First, let’s give Gergis, Karoly and coauthors some props for conceding that there was a problem with their article and trying to fix it. Think of the things that they didn’t do. They didn’t arrange for a realclimate hit piece, sneering at the critics and saying Nyah, nyah,
what about the hockey stick that Oerlemans derived from glacier retreat since 1600?… How about Osborn and Briffa’s results which were robust even when you removed any three of the records?
Karoly recognized that the invocation of other Hockey Sticks was irrelevant to the specific criticism of his paper and did not bother with the realclimate juvenilia that has done so much to erode the public reputation of climate scientists. Good for him.
Nor did he simply deny the obvious, as Mann, Gavin Schmidt and so many others have done with something as simple as Mann’s use of the contaminated portion of Tiljander sediments according to “objective criteria”. The upside-down Tiljander controversy lingers on, tarnishing the reputation of the community that seems unequal to the challenge of a point that a high school student can understand.
Nor did they assert the errors didn’t “matter” and challenge the critics to produce their own results (while simultaneously withholding data.) Karoly properly recognized that the re-calculation obligations rested with the proponents, not the critics.
I do not believe that they “independently” discovered their error or that they properly acknowledged Climate Audit in their public statements or even in Karoly’s email. But even though Karoly’s email was half-hearted, he was courteous enough to notify me of events. Good for him. I suspect that some people on the Team would have opposed even this.
The Screening Irony
The irony in Gergis’ situation is that they tried to avoid an erroneous statistical procedure that is well-known under a variety of names in other fields (I used the term Screening Fallacy), but which is not merely condoned, but embraced, by the climate science community. In the last few days, readers have drawn attention to relevant articles discussing closely related statistical errors under terms like “selecting on the dependent variable” or “double dipping – the use of the same data set for selection and selective analysis”.
I’ll review a few of these articles and then return to Gergis. Shub Niggurath listed a number of an interesting articles at Bishop Hill here.
Kriegeskorte et al 2009 (Nature Neuroscience) in an article entitled “Circular analysis in systems neuroscience: the dangers of double dipping” discuss the same issue commenting as follows:
In particular, “double dipping” – the use of the same data set for selection and selective analysis – will give distorted descriptive statistics and invalid statistical inference whenever the results statistics are not inherently independent of the selection criteria under the null hypothesis.
Nonindependent selective analysis is incorrect and should not be acceptable in neuroscientific publications….
If circularity consistently caused only slight distortions, one could argue that it is a statistical quibble. However, the distortions can be very large (Example 1, below) or smaller, but significant (Example 2); and they can affect the qualitative results of significance tests…
Distortions arising from selection tend to make results look more consistent with the selection criteria, which often reflect the hypothesis being tested. Circularity therefore is the error that beautifies results – rendering them more attractive to authors, reviewers, and editors, and thus more competitive for publication. These implicit incentives may create a preference for circular practices, as long as the community condones them.
A similar article by Kriegeskorte here entitled “Everything you never wanted to know about circular analysis, but were afraid to ask” uses similar language:
An analysis is circular (or nonindependent) if it is based on data that were selected for showing the effect of interest or a related effect
Vul and Kanwisher here, entitled “Begging the Question: The Non-Independence Error in fMRI Data Analysis” make similar observations, including:
In general, plotting non-independent data is misleading, because the selection criteria conflate any effects that may be present in the data from those effects that could be produced by selecting noise with particular characteristics….
Public broadcast of tainted experiments jeopardizes the reputation of cognitive neuroscience. Acceptance of spurious results wastes researchers’ time and government funds while people chase unsubstantiated claims. Publication of faulty methods spreads the error to new scientists.
Reader fred berple reports a related discussion in political science here “How the Cases You Choose Affect the Answers You Get: Selection Bias in Comparative Politics”. Geddes observes:
Most graduate students learn in the statistics courses forced upon them that selection on the dependent variable is forbidden, but few remember why, or what the implications of violating this taboo are for their own work.
John Quiggin, a seemingly unlikely ally in criticism of methods used by Gergis and Karoly, has written a number of blog posts that are critical of studies that selected on the dependent variable.
Screening and Hockey Sticks
Both I and other bloggers (see links surveyed here) have observed that the common “community” practice of screening proxies for the “most temperature sensitive” or equivalent imparts a bias towards Hockey Sticks. This bias has commonly demonstrated by producing a Stick from red noise.
In the terminology of the above articles, screening a data set according to temperature correlations and then using the subset for temperature reconstruction quite clearly qualifies as Kriegeskorte “double dipping” – the use of the same data set for selection and selective analysis. Proxies are screened depending on correlation to temperature (either locally or teleconnected) and then the subset is used to reconstruct temperature. It’s hard to think of a clearer example than paleoclimate practice.
As Kriegeskorte observed, this double use “will give distorted descriptive statistics and invalid statistical inference whenever the results statistics are not inherently independent of the selection criteria under the null hypothesis.” This is an almost identical line of reasoning to many Climate Audit posts.
Gergis et al, at least on its face, attempted to mitigate this problem by screening on detrended data:
For predictor selection, both proxy climate and instrumental data were linearly detrended over the 1921–1990 period to avoid inflating the correlation coefficient due to the presence of the global warming signal present in the observed temperature record. Only records that were significantly (p.&.lt.0.05) correlated with the detrended instrumental target over the 1921–1990 period were selected for analysis.
This is hardly ideal statistical practice, but it avoids the most grotesque form of the error. However, as it turned out, they didn’t implement this procedure, instead falling back into the common (but erroneous) Screening Fallacy.
The first line of defence – from, for example, comments from Jim Bouldin and Nick Stokes – has been to argue that there’s nothing wrong with using the same data set for selection and selective analysis and that Gergis’ attempted precautions were unnecessary. I have no doubt that, had Gergis never bothered with statistical precaution and simply done a standard (but erroneous) double dip/selection on the dependent variable, no “community” reviewer would have raised the slightest objection. If anything, their instinct is to insist on an erroneous procedure, as we’ve seen in opening defences.
Looking ahead, the easiest way for Gergis et al to paper over their present embarrassment will be to argue (1) that the error was only in the description of their methodology and (2) that using detrended correlations was, on reflection, not mandatory. This tactic could be implemented by making only the following changes:
For predictor selection, both proxy climate and instrumental data were linearly detrended over the 1921–1990 period to avoid inflating the correlation coefficient due to the presence of the global warming signal present in the observed temperature record.Only records that were significantly (p<0.05) correlated with thedetrendedinstrumental target over the 1921–1990 period were selected for analysis.
Had they done this in the first place, if it had later come to my attention, I would have objected that they were committing a screening fallacy (as I had originally done), but no one on the Team or in the community would have cared. Nor would IPCC.
So my guess is that they’ll resubmit on these lines and just tough it out. If the community is unoffended by upside-down Mann or Gleick’s forgery, then they won’t be offended by Gergis and Karoly “using the same data for selection and selective analysis”.
Postscript: As Kriegeskorte observed, the specific impact of an erroneous method on a practical data set is hard to predict. In our case, it does not mean that a given reconstruction is necessarily an “artifact” of red noise, since a biased procedure will produce a Stick from an actual Stick signal. (If the “signal” is a Stick, the biased procedure will typically enhance the Stick.) The problem is that a biased method can produce a Stick from red noise as well and therefore not much significance can be placed to a Stick obtained from a flawed method.
If the “true” signal is a Stick, then it should emerge without resorting to flawed methodology. In practical situations with inconsistent proxies, biased methods will typically place heavy weights on a few series (bristlecones in a notorious example) and the validity of the reconstruction then depends on whether these few individual proxies have a unique and even magical ability to measure worldwide temperature – a debate that obviously continues.





374 Comments
I would hope they would re-do the paper, taking into account the friendly advice offered here. Unfortunately, those changes, including adding more truly AUSTRALIAN proxies,
extending the proxies further back into time by using non-cooperative proxies, forgetting the pre-screening process will add more time, and likely prevent this paper from being
accepted into AR5. Better to do a good paper, than to try to rush one that is not ready.
Speed is of the essence. From Gergis’ (now hidden) blog…
“The challenge is to help people visualise our future climate and, in turn, provoke a strong emotional response… But the question is, can we process the science fast enough for us to see it in our imaginations?”
OMG. I never associated any of my own published research with a “strong emotional response” from my putative readers.
What happened to simple data collection and evaluation?
NO this paper is abut AR5 , once in there no matter how bad it becomes unchallengeable as accepted ‘wisdom ‘
This is political game not a science one , what has been has been clear since the first ‘hockey stick ‘ , the quality of the science is a very poor second to the political usefulness of the papers claims .
I am an engineer by profession and find this whole issue utterly incomprehensible. Not because I do not understand the issue of circular reasoning or whatever you want to call the practice in all its guises but because it is such a basic error of reasoning, for adults that is. It seems to me to be more in the realm of astrology vis a vis the traditions of the enlightenment, a bit like taking a picture of a bulls head, indicating some points that mark out the extent or position of key features and then looking in the sky for a match and …. eureka – you have identified a God!!!
It is so utterly bizarre for a branch of science( slender and flexible new growth as it is ) to adopt such practices.
What you say is true, but I suspect that this three year project was carefully timed to produce a paper just meeting the the deadline for inclusion in AR5, and thereby preclude any paper rebutting theirs meeting the AR5 deadline.
Sorry, this comment was directed at EDeF.
“If the community is unoffended by upside-down Mann or Gleick’s forgery….”
As scientists community opinion should be irrelevant. It is clearly unacceptable scientific practice to proceed in this manner and if they do, they should be severely reprimanded and dismissed/expelled by their employer and by all of the scientific organisations which they hold membership.
“but which is not merely condoned, but embraced, by the climate science community.”
I think this misstates what the climate science community, as opposed to the blogging community, sees as the purpose of the proxy analysis. It isn’t to get a better understanding of C20 temperatures. Proxies are never going to do as well as instruments. The purpose is to extend the instrumental readings backwards in time.
So it is true that selecting on 20C temperatures is always going to give a biased proxy measure there. That is unavoidable; you can’t use the same data for training and measurement. I believe in fact that proxy part of reconstruction measures should not be shown in temp plots at all in the training period. So yes, many climate publications are at fault there.
This has some corollaries. One has to recognise that the proper temp reconstruction (hockey stick) consists of the C20/21 instrumental combined with (spliced to, if you like) the proxy shaft. The splicing isn’t a bug, it’s a feature. The whole calibration etc was designed to make it valid.
It means that the endless fussing here about whether some procedure might have favored a HS appearance in proxies is irrelevant. Don’t show it; it’s not informative.
It also cuts off arguments about hide the decline and 1960. It would all be gone.
Steve: Nick, you’ve misunderstood the point entirely.
That strikes me as unprecedented.
It strikes me like comments from a reverse universe. Like the ones in TV and science fiction where everything is opposite from our known existence. Close the portal quick! CA might be nearing an event horizon!!
snip –
Steve: your response was reasonable. But Nick’s point is so obtuse that I’m uninterested in having people discuss it. Please look at the original papers.
“if you are purporting to represent that a proxy is representative of a later temperature record”
But they’re not. The proxies have been chosen to align as best possible in the later period. That choice is made in the interests of being able to extebd backwards.
There is some point in showing them in the overlap period, just to show you chose well. Or even to show that a good choice is possible. But not to show that proxies reinforce the instrumental temperature estimate.
That’s the legitimate criticism of he post-1960 cut-off. It isn’t hiding a decline, it’s hiding a divergence. The proxy correspondence isn’t as good as it looks.
To which there are two counters. One is that the divergence has been much discussed in published papers, so it isn’t secret. And the other is that they didn’t use that section for calibration. The fact that a period is unusable remains a problem.
Steve: this has nothing to do with the issue. Deleting adverse data is contemptible, but is a different issue. I ask that readers not engage on this diversion.
If you are correlating noisy proxy data with thermometer data, the noise can’t be too great, otherwise you might be correlating with the undesired proxy noise rather than the desired proxy signal. If you filter out those proxies that didn’t correlate, how do you know that those you kept aren’t just the ones with the lucky noise shape? If the data correlates with one period (er, ah, training period) and then diverges for another period, that’s a pretty good hint that it is just a lucky period of noise that correlated.
Every proxy data plot that I have seen looks rather noisy compared to the thermometer data. They all seem to have either divergence with thermometer data, or at minimum, divergence with other proxy data that otherwise passed the authors filtering process.
Re: Nick Stokes (Jun 10 20:17),
This would not advance science IMHO. The selection fallacy is a result of why they hide the decline.
It seems to me what these paleo climatology hockey stick papers are focused on is whether the warming of the last 150 years is unprecedented in 100, 200 etc. years or what ever long period they can proxy. It is all about the shaft not the blade (MWP).
The hide the decline after 1960 issue is hiding the divergence problem, something that undermines dendro-climatology at its core. If tree ring analysis will not “respond” linearly once a certain level of warmth is reached (or actually starts to resemble cooler climates), it can’t be a proxy for climate warmth, because it would not show warm periods like the present day if that warmth occurred in the past and perhaps even show it as cooler like the divergence from the IR in recent decades.
That is why the “community” is so focused on finding tree ring series that do respond in warmer climates, but also in cooler times in some linear fashion. It is also why so many other dendro papers only go half way into the 20th century (it side steps the divergence problem). Temperature responding tree ring series (those the correlate with the instrumental record) of course leads them straight into what Steve refers to as the “selection fallacy”.
The only valid move they have left is to establish what conditions (independent of temperature) cause one tree to be a valid “responder” and another not, and select on that non-temperature based condition. How they might verify this conditional selection criteria on preserved logs 1 to 2 thousand years old to distinguish the few “responders” becomes a bit of a problem though. Alas it is easier to preserve entire careers and bodies of work by putting up justification for bending statistical practice.
The issue of whether dendro-climatology is a valid paleo temperature proxy at all is why (IMO) Briffa says it must be an as yet understood modern (anthropogenic no less) cause. Convenient because he doesn’t need to explain whether or not his shafts are scientifically meaningful regarding the MWP or any period going past the instrumental record.
Re: Don McIlvin (Jun 10 21:57),
Opps..
should read “unprecedented in 1000, 2000 etc. years”
Steve, first let me thank you for all your work in presenting all these problems.
I think Don McIlvin has condensed it down to the essential:
It seems to me what these paleo climatology hockey stick papers are focused on is whether the warming of the last 150 years is unprecedented in 100, 200 etc. years or what ever long period they can proxy. It is all about the shaft not the blade (MWP).
Steve, I need to share one observation I made with your blog-posts. One does need take time, read your entire post, front to end, in order to “get it”, to get the point you want to bring across. When I want to post a link in my blog to your blog-posts, I find it hard to get the point across you want to make – there is not one central paragraph one could copy as a kind of summary or an “teaser”. It is usually in the comments that someone boils it like this example above. You seem to leave the “getting and understanding the point” part to the reader – which is good and educational. But it would help you to get the message across you want to make better if you’d add a paragraph at the end with a sort of summary (or an “abstract”) with what you found, or what questions remain, or what you learned, or or or… I understand that you do this on your own time, but so do most of the readers here. There are many commentators here much brighter than I am, may I suggest you take advantage of this and copy one paragraph from a commentator if you think she/he hits the nail on the head? Might focus the discussion more and may avoid “piling on” better than admonishments.
Don,
“It is all about the shaft not the blade (MWP).”
Indeed. That’s exactly my point. Proxies tell you about pre-1900 – the shaft. They don’t tell you about the blade – that’s instrumental. They may follow the blade, but you can’t regard that as independent information; it’s influenced by their selection.
Nick, for someone who clearly understands and use statistical methods, your logic never ceases to amaze me.
Selecting proxies for 20th Century “correlations” with temperature (often with instrumental records remote from the proxy site – almost anywhere will do!) more or less guarantees a “flat” shaft.
And you know exactly why. It minimises temperature variability in the precalibration period.
But that is the point isn’t it? Gets rid of the “inconvenient” MWP and keeps climate “sciences'” gravy train running at full steam.
Don K,
“Selecting proxies for 20th Century “correlations” with temperature (often with instrumental records remote from the proxy site – almost anywhere will do!) more or less guarantees a “flat” shaft.
And you know exactly why.”
No, I don’t. And you need to explain why it is so.
Suppose the proxies really are acting as thermometers. Then however they were selected, they will track past temperatures correctly. All the correlation does is to scale them.
They are, of course, imperfect thermometers. But why does that create a bias toward flatness?
Nick Stokes, I find it hard to believe that you do not understand that screening and selecting multi proxies based on their correlation with the short period of the temperature record of the near past will invariably lead to a hockey stick blade representing the temperature record that was the selection basis, and a long flat shaft.
As the chosen proxies are chosen because they correlate with the temperature record, they are also in agreement with each other over this brief period of time. However, this selection fallacy will lead to a long flat shaft representing the “historical temperatures” as the proxies do not correlate equally well with each other outside of the temperature record period. The noise and lack of corrrelation with each other outside the period of the temperature record means, when averaged, that the proxies will tend to more of less cancel each other out, thus creating the flat shaft representing the “historical temperatures”.
If you really do not understand this rather obvious effect, read this:
http://rankexploits.com/musings/2009/tricking-yourself-into-cherry-picking/
George,
I’ve said from the beginning in this thread that of course, selection by correlation to temperature will caused the proxy measure to track temperature in the training period. Which likely means a blade, and should not be taken as an independent measure of temperature there.
Proxies not correlating in the earlier period to some extent mimics the behaviour of multiple thermometers which do not correlate. So the target average is flattened on either measure. But OK, I can imagine that the extra noise in proxies might amplify the effect. What I can’t see is how that can be affected by screening.
I wouldn’t say that this procedure “invariably” leads to a HS — just that it can.
Suppose, for example, that trees really are valid indicators of temperatures (a big “if” admittedly), and that past temperatures shows a lot of variation (LIA, MWP, etc). Then the procedure would likely end up showing the true variation of past temperature. The fit would be deceptively tight because the noisy trees that didn’t fit well have been tossed, but that would only make the confidence intervals too small, not the shaft too flat.
The problem is that if you feed in serially correlated noise unrelated to temperature as in the Lucia post you cite at http://rankexploits.com/musings/2009/tricking-yourself-into-cherry-picking/ , you are likely to get a HS that fits instrumental temperature in the calibration period but has a meaningless flat shaft before that.
So if you use this procedure and then get a HS reconstruction, you have no way of knowing whether the answer is spurious or if temperatures really were flat before the calibration period.
The standard way to tell if TRs are really a temperature proxy would be to run a multiple regression of temperature on all the TR proxies, and then use an F test to test whether all the coefficients could be zero. But if the proxies are pre-screened for correlation for temeperature, this F test will be distorted towards spuriously rejecting the null.
(If you’re running out of DOF using all the proxies, PCA could be legimately used to reduce rank, but that’s not the conceptual issue at hand.)
Hu and George,
Lucia’s post is saying exactly what I am saying. If you select on temperature in a training period, your proxies will follow the temperature in that time. She did that with white noise post-1960 and got a HS post-1960. That is not a valid measure of temperature there. And when she extended the training period to include a test period post-1900 rabdom proxies tracked Hadcrut there too.
And yes, she got a meaningless shaft, by design. That’s the noise. The proxies are doing the right thing there (nothing), and this has nothing to do with the selection.
Fair point Hu. I should have said “almost invariably”, no problem with that!
Of course, it could happen by chance or by very selective screening, looking for correlation outside the period of the temperature record that the shaft ended up with a less flat shape, even mimicking an expected result, i.e. showing a LIA and MWP and other variations. Still, I would hold that the result would either most likely be spurious or just a result of even more dubious screening methodologies, even though the output may seem more sound on the surface.
Why? Well, I must admit that I by now hold no confidence whatsoever in the assumption that tree rings (and a number of other proxies for that matter) are useful as “thermometers” in the first place. There are just too many unknown or non correctable factors to begin with. Many mechanisms that may play into the result are not understood nearly well enough.
Also, the methodology that is applied has so far not been sound, as shown in time and time again on this site. I have a hard time seeing how we could ever get to the point where we could make such a reconstruction with reasonable and true confidence in the objective correctness of the result.
The methodology applied and the stats and maths that go into them are interesting from an academic point of view. The discussion here at this forum is of great scientific value, even though the reconstructions themselves hold no or little value in themselves. I believe I am not alone in thinking that.
So, when we keep on discussing them in detail from a technical point of view, it is not out of interest for the results or the validity of the results, but for the methodology applied. For an outsider or a believer in CAGW it may seem that since we are spending so much time discussing the reconstructions, they must have some merit in themselves. It is easy to misunderstand or to forget the underlying premise for many of us, that even though we do spend time discussing these reconstructions, that does not in any way indicate that we ascribe any scientific value to the results they purport to give, or that we ever will. Rant mode off 😉
A lot of other comments in this thread take care of the rest of my objections and the remaining problems with the methodology and assumptions that goes into these “reconstructions” and hence, why they are most likely close to useless. I see no need to pile on. Thanks!
And while I am at it: a big Thank You! to Mr. McIntyre and many other contributors on this blog for your outstanding work!
Re: Nick Stokes (Jun 10 21:13),
Nick, I think you are successfully replacing the Hockey Stick with another stick.
Was this a joke comment from someone posing as Nick Stokes?
Nick, the problem is the methodology as implemented by climate science is inherently flawed. Selection on the dependent variable does not reduce the noise. The process leads to erroneous conclusions, while at the same time making the results appear significant.
It is a mathematical blunder. A trap for the unwary that statistics students are taught to avoid. Apparently climate science never got the memo.
Amusing. On May 31, Steve Mc wrote: “CA readers will recall the long-standing blog criticism of the “Screening Fallacy”, not just here, but at other technical blogs as well. Not understanding the problem is almost the litmus test of being a professional climate scientist.”
As Nick Stokes describes himself as “An Australian scientist (not climate) with an interest in the climate debate” perhaps Steve Mc could widen his definition just a tiny bit.
On a tangential issue, it is worth comparing Nick Stokes’ comment “The splicing isn’t a bug, it’s a feature” with RealClimate’s 2004 assertion:
“No researchers in this field have ever, to our knowledge, “grafted the thermometer record onto” any reconstruction. It is somewhat disappointing to find this specious claim (which we usually find originating from industry-funded climate disinformation websites) appearing in this forum.”
Nick Stokes: feel free to take up your feature-not-bug argument with Michael Mann: I think it is accepted that he is the “mike” who authored that RealClimate comment.
“RealClimate’s 2004 assertion”
This is just a silly echoing of a talking point. I am talking about the quantitative basis for matching past proxies with recent instrumental. Mann was talking about graphical presentation. He was accused of showing proxies and instrumental as if they were one curve, and said people don’t do it. I’ve seen this gotcha often repeated, but never with a counterexample of people who have done it. And I ron’t think they should (or have).
He went on to say:
“Often, as in the comparisons we show on this site, the instrumental record (which extends to present) is shown along with the reconstructions, and clearly distinguished from them (e.g. highlighted in red as here).”
Indeed.
Steve: there are a number of counter-examples. The most famous is the graphic in the “trick to hide the decline” memo. In the context of Gergis et al, Cook’s presentation of the Oroko Swamp chronology, one of two long chronlogies used by Gergis, replaces proxy with instrumental data after 1957 without a change in color. There are other examples.
Mann himself at RealClimate has admitted to it deceptively. Saying that the mean at the endpoints was taken from the instrumental record.
“padding with the mean of the subsequent data (taken from the instrumental record)”
Mann at RealClimate.
They surely would. This first section is a masterly summary of the personal and political aspects, the rest is extremely helpful on the statistical issues. What an excellent weekend’s work.
I don’t think that screening is always wrong. As the tendency of autocorrelated records is to fool us into thinking the proportion of spurious records is lower than it is, then the simplest, most straightforward remedy is to increase the critical value so that the actual proportion of spurious records is once again, around the desired 5% level. This might mean adopting a 99% critical value, a 99.9% or a 99.999% critical value depending on the degree of autocorrelation.
Fuller post over at my blog, but please keep discussion here.
Hi David, The argument on your blog site reminds me of my single days when I selected from a population of women, some of whom responded to charm and some to existing husbands – and there were some in both groups. It was a challenge to formulate a way to deselected the worse ones, because often the marrieds gave a more sensitive and long lasting response; but that response was conditional and caused a priori rules, like “Before I start, can I run faster than that ugly brute she married?”
In the more measured tone of your example, have you ever met an experimental design in climate work where the deselection was so thorough that your conditions were met? Your argument is OK qualitatively, but I can’t think of an example that passed your quantitative guidelines. Can you?
I have a moral failing because I trivialise correlation coefficients worse than about 0.7, on the grounds that poorer correlation coefficients are often a signal that uncontrolled variables have not been adequately treated. I have another moral failing, that I have passed the point of no return with temperature reconstructions based on tree rings. I no longer accept them as valid for proxy reconstructions.
If modern authors have to select so few trees to meet their criteria in the instrumented period, there is great risk in assuming that these same trees behaved themselves before then, for periods up to hundreds, nay, thousands of years.
But of course, virgins do exist, both real and idealised, even some free of prox, even some with more than 7 standard deviations, but they seldom last a lifetime in that state.
Geoff, whether they behaved themselves in the past is the uniformity problem as they say. But talking about trees not women, I would make sure I had a good robust physiological model first. That is, lets assume temperature and rainfall are the only drivers of tree growth, and develop this bivariate model in the calibration period. Its a reasonable assumption to use only temperature and rainfall, and it is the minimum number of variables that you should be working with IMHO. Its very prone to error to be using partial models, or trying to select those special sites that are partial in temperature only. Using a bivariate model you could then use all sites in your analysis. Whether it would work or not, who knows unless you try it. I haven’t seen anyone do it yet.
“I would make sure I had a good robust physiological model first. That is, lets assume temperature and rainfall are the only drivers of tree growth”
Your understanding of plant physiology is inadequate to formulate a valid model.
Carbon dioxide, the supposed driver of temperature, directly drives plant growth, as has been demonstrated in numerous controlled studies. So how can you differentiate between the direct effect of CO2 on tree growth and its indirect effect via a presumed effect on temperature?
Laterite,
The problem is not that some paleoclimatologists, when screening, fail to correct their critical values for serial correlation and hence accepted too many proxies, but rather that they screen in the first place.
Once you assume that not all tree ring data series are effective temperature proxies then there is a real and valid selection issue, like deciding which thermometers are operating as intended or designed. Surely one solution is to test the tree ring data either against a relatively small randomly selected sub-set of temperatures/dates and exclude those that fail to meet a defined hurdle rate. I suppose one could also predefine a set of marker temperature/dates. After all one can test a thermometer by calibrating it against boiling water or freezing water. So why use a correlation measure to begin with?
A selection process on thermometers is valid because the thermometers (temperature) is the independent variable.
However, if you were trying to determine which brand of thermometer made for the most accurate temperature, and then screened the thermometers so that only those that were accurate were selected for the study, this would lead to the misleading conclusion that all brands were equally accurate.
The problem is that trees (growth rings) are not the independent variable (temperature), they are the dependent variable. As soon as you start selecting upon the dependent variable, you can create the illusion of significance where no significance exists.
“The problem is that trees (growth rings) are not the independent variable (temperature), they are the dependent variable.”
Ferd, that’s the wrong way around, and it’s where your logic is astray. For the analysis, growth rings are the independent variable. They are the data. Inferred temperature is the dependent variable – it’s what you calculate from the data.
Bernie’s thermomneter analogy is the right one. Suppose that you’re making them old-style. You have 1 reference instrument and many newly made blanks. You choose 62 that look OK, and then calibrate them against the reference. 27 of them show predictable correspondence to reference and you can mark a scale.
Then those 27 can be sent out into the field. You don’t have to scrutinise the rejection process (except for economy). Where the selection fallacy comes in is that you can’t measure the temperature in the room with your 28 thermometers and say it’s more reliable because they all agree. That would be circular; you have no improvement on reference. But you still have 28 useful instruments.
But don’t you need the reference tree ring model that you are calibrating the others against?
But you have something which gives a hockey stick even if you feed in random data.
The problem people who defend (as you do) this methodology have is that even a non-specialist can see that this means the approach is fatally flawed.
And since even the authors of this article appeared to recognise that they should detrend the data, I think you’re wasting your time by arguing (as you appear to) that they don’t need to.
Steve: I’m not saying that screening on de-trended is “right”, but less overt bias than screening on trended. The validity of screening as an operation needs to be demonstrated in each case.
Nick. Really! You cannot reverse the arrow of causation. The theory is that tree rings vary in response to temperature, and temperature is therefore independent variable, and tree ring growth the dependent. Any inferences you draw are not variables at all – they are inferences. The experiment consists in calibration, not in extrapolation.
HAS
“But don’t you need the reference tree ring model that you are calibrating the others against?”
No, you are calibrating expansion of fluid against what you want to measure – temperature. In that analogy, the reference could have been a thermocouple, gas thermometer, triple points, whatever.
gober
“But you have something which gives a hockey stick even if you feed in random data.”
I think you’re referring to PC1 in decentred PCA. That’s a different story, not relevant here.
bobd
“arrow of causation”
dependent/independent is terminology about how you calculate. Wiki says:
“The independent variable is typically the variable representing the value being manipulated or changed and the dependent variable is the observed result of the independent variable being manipulated.”
Tree rings are not the observed result of a calc.
Nick, the calibration issue of which way to run the regression is important and has been discussed at CA at length in the past, but is off topic relative to the topic of this post, which is the screening fallacy.
Well, Hu, you may be able to explain – if you don’t screen, what do you actually do with “proxies” where you can’t find a relation to temperature?
Steve: you have to choose a criterion ex ante and stick to it. If you think white spruce at treeline are a proxy, use them all or don’t use them at all. It’s simple. If some of them don’t have a relation to temperature, then much of the apparent relation to temperature in the others is probably spurious.
Nick, one of the major reasons that screening proxies is a problem in most current reconstructions is that, once a proxy is accepted, there are few mechanisms for evaluating its validity and its individual effect on the reconstruction. If there were such mechanisms built in then “all or none” could indeed be a viable option.
There are some simple ways to do so. For example, regressing the proxies individually on the (independent variable) reconstruction and looking at the patterns of the residuals can give information about how well the proxy relates to the reconstruction throughout the entire time period. One can identify which proxies could be problematical in such a fashion.
Another way is to use a methodology which allows for proxies to de facto “deselect” themselves during the reconstruction by having little or no effect on the final product. Going into the details here would be off topic.
Your argument that screening is the only path that works with current methods indicates that maybe some rethinking of those methods is required.
My sense is that the potential selection fallacy gets magnified because the calibration period is relatively speaking so extensive, hence my suggestion to severely limit the calibration period or simply chose a couple of distinct markers. Surely you simply want to identify and throw out the poor temperature proxies. For example, I would assume that strip bark first get recognized as poor proxies because they do not calibrate and then someone recognizes that most or all strip barked cores are poor proxies and therefore they should not be used the same way as other cores from the same type of trees.
The chosen calibration markers could/should be site specific – e.g. you would have to adjust the boiling point of water to reflect the altitude/pressure of the sites where you are assessing the temperature.
Steve, Roman, anyone
“If you think white spruce at treeline are a proxy, use them all or don’t use them at all. It’s simple.”
Well, in due course I’ll ask why. But for the moment, just an answer to that question of how would help. Use them all – but with what temperature scaling?
In any case, I don’t think this individual tree level is the one criticised with Gergis. There it’s selection of proxies aggregated from a region. And the same question – if you don’t discard proxies that you can’t calibrate (out of her 62) what do you do with them?
Nick, my comments referred to any multiproxy reconstruction (although it certainly also applies to a collection of trees at a site).
I will also stress that the methodology used by Gergis et al. has the weakness that once a proxy is in, it stays in. That means there is no mechanism to separate out spuriously correlated proxies from those which may contain some genuine temperature information nor is there any attempt to evaluate the proxies.
Nick Stokes:
“gober
“But you have something which gives a hockey stick even if you feed in random data.”
I think you’re referring to PC1 in decentred PCA. That’s a different story, not relevant here.”
No, I was referring to any technique in which the selection is based on giving a predefined signal. Steve Mc put it better than I can: “The problem is that a biased method can produce a Stick from red noise as well and therefore not much significance can be placed to a Stick obtained from a flawed method.”
You could argue that nobody here is in a position to know what the actual effect is in this case (the SH reconstruction) and you’d be right – because the authors have refused to give the full set of data used. As Steve Mc has previously documented, climate scientists seem to systematically regard data which didn’t pass the selection process as not used and therefore irrelevant.
Abstracting from the important but OT issue of which should be the LHS and RHS variables, you should leave them in when you compute your regression F statistic for the joint hypothesis that all the proxy coefficients are zero. Then also leave them in when you compute confidence intervals for your predicted values. If you just drop them, both the F test and the CIs will be invalid.
If you have a lot of proxies relative to calibration observations, it may be legitimate to reduce their rank first via Principal Components. Then if PC1 is temperature, the uncorrelated proxies will just end up in the omitted noise PCs. I’ve discussed this elsewhere in this thread.
“Wrong sign” proxies are another important but OT issue for another day. Even if one or two are individually significant with the wrong sign, the model needn’t be rejected unless you can reject that all the wrong-sign coefficients are jointly zero. But then should you set all the wrong signs to zero, or just live with them? Michael Mann says we should just live with upside-down Tiljander, but Steve would drop it.
Regarding the Thermometer Factory analogy;
‘Calibrations’ come with a time limit. Accuracy is not guaranteed indefinitely.
The usage of the proxy ‘thermometers’ is analogous to strapping them into the seat of a time machine and transporting them back multiple centuries.
While the authors of science fiction have license to assume that time-travel is scale invariant, the extension of the purportedly ‘calibrated’ thermometric proxy response to uncalibrated time epochs is simply wild extrapolation.
Why is it OK to discard the majority of otherwise indistinguishable proxies for failure to ‘calibrate’ , and then assume that the ‘calibrated’ timeframe can be extended tenfold without need for further screening/dropout?
In my lab it is scientific malpractice to rely upon a quantitative instrument beyond its calibration certificate.
Drift/shift is inevitable.
RR
Hu,
“you should leave them in when you compute your regression F statistic for the joint hypothesis that all the proxy coefficients are zero”
This is what is so frustrating and elementary – leave what in. Without calibration you have no numbers that you can use. Proxies come with varied scalings, and often units – eg Gergis’ mix of various tree species and isotopes. It is the temp calibration that puts them on the same scale where you can combine them.
But who made a hypothesis that all proxy coefficients are zero? And why do you want to test it? We’re not studying statistics of a population here.
Nick I think if you are using the analogy of having a master thermometer to calibrate others, you do need the master temp model to have been established and verified before you start replicating other thermometers. You need to know that liquid expands uniformly over a range of temperatures in a range of environments before you can start replicating (and with trees it’s a lot more complex).
I think what is being debated here is establishing the master thermometer (as it were), not the replication. We are establishing that tree rings have some relationship with temp so we can go on to use them more extensively.
If we were simply calibrating new tree ring thermometers against a known existing tree ring thermometer that would be fine – as I said in an earlier comment using a model of how tree rings respond to temp (including a wide range of environmental variables) to select tree ring thermometers would be a robust scientific approach, but note the model needs to specified before you begin.
And also note to validate your master thermometer the causality goes from temp to tree ring.
Wiki is correct. Your remarks are cryptic. The variables are observations, not computations. The computations are 1. correlation, which will hopefully establish that the putative dependent variable is indeed dependent, that is never a foregone conclusion (unless the data has been pre-screened). 2. a conversion factor to convert tree ring records to temperature. These things are done within the instrumental temperature record. Nothing outside of the instrumental temperature record is part of the experiment and there cannot be an independent and dependent variable because there is only one data set. Converting tree ring records preceeding the instrumental record is the same as converting farenheit to centigrade, it is not an experiment
Nick,
In answer to your 8:35 post, and I’m responding specifically to the “white spruce at treeline” example, not multiproxies; this is what you were responding to in that post.
I am not sure exactly what you mean by “that you can’t calibrate”. I’m assuming you mean ones that can’t be used to match the actual temperature over the calibration period.
If your selection criteria for valid proxies turns out to include a lot a data that doesn’t calibrate, then your selection criteria is invalid. Continuing, in this case, means coming to the conclusion, and reporting, that your selection criteria is invalid, that the science is incomplete, and new theories need to be tested.
If you exclude the instances that don’t calibrate, then all you’ve done is abandon your selection criteria and used anything that happens to calibrate. If you do that, there’s no way to say that the ones that calibrate don’t do so totally randomly. That’s the purpose of having a selection criteria in the first place, so you can elimate the idea that those that calibrate aren’t random happenstances.
In other words, you need a selection criteria that (statistically meaningfully “all”) select data that calibrates. That would mean that the methodology you’ve used is reliable and repeatable. Then you’ve got a case to claim that it is good data for working backwards. Otherwise, you’ve just tossed a population lasso over that data and everything you pull that works may work by luck, without indicating any reliability.
RDC,
I let the white spruce pass at that stage, but this thread is actually about Gergis. And we do have that screening procedure in front of us. Different kinds of proxies from 62 sites were tested for statistically significant correlation. 27 were said to pass.
Now the 62 weren’t “selected as valid proxies”, except in the sense that they had been published and were in the right area (approx) and there were some grounds for expecting temperature sensitivity. I don’t think there was any expectation that they would all pass. They were simply deemed worth the effort of testing.
As to whether they might work by luck, that’s what the significance test is for. To avoid “happenstances”.
There are other issues at the very local (spruce) level, but I’m trying to stay on topic.
Steve: nick, your lack of understanding of baby food statistical principles is numbing.
“Steve: nick, your lack of understanding of baby food statistical principles is numbing.”
Well, why not explain it properly? What results are actually affected by this “screening fallacy” and how? I’ve given my version.
Steve: Nick, I think that the methodological issue has been explained clearly enough. I think that it’s reasonable to point out the methodological error and let the authors try to assess the impact. It’s their responsibility. In any event, without the complete data set, it’s impossible to assess the effect in this particular case. Unfortunately, Karoly supported Gergis in her refusal to provide the data.
“Nick, I think that the methodological issue has been explained clearly enough.”
No, it hasn’t been explained at all. You’ve given social sciency references with waffle about circularity and said specifically only that it imparts a bias towards hockey sticks. I said that indeed, if you select proxies on correlation in the training period you’ll get correlation in the training period. That, AFAICS, is the extent of the circularity. And the obvious inference is that you should not regard proxy measures in the training period as an independent measure of temperature. I cannot see that Gergis et al have done so.
You for some reason regard this as an obtuse point. But it is exactly what Lucia demonstrated in her thread linked elsewhere. And it is the extent of the “selection fallacy”.
“Nick, I think that the methodological issue has been explained clearly enough.”
No, it hasn’t been explained at all. You’ve given social sciency references with waffle about circularity and said specifically only that it imparts a bias towards hockey sticks. I said that indeed, if you select proxies on correlation with instrumental in the training period you’ll get correlation in the training period. Which may well work out a bias towards hockey sticks for proxies in that time period. That, AFAICS, is the extent of the circularity. And the obvious inference is that you should not regard proxy measures in the training period as an independent measure of temperature. I cannot see that Gergis et al have done so.
You for some reason regard this as an obtuse point. But it is exactly what Lucia demonstrated in her thread linked elsewhere. And it is the extent of the “selection fallacy”.
Nick – do you really think that this issue hasn’t been explained enough ? Its obvious to me, and I suspect everyone else here, that there is a serious methodological flaw in the way hockey sticks are extracted. The reasoning is very clear and is pretty unambiguous. The hockey sticks may survive an improved methdology but such methodologies must be attempted. I hesitate to use the word, but it does seem appropriate here. The fact is that you’re denying basic statistical reasoning.
“I cannot see that Gergis et al have done so. “
I see on reviewing the text that they cite reconstructed temperatures in Table 2 for the warmest decades. They should have cited instrumental, but it would make little difference.
Roger
“The fact is that you’re denying basic statistical reasoning.”
The notion that proxy reconstruction of past temperatures is statistically unsound because of “selection fallacy” is a local view. It was not shared by the NRC North report, for example, which had statistician Bloomfield on its panel, and was reviewed by David Brillinger. Nor was it one of the criticisms made by Wegman.
The NRC report included a chapter on the statistical methods, of which one summary point was:
“The standard proxy reconstructions based on linear regression are generally reasonable statistical methods for estimating past temperatures but may be associated with substantial uncertainty.”
The way I look at it is to say “under what conditions can I separate out a subset of proxies which are driven by temperature from a population that is random, autocorrelated, or correlated with something else, with a defined low error rate.” This seems doable by screening.
It does put the onus on the researchers to demonstrate the conditions under which a specific method will succeed (something the field doesn’t do well). Classical statisticians are fond of saying that you cant do this or that, but from a machine learning perspective, many things are possible if the conditions are suitable even though they are not classically blessed.
Nick – instead of quoting from a document, please explain why it *is* reasonable given that the methodology would promote hockey sticks from random noise.
Roger, The statistical flaws in the method are obvious to you – I simply suggest that you could explain them to Profs Bloomfield, Brillinger and Wegman. It’s baby food statistics.
For my part, I have explained over and over. The method requires that you find proxies that correlate with instrumental during a training period. They will indeed do that, even if random, though you will have to look at very many random proxies to find a few that correlate satisfactorily.
Yet again, proxy data that has been selected to match during a training period is not an independent measure during that period. But you don’t need a measure there – you have instrumental. You have not trained the proxies in the period where you do want information. No circularity there.
Let me get this straight Nick: 35 of 62 do not correlate, so you ignore them and use the other 27?
Nick, when 35 of 62 observations do not correlate, that means whatever the hell you are using isn’t a valid proxy. It means trees are not thermometers. Goodness, it is mind numbing how basic this is: you don’t get to just use the data that agrees with your bloody hypothesis.
Well, RTK, you could say it’s worse. There are billions of trees in the world, and maybe one in a million (SWAG) would make good temperature proxies. Probably only one in a thousand would make good telegraph poles, but that doesn’t invalidate telegraph poles.
The fact is, the number of things that one might contemplate as a proxy is vast. So they are whittled down. The 62 represents someone’s idea of a short list. The final test is computed correlation, and that is what they apply, and the only thing that eventually counts. If whoever chose the 62 had been more picky, you’d have a different ratio.
That’s why peole’s notion of sampling issues is so astray. The population (62) is arbitrary.
This is elementary multiple regression analysis, Nick — If you want to claim that your regression model has any explanatory power, you first need to test the joint hypothesis that all the coefficents (aside from the constant) are zero. This is called the regression F statistic, and can be computed from the R2 together with the sample size and number of regressors.
It was probably R.A. Fisher who said so, about 100 years ago.
Hu,
This thread is now unwieldy, but I think the problem you have in mind needs to be specified. What multiple regression? There are variants of the methods. but the basic one is described in the North report. A simple regression of proxy variable against T over the range covered in the training period. I can’t see what joint hypothesis you have in mind.
And yes, they do effectively test whether the single regression coefficient is different from zero.
Steve’s emulation of the Gergis analysis has only 27 single variable regressions.
Nick, I do think that rather than repeating the points about the method you do need to go back to the underlying physical models from which the statistical methods derive. You are assuming here a physical world from which the various statistics (eg correlations of proxies to instruments in training periods) are derived, and upon which the statistical tests depend.
So what I don’t understand in your constant repetition is “What is your model of why tree rings and temperatures might be correlated”. Until you address that we can’t tell whether ignoring some that don’t correlate is consistent with that (hopefully) prior assumption.
This is really just a repeat of my comment above, that you didn’t address.
PS IMHO this has nothing to do with whether you can get erroneous hockey sticks, it’s about whether the method has integrity (i.e the results follow from the observations and the assumptions).
HAS,
Uniformity has been addressed in books and papers from Fritts onward. It has to be argued for each proxy, and of course is never certain. The North report summarises issues considered for the various proxy types.
You don’t assume correlation in the training period – you look for it. Uniformity is cited to say that the correlation found will extend back in time. It’s based on physical, not statistical, reasoning and the justification may be affected by exceptions like divergence. For the mathematics it’s not necessary to assume causation – just correlation.
Nick, I don’t think uniformity is sufficient unto the ends here.
We are not dealing with the stage at which a hindcast occurs, we are dealing with why some items correlate during “training” and some don’t (and you should think a little about why one might look for correlation during training if it doesn’t represent some physical phenomena we assume is occurring).
The problem everyone here seems to be dealing with is the process of dropping items during/based on “training”.
Pay attention 🙂
Isn’t “screening fallicy” or “double dipping” just a statistical ruse to justify “cherry picking” data? I assume that the term “cherry picking” is considered inflammatory or slang and not used in scientific arguments.
Steve: “cherry picking” is a little different.
Steve — I don’t see the difference from “cherry picking”.
Both are a little different from what I call “lemon dropping”, ie omitting observations that distinctly go the wrong way, while keeping what you have called the “apples” that aren’t driving the desired correlation, but aren’t contradicting it either.
Cherry picking/screening, on the other hand, omits both the lemons and the apples. But the results are distorted whether the apples are included or excluded.
A more subtle fallacy is to reduce the standard error of the slope and therefore its apparent statistical significance without necessarily altering its point estimate, by dropping outliers and still pretending that the data generating process was Gaussian. But this goes beyond the topic at hand.
Hu brings to fore an interesting observation that could be applied to proxies and in the categories of cherries, apples and lemons. I have planned to use the NOAA proxy repository to look at how these three groups would be populated when randomly selecting proxies.
Of course, the screening fallacy is more complicated when a proxy or a few proxies can be choosen that can dominate the final result. Maybe I’ll need to add sweet cherry and sour lemon categories.
I haven’t yet settled on a fruit name for the neutral outliers that don’t affect the slope perceptibly, but still jack up the estimated variance and therefore the standard errors and so are tempting to drop.
“Kiwi” comes to mind as something strange and inexplicable, but some of our readers might take offense. 😉
How about “ugli”?
Thank you for posting this additional thread on this “double dipping” issue. I had followed the previous thread and Fred B’s article. But as a layman I sure didn’t find this error to be intuitive, especially when it is added that the impact of the error is difficult to predict.
I see you are not cutting back on your blogging one bit! You are much appreciated!
How about “Quince”. Kind of looks like an apple, but is sour as hell in its raw form, but enhances the flavour of the Apples when properly cooked.
“Quince reducing” might work…
As all real_climate_scientists agree the rise in temperature from 1920-1990 is unprecedented in the last 1,500 years, there is a far simpler test that one can perform on all the detrended proxies; is the fit of the detrended temperature from 1920-1990 across all years. If the fit from the proxy chronology between 1920-1990 is best, accept it, but if you get a better fit between, say 1820-1890, then the data must be rejected.
As we know we have an ‘unprecedented’ temperature rise at the right, a true temperature proxy cannot give a better fit anywhere else.
This should be a required internal control for all proxies.
This seems a little too obvious, but doesn’t correlation of the proxies with each other outside of the instrumental (screening) provide an indication of robustness? Previously we’ve seen plots of the proxies in their entirety, I believe here and perhaps from Willis at WUWT, and they usually show a blur of spaghetti – a bad sign. This is something these papers should always include as well as indicative statistically derived measures. Such correlation doesn’t rule out the possibility that a second variable was at play and which itself correlated with temperature in the screening period, but would seem unlikely.
Steve: absolutely. the inconsistency of the “proxies” is the heart of the problem.
Jim Bouldin has said that Mann 08 used an internal correlation screening separate from the instrumental correlations. That the cores within a site had a certain minimum correlation.
Consistency between a number of trees at the same site could be due to any number of reasons (E.g. reindeer crap – https://climateaudit.org/2011/04/09/yamal-and-hide-the-decline/). But one tree-ring site (or a set of sites) makes up one proxy. David is asking about correlations between multiple proxies – coral O18 in one part of Australasia and tree-rings in another part. Such correlations often looks like that between two red noise time series.
They may (should) look close during the screening period where their correlation with temperature, and hence each other, was the basis for inclusion in the screened subset. It’s outside of that period where the real test occurs.
Now just chucking an idea out there to show there are other ways to go about it. We could start with an initial step which finds those proxies which do correlate with each other for the periods where overlap exists. This may produce multiple correlating groups, or none. A correlation group which aligns with the instrumental record may be considered to provide a temperature proxy. We didn’t select on the dependant variable*, though an assumption exists that our group which correlates with temperature hasn’t done so by chance and that the correlation is maintained beyond the instrumental period.
* OK we did in the end, but not the group members! Hopefully one group with lots of members, if not what were they doing there to start with?
Consistency of the proxies outside the calibration period is another big problem — and if proxies were selected for their correlation with instrumental temperatures, they will tend to be inconsistent with one another during the reconstruction period if that correlation was spurious.
(This is different from the “divergence problem”, where a proxy correlates with part of the instrumental record but then goes haywire in the rest of it.)
The BEST results of the variance of the distribution of the rate of temperature change in the modern period was rather interesting
See Figure 3
Click to access berkeley-earth-uhi.pdf
Roughly 50% of the sites have a temperature rise ranging from 0 to 2.5 degrees per century, with the mode at about 1.25 degrees.
So in a percent tree grove the rate of temperature change might be close to mean +/- SD.
This would play merry hell with calibration. When fitting the proxies, the temperature signal is the mean, not mean +/- SD.
snip –
thanks but I don’t think so.
Reblogged this on Climate Ponderings.
Basically, I think Nick Stokes’ reasoning is flawed. In fact, if most proxies exhibit the divergence problem, it throws into doubt the whole paleoclimate enterprise. I would ask why in the world one would expect convergence of a proxy to the recent temperature record to guarantee that it would converge to the temperature in the past. Seems to me that given the level of noise in proxy data, recent convergence might be just chance and not an indication of proxy goodness in replicating past temperatures.
I don’t see what part of my reasoning that relates to. Yes, divergence is a problem, and if there were more of it, it would cast everything into doubt. What IU’m saying is that what is wanted of proxies is that they correlate with temp in the overlap period. Divergence is a failure there. What is not wanted of proxies is that they act as an additional source of information on training period temperatures. Thie post correctly says that the “selection fallacy” acts against that. We knew that.
“Seems to me that given the level of noise in proxy data, recent convergence might be just chance”
That’s exactly what these detrended/not significance tests are about. If they pass, the claim is that accidental convergence is unlikely.
Steve: Nick, this is as simple as upside-down Tiljander. Yes, one wants proxies that are proxies. But if you think that white spruce at tree line are proxies, then you have to take them all. You can’t decide after the fact that one otherwise similar sites is a “proxy” and the other isn’t, merely because one, after the fact, correlates to temperature and the other doesn’t. Gergis has to take all the NS tree ring sites of the same class or none of them; all the corals or none of them.
This is baby food statistics. It is a bore talking about such banalities. It is appalling that such things have to be explained to climate “scientists”.
Steve,
“then you have to take them all. You can’t decide after the fact that one otherwise similar sites is a “proxy” and the other isn’t, merely because one, after the fact, correlates to temperature and the other doesn’t.”
How do you “take” a proxy that doesn’t correlate with temperature? What do you do with it? You have no scale to apply?
But I think the fallacy here is a notion that people are somehow trying to get the statistics of the tree population. All they are looking for is a time series – any series, however found – that correlates with instrumental temperature. Then they apply the uniformity principle. That last step is highly arguable and relates to the underlying physics of the series and the plausibility that correlation would be maintained over time, but doesn’t relate to the selection process.
Steve: Nick, you and your field are hopeless.
“Then they apply the uniformity principle. That last step is highly arguable and relates to the underlying physics of the series and the plausibility that correlation would be maintained over time, but doesn’t relate to the selection process.”
========
Nonsense. The “uniformity principle” is a selection process. You are saying the selection process doesn’t relate to the selection process.
The “uniformity principle” is a selection process.
No. According to the North Report p 48:
“All paleoclimatic reconstructions rely on the “uniformity principle” (Camardi 1999), which assumes that modern natural processes have acted similarly in the past, and is also discussed as the “stationarity” assumption in Chapter 9.”
not to mix issues but wrt: https://climateaudit.org/2012/06/10/more-on-screening-in-gergis-et-al-2012/#comment-337550
How is the uniformity principle as defined by North reconciled with the recent NH “divergence problem”.
I should add there that when saying “however found”, there is an issue of interpreting significance of correlation. Obviously if you test large numbers, you risk getting chance correlations. You have to choose an appropriate cut-off level.
this doesn’t work either. You can’t tell if you have a false or chance correlation without including the data for the trees that don’t correlate.
Suppose I presented you with a sample of 1000 tall, brown haired, women. From this sample I concluded that brown hair made women tall.
Unless you saw all the data (the women that were not tall and not brown haired) how you would know if my conclusion was valid?
By refusing to publish all the data, climate science is preventing analysis of false or chance correlations.
Again a false comparison. No deductions are being made about the statistics of the population of trees.
Reading Nick Stokes always reminds me of Wiki’s TLW
I believe the statistics-speak is clouding the fundamental empirical issues at stake in this discussion. The “uniformity principle” isn’t some logical axiom. It’s an empirical assumption–and a testable one, at that. And the so-called “divergence problem” isn’t a statistical artifact or refutation (depending on whom you believe)–it’s a piece of empirical evidence calling the “uniformity principle” into question.
We actually have lots of data with which we can test the degree to which the “uniformity principle” holds for specific types of proxies. And we have at least some evidence (the “divergence problem”) that this principle does not in fact hold consistently. So rather than argue statistics or “principles”, somebody should crunch the proxy data and answer the question once and for all: to what degree does, say, a tree ring proxy’s close correlation with the instrumental temperature record in one time period predict its close correlation with the instrumental temperature record during some other time period?
Until we have good answers to that question for different proxies, the “uniformity principle” is simply an statement of blind faith.
Steve: the divergence problem doesn’t challenge the “uniformity” principle – only whether there’s a linear relationship between tree ring chronologies and temperature.
.
Baby food indeed.
Valid sampling procedures requires a blind selection procedure. Any procedure that allows you to peek at the output data before selection introduces spurious outcomes. They are interesting mathematical exercise, but not revealing nor dependable and statistical significance is highly questionable.
But again, it’s not a sampling procedure. What do you think you are trying to sample?
And you’re not peeking at output data. You’re peeking at correlation. But more than peeking. You’re calculating a relation with temperature, without which you can’t proceed.
I wish I could get an answer to that elementary question – if you don’t discard the proposed proxies that you can’t calibrate, what can you do with them?
What’s In A Name?
stokes wrote;
‘You’re calculating a relation with temperature, without which you can’t proceed.
I wish I could get an answer to that elementary question – if you don’t discard the proposed proxies that you can’t calibrate, what can you do with them?’
AFAICT, the error is in the use of the keyword “calibrate”; that is a bridge too far.
Just because some subset of a proxy class has apparently good correlation with a short temperature record somewhere on the globe, does not provide a basis for extrapolating its behaviour beyond that period.
Just because you gratuitously call the process ‘Calibration’ doesn’t make it so.
Let’s consider “Fudge Factory” as the dielectic opposite of “Calibration”; the truth is probably somewhere in between. Trustworthy calibration can be directly traced to a rigorous standards body.
Repeatability is the hallmark of decent calibration.
The short answer when the majority of a group won’t ‘calibrate’;
Do Not Pass GO.
Do Not Collect $200.
RR
Nick,
Sampling tree as valid proxies is just like sampling thermometers. You keep all samples unless you can independently establish that they are malfunctioning. Alcohol and mercury thermometers operate on the principle of thermal expansion.
If I took all the thermometers at weather stations and selectively picked out the ones that showed a 4 celsius degree rise in the 20th century, what results do you think I would get? The process of selecting tree for temperature proxy is exactly the same pattern of behavior, and the results you get are entirely spurious.
Nick:
“if you don’t discard the proposed proxies that you can’t calibrate, what can you do with them?”
It really is incredible your persistence in ignoring what is plainly invalid methodology.
If 50% of the proposed proxies do not calibrate due to a combination of unknown and quite possibly random factors R1 to R500, which of the remaining proxies which do correlate, correlate only or substantially due to the spurious effect of the same unknown factors R1 to R500 ? If you can’t answer that question, there can be no objective faith in the proxy reconstruction. You simply do not know which, nor even how many, of your remaining proxies correlated merely due to the same random effects that caused you to discard the first 50%.
So the question is not “what can you do with the discarded proxies” but “how can you trust proxies which calibrate merely by chance over some short period to have calibrated over the long period, when 50% of proxies don’t even calibrate over the short period”.
You are not a stupid person Nick, you surely understand this simple matter.
Steve: “the divergence problem doesn’t challenge the “uniformity” principle – only whether there’s a linear relationship between tree ring chronologies and temperature.”
Point taken–I was taking the definition of the “uniformity principle” (vaguely phrased by Nick Stokes as, “modern natural processes have acted similarly in the past”) to imply “once a good proxy, always a good proxy”, but as you say, a weaker interpretation of the “uniformity principle” would imply only that “tree rings always respond to temperature the same way”, and therefore still be correct without necessarily implying “once a good proxy, always a good proxy” (as in the nonlinear response scenario you suggested).
Regardless, I believe my main point stands: the hypothesis that a proxy shown to be strongly correlated with temperature during one time period is reliably accurate during other time periods is an empirical one that can be tested using available proxy data and the instrumental record–and appears to fail the test rather badly in at least some instances.
good elucidation of this point, cleared up a question of mine. thanks
Who says that falsifiable prediction is impossible in climatology? Here Steve has predicted how Gergis et al will modify their methodological verbiage to fit the preordained outcome. Perhaps science is returning to the field…after several years of careful study the basic tenets of climatologist behavior have been codified and have become testable.
There will be a polite email from Karoly indicating that they had, in fact, “also” decided to change the wording on the paper; that it now reads identically to that suggested here; and that this decision was taken on Jun 10, 2012 at 6:00 PM
You’re probably right, ZT, but in this case it would be more blatant than most, since they’ve already said what they think is the right approach: detrend the data.
So to then decide that they don’t need to detrend the data after all would lay bare the extent to which they will twist the methodology in order to get the answer they want.
Steve Mc made the point above: “I’m not saying that screening on de-trended is “right”, but less overt bias than screening on trended. The validity of screening as an operation needs to be demonstrated in each case.” I don’t dispute that – just that given that since the authors had publicly accepted they should detrend in this case, it will be hard for them/their supporters to argue that the results are better if they don’t.
Assume there are 150 years of temperature data. If someone wanted to select a set of proxies that correlated with 75 years of the changes in the data and build a model it would seem reasonable to test that model against the other 75 years that had been held back. But you don’t get multiple bites at the apple, because if you repeat that procedure until your model both gets selected and then matches the other 75 years you have used up all your data for training. Of course you also don’t get to throw out some portion of the 150 years because it “diverges” from the model you built, or doesn’t train your model “properly.”
Am I missing something? Do any of these paleo models/reconstructions do this?
Steve: Nic, Nick Stokes has muddied things. We’re not talking here about hide-the-decline, but a different fallacy. Making a subset of (say) white spruce chronologies based on after-the-fact correlations and then using that data for a temperature reconstruction. Very standard paleoclimate practice, but classic double-dip.
I think I understood that Steve, but I am arguing that there is nothing completely wrong with doing that if you hold back a set of the data separately from the data that you used to make the selection. You can then test the model you built using the selected chronology against the held back data.
What you can’t do is keep repeating that process until you find a set of rules for selection that work. And this would be extremely hard to detect after the fact if it wasn’t reported. And as I write this the tendency to do it is so strong even if informally that this process is fraught with difficulty. In the best case the model builder would only know about the 75 years they use to “train” the model and would be unaware of the other 75 years until after the model is built and tested.
My comment on divergence was simply that given 75 years of data to train and 75 years to test you can’t arbitrarily throw out parts of the training data just because the resulting model doesn’t work against the other 75 years. And in advance how could you possibly know to throw the data out?
Nicolas, this procedure might be viable if you are dealing with the case where either (almost) all of the proxies are good or (almost) all are not. However, when the proxies are a hodgepodge mix from a variety of types and sources, how could one meaningfully divide them into two representative groups to use this approach?
Nicolas —
What you are describing is incomplete 2-fold Cross Validation.
IMHO, if you believe the model, you should fit it with the full calibration sample, and test its “skill” with the full sample regression F statistic.
Then, if it passes, you can use Cross-Validation as a specification test to see how well it fits out-of-sample. Most CV practitioners would use more groups than 2, but I don’t think there is anything wrong with it a priori. If the model flunks CV, something must be wrong with it.
A “switching regression” test for non-constant coefficients would have a similar effect, though I think CV is a little more general.
Thanks Hu,
So this article at Wikipedia seems to be a pretty good description of the variety of possible CV techniques. In particular i noted the misuse description at the end. From the description it seems to me that the paleo methods as described suffer from one or more of these issues.
http://en.wikipedia.org/wiki/Cross-validation_%28statistics%29
—————
These are some ways that cross-validation can be misused:
By using cross-validation to assess several models, and only stating the results for the model with the best results.
By performing an initial analysis to identify the most informative features using the entire data set – if feature selection or model tuning is required by the modeling procedure, this must be repeated on every training set. If cross-validation is used to decide which features to use, an inner cross-validation to carry out the feature selection on every training set must be performed.
By allowing some of the training data to also be included in the test set – this can happen due to “twinning” in the data set, whereby some exactly identical or nearly identical samples are present in the data set.
“So my guess is that they’ll resubmit on these lines and just tough it out. If the community is unoffended by upside-down Mann or Gleick’s forgery, then they won’t be offended by Gergis and Karoly “using the same data for selection and selective analysis”.”
First CA tells ’em the problem, the you give ’em the solution. Clearly this paper is a pre-accepted, important political paper for AR5 they will take the simplest route and bluster it out. They’ve been getting away with it for years so they are certain they won’t be called out on it by anyone in the climate science community.
It seems to me that there is a fundamental problem with many of the proxies used for palaeoclimate reconstruction and that is there is neither a robust phenomenological description of the relationship between a proxy response and temperature, or a constitutive understanding of the physical and chemical processes that lead to the response. This is most obvious for tree rings. No amount of double dipping, or a posteriori selection will resolve this issue. As Steve says if white spruce at tree lines are supposed to respond to temperature you take every sample and site and don’t select.
It is unfortunate that most, if not all proxies used for palaeoclimate reconstruction suffer from a lack of phenomenological or constitutive understanding of their response to temperature. Oxygen isotopes in corals will respond to temperature as a result of the thermodynamically controlled fractionation of oxygen isotopes between ocean water and the precipitating coral. However, to use as a temperature proxy one must assume that the water has a constant isotope signature. This certainly is not the case and their are documented examples of large changes in water composition as a result of, for example, annual flood water events discharging large volumes of fresh, 18-O isotopically depleted water into surface coastal waters. From memory one location where such events have been documented is the Great Barrier Reef.
Perhaps the only ‘robust’ proxy we have where we have a degree of both phenomenological and constitutive understanding is the isotopic composition of mid to high latitude precipitation. As a result of this isotopes in the water cycle are now embedded in some GCM models.
Watching the debate about tree ring chronologies unfold and the discussion of statistics here and at other blogs I am convinced that there is little point in pursuing tree rings as valid climate proxies. Certainly not until we understand the physiological response of trees to temperature, and all other growth limiting variables, and can develop orthogonal means of selecting, ex ante, appropriate sites for developing chronologies.
@ Paul Dennis. Quite so. As I’ve often written before, a “mechanism” helps. For an example of a growth mechanism, plant biologists have a reasonable explanation as to why tree roots grow mostly downwards and how they adjust their slope if disturbed. Put too simply here, it’s gravitropism and it relies on calcium ion concentrations in little mobile structures resting on the base of cells releasing growth promoters/inhibitors like some auxins, causing the top or bottom of the root to grow faster or slower as appropriate.
As to causes of tree ring widths, my reading is non-specialist, but I suspect that I have caused some changes in the garden by using giberellins. I’ve read less on other mechanisms simply because fewer papers fell before my gaze.
To make the story go full circle (a condition sought for tree ring work), Japanese scientists did indeed study the growth of children fed giberellins extracted from rice, ref ferd berple Posted Jun 11, 2012 at 2:37 AM.
(Probably too lightweight for this board, just how I currently understand this issue…)
If I understand that posting, even screening with detrended series may produce a bias (though smaller).
And yes, I think this is going to happen:
With detrended series, the selected series would follow the year to year wiggles in the calibration period.
Many would then look like temperature proxies and follow the uptrend as well, though some may have no trends and some even a downtrend.
Outside the calibration period, some proxies stop to correlate with temperature, some start to correlate with temperature, but as an overrepresentation of the former had been selected, more will stop than start to correlate.
The result will be, that temperature maxima and minima outside the calibration period are flattened.
On top comes the weighting issue, series with the wrong trend within the calibration period may receive small or even negative weighting, the latter making the reconstruction meaningless anyways. Removing those upside down series compromises the initial step of detrending.
It remains a mess. Why not concentrate on high quality proxies only, in the first place ?
Here is a simple example of the screening fallacy. Take the US GDP for the past 100 years. This is the average of all 50 states.
Now take the 10 states that for the past 10 years most closely match the average GDP for the past 10 years. This is exactly the same process as calibrating trees.
Now tell us. Which group best matches the average GDP for the past 100 years? Is it the 10 states that matched the past 10 years, or is it the full 50 states?
If you have been following you will realize the correct answer is the full 50 states.
This is the problem with selecting trees simply because they match the average. It looks good on paper but it gives a false result.
Haven’t you missed a step? Having selected the 10 best matches for the last ten years, you need to verify these aginst the previous ten years, and reject the five that diverge. And then extrapolate the previous 100 years using these 5.
And don’t forget to ignore any GDP mismatch in the last two or three years that might have arisien since you started this process.
Suppose you have a bunch of real, but uncalibrated, thermometers of uncertain origin. Suppose you then “calibrate” these thermometers over 10% of their range and throw out those that do not pass. Suppose that you then perform all of your measurements with the 90% of the range that was not calibrated. In what discipline of science, other than climate science, would an experiment performed using such instruments be acceptable for any purpose? Just a thought.
“Steve: But if you think that white spruce at tree line are proxies, then you have to take them all. You can’t decide after the fact that one otherwise similar sites is a “proxy” and the other isn’t, merely because one, after the fact, correlates to temperature and the other doesn’t.”
Although a fallacy I think the converse situation is unrealistic. You could never trust that white spruce which do not correlate at all with local temperature are useful proxies. Micro-climate conditions are important – certain trees just like certain proxies will be more sensitive to temperature rather than other factors. If you have a series of trees from a very close site you still can’t predict that microclimate conditions are similar for each tree and that there are not constraints which would keep certain trees from being temperature sensitive whereas others are not.
Including crap data (ie trees with no relationship with local temperature) in a reconstruction makes much less sense than the approach employed by others such as D’arrigo et al (2006).
Think of it in the context of ice cores – if you take 5 ice cores from an ice cap and 4 are useless for temperature (O18) whereas 1 core shows a strong correlation – you do not just ram the 5 together into a reconstruction – you take the one which we know has some relevance for temperature…
All or none is a simplistic approach in my view. That being said there are significant issues with only using local temperature to select proxies without additional assessment to confirm relationships actually exist… progress is needed but I don’t feel taking a purely statistical approach of All or none is justifiable.
However you do need a hypothesis for why the other ones are crap, and verify that hypothesis – otherwise who knows what babies are being thrown out with the bathwater.
Robert Posted Jun 11, 2012 at 1:44 AM
certain trees just like certain proxies will be more sensitive to temperature rather than other factors
====
What if we studied the height of children and how they grew in response to nutrition.
Now, select those children whose growth for the past year best matched the average nutrition supplied to all children to the past year.
Would the history for these specific children for the past 10 years provide the best measure of average nutrition supplied to all children over the past 10 years?
Or would the average of all children provide the best measure of the average supplied to all children over the past 10 years?
When stated in those terms most people can see the fallacy in the selection methodology.
The problem lies in thinking that trees are thermometers. They aren’t any more than children are scales to weigh food.
Agreed. And how do they know that the trees are responding to temperature and not some other variable that is currently tracking temperature? There aren’t many things that don’t respond to temperature.
If I went to a beach, I bet I could find some pieces of exfoliating rock that recently tracked temperature. It’s just a question of how many pebbles I had to interview to get a “statistically significant” number. Just because something is statistically significant, it doesn’t make it meaningful.
If one had the slightest interest in knowing anything about the climate of the past, one would start with the proxies, or what one believe might be a proxy and HOW it is a proxy. The better knowledge about a proxy, the better reconstruction of the past.
To seek knowledge of a proxy without dealing with the spices not correlating with a ‘predefined’ signal, well it’s not seeking knowledge. And it never was, I guess.
another example of the problem:
Click to access ACMR_final.pdf
In “The Strategic Logic of Suicide Terrorism,” Robert Pape presents an analysis of his suicide terrorism data. He uses the data to draw inferences about how territorial occupation and religious extremism a®ect the decision of terrorist groups to use suicide tactics. We show that the data are incapable of supporting Pape’s conclusions because he “samples on the dependent variable.” (The data only contains cases in
which suicide terror is used.) We construct bounds (Manski, 1995) on the quantities relevant to Pape’s hypotheses and show exactly how little can be learned about the relevant statistical associations from the data produced by Pape’s research design.
I think that the authors won’t try to salvage the paper, it will become an “unpaper” never to be mentioned again. Although the desire to get a southern hemisphere hockey stick paper into AR5 is strong, the contortions required to explain what the detrending step was doing there in the first place and how dropping it is an improvement would be agonizing.
Aren’t these “proxy studies” actually employing triple dipping? First they screen, then they use PCA and then they perform a regression analysis – all on the same data. I understand that they try to avoid “the third dipping” by using separate validation periods, but is that really a sound method that guarantees that the significance tests for the regression are meaningful? Many years ago, while still a student, I helped a biology professor with some statistics which isn’t too different from this (although time series were not involved). We used stepwise regression instead of PCR, but I was very clear (and consulted a professor in statistics to be 100% sure that I was right) that we would need a second data set if we were going to do sound tests of the regression.
One thing which is particularly confusing about the Gergis et al paper is that at first sight, they seem to be using the same period for the PCR analysis and for verification, but after a second read, I understood that they’re using different subsets of the 1921-1990 interval for verification in their strange combinatorial approach. That does make more sense, but the combinatorial approach is very opaque to me. What’s easier to understand, though, is their 1900-1920 “early verification period”, and I note that in figure 3, the RE values against the “early verification period” are very low for the pre-1600 period. That’s the lower red graph in their Figure 3. The black graph showing much better RE values, is “the ensemble median RE over verification intervals within the 1921-1990 overlap period”, which I wonder if is a useful measure of anything at all.
Espen — “RE” was a well-intentioned effort by HC Fritts (1976) to invent what is now known as cross-validation. However, since Fritts only looks at one verification period, he ends up with a lopsided statistic that has no clear meaning.
K-fold cross-validation instead partitions the entire data set into k verification subsets and then looks at how well each of these subsets is explained by coefficients fit to the rest of the data. The Q2 statistic then combines all these verification errors. If it is lower than expected relative to the full-sample R2, there could be an issue of nonlinearity, changing coefficients, or important omitted variables, even if the full sample regression F statistic (which is derivable from the full sample R2) looked good.
Fritts’ RE (or CE) test is best thought of as “incomplete cross-validation.” Again, it was well-intentioned, but now is long obsolete, even though it is used by climate scientists to this day.
In defense of Michael Mann, however, I don’t see that the verification r2 statistic (not to be confused with the calibration R2 statistic) adds anything to RE.
Steve: I disagree 100% on this latter point. Spurious RE statistics are easy to generate. If there is a true relationship between temperature and a proxy, it will pass a verification r2 test as well. Fritts and his school looked at RE only after a verification r2.
I guess we disagree here.
I say look at the cross-validation Q2 statistic only after you’ve passed a full-sample regression F statistic (computable from the full-sample R2). If the OLS model was well-specified (linear, constant coefficients, Gaussian errors), then Q2 should be redundant, but it may pick up misspecifications if these assumptions don’t hold.
But forget about Fritts’s well-intentioned incomplete cross-validation “verification” statistics altogether.
Most cross-validators would use more than 3-fold CV, but there’s nothing a priori wrong with it. But don’t just stop with comparing the first third of the data to coefficients fit to the other two thirds. Rather, compare each third of the data with coefficients fit to the other two thirds, and compile all the errors into a single Q2 statistic. Its distribution is computable in the absence of serial correlation, but may have to be simulated when it is present.
‘John Quiggin, a seemingly unlikely ally in criticism of methods’
John Quiggan (Queensland, Australia) wrote a very good article on the Y2K scam. It is worth reading, but one may have to email him for a copy.
Other than this interest, I suggest his blog is followed by government employees and the like in need of verbatim quotes and vitriol. The University of Queensland (Australia) is likely little different from University of Melbourne (Australia), where many utilise tax-payer funded employees and ‘volunteers’ to obtain data and leg-work for their academic grant funded projects and planning schemes. Called ‘in-kind’. Difficult to quantify.
http://www.polsis.uq.edu.au/quiggin
Further to previous post, but not the published articel
John Quiggan, … since I have such a big finnacial stake in Y2K………
‘Panic Merchants owe us a bottle’
http://www.uq.edu.au/economics/johnquiggin/news99/Millennium9912.html
Pardon,
spellos:- article.. financial…….
I know this is Climate Science, but it’s hard to believe that the Journal would simply accept a change in the description of the methodology, especially when the original manuscript provided an explanation for the choice of de-trending the series.
At the very least one would expect them to require a comparison of the results trended/de-trended, and perhaps a further round of peer review, regardless of the desire to get the publication into AR5.
Then again, maybe they really are prepared to weather the storm.
Regarding the real climate post, they really seem to have lost the plot a bit. Steve – you must be getting to them.
I read through it but it didn’t relate too well to reality. The first thing I saw was the original Mann hockey stick together with the assertion that it was independently replicated by his former student. That may be true but its hardly the point. It was biased towards producing a hockey stick out of noise thereby negating the claimed significance of the work. Furthermore, they had to do more damage to statistics to claim significance wrt the correlations with the temp record. In addition, while Mann’s former student can replicate the work, this wasn’t possible by anyone else owing to the lack of a full methodological description. I note they didn’t cite the Wegman report on this.
I also noticed that they sidestepped questions such as “if science is so open why did it take FOI requests, appeals to journal policy etc. to get hold of certain info”. It was also notable that they ascribe positions to Steve and others which they simply don’t hold.
Writing that type of post isn’t how science should be done. Its pure juvenilia. If I did something like that against the folks who thought my experiment will destroy the world I’d have been sharply criticised within my community. As scientists we’re supposed to be dispassionate reporters of our understanding of nature, end of story.
Funnily enough, there is a possible analogy between research in my area and the temperature reconstructions. A few years ago many experiments reported the observation of a new type of particle, the pentaquark. Lots of evidence emerged and it looked solid. However, once we started to check if the observations were consistent with each other or whether our discoveries were artefacts of a statistical bias (eg if you look at enough distributions you’ll see a bump in some of them through chance alone) the evidence was weakened and now nobody takes pentaquark evidence particularly seriously. I’ve no idea if the hockey stick will go the same way. However, I see no evidence that anyone in the community is trying to falsify the hockey stick hypothesis rather than promote it. Our philosophy is always that if you can’t get rid of an effect (and you must really, really try to do this) then you have to begrudgingly accept it as being part of nature. This is the safest way to do science. Otherwise, if you go looking for something and expect to find it, you’ll usually find something whether its real or not.
I have a “probably silly) statistical question..
Let’s assume I have :
1) a dozen “hypothetical” proxies extending back 400 yrs
2) an instrumental record going back 120 yrs.
Would it be acceptable to test the proxies by regressing them against HALF of the instrumental series,and selecting ONLY the proxies that also correlate well with the non-regressed half of the instrumental series?
I’ve misplaced my copy of Darrell Huff’s 1954 “How to Lie with Statistics,” but I bet he had a chapter on what Steve is calling the Screening Fallacy.
Does anyone who still has their copy check? Thanks!
http://en.wikipedia.org/wiki/How_to_Lie_with_Statistics
Click to access Lie-With-Statistics-Darrell-Huff.pdf
Bill — Thanks for the link.
Although there is a passing reference to what Steve is calling the screening fallacy on p. 38, there is no chapter devoted to it as I had recalled.
Perhaps I was think of a piece by Lancelot Hogben — something about short-weight loaves of bread.
This was one of the textbooks we were set when we studied Statistics (for scientists) at undergraduate level.
It really is very good for showing you how wrong you are in your ‘feelings’.
It is claimed that cross-correlation of proxies (not individual trees) can be used as a screening tool. However, because of things like el nino and other oscillations (lke ITCZ) some regions warm/cool while other regions do the opposite. They might not correlate or the correlation would be negative even if they were perfect thermometers.
Looking at the correlation of proxies with each other, they fail statistical tests, so IPCC just uses eyeball tests, which are more forgiving (“hey, look, they agree!).
Cross-correlation of proxies can be a useful dimensionality-reduction tool. In fact, this is what Principal Components analysis tries to do. PCA can be very useful when there are many proxies relative to calibration observations, as in Gergis (62 proxies with only 70 calibration observations). However, the rules for PC selection and retention should be carefully laid out, not hidden in a 3000-variant smoke cloud as in Gergis.
Correlations may be present that have nothing to do with the signal of interest, so it may be necessary to look at more than just the first PC. If this is done, however, the PCs should not just be cherry-picked for best fit without some statistical discpline on how they are selected. For example, I don’t think PC5 (to take a famous example…) should be accepted, even if it passes a t-test by itself, unless an F test rejects the hypothesis that the first 5 PCs all have zero coefficients. In fact, PC5 shouldn’t even be considered unless it stands out with something like Preisendorfer’s “Rule N.”
Then, having settled on a calibration model, it doesn’t hurt to try cross-validation to check for nonlinearities and unstable coefficients, and then also to see if the proxies are at least consistent with one another outside the calibration period.
“Steve: I disagree 100% on this latter point. Spurious RE statistics are easy to generate. If there is a true relationship between temperature and a proxy, it will pass a verification r2 test as well. Fritts and his school looked at RE only after a verification r2.”
I think this comment bears on the critical point that Ross McKitrick made in another thread and that is a valid proxy would fit both the higher and lower frequency parts of the instrumental series.
I think Nick Stokes presents an interesting and informative foil here for understanding why otherwise intelligent people (and evidently a number of climate scientists) evidently do not completely comprehend and appreciate the screening fallacy. I have seen this same phenomenon manifested at investment blogs. Once in awhile, an individual would have a light bulb moment but that happened not very often. Part of the problem is that the result of selection gives an answer that is in agreement with those who do not understand the fallacy. In other words, the underlying process must be valid since it gives the correct answer.
Nick, it is quite simple- even our third year project students can understand the concept.
1) They come up with a hypothesis
2) They produce a null hypothesis to be tested (I have yet to see one of these in tree ring reconstructions)
3) They design an experiment to collect the data
4) They do a “power calculation” to determine the number of sujects/amount of replicates they need to have a good chance of properly testing the null hypothesis
5) They go away and collect the data.
6) Then they analyse ALL the data.
7) Very often one or two “outliers” mean you do not get a significant result
8) That is tough- if they have time they will collect more data
What climate “scientists” seem to do is;
1) Discard all the data that doesn’t fit their hypothesis or
2) Only include the outliers (such as YAD 061) that fit their hypothesis in the analysis
To quote Gergis- it is called “research”.
Re: Don Keiller (Jun 11 09:50),
On step #8 — collecting more data. Even collecting more data can be problematic! Time to again bring up a fascinating study, False-Positive Psychology : Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant [Simmons et al, 2011] demonstrates that adding more data until significance is achieved introduces a significant risk of false positives (see Fig 1).
The same paper discusses a number of other fallacies in data handling, including a variant of the selection fallacy.
Don K,
“4) They do a “power calculation” to determine the number of sujects/amount of replicates they need to have a good chance of properly testing the null hypothesis”
I’ll just pick this out to show why you and so many here have the wrong concept. You’re describing sampling a population to estimate population statistics. That’s not what is happening here. No such statistics are being estimated. There isn’t even a reasonably defined population.
They are just looking for proxies (eg trees) which
1. are temperature sensitive, as indicated by instrument correlation and
2. to which the uniformity principle can be reasonably imputed.
Neither of these criteria are affected by how the selection process went. You just have to find them.
“4) They do a “power calculation” to determine the number of sujects/amount of replicates they need to have a good chance of properly testing the null hypothesis”
I’ll just pick this out to show why you and so many here have the wrong concept. You’re describing sampling a population to estimate population statistics. That’s not what is happening here. No such statistics are being estimated. There isn’t even a reasonably defined population”
One performs a power analysis to know what n numbers one requires to examine two or more sub-populations in a larger population. The definition of a sub-population is one which has a different mean or different frequency distribution with respect to an effector. The small the difference in mean the larger the n required. With an altered distribution, where two populations have the same mean, the nearer the distributions are to each other the larger the n required to decern the two groups.
This is entry level statistics. You believe that you have two sub-populations; one which is a thermometer and one not a thermometer. You eben have a huge advantage in trees as you believe that the ones at high altitude are more thermometer-like than ones at lower elevations. So the power analysis should be a doddle.
You are so damned lucky, sample the postulated non-thermometer trees, those at lower, warmer altitudes, and core those; result no correlation with the modern period at all.
Easy Nick. That is why Real_Climate_Scientists always cite these studies.
“This is entry level statistics. You believe that you have two sub-populations; one which is a thermometer and one not a thermometer.”
Yes, but it’s not what they are doing. They are not studying populations.
“The first line of defence – from, for example, comments from Jim Bouldin and Nick Stokes – has been to argue that there’s nothing wrong with using the same data set for selection and selective analysis and that Gergis’ attempted precautions were unnecessary.”
Negative.
I’ve never made any such statement here, or anywhere else, not even remotely. Rather, you’ve misinterpreted the arguments that I have made, most of which have had to do with your so-called “Screening Fallacy” (or I guess it’s now apparently a “Screening Irony”). People who’ve followed the conversations know this, or at least they should. People who haven’t, will not likely read through the previous posts across which those comments are scattered, they will just take your word for it, and you well know that.
Steve: Jim, my apologies if I misconstrued your position. I thought you supported ex-post screening on non-detrended data (which is a standard practice in the field but which necessarily requires the same data set for selection and selective analysis).
UPdate- Paul matthews quotes you as follows:“If it turns out that they used the trended data instead of the detrended for determining the calib. relationships, then I’m fine with that, because there’s nothing obviously wrong with that”
Jim, simply give us here a succinct and brief statement on how you would handle the issue. Your statements have been unclear for me. I recall you seemingly to agree with the Gergis screening process and seemed to insist on the detrended procedure. Later you referred to either selection process – detrended or not detrended – could be used.
Jim – so you oppose the use of selected data in analysis?
Actually, data selection on the independent variable can be a very powerful method. It can allow you to turn non-normal data into pseudo normal data, allowing for standard statistical methods to be applied reliably.
However there are in mathematics some operations that are forbidden, because the lead to spurious results. For example, multiplication by zero: 6×0 = 7×0, therefore 6=7
Similar rules exist in statistics. You cannot select on the dependent variable (trees) if you want to draw conclusions about the independent variable (temperature) because this leads to spurious results. You have broken the independence of the independent variable, by introducing temperature on both sides of the equation. It is the statistical equivalent of multiplying both sides by zero.
This is more subtle than the screening fallacy, but I’d disagree with this as well.
If the data is conspicuously non-Gaussian, then instead of trimming the data to fit the model, a statistical method that takes this non-Gaussianity into account should be used instead.
A common problem is heavy tails. In this case, my favorite alternative is to generalize the Gaussian distribution with the “Paretian” or “Levy” stable distributions that come out of the Generalized Central Limit Theorem:
http://econ.ohio-state.edu/jhm/jhm.html#stable
Example: I want to estimate how the traffic along a stretch of road varies over a day. I try and count every car, but at busy times there are too many and I get confused. So instead, I only count white cars, and get a distribution for the full day. I then select a quite time of day, and count the proportion of cars that are white. Job done.
This assumes of course that white cars are not more common at night.
Jim B on previous thread:
“If it turns out that they used the trended data instead of the detrended for determining the calib. relationships, then I’m fine with that, because there’s nothing obviously wrong with that”
I’m not engaging the debate (since I’m no stats expert) but here are a couple of possibly relevant comments from Jim Bouldin on the “Gergis on Hold” thread in case others want to discuss:
Jim Bouldin comment A
“…. I don’t know why they calibrated on detrended data (if in fact they did, which is uncertain now). There are reasons to be made both for and against such a practice, regardless of how common it is. But I do know that if they actuall calibrated without detrending, then (1) my arguments above apply and (2) both Nick Stokes and Kenneth Fritsch have provided their calculations indicating that a high percentage of their 27 sites would have passed a p = .05 screening criterion.”
Jim Bouldin comment B
“If it turns out that they used the trended data instead of the detrended for determining the calib. relationships, then I’m fine with that, because there’s nothing obviously wrong with that. If it turns out the problem is deeper, then they will have to re-do their analysis. It happens.”
Don’t forget
“…one can test this conclusion even further, by the further test of detrending the composite ring series (not the original detrending of each core to remove the size effect, but a second detrending on the chronology), and then evaluating, statistically, whether there is a relationship between the resulting residuals and similarly produced climate residuals. If the generating process for the ring series was non-climatic, there will be no stat. significant relationship observed therein. If, instead, there *is* a relationship, it will show up. And lo and behold!…this is exactly what Gergis et al did, and exactly what they found.”
Bingo Paul.
Need it explained to you?
Again?
Jim, I am a bit hard of thinking so could you explain it to me?
Here is the bit that I don’t understand.
They state in their methods section, that a prior, using detrended data for deciding which data-sets are temperature proxies is superior to using undetrended data.
They then, accidentally, use the method they have declared inferior, and have selected data which meets this criteria.
They then analyze a series of proxies chosen by the inferior methodology.
Here is the question Jim, now their error has been discovered should the authors;
1) repeat the reselection process using detrended data and use EXACTLY the same methodology they have used previously.
2) state that using undetrended data is as good as using detrended data for sample selection, slightly alter the text, and state their analysis is correct.
I really want to know what you think Jim, because the question about intellectual honesty in general and the ethical standards of climate science in particular.
You see the thing is if I was in their position and I followed 1) I would be fired.
Whoops, didn’t follow 2).
Doc,
I agree with Jim here. And the thing is, we’re actually interested in the temperature prehistory of Australasia. Not in how these authors reconcile their opinions, or how the journal manages the matter. What we have here seems to be an analysis done unintentionally in the orthodox style. If it’s a correct analysis, it doesn’t matter who did it or how it came to be done. It’s the results that are of interest.
Now there do seem to be other faults. They should use one-sided tests, and as HaroldW noted, a couple of proxies will probably have to go. And there may be more. But that’s another matter.
Jim, I think like many others, I am confused by your last statement. I followed the conversation and had the same interpretation of your views as Steve did based on your comments in the earlier thread. Can you clarify your opinion on trended versus non-trended?
This comment from Jim Bouldin two days ago seems to directly contradict the one above:
This “screening fallacy” with respect to climate reconstructions is just crying out for a peer-reviewed paper to highlight the issue. It doesn’t even have to be submitted to a climate journal (and therefore be hostage to climate gatekeeping) but can be in an applied statistics or similar journal. How about it Steve? Ross? David Stockwell?
No statistics journal would accept such a paper because practicing and theoretical statisticians already know about the “screening fallacy” and why it should be avoided.
Steve: you have to choose a criterion ex ante and stick to it. If you think white spruce at treeline are a proxy, use them all or don’t use them at all. It’s simple. If some of them don’t have a relation to temperature, then much of the apparent relation to temperature in the others is probably spurious.
=============
Exactly, the trees that you didn’t select are telling you that the trees you did select are likely not good proxies, but simply appear to be good proxies by chance.
For example, if you have 100 trees and 99 correlate with temperature, then they are quite likely good proxies and it will do no harm to the analysis to include the 1 one tree that didn’t calibrate.
But if you have 200 trees and only 99 correlate with temperature, then the 101 trees that don’t calibrate tell you that the other 99 are probably not very good proxies either.
In this case you want to include the 101 that didn’t correlate, so you don’t over estimate the confidence and under estimate the error in the result.
However if you only report the trees that do calibrate, then both groups of 99 trees will appear of equal quality when in fact the first group is very likely a much better proxy than the second.
This leads to spurious conclusions because you will then weight each group of trees equal in reliability when in fact they are not at all equal.
The problem is that climate science hides the trees that don’t correlate which makes all trees look like equally good proxies, even when a high number of trees are telling you they are not reliable.
The attempted diversions from the post topic “Screening Fallacy***” aside, it is becoming much more evident that the fundamental approach of some paleo reconstructions of tempurature that are widely used and highly favored by the IPCC assessment reports are based on a fundamental statistical fallacy. With statistical error at such a root level, such paleo temp reconstructions simply should not be uncritically accepted as scientifically significant in the AR5 assessment of AGW.
*** also know as:
1) “double dipping – the use of the same data set for selection and selective analysis”
2) “the Non-Independence Error – which is ’selecting on the dependent variable”
3) “Selection Bias”
John
Jim Bouldin, I think your comment below requires you to let us know succinctly where you now stand on selection screening before we can have an intelligent discussion with you here on that issue.
“If the generating process for the ring series was non-climatic, there will be no stat. significant relationship observed therein. If, instead, there *is* a relationship, it will show up. And lo and behold!…this is exactly what Gergis et al did, and exactly what they found.”
Jim’s comment above was in reference to what he thought was the series detrending that Gergis did and that we found out later that was not detrended in Gergis.
From my point of view, the problem with spurious correlation is not the fact that if there is a relationship you’ll find one, but you can have a significant correlation when no underlying relationship in fact exists. That’s where having a prior method for selection of proxies is important, and why it’s necessary to have multiple samples from the same site: I believe comparing multiple samples against each other that according to some hypothesis are supposed to behave as temperature proxies goes under the rubric “testing internal consistency”.
It’s absolutely critical to do, and anybody who doesn’t understand this (a “statistics denier” if you will), needs to bring a statistician on board to help them with their experimental design. It’s that simple.
There are ways of testing whether you have spurious correlation outside of the calibration period, and if you are familiar with the literature, you will know that the researchers in many (but not all) cases are aware of those. But I think it’s fair to say that many of the selected proxy series fail to verify when correlated against each other, and further, that the people have claimed their series passed verification had to use some highly imaginative methods to get them to pass verification, while neglecting to mention that traditional methods that they were documented later as having tried failed to verify.
Curiously these same people used the argument of spurious correlation as an argument against using correlation as a method of verification. It’s curious because it makes no bloody sense. It would be a different thing if they a) weren’t already using correlation elsewhere in their methodology and b) if they were worried about spurious correlation instead of the lack of a significant correlation (which is the case here with the proxies). We also know they were aware of some of the problems with this because they ran Monte Carlo’s and reported the results of these (they just screwed up their analysis, or tortured it until it confessed, depending on your perspective).
Out of 1200 proxies, Mann got 400 that passed screening. If this had instead been 1000, would that change your opinion with regards to the screening fallacy?
I realize the 400 passing is influenced by some cheats. I’m just wondering is there a level where the red noise would do the same thing argument evaporates?
MikeN, after removing the “cheats”, as you referred to MXD proxies lopped off at 1960, the instrumental proxies and the upside down Tiljander proxies, you are left with about 25% of the proxies. I did ARFIMA simulations with a fractional d value and came up with about the same percentage passing the Mann(08) p=<0.13 test.
Re: Nick Stokes (Jun 11 15:44),
Nick, why is filtering for validity by correlation to temperature necessary? If our hypothesis is that they are a valid measure, they should correlate nicely to one another.
If the uniformity principle is valid, then by definition it can be applied.
To put it another way: the data should be selected, filtered, correlated, etc while the temperature to be tested against is in a locked box. We are not allowed to see what’s in the box.
Once we have selected our data that we believe fits our hypothesis, then we open the box and see if our hypothesis is correct.
Seems to me this is quite simple:
– Create an hypothesis (phenomena with physical characteristics X, Y, Z are valid temp proxies)
– Collect data
– Toss bad data based on (valid, previously-defined criteria) of the data not black box temps)
– Now we open the black box to discover:
a) How well does the data correlate to instrumental temperature?
b) What is the uncertainty range for the correlation?
c) Based on a and b, what does this data tell us about non-instrumental temperature?
Maybe I have a bad college education, but AFAIK it is never valid to select/filter data based on information in the black box.
It is an axiom of manufacturing quality control that you cannot “inspect quality into a product.” Statistics can be used to measure the quality of a manufacturing process, but improving the quality of it is an engineering exercise – not a statistical one. In this case, the production of chronologies can be considered a manufacturing process, from the choice of raw material (what region to choose, what stands within a region, what trees within a stand and coring choices per tree) through all of the steps to the final product: a time series. According to the authors, this manufacturing process has a very high rate of defects: about 56% (35/62), not counting apparently “defective” series such as a Law Dome, etc and assuming that this rate refers to trended proxy data compared to trended instrument data.
Furthermore, this 56% defect rate was the result of only calibrating the instruments over just 10% of their range. Applying the uniformity principle, one would expect that, if it were possible to calibrate these instruments over an additional 10% of range, then perhaps another 56% of the remaining 27 would be rejected as defective. Applying this procedure to successive 10% range intervals and taking into account how many series are in each century, I have calculated the following table.
Century…….Proxies Remaining
20th……………..27
19th……………..12
18th……………..5
17th……………..2
15th……………..1
14th……………..0
13th……………..0
12th……………..0
11th……………..0
10th……………..0
Thus, given the high defect rate of chronology manufacturing, all proxies would be eliminated as defective by the time half of the total range was tested. That may seem too harsh. The argument could be made that the defect rate would decay as more 10% ranges of the instruments were tested. For example, one could say that the testing of the first 10% range would reject all the instruments that were defective over the entire range. When testing the 2nd 10% range, only the instruments that were defective over part of the total range would be identified. Accordingly, just for fun, I assumed a decay rate of 2, which means that the defect rate of 56% would be divided by 2 for each successive 10% range, so the 2nd range would have a defect rate of 28%, the third 14% and so on. I have grouped the results by proxy length (in centuries) and century range below:
Length..Proxies..20th…19th…18th…17th & higher
2…………..6……….6……….3
3………….10……..10………4……….3
5…………..4……….4……….2……….1……….1
6…………..4……….4……….2……….1……….1
9…………..1……….0……….0……….0……….0
10…………2……….1……….1……….1……….1
One could play with different decay rates, but climate science I think wrongly assumes that no further proxies would be found to be defective if it were possible to calibrate them over the entire range. In total, only 9 proxies would remain (adding the right most numbers from each group together) from the original 62, upon which the proxy reconstruction would be calculated. Since calibration in the other centuries is not possible, I would think that the confidence intervals would need to be wider somehow. The high defect rate of the process that manufactures chronologies is the key issue here. If you wish to test using detrended data, then the defect rate would be even higher and would probably result in an unacceptably high rejection rate.
Of course, this problem could be avoided by simply using all of the chronologies and not considering any of them to be “defective.” 🙂
“Liar’s poker is a bar game that combines statistical reasoning with bluffing, and is played with the eight-digit serial number on a U.S. dollar bill. Normally the game is played with a stack of random bills obtained from the cash register. The objective is to make the highest bid of a number that does not exceed the combined total held by all the players. ”
“Normally the game is played with a stack of random bills”
Some people cheated by saving bills with a better serial number.
Same with proxies. Climate Scientists save up the right set of proxies and reuse them every time the game is played.
snip
Steve– Jim, I’d already deleted that comment for its tone.
Give him a guest post. He is quite confident that Mann is doing it right.
My comment here may be all or partly OT, so feel free to snip away: I come from a chemistry background, where we get to do experiments and do not have to rely on statistics. I am thinking that it is not too late to inject some actual experiments into this paleo-climate stuff. Such as, if one suspects that white spruce at the tree line are valid temperature proxies, select several such sites and place around each a bevy of solar-powered “weather stations”. Thirty-or-so years from now we begin coring these trees and comparing our core data to the recorded instrumental data at each site. And voila!, now we have some actual experimental results! And right there we have a paper which will say SOMETHING about our supposition that white spruce at the tree line are valid temperature proxies (assuming, again, that we include in our study and in our paper ALL of the trees we cored, not just the ones that may correlate with temperature).
“I think I understood that Steve, but I am arguing that there is nothing completely wrong with doing that if you hold back a set of the data separately from the data that you used to make the selection. You can then test the model you built using the selected chronology against the held back data.”
This procedure sounds good but in practice it can be something very different. How would one know that the full set of data was not looked at before separating it into a training and verification periods? How often would a paper be published that showed that while the relationship looked good in the training period it failed in verification? I know I have not seen those results reported.
The way around this is to test the model with out-of-sample data. Investment strategies that promise huge returns with in-sample data and testing can often fail miserably out-of-sample. In the real world what happens. Well, the failed strategies are soon forgotten and those strategies that succeed by pure chance are touted as showing the strategists great skills.
Good points made by the kriegeskorte et al. (as well as the ‘False Positve paper’ linked to in the comments). Knowing the state of affairs in fMRI research, I am not at all surprised if similar biases taint climate research modelling.
There ought to be a way to do this. Hypothesize one or more common signals across all proxies, and time-series for each proxy type. Only the amplitude, phase, and sign are unknown. Iteratively try various combinations of proxies, to search for these common signals. Each proxy type gets a common A/Ph. Test for more than one strong signal.
Once you think you have one or more strong signals, they should remain close to invariant across many random subsets of the time-series.
When after much searching, you have found proxy-selection invariant signals, only then do you compare to the recent instrumental record. If one of the found signals looks like the temperature record, you now have a separate task: to find independent physical evidence that the found signal is not a spurious match. You also have to explain the phase and amplitude differences between proxy types.
The problem is, of course, that the found signals may look like nothing in the instrumental record. In which case, no more grant money for you. Who would take that risk?
“Survivorship Bias” is also a well-known fallacy in financial circles.
https://en.wikipedia.org/wiki/Survivorship_bias
Steve
OT but the new santer paper might be worth a similiar parsing
http://www.nature.com/nclimate/journal/vaop/ncurrent/full/nclimate1553.html
The argument **for** screening seems to be that confounding factors may mask the temperature signal in the ring width data. OK, fair enough, that’s almost certainly true. If those factors are a priori identifiable (tree location, number of neighboring trees, tree size, tree age, whatever) then there is no problem – eliminate them from the data, or better, do not even take the data, since the factors are identifiable in advance. To make these factors a priori identifiable and a valid justification for elimination would require a very large amount of empirical data, or better, controlled experimental evidence, coupled with a tree ring growth model. This process could be justified, and it could fairly be called screening by **empirical situation**. It would not involve any type of correlation measurements. It happens ahead of time.
In the absence of that empirical screening, screening by **statistical means** – ie by correlation with some variable, is quite a different matter. It presents all the problems outlined in the above commentary, which need not be repeated. It is not remotely justifiable. By definition what it admits is that the confounding factors and their magnitude are not known, for if they were **the screening would take place in advance of the statistical analysis.**
Screening for this type of analysis cannot be statistical. It can however be fairly implemented on other rigorous empirical or experimental grounds.
“John A. Fleming
There ought to be a way to do this. Hypothesize one or more common signals across all proxies, and time-series for each proxy type.”
I am afraid not, we are dealing with a biological process here and so could be dealing with storage and utilization of information.
Let me put this a as a postulate:
“Tree in their youth gather ‘inprinting’ information that alters their reproductive strategy”
In take home terms a tree during its first decade or so gathers information of what the weather is like in the spring (when it will begin investing in a years reproductive capacity) and compares it to the late summer (when it will shed its seeds). Based on this stored information the tree will adjust its reproductive strategy, based on the spring weather, based on a stored template that was acquired in its youth.
In the case of Tree (X) cool dry springs indicated warm moist summers, the ideal medium for its seeds, but warm wet springs correlated with dry hot summers. Tree (X) would therefore maximize its opportunity cost by producing few seeds, but large tree rings, in seasons where the spring was warm and wet, but would direct almost its resources to making seeds when it detected a cool dry spring.
So trees could be ‘conditioned’ at a early stage to juggle their allocation of resources between tree ring width (self investment) or seeds (generational investment).
The evolutionary advantage of information storage and its use in resource allocation is huge, which is why it is ubiquitous in biology.
If you think that trees can have no intelligence, as defined by a condition reflex, may I point out that Hennessey (1979) showed that the single-celled ciliate, Paramecium, could be trained, for life, conditioned vibration stimulus, by associating the vibration with an electric shock.
Click to access fulltext.pdf
So the key here is to understand that a tree is not a material like mercury in a sealed tube. It is a responsive replicon, which has the aim, not to increase the size of its trunk, but to have the highest number of living progeny for the smallest cost.
What was the result of “They didn’t arrange for a realclimate hit piece, sneering at the critics and saying Nyah, nyah,”
Sorry, but I need to connect the dots here. Is this the Yamal proxy? Is it correct that one tree some many sigmas out of the norm had a significant impact on the reconstruction?
If so, what is the state of amending the data?
Steve writes:
Quite so. Seems to me that if they “missed” their error prior to submitting for publication, the chances of them “independently” discovering it after peer review ‘n publication – with all the accompanying hype and hoopla (not to mention citation in AR5) – are highly unlikely.
I would be inclined to give Karoly’s creatively ambiguous E-mail the benefit of the doubt if he had:
a) Made an appearance here when the error was under discussion; and/or
b) Also requested that you be kind enough to publicly review and critique their revisions prior to re-submission.
But, obviously, he did neither.
As for the response of the Team, perhaps Gavin’s announcement of the “disappearance” is the most telling. As I had commented in the Significance thread (before I saw “…on hold”, honest!):
[Skiphill had quoted Gavin at RC]:
[To which I responded:]
Nick Stokes says he isn’t a climate “scientist” but he has such a masterly grasp of the methods used that he would probably be an extremely successful one.
One aspect of the problem for people with zero math skills.
Here are six scattered chronologies in abstraction of randomness, which, if all averaged together, produce a flat line. Only two of these chronologies correlate with modern temperatures-the red circles. When those two are averaged, voila, a hockeystick magically appears.
It may be true that hockey sticks may exist in the data, but a method that produces a hockeystick from random data does not tell us if so.
Re: jeez (Jun 12 01:43), ok, that image worked fine in preview mode. Could one of you admins fix so that the diagram shows and then delete this comment.
Also, if the data is, say, red noise, you can project future temperatures. And also, you don’t have to do all that nasty work looking at corals, freezing your buns off for ice cores, etc. It’s cheap! Who knows, perhaps the predictive power for future temps is as good as the models.
ed-
Excellent comment! Assuming the instrumental temperature sieve is valid, it is highly plausible that running excel on a $500 laptop could provide centennial temperature predictions that are at least as prescient as the most expensive coupled climate models!
🙂
Worthy of Tufte, thanks.
Stunningly brilliant, Jeez.
Interesting article at http://www.theage.com.au/environment/climate-change/climate-warming-study-put-on-hold-20120611-2065y.html
“Study co-author and climate science professor David Karoly said one of the five authors found the method of analysis outlined in the paper differed to that actually used.
The Climate Audit blog – run by Canadian Steve McIntyre, who has challenged the validity of palaeoclimatic temperature reconstructions – claimed credit for finding the issue with the paper. Professor Karoly said the authors uncovered the problem before Climate Audit blogged about it.”
Roger, Its it reasonable because the methodology promotes valid proxies with a limited proportion of random noise. The valid signal is stronger than the random if the screening is strict enough.
Given the situation, a signal such as a MWP is valid. However, if a straight hockey stick blade is produced we cannot say anything, because it could be that there were more random ones than we thought. So we CANNT deduce that 20th century temperatures are unprecedented, only that they are NOT unprecedented, if we are successful.
Nick, the circularity occurs if you conclude that temperatures are unprecedented, because the straight handle is encoded in the random proxies and you don’t know if uniformity holds.
David,
I presume you don’t mean random proxies.
Uniformity is the basic requirement, which has to be argued on the physics. It isn’t stats.
There is circularity if you rely on proxies in recent years to says temperatures are unprecedented. I objected to that usage in Gergis Table 2. But it would not be circular for Gergis to say that recent instrumental temperatures have no precedent in her proxy record.
Nick, I think we agree that you have to be very precise about what can and cant be said in this situation, and that the physiology of trees’ response to temperature and rainfall have to be used as constraints on the possible states. Its what makes it interesting. This thread is a mess to follow though.
Nick Stokes says: “There is circularity if you rely on proxies in recent years to says temperatures are unprecedented. I objected to that usage in Gergis Table 2. But it would not be circular for Gergis to say that recent instrumental temperatures have no precedent in her proxy record.”
No, that is equally invalid since there are NO temperatures in any proxy.
All you could say is that recent changes in the proxy are without precedent in the remainder of the proxy record.
However, for that to have the meaning everyone will incorrectly read into into it, you also have to show that the proxy is a proxy of temperature and only of temperature and ALSO that both those conditions were true for the remainder of the period before the calibration period.
In reality NONE of that is established as has been pointed out by several people here.
Sorry, this is cargo cult science, no more.
Nick, I am a plant physiologist, by training.
And I am having a hard time in understanding the biological rationale for proxy selection.
Take tree rings, for example.
You have a group of 10-15 trees, growing at their latitudinal/altitudinal extreme- the treeline.
Clearly they are limited by some environmental factor.
You compare tree ring widths with temperature- and here I need a good explanation why this is often not local temperature, but rather “teleconnected to the Global temperature field”, or some other astrological munmbo-jumbo?
Let’s say one of these sets of tree rings “matches” the “instrumental target temperature” (whatever that may be).
By climate “science” reasoning this one tree is a “thermometer”, the others are non-responders and are deselected.
So to the questions:
1) Why do the other trees, growing under the same conditions, apparently not respond to temperature?
2) How do you know that the one match observed is not a spurious correlation?
3) How do you know that this one tree remains temperature sensitive outside the calibration period?
4) How do you know that the deselected trees did not show temperature sensitivity at some point(s) outside the calibration period?
5) What about the “divergence” problem?
Climate Science, if it is to have any credibility needs to answer these questions properly.
Don,
I think this is getting a long way from Gergis and the selection “irony”. There’s a lot of literature. I find the NRC North report a good guide.
Steve: Don’s questions are exactly on point to the Selection Fallacy. For present purposes, his points should be expressed in terms of site chronologies but the issue remains.
Nick:
In the past I believe you have made the case that proxies are not that important and it is the physics of GHG’s that matter. Well this thread is about tree selection and it seems to me that Don’s questions are about the physics/biology of tree selection. I don’t see how Don is “getting a long way from Gergis”. Isn’t he hitting right at the heart of the matter by questioning the lack of a physics/biology based ex ante method of tree selection?
Gergis is a long way from tree level. She deals with 62 already archived proxies, of which about half are non-tree. And the thread is about selecting proxies from those 62.
But as I said, there is a plentiful literature, and a mass of tree selection protocols.
Nick Stokes
“Gergis is a long way from tree level. She deals with 62 already archived proxies, of which about half are non-tree. And the thread is about selecting proxies from those 62.
But as I said, there is a plentiful literature, and a mass of tree selection protocols.”
And the authors already decided what the best method of selecting those proxies would be, and spelled it out in their paper. (It’s entirely another question whether their preferred method introduces other biases or contains other flaws.)
The immediate issue is that they didn’t actually follow what they said their preferred method would be, and because they haven’t released the necessary data, nobody else can run the necessary calculations to see what the effect of this is.
The real question is whether they will decide that they don’t actually like the result they get when they run their data using their preferred method, and so decide to change their method – in which case it will be absolutely blatantly obvious to everyone except climate scientists (and perhaps the occasional “scientist (not climate) with an interest in the climate debate”) that they have fudged their methodology to get the answer they want.
Are you (Nick) laying the groundwork for that? Would you at least admit that they should published their revised paper using the methodology that they said was appropriate, when they thought it gave them the result they wanted, regardless of what the result actually is?
We all know that, if the revised calculation does not give a hockey stick, it is almost certain never to see the light of day in any “peer-reviewed” publication. And the fact that we all (including you) know that is a sign of just how corrupt climate science has become.
Where are these 62 already archived proxies archived Nick?
Steve: where indeed. The unused coral series appear to be taken from NOAA, but the unused tree ring series have been kept top secret. In addition, the measurement data for some used tree ring sites is no archived. This is the same problem as I had with Briffa’s Taimyr and Tornetrask, where it took many years to get access to the data.
Based on Karoly’s comment to you about assistance on “The testing of scientific studies through independent analysis of data and methods strengthens the conclusions,” is it worth asking him for the unused series?
I would say put the Gergis et al paper “on hold” until these archived proxies are in the open….
My questions may already be answered, but (1) was the temperature record also based on surface stations dropped before 1991 and (2) are bivariate scatterplots of the proxies and the record available?
In the same Geddes article cited in the main post:
> All the studies discussed in this are intelligent, plausible, insightful, and possibly true. All have been advanced by highly respected social scientists. The effort here is not to discredit arguments — who are, after all, working within accepted conventions — but to demonstrate the deficiencies of the conventions.
Stokes asserts that uniformity assumption has been discussed in the literature so one can proceed with analysis. But discussing it is not the same as proving it. The same with divergence, just because it was discussed and some hypotheses given about it does not justify the chopping of series in 1960. Also the selection fallacy has been “discussed” but until the Gergis paper (ironically) no one tried to control for it. And that is the key: if there are known possible biases or contaminants in your analysis, you must control for or eliminate them, not ignore them. This is the basis for double-blind studies in drug trials–the placebo effect was so strong and the effect of doctor knowledge of who got what so strong that nothing reliable could be known without it. It was not sufficient to say it had been “discussed”. The same with the controlled experiment in physics: you try to shield out magnetic fields, create vacumns etc to eliminate spurious effects on your results.
The point of contention here seems to be the difference between using a proxy and defining one. Mr Stokes’ reasoning makes perfect sense if you, prior to the statistics, assume that the things you call “proxies” are indeed proxies. Then it’s ok to filter out the good ones and use them (preferably not on the calibration data but everyone agrees on that). The problem is that to assume this, you need soemthing prior to the statistics to define “proxy”, like a physical theory.
What actually goes on in such studies is that people constantly switch between defining a proxy and using it to reconstruct that which it is ostensibly a proxy for. You cannot logically do both at the same time. If you are attempting to define a proxy, that is, establish something as a proxy, then I’m afraid that all of the exasperation with the climate science standard procedure here is justified. If you are attempting to use otherwise established proxies to reconstruct past temperature, then you need a serious “otherwise” prior to starting and it is not clear at all that this exists.
I think we can reconstruct the temperature of Europe by tracking the first names bestowed on children.
Firstly, we know that choice of name is a strong proxy for religion and secondly we know that some religions come from hot regions and some from cold. Thus, if Europe cools then we will see a rise in Scandinavian Norse derived first naming practices, but if Europe warms we should observe more Middle Eastern religions names. Moreover, as Arabia is hotter than Israel, if we have unprecedented warming in Europe we should observe a switch from Christian based first names to Islamically based first names.
I have just run a first pass on the ratio of Christian/Islamic names as a fraction of newborns and it quite clearly shows a massive change in these proxies in Europe and not only does it show a shift from warm to hot religions, but that this shift is unprecedented in European history. As an internal control I examined the number of children named Odin or Thor born in the UK last year. There were none; quite clearly Europe is heating and destroying the older, colder, religions and the temperature favors the expansion of the hottest Middle Eastern religion.
Nick is right, we are not analyzing a population, only signals that correlate with temperature.
Perhaps Nick could do a bigger study on European first names, as a temperature proxy, and publish his own Hockey Stick?
@PLk
Thanks for that, very helpful and concise.
Craig Loehle: This is the basis for double-blind studies in drug trials
Gergis is the paleo equivalent. You don’t know whether your time series really is a proxy and you don’t know whether your result is meaningful.
It’s a double-blind study, paleo style.
Nick’s question is still hanging there:
“I wish I could get an answer to that elementary question – if you don’t discard the proposed proxies that you can’t calibrate, what can you do with them?”
The basic point is that your calibration step may be false correlation, so just don’t do it. Select your population of treeline trees based upon similarity of siting. This is your first “selection.” Make sure they are round, healthy trees in full sun. Core and measure the width of the rings for each tree. Standardize as anomalies around a growth curve that is appropriate for the population. Now discard the trees that are too far off of the standard growth curve. This is your second and last selection. For the survivors, calculate an average ring width for each year. Are the standardized average ring widths from the last thirty years larger than all others in the reconstruction? If so, you have found “unprecedented warmth.” Now if you want you can play around with correlating your width curve to a temperature curve, but you are done with the “unprecedented warmth” question.
Matt, I believe you are closer to the right way of doing things.
However, the belief that a larger ring width is due to a difference in temperature alone is only an assumption. It is not necessarily a sign of “unprecedented warmth”. A number of other factors may be cause such variations in growth. CO2, moisture, prevailing winds, changes in cloud cover, precipitation patterns, diseases, changes in ground fertilization, changes in nearby rivers or creeks, changes in ground water levels, changes in surrounding vegetation, and an unknown number of other factors. Just how much tree ring width differs due to temperature alone is impossible to know.
Outside the range of living specimens, which can not be calibrated to other records, like temperature, in any way, (the proxies for “historic temperatures”) the same as mentioned, plus a number of other additional factors, will be both unknown or unverifiable or even if known, difficult to correctly compensate for. A 500 year old piece from a beam in an old cathedral for instance: where was the tree taken from? How was that place and the surroundings, precipitation and weather patterns and all the other non temperature growth conditions in that tree’s lifetime? Was the wood in any way cultivated? What genetic strain is it from, and have there been changes or mutations since then? What about the fact that the tree has been dead and “stored” for some hundred years? Was it treated with tar or other stuff at any point in time? Was the tree cultivated during its growth to maximize tar content and density? The list goes on and on, but no one knows where it ends.
Taking into account that the differences in temperature we are looking for are tiny, I have a problem with the assumption that tree rings and other proxies are accurate and good thermometers.
George,
Yours are basic dendro questions. Please consider that thousands of scientists and grad students have come up with lots of clever ways to look at this over the last few decades. You can find plenty of open access papers that address these issues with simple web searches. That being said, Craig Loehle, who is much better versed in dendro than I and has published in the field, agrees with you for all the same reasons.
Remove proxies that don’t show the signal you want, and you are left with proxies that tend to show the signal you want. Remove papers that don’t argue the point you want, and you are left with a scientific consensus on global warming.
“Had they done this in the first place, if it had later come to my attention, I would have objected that they were committing a screening fallacy (as I had originally done), but no one on the Team or in the community would have cared. Nor would IPCC.”
Makes me wonder how much things would be different if someone had challenged MHB98, back in 1998. Since MHB98 went unchallenged until much later, the flawed methods used, and the practice of “acceptable” cherry picking, had plenty of time to become accepted scientific dogma in the climate science world.
Nick’s question is still hanging there:
“I wish I could get an answer to that elementary question – if you don’t discard the proposed proxies that you can’t calibrate, what can you do with them?”
This question points to the heart of the problem. If it IS a proxy it will already be calibrated. If it is not calibrated, it means that you *don’t know* whether is a proxy or not.
This is EXACTLY the problem. What you have is a red noise sample, that you are going to select or reject based on whether it bears a mediocre correlation to a small , non representative subset of your study period.
Worse, you actually are out to prove that what you are using as the calibration period is itself *anomalous*.
The fact that you regard this as 1) a valid selection process and 2) “calibration” goes to the heart of the problem with much of this new paleo-*-ology pseudo science.
You have had to reinvent both science and statistics along the way.
The problem I have, and I touched on this earlier, is that the proxies in Gergis are ensembles that have been (presumably) shown to track temperatures somewhere on the globe (eg Oroko Swamp and Hokitika instrumental record, at least until that got changed).
Gergis et al tell us “Our instrumental target was calculated as the September–February (SONDJF) spatial mean of the HadCRUT3v 5o x 5o 179 monthly combined land and ocean temperature grid for the Australasian domain over the 1900–2009 period.” so what we are doing is taking proxies deemed fit for measuring points in this region, and reassessing them as proxies for a regional series.
So you actually know quite a bit about the discarded proxies, because (inter alia) there failure to perform as regional proxies has as much to do with the failure of the instrumental record at points in the region to replicate the regional average, as it does to the nature of the proxies themselves.
I’ve been coming here for years.
snip –
Steve: thanks for the compliment.
If one selects selects a dramatically-warming hockey stick by rejecting 50% of “fake proxies” constructed from red noise, intuitively the rejected proxies should contain an equally dramatically-cooling hockey stick. Has anyone discussed the signal present in proxies rejected because they don’t correlate with instrumental temperature? If rejected real proxies actually represent random noise, then they certainly should contain no signal in the validation period.
re. detrending as a check on screening fallacy.
The ubiquitous detrending that is found throughout climate science is basically a very crude kind of frequency filtering.
The authors so do not seem to explain why they think testing high pass filtered data is a better test than low pass or unfiltered data. (Do they even realise this is what it represents?)
Are there any existing studies of the effect detrending on selection bias? I don’t see it in their reference section. This tends to suggest they just made it up. It’s shake and bake science.
Since the fundamental question is to study _long term_ temperature trends, testing for correlation in short term changes may actually be less appropriate, not a safeguard.
How about testing independently for both long and short term correlation ? Like many of climate science’s methods this seems to be ad hoc, if not totally arbitrary and without any science (knowledge) of the consequences.
Of course , none of this gets around the fundamental problem that it involves a “screaming fallacy”. Which particular flavour of fallacy you chose is largely immaterial.
Wow. Just for a day or two there I thought we might be heading towards some interesting and useful exchanges between consenting adults. Let the shouting resume.
Jon Grove, was there some logical point you wanted to make? Or do you think people making reasonable arguments is “shouting”?
Yep: there was a logical point — but my comment was left high and dry by editorial snipping of a preceding loudly emotive comment. May as well snip mine too (including this one) unless it’s considered helpful to have me sound like an ass.
J
In a under-appreciated post just prior to Exeunt gergis et al., Jean S posted a really cool link to a review article on ~spurious correlation here; https://climateaudit.org/2012/05/31/myles-allen-calls-for-name-and-shame/#comment-335930
The link was this one;
http://www.hindawi.com/journals/jps/2009/802975/
I don’t know how to make the links show up with groovy labels like Jean, but this is my attempt to put a worthwhile link at the end of this thread on a specific example how some folks justify dubious practices.
OK, so lets assume they don’t bother with detrending, and the analysis stays the same:
Is it possible to get a better correlation by scaling either the proxy series or the instrument series? If you multiplied the instrument record by X, would that increase or decrease correlation?
Entirely justified (if one could be bothered with all this garbage) given the uncertainties…maybe they already did this? Maybe they didn’t. I thought the long “ice” hockey stick blade is more of a Northern hemisphere phenomenon…
X,
Scaling has no effect on correlation. If you have two data series that have some correlation, then multiplying one of the series by, say, 1000 will have no effect on the correlation between the two data series.
Thanks, I was semi-aware of that but had forgotten.
So giving all the weighed proxies more “weight” relative to the instrument record has no effect on r squared? Why not make the proxy period the size of small building?
Hard to believe. I don’t understand how one could objectively say change in coral “x ” equals “this much temp”
Obviously (or not) this would be part of the tricksy part when they stitch the two series together???
Arr. Now I get it.
They need to make available ALL the data. This is the key. A detrended analysis would select entirely different proxies (most definite). It remains possible that such an analysis would yield as good as correlation compared with non detrended data.
The results “could” therefore be “just as robust” by the standards stated by the authors originally.
And these results “could” be much more tricksy for the “warmist” establishment (but still essentially garbage as far as science is concerned)
Unless we get that data, via FOIA, we may never know.
I am getting this now? OMG.
WHERE’S THE DATA!!!
Short article in the Australian today on this. David Karoly is interviewed. He mentions the problems they had with detrending. He also states that there are valid techniques for screening without detrending.
Steve: http://www.theaustralian.com.au/higher-education/climate-paper-flawed/story-e6frgcjx-1226393519781
Re: Mark W (Jun 13 01:03),
is that on-line somewhere?
Just what I thought: they are going to stick to those ~27 proxies, and somehow reason that the original selection is “robust” and correct anyway. Let me further guess: the key parts of this groundbreking methodoly, that shows how robust the selection of 27 proxies actually was, is referred to a new publication (in preparation) at the time Gergis et al. 2.0 appears. I wouldn’t be suprised if the author list of that paper contains some familiar names outside the original five authors of Gergis et al. 1.0.
Perhaps this http://www.theaustralian.com.au/higher-education/climate-paper-flawed/story-e6frgcjx-1226393519781 – suggests if I read it right that they plan to stick to Plan A (ie exclude the 70 year trend).
I don’t understand the comments attributed to Climate Audit (or at least the penultimate para).
It’s here
An interesting DK quote:
“He said this was picked up when team members were responding to requests for more data, including from a website set up by Canadian mining consultant Steve McIntyre with the stated aim to “audit” the results of climate change studies.
…
He hoped the paper would be ready to go back to the journal for peer review by late July or early August. “Each time (there is an error in a study) you curse yourself and hope that it doesn’t happen in the future,” he said.
… “
But he sticks with detrending for now:
“Professor Karoly said the data would be reanalysed using the year-to-year variations only. A switch in the computer code was wrongly set to include the long-term trend and this went unnoticed.”
Steve: their response to my requests for more data was to tell me to suck eggs.
“He [Karoly] hoped the paper would be ready to go back to the journal for peer review by late July or early August.”
I’m betting on July. In order to be cited in AR5 WG1, a paper must be submitted by July 31.
But if they don’t make that deadline, I wouldn’t be surprised if they retain the original submission date. After all, the paper wasn’t withdrawn according to editor Broccoli. If one ignores the previous acceptance of the paper, then this is just another revision due to peer review.
Sticking to detrending eh? I’ll make a friendly bet with you Nick that if they stick with the original outlined methods for detrending, that there will be no publication in time for AR5.
It is entirely possible that the reason why many of the samples did not track regional or global trends is that at any one time local climates may be moving in the opposite direction from either regional or global trends. For example, Mueller and others have noted that a relatively high percentage (about 30% or so) of locations recording temperatures have experienced declining temperatures over the past century. Trees in such locations should therefore correlate with declining local temperatures and would not correlate with global temperature movements. Does Gergis’ analysis take into account the behavior of a local temperature anomaly during the instrumental period? If so, then there is no reason to throw out the proxy even if it doesn’t correlate with global temperature movement. If not, then the observed behavior of the proxy may be due to local temperature conditions that differ from the global trend.
Exactly. If the proxies are good thermometers at various local points in the Australasian region then before screening them simply on the basis of their relationship with a constructed temp for region it would pay to explore the relationship between the instrumental records at the local points and the regional construct.
Ho hum.
I suggest we do this backwards. We start by selecting those proxies which we know have the right shape. A hump in the MWP and a dip in the LIA.
Then we throw out those that dont corelelate with the instrument record and call it a day.
oh, and if they corelate with 1850 to 1960 but screw up after that we just lop off the offending bits
“We start by selecting those proxies which we know have the right shape. A hump in the MWP and a dip in the LIA.”
Yes, that would be selecting on the dependent variable, correctly interpreted. And would give spurious information about the MWP and LIA.
But it’s not what they do.
No, I’m using them as predictors of the current temperature.
Jim has indulged me over at RC for a nagging question I had regarding the huge number of total trees in a region vs. the number of cores taken from them for analysis (which was nagging in my mind if the argument was that site selection made the biggest difference– you’d think you’d need ‘all the data’ to get a high enough power on your results to speak for all the trees)…However, the response was that for any site that has cores taken, ALL the cores are used to create an average series (if I’m understanding him correctly)
Here’s what he said…
“..all the cores of a site, not just some fraction thereof, are used to provide the climate signal of interest. But to your point specifically: please point me to any verbal concept, any algorithm, any model code, ANY WAY in which a stochastic process can lead to the types of high inter-series (i.e. between cores) correlations typically seen in the tree ring data archived at the ITRDB. Just go there and start randomly looking at the mean interseries correlations documented in the COFECHA output files of each site, and tell me exactly how you would generate such high numbers with any type of stochastic process that’s not in fact related to climate. And then how you would, on top of that, further relate the mean chronology of those sites to local temperature data at the levels documented in many large scale reconstructions…”
I think I remember back with the Yamal data set, were the individual trees further weighted with respect to how well they depicted the instrument data, so that the ‘mean chronology’ was not the same as a raw average? I remember seeing the image of about 8-10 of the individual cores that included the famous YAD061, but Jim’s saying it’s uncontroversially obvious that various mean chronologies are successfully responding to temperature.
Further, he goes on to state that it’s also a matter of physics/biology, etc. such that it’s not how many bad thermometers you have, but rather what the good thermometers are saying– that sort of thing. In that light, it wouldn’t matter how many proxies contribute to a study, though the amount happens to be satisfying anyway.
I read the exchange at RC and found it amusing. As I (and no doubt others) have pointed out before, if you dissect the standard team methodology, you come to the conclusion that for each paleo study based upon proxies, the final curve should really just be based upon the one tree that best tracks the target. All others just add noise. The cut-off for significance has no real world meaning. So why do they try to pad the number of trees? All the reasons have to do with how the paper is perceived by others, and nothing to do with the accuracy. The folks at RC have danced all around this.
“..all the cores of a site, not just some fraction thereof, are used to provide the climate signal of interest. But to your point specifically: please point me to any verbal concept, any algorithm, any model code, ANY WAY in which a stochastic process can lead to the types of high inter-series (i.e. between cores) correlations typically seen in the tree ring data archived at the ITRDB. Just go there and start randomly looking at the mean interseries correlations documented in the COFECHA output files of each site, and tell me exactly how you would generate such high numbers with any type of stochastic process that’s not in fact related to climate. And then how you would, on top of that, further relate the mean chronology of those sites to local temperature data at the levels documented in many large scale reconstructions…”
Jim Bouldin is being way too vague here to define the characteristics a good proxy thermometer. The wiggle matching he is talking about means that the trees in a stand can be reacting in concert to some part of the climate and it might even be partly or all to temperature. That does not provide a good thermometer. He has strawmanned to death the issue of a stochastic model series not being able to randomly emulate the wiggles. Nobody denies this, but that counter to what he appears to imply does not make the wiggle matchers good thermometers. You can get a decent wiggle match and not match the temperature trend. The amplitudes of those wiggles has to match the temperature reasonably well at most times in order for it to be considered a thermometer for estimating temperature.
Gergis was a good example as the average inter annual correlation of the detrended proxies to instrumental temperature was 0.17 while the not detrended annual correlation was more like 0.38, as I recall. This indicates that trend matching was better than the higher frequency wiggle matching. The dilemma here for the dendros and others doing reconstructions is that, while a decent high frequency wiggle match does not lead directly to a reasonable thermometer (think divergence), matching a temperature trend to proxies or a group of proxies brings to the fore the issue that Bouldin evidently does not want to talk about: Proxies, like the stochastic models produced using ARIMA/ARFIMA simulations, do have series ending (instrumental period) trends both upwards and downwards and it is this characteristic that makes for the screening fallacy.
“a layman” asks Jim over at RC about the likelihood of one tree (one thermometer) being good enough, and is informed that “the mean interseries correlations and their relationship to local temperature are… too strong and too frequent to be explained by chance.” He is further informed that it’s not a topic for legitimate consideration. That surprises me, another layman.
What is it, biologically, that explains how one tree is a trustworthy thermometer (given its match to recent instrumental data) whereas its neighbor is no longer operating reliably, though still alive. And whatever the explanation for that, how do we infer that the good thermometer has always been good, and the bad has always been bad? Have not both trees, in their lifetimes, reflected temperature as they grew? Surely, given that there is more than one factor in annual ring growth — unless I am wrong about that — ahould not scientists avail themselves of the law of large numbers if those numbers are there for the taking?
Nick Stokes explains the AGW version very well and I enjoy his contribution but his words always remind me of a character in literature:
“When I use a word,” Humpty Dumpty said, in rather a scornful tone, “it means just what I choose it to mean—neither more nor less.”
“The question is,” said Alice, “whether you can make words mean so many different things.”
“The question is,” said Humpty Dumpty, “which is to be master that’s all.”
Alice was too much puzzled to say anything, so after a minute Humpty Dumpty began again. “They’ve a temper, some of them—particularly verbs, they’re the proudest—adjectives you can do anything with, but not verbs—however, I can manage the whole lot! Impenetrability! That’s what I say!”
If this duplicates, apologies, microsoft decided to do an update while I was posting last time and closed everything down.
OK, the latest word from the Gergis/Karoly camp is as follows – from The Australian:
Climate paper flawed
by: Bernard Lane
From: The Australian
June 13, 2012 12:00AM
Increase Text Size
Decrease Text Size
Print
A PIONEERING paper on climate change has been put on hold after a mix-up in its methodology was identified.
The study, published online last month by the US-based Journal of Climate, was led by a University of Melbourne scientist Joelle Gergis at the head of a 30-strong international team.
It was reported as the first large-scale reconstruction of Australasian climate and confirmation that the period since 1951 has been the warmest in 1000 years, an outcome consistent with an increase in greenhouse gases.
The results are to be the Australasian region’s contribution to an Intergovernmental Panel on Climate Change report on past climate.
But print publication has been put on hold after one of the authors discovered that the paper wrongly described how the data had been processed, according to team member David Karoly, professor of meteorology at Melbourne.
He said this was picked up when team members were responding to requests for more data, including from a website set up by Canadian mining consultant Steve McIntyre with the stated aim to “audit” the results of climate change studies.
Professor Karoly said the team would carry out a fresh analysis of the data, which could produce different results, and had done “the scientifically ethical and correct thing” by alerting the Journal of Climate editors.
He hoped the paper would be ready to go back to the journal for peer review by late July or early August. “Each time (there is an error in a study) you curse yourself and hope that it doesn’t happen in the future,” he said.
“It’s better that we admit our mistakes – and it’s not even clear that it’s a mistake.”
He said a key step in the study was to establish the relationship between temperature variation and the response of natural systems, such as tree rings and ice-cores, by looking at the period (1920-1990) when yearly temperature records were available.
Once these natural responses had been “calibrated” they could be used to estimate temperature variation far back into the past.
There was a choice of two methods for the data analysis; one using only the year-to-year temperature variations, the other using this data as well as the long-term trend for the 70 year period.
Although there were respectable scientific arguments for including this long-term trend, Professor Karoly said the Gergis team had intended to use just the year-to-year variations.
“We felt that by including that longer term trend you’re including part of the answer that you’re looking for,” he said.
The McIntyre website, Climate Audit, says “the irony in the Gergis situation is that they tried to avoid an erroneous statistical procedure … which is not merely condoned, but embraced, by the climate science community”.
The website suggests that the way the Gergis study inadvertantly analysed the data is circular and distorts the results.
Professor Karoly said the data would be reanalysed using the year-to-year variations only. A switch in the computer code was wrongly set to include the long-term trend and this went unnoticed.
Share on email
Share on linkedin
Good find, they have tipped their hand on what they intend to do. Now consider this…using undetrended data, Jean S. and Steve found that only 6-8 of the 27 proxies included in the paper cleared the significance threshold. How can a proxy that is not significant when tested this way turn out to be significant with the trend removed? I don’t mean statistically, maybe that can happen…how can there be a physical model for that which is consistent with the biology? To resurrect any proxy beyond the 6-8 (which may also fail when detrended), they would have to argue that they can improve the fidelity of the reconstruction with proxies that track the wiggles but not the trend!
Note to Karoly et al.
A scientist selects his/her methodology and must live with his/her result. This is how science is done. To do otherwise is effectively to choose your result and that’s simply not allowed, however appealing the chosen result may be. Ask yourself what you would advise another scientist in a different field to do should he/she be in the situation you’re in.
If you make a poor decision this whole thing could come up as a topic on a class on scientific ethics. Furthermore, should someone make an allegation of poor scientific ethics then any investigation may well also investigate how and when the original mistake came to light and whether or not appropriate credit was given (credit being another important issue in scientific ethics).
Steve: Maybe you should write a paper, which demonstrates proxy selection procedure problem by using real temperature measurements as “perfect proxies” and shows how the end-result differs from the real temperature history. Good case example might be Australia.
Reportedly Gergis located mis-located Palmyra and Raratonga in their study. Both islands are at W latitude, not E latitude. Additionally, Palmyra is in the N hemisphere, not S.
Steve: yes, she did mislocate Palmyra in Table 1 but it’s correct in the location map. Palmyra is within the proxy box boundaries, so the mislocation wouldnt be relevant.
How many possible selections of 27 proxies, out of a pool of 62, are there ?
I came up with 279,692,573,246,310,016.
However I am a bit of an idiot. I can believe that smart people like Nick Stokes and Jim Bouldin would think that it makes no real difference that one follows an a prior selection method.
Well, that number doesn’t prove it. But fussing about that selection step is a bit precious. Where do you think the 62 came from? More selection.
Thinking of tree proxies, there are billions of trees. So they go to remote places where they think trees are more likely to correlate with temp. Then there’s a whole protocol and lore for finding sites within those areas. Then trees are selected. All trying to improve the chances of sustained temperature correlation.
So why is it so different to actually measure the correlation as part of the selection? And what’s the alternative? Treat the billions of trees equally?
So I guess this indicates problems with the lore and protocol? Is lore and protocol another way of saying “theory”?
There is a very big difference between a priori selecting a sample based on physics versus discarding observations based an ex post statistical analysis of the data. I guess Nick Stokes has never worked on clinical trials. It would be inconceivable to try pull a stunt like that with the FDA.
Again clinical trials are determining effects through analysis of population statistics. That’s not what is happening here.
The alternative might be to admit the temperature sensitivity of tree growth is not sufficiently good to back out an unambiguous historic temperature record with a level of confidence that could render the reconstruction informative.
There are lots of things that are insufficiently temperature sensitive and people have no difficulty admitting they can’t be used to develop a temperature record. We could come up with all sorts of examples: The average femur length of felines. The size of brain cavities of marsupials. And so on.
The temperature sensitivity of the population of trees is not good enough for that. Nowhere near. We’re looking for trees that do have that property. They may be few. But the test is the measured sensitivity. And when you’ve found them, they are found. The rest don’t matter. It’s like looking for potential telegraph poles in a forest.
There’s the separate question of whether the correlation can be expected to persist in previous times. Uniformity. But that isn’t statistical.
Nick:
I think the discussion goes way beyond uniformity or at least the uniformity principle becomes more suspect as the % of trees that appear to incorporate a temperature signal goes down.
Nick –
As to the consistency of the statistical relationship of proxy to temperature, it is interesting to compare the sensitivity to temperature (OLS slope) of the Gergis proxies over halves of the reference period. See this scatter plot.
Nick, I have some questions.
Do you think that it would be appropriate to use correlation to screen tree rings in a particular site or region when doing a temperature reconstruction for that site? Would you not be concerned that the process could bias the result even if the trees did contain actual information about the temperature?
I like your line:
Mind if I use it? 😉
Roman, let me counter with a question,
“bias the result”
Bias from what? You’re using the language of population statistics. But what is the population? And why do you want to know its statistics? What is it biased from?
But to answer yours, yes I do. The proxy result is going to track instrumental in the training period. That’s intended, and means it isn’t independent information. But how does it bias what you want, which is the pre-training signal?
Two more genuine questions: Have you ever taken a genuine probability based statistics course taught by someone with a math and stat background? If so, at what level was the content of the course? Please give me a straightforward answer. I would like to know where you are coming from so that I would know how to better explain what I am trying to get across to you.
You seem to have the idea that statistics can only be based on simple sampling from some sort of physical population. Nothing is farther from the truth. A population can be defined by a probability model which reflects a physical reality. When you calculate a correlation and make probability statements about the possible behavior of that correlation coefficient, what population are you talking about? Do a regression and estimate coefficients from the equation, what is the population? These are populations defined by the characteristics of the model within which the calculation is taking place.
Why do I want to know the statistics? Because the parameters I would be estimating would be the (unknown, but assumed to exist) temperatures in the past.
Bias is simply the tendency for an estimator to consistently over- or underestimate a parameter of the model. Bias from what? It can be a result of the process in which the real world information is gathered or by a calculation procedure through which the estimate is produced. These are well understood concepts in mainstream statistics.
In this particular case, I asked you if you thought that for the situation I described, whether you thought that screening based on correlation could possibly induce bias by producing reconstructions that systematically missestimated the temperature value due to the screening process. I would allow you to assume that the proxies were linearly related to the temperature with added noise. No random AR processes unrelated to temperature would be involved in this situation.
As a teaser, did you know that if you calculate the regression equation between two standardized variables (each mean zero and standard deviation equal to 1), the slope coefficient is equal to the correlation coefficient. If you screen proxies for a larger correlation coefficient. you are also selecting for a larger slope. Do you not think that this might affect the calibration process and the reconstruction? My question to you was whether you thought that there might be circumstances where this could be counterproductive and lead to undesirable consequences. In fact, would you be surprised if I suggested that the effect could be a flattening of the shaft of the stick. 😉
Roman,
I did a mathematics course with a small statistics component. I then spent thirty years as a research scientist in CSIRO’s Division of Mathematics and Statistics, which despite the name order was very much a statistics division.
I don’t have the idea of limitation to sampling from a physical population, but I think that underlies a lot if the misplaced thinking here. But there is still the notion of population, defined physically or by model, and you still have answered that basic question – what is that population? Because when you talk of bias, you must have a reference value in mind. Where did it come from? And why is it related to the selection process?
I think for discussion of screening, we had better stick to the relatively simple approach of Gergis et al. For the CPS and EIV approaches used by Mann and others it is more complicated.
On your questions leading up to the variance reduction effect, I’m aware of the latter, but again I can’t see how tinkering with the selection process can modify it (again in the Gergis method). There’s more to be said about the calibration issue, but I’m currently away from home, and have to be on the road, so maybe later.
But I’ll end with another question. Several statisticians have reviewed the process of proxy reconstruction. Bloomfield was in the North NRC Panel – Brillinger reviewed their report. Wegman was famously involved. If it’s so obviously wrong to select on the basis of ability to calibrate, then why weren’t they rejecting the procedure?
Nick, I don’t think Gergis were engaged in screening as you are describing it. They took proxies that were deemed to measure temp at locations and screened them on their ability to measure a regional temp construct.
I think it would help the discussion if you wrote down the model of the physical world that you are using to underpin the inferences you are seeking to make. That would make clear the assumptions you are making and the role that statistical techniques might play in those inferences.
If you aren’t seeking to make any inferences then knowing that would also help the discussion.
Roman, HAS
On technical things, I can answer HAS and Roman on one point – the model for the process. The methods usually used, like CPS and EIV, are more complicated, but I’ll refer to the model described on p 85 in the stat methods section of the North report (NRC) and illustrated in Fig 9.1. You have a series of eg ring widths over 1000 years, perhaps from a single tree. You have 100 years of measured temp. You correlate ring width against temp (Fig 9.1) and use the resulting relation to deduce temps over 1000 years. If the correlation fails significance at some appropriate level, you reject the proxy.
Now this might fail because the relation changes at some past time (uniformity). That’s unrelated to how you selected the tree. Nor does selection matter to the model.
Roman, I’d invite you to address that model, since it was likely written by Prof Bloomfield, of NC State Univ, and reviewed by Prof Brillinger.
Roman says:
“If you screen proxies for a larger correlation coefficient. you are also selecting for a larger slope. Do you not think that this might affect the calibration process and the reconstruction?”
No, you don’t screen for large correlation coefficients. You screen for significant coefficients. The size is a property of the proxy. That is what determines the calibration. And the slope/correlation just sounds like mixing up concepts. Your use of slope is trivially synonymous with correlation, but sounds like the gradient over time. It lsn’t.
As I mentioned, there are some factors that can lead to diminution of variance. This is described on p 86 of the North report thus:
“This phenomenon, identified by Zorita and von Storch (2005) and others, is not unexpected. Within the calibration period, the fraction of variance of temperature that is explained by the proxies naturally decreases as the noise level of the proxies increases. If the regression equation is then used to reconstruct temperatures for another period during which the proxies are statistically similar to those in the calibration period, it would be expected to capture a similar fraction of the variance.”
No mention of selection.
equation is then used to reconstruct temperatures for another period during which the proxies are statistically similar to those in the calibration period, it would be expected to capture a similar fraction of the variance.”
No mention of selection.
As I mentioned, there are some factors that can lead to diminution of variance. This is described on p 86 of the North report thus:
“This phenomenon, identified by Zorita and von Storch (2005) and others, is not unexpected. Within the calibration period, the fraction of variance of temperature that is explained by the proxies naturally decreases as the noise level of the proxies increases. If the regression equation is then used to reconstruct temperatures for another period during which the proxies are statistically similar to those in the calibration period, it would be expected to capture a similar fraction of the variance.”
No mention of selection.
Nick, that was useful because the rest of us here aren’t discussing the hind casting model i.e. how you move from 100 to 1000 years.
What is being discussed here is the model of the real world that allows you to select proxies based on the 100 year instrumental record. We haven’t started the hind casting process.
If you are selecting proxies the model of the real world has to be that there is some physical relationship between tree rings (say) and temp.
Can you take your argument from there to help us all understand?
HAS,
I’ve described the quantitative process. It requires a basis for assumption of uniformity significant and a significant correlation. Or more correctly correlation with adequate error range on the coefficient.
You don’t need anything to allow you to select proxies. You just do it as efficiently as you can. That is, to get to a stage where you have enough proxies with identifiable temp relations, and where you have a physical basis for saying uniformity is reasonable (it can never be proved beyond doubt). The only interaction with the selection process is that you need to set the significance levels in the light of the final stage selection. But in situation like Gergis, the fate of most proxies is unlikely to be altered by such changes.
Again I’m speaking there of the simple NRC model. Many multi-proxy models do a joint calibration. But ultimately, you still have to select.
Nick, I didn’t understand that.
What is the physical model of proxy behaviour that you are assuming when you look for the correlation between proxy and temp? (Also the physical model you are assuming when the correlation doesn’t occur)
Perhaps give me the equations (and the physical rationale).
HAS,
It’s much simpler. You just measure correlation, and find a linear relation. You don’t have to assume a cause or physical model. To hindcast, you just use that linear relation. Equations in North report p 85.
Where you may want to look at a cause is in justifying the uniformity claim. But that has no relation to the selection process. And you don’t have to worry about why some trees in that final sample didn’t correlate adequately. Most trees in the world don’t. You’re looking for ones that do.
But the cause that one often has in mind is that treerings usually do vary with temperature. And vary with many other things, so the S/N is low. The trees that pass are not uniquely temperature sensitive – they have a high S/N because effects other than temp are small.
Nick, I don’t have time this morning to address all of your unscientific statements and errors because I am otherwise occupied. However, I will try to post some comments this evening.
I hope to cobble up a post regarding the practical mathematical faults inherent in screening proxies with low correlation this weekend in order to explain what happens.
Nick –
The linear relation of (most) proxies to temperature varies over time, because so many other factors are at play. See this plot to see this for the Gergis proxies. By selecting on significance in the correlation (which is much the same as selecting for slope), you’re tending to pick the proxies which happen to be showing a high slope for the calibration period. It’s similar to the “hot hand” fallacy.
HarolsW,
No, it doesn’t select for high slope – it can’t. There’s no notion of “high” until calibrated. There’s a scaling factor that is adjusted to match.
Nick –
I think you misread the previous(7:21 AM). The slope it refers to, is the slope obtained by regressing proxy values vs. instrumented temperature. It precedes calibration.
.
Roman wrote above (Jun 14, 2012 at 8:21 PM) “if you calculate the regression equation between two standardized variables (each mean zero and standard deviation equal to 1), the slope coefficient is equal to the correlation coefficient.”
.
OK, that may not have convinced you. I ran a simple Monte Carlo, generating 100 “proxy” series of 70 points each, generated by a linear function plus i.i.d. unit Gaussian noise. [That is, y(n) = 0.01*n + noise.] Each series’s correlation coefficient r (correlating to the series {0,1,2,…69} of course) is plotted here against its OLS slope. It demonstrates Roman’s point that correlation is very strongly related to slope.
.
Now let’s pretend this is our set of candidate proxies. Remember, all of these proxies are in fact identical statistically. Cutting off at p=0.05 (r~=0.2) discards about half of the proxies, similar to Gergis. The average r of the proxies which pass screening is around 0.3, not far from the average |r| of ~0.4 for Gergis’s screened proxies. In the Monte Carlo case we *know* what the calibration should be — a slope of 0.01. But of the “significant” samples, the average slope of the screened set is around 0.015. Looks like bias to me.
Rats! I was hoping to use that as a bit of a surprise factor in the post that I intend to do this weekend. 😉
You figured out what is going on. It doesn’t matter what the cutoff point is – there will be bias in the estimated slope. However, the higher the cutoff, the larger the bias in the coefficient.
I don’t know how you calculated the values in your graphs, but it is easy to tell that the slope is exactly to the correlation coefficient by looking at the formulae at this wiki site and seeing what happens when the standard deviations of the two variables are both equal to one.
OK Nick, we have now got you to the point where you agree that you are selecting on the basis of a linear model between Ring Width and Temp. Those that fit with better than a certain probability are preferred (i.e. you are using a probabilistic model as part of your selection procedure).
Now let’s think about what is happening at the level of inference in this experiment. Take another attribute of tree rings say redishness. Obviously no physical or casual reason why you’d choose on this basis. So in your book that could equally have been used by Gergis as the basis for selecting proxies.
But hang on you will say that’s stupid.
The point is that the use of the significance of the correlation as the basis for screening carries an implicit assumption, namely that those proxies are “better” for some reason. Ultimately Gergis (and you) want to imply that the proxies selected do a better job at forecasting than some other selection of proxies.
Now they (and you) can assume that, and carry that assumption through the rest of the inferences in the experiment (and I suspect this rather significantly detracts from any conclusions – if we had eggs, we could have ham and eggs, if we had ham), or you treat it as an empirical question to be tested (or the degree of “bestness” assessed).
So can you perhaps confirm that you are simply assuming that proxies that give the best linear fit are the “best” proxies, that that assumption needs to carried through to the statement of any conclusions, and leave this discussion there?
On the other hand there will be the churlish ones here that want to draw attention to the problems this assumption of linearity causes for subsequent bits of the analysis.
HaroldW,
I’m not sure what you are doing in that last diagram. As I think Roman is saying, the beta, regression slope, is exactly the correlation coefficient r that you wrote. So it isn’t clear to me why they dont fit exactly on the line, and just correspond to a distribution of beta.
But on the general proposition, you have a number of proxies with a distribution of “sensitivities” – ie rate of change of MXD (or whatever) with T. And a test for sensitivity will tend to shoose the higher sensitivities. That’s because you are in effect looking for high S/N, and sources with high signal strebgth will tend to be preferred. What’s wrong with that?
.
Roman,
Sorry if I stole any of your thunder. But I’m sure you’ll explain it better.
The regression slope (I call it m_hat; the Wiki article calls it beta) isn’t *exactly* the same as the correlation coefficient r. Comparing the formulas, the denominator of the regression slope is SUM (xi – xbar)^2 ~ Var[x] whereas the denominator of the correlation coefficient is sqrt (Var[x]Var[y]). If the x&y random processes have identical variances, mhat and r will *tend* to be similar, but the variances of the particular x & y sequences generated for any run, will likely differ. Hence, the strong connection but not exact equivalence of mhat & r. In my toy problem, {x} is deterministic [=0,1,…,69] so one wouldn’t expect equality in any case.
Nick,
The screen is indeed trying to select for higher signal-to-noise ratio, and that is a good thing. Returning to the toy problem, if there were another 100 proxies which had no intrinsic connection to the independent variable — that is, were pure noise — the screener would only pass (on average) 5 of the 100 noise proxies, while passing around 50 of the proxies which truly have a connection. Everyone’s happy with the general improvement in quality. BUT, the screening has a side effect. Someone else (Carrick?) wrote that screening is not a statistically neutral procedure.
.
In the toy problem, every proxy is an identical random process with a fixed sensitivity. After rolling the dice though, the slope which we compute is not *the* sensitivity, but is a random variable whose mean is the correct sensitivity but has a certain probability distribution. By selecting the high-correlation sequences, we’re also selecting for higher slope — that is, higher apparent sensitivity. The average slope of the surviving proxies is higher than the true sensitivity; in the example given above, about 50% higher. Why does this matter? Because the calibration which we perform yields a mapping of the proxy value P to an inferred temperature T along the lines of T = (P – b_hat)/m_hat, where b_hat & m_hat are the intercept & slope obtained by regressing P vs. (instrumental) T in the reference period. A too-large value of m_hat means that the range of the inferred T is too small; in other words, the reconstruction outside of the reference period will be compressed. In the toy problem, it would be compressed by a factor of about 1/1.5 = 2/3.
.
But one must remember that the toy problem was idealized in that the proxy was nothing more than a noisy linear replica of temperature. The screening process favors those sequences in which the noise happens to correlate better than average with temperature (and also with the same sign as the proxy’s true temperature dependence). In the messy real world, many other factors are at play with proxies such as tree ring width and coral delta_O18, meaning that the screening process is going to also favor those proxies in which the non-temperature factors happen to correlate with the instrumental temperature over the reference period. And the other factors will spread the distribution of slope wider than just the noise would, moving the average slope even further from the true sensitivity.
Your statement that the two are not identical in the standardized case will come as a quite a shock to all statisticians (including myself). 😉
The complete formulae are
Slope = Covariance(X,Y) / Variance(X)
and
Correlation(X,Y) = Covariance(X,Y) / sqrt( Variance(X) * Variance(Y) )
If Variance(X) = Variance(Y) = 1, the two formulae give the same result.
For unstandardized variables, the above shows that
Slope = Correlation(X,Y) *( sqrt( Variance(X) / Variance(Y) )
so that the slope is just a simple multiple of the correlation.
HaroldW
“The average slope of the surviving proxies is higher than the true sensitivity”
What is the “true sensitivity”? It seems to come back to this notion that you care about the population statistics of the short list. Even “average slope” is dubious since you could calibrate each proxy individually. If you don’t then indeed you need to average carefully, as always.
“In the messy real world, many other factors are at play with proxies such as tree ring width and coral delta_O18, meaning that the screening process is going to also favor those proxies in which the non-temperature factors happen to correlate with the instrumental temperature over the reference period. “
The analysis requires only that the proxy can be calibrated, and that the relation found to T extends back in time. It doesn’t matter if the real correland is a composite effect. In fact, the temperature that counts is probably dominated soil temperature in some month, or late frosts or some such. They in turn are correlated with the measured temp at some nearby station, which in turn is correlated with the aggregate temperature target.
HAS,
“So can you perhaps confirm that you are simply assuming that proxies that give the best linear fit are the “best” proxies,”
Here’s what the North report says, Chap 9:
The most common form of proxy reconstruction depends on the use of a multivariate linear regression. This methodology requires two key assumptions:
1. Linearity: There is a linear statistical relationship between the proxies and the expected value of the climate variable.
2. Stationarity: The statistical relationship between the proxies and the climate variable is the same throughout the calibration period, validation period, and reconstruction period.
There is quite a lot on deviations from linearity, and of course stationarity is much discussed, with divergence just one issue.
As to whether a linear fit is the criterion, it’s generally a sine qua non. Beyond that, practices vary. Some methods weight according to measure of fit, some just have a cutoff. And some are doing more elaborate aggregations. But yes, goodness of fit is really the only quantitative discriminant available. And you do have to discriminate. There are plenty of worthless proxies. Every tree in the world has rings.
Nick, we’re now making progress.
Proxy selection do rely upon the use of models of the real world. It took us some time to get there but I hope we’ll stop hearing all this stuff about proxy selection having nothing to do with the real world.
Now let’s turn to the issue of what models are best for proxy selection, and how good Gergis was in this regard. The bible (aka the North report) tells us that the most common (NB not necessarily the “best”) proxy selection relies upon the assumptions of the multivariate linear regression being satisfied.
Since Gergis assumed a very simple linear model to do her screening (no variable other than temp) and don’t test that linearity and stationarity assumptions have been satisfied with the dataset in question, is it not possible that “better” proxies have been eliminated as part of this analysis?
To justify the use of this simple linear model she needs to show that that this model is better than other potential models, and that, unfortunately, consumes data. You are on the slippery slope that you have been refusing to acknowledge of having to hold out data from subsequent analysis.
And further, can you not see that if you haven’t held out data this will bias all subsequent results?
As I’ve said before she is quite at liberty to simply say “I’m assuming a simple linear model is best”, but if she goes down this path don’t be surprised if others don’t agree.
And a piece of advice don’t try and defend this assumption by saying all that she has done is calibrate a thermometer in a routine way that has nothing to do with assumptions about the real world.
HAS
“is it not possible that “better” proxies have been eliminated as part of this analysis”
Yes. But the only quantitative measure you have that is routinely used is correlation with observed temperature. You can’t change that with holding out data. It’s true that you could try cross-correlation with other proxies, but that is complex and noisy.
Departures from linearity and stationarity are dealt with ob p 87 of the North report. Linearity is just a matter of modifying the regression formula, but having enough data to find a significant second parameter is a problem. For stationarity, again its hard to have enough data, although North mentione a check using the validation interval.
Maybe a joint regression can help overcome this data shortage. But it brings problems of its own.
Nick, pleased to see you’ve started talking about the real world.
In terms of improving proxies in the case of Gergis we rather obviously have the relationship between the instrumental record at the site the proxy was developed for and the target regional construct.
And are you saying Gergis was best of breed for dealing with linearity and stationary in their proxy selection?
HAS,
I think one of the Gergis problems was that the Hadcrut grid had many missing values. That’s probably why they used the regional mean.
And no, I don’t think the Gergis analysis was sophisticated. And they definitely should have corrected for autocorrelation.
However, I’m not seeing selection issues in what you’re saying.
Nick –
“What is the “true sensitivity”? It seems to come back to this notion that you care about the population statistics of the short list. Even “average slope” is dubious since you could calibrate each proxy individually. If you don’t then indeed you need to average carefully, as always.”
.
First, you ask what the true sensitivity is. In the toy problem, the true sensitivity is given to you — the proxy changes, on average, by .01 for each degree of temperature. For real proxies, it’s true that we don’t know the value, and indeed it’s different for each sample.*
.
We don’t know the value of sensitivity for any real proxy. What we can to do is estimate it, in this case by regressing proxy vs. instrumented temperature for the reference period for which temperature is known. The step is called “calibration”, but that’s a misleading term, because calibration implies an external, precise standard against which we compare our measurements, and can compute a relationship which corrects for the errors in measurement. For some proxies, the regression slope will be high (overestimating sensitivity), and result in a reconstruction which doesn’t show as much variability as the actual temperature. Others will estimate too low, and result in a reconstruction which varies more than the actual temperature did. One hopes that these will average out in general in the final reconstruction, But if there are no (or few) too-low estimators, because they’ve been screened out, then the reconstruction using all proxies will tend to show less variability than actual temperature did. The toy problem is intended to demonstrate how the bias arises.
.
Yes, real proxies aren’t all the same in their characteristics. But that doesn’t change the fact that we’re *estimating* sensitivity, and this estimator is biased. You seem to think that because the actual data, and the slope derived therefrom, are all that we have, it must be the correct value. If we had proxies with r=0.99, screening wouldn’t be a problem, becuase all of those proxies would pass, and each one’s estimated sensitivity would be extremely close to the true (hidden, in this case) sensitivity. But we don’t; all we have are proxies with small signal-to-noise ratio.
*In fact, linear sensitivity (in proxies such as tree ring widths & coral delta_O18) doesn’t even exist, except as a model with which to analyze! Proxies respond to all sorts of causative factors, and there’s only a generalized hope that can, on average, assess this as linear to temperature.
Nick @ Jun 16, 2012 at 5:39 AM
“I don’t think the Gergis analysis was sophisticated”
“I’m not seeing selection issues in what you’re saying.”
To see the selection issues we need to go back and think about how this experiment should have been run. Let’s simplify for expositions but generalising is straightforward.
We have a composite measure of SH temp derived from the instrumental record. Let us assume this is a straightforward linear function. Let us assume we have proxies (3 as I recall) that have been validated (there are issues here, but for the sake of argument ..), and they provide a hindcast back to the MWP. Also for the sake of exposition let’s ignore the other proxies that don’t give us direct hindcasts at their respective locations back to this time.
Now what approach would you use to try and falsify the hypothesis that the MWP was hotter then the current temps? Would you one by one eliminate any of the proxies that didn’t correlate with the composite over the instrumental period and then do a hindcast based on the last men standing?
Probably not, and the reason is pretty obvious.
Your selection criteria has changed the dataset that you then go onto use for your subsequent analysis in a way that could very likely bias the results. The way I think about this is that you have thrown away information both about the estimates and their uncertainty without due cause.
I think this is what people here are concerned about when they discuss selection bias.
As I said your mistake was to think that proxy selection had nothing to do with the real world.
HAS,
Yes, I think this may be getting closer. You’re now asking how you combine information from different proxies when the analysis is under way. The more sophisticated algoritjms do this by weighting, according to various things, but you could think of weighting by significance of correlation as representative. There will be some weighting formula involved. And weighting has the same kind of effect as selection.
In fact, you can think of selection as weighting with a step function. One complaint made about Mann’s methods is that weighting disparities can be large. A step function provides a cut-off.
Weighting is used to make best use of the information you have. It doesn’t have to represent the information you might have had if you had looked elsewhere.
So we are now at the point where I have you agreeing that proxy screening once the “analysis is underway” shouldn’t be selective.
In the case of Gergis I’ll bank that concession and observe that on that basis you can’t therefore be objecting to our host’s main post that started all this.
Let us now turn to the problem of defining when the analysis gets under way.
In fact the analysis is build upon what has gone before and all the assumptions built into this. In the case of Gergis we are assuming all the work developing the individual proxies. The study is defined by the set of proxies available in the body of literature at the time it was done, and it is essential to question the selection of those for use in this study (eg the discussion that has been going on about some that have been left out).
The inclusion or otherwise of proxies in the ambit of the study (i.e. before analysis is underway) is a matter that needs to be justified within the study, and any potential selection bias discussed before the analysis.
So the assumptions made before the analysis begins are critical parts of the analysis. If you accept that selection bias can occur once the “analysis is underway” you are accepting that selection bias can occur before the analysis begins.
Your final aside about not knowing what you didn’t look for is trivial. Your state of knowledge is implicit in your experiment, and if it is lacking calls your experiment into doubt. Mann didn’t know that you could get hockey sticks out of red noise (at least we hope so). It turns out you can. His experiment fails.
And I also hope you acknowledge the risk that the current available body of tree ring proxies may well be biased by what the investigators thought should be the right answer (leading them not to include some that didn’t conform to that preconceived notion).
HAS,
WEell, I think I have you agreeing that weighting is needed. All proxies are not equal. And ultimately, the principle of weighting is whether the observed behaviour in the calibration period indicates a temp tependence.
You can use various weighting functions. One is a step function, based on significance of correlation. It’s rough, doesn’t discriminate much, but then again avoids the MBH criticism of overweighting small numbers. But it has one major feature; you can apply it before you even begin. You don’t have to – it makes no difference to the result when you do it. If you do it in advance, it would be called selection. But from this point of view, it is just weighting.
“Mann didn’t know that you could get hockey sticks out of red noise (at least we hope so). It turns out you can. His experiment fails.”
That’s completely wrong, on all counts
Nick I don’t recall ever saying that I had a problem with using regression in its various forms for parameter estimation in models. In fact earlier I thought we agreed that one needed to make sure that the assumptions are met before use, and this was something Gergis failed to do.
One of those assumption is that the parameters aren’t picked before hand, rather than let the data speak. It was a mistake that Gergis eliminated (screened out) Law Dome without looking at whether including it along with the other early proxies gave a better fit to the SH temp construct than without it.
I note that this is a methodological error, not an analytic error. You seem at pains to assure me that everyone is doing the analysis OK.
To understand this debate you need to think at the methodological level. For some reason this doesn’t seem instinctive to you, and you seem to worry unduly about specific techniques and what name to give them.
Take the issue of “proxy selection” and “proxy weighting” – its trivial that the first is a special case of the second as a technique. I’m surprised you spent so much time debating with others what “proxy selection” might be, even if you couldn’t see the pitfalls associated with incorrect selection/weighting.
The issue to reflect on is how and when in your experiment you determine the weights.
On your last comment am I wrong that Mann didn’t know he could get hockey sticks out of red noise, or that you can get hockey sticks out of red noise, or that his experiment failed?
HAS,
For what regression are you saying that an assumption failed? It’s possible that Gergis did a regression over some group of proxies jointly, but I don’t currently know what it is. I thibk her Monte Carlo technique is equivalent to a regression (Proxy prob vs T) over proxies individually. It’s followed by a grid-based averaging, which AFAICS does not involve a joint regression.
I assume that with Law Dome she did that correlation test and failed to reach significance. As with the other rejected proxies. It might be possible to devise methodologies that would extract information from it, but she followed hers – I don’t see an error there.
As to time of determining weights, as I said, for her particular scheme, it doesn’t matter. She determines the criterion at the start with information available, and if it fails, that proxy cannot contribute to the analysis. It would be accorded zero weight.
On the last, one can go on discussling MBH forever. Lucia’s claim that selecting (or weighting) by concordance with calibration T facors proxies with that property is obvious, and I’m sure he knew it. If you’re referring to Wegman’s claim that decentred PCA produces hockey sticks, that was exaggerated by a gross selection issue, and was demonstrated only for PC1. And I don’t believe any of this caused the experiment to fail. Wegman’s mantra was Method Wrong + Answer Correct = Bad Science”. I don’t agree with the wrong bit, but “Answer Correct” is worth having.
Steve: your assertions here are untrue. I’ve posted a short reply but please do not take my lack of interest in debating this with you as any form of agreement. Your article is very misleading and disinformational.
Since you haven’t called for the retraction of Mann et al 2008 for its use of contaminated Tiljander data or condemned even short-centering, you obviously have zero interest in having a correct method. And if you don’t have a correct method, you have no way of knowing whether you have a correct answer.
And it’s not that merely fixing these problems would make either study “right”. Both are laboratories of statistical horrors.
Nick, the methodological question you should ask yourself is: “given the datasets to hand, should Gergis have screened the locational proxies directly against the SH construct (as they did), or should they have investigated the joint relationship between the locational proxies that were live in the MWP and the construct (at least for the purposes of comparing the MWP with current temps)?”
Read the paper and form a view.
Having read the paper and formed a view, and assuming Law Dome would have made a significant contribution jointly, ask yourself “Did her screening methodology bias the outcome of the experiment?”
In doing this put aside everything you know about all the fancy statistical techniques you have ever learned about, and focus on the experimental design and the methodology.
Nick Stokes:
I don’t know why you’d focus on a graphical depiction of an issue rather than what underpins it. Personally, I think the amount of focus the particular figure you discuss has gotten serves as a diversion, but regardless, if we’re going to discuss it, we should discuss it properly.
Your figures are inherently unfair. The orientation of a hockey stick is irrelevant, hence why the MM code flipped ones with negative orientations to have positive orientations. Whenever you show a figure with the MM approach, you keep this effect. Whenever you show a figure with “a properly representative sample,” you remove it.
You’re forcing half of generated series to appear upside down. The effect of this is to greatly increase the visual disparity between the MM approach and what you claim is the right approach. Through this visual trick, you create a massively misleading impression.
In fact, your trick has a far greater effect than anything you accuse MM of. In fact, it is about the only reason any significant difference exists in the impression given by your figure and that given by MM’s.
Brandon,
you’re 100% right on this. In our original article, we showed the distribution of “Hockey Stick Indexes” clearly showing a bifurcated distribution – half negative and half positive.
It’s also not a given that the orientation of even a PC1 as it emerges from a PC algorithm will have the “natural” orientation. For example, the MBH99 North American PC1 had a negative orientation as it came out of the algorithm and was flipped to show the up-pointing hockey stick. Further, in the MBH methodology, PCs entered into a regression step where the proxies were regressed against a temperature trend, which again oriented the PCs.
Mannian short-centering was a method strongly biased towards the production of hockey sticks. This is unarguable and Nick’s postings to the contrary are disinformation. No result using this method can be relied on nor cited. The power of the bias was demonstrated by showing that hockey sticks resulted from the application of the method to red noise. Not universally and not always with the same blade, We showed a distribution of the Hockey Stick Index over 10000 examples – a diagram that Nick did not show or discuss.
Mann claimed that his results were 99% significant. We showed that high RE statistics were generated even from red noise and showed examples of the sort of MBH-looking hockey stick that could be obtained at the 99% level to show that the MBH stick was not as “significant” as it appeared.
We did not argue that the empirical networks were simply red noise. Application of the MBH method to his actual network strongly emphasized bristlecones and made their shape appear to be the “dominant pattern of variance” when they were a lower order effect. Bristlecones were overweighted.
MBH had retained only a couple of principal components in its early network to ensure geographical balance. When their short-centering method was shown to be flawed, Mann changed other aspects of his method in realclimate posts, now arguing that lower order PCs should be included. This is merely a rationale for including bristlecones.
Although the NAS panel did not thoroughly examine many proxy issues, they did turn their minds to bristlecones and said that strip bark chronologies should be “avoided” in reconstructions. Nick conveniently ignores this. Acceptance of this policy reverts the PC results to the results in the “censored” directory.
There is an ample record on the MBH debate and I’m not interested in posting further on it in discussion with Nick, who admits nothing.
Even properly centered principal components
I may need to correct something I just said. I said “the MM code flipped ones with negative orientations to have positive orientations” because the orientation didn’t matter. It occurs to me the code may not have actually flipped any, but instead only picked ones with a positive orientation. Without checking the code, I can’t say for sure which was done.
It doesn’t really matter since the net effect is exactly the same, but I’d rather not add an additional nit for someone to pick at. The point is it was perfectly appropriate to show only positively oriented series, and it was misleading for Nick Stokes to change an aspect of what was done without disclosing either the change, or the impact from the change.
Brandon,
It didn’t need to flip any. It ran 10000 and selected the top 100 by signed HS index. Naturally they all had the upward orientation. Then it selected a dozen of that top 100 to show how decentring produced hockey sticks in PC1.
Nick Stokes, thanks for clarifying that nit. I explicitly clarified the issue myself so it wouldn’t need to be nitpicked, but I’m glad to see that didn’t stop you. It would truly be a shame if you focused on the methodological issue I pointed out causes a severe false impression in anyone looking at your figure. That would require an attempt at communication rather than obfuscation, and I would hate to burden you like that.
I mean, why should you discuss the fact your claimed “properly representative sample” is grossly distorted in relation to what you compare it to due to your methodological changes?
Steve McIntyre, I nearly missed your response since it didn’t appear at the end of the current fork. Apparently moderators can insert comments where a normal user can’t. I didn’t realize that.
Anyway, I want to expand upon a couple points you made. Your comments about the orientiation issue reminded me Nick Stokes explicitly acknowledged the orientation doesn’t matter, saying “In the PCA analysis, sign doesn’t matter, so the sign variations don’t cancel.” Despite acknowledging the orientation made no difference, he chose to allow negatively oriented series, something which could only artificially increase the visual disparity between his figures. And as you say:
There are many different demonstrations of the effect you demonstrated which Nick Stokes (and others) seem to like to ignore. They seem to prefer to focus on the issue of how an image was made, acting as though that was all there was to the argument. In reality, even if one completely dismissed the image in question, both the Wegman Report and your paper would still show MBH was fatally flawed.
Had Nick Stokes simply pointed our that figure wasn’t a true random sample, I’d have agreed with him. It was made in a way which emphasized a certain point, and I see nothing wrong with pointing that out. However, neither Nick Stokes nor anyone else discussing that figure seems interested in discussing the impact of it. It seems like nothing more than petty “Gothca!” games where they (perhaps implicitly) claim everything you say is wrong based on a single possible issue.
Given his willful obtuseness and hypocrisy, nobody could fault you for not wanting to discuss things with Nick Stokes.
Nick’s posts denying almost every statistical principle would be aptly titled (as I observed at Lucia’s just now): “Slaying the Statdragon”.
Steve and Brandon,
I think it is very likely that HAS was referring to Fig 4.4 of the Wegman report, subtitled “One of the most compelling illustrations that McIntyre and McKitrick have produced is created by feeding red noise [AR(1) with parameter = 0.2] into the MBH algorithm….”. It showed twelve HS plots, implying that this is the kind of thing Mann’s algorithm returned. But unstated was that they had been selected from the top 100, out of 10000 calculated, by HS index. That I referred to as a selection issue.
The other issue relevant to HAS comment is that this is a demo applying to PC1 only. And yes, there is a tendency for decentering to promote HS like PC’s in rank. You then need to see what that does to the final recon. Wegman did not do that.
I don’t know what has disturbed Brandon with proxy sign. I’m not aware that anyone flipped any.
Nope not Wegman, more advice from my brother never to trust Bayesians or people who use PCA. If they think they’ve found something useful they’ve violated the assumptions:)
Nick Stokes makes an amazing remark:
He made a methodological choice which caused a drastic change in the visual impact of a graph, and he says he doesn’t know what disturbs me about it, despite the fact I explained why it was a problem. He simply ignored that explanation even as he responded to an irrelevant point made during the explanation. He now says he doesn’t understand the problem without making any effort to talk to me about it. In other words, he says he doesn’t understand something he is going out of his way to not discuss.
Incompetence is one thing, but obtuseness is another.
Brandon,
Could you please calm down and say which graph you think has this error, and what it is?
Nick Stokes:
No. First off, I’m perfectly calm. You saying “calm down” serves no purpose other than to insult me. You are acting as though I’m being emotional or irrational, and thus behaving unreasonably, but there’s no basis for such. It’s a petty and pathetic rhetorical trick, and I won’t encourage it.
Secondly, I’ve already explained the matter. If you thought my explanation was unclear, you could have responded to it, explaining your confusion. You didn’t. You just ignored what I said. I have no intention of repeating a point you willfully ignored simply because you choose to be obnoxious.
If you decide to behave reasonably, I’ll respond in kind. Otherwise, you’re just wasting everyone’s time.
Brandon,
I showed four cases, summarized in the block at the end. Two were selected (100 from 10000) by HS index, as in Wegman. Since that is signed, they all have upward HS. Two were unselected. I did not modify their orientation, and some go up, some down. Wegman did not modify orientation either in his 4.4. I can’t see your issue.
Nick Stokes:
I can’t see your issue.
That’s hardly surprising given you’ve made no effort to see my issue. If you actually had any interest in the issue I raised, you’d have addressed what I said, even if only to express your confusion. The fact you chose to instead ignore what I said indicates, quite clearly, you have no interest.
I have no desire to engage you on the fact you willfully ignore an issue then express confusion over the issue. Willful obtuseness holds no appeal for me.
I am not well versed in stats, but will give it a go.
Let us assume, for the sake of the arguement, that tree rings do NOT respond to temperature at all – of course, we know they do, but let’s pretend, OK?
If you are using correlation with temperature as a selection criteria, what would you prove with the results?
If, however, you used, say, treeline vicinity and got a significant result, what would *that* tell you?
See the difference?
Well, they use treeline vicinity and correlation/calibration. They do their best to figure which trees will work. Then they check.
But they are not surveying to find what fraction of trees satisfy. They just want the actual trees. Short-listing is a means to the end.
If indeed proxies did not respond then you’d get a tail distribution of a few proxies satisfying the correlation requirement, and then only just. But Gergis got 27 out of 62, and 14 of those satisfied at a p-value less than 0.0005. That’s not chance. Even after adjusting for autocorrelation (as one should) 20 passed at p<0.05, with four at p<0.0005.
Nick wonders why other statisticians have not been long-ago questioning these filtering methods.
If I may suggest a simple answer: people generally do not follow lines of questioning, even internally, that they consider ridiculous.
I’d like to suggest another very simple analogy for the discussion between Nick and RomanM. Nick asks:
A LaTeX example: 🙂 .
.
Suppose we are looking for proxies for natural phenomenon
We find biological entities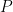 in a region, many of whose attribute
in a region, many of whose attribute 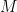 correlates quite well to
correlates quite well to  over a number of years in the modern era. So we select for
over a number of years in the modern era. So we select for 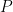 whose
whose 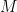 correlates with
correlates with  in that period.
in that period.
According to Nick’s logic, we may well have found a good proxy, and he can’t see why this selection process could introduce a bias.
Up until now, I have not introduced additional knowledge of the data or the context.
Slowly Revealing My Cards in the physical world is not related to
in the physical world is not related to  . And yet the correlation is measurably significant. Should that make us cautious?
. And yet the correlation is measurably significant. Should that make us cautious?
Now, let’s introduce proof that
Next, let’s introduce proof that only correlates during the period for which
only correlates during the period for which  has been measured, but (by our knowledge of the physical characteristics of
has been measured, but (by our knowledge of the physical characteristics of  ) we can prove it was wildly different in the distant past, and will be different in the future. In other words, the uniformity principle does not apply to either
) we can prove it was wildly different in the distant past, and will be different in the future. In other words, the uniformity principle does not apply to either  or
or  . Should that make us cautious?
. Should that make us cautious?
My point, which many have argued in other ways: without physical knowledge and evidence of the underlying reason for a correlation, we can’t just trust a data set (or 27!) to inform us of physical reality. Too easily, a tiny bit of physical understanding will completely refute whatever our wondrous correlation-induced vision is telling us.
This whole community discussion is a very interesting study in how strongly, and for how long, group think can affect a community of otherwise very smart people. I’m glad that I truly don’t know much. 😀
PS One might argue that my scenarios are ridiculous. But there’s no basis for such an assertion.
Yule [1926] did a study on Church of England Marriages. Interestingly, if one knows the context of that data source, it is clear there were none before ~500AD, and the CoE population has not been growing in correlation to the Total population there since the mid 20th century.
Mr Pete,
I’m not asking why any old statisticians didn’t go to the authorities with suspicions of screening. I’m referring to two noted statisticians, Prof’s Bloomfield and Brillinger. Prof Bloomfield was on the NRC Committee chaired by North, asked to report on “Surface Temperature Reconstructions for the Last 2,000 Years”. He was one of the panel. Prof Brillinger was one of the reviewers. It was their explicit job to report on the methodology. And they said:
“The standard proxy reconstructions based on linear regression are generally reasonable statistical methods for estimating past temperatures but may be associated with substantial uncertainty”
Does that sound like people who comsidered the methods ridiculous? Gagging on “baby food statistics”?
“We can’t just trust a data set (or 27!) to inform us of physical reality”
What else does science do but trust data sets to inform us of physical reality? Your counter is based just on the proposition that the uniformity principle might fail. Well. it might, but that has nothing to do with how the proxies were selected. Uniformity could fail because of some unexpected past event or change. No adjusting the calibration process will detect that.
Nick, Maybe the reason those experts on that committee didn’t go into the issue of proxy screening is that proxy screening wasn’t used in the papers they were looking at.
Paul, it was a survey – they were supposed to look at all the papers in the field.
But in any case, in their stat method chapter (p 85), they give a single proxy illustration where you regress proxy against T to get the relation to interpret proxy data. They describe significance levels. They don’t explicitly say so, but clearly if you don’t get a significant coefficient, you can’t use the proxy.
With regard to Brillinger the following statement from the 2006 NAS report applies:
“Although the reviewers listed above have provided many constructive comments and suggestions, they were not asked to endorse the conclusions or recommendations nor did they see the final draft of the report before its release.”
And here is what Bloomfield had to say about the models Congressional testimony:
“Our committee reviewed the methodology used by Dr. Mann and his coworkers and we felt that some of the choices they made were inappropriate. We had much the same misgivings about his work that was documented at much greater length by Dr. Wegman.”
Yes, Bloomfield and Wegman both criticised MBH. but not for a selection fallacy.
And if the methods, which include the one explained in NRC Chap 9, presumably written by Bloomfirld, were failing “baby food statistics”, I can’t imagine Brillinger allowing himself to be quoted as reviewer.
Steve: MBH suffered from many problems but did not use selection fallacy screening. So why would you expect North or Wegman to get into it? Mannian short-centered principal components had a very similar effect. Nor should you be under any illusion that North was any sort of thorough investigation or even competent on all points. After recommending that bristlecones be “avoided” in reconstructions, they illustrated reconstructions using them. I asked North about this and he conceded that i asked awkward questions. In a seminar at Texas A&M, North described panel operating procedure by saying that they “didn’t do any research”, that they just “took a look at papers”, that they got 12 “people around the table” and “just kind of winged it.” He said that’s what you do in these sort of expert panels. It’s too bad that this impresses you.
Re: Nick Stokes (Jun 15 01:40),
I guess it comes down to which is the cart and which is the horse:
Model A
1) Develop an hypothesis for how physical attribute XYZ may be a proxy for temp.
2) Collect data for XYZ.
3) Analyze the data statistically (vs itself and vs temp) to determine uncertainty levels, quality of fit, etc.
Result: Temp data introduced after filtering. No data snooping, no extraneous degrees of freedom. Proper conclusion that XYZ is or is not a significant temp proxy.
Model B
1) Identify a number of possible proxies for temp and other things: ABC, DEF, … XYZ.
2) Collect data for them all
3) Analyze (vs one another and temp) to discover which proxies have statistical significance
4) Eliminate “invalid” proxies, declare XYZ the winner (if it is)
Result: Temp data introduced at time of filtering. Data snooping, sharpshooter fallacy, double-dip, etc. all possible. Serious risk of XYZ as false-positive proxy.
Please tell us how your perspective is not Model B?
It sounds like Model B, though they are not looking for a winner – a pass will do.
But it’s not a sharpshooter fallacy. The target is the pre-1900 temperatures, and you can’t peek at those. It’s not “data snooping”; they aren’t trying to predict the data. Lucia has a new post which in my view nicely shows how selecting proxies by the training period does not affect the result in the target period.
Steve,
The North Committee made a general survey of proxy reconstruction. Their full title was “Committee on Surface Temperature Reconstructions for the Last 2,000 Years”. The report are 17 pages of references – it isn’t just MBH. And the example they discuss in Chap 9 on stat methods involved calibrating proxies directly with temperature.
MBH didn’t reject proxies outright based on correlation significance. But they weighted by a comparable measure, which has a similar effect. No analysis can reasonably treat all candidate proxies equally.
And I’m still looking for a definition of selection fallacy.
Nick: the North Report is now six years old. A lot of water has gone under that bridge and in fact the water may have risen high enough to wash out the bridge. To suggest the North Report was an in-depth study and the last word on these matters is a dubious assertion at best.
If you are looking for an authority on the questions at hand, I don’t think you can do better than the archives of this website, where you will find a voluminous amount of actual work and not merely a cursory look at existing literature.
And I’m still looking for a definition of selection fallacy.
Selection Fallacy:
The fallacy or unproved assertion that screening proxies by correlation produces a more informative
reconstruction than one obtains by not screening.
If you want to establish that at least some of the 62 proxy candidates have explanatory power, you have to reject the null that all of them have zero explanatory power.
Philip Brown (J Royal Statistical Society 1982) on “Multivariate Calibration” gives an F-test of this joint hypothesis that appropriately takes temperature as the exogenous variable and takes into account the correlation across proxies in of the residuals from simple regressions of the proxies on temperature.
The more naive approach under discussion is to just regress temperature on the set of proxies in a multiple regression and look at the regression F statistic. This gives an over-attenuated reconstruction and inconsistent estimates of the transfer function, but may give tests of statistical significance that are similar to Brown’s.
If the proxies were exactly uncorrelated, the reduction in variance from this multiple regression would be exactly the sum of the reduction in variance from the simple regressions you describe. But since they are probably highly correlated, especially within class, simple regressions are not a substitute for running the multiple regression.
(Likewise, in Brown’s MV Calibration paper, ignoring the correlation across proxies in the simple regression residuals would give a very different F test than the one he describes.)
The principles are the same if you first reduce the rank of the proxy network to something manageable by considering only the first (few?) PCs from each class of proxy instead of the 62 raw proxies themselves.
But if you first pick out the 27 proxies with the highest correlations to temperature, the burden of proof is still on you to show that the reduction in variance they give together exceeds the threshold for significance if all 62 proxies were included in the regression. As I have shown in an earlier related thread, this is not likely to be the case.
“If you want to establish that at least some of the 62 proxy candidates have explanatory power, you have to reject the null that all of them have zero explanatory power. “
Why? If I want to establish that yesterday was cold, do I have to reject the null that the week was not cold?
The explanatory power is not established statistically from a population. It results (in the simple case of Gergis, which is exemplified in the North NRC report Chap 9) from the significance of the correlation of each proxy. The only assumption is that that correlation is maintained back in time, but that is justified on physical, not statistical grounds.
It’s true that eg CPS does some joint regression and it gets more complicated. But I don’t think that relates to Gergis.
A major counter is, what is special about the 62? It’s just someone’s idea of a short list – a stage along the way from the vastness of possible proxies (eg all trees) to a set you can actually analyse. In Gergis’ case, it seems to be all published chronologies (with no particular claim to temperature suitability) that fell in the right area, liberally interpreted. Why should it matter what was and was not included?
Occasionally when I mull this over in my mind, I keep coming back to “what if the ‘Divergence Problem’ is the reality, and one whose explanation is as yet unknown?
We’re out there only grabbing trees whose mean average chronology for a site resembles that of the instrument temperature record in recent years (even if there is a YAD061 in there dragging along a set of wildly variable cores)– therefore assuming what constitutes an accurate modern thermometer. But, what if these days (because of the inordinately high amount of CO2 yadda yadda yadda) the ‘real’ expression of trees is actually different from the instrument temperature record, while the ones that are following differently are simply correlated gibberish? Even despite the correlation of proxy means, isn’t there an article of faith going on here?
Has anyone ever conducted some sort of ‘goose-chase’ study with the available tree record to show that: IF you have a preconceived notion of what you want the end-stage mean chronology to look like (ie, instrument record), but instead something wildly different (like a divergence), you can find a whole slew of mean chronologies that behave in “uncanny lockstep” to that temperature line?
Jim Bouldin’s line of argumentation was that there was no other way to explain how all these trees, er, mean chronology of trees, are corresponding similarly to the variable of interes…. Theoretically, if it can be proved that a similar number of ‘mean chronologies’ can be assembled for a whole range of pressuposed temperature lines (including the opposite of the instrumental), why would this discovery be completely meaningless?
Nick Stokes said:
“If you want to establish that at least some of the 62 proxy candidates have explanatory power, you have to reject the null that all of them have zero explanatory power. “
Why? If I want to establish that yesterday was cold, do I have to reject the null that the week was not cold?
————————————————-
Nick, it’s the pea and thimble trick again from you. Your proposed null is just pulled out of the air, and misleadingly at that. Whether it was cold or not that week (a time series) and whether or not it was cold yesterday (a single point in time) might have some broad correlation – e.g., it might be winter. But, they have no particular power to prove anything in relation to each other. A few years ago, it snowed on Christmas Eve not far from my place (Canberra) in a month when average maxima are in the range of 25 to 30 degrees celsius. So what? Making comparisons between the average temperature that week – which was close to normal – and one event (it was cold yesterday) is meaningless. It is not about how well or badly they correlate. It is the fact that it is irrelevant to what yesterday’s temperature actually was.
Since I stopped formally studying mathematics at the age of 15, I am not qualified to comment on the more esoteric issues. But, you need to choose your examples more carefully if you expect to convince readers here who have much more expertise than I do.
Yes, it’s pulled out of the air, but to illkustrate that the 62 proxy issue has no more validity. It looks to me as if Gergis simply collected all the proxies she could analyze. That is, those that were published, in the region, and maybe in electronic format. In terms of proxy function, that’s as arbitrary as the relation of a week to a day. But the collection has proxies she wants, and she finds them by correlation. The nature of the others that turned up in the collection of 62 is not relevant.
Nick you are absolutely correct. She wants proxies that correlate well with a particular model and she finds them by correlation. Can’t fault that.
But how valid are her (and your) wants?
No, she correlates with temperature in the instrumental period. Not with any model. What do you think would be a quantitative measure of a good temperature proxy?
She correlates using a linear model. With your training you should be able to write down the equation she is assuming when she does her correlation, and know that an equation is a particular type of model.
It is quite possible that the model (equation) she assumes isn’t the best qualitative measure of a good temp proxy. You are free to assume that to avoid demonstrating that, but it is just that an assumption.
Sorry “… assume that it is to avoid ..”
I think the fallacy here that we are all ignoring is that those who do not understand the screening fallacy really do not want to understand the screening fallacy. Nick Stokes is here to defend the scientists, and evidently some statisticians, from what he sees as unfair and uninformed criticism. Rather than attempt to understand the fallacy he puts his faith, as always, in the scientists. It is not going to be a logical debate so why waste your times.
Actually the fallacy is that those who do not understand the screening fallacy want to understand it.
Kenneth,
I’ve put plenty of logic as to why I think there is no fallacy. And I’ve asked for a clear specification and never got one.
And now Lucia has tried to pin it down by way of worked example. And it evaporated. So we’ll never know what it was.
***And I’ve asked for a clear specification and never got one. ***
And you are likely looking for a definition that agrees with your beliefs.
Re: Nick Stokes (Jun 15 18:49),
> And now Lucia has tried to pin it down by way of worked example. And it evaporated.
”It evaporated”? This may be a colloquialism I’m not familiar with — perhaps it translates as, ”the discussion over there is continuing.”
However, the more substantial thread at Lucia’s on this subject follows her June 14th post on proxies. The latest comment there is here, at this writing.
Well, discussion has moved to uniformity principle. It’s true tha some people still confuse that with “selection fallacy”. That’s why a proper definition of SF is needed.
Steve: Nick, there’s no issue with the “uniformity principle”. There is an issue with the selection fallacy. Please do not misinterpret a disinterest in engaging with your seemingly wilful obtuseness with a concession that you’ve made any sensible points.
Steve,
I’m referring ot the discussion at Lucia’s, in response to Amac’s remark.
Steve: your comment was untrue there as well, as Lucia pointed out.
The fallacy is simple:
“The unproven assertion that one gets a more informative reconstruction using screening”
This assertion is made but unproven. All synthetic experiments I have seen, RomanMs is the latest , show that screening does not improve a reconstruction. I am waiting for a demonstration that shows that screening is justified and that screening produces a more informative reconstruction. Basically, a demonstration that
justifies Jacoby’s hypothesis: a few good men are better than many mediocre men.
The party that drops the data has the burden of proving that this choice introduces less bias than keeping the data. A simple synthetic experiment would suffice. Hand waving won’t. At its core the fallacy is believing that hand waving arguments about screening being the best method.
I remember Mann et al in PNAS having 4 comments, including M&M. One by a Bruger. Yet I am not finding any other than M&M, which itself isn’t linked directly. Am I misremembering this?
Steve, If you look at and around year 1160, you will find that there are only three proxies.
Two Mt Read and Oroko are full length, and track very nicely. Then there is slab of Palmyra, which runs from 1151 to 1221.
Plot Mt Read vs Oroko and Palmyra
Oroko = 0.1906x(Mt Read) + 0.4297
R2 = 0.0393
Palmyra = -0.0865x(Mt Read) – 0.6568
R2 = 0.0173
Why add this Palmyra proxy?
Because if you just use Mt Read and Oroko you get a peak that is the same size as the modern day.
I think that it would be very nice to have an original data set from Oroko. I want to know if the point at year 1160 in the excel spreadsheet is EXACTLY the same as in the original archive.
Does anyone have a long time saved version of Oroko/
“Why add this Palmyra proxy?
Because if you just use Mt Read and Oroko you get a peak that is the same size as the modern day.”
Doc, once you get beyond worrying about a selection fallacy in the instrumental period I suppose for the true believers it is easy to rationalize selection in the pre-instrumental period. If it is confirmed what you say here it confirms my skeptics suspicions. Using pieces of a proxy like Pamlyra always raises my skeptics hackles. I have not had sufficient time to look, but Palmyra has many pieces available at the NOAA site and there is lots of overlap of these pieces even though there are gaps in the overall record. My point being here that I think one would have selections to make from which pieces were used.
Also, Doc, it is important to remember that, while not only was a slab of Palmyra used, that proxy was brought into an Australasia reconstruction defined as 0 to 60S and 110E to 180E. Palmyra’s coordinates are at 6N and 162W. Like I said, once you can rationalize overlooking the selection fallacy it is not much of a step to do some other selecting to support a preconceived conjecture. You could also do things like cutoff an inconvenient downward trend and replace it with something upward (Mann08).
Oh, it does require some hand waving at justifications for making these selections and that is where the lawyerly skills of a defense attorney comes in – kind of like the vague arguments Nick Stokes makes.
http://www.theaustralian.com.au/higher-education/bloggers-scientists-claim-high-moral-ground-on-climate-data-error/story-e6frgcjx-1226396038196
“David Karoly, the co-author who has taken the lead in explaining what happened. “It is better that we admit our mistakes — and it’s not even clear that it is a mistake.””
In modern climate science, it’s not clear that it’s a mistake when the results you announce don’t actually derive from the procedure you state you followed. That’s quite remarkable. The reason it’s not clear it’s a mistake is presumably because they got a hockey stick, which was the desired result. Mainstream climate scientists still need re-education in understanding that Method Wrong + Answer Correct = Bad Science.
Well, I think some people need better understanding of what “Answer Correct” means. Scientific literature isn’t an exam, it’s to provide information. For me, if thare’s a correct answer there, I want to know about it.
So Nick, you don’t agree that it’s a mistake in the paper when their results are not actually derived using the methodology they claimed they used ? Either you agree with me that it’s clearly a mistake, or you agree with Karoly that it’s not clearly a mistake. If you agree with Karoly, you would only consider it a “mistake” if the answer using a “corrected” method gave the same result… that’s just bad science.
Yes, I think they didn’t detrend when they said they did. And I think detrending is a bad idea anyway. So I’m left with an analysis that gets a correct answer (at least as far as that is concerned). And there is embarassment for the authors, and maybe the journal, because of the misdescription, and maybe advocating a bad idea. But for me, I mainly want to know the Correct Answer.
Nick:
“Yes, I think they didn’t detrend when they said they did.”
So you agree its CLEAR they made a mistake, though you can’t quite bring yourself to state that ? As I said, it’s amazing that the authors themselves are NOT clear they made a mistake.
“And I think detrending is a bad idea anyway.”
That particular step was important though because it was the way they sought to address the significant problem with these reconstructions, that by screening noisy data against a hockey stick, you get a hockey stick. If you really want to know the Correct Answer, you have to find a solution to the screening problem. You can’t just do nothing, or you are not going to get the Correct Answer.
Well, I don’t think there is a screening problem. And I don’t think detrending would help anyway. It would still be screening.
Nick
“Well, I don’t think there is a screening problem”
I could present you with 10 proxies from a region, with a known average temperature curve over some period. You’d screen out any failing to correlate sufficiently over that period and make your reconstruction on the remainder. Then I tell you the proxies were actual temperature measurements. That’s ok you’d say, my reconstruction is fine because the temperature measurements were wrong if they did not correlate, and theres no such thing as a screening problem. Come on Nick.
“And I don’t think detrending would help anyway. It would still be screening.”
Yes it would still be screening and I would not be surprised if you can still pretty much guarantee a hockey stick because as far as I can understand (have not thought too much about it) any effort to match a “signal” on one end in noisey data as a filter is going to cause the pretty much random noise at the other end to form a shaft. Until they have a heavily analysed and tested scientific method, the simple average of ALL data seems the most reliable first estimate. Unfortunately for climate science that invariably seems to return a relatively warm middle ages, followed by a cool little ice age then modern warming which is not an acceptable answer for them.
Looking into Oroko Swamp proxy; one of the only two full length proxies in the study.
Here is Ed Cook’s 2002 paper.
Click to access Cook-2002.pdf
Money shot:-
“With the current chronology, this conclusion applies only to the AD 1200–1957 period. The weak chronology signal strength prior to AD 1200 and the disturbance impact after 1957 render those periods presently non-interpretable. Given these limitations, it is possible to compare the 20th Century with the prior seven centuries of inferred high-summer temperature.
However, to do this for the full 20th Century requires that the instrumental data be spliced in with the treering estimates to account for the loss of signal in the tree rings after 1957”
Thus, Ed Cook was of the opinion that calibration to temperature could not be performed after 1957.
This proxy cannot be calibrated using 1920-1990.
Again, of interest is the large peak at 1160. This feature is present in both long term proxies and is larger than the present day. Finding a peak in the hockey stick 900 years ago showing that conditions were warmer then must have taken a long while for the authors to deal with.
The addition of an orphan Palmyra stretch solved this.
I don’t know how they reconstituted this stretch. All the proxies have a peak at 1160(ish) that is bigger than either side; however this isn’t present in the reconstruction.
I seriously think this is the bit we should examine.
Re: DocMartyn (Jun 16 10:38),
From page 212 (pg 4 of the pdf):
Also Fig 2 on page 213 charts year of death for about 70 felled trees presumably from the “disturbance history analysis. The text says 71 trees were cross-dated, but the total number of dots in Fig 2 is only 68. It is unclear how many of these were used in the chronology, but presumably the 20 or so whose “year of death” was before the 20th Century were used as well.
My question is how in the world were the sub-fossil samples from trees whose “year of death” was before the 20th century calibrated (period of calibration 1894 to 1957)? Is there an SI that details how far back the samples with “year of death” within the calibration period go? In any event, under what statistical argument can you “extend” a chronology using sub-fossil trees that are not calibratable or verifiable? If you do not use the sub-fossil samples, does Oroko remain a full-length proxy?
I am betting that they used the recent trees to develop the calibration and the just ASSUMED that already dead trees from the same site are also valid and follow the same calibration.
this same issue arises for the subfossil trees in Siberia used to extend the chronology there.
Graybill’s bristlecones and Tiljanders sediments also had the caveat that the more recent results were not useful due to contamination. So don’t the paleo “experts” bother to read the accompanying papers prior to using the proxies or are they deliberately practising bad science?
I sometimes think we lose sight of some important but more general issues with these reconstruction analyses when we discuss the details. In Gergis (2012) the setting for this analysis is the upcoming IPCC review and specifically of the Australasia region in part as an answer to what apparently was a lack of extensive data for the previous IPCC proceedings. In Gergis the authors state: “The Australasia (Aus2k) working group is examining the Indo–Pacific region consisting of the landmasses of Australia, New Zealand, the Indonesian archipelago and the neighbouring islands of the Pacific Ocean… In this study, Australasia is defined as the land and ocean areas of the Indo–Pacific and Southern Oceans bounded by 110E–180E, 0–50 S.” This is an important definition by way of the proxy selections made in Gergis – as I intend to point out later in this post.
What I wanted to compare in this post was the Gergis coral proxies versus coral proxies from other locations in the SH with some of those not-Gergis proxies located in the Gergis defined region and some out of that region. The best comparison, given how the data were available, was to use annual coral proxy averages and the mean annual GHCN temperatures for the Australasia region. GHCN data was complete (as it comes to KNMI already in-filled) while the HadCRUT set that Gergis used was incomplete at the KNMI web site and would have required in-filling. GHCN at KNMI is at:
http://climexp.knmi.nl/select.cgi?id=someone@somewhere&field=ncdc_temp
I calculated the one sided (less) Pearson correlation coefficients (r) of the annual proxy data for Gergis and not-Gergis to the annual Australasia mean temperatures and presented it in the first link below along with the pertinent correlation related statistics . The period covered was from 1920 forward in time to the end of the proxy data. The correlations fit generally the selection criteria used in Gergis. Of the 12 Gergis coral proxies (I could not find data for Fiji AB) 3 would probably not meet the Gergis correlation criteria if the degrees of freedom were adjusted forAR1. Under the same calculations 3 of the 18 not-Gergis proxies would have met the Gergis criteria.
The second link below shows the pertinent statistics for the trends of the proxies from above compared to the annual GHCN temperatures for the same period. There is wide range of trends in both groups of proxies with the Gergis proxy trends, as expected, being on average higher than the not-Gergis proxy trends. None of the trends matched the GHCN counterpart.
In the third link below I show plots of the Gergis proxies for the entire series except for Palmyra which I show only the latest slab of data. The not-Gergis proxies are shown in the fourth link. The not-Gergis group has a mix of O18 and Sr/Ca proxies. The Australasia GHCN annual temperatures are shown in a plot with each group for better reference. My observation of the individual proxies is that (1) the proxies do not appear to have that much synchronous response which provides a wide range of possible selections for those playing that game, (2) there is not a line of demarcation between the Gergis and not-Gergis groups of proxies but rather the groups blend one into another and (3) closer examination of those proxies in close proximity show differences in response in parts of the series. For the plots I inverted the proxy series for easier comparison with temperature.
Finally, what I find rather peculiar is that the authors ostensibly chose the Australasia region for study and then went outside that area to select 3 out of the 4 proxies which give the greatest upward swing in temperature at the end of the series. Those series were Palmyra, Rarotonga and Rarotonga.3R. Those proxies are incorrectly labeled in the table as being within the Australasia region but are shown properly located in the map outside the region.
DocMartyn has posted that without the Palmyra slab early in the series the presence of a temperature peak in the early series would evidently render the reference to unprecedented modern warming period invalid.
Because you won’t pass the “screening” for AR5 if you don’t have a hockey stick?
I am posting here some results I found after a rather lengthy search investigating TRW series from Australasia. I thought I did a reasonably thorough research effort, but I was unable to find TRW series that ended later than 1989 similar in structure to those TRW proxies found in Gergis (2012). I found series that were at or very near the Gergis proxies and for the nearly same time period but none match in the plotted series.
I though perhaps I was using a chronology different than what is normally used in temperature reconstructions. I went to Mann (08) for reference and matched the many TRW series from New Zealand and Australia in Mann (08) with those I found in the NOAA repository for proxies (linked below) and used in my analysis.
http://www.ncdc.noaa.gov/paleo/paleo.html
I finally plotted the both the Standard and ARSTAN chronologies, where available, for all series used in my analysis. I found that most series generated with both chronologies correlated very well and produced very similar time series with regards to modern warming or the lack thereof.
I found that Mann (08) used the standard chronology even though the paper refers to preferring the ARSTAN chronology when the authors required a chronology from raw TRW data. Also worth noting, Mann (08) used many TRW series from New Zealand that ended in the 1970s. For the reconstructions Mann (08) these series (amongst many others) were in-filled for 20 plus series ending yearsusing other proxy series.
Below is linked plots and correlation and trend statistics for 33 TRW series that I found in the NOAA repository of proxies. Linked for comparison are the TRW proxy series data from Gergis (2012).
I used the Standard Chronology data since it differed little from the ARSTAN chronology and was available for all 33 series. I used both the mean GHCN Australasian annual and SONDJF (was the case for Gergis 2012) series. I report here only the statistics using the annual temperatures as there were little differences between the correlation and trend statistics. All TRW series plotted in the links below were standardized using the series standard deviations and anomalies based on the mean of the series divided by the standard deviation.
The 33 TRW series show no indication of an unprecedented modern warming and show little corresponding structure even for those series at near or the same location. While some of the Gergis TRW proxy series show similar meanderings, there are a number that show the late upward trend even if these series do not all show unprecedented modern warming.
The table linked below shows correlation r values and pertinent statistics for the 33 TRW series with the Australasian annual mean temperature series. After adjusting for AR1 only one series would pass the p value <=0.05 used in Gergis (2012). Please note that these series were not detrended and as such were handled that same as those Gergis TRW series were in Gergis 2012 (by mistake).
I am at a loss at this point to determine where the Gergis (2012) TRW series are found. They may have used available raw TRW data and used some very different chronology to generate their data. I would appreciate anyone letting me know where or how the Gergis TRW series were generated. The following statement excerpted from Gergis 2012 indicates that the authors did not use the Standard or ARSTAN chronologies: "All tree ring chronologies were developed based on raw measurements using the signal-free detrending method (Melvin et al., 2007; Melvin and Briffa, 2008)." The article is linked here:
Click to access Melvin2008.pdf
I have read this article and it appears on first read to be proposing an iterative method that uses the trends generated by the first iteration using a chronology method, like ARSTAN, in the second iteration and second to third and so on until the subsequent iterations converge. It is difficult to determine what differential effects this chronology adjustment would have on the 33 TRW series I looked at here. I am guessing that difference would not be large, but it would be valuable for that difference to be determined by having the adjustment code to run. The authors noted in the article that Cook was planning to incorporate the adjustment into ARSTAN. It is unclear to me at this time if and when that might have occurred.
If indeed the authors of Gergis (2012) thought the chronology procedure would make a large difference in finding selection candidates for their reconstruction, it would have been good of them to clearly state that in the paper.
Kenneth, can you post up a csv showing the concordance of sites that you’ve used here?
SteveM, I’ll email the data to you from Excel spread sheets. That is where I stored it after donwloading with R.
SteveM, I sent you my Excel spreadsheets of the 33 Australasia TRW series with data from the both the standard and ARSTAN chronologies from the NOAA repository, but I suspect what you wanted was the raw data so that you could obtain the RCS chronologies for the raw TRW data. I plan to obtain all the necessary urls for these raw TRW data which I can send to you. I planned to obtain and run these data with the R program in library(dplR) and obtain RCS chronologies on the 33 series. We could compare results if you use your nls program. The dplR looks like it will be simple to run and helpful in putting the NOAA data into proper form.
The program dplR requires a pith offset value to run and after reading the Esper article linked below I suspect I can default that offset to 1 and not worry about it affecting the results. I have read a CA thread which discussed the pith offset. Do you have any thoughts on the matter?
Click to access esper_etal.09_trace.pdf
Using RCS would put me one step closer to the process that Gergis used for her TRW proxies. What is left is the Melvin-Briffa iteration steps. I have emailed Melvin about providing sufficient information about the iterations such that I could code it in R.
Steve: I have collations of all measurement data at NOAA.
Re: Kenneth Fritsch (Jun 22 13:42),
> Mann (08) used many TRW series from New Zealand that ended in the 1970s. For the reconstructions Mann (08) these series (amongst many others) were in-filled for 20 plus series ending years using other proxy series.
Off topic but perhaps interesting: if I am reading this correctly, Kenneth is stating that many of the NZ TRW series used in Mann08 ended in the 1970s. Thus, for these series, the final 15 to 24 years culminating in 1995 (the terminus of the screening period) were generated by Mann08’s authors through infilling (via the RegEM procedure).
As best I can tell — I welcome correction on this point — “infilling via RegEM” simply generates numbers that plausibly fit the pattern of the time series, past the point where actual data do not exist. There was no need to stop in 1995, as the technique could have supplied values through 2010, or 2035.
Mann08’s authors used two sets of calibration and validation times. An early (1850–1949) calibration/late (1950–1995) validation, and a late (1896–1995) calibration/early (1850–1895) validation. (Mann08, PNAS, pg. 13254).
Assume a NZ TRW series was “infilled” from 1976 on. That would mean that for that proxy, imaginary data was generated for the final 25 years of that series. This would have accounted for 44% of the validation time period under the early calibration/late validation scheme, and for 20% of the calibration time period under the late calibration/early validation methodology.
Say it ain’t so!
Steve: For the 76 or so Briffa MXD series in Mann et al 2008, they didn’t just infill missing values, they deleted post-1960 decline values, infilled post-1960 values and used this for calibration/validation.
AMac, I did not actually realize how much infilling was required in Mann (08) until I really looked at the proxies and then read what was in the SI. Actually if you read carefully and in detail it is all there in Mann (08) and the SI. In-filled data was used in screening test also. It was actually 105 MXD series that were looped off at 1960 and then in-filled.
The Mann (08) SI at some point summarizes were the proxies end and thus you can conclude how much in-filling was done. Or you can go to the data through an SI link and make that determination yourself.
It is a little late in the day and thread, but I finally used the R library (dplR) to download the raw TRW series (33 not-Gergis from the Australasia region) from the NOAA repository (linked below) and produced chronologies with the rsc function in R. A good summary of the R program is linked below.
http://www.ncdc.noaa.gov/paleo/treering.html
http://www.sciencedirect.com/science/article/pii/S1125786508000350
I was curious whether the RCS (Regional Curve Standardization) would produce the TRW series with series ending upward trends from which Gergis was able to select. Gergis used RCS and combined that with an iterative method that was described by Melvin and Briffa here.
http://www.sciencedirect.com/science/article/pii/S1125786508000374
I have contacted Melvin (with no reply to date) about an outline that would allow me to combine the iterative process with RCS in an R program.
I had a concern about using the rcs function in R in that it asked for the pith offset. That piece of meta data is not available with most of the TRW series in the NOAA repository and thus I had only the option of setting it to 1 for all the TRW series. The value of the offset would appear to be downplayed by Esper in the article linked below.
Click to access esper_etal.09_trace.pdf
Before continuing with my analysis of the RCS results here I should link to a very good post by RomanM at CA explaining the basis for RCS and his analysis of the Yamal data with it.
What I found in a direct comparison chronologies of these not-Gergis TRW series was that, indeed, RCS tended to produce the series ending trends more than the Standard or ARSTAN chronologies. The comparison can be viewed in the links below.
While even with RCS, the TRW series appear to be more or less random editions of red noise, the RCS chronologies produced visually perhaps as many as 5 candidates for the Gergis selection process. It is these 5 series that I studied further. I found that grouping the trees by age produced different series ending structure with the older trees producing the upward trends and the younger trees producing little or no trends. I thought that the effect might be the result of the mixing of a tree ages in the RCS process to obtain the regional growth curve. When I obtained much the same differential results when I either used only the older and younger trees to produce 2 separate chronologies or used all the trees in chronology and then extracted the older and younger tree series from that chronology, I think I can conclude that it was not the mixing of tree ages but the trees in the two age groups that gave the differences.
I link both the 5 series below with the grouped tree ages and the growth curves with the tree ring widths plotted by cambial tree age for the entire series. There appears to me to be less of the expected fall off in the growth curve that is modeled by a negative exponential, but that might be because I have not viewed that many TRW series growth curves.
I need to look further into exactly what the rcs function is doing in R and determine whether I can produce the Standard and ARSTAN chronologies in R as these data appear in the NOAA repository. The Standard and ARSTAN processes deal with the TRW series individually in detrended the natural growth while the RCS process uses all the data arranged by cambial age to produce a growth curve for detrending. My initial look, given the TRW data, did not reveal an obvious cause of the difference that RCS method produces compared to the Standard and ARSTAN methods.
If anyone is interested in looking further at these TRW series I analyzed here I give the urls below to the raw tree ring data from the NOAA repository:
urls to raw TRW data and for rcs in R:
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz091.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz088.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz079.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz081.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz087.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/ausl022.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/ausl023.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz077.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz084.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz083.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz059.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz064.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz065.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz072.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz073.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz074.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz066.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz067.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz060.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz061.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz068.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz070.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz069.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz071.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz062.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz076n.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz076i.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz076t.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz076l.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz076x.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz076e.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz076.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz063.rwl
ftp://ftp.ncdc.noaa.gov/pub/data/paleo/treering/measurements/australia/newz075.rwl
I have made some progress in determining the chronologies used for the Standard or .crn result in NOAA for the 33 not-Gergis TRW series from the Australasia region. The Spline method in the R function detrend replicates the .crn series almost exactly when applied to the individual trees and then combining those tree chronologies into a series. Using the Modified Negative Exponential (MNE) method under the same conditions produces more of a series ending upward trend not unlike that produced by the rcs function in R. I thought I might be on to something until I realized that the rcs function in R using a Spline method and not the MNE method.
I have parsed the R code so that I can do both the Spline and MNE methods with the rcs function in R.
Wow.
Steve M has done so much to point out the spuriousness in AGW work, especially by The Team. The highlighted sentence says it all.
I came into this all out of curiosity, expecting the work to be reasonably sound, but immediately found reason to think otherwise – and not from coming here or WUWT. NO due diligence seemed to have been done, and that is still the case today. It is just that today we have so much more evidence of the several ways data has been contorted.
Government funds HAVE been wasted – and continue to be wasted – while people continue to chase unsubstantiated claims.
Steve Garcia
‘I remain mystified by Thompson’s intransigence in establishing a comprehensive and meticulous archive of his measurement data’
Information is power , never forget that the control of the data gives those controlling it power over how its used .
The professional becomes the personal , in some cases the researcher start to feel more like a ‘parent’ to what they see has theirs, especial if then have had it for long time and invested a great deal in it , and who gives their children away .
I will do it later, this happens when the researcher does not bother to clean there data or organize in such a way that others can understand it, they mean to short it out but they never get around to it and has the data gets bigger the task gets harder so keep getting put off.
They are merely human after all and there are a number of reason why they may fail to archive data that are not becasue they are being tricky but becasue they just being human . The issue is none of these have a roll to play in the scientific approach that demands a behavior which some fail to match .
Steve and all, I found this interesting although there’s not much detail — but it does seem that Gergis et al (2012) grew out of this process, and it is said here that they were aiming at a special issue for AUS2k in the Journal of Climate with up to 15 papers to be submitted. Vice Chancellor of UWA welcomed the conference with opening remarks, so he and UWA admin are not exactly unaware of climate issues, although what they may think about Lewandowsky at this point is another question.
Anyone know if the eventual Gergis et al (2012) was to have been part of such a special issue or not? I see that the Volume 25, Issue 14 (July 2012) has approx. 8 papers which deal with tropical Pacific, southern hemisphere, and/or AUS although there are various other papers so the issue is not devoted to SH — still it could be they were trying to have as large a group of papers as possible for that issue. Wonder what current status is for Gergis et al (2012), they seem to be very quiet down under….
…. [and in conclusion] …..
link for the PDF document with summary of PAGES AUS2k workshop as quoted above:
Univ. of Western Australia hosted PAGES Aus2k working group in April 2011
9 Trackbacks
[…] at Climate Audit, Steve McIntyre has more on “Screening Fallacies” and the Gergis affaire. But whenever “scientists” engage in screening fallacies (the use of the same data-set […]
[…] McIntyre also has some additional thoughts in a new post yesterday: More on Screening in Gergis et al 2012. The first section […]
[…] many know, Climate Audit discussions identified a problem with the way Gergis et al sifted their data for hockey stick. Once […]
[…] you want to understand more, head over to The Blackboard or Climate Audit, there’s lots to […]
[…] comments at climate audit Jeez explained the screening bias in cartoon form: One aspect of the problem for people with zero […]
[…] and greatest IPCC report – along with such sterling “scientific” luminaries as Gergis and Karoly. Share this:ShareEmailFacebookDiggRedditStumbleUponPrintTwitterLike this:LikeBe the first to like […]
[…] reply was Roman, let me counter with a […]
[…] – More on Screening in Gergis et al 2012 Steve McIntyre Jun 10, 2012 at 6:12 PM https://climateaudit.org/2012/06/10/more-on-screening-in-gergis-et-al-2012/ “First, let’s give Gergis, Karoly and coauthors some props for conceding that there was a […]
[…] June 10, a few days after the Gergis-Karoly-Neukom error had been identified, I speculated that they would try to re-submit the same results, glossing over the fact that they had changed the […]