indicated. Composites indicated with an asterisk (*) can be obtained from Raphael Neukom (neukom@giub.unibe.ch), other composite series will be provided only with permission from the original authors.
Record______________Source________________Record________________Source
Zimbabwe___NOAA Paleo-DB_________Rodrigues Sr/Ca___Jens Zinke pers. comm.
Die Bos,South Africa___NOAA Paleo-DB_Rodrigues d18O___Jens Zinke pers.comm.
Teak Inonesia___Rosanne D’Arrigo pers. comm.___Mentawai West Sumatra___NOAA Paleo-DB
Northern Territory Callitris___Rosanne D’Arrigo pers. comm.___Abrolhos__NOAA Paleo-DB
Western Australia Callitris___Pauline Grierson pers comm.___Ningaloo___NOAA Paleo-DB
Kauri NZ___Anthony Fowler pers. comm._____Bali________NOAA _Paleo-DB
Baw Baw Victoria___Matthew Brookhouse pers. comm.___Bunaken___NOAA Paleo-DB
Urewera NZ___NOAA Paleo-DB_________Laing____________NOAA Paleo-DB
North Island LIBI Composite 2*___NOAA Paleo-DB___Guam___NOAA Paleo-DB
Mangawhero NZ___Rosanne D’Arrigo pers. comm.___Madang Lagoon___NOAA Paleo-DB
North Island LIBI Composite 1*_NOAA Paleo-DB_Great Barrier Reef precip recon_Janice Lough pers. comm.
Takapari NZ___NOAA Paleo-DB______Kavieng Sr/Ca__________NOAA Paleo-DB
Moa Park NZ___NOAA Paleo-DB______Kavieng Ba/Ca________NOAA Paleo-DB
Flanagans Hut NZ___NOAA Paleo-DB___Rabaul Sr/Ca________NOAA Paleo-DB
CTP East Tasmania___Kathy Allen pers. comm.___Rabaul d18O___NOAA Paleo-DB
++++++++++++++++++++++
One can understand that Joelle Gergis cannot send other people’s unpublished work to third parties. However, the contact information in the Table is completely inadequate.
Apart from the 15 entries listed here, Table 3 lists a further 81 data sets (total 96), all equally cryptic and inconvenient.
Joelle Gergis is in a position to supply full contact information, which she should do. Responding in a snippy way, especially to a researcher of Steve McI’s standing, is inexcusable.
If she were properly cooperative, Joelle Gergis would take it upon herself to directly contact her data sources, and pass along Steve’s request.
Given the very inadequate information she has provided in Table 3, Joelle Gergis really owes it to any researcher to facilitate requests for data.
Apart from being baffled by the concept of filter biasing, far too many climate scientists seem unable to put aside egotistical politics in favor of scientific ethics.
When gangsta music meets with gangsta science we get Climate Rap, commonly known in the streets of Baltimore as ‘CRap’ 😉
Have you considered producing rap music video of your own, Steve? That’s gotta be the surest way to clinch your popularity among the mainstream climate science community and bring home the data.
It only takes one bad apple to spoil the whole barrel.
You have made them aware of the bad apples … unless and until they have a policy removing bad apples it is fair to assume the whole barrel is corrupt.
Perhaps the better expression would be one bad potato, because that one bad one creates a stench that means you have to throw the whole batch out if any liquid from it got on them.
Joelle Gergis:
“The compilation of this database represents years of our research effort based on the development of our professional networks. We risk damaging our work relationships by releasing other people’s records against their wishes. Clearly this is something that we are not prepared to do.”
In fairness, she has a point here. She cannot give away other people’s work against their wishes. However, if the original authors refuse to disclose data, what then?
Well, if individual scientists refuse to disclose data, then institutional science must compel them to do so. The mouthpieces of professional scientific networks, especially the peer-reviewed journals, must refuse to utter the findings of any new ‘truth’ that’s not backed by open data and methodology.
After all these years of controversy, it is appalling to see climate scientists still behaving badly and still expecting us to take their words for any claim they make.
To a large extent I agree with you, but the real problem here is that the scientific method is a mill that grinds fine, but that also grinds slowly. In the longer term, this kind of thing doesn’t matter at all to science. If you have to wait a hundred years for sufficient data to refute an argument, so be it – the argument will be refuted eventually.
People are currently acting as if the scientific method works immediately, when it manifestly does not. Don’t be sucked into making the same mistake. I’d say that less needs to change in the way science is done than in the way scientific results are treated.
I agree. I often think that if only the climatologists were to stress the exploratory nature of much of their work my view (and probably that of others) would be that this is an exciting and developing field in which mistakes are made, knowledge gained, ideas tested, rejected, refined etc with some type of consensus now (probably) emerging. Instead, my view is that they have their heads in the sand, are over-sensitive to well reasoned criticism, and have dug themselves into a hole by cliaming a certainty which simply isn’t warranted by a dispassionate look at all of the data.
My view of this is that contrary to physicists at CERN who positively seem to enjoy finding new stuff and proving each other wrong, climate scientists seem to bend over backwards not to find anything new. As far as I can tell, their discipline hasn’t advanced one whit in decades.
If you define academic science as a field like industry science where actors legitimately have legally defensible trade secrets, I guess you might be correct. But that strikes me as being antithetical to most models of science. Surely in academic science, once someone has gone public and made scientific claims based upon ownership or access to data sets, there is no reasonable defense to witholding the data from those interested in verifying the validity of public scientific assertions? It is arrant nonsense to claim somehow that the time invested in building personal networks that allow unique access to unarchived data somehow is a defense against archiving said data once it has been relied on to make scientific assertions.
Surely, proper citation credit and opportunities for co-authorship is the coin of the realm?
I think the solution here is that the climate community should undertake to archive all relevant information from a given series following a fair and appropriate amount of time for an individual researcher to properly analyse and publish the data, given that data collection and preprocessing may also take some time. Then a ticking clock rule applies. If the data still remain unarchived after the grace period then any other researcher who happens to possess these data should regard them as being public and pass the data on upon request.
It won’t happen.
sHx:
In fairness, she has a point here. She cannot give away other people’s work against their wishes.
1. She is not supposed to “give away” other people’s work (quite loaded choice of words, me thinks) – she is supposed to make a copy of the underlying data available.
2. My math teacher *always* wanted to see how I reached a result – he had his reasons.
3. Especially if a scientific work is used to influence conclusions and public policies, I think we have a right to have everything that was used to come to this conclusion open in the public.
4. Science is not about secret sauces – science is about the creation of knowledge and hence has to always be open.
Seems to me the rot is in institutional science, that is failing to exercise the requisite compulsion. We thus need to figure out how to compel institutional science to compel individual scientists. Some sackings at the top levels of funding agencies perhaps ?
Leona Marshall Libby’s 1983 book Past Climates, Tree Thermometers, Commodities, and People arrived yesterday. (It had spent its youth at the SMU library, having been checked out 5 times between June 1, 1983 and January 14, 1991.)
Libby believed trees were a good proxy for temperature, when using the O18-O16 ratio. She recognized that ring width was affected by many factors besides temperature. She described her analysis in detail, and what analysis they did not follow and why. She hoped other scientists would expand upon what she had done.
Refreshing. Those were the days, my friends.
Bishop Hill came across an interview with Gergis about the study. It seems somewhere along the way they are comparing to climate models to validate their results. Ugh.
http://bishophill.squarespace.com/blog/2012/6/1/joelle-gergis-talks-up-her-results.html
Folks – and especially scientists extrapolating from their experience in other fields,
The use of articles by IPCC changes the dynamic materially. The Neukom and Gergis articles are being cited in AR5, which in turn is being used to inform policy.
If scientists wish not to archive their data for others to examine, then their articles shouldn’t cited in IPCC assessment reports.
I raised IPCC’s separate obligations on data archiving with Susan SOlomon in 2005 and she said that an IPCC policy would “interfere” with the journals.
Tough noogies. The IPCC has a different mandate than journals and should ensure that it is not embarrassed by complaisant journals and obstructive authors. Such a policy by IPCC would also raise the game of journals like The Holocene.
Steve, you are too kind 🙂
You betcha. Well done to Myles Allen for what you report he’s said – but let’s please hear his and every other climate scientist’s amen on this crucial statement of yours.
Perhaps a worthy exercise would be to produce a kind of overall Archiving Report – a list of all the papers cited by the IPCC, the journals they appeared in, together with a Yes/No as to whether they are fully archived.
This will allow us to assign both the IPCC and each the relevant journals an overall Archiving Index – 100%, 50%, … 0% etc. Then let the serious naming and shaming commence. (Perhaps someone like Donna Laframboise is already onto this sort of thing?)
The focus of enforcement should be on the policymakers and their tool, the IPCC. If the science isn’t available for review, audit, replication by the public, the governments should not use it to make policy. Their citizens, as a matter of basic civil rights, should be able to examine the evidence used to infringe on their lives, liberty and property.
If the US government told the UN and the IPCC to get its house in order on these issues, it would. If the USA or another prominent nation publicly declared that the IPCC in its present form was worthless because of major shortcomings in these areas, the IPCC would cease to be seen as relevant.
The scientists in the climate science community have demonstrated repeatedly that they have no intention of voluntarily making the needed changes. If people wish to see some changes made, they should educate their elected representatives. I think it would be easier to get the US Congress to pass some kind of Civil Right to Access to Science Act than to get these scientists to reform.
Steve
You summarize the “Screening fallacy” on paleo records:
However, the IPCC has very publicly relied on those results, and can ignore blogs and “gray” literature.
I strongly recommend you rewrite this post as a formal Letter explicitly explaining this fallacy and specifically “naming” the authors and detailing the papers committing this fallacy, and those refusing to archive the data needed to test for this fallacy. Highlight
You cite discussions by Ross McKitrick, David Stockwell, Lucia Liljigren, and Lubos Motl. Include as joint authors these statisticians you listed, and any others like Myles Allen, willing to support this letter.
Note: IPCC’s deadline is July 31st for documents to be submitted to journals.
This letter would then can be citable to formally reject those papers for AR5, and to publicly “Name and Shame” journals to uphold open archiving and reject papers with this fallacy. You and others have already done > 90% of the work. Such a Letter would put some real teeth behind all your efforts.
David L. Hagen
Has there actually been any PUBLISHED studies that directly attempt to evaluate the worthiness of the ‘screening’ fallacy?
I mean, on the one hand, it seems as simply as the scientists declaring that they only want to evaluate four-leaf clovers and leave all the three-leafed ones alone– which is why they don’t bother saving them if they happened to scoop up a bunch of these non-qulifiers. In a way of reading, it makes complete sense to dump that stuff.
Has it become implicitly accepted that a scientist can grab any set of trees they want, then look at their chronologies with respect to the observed temperature record, the ‘screen out’ anything that doesn’t approximate the instrument record for an end-point? All this without a publication stipulating that that methodology is proven skillful without false positives or negatives? It just seems equally obvious if you’re only after what’s in the last 5% of a chronology and fix that as a screening requirement, that the rest of the data that each of these selected candidates (if random) will essentially cancel themselvesout, revealing a messily flat line followed by a sharp rising at the end.
How does one go about attempting to demonstrate that (a) a tree that doesn’t exhibit the post 1950 instrument record can indeed be a good temperature proxy; or (b) one that does exhibit it does not end up being a good temperature proxy? For some reason, the fact that you need to screen out 95% of a sample (or even 50%) to get this data has not raised any questions in the minds of scientists that luck/randomness might play a role.
Instead of Steve McIntyre being challenged to produce his own chronology (which technically he has with his ‘instareconstruction’), perhaps he should be challenged to demonstrate in a different way the weakness of excress screening requirements to develop a good proxy. Perhaps ‘rescreen’ these trees and instead look for how other papers have drawn out a different time period that is less cared about (say 1700-1900) (where there’s some temperature record in there) … and then just what these new wonderful candidates that screen perfectly for this data reflect for end-point data post 1900 (when it’s off the magnifying glass of the screening process). Theoretically if it were random or autocorrelated, the rest of the data before/after that point would flatten out too yes?
…Or has that already happened and my mind is blanking because I’ve been in surgery all morning…
See http://press.princeton.edu/books/lo/chapt8.pdf for example.
The issue is so well understood and know in statistics and econometrics that one shouldn’t have to argue the toss.
To put it another way: conditional on there being a relationship between proxies and temperature (the pre-screening they do) we find that there is a relationship between proxies and temperature.
See the flaw? By prescreening the data they completely destroy the power of any statistical inference they conduct thereafter. Similar issues arise when people do repeated Chow tests for structural breaks in data. Essentially, standard statistics uses a 5% chance that the result happened by chance as a cutoff. But, if you run the test enough times, you will get ‘significance’ about 5% of the time even when there is none.
Search for:
red noise hockey stick site:climateaudit.org
Salamano, the argument is wrong; the so called “fallacy” is the fallacy. Here’s why.
The argument posits that an autocorrelated (= “red noise”) time series will, with a frequency depending on the magnitude of the ac, sometimes produce a “hockey stick” shape (after calibration and subsequent paleo-estimation (= climate “reconstruction”)). So far so good. The problem is, the argument is irrelevant to the vast majority of existing tree ring chronologies, because it ignores a couple of crucial facts that collectively nullify it.
Once a time series is autocorrelated, at some defined significance level, it is no longer a random series. It is instead driven by some type of (apriori unknown) structuring process–otherwise it would not have the structure that it has–and thus be entirely “white” (= purely random). The argument being made by those who make it, is that, whatever that driver is, it’s not the climate variable of interest, typically a seasonal to ~semi-annual temperature.
The most important point here is that tree ring series are replicated; this point is absolutely critical. The typical tree ring site has a minimum of 20 cores taken per site, sometimes much, much higher, rarely lower. Remember, the posited null model being used by those making these claims, produces spurious correlations strictly by chance–no relationship to temperature involved. If this is the case, then your chance of getting 20 or more cores, the **composite** of which (typically, via Tukey’s robust mean or similar) forms a statistically significant and stable relationship with the climate variable, during the calibration and validations periods, is ***exceedingly*** small. EXCEEDINGLY small.
Rather it is MUCH more likely that, if one does in fact observe just such a relationship, that the rings are in fact, responding to that climate variable of interest. Furthermore, one can test this conclusion even further, by the further test of detrending the composite ring series (not the original detrending of each core to remove the size effect, but a second detrending on the chronology), and then evaluating, statistically, whether there is a relationship between the resulting residuals and similarly produced climate residuals. If the generating process for the ring series was non-climatic, there will be no stat. significant relationship observed therein. If, instead, there *is* a relationship, it will show up. And lo and behold!…this is exactly what Gergis et al did, and exactly what they found.
So in summary, the argument has no merit and ring series replication is the key reason.
Jim, not only dendroclimatology has the unique advantage of the ability to pick and choose which samples to use but also their (highly autocorrelated) resulting time series magically escape the spurious regression phenomenon! Amazing!
Those of us who are not working in that privileged and blessed field, might want to study a recent review article:
Ventosa-Santaulària, D. (2009) Spurious Regression;
Journal of Probability and Statistics, vol. 2009, Article ID: 802975, 27 pages.
Jim, have you never heard of the “divergence problem” of trees in the past decades? Near one-third of all tree series goes in the wrong direction with higher temperatures, one third goes in the right direction and the rest stays where they are. Thus if you have 99 series of tree rings and uses a screening method that selects the “right” tree ring series, how can you be sure that these were indeed respomding to temperature in the right way in the past?
Re: Jim Bouldin (Jun 1 14:22),
…and it never occured to you, or these other scientists, that there just might be some other physical phenomenon that leads to a correlation between the collected samples?
Note that these samples are collected in a highly specific manner, that does not necessarily have anything to do with climate theory. Just for example, from our field experience with the Almagre Adventure (see categories on this site), it is clear that while strip bark BCP’s tend to exhibit recent growth spurts, their non-stressed whole bark cousins in the same location are far more complacent. But whole bark BCP’s never show up in climate studies. Funny thing.
Well I knew the misdirections and misinterpretations wouldn’t be long in coming.
Jean S: Can you give me an idea of the likelihood of some given AR1 process generating say 20 to 30 cores, the robust mean of which correlates at say p = .05 over both the split calibration and validation sub-periods (repeated in both directions) of say a typical 100 year instrumental record period, and which also pass validation (aka “verification”) tests like Nash-Sutcliffe Efficiency?
Feridi: Yeah, I’ve heard a thing or two about that divergence thing. What is the source of your claim that 2/3 of all tree ring series divergence from the instrumental record? Have you read, e.g. Esper and Frank (2009) Climatic Change (2009) 94:261–266? Does divergence always imply a physical cause?
Mr Pete: Yeah, it’s occurred to us, and yeah, I know about sampling protocol for tree rings. And the discussion here’s not about discussing bristlecone pines or strip bark phenomena is it?
You really should read that link I gave about financial data. They observe that in financial markets the use of portfolios of stocks is common in testing – just like your claim about the taking of multiple tree cores per site. And that is half the problem in the case of financial data – the selection process taints the results.
To quote:
“Because there are often many more securities than there are time series observations of stock returns, asset pricing tests are generally performed on the returns of portfolios of securities. Besides reducing the cross-sectional dimension of the joint distribution of returns, grouping into portfolios has also been advanced as a method of reducing the impact of measurement error. However, the selection of securities to be included in a given portfolio is almost never at random, but is often based on some of the stocks’ empirical characteristics. The formation of size-sorted portfolios, portfolios based on the market value of the companies’ equity, is but one example . Conducting classical statistical tests on portfolios formed this way creates potentially significant biases in the test statistics.”
Substitute trees for stocks, composite for portfolio and you get the idea… “The selection of tree cores to be included in a given composite is almost never at random, but often based on some of the cores’ empirical characteristics… Conducting classical statistical tests on composites formed this way creates potentially significant biases in the test statistics.”
Sorry John, no can do. Let me explain.
If I had unlimited time, 9 lives say, I’d go ahead (maybe) and read the chapter you link to. But I don’t. I should have been working on my tree ring analysis paper today. Instead, I sacrificed time on that to read this post, then go track down and read parts of this Gergis et al paper, and then also the Neukom and Gergis (2012) paper which describes the larger set of proxy sites from which the former drew their sample. Then I spent some time reading some comments, and then some more time responding to Steve and others. If you can give me some concrete explanation of how that chapter relates specifically to the claims of why screening proxies, or my counter claims, or how and why stock portfolio analysis is a suitable analog for the tree ring issues raised, then I think you should try to do that.
Jim,
I’ve parsed the data a little more. My sense right now is that there is a “screening” issue but it arises from (very) small sample properties of this particular data set.
There are only three proxies in her roster that go back before 1000: Mt Read, Oroko Swamp and Law Dome. Law Dome has been a thorn in the side of proxy reconstructions for some years – see CA discussion https://climateaudit.org/2010/04/05/ipcc-and-the-law-dome-graphic/.
Law Dome has been screened out. I’m not sure what the specific test is that excluded it. Or why Vostok d18O is supposed to be a valid proxy if Law Dome d18O isn’t.
If Law Dome were combined with the other two long proxies, it looks to me like it would yield a high MWP.
Jim,
Some long time ago. I have seen the graphs which shows the distribution of the “divergence problen” in NH tree rings which was about 1:1:1 between non-divergent, divergent and neutral (thus still divergent). The fact that even this study only uses 27 out of 62 proxies, including several non-tree ones, shows that the majority of the temperarure proxies are divergent…
See also at https://climateaudit.org/2011/12/01/hide-the-decline-plus/
“Strong evidence has been accumulating that tree growth has been disturbed in many Northern Hemisphere regions in recent decades (Graybill and Idso 1993; Jacoby and D’Arrigo 1995; Briffa et al. 1998; Feng 1999; Barber et al. 2000; Jacoby et al. 2000; Knapp et al. 2001) so that after 1960-1970 or so, the usual, strong positive correlation between the tree ring width or tree ring maximum latewood density indices and summer temperatures have weakened (referred to as “anomalous reduction in growth performance” by Esper et al. 2002a).”
But the main problem is what Kenneth Fritsch has written elsewhere: you do statistics on a subset of a population, after selection. The selection itself gives the bias.
If you don’t know why the other series do diverge, you can’t have any idea why the “right” series are right too. If e.g. the “bad” series show that the tree (ring) growth is over its temperature optimum, then the “good” series might have had troubles too in the MWP, if the temperatures then were higher than today. With other words, tree rings are an unreliable temperature proxy.
Jim Bouldin (Jun 1 15:27),
No, I have not done any calculations of that sort, have you? Why does it need to be AR1, are you saying that it is the correct model for tree ring chronologies!? For those unfamiliar with Jim’s jargon, the fancy sounding Nash-Sutcliffe Efficiency “test” is simply hydrology term for coefficient of determination in statistics…
Ref Jean S 4:17. Nash Sutcliffe efficiency runs from minus-infinity to 1 so is not the same as Coefficient of Determination.
Strangely enough, Wikipedia seems to disagree with you:
From the definition of the latter, one can see that they are in fact identical. This is a good example of statistical inbreeding where known statistics and methodology are re-branded by insular areas of scientific practice.
You don’t contradict JeanS. 🙂
Roman at 6:16 – clearly Wikipedia is in error – R-squared lies between zero and 1, NSE does not; the formulae differ, in particular there is no constraining the numerator. I published a paper in a Hydrological journal on matching modelled and observed flood hydrographs pointing out that interpreting NSE as R^2 led to exaggerated idea of level of fit. Practical constraints on the type of event that is modelled tends to lead to a shared unimodality and this simple fact alone creates high values of NSE even with a no-skill model.
Maxberan:
The two definitions are operationally identical. Given a model which produces a set of “predicted” values along with a set of “observed” values, the statistic is
1 – sum((pred – obs)^2)/sum((obs – meanobs)^2)
where meanobs is the mean of the observed values.
This statistic can theoretically take any value from 1 down to minus infinity.
In the situation where (1) the model is selected by minimizing the numerator of the above ratio from a set of possible model choices and (2) the specific model that “predicts” meanobs for every observed value is one of the possible model choices, the statistic will always be greater than or equal to zero. Simple regression which includes an intercept term is such a case.
However, without the intercept term, linear regression will not satisfy this constraint and the expression given above can very well be negative. Interestingly, in this case, the R statistics program will set meanobs equal to 0 and then the calculated R^2 remains non-negative.
[RomanM: I didn’t see the prior dialogue between Max and JeanS when I first posted this 🙂 ]
Capitulation posted 7:36 but detached from this subthread for reason not understood.
I will quote from the introduction to that chapter:
“THE RELIANCE OF ECONOMIC SCIENCE upon nonexperimental inference is, at once, one of the most challenging and most nettlesome aspects of the discipline. Because of the virtual impossibility of controlled experimentation in economics, the importance of statistical data analysis is now well-established. However, there is a growing concern that the procedures under which formal statistical inference have been developed may not correspond to those followed in practice.”
These issues affect the non-experimental science involved in the study of tree rings. The statistical issues involved are frequently one and the same. A thorough appreciation of the pitfalls associated with non-experimental inference is, thus, important. In this respect, pre-screening is but one of the pitfalls. Economists have made many inferential mistakes and subsequently learned from them. Others in non-experimental areas can benefit from this.
That reference is perhaps not the best one if one wants to appreciate the broader issues involved – it was but the first Google provided to me that seemed apposite. But the fact that there are big and deep statistical issues associated with the analysis of non-experimental data seems poorly appreciated by many studying tree rings. Do you appreciate it? For example, do you appreciate why the issue of spurious correlation is so relevant and why it undermines much of the inference that is conducted?
Ferdi,
The divergence phenomenon (DP), regardless of how frequently observed or the cause thereof, does not preclude or negate the points I made above regarding the importance of replication and the consequently extreme low likelihood that a non-climatically-related, AR1 process will produce the kinds of patterns seen in tree ring samples world wide. To easily demonstrate this to yourself, just go to the ITRDB site and start looking randomly through the COFECHA statistical summaries, specifically the mean inter-series correlations. There is NO WAY you can explain those repeated, high correlations with this kind of AR process.
Wilson et al (2007)* is one of about 5 to 7 papers that specifically focus on the extent, nature and/or causes of the DP. They provide a good summary of the situation, as do Briffa et al (1998) and D’arrigo et al (2008). Many sites diverge, many others do not, and again, the presence of divergence does not imply a physical cause, depending on temporal scale, detrending method, definition of predictors and predictands and other things (Esper and Frank, 2009)
* JGR, DOI: doi:10.1029/2006JD008318
And with that, I am done for the day on this.
Jim, you are a little bit quick to take offense I think. There are multiple reasons why a group of trees in a locality could exhibit a correlation with temperature that is spurious. Merely taking 50 trees does not eliminate this problem. The most prominent climate “signal” in the literature is given by stripbark trees, which are damaged and which show compensatory growth–see comment nearby on this. Another is the six-sigma yamal larch, which appear to be trees switching from a shrub to a tree growth form. These few trees (less than 40 iirc) heavily taint the overall dendro literature. They are NOT hundreds of trees.
A second problem can occur when local growth is correlated with hemispheric temperature (in the case of Bristlecones in fact)– A method used my Mann many times.
A third problem can occur when changes in rainfall over a few decades give a growth response that seems to match a temperature response (precip and temp changes are correlated) or some other factor (N deposition, reduction in local air pollution) enhances 20th century growth in a way unrelated to temp but correlated with it.
Finally, the problem is aggravated by allowing very low correlations (like 0.1) of tree growth to be considered “signal”, which makes it even easier to get a false signal.
I read your poster last year and your ideas seem interesting, but forgive us for not taking your word for your ability to id a temp signal when you have not yet published your work (if you have please post a link).
“No, I have not done any calculations of that sort, have you?”
OK, that’s fine, because the computations aren’t probably needed if you just think about the issue carefully, and look at the typical numbers of cores sampled at tree ring sites, and the likelihood of getting the types of mean inter-series correlations reported at the ITRDB with any sort of autocorrelation generating process. So, have you done that?
“Why does it need to be AR1, are you saying that it is the correct model for tree ring chronologies!?”
Well, you need to ask Steve that question. He (and others) are the ones promoting this idea, so you might do well to ask them what they mean exactly (as I have, here), don’t you think? I’ve asked him what his null model was already, twice.
“For those unfamiliar with Jim’s jargon, the fancy sounding Nash-Sutcliffe Efficiency “test” is simply hydrology term for coefficient of determination in statistics…”
It’s the Coefficient of Efficiency (CE), the originators of which were Nash and Sutcliffe (1971), and by which it is sometimes referred, or abbreviated as NSE.
I think we are talking past one another here. The reference to selecting HS like trends from an AR1 model ( I prefer an ARFIMA model) series comes from these series having relatively long trend like segments originating in series that has no deterministic trend by design. One can view these series with upward (and downward) ending trends that approximate the trend we see in the instrumental temperature series. What Bouldin’s is referencing is the inter annual correlation of proxies to each other and the instrumental temperature. He is saying, I think, that you will not match the actual inter annual correlation with the AR1 or ARFIMA model series. The more noise the series have the less likelihood of a match above chance.
My argument with Bouldin is that the inter annual correlations are no guarantee that the proxies will respond to long term trends in temperature as we see from the divergence problem. As I stated on this thread before you can wiggle match the tree ring and temperature (and with other tree rings) at a given year but not necessarily at near the same magnitude. The key to a proxy being a valid thermometer is whether like a real thermometer it does not merely respond up and down with temperature but at some reproducible amount and to just temperature and not some other variable.
We were having a discussion with Jim Bouldin at TAV on this very subject but he was not able to finish it. I was pointing to the Mann (08) tree ring proxies and the poor correlations (inter annual ) of his 900 plus tree ring proxies. Only 25% passed Mann (08) pre-selection criteria of p=0.13 for correlation and those that passed had correlation with the instrumental data of approximately 0.20.
Craig,
At issue is this ongoing blog contention, raised here again by Steve, that a strictly red noise generating process–apart from any actual relationship with the climate variable of interest–is responsible for the types of correlations seen in (1) this study by Gergis et al, and (2) more generally in dendroclimatology. The fact that there are other reasons why you might get a spurious correlation is beside this point, and not all would be relevant here even if this were not the case, as e.g., bristlecones are not involved in Gergis et al and are a very small fraction of the total tree ring sites more generally, as are Yamalian Larix.
Hopefully there will be time at some point to discuss your “third problem”, because this too is easily misunderstood and is potentially addressable with the right analysis methods, particularly related to the temporal scales of the phenomena you cite.
And unrelatedly, maxberan is exactly correct on the Nash-Sutcliffe point.
Jim,
you’re mis-construing what I said on a number of counts.
First, the point is not directed particularly at site chronologies, but at multiproxy studies.
Second and the nuance is important here, if the true signal were a hockey stick, then you can “get” a hockey stick without using a flawed method e.g. by averaging. Ex post screening is a flawed method but there are other flawed methods.
One of the bad attributes of CPS methods is that if you have a network of 1-2 h0ockey sticks plus 40 low-oreder red noise series, the CPS reconstruction gives you back the original hockey stick plus a little fringe of noise. So the validity of the “reconstruction” is no better and no worse than the validity of the 1-2 active ingredients. In many cases, the active ingredients are a very few number of series – strip bark bristlecones, Yamal, the Yang CHina thingee,… If these are magic thermometers, then the recons are also magic. But then the $64 question is showing that they are magic thermometers – reconciling to all other info in the region, an exercise unfortunately neglected in the field.
Kenneth, at 5:26 PM:
“I think we are talking past one another here. The reference to selecting HS like trends from an AR1 model ( I prefer an ARFIMA model) series comes from these series having relatively long trend like segments originating in series that has no deterministic trend by design. One can view these series with upward (and downward) ending trends that approximate the trend we see in the instrumental temperature series. What Bouldin’s is referencing is the inter annual correlation of proxies to each other and the instrumental temperature. He is saying, I think, that you will not match the actual inter annual correlation with the AR1 or ARFIMA model series. The more noise the series have the less likelihood of a match above chance.”
Completely out of time now have to go. The main point I am making is that you will very rarely, if ever, get a TR chronology, (each year being computed as the robust mean of the indices from the set of the cores sampled in those years), that correlates at some standard p value, or even Craig’s elevated p = .1, and passes whatever verfication stat you like (RE, CE, KGE etc) by a red noise generating stochastic process alone.
Will have to pick it up later.
Jim Bouldin, you say repeatedly that these problems can be fixed with the “right” methods. The question is, have they been fixed in the existing literature? I don’t think so. Which papers show the right methods? Mann used PC methods that heavily weight bristlecones or another small set of trees, local trees are selected if they match hemispheric trends, the divergence problem is discussed but not resolved, etc. While bristlecones and Yamal are a small subset of all data, they are used repeatedly in multiple studies and when dropped from a dendro analysis there is often no hockey stick.
You claim that the excellent agreement of local trees with each other precludes a false correlation with climate, but I gave you several ways this could happen in a post today and I know for a fact that most trees respond more to precip than to temperature. There IS an inherent lag or autocorrelation in stand growth–if the stand has good growing conditions but gets overcrowded, there will be a long mutual slowdown in growth until some trees die. This will occur across the local forest if the area was all established at the same time after fire for example.
Thus there are ways to get a red noise type effect in a group of trees and I gave others elsewhere today.
“The main point I am making is that you will very rarely, if ever, get a TR chronology, (each year being computed as the robust mean of the indices from the set of the cores sampled in those years), that correlates at some standard p value, or even Craig’s elevated p = .1, and passes whatever verfication stat you like (RE, CE, KGE etc) by a red noise generating stochastic process alone.”
That may be – but I have not seen that statistically tested in the literature that claims to generate robust temperature reconstructions. The tests that have been done – when done properly – can not reject H0 that the series in question are merely red noise. The claimed significance is spurious and based on an incorrect application of statistics to stochastically trending series. Tests may exist that rely on your observed cross correlations that may prove something relevant – but those are not the tests that have been done.
(And I am not initially convinced about the meaning of the cross-correlation. In this I think of stock markets. There are thousands of stocks that have been analysed over the minutest time scales and many purported patterns have been found and then subsequently found to be evanescent. All the stocks quite clearly correlate with something and they all correlate with each other, but what that something is and what it means turns out to be remarkably elusive.)
CPS does such a poor job (even Mann 08 admits to this compared to their errors-in-variables method) that I’m amazed anybody is still using it. Maybe if they submitted their code and data, they’d get useful criticisms and they’d stop making egregious errors.
If you compare Mann CPS against other “modern” well-designed proxy reconstructions, you find it whistles it’s own tune.
(This is Pearson correlation coefficient in a sliding 300-year rectangular window. )
Steve: There’s no theoretical reason why errors-in-variables is “better” and I’m not convinced that it is.
maxberan (Jun 1 19:27), can have also negative values as correctly observed in the preamble of the article.
can have also negative values as correctly observed in the preamble of the article.
no, Wikipedia is not in error here,
I don’t see any difference in the definitions given in Wikipedia. Substitute –>
–>  and
and  –>
–>  and you get:
and you get:
![SS_{tot}=\sum_t[(Q_o^t-average(Q_o))^2]](https://s0.wp.com/latex.php?latex=SS_%7Btot%7D%3D%5Csum_t%5B%28Q_o%5Et-average%28Q_o%29%29%5E2%5D+&bg=ffffff&fg=000&s=0&c=20201002) and
and ![SS_{err}=\sum_t[(Q_o^t-Q_m^t)^2]](https://s0.wp.com/latex.php?latex=SS_%7Berr%7D%3D%5Csum_t%5B%28Q_o%5Et-Q_m%5Et%29%5E2%5D+&bg=ffffff&fg=000&s=0&c=20201002) , and hence
, and hence
![R^2=1-\sum_t[(Q_o^t-Q_m^t)^2]/ \sum_t[(Q_o^t-average(Q_o))^2]](https://s0.wp.com/latex.php?latex=R%5E2%3D1-%5Csum_t%5B%28Q_o%5Et-Q_m%5Et%29%5E2%5D%2F+%5Csum_t%5B%28Q_o%5Et-average%28Q_o%29%29%5E2%5D+&bg=ffffff&fg=000&s=0&c=20201002) ,
,
which is the same as the definition for “E” here as far as I can see.
Jim Bouldin (Jun 1 17:10),
I’m not interested in “thought experiments” instead give a clear mathematical explanation why spurious regression may/is not occuring with regards to tree ring chronologies. You asked me if I had done calculations along those lines, I have not. But it seems that you have not done that either, and all you have to offer is some rigorous handwaving.
AR1 is proposed in some circles as a model for noise mainly in temperature series, but I’m asking that if you are also proposing that AR1 is an adequate model for “noise” in chronologies. To be precise, are you saying that a model , where y is a chronology,
, where y is a chronology,  (local) temperature and
(local) temperature and 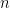 is AR1 is a good statistical description of a chronology?
is AR1 is a good statistical description of a chronology?
No, it is not if the definition given for NSE is correct in Wikipedia or, e.g., here (which is somewhat wrongly calling the correlation coefficient as the coefficient of determination). Using definitions given in NRC report, it is seen that NSE is the same as reduction of error (RE) of paleoclimatogists, which is the same as the coefficient of determination in statistics.
Steve on Jun 1, 2012 at 5:56 PM,
There are in fact eleven d18O temperature profiles from Antarctic glaciers over the past 10,000 years. rather coarse resolution, but most show a cooling over the past 1,000 years:
Click to access masson.pdf
The borehole temperature / d18O controversy can be resolved, as the borehole temperature gives the local temperature at the borehole site (worse accuracy back in time), while the d18O or dD shows the sea surface temperature at the origin of the water vapour + air temperature at the condensation area, thus reflects the temperature of a much larger area. That may give opposite trends over time…
“The main point I am making is that you will very rarely, if ever, get a TR chronology, (each year being computed as the robust mean of the indices from the set of the cores sampled in those years), that correlates at some standard p value, or even Craig’s elevated p = .1, and passes whatever verfication stat you like (RE, CE, KGE etc) by a red noise generating stochastic process alone.”
I’ll attempt to give my views on this issue here and as succinctly as possible.
The medium to lower frequency structure of many proxies looks similar to series that can generated by ARIMA/ARFIMA models and in fact a number of proxies fit well with these models. Those models can produce longer segments that are indistinguishable from deterministic trends when just that segment is considered.
Proxies and particularly tree ring proxies can have higher frequency structure that can produce reasonably good inter annual correlations. Those good correlations do not, however, make those proxies valid thermometers as that requires matching reasonably well the longer term trends measured in the instrument period. In fact it can be shown that proxies with reasonably good inter annual correlations can actually diverge from the instrumental temperatures. Since proxies and reconstructions acting as useful thermometers require reasonably longer term matches to temperature trends, the inter annual correlation does not define a proxy as a valid thermometer.
A pre-selection process from several runs of synthetically generated series using ARIMA/ARFIMA models would obviously allow “finding” upward ending trends in a series simulated without one. Even if proxies are not completely characterized by ARIMA/ARFIMA models the chance generation of longer segment trends could be a character shared by both. In that case pre-selected proxies with upward ending trends for proxies is a distinct possibility and one to be considered if biasing the results is to be avoided.
Even though on the surface the pre-screening in Gergis et al 2012 (detrended inter annual correlations) would appear to be of a characteristic that should not be used to qualify a proxy as a valid thermometer, biases generated by the pre-selection used in that paper cannot be analyzed without knowing exactly what was selected and what was not and exactly how the selection rules were applied.
Jim Bouldin:
I just wanted to make it clear that all you need is a noise spectrum that has a 1/f^nu, nu > 0 behavior in order to reproduce the hockey stick shape (artificially flattened tail), and that this spectral shape is present in the real data that are being selected. You can also use the measured noise spectrum as the basis for Monte Carlo’ing the effects of the “red noise”. That’s the approach I use and it seems to me “as good as it gets”.
Steve:
it does match up much more closely with other “modern” reconstructions, including Loehle, Moberg and Ljungqvist, so from pragmatic considerations, we have evidence it works better. But I agree this is an issue that needs to be carefully examined.
I’ve parsed the linear algebra of Mannian EIV and it’s weirder than we thought. I think that I alluded to some of these features in a post pre-Climategate, but I haven’t fully discussed it. Because of these weirdness, I don’t think that it can be considered a “better” method, but I haven’t fully expounded this.
these “modern” reconstructions each have their own problems. Their methodology, in linear algebra terms, is more like CPS than EIV as well. I don’t place any weight on “similarity” between reconstructions as evidence of methodological validity as there is an interaction with choice of proxies.
“Jim, you’re mis-construing what I said on a number of counts. First, the point is not directed particularly at site chronologies, but at multiproxy studies.”
Steve, please. The issue of spurious correlation with tree ring chronologies is a site-level phenomenon, since the vast majority of studies correlate the site with local climate data.
“Second and the nuance is important here, if the true signal were a hockey stick, then you can “get” a hockey stick without using a flawed method e.g. by averaging. Ex post screening is a flawed method but there are other flawed methods.”
Well, that’s a red herring, because that’s not the issue you raised here. That’s a separate question, as are all of the succeeding points in your response.
ONE ISSUE AT A TIME PLEASE
SteveM:
Yes I remember some of that. We’ve used EIV successfully for our work (several variations on it in fact) and it didn’t seem particularly difficult to code up at the time (ground truth helps a lot of course), so I’ve (naively perhaps) assumed that Mann could implement the method correctly. There’s also the issue of the proxies selected in Mann 08, if I had an objection to taking Mann seriously it would be from there. [I’m not sure this is the place for me to be totally honest why I’m including Mann 08 EIV… it’s a type of “sensitivity study”, let me leave it at that.]
As you probably noted, I’m also comparing the other series with Loehle (2007), who “obtained data for long series that had been previously calibrated and converted to temperature by their respective authors,” so that reconstruction at least should not suffer from any problems of CPS. Please correct me if I’m wrong. I also don’t see Ljungqvist as suffering from the same problems as the others, perhaps you can comment on too.
Thanks in either case for your remarks,
Carrick
I am a big supporter of “simple” methods. If there really is a “signal” then it should emerge by averaging. At the end of the day, multivariate methods just assign weights to the proxies. If they are proxies, you should know the sign ex ante and orient them accordingly. As eigenvectors are added in the EIV algorithm, some proxies will get assigned negative weights (that shouldnt have negative weights) detracting from the signal. If they are proxies and you know the sign, then the eigenvector 1 will give the “best” weights. Because Mannian EIV uses multiple eigenvectors, it can give odd results.
I would also prefer that “new” studies focus on data that actually is “new” rather than mixing in new data with bristlecones and Yamal. Otherwise, it’s very time consuming to determine whether there actually is any fresh information in the new study or whether you’re just getting bristlecones and Yamal in new clothes.
I haven’t parsed Ljungqvist’s recent study (he’s been very cordial with data), but it looks to me like he screens from a larger network. And he uses bristlecones and Yamal and other proxies with very known properties. Whether there is anything “new” in his most recent study, I dont know.
SteveM:
That’s pretty much our philosophy too. We developed the other methods because they gave less biased estimates of the position in our triangulation algorithms used for gun-fire localization. There was, as you can imagine, a trade-off between speed and how good a job the algorithm did of removing bias. (Eventually the sponsors requirement was real-time algorithms as you can imagine.)
It turned out that source direction was more important than range (which is where the bias was showing up in simple OLS-based methods), so we used a hybrid method where the uncertainty in the microphone positions were treated in an approximate, first order fashion, rather than using the full framework of EIV.
There are a few cases where more sophisticated algorithms can improve your detectability of a signal. These usually (ironically to me anyway) are methods that leverage on our understanding of the noise that is interfering with signal detection. Gaussian white noise, there is little you can do anything about, but real-world noise is “bursty”, and the idea is to measure between the “bursts”. (I have a colleague who developed the “fluctuation based” method. Originally it was used for submarines, and there was a period where it was so deeply classified he didn’t even have access to his own notes… long story.)
But generally I agree with your comments here. The algorithm needs to be robust against “sign flips”. You need sufficient meta data that you prescreen your specimens based on other metrics besides correlation. More complex algorithms tend to resemble Rube Goldberg machines. And only if you think Rube Goldberg machines are “elegant” do these algorithms resemble anything “elegant”.
Carrick
Steve – I think it’s time for some standard “grades” to be established for research. The lowest grade, let’s say “general”, is the way they do things now. Anything goes, and spaghetti code is ok. This is acceptable for research with no particular end use in mind.
Commercial grade would be for industry funded research. There would be some boilerplate standards, but most of the standards would be negotiated between the funding party and the researcher.
Perhaps some other grades as well, but the top grade would be “public policy grade”. Any research whose results are used to advise public policy would have to conform to this grade. Part of the requirements would be that public policy grade research could only use public policy grade input. Then all the archiving and public access requirements (among others) cold be rolled into the grade requirements.
It wouldn’t matter who is funding it; if it’s to be used to advise public policy, it would have to conform to public policy grade research standards.
I can dream, can’t I?
@ Che (Posted Jun 1, 2012 at 4:11 PM )
That would be ‘change’ I could believe in. Hope it happens.
An old blog of Gergis’has surfaced on several Australian websites which clearly shows her as being a long term green activist with a huge emotional involvement in one side of the climate debate.
http://joellegergis.wordpress.com/
Reading it, I think expecting her to behave as an objective scientist is a tad optimistic.
Wow, the blog has been deleted
That’s climate transparency for you.
Yes, transparent as in “invisible.”
Re: Shona (Jun 2 04:39),
as said in earlier comments, it is still all preserved here and here.
I just happened to take a stroll through one of Gergis’s blogs and happened upon this article which may not yet have been noted.
http://www.cosmosmagazine.com/opinion/no-more-climate-distractions/
Obliterated.
http://wayback.archive.org/web/*/http://joellegergis.wordpress.com/
This one from JeanS works, but it takes a couple of seconds to load:
http://web.archive.org/web/20110207232359/http://joellegergis.com/
And CS wonder why they have such a hard time having the regular peoples trusting them? If Dr. Allen is still reading here, here is the perfect example.
re DeNihilist Jun 2, 2012 at 12:07 PM
Considering that in the previous thread, Allen had requested that Steve replace his initial “response” to Lucia (elevated to the headpost at his own request) with a much later one, there is some doubt in my mind as to whether or not Allen would fully appreciate the depth of our concern regarding Gergis’ behaviour.
I also note that by her actions, Gergis has put paid to my very tentative hypothesis regarding some differences between male and female climatologists 😉
Re: ChE (Jun 2 11:26),
I hope someone archives this. Archive.org is not permanent/secure. It too may soon disappear.
Presuming that Steve’s main concern is with the statistical “damage” of pre-screening it may not be necessary for him to be sent the raw data of the missing 35 themselves but just some salient statistics sufficient for simulations to be run on the consequences of selecting the top 27 from a base sample of 62. So maybe a request for such summarising statistics would satisfy the putative need to protect the interests of the data originators – I’m thinking p values, trend coefficients, and serial and inter-tree correlations. It may not even be necessary to identify individual sources for such an exercise that would establish limits on the impact of pre-screening on the reliability of the author’s conclusion.
Maxberan
What does your comment above “…the putative need to protect the interests of the data originators…” refer to ? Seems to be some kind of justification for secrecy… What interests are these? Thanks.
I guess I could have written “stated” and avoided any implication of the sort you detect. What was in my mind was the monetary value of some types of climate data, this being what is behind many refusals for data sharing.
It is an unfortunate fact of recent life that met data comes at a price especially if supplied by a central agency such as the UK Met Office. The justification is that the agency has added value to the raw data by running it through quality control checks. This charging policy is sanctioned by the World Meteorological Organization and is now quite ubiquitous; the USA is unusual in that the NWS makes data freely available.
However I seriously doubted that tree ring or coral data would have market value so there must be some other reason.
And these value would be calculated by the very same people who have demonstrated such a poor grasp of statistics in the past?
How would one be able to check the veracity of the statistics?
“The compilation of this database represents years of our research…”
Among the array of fallacies Climate Science uses to justify things, the Appeal To Time really ticks me off. 😉
Andrew
bad andrew! bad andrew!
oh wait, that’s the other guy…
Did Myles miss an opportunity to name and shame in 2009, when Phil Jones was secretly sharing protected information about FOI requests? See: http://climategate2011.blogspot.com/2011/11/4945txt.html ?
There is an interesting statistical test used for checking proprietary trading strategies called Whites’ Reality Check. Effectively it is a Monte Carlo simulation of all possible trading strategies at the meta level applied to random noise. By examining the universe of results of all meta decisions, you can determine the statistical significance of any particular result. I think it would apply very well to these types of reconstructions.
http://www.secondmoment.org/articles/datamining.php
This is the sort of approach I had in mind with my 8:27 post. Essentially what one is doing is constructing a tailor-made t-test for the specific sampling strategy. But to make this convincing the random noise generator has to share key features of the population of observed data such as time series and correlation structure, hence my suggestion for a modified request for information.
I have some experience of this with hydrological data where quite innocent sounding data selection strategies turn out to have a seriously biassing effect, lowering the bar on the significance test to allow the researcher to report a positive effect. One example was allowing an extreme event to prompt analysis, another was shared unimodality of input and output, a third amounting to employing a one-tail test where the sign of the association was not prestated (shades of Tijander), a fourth related to data mining when searching teleconnections where the locations are not pre-stated on physical grounds but allowed to emerge from the analysis.
In the Gergis case quoted by Steve, apart from the site selection, I note that the target temperature series was for a specified subset of months. This also amounts to a hidden selection whose effect needs to be incorporated as the period was probably determined post-hoc and in any case needs accounting for when scaling up to quote whole-year conclusions.
The deep-down problem is the reluctance among climate scientists (and environmental scientists more widely) to involve (and share the glory with) statistician colleagues down the corridor, a key finding of Wegman. In most cases long-term consequences are minor as other workers fail to replicate the finding so it just fades into oblivion. The tragedy of global warming is that it has such a head of steam behind it that this normal ineluctable decay process isn’t allowed to happen and we keep getting the old “worse than previously thought” press release so bad science joins the onward march of the living dead.
Correct, you would want to have a model for the data. You can use actual data, but you don’t have much of it. If you create a model you can run many chronological histories as well as vary the parameters in your study. This is another kind of common bias – optimizing over one or two events in the actual historical data.
Most of the time using random noise data is enough to show that the results of these types of data mining is not significant.
Here there is some type of tree growth model I guess, so it’s not pure data mining. You should be able to posit a physical model and really test it pretty well experimentally. There are lots of trees. Picking and choosing good and bad trees based on historical data match to temperature sounds about as bad an error as you could make for this type of study.
You can keep the data hidden as long as you like, but you can’t then expect to be taken seriously by the public until it is released. If the situation is as time sensitive as the climate community says, and the consequences to all of humanity are as stark as they claim, why worry about the petty concerns of a few pampered individuals? All the data must be immediately released for the good of humanity.
Unless someone has posted it before and I’ve missed it, the paper is here. H/T HaroldW at Bishop Hill.
Michael Kottek, I’m not an alumnus of Melbourne Uni, but I am (was) an Australian scientist (now retired). If you want any backup or wish to put in a joint FOI submission please email me at grantsb48 AT gmail dot com. This sort of arrogant and pretentious BS is an embarrassment to science and must stop.
Now why do you suppose that the statistical creativity shown in other climate papers has not been applied to the detection of temperature sensitivity in tree rings? With only a smattering of dendro myself, and a low level of statistical sophistication, I can think of a few candidate approaches that might get rid of the red noise issue. Another interesting aspect of this debate is the seemingly arbitrary cut-off point (at least between papers if not within them). If it is true that trees show varying sensitivity to temperature, it follows that one tree in the population is most sensitive. Why add 26 noisier data sets? Perhaps we should be celebrating and not maligning YAD 061!
Valérie Masson-Delmotte “(CLA of the paleoclimate chapter of AR5)” has honorably
See her public CV and contact details
“This is commonly referred to as ‘research’.”
Climate science seems to me to be characterized by:
– Circular reasoning.
– Nastiness.
I recommend everyone view the YouTube video Steve references if you want some indication of, if not the current state of climate science, then it’s future:
Re: “Gergis et al 2012 and the “Screening Fallacy””
Pretty sure you (and the others you link to) are wrong on your thesis in that section but, just to make sure I correctly understand your argument, your null model in your example, for the time series of the tree ring response variable of interest is “autocorrelated red noise”, by which you mean some (unspecified) degree of lag 1 autocorrelation.
Correct? And if correct, care to specify that value?
Steve: I’ll ask Jeff Id what he used in his graphic. I’ll look through my scripts from 7 years ago or so to see what I did re Jacoby. The effect increases as the autocorrelation increases. As I recall, in some networks, the effect was not dissimilar to Mannian short-centering. The downstream part of the argument plays out the same way as well. An erroneous method doesn’t mean that you can’t “get” a Stick using a “correct” method (though I dispute that Mann salvage methods qualify as correct methods). It merely means that the study has used a flawed method and should be redone. As I noted in the post, detrending may mitigate the “screening fallacy”.
There are some other puzzles in Gergis now that I look a little closer. There are only two long series that met the screening criteria _ Tasmania and Oroko. Both used in Mann and Jones 2003, which was criticized behind the scenes in CG. Law Dome is another long series (where I have the data). I can’t figure out how their screening actually was implemented – in a replication sense.
“…The effect increases as the autocorrelation increases. As I recall, in some networks, the effect was not dissimilar to Mannian short-centering. … An erroneous method doesn’t mean that you can’t “get” a Stick using a “correct” method … It merely means that the study has used a flawed method and should be redone. As I noted in the post, detrending may mitigate the “screening fallacy”.”
It’s good that you added that note later, because it definitely nullifies your argument wrt Gergis et al getting “hockey sticks” due strictly to presence of red noise. And yes, I agree that the effect increases as the ac increases. Indeed, your argument depends strongly on a high lag 1 ac.
However, wrt more general arguments on this issue, I still need to know exactly what your null model is in your argument wrt to the time series of the ring response.
I’ll have to look up a script. My own analysis on this was pre-blog and I haven’t looked at this line of argument for a number of years.
In my experiments I would have used AR1 coefficients calculated from Jacoby tree ring chronologies in their network or from the NOAMER network. I probably did some arfima experiments as well.
The modeling of red noise brings up some issues that arose in the short-centering discussion. Ritson, for example, argued that the calculation of an AR1 coefficient from observed results would over-estimate the AR1 coefficient of the “noise” since the “signal” would have its own AR1-ness. I’m not convinced by this line of argument but note it for the record. Also the style of arfima calculation that I did in 2005 has been criticized on similar grounds. This sort of argument doesn’t alter the existence of the bias from short-centering, only the degree.
Red-noise is in general just noise that has a 1/f (or 1/f^nu for some conventions) power spectrum. Temperature and the real proxy data have this characteristic (otherwise the proxies wouldn’t have a hope of replicating temperature.)
Detrending removes the very low-frequency portion of this, but correlation isn’t particularly sensitivity to that in any case (if you have a constant trend, by construction it is insensitivity to it), so it’s not clear that deterending will meaningfully help the issue with prescreening of data.
Jim makes a lot of claims, it’s not been my experience that many of them pan out when you look at them in any detail. YMMV.
Jim Bouldin says..
Steve said in the post:
I took the above immediate blockquote to be Steve’s “thesis” in that section. To my mind, the specific analysis he (and others) use to demonstrate the incorrect nature of the method is almost immaterial. It’s quite humorous to me that you can get hockey sticks from red noise, but that actually comes across as just a happy irony.
The method is wrong because it fails to provide a path to first physical principles, no caveat full stop. Finding autocorrelated proxies to a instrumental record should be only the first step in understanding how that historical proxy responds to the one variable in question. When multiple variables affect a proxy (as is the case with tree rings and numerous other proxies), you can really only use correlation to tell you what specific proxy records to analyze further for a physical description of how they responded. You cannot simply jump to say that because the correlation to one variable was so good in time X, that it therefore must have been correlated in time X-500. You must at the very least demonstrate that no time-dependencies exist w.r.t. the other variables of the proxy, to say nothing of a final relation to that which is measured.
You cannot avoid the basic physical questions by simply running corr(A,B) in Matlab and calling it historical temperature. Hand-waving your physical model doesn’t buy anyone anything either. Until someone shows a basic equation of growth for a specific species of tree, then solves this to effectively remove signals from everything but temperature (good luck with that PDE), then shows how well their equation works when compared to experimentally grown trees… anyone with an understanding of how seductively statistics can fool us into believing that up is down will question this methodology of paleoclimatologists. Believe me when I say that I understand the bitter flavor of complexity to what I am suggesting is a slap in the face, but it’s safer to accept this from colleagues than nature.
Jeremy sez “It’s quite humorous to me that you can get hockey sticks from red noise, but that actually comes across as just a happy irony.”
Agreed. “Getting” the “right answer” from a data series should depend on selecting the data series BEFORE doing the statistics. Otherwise some (not all ) noise will “get” you desired similar results, as will some upside down data, as will some completely unrelated ironic data records tracking crop prices, women’s skirt’s hem line lengths, and mortgage failure rates in Iowa. If you’re allowed to pick from among ANY KIND of long term data that overlaps your short term instrument record, find a match, and project it back, you’ll wind up with hockey stick flat handles and sharply rising blades. The data characteristics of the historical data may be red or white, stationary or not, or even falsified. Until the provenance and physical relationship is established the “proxy” should not be used and if any proxy IS used, the results of that proxy (matching or not) should be reported.
The Gervis study says their target area is 0-50S, 110E-180E, yet they include two proxies from Vostok(78S, 107E) which is 3100 km outside the southern boundary of their target area. Then instead of using the 400,000 year Vostok ice core record, they use ice pit data going back only to 1774.
I couldn’t find a reason given for inclusion of Vostok data at all or their proxy preference. One might suspect Vostok improves the overall study metrics.
One might make a similar comment upon the inclusion of Rarotonga (2 proxies of the 27) at 160 W longitude, or Palmyra (the only coral record prior to 1600), also around 160 W longitude.
Indeed, the excellent Figure 1 shows that mainland Australia, the elephant in the region, is represented only by 2 coral proxies off its west coast. And half of the corals in the study are within 10 degrees of the equator, for which seasonality is likely to be muted.
It would seem to reinforce the notion that Southern Hemisphere proxies are in much shorter supply than Northern Hemisphere ones.
Craig Loehle
Re: “A third problem can occur when changes in rainfall over a few decades give a growth response that seems to match a temperature response (precip and temp changes are correlated) . . .in a way unrelated to temp but correlated with it.“
Note the rainfall versus temperature trend appears to be OPPOSITE in the temperate regions than in the tropical region. This may impact how trees correlate with temperature in the temperate vs tropical regions.
See: Willis Eschenbach, Natural Variability in the Widths of the Tropics, at WUWT May 25, 2012
See especially the Change in Rainfall with Temperature
Willis cites: Satellite-based global-ocean mass balance estimates of interannual variability and emerging trends in continental freshwater discharge Tajdarul H. Syeda, et al. http://www.pnas.org/cgi/doi/10.1073/pnas.1003292107
However, discharge needs to be corrected for increasing irrigation.
Citation: Konikow, L. F. (2011), Contribution of global groundwater depletion since 1900 to sea‐level rise, Geophys. See also: Hydrol. Earth Syst. Sci., 15, 3785–3808, 2011 http://www.hydrol-earth-syst-sci.net/15/3785/2011/ doi:10.5194/hess-15-3785-2011
For the record, I have had totally the opposite experience with Fredrik Ljungqvist. I’ve contacted him in the past and re-contacted him today. He has been promptly helpful and consistently cordial.
At BH, Frank says that because they detrend the target instrumental data before screening, the ‘bogus hockey stick effect’ goes away. Thoughts?
Steve: I had already pointed that this might mitigate the error in this case earlier this morning:
However, there are only 3 long series available. One of them – Law Dome O18 – has a very pronounced MWP and was excluded, while Vostok O18 was included. My guess is that Law Dome O18 would by itself make a difference. It was a bit of a battleground issue in Climategate emails, where Osborn and others twisted themselves into knots rather than show Law Dome in their proxy graphic.
Correct, that’s one problem with the argument. But there are other, more widely applicable reasons why the argument is bogus for tree rings in general, not just for this Gergis et al study.
Steve: Jim – for those of us who have disabled threading, which comment are you responding to?
“Steve: Jim – for those of us who have disabled threading, which comment are you responding to?”
Paul Matthews at 12:07
Specifically, was responding to this statement:
“…because they detrend the target instrumental data before screening, the ‘bogus hockey stick effect’ goes away. Thoughts?”
Detrended instrumental data would imply detrended proxy series were used in a selection process that was based on correlation between detrended series. If this were the case, I would suppose that it would allow the use of proxies that followed the high frequency of the structure of the instrumental series, but had differences in trends in the instrumental period with temperature anomalies, to be used. This would not be much different than the calibration/validation processes used in reconstructions where the r values based on annual series are used.
I have had a quick look at the paper under discussion here and it would appear to be rather unexciting with regards to the recent warming being unprecedented except for the final few years of the reconstruction as shown in the graph. The reconstruction appears to end around 1995. The grouped proxy correlations with the instrumental series reported in the paper appear to me to be much higher than I have seen in other papers reporting reconstructions, e.g. Mann (08).
Interesting that the paper pre-selects proxies and than does extensive statistic analyses on those pre-selected choices. Kind of like putting lipstick on a pig.
shub at Bishop Hill’s blog has an interesting comment: detrending only shows the interannual variability in temperature, which may correlate with some of the series (like tree rings) to a certain degree. But selecting these short-term correlated series doesn’t implement that these are good proxies on longer term temperature. Think of tree rings which do change in width from year to year with temperature (and precipitation) at any temperature level, but show an upside down U-shape distribution for wider changes in temperature over longer term. Short-term correlation doesn’t imply long-term correlation…
“shub at Bishop Hill’s blog has an interesting comment: detrending only shows the interannual variability in temperature, which may correlate with some of the series (like tree rings) to a certain degree. But selecting these short-term correlated series doesn’t implement that these are good proxies on longer term temperature.”
I agree with this statement as it is easy to show that a good correlation between two series can be obtained and at the same time these series would produce a difference series having a significant trend. Having said that that is not the issue with the pre-selection process – that problems is pre-selection. And that problem is further aggravated by the lack of nowing exactly what was not selected and for exactly what reasons.
While some tree ring series can be wiggle matched with each other and instrumental temperature data, the problem becomes that the magnitude of those wiggles do not match. The temperature signal is only a fraction of the overall effects which can be many in number and not react quantitatively in concert with temperature.
So far the validity of temperature has been understated. It was my understanding that at least some of the earlier Tasmanian dendro work had become regarded as not useful because of the quality and separation of the temperature data in Tasmania.
Note that the Australian BOM has recently released a new temperature data set version named Acorn-SAT. Presumably proxy calibrations done against it will differ to earlier – though not many of the final proxy sets used by Gergis et al in the most recent paper are upon the Australian mainland, to which most of Acorn-SAT applies.
New Zealand appears to have an unresolved problem with its historical temperature records.
Let’s not get too involved with statistical theory until all are happy with the temperature data. That is why I would like to see what was culled from the Gergis paper.
Oh Gav i says why are you so upset lovely boy?
Well Stace Im a Climate Scientist and there’s this really cool video out and they didn’t ask me to sing.
Oh Gav dunt you worry now I’ll write some rappy crappy lyrics you and The Team can sing, it’ll go viral love you wait and see.
Ise a reAL f****ng climate scientist
Don’ya f***i*g know
Da ball isa f****ng warming
Making more snow
Sho na data Mann
Sho na data Mann
Coz ise real f***ing climate scientist.
Don’ya f***i*g know
Oh Stace you are brilliant. Hey Gav I know.
These people use methods of phrenology in climatology.
Steve –
Have you asked for (or received) the software which performs the detrended correlation of Gergis et al.? The code presumably belongs to the authors and not other researchers.
Joelle Gergis:
“We have already archived all the records needed to replicate the analysis presented in our Journal of Climate paper with NOAA’s World Data Center for Palaeoclimatology.”
False. Your analysis involves an act of selection among 62 datasets. Unless you have archived those 62 datasets no one can replicate that act of selection and therefore no one can replicate your analysis. Put another way, you chose 27 of the 62, but no one can check that you should not have included any or all of the remaining 35.
I’m not a scientist but this seems so thumpingly obvious on an analytical level that I cannot understand how climatologists continue to get away with this kind of behavior! Any first semester stats or physical science course should make it obvious to anyone that this kind of behavior is un-scientific. How do they report it with a “straight face” and how does the “community” of scientists allow them to get away with it??
This might prove to be quite challenging for the authors, considering that the IPCC guidelines often, well, diverge from the IAC recommendations.
As for the Gergis dance of delay** … it occurs to me that it must be most fortunate for the authors that the data they did use and (presumably) publicly archive was not subject to the same “confidentiality” concerns.
**A parody of Tom Lehrer’s Masochism Tango is called for, methinks!
Part of the point is, of course, that they “did use” all the series.
Very true! But I was using (!) her, well, apparent redefinition of “use” 😉
How convenient(and ironic) for Gergis that, when she contacted other researchers for permission to use their data in her research, she wasn’t told, ” We’ve got years tied up in gathering these records. Go do it yourself. It’s called ‘research.'”
re: “… This is commonly referred to as ‘research’.
We will not be entertaining any further correspondence on the matter.
Regards
Joelle
–
Dr Joelle Gergis
Climate Research Fellow”
And that is commonly referred to as ‘Reaction from one who is afraid of their data analysis facing scrutiny.’
The gracious Joelle Gergis has deleted her entire blog since yesterday. http://joellegergis.wordpress.com/
Someone saved it before she deleted it. Wonder what she’s hiding.
Steve: It’s a testament to the power of your blog that you can make a warmist blog disappear.
Here’s the site where her blog was cached from a link at Australian Climate Madness:
http://www.webcitation.org/67j0qvxbP
Unless I’m reading it wrong, it looks like all the archived material under “pages” in the right column has been deleted.
Curious?
Then you may be interested to know that her blog site has been archived by the Internet Archive Wayback Machine: http://web.archive.org/web/20110207232359/http://joellegergis.com/
And in the context of her reply to you, this post is richly ironic:
2007 Finalist
YOUNG LEADERS IN ENVIRONMENTAL ISSUES AND CLIMATE CHANGE
MIND THE GAP! ENCOURAGING DIALOGUE BETWEEN CLIMATE SCIENTISTS, POLICYMAKERS AND THE PUBLIC.
“For research into the history of El Nino-Southern Oscillations and for communicating climate science to facilitate a dialogue between scientists and the public. Dr Gergis has a demonstrated commitment to communicating with the public through professional and community groups and is working to encourage dialogue between climate scientists, policy makers and the public.”
http://liveweb.archive.org/http://eureka.australianmuseum.net.au/index.cfm?objectid=4FB44DEE-C21B-A209-2277B125C645BEB8
“Dr Gergis has a demonstrated commitment to communicating with the public through professional and community groups and is working to encourage dialogue between climate scientists, policy makers and the public.”
It seems the good Dr. has given up on communicating with the public and may try her luck with policy makers. Good luck with that.
“The (he)art of climate change
September 25, 2008
As a scientist with a genuine interest in communication,”
This is funny too ….
“Not understanding the problem is almost the litmus test of being a professional climate scientist.”
Sorry Steve but this grossly exaggerates the difficulty of the issue – anyone who paid attention in high school statistics can understand it! I thought of the possibility before I understood the technical jargon describing why Mann’s method was a hockey stick generator. The “screening fallacy” is just too easy to understand: surely it couldn’t be that simple, I thought.
Unscreened noise cancels to a produce a flat result. (the handle)
The screened section presents as whatever was screened for. (the blade, in this case)
The blade just has to be there somewhere, correlated or not. I think for a lot of people the true simplicity of this issue gets lost in the noise of the more advanced technical discussion. Once layman’s terms are used it clicks.
(Anyone here know to get a comment to appear at the BOTTOM of ALL other comments, ie not in the middle somewhere (as if it’s a Reply to some existing comment?))
Eroica Jun 2, 2012 at 1:41 AM
I’m not sure, but I think that the problem may derive from WordPress and/or one’s choice of browser – and the last click of one’s mouse prior to commencing one’s comment. What you might try before your next comment (rather than reply!) is to click somewhere in the headpost, then in the “Comment” box.
1. When making future requests for data it might be a good to ask also for the temperature records used for calibration. In the few cases I’ve looked at in detail the observed record does not show a hockey-stick.
2. A point I’ve made before but it’s worth repeating. Just because calibrating red noise to a teperature record can produce a hockey-stick, it does not prove that all proxy records with a hockey-stick are red noise. Selecting a proxy record which agrees with observed tempeperature is valid; a second step, which as far I know is not done, is to demonstrate that the selected data are statistically different to the rejected data for the whole period of data extension.
Ron Manley writes “Selecting a proxy record which agrees with observed tempeperature is valid; a second step, which as far I know is not done, is to demonstrate that the selected data are statistically different to the rejected data for the whole period of data extension.”
I do not believe this strategy adequately accounts for the dangers arising from the original pre-selection which are more directly allowed for by reframing the significance test to explicitly incorporate the fact that the final subset was, for example, the best 27 from a total of 62 possibilities according to a sample correlation coefficient.
I prefer what Dr Gergis did to Ron Manley’s suggestion where she successively cuts down the muber of samples which I can interpret as a type of robustness analysis or bootstrapping (subject of course to even-handedness in that further sub-selection). But the gold-standard has to be a test of significance that mirrors as precisely as possible the actual manner of drawing samples from a larger candidate set.
You seem to have it nailed. Monte Carlo studies are popular for exactly this reason and have shown many a ‘significant’ result to be mush.
In an experimental science you just go and get new data. In a non-experimental science you can’t do that and so the problems of data snooping and pre-selection pop up all over the place. Many climatologists, however, come from an experimental science background and their statistical knowledge is based in that paradigm. The transition to dealing with non-experimental data is apparently difficult to make, but surely not impossible.
Reminds me of the joke about psychologists: How many psychologists does it take to change a lightbulb? Only one, but the bulb has to want to change. And some bulbs don’t want to change.
Not sure about your statement that “Many climatologists, however, come from an experimental science”. In the Anglo-Saxon world I see two broad categories – the “soft” climatologist with a background in geography and the “hard” climate scientist who comes to the topic through one of the sciences (though not necessarily with lab experience). The first has a descriptive bent and lots of knowledge about climate patterns around the world. It is they who populate the groups concerned with assembling databases, palaeoclimatology and also most climate change impacts. The second is more interested in physical and chemical atmospheric and Earth System processes and employ the mathematical modellers.I realise this is a bit of a caricature and one can point to many cross-over types.
Statistics though is often a bit of a closed book to both groups and doesn’t come naturally although modern geography departments do teach techniques to students so they can run a statistics package but mostly in a mechanistic way. Few would have the confidence or appreciation of eg sampling theory to construct their own test which is why discredited ideas have to await a decay process of non-replication rather than being trapped at the outset.
Historically it was the soft types who ran first with global warming often dismissed by kosher meterologists (who considered themselves a cut above the geographical climatologists). However it didn’t take long for that initially sceptical group to realise what they were missing in terms of public recognition, opportunities for travel, funding, and the warm feeling that comes from saving the planet.
By an experimental science background I meant that they did physics or chemistry or both as undergrads and that paradigm continues to shape their thinking even if they went ‘soft’ as you say. I suspect part of the closed book comes from statistics rarely being needed above the level of dealing with measurement error.
So what is an appropriate way for the institutions of science to deal with Joelle’s obstructionism ?
A three-month suspension without pay ?
“Our temperature proxy network was drawn from a broader Australasian domain (90E–140W, 10N–80S) containing 62 monthly–annually resolved climate proxies from approximately 50 sites (see details provided in Neukom and Gergis, 2011)…
Only records that were significantly (p<0.05) correlated with the detrended instrumental target over the 1921–1990 period were selected for analysis. This process identified 27 temperature-sensitive predictors for the SONDJF warm season (Figure 1 and Table 1) 228 henceforth referred to as R27."
Any trained statistician would first enquire as to why 35 out of 62 climate proxies did not "correlate significantly with the detrended instrumental target".
Since the advent of computers it is too easy for scientists and others to collect data, play with it select that which supports their preconceived hypotheses and discard that which does not. This can only be acceptable if they can then come up with valid explanations as to why the data that they have discarded did not support the hypothesis.
Sadly my scientist friends tell me that this slackness is persavive not just in climate science (and economics) but is beginning to be seen in other fields such as biology.
I wouldn’t tar economics with that particular brush. People seem to have difficulty appreciating that the thing that makes economics tricky is that it is a non-experimental science – but that is also where its current methodological strength comes from, dealing with that very fact.
This slackness you refer to has been driven out of economics. Forty years ago that may have been the case, but there have been massive strides in dealing with these issues in economics since then. Econometrics is built around the understanding that the data are non-experimental and have many and varied ways of dealing with the selection problems.
Solomon Green Posted Jun 2, 2012 at 5:32 AM | Permalin
“Any trained statistician would first enquire as to why 35 out of 62 climate proxies did not “correlate significantly with the detrended instrumental target””
Perhaps you need to put this question to Roger who states:
“However, each study represents a stripped down set of data. If someone wants all the data from the Ca 1000 billion collision events which were eventually whittled down to, say, 10 interesting events from, say, possible Higgs boson decays then they will have to wait.”
Melbourne University newsroom notes
“31 May 2010, 12.09 PM
An international workshop to reconstruct climate change history in the Australasian region is being held this week at the University of Melbourne on Monday 31 May to Wednesday 2 June 2010”
Was climate change history reconstructed just a year ago, or was it deconstructed?
Thank you for that JeanS and Roman – I was not at all aware of this generalisation of Coefficient of Determination. Sorry if I cast “nasturciums”.
The context I had studied it (and noted its departure from what I understood were the statistical norms) was close to Nash and Sutcliffe’s where I was comparing the time distribution of measured river discharge with that modelled through convolution of a unit response function and effective rainfall. This is of course far removed from regression though the f and the y series are constrained to a shared average by the use of effective rainfall in which the total input is equated to the total river flow output. In fact my own exercise explored deliberately randomised unit response functions (unit hydrographs in our jargon) to illustrate that a no-skill baseline equated to a surprisingly high value of NSE. As a result of the unimodality of most segments of discharge data selected for analysis almost any random unit hydrograph could reproduce the major features of the response and achieve a high NSE. So hydrologists should not congratulate themselves on achieving matches like 0.8.
This of course has a loose parallel with the Gergis case where accepted practices can hide nasty surprises.
I occasionally see John Sutcliffe who was my boss for a lengthy period at the Institute of Hydrology in Wallingford UK and ask whether Eamonn Nash (ex Prof at Galway and father figure of statistical hydrology in the British Isles, now deceased) and he recognised the difference between their measure and the conventional (as I understood it) statistical measure of Coefficient of Determination. Of course it is all more than a quarter century ago.
“Our purpose is to provide a starting point for researchers interested in reconstructing climate over the past 2000 years from the region.” – Neukom1 & Gergis (2011)
ROFLMAO!
Lets just be glad they’re not English teachers.
If we for a moment assume that their screening method is sane, I’m still not convinced that this analysis has any value before around 1600. There are only a few proxies that extend before that, and they’re all tree rings. I’m trying to understand how well the earlier part of the “stick” validates, but their funny multiple subset method is very opaque to me. And of course they use RE… But looking at their fig 3 – aren’t the pre-1600 RE values very low?
How Gergis et al(2012) is going to be treated in AR5 will be a very visible test of Masson-Delmotte’s statement that “. . . we are confident that the next draft of our chapter will be based on new publications associated with publicly available datasets.”
Of course, Gergis et al can argue that the datasets used are publicly available. It’s the missing datasets that are not. I wonder what Masson-Delmotte’s answer will be. Maybe Steve can follow up with her and ask for more specificity.
The questions I have are (1) will AR5 deal with the “screening fallacy” issue at all and (2)if they do and disallow such papers, what will the report look like?
I just thought of an example of the screening fallacy that maybe Jim Bouldin will accept. Let us posit that the world is not warming uniformly since 1850. Further stipulate that the proxies are noisy. Given these 2 premises, screening proxies that correlate with temperature in spite of noise will select those proxies that are from a region where there was the most warming or where other factors (e.g., changing precip) had the least effect, or both. This has the net effect of NOT merely giving a better signal/noise ratio, but of exaggerating how good the proxies are at capturing temperature and of amplifying the warming predicted by the proxy. This will drastically reduce the perceived variance and inflate the goodness of fit by whatever statistic.
Other issues remain, or course.
Re: Craig Loehle (Jun 2 11:12),
Craig, I have a short question …. how might your commentary above be applicable to claims made by climate scientists that the warming trend in Greenland during the Medievel Warm Period was anomalous not only to the Northern Hemisphere, but also to that small portion of the Northern Hemisphere occupied by Greenland?
As an aside here, given that the Vikings were farming in Greenland during the MWP, and this fact is indisputable, one has to wonder what the Arctic’s sea ice extent might have looked like during that period, as it existed near Greenland.
Scott: In my reconstruction, I had a composite from China (from 8 proxies across china), 2 from Africa, one off Indonesia iirc, and 1 compiled from pollen records across North America–and MWP showed up. I think using the methods used by Mann et al., the ability of the methods to reliably detect a warm period 1000 yrs ago is just about nil, and they will tend to flatten out any peaks/bumps in the past for various reasons (divergence, the handle of the stick being just noise, etc.).
Yes but Craig your method is fraught with other issues.
I’m still a bit puzzled about how you incorporated the pollen data with any sort of confidence considering they’re so low frequency and show significant fidelity to the calibration data.
We can criticize many others for not testing the sensitivity of their reconstructions to the methodologies and yet you do not either. We can equally criticize some of the earlier reconstructions (and some newer) for having issues that are significant but to be frank if your reconstruction is an accurate representation of the last 2,000 years – then it is by fluke not skill.
Robert, you argue that I do not test the sensitivity of the reconstructions to the methodologies, but in my method I took a simple mean of the proxies on the assumption that they were samples from a population. There was no fancy PCA or weighting and all the proxies covered the whole interval. Interpolation was used to fill in the non-annual data. I was testing what happens when you do not use tree ring data. I did 3 types of test for error: bootstrap, jack-knife and Hu helped me with real confidence intervals. I do not claim high accuracy for my method, but there are no hidden tricks in the code.
I don’t think the “it’s better than them” method is really . I’ve seen you speak elsewhere and here about your results and when Ljungqvist came out you opined on the similarity between his result and your own. There are some in the Paleo community who have claimed high accuracy when their methods (or data) did not support that conclusion. That is obviously a bad thing. But just because you didn’t say that it was accurate doesn’t mean that you haven’t implied that it was more accurate than it is.
Truthfully we know it really isn’t accurate. Think about what you’re doing with the pollen data – you are interpolating century scale data linearly to annual for your reconstruction… You’re knowledgeable on ecological systems – you know the inherent issues and things that you have to accept about the pollen data and yet you used it in a way that really isn’t justified.
I understand that the purpose was to examine the data if Tree Rings were not used – to create a simplified reconstruction using bare bones basic stats and data but at the end of the day the paper brings more questions than answers.
You’re explaining to someone how the MWP is shown in your data from many locations leaving a certain implication. (He asked about the extent, sea ice etc…)
I do not doubt the MWP was there – nor do I believe in a flat hockey stick – but your reconstruction isn’t the answer either (to his question). I understand people like to plug their own work but you know how your recon has issues – not expressing caveats is more team like…
Just ones opinion. I’ll have more on some sensitivity tests I did for various reconstructions at capturing high/medium/low frequency climate variability at a later date.
It’s too bad Erik the Red didn’t have the foresight to establish a Norsemen Arctic Survey Agency (NASA) to monitor sea ice extent near Greenland during the MWP. It might still be functioning today if he had.
Scott —
In fact, the Koch Sea Ice index used by the recently discussed Kinnard et al study goes back to the 9th century, as I recall, and is based on literary accounts of the ice presence. When I get a chance I’ll write a CA post on it.
Craig,
There is a very decided tendency here, and elsewhere for people to jump from one issue to another when they find that there is a significant challenge to some point they’ve made. I’m sticking here strictly with the issue raised in the post–that autocorrelated tree ring time series can lead to spurious correlations with an env. variable of interest (typically a climate var. in these discussions). That was the issue that Steve raised, supporting his position by links to several similar arguments. I’m sticking to slaying that zombie right now, because it’s wrong and it needs to be slayed.
But we can certainly discuss the points you raise as time allows. My very quick answer right now to your scenario is that, one should always spatially weight these type of things, based on some combination of the spatial configuration of the samples, and their statistical reliability. How to do so is a whole discussion or several, in itself.
Jim: I was sticking to the zombie thing you think you are slaying. If trees responded only to noise and temperature, what you say would be more true. I can think of multiple cases where the “signal” of a group of trees appears to be temperature but is not:
1) Strip bark trees that were damaged within the last 150 yrs show a compensatory growth response on the undamaged side of the tree, giving them a huge growth boost in recent years that undamaged trees nearby do not show. Mann did not correlate their growth with local temperature but with N. Hemis temp (teleconnection).
2) Yamal larch (small sample too) that may be switching from prostrate to tree growth form so the six-sigma growth boost is NOT related to temperature and is not shown by trees nearby.
3) Other examples where say the forest was thinned out by insect attack 100 yrs ago and remaining trees are showing increased growth (most of the trees over a wide area).
4) Shift in a rainfall belt like the Sahel where an entire region will be wetter or dryer for maybe 50 yrs, enough to give a false correlation with some temperature excursion during the calibration period.
5) Sample bias where the oldest trees in a stand are genetically slower growing than the younger ones but there are fewer of them, giving an apparent uptick in growth in recent 50 yrs or more merely by differential aging/survival.
I have given other examples where nearby trees respond to some factor other than temperature. My 1 & 2 here are used in most reconstructions and I say they are biologically anomalous and should not be used. Not only are they used repeatedly, but they are weighted heavily by the various multivariate methods.
Jim,
(1) if you make a network of autocorrelated red noise of autocorrelations observed in typical tree ring networks;
(2) select a subset by screening by correlation against a trend
(3) average the subset by CPS or equivalent
you get a Hockey Stick. This can be shown quite simply. Are you disputing this?
I take it that you’re arguing a different point – that such a red noise composite would not pass a statistical verification test. Two comments.
First, in past debates on this topic, Mann and associates rejected verification r2 (correlation) as validation (though it was shown in MBH98 Figure 3 and used in other articles) and said that the RE statistic should be the exclusive measure. You can get spurious RE statistics very readily under a variety of circumstances – the classic Yule spurious regression has a very high RE statistic.
Second, when you take a bad method and apply it to actual data which has bona fide correlations in it, it remains a bad method and biases results. It will exaggerate the hockey stick-ness of the result simply because that’s an inherent defect of the method (just as Mannian short centered did.) To the extent that the real data actually contains a valid relationship, this will show up in statistics even with a biased method, but it doesn’t show that the method wasn’t biased.
The point is a bit subtle and has been thoroughly misunderstood in the Mannian short-centered debate (both by opponents and supporters.)
Roman M: This is a good example of statistical inbreeding where known statistics and methodology are re-branded by insular areas of scientific practice.
Indeed, but not quite as good as the example of the medical paper that reinvents integration and gets 75 citations! (well, it’s really pure math and not statistics, but even more amusing :))
I suggest that all of sceptic blogs carry a common post inviting readers to contact the IPCC, their elected representatives, journalists etc to ask them to push the demand that only publicly archived data is used for the next IPCC report + any subsequent policy-forming climate work.
I’m aware that, to an extent, this is at variance with the way things currently work. Despite the accusations, I’ve seen no evidence that Steve, Bishop Hill, Anthony Watts etc. are part of a vast conspiracy. All the evidence points to them speaking for themselves. However, collectively they would carry weight and, for an eminently reasonable message such as public data archiving, it would be difficult (though not impossible) for the climate community to publicly oppose it.
Steve + other bloggers (who I guess may read this) – would you consider this ?
Young climate scientists (who I’m pretty sure are also reading this, I would were I a PhD student or postdoc) – would you support this ? I really don’t think your community is staffed by a bunch of incompetents as many people claim (though some of you are guilty of over-claiming and could do with sharpening your statistics knowledge). Why don’t some of you step up and promote good scientific practice ? It really is unacceptable you know that data underpinning studies apparently showing that the world is undergoing unprecedented warming are not publicly available. It doesn’t matter what your tribal elders say – data retention in this case is wholly unacceptable, and you know it.
Roger,
most climate scientists support the data obstructionists as heroes of the revolution.
However, even mid-career and successful scientists have been reluctant to speak out publicly. In 2006 or 2007, two mid-career scientists whose names would be well-known in the community told me privately that they felt that our critique of Mannian style reconstructions had shown the futility of that type of analysis and that the only way forward in the field was through the development of better proxies, not by trying to extort flawed and inconsistent data. Both made me pledge confidentiality as they were afraid to be publicly identified.
A few young scientists have said that they envied my ability to speak out. I can do so because I’m independent of the field and not dependent on grants and looking for a job. Only a few.
Steve McIntyre (Jun 2 13:45):
So who was this programmer called Napoleon and how good was his coding?
What is the logic behind using detrended data? So if it’s colder than the trend, but still got warmer, I would expect more growth not less.
I guess with a tiny trend that doesn’t matter, as each year’s variation would be higher.
I don’t know about corals but tree ring width decays naturally through time independent of climate and other effects. It’s a long time since I was involved but I recall Fritts, a pioneer of dendrochronology, advocated the removal of a negative exponential decay from the series and to associate the residual with climate. So there is at least one sound physiological reason for not using the width in its raw form when looking for an external signal. On some trees there is also the possibility of extracting two widths per year arising from early and late season growth and also using wood density as well as ring width to form time series – others here may be better versed in all this. Nor do I know whether the error properties of removal of a decay trend are specifically accounted for when pooling data.
Steve: Max, the issue in the head post is the calculation of a temperature “reconstruction” from a set of proxies, including tree ring “chronologies” – the chronologies themselves are an input. The calculation of a tree ring “chronology” from ring widths, as you say, uses a growth curve. There are interesting statistical issues in the calculation of a chronology – the existence of these issues is not even known by the practitioners who apply recipes. I think that the procedure can be placed in the context of random effects statistical methods with interesting results. I can calculate “chronologies” using the Pinheiro-Bates random effects program with IMO pretty results. The people in the field are profoundly uninterested in such “academic issues”. Their principal interest seems to be the development of abstracts for citation in the next IPCC assessment report.
A few years ago I played around with generating a chronology using very simple panel data statistical techniques. Simply run a regression of all cores against a full set of time dummies and a full set of age dummies. This will fit to the data the best (statistically speaking) growth curve for those trees and the best chronology for a given site – simultaneously and efficiently (statistically speaking). In addition to not being constrained to a simple decay trend for tree growth it also gives standard errors around the resulting chronology. It is so much superior to the apparent ‘state of the art’ and yet so simple. I really should follow this up I guess to see where it might be publishable – but publishing outside your field is fraught with difficulties.
Steve: I;ve done something similar using Pinheiro-Bates’ lmer random effects package in R. The “chronology” emerged as the random effect for each year, bringing with it a statistical interpretation. For young applied statisticians, tree ring networks ought to be really interesting as they have all sorts of interesting problems: autocorrelation, heeroskedasticisty, random effects.
“Joelle Gergis has deleted her entire blog since yesterday.” – SMc
“She says that I should try to get the unarchived data from the original authors” -SMc
Pretty please Joelle, could you send me the contents of your ex-blog as it may help me with my ‘research’
Thanking you in anticipation.
RoyFOMR
Regarding the random 3,000 ensemble of Gergis et al 2012. Page 10 describes the method used to generate these random reconstructions, of which predictor selection is 1 of 4 kinds of randomisations. For this they describe “Removing five predictors from the full predictor matrix”. I take this to be a 27 choose 22 combinatorial problem, no replication. For this alone there are 80,730 possibilities. Then you have the 3 other randomisations performed in conjunction with this: varying the percentage of total variance (retained PCs), calibration/verification period, and weight scaling for each proxy. I assume there must be at least millions if not billions of possible unique parameterisations (strictly infinite if non-discrete numbers) but they settled on 3,000 as the cut-off. Could they not allow millions to maximise convergence? Computing power? Or what if — just a what if — what if multiple lots of 3,000 are run and the ‘best’ one were chosen? If you run enough to approach convergence then such an accusation is not possible.
It is also important to know the location of the instrumented temperature data with respect to the proxy. Is it a local station, or one hundreds of miles distant? There is the problem with having a proxy show a rise in its parameter of interest(ring width, ring density, varve width, etc) at the same time as a distant temperature location when the
local station shows no such thing. You might be inadvertently correlating urban heat isle effect with something else going on with the proxy(destruction of competitors due to fire or urbanization, road construction etc) that is bogus. I want to see the local station data that is near the proxy, and not some teleconnection signal from 500 km distant.
Proxies must be apporoved ahead of the testing. You have picked proxies that are sensitive of temperature, and you have pretty much satisfied yourself that they havent been adversely
affected by the above mentioned human interactions. Unless you can a priori kick proxies out of the test due to your checklist, you have to include the data from ALL of the proxies once the test is on. This process may be as old as Aristotle. Scientific publications need to show all of the data and
archive it all. It is not up to the individual auditor to go out hat in hand to beg for data. If scientists want it that way, then maybe they need to go door to door to get funds
from the public for research that is funded by the public.
Reblogged this on Climate Ponderings.
Question for Myles : How does one shame the shameless ?
Law Dome O18 is one of only three long series in the Gerger candidates. It was screened out – a topic that is interesting. I’ve corresponded with its originator, Tas van Ommen, from time to time over the past 8 years. Some of the correspondence appears in the Climategate letters as van Ommen checked with Phil Jones on how to respond to my initial inquiry.
Gergis has a new version of Law Dome O18. I asked van Ommen for the data that he provided Gergis; he refused, but said that the post-1800 portion, which was used for screening, matched the 1800-1999 data of Schneider, et al 2006 and is online. I asked a clarification on some differences and received a responsive reply concluding:
So not all Australian climate scientists are as pugilistic as Gergis.
Gergis copied her surly response to David Karoly, her coauthor. Karoly’s been prominent in the IPCC movement and apparently saw nothing wrong with her response. Karoly has also been prominent in the Australian news stories about alleged threats against climate scientists – see for example a December 2009 news story linked from Gergis’ deleted blog – http://web.archive.org/web/20100117162320/http://www.abc.net.au/news/stories/2009/12/09/2766874.htm?.
In the post, Steve quotes his request to Gergis for the full 62 series:
While the data for all the series considered would be necessary to perform a full analysis of it, the effect of screening can be quantified simply if we know the number of series considered (which we do, at least for the post-1884 portion of the reconstruction when all 62 are present).
On p. 13 of the MS on the JC website (May 19 early release, not yet formally published), the squared correlation R2 between the reconstruction and the 1921-90 instrumental data is reported as 0.69. This is a lower bound on the R2 that would have been obtained had all 62 proxies been included, but since the omitted ones are the weakest, the increase in R2 would be small.
In a linear regression with q regressors plus a constant term, the regression F statistic testing the hypothesis that all regressors have zero coefficients is
F(q, n-q-1) = R2/(1-R2) * (n-q-1)/q
(I think this is right — I’m at home and can’t check my references).
Here n = 90 and q = 62. Matlab says the F 95% critical value for 62 and 27 DOF is 1.7816, which corresponds to an R2 of 0.8036.
So if Gergis et al had obtained an R2 in excess of 0.8036 using their 27 series subset, and if there is no serial correlation (a big if — they make no mention of any correction for it), then their network would have statistically significant explanatory power. But since their R2 was only 0.69, the burden is on them to prove that the correlation is signficant. Because we don’t have the omitted series, we can’t do this for them, but that’s not our job as readers.
In fact, their reconstruction is not a direct linear regression involving temperature and the 27 included proxies, but rather a composite of 3000 modified linear regressions in which proxies are randomly omitted and/or Principal Components reduced in number. It’s not clear what this adds, if anything, beyond obfuscation. The interviewer on Utube interview with Gergis was appropriately dazzled by the 3000 element “ensemble.”
Other problems I see with the paper:
1. Before 1884, only a reduced number of series is available, so that even if the correlation with the full data set was signficant, that would be irrelevant for this portion of the reconstruction. At least MBH 98/99 recalibrated earlier periods that had reduced data available. Before about 1300, only 2 screened series are consistently available! (The original Kaufman 2009 paper had a similar problem — see https://climateaudit.org/2009/09/18/invalid-calibration-in-kaufman-2009/ )
2. The reconstruction relies heavily on Tree Rings, yet no attempt was made to control for CO2, which is known to have increased greatly starting about 1950, and which is known to feed trees. In fact, all but 1 proxy before 1617 is TR.
3. The 30-year loess filter shown in the diagrams has a strong endpoint effect, as UC has demonstrated in his animated graphs in a recent discussion here. The extreme endpoint therefore may simply be a smoothing artifact. (The 10- 30- and 50-year averages discussed in the text and the tables would not be subject to this criticism, however.)
I find Jim Bouldin’s engagement on this topic as exceedingly helpful and illuminating. It’s often hard to piece together different threads of this sort of thing originating in 2392 places on the web, so responses like “This has been talked about forever and everyone knows xyz” can not be true, much like the phrase “just take my word for it”.
It’s this specific context of the papers and methodology that Bouldin (and others) describes and that Steve (and others) critigue that is of high interest. Indeed, should not the “literature” include all the different dimensions to the conversation of significance and validity of the screen-testing of these chronologies in local/regional settings? Or, has the prevailing scientific/statistical world settled in on one ‘side’ vs. the other?
From what Bouldin has been describing, it does seem that there is at least a line of reasoning that would qualify a ‘screening process’ as being statistically significant and reproducible for the ‘indicated variable’– but it would be nice to see what the ‘rejected’ samples look like (otherwise it’s a ‘trust me, they don’t qualify’ kind of thing).
From what Steve has been saying is that even with these methods, you get down to such a paltry number of actual samples/cores prior to 1800 (1700?)(1400?) that surely this methodology loses its significance. I don’t know what the magic core-sample number is, but I certainly don’t think it’s a handful. I would also think that just taking samples that “work” in modern times under that methodology and then just presuming they also therefore “work” centuries earlier is problematic. Indeed, from what I’ve been reading, the robustness of this kind of exercise falls apart at around year 1400-1500, right?
Even though many climate scientists say the MWP is a negligible matter in the total realm of anthroprogenic global warming, or perhaps more sinisterly a red-herring to get policy-makers an excuse to ‘not act’ on climate change… it stands to reason that the precedence of globally avereged temperature is important. Tree-ring chronologies dominate this era, but recently there has been more data of other sources coming to the fore that can shed light on this subject.
It’s too bad that the MBH criticisms by SM can’t be declared as valid publicly by the science community, because that would grant climate communication a huge leap of credibility and inertia for such a small step. This, especially if there are so many other methods of proving AGW and past reconstructions that the prior stuff is now ‘irrelevant’.
Salamano, I found your comments here on the pre-selection problem to a be a bit too vague to be discussed or countered. Jim Bouldin has only stated in this thread that tree rings can have inter annual correlations with the instrumental record that cannot be reached with an AR1 model. That does not show that inter annual correlation is a valid pre-selection criteria nor does it say anything about pre-selection bias in general.
As for the Gergis et al. (2012) paper, it only cries out for what is wrong with pre-selection and particulaly so when the authors are not forthcoming in the details of the process.
Yes, unless you have some superior explanatory model/explanation for the occurrence of such patterns, which you do not, it does show that, apart from the fact that I have no idea what you mean by “pre-selection bias in general”, and furthermore, that’s not the argument that Steve and the numerous others he links to here, have been making. They’ve been making the argument that I responded to.
What I have argued is that a series of time series (i.e. a group of tree cores) produced by a generating process that is unrelated to the climate variable of interest (temperature in this case), but which has some degree of (unspecified by Steve) auto-correlation structure, will very rarely, if ever, produce a mean chronology (the time series of the robust mean of the detrended ring values (= ring indices)) in which the kind of claimed, spurious correlations with the instrumental temperature record actually arise during the screening process.
Even in the very rare case that you might get something like that, say at a site with a very small core sample size and a very high lag 1 autocorr. value (and even then, unlikely), (1) the correlation of the yearly residuals, from detrends of the ring chronology and the temperature data, will be zero, because that component is random (~ white) and uncorrelated under the proposed AR1 generating process, but will often *not* be when there is an actual relationships with temperature and (2)such rare occurrences will at any rate be swamped out by the sites in which these correlations are indeed valid.
To see this wrt the Gergis et al paper, that is the focus of this post, look at the 20 tree ring sites from which the 11 screened ones were taken (from Neukom and Gergis, 2012*). Now tell me the odds that ANY AR1 process, no matter **how** strong, **will cause even ONE of these sites to spuriously pass the screening process**, let alone 11 of them.
And all this, not even raising at all, the additional filtering imposed by calibration and validation testing process, NOR THE ISSUE OF INTER-SERIES CORRELATION over the chronology.
Site n (cores)
Teak Indonesia 239
Northern Territory Callitris 54
Western Australia Callitris 62
Kauri NZ 527
Baw Baw Victoria 223
Urewera NZ 68
North Island LIBI Composite 129
Mangawhero NZ 56
North Island LIBI Composite 235
Takapari NZ 63
Moa Park NZ 49
Flanagans Hut NZ 33
CTP East Tasmania 165
CTP West Tasmania 301
Mount Read Tasmania 317
Pink Pine NZ 356
Buckley’s Chance Tasmania 84
Ahaura NZ 74
Oroko Swamp NZ 330
Stewart Island NZ 106
CONCLUSION: IT’S IMPOSSIBLE! And the same reasoning applies to any set of tree ring sites that have passed a typical screening procedure.
* Neukom and Gergis, 2012; http://climatehistory.com.au/wp-content/uploads/2009/12/Neukom_and_Gergis_20111.pdf
Jim, you say:
In blog posts in 2008 on the network of Mann et al 2008, I considered his empirical claims about his proxy network:
Even Mann assumed that some fraction passed his screening by chance. Mann’s actual claims were inflated (see contemporary posts http://www.climateaudit.org/tag/screening by such peculiarities as including the Luterbacher series in the 484 passing (even though they used instrumental data).
Of the 927 dendro series (other than RegEM’ed Briffa data), only 143 (15.4%) pass the simple test of having a “significant” relationship in M08 sense in both the 1850-1949 and 1896-1995 periods – see https://climateaudit.org/2009/01/21/more-on-voodoo-correlations/.
So whatever theoretical reasons might exist, the empirical M08 network was hardly compelling.
Jim Bouldin: you are misunderstanding Steve. The red noise (autocorrelated) data is an example of the type of data that LOOKS LIKE tree ring proxies. When you select from available groups of trees (not individual trees) or other proxies you can get a hockey stick because in earlier periods you get variance loss (poor fidelity to multidecadal parts of the signal). Several studies have been done comparing the time-correlation of the various reconstructions, and it is terrible. If you were right, the various proxies should agree, but don’t in spite of much data overlap. How would you explain that by your reasoning that the methods are valid? Also, please look at some of my other entries on this post which respond to your claims.
“Jim Bouldin: you are misunderstanding Steve. The red noise (autocorrelated) data is an example of the type of data that LOOKS LIKE tree ring proxies. When you select from available groups of trees (not individual trees) or other proxies you can get a hockey stick because in earlier periods you get variance loss (poor fidelity to multidecadal parts of the signal). Several studies have been done comparing the time-correlation of the various reconstructions, and it is terrible. If you were right, the various proxies should agree, but don’t in spite of much data overlap. How would you explain that by your reasoning that the methods are valid? Also, please look at some of my other entries on this post which respond to your claims.”
No, I’m not misunderstanding; what Steve said was very straightforward, and it’s clear what he meant because he linked to about 5 other blog posts which argue the very same thing.
Rather, I think you are misunderstanding me, and further you are misunderstanding the process of how chronologies are created in the first place, and indeed, this is the very essence of my points here.
Chronologies are MEANS OF INDIVIDUAL SERIES. Therefore this whole zombie idea that you can get a spurious correlation with a SITE, based on a red noise generating process of some sort, but with no actual relationship of the rings to climate, is….WRONG. And the reason it is wrong is because you have to apply that process to EACH TREE, because that’s the process model that has been postulated. At this point, you will note, that THIS IS EXACTLY WHY I ASKED STEVE TO SPECIFY HIS NULL MODEL, so I could know for sure that this was indeed what he meant. He didn’t give me an answer but at any rate it doesn’t matter, because growth processes act on individual trees, and individual tree core are the entities that are detrended to produce the indices from which the chronologies are derived.
YOU CANNOT GENERATE MULTIPLE RING SERIES WITH A RED NOISE PROCESS AT A SITE AND GET A SPURIOUS CORRELATION OF THE RESULTING CHRONOLOGY WITH THE CLIMATE ON ANY BUT THE RAREST OF FREQUENCIES. The only way you can do that is for your random generating process to give a similar pattern over the instrumental period (typically 100 years). What is the chance of that happening? Furthermore, SHOW ME THE DEFINITE EVIDENCE IN THE LITERATURE–OR ANYWHERE FOR THAT MATTER–WHERE THIS HAS BEEN DONE.
As for your “other entries”, I just responded to one of them, and in the other one you state that I am always claiming that better methods must be used–which no, I have not been doing, but yeah, so what, I certainly believe that better methods are certainly, well, better, but who doesn’t? I mean, you’re going to criticize me for THAT, when all anybody does here is complain about how bad the methods in current use are, and call for BETTER METHODS????????
Seriously, where are you coming from?
Jim,
as mentioned before, I’m puzzled by your point. My position on tree ring chronologies is not necessarily the same as readers.
1. I recognize that chronologies are a sort of averages of cores at a site, after allowing for juvenile growth. I do not believe, nor I have ever suggested, that a tree ring site chronology is an artifact of red noise processes. I agree with you that there is a statistically significant effect being observed in a typical chronology. If you think that I’m disagreeing with you on THIS point, you’re misunderstanding.
2. If you believe that a class of tree ring chronologies selected ex ante (e.g. white spruce treeline) contain a temperature signal plus low-order red noise, then you should take all of them without screening for correlation.
3. Ex-post correlation screening is a biased methodology which accentuates Hockey Stickness. This bias can be shown because one can get Sticks from AR1 red noise using this method.
4. Such a test is not saying that the data is an artifact of red noise. It is a mathematical point about the bias of the method.
5. This does not mean that a given Stick is merely an artifact of the method, as it may well be that a Stick (though almost universally a lesser one) can be obtained using an unbiased method. Conversely, showing that you can get a Stick with an unbiased method doesn’t show that the original criticism was incorrect. I’ve had lots of battles on this with Mannian short-centering, where I do not agree that methodological defects “don’t matter”, but have gotten weary discussing this.
6. The largest issue on correlation screening comes in correlation against trending series – which has been the “classic” form of correlation screening (Mann et al 2008 on an algorithmic basis, but by hand in the literature.) I concede that the form of screening in Gergis is high-frequency and that it may not have as deleterious an effect. I still regard it as a very unsafe practice. In order to assess the potential effect of an unsafe practice (which might in the particular case not matter to much), one has to examine the prescreened data, not all of which is available. (The coral data is mostly available at NOAA; it’s the dendro data that isnt.)
Jim Bouldin (Jun 3 18:36),
oh boy, they are using two-sided tests (see tables 5-8 in the paper Jim linked)!!
Jim, as you are an expert in these issues, can you handwave me how, e.g., Polylepis tarapacana -trees in Bolivian Andies know if they should respond to ENSO positively (ALT Composite 2) or negatively (ALT Composite 3)?!? Or how the clever guys in your field know that they take only positively responding samples to one composite and negatively responding samples to another?!
re: Steve McIntyre Jun 4, 2012 at 9:39 AM
If I had time, I would explore this further. I am not at all convinced that detrending magically prevents, or even improves, the bias inherent in the screening method. Jeff Id has a post or two from a long time ago (no time to dig up the links) doing correlation screening of the Mann 08 proxy pool using fake temperature signals. He was able to succesfully screen with negative trends, sinusoid, etc. Also, IMO detrending of a series characterized strictly by stochastic processes (and not deterministic trends) is a potential flaw in the method.
Steve: I agree that the method is flawed. I don’t understand why Jim doesn’t see this. However, I haven’t directly examined this form of screening and am therefore limiting more categorical statements to forms of screening that I have examined.
Salamano,
From Table I of Gergis et al., only 3 of the 27 selected proxies extend before 1430 — two tree ring series (from Tasmania & New Zealand, as are all of the selected tree ring series) and a coral series which isn’t even from the designated region. [Palmyra atoll is about 6 degrees N and 18 degrees E of the 0-50S, 110-180E region.] Figure 1 indicates that the 30-year period judged warmest of the pre-industrial era by Gergis (1238 to 1267) is covered only by the two tree-ring proxies.
One pre-1430 proxy, Law Dome O18, was screened out.
Despite their claims of novelty, the same proxies were used in Mann and Jones 2003 – Oroko, Tasmania, Law Dome plus Quelccaya. Mann and Jones 2003 also screened, but screened out Oroko rather than Law Dome, saying that Oroko had no correlation to local temperature. There are interesting local problems at Oroko – as the original authors said that the series was contaminated by logging after 1957 or so and, in the graphic in the original article, spliced instrumental temperature with proxy data. IPCC AR4 illustrated Oroko and Tasmania tree rings, but refused to illustrate Law Dome.
If Law Dome is included, the results are quite different.
“I find Jim Bouldin’s engagement on this topic as exceedingly helpful and illuminating. It’s often hard to piece together different threads of this sort of thing originating in 2392 places on the web, so responses like “This has been talked about forever and everyone knows xyz” can not be true, much like the phrase “just take my word for it”.
It’s this specific context of the papers and methodology that Bouldin (and others) describes and that Steve (and others) critigue that is of high interest. Indeed, should not the “literature” include all the different dimensions to the conversation of significance and validity of the screen-testing of these chronologies in local/regional settings? Or, has the prevailing scientific/statistical world settled in on one ‘side’ vs. the other?”
Salamano,
Glad what I said was helpful. Indeed, the blogosphere on these topics is a complete nightmare. Because of this, you have no choice but to develop your own ability to discern what’s correct, based on knowledge of statistics and the science. It can be very slow and time consuming but there’s no other way.
The literature does not, and should not include discussions of things that are irrelevant or off base. There’s no room for that–one has enough difficulty just including the things that are important. Nevertheless, I have no problem whatsoever with including information on sites that were excluded from an analysis because they did not pass a screening procedure, which is easily done in a Supplemental Info section. It would be even better if they included estimates of the probability of sites that did pass the screening, doing so by chance alone. Doing so would put these kinds of bogus arguments to rest quickly. Well, they should anyway.
Jim —
Even with the best of tests and the biggest of samples, the probability of a correlation that is falsely significant at the 5% level is exactly 5%, so this is not so rare. Furthermore, if serial correlation is present, the probability of getting this result using the false assumption of no serial correlation becomes more than 5%, and can be quite high as the limit of non-stationarity is approached.
An AR1 process typically does not have white noise residuals about a trendline as you claim, so that even the detrended series may show spurious correlation.
Jim,
You said above: “Chronologies are MEANS OF INDIVIDUAL SERIES. Therefore this whole zombie idea that you can get a spurious correlation with a SITE, based on a red noise generating process of some sort, but with no actual relationship of the rings to climate, is….WRONG. And the reason it is wrong is because you have to apply that process to EACH TREE, because that’s the process model that has been postulated.”
Is there any max tolerance for deviation from the mean as part of this inclusion? I’m recalling (for example) the Yamal series. If I’m not mistaken, individual trees were all over the place (in terms of where the mean ended up). Is it possible that with certain individual trees that deviate one way you could bring in trees that deviate the same amount another way such that the mean remains the same and indicates the same for the chronology? I bet there’s something I’m still not understanding here. What’s to stop a series mean from incorporating just one more tree of lesser (or questionable) significance if the mean is still acceptable? Is it possible there are ‘borderline’ trees that get rejected that may have shifted the mean if accepted? Or…is it something where after the postulated methodology is applied to each tree a certain number of trees behave in observable lockstep while all the other trees deteriorate into obvious unintelligble nothingness?
Salamano:
“Is there any max tolerance for deviation from the mean as part of this inclusion? I’m recalling (for example) the Yamal series. If I’m not mistaken, individual trees were all over the place (in terms of where the mean ended up). Is it possible that with certain individual trees that deviate one way you could bring in trees that deviate the same amount another way such that the mean remains the same and indicates the same for the chronology? I bet there’s something I’m still not understanding here.”
The maximum tolerance is whatever is built into the Tukey’s biweight robust mean calculation that is typically used to generate the single yearly value from the collection of each year’s index values. I believe this calculation weights each each single value, within a year, by the number of standard deviations from the mean, such that when you get out to about six sigma, the weighting is zero. However, I’m not sure on that.
“What’s to stop a series mean from incorporating just one more tree of lesser (or questionable) significance if the mean is still acceptable? Is it possible there are ‘borderline’ trees that get rejected that may have shifted the mean if accepted? Or…is it something where after the postulated methodology is applied to each tree a certain number of trees behave in observable lockstep while all the other trees deteriorate into obvious unintelligble nothingness?”
As far as I know, the biweight computation process is automatic and strict. It’s integrated into ARSTAN and dplR, ARSTAN being by far the most common program used. Statistics that relate the coherence of the individual cores are calculated afterward, things such as the SNR, the mean inter-series correlation, the mean sensitivity, and perhaps some others.
Hu,
“Even with the best of tests and the biggest of samples, the probability of a correlation that is falsely significant at the 5% level is exactly 5%, so this is not so rare.”
Yes. But the point is that you would have to get a large fraction of your site’s cores moving in the same direction, during the calibration period, to get the kind of spurious correlation being described here.
“Furthermore, if serial correlation is present, the probability of getting this result using the false assumption of no serial correlation becomes more than 5%, and can be quite high as the limit of non-stationarity is approached.
Yes, autocorrelation will raise the probability of a single core trending spuriously in sync with the climate, but it will *not* affect the *collection* of cores this way. Furthermore, you need high autocorrelations for this to happen for even one core.
“An AR1 process typically does not have white noise residuals about a trendline as you claim, so that even the detrended series may show spurious correlation.”
That depends on time scale (i.e. flexibility) of the detrending process. It doesn’t alter my point.
Jim —
While it’s true that 27 out of 62 would be pretty impressive if the proxies were independent in cross section (and if there were no serial correlation), word has it that trees everywhere eat CO2, and that since 1950 or so, CO2 has been way up. It would be more impressive if these were partial correlations after CO2 had been taken into account.
I don’t know about corals at present, but I do know that the correlation between Lonnie Thompson’s CC03 ice core d18O values (when regressed on the temperature index he cites) are about 0.4 whether within regions or between regions (except for nearby Quelccaya-Sajama, which is much higher). This suggests that there are global fluctuations in atmospheric d18O that have nothing to do with local temperature at time of snow deposition. Perhaps something similar happens with corals.
Hu, that’s a separate issue from whether chance can generate spurious correlations, and even one 1 out of 20 would be highly impressive, given the large numbers of cores sampled at the sites described by the authors, which I provided the data for earlier.
But to speak to it anyway, CO2 is indeed a potentially tricky issue.
The fact that CO2 is increasing does not mean that all trees are responding to it favorably–such as those sites where the mean chronology trends flat or downward over those later decades. In those sites where this is not the observed pattern, the CO2 effect hypothesis (i.e. fertilization) can potentially be at least partly explored by the use of detrended residuals like the authors use, because the time course of the temperature and [CO2] dynamics will be quite different, at least at some sites, with the [CO2] being much more predictable across sites.
There could of course also be sites in which neither driver explains much variation, because something else is muting or masking these effects, like water stress. This particular possibility leads to analytical difficulties because of the positive effect (= negative growth feedback) of increased CO2 on water use efficiency in many species; you will indeed have a hard time disentangling these opposing effects and the scenario calls for some sophisticated analyses and maybe better data, precip and soils in particular.
There are a few observations I have made on my first read of the yet to be published Gergis et al. (2012) that got my skeptic’s hackles up a bit.
First of all we see only one graph of the inter annual reconstruction and then nothing beyond that in the paper is shown but instead graphs with a 30 year filter of the reconstruction. That one graph is revealing in that we see divergence in the last few years. The authors only mention that divergence in the last pages of the SI and then only by claiming that although it involves a couple of tree ring proxies that it is a calibration issue. I find that hand waving in my book, but further to the point is how can 2 proxies have such a profound effect on the entire 27 proxy reconstruction?
The analysis in the paper shows 4 networks of proxies noted by R4, R14, R21 and R27 which are really proxies separated by how far back the series go in time. The description of these networks are given in the SI (S2) and from that I surmise that R4 includes 4 pre-1457 proxies, R14 includes 14 pre-1701 proxies, R21 includes 21 pre-1801 proxies and R27 obviously includes all 27 proxies in the reconstruction. Please note that R14 includes all of R4 and R21 includes all of R4 and R14 and of course R27 includes all of R4, R14 , R21 and six additional proxies coming exclusively from periods later than 1801. In the paper is a graph that compares all 4 networks and shows all proxies over the entire period. It also shows a near perfect match of the proxies pre-1457. And now is not that amazing.
I mention this analysis not for the innocent display of the 4 networks but to bring to fore a very important missing part of this paper and that is as follows:
There is no valid reason for not showing all the correlations of the separate proxies with the instrumental period along with probabilities and at least AR1 of the residuals on regressing against time. That would not violate any confidentiality agreements and particularly if the correlation values were published without identifying the proxy. It otherwise appears that through the manipulation of the proxy data together with principal components methods (that are only referenced in the paper and not detailed to the specifics of this study) that we suddenly have this excellent agreement between proxies and the instrumental records.
What if a couple or a few proxies were dominating the PC calculation and what if those proxies were contained in the R4 network? Why would not a reviewer want those questions answered?
Jim Bouldin, perhaps you need to be clearer on your thoughts on pre-selection. Any valid selection criteria has to be determined before selection and has to make sense from a physical standpoint. I have already noted that a TRW proxy can have a reasonable correlation with the instrumental record on an inter annual basis and still not be valid thermometer because that does not guarantee that a lower frequency correlation is good. In order to match instrumental trends you need that lower frequency correlation – otherwise a good proxy inter annual correlation could result in divergence.
I quickly perused that link to the proxies by Neukom and Gergis, 2012 and while they mention a coorelation p <0.05, I did not see any actual correlations values listed. Perhaps you coud provide the p value, r and AR1 values for those proxies or better for the ones used in Gergis et al. (2012)
Kenneth, I haven’t even used the term “pre-selection” here, or anywhere else for that matter.
The temporal scale at which correlations are computed, and their effect on the reconstruction, is a separate issue; it is not the one Steve has raised here.
But I’ll indulge a little since this issues is so badly misunderstood here.
The selection criteria ARE determined before selection. This involves setting the criteria for p values over the calibration intervals and sub-intervals, the criteria for calibration and validation statistics. and designating the climate stations or grid cells that will be used during the calibration. Then you stick with those criteria.
The problem is people completely confuse this issue with the fact that not all sites are going to be equally good recorders of the environment.
Jim Bouldin: I confess to being a little puzzled. I am giving examples of cases where individual sites composed of many trees or a lake core or whatever give a FALSE correlation with temperature over the calibration interval and are therefore included after screening in the regional reconstructions as in Mann’s work. This yields a regional or global reconstruction of temperature that includes or is based on uninformative proxies. This is the preselection or screening fallacy. The problems I have mentioned here (as well as my divergence paper) plus the issues of assuming precip does not vary over time, and so on, have NEVER been resolved, just brushed aside.
Not only are you not taking anyone seriously, you seem quite angry.
“The selection criteria ARE determined before selection. This involves setting the criteria for p values over the calibration intervals and sub-intervals, the criteria for calibration and validation statistics. and designating the climate stations or grid cells that will be used during the calibration. Then you stick with those criteria.”
Would that be a p value that takes serial correlation into account? Mann used a pre-selection of p value = 0.1 but that became 0.13 when the AR1 was estimated. When he ran into the divergence of the MXD Schweingruber series he merely lopped off the diverging part and replaced it with something else. Could you give me a reference where a paper on a temperature reconstruction recognizes the pre-selection bias problem and informs how and why the criteria were determined and before selecting proxies and shows the population from which the selections were made and further insures that that larger population was not pre-selected?
The criteria that you have noted above deal with the interannual correlations, I assume, and in that case as I have noted previously a good inter annual correlation does not necessarily mean you have a valid thermometer. In fact it is the lower frequencies correlations that are important in producing a thermometer.
By the way the paper, that you referenced above by Nuekom and Gergis 2012, had some correlation data relating tree ring proxies to some climate indexes and those correlations while evidently with p<0.05 had low correlation coefficients. The paper also noted the problem with proxies that have good inter annual correlations and poor lower frequency ones.
Also Gergis 2012 shows a series ending divergence.
Ealier, Jim Bouldin sais “The problem is people completely confuse this issue with the fact that not all sites are going to be equally good recorders of the environment.” How can this be reconciled with Jim’s description of site chronology construction, that claims that it is exceedingly improbable that chronologies DO NOT correlate with climate? I guess that if site chronologies do correlate with climate, why should some of them be better “recorders of the environment than others”?
I’ve now had a chance to double-check the above formula for the regression F statistic in terms of R2, in Pindyck & Rubinfeld Econometric Models & Economic Forecasts, 3rd ed, p. 79, and find that it is correct.
But unfortunately, even though my formula was right, my computation of “n” was wrong — 1921-1990 is n = 70 years, not 90 years as I stated above on 6/3 at 9:22AM!
This means that if all 62 proxies were entered into the same regression, there would be only n-62-1 = 7 denominator DOF in the regression F statistic (but still 62 in the numerator).
The 95th percentile of the F distribution with (62, 7) DOF is 3.3020. This implies that the a critical R2 for a regression of temperature on a constant plus all 62 candidate proxies, and with no serial correlation, is then 0.9669, not 0.8036 as I had stated before. (5% test size. An upper tail test on R2 corresponds to a 2 tailed test on the correlation itself.)
Gergis et al report an R2 of only 0.69 between their reconstruction and instrumental temperature. Including the omitted proxies would increase their R2 somewhat, but not by much, since the omitted ones have the least stand-alone explanatory power. The burden is therefore on them to show that including them would raise their R2 to at least 0.9669, if they are to claim that this group of proxies has explanatory power, even ignoring serial correlation.
The naive 5% critical value for R2 in a regression with a constant and one regressor, with sample size 70 and ignoring serial correlation, is 0.0553, so this is presumably what Gergis used. (finv(.95, 1, 68) = 3.9819, corresponding to t(n-k) = sqrt(F(1,n-k)) = 1.9955, or R2 = .0553).
With so many proxies killing the unconstrained degrees of freedom, it would be reasonable to first extract the first few principal components from the network of 62 candidate proxies, and then to investigate the correlation of temperature with these. But the choice and treatment of the PCs should be spelled out explicitly, not buried in a 3000-variant PC/proxy “ensemble”.
A further issue (besides serial correlation) is sign flipping. My preference there would be to divide each PC into its “+” and “-” components, where “+” is “right way” and “-” is “wrong way” when there is a prior presumption of sign. Then sort these split PCs by variance, and consider only the first few. If none of the wrong sign ones with big variance come in significant, then not to worry.
Before computing PCs, one might separate proxies by type, retaining only one PC (before splitting by sign) per type.
I have been looking at the methodology used in the Gergis etal paper and what they have done is more complicated than it first appears. From 2.3. Ensemble reconstruction method and verification:
The details in their own papers are pretty much non-existant, however the 2002 Luterbacher paper (Luterbacher, J., E. Xoplaki, D. Dietrich, R. Rickli, J. Jacobeit, C. Beck, Gyalistras, C. Schmutz and H. Wanner, 2002: Reconstruction of sea level pressure fields over the Eastern North Atlantic and Europe back to 1500. Climate Dynamics, 18, 545-561) is more informative. The methodology is used to take a collection of predictors and perform a gridded reconstruction over a region. The resulting hockey stick would presumably represent the average of the gridded temperatures rather than be a direct calculation from the proxies.
The Luterbacher paper gives a sufficiently tractable description of the procedure (assuming I read it correctly – there were some typographical(?) errors):
-Divide the time period into two parts, calibration and reconstruction.
-Form two matrices from the calibration time period: predictor (proxy) series and temperature series. These are both standardized to be mean zero (and presumably SD equal to one) for that period.
-Carry out a singular value decomposition for each matrix. Retain some smaller number of PCs (eigenvectors) from each set depending on the size of the eigenvalues.
-Do a multivariate regression to predict the temperature PCs from the proxy PCs.
-Form a second proxy matrix using proxy data from outside of the calibration period. Standardize the data using the values from the calibration period.
-Calculate the “PCs” for this proxy matrix by using the coefficients from the calibration period SVD.
-Estimate the “PCs” for temperature from the multivariate regression.
-Reconstruct the gridded temperatures from the latter “PCs” using the coefficients from the calibration SVD.
The Gergis paper contains zero detailed information (that I could find) on how they performed the PCR.
I also tried to chase down some of the proxies they “used” with little success. I doubt that many of them are actually archived anywhere in an openly accessible environment.
How could anyone carry out a proper peer review under these circumstances???
“-Carry out a singular value decomposition for each matrix. Retain some smaller number of PCs (eigenvectors) from each set depending on the size of the eigenvalues.”
Roman, are there rules prescribed for retaining PCs or can this be arbitrary?
Here is the quote from the 2002 Luterbacher paper:
The SLP referred to is sea level pressure which the study was trying to reconstruct.
I think that the above is not unreasonable because the number of PCs would depend strongly on the total number of variables in the decomposition as well as the number of non-random factors whose effect may be discernible in the data.
Roman, I think that the Luterbacher method is probably a lot like MBH98, which also did principal components on temperature as well as, famously, on tree rings.
Roman —
Does computing the initial PC’s from just the calibration period data create the sort of problem Steve and Ross found in MBH 98/99?
Also, did Luterbacher do anything like Gergis’s 3000-fold procedure?
I haven’t looked at the methodology long enough to form an opinion on what warts might arise from it. It struck me when I read the description in Luterbacher that standardizing both the temperatures and the proxies during calibration, then applying the calculated transfer function to external “decentered” data was indeed similar to the early Mann work. However, the deecentered data here did not play any role in the calculation of the SVD and in my understanding that is different from the Mann case. Perhaps Steve could correct me if I am incorrect.
No, the 3000 repetitions was not part of Luterbacher’s work. I suspect it is an invention of this particular paper.
This is way too complicated to just refer to the methods in another paper (Luterbacher et al). They should have included the code in the SI. I bet there are a dozen tuning parameters or choices made (e.g., # of EOFs) which on top of the screening could give any result at all. It is not possible to replicate this work even if one had the data. There is furthermore the possibility of heavy weighting of a couple of series, as in MBH98.
I firmly agree with you on the lack of explanation for what was done.
It is not even apparent as whether they used all of the grid cells in the “combined land and oceanic region of Australasia (0ºS–50ºS, 110ºE–180ºE)” or whether they only used cells which contained proxies. The latter however would seem not to be applicable since Vostok is well outside of this region.
I have spent the afternoon just playing with the HadCrut3v gridded data and I find it very surprising on how much missing data there seems to be in the target region. They mention infilling the predictor matrix (presumably proxies ), but there is does not seem to be any mention of infilling the calibration temperatures.
They say they infill 0.4% of the predictor matrix using a PC method. This can’t make much difference, and may be a lot easier than formally dealing with missing observations.
Likewise, Tapio Schneider’s article on RegEM illustrates it by filling in just a few percent (3% as I recall) of a temperature-like data set. This is a far cry from using it to construct most of the data, as in Steig 09!
I don’t have any trouble with that small a percentage of the proxies being infilled. What bothers me is that there seems to be a much larger percentage of the calibrating temperatures missing. Given the methodology, this would have a very large uncorrectable effect on the entire procedure.
To be brutally frank about the location of the proxies what we have is all the TRW proxies in either New Zealand (9) and Tasmania (3). Some of these TRW proxy sites are closely spaced in these already confined regions.
The ice core proxies (2) are both from Volstok. The Coral proxies (13) are spread out over the SH but most of these proxies do not go back far in the history. The mainland of Australia has no proxies.
The R4 network with the proxies that go back further than 1457 contains 3 TRW proxies (2 from Tasmania and 1 from New Zealand) and one Coral proxy (at 6S and 162E).
If you look at the proxy location and the duration of these proxies the time/space coverage is quite sparse.
I’m sure many of these proxies were also used in a previous climate paper to predict historical river flow in the Murray-Darling (Victoria/NSW) river system which is no where near any of the proxies.
Click to access SEARCH_River_Murray_Information_Sheet.pdf
Coral in Bali was used to predict inland streamflow 4000km away. It’s like reverse engineering the butterfly effect. And we have rainfall records for a large part of that period which didn’t get a look in.
Steve: The proxy network of this study is shown below. The ones in bold are NOT used in Gergis et al 2012. The Teak recon is at NOAA, but the other items in bold are unarchived. Why dont you ask Ms Gergis for the data for this network – as it hasn’t been archived?
Kauri NZ
Teak Indonesia
Western Australia Callitris
Mount Read Tasmania
Celery TP West Tasmania
Celery TP East Tasmania
Fiji_AB
Great_Barrier_Reef_precip_recon
Bali
Kenneth Fritsch (Jun 3, 2012 at 7:17 PM) –
A minor correction — the Palmyra coral is not at “6S and 162E” as you wrote, but at 6N 162W. E.g., see here. Gergis’s Table 1 erroneously implies all sites have S latitude and E longitude, but their Figure 1 accurately indicates the locations.
HaroldW, thanks, I stand corrected. There is no site at 6S and 162E.
Re: RomanM (Jun 3 12:28),
Seem to me that we’re closing in on some of the process recommendations in Simmons et al 2011 as noted on the recent Schmidt thread.
For example (see the latter link for the complete list):
Requirements for authors
1. Authors must decide the rule for terminating data collection before data collection begins and report this rule in the article.
3. Authors must list all variables collected in a study.
4. Authors must report all experimental conditions, including failed manipulations.
5. If observations are eliminated, authors must also report what the statistical results are if those observations are included.
6. If an analysis includes a covariate, authors must report the statistical results of the analysis without the covariate.
Guidelines for reviewers
1. Reviewers should ensure that authors follow the requirements.
3. Reviewers should require authors to demonstrate that their results do not hinge on arbitrary analytic decisions.
One of their primary points was that scientists too easily give themselves a huge number of degrees of freedom in their analyses, with the necessary result of many false positive results.
Right now, I’d just settle for a genuine description of what these authors do when they write papers. One can chase down the methodology, but there is no way of determining the arbitrary choices made in the application of that methodology without looking over their shoulders. or course, having a smoke screen to hide behind can be useful – particular if you don’t have a proper understanding of it and are merely using canned procedures.
Providing the data used in the papers would at least be a starting point. However, where would on be without the thrill of doing the “research” just to guess what they might have done…
re RomanM Jun 3, 2012 at 12:28 PM
Perhaps the peer reviewers used the tried and true mode of peer review, as evidently practiced by Phil Jones; he calls it “intuition“.
Roman, from your description of the PCR method used by Gergis is not the method “forcing” a good correlation between temperature and the reconstruction and further is the (high) correlation meaningful and would we expect that the proxies making up that reconstruction could well have much lower correlations with temperature. The correlation reported in the Gergis paper appears much higher than I have seen for individual proxies in reconstructions.
The method as described in the Luterbacher paper basically comes down to the case where the calibration period gridded temperatures are regressed on the calibration period proxies to calculate a linear equation for predicting the temperatures from the proxies.
The difference here is two-fold. In order not to overfit, the predictor proxies series are replaced by a smaller set of EOFs (i.e. principal components). Furthermore, rather than predicting each grid point separately (thereby having to estimate a very large number of parameters), the temperature series are replaced by a smaller set of EOFs as well. The two EOF sets may be of different sizes. The rest of the process is initially going from observations to EOFs and then reverting back to “observations” when the regression has been completed.
Examining what happens using matrix algebra is informative. Assuming no misunderstanding or oversight in the calculation (whose derivation is left to the reader – only the end result is shown):
P = proxy matrix. T = temperature matrix. Both matrices are “standardized” whatever that may mean. Later calculations in Luterbacher’s exposition indicate that the means of the columns of both matrices must all be equal to zero. However, there does not seem to be a corresponding implicit requirement for standard deviations to be equal.
For each matrix, calculate a matrix of reduced rank equal to the number of retained EOFs using singular value decomposition. For example, P = UDVT. Replace U by Ur consisting only of the retained EOFs. Similarly, D and V are replaced by Dr and Vr removing the elements corresponding to the retained EOFs. Finally Pr = UrDrVrT. If doing this in R, it is simpler to replace the eigenvalues in D corresponding to the unneeded EOFs with zeroes and multiply UDVT together.
Perform a similar calculation to get the “reduced” temperature matrix Tr.
The “transfer matrix” M = pseudoinverse(Pr) Tr where the pseudoinverse(Pr) = VrDr-1UrT is defined here.
To calculate the reconstruction for a matrix X of proxies (scaled to be consistent with the scaling during calibration), simply multiply X on the right by M: Recon = XM. This clearly indicates that the reconstruction is a simple linear combination of the proxies with the weights determined from the calibration period.
How the end result relates to the individual proxies is not immediately clear from the mathematics here since the proxies have been replaced by the lower order approximation. It would be necessary to look at the correlations between the proxies and the reconstructions in each case.
Steve: Roman, this looks pretty much identical to MBH98, Except that MBH98 idiosyncratically did PC on some proxy networks but also used some proxies individually. Mann never realized that all the matrix operations were associative i.e. you could multiply out the right matrices once to get weights for the individual proxies. He repeated the same calculations over and over. As also Mann et al 2008. I’ve parsed this matrix algebra in detail.
It is like eating soup with a fork. Do they mean to imply in the Gergis ms that it makes sense to create a “field” of temperature from data this widely scattered in space and irregularly distributed? It was bad enough when something like this was done for Antarctica and spatial correlations (Chladni patterns) showed up. The potential for a single series to have most of the weight is obvious and would need to be explicitly presented to avoid the appearance of slight-of-hand.
I think that one of the main tricks in Gergis et al is one that was used in Jones et al 1998. It also looks like it affects Kinnard et al 2009. It’s a splicing issue.
Let’s say that you have one long proxy that has negligible long-term variation even from the LIA to the modern period. Now let’s suppose that you have some proxies that increase in the LIA-to-modern period.
Now do a “stepwise” procedure in Mann-Luterbacher style. The stepwiseness aspects of these algorithms has been very much understudied. because the long proxy has no long-term variability, you get a MWP of negligible ampliture attached to a LIA_to-modern transition with real amplitude.
The right answer is that because the proxies stretching back to the MWP do not replicate the amplitude of the LIA-to-modern transition, the error bars on the MWP recon are huge.
The calculation of confidence intervals in these Mann-style reconstructions has always been an area that is hard to understand. Not just us. It seems that Myles Allen also gave up trying to figure it out for Mann et al (from a Climategate letter.) My guess is that the Gergis confidence intervals are not calculated any more reasonably.
Wow, so after all the jargon and mighty wind, the Reconstruction is just a weighted sum of the proxies, where some proxies get a negative weight.
Any idea why they bother to screen out some proxies (when they could just get ~zero weight) ?
Do some series get segmented and individually weighted?
I guess (I hope) this is not the situation with individual tree-ring records. IS a tree-ring ‘proxy series’ made in a similar way, or perhaps the individuals have an age-related factor first applied?
This seems like an opportunity to speak simply and clearly about some mystifying math.
Thanks
RR aka AC
“This is commonly referred to as ‘research’”
If a researcher in group A and a researcher in group B both do ‘research’ this way, but reach different conclusions, how are we to asses who is more correct without being able to dig into the guts of their work?
Clearly this approach leads to a dependence on which group is larger as the primary indicator of correctness and is therefore obviously non scientific.
My limited understanding is that there are two different cases here:
– research that has been paid for in part by taxpayer funds, thus belongs to the taxpayers in the funding countries.
– other, in which case it might be wise for the researcher to release data but not required as it is privately owned.
In a related field, I particularly commend US government agencies for not charging for copies of regulations, whereas Europe has different ideas, Canada often in the middle.
A problem area is industry organizations like IEEE whose standards are referred to by government in regulations as the source of mandatory specifics. The organizations make much of their income from selling the standards, though in most cases the technical work was voluntary.
(Cost of reproduction is negligible these days.)
Line up some tree proxies as of last year
And presto! Your treemometer’s nifty!
But line them up 500 years back and here
Your today’s 90F now … or 50!
If a wiggle match works for the current events
Well in principle, it works for any!
But results are all over — no physical sense
Should this fool scientists?
Well, not many.
===|==============/ Keith DeHavelle
Suggestion:
Why not create a study using their same methods but use a negatively biased proxy of low sample size so it shows cooling. For them to debunk it they would have to admit to their own methods?
Steve: I’ve done lots of posts showing that the medieval-modern differential in individual reconstructions changes with trivial changes to proxy inclusions (primarily by replacing bristlecones/Yamal with other plausible choices. The point seems so trivial and obvious that it is puzzling that specialists don’t seem to understand it. However, as long as they don’t seem to understand upside-down Tiljander, its pretty hard to get anywhere.
I agree, which is why I suggest publishing a paper that showed cooling using these same biased methods and touted around publicly, this would force them to debunk it using the same exact arguments as you have done – effectively invalidating themselves.
@ Poptech Posted Jun 3, 2012 at 11:29 PM
================
Steve, I’m not suggesting that you spend your time doing as Poptech has suggested. But he makes a good point as to gaming the game.
It wouldn’t work. Prominent scientists ritually explain away both the mid 20th century temperature dip and now the post ’98 temperature “pause” with a magic aerosol cooling argument. Now imagine a paper that said the very good solar-temperature correlation breaks down after 1985 only because of aerosol cooling. Exactly the same dumb argument but the former is pessimistic. Mainstream climate scientists just want to believe man is destroying the planet and it affects their judgement.
Steve, Roman, or somebody ;), what am I doing wrong here? I tried to check the screening correlations of Gergis et al, and I’m
getting such low values for a few proxies that there is no way that those can pass any test. I understood from the text that they used
correlation on period 1921-1990 after detrending (both the instrumental and proxies), and that the instrumental was the actual target series (and not the against individual grid series). Simple R-code and data here.
Jean —
Their SI gives the actual correlations they estimated. Do they not match what you get?
Hu, where did you find the correlations of the individual proxies with the Australasia mean temperature for SONDJF in the Gergis SI?
I went to KNMI and was able only to obtain the GHCN SONDJF monthly mean temperatures for the area used in Gergis. It replicated well the graph shown in Gergis.
http://climexp.knmi.nl/selectfield_obs2.cgi?id=someone@somewhere
I found a number of the proxies from Gergis in the NOAA repository at the link below, but have not had an opportunity to do correlations yet. I am very interested to see what Jean S gets.
Low proxy to temperature correlations are the norm as one can see from the 1200 plus proxies in Mann (08). That is not to say that someone could pre-select a few with higher correlations, but again that means it has good inter annual correlations and that does not lead directly to a good proxy thermometer.
http://www.ncdc.noaa.gov/paleo/paleo.html
Jean S –
Using your data, I replicated your correlation coefficients (natural & detrended) with Excel, so I don’t think there’s a problem with your R code. Either the data or the method must be the source of the discrepancy.
.
By the way, I noticed that the Urewara tree ring series correlates to instrumental temperature (neither detrended) with r=-.34. All other tree ring series have r>0, as expected. Another upside-down series? It doesn’t have a hockey-stick shape, though, so this is likely irrelevant in the big picture.
when I try to download, it asks me to do a setup.exe. Is this part of the download?
Jean S: No. I’m not getting anything like that. The zip file should only include three files (two .csv and one .R file).
Thanks Harold! Yes, seems that they are opportunisticly using two-tailed screening as I anticipated earlier. Data is from here, so that should not be a problem. I guess I must have misunderstood their description of the procedure.
The detrended correlations I get are:
Mt.Read Oroko Buckleyâ..s.Chance Palmyra Celery.Top.Pine.East Kauri Pink.Pine.South.Island.composite Mangawhero Urewera
[1,] 0.3652164 0.04252273 0.2291246 -0.1843481 0.1821315 0.3158175 0.1725652 0.1186184 -0.179043
North.Island_LIBI_Composite_1 Takapari Stewart_Island_HABI_composite Fiji_AB New_Caledonia NI_LIBI_Composite_2 Rarotonga Vostok_d18O
[1,] 0.2301791 0.2386844 0.1397027 -0.3171772 0.03182531 0.1423895 -0.3007384 0.307115
Vostok_Accumulation Fiji_1F Bali Abrolhos Maiana Bunaken Rarotonga.3R Ningaloo Madang Laing
[1,] 0.2045613 -0.1540278 -0.04817993 -0.08125016 -0.03874459 -0.3797934 -0.1161867 -0.331931 -0.0960036 -0.4123975
The normal correlations are:
Mt.Read Oroko Buckleyâ..s.Chance Palmyra Celery.Top.Pine.East Kauri Pink.Pine.South.Island.composite Mangawhero Urewera
[1,] 0.6142767 0.2867239 0.4435069 -0.4002756 0.4395454 0.5258422 0.4300725 0.4595843 -0.3381076
North.Island_LIBI_Composite_1 Takapari Stewart_Island_HABI_composite Fiji_AB New_Caledonia NI_LIBI_Composite_2 Rarotonga Vostok_d18O
[1,] 0.356136 0.5857284 0.3634118 -0.4647431 -0.2502446 0.4129373 -0.5295329 0.4260891
Vostok_Accumulation Fiji_1F Bali Abrolhos Maiana Bunaken Rarotonga.3R Ningaloo Madang Laing
[1,] 0.3188423 -0.3046171 -0.2993104 -0.2748438 -0.3156338 -0.3665768 -0.4709854 -0.4843583 -0.2200733 -0.425169
JeanS, it appears that you have found all of the Gergis proxies. I have found most of them with a preliminary search of the NOAA repository linked above. If that is the case why should Gergis have reacted to SteveM’s email as she did?
Also could you post the probability values for the correlations – both one and two tailed?
Jean, as I understand it the selection is based on p<0.05, regardless of how small r is.
Jean S: Yes, the (detrended) p-value, for example, for “Oroko” is 0.7267…
Kenneth Fritsch (Jun 6 09:51),
the 27 proxies (and the instrumental target) are given on the page I linked. Those are the proxies that did supposedly pass the screening, not all of them, see under “Archiving” in this very post.
Re: Jean S (Jun 5 16:42),
Jean S,
I’ve re-checked your calculations from scratch and confirm them.
Re: Steve McIntyre (Jun 6 10:00),
thanks! It is really hard to figure out explanation for this apart from the obvious that the screening was not performed as described.
Re: Jean S (Jun 6 11:24),
I’ve posted this up as a separate topic.
This is what happens when one allows non Statisticians to play with data using powerful computer black boxes. I have invented a new box which looks at all possible subsets and finds the one that most strikingly makes ones desired point. It does not mind garbage in and will oblige with the corresponding out.
Jean S (Jun 4 03:41),
Jean S, note that Neukom and Gergis 2011 used “Spearman correlations”
I wonder if they did the same thing in Gergis et al 2012 without telling anyone.
Spearman correlations are almost the same as ordinary correlations:
Myles Allen, in an email disclosed by an FOIA request, clarified that the burden falls on the editor: “If the editor thinks that a dataset is relevant and a challenge is serious, then he or she should be in a position to require disclosure of the relevant data or code or demand a paper’s retraction. Journals that consistently fail to do so can be named and shamed.”
It seems that editor Broccoli of the Journal of Climate did not enforce this disclosure. Or perhaps he merely accepted Karoly’s word that all relevant data had been provided. Karoly had written
. Broccoli replied only that “Section 2 of the Ethical Guidelines for Authors is the only guidance from AMS that I am aware of regarding data access and data archival.”
Shouldn’t the focus be on Broccoli? It would seem a trivial matter to ask each reviewer, as a matter of course, to tick a box stating that he believes that the paper is compliant with Section 2. More importantly, with a challenge to the sufficiency of the data, he merely stood aside, writing “Please communicate directly with the authors regarding access to their data.” His inaction seems to indicate a disregard for conformance to his journal’s policy.
24 Trackbacks
[…] Myles Allen Calls For “Name and Shame” May 31, 2012 – 9:10 PM […]
[…] Jones: ‘Contact NMS’s for raw data’ door Marcel Crok op 1 juni 2012% Over at Climate Audit there is renewed interest in data availability with McIntyre asking whether journals that […]
[…] at Climate Audit there is renewed interest in data availability with McIntyre asking whether journals that don’t […]
[…] McIntyre's requests for data have been met with snotty and offhand refusals: Steve McIntyre's latest post seems to me to be of huge importance. The refusal by Joelle Gergis and colleagues to release data […]
[…] requests for data have been met with snotty and offhand refusals: Steve McIntyre’s latest post seems to me to be of huge importance. The refusal by Joelle Gergis and colleagues to release data […]
[…] https://climateaudit.org/2012/05/31/myles-allen-calls-for-name-and-shame/#more-16194 […]
[…] Jean S observed in comments to another thread that he was unable to replicate the claimed “significant” correlation for many, if not, most of the 27 Gergis “significant” proxies. See his comments here here. […]
[…] from Nutall. Your chances of success are about as likely as Steve McIntyre’s recent efforts to obtain data from Joelle Gergis regarding her latest and greatest contribution to the annals of […]
[…] Myles Allen Calls For “Name and Shame” […]
[…] inconsistency between replicated correlations and Gergis claims was first pointed out by Jean S here on June 5 at 4:42 pm blog time. As readers have noted in comments, it’s interesting that […]
[…] Myles Allen Calls For “Name and Shame” […]
[…] problems have been widely discussed at ClimateAudit since 2006, and my publications probably grew out of those discussions. Moreover, the circular […]
[…] Steve McIntyre asked for the full data, she refused. Gergis has an activist past which she has recently tried to hide. She was proud […]
[…] about the latest HS at Steve McIntyre’s Climate Audit, a commenter/reviewer (one Jean S) asked, Steve, Roman, or somebody , what am I doing wrong here? I tried to check the screening […]
[…] study was apparently first questioned by Steve McIntyre on the climate change skeptic site Climate Audit on May 31 (second half of post). On Friday, June 8, McIntyre reported that the study had been put “on […]
[…] after questions were raised publicly about one of the researchers’ methods, starting with a comment on Steve McIntyre’s Climate Audit blog. This field of study uses sophisticated statistical […]
[…] after questions were raised publicly about one of the researchers’ methods, starting with a comment on Steve McIntyre’s Climate Audit blog. This field of study uses sophisticated statistical […]
[…] http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1850704 https://climateaudit.org/2005/02/06/jacoby-1-a-few-good-series/ https://climateaudit.org/2012/06/10/more-on-screening-in-gergis-et-al-2012/ […]
[…] are aware, the issue of screening in Gergis et al 2012 was first raised in a CA post in a May 31 blog post, a discussion that directly quoted the following paragraph of Gergis et […]
[…] et al, deserve a mention for prescreening of data (see subtitle “Screening Fallacy” here); selection of proxies in this manner constitutes partial publication – by only publishing […]
[…] et al, deserve a mention for prescreening of data (see subtitle “Screening Fallacy” here); selection of proxies in this manner constitutes partial publication – by only publishing the […]
[…] et al, deserve a mention for prescreening of data (see subtitle “Screening Fallacy” here); selection of proxies in this manner constitutes partial publication – by only publishing the […]
[…] loads of warming in Australia – it even passed peer review. However in response to a data request she said: […]
[…] [3] https://climateaudit.org/2012/05/31/myles-allen-calls-for-name-and-shame/ […]