I then compared verification statistics for the different reconstructions as shown below. OLS yielded much the “best” fit in the calibration period, but the worst fit in the verification period.
If OLS is equivalent to ICE, it actually finds the best fit (minimizes calibration residuals), and in proxy-temperature case makes the most obvious overfit. Let me try to get an understanding of the methods applied. As we know, core of MBH9x is the double pseudoinverse, in Matlab
RPC=P*pinv(pinv(TPC(1:79,T_select))*P(903:end,:));
where P is standardized (calibration mean to zero, calibration de-trended std to 1) proxy matrix, TPC target (temperature PCs) and T_select is that odd selector of target PCs. After this, RPCs are variance matched to TPCs, and brought back to temperatures via matrix multiplication. As you can see, I can replicate MBH99 reconstruction almost exactly with this method:

\
Differences in 1400-1499 are related problems with archived data, and in 1650-1699 they are due to unreported step in MBH procedure. Steve and Jean S have noted these independently, so I’m quite confident that my algorithm is correct.
I’ve considered this method as a variation of classical calibration estimator (CCE) and Steve’s made a point that this is one form of PLS. These statements are not necessarily in conflict. Original CCE is (with standardized target)
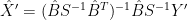
where matrices 
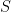

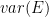
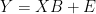
By setting 
Back to OLS (ICE) estimate, which is obtained by regressing directly X on Y,
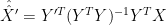
this is justified only with a special prior distribution for 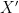
![\hat{\hat{X}}'=[(X^TX)^{-1}+\hat{B}S^{-1}\hat{B}^T]^{-1}(\hat{B}S^{-1}\hat{B}^T)\hat{X}'](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Chat%7BX%7D%7D%27%3D%5B%28X%5ETX%29%5E%7B-1%7D%2B%5Chat%7BB%7DS%5E%7B-1%7D%5Chat%7BB%7D%5ET%5D%5E%7B-1%7D%28%5Chat%7BB%7DS%5E%7B-1%7D%5Chat%7BB%7D%5ET%29%5Chat%7BX%7D%27+&bg=ffffff&fg=000&s=0&c=20201002)
It would be interesting to compute MBH99 results with real CCE, but S does not have inverse for AD1700 and later steps. But results for up to AD1700 are here, CCE:


ICE:


As you can see, variability of ICE is lower, as it is weighted towards zero. But hey, where did that hockeystick go ?





87 Comments
In MBH98, Mann says that “conventional approaches” were “relatively ineffective”:
14. Fritts, H. C., Blasing, T. J., Hayden, B. P. & Kutzbach, J. E.Multivariate techniques for specifying treegrowth and climate relationships and for reconstructing anomalies in paleoclimate. J. Appl. Meteorol. 10, 845864 (1971).
15. Cook, E. R., Briffa, K. R. & Jones, P. D. Spatial regression methods in dendroclimatology: a review and
comparison of two techniques. Int. J. Climatol. 14, 379402 (1994).
16. Briffa, K. R., Jones, P. D. & Schweingruber, F. H. Tree-ring density reconstructions of summer temperature pattern across western North American since 1600. J. Clim. 5, 735753 (1992).
17. Schweingruber, F. H., Briffa, K. R. & Jones, P. D. Yearly maps of summer temperatures in western Europe from A.D. 1750 to 1975 andWestern North American from 1600 to 1982. Vegetatio 92, 571 (1991).
18. Fritts, H. Reconstructing Large-scale Climatic Patterns from Tree Ring Data (Univ. Arizona Press, Tucson, 1991).
19. Guiot, J. The combination of historical documents and biological data in the reconstruction of climate
variations in space and time. Palaeoklimaforschung 7, 93104 (1988).
20. DArrigo, R. D., Cook, E. R., Jacoby, G. C. & Briffa, K. R. NAO and sea surface temperature signatures
in tree-ring records from the North Atlantic sector. Quat. Sci. Rev. 12, 431440 (1993).
21. Stahle, D.W. & Cleaveland, M. K. Southern Oscillation extremes reconstructed from tree rings of the Sierra Madre Occidental and southern Great Plains. J. Clim. 6, 129140 (1993)
This is one of those posts which makes me want to go off and study statistics, but I don’t know when I’ll get a chance. I was able to follow it enough to decide it’s probably an important one and perhaps easily converted into a journal article. Will there be feedback from real climate people? Who knows but from previous history, probably not.
BTW: how do those track-back rats glom on to new posts here so quickly? Are they subscribed to some RSS feed you could block them from?
ineffective= no hockey stick ? 🙂
Dave,
the reason why I think this is important:
1) If you diverge from conventional approach, you have millions of degrees of freedom to derive any conclusion you please.
2) Statisticians have made quite an effort to calculate the CIs with the conventional approach. All that is gone when you apply these modified approaches.
I have to admit that when the snake oil salesman came to town (i.e when MBH98 was published), I bought in rather uncritically. I took them at their word that they had developed a new and better method capable of extracting signals that traditional methods could not. This goes to illustrate the cost of assuming other people know what they’re doing. Most of all it proves the value of transparency of calculations and of accountability for choices made in analysis.
MBH should have published their method in the statistical literature before publishing the Nature paper. And the Nature Editor who let this slip should also be accountable for this major error. In the future Nature should stick to nature and leave the math to the mathematical journals. Never again will I trust another mathematical argument in Nature, unless it is 100% clear that the mathematical methods have have had time to season in the peer-reviewed mathematics literature.
Can anyone translate this for us non-statistical types?
Steve: Not likely. Just try to get the gist.
#6. When you think about it (and I’d be interested in UC and Jean S’ thoughts on this), it’s very difficult for a statistical method to be so incorrect that the algorithm itself can be said to be “wrong”.
When you add the withdrawal of the Rutherford et al 2005 RegEM code in June 2007 to MBH98, you now have two out of two cases up to 2006 where Mann has introduced his own statistical program to great fanfare and where defects that do not rise above programming errors have been identified. As Mann said to NAS, he is “not a statistician”.
As with MBH98, Rutherford et al 2005 was not published in a statistical journal, but in J Climate, once again without establishing the statistical properties of the method. It had several programming defects, any one of which would have been fatal.
Mann et al 2007 is a third go, where Mann is once again publishing a complicated and unknown statistical method in a non-mathematical journal. From a statistical point of view, the lacunae in the presentation are astonishing: the method is tested against a climate model with a signal but not against other methods and not against data sets that are contaminated.
Given this track record, it’s amazing that JEG and Kim Cobb seemingly view Mann et al 2007 as some sort of resolution or vindication of the HS controversy rather than as road kill waiting to happen – especially when he hasn’t even bothered fixing his PC methods.
We need a Journal of Statistical Climatology. That’d fix ’em.
Bender,
Why go to such a journal when normal climatology journals will publish any old rubbish?
I would also add a rather special assumption that the targets are PCs. This is rather strange if you think it in terms of assumed calibration experiment model! For instance, tree rings are assumed to be determined by a linear combination of (global) temperature PCs plus noise. Talking about teleconnections…
#7 (pk): UC is essentially arguing that MBH9x can be viewed as classical calibration estimator (CCE) with some rather strange additional assumptions and additions. Hence, there is not really anything very novel about the MBH method unlike the team is arguing. Then he proceeds to show what happens if one of those additional strange assumptions (noise covariance S=I) is removed.
#10 Because then manuscripts heavy in experimental statistical methodology that are sent to, say, the Journal of Rubbish Climatology could be re-directed (in whole or in part) by an Editor or reviewer to a venue that is more appropriate: a Journal of Statistical Climatology, published by, say, the American Statistical Association. Yes, authors with a novel idea may prefer to submit to JRC, but they do not have the only say as to how novel ideas are routed. The existence of an alternative would free the climatological reviewer from the responsibility of having to review the novel statistical portions of a paper. He could reject out of hand as “inappopriate for JRC; please submit to JSC“. And, guaranteed, JSC would have a rigorous standard that certain folks discussed at CA could probably never reach. And finally, methodologically flawed papers that somehow managed to get published in JRC could be criticized openly in JSC.
The world needs this service. And the ASA knows it.
Re 9 Bender,
I actually had that idea brought up when I was at Pielke’s conference in August I had lunch with Robert Lund, of Clemson, who presented “Change point detection in periodic and correlated settings.”, which was about detecting station moves in temperature data. Curiously he started the presentation with detecting a changepoint in Mauna Loa CO2 data.
Lund worked on helping NCDC setup USHCN V2, and then promptly told me when I asked his opinion of it that “they did it wrong”. He opined that a “Journal of Statistical Climatology” was something he was thinking about starting to address such concerns. I agreed and encouraged him to do so and mentioned Steve M’s work.
I think there is no time better than the present. In fact, I think this entire idea could be bootstrapped with a minimal cost. It would provide a venue to promote new analytical ideas, encourage review of methods, and provide a forum for review.
I feel this is very important, and that it can offer much in the way of contributing to the quality of Climate Science.
#12 – Jean S…thank you for the explanation.
Then these kinds of conversations must have been occurring at the ASA workshop. One wonders what the results were. Surely there are backroom conversations going on about putting together a strategic NSF grant application to develop a working group on statistical climatology? Yes, an online journal would be cheap to set up and run, but cash always helps.
RE16 Bender, I’m thinking of a business plan here, not for profit, but to get the journal up and running to a point of self-sustainability. How much cash do you think it would take?
As I see the steps in the simplest form they would be:
1) website, with mission and standards,
2) a call for editors and reviewers
3) a call for papers
4) a call for subscribers, and sustaining members
5) publish first journal online, in PDF, and in printed form
6) rinse and repeat
RE 14.. Ushcn v2 has all sorts of new change point stuff in it. papers HARDLY RIPE
for chrissakes ( published in 2005) You guys should have a look at the New v2 methodology
I could not get to the primary texts..
#20: There were a few posts back complaints about important comments being buried in the flood of comments. So now that Steve has raised few comments (originally meant to be comments like this one by UC), which I suppose he felt were interesting, as separate posts, we hear complaints about posts being incomprehensive. If Steve had asked UC to make a real post about the topic, I’m sure we would hear complaints about his anonymity like happened last time. If anonymity issue could be solved, I’m sure someone would complain about English. If that could be solved, I’m sure there would be other things to complain about.
C’mon people, what do you expect? Steve, UC, me, or other people are not paid anything to do this. This is a blog, not a scientific journal nor a popular science magazine. UC had probably spent quite a few hours of his spear time to give you the above information. Steve has better things to do than start expanding acronyms and explaining background. Kind of bugs me that all they get for their hard work is a collection of complaints.
UC, I’ve got an idea on what might be happening in the 1400-1450 and 1650+ interval. We’ve been assuming that Mann’s description of the number of TPCs used is accurate. Nothing else is accurate – why should we assume that this is an accurate description. If you look at this post http://www.climateaudit.org/?p=776 , the impact of adding a Temperature PC to the reconstruction can be very large. Maybe he uses 2 temperature PCs in the AD1400 step?
re steven mosher #24:
best laugh I’ve had all day. Thanks!
DWhite
Re: Jean S, November 25th, 2007 at 6:23 pm
I agreed with “braddles”, who had what seemed like a constructive suggestion and I also asked some questions. Steve McIntyre seems to be a perfectionist when it comes to statistics and has an amazing memory and grasp for the issues, and that is one of the reasons that I voted daily for this as the Best Science Blog site, so don’t prejudge my motives. I am in awe of the amount of work that Steve does here, and could not imagine that he could do more. I am not qualified to assist in the implementation of any of the tweaks that have been suggested.
Other’s have suggested that more of Steve’s work should be published in peer reviewed publications. I agree, but that does not mean that I am complaining, such a thought is a compliment. I will continue to try to understand the gist of the issues.
RE 19. I thought it was genius myself. Glad you enjoyed it. Tangent Man!
headed off in unknown directions.
RE 19. I thought it was genius myself. Glad you enjoyed it. Tangent Man!
headed off in unknown directions.
Don’t know what was so offensive about my post that it didn’t even make it into unthreaded.
I’ll try to be less what ever I was next time.
#8
John A, if AAGW is a “moral issue” then does ASA not have a moral obligation to start up a journal seeking to empower the climatologists?
(Or do I sense yet another AAGW double-standard?)
RPC5 is here and starts 1650. Might be possible to reverse-engineer this out.
Or maybe someone can ask RC, in http://www.realclimate.org/index.php?p=121 they say all the data used are freely available. So,
1) they are lying, or
2) there is data1650.txt somewhere
Concerning a theoretical Journal of Statistical Climatology, if it was representative of the ASA, how much control would an ASA chair like Hesterberg have over such a journal?
UC said:
I looked at the data link they have there, and maybe it’s my system, but they wouldn’t let me get into it. Have they locked down their data?
I think same information can be found from
http://www.nature.com/nature/journal/v430/n6995/suppinfo/nature02478.html
http://holocene.meteo.psu.edu/shared/research/MANNETAL98/
But data1650.txt (or .dat) is missing. Special prize for a reader who finds it. Extra points for finding data1400.txt and data1450.txt (and targets) that were really used in MBH98.
Try looking at the link below for data1400.txt and data1450.txt. I can’t find 1650.txt, but I bet there is one. Comparing the proxies used in 1600.txt vs. 1700.txt and the dataall.dat file, there is data used in 1700.txt that goes back to 1650, but not to 1600.
http://www.meteo.psu.edu/~mann/Mann/research/research.html
Found another link, but not to the FTP site.
http://holocene.evsc.virginia.edu/MRG/index.html
Once again, cannot get any farther than that…
This might be identical, but it is a different source for data1400.txt ncdc.noaa.gov Mann1998 corrigendum 2004
#31. We know that data set. Either Mann’s data archive is not what he used in MBH98 or there’s a still unreported methodology.
You know, it’s funny, but the inconsistency that UC plotted here is what led to the Barton Committee and the NAS Panel. When I was interviewed by the WSJ in early 2005, despite identifying several major errors, I said that I still wanted to see his code and data because there were still discrepancies. Any auditor in the world would refused to sign off with discrepancies such as the ones shown here. The WSJ asked Mann about it and he said that he would not show his algorithm as that would be giving into intimidation tactics – as though me, a private citizen in Canada – had any authority or jurisdiction over him. The WSJ reporter wrote Mann’s answer up and, to anyone other than a real climate scientist, anyone that actually had a job where they had to report to people, it looked bad. It caught the eye of the House Energy and Commerce Committee and one thing led to another.
But after all those folks looked at this, and even after Mann produced his source code, he produced incomplete source code that didn’t work with any data on archive and still no one knows how the exact 1400-1450 results were obtained. (However we reconcile perfectly to Wahl and Ammann’s version which was subsequent to ours.)
#28. This link might be relevant?
http://www.nature.com/nature/journal/v430/n6995/extref/nature02478-s1.htm
Steve: We know all this stuff. This was produced in response to our Materials Complaint. I’ve been over it in microscopic detail.
pk,
worth checking. But after finding the correct proxy data we still need to select target TPCs. See
http://www.climateaudit.org/?p=776
Mann’s explanation ( http://www.nature.com/nature/journal/v430/n6995/extref/nature02478-s2.doc )
And this was published in Nature, one of the most prestigious journals . It is quite alarming!
I anticipate some RC-style responses for this thread
1) These errors do not matter
2) It is a ten-year old study. We have moved on.
To save time, my responses are here:
1) They do matter, with conventional statistical approach the hockey stick disappeared. And this is completely independent of BCPs or no BCPs issue. If someone wants to make the full reconstruction with singular S, I suggest to read and implement [1]. Maybe even Sundberg would be interested on this.
2) In science, you should move on after the error elimination phase. Why RegEM if there’s nothing wrong with MBH98 algorithm?
Now, back to work. CA is fun, but the salary sucks 😉
[1] Multivariate Calibration with More Variables than Observations Rolf Sundberg, Philip J. Brown Technometrics, Vol. 31, No. 3 (Aug., 1989), pp. 365-371
#34. The situation with Nature is actually much worse than simply accepting the above language. This is not from MBH98 but from the Corrigendum. The original article said (without explaining) things like:
You’ve quoted a section not from the Corrigendum but from the Corrigendum SI:
In addition to being unintelligible as written, it also differs from the original statement and should have been in the body of the Corrigendum.
I have been able to determine that the Corrigendum was not externally peer reviewed (merely edited) and that the Corrigendum SI was not even reviewed by Nature editors. Nature said that their policies do not require them to peer review Corrigenda – a surprising policy when you think about it: you’d think that these are the situations that require particular care, rather than the opposite.
The Corrigendum SI was not even reviewed by Nature editors, much less peer reviewed.
#36
Interesting. Hard to find significance levels for those REs and CEs without knowing what the exact rule is. With all 16 targets, 1509 will be the warmest year.
UC #35
Technometrics! Thank-you for mentioning my favorite statistics journal. Great Statisticians applying novel techniques to real-world problems. If there is to be a model for the proposed “Journal of Statistical Climatology,” Technometrics is it.
Now, off to my basement to see if I have that 1989 issue stuffed in a box somewhere.
I apologize in advance if this is way off and I expect Steve to delete it, but I followed the second link in #28 and reviewed the Algorithm discussion in the Methods section and found this closing sentence:
“It should be stressed that reconstructions that did not pass statistical
cross-validation (i.e., yielded negative RE scores) were deemed unreliable.”
Isn’t this basically saying MBH98 is a curve fit and any reconstructions that didn’t support the desired curve were discarded, based solely on the fact they had negative RE scores?
#38
I second that.
#39
That negative-RE limit sets quite tight limit for tolerated reconstruction error. Meanwhile, verification r2 can be anything. Hockey stick is handcrafted.
I’m finding this very interesting, but like pk (#13) had a hard time figuring out what was being discussed. It turns out that CCE and ICE are defined on UC’s Filtering Theory page, which is linked to his identifier on this blog. There was also some relevant discussion of PLS at thread # 1338 last April.
It turns out that CCE (Classical Calibration Estimation) is very clever — Suppose we have a bunch of proxies Y and a target variable X (global temperature), and a lot of observations on both during a calibration period. Ignoring the intercept for the moment, our model is
Y = XB + E,
where B is a vector of proxy-specific slopes. We can estimate this equation proxy-by-proxy across time by OLS or, perhaps more efficiently, by what econometricians call Seemingly Unrelated Regression (SUR), which takes into account the covariances of the errors across proxies. (This may be what UC means by ML estimation)
Then in each reconstruction period, we observe Y’ and want to know what X’ was. The above equation is still valid, but we can’t tell if X is multiplying B or vice-versa. So instead of taking the data as given and estimating the coefficients, we take the coefficients as given (as estimated during the calibration period) and just estimate the data! This is a separate cross sectional regression across proxies for each reconstruction date.
OLS will give unbiased estimates of X’, but Generalized Least Squares (GLS or Aitken’s formula) is more efficient, so CCE computes G, the covariance matrix of the E’s across proxies, or equivalently, UC’s S which is proportional to G, and uses it to do GLS.
Using XT to represent the transpose, the pseudoinverse (pinv) discussed is (according to wiki) simply inv(XT*X)*XT, the matrix that generates OLS results. So the MBH double PINV is apparently just doing OLS on OLS, and therefore is equivalent to CCE, but with OLS in the second step rather than GLS. This is not “incorrect” or “strange” as charged by UC and Jean S (#10), but at worst merely “lazy” and “inefficient.” Note that in GLS, setting S = I is equivalent to setting S = vI for some constant v, so that the double pinv formula does not really make a specific false assumption about the variances. GLS will estimate v and incorporate it into its standard error calculation.
Although second stage OLS is unbiased and not unreasonable, the usual OLS standard errors will be wrong, since they do not take into account the unequal variances and correlations between the proxies. This can be corrected using G (or S). But MBH don’t even attempt to compute the OLS standard errors of their reconstructions, as discussed on another recent thread here, so this point is moot at it stands.
However, a big problem I do see with CCE (or double pinv) is errors-in-variables bias that arises because B is in fact measured with a lot of error in the first stage regressions. This bias generally makes the coefficients too close to zero, so that the reconstructed temperatures will be too flat. I.e. no MWP, no LIA — sound familiar? (In fact, UC shows that CCE doesn’t even give a hockey stick…) This bias can be corrected with a formula that goes back to Milton Friedman’s Theory of the Consumption Function, but that’s getting to be a lot of work.
So at this point, ICE (Inverse Calibration Estimator) is starting to look good: Just run X on Y during the calibration period, even though the causality goes the other direction, and then use this to estimate X’ from Y’ during the reconstruction period. If there are more proxies than calibration observations, this regression won’t even run, but then it would actually make sense to extract principal components (PCs) from the proxies, and consider only the first few of those instead of the whole proxy set.
Of course, MBH’s “creative” construction of their PC’s (to put it charitably) raises a lot of issues. Mann on RC objected to the MM critique that if the standard calibration were used in place of their HS-generating one, their stripbark-dominated PC1 would still come through, as PC5. This raises some interesting data mining issues in addition to the stripbark matter, but I’ll leave that for now.
PS: Steve, when you delete or move inappopriate or off-topic comments, would it be possible to leave the comment number, so that cross-references remain intact for the record? Thanks!
#41: You are getting into the Mannian world 🙂 I generally agree what you say, a correction though:
UC or I were not referring to that. UC referred to the “variance matching” which happens after the CCE estimation. That is, after the targets (instrumental PCs) have been estimated, MBH matches the variances of the estimated PCs to the true variance of the instrumental PCs. I referred (by “strange” in #10) to the same thing as UC plus the thing I mentioned in #9 and the asumption S = I (in reality you cannot even assume even that the proxies has equal variance noise).
#41
Good, good. I wasn’t so confusing after all 😉
My writings are mostly based on Brown’s Multivariate Calibration, excellent paper that I can send upon request.
Yep, leads not to ML estimate, but according to Brown it is quite close. However, in proxy-temp case I wouldn’t count on it. So much noise, u know 😉
Using S=I changes the result, though. In addition, at AD1700 step (and after that ), S would be singular. Not sure how good S=I assumption is after that, but note that same happens for ICE at AD1730 – there’s no S, but inversion problems with YT*Y. (and pinv(X) or (XTX)\XT are not equal then)
Mannian CIs assume that B is fully known. Perfect calibration, that is.
Careful. It kind of applies prior distribution for X’. Mark T derived the proof here somewhere..
When you asked the Kalman question, I believe.
Oh, send the Brown paper to me if you can, UC. Thanks,
Mark
UC writes in #43,
I guess that occurs when there are more proxies than calibration observations? But couldn’t you still do CCE with Principal Components of the proxy data? How then do you get answers after 1700? By using a truncated pre-1700 proxy set?
Uncertainty of B should not directly affect the CI’s in the second step, just the point estimates. But that’s bad enough.
Please let me know if you can find his proof. Meanwhile, I have found Brown’s paper on JSTOR and will take a look at it.
When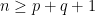 , at AD1700 step n=79, p=5, q=74. For ICE, problems occur when
, at AD1700 step n=79, p=5, q=74. For ICE, problems occur when 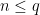 . At step AD1730 n=79, q=79.
. At step AD1730 n=79, q=79.
That’s possible, and article mentioned in #35 talks about canonical transformation that helps. Mann uses principal components of the proxy data + proxies as Y and principal components of temperature data as X. I can’t tell why.
Mann’s steps are 1000-1980 , 1400-1980, etc. I just stop after 1600-1980 step.
It should affect the CIs. Simple example, assume that true B is a zero matrix. You’ll get non-zero in the first phase, quite high calibration R2 and low verification R2s. And calibration residuals are not informative at all. Errors in B act as are scaling errors in the second phase. Scaling errors are not independent of X’. For much better explanation, see Brown’s paper or,
in the first phase, quite high calibration R2 and low verification R2s. And calibration residuals are not informative at all. Errors in B act as are scaling errors in the second phase. Scaling errors are not independent of X’. For much better explanation, see Brown’s paper or,
Errors-in-Variables Estimation in Multivariate Calibration Edward V. Thomas Technometrics, Vol. 33, No. 4 (Nov., 1991), pp. 405-413
wherein it is said that
cc. Editors of Nature and Science
http://www.climateaudit.org/?p=1515#comment-109240 (univariate case).
Correction:
When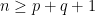 is not satisfied.
is not satisfied.
UC —
Thanks! I think I’m slowly beginning to understand ICE etc.
In general, p(X’|Y’) = p(Y’|X’)p(X’)/p(Y’). In the classic regression of Y on X with known variance, p(Y’|X’) is Gaussian (or Student t to be precise) with a mean that is linear in X’ and a variance (given by Brown) that depends on the standard errors of the regression coefficients from the calibration step as well as the error of Y’ about its population mean.
If the (X, Y) are bivariate Gaussian and pairwise independent, the prior p(X’) is the marginal of the joint distribution observed during the calibration period, and ICE gives the correct posterior. A Y’ say 5 sd outside calibration experience can give a point estimate of X’ that is outside experience as well, but it will be attenuated by a factor of R2, because of the strong pull of the Gaussian prior. But this prior is much too strong for most paleoclimatic questions.
If instead we let the prior for X’ be uninformative, i.e. uniform, the posterior for X’ looks just like p(Y’|X’), but as a function of X’ holding Y’ at its observed value. Unfortunately, this function integrates to infinity, so that after normalization (division by p(Y)), the posterior is everwhere zero, i.e. just as uninformative as the prior!
Brown cogently gets around this by advocating inverting the Y confidence intervals, i.e. finding those values of X’ for which the observed Y’ lies within say its 95% CI. This requires solving two quadratic equations, and gives an asymmetric CI, with the long tail extending outward from the calibration experience of X. The point estimate is then just the inversion of the regression line of Y on X.
For confidence levels above that with which a zero slope coeffient could be rejected, the Y-CI boundaries are not monotonic in X. In these cases, Brown interprets the CI for X’ to be the whole real axis. This makes sense given we don’t even know which way the slope goes at this confidence level.
I haven’t gotten to Brown’s MV section yet, but the logical extension of the above would be to invert the confidence ellipses for Y’, taking into account the covariance across proxies as well as the uncertainty of each proxy’s regression coefficients. This could be done numerically by checking a grid of X’s, and seeing which fail to reject the observed vector Y’. CCE would evidently give a valid point estimate, but would not tell us what the CI is, not even using the GLS coefficient covariance matrix.
In the MV case, there is likely to be a severe data mining issue, but that goes beyond the present problem of calibrating with a fixed set of proxies.
Yes, and in [1] this is called loss of variance. But that’s another funny story.
See Brown’s Eq. 2.8. CCE comes into play at Eq. 2.16, confidence region degenerates to CCE.
[1] von Storch, H., E. Zorita, J. Jones, Y. Dimitriev, F. González-Rouco, and S. Tett, 2004: Reconstructing past climate from noisy data, Science 306, 679-682, 22 October 2004
Inspired by discussion in http://www.climateaudit.org/?p=2405 , I’ve been playing with Brown’s confidence region formula,
This one works with pseudo-proxy simulations very well.
But it seems that something weird happens when this is applied to MBH99 (assuming confidence region is sphere instead of ellipsoid)
Classical estimate in black, 95 % CIs in yellow. Accuracy is degraded when more proxies are applied..
Short update, re Jean S # 10
To obey mike’s order, I’ve re-read MBH9x. Maybe I have advanced a little bit in my ‘Learn MBH9x in few years’-goal. The basic model seems to be actually
where Y is proxy data matrix, matrix D downsamples (by averaging) monthly data to annual, X is the monthly grid-point data matrix, B is the matrix of unknown coefficients and E is noise matrix. So each proxy (at year i) responds to annual average of linear combination of grid-point data (at year i). B is huge matrix, so Mann compresses monthly data utilizing singular value decomposition (relation to principal components regression is obvious, see any textbook on subject), the model at this point is:
(relation to principal components regression is obvious, see any textbook on subject), the model at this point is:
Now compress data by truncating, take only k column vectors of U, V (and corresponding largest singular values), and the model becomes
re-write as
where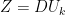 and
and 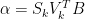 . Now Z contains the U-vectors you can download from Nature pages pcxx.txt (with special scaling, but that’s not important now). Diagonal of S is in tcpa-eigenvalues.txt, and V-vectors are eofxx.txt .
. Now Z contains the U-vectors you can download from Nature pages pcxx.txt (with special scaling, but that’s not important now). Diagonal of S is in tcpa-eigenvalues.txt, and V-vectors are eofxx.txt .
In textbook principal components regression, takes simple form, as new variables are orthogonal. Here we don’t have that luxury, as Z is made by downsampling the original U vectors (and X-data has values up to 1993 unlike proxy data). I’d still like to know if there is some short form of CCE with unitary Z. Anyway, from this point we’ll just do CCE (with that noise assumption) as explained in above post, and obtain estimate of annual grid-point data,
takes simple form, as new variables are orthogonal. Here we don’t have that luxury, as Z is made by downsampling the original U vectors (and X-data has values up to 1993 unlike proxy data). I’d still like to know if there is some short form of CCE with unitary Z. Anyway, from this point we’ll just do CCE (with that noise assumption) as explained in above post, and obtain estimate of annual grid-point data, 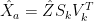 .
.
Some notes
1) This is just a pre-treatment before CCE, my criticism of variance matching and incorrect uncertainty estimation applies (until you refute them)
2) Some vectors of Y are also PCs, different topic (which I know nothing about, read CA, consult SteveM, Wegman, Jean S for more information 🙂 )
3) I can’t see any restriction for B, have I missed something? Any ‘teleconnection’ goes ?
Steve,
It’s part of 500 lines m-file experiment, and too ugly code to publish (at this point). The basic idea was to find that confidence region (year-by-year) by going through all sensible values of one component of X’, while keeping the others at ML-estimate value, i.e. try scanN times
X(:,X_index)=linspace(min_V,max_V,scanN); % other columns of X are filled with corresponding ML estimate
for j=1:scanN
R(j,X_index)=(Y(year,:)’-Bh*X(j,:)’)’*iS*(Y(year,:)’-Bh*X(j,:)’)/(1+1/NCal+X(j,:)*inv(Xc’*Xc)*X(j,:)’);
end
then find the values of R that are less than right-hand side of the equation,
dof=NCal-NX-NObs; Fv=finv(0.95,NObs,dof); qvFv=NObs*Fv/dof;
i95=find(lt(R(:,X_index),qvFv)); % lt = less than, WordPress prefers this format 😉
Now first and last value of i95 define 95 % limit for that component, approximately, i.e region should be ellipsoid, and the ellipsoid axes should be parallel to the coordinate axes. Works well with noise simulations, so that’s enough for me. Don’t use in life-critical applications, though 🙂
And no complaints, please, this is voluntary work, there are some secret plans to publish OS MBH99 Matlab project, and even this explanation is better than the one for MBH99 CIs 😉
Code tag didn’t work. Doh.
Code Tag
Hmmm… never noticed that before.
Mark
And note, it did not work for me, either, but it looked correct in the preview pane.
Mark
#53 continues,
CIs were for reconstructed PCs (rpc0x.txt in here , in #51 ). rpc to NH mean is just a linear transformation, so I used normal error propagation procedure to obtain CIs for NH mean. Slightly fiducial, but better than Mann’s best effort. And then you need to assume that basic model holds, and then you read CA..
in #51 ). rpc to NH mean is just a linear transformation, so I used normal error propagation procedure to obtain CIs for NH mean. Slightly fiducial, but better than Mann’s best effort. And then you need to assume that basic model holds, and then you read CA..
For grid-point my CI method yields some +- 15-50 deg C 95 % limits. Quite long intervals, but I can’t directly blame the method, one example ( MBH98-style recon)
This must be something related to verification statistics for other steps than AD1820.. See http://www.climateaudit.org/?p=319 ,
UC I’m trying to understand the CCE method at the moment but I was curious if you ever tried to apply it where X is several columns which include the grid point temperatures and precipitation levels along with the CO2 concentration. Then from estimating X, average the values of T to get the mean global temperature.
Actually after thinking about it I don’t think there would be any advantage of using the technique on the grid cells if you are trying to estimate the global mean temperature.
#50 US from you graph it doesn’t look as though the proxies are of any use at predicting the temperature at all.
#59
I did replace X with solar data,
http://www.climateaudit.org/?p=2304
If we don’t know are the proxies responding to solar or temperature or precipitation or CO2, then we should include all those in X. But I have a feeling that this is not the right way to go. More physiology and local reconstructions. That would leave less weight to the statistical method applied.
#62, I think local reconstruction is the way to go because as you have stated adding more proxies increases the error bounds. I don’t think that the other extreme where one proxy is used to measure one temperature is desirable either. What should be done is a temperature point on the globe should be chosen, then enough available proxies near that point should be chosen so that the best balance between the size of the error bars and the size of the residual. My hunch is if you do this you won’t be using proxies from half way around the world.
UC and Jean S —
I take back what I said in #48 about forming multiproxy confidence intervals as in Brown’s 2.8 or UC’s post 50 above. In fact, these intervals are all wrong!
To see the problem, fast forward to p. 320 of Brown’s discussion of the comments immediately following his article. He writes,
But in fact this is not the sampling theory approach. Define Chisq(x) = (Y1-x)^2 + (Y2-x)^2. This represents the “unlikelihood” as it were of Y1 and Y2 given x, and in fact is -2*log L(x) (+ const). Minimizing this unlikelihood, or equivalently, maximizing the likelihood, gives the sampling theory estimator Ybar = (Y1 + Y2)/2. Any Stats 101 student can tell you that Ybar-x ~ N(0, 1/2), whence t(x) = (Ybar-x)/sqrt(1/2) ~ N(0,1), or t(x)^2 ~ chi-squared(1DOF). The proper sampling-theory way to form a confidence interval for x about Ybar is using t(x) (or equivalently t(x)^2), not with Chisq(x).
All Chisq(x) tell us is whether (Y1, Y2) is ex ante likely to happen or not. What we want to know is, given that (Y1, Y2) did in fact happen, what must x have been? There is no point in shaking your fist at the storm just because your model told you that it was statistically impossible (or virtually impossible). Given that the storm is occurring anyway, you may as well come in out of the rain and try to figure out what the combination of state variables must have been that most likely allowed it to occur.
However, it turns out that t(x)^2 identically equals Chisq(x) – Chisq(Ybar), and thus, when everything is Gaussian, the LR statistic as well. Thus it is not Chisq(x) itself, but rather the change in Chisq(x) from its minimal value that should govern the confidence inverval on x! When the variances are estimated, the chisquared stats become F stats, and presumably it is the change in the F stat from its minimal value that should govern the confidence interval on x, not the F stat itself.
When p = 1, Ybar = Y1, so Chisq(Ybar) = 0, and the change in Chisq(x) equals Chisq(x) = t(x)^2 itself. So there really is no difference between p = 1 and p > 1.
If everything is Gaussian and the parameters and variances are perfectly known, the posterior density, likelihood function, and sampling theory all give the same answers under a diffuse prior for x. When the parameters are estimated, there is the problem that the posterior density for x doesn’t integrate for p = 1, so that inverting the confidence intervals for Y as a function of x must be used. However, for p > 2, this problem goes away, as Brown himself notes on p. 297. For p = 1, the posterior density has hyperbolic power tails that behave like |x|^(-1). But for p = 2, the tails behave like |x|^(-2), which integrates. This density is Cauchy-like in that it does not have a mean, let alone a variance, but it can still be used to compute good confidence intervals. In general, the tails are like |x|^(-p), so that the posterior mean is well defined for p > 2 and the variance exists for p > 3. It becomes a matter of taste whether to use the change in the F-stat as above or the posterior to form confidence intervals, but it wouldn’t hurt to compute both.
Of course, it is impossible that global temperatures at any time in the past 10000 years were either below absolute zero or hot enough to melt the Rockies, so that a completely diffuse prior is not really justified. Nevertheless, any reasonable limits are bound to be subject to criticism. It’s best to approach the data with a completely open mind about x (if not the model), so that no one can say that you pre-supposed your answer.
Brown in fact prefers ICE (regressing X on Y) for his examples, but in the first one, at least, he has randomly removed (X, Y) pairs from his calibration sample to be used for illustrative estimation. In doing, this, the prior for X’ becomes the distribution from which the calibration X’s were drawn, and so ICE really is appropriate. A diffuse (uninformative) prior for X’ requires CCE. (I haven’t figured out his second example yet).
In quoting Brown above, I forgot that you can’t use Less Than signs in HTML, since it thinks these are tag names. Using .LT. for Less Than etc, his criterion, with my parenthetical remark in brackets, should read
In other words, UC’s CI’s in #50 are much too narrow!
SMc
$100 OZ in the tin. I hope it helps set up the Journal (with complimentary Starbucks)
regards.
by the way we are having a coooool summer here in southern OZ. will be interesting to hear what the pump-monkies at the CSIRO have to say.
Hmmm, I tried that formula with simulations and it kind of worked.
Or do you mean l ? In Brown’s notation, p is width of X, and l is the number of responses per fixed X’.
I agree that those CI’s are too narrow at least for two reasons,
1) proxy noise is assumed white (in time), and Mann admits that the noise is correlated, ( http://www.climateaudit.org/?p=1810 )
2) The model includes S and V matrices in the unknown ‘B’ matrix, and thus it is assumed that EOFs are stable ( http://www.climateaudit.org/?p=2445#comment-199588 , run out of alphabet, so S here is singular value matrix, not the estimated covariance matrix ). There’s been some criticism here against this assumption, see http://www.climateaudit.org/?p=483#comment-208171 , http://www.climateaudit.org/?p=588 , and for sure there must be some change in EOFs as the time goes by.
You’re right — I wasn’t minding my p’s and q’s correctly! Brown’s simple example involves two proxies, with a single response each. However, to keep it simple he is assuming that the estimated intercepts happen to come out to 0 and the estimated slopes happen to both come out to 1, so that it does look like two responses to a single x’ (and should therefore give the same CI!).
Here is a version that corrects this, as well as another HTML error that I didn’t catch:
UC and Jean S —
I take back what I said in #48 about forming multiproxy confidence intervals as in Brown’s 2.8 or UC’s post 50 above. In fact, these intervals are all wrong!
To see the problem, fast forward to p. 320 of Brown’s discussion of the comments immediately following his article. He writes,
But in fact this is not the sampling theory approach. Define Chisq(x) = (Y1-x)^2 + (Y2-x)^2. This represents the “unlikelihood” as it were of Y1 and Y2 given x, and in fact is -2*log L(x) (+ const) when the errors are Gaussian. Minimizing this unlikelihood, or equivalently, maximizing the likelihood, gives the sampling theory estimator Ybar = (Y1 + Y2)/2. Any Stats 101 student can tell you that Ybar-x ~ N(0, 1/2), whence t(x) = (Ybar-x)/sqrt(1/2) ~ N(0,1), or t(x)^2 ~ chi-squared(1DOF). The proper sampling-theory way to form a confidence interval for x about Ybar is using t(x) (or equivalently t(x)^2), not with Chisq(x).
All Chisq(x) tell us is whether (Y1, Y2) is ex ante likely to happen or not. What we want to know is, given that (Y1, Y2) did in fact happen, what must x have been? There is no point in shaking your fist at the storm just because your model told you that it was statistically impossible (or virtually impossible). Given that the storm is occurring anyway, you may as well come in out of the rain and try to figure out what the combination of state variables must have been that most likely allowed it to occur.
However, it turns out that t(x)^2 identically equals Chisq(x) – Chisq(Ybar), and thus, when everything is Gaussian, the LR statistic as well. Thus it is not Chisq(x) itself, but rather the change in Chisq(x) from its minimal value that should govern the confidence inverval on x! When the variances are estimated, the chi-squared stats become F stats, and presumably it is the change in the F stat from its minimal value that should govern the confidence interval on x, not the F stat itself.
When q = 1, Ybar = Y1, so Chisq(Ybar) = 0, and the change in Chisq(x) equals Chisq(x) = t(x)^2 itself. So there really is no difference between q = 1 and q > 1.
If everything is Gaussian and the parameters and variances are perfectly known, the posterior density, likelihood function, and sampling theory all give the same answers under a diffuse prior for x. When the parameters are estimated, there is the problem that the posterior density for x doesn’t integrate for q = 1, so that inverting the confidence intervals for Y as a function of x must be used. However, for q > 2, this problem goes away, as Brown himself notes on p. 297. For q = 1, the posterior density has hyperbolic power tails that behave like |x|^(-1). But for q = 2, the tails behave like |x|^(-2), which integrates. This density is Cauchy-like in that it does not have a mean, let alone a variance, but it can still be used to compute good confidence intervals. In general, the tails are like |x|^(-q), so that the posterior mean is well defined for q > 2 and the variance exists for q > 3. It becomes a matter of taste whether to use the change in the F-stat as above or the posterior to form confidence intervals, but it wouldn’t hurt to compute both.
Of course, it is impossible that global temperatures at any time in the past 10000 years were either below absolute zero or hot enough to melt the Rockies, so that a completely diffuse prior is not really justified. Nevertheless, any reasonable limits are bound to be subject to criticism. It’s best to approach the data with a completely open mind about x (if not the model), so that no one can say that you pre-supposed your answer.
Brown in fact prefers ICE (regressing X on Y) for his examples, but in the first one, at least, he has randomly removed (X, Y) pairs from his calibration sample to be used for illustrative estimation. In doing, this, the prior for X’ becomes the distribution from which the calibration X’s were drawn, and so ICE really is appropriate. A diffuse (uninformative) prior for X’ requires CCE. (I haven’t figured out his second example yet).
[end of corrected earlier post]
I don’t pretend to understand how MBH actually computed their reconstructions from their complicated data base, but the above remarks would apply to CCE calibration in general, which I gather they sort of used. Of course, if they assumed their proxies were orthogonal and they in fact were not, that would further understate the CI’s.
I’m currently playing with trying to calibrate Thompson’s 2006 PNAS ice core data to HadCRUT3-GL, in order to find out what the calibrated temperatures and CI’s look like. This is a much simpler problem, or at least should be, were it not for the fact I have noted elsewhere that there are no fixed coefficients that will generate his Himalayan composite Z-mometer from the raw data for the 4 component sites…
IMO the distinction here is relevant. In Brown’s example, we know that the distribution of Chisq(x) statistic is Chi-squared on two degrees of freedom. In addition, as you show, we know that distribution of t(x) is standard normal. Now we can form confidence interval using both methods,
for the former case, and
and  are the roots of polynomial
are the roots of polynomial
and for the latter case
and
There is nothing wrong with the former CI, except maybe that it is, on the average, longer interval than the latter. But that’s probably because in the example scales (B) were equal, and we use that information when forming the CI.
Yes and no.
Yes, you are right that the chi-squared CI can sometimes be longer. This occurs when the proxies are relatively in accord, the most extreme case being Y1=Y2. Then, I was right that chisq(x) = t(x)^2. However, the CI’s are different, because chisq(x) is being given 2 DOF (with a 5% cv of 5.99), whereas t(x)^2 is being treated as chi-squared with only 1 DOF (cv = 1.96^2 = 3.84). In this extreme case, the chi-squared CI is Ybar +/-1.73, while the t-based CI is Ybar +/-1.39.
When Y1 and Y2 are typically divergent, as in Brown’s example (1, -1), both intervals are essentially (identically?) the same, namely Ybar +/-1.4. But when Y1 and Y2 clash, the chi-squared interval becomes smaller, and quickly (at -1.73, 1.73) shrinks to a single point and then disappears completely into ImaginaryNumberLand.
So yes, either could be larger, but no, chisq(x) never gives us the right CI except by accident. When the CI is a single point, that does not mean that we are any more certain about where x is than when the proxies are just by accident in perfect accord. And when the CI is a pair of complex numbers, that is not just “strange”, as Aitchison put it, but downright wrong.
Of course all this takes the parameter estimates as given (if only imprecisely as in the more realistic case in Brown’s Section 2). If Y1 and Y2 gave really divergent estimates of x, and we were more ambitious, we could use this information to revise our estimate of the regression variances and therefore of the standard errors of the coefficients. Or even more ambitiously, we might even consider a non-Gaussian leptokurtic distribution for the errors such as the Levy stable class (my favorite). But the standard simple case is just to assume the errors are appoximately Gaussian and then to use the calibration period (only) to estimate the variances.
If the estimated slope coefficients on the two proxies turned out to be different, the same considerations would still apply.
I’m trying to avoid fiducial / Bayesian / classical CI debate, as I’d probably loose 😉 Anyway,
If the model is correct, that CI (based on roots of the polynomial) is, in classical sense valid CI. Sometimes that CI might be a single point, the classical approach accepts this ( we shall be right in about 95 % cases in the long run ). With fiducial approach and Bayesian approach the assertion is different. So, if we accept classical CI approach, there’s nothing wrong with Brown’s Eq. 2.8 (or am I missing something? )
Don’t sell yourself short. Here’s a very readable paper on the subject. I like Efron’s triangle on page 17.
Mike B, Thanks for the link, very interesting paper! The point that we have 10^7 computational advantage over Fisher is worth a thought. For example, to seek for an answer to the correctness of CIs in #69, I can run this code with 100000 repetitions, to obtain a result
tic,sampletest,toc
Method 1
ans =
0.0495
Method 2
ans =
0.0501
Elapsed time is 15.527502 seconds.
(and the code is far from optimized)
UC, I located the Brown & Sundberg 1989 Techometrics paper referenced in your Re #35, but that paper doesn’t have an eq 2.8 or 2.16 and doesn’t cover your above discussions in Re #49 and #50. Are you referring to another one of his papers?
Sorry about missing ref, the discussion here is mostly based on
Brown 82: Multivariate Calibration, Journal of the Royal Statistical Society. Ser B. Vol. 44, No. 3, pp. 287-321
Tried to collect relevant parts of it (wrt. hockey stick) to this post
http://signals.auditblogs.com/2007/07/05/multivariate-calibration/
UC writes (#73),
This shows empirically that both formulas give the right coverage for their respective questions, yet the answers are different. The issue, then, is which question is the right one?
Question 1 asks, for what values of x is the probability of getting predicted x values no more disperse than observed 95%?
Question 2 asks, for what values of x is the probability of getting predicted x values no higher on average than observed 97.5, and vice-versa for the lower bound?
I’m just arguing that Question 2 is the relevant one for the problem at hand.
Yes, and of course it makes sense to choose the one that gives the shortest interval (on the average). I have no doubt that the second method is better, maybe even uniformly most accurate CI. But it is obtained assuming perfect calibration ( * ), while the first method is a special case of Brown’s Eq 2.8. From time to time it gives empty sets for CI, and maybe then it is a good procedure to change the CI method post hoc ( conditional reference sets or whatever). But IMO it is incorrect to say that CIs by Method 1. are wrong (as you say in #68).
(*) Infinite calibration data, which means regression parameters
which means regression parameters  will be perfectly known. Mann implicitly makes this assumption when he uses calibration residuals in constructing CIs of MBH98.
will be perfectly known. Mann implicitly makes this assumption when he uses calibration residuals in constructing CIs of MBH98.
Re #68, 70, 76, 77, here’s my proposal for a Multiproxy generalization of the univariate CI that (unlike Brown’s!) never comes up empty or imaginary:
Simplifying Brown to the case p = 1, assume
Yi ~ alpha + beta xi + N(0, Gamma), i = 1, … n
in the calibration period, where Yi is the i-th (qX1) vector of proxies, xi is the i-th observation on temperature (or whatever), and Gamma is a qXq covariance matrix. (I’m too lazy to set subscripts and greek letters in tex, particularly without a previewer!) Let x = (x1, … xn)T be the nX1 vector of temperature observations, where T represents Transpose. For convenience, suppose x has been demeaned as in Brown.
Let a and b be the single equation OLS estimates of alpha and beta, and G be an appropriate estimate of Gamma (see below). Confirm that there is no significant serial correlation in the errors.
Since b ~ beta + N(0, Gamma/xTx), we may test beta = 0 (in all its components) with
(xTx)bT G^-1 b.
This is approximately chi-squared(q), and in some cases exactly qF(q,d) for some appropriate DOF d. (see below) If (and only if) we can reject beta = 0 at some sufficiently small test size pmin, we may proceed with prediction.
Let Y’ be the qX1 vector of proxies in a given prediction period, and x’ be the unobserved scalar temperature to be estimated. Then
Y’ ~ a + b x’ + N(0, sigma^2(x’)Gamma),
where sigma^2(x’) = 1 + 1/n + x’^2/xTx.
For any qX1 vector c of known constants,
cTY’ ~ cTa + (cTb)x’ + N(0, sigma^2(x’) cT Gamma c).
In particular, since we know what b and G are, we may set c = bT G^-1 so that
bT G^-1 (Y’-a) ~ (bT G^-1 b)x’ + N(0, sigma^2(x’) bT G^-1 Gamma G^-1 b)
Dropping the error term and solving for x’ gives the CCE estimator of x’ (Brown’s 2.16):
x’hat = (bT G^-1 b)^-1 bT G^-1 (Y’-a).
Furthermore, since the scalar bT G^-1 (Y’-a) is monotonically increasing in x’ (at least to the extent that we’re confident beta is not 0), we may use this scalar to form a non-empty (1-p) confidence interval for x’ that generalizes the univariate case for any p > pmin. Substituting G for Gamma, we have at least approximately
bT G^-1 (Y’-a) ~ (bT G^-1 b) x’ + sigma(x’) sqrt(bT G^-1 b) T(d),
where T(d) has at least approximately student t distribution with the same appropriate degrees of freedom d used for the F test above. If tc is the critical value for the desired confidence level, the confidence bounds xCI may be found by solving the quadratic equation
x’hat = xCI +/- sigma(xCI) tc / sqrt(bT G^-1 b)
for its two real roots.
If Gamma = gI for some scalar g, then g may be estimated by pooling all nq errors and the test and CI are exact with d = q(n-2) DOF. Furthermore, according to Brown (if I understand his rather complicated Wishart argument correctly), if Gamma is estimated without restriction by S/(n-q-1), where S = ETE and E is the nXq matrix of all the calibration errors, then d = (n-q-1) and the F-test and t-based CI are again exact.
If q >= n, S is not of full rank and we can’t use it to estimate Gamma without some additional restrictions. However, we don’t have to go all the way to Gamma = gI. For example, we might estimate the diagonal elements without restriction, but then model all the correlations with just a couple of free parameters. In this case I don’t think there is an exact distribution, but it is asymptotically normal, and probably the F and t distributions with d = n-2 or so would be a very good approximation.
I’m planning to use this to calibrate Lonnie Thompson’s 6-core data from CC 03 to temperature. Any input would be welcome!
Hu, very interesting, I’ll take a look. Note for new readers:
The issues with multivariate calibration -based reconstruction uncertainties in MBH98, MBH99 and many more reconstructions, are independent of PC-stuff and other proxy problems discussed at CA. That is, if you spend many blog threads to explain that treeline11.dat and pc01.out are ok to use, you still need some 10 more blog threads (*) to explain why MBH9x does not use conventional multivariate calibration methods, well described in statistical literature.
Note how latest IPCC report deals with this issue (CH6 page 472):
Hu, your x’^2/xTx term is not mentioned, I wonder why..
(*) Hi Tamino 😉
RE x’^2/xTx term
See also
http://www.climateaudit.org/?p=2563#comment-191063
and
http://wmbriggs.com/blog/2008/03/09/you-cannot-measure-a-mean/
Re #78 etc, these formulas have two important but easy special modifications.
First, if one or more proxies are missing for a particular reconstruction date, there is no need to recalibrate the whole system (as there would be with direct multiple regression of temperature on the proxies). All you need to do is omit the relevant elements of a and b (which, I neglected to mention are qX1 vectors to start with, as are alpha and beta), and also remove the corresponding rows and columns of G before inverting it. This will gradually widen the CI’s as proxies drop out, but there is no need to have a sudden change in the system every couple of centuries (as I gather MBH did).
And second, if you smooth the reconstruction by averaging over m periods, the reconstruction using the smoothed proxies is the same as smoothing the reconstruction using the unsmoothed proxies. However, the CI of the smoothed reconstruction is considerably smaller than what you would get if you just smoothed the CI bounds of the unsmoothed reconstruction. The coefficient uncertainty, measured by 1/n and x’^2/xTx in sigma^2(x’), is the same in both cases, but the lead term 1 that represents the disturbance uncertainty gets replaced by 1/m, assuming as in Brown’s benchmark case, that the disturbances are serially uncorrelated.
(Note that the X’s and Y’s can both be highly serially correlated without the disturbances being serially correlated. I don’t know about annual treerings, but this is the case with a few decadal ice core series I have looked at.)
Hu (78),
p=1 case is seen in reconstructions where global average is used as target. I tried Brown’s formula for Juckes’ reconstructions, see this post
http://signals.auditblogs.com/2007/07/09/multivariate-calibration-ii/ , those floor-to-ceiling peaks are empty CI-cases. You can download the data from here,
http://www.cosis.net/members/journals/df/article.php?a_id=4661 if you want to try your method. It seems that conventional statistical methods give wider CIs than those you see in MBH9x and Juckes etc…
Note also that p=1 does not hold in MBH9x, except for AD1000 and AD1400 steps.
78,
See Mann07,
Errors are as autocorrelated as proxies, sound like beta=0 to me 🙂
Mann07: Robustness of proxy-based climate field reconstruction methods, Journal of Geophysical Research, Vol. 112
UC (#82) writes,
Empty CI and infinite (or huge) CI are separate issues. Brown’s CI can come up empty because it asks the wrong question, namely whether the observation was possible or not in terms of the model. In this case, even the point estimate should be rejected if this is your question, IMHO.
My CI (in #78) instead asks how high or low could x have been, given the observation that somehow or other did occur. This can be huge as in the univariate case, and will even be unbounded on at least one side if you ask for a confidence level that exceeds your confidence that the relationship is invertible (ie beta /= 0).
In MBH9x, I can see that each proxy should correlate better with its own local temperature than with global (or NH) temperature, but does this step (with p > 1) really serve any purpose if all that is ultimately desired is an estimate of global (or NH) temperature?
I’m planning to try it out with Thompson’s 2006 CC data and will let you know what turns up. So far it looks like there really is a HS if you use his choice of core for each site, albeit a very noisy one.
Hu,
That’s true. More correct way to represent those empty cases would be no CIs at all ( classical interpretation, #71 ). That post needs some updating, but the main point remains, calibration-residual based CIs are not valid. And IPCCs explanation with ‘considerable 0.5 deg’ and ‘minimum uncertainties’ is just silly.
Not necessarily local correlation, it can be teleconnected to anywhere.
They wanted more, local reconstructions as well, see for example http://www.ncdc.noaa.gov/cgi-bin/paleo/mannplot2.pl
Re #78,
I tried implementing this and got very inconsistent results when testing beta = 0 using the F test or my t-based test.
I think my problem is here:
In fact, since b is random (and perfectly correlated with b itself), it’s not really legitimate to set c = bT g^-1, or at least when we do bT g^-1 (Y’-a) does not really have a normal distribution. Rather it the convolution of a non-central chi-squared distribution with q DOF with the normal distribution of the disturbance term, which is way to messy for me.
So I’ll retract my proposal in #78. However, I still think Brown’s sometimes empty CI answers the wrong question. The answer must lie in the change in the F statistic from its minimum (as in #68 above), the LR statistic (which may amount to the same thing as the change in F asymptotically), or the posterior distribution (calculable for q > 2).
Back to the drawing boards…
Hu #78,
This might be relevant article,
Conservative confidence regions in multivariate calibration, Thomas Mathew and Wenxing Zha, Ann. Statist. Volume 24, Number 2 (1996), 707-725.
Sent it to you.
One Trackback
[…] Calibration Estimation” discussed by Brown (1982), and advocated on CA by reader UC. In general, it would be more efficient not to weight the individual normalized series equally, but […]