Paul Linsay contributes the following:
Using Landsea’s data from here, plus counts of 15 and 5 hurricanes in 2005 and 2006 respectively, I plotted up the yearly North Atlantic hurricane counts from 1945 to 2004 and added error bars equal to 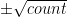
The result is in Figure 1.

Figure 1. Annual hurricane counts with statistical errors indicated by the red bars. The dashed line is the average number of hurricanes per year, 6.1.
There is no obvious long term trend anywhere in the plot. There is enough noise that a lot of very different curves could be well fit to this data, especially data as noisy as the SST data.
I next histogrammed the counts and overlaid it with a Poisson distribution computed with an average of 6.1 hurricanes per year. The Poisson distribution was multiplied by 63, the number of data points so that its area would match the area of the histogrammed data. The results are shown in Figure 2. The Poisson distribution is an excellent match to the hurricane distribution given the very small number of data points available. I should also point out that I did no fitting to get this result.

Figure 2. Histogram of the annual hurricane counts (red line) overlaid with a Poisson distribution (blue line) with an average of 6.1 hurricanes per year.
I conclude from these two plots that
- The annual hurricane counts from 1945 through 2006 are 100% compatible with a random Poisson process with a mean of 6.1 hurricanes per year. The trends and groupings seen in Figure 1 are due to random fluctuations and nothing more.
- The trend in Judith Curry’s plot at the top of this thread is a spurious result of the 11 year moving average, an edge effect, and some random upward (barely one standard deviation) fluctuations following 1998.





188 Comments
Solow and Moore 2000, cited by Roger Pielke, also fitted a Poisson model to hurricane data and concluded that there was no trend to the hurricane data that then had accrued. The 2005 hurricane does appear loud to me in Poisson terms but then so would be 1933 and 1886, so the process may be a bit long-tailed.
Steve, nice job!
I question the meaning of “error bars” in the first figure. Ignoring the undercount issues, we know the values exactly. The second graph makes the point that the data could have come from a Poisson population.
Steve: TAC, you mean, “nice job, Paul “
Not very familiar with this, any reference for layman?
#3 — The error bars in Figure 1 assume a completely random process. That would be the null assumption (no deterministic drivers). The Poisson plot shows that the system has a driver, but is a random process within the bounds determined by the driver.
It’s a lovely result, Paul, congratulations. You must have laughed with delight when you saw that correlation spontaneously emerge, and with no fitting at all. That feeling is the true reward of doing science. I expect Steve M. has experienced that, too, now.
In a strategic sense, your result, Paul, shows that a large fraction of the population of climatologists have a pre-determined mental paradigm, namely AGW, and are looking for trends confirming that paradigm. They have gravitated toward analyses — an 11-year smoothing that produces autocorrelation, for example — that produce likely trends in the data. These are getting published by editors who also accept the paradigm and so accept unquestioningly as correct the analyses that support it. Ralph Ciccerone’s recent shameful accomodation of Hansen’s splice at PNAS is an especially obvious example of that. These are otherwise good scientists who have decided they know the answer without actually (objectively) knowing, and end up enforcing only their personal certainties.
Honestly, your result deserves a letter to the same journal where Emanuel published his trendy (in both senses) hurricane analysis. Why not write it up? It’s clearly going to take outside analysts to bring analytical modesty back to the field. Being shown wrong is one thing in science. Being shown foolishly wrong is quite another.
Actually, now that I think about it, does the pre-1945 count produce a Poisson distribution with a different median? If so, you could show that, and then include Margo’s correction of the pre-1945 count, add the corrected count to your data set and see if the Poisson relationship extends over the whole set. Co-publish with Margo. It will set the whole field on its ear. 🙂 Plus, you’ll have a really great time.
#4 “Emanuel” — that should have been Holland and Webster (Phil. Trans. Roy. Soc. A) — but then, your result deserves a wider readership than that.
Nice job, Paul!
re #4:
For that, one could use, e.g., the test I referred here. Since people seem to have both interest and time (unfortunately I’m lacking both right now), just a small hint 😉 :
I think there was the SST data available somewhere here. Additionally R users look here:
http://sekhon.berkeley.edu/stats/html/glm.html
and Matlab users here:
http://www.mathworks.com/products/statistics/demos.html?file=/products/demos/shipping/stats/glmdemo.html
Too funny! I was just reading Jean S’s suggestion on the other thread. My precise thought was: I should correct my analysis for poisson distributions! 🙂
Paul, ha, like yesterday you beat me to it again. I plotted the data from Judith Curry’s link from yesterday and it is not quite such a good fit to a Poisson distribution as the graph you show above, but pretty good. To look at the correlation to a Poisson distribution I plot the fractional probability from the hurricanes per year (the number of years out of 63 that have a particular number of hurricanes in it divided by the total 63 years) against the probability for that particular number of hurricanes from a Poisson distribution with that mean value. Then a perfect correlation would be a straight line of gradient 1. An analysis of the error bars on that graph shows a good correlation to a Poisson distribution with R2~0.7 but the error bars are so large (a consequence of the small numbers) that it very difficult to rule anything in or out.
#2 TAC, the words ‘error bars’ here are not ‘errors’ in the sense of measurement errors. The assumption here is that the number of hurricanes is the actual true number with no undercounting or any other artifacts distorting the data (as if you had god-like powers and could count every one infallibly), but if you have a stoichastic process (something that is generated randomly) then just because you have 5 hurricanes in one year, then even if in the next year all the physical parameters are exactly the same, you may get 3, or 8. Observed over many years you will get a spread of numbers of hurricanes per year with a certain standard deviation. That perfectly natural spread is what has been referred to as the ‘error bar’. It is a property of a Poisson distribution that if you have N discrete counts of something, then the standard deviation of the distribution is equal to the square root of N. Try Poisson distribution on Wikipedia. As N becomes larger and larger, the asymmetry reduces and it looks much more like a normal distribution. But where you have a small number of discrete ‘things’ – as here with small numbers of hurricanes each year, then the distribution is asymmetrial (because you can’t have less than 0 storms per year).
I would say that the excellent fit to a Poisson distribution shows that hurricanes are essentially randomly produced and what is more, the small number of hurricanes per year (in a statistical sense) makes determining trends statistically nonsense unless you have vastly more data (vastly more years).
As I noted in the other thread yesterday, concluding that hurricanes are randomly produced does NOT preclude a correlation with SST, AGW, the Stock Market, marriages in the Church of England or anything else. If there is a correlation with SST over time, for the sake of argument, what you would see is a Poisson distribution in later years with a higher average than the earlier years. What always seemed to have been omitted in these arguments previously like in the moving 11 year average by Judith Curry is that the error bars (natural limitations on confidence) are very large. How certain you can be about whether that average really has gone up or not, is almost non-existant on this data. You might suspect a trend but can’t on these numbers show a significant increase with any level of confidence.
By the same token, Landsea’s correction is way down in the noise.
#3 Steve and Paul, I apologize for mixing up your names. Oops!
#4 Re error bars: By convention these are used to indicate uncertainty corresponding to a plotted point. In this case, there is no uncertainty (again, of course, ignoring the fact that there is uncertainty because of the undercount!). Thus the error bars should be omitted from the first figure.
Going out on a limb, I venture to say that the error bars were computed to show something else: That each observation is individually “consistent with” the assumption of a Poisson df (perhaps with lambda equal to about 6). Anyway, it appears that each error bar is computed based only on a single datapoint (N=1). This procedure results in 62 distinct interval estimates of lambda. However, it is not clear at all why we would want these 62 estimates. The null hypothesis is that the data are iid Poison, so we can safely use all the data to come up with the “best” single estimate of lambda and then test H0 by considering how likely it is that we would have observed the 62 observations if H0 is true (e.g. with a Kolmogorov-Smirnov test).
Finally, I agree with you that it is a “lovely result,” as you say 🙂
Argh, sorry TAC, just realised I misread the comment numbers and should have addressed my comments on Poisson statistics to UC in #3, not you.
There was a link to hurricane data that was inadvertantly dropped.
#3. UC, The best I can do for you is “Radiation Detection and Measurement, 2nd ed”, G. F. Knoll, John Wiley, 1989. Chapter 3 is a good discussion of counting statistics. Suppose you have a single measurement of N counts and assume a Poisson process. What is the best estimate of the mean? N. What is the best estimate of the variance? N.
#4, Pat
How does it do that?
The analyses all around here at CA on TC frequencies and intensities have been most revealing to me, but the results have not been all that surprising once I understood that the potentional for cherry picking (and along with the evidence of how poorly the picking process is understood by those doing it) was significantly greater than I would have initially imagined. What will be more revealing to me will be the reactions to these analyses.
The analyses say be very careful how you use the data, but I fear the inclination is, as Pat Frank indicates, i.e. here is what we suspect is true and here is the analysis from these selected data to substantiate it.
#9 TAC (really this time), I have to disagree with you about the ‘error bars’ on the graph, they shoudn’t be omitted, they are vital. There may be no uncertainty in the measured number of storms in a year but what should be plotted is ‘confidence limit’ – error bar is perhaps a loaded term. If you could run the year over and over again then you would get a spread of values, that is the meaning of the uncertainty or ‘error bar’ plotted in the figure 1.
#13 IL, do you agree that the same value of the standard deviation should apply to every observation? If not — and the graph clearly indicates that it does not — could you explain to me why?
There is a scientific response to this: “Ack!”
The RealClimate response: “*sigh* so how much was Paul Linsay paid through proxies some laundered money from Exxon-Mobil to confuse the public with regard to the scientific consensus on global warming?”
My response: “Holy crap, we’ve been trying to predict a random process all of this time. Someone should call Hansen and Trenberth and recommend a ouija board for their next forecast – unless they’re already using one”
#14, no, because the count in each year is an independent measurement and the years are not necessarily measuring the same thing. It is conceivable for example that a later year has been affected by a positive correlation with SST (or any other mechanism) so the two periods would not have the same average. If you have measured a count of N then the variance of that in Poisson statistics is N. If you hypothesize that a number of years are all the same so that you add all the counts together then you have a larger value of N but the fractional uncertainty is lower since it is the standard deviation divided by the value N but since the standard deviation is the square root of N then fractional uncertainty is (root N)/N = 1/(root N) and thus as N increases, the relative uncertainty decreases.
If you treat each year as separate then I believe that what Paul has done in figure 1 is correct.
John A – just because it is a random process does not mean that there cannot be a correlation with
#8
Its quite reasonable to look to see if there is a correlation with time, SST or whatever. I have no problems with that. What I do think though is that the statistics of these small numbers make the uncertainties huge so that the amount of data you need to be able to confidently say that there is a real trend is far larger than is available. You would need many years’ more data to reduce the uncertainties – or if there was a real underlying correlation with SST – or whatever – it would have to be much more pronounced to stick up above the natural scatter.
Il,
Well, under the null hypothesis the “years” are measuring the same thing. Each one is an iid variate from the same population. The variates (not the observations) have the same mean, variance, skew, kurtosis, etc. Honest!
I’ll try to find a good reference on this and post it.
Elsner is using Poisson regression for Hurricane prediction:
Elsner & Jagger: Prediction models for annual U.S. hurricane counts, Journal of Climate, v19, 2935-2952, June 2006.
Click to access ElsnerJagger2006a.pdf
He has some other interesting looking publications here:
http://garnet.fsu.edu/~jelsner/www/research.html
and a (recently updated) blog here:
http://hurricaneclimate.blogspot.com/
Re 17:
IL, thanks for making me laugh. We’re now generating our own statistics-based humor on this blog.
Re #11:
Paul, what happens if you apply the same analysis to the global hurricane data? Now I’m curious. Because if the global data follows the same Poisson distribution then we’re looking at an even bigger delusion in climate science than temperatures in tree-rings.
What type of curve would arise with a Poisson constant gradually rising , for instance from alpha=5 in 1950 to alpha=7 in 2000 ? Would that curve be distinguishable from a Poisson graph with intermediate alpha, given the coarseness resulting from the fact that N = 63 only?
#20 John A – glad I have some positive effect
#18 TAC, No, I don’t think so (although I am always aware of my own fallibilities and am willing to be educated).
I think I understand the point you are making but I am not sure it is correct here in the way you imply. There are a lot of examples given in http://en.wikibooks.org/wiki/Statistics:Distributions/Poisson
one example is going for a walk and finding pennies in the street. Suppose I go for the same walk each day. Many days I find 0 pennies, a few days I find 1, a few days I find 2 etc
I can average the number of pennies per day and come up with a mean value that tells me something about the population of pennies ‘out there’ and it will follow a Poisson distribution. If I walk for many more days I can be more and more confident of the mean value (assuming the rate of my neighbours losing pennies is constant) but I then cannot say anything about whether there is any trend with time – eg are my neighbours are being more careless with their small change as time goes by? In order to test whether there is some trend with time I need to look at each individual observation and treat that as the mean value which is what Paul did in the original graph. Yes, if I assume that there is some constant rate of my neighbours losing pennies, some of which I find, I can look at the total counts and I can then get a standard deviation but I would then not have 63 data points all with the same ‘error bar’, I would have one data point with the ‘error bar’ in the time axis spanning 63 years.
Yes, you can look at (for the sake of argument) pre 1945 hurricane numbers and post 1945 hurricanes and get a mean and standard deviation from Poisson statistics and infer whether there has been any change between those two periods with some sort of confidence limit but then you only have 2 data points.
I would like to announce my official “John A Atlantic Hurricane Prediction” for 2007.
After extensive modelling of all of the variables inside of a computer model costing millions of dollars (courtesy of the US taxpayer) and staffed by a team of PhD scientists and computer programmers, I can announce:
Hey everybody.
Speaking of “error bars”, what do you actually mean by that? Is it a definite limit of values which is
acceptable as long as they stay within some given boundaries, or is it some definite “borderline” whose going beyond
will cancel the veracity, or whatever you might call it, of your calculations?
In Danish I think we call it “margin of error”, but I am not sure you mean the same by “error bars” so
will somebody please inform me!
It makes it easier for me as layman to follow your discussion on this thread.
Thank you.
HK
#22 Il, I think I understand the purpose that the “bars” in the first graphic were intended to serve. My concern had to do with whether use of bars for this purpose deviates from convention.
I spent some time looking on the web, expecting to find a clear statement on error bars from either Tukey or Tufte. Unfortuntately, such a statement does not seem to exist.
I did find one statement which can, I think, be interpreted to support your position:
However, this appears in a discussion of plotting large samples, and it seems likely that the word “population” was intended to refer to the sample, not the fitted distribution based on a sample of size N=1.
Where does that leave things? Well, I continue to believe that we should reserve error bars for the purpose of displaying uncertainty in data. For the second purpose, to show how well a dataset conforms to a specific population, there are lots of good graphical methods (I usually use side-by-side Boxplots, admittedly non-standard but easily interpreted; I’ve also seen lots of K-S plots, overlain histograms, etc.).
However, returning to error bars for the moment, perhaps the important point is already stated in the quote above: “Because of this lack of standard practice it is critical for the text or figure caption to report the meaning of the error bar.”
11, thanks for the reference, I’ll try to find it. Like I said, not very familiar with counting processes. However, let’s still write some thoughts down:
Yes, the mean of observations from Poisson process is a MVB estimator of intensity (lambda, tau=1), and variance of this estimator is lambda/n, where n is the sample size. And I guess that the mean is best estimate for the process variance as well. But I think you assume that each year we have different process, which confuses me.
How about thinking the whole set (n=60 or something) as realizations of one Poisson process, and testing whether it is a good model (i.e. Poisson process, constant lambda, estimate of lambda is 6.1). Plot this constant mean, add 95,99 % bars using Poisson distribution and plot the data to the same figure.
If Figures 1 and 2 were presented the other way around, the meaning of the “error bars” in Figure 1 could be presented more logically. From Figure 2 one can deduce that the data are from a Poisson distribution. Each annual count then is an estimate of the Poisson mean, with the one sigma confidence values on that mean as shown. The time series then can be examined to see if there is evidence of a change in the mean of the distribution.
There are three types of error here:
Sampling error Early samples were taken from land and shipping lanes leaving large areas unsampled or under sampled. The size of this error has gone down with time.
Methodological error Which includes everything from indirect methods of estimating location, winds speed and pressure to accuracy and precision of instruments. This also has gone down with time but is still non-zero.
Process error We assume that even if the “climate” doesn’t change from year to year, the number of storms will.
Any meaningful “error bars” would have to include (estimates of) the above.
I still don’t understand why the nice fit in the second plot implies the absence of a trend. Suppose that there was a very clear trend, with 1 hurricane in 1945, 2 hurricanes in 1946, … , and finally 12 hurricanes in 2005 and 15 hurricanes in 2006. Figure 2 would remain competely unaltered. So the fact that the Poisson distribution fits the histogram seems irrelevant as far as the existence of a trend is concerned. It is possible to obtain a Poisson distribution with one global rate, just by adding smaller distributions with different rates.
#26 UC: I completely agree with what you’ve written.
#29,
True, histogram doesn’t care about the order.
If google didn’t lie, 0.01 0.05 0.95 0.99 quantiles for Poisson(6) are 1 2 10 12, respectively. So, to me, the only problem with Poisson(6) model in this case are the 10 consecutive less-than-averages in 70’s.
Just checked, term ‘trend’ is not in Kendall’s ATS subject index. What are we actually looking for? IMO we should look for possible changes in the intensity parameter.
#29 James, your point is well taken. You could have a strong trend and still obey a Poisson distribution. However, it appears that is not the case here; there is no trend in the data.
Incidentally, landfalling hurricanes were considered (here), and it seemed that the data were almost too consistent with a simple Poisson process. It made me wonder what was going on.
TAC, re #9: search on “ergodicity” at CA (or “count ’em, five”. This was the subject of argument between myself and “tarbaby” Bloom. The counts are known with high (but not 100%) accuracy, but counts are not the issue; it’s the behavior of the climate system that’s the issue, and your desire to make an inference *among* years. If the climate system were to replay itself over 1950-2006, you’d get a different suite of counts. That’s the sense in which “error” is meaningful for a yearly count. This is going to sound fanciful to anyone who has not analysed time-series data from a stochastic system. However it is epistemologically and inferentially correct.
#32
What test have you used to establish that there is no trend?
A GAM fitted to these data, with Poisson variance, finds significant changes with time (p=0.027). This is only an approximate test, but a second order GLM, again with Poisson variance, is also significant (p=0.039).
#23 John A
“After extensive modelling of all of the variables inside of a computer model costing millions of dollars (courtesy of the US taxpayer) and staffed by a team of PhD scientists and computer programmers, I can announce: For 2007, the number of hurricanes forming in the Atlantic will be 6 plus or minus 3”
I’ve very disapponted that as a fellow UK taxpayer you do not appeciate the fact that inorder to justify the signifcant sums of money we spend of funding this vital (to saving the planet) climate research that your supercomputer can only calculate to one significant figure. As a concerned UK taxpayer I have taken he liberty to once more fire up my retired backofthefagpacket supercomputer (which was retired from AERE Harwell some years ago after it was no longer required to solve the Navier-Stokes equations) and based on its the results it has output my prediction (endorsed by the NERC due to its high degree of precision) is
6.234245638939393 (+/- n/a as this calculation has been peformed by a supercomputer that can calculate pi to at least 22514 ecimal places as memorised by Daniel Tammet).
As a UK tax payer I feel that it is important that such calculations must be highly precise and certainly not subject to any uncertainty. As a Church of England vicar I also appreciate that my mortality has already been determined (something which sadly people like Yule did not understand). I do confess however to be puzzled as to why inflation appears to have remained relatively constant and low since 1997 yet as a result of AGW it is now much rainier in the UK?
KevinUK
#33 Bender, I’m not sure I understand your point. FWIW, I have a bit of familiarity with time series. However, the question here has to do with graphical display of information, and specifically the use of error bars. At the risk of repeating myself, where the plotted points are known without error, by convention (i.e., what I was taught, but it does seem to be accepted by the overwhelming majority of practitioners) one does not employ error bars.
Of course I understand your point about ergodicity. I agree there is a perfectly appropriate question about how the observations correspond to the hypothesized stochastic process, and clearly the variance of the process plays a role. As I think we both know, there are plenty of graphical techniques for communicating this information, some of which are mentioned above. But I do not see how this has anything to do with how one plots original data.
It is ironic that this debate about proper graphics is occurring in the context of a debate about uncertainty in hurricane count data. For example, I thought Willis (here) presented an elegant way to display the uncertainty of the hurricane count data using both error bars and semicircles. That’s what error bars are for: to communicate the uncertainty in the data (which could be measured values, model results, or whatever). Climate scientists need to get used to thinking this way, and, as with other statistical activities, it is important to employ consistent and defensible methods.
In a nutshell, plotting the 2005 hurricane count as 15 +/- 3.8 suggests that there might have been 18 hurricanes in 2005. That’s simply wrong. Said differently, the probability of an 18 in 2005 is zero; the number was 15. That number will never change (unless…). Data are data, data come first, and the properties of the data, including uncertainty, do not depend on the characteristics of some subsequently hypothesized stochastic process (at least in the classical world, where I spend most of my time).
Finally, to be clear: I am raising an issue of graphical presentation. If the graphics were done differently — UC had it right in #26 — there would not be a problem. The problem with Figure 1 is that it overloads “error bars” in a way that’s bound to cause confusion.
That’s my $0.02.
#36. TAC, that makes sense to me as well.
#34 RichardT, I may have made a mistake in keying the data, but here are my results showing no significant trend:
% Year
[1] 1944 1945 1946 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960 1961 1962 1963
[21] 1964 1965 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975 1976 1977 1978 1979 1980 1981 1982 1983
[41] 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003
[61] 2004 2005 2006
% Hc
[1] 7 5 3 5 6 7 11 8 6 6 8 9 4 3 7 7 4 8 3 7 6 4 7 6 4 12 5 6 3 4 4 6 6
[34] 5 5 5 9 7 2 3 5 7 4 3 5 7 8 4 4 4 3 11 9 3 10 8 8 9 4 7 9 15 5
% cor.test(Year,Hc,method="pearson")
Pearson's product-moment correlation
data: Year and Hc
t = 0.9513, df = 61, p-value = 0.3452
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.1307706 0.3579536
sample estimates:
cor
0.1209120
% cor.test(Year,Hc,method="kendall")
Kendall's rank correlation tau
data: Year and Hc
z = 0.3654, p-value = 0.7148
alternative hypothesis: true tau is not equal to 0
sample estimates:
tau
0.03313820
% cor.test(Year,Hc,method="spearman")
Spearman's rank correlation rho
data: Year and Hc
S = 38969.32, p-value = 0.6145
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.06467643
Warning message:
Cannot compute exact p-values with ties in: cor.test.default(Year, Hc, method = "spearman")
%
#36 & 37
What are the errors for the time series of hurricane counts? Suppose you could re-run 1945-2006 over and over like in Groundhog Day. The number of hurricanes observed each year would change from repetition to repetition. You could then take averages and get a good measurement of the mean and variance of the number of hurricanes in each year. But you can’t. So the best you can do is assume each year’s count is drawn from a Poisson process with mean and variance equal to the number of observed hurricanes.
The same applies to the histogram. The error on the height of each bin is given by Poisson statistics too.
If you fit a function to a series of counts these are the errors that should be used in the fit.
This has been standard practice in nuclear physics and its descendents for close to 100 years. As an example here’s a link from a nuclear engineering department. Notice the statement that “Counts should always be reported as A +- a.”
Re 36:
… where the plotted points are known without error, by convention (i.e., what I was taught, but it does seem to be accepted by the overwhelming majority of practitioners) one does not employ error bars.
The plotted points are not known without error.
Observing Methods
As has been discussed here before.
#39 Paul, thanks for the link to the interesting document. You have to read it pretty carefully, and it deals with a slightly different problem (estimating the true mean, a parameter) but it does shed a bit of light on the topic. One particular thing to note: It specifies estimating sigma as the square root of the true mean, m, not the count, n. Thus, following the document’s prescription, all of the error bars in figure 1 should be exactly the same length, as implied by UC (#26) and also in #14. However, if you try to apply this to the hurricane dataset — for a small value of lambda where some of the observed counts are less than the standard deviation — you’ll find it doesn’t work very well (some of your observations will have error bars that go negative, for example).
Does this clear anything up or just create more confusion?
Let me try a different approach: In 2005, we agree there were n=15 hurricanes. We also agree that the expected count (assuming iid Poisson) was approximately m=lambda=6.1, and therefore the standard deviation of the expected count is approximately 2.5. So here’s the question: Is the n=15 a datapoint or an estimator for lambda? I expect your answer will be “both” — but I’m not sure.
Anyway, I’d be interested in your response.
#40 James, I concede the point. However, in the interest of resolving the issue about error bars, can we, just for the moment, pretend that things are measured without error? Thanks! 😉
#41. A question – hurricanes are defined here as counts with a wind speed GT 65 knots. There’s nothing physical about 65 knots. Counts based on other cutoffs have different distributions – for example, cat4 hurricanes don’t have a Poisson distribution, but more like a negative exponential or some other tail distribution. Hurricanes are a subset of cyclones, which in turn are a subset of something else. If hurricanes have a Poisson distribution, can cyclones also have a Poisson distribution? I would have thought that if cyclones had a Poisson distribution, then hurricanes would have a tail distribution. Or if hurricanes have a Poisson distribution, then what distribution would cyclones have. Just wondering – there’s probably a very simple answer.
re: #43
I think it’d be similar to a pass-fail class. You might set an arbitrary value for pass on each individual test during the semester and then you could then give a number of tests, some harder and some easier, randomly. You’d have a Poisson distribution, possibly. But you might also, on adding up the various test results for each individual in the class decide you want to set things for 85% of students passing and this could be set at whatever value gives you that ratio. This could be regarded as a physical result while the arbitrary value for passing an individual test would not be.
As for cyclones, they’d be everything which passes the “cyclone” test. There’d be a finite number of such cyclones each season, so they should distribute just like hurricanes do. Just with larger numbers. I think someone here was saying that as the numbers get larger, the curve gets more like a normal distribution, which makes sense, so I’d expect the distribution of cyclones to be more normal than the distribution of hurricanes. This being the case, it would seen that the distribution of a tail is simply a poisson distribution with the pool of “passing” candidates starting where the tail was chopped off.
Re #42
Wait a sec, TAC. Don’t concede too much here. Measurement error and sampling error are different things. This issue is all about sampling error. [Linsay’s #39 clarifies my ergodicity argument.]
The hypothesis we want to test is whether the observed counts are likely to be drawn from a rondom poission process (or truncated possoin, whatever) with fixed mean = fixed variance. Each year is a random sample from a stochastic process. Alternative hypothesis: there is a trend in the mean. Paul Linsay has plotted the variance around each year’s observation as though that observation *were* that year’s mean. That’s wrong, and that’s why your complaint about the difference count-variance dropping below zero for low counts is valid.
The reason it’s wrong is that the null hypothesis is that there is only one fixed mean. If any obs fall outside the interval, such as 2005, there’s a chance we’re wrong. If, further, the proportion of observations falling outside the 95% confidence interval increases with time, then there’s a trend and the mean is not fixed.
All this assumes that the variance is constant with time. But there is no reason this must be true. If the process is nonstationary, it is not ergodic. Then inferences about trends starts to get dicey. That’s where the statistical approach breaks down and the physical models start to play a role.
re: 44 cyclones … and by extension, tornados exhibit a poisson distribution? In an AGW theory of everything, shouldn’t f3-f5’s be increasing in frequency? Or is it because they do not tap directly into the catastrophic global increase of SSTs?
SINUSOIDAL POISSON DISTRIBUTION
Paul, a very interesting post. I disagree, however, when you say:
When I looked at the distribution, it reminded me of a kind of distribution I have seen before in sea surface temperatures, which has two peaks instead of one. I’ve been investigating the properties of this kind of distribution, which seems to be a combination of a classical distribution (e.g. Poisson, Gaussian) with what (because I don’t know the name for it) I call a “sinusoidal distribution.” (This is one of the joys of not knowing a whole lot about a subject, that I can discover things. They’ve probably been discovered before … but I can come at them without preconception, and get the joy of discovery.)
A sinusoidal distribution arises when there is a sinusoidal component in a stochastic process. The underlying sinusoidal distribution is the distribution of the y-values (equal to sin(x)) in a cycle. The distribution is given by d(arcsin(x))/dt. This is equal to 1/sqrt(1-x^2), where x varies from -1 to 1. The distribution looks like this:
As you can see, the sine wave spends most of its time at the extremes, and very little time in the middle of the distribution. Note the “U” shape of the distribution. I looked at combinations of the sinusoidal with the poisson distribution. Here is a typical example:
Next, here is the distribution of the detrended cyclone count, 1851-2006.
Note the “U-shape” of the peak of the histogram. Also, note that the theoretical Poisson curve is to the left of the sides of the actual data. This is another sign that we are dealing with a sinusoidal Poisson distribution, and is visible in Figure 2 at the head of this thread.
One of the curiosities of the sinusoidal distribution is that the width (between the peaks) is approximately equal to the amplitude of the sine wave. From the figure above, we can see that we are looking for an underlying sinusoidal component with an amplitude of ~ 4 cyclones peak to peak. A periodicity analysis of the detrended cyclone data indicates a strong peak at about 60 years. A fit for a sinusoidal wave shows the following:
Clearly, before doing any kind of statistical analysis of the cyclone data, it is first necessary to remove the major sinusoidal signal. Once the main sinusoidal signal is removed, the reduced dataset looks like this:
As you can see, the fit to a Poisson distribution is much better once we remove the underlying sinusoidal signal.
CONCLUSION
As Jean S. pointed out somewhere, before we set about any statistical analysis, it is crucial to first determine the underlying distribution. In this case (and perhaps in many others in climate science), the existence of an underlying sinusoidal cycle can distort the underlying distribution in a significant way. While it might be possible to determine the statistical features (mean, standard deviation, etc.) for a particular combined distribution, it seems simpler to me to remove the sinusoidal component before doing the analysis.
My best to everyone, and special thanks to Steve M. for providing this statistical wonderland wherein we can discuss these matters.
w.
TAC plus bender #45. I see we are arguing about 2 different things here, the first perhaps a little more to do with semantics, the second more substantial.
In #36 TAC argued that if the counts for 2005 were 15 then (assuming perfect recording capability) that was an exact number and so should have no error bar. He (? sorry, shouldn’t make assumptions) in #36 says that if you put 15+/-3.6 then that implies that the count could have been 18 which is wrong.
I disagree. I think those are confidence limits – estimators if you prefer. In a physics experiment if I measure something numerous times with a measurement error, what the error bar is telling me is what is the probability that if I measure it again that I will get within a certain range of that value. In a literal sense we can’t ‘run’ 2005 again but the graph as plotted by Paul Linsay is meaningful to me as the confidence limits for each count – if we were to have another year with the same physical conditions as 2005, what is the likelihood that we would get 15 storms again. To me the correct answer is 15+/-3.6 (1 sigma). Its like the example from the physics web page linked by Paul, if I measure the number of radioactive decays per minute and I record the decays per minute for an hour. After the hour I have 60 measurements each of an exact number but that does not say to me that there are no error bars on those numbers. If I have N counts in the first minute then the standard deviation (the expectation of what I might get in the second minute) is root N. If I was to plot all of those 60 measurements against time I would plot each count value with its own individual confidence limit of root N (N being the particular count in that particular minute).
Yes, if I take all the counts for the whole 60 minutes I can get a mean value for the hour. The confidence limit on that mean value will be root of all the counts in the hour (approximately 60N and the standard deviation will be root 60N). But that is not the confidence limit on an individual measurement. I could plot that mean value with its confidence limit root 60N but I would then only have a single point on the graph.
Paul says he comes from a physics background, so do I and maybe this is where we are differing with TAC, Bender etc (maybe, again don’t want to make assumptions). In #45 Bender says that it is wrong to plot each point with the variance given by the mean of that point. Sorry Bender, I disagree with you, I believe it is correct. I am looking at it from the perspective of the radioactive decay counting experiment described above. You can reduce the uncertainty by summing together different years (although your uncertainty only decreases by root of the number of years that you sum) but then you have reduced the number of data points that you have! If you have the 63 years’ worth of individual year measurements then each individual one has a standard deviation which should be plotted, they are not all the same. If you want to address hypotheses such as ‘are the counts changing with time’ then you have to address the uncertainty in each data point if you retain all 63 data points and look for a trend that is significant above that noise level. Yes, you can reduce the uncertainty by summing years but then you have a lot less data points on your graph.
No, the variance count does NOT drop below zero because this is Poisson statistics, it is asymmetrical and doesn’t go below zero.
Let’s see if I clarify or confuse:
Yes, we are testing H0: the data are samples from Poisson(lambda) process. We don’t know lambda. We need to estimate it using the data. We want to find a function of the observations (a statistic) that tells something about this unknown lambda. Now, assuming H0 is true, we have quite a lot of theory behind us telling that average of the observations (say![\hat{x}[\tex]) is the best ever estimate of lambda (MVB, for example). We also know that variance of this estimator is](https://s0.wp.com/latex.php?latex=%5Chat%7Bx%7D%5B%5Ctex%5D%29+is+the+best+ever+estimate+of+lambda+%28MVB%2C+for+example%29.+We+also+know+that+variance+of+this+estimator+is+&bg=ffffff&fg=000&s=0&c=20201002) latex \hat{x}/n[\tex], where n is the number of independent observations. You cannot find unbiased estimator that has smaller variance than this. Estimate obtained this way will be distributed more closely round the true lambda than any other estimator. And the number of observations in this case is 60 (?), so we can see that sampling variance is small (I think I could say ‘sampling error is very small’ in this context as well). You can try this with simulated Poisson processes, take 60 samples of Poisson(6), take the average, and see how often it is less than 5 or more than 7. If you take only one sample, the sampling error is much larger. This is actually shown in Figure 1 (IMO).
latex \hat{x}/n[\tex], where n is the number of independent observations. You cannot find unbiased estimator that has smaller variance than this. Estimate obtained this way will be distributed more closely round the true lambda than any other estimator. And the number of observations in this case is 60 (?), so we can see that sampling variance is small (I think I could say ‘sampling error is very small’ in this context as well). You can try this with simulated Poisson processes, take 60 samples of Poisson(6), take the average, and see how often it is less than 5 or more than 7. If you take only one sample, the sampling error is much larger. This is actually shown in Figure 1 (IMO).
Completely another business is the testing of H0. Knowing that lambda is close to 6, we can compute [0.01 0.05 0.95 0.99] quantiles from Poisson(6) – if, for example 0.99 point exceeded 10 times in the data, we can suspect that our distribution model is not OK. In addition, there should be no serial correlation in the data if H0 is true.
And, I didn’t mention measurement errors in the above. Measurement errors affect both estimate of lambda and testing of H0.
And finally, if Figure 1. bars represents sampling error, there is basically nothing wrong with it. Sampling variance is $latex \hat{x}/n[\tex], n=1. But I think that approach doesn’t bring up very powerful test for H0.
Re #47
If sinusoidal, why not “multistable”?
You see the problem? Detection & attribution. (What is the frequency of your sinusoid? Is there more than one frequency? Or maybe the process is “multistable”? What are the attracting states?) Problem specification is a mess. Stationary random Poisson is just a starting point.
The biggest reason arguing against Linsay’s Poisson is the high bias in the 1-2 counts and the low-bias in 3-4 counts. Systematic bias usually implies error in model specification. Essenbach’s cycle-removed Poisson, interestingly, removes this systematic bias.
Re #48
Unfortunately, I am correct (in terms of the inferences that are being attempted with these data, which assume that you are observing a single stochastic process). If you suppose that the mean fluctuates from year to year (hence plotting variance around each observation, not the series mean), then you can not suppose that the variance is fixed. Either you are observing one stochastic process (one mean, one variance), or you observing more than one (multiple means, multiple variances) which has been stitched together to appear as one.
Why would you ever plot a variance around an observation (as opposed to a mean)? What would that tell you?
Re #49
You clarify, at least up until the very end:
What’s right about plotting error around observations? Error is to be plotted on means; individual observations fall inside or outside those error limits.
Re #48
It’s not 15 +/- 3.6 that should be plotted, it’s 6.1 +/- 3.6. If the series is stationary then the obs. 15 should be compared to that. In which case 15 is extreme.
Essenbach shows that the mean and variance might not be stationary but sinusoidal. Now the obs 15 must be compared to the potential range calculated during 2005 to determine if it’s extreme. In which case 15 is still extreme.
around observation. Mean of one sample is the sample itself. Observe only one sample from Poisson with unknown lambda. Best estimate of the lambda is the observation itself. Sampling variance is the observation itself.
#38
The Pearson Correlation coefficient you are using to find trends assumes that the data have a Gaussian distribution. Given the discussion of the Poisson nature of the data on this page, this choice need justifying. A more appropriate test for a linear trend when the data have Poisson variance is to use a generalised linear model with a Poission error distribution. I’ve done this, and you are correct, there is no linear trend.
The absence of a linear trend does not imply that the mean is constant – there may be a more complex relationships with time. This might be sinusoidal (#47) but alternative exploratory model is a generalized additive model. A GAM finds significant changes in the mean. (This test is only appropriate)
Everybody (except #47) seems to be happy with the statement that the “annual hurricane counts from 1945 through 2006 are 100% compatible with a random Poisson process” without any goodness of fit test. Are they? Doesn’t anyone want to test this assertion?
curry#55 RichardT
This point is well taken. The Pearson version, as you correctly note, requires an assumption about normality. Given that we are looking at Poisson (?) data, there is reason to wonder about the robustness of the test.
In #38 I also provided results from two nonparametric tests: Kendall’s tau and Spearman’s rho. They do not require a distributional assumption. Also, because they are relatively powerful tests even when errors are normal, they are attractive alternatives to Pearson. However, while these tests are robust against mis-specification of the distribution, they are not robust against, for example, “red noise”. SteveM has written a lot on this topic; search CA for “red noise” and “trend”. Among other things, “red noise” can lead to a very high type 1 error rate — you find too many trends in trend-free stochastic processes.
Note that in this case all three tests, as well as an eyeball assessment, find no evidence of trend (the p-values for the 3 tests are .35, .71, and .61, respectively (#38)). I think we can safely conclude that whatever trend there is in the underlying process is small compared to the natural variability.
#56
These non-parametric tests, which will cope with the Poisson variance, can still only detect linear trends. If the relationship between hurricane counts and year is not linear, these tests are suitable, and there will be a high Type-2 error. Consider this code
xEven though there is an obvious relationship between x and y, the linear correlation test fails to find it.
You correctly state that these tests non-parametric are not robust against red noise. If the hurricane counts are autocorrelated, then they are not from an idd Poisson process, and the claim that the mean is constant is incorrect.
The code
x=-10:10;
y=x^2+rnorm(length(x),0,1)
cor.test(x,y)#p=0.959 for my simulation
First, I want to join Willis (#47) in offering “special thanks to Steve M. for providing this statistical wonderland wherein we can discuss these matters.” CA really is an amazing place.
I would also call attention to Willis’s elegant and expressive graphics. Graphics are not a trivial thing; they are a critical component of statistical analyses (for those who disagree, Edward Tufte (author of “The Visual Display of Quantitative Information,” one of the most beautiful books ever written) presents excellent counter-arguments including an utterly convincing analysis of the 1986 Challenger disaster — it resulted from bad graphics!).
WRT #44 – #56, there’s been a lot of comments, almost all of them interesting.
I think bender has it right, but the arguments on both sides deserve careful consideration. The reason for the disagreement, as I see it, has to do with ambiguity about rules for graphical presentation, specifically what is “conventional,” and some confusion about what we are trying to represent with the figure.
There is a also subtlety here that I am not sure I fully understand myself, but here goes: When you plot parameter estimates, error bars mean one thing (some sort of measure of the distance between the estimated value and the true parameter); when you plot data, they mean another (corresponding to the distance between the observed value and that single realization of the process). These two types of uncertainty are recognized, respectively, as epistemic and aleatory uncertainty (aka parameter uncertainty and natural variability). That’s why I asked the question in #41
which Il answered in #48
When looking at a graphic, the clue about which type of uncertainty is presented — i.e. what the error bars refer to — is whether or not we are looking at data or estimates. When estimates are based on the mean of samples of size N=1, as is the case here, there is an obvious problem: The viewer may assume that the plotted points are data. However, you could argue, as some have, that these are not data but estimates based on samples of size N=1. (IMHO, it makes no sense to estimate from samples of size N=1 when you have 63 observations available; but that’s another discussion). Unless care is taken in how the graphic is constructed, the ambiguity is bound to cause confusion.
Oops! Please note that in the last paragraph of #59, the “aleatory/natural variability” is incorrectly defined.
#59 Now that I look at it, the whole section containing the word “aleatory” is a mess. Best just to ignore it. 😉
#51 Bender, sorry to prolong an argument, but
No, I don’t think you are and I’m not sure you have understood what I was arguing based on your response additionally in #53. This is not a case where we have some large population where there is some defined population mean and standard deviation and by repeatedly sampling that population we can determine the mean and standard deviation of the sample and from that determine the whole data set which is what you seem to be arguing when you think that each data point is representative of that mean and should have that same variance. When you have a few random, independent processes like radioactive decay, and I submit, for the storm counts per year, you do not have the situation that you describe.
Have you ever done an experiment where you have small counting statistics like a radioactive decay counting experiment for example? The process is described well in that link that Paul Linsay gave and it additionally describes the standard deviation on each individual data point as root N.
http://nucleus.wpi.edu/Reactor/Labs/R-stat.html
Exactly the same situation applies to photons recorded by a photomultiplier but also to more commonplace situations such as calls to a call centre, admissions to a hospital etc. Each summed count within a time interval gives a number – the mean therefore for that time interval which if the count is N in that time interval, the variance is N and the standard deviation is root N. Each individual observation – each time period in the radioactive counting experiment or each year in the counting storms ‘experiment’ is an individual number subject to counting statistics. Where you have small probabilities of things happening but a large number of trials so that probability x trials = a significant number, you are subject to counting statistics. Then each data point (each year in the storms’ case that started everything off) has its own variance based on the number of storms counted in that year. Here I am making no assumptions about time stationarity or anything else, I am just looking at a sequence of small numbers generated by a process subject to counting statistics. This whole debate started because Paul Linsay put counting statistics confidence limits on the data points in figure 1. These are different for each point and I agree with him, you do not have the same confidence limit on each data point because each one is an independent measurement. If you want to compare them – to look for anomalous values or correlations with time or anything else then we must look at the confidence limits for a particular year, if you wish to test if a particular year is anomalous or we test for changes in the mean if we wish to test if there is some correlation with time.
The mean value for all of the 63 years is 6.1 – suppose a particular year records for example 15. You might want to know what is the probability that that year is anomalous and you would look at the variance of that year which is root 15 and compare it with other years. If you want to compare with neighbouring single years then you would be comparing with the mean and standard variation of each of those individual years, if compared with the remaining 62 years then you would sum up all 62 years and derive a mean value and standard deviation which is root of all the storms in the 62 years.
#62 IL: Please take another look at the article that Paul provided and that you cite. It does not say:
Rather — and this is important — it specifies root M, where M is the true process mean (i.e. the expected value of N), which is not the observed value N.
Since this has become a forum on measurement error, let’s continue. It’s an interesting topic all by itself.
When you make a measurement there are two sources of error. One due to your instrument and the second due to natural fluctuations in the variable that you are measuring. The total error is the quadrature sum of these two.
An an example, consider measuring a current, I. It is subject to a natural fluctuation known as shot noise with a variance proportional to I. I can build a current meter that has an intrinsic error well below shot noise so that the error in any measurement is entirely due to shot noise. Now I take one measurement of the current. It’s value happens to be I_1, hence the assigned error is +-sqrt(I_1) at the one sigma level. The experimental parameters change and a measurement of the current gives I_2, this time with an assigned error of +- sqrt(I_2). And so on. I never take more than one measurement in each situation but no one would argue with my assignment of measurement error. [Maybe bender would, I don’t know!]
Now translate this to the case of the hurricanes. Instrumental error is zero. I can count the number this year perfectly, it’s N. If hurricanes are due to a Poisson process the count has an intrinsic variance of N. Hence the assigned hurricane count error is sqrt(N), exactly what I did in Figure 1.
#47, Willis
The bin heights of the histograms are subject to Poisson statistics too. Hence the errors are +-sqrt(bin height). You have to show that the fluctuations in the distributions are significantly outside these errors to warrant the sine wave. To paraphrase the old joke about the earth being supported by a turtle: It’s Poisson statistics all the way down.
#63. Maybe that wasn’t the best link to work with since it discusses Gaussian profiles and says that Poisson statistics are too difficult to work with! Its only the true process mean M when you have a large number of counts so that a Gaussian is an appropriate statistics to use. It makes the point lower that when you have a single count, then the count becomes the estimate of the mean.
I therefore go back to my point that the appropriate confidence limit on a single year’s storm counts is root N where N is the number of counts in that year. If I had thousands of year’s worth of data, on your argument I would take the standard deviation of the total number of storms which would number (say) 10,000 which the standard deviation would be a 100. Are you going to argue that the appropriate error on each individual year is +/-100?, or a fractional error of 100/10000 = 0.01 (times the mean of 6.1 = confidence limit of 0.061 on each individual data point)? The former is clearly nonsense and the latter is wrong because each year does not ‘know’ that there are thousands of years worth of data. Its like tossing coins, I can toss a coin thousands of times and get a very precise mean value with precisely determined standard deviation but if I toss a coin again, that is not appropriate for working out the probability of what is going to happen next time since the coin only ‘knows’ what the probability is of it coming up a particular result for the next throw! Ditto if I want to look at an individual year in that sequence I have to look at the count I have got for that year.
Please note, in that example of counting for thousands of years and getting 10,000 storms I would be confident that I could determine the mean over all those years with a confidence limit of 1% but the uncertainty in time on that mean value would then span that whole period of thousands of years. If I want to see if there are long term trends in that data I can combine 100 years at a time to reduce the fractionational error in each of the mean values for each of those centuries and compare the mean value for each of those centuries with its standard deviation to test whether there is significant change with time. But then you would plot a single mean value for each century with the confidence limit on the time axis of one century.
#47. Willis, this is rather fun. Off the top of my head, your arc sine graphic reminded me of two situations.
First, in Yule’s paper on spurious correlation, he has a graphic that looks like your sinusoidal graphic.
Second, arc sine distributions occur in an extremely important random walk theorem (Feller). The amount of time that a random walk spends on one side of 0 follows an arc sine distribution. When I googled “arc sine feller”, I turned up a climateaudit discussion here that I’d forgotten about: http://www.climateaudit.org/?p=310 .
So there might be some way of getting to an arc sine contribution without underlying cyclicity (which I am extremely reluctant to hypothesize in these matter.)
49,54 Correction:
lambda/n is the variance of the estimator, we don’t know lambda, but using![\hat{x}/n[\tex] wouldn't be too dangerous I guess(?). Compare to normal distribution case (estimate the mean, known variance sigma2),](https://s0.wp.com/latex.php?latex=%5Chat%7Bx%7D%2Fn%5B%5Ctex%5D++wouldn%27t+be+too+dangerous+I+guess%28%3F%29.+Compare+to+normal+distribution+case+%28estimate+the+mean%2C+known+variance+sigma2%29%2C+&bg=ffffff&fg=000&s=0&c=20201002) latex \hat{x}[\tex] is the MVB estimator of the mean, with variance sigma2/n.
latex \hat{x}[\tex] is the MVB estimator of the mean, with variance sigma2/n.
I find Willis’ point (#47) about eliminating the sinusoidal wave interesting from a statistical perspective, but it also speaks to the underlying climate issues. What is the cause and climatic signficance of the sinusoidal pattern Willis eliminated?
You have a record of 63 years, which in climate terms is virtually nothing. I have long argued that the use of a 30 year ‘normal’ as a statistical requirement is inappropriate for climate studies and weather forecasting. Current forecasting techniques assume the pattern within the ‘official’ record is representative of the entire record over hundreds of years and holds for any period, when this is not the case. It is not even the case when you extend the record out beyond 100 years. The input variables and their relative strengths vary over time so those of influence in one thirty year period are unlikely to be those of another thirty year period.
Climate patterns are made up of a vast array of cyclical inputs from cosmic radiation to geothermal pulses from the magma underlying the crust. In between is the sun as the main source of energy input with many other cycles from the Milankovitch of 100,000 years to the 11 year (9-13 year variability) Hale sunspot cycle and those within the electromagnetic radiation. We could also include the sun’s orbit around the Milky Way and the 250 million year cycle associated with the transit through arms of galactic dust. My point is the 63 year record is a composite of so many cycles both known and unknown that to sort them out in even a cursory way is virtually impossible with current knowledge. Is the 63 year period part of a larger upward or downward cycle, which in turn is part of an even larger upward or downward cycle? Now throw in singular events such as phreatic volcanic eruptions, which can measurably affect global temperatures for up to 10 years and you have a detection of overlappping causes problem of monumental proportions.
Interesting discussion.
#55
Not 100 % compatible, that would be suspicious. And I think if I estimate lambda from observations, and then observe that 0.01 and 0.99 quantiles are exceeded only once with n=60, I think I have made kind of goodness of fit test. I don’t claim that it is optimal test, but at least I did it 😉
#62
Having trouble understanding what you are saying (sorry). In your link it is said that
IMO this is not the case here. TAC seems to agree with me.
#64
Makes no sense to me.
Re: #56
I have to continue going back to this statement and others like it to keep, what I view as the critical result coming out of this discussion, firmly in mind. To a layman with my statistical background I find the discussion about the Poisson distribution (and beyond) interesting and informative, but I also am inclined to view it as cutting the analysis of the data a bit too fine at this point.
I would guess that a chi square goodness of fit test or a kurtosis/skewness test for normality would not eliminate a Poisson and/or a normal distribution as applying here (without the sinusoidal correction). Intuitively, if one considers the TC event as occurring more or less randomly and based on the chance confluence of physical factors, the Poisson probability makes sense to me.
I agree with the Bender view on applicability of statistics and errors (but not necessarily extended to valuations of young NFL QBs) and his demands for error display bars. I have heard the stochastic mingling with physical processes arguments before but I keep going back to: stochastic processes arise from the study of fluctuations in physical systems.
Standard statistical distributions can be helpful in understanding and working with real life events but I am also aware of those fat tails that apply to real life (and maybe the 2005 TC NATL storm season).
68, Tim Ball: great post!
Steve Sadlov’s 2007 prediction : 6.1 +/- 2.449489743 — LOL!
Sorry I meant 6.1 +/- 2.469817807 😉
It would be more interesting to find a 95% confidence interval for any hypothetical trend that can be included/hidden in the noisy data. Do climate models make predictions that are outside this confidence interval?
Paul,
I see John Brignell gave your post a mention at his site.
A little over half way down the page.
Steve M, you say:
I agree whole heartedly. I hate to do it because it assumes facts not in evidence. I’ll take a look at your citation. Basically, what happens is that lambda varies with time. It probably is possible to remove the effects of that without assuming an underlying cycle. Exactly how to do that … unknown.
w.
#65 IL: Thank you for your thoughtful comments.
Believe me: I understand your argument. I am familiar with the statistics of radioactive decay, and I know something about how physicists graph count data. The error bars corresponding to that problem — you describe it well — are designed to serve a specific purpose: To communicate what we know about the parameter lambda. The “root N” error bars (though not optimal (see below)), are often used in this situation, and they are likely OK so long as the product of the arrival rate and the time interval is reasonably large. I have no argument on these points.
So what’s the issue? Well, we’re not dealing with radioactive decay, or with any of the other examples you cite. We’re dealing with statistical time series, and, IMHO, the relevant conventions for plotting such data come from the field of time series analysis, not radioactive decay. Specifically, when you plot a time series with error bars, the error bars are interpreted to indicate uncertainty in the plotted values. That’s what people expect. At least that’s what my cultural background leads me to believe.
[This discussion has a peculiar post-modern feel. Perhaps a sociologist of science can step in and explain what’s going on here?].
Anyway, here are some responses to other comments:
This is approximately correct if the only sample of the population that you have is the N observations and you are concerned with estimating the uncertainty in the arrival rate. If you want a confidence interval for the observed number of arrivals, however, the answer is [N,N]. (Incidentally, the root N formula is actually not a very good estimator of the standard error. For one thing, if you happen to get zero arrivals, you would conclude that the arrival rate was zero with no uncertainty).
That’s a good point. Under the null hypothesis we have one population (of 63 iid Poisson variates). To estimate lambda, just add up all the events and divide by 63.
Then I would plot the data — the 63 observations, no error bars — and, as bender suggests, perhaps overlay the figure with horizontal lines indicating the estimated mean of lambda (imagine a black line), an estimated confidence interval for lambda (blue dashes), and maybe some estimated population quantiles (red dots). However, I would not attach error bars to the fixed observation. You know: The observation is fixed, right? However, the overlay would describe the uncertainty in lambda as well as the estimated population quantiles.
OK. So how would you plot error bars for the time series of coin tosses? Note: Coin tosses can be modelled as a Bernoulli rv, whose variance is given by N*p*(1-p); since N=1, \hat{p} is always equal to either zero or one, and your error bars have length zero…
If it’s random then that means we have no clue at all what causes it. Neatly done Paul.
#77 TAC. Thanks for your comments, particularly the first paragraph seems to indicate that maybe we are not as far apart as I thought. Maybe this is a difference from different areas of science and we are arguing about presentation rather than substance but, to me, Paul’s figure 1 is correct and meaningful. What you say
doesn’t make sense to me because if you have assumed a null hypothesis of no time variation and have summed all the 63 years’ worth of data then we only have one data point, the mean of the whole ensemble, with smaller uncertainty on that ensemble mean but spanning the 63 years. What you suggest is having your cake and eating it by taking the data from the mean and applying that to individual data points.
I can see what you are getting at but in all the fields I have worked in (physics related) what you suggest would be thrown out as misleading. I would never see a data point with no error bar because I always see predictors and even if its a perfect observation of a discrete number of storms, to present that as a perfect number to me lies about the underlying physics. Perhaps ultimately as long as there is good description of what is going on and we calculate confidence limits, significance of anomalous readings and trends correctly then maybe it doesn’t matter too much.
I still think though that the basic problem here between us is when you say
No, physically this is exactly like radioactive decay or finding the pennies that I described or admissions to a hospital or any of those similar situations where counting statistics applies – the underlying physics is the same where we have a very small probability of a storm arising in a particular time or place but over a year there are a few. It is not then a statistical time series where I am sampling from a larger population with some underlying mean and variance.
I guess as I say, as long as we correctly calculate the significance of time variations etc and its well explained what is done or displayed then this discussion has probably gone about as far as it can.
My final 2p on all of this. To me Paul’s figure 1 conveys correctly the uncertainties inherent in the physics, what you and Bender suggest to me with my background is misleading and what Judith Curry presented (way back in the othe thread that started all of this with the 11 year moving average) is wrong and dangerously misleading.
Paul:
1) What if the count for some year is zero (TAC’s point in 77)?
2) How would you draw those bars if you assume Gaussian distribution instead of Poisson?
I think I understand now (pl. correct if I’m wrong!). You observe y(t), y(t)=x(t)+n(t), n(t) is error due to instrument. x(t) is a stochastic process. x(t) varies over time, and you are not very interested of x(t) per se, you want to get more general estimate: what is x(t+T), x(x-T), etc. If the process is stationary, it has an expected value. Your second error is E(x)-x(t), am I right? If so,
1)I think that ‘error’ is misleading term
2) ‘natural fluctuations’ without explanation opens the gate for 9-year averages and Ritson’s coefficients.
If you define it as stochastic process, you’ll have many tools that are not ad hoc (Kalman filter, for example), to deal with the problem.
Often ad hoc methods are as effective as carefully defined statistical procedures, but the difference is that the latter gives less degrees of freedom for the researcher. If you have 2^16 options to manipulate your data, you’ll get any result you want from any data set. Popper wouldn’t like that.
#79 IL: I agree that our difference has to do almost entirely with form, not substance, and even there I agree we’re not far apart. When you say:
My only quibble would be that the physics are different; its the stats that are the same; and the “cultural context” — the graphical conventions employed by the target audience — differ.
So, the remaining issue: How to communicate the message, which we agree on, as unambiguously as possible to the community we want to reach.
As I understand it, you are comfortable with — prefer — error bars attached to original data; I worry that such error bars introduce ambiguity to the figure (I also question their statistical interpretation, but that’s a secondary issue). I prefer an overlay or separate graphics.
Of course, we do not have to resolve this. But, having now debated this thorny issue for half a week, perhaps this could be a real contribution to the literature. Consistency and rigor in graphics is important — perhaps as important as consistency and rigor in statistics, though less appreciated.
Perhaps we could come up with a whole new graphical method for plotting Poisson time series — get Willis involved to ensure the aesthetics, and other CA regulars who wanted to get involved could contribute — and share it with the world ;-).
I say we name it after SteveM!
Time to get some coffee…
#79 IL: One final point:
I don’t know if I should admit this, but, in the sense you describe, statisticians do “have their cake and eat it too” — it is standard practice in time series analysis. For example, one often begins a data analysis by testing the distribution of errors assuming the sample is iid — before settling on a time series model. Then one looks at possible time-series models, rechecking the distribution of model errors based on the hypothesized model, etc., etc. It’s called model building. Perhaps it is indiscrete of me to mention this…
It does raise a question: How would you develop error bars for a non-trivial ARMA — let’s start with an AR(1) — time series with Poisson errors?
Don’t know about a coffee TAC, perhaps we could have a beer or two….
I’m not really trying to get in the last word, but I think the physics IS the same.
OK, in a literal sense, radioactivity is due to quantum fluctuations and tunnelling and hurricanes are a macroscopic physical process but what is fundamental to the problem and why I think that what you and Bender suggest is inappropriate is that there is a very small probability of hurricanes arising in any given area at any given time, its only when we integrate over a large area – ocean basin and long time (year) that we find up to several hurricanes. Each – on the treatment above – is a random, independent event caused by a low probability process which is why the statistics and the underlying physics of that statistics are the same as these other areas of physics.
Getting climate scientists like Judith Curry to discuss that inherent uncertainty in years’ counts would be really interesting. Having said that, and this is where it could get really interesting, as Margo pointed out some time back, there is a possibility that hurricane formation is not independent, that the more hurricanes there are in a year, the more predisposed the system is to form more through understandable physical mechanisms. That would take us to a new level of interest but since I see conclusions on increasing hurricane intensity based on 11 year moving averages with no apparent discussion of the inherent uncertainties in a probability system like this, I think there is a long way to go before we can tackle such questions.
#80, UC
(1) sqrt(0) = 0, no error bars, just a data point
(2) once N is large enough, about 10 to 20, the difference between Poisson and Gaussian becomes small. The Gaussian has mean N and variance N. The error bars would still be +- sqrt(N) at one sigma.
Ritson used to be an experimental particle physicist, my training and career for a while too, so I’d expect that he would understand the way I plotted the data and error bars.
The problem with climate time-series data like these hurricane data is that you have one instance, one realization, one sample, drawn from a large ensemble of possible realizations of a stochastic process. You want to make inferences about the ensemble (i.e. all those series that could be produced by the terawatt heat engine), but based on a single stochastic realization.
Any climate scientist who does not understand this – and its statistical implications – should have their degree(s) revoked.
In contrast, physical time-series data that are generated by a highly deterministic process do not face the same statistical challenge. Often the physical process is so deterministic that you never stopped to think about the existence of an ensemble. Why would you?
Hey people, off topic I know, but seeing what good work you amateurs are doing, I can’t resist citing this little gem, which seems taken directly from RealClimate:
This was from G. G. Simpson, talking about proponents of Continental drift in 1943….
(quoted in Drifting Continents and Shifting Theories, by H.E. LeGrand, p. 102)
I got lost. Did you guys agree whether “error bars” should be put on the count data?
#87
No, didn’t agree. But I’ll try to find the book suggested in #11 and learn (found William Price, Nuclear Radiation Detection 1964, will that do? )
1) and 2) in #84 makes no sense to me (*), but I’m here to learn. I agree with #85.
(*) except ‘difference between Poisson and Gaussian becomes small’, but replace 10 to 20 with 1000
#87 No, I guess not. But there is no way I am wrong – or my name isn’t Michael Mann
🙂
A count is not a sample; it is an observation. Observations are subject to measurement error, not sampling error. Sample means are calculated from sample observations (n gt 1) and are subject to sampling error. We do this because we want to compare the known sample mean to the unknown population mean. In stochastic time-series the population being studied/sampled is special, in that it is virtual and it is infinite: it is an ensemble. In stochastic time-series you are trying to draw inferences about a system’s ensemble behavior, but you have to do that with a single (long!) realization, and you have to invoke the principle of ergodicity: the sample statistics converge to the ensemble statistics. If your series is short, or if the ensemble is changing behavior behavior as you study it, then you will not get the convergence required to satisfy the ergocidity assumption. Then you are in trouble.
So … why on earth would you apply sampling error to a set of observations when the thing that produces them is a highly stochastic process that only ever gives you one (possibly nonstationary) sample?
I agree with me.
I remember just enough about statistics to be dangerous (maybe I could be a consultant for the Team? :)), but I think Bender is right. A hurricane count is simply an observation, not a collection of observations, like a sample. Thus, how can you justify applying a statistical parameter to it?
Ok, its a fair cop, my name is not Michael Mann so given what Bender has just posted in #90, maybe this one is just going to run and run, I had better not try and move on.
Its not a sampling error and it is not a measurement error!! Its part of the fundamental physics of the process. Observations produced by random processes with small probability are subject to considerable uncertainty!
Yes, the observation that there were 15 Atlantic named storms last year (or whatever the number actually was) is an exact number, there were 15, no more, no less, if none were missed by all the satellites, ships and planes. But so what??!
There is nothing magic about that number 15 even though its an exact observation. The conditions in the ocean basin were not so constrained that it had to be 15 with a probability of 1! If conditions remained exactly the same it could easily have been 14, or 13 or 17 – and we can calculate the probability that that number of 15 has come up purely by chance and we can also calculate the probability that any given number of named storms ranging from 0 to as large as you like – and including 15 could have occured last year given that 15 were observed. That is what Paul plotted and I think this is where the disconnect in our talking to each other is occuring.
The fact that there were 15 does not mean that there was probability of unity of the number 15 occuring. So we calculate the probability that 15 could have occured even though 15 were observed!! I’m sure that to some that will still sound a bit gobbledegook but think about throwing a dice. I throw it and throw a 2. Its an exact number and an exact observation but the chance of me getting that 2 is not unity, its 1/6 so I can calculate the probability that that 2 came up by chance. (I know this is not a good analogy for the storms since with the dice we have 6 numbers each with equal probability but that is the principle).
That treatment is fundamental to understanding the nature of the process and the inherent uncertainties when you have a process generated by such a fundamentally random process that gives you a few observations per year.
Ok, storm over and calming again – to try and answer jae’s question. I hope I don’t put words in TAC’s mouth or anyone elses for that matter but I think we fairly well agree on fundamentals about uncertainties when we want to compare observations over time to test for trends etc, the difference (pace what I said to Bender above) seems mainly to be communication and how you present data. I think that we are agreed that moving 11 year averages with no consideration of these sorts of uncertainties is definitely not correct.
Someone did say this, but I’m afraid it wasn’t me! I thought it was an interesting idea. (Since I’ve used that word with irony here before, I think I should say I mean interesting in a good way.) I’m afraid I don’t know if one hurricane forming affects the probability of another one forming later on.
I don’t think you would. But, you might illustrate the estimated measurement uncertainties in some cases. So, the if the “official” count recorded for a given year can hypothetically differ from “real number”, then, there might be cases where you want to show this.
As it happens, when I see graphics, I’m content if they capture the major factors contributing to uncertainty. In the case of hurricane counts, if the annual numbers are presented unfiltered, I don’t usually feel the need for anyone to add the “measurement uncertainty” to the hurricane count for each individual year. But if someone averages or smooths the count, then you bet I want to see uncertainty interval. (Better yet, come up with “error” bars that account for both the statistical uncertainty in the mean and the measurement uncertainty. There are techniques for this.)
Basically, you want “honest graphics” that convey a reasonably decent estimate of the uncertainty.
#90 , you say (n gt 1) , why (n greater than or equal 1) would not work?
Nevermind, I withdraw my agreements and disagreements, short time-out for me.
#93 Sorry Margo, my bad again. Sadly, senior moments have a strong correlation with time and have long since moved out of where I can describe them by Poisson statistics but instead by Gaussian with high (and rising) mean. I’ve just searched and it was Sara Chan, comment 39 on the Judith Curry on Landsea 1993 thread – the thread that spawned all of this. Where is Judith Curry anyway? I would really like to know what she makes of these discussions.
#93. I don;t see why hurricane formation would necessarily be independent. If you drive a motorboat through water, you get a train of vortices. I know the analogy isn’t very close, but why would it be impossible that one vortex wouldn’t prompt subsequent vortices. My guess as to a low 2006 season was based on this analogy.
Re #96 Spatial patterns of vortices lead to temporal patterns of anti-persistence and, therefore, statistical non-independence (at least at some space-time scales). Logical.
Re #94
If n = 1, what do you get for a standard deviation?
Regarding the error bars (Fig 1): if a frequency is determined then the error must be a result of categorising the event as a hurricane or not. If it’s based on wind speed then does that mean the error bar is the propagation of errors for the given hurricanes in question? How were the errors combined for data collected by (presumably) various measuring schemes over the decades?
Paul, IL, bender, UC, jae and all: #87 asks: “Did you guys agree whether “error bars” should be put on the count data?” Well, I think the answer is we have some work to do. I was semi-serious when I suggested in #81 that:
Why? Well, I think IL is correct that (#92) “we fairly well agree on fundamentals about uncertainties” and that our differences relate primarily to “how you present data.”
However, I also agree entirely with bender that the error bars are wrong because, among other things, they violate a convention of time-series graphics (#2, #9, #14, #36) and are likely to be misinterpreted.
However, apparently IL and Paul are used to viewing count data this way and, for them, the error bars do not present a problem. Nonetheless, I imagine they can accept the idea that some of us find the error bars confusing if not offensive.
This leads me to think we need a new graphical method that we can all agree to, something unambiguous, compact, beautiful and expressive.
We have plenty of creative talent right here at CA to do this ourselves, and I am not aware of any prohibition on contributing constructively to the science. We are not just auditors 😉
That’s my $0.02, anyway.
SteveM Re 96: I also don’t see why a hurricane occurring right now might not affect the probability of a hurricane forming a short time later. I just don’t happen to know. I could speculate but the physical arguments in my own speculation would sound like mumbo-jumbo — even to me.
As long as you mentioned the Von Karman vortex street, voila:
(The solid object is an island! )
Shoot! I hope this shows.
Re #100
This is child’s play for a heavy like Wegman. That’s why I don’t bother. There are people who are already paid to solve these problems. Why are they not solving them? Why does it take volunteer efforts?
#103 I agree with bender on this point, everything we have been debating for hundreds of comments over several threads must be well known to professional statisticians, thrashed out in papers and books.
I don’t know that, but since Poisson statistics has been around for nearly 200 years, all of these things must have been well chewed over.
#100 TAC – I can perfectly well accept that there are different ways of viewing the world, it sounds like Paul and I are coming from a physicist’s viewpoint and need to understand the world from underlying physical principles. As long as we all accept the fundamental uncertainties given by the physics and calculate probabilities and confidence limits correctly when we calculate if there is a significant change with time etc then, ok, I can live with people wanting to present the data in a different way.
What you want would get thrown out of a physical science journal though because its ‘unphysical’
#96 Steve, yes, hurricane formation may indeed not be truely independent, I and others mentioned this a little. Unless the correlation becomes very high though so that hurricanes are more or less forming as soon as one is leaving a formation area in the ocean it will be extremely hard to tell.
Behind all this debate are the small numbers of hurricanes per year and a small number of year’s worth of data that makes the uncertainties so large, its very difficult to study anything at all.
Nobody has really responded to my hissy fit in #92, does this make sense to you? Or did you understand this all along?
Ok, too interesting, but other work to do, one more post;)
#90
http://en.wikipedia.org/wiki/Ergodic_hypothesis says
I’m not very familiar with this, but I know that if we have a stationary process (strict sense), we can estimate the finite dimensional distributions from one (long) realization. So, in this context, I think it makes no difference if we speak about ergodicity or stationarity (if math gurus disagree, cases of singular distributions etc, pl. tell it now). Stationarity is easier concept for me (for some unknown reason).
#90,91 why the sample size cannot be 1? With sample size of one you cannot estimate standard deviation of Gaussian distribution, but Poisson distribution is different case.
Paul, IL:
Price, Nuclear Radiation Detection has a chapter ‘Statistics of detection systems’. As an example, there is a data from 30 separate measurements, each taken for a 1-min interval, Geiger-Muller counter. (I can post the data later, if needed). Average is 28.2 counts.
It is assumed that n_i=(approx) mean(n)=(approx) lambda=sigma^2. Using the example data it is found that 27 % of the n_i +- sqrt(n_i) limits do not contain the mean(n). But the story continues:
And TAC said in #77
I see no conflict here, with sample size of one you have to use
n_i=(approx) mean(n)=(approx) lambda=sigma^2
but with larger sample size you average them all.
And no conflict with my #80 either, we are not very interested in n_i per se, we want more general estimate (capability to predict, or to reconstruct the past, for example).
To me, the Figure 1 looks like a result of model
observation = the true lambda + error
where the error term distribution is Poisson(lambda)[lambda+x], E(error) is zero and Var(Error) is lambda. Each year there is a new lambda, and past lambdas don’t help in estimating it. Each year a new estimate of error variance is obtained from the observation itself. And that’s why I think it is a confusing figure.
UC and TAC, thanks as always for your thought provoking posts. I got to thinking about your statement that:
and TAC’s statement that:
It seemed to me that we could estimate the mean in a different way, which is that the mean is the value that minimizes the RMS error of the points (using the usual Poisson assumption that the variance in the dataset is equal to the mean). Using this logic, I took a look at the RMS error. Here is the result:
The minimum RMS value is at 8.9. I interpret the difference between the arithmetic mean and the mean that minimizes the RMS error as further support for my conclusion that lambda is not fixed, but varies over time … and it may say that we can reject TAC’s null hypothesis.
w.
A question: suppose that Atlantic storm count is affected by a random process (El Nino / La Nina) as well as a trend (SST). Would that be detectable by this analysis?
(Pardon my likely poor posing of the question but I hope the gist of it is apparent.)
There’s evidence that year-to-year count is strongly affected by El Nino, which appears random. There’s also the thought that SST affects count, which is believed to be a strong effect by some (Webster etc) while others (like me) think there’s probably a weak effect.
#100, #103, #104: I admit developing a new graphic was fanciful. As bender and IL note, it is someone else’s job.
#105 When bender (#90) talks about n .gt. 1, I think he’s using “n” to denote the number of Poisson observations (each observation would be an integer .ge. 0). When n=1, we have the non-time-series case that IL and Paul (I think) are used to working with.
However, we have also used the letter “n” to denote the number of arrivals, and there is an interesting issue here, too. I’ll now use K, instead, to denote a Poisson rv, and k to denote an observed value of K. The most obvious problem with the \sqrt{K} formula occurs when k is zero (#77). In that case, applying the “\sqrt{K} reasoning” yields an arrival rate of zero with no uncertainty. Whatever our disagreements, I think we can agree that this is nonsense. Also, it should be troubling given that, for Poisson variates, K=0 is always a possibility.
IL: I’m still having a hard time understanding what is meant in #79 by
For me, I cannot even see how the physics of a die and the physics of a random number generator are the same. However, if you want to argue that a rolling cube and a CCD detector in a dark room have the same physics (and then there’s the hospital), I’m all ears. What is really going on here? I think IL may have defined statistics as a subset of physics — I guess that’s his prerogative — in which case the result is trivial. However, statisticians might now see it that way; they tend to draw the lines somewhat differently. They talk about events (for the die, the event space looks something like {.,:,.:,::,:.:,:::}) which are governed by physics, and the corresponding random variables (which take on values like {0,1,2,3,4,5,6}) which have statistical properties that can be considered without reference to physics.
As for the rest, I think most of the arguments have been made. I still agree with bender; I don’t like the error bars. I see small problems with the error bars (e.g. as defined, when k=0 they don’t work); I see medium-sized problems with the error bars (where the estimated error and the estimated statistic are correlated, unsophisticated (e.g. eyeball) statistical tests and confidence intervals will tend to be biased toward rejecting on the left (btw: this bias is connected with Willis’s RMSE estimator in an interesting way)); and then there’s the BIG problem: Potential misinterpretation. They also add clutter to the graphic and require explanation. Overall, not a good thing.
However, I don’t hold out much hope that repeating these arguments, or bender’s arguments (which I also happen to agree with), will change any minds.
Re: #107
David S, I can give you my layman’s view (and repeat myself as I am wont to do) and that is that TAC’s comment in #56 and quoted below would indicate that a statistically significant trend is not found. I also believe that the point has been made that the use of lower frequency filtering needs to be justified before applying and that the filtering application, if justified, must make the necessary statistical adjustments (to neff).
The remainder of the discussion (which comprises most of it) comes by way of a disagreement on the display of error bars and the thinking behind it. From a layperson’s view, I agree with TAC and Bender on the matter of the thinking behind the error bars and have appreciated their attempts to explain the interplay of stochastic and deterministic processes and the appropriate application of statistics. My agreement may be because this is the approach to which I am familiar. Perhaps it is my layperson’s view, but I am having trouble understanding the other approaches presented here and their underlying explanations. I am not even sure how much of the differing views here result from looking at deterministic and stochastic processes differently.
This discussion has been very friendly compared to some I have experienced on this subject. I do think that there is a correct comprehensive view of how statistics are applied to these processes and not separate deterministic and stochastic ones.
To sew these threads up we should get back to the project we were working on prior to the publication of Mann & Emanuel (2006), which would require translating John Creighton’s MATLAB code (for orthogonal filtering) into R and applying it to these data. Because when you account for the low-frequency AMO (similar to what Willis has basically done), and Neff, and the Poisson distribution of counts (as Paul Linsay has done) I am sure that what you will find is no trend whatsoever. The graphical display would be cleaner and more correct than Linsay’s here, but would still prove his basic point: this is a highly stochastic process which is statistically unrelated to the CO2 trend (but might be related to a decadal oscillatory mode that is a primary pathway for A/GW heat exchange).
Well … nothing is as simple as it seems. I had figured that if the standard deviation as used by Paul in Figure 1 was an estimator of the underlying lambda, I could use that to figure out where lambda was as I did in post #106 above. This showed that lambda estimated by that method was smaller than the arithmetic mean.
However, the world is rarely that simple. Having done that, I decided to do the same using R with random Poisson data, and I got the same result, the lambda calculated by the same method is smaller than the actual lambda … so I was wrong, wrong, wrong in my conclusions in #106. However, this also means that the use of sqrt(observations) as error bars on the observations leads to incorrect answers … go figure.
w.
#110, bender. For fun I showed Figure 1 so some of my former physics colleagues. Nobody even blinked. The only point anyone made was that the error bars for very small n should be asymmetric because of the asymmetric confidence intervals for the Poisson distribution. Which I knew but didn’t want to bother with for an exercise as simple as this.
In any case, the error bars as plotted (with the asymmetrical correction at small n if you want to be fussy) are the values needed to fit the data to any kind of function. They have to be carried through into any smoothing function like the running average used by Curry or Holland and Webster.
For fun I’ve also looked at the data back to 1851 without bothering about possible undercounting. The mean drops to 5.25 hurricanes/year from 6.1 but the data still looks trendless. The distribution and overlaid Poisson curve match as well as in Figure 2. With 156 years of data it provides an interesting test of the Poisson hypothesis. The probability of seeing a year with no hurricanes is exp(-5.25) = 0.0067, quite small. But in 156 years I’d expect 156*exp(-5.25) = 1.05 years with no hurricanes. In fact, there are two years, 1907 and 1914, that have no hurricanes.
Surely a quick and easy way of showing a trend would be to plot the Poisson distrib. for several time periods, say every 40 years? Then you could see if the mean shifts.
Re #112
Send your physics colleagues here and maybe they’ll learn something about robust statistical inference if they read my posts. Those error bars are meaningless in the context of the only problem that matters: hurricane forecasting. People who don’t blink scare me.
be afraid, verrrry afraid.
Re #109 Ken, thanks. That’s about what I gathered. One day I’d like to learn about the statistical characteristics of processes which are driven by both random and trended factors.
115 Yes, well, I suppose you have nothing to lose being wrong, so why should you be afraid. Go ahead and mock me. Just be sure to send your physics friends here.
TAC #108
I guess I’m not quite in the category of Lord Rutherford who said ‘All science is physics or stamp collecting’ but maybe my view of physics is more catholic than most (here anyway).
What I meant was that although radioactive decay, the hurricanes and the hospital admissions have different physical processes, (quantum fluctuations/heat engine of the ocean/infection by pathogens) neveretheless, when you strip each to its bare essentials, they are working in the same way.
The probability of any given radioactive atom decaying in a certain time is completely minute, but there are a vast number of atoms in the lump of radioactive material so that the tiny probability times the number of atoms gives a few decays per second (say).
The probability of a hurricane arising in a particular area of ocean at a particular time is tiny but when you add up all those potential hurricane forming areas over the whole of an ocean basin and over a long enough time you get a few hurricanes per year.
The probability of any one of us as an individual getting a pathological disease is really tiny, but there are a lot of people so a hospital sees a small but steady stream of people each day. (I say steady, what I mean is a few each day but the numbers who are admitted each day fluctuates according to Poisson statistics).
(Of course, if the events are no longer random with small probability such as if an infectious disease starts going through a neighbourhood then the Poisson distribution breaks down. The same would happen if hurricanes formed at a higher rate so that the formation of one affected the probability of another forming).
Whenever you have a small probability of something happening to an individual (person/area/thing etc) but an awful lot of persons/areas/things then you get Poisson statistics.
I call that stripping a problem to the essentials ‘physics’, (maybe I do follow Rutherford after all), but that’s not important, what is, is that understanding of the inherent and large uncertainties in the system.
Strictly peaking of course, you are right that the error bars on the graph are not necessary for ‘robust hurricane forecasting’, you can correctly study the statistics of the sequence of numbers without plotting the error bars on figure one BUT THEY ARE THERE! and if you want to understand the underlying physics (there I go again) of a problem, ie its most fundamental essentials, I, and Paul and clearly from Paul’s colleagues of a ‘physics’ pursuasion, these are the sorts of things you need to think about.
From many of your posts and from others’ posts here, I still don’t think many people here fully understand the underlying principles and fundamental large uncertainties when you have a random process at work.
#112
Yes, yes. Absolutely. Why can’t this be seen? If bender and others are calculating ‘robust time series’ correctly (I am not doubting that bender does, I don’t think Judith Curry does), then this is all implicit in their work even if they don’t realise it – Paul and I are just making it a bit more explicit.
#119 Il:
I think I appeciate what you mean by
In its dedication to a search for grand theories, for unifying explanations of seemingly unrelated phenomena, physics is magnificent. When I wrote (#108) “I think IL may have defined statistics as a subset of physics,” that is what I had in mind. It is a great and noble thing.
However, I hope you appreciate that statisticians sometimes see things differently. For example, statisticians will bristle when they read what you endorsed (#119) “fit the data to any kind of function.” You see, statisticians, in their parochial ways, believe that one fits functions to data — never the other way around. However, based on a sample of N=2, can I conclude that physicists do not subscribe to this principle? 😉
[OK: That last part was undeniably snarky].
Anyway, I think we are mostly in agreement. When are we having that beer?
#107
If we deal with a random variable X whose distribution depends on a parameter which is a random variable with a specified distribution, then the random variable X is said to have a compound distribution. One such example is negative binomial distribution (The lambda of Poisson distribution is specially distributed rv):
http://en.wikipedia.org/wiki/Negative_binomial_distribution
Hey, they mention ‘tornado outbreaks’..
AGW oriented model would be of course lambda=f(Anthropogenic CO2) (which is a possible alternative hypothesis to our H0: lambda=constant, which we have been testing here many days). And by figure 1 Paul says that a lot of very different lambda-curves could be well fit to this data.
Paul,
Let’s put this value to Price’s text: This value is reported as 0 +- 0. There are only about 33 % chances out of 100 that the true average number of counts for this time interval differs from 0 by more than 0.
1) Not very true, underestimates the percentage
2) No error bars: people get an idea that this is something exact, something completely different with in the other cases (1,2,3,..).
+-sqrt(n) is a confusing rule for me, that’s all. But I think I understood your message now.
Re: UC request in comment #3
In keeping with my obsession to retain the major points of threads such as this one in a reasonable summary, I would like to see any reference presented to answer UC’s question from very early in the thread — as my perusal failed to come up with one. I would like to add a request to see a reference that handles the 0 count with this approach. The reference should be for an application other than radioactive decay.
Also I assume we are talking here, not about counting error as in radioactive decay for many independent measurements where if you have only one measurement the counting error is N^(1/2), but many measurements from the same system where the mean becomes N bar and the standard deviation becomes (N bar)^(1/2) which are the mean and standard deviations for a Poisson distribution as derived from the all of the data points.
Once a contained weather system begans moving over the surface of the earth it is subjected to the factors created by movement over a rotating surface and also the movement of an object through a uniform medium. The speed within the hurricane has been discussed, but we also need to consider the speed with which the system moves over the surface.
The deflection of the trajectory of a system as it moves away from the equator is affected by increasing coriolis effect and an important part of this is changing angular momentum (am). The latter influence (am) varies with the speed of the system.
The photograph Margo provides (#102) apears to indicate the second factor and that is sinuosity. There is clear sinuosity in the circumpolar vortex and in the flow of the Gulf Stream and North Atlantic drift. It is logical to assume that a weather system moving through the uniform medium of the atmosphere will be subjected to sinuosity.
As I understand nobody has effectively explained the development of sinuousity. The best explanation I have heard is that it is the most efficient way of moving from A to B with the least amount of energy used – a natural conservation of energy process.
I see the problem now. Two issues have been conflated here. I have been arguing about what kind of graphical representation and error structure is required to make robust inferences about changes in the ensemble mean number of hurricanes expected in a year. The physics people are concerned about propagation of error, arguing that if you are going to use some observation in a calculation you need to know the error associated with the observation and carry that through the calculation. I won’t disagree at all with the latter, but I would add that you had better understand the former if you want to understand what it is the hurricane climatologists are asking. My point is that it doesn’t make sense to treat an observation as though it were a representative sample of the ensemble. You physics people need to think about what it means to infer a trend based on a sample realization drawn from a stochastic ensemble. Until you understand that you will continue to bristle at my comments.
Sampling error and measurement error are not the same thing.
Tim B., thanks for the post. You say:
Sinuosity is quite well explained by the Constructal Law. This Law actually explains a whole host of phenomena, from the ratio of weight to metabolic rate in mammals to the general layout of the global climate system.
There is a good overview at the usual fount of misinformation, I think William Connelly hasn’t realized that Bejan’s work covers climate.
The Constructal Theory was developed primarily by Adrian Bejan. His description of the theory is here. A two page Word document, The design of every thing that flows and moves, is a good introduction to the theory. He is one of the 100 most highly cited engineers in the world. His paper:
is a clear exposition of the major features of the global climate from first principles.
Sorry to harp on this, but Bejan’s work has been wildly under-appreciated in the climate science community.
w.
#120 TAC Steve has my email. Probably about time to go back to lurk mode.
IL, Paul, bender, et al. I enjoy debating with smart people, and this time has been a particular pleasure. I think the discussion helped clarify the issues, and made me aware of things I had not thought about in a long time, if ever (bender summarized it elegantly with “Sampling error and measurement error are not the same thing” — but they are both real and they both matter).
I’m disappointed that no one jumped on the opportunity to point out, gratuitously, that “fitting data to functions (models)” seems to be SOP among some climate scientists. I thought that qualified as “low-hanging fruit”; you guys are so polite!
Thanks!
TAC
#47
Willis,
Not sure about sinusoidal distribution, but how about Poisson distribution where lambda is a function of some other random process (see 107,121, and I think the paper Jean S linked in #19 is relevant as well). I noted that there are extremes that don’t fit well to your histograms (3rd Figure) – and these extremes are not necessarily recent ones (1887, 1933). One way to model overdispersed count data (variance greater than the mean) is using the negative binomial distribution (lambdas follow Gamma distribution), but in this case some stochastic process as a ‘lambda-driver’ would probably do.
And now we are so close to Bayesian data analysis, so I have to ask:
Can anyone give a predictive distribution for future hurricanes given the SST? i.e. yearly p(n|SST). How different it would be from John A’s Poisson(6) ? We don’t know the future SST, but we can plug those values in later. And the same for global temperature, give me p(T|CO2,Volcanic,Solar). I will check the accuracy of our knowledge ten years later with realized CO2, Volcanic and Solar values.
TAC, I wrote an example on fitting data to functions
#63 in http://www.climateaudit.org/?p=1013
But let’s not blame climate scientist for everything, this kind of fitting was invented earlier that climate science, I think:)
#126
Thanks Willis:
It appears this is the information I had heard about, namely that sinuosity is an atttempt to maximum energy efficiencies by overcoming restrictions such as friction throughout an entire sysem.
I would still like some response to my other points about angular momentum and sinuosity as applied to the movement of hurricanes. The deflection of all the tracks to the right as they move away from the equator in the Northern Hemisphere is mostly a function of adjustment to changing rotational forces. The degree of adjustment is a function of the speed of the entire weather system. Depending on which way this macro guidance sends the system then determines the geophysical and other factors that will come into play.
I realize this is not statistics, but the number of occurrences, such as US landfall of hurricanes, intensities achieved, and many of the factors being dicussed here, are directly determined by them.
Re: #129
Interesting point. Bill Gray uses past TS data to construct a predictive model for forecasting TSs weeks ahead of the season and then massages the data again to “adjust” his predictions. The way I look at what he has accomplished is that the predictive power of the advanced model is not statistically significant but that closer to the event prediction is. I would think that someone must have published models for hurricane events using past data without the attempt to be predictive, i.e. after the fact. Gray uses numerous variables in his predictive models and SST, as I remember, plays a part, albeit a small one. As I recall Gray rationalizes his use variables by attempting to explain the physics involved.
Modern computer models are used to predict TSs but have very little out-of-sample results to judge them by. What we really need, at least as a starting point ,is a computer model that uses the actual conditions at the time of the TS event as predictor of TSs.
But are not we getting a bit ahead of ourselves when data seem to indicate a trendless line of TSs versus time.
Re: #130
I am sure you know better than I, but is it not a fact that one thing computer models have been able to accomplish with some success is to predict the tracks of TSs. What inputs do they use?
#131
Ken, thanks for the response. The ability to predict track and speed has not been very successful, especially when you consider the limited range of directions. That is, they all move in a general pattern in one relatively small quadrant of the compass. In addition, the predictions of different computers of a single hurricane vary considerably.
Oh, good grief. Hurricanes are one of the ways that Earth dissipates heat. When the SST is hotter and atmospheric conditions (wind speeds, shear, etc.) are at the right level, the hurricanes increase in number and strength (as well as “simple” thunderstorms). It has to be related, in the long run, to SST. I’ll bet there were a lot more severe hurricanes during the MWP. It’s too bad we don’t have reliable proxies for past hurricanes.
RE #132 The computer models use standard meteorological inputs and generate a path and intensity prediction. One thing that’s been found is that an “ensemble” (average prediction, or range of predictions, from many models) is often better than the prediction from just one model.
It’s also been found that flying jets into the surrounding atmosphere to gather data results in much-improved forecasts. It seems that the computers suffer from GIGO, which is not a surprise.
I am very interested in seeing the European (ECMWF) computer sstorm season predictions this year. As I understand it, they let the computer run months of weather map predictions and then count the storms the computer generates.
Good luck with that.
What I have been attempting to point out about models used to predict a TS event or its path is that the predictive capabilities appear to improve as data from actual current or near current time conditions are used to continually readjust the predictions. Longer term predictions have to first make educated guesses as to what these conditions will at a future time and then use those “guesses” of conditions to determine the probability of a TS event or probability of the direction of its path.
What I would like to see is how well do these models perform if they have all the data of the existing conditions for an incremental step and then as conditions change how well they perform for the next step and so on. In other words how well can they simply process current data by excluding the prediction of conditions?
A plot of NHC storm forecast errors is shown here . The forecasts are one-day to five-day. For example, the chart shows that the typical error for the 2-day (48 hour) forecast is about 100 nautical miles. These can be thought of as computer + human forecasts.
As shown, the farther into the future the forecast goes, the greater the cumulative error. I will say from watching many storms that, beyond five days, the forecasts are almost useless. This is why I’m fascinated to see what the Europeans will forecast from their computer-generated storm seasons.
The computer-only performance is shown here , for the 2-day forecast. The computers do a little worse than computer + human, but they are improving. Interestingly, the Florida State Super Ensemble (FSSE) does as well as, or slightly better than, the human + computer performance. My understanding is that the FSSE looks at all computer models and considers their historical error tendencies in making its forecast.
#134
By implication then the problem is not enough models. More models and therefore better approximations.
I also note the comments about better accuracy as the actual event approaches. This is the practice I see in Canadian forecasts. I call it progressive approximation. With regular weather forecasts I understand that if you say tomorrow’s weather will be the same as today you have a 63% chance of being correct. This is based on the rate of movement of weather systems which generally take 36 hours to move through. Hence the probability of the weather being the same in 12 hours is 63%.
Surely lead time is essential in forecasting for extreme events to provide time for evacuation or other reactions. How many times will people pack up and leave when there was no need?
Tim Ball, you say in #130:
Actually, it sound like you are talking about something different, the minimization of entropy. The Constructal Law is something different and much more encompassing. It was stated by Bejan in 1996 as follows:
The basis of the theory is that every flow system is destined to remain imperfect, and that flow systems evolve to distribute the imperfections equally. One of the effects predicted by the Constructal Law is the one that you have alluded to above, the maximization of energy efficiencies. The Constructal Law predicts not only the maximization, but the nature and shape of the resulting flow patterns.
Because of this power, it has found use in an incredibly wide variety of disciplines. See here for a range papers utilizing construcal theory from a variety of fields, including climate science
All the best,
w.
RE #137 I think the key to using multiple models in an ensemble is to know their weaknesses and then make an adjustment for those biases. The GFS model, for instance, may be slow at moving shallow Arctic air masses, so ignore it on those and look at the other models. The NAM model continuously generates a tropical storm near Panama during the hurricane season, so ignore it on that regard. And so forth. I think that’s what the ensemble method does. Seems, though, that the better approach is to fix the models.
I have a question which you or someone else might be able to help me answer. The question is, why doesn’t the temperature in the upper Yukon (or other snow-covered polar land) on a calm night in the dead of winter fall to some absurdly low temperature, like -100C? It seems to me that there is little heat arriving from the earth, due to snow cover, and little or no sunlight, and (often) clear skies allowing strong radiational cooling What brakes the cooling? Thanks.
David, where is the trick? A night in the dead of winter over there is the same as a day: without sun.
I would like to resurrect this thread if that is possible because I believe that everyone has missed the point.
We were discussing statistical inference. Statistical inference involves hypothesis testing. Hypothesis testing involves setting up a Null Hypothesis. Discussions such as the one about whether we should or should not show confidence limits on graphs can often be resolved by asking the question “What is the underlying null hypothesis?”.
Indeed is there a null hypothesis underlying Paul Linsay’s claim that the sample data are a “good” fit to a Poisson distribution?
I will now set up a null hypothesis for dealing with Paul’s proposition about the hurricane data. My null hypothesis is the following statement: “The annual hurricane counts from 1945 to 2004 are sampled from a population with a Poisson distribution and the hurricane count of 15 for the year 2005 is a sample from that same population.”
The mean count for the 60 years 1945 to 2004 inclusive is 5.97. We will use this as an estimate of the parameter of the distribution. I have calculated that the probability of obtaining a count of 15 or greater from a Poisson distributed population with a parameter of 5.97 is .0005, ie 1 in 2000. We can therefore reject the null hypothesis at the 0.1 percent level.
It follows that either 2005 is an exceptional year which is significantly different from the 60 preceding years or that the process which generates annual hurricane counts is not a Poisson distribution. Personally I prefer that latter interpretation. Hurricane generation is likely to depend on large scale ocean parameters such as mixed layer depth and temperature which persist over time. Because of this it is unlikely that successive hurricanes are independent events. If they are not independent then they are not the outcome of a Poisson process. Poisson works only if there is no clustering of events.
A back-of-the-envelope calculation indicates that 15 is rather a large sample value. With a mean of about 6 and a standard deviation of about 2.5, 15 is more than 3 standard deviations away from the mean. It will certainly have a low probability.
Ironically Paul Linsay’s data examined in this way leads to a conclusion which is diametrically opposed to his original intention in presenting the data. All the same it was a great idea and one certainly worth discussing on Climate Audit. Thanks Paul.
JR
It seems to me, accepting your figures, that your 1 chance in 2000 is the statistic that gives the chance of having 15 hurricanes in any one year. However, there are 60 years in 1945-2004, and so your 1 in 2000 becomes 60 in 2000 for any set of sixty years. From your calculation, there’s a 3 percent chance that in any 60 year period, one year will have 15 hurricanes. From Paul’s figure, we see one 15-hurricane year. So, your null hypothesis is rejectable at the 3 percent level. Not very significant.
Re #141, 142: And for us lay folk, the conclusion is??
#141, 142: Pat’s analysis is the correct one. In my original calculation I got a mean of 6.1 hurricanes per year. This gives a probability of 1.0e-3 of observing 15 hurricanes in any one year. In 63 years the probability is 6.5e-2 of observing at least one 15 hurricane year.
Next point: When should a rare event generated by a stochastic process occur? Only when you’re not looking? Only if you’ve taken a very long time series? The correct answer: They happen at random. It’s hard to build up an intuition for these kinds of probabilities. In my youth, I spent many sleepy nights on midnight shift at Fermilab watching counter distributions build up. They always looked strange when there were only a few tens to hundreds of events. It takes many thousands of events to make the distributions look like the classic Poisson distribution. We just don’t have that kind of data for hurricane counts.
There is another very strong piece of evidence for the Poisson nature of hurricane counts that is not shown on this thread but is shown in the continuation thread. If you scroll down to Figure 5 you will see a plot of the distribution of times between hurricanes. Hurricanes occur at random but the time between them follows an exponential distribution, which is the classic signature of a Poisson process. The same distribution occurs if the data is restricted to 1944-2006, and within errors, with the same time constant.
Pat Frank, you say
but my null hypothesis was not about ANY year of the 60 years it was specifically about THE year 2005. The hypothesis that the high count in 2005 arose purely by chance can be rejected at the 0.1 percent level as I stated.
It might be more appropriate to criticize my choice of a specific year in my null hypothesis. I did so because it is a recent year. We are looking for a change in the pattern. The subtext of all this is that the Warmers are saying that global warming is causing more cyclones and Paul is saying “No it’s just chance”. When, after 60 years of about 6 cyclones a year, we suddenly get a year with 15 cyclones is that due to chance? I have shown that it is not. It is too improbable. It is highly significant and we need to look for another explanation.
With regard to Figure 5 on the other thread – the real issue is whether the displayed sample is significantly different from the exponential law expected for a Poisson distribution, not whether the graph looks good. To test this you would need to use chi-square or Kolmogorov-Smirnov as suggested by RichardT on the other thread.
Quantitative statistical methods provide the best way of extracting the maximum amount of information from a limited amount of data. Qualitative methods like eyeballing a graph really don’t tell us very much, it is too easy to fool yourself.
Even though 2005 had a significantly greater number of cyclones I do not believe that this supports AGW. All it does is imply that a mechanism exists for generating an abnormal number of cyclones in some years. The modest count of 5 in 2006 suggests that 2005 was one-off rather than a trend.
A one in two thousand year probability and you don’t think that is significant.
JR
John Reid, I don’t understand the logic. If you picked a year at random, it might be true, but if you pick just the highest year out of the bunch, you have to look at the odds of that turning up in a sample of N=60, not N=1.
w.
Right, if the chance of a given year having x hurricanes is 1 in 2000, then the chance of at least one year out of 60 having x hurricanes is 60 in 2000. So, while it’s highly unlikely that 2005 be that year, it’s not as quite unlikely that that year should be between 1941 and 2000 (for example).
I essentially agree with Paul Linsay’s comments, i.e. that the counts are best fit with Poisson distributions and that the year 2005 was a very unusual year. I also think that since a better fit is derived for a Poisson distribution by dividing the time period and we have some a priori doubts about the early counts that the results from splitting the data would agree with an undercount (a random one that is).
The error bars have nothing whatsoever to do with these arguments, but error bars representing the mean (square root of it) for the entire period would be more appropriate. Thought I would sneak that in. My background on using the square root of the mean for an individual count to indicate statistical error is appropriate if I were counting a radioactive decay that I knew would yeild a Poisson distribution and I make only 1 count. If I made multiple counts I would average them and use the resulting mean to calculate the statistical error.
Paul, I reside close to where you spent your midnight shifts.
#145 — John, thinking statistically is an exercize in counter-intuitive realizations. If you choose any event and ask after the probability that it would happen just when it did, that number will be extremely small. Does that mean no events at all will ever happen?
With regard to your admirable calculation, you can choose 2005 to be your year of study, but the statistics of your system include 60 years and not just one year, because you applied it to Paul Linsay’s entire data set. That means a 15-hurricane year has a 3 percent chance of appearing somewhere in that 60 years. The fact that it appeared in 2005 is an unpredictable event and has the tiny chance you calculated. But that same tiny chance would apply to every single year in the entire 2000 years of record. And in that 2000 year span, we know from your calculation that the probability of one 15-hurricane year is 1 (100%). Even though the chance of it appearing in any given year is 0.0005.
So, how does one reconcile the tiny 0.0005 chance in each and every year with a probability of 1 that the event will occur within the same time-frame? One applies statistics, as Paul did, and one shows that the overall behavior of the system is consistent with a random process. And so the appearance of unlikely events can be anticipated, even though they cannot be predicted.
You wrote: “When, after 60 years of about 6 cyclones a year, we suddenly get a year with 15 cyclones is that due to chance?” Look at Paul’s original figure at the top of the thread: there was also a 12-hurricane year and two elevens. Earth wasn’t puttering along at a steady 6, and then suddenly jumped to 15, as you seem to imply. It was jumping all over the place. There was also a 2-hurricane year (1981). Isn’t that just as unusual? Does it impress you just as much as the 15-year?
John,
What you are doing is a post hoc test – finding an interesting event and showing that it unexpected under the null hypotheses. This type of test is very problematic, and typically has a huge Type-1 error.
But you are correct that Paul Linsay’s analysis is incomplete. A goodness-of-fit test is required, AND a power test is required to check the Type-2 error rate.
Willis says:
I didn’t pick it because it was the maximum, I picked it because it was recent. I am testing for change. It is a pity that this conversation didn’t happen a year ago when it would have been THE most recent year. I agree that the water is muddied slightly by it not being the most recent year.
Ken Fritsch says:
Thank you Ken. So unusual in fact that a year like this should only occur once in 2000 years if the Poisson assumption is correct. I agree with what you say about error bars.
Pat Frank says:
Where did you learn statistics? By your argument the probability of a 15-hurricane year in 4000 years would be 2. In fact the probability of a 15-hurricane year in 2000 years is 1 – (1-.0005)^2000 = 0.632 not 1.
and:
The mean of the whole 62 year period is 6.1. I have calculated the Poisson probability of 11 or more hurricanes in a single year to be .0224. The probability of of 11-or-more-hurricane years in 62 years is therefore 0.75 The probability of 4 such events is .19. No it doesn’t impress me.
The method I used whereby I partitioned the data into two samples, used the large sample to estimate the population parameter and then tested the other sample to see if it is a member of that same population, is a standard method in statistics.
JR
Re: #150
I did a chi square test for a Poisson fit and a normal fit and the fit was significantly better for a Poisson distribution than for a normal one. The fit for the period 1945 to 2006 was excellent for a Poisson fit and good for the period 1851 to 1944 — using of course two different means and standard deviations.
Re: #151
If essentially all of the data fits a Poisson distribution and one year shows a very statistically significant deviation I would not necessarily be inclined to throw out the conclusion that the data fits a Poisson distribution reasonably well. A 1 in 2000 year occurrence has to happen in some 60 year span. The evidence says that the occurrence of hurricanes can be best approximated by a Poisson distribution, and with all the implications of that, but that does not mean that nature allows for a perfect fit as that is seldom the case.
Also what if some of the hurricanes in 2005 were counted simply because of marginal wind velocity measurements? After all we are counting using a man made criteria and measurements. It is not exactly like we are measuring hard quantities in the realm of physics.
#47 Whiles, I’ve heard of sinusoidal distributions but it never crossed my mind to combine it with a poison distribution. Great idea :). Have you looked at the power spectrum of the hurricane’s. Perhaps you can identify a few spectral peaks.
Ken Fritsch says:
Reminds me of my granny who used to say “well someone’s got to win it” whenever she bought a lottery ticket.
and:
Is this the evidence which is under discussion here or do you know some other evidence that you haven’t told us about? If not, aren’t you assuming what you are trying to prove?
Go back to my original post and look at the null hypothesis which I set up. Because the computed probability was extremely low we must reject the null hypothesis. Okay?
Therefore EITHER 2005 was a special year OR the underlying distribution is not Poisson distributed. It’s your choice. It appears you have chosen the former. I am happy with that. 2005 was a significantly different year from the preceding years. The next step is to find out why. Let’s use statistics as a research tool rather than a rhetorical trick.
I am not arguing in favour of AGW. I am arguing against eyeballing graphs and in favour of using quantitative statistics. Paul Linsay picked a lousy data set with which to demonstrate his thesis. Its a pity he didn’t do it 2 years ago, it might have worked without the 2005 datum.
JR
I could really use a latex preview. Please delete the above post:
I find this an intriguing discussion. I think John Ried has a good point. A poison or sinusoidal poison may be a good distribution to describe most of the process but may not describe tail events (clustering) well. John Ried also puts forth the other hypothesis that in recent years the number of hurricanes is increasing. So then why not use some kind of poison regression:
Say: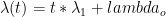
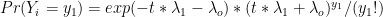

Then :
For the case of N independent events:
I think if you take the log of both sides and then find the maximum value by varying lambda_1 and lambda_o you will get the optimal value. Recall the maximum occurs where the derivative is equal to zero. It looks like you could reduce the problem to finding roots of a polynomial. Perhaps there are more numerically robust ways to handle the problem. That said using the roots of a polynomial could give an initialization to a gradient type optimization algorithm.
Another thought, once you have found the optimal value for the slope of the mean in the poison distribution, one could do as Willis has done in post 47. But this time instead of plotting a sign poison distribution we plot a distribution which is a composition of linear distribution with a poison distribution. Given in reality the mean has a sinusoidal component for sure and maybe a linear component it should be pretty clear the class of distributions we should be looking at.
We must remember all models are an approximation. The point is not to disprove a model but find the model that is the best balance between the fewest number of parameters and the greatest accuracy.
Isn’t the real question not whether the data approximate a Poisson distribution, but whether the mean of the distribution is constant or varies with time? The Cusum chart that I posted as comment #19 on the continuation of this thread clearly demonstrates the mean isn’t constant and that the mean has increased to about 8 since 1995. Hurricanes occur in small numbers each year. You can’t have less than zero hurricanes. Of course the distribution will appear to be approximately Poisson. How can it not be?
I found an informative primer on tropical cyclones. Global Guide to Tropical Cyclone Forecasting
Here are a couple excerpts from chapter one related to Poisson distribution.
DeWitt Payne,
The sinusoidal poison distribution is exactly that. It is a poison distribution where the mean changes with time. A sinusoidal poison distribution should be more tail heavy then the linearly increasing mean which was suggested with John Read. However, perhaps a modulated linearly increasing mean would be even more tail heavy.
I agree that the count data and Poisson distribution fitting is better approximated by a Poisson distribution that has a change in mean with time. I suspect that your Cusum chart is probably overly sensitive in picking up a statistically significant change in mean.
To reiterate what I found for the time periods below for a mean, Xm, and the probability, p, of a fit to a Poisson distribution:
1851 to 2006: Xm = 5.25 and p = 0.087
1945 to 2006: Xm = 6.10 and p = 0.974
1851 to 1944: Xm = 4.69 and p = 0.416
Now the probability, p, for the period 1945 to 2006 shows an excellent fit to Poisson distribution, while 1851 to 1944 shows a good fit and 1851 to 2006 shows a poorer fit but not in the reject range of less than 0.05. As RichardT noted we need to look at Type II errors and those errors of course increase from very small for 1945 to 2006 and intermediate from 1851 to 1944 to large for 1851 to 2006 as evidenced by the values of p.
My other exercise in this thread was to determine the sensitivity of the goodness of fit test to a changing mean and found that while the test does not reject a fit for excursions as large as 1 count per year from the mean, the value of p decreases significantly. If one had a small and/or slowing changing sinusoidal variation in mean shorter than the time periods measured (for a fit to a Poisson distribution) it is doubtful that the chi square test would detect it.
I think one can make a very good case for the Poisson fit from 1945 to 2006 and a complementary reasonable case for a Poisson fit from 1851 to 1944 with a smaller mean. With the evidence for earlier under counts of TCs, the smaller early mean with a Poisson distribution could agree with that evidence — if one assumed the earlier TCs were missed randomly. Or one could, if a priori evidence was there, make a case for large period sinusoidal variations in TC occurrences. I am not sure how a case would be made for a slowly changing mean from a Poisson distribution as a function of increasing SSTs for the period 1945 to 2006, but I am sure that someone has or will make the effort.
Small changes in the 1945 to 2006 mean due to under (or over) counting and/or trends due to small temperature changes and/or a small cyclical variation probably would not be detectable in the chi square goodness of fit test. Having said all that, the fit for that time period is excellent.
Minor note: the period 1945-2006 saw a drift upwards in storm count due to increased counting of weak, short-lived storms and of those hybrids called subtropical storms. If anyone desires to remove those, so as to give a more apples-to-apples comparison, then remove those that lasted 24 hours or less (at 35 knot or higher winds) and the storms which were labeled in the database as subtropical.
Re: #160
The cusum chart is designed to detect small changes in a process, in the range of 0.5 to 2.0 standard deviations, more rapidly than a standard individual control chart. So I don’t think it is overly sensitive considering that the changes observed are likely to be small. In fact, I’m rather surprised that hurricane researchers haven’t already used it. But then it is a technique used mostly in industry.
If the annual count of hurricanes were truly random then annual hurricane predictions would have no skill compared to a prediction based on the median (or maybe the mode) of the distribution. This should be testable and probably already has been. Anybody have a quick link to the data before I go looking?
RE #162 Bill Gray’s individual hurricane forecasts, including his review of their forecast skill, can be found in the individual reports located here .
I don’t know of any comprehensive study, though I seem to recall that Greg Holland did some kind of review (which CA’s willis later found to be of little merit). I also seem to recall that willis did a review on CA and found skill in Gray’s forecasts.
Solow and Moore 2000 which I mentioned in #1 above includes a test for whether there is a secular trend in the Poisson parameter (concluding for Atlantic hurricanes 1930-1998 that there isn’t.) If anyone can locate an implementation of this test in R (which seems to have every test under the sun), I’d be interested. IT seems to me that the strategy for testing the presence of a secular trend (see the null hypothesis H0 described there) would be equally applicable, mutatis mutandi, for testing the presence of a sin(b*t) term rather than just a t term.
Andrew R. Solow and Laura Moore, Testing for a Trend in a Partially Incomplete Hurricane Record, Journal of Climate Volume 13, Issue 20 (October 2000) pp. 3696’€”3699 url
Re: #161
I would agree that ideally as much of the observational differences as can be presumed should be removed from the data before looking at fits to Poisson distribution.
Re: #162
I am not aware of a Cusum analysis being used to evaluate statistically significant changes in means, but have seen it used exclusively as an industrial control tool. Maybe a good reference to a statistical book or paper would convince me.
Re: #163
I found that without the late adjustments (closer to event) that there was not skill in Gray’s forecasts. I also have the idea that he used some adjustments that where not necessarily part of any objective criteria but more subjective. I did find skill when late adjustments were used.
Re: #164
I need to read this link more closely but if they have looked at a fit of land falling hurricanes for fit to a Poisson distribution, I must say: why did not I think of that.
John Ried (#141) writes:
“The mean count for the 60 years 1945 to 2004 inclusive is 5.97. We will use this as an estimate of the parameter of the distribution. I have calculated that the probability of obtaining a count of 15 or greater from a Poisson distributed population with a parameter of 5.97 is .0005, ie 1 in 2000. We can therefore reject the null hypothesis at the 0.1 percent level.
It follows that either 2005 is an exceptional year which is significantly different from the 60 preceding years or that the process which generates annual hurricane counts is not a Poisson distribution. Personally I prefer that latter interpretation. Hurricane generation is likely to depend on large scale ocean parameters such as mixed layer depth and temperature which persist over time. Because of this it is unlikely that successive hurricanes are independent events. If they are not independent then they are not the outcome of a Poisson process. Poisson works only if there is no clustering of events.”
I was thinking about your comments and I’ve decided that if you are interesting in a good fit of the tail statistics then you should not estimate the mean via a simple average. You should use maximum likely hood to estimate the mean. This will mean that the fit you obtain for the distribution will have fewer of these highly unlikely events but will have a worse Chi Squared Score.
#151 — I never claimed to be an expert in statistics. Whatever I may be expert in, or not, doesn’t change that no matter when a 15-hurricane year showed up across however many years you like, your method of isolating out that particular year requires it to be highly improbable and demanding of a physical explanation. Your null experiment, in other words, telegraphs your conclusion.
There is a physical explanation, of course, but in a multiply-coupled chaotic system a resonance spike like a 15-hurricane year will be a fortuitous additive beat from the combination of who-knows-how-many underlying energetic cycles. It’s likely no one will ever know what the specific underlying physical cause is for the appearance of any particular number of hurricanes.
There is another aspect of this which is overlooked. That is, in a short data set like the above, there won’t have been time for the appearance of very many of the more extreme events. That means the calculated mean of what amounts to a truncated data series is really a lower limit of the true mean. A Poisson distribution calculated around that lower limit will leave isolated whatever extremes have occurred, because the high-value tail will attenuate too quickly.
For example, the Poisson probability of 15 hurricanes in a given year increases by factors of 1.7 and 3.2 over mean=6.1 if the true mean is 6.5 or 7 hurricanes per year, resp. That 6.1 per year is a lower limit of the true mean then makes 15 hurricanes less unusual, and so perhaps less demanding of an explanation that, in any case, would probably be unknowable even if we had a physically perfect climate model.*
*E.g. M. Collins (2002) Climate predictability on interannual to decadal time scales: the initial value problem Climate Dynamics 19, 671’€”692
Re #164 Good question.
#141. I agree with John Reid. Poisson is only a hypothesis. Some sort of autocorrelation certainly seems possible to me, especially once the year gets started. My guess as to a low 2006 season was based on the idea that it had a slow start and whatever conditions favored the slow start would apply through the season. Also, for all we know, the true distribution may be a somewhat fat-tailed variation of the Poisson distribution. I doubt that it would be possible to tell from the present data.
#141. John Reid, wouldn’t it make more sense to test the hurricane distribution for 1945-2006 as Poisson rather than calculating a parameter for 1945-2004 and then testing 2005. A test for Poisson is that the Poisson deviance is approximately chi-squared with degrees of freedom equal to the length of the record. HEre’s a practical reference. Here’s an implementation in of this test in R:
The value of x_hat here is no surprise as it is very close to the mean. Including the 2005 and 2006 records, the Poisson deviance is almost exactly equal to the degrees of freedom.
Re: #170
I was concerned that the numbers in your post did not match the chi square test I used to obtain a p = 0.97 for a fit of the 1945-2006 hurricane counts to Poisson distribution. I then read the paper linked and believe that I see the approach used there is much different than the one I used. (I excerpted it below and ask whether I am correct that this is what you used — without the a priori information incorporated).
The p = 0.51 for a Poisson fit that I believe I can deduce from your print outs, while indicating a good fit, is significantly below that that I calculated using the approach with which I am familiar. I am wondering whether the binning involved in my approach that requires at least 5 counts per bin is what makes the difference here. The df in my approach are of course related to the counts ‘€” 2 which in this case could not exceed 13 but is made smaller by the binning of more than one number to meet the 5 minimum requirement. In binning the 15 count for 2005 with other lesser counts to meet the 5 minimum binning requirement, in effect takes a very low probability appearance of 1 occurence at 15 counts and combines it into one where the probabilty goes to a probability of 5 counts over 11 or 12 which will have a higher probability.
Does anyone have the land falling hurricane data and/or link to it for the NATL over the extended period of 1851 to 2006 — or a shorter period such as 1930 to 2006? I would like to see how well that data fits a Poisson distribution over the whole period and perhaps for split periods.
I collated the landfall data into a readable form. The HURDAT data is formated in a very annoying way.
TRY:
Here is some code that can be used to give an appreciation of the type-2 errors in Paul Lindsay’s analysis.
This simple analysis tests if Ho (the process is Poisson) is rejected for mixtures of Poisson processes using a chi-squared test. The mixture has two populations of ~equal size, with means 6.1+offset and 6.1-offset, where the offset is varied between 0 and 3. This is repeated many times, and the proportion of types Ho is rejected is summed.
library(vcd)off.set
When the offset is zero, Ho is rejected 5% of the time at p=0.05, this is expected. The test has almost no power with small offsets, the proportion of rejects is only slightly higher than the type-1 error rate. With an offset of 2, i.e. population means of 4.1 and 8.1, Ho is rejected about half the time. Still larger offsets are required to reliably reject Ho.
This case is extreme, using two discrete populations rather than a continuity, but still Ho is not reliably rejected unless the difference between populations is large - Paul Lindsay's test has little power. An alternative test, GLM, is much more powerful, and can be used to shows that the hurricane counts are not Poisson distributed.
Code again
library(vcd)off.set=seq(0,3,.25)#offset
N=100#increase to 1000 for more precision
nyr=63 #number of years in record
rejectHo
last try
library(vcd)
off.set=seq(0,3,.25)#offset
N=100#increase to 1000 for more precision
nyr=63 #number of years in record
rejectHo=sapply(off.set,function(off){
mean(replicate(N,{
x=rpois(nyr,6.1+c(-off,off))
summary(goodfit(x,"poisson","MinChisq"))[3]<0.05
}))
})
plot(off.set,rejectHo, xlab="Offset", ylab="Probability of rejecting Ho")
rbind(off.set,rejectHo)
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13]
#off.set 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 2.25 2.50 2.75 3
#rejectHo 0.05 0.07 0.09 0.09 0.17 0.20 0.44 0.49 0.63 0.83 0.97 0.98 1
Re: #174
I found that for the chi square goodness of fit to a Poisson distribution from 1945 to 2006 went from 0.974 with a mean of 6.1 to a p
Re: #174
I found that for the chi square goodness of fit to a Poisson distribution for 1945 to 2006 hurricane counts went from 0.974 with a mean of 6.1 to a p
Re: #174
I found that for the chi square goodness of fit to a Poisson distribution for the 1945 to 2006 hurricane counts went from p = 0.974 with a mean of 6.1 to a p less than 0.05 when I inserted means of 5.0 and 7.2. The value of p decreases slowly for the initial incremental changes from 6.1 and then decreases at an ever increasing rate as the changes get further from 6.1.
Do you have more details on the alternative GLM test?
I now remember that the greater or lesser than signs will stop the post.
Steve McIntyre says (#170)
Yes it would. I only did it the way I did it to allow me to make the either/or argument more clearly. As it happens it may well be that the first 60 years is not significantly different from a Poisson distribution. I’ll have a look at it.
JR
I tried the following test for a trend in the Poisson parameter (calculating glm0 as above). The trend coeffficient was not significant.
glm1=update(glm0,formula=x~1+index)
summary(glm1)
anova(glm1,glm0)
#181
try a second order term in the GLM model, else use a GAM
Doing my standard chi square test for goodness of fit for a Poisson distribution for land falling hurricanes for the time periods 1851 to 2005, 1945 to 2005 and 1851 to 1944, I found the following means, Xm, and chi square probabilities, p:
1851 to 2005:
Xm = 1.81 and p = 0.41
1945 to 2005:
Xm = 1.70 and p = 0.03
1851 to 1944:
Xm = 1.88 and p = 0.58
The trend line for land falling hurricane counts over the 1851 to 2005 time period has y = -0.0016x + 4.93 and R^2 = 0.0025.
Re: #174
RichardT, I am not sure how to interpret your findings, but I would say that the p values that you and I derived for the 1945 to 2006 hurricane count fit to a Poisson distribution are close to same: 0.95 and 0.97. It is that number that informs of the fit for that time period and gives the measure of Type II errors. Those numbers indicate a small Type II error. Your sensitivity test is something that shows considerably less robustness for detecting changes in means than my less than formal back-of-an-envelop test did, but that exercise is besides the point as it does not change the p value for the actual fit found.
I know that chi square goodness of fit tests can be less than robust and more sensitive tests where applicable should be applied. For a goodness of fit for normal distribution, I was shown years ago that skewness and kurtosis tests could be superior to the chi square test and particularly when the data is sparse and binning of data becomes problematic.
I do not know how to interpret the difference in the goodness of fit tests between that for all hurricanes and land falling hurricanes for the 1945 to 2005(6) time period except to note that the sparse data for a small Poisson mean reduces the degrees of freedom to very small numbers for a chi square test. The discrepancies between a predicted Poisson and the actual distribution for land fall hurricanes were in the middle of the range and not at the tails.
The telling analysis to me are the lack of trends in the land falling hurricanes and in the partitioned data that Steve M and David Smith have presented and analyzed ‘€” all of which point to some early undercounts and (lacking better explanations for these findings than I have seen) an immeasurable trend in total hurricanes.
I am hoping to see more details from you or Steve M on the Generalized Linear Models alternative test as I do not have much experience with fitting these models with a Poisson distribution (and ??).
Speaking of counting things, would the same type of analysis apply to counting days of record-setting high and low temperatures as described here?
#186 Dan, I think a similar type of analysis would work but record high temperatures aren’t really a poison process. If you find the average distance from the mean temperature at which recorded high temperatures occur and instead count the number of days which the temperatures deviates from the mean by this amount or more you would have a poison process. This could match closely the counts of record high temperatures but will not equal it exactly.
NAMED STORMS AND SOLAR FLARING
Some meteorologists have observed that the key circumstances that factor into hurricane formation are primarily sea surface temperatures, wind shear, and global wind events.
They also believe that stationary high pressure centers over North America and
El Nino cycles in the Pacific cause the Atlantic Hurricanes to turn north into the Mid-Atlantic. Also there appear to be fewer hurricanes during El Nino years more recently
While all this may be true in terms of outer symptoms, it does not explain the inner causes of hurricanes nor do they help to predict future number of named storms, a process which more recently has not been accurate.
Standard meteorology does not yet embrace the electrical nature of our weather, plasma physics, nor the plasma electrical discharge from near earth comets. Solar cycles and major solar storm events like X flares are mistakenly ignored. Yet solar flares disrupt the electrical fields of our ionosphere and atmosphere and cause electrical energy to flow between our ionosphere and upper cloud tops in developing storms.
Here is what Space Weather recently said and recorded when showing an electrical connection from the ionosphere to the top of storm clouds on August 23,2007.
GIGANTIC JETS: Think of them as sprites on steroids: Gigantic Jets are lightning-like discharges that spring from the top of thunderstorms, reaching all the way from the thunderhead to the ionosphere 50+ miles overhead. They’re enormous and powerful.
You’ve never seen one? “Gigantic Jets are very rare,” explains atmospheric scientist and Jet-expert Oscar van der Velde of the Université Paul Sabatier’s Laboratoire dAérologie in Toulouse, France. “The first one was discovered in 2001 by Dr. Victor Pasko in Puerto Rico. Since then fewer than 30 jets have been recorded–mostly over open ocean and on only two occasions over land.”
The resulting increased electrical currents affect the jet streams [which are also electrical] and which energize and drive our developing storms and hurricanes.
Here is what NASA said about the recent large X-20 solar flare on April 3, 2001[release 01-66]
“This explosion was estimated as an X-20 flare, and was as
strong as the record X-20 flare on August 16, 1989, ” said Dr.
Paal Brekke, the European Space Agency Deputy Project
Scientist for the Solar and Heliospheric Observatory (SOHO),
one of a fleet of spacecraft monitoring solar activity and its
effects on the Earth. “It was more powerful that the famous
March 6, 1989 flare which was related to the disruption of the
power grids in Canada.”
Canada had record high temperatures that summer [This writers comments. not by NASA]
Monday’s flare and the August 1989 flare are the most powerful
recorded since regular X-ray data became available in 1976.
Solar flares, among the solar system’s mightiest eruptions,
are tremendous explosions in the atmosphere of the Sun capable
of releasing as much energy as a billion megatons of TNT.
Caused by the sudden release of magnetic energy, in just a few
seconds flares can accelerate solar particles to very high
velocities, almost to the speed of light, and heat solar
material to tens of millions of degrees.
The flare erupted at 4:51 p.m. EDT Monday, and produced an R4
radio blackout on the sunlit side of the Earth. An R4
blackout, rated by the NOAA SEC, is second to the most severe
R5 classification. The classification measures the disruption
in radio communications. X-ray and ultraviolet light from the
flare changed the structure of the Earth’s electrically
charged upper atmosphere (ionosphere). This affected radio
communication frequencies that either pass through the
ionosphere to satellites or are reflected by it to traverse
the globe.
[Note red highlighting is by this author ,not NASA]
Here is what flares affect
.
Industries on the ground can be adversely affected, including electrical
power generation facilities, ionospheric radio communications, satellite
communications, cellular phone networks, sensitive fabrication industries,
plus the electrical system of our entire planet including equatorial jet streams, storm clouds, hurricanes, ionosphere, northern and southern jet streams, earths atmosphere, vertical electrical fields between earths surface and the ionosphere just to mention a few.
The reason for all the extra named storms recently 2000-2005 is not global warming but the increased number of significant solar flares, comet fly byes and the unique planetary alignment during the latter part of solar cycle #23. These events can occur any time during a solar cycle but are more prominent around the years of the solar maximum and especially during 6-7 years of the ramp down from maximum to minimum. Refer to the web page of CELESTIAL DELIGHTS by Francis Reddy http://celestialdelights.info/sol/XCHART.GIF for an excellent article and illustration of solar flares and solar cycles during the last three solar cycles.
The use of simple Regression analysis of past named storms to predict future storms will continue to be of limited value unless these randomly occurring solar events are taken into account as well .One cannot accurately predict the score of future ball games by simply looking at past ball games. You have look at each new year based on the unique circumstances of that new season
The attached table clearly illustrates why there were so few storms [only10] in 2006 and why the previous years 1998-2005 was so much more active in terms of named storms namely [16-28 storms/year] .The table for example shows that during 2003 there were 16 named storms and twenty [20] X class solar flares during the main hurricane season of June1-November 30. Three of the solar flares were the very large ones like X28, X17 and X10. On the other hand during 2006 there were only 10 named storms and only 4 X size solar flares of which none were during the hurricane season. During 2005 and 2003 there were 100 and 162 respectively of M size solar flares while in 2006 there were only 10. The 2000-2005 increase of named storms was not due to global warming or the years 2006-2007 would have continued to be high in terms of storms. During the period 2000-2005, much more electrical energy was pumped into our atmosphere by the solar flares especially the larger X size flares. There may have also been planetary electrical field increase brought on by the close passing of several major comets and special planetary alignments, like during September 6,1999 and August 26-29,2003. The year 2007 will likely be similar to 2006 with fewer storms as there has been no major solar flaring to date or major passing comets. It is possible but unlikely that major solar flaring will take place during a solar minimum year which the year 2007 is. Unless there will be significantly more solar flaring during the latter part of this year, the number of named storms will again be closer to the average of 9- 10 and not 15-17 as originally predicted nor the current predictions of some 13 -15 storms.
YEAR # OF X SIZE DURINGG EL NINO # OF NAMED SOLARR COMETS
SOLAR LARGE HURRIC. YEAR STORMS PHASE Near
FLARESS FLARES SEASON adjustedd not adjust.
1996 1 1 13 12 solar min HALE BOOP
1997 3 X9.4 3 YES 8 7
1998 14 10 NA 15 14
1999 4 4 13 12 PL LEE
2000 17 X5.7 13 16 15 solar max ENCKE
2001 18 X20,X14.4 8 16 15 PL[six] C-LINEAR 2001A2B
2002 11 9 YES 13 12
2003 20 X28,17,10 15 16 16 PL NEAT V1
2004 12 11 YES 15 15
2005 18 X17 12 NA 28 28
2006 4 X9 0 YES 10 10
2007 0 0 NA 5 5 solar min
to date to date 0 to date to date
* assumed season June1 to
Nov-30
C&M flares were not included
Some flares last longer and deposit more energy. This was not noted.
NA EL NINO present but not during hurricane season
Very minor EL NINO months at the beginning of year
PL Special planetary alignment during hurricane season
Since major solar flares are difficult to predict, one can recognize in what phase of the solar cycle one is predicting into and use that as an indicator of possible below average, average or above average solar storm level which in turn translates to below average, average or above average named storms. See paper by T.Bai called PERIODICITIES IN FLARE OCCURRENCE ,ANALYSIS OF CYCLES 19-23 on bai@quake.stanford.edu
Above average flares occur during 6-7 solar ramp down period and to a lesser extent, the 3-4 years around the solar maximum. Average and below average flares occur at solar minimum and the 2-3 of the solar build up leading to solar maximum. Specific planetary alignments and the swing of major comets around our sun will also tend to increase the named storm activity. There are exceptions to every rule and sometime things are different from the normal or the past.
For more information about the new science of weather and the electrical nature of our planet and our planets atmosphere refer to the writings of James McCanney and his latest book PRINCIPIA METEROROLOGIA THE PHYSICS OF THE SUN
Months late, I know, but I just wanted to suggest that an time-variable observation bias is quite likely in hurricane detection. A hurricane is defined as a storm in which sustained windspeeds of more than a certain speed are found, at some point in its career. In the past, windspeeds could mostly only be measured accurately on land. Now, windspeeds can be measured remotely by radar. It is therefore more likely now that a storm which qualifies as a hurricane will be identified as such as than it was, say, 60 years ago. Or have I, too, missed something?
One Trackback
[…] to that number 15, there seems to have been an outbreak of Data Deficiency Disorder over at Climate Audit. When you are stuck with a limited number of data, it is tempting to try all sorts of a posteriori […]