In browsing AR4 chapter 3, I encountered something that seems very strange in Table 3.2 which reports trends and trend significance for a variety of prominent temperature series (HAdCRU, HadSST, CRUTem). The caption states:
The Durbin Watson D-statistic (not shown) for the residuals, after allowing for first-order serial correlation, never indicates significant positive serial correlation.
The Durbin-Watson test is a test for first-order serial correlation. So what exactly does it mean to say that the a test on the residuals, after allowing for first-order serial correlation, does not indicate first-order serial correlation? I have no idea. I asked a few statisticians and they had no idea either. I’ve corresponded with both Phil Jones and David Parker about this, trying to ascertain both what was involved in this test and to identify a statistical authority for this test. I have been unable to locate any statistical reference for this use of the Durbin-Watson test and no reference has turned up in my correspondence to date. (My own experiments – based on guesswork as to what they did – indicate that this sort of test would be ineffective against a random walk.)
The insertion of this comment about the Durbin-Watson test, if you track back through the First Draft, First Draft Comments, Second Draft and Second Draft Comments was primarily in response to a comment by Ross McKitrick about the calculation of trend significance, referring to Cohn and Lins 2005. The DW test “after allowing for serial correlation” was inserted by IPCC authors as a supposed rebuttal to this comment (without providing a citation for the methodology). I’m still in the process of trying to ascertain exactly what was done and whether it does what it was supposed to do, but the trail is somewhat interesting in itself.
Once again, the caption to Table 3.2 says:
Trends with 5 to 95% confidence intervals and levels of significance (bold: <1%; italic, 1—5%) were estimated by Restricted Maximum Likelihood (REML; see Appendix 3.A), which allows for serial correlation (first order autoregression AR1) in the residuals of the data about the linear trend. The Durbin Watson D-statistic (not shown) for the residuals, after allowing for first-order serial correlation, never indicates significant positive serial correlation.
Appendix 3.A doesn’t add much to this, other than providing a reference (Diggle et al 1999):
The linear trends are estimated by Restricted Maximum Likelihood regression (REML, Diggle et al., 1999), and the estimates of statistical significance assume that the terms have serially uncorrelated errors and that the residuals have an AR1 structure. … The error bars on the trends, shown as 5 to 95% ranges, are wider and more realistic than those provided by the standard ordinary least squares technique. If, for example, a century long series has multi-decadal variability as well as a trend, the deviations from the fitted linear trend will be autocorrelated. This will cause the REML technique to widen the error bars, reflecting the greater difficulty in distinguishing a trend when it is superimposed on other long-term variations and the sensitivity of estimated trends to the period of analysis in such circumstances. Clearly, however, even the REML technique cannot widen its error estimates to take account of variations outside the sample period of record.
As I mentioned above, it’s interesting to see the provenance of this “test”. It’s not mentioned in the First Draft. In a comment on Table 3.2, Ross McKitrick said (and I was unaware of his interest in this prior to researching this post):
3-425 A 9:0 Table 3.2. Here, and in Appendix 3.A.1.2, reference is made to “Restricted Maximum Likelihood” standard errors, but the citation is to a general text book (Diggle), not a published article. Considering the importance of the contents of this table to the Chapter, the reader needs considerably more guidance about the estimating methodology, as well as reference to current literature.
There is a substantial literature dating back to the early 1990s showing that anomaly data have long autocorrelation processes in them, making for long term persistence and near unit-root behaviour. It is well known in the climate literature that this can severely bias significance estimates in trend regressions. Yet there is no mention of this problem and it seems that the t-stats in this table reflect only a first order autocorrelation correction, almost certainly making them misleading. I will suggest some improved wording, but I believe this table needs a serious re-do and the reader is owed a substantial discussion of the problems of estimating significance of trends in climatic data. Below I cite a forthcoming treatment of the issue by Cohn and Lins, who comment “It is therefore surprising that nearly every assessment of trend significance in geophysical variables published during the past few decades has failed to account properly for long term persistence…. For example, with respect to temperature data there is overwhelming evidence that the planet has warmed during the past century. But could this warming be due to natural dynamics? Given what we know about the complexity, long term persistence, and non-linearity of the climate system, it seems the answer might be yes.” All the trends should be re-estimated using, at minimum, an ARMA(1,1) model, not an AR(1) model; and the lag processes need to be extended out to sufficient length to ensure the ARMA coefficients become insignificant.
The treatment of this key issue in this chapter is at least 10 years behind the state of the art (see, for instance, Woodward and Gray JClim 1993, who were already ahead of where this discussion is), and unless substantial improvement is made this Table and related discussions should be removed altogether.
[Ross McKitrick]
In response the authors introduced the “IPCC Test” for long-term persistence (although the DW statistics were not actually included in Table 3.3 as promised):
Discussion expanded to new appendix. Residuals from linear trends after fit of AR(1) model do not show strong long term autocorrelation processes as illustrated by the Durbin-Watson statistics now given in Table 3.3.
I consulted the statistical reference, Diggle et al, Analysis of Longitudinal Data, (incorrectly cited as 1999 rather than 1994). It does not mention the Durbin-Watson statistic. When I tried calculated Durbin-Watson statistics on trend residuals applied to HadWWT2, CRUTEM3 or HadCRU3, I obtained values showing substantial serial correlation in the residuals (e.g. HadSST2 1850-2005 had a DW – 0.47 well below the limit of 1.5). There are some other odd features in the trend calculations (the perhaps idiosyncratic use of REML methodology), but I’ll revert to them on another occasion.
Anyway, last week, I wrote to Phil Jones, the co-lead author of AR4 chapter 3, (copy to the University of East Anglia FOI), and inquired as follows:
Dear Phil,
In Table 3.2 of IPCC AR4, you refer to Durbin-Watson statistics for various trend calculations, but do not show them. Could you please provide me with these statistics.I am unfamiliar with any prior use of the Durbin-Watson statistic “after allowing for first-order serial correlation”. Could you please provide me your statistical reference showing how one calculates a Durbin-Watson statistic “after allowing for first-order serial correlation” and giving significance levels for the statistic “after allowing for first-order serial correlation”.
Could you please identify the statistical packages used in your calculation of REML trends and Durbin-Watson statistics?
Would it be correct to say that (1) fitted a trend to the various series; (2) fitted an AR1 arima model to the residuals from (1)? (3) carried out a Durbin-Watson test on the residuals from (2)?
Where applicable, these requests are made under FOI provisions.
Thank you for your attention, Steve McIntyre
I received a prompt and semi-responsive answer. Jones sent me the requested Durbin-Watson statistics; their value for the 1850-2005 HadSST2 trend was 2.20 versus my calculation (using a standard function in R) of 0.47. Jones described the calculation of the Durbin-Watson statistic, which I knew how to do – my question pertained to their methodoogy of using the Durbin-Watson statistic after allowing for first-order serial correlation:
Steve,
The Durbin-Watson statistics were in an earlier draft of the chapter. They were removed simply for space reasons, as none were significant. As you can see, we also removed the lag-1 autocorrelations as well.REML comes from Diggle et al 1999 (section 4.5 pp 64-68). This reference is given at the end of the chapter. The page numbers refer to the 1999 edition of the book. There is a later one available on Amazon, so the page numbers may differ in that edition. David Parker programmed the calculations of all the trends. As far as I know he didn’t do this with any specific statistical packages. He likely used PV-WAVE which the Hadley Centre used for almost all their analysis work. The use of REML is discussed in Appendix 3.A.
DW is very simple to calculate. We used the lag-1 autocorrelations to calculate the reduced number of degrees of freedom of the residuals. This number was used with the DW statistic to estimate the significance. Basically, any DW value above about 1.8 is not significant. DW Tables are in some statistics books. There should be two significance values (for any DW value and N, here the effective number of degrees of freedom). For the lower of these, values below would be significant. Values above the upper are not significant. For values in between nothing can be said. We were always above the upper value. For random numbers, the DW statistic should return a value about 2. There are different sets of Tables for different significance levels (1%, 5% etc). We used 5%, which is generally the one given in text books.
Any statistical package would likely not use the reduced number of degrees of freedom (reduced based on the lag-1 autocorrelation) when giving the significance of DW. Using the reduction to the degrees of freedom makes the test harder to pass.
Phil
While the response is polite and did provide the requested DW statistics, my request was not about how to calculate a DW statistic – which I obviously know and for which there are many references – but for the DW statistic “after allowing for serial correlation”. In addition, Jones explained that the effect of “allowing for first-order serial correlation” was to change the benchmarks for significance of the DW depending on the number of degrees of freedom – an explanation that did not accout for the discrepancy between the reported DW statistic and what I calculated. So I wrote back to Jones seeking further clarification and attaching an R-script for my calculations:
Dear Phil, thanks for the prompt reply, but there are a number of points that remain very unclear. I am extremely familiar with the Durbin-Watson statistic as it is familiar to all econometricians. I use the R language which has a convenient Durbin-Watson test in the lmtest package (the dwtest function.) When I ran a Durbin-Watson test on residuals from fitting a trend, I obtained a Durbin-Watson statistic of 0.49 for an OLS-fitted trend to the HadSST2 series presently online (over 1850-2005).When I re-fitted a trend line using the reported slope of 0.038 deg C/decade, I obtained an even lower Durbin-Watson statistic of 0.27. For this same situation, you reported a DW statistic of 2.2. I’ve attached a script in R. You say that “We used the lag-1 autocorrelations to calculate the reduced number of degrees of freedom of the residuals.” In order to get a Durbin-Watson statistic of 2.2, you must have done something to the data that is not a typical procedure and which is not explained in Diggle. The best guess that I could come up with as to what you did was that you might have fitted an AR1 arima model to the trend residuals and then calculated a DW statistic for the residuals for the arima-fit. However, this is just speculation and there is no clue in AR4 as to what was done.
BTW the usual interpretation of the DW test in econometrics is as a test for first-order autocorrelation, so the exact meaning of using a DW test “after allowing for first-order serial correlation” is by no means obvious. Again, if you can direct me to an article describing the exact procedure that you used together with its statistical properties, I’d appreciate it.
Regards, Steve McIntyre
Jones (who is generally a prompt and courteous correspondent) replied:
Dear Steve,
The DW test was carried out on the residuals after removing the AR1 persistence. So with respect to your earlier email, you are correct that the three procedures were in essence your three points below.“Would it be correct to say that (1) fitted a trend to the various series; (2) fitted an AR1 arima model to the residuals from (1)? (3) carried out a Durbin-Watson test on the residuals from (2)?”
The AR1 persistence is modelled by REML. Maximum likelihood widens the error bars to account for the AR1. The DW test is to see whether any further widening is needed and the results show it isn’t.
Regards
Phil
If Jones’ response is correct, then I’m pretty sure that the AR4 has goofed in using the “IPCC Test” as a test for long-term persistence, since, in a couple of experiments on trend portions within a random walk, I got DW statistics above 2 as well – and the IPCC Test looks ineffective to me against a random walk null.
However, I’m not sure that Jones has described the procedure correctly. Concurrent with this correspondence, David Parker sent me an email that some of the daily station temperature data used in “A demonstration that large-scale warming is not urban” had been posted up at http://www.hadobs.org/ – under “Land surface data”, click on Urban. Since Jones had attributed the calculations to him, I also asked him about statistical references for the methodology as follows:
Dear David… On another topic, I asked Phil Jones about the calculation of trends in AR4 in which a Durbin-Watson statistic was cited “after allowing for first-order serial correlation”. He said that you did the calculations. I’m very familiar with the Durbin-Watson statistic which is widely used in econometrics, but I am unfamiliar with any statistical authorities describing the use of this statistic “after allowing for first-order serial correlation”. He was also unable to describe exactly what the methodology was for doing this. Can you give me a reference for this exact procedure and a description of how you carried out the calculation.
Regards, Steve McIntyre
Parker (also a prompt and courteous correspondent) replied:
Steve
The Durbin_Watson statistic was done on the residuals from the linear regressions after removing the AR1 persistence as modelled by the restricted maximum likelihood software. That is why the values were close to 2. This procedure is correct because the restricted maximum likelihood software will already have widened the error-bars to take account of AR1; the DW is a test to see whether any further widening is needed, and the results showed that it wasn’t for the IPCC series. The restricted maximum likelihood method is described by Diggle et al. cited in the IPCC Report.
We did the calculations using PV-Wave language. In the restricted maximum likelihood software, an iterative procedure was used to choose the best fit to the series: the iteration was done simultaneously in 2 parameters – the AR1 coefficient and the variance of the residuals. After the fit was chosen, the residuals were pre-whitened by subtracting the AR1 component.
I hope this helps
Regards
David
Again, a courteous reply, but notably no statistical reference showing that they’ve used the Durbin-Watson test appropriately under these conditions. So I wrote back once again:
Dear David, thank you for the courteous note. I am familiar with REML methods, but I am not familiar with any description of the properties of the Durbin-Watson statistic in the form that you describe in any peer-reviewed statistical literature and I take it that there is no such reference. I’ve never seen the DW statistic described previously as a “test to see whether further widening is needed”. At present, I haven’t formed any conclusion as to whether such a use is right or wrong; it’s just that I’ve never seen the DW test used in the way that you describe and so far, neither you nor Phil Jones have been able to show me any statistical authority for this use. In the absence of such a reference, could you send me the code for the calculation of the DW statistic in the PV Wave software as you’ve done it so that I can see precisely what you’ve done.
Thanks, Steve McIntyre
Parker promptly replied as follows:
Steve
Here’s the coding.
nz=n_elements(z)
zsqsum=0.0
zdiffsqsum=0.0
durbwat=0.0FOR iz = 1 , nz-1 DO BEGIN
zsq = z(iz-1)*z(iz-1)
zsqsum = zsqsum+zsq
zdiff = z(iz)-z(iz-1)
zdiffsq = zdiff*zdiff
zdiffsqsum= zdiffsqsum + zdiffsq
ENDFORdurbwat=zdiffsqsum/zsqsum
It was applied to the residuals in 1-dimensional array “z” after the AR1 fit had been subtracted from them.
The Durbin-Watson statistic is described in Section 12.1.5 of H von Storch and F W Zwiers, “Statistical Analysis in Climate Research”, Cambridge University Press 1999.
Regards
David
So once again, I had the Durbin-Watson statistic explained to me – the one thing that I wasn’t inquiring about. Reviewing my latest letter, it wasn’t perfectly specified. In my email to Jones, I attached a script showing calculations top to bottom so that he could see what I was doing. I’ll inquire one more time with Parker and see what turns up.
I’ve used the nlme package in R a lot and it covers many of the same issues as Diggle and uses an REML algorithm. The nlme package is written by Pinheiro and Bates and Pinheiro has coauthored with Diggle – so this is pretty familiar turf for me – and I rather enjoy the exploration. At this point, my hunch is that trend portions of random walks will routinely generate DW statistics above 2 and that the “IPCC Test” is accordingly completely ineffective at excluding random walks. If so, then there is a real problem in all the significance calculations attached to Table 3.2. However, so far, I remain unable to replicate any of the reported calculations even for trivial calculations in Table 3.2. So right now I’m merely observing that there are issues with AR4 Table 3.2 and that I’m trying to resolve them.





45 Comments
Very nice, brilliant stuff. Thank you.
I think what they are saying is that they regressed Y(t)=a+bt+e(t) where Y(t) is the temperature series and e(t) are the residuals, modeled e(t) = rho.e(t-1)+u(t), ie an AR1 process for e(t), computed a DW stat for u(t), and instead of using the tables based on T-2 degrees of freedom, computed the “effective degrees of freedom” concept, which is a formula involving rho.
I’d have to look it all up but I’m pretty sure you can’t use the DW stat on u(t) since the distribution of the DW stat assumes there are no lagged dependent variables, and here it’s being tested on residuals from an equation with a lag-1 depvar. There are standard methods for testing for higher-order autocorrelation–they ought to have used them.
have you tried something like
fm2=lme(tt~year,data=Data[temp,],method=”REML”, correlation = corAR1());
Perhaps a question from ignorance, but is there a quick reference
where someone has cast these types of issues in terms of
the integration/cointegration framework familiar to the likes of
simple-minded econometricians? My impression is that much of the
confusion is due to not explicitly tackling nonstationarity from
the start, perhaps from fear that the tool box of inference will
vanish.
Isn’t this what the Durbin h-test is supposed to consider?
#3. Yes. I did exactly that (to the comma).
#6
The lme model in the R-script you linked to doesn’t include a correlation structure.
#7. I did other analyses besides the ones shown in the script. I sent a condensed version to Jones so that the trail would be clear. I’ll tidy up the script for other analyses and post up.
I’ve tidied up some other calculations and posted up an extended script at http://data.climateaudit.org/scripts/ipcc/trends.table3_2.v2.txt
In this script I’ve done a plausible interpretation of their REML calculation. I’ve also simulated the selection of a 156 year trend portion from a random walk and done an equivalent procedure on that, yielding a DW statistic around 2. As far as I can tell, the “IPCC Test” as applied to a random walk yields identical results as their test applied to temperature data.
I’m not suggesting that this shows that temperature data is a random walk, only that their jury-rigged test for persistence isn’t any good, showing the problems that result when people try to invent procedures on the run. IPCC should have submitted their proposed test to a statistical journal for consideration before using it in a big report.
Steve: For those of us not quite up to the intracacy of everything you have talked about here, is it possible for you to give a more general overview of the possible effect of what has been done by the IPCC?
#9
I remain to be convinced that your random walk is a useful comparison. The IPCC’s use of the DW statistic appears to be motivated by the desire to check if the autocorrelation in the residuals was more complex that an AR1. Your random walk model is AR1, so is it surprising that the IPCC’s DW test finds no more autocorrelation in the residuals?
Secondly, even though you have selected a non-random portion of the random walk, the REML model with an AR1 correlation structure has a non-significant trend. This is in contrast to the significance of the trend in the HADSST data.
Steve,
Dumb question: I thought the DW test was supposed to be about detecting autocorrelation in first order residuals. Now I take it that Jones and Parker have taken out the first order residuals and are using the DW test on the higher orders. Did I get the nuance?
It seems to me that its like surveying a Safari Park in Africa and saying that after accounting for poachers, poaching appears to be near zero.
The debate has descended to this ???
I do wonder how many angels could be fitted onto a pinhead………….
re #13 (Louis): I beg to disagree. I think this is a very important topic with possible wide implications. If indeed the time series in question do have near unit-root behavior, as it seems to me and some other people also, the handling of these series requires special care and “the standard methods” do not apply. This is especially important in the question the tables 3.2 and 3.3. are all about: is the trend significant?
Ross in his reviewer comments (see also SO comment 3-33 by Govt. of USA!) tried to push the IPCC authors to even acknowledge that there might be a problem here. The authors’ response was to include this DW thing, which, IMO, is absurd. Showing this (as Steve is here trying to do) might lead also to menaingful discussion of the true nature of these temperature series.
As a side note, Ross said (#2):
Yes, indeed. Even wikipedia gives you a better way to handle the problem, so I’m wondering the way these scientists work: instead of looking from the literature an appropriate method to use (or asking a statistician/econometrician who might actually be an expert), they pretty much invent a method of their own.
Confused I am, question:
When does such statistic indicate significant positive serial correlation?
I would like to track this discussion, but my stats are way too rusty to follow the intricacies. What physical explanations are likely to be relevant for apparent first and second order significant autocorrelations? Assuming Solar cycles are one source, what are the others? Economic cycles? El Nino? Or am I reading the issues incorrectly?
re #15: Durbin-Watson statistic. The use of the word “positive” in indeed interesting, did some residuals indicate negative (first order) serial correlation?
bernie: Apart from the physical (and real) explenations, another possible source is simply data handling. These are composite series of “adjusted” original series… The real question here is not if the series have first (or second) order autocorrelation, but if the series have “long term persistance”. In other words, if the series are (close to) random walks.
I think it would be important first to establish what type these series actually are, and then try to figure out the (physical) sources. There actually exists some climate literature related to these topics: apart from a couple of papers cited by Ross, see, e.g.,
Kaufmann, R. K., and David I. Stern (2002), Cointegration analysis of hemispheric temperature relations, J. Geophys. Res., 107(D2), 4012 (Correction)
IMO a relatively nice and accessible introduction to these ideas (and time series in general) is
Shumway & Stoffer: Time Series Analysis and Its Applications: With R Examples, 2nd edition, Springer, 2006.
BTW, the book argues (in examples) that the global mean temp series is integrated of order one.
#17
I mean significant positive correlation after allowing for first-order serial correlation
#16,18: Autocorrelation isn’t necessarily generated by cyclical inputs. It can be introduced by model mis-specification, such as fitting a linear trend to a curved series.
Theoretical explanations for random walks (unit roots) in economics arise from the theory of how markets use information: e.g. if the stock market is efficient then there should be no systematic component in the price increment from day to the next. Physical explanations for autocorrelation in climatic systems depend on the process. Hurst studied hydrological data and proposed explanations for the persistency he detected.
Regarding temperature data, I suppose we would expect complex lag structures because the land and oceans store and release energy at different rates, and solar data has its own persistency structure, which Karner has estimated. Demetris Koutsoyiannis has a nice demonstration in one of his papers of how three low-order autocorrelation processes can add up to look like a single long-term persistent series (though still stationary).
Temperature data sometimes look like unit roots, other times like stationary + high-order autocorrelation, indicating that it seems to be in a boundary region where significance tests for trends can easily be misspecified. That’s why this is such an important topic in the literature and ought to have been dealt with in the IPCC report. People like Cohn and Lins, Koutsoyiannis and others from the hydrology field are introducing fractional integration models, math/stats guys like Karner and Tsonis have also used Hurst and FI methods to characterize climate data, econometricians like Terence Mills have applied stochastic trend-cycle decomposition methods, Kaufmann and Stern have applied unit root and cointegration tests, and there are lots of papers that used ARMA models to evaluate trend significance.
And then there’s the Jones-Parker method, which to me seems rather ad hoc, to say the least.
For me this is an excellent thread. I knew that I had much to learn about the statistics of time series and this thread (and others like it appearing at CA) gives me an accounting of how much that much is.
It would appear that “inventing” statistics, or at least inventing rather unique ways of using statistics, that cannot be readily sourced to any published literature is a feature of climate science. Is this a “problem” or feature in other fields such as econometrics?
Kenneth, in econometrics you would not get away with (i) ignoring standard procedures that are known to test the hypotheses and/or provide the parameter estimates you are interested in; (ii) introducing new procedures with no analysis of their efficiency, bias or consistency properties; (iii) using these new procedures to obtain your main results without writing out the math so your readers can understand what you are doing.
Where do the statistics that climate scientists use come from? Are they home grown or have they imported procedures and techniques from signal processing or econometrics, since the analysis of time series is clearly fundamental to any analysis of trends?
A more profound question, why do books on statistics cost so much?!!
Re#23, I’d like to know why they aren’t publishing relevant methodology prior to using it and/or why they aren’t involving statisticians for the more statistically-intensive publications.
#23. In some cases, climate scientists have their own little recipes for statistical procedures. This one is odd even by climate science standards since it occurs nowhere in any publication and is used on the run for the first time in AR4. Obviously Ross pointed out problems with this section, not in the detail presented here, which has benefited from the publication of the Review Comments and correspondence with the authors, but enough that the Review Editors (Jean Jouzel and John Mitchell) should have been alert to the issue. Obviously they weren’t.
I’m not that up on the technical side, but I know a rat when I see one. I investigate finacial fraud for a living. Its great to see this site challenging the orthodox view. A legal perspective certainly makes you challenge things in a robust manner. I read RC and I’ve come to the conclusion that they like to baffle people with bull or if any one dares challenge them the response is a nasty little put down .My understading is that the IPCC is still only currently 90% certain of its scenarios and this must leave some room for questioning with out being labelled a “denialist” or ” contrian”. Most court cases comes with strong opinions and experts on both sides and yet there is only one winner. The history of science is littered with strong fashionable opinions that have not stood the test of time. A calm and collected approach is necessary. Well done Climate Audit
#25. It should be added the virtually all the work mentioned in #20 propose increased variability/uncertainty from these methods and as a consequence no or marginal significance to various temperature trend claims so dear to the hearts of the IPCC. If in fact they are not aware of all these studies, it seems very convenient, to say the least.
#25, #27: The problem was spelled out for the authors in a rather constructive SO comment 3-33 I mentioned earlier. I reproduce it here as I think it deserves wider acknowledgement.
The answer is priceless:
The answer sounds like something from realclimate, doesn’t it? Now that I think of it, I don’t know of any “peer reviewed” article that shows that Cohn and Lins are “likely wrong” or that their method “misrepresents statistical significance”. The only adverse commentary came from Rasmus at realclimate 👿 I guess that was enough for IPCC to disregard a comment from the US Government.
#26
Adrian,
I’d like to second your comment about Climate Audit. I only discovered it a few months ago. Some of it is a bit difficult to understand, while much of it is crystal clear. The picture that is slowly emerging here is extraordinary.
As you say, many scientific consensuses turned out to be completely wrong. How many people today believe the Sun goes around the Earth? And just a few decades ago scientists were scaring us with stories about a new ice age.
I recently came across a fascinating little story in a book about genetics (Genome, by Matt Ridley). In the 1920’s a scientist first counted the number of chromosomes in the human genome: 24. This quickly became the scientific consensus and appeared in all the text books. A group of scientists abandoned their project because they measured 23 and therefore their technique must have been flawed.
Not until the fifties, after thirty years, was the true number discovered: 23. It turned out that a photo in one of the text books clearly showed there were 23 chromosomes. As Ridley commented, ‘There are none so blind as do not wish to see’.
When you hear someone say ‘The consensus has never been stronger’, remember this little story. Let’s hope we don’t have to wait thirty years before the truth emerges, whatever it might be.
#29: Oh, you mean this classic 😉
Does anyone know who “Govt. of United States of America (Reviewer’s comment ID #: 2023-132)]” is? Doesn’t single comment amounts to saying “we are not sure if AGW exists or not”?
#31. I made a number of contemporary posts about this issue: http://www.climateaudit.org/?p=460 http://www.climateaudit.org/?p=464 http://www.climateaudit.org/?p=467 http://www.climateaudit.org/?p=483 http://www.climateaudit.org/?p=489 http://www.climateaudit.org/?p=469 . It’s fun to read the posts now that IPCC has seemingly relied on Rasmus to conclude that Cohn and Lins are “probably wrong”. Rasmus had rather a hard time supporting i.i.d. in climate series and eventually Gavin was eventually forced to put him in the penalty box and took over the file. At the time, I called for the start of a movement to Free Rasmus! and offered him facilities to post here after he got suspended by Gavin, but to no avail.
They are inventing the wheel again. This time it isn’t round.
I’m no whizz at stats, analysing undergraduate project data on SPSS is about my limit so alot of the technical discussion has gone over my head. However am I right in this summary?
1) IPCC says recent warming is down to increased [CO2]
2) But some peer reviewed papers say that long term persistence in climate records raise questions about this assumption
3) Invent non standard statistical method to demonstrate that long term persistence is not significant
4) Hey Presto problem solved- IPCC business as usual.
#35: Hmmm… I would summarize it this way:
1) IPCC calculates significances associated with various trends
2) These significance calculations are based on a simple model which is known not to apply to these series due to LTP. Hence these calculations are in gross error.
3) Ross and others point out 2)
4) IPCC authors invent a method purporting to show (which it actually does not) that LTP does not exist in these series. Hence no need to change the significance calculations.
I think the wierdest thing here is that they could have easily avoided the problem by not reporting the “significance” as suggested in the comment in #28. Why they insist on reporting those wrong significances is beyond me.
There’s an old Lambert post from 2004 on Mckitrick 2002 Global Average Temperature Series graphs, and it’s funny seeing everyone misunderstand the point, at least as far as I got it. It seemed to me the point Steve was making was that we have to know the methods you used to calculate your results, because there are different ways of doing things, ways that will give improper answers. They seemed to have been convinced he was saying any method of calculation is as good as any other. I suppose that’s because that’s how they do a number of things themselves…..
#2
With model Y(t) = a +bt + e(t), and unknown covariance matrix of e(t), where can you go?? Maybe they, for some reason, know that structure of that covariance matrix is the one of AR1 process, but still the variance and rho remains to be estimated. How to deal with the case b = 0? That yields completely different estimate of covariance matrix.
One answer to my question in #15 seems to be the exponential function, or integrated RW, cumsum(cumsum(white noise)). Hopefully we’ll see the exact code soon, maybe it makes sense, I’d be happy to learn new stuff.
Comment #67, RC UHI discussion , gavin computes CIs using
and i.i.d Gaussian e(t). He shows that very significantly e(t) is not i.i.d, funny guy.
Ooops, meant Y(t), but probably e(t) is neither,
[P,dw]=dwtest(res,X)
P =
0.0107977427341995
dw =
1.52406604865248
Quick latex test.
$$(1-\alpha)F_{o}=\epsilon\sigma4T^4$$
Bob,
In order to use LaTeX, you need to put the expressions between [tex ][/ tex] tags (except without the spaces) and not use the $$ commands.
Thus your test would be
[tex ](1-\alpha)F_{o}=\epsilon\sigma4T^4[/ tex]
which will render to
Thanks John. Just to confirm I’ll try once more.
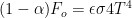
Bob
Here’s something related (found this article by chance) , , with
, with  latex \hat{\beta}\SE(\hat{\beta}) $ is ‘borderline’ there is a real issue in addressing such alternatives. </blockquote>
latex \hat{\beta}\SE(\hat{\beta}) $ is ‘borderline’ there is a real issue in addressing such alternatives. </blockquote>
<em>Residuals For the Linear Model With General Covariance Structure</em> John Haslett; Kevin Hayes Journal of the Royal Statistical Society. Series B (Statistical Methodology), Vol. 60, No. 1. (1998), pp. 201-215.
They use Jones and Briffa (1992) global temperature data, and fit a trend.
<blockquote>With V estimated as below,
It is all about how you model the covariance matrix of the noise term (V in the quote).. Gavin uses a bit naive model in the above, and IMO trend with CI is quite useless in such data where the generating model is almost completely unknown.
tex almost worked, simpler quote:
One Trackback
[…] Statistics In May 2007, also arising out of AR4, I submitted a second FOI request to CRU (see post here) regarding the calculation of Durbin-Watson statistics in IPCC AR4, then hot off the […]