As a diversion from ploughing through Mann et al 2008, I took a look at Santer et al 2008 SI, a statistical analysis of tropospheric trends by 16 non-statisticians and, down the list, Doug Nychka, a statistician who, unfortunately, is no longer “independent”. It is the latest volley in a dispute between Santer and his posse on one hand and Douglass, Christy and a smaller posse on the other hand. The dispute makes the Mann proxy dispute seem fresh in comparison. Santer et al 2008 is a reply to Douglass et al 2007, discussed on several occasions here. Much of the argument re-hashes points made at realclimate last year by Gavin Schmidt, one of the Santer 17.
The statistical issues in dispute seem awfully elementary – whether an observed trend is consistent with models. In such circumstances, I would like to see the authors cite well-recognized statistical authorities from off the Island – preferably well-recognized statistical texts. In this respect, the paper, like so many climate science papers, was profoundly disappointing. No references to Draper and Smith or Rencher or any statistics textbook or even articles in a statistical journal. In their section 4 (setting out statistical procedures), they refer to prior articles by two of the coauthors, one in a climate journal and one in prestigious but general science journal:
To examine H1, we apply a ‘paired trends’ test (Santer et al., 2000b; Lanzante, 2005)
Lanzante 2005 (A cautionary note on the use of error bars. Journal of Climate 18: 3699–3703) is a small article at an undergraduate level, arguing that visual comparison of confidence intervals can play tricks (and that this sort of error was prevalent in many then recent climate articles in IPCC TAR):
When the error bars for the different estimates do not overlap, it is presumed that the quantities differ in a statistically significant way.
Instead of this sort of comparison, Lanzante recommended the use of the t-test for a difference as described in any first-year statistics course. Lanzante 2005 cited Schenker and Gentleman (Amer. Stat. 2001), an article in a statistics journal written at a “popular” level. One can easily see how the standard in Lanzante 2005 raises the cut-off point in a simple case where the two populations have the same standard deviation σ. If typical 2σ 95% confidence intervals are applied, then, for the two confidence intervals not to overlap, the two means have to be separated by 4σ i.e.
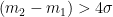
For a t-test on the difference in means, the standard is:
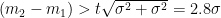
Note that equality is the “worst” case. The value goes down to 2 as one s.d. becomes much shorter than the other – precisely because the hypotenuse of a right-angled triangle becomes closer in length to the x-length as the angle becomes more acute.
While the authority of the point is not overwhelming, the point itself seems fair enough.
Santer et al 2000b is more frustrating in this context, as it is not even an article on statistics but a predecessor article in the long-standing brawl: “Santer BD, et al. 2000b. Interpreting differential temperature trends at the surface and in the lower troposphere. Science 287: 1227–1232.” They stated:
All three surface – 2LT trend differences are statistically significant (21), despite the large, overlapping 95% confidence intervals estimated for the individual IPCC and MSUd 2LT trends (Table 1) (22).
Reference 21 proved to be another Santer article also in a non-statistical journal and, at the time still unaccepted:
21. The method for assessing statistical significance of trends and trend differences is described by B. D. Santer et al. ( J. Geophys. Res., in press). It involves the standard parametric test of the null hypothesis of zero trend, modified to account for lag-1 autocorrelation of the regression residuals [see J. M. Mitchell Jr. et al., Climatic Change, World Meteorological Organization Tech. Note 79 ( World Meteorological Organization, Geneva, 1966)]. The adjustments for autocorrelation effects are made both in computation of the standard error and in indexing of the critical t value
Santer et al (JGR 2000) proved to have much in common with the present study. Both studies observe that the confidence intervals for a trend of a time series with autocorrelation are wider. I agree with this point. Indeed, it seems like the sort of point that Cohn, Lins and Koutsoyannis have pressed for a long time in connection with long-term persistence. However, Santer et al carefully avoid any mention of long-term persistence, limiting their consideration to AR1 noise (while noting that confidence intervals would be still wider with more complicated autocorrelation. Although the reference for the point is not authoritative, the point itself seems valid enough to me. My interest would be in crosschecking standards enunciated here against IPCC AR4 trend confidence intervals, which I’ll look at some time.
Now for something interesting and puzzling. I think that reasonable people can agree that trend calculations with endpoints at the 1998 Super-Nino are inappropriate. Unfortunately, this sort of calculation crops up from time to time (not from me). A notorious example was, of course, Mann et al 1999, which breathlessly included the 1998 Super-Nino. But we see the opposite in some recent debate, where people use 1998 as a starting point and argue that there is no warming since 1998. (This is not a point that has been argued or countenanced here.) Tamino frequently fulminates against this particular argument and so it is fair to expect him to be equally vehement in rejecting 1998/1999 as an endpoint for trend analysis.
Now look at the Santer periods:
Since most of the 20CEN experiments end in 1999, our trend comparisons primarily cover the 252-month period from January 1979 to December 1999
Puh-leeze.
If the models weren’t run out to 2008, get some runs that were. If they want to stick to old models and the old models were not archived in running order, the trend in CO2 has continued and so why can’t the trend estimates be compared against actual results to 2008? Would that affect the findings?
It looks to me like they would. Let me show a few figures. Here’s a plot of a wide variety of tropical temperatures – MSU, RSS, CRU, GISS, NOAA, HadAT 850 hPA. In some cases, these were calculated from gridcell data (GISS), in other cases, I just used the soure (e.g. MSU, RSS.) All data were centered on 1979-1998 and MSU and RSS data were divided by 1.2 in this graphic (a factor that John Christy said to use for comparability to surface temperatures), but native MSU [,”Trpcs”] data is used in the CI calculations below. The 1998 Super-Nino is well known and sticks out.

I’ve done my own confidence interval calculations using profile likelihood methods. Santer et al 2000, 2008 does a sort of correction for AR1 autocorrelation that does not reflect modern statistical practice, but the Cochrane-Orcutt correction from about 50 years ago (Lucia has considered this recently.)
Instead of using this rule of thumb, I’ve used the log-likelihood parameter generated in modern statistical packages (in the arima function for example) and calculated profile likelihoods along the lines of our calibration experiments in Brown and Sundberg style. I’m experimenting with the bbmle package in R and some of the results here were derived using the mle2 function (but I’ve ground truthed calculations using optim and optimize).
First let me show a diagram comparing log-likelihoods for three methods: OLS, AR1 and fracdiff. The horizontal red line shows the 95% CI interval for each method. As you can see, even for the UAH measurements, for the 1979-1999 interval, the observed mean trend of the models as an ensemble is just within the 95% interval of the CI for the observed trend assuming AR1 residuals. If one adds an uncertainty interval for the ensemble (however that is calculated), this would create an expanded overlap. Fractional differencing expands the envelope a little but not all that much in this period (it makes a big difference when applied to annual data over the past century.) Expanding the CI interval is a bit of a two-edged sword as no trend is also and even further within the 95% interval. So the expanded CI (barely) enables consistency with models, but also enables consistency with no trend whatever. I didn’t notice this point being made in either Santer publication.

Figure 1. Log Likelihood Diagram for OLS, AR1 and Fracdiff for 1979-1999 MSU Tropics. Dotted vertical red line shows the 0.28 trend of model ensemble. [Update – the multi-model mean is 0.215; the figure of 0.28 appears in Santer et al Figure 1, but is the ensemble mean for the MRI model only.]
On the face of it, I can’t see any reason why the model ensemble trend of 0.28 can’t be used in an update of the Santer et al 2008 calculation in a comparison against observations from the past decade. The relevant CO2 forcing trend has continued pretty much the same. Here’s the same diagram up to date, again showing the model ensemble trend of 0.28 deg /decade as a vertical dotted red line. In this case, the ensemble mean trend of 0.28 deg C/decade is well outside the 95% CI (AR1 case).
Now some sort of CI cone needs to be applied to the ensemble mean as well, but 47 cases appear to be sufficient to provide a fairly narrow CI. I realize that there has been back-and-forth about whether the CI interval should pertain to the ensemble mean or to the ensemble population. As a non-specialist in the specific matter at hand, I think that Douglass et al have made a plausible case for using the CI of the ensemble mean trend, rather than of the model population. Using a difference t-test (or likelihood equivalent) along the lines of Lanzante 2005 requires a bit more than non-overlapping CIs, but my sense is that the spread – using an ensemble mean CI – would prove wide enough to also pass a t-test. As to whether the s.d. of the ensemble mean or s.d. of the population should be used – an argument raised by Gavin Schmidt – all I can say right now is that it’s really stupid for climate scientists to spend 10 years arguing this point over and over. Surely it’s time for Wegman or someone equally authoritative to weigh on this very elementary point and put everyone out of their misery.

Figure 2. Same up to 2008. [See update note for Figure 1.]
Here’s the same diagram using RSS data. The discrepancy is reduced, but not eliminated. Again, analysis needs to be done on the model CIs, which I may re-visit on another occasion.

Figure 2. Same as Figure 1 using RSS data. [See update note for Figure 1.]
I think that these profile likelihood diagrams are a much more instructive way of thinking about trends than the approaches so far presented by either the Santer or Douglass posses. In my opinion, as noted above, an opinion on model-observation consistency from an independent statistician is long overdue. It’s too bad that climate scientists have paid such little heed to Wegman’s sensible recommendation.
Similar issues have been discussed at length in earlier threads e.g here





232 Comments
Here’s how these calculations were done. This is not quite turnkey and I’ll tidy up tomorrow.
First the functions and packages:
Now loading a variety of tropical data in a monthly format. This requires downloading some very large files of gridcell data for e.g. GISS. I’ll post this up tomorrow as I’m off to squash league right now.
Now pick out the time series for analysis. This needs to be made into a function but I haven’t done that yet.
Now do log-likelihood analysis. This has some pretty examples of how to use lists and, in particular, using the sapply function with lists to do things that would take pages of Fortran.
Now plot. The xlim values need to be done manually for best results. Again the subscripting in lists makes the plotting very convenient. All in all, there’s a lot of analysis here in a pretty short script.
Check out the discussion Lucia has about Santer on her blog. Interestingly I’ve asked gavin 2 simple questions all of them unanswered. ( and I asked nicely with no snark)
1. His chart shows that the mean of the models ( for trend) is greater than the mean of all 14
observational datasets ( 10 tropo datasets and 4 surface [ 2 STT and 2 Land+Ocean]) What does
that suggest?
2. Did the models include volcanic forcing?
On this question he refused to answer but in comment #2 and comment 21 he indicates that the models in Santer did include volcanic forcing. Cross checking The models used in Santer with the
description provided in AR4 ( chapter 10 ) indicates that this might not be the case. FWIW.
Anyway, Lucia has a nice post on Santer ( from a different angle than you take) that is worth a read for CA regulars.
The statistical issue is elementary, but the issue is not the one raised re. Lanzante. which is a relatively minor issue.
The key problem with Douglass et al. statistical test is that they use a test for the difference between means to establish the inconsistency of the models. However, this is obviously invalid as you would expect there to be a difference between the means even if the models were ideal. This is becuase the ensemble mean aims to estimate the trend after averaging out the effects of e.g. ENSO. ENSO hasn’t been averaged out in the observational data, so there is no reason to expect the means to be the same.
If you want to test whether the ensemble is consistent with the observations, you need to see if the observations lie within the variability of the models.
Re: beaker (#3),
This is a valid test when dealing with many runs of the same model. However, it does not make a lot of sense when dealing with different models which make different physical assumptions and have different parameterizations.
That is why Douglass and Christy applied a test to the models and only included those that actually replicated the GMST.
Raven: You are missing the point, Douglass et al. test for a difference in the means that we would expect to exist even if the models were ideal and therefore it can’t be a fair test of consistency.
If you want to be really throrough there are tests you could do that don’t assume normality, addressing your first concern. However, again that is a minor issue compared to the SD-v-SE issue, which is the fundamental flaw with the Douglass et al. statistical argument.
Why is Doug Nychka no longer independent?
Why would one select, as the starting point, 1979, which is after a major negative to positive PDO mode shift? I would think one would want to encompass as many such mode shifts as possible.
I haven’t read the blogs but want to establish a couple of things. In Douglass et al., we tested what the IPCC calls the “best estimate” – in other words we tested a single realization (“best estimate”) which we could determine with high confidence (small error bars) because we had a relatively large sample size of 22. We did not test the range of the individual models – but may in the future – because that was not our intent. The issue about including natural variability is moot because our test carried a pre-condition, that the model “best estimate” had a surface trend very similar to the observational trend. So, no matter how ENSOs or volcanoes were distributed (many models had the volcanoes), the single metric of surface trend was consistent between the two. There is exceptionally high coherence between surface and tropospheric temperatures for all models (and observations) – so unless there is a large amount of interannual variability affecting the multi-decadal trend difference of surface v. troposphere (which we cannot find), then we do not need to assess natural variability.
Beaker, the problem with your suggested test is that it is no test at all. The observations will always lie within the variability of the models as long as the models are variable enough, hence all you can ever say is that the models are variable. Example, include two extra models. one of which has large positive anomalies, and one with large negatives, and then that group of models cannot in your terms ever be said to be inconsistent. Thus that argument is in general terms simply an argument for saying that the models cannot be made inconsistent unless some selection criteria is applied. This is it would seem exactly what is happening, the models are still “consistent” it is claimed, but the cost is that they can have no predictive value whatever and have “error bars from floor to ceiling”.
No, on logical grounds comparing the means is a stronger but still legitimate test. As for using the standard error, I am yet to be convinced it is erroneous, a conviction made stronger by the fact that the principal argument against it seems to be that the results are “wrong”. If Douglas had concluded that the models were consistent then the paper would no doubt have been happily accepted.
beaker, you say:
I fear that Santer, et all of us as well, are trying to answer an ill-posed question. The underlying question is “are the models skillful (in some undefined sense) at calculating the tropospheric temperature trends?” The difficulty lies in the fact that different people have different definitions for “skillful”. All of them have some claim to being the “right way” to determine if the models are any good at doing what they claim to do, and there is no clear way to pick the best definition.
Your definition of “skillful” seems to be whether the ensemble is “consistent with” observations. You define “consistent” as “there is at least one model result higher and one model result lower than the observations.” While this is certainly one possible definition of skillful … is it a useful definition? I mean, does the fact that there’s at least one model result higher than observations and one lower than observations tell us anything useful about the models?
If your answer is “yes”, then I would ask you to consider all of the model results that ended up on the cutting room floor because the modelers didn’t like the results enough to even report them. Now by your definition, including all those rejected model results would increase the “skill” of the model ensemble. I fear that I don’t see the logic of that. Reductio ad absurdam.
I would submit that Steve’s use of log-likelihood above is a more useful definition of “skillful” than the one you are using.
w.
Re: Willis Eschenbach (#10),
Hear Hear!. And as many times as it takes. Also, where is the demonstration of the sub-components of each model, each with its own errors, that should be properly summed and propogated through to the end of each model?
J Christy: The ensemble mean is the best estimate available, however a statistically significant difference between the ensemble mean and the observed trend does not establish that the observations are inconsistent with the ensemble. This is because the ensemble mean does not aim to represent the observed trend itself but the expected value of the observed trend (i.e. the average value you would observe over a large population of replica Earths identical in all respects but the initial conditions giving stochastic variability), which just happens to be the best predictor available as we can’t predict the weather.
Ed Snack: consistency does not guarantee usefullness. See my comments on the earlier thread.
Willis: Consistency is not a test for skillfullness, it is only a pre-requisite. Hence a claim of inconsistency is damning and needs strong support. My concern is proper use of statistics, the test must support the claim that is made, in Douglass et al. sadly it does not (for the reasons outlined above).
However, this is groundhog day, I answered these points repeatedly on the previous thread and I’d rather not re-iterate them here!
Beaker, you’re getting caught in terminology. My point still stands. “Consistency” as you have defined it is such a weak test as to be meaningless. By your definition, picking 22 random normal numbers from the distribution mean = 0, sd = 1 will show clearly that normal random numbers are “consistent” with tropical temps … so what?
w.
Willis, this is science, accurate terminology is vital. I am a statistician (of sorts) and saying that a model is inconsistent with the data has a specific meaning, namely that the observations cannot be explained by the model taking all uncertainties into account.
Yes, if the observations lie within N(0,1) then N(0,1) is a consistent model for the observations. HOWEVER THAT DOESN’T MEAN IT IS A GOOD MODEL!
The fact that consistency says so little is exactly why asserting inconsistency is such a large claim requiring proper support.
It’s well known that bender hates SEM. Let’s move on. 😀
I suggest a dart board.
So what’s the vote so far if SE is the best test when dealing with many runs of the same model and if SEM the best test when dealing with different models which make different physical assumptions and have different parameterizations?
In this case, neither? SE always passes if the spread is wide enough. SEM never passes because the models are too random and wacky and assumes the climate can be treated as a stochastical system over some time frame or not.
Or in other words a hypothesis that
Deja vu all over again! This thread is going to go the way of the Douglas thread, hijacked by a vacuous (statistically official – not!) definition of “consistent”, meaningless justifications of the scientific value of calculating averages and standard deviations of single runs of a variety of dissimilar models (throw in some garbage, it will make the results look more “consistent” – what exactly is the value of such “consistency?) and claiming that the standard two-sample t-test is invalid (“this is obviously invalid as you would expect there to be a difference between the means even if the models were ideal” – all that time wasted teaching that invalid statiastical test to young minds!).
Come on! A suitably constructed set of pseudo-random number generators would be found to be “consistent” using the beaker definition. Meanwhile, the actual work of looking at the data and results gets ignored in the navel-gazing generated by this line of discussion. Move along, nothing to look at here…
beaker, you say:
beaker, this is science, a citation backing up your claim is vital. I have searched long and hard for a statistics text or expert who says that your interpretation of “consistent with” is an accepted term of art in statistics.
However, I’m always willing to learn, so bring on your citation that proves me wrong.
w.
Willis: Deja vu You asked for this on the Tropical Trophosphere thread and I gave an example of this usage there. You can find more using the obvious query in google scholar.
There was a post of mine at RC with respect to Santer et al 2008 which simply disapeared completely. I admit I didn’t keep a copy. But the essence was this:
a) Santer et al 2008: “To facilitate the comparison of simulated and observed
tropospheric temperature trends, we calculate synthetic MSU T2 and T2LT temperatures from gridded, monthly mean model data using a static global-mean weighting function.”
Why do they use global weighting function to reconstruct MSU cannel responses when they want to discuss tropical temperature trends?
b) T2lt not at all is an independent measurement from T2, it’s a derivate. UAH uses differences of askew MSU viewing into the atmosphere to determine it, RSS uses a synthetic weighting with MSU looking straightly downward. One way or the other – have these T2lt-T2 interdependencies been accounted for?
It takes oh so little to provoke the Spanish Inquisition. Try for yourself, everybody.
Beaker #18
examples of people using a term is NOT an authoritative explanation of the term.
people adopt many terms through common usage. This does NOT make the term, or its usage, authoritative.
Try again.
My favourite comment on this paper comes from the RealClimate site where the poster notes to gavin,
The paper does try to argue that no warming would still be statistically within a 2-sigma spread of the models.
Of course, I also like my comment:
Just noting the paper uses 30S to 30N for some reason rather than the traditional 20S to 20N or at least the definition of the tropics of 23.5 degrees.
I have used Google Scholar, and found nothing that was a definition. I found lots of examples of people using it in a very different way than you use it, like the first entry returned by my GS search:
I have also used Google, and found nothing. The google search term “define:” finds words in glossaries and definitions … but it has no entries for “consistent with”, and the entries for “consistent” are other meanings.
In addition, the “Statistics Homepage Glossary” has no entry for the term. The “Oxford Statistical Dictionary” says nothing. The “Internet Glossary of Statistical Terms” is silent on the subject. “A Glossary of Statistic” is mute.
Statistics.com has an entry saying:
Which is clearly not the way you are using it … you better go inform them of their error. You’ll also need to tell the Statistics Glossary, which says things like
I find information on “consistent estimators”, and “consistent statistics”, neither of which have anything to do with your claimed usage … wait, here’s something a bit more helpful (emphasis mine) from the UK distance learning course on statistics:
Clearly, they are not using it in any way like the way you claim it is defined. It does not mean that one distribution encloses the other as you say.
Nor was your post on the prior thread any help, that was just someone using the term in a way roughly similar to the way you use it. It was not anyone saying “‘consistent with’ is defined as …” or anything like that. I had hoped that since that time you would have found a real citation from some statistical authority that agrees with you … but evidently that is not the case.
Since “none” is currently all the cites you have been willing to share with us, let me suggest that you either provide some, or retire from the fray. On this blog, pointing at Google Scholar and saying “the answer is there, just go look” does not enhance your reputation.
My best to you,
w.
Yup. I’ve raised this at realclimate and other forums. The point gets studiously ignored there too. Put simply, these guys don’t seem to appreciate that wide error bars is not a virtue.
The notion of “consistency” between obs and models is a subject we’ve gone around and around with our our blog as well.
http://sciencepolicy.colorado.edu/prometheus/the-helpful-undergraduate-another-response-to-james-annan-4419
As discussed above we find the logic to be that the larger the uncertainties the greater the chances for “consistency”. This makes “consistency” a meaningless concept. Skill is a much better metric to use and this means making predictions about the future in the context of a naive baseline.
http://sciencepolicy.colorado.edu/prometheus/do-ipcc-temperature-forecasts-have-skill-4421
Re: Roger Pielke, Jr. (#24),
Fully agree with the above comment .
This kind of discussion has everything it takes to drive any physicist up the wall .
It is for the first time in the history of science that proponents of a theory argue that it is not inconsistent with the data because the CI of the theory are so large that virtually any data will be within the CI !
I mean it is like if somebody argued that newtonian mechanics is the right theory to describe relativistic electrons because he added an AR(whatever) noise term whose CI are so large that the data are not inconsistent with the theory .
The whole discussion about “ensemble means” is completely surrealistic because it boils down to a statement that if one includes a sufficiently large number of partially contradicting models and makes an average of their predictions then even the sense of variation of the relevant dynamic parameters becomes uncertain and it is presented as being a GOOD thing for the theory .
.
Consistency is a red herring .
Come on , D.Koutsoyiannis has alreday shown that even the basic hypothesis that there is non stationnarity (aka trends) in the data is dubious and that scaling processes are probably a more correct hypothesis (at least for hydrological data) .
Steve Mc:
What?? Allow actual real statisticians to become involved in climate science on issues of statistics? Remember what happened last time?
What planet are you on???
Re: John A (#25),
What is so odd, is that they could easily heed the “hint” and get a competent statistician on board. But, NO, not the Team! Because they KNOW in their heart of hearts that no competent statistician exists that would sign off on their monkey-business. And that is their ultimate undoing. Thanks, again, Steve Mc for making this so clear to an outsider.
Re: jae (#26),
Except of course they did bring a statistician onboard! Interestingly the response is not ‘oh good the Team have taken the hint’ but rather to diminish his contribution (on the 2nd and 3rd line of the post).
In the summary it’s stated: “It’s too bad that climate scientists have paid such little heed to Wegman’s sensible recommendation.” And yet the co-author mentioned above is one of three ‘mainstream statisticians’ specifically named by Wegman as appropriate choices for collaboration in this area!
I’m no statistician, but I have spent time on scientific models and as far as I can see putting any kind of error bars on the IPCC models is just putting lipstick on a pig. Which surely makes the whole argument about what is the “right” statistical test to apply entirely redundant?
Firstly, the models make similar assumptions of unknown quality about the science so they are certainly not a random selection of possible models and any combinatorial assessment of their outputs has no statistical meaning I can see.
Secondly, the output of an individual model apparently has a chaotic sensitivity to its own assumptions and initial conditions and I don’t see any good reason to believe either that such a model is accurately describing the world in a useful way or that some arbitrary subset of chosen parameters and runs of it can be any more useful in assessing the accuracy or the value of the model’s “prediction”.
All this nonsense seems to achieve is to make the effective “model” less transparent, reproducible, falsifiable and testable.
Folks, the mean vs population issue was discussed at length in the Tropical Troposphere thread without really resolving anything. I, for one, remained unconvinced by his arguments that the population s.d. – rather than the std dev of the ensemble mean – was the appropriate usage. As I expressed at that thread, if I were a reviewer of this article, I would have asked the authors to provide an on point third party statistical authority for this position, rather than passim examples from Google. I think that it is unfortunate that Gavin Schmidt and the posse did not provide such an authority. Given that the issue seems very elementary, I presume that there is authority in a textbook somewhere, but no one has provided such a reference.
Be that as it may, can we have a short moratorium on this and try to focus for a while on what Santer calls the H2 hypothesis – since this deals directly with the ensemble mean, temporarily making the above matter moot.
Let’s focus for a while on Santer Figure 3b, where the right hand side shows an overlap between the CI interval for the observations and the ensemble mean.
Relative to my calculations – and please bear in mind that Santer et al have failed to provide any Supplementary Information with precise documentation of their data and code so I’m feeling my way through this particular calculation – their Figure 3b shows the ensemble mean trend for the 1979-99 period as more squarely within the observational SI than my Figure 2 above.
However, when data through to 2008 is included as in my Figure 3, I think that this would modify the impression of their Figure 3. A couple of points on this figure which I think that I’ll carry forward to the head post:
– in their Figure 1, the ensemble trend is said to be 0.28 deg C/decade, but in their Figure 3b, the ensemble mean is illustrated as being about 0.23 or 0.24 deg C/decade, visually less than 0.25 deg C/decade based on the tick mark. According to their Figure 3b, the CI for the ensemble mean trend is very tight plus-minus a few hundredths of a degree either way – which would carry over to my Figure 3 in the above post.
– their AR1-based CIs for the 1979-99 using rules of thumb are about 0.04 deg C wider at each limit (their CI is visually about -.24 to +0.32 as compared to -.22 to +0.28 deg C/decade according to my likelihood based calculations shown in my Figure 2.)
These two differences account for the relevant difference between their Figure 3b and my Figure 2: their illustrated ensemble trend of 0.24 is noticeably below their upper CI of 0.32, while their reported ensemble trend of 0.28 is right at the upper CI of my 1979-99 calculation.
Bring this forward to 2008 making the plausible assumption that the ensemble trend of 0.28 deg C/decade remains valid under the forcing of the 2000s. Allow 0.04 deg either way as the CI of the ensemble mean per Figure 3, thus 0.24-0.32 deg C/decade as the CI interval for the ensemble mean. My likelihood based CI for the observed trend using AR1 errors and UAH measurements is -0.08 to 0.18 deg C, so there is a noticeable non-overlap. I’ll try to dress this up in a t-test tomorrow, but as I observed in the head post, you can get a sense for t-test results from inspecting the CIs and the non-overlap here appears large enough that I’d be very surprised if this gets through a t-test.
So at least part of the Santer results appear to rely on their use of a 1999 endpoint. When one recalls the excoriation of things like Swindle for using obsolete temperature data, it’s pretty remarkable that Santer, Schmidt and the others should have used such obsolete data, especially if, as it appears, one of their key results is not robust to usage of up-to-date data.
–
#28. I noted in my head post that Nychka is a statistician and it is annoying that this was ignored in #26. I met Nychka in Washington and found him very likable and have found him very cordial in brief correspondence. However, he’s not always been able to provide statistical support for papers where he’s been acknowledged for statistical support. For example, Wahl and Ammann thanked him for statistical support, but, when I asked him to provide a statistical authority for one of their claims, he was unable to do so and turned me back to Ammann, who refused to provide one.
As opposed to the comment in #26, I also place importance on independence. Right now Nychka is a bit like a company geologist. You need company geologists and their results are not wrong because they are company geologists. But you also need independent geologists when it comes to assessing properties. Given how long this dispute has gone on, I’d be feel more comfortable with an independent assessment.
#24. This is a good point. Elsewhere the Team advocates RE as a skill test. I wonder what the RE of a continuation of the ensemble trend at 0.28 deg C/decade. Bet it isn’t any good.
Doesn’t common sense play any role in Climate Science?
Ignoring the discontinuity in the temperature data after 1998/9 when testing a model’s linear trend against the data doesn’t need any statistics to be judged inadequate and lacking integrity if a wilful choice.
Some months ago I did an interesting exercise. I took a graph of the global temperatures of the last century, according to GISS (which is one of the most alarmist graphs), and I superposed a 0.6C/century line crossing it in 1900 ar -0.25C. The result seemed to indicate, from a visual point of view, that an underlying climate trend of 0.6C/century was perfectly believable, with the GISS plot getting both over and under the line all along the century, but also suggested that a slightly curved line instead of a straight one would be more appropiate, with a slope more similar to 0.5C/century in the first half and 0.7C/century for the later half. We would be now over the line since 1995, like we were in 1900-1903 or 1930-1947. But not too much over the line, as the difference was bigger in the 60’s and 70’s in the opposite direction.
Then I looked at the individual yearly temperatures in the chart and found eye-catching similarities between our last decade of temperatures and the one beginning by 1938. Big increase until then, followed by several years of more or less stable temperatures which still seemed to suggest a growing trend… and then a big fall down. If the same happened now, which is also plausible as we are facing a shift in the PDO index similar to the one experienced in the 40’s, we would quickly match again the warming trend lines that I had plotted. Which was excellent news, because if the lines were to correctly represent the underlying trend for the next century too, we would finish the century at probably only +0.5C +/- 0.2C from this decade’s temperatures. That’s like 1/3 of the warming predicted by the IPCC!
Now thanks to Steve I can see that a 0.7C/century slope is well in the middle of the confidence interval for the actually measured tropical tropospheric temperatures increase in the last decades. I only wish we had data about what happened to the tropical tropospheric temperatures back in the 40’s. On the other hand, we do have data about the ENSO conditions by then. In the decade of the 40’s, the sustained high temperatures were not really aided by El Niño conditions, as the ENSO index remained neutral. Now, however, we have had sustained high temperatures with three El Niño ocurrences in 2002, 2005 and 2007. This would indicate that perhaps those El Niño ocurrences were masking a fall down which should have started earlier than 2008, had ENSO not played a warming role.
Now, as ENSO starts to turn negative, PDO gets even more negative and the Sun is at minimum activity, I would expect a few years of very obvious, strong and undeniable cooling. Why this is not predicted by the models and the warmies (no offense), really escapes me.
#29. Yes, consistency is not even mentioned in the paper, the word is hardly used. More interesting are the lapse rate tests. A much better approach to the problem overall.
Roger Pielke, Jr.: Consistency is a meaningful concept because inconsistency establishes that the model is falsified by the observations. Whether a model has been falsified or not is a big and meaningful distinction. In claiming that the inconsistency is resolved Santer et al. are not claiming the models are skillful, just that the models have not been falsified. If they explicitly claim that consistency does establish useful skill, give a quote for me to criticise!
Would you agree that the phrase “the models are inconsistent with the data” suggest that “the data contradict the ensemble prediction”. Well the ensemble prediction says that the trend lies with high probability within two standard deviations of the ensemble mean, not within two standard errors, so how can you tell if the data contradict the prediction by looking at the standard errors instead of the standard deviation?
Looking at the SEPP press release, Douglaass et al. certainly interpret inconsistency as falsifying the models, but their test does not establish a contradiction unless you incorrectly interpret the ensemble prediction by ignoring the models stated confidence.
Are’nt all these comparison between models and data missing the point? For future prediction one needs to identify the differences and make studies to identify what are these discrepancies, why are they there and how are errors going to be propagated in the future projections.
Eilert: Quite, but it was Douglass et al. that chose to make consistency the battle ground (by making a very strong and unsupportable assertion of inconsistency). The original RC criticism highlights the uncertainties and mentions several known model defficiencies that are being actively worked on, that seems well in accord with your suggestion, but the discussion has become so partisan that that fact has been largely ignored.
Tom Vonk: SSSHHH! I think I can hear Karl Popper spinning in his grave! ;o)
Roger Pielke Jr: BTW, I’m not surprised to that “Megan” gave you the answer she did, it was the right answer, … to the wrong question. Instead of asking of the two datasets represent similar distributions, the correct question should have been “is it plausible that the observations, given measurement uncertainty, is a sample from this distribution.
Re: beaker (#41),
The distinction you are trying to make is reasonable but the problem is Santor et. al. do not pose the question is that way. They seek to imply that if the observations are “consistent with” the models then the models can be presumed to be skillful. I think it is this implicit and unjustified leap of logic that has most people here annoyed.
Steve, You pointed to people who use 1998 as a starting point and argue that there is no warming since then, and noted that this ‘is not a point that has been argued or countenanced here.’ One of those who’ve allegedly misused 1998 is Lord Nigel Lawson, and his accuser was The Times of London. I believe that they were wrong and I hope you don’t mind my taking space to tell the story here. .
The Times has taken to running a weekly series on ‘Bad Statistics’, and invites readers to send examples to a ‘badstats’ website they’ve established to feed the column. On 9 July last, the anonymous compiler of ‘Bad Statistics’ claimed that Nigel Lawson had said in promoting his book ‘An Appeal to Reason’ that there’d been ‘no warming’ since 1998. On 13 July I sent the following letter to the Editor:
[Letter no. 1 to The Times begins]
The criticism of Nigel Lawson in your ‘Bad statistics’ column (Features, July 9) is misdirected. His claim that ‘There has been no further warming since the turn of the century’ is fully supported by the absence of a positive trend during this period in the global temperature estimates reported by all of the leading compilers.
Your column finds a ‘more accurate soundbite’ in the fact that eight years in the past decade have been among the ten hottest on record. Similarly, the IPCC reported in 2007 that each year’s global temperature since 2001 had been among the 10 warmest in the instrumental record’, and the Hadley Centre and Climatic Research Unit jointly proclaimed last December that ‘the top 11 warmest years all occur in the last thirteen years’.
Nigel Lawson deftly captures the limitations of such formulations in his observation that ‘It is rather as if the world’s population had stopped rising and all the demographers could say was that in eleven of the last twelve years the world population had been the highest ever recorded.’
Accurate soundbites mutate easily into inaccurate conclusions. In its 2007 report, the IPCC found that ‘Six additional years of observations since the [2001 report] show that temperatures are continuing to warm near the surface of the planet’ – and the BBC reported the above-mentioned Hadley Centre/CRU news release under the heading ‘2007 data confirms warming trend.’
Wrong. The 2007 global mean temperatures were the lowest for the century so far, and those for 2008 will almost certainly be lower again.
Ian Castles
Former Head
Australian Bureau of Statistics
[Letter no. 1 to The Times ends]
I received an immediate automatic acknowledgement but no further response. On 18 July I wrote again to the Editor, as follows:
[Letter No. 2 to The Times begins]
This letter is NOT FOR PUBLICATION.
Last Sunday, 13 July, I wrote to you about your article “Bad Statistics: Global warming” (Times2, 9 July, p. 3). I received an acknowledgement on the same day but my letter has not been published. My purpose in writing is to request that you reconsider your apparent decision to reject the letter.
Your article makes the following damaging criticism of Nigel Lawson:
“When Nigel Lawson says, promoting his book An Appeal to Reason: A Cool Look at Global Warming, that there has been no warming since 1998, he is not lying. But neither is he answering the real question.”
The impression that most readers of The Times would gain from these sentences is that Lawson either does not understand what the “real question” is or that he has been deliberately misleading.
For reasons explained in my letter, I believe that it is the author of the “Bad Statistics” article, not Nigel Lawson, who does not answer the real question. In fact, the assertion that eight years in the past decade were among the ten hottest on record says nothing in itself about the trend in temperatures over the decade.
This leads me to ask what arrangements you have in place to review the “bad statistics” that are sent to the “badstats” website. Who determined that the anonymous author of your column is right and that Nigel Lawson is wrong?
Incidentally, I’ve been unable to establish that Lawson has made the statement about “no cooling since 1998” that you attribute to him. Did the author of the “Bad statistics” column provide a source for this claim? Certainly there is no statement to this effect in Nigel Lawson’s book, or in his lecture on “The Politics and Economics of Climate Change” that I had the privilege of hearing in Sydney last November, or in any of the other major lectures he has given during the past year. The relevant statement in An Appeal to Reason … is that “There has, in fact, been no FURTHER global warming since the turn of the century, although of course we are still seeing the consequences of the 20th century warming” (p. 7, EMPHASIS added). This statement is in my view unexceptionable.
For your background information, I was Head of the Australian Bureau of Statistics from 1986 to 1994. During this period I served a term as President, International Association of Official Statistics. In 1991 I was one of five experts who were invited by the Editors of the Journal of the Royal Statistical Society to comment on the Society’s report on concerns that had been raised about the integrity of Britain’s official statistics (Official Statistics: Counting with Confidence). In 2005 I made a written submission to the Inquiry into The Economics of Climate Change by the Select Committee on Economic Affairs of the House of Lords (Report: Volume II: Evidence, pps. 207-210). In its unanimous report this all-party Committee, of which Lord Lawson was a member, referred favourably to several papers that I had published in co-authorship with Professor David Henderson (Report, paras. 52-53).
I should also mention that my letter of 263 words is 141 words shorter than the letter from the Director-General of the Royal Horticultural Society that was published on your Letters page on the same day as the “Bad Statistics” column to which I am objecting.
I will resend my letter as a separate message, for your further consideration.
I am sending a copy of this letter to Nigel Lawson.
[Letter No. 2 to The Times ends]
Again I received an automatic acknowledgement, both of this letter and the resent letter – but again I heard no more.
The Times is entitled to select the letters it chooses to publish, but their treatment of Lawson and their failure to reply to my ‘Not for publication’ letter are unconscionable. It seems that the newspaper has no process to ensure that there’s any substance to the claims made by correspondents to the ‘badstats’ website, that Nigel Lawson never made the statement they attributed to him, and that there was no basis for their miserable charge that he was ‘not lying’ but …
Santer et al:
Durbin & Watson:
Maybe a minor issue, but doesn’t give a good impression about the quality of the statistical treatment.
It is interesting that climate people are now calling for wider uncertainties (gavin himself here
). Remember MBH98, where a huge matrix of scales was estimated with multivariate regression, and then calibration residuals where used to obtain uncertainties. So, when the work of Brown & Sundberg is discussed at RC ? Or are these wide CIs too inconvenient in proxy reconstructions ? See http://www.climateaudit.org/?p=3720#comment-305039 , maybe there’s no divergence problem, but too narrow CIs ? And does somebody want to hear what Beran’s book says about GMST residuals (hint, not AR(1) )?
Raven: Give a specific quote where Santer explicitly claim that consistency implies useful skill, AFAICS they make no such leap, however I have not given it a detailed reading yet, so it is possible I have missed it.
Re: beaker (#45)
I was thinking more of the spin and tone on RC where they mae no mention of the distinction between skill and consistency. If the had made it clear that consistency does not imply skill (like you have) then I don’t think we would be having this argument.
BTW – I did check the paper in response to your post and found this:
This is a startling admission from the team and it is not clear to me why the same criteria could not be applied to GMST measurements over the same period which are held out as ‘evidence of warming’.
The quote you give does not suggests that the models have useful skill, just that you can’t conclude that they do not, nothing more. The second part merely states that the observational data are subject to considerable uncertainty, which is well justified by the considerable variabiation in the available estimates. I think you are reading far ore into Santer et al. than is actually there.
As for RC, have you forgotten the ending of the original article, where Gavin Schmidt says:
Here is is saying quite plainly that consistency does not imply great skill.
Re: beaker (#47)
The entire narrative from the team at RC is the models have sufficient skill to justify major policy decisions.
Gavin saying that that “the tropical trends in the model simulations or the data are perfectly matched” does not address this point at all. If anything, he is trying to minimize the question of skill by implying a few tweaks to the model parametrization would rectify the remaining problems without changing the conclusions already drawn from the models.
The quote from Santor paper is surprising because it is saying that we have no evidence of statistically significant warming in the tropical troposphere. This implies that we have no statistically significant evidence that the greenhouse effect as described by the models is actually occurring outside of the very narrow criteria of GMST.
Why do we waste all this bandwidth for irrelevant consistency musings ?
With large CI anything is consistent with anything and if the game is to prove that the CI should actually increase even more , it borders on ridiculous .
If Santer thinks that it is no problem not to be able to distinguish between negative and positive numbers then he contributed exactly zero to the debate .
UC :
Yes , I’d be very interested about what the Beran’s book says about GMST residuals .
I have always been convinced that they were not AR(1) 🙂
Re: Tom Vonk (#49),
Data set: Monthly temperature for the northern hemisphere for the years 1854-1989, CRU
p. 173
p. 180
beaker-
I have documented in depth how the notion of “consistency” between observations and models is indeed used to suggest skillful predictive capabilities. I summarize some of this here:
http://network.nationalpost.com/np/blogs/fpcomment/archive/2008/06/17/overheated-claims.aspx
And if you want more go to our blog and search for “consistent with”
The figure here illustrates the practical meaninglessness of “consistency” in this context:
I tend to agree with Steve that this argument is philosophical rather than pragmatic. I’ll let a commenter from my blog explain why:
As Alan Murphy has argued there are many valid ways to evaluate the relationship of forecasts and obs, those arguing for the one true way are simply wrong. Were he alive today, I’d bet a lot of this nonsense would be cleared up pretty quick.
Raven: Of course the RC crowd think the models have useful skill, otherwise they would not be involved in their development and use, however they are not basing this on consistency as you charge.
The quote from Santer et al. simply says that the uncertainty in the measurements is too great to be sure that they provide any support for the models or AGW theory. If you are surprised by this it is becuase you rather uncharitably suggest they are driven by an agenda other than good science. The fact that they are willing to make such statements so unambiguously is evidence that this is probably not the case.
Re: beaker (#51)
Careful caveats buried in complex papers are not evidence of good science if these caveats are completely ignored when the authors make public statements intended for consumption by lay people and policy makers.
When it comes to evidence of model skill it is not clear what the RC relies on for their beliefs other than the ability to hindcast GMST.
Roger Pielke Jr: So the media don’t appreciate the scientific meaning of “consistent with the models”, i.e. “does not contradict the models”. It is just another case of “journalist misunderstands scientist – News at 11”!
AFAICS the article only reinforces this misunderstanding by indicating how it is normally (mis)interpreted by the lay audience, but not explaining what the scientist actually meant (which could easily have been done in the paragraph where you dismiss it as and empty statement – nice rhetoric).
typo, and [-0.000158, 0.000802] if long memory is taken into account. So here’s something for people who are requiring wider CIs, 17 X ! 🙂
Raven: So making a clear statement that arguably weakens their case is evidence of pushing an egenda rather than good science? LOL, no point in arguing with you then!
Re: beaker (#56)
It does not weaken their case in their minds because the wide CIs allow them to claim that the data is not inconsistent with the models. Lucia’s analysis says the warming is statistically significant but the models are inconsistent.
IOW – I suspect they decided to concede the point on the statistical significance of the warming because it was necessary ensure the models could not be ruled ‘inconsistent’ with the data.
Re: beaker (#56)
It does not weaken their case in their minds because the wide CIs allow them to claim that the data is not inconsistent with the models. Lucia’s analysis says the warming is statistically significant but the models are inconsistent.
IOW – I suspect they decided to concede the point on the statistical significance of the warming because it was necessary ensure the models could not be ruled ‘inconsistent’ with the data.
That is trivially true if the clear statement is contradicted or obfuscated by policy statements.
Jaye+Raven: LOL, I suggest you read the SEPP press release that accompanied the paper by Douglass et al.!
There are two different questions that can be asked. We can treat the data as real and ask if the models fall outside the distribution of the data. This seems sensible to me. Santer and Beaker and Gavin seem to be asking, given the models are real, does the data fall outside the distribution of the the model outputs? It is this second case where adding worse models or more stochastic runs gives a bigger variance (CI) and allows you to not reject any real trends. BUT the models are not real, they are the hypothesis. In case you didn’t know. And when we usually test a hypothesis against data, we see if the hyp. is outside the distribution of the data, not the other way around.
It’s worth going back and re-reading Douglass et al as we find out more about Santer et al 2008.
Douglass et al 2007 is, to a considerable extent, a commentary on CCSP and this needs to be kept in mind. Douglass et al 2007 considered temperature data up to 2004, while CCSP considered data only to 1999 (obviously affected by the big 1998 Nino at its endpoint). Douglass et al 2007 noted that use of data up to 2004 mitigated the impact of the Nino on trend estimates. They compare the updated data against the prior trend estimates.
Santer and Gavin Schmidt revert back to a 1999 end for their observational period – with no effort to reconcile to 2004 data presented in Douglass et al 2007 – or for that matter without any effort to bring matters up to mid-2008 as can be done with miniscule additional work. I updated records to the most recent available for a blog post – why can’t they get to at least early 2008 for an October 2008 journal article?
Obviously I picked up the 1999 end in my post, but I hadn’t turned my mind at the time to the fact that Douglass et al had used more recent data, so that this option was very much on the table for Santer and Gavin Schmidt.
Craig: The hypothesis embodied by the ensemble is that the true trend lies within the uncertainty (variability/spread) of the individual model runs, e.g. within two standard deviations of the ensemble mean. If you think the hypothesis is anything different, you don’t understand the aim or operation of a ensemble.
Re: beaker (#63),
Nothing that Craig said is contrary to your point. What he is claiming is that the model runs are hypothetical in and of themselves, i.e., the model runs are hypothesized to represent the system. In order for the true trend to lie within the uncertainty of the model runs, they must first be proven to be representations of the possible states of the system rather than just lines drawn on a sheet of paper. If you don’t understand why this is, then you don’t understand the aim or operation of an ensemble.
I don’t even want to get into the floor-to-ceiling CIs followed by claims that anything that happens isn’t inconsistent with the models.
Mark
Re: beaker (#63),
What statistical distribution should be shown by the ensemble of models to qualify to be treated as though 2 x sd is a meaningful test? Does this ensemble indeed qualify?
Re: RomanM (#92),
Doesn’t weighting the model trends like this simply reduce the degrees of freedom and the power of any confidence test further?
Santer et al. should have used the same period as Douglass et al. unless they gave a good reason not to, if only for direct compatibility. I would ask at RC, but I am a statistician not a climatologist, so I probably wouldn’t understand the answer!
#63. I wonder how much of this argument is rhetorical, in the sense that there may be common ground operationally beneath the terminology. Douglass et al 2007 stated:
This seems like a fair enough description of what they mean by the standard deviation of the ensemble mean trend.
Douglass et al also discuss this ongoing debate over “consistency” using a similar argument to ones presented here. They said:
As an outsider who has been observing for some time (a retired physicist, with a smattering of statistical training), I would like to make the following observations.
Throughout my professional career if ever my work involved statistics I would go and get advice from one or more statisticians.
I don’t know what the background of dendroclimatologists (or dendrochronologists or palaeclimatologists or whatever other labels are used) is; they may be physicists or botanists for all I know. But it is evident that they are not statisticians and seem to prefer to invent their own type of statistics to suit their needs, rather than consult expert statisticians.
It seems to me that these people should gather their data (on tree rings, coral, lake beds, temperature or whatever), archive them carefully and then hand them over to statisticians to tease out from the data what it all means.
A totally independent audit of the data and a proper verified statistical analysis (which is what you are doing Steve) is the only way to ensure that the truth is revealed.
#64. While the articles are written by climatologists, the matters in dispute are almost entirely statistics. I agree that, as a statistician, you would probably not understand the RC answer. You’re not the only one.
I said:
but meant:
Mark
Steve: Douglass et al are right to say that the ensemble mean will lie in that range 95% of the time, but they assumes the hypothesis embodied by the ensemble is that the true trend should be close to the ensemble mean, which is not correct.
Steve: This Douglass quote is at the heart of their error:
It is a bit like saying that a robust estimator of the variability of the weight of apples is the uncertainty of the mean of a sufficiently large sample. If that were true as we approached an infinitely large sample all of the apples would have to have exactly the same weight, which is obvious nonsense.
The SE simply is not a measure of the variability of a sample, but that is how they use it.
beaker, have you read the CCSP study?
No, I need to give the Santer paper a good read first. However this doesn’t effect the point raised in #71, the SE simply is not a measure of model variability (robust or otherwise) as Douglass et al. claim.
I haven’t read the papers yet, but I hope to get to them soon. But let’s stop the “consistency” bun fight. In statistical theory one doesn’t talk about data being inconsistent (i.e. observations inconsistent with models), but about estimators being consistent or inconsistent. An estimator is consistent if its expected value is composed of the true value plus another term that has a probability limit of zero. Estimators can be biased and inconsistent, unbiased but inconsistent, biased but consistent, etc.
The word “consistency” also has usage in ordinary English. It sounds to me like Douglass and coauthors used it in an ordinary and perfectly reasonable sense to discuss the gap between the models and the data, some hair-splitters started droning on about how that’s not the statistical meaning of the word, and on we went. The thread above makes the point perfectly clearly: anyone defending the models against the charge of inconsistency with the data by saying their spread of outputs is so wide that they encompass every conceivable outcome only ends up sounding like the Humphrey Appleby of science. It is a transparently foolish position to argue. It rebuts the charge of inconsistency by arguing vacuity. Fine, have it your way.
From a regression standpoint, the “consistency-with-the-data” test should be done as follows. For each of (n) models take a vector of (k) trends by altitude. Likewise for each of (m) balloon and/or satellite data sets. Now you have an (n+m)xk panel. Do a panel regression on a set of (k-1) altitude 0-1 dummy variables interacted with a 0-1 dummy variable taking the value 1 if the datum is from a model and 0 otherwise. The coefficients from these interaction terms can be tested using H0:(b=0). If the test rejects the models are significantly different from the data. Easy. End of story, end of feud, last one out turn out the lights.
Re: Ross McKitrick (#74),
I posed the question of doing a statistical test that covers the shape of the temperature trend to pressure level curves (which vary considerably) in a recent post on the Douglass thread and know you have apparently shown the way.
So who will do that test? I am leaving the room, but with the lights on.
beaker, this point is really going on and on without getting anywhere. It’s not that your examples aren’t relevant – they might very well be. But this entire Santer-Douglass thing is taking place in an argumentative context and there should be some dry treatment of ensembles from a statistical perspective that an interested reader can consult for procedures and tests and consider the Santer-Douglass dispute from that perspective. Santer did not provide any relevant statistical authorities: I’m interested in something other than prior argumentation by the same coauthors – do you know of any? If not, doesn’t this seem like an alarming lacuna and no wonder innocent readers can be confused.
Also could you spend a little time on the H2 hypothesis in Santer. This “hypothesis” does not rely on this particular issue that some much bandwidth has been devoted to and often changing focus helps. My own sense is that the Santer-SChmidt position on the H2 hypothesis is an artifact of the 1999 endpoint in their analysis and does not survive a 2008 endpoint regardless of how the numbers are crunched.
Beaker: in statistical terms, I have a population of observations of the real world with a distribution. I have a hypothesis I wish to test (a medicine give a better result than a placebo perhaps). I compare the medicine value with the distribution.
Ho: the test value is within the distribution
Ha: the medicine is different
we reject Ho, and accept Ha for this particular test. Ok so far? Now the data is observations of tropo trend and the Ha is a particular GCM output. We reject most of the 22 independent GCM models (in the sense above). Now someone says: but the ensemble mean is better (in some sense). We test:
Ho: the test value (ensemble mean) is within the distribution
Ha: the test value is different
and we reject Ho. Do you have a problem with this? If faced with a population of responses to a drug would you say that the range of drug responses overlaps the control so it is ok? Or that the mean response to the drug is adverse so we reject it as safe? By the way, be careful being condescending on this blog. I’m not as stupid as you seem to think.
Steve, it seems to me that some sort of discussion on what a model ensemble aims to achieve would be very much in order, I use ensembles all the time to ameliorate the effects of uncertainties I can’t exclude, it is perhaps too inherently obvious to me that I have difficulty explaining myself in non-specialist terms. I did try on a previous thread, but got no-where because of this fixation with the ensemble mean.
Look at #71, the quote shows that the Douglass et al test statistic, the SE, doesn’t measure what they said it measured, the SD does.
Craig: I did not intend to be condescending either. Stupidity and ignorance are not the same thing, there are plenty of things I don’t know and people often have difficulty in explaining them to me in terms I can understand as well!
I like the fact that Steve M is looking at the Santer et al. (2008) data with another statistical tool and from another angle and do not want to detract from that line, but I do think that we cannot get too far away from a direct view of the floor to ceiling CIs for the tropical surface to troposphere temperature trends for model and observed results as shown by the graph below from Santer et al. I also think that a critical point to remember is that it was the difference (ratio) of surface to tropospheric temperature trends that were of interest to Douglass et al. (2007). Santer et al. spends much time discussing and analyzing tropospheric and surface trends separately and then graphing the trends that way in the graph I show below, and then finally, with lowered voice, talking about the differences in trends later in the paper.
The graph would be perhaps apropos for someone complaining about a scalp disease that was uncertain to its existence because of all the intervening tangle of hair.
beaker, I’m not asking you to write more notes on the statistics of ensembles – I’m requesting your recommendation to a statistical authority on the matter.
Kenneth: I seem to remember making a similar comment (that the diagram on RC was a more effective criticism of the models than Douglass et al.) on an earlier thread ;o)
Steve: Can’t think of a reference off-hand, unfortunately GCM ensembles are used in a slightly unusual manner (for a start they are not statistical models in the usual sense).
As for a statistical authority, modesty prevents me from mentioning my research interests are pretty relevant! ;o)
One would imagine if somebody starts talking about consistency at all, that there’s some point to it; there’s not just a match but there’s meaning behind it. Or that this consistency is over a wide range of an ensemble rather than just a piece of it. Not just that there’s some meaningless match somehow.
Has this been referenced?
http://www.emc.ncep.noaa.gov/gmb/ens/postprocessing.ppt
Re: Sam Urbinto (#84), Not surprisingly, perhaps a little coincidentally, I was browsing around and ran across that same slide show. I don’t know why, but the name Zoltan Toth seems eerily familiar.
Engineers are typically taught out of the Papoulis book, and there are some lecture slides located here though I’m not sure if they contain what Steve is looking for (Lecture 12 gets into the consistency argument, but no real detail other than an estimator variance that approaches zeros as n grows).
Mark
How about Kacker et al Bayesian posterior predictive p-value of statistical consistency in interlaboratory evaluations
It appears (with login) to be downloadable for 30 days after publication, this is the October issue of Metrologia
Re: Sam Urbinto (#85),
From your quotation
This is questionable as follows. In a laboratory analysis, there are commonly a number of steps. The first might be to dry a specimen. If this is partially done, the error will not be normally distributed becuse there is a cutoff at 100% dry. The next might be to weigh a specimen. The balance used for weighing has both a possible bias error and a possible precision eror. In an extreme example, its readout might be defective, so all readings greater than 1 milligram show as 1 milligram, so then its error function is not normal. But let’s assume that we can compute an error function from weighing the same object many times over.
The next step might be to dissolve the specimen in an acid, given weight to given volume. This relies upon a correct measure of acid volume and there is a dirtribution of errors around the volume measurement and a possible bias also. And so on through the whole laboratory process. The final result is actually an ensemble of a number of prior steps. In theory, one can calculate error distributions either by (a) analysing portions of the same material many times over; or (b) by mathematical combination of errors from the preceding sub-processes. The expectation would be that two different estimates would be obtained and that (a) would be smaller in error than (b) because of the greater chance of plus errors balancing minus errors.
Next step is to compare several laboratories with each other. They might have instruments with different error distributions. Some might have logarithmic response physics, some linear, some microchip corrected by maths unknown, a further complication. But, the results submitted for the inter-laboratory comparison would usually be the class (a) above, this being customary procedure.
It is new and alarming to me that “If the model fits reasonably then the results may be regarded as statistically consistent.” Two problems. First, this is s subjective statement that depends on judgement or purpose for no good reason. Second, what is the response when “If the model DOES NOT FIT reasonably ….”?.
There is quite a parallel here with the above discussion on tropical tropospheres. But the parallels cease to be so when a new method of subjective interpretation replaces a perfectly satisfactory, time-honoured objective method.
In my time if a trace element anlysis has a nominal value of 100, one would be content to come in between 80 and 120. This reporting of tropospheric trends to thousandths of a degree C per decade is off with the fairys at the bottom of the column, where the temp jumps from atmosphere to ground in a way better explained by Ferenc Miskolczi. See the graph in Kenneth Fritsch #79 above.
(Incidentally, I was part-owner and founder of a large analytical laboratory and these comments are not made without experience. I participated in many interlab comparisons and wrote a manual on quality control of analysis of geological materials).
The angels are gathering on the head of the pin again.
Re 74 Ross, & all, the papers are
Douglass, David H., John R. Christy, Benjamin D. Pearson, and S. Fred Singer, 2007. A comparison of tropical temperature trends with model predictions. International Journal of Climatology, published online before print December 5, 2007, online http://scienceandpublicpolicy.org/images/stories/papers/other/Singer_model_wrong.pdf
Santer, Benjamin D., P. W. Thorne, L. Haimberger, K. E. Taylor, T. M. L. Wigley, J. R. Lanzante, S. Solomon, M. Free, P. J. Gleckler, P. D. Jones, T. R. Karl, S. A. Klein, C. Mears, D. Nychka, G. A. Schmidt, S. C. Sherwood, and F. J. Wentz, 2008. Consistency of modelled and observed temperature trends in the tropical troposphere. International Journal of Climatology, published online October 10, 2008, online https://publicaffairs.llnl.gov/news/news_releases/2008/NR-08-10-05-article.pdf
Well, despite the efforts of several posters to get back to the business of examining the analysis in the paper, a lot of time did get eaten up in the pursuit of the bogus “consistency” concerns.
One of the things nobody seems to have noticed is that the H2 hypothesis is done in a statistically inefficient fashion. The estimate of the overall model trend is calculated using the simple average of all the model results – in effect treating all of the models as if they were equally good at estimating the trend (one of the serious objections to the inclusion of garbage models in this line of comparison).
However, in H1, they claim to compare each of the models to the instumental temperature records. Now in order to do this, they must calculate the variability of the estimated trend for each of the models separately – the methods are described in the paper. This (valuable) information is then inexplicably thrown away in the subsequent H2 situation. In reality, the optimum estimate of the “ensemble mean” is obtained by using a weighted average of the individual model trends where the weights are proportional to 1 / variance of the model. The result has a smaller standard error than that of the sample average with a correspondingly narrower 2 SE interval. However, the weighted average may also be different from the simple average so it isn’t immediately clear what the corresponding changes in the results would look like. There is another side effect. From Figure 3, it is quite clear that the model variabilities differ (sometimes substantially) from each other, so with the extra information, the “ensemble standard deviation” does not represent any meaningful quantity.
Now, it wouldn’t be a difficult task to calculate the relevant quantities … except that the data do not seem to be present anywhere in either the original manuscript nor in the copy of the SI that I have. Of course, if they were, just anyone, even an amateur, might also be able to look at how each model compares to both the instrument data and the other models and do a more proper assessment of the consistency of the models. Hmmm …
Re: RomanM (#88),
My assumption was that they are all equally bad at it, and thus not representative of anything real anyway.
Mark
Re: RomanM (#88),
Is THAT a documented standard procedure in statistics?
Re: jae (#91),
Caught after dinner and some wine. OK, let’s get technical.
Lay out the assumptions: We assume that the variables x1. x2, …, xn are our set of data. They are uncorrelated and come from populations having the same mean µ and with possibly different SDs σk. “Optimum” is defined as: we wish to find the minimum variance unbiased linear estimator of µ, i.e.
Estimator = w1 *x1 + w2*x2 + … +wn*xn
(determine the {wk} such that the variance (or SD) of the estimator is as small as possible). This result is often proved or given as a problem in an upper level mathematical statistics text book and uses a calculus method called Lagrange multipliers in its solution. The answer is basically what I mentioned:
wk = (1/ σk^2) / Σ (1/ σj^2)
(Read that as one over sigma-k squared divided by the sum of all of one over each of the sigmas squared – I’m too lazy to try to do tex on this right now).
Finding references on the web was more difficult that I thought it should be. I went to weighted average on Wikipedia and it is there (sort of), but given implicitly at the bottom of the page and you have to understand correlation matrices. There is a readable proof I found for the case n = 3 which illustrates what I mean in some pages of a book.
It’s a pretty well-known straightforward result. Trust me, I’m a doctor. 😉
Re: RomanM (#92),
Thanks, but too much detail for a statistics-challenged chemist. I was hoping for a “yes,” or a “no” (but I really knew better). There are just too many “maybes” in this world, anymore. 🙂 It just seems to me at my level of understanding to be an “opertunistic” way of treating model outputs (maybe the word “spurious” even fits here). If a model just HAPPENS to match reality better, it’s weighted very high. I see it as Luck and Circumstances, but I defer to those with more statistical prowess….and I will shut up.
Rendering the consistency argument moot.
Like trying to determine the effect of a drop of hydrochloric acid on the Atlantic Ocean’s pH levels.
Sam Urbinto #85,
Actually not new to me since first looking at the IPCC GCModels last November. I was shocked then.
In the meantime I have discovered in the literature of AR4 the following quote that I keep repeating on Wattsup so that people realize what we are talking about:
The AR4 waffles on the errors:
From chapter 8 that is supposed to evaluate the models:
So you see that they clearly know they are selling us, as we say in Greece, “sea weed for silk ribbon”. It seems climate “science” bases errors primarily on “experience” and “physical reasoning” which has been a “norm”. That is why I have put science in quotes.
How can there be any meaning in testing data statistically against such models? It is practically like checking astrological predictions. The only meaning in checking statistically is for trends in the data itself, where at least one expects that the errors are according to scientific rules, at least for the satellites data.
I was interested in your statement:
I see that GCM modelers, by calling their model runs as “experiments” have come to believe they really are experiments, and that different models are the different laboratories of your quote above.
There seems to be consensus amongst “real” scientists here that whatever climate modelling is, it certainly is not science.
As far as I can tell, an ensemble of model runs is simply a more opaque, less reproducible and more arbitrary model. And the distribution of its component runs is meaningless, both scientifically and statistically.
I hate to spoil a party but what we need here are not statisticians but philosophers schooled in logic.
I’m neither a statistician nor a philosopher but I’m trying to follow the logic – or lack thereof – behind the skill/use/possible conclusions of/from the climate models.
Traditional logic behind the models :
1. The main objective of the models is to demonstrate that natural forcings are not sufficient to explain global warming by showing that the inclusion of (man-made) CO2 forcings is required for a proper fit.
2. If the temperature data is within the models’ confidence intervals, global warming must be man-made.
First corrolary :
The conclusions under item 2 cannot be reached unless it has been shown that the temp data lie outside the models’ CIs when using ONLY natural forcings while the same models show that data lie within the CIs when using BOTH natural AND man-made forcings. I think this is the most important point when discussing climate models which assess the putative role of anthropogenic forcings.
Second corrolary :
If natural forcings other than those included in the models are ignored or if the sensitivity of the natural forcings included in the models is wrong, then the conclusions from the models cannot be valid.
Third corrolary :
A model may yield a false positive result w/r to CO2 (good fit with data but CO2 not a significant forcing) if natural forcings causing warming had not been identified and therefore not included in the model (e.g. ?? albedo, clouds, gamma rays, etc). Or a model may yield a false negative result (no fit with data but CO2 a significant forcing) if natural forcings causing cooling had not been identified and therefore not included in the model. Conclusions from models may therefore be invalidated retrospectively as natural forcings are identified.
Fourth corrolary :
Since models have been developped for the purpose of fitting a warming climate, the lack of warming since 2001 is, at this time, an obligatory indication of modeling failure irrespective of fancy statistics and time factors. Natural forcings have obviously been underestimated.
Statisitics can only help w/r to defining the CIs. We need research to better understand natural forcings. Until then, modeling is useless. But if models are used, we must require that modelers provide us with results from their models using natural forcings ONLY in addition to results using ALL forcings.
François GM
Morning all!
As I am not allowed to talk of [word that cannot be uttered here] any more, I shall have to be careful how I address a question directed at me here! ;o)
Alan Wilkison #93: The 2 x sd test establsihes whether the observations lie within the variability of the models (which represents the uncertainty of the model hindcast). Douglass et al. evidently though that this was what they were doing as they said:
However, as I explained in #71, the standard error of the mean is not an estimate of model variability as they say, it is an estimate of the uncertainty in estimating a population mean from a sample. The uncertainty in estimating of the ensemble mean is caused by the model variability of the sample, however as the ensemble grows the uncertainty in estimating the mean goes away, but the model variability does not, which shows that the SE is not the robust estimate of model variability that they claim.
For competent impacts modelling, we wouldn’t use only the ensemble mean, we would use the whole ensemble so that the uncertainty in the GCM projections (i.e. the 2 x sd error bars) is propagated properly through to the downscaling and impacts models so that we have the appropriate uncertainty (error bars) in the estimates of the impacts. In making policy, the uncertainty of the ensemble is every bit as important as the mean, this is the principal benefit of using an ensemble!
Francois GM #98:
If you start off with invalid assumptions, the corrolaries are meaningless:
No the main objective of GCMs is to explore the consequences of a set of assumptions regarding the physics that governs the climate. If a GCM cannot be constructed that gives a good fit without CO2 that is evidence, but not proof that CO2 is relevant.
No, if the data lies within the confidence interval of the model, this means the model is not falsified by the data, in other words the data are [word that cannot be uttered here] with the model. All this means is that the model remains plausible, nothing more, specifically it doesn’t imply the data provide strong support for the model. If the data lie outside the confidence interval of the model, this means that the models are refuted with a high degree of confidence and the model builder needs to go back to the drawing board. A scientist might say that the models are [word that cannot be uttered here] with the data as the most damning criticism of a model he could make. This is why [word that cannot be uttered here] is not the “empty statement” of Roger’s article.
Re: beaker (#99),
No. Model builders need to go back to the drawing board if a model has a poor skill!
And using an ensamble of bad and less bad models is not an excuse for you not to do anything else.
It’s not clear what you mean. What is evidence for you? It doesn’t seem correlation.
François GM 98
Please read my #96 above. In order to have a Confidence Inteval of the models, one needs real errors of the models and not estimates according to the feelings of the modelers, which is what the errors provided in AR4 are. They are not true CI, but artist’s estimation of what they should be.
True errors in models I have used, in a different field, mean that one varies all the parameters that enter into the modeling by their error in a systematic way, and looks at the output. The difference of the fit to the varied by 1 sigmas fit gives the error band of the model. This is not what they have done, as the quote in #96 clearly states. They used their intuition. This is because even changing 1 sigma only the albedo, will put the temperature curve off by a degree C , which means make the model fit meaningless. I am asserting this having played with the model in http://www.junkscience.com/Greenhouse/Earth_temp.html and assuming that the albedo error is 3% the change in temperature is 1 degree Celcius. I am really curious to see a GCM output where only the albedo is changed by 1 sigma clearly stated and drawn.
anna v #100: The uncertainty of the ensemble (i.e. model variability) is more properly regarded as a credible interval rather than a confidence interval. I noted earlier that GCMs are not statistical models (in the usual sense) and this needs to be considered in their analysis.
N.B. I am an objective Bayesian by inclination, but I have no nproblem with subjective Bayesianism if it is used properly. IMHO your problems with uncertainty here
stem from forcing a subjective Bayesian model into an incompatible frequentist framework.
Re: beaker (#101),
Then WG1 AR4 Ch02 p. 152 :
should say credible interval ? Needless to say, I’m a bit confused here (I’m not a statistician, but I’ll listen what RomanM has to say 😉 ) .
BTW, AR4, Ch03, p. 248, Table 3.3 caption (my bold)
This seems to be in conflict with Beran’s (
http://www.climateaudit.org/?p=4101#comment-305849 )
4 X or 17 X , that is the question ..
Beaker, #100
It can be anything the artist/modeler wants, but it cannot be treated as a true confidence interval in the statistical sense, so as to draw mathematically reliable conclusions, IMO.
I would think that the real world, i.e. data, is not a subjective Bayesian model, whatever that may be. To treat it as such is working in virtual reality land, and any conclusions are irrelevant to the real world, except artistically. Statistical significance is not left to the eye of the beholder.
Nevertheless politicians are being stampeded into reacting as if these video games are real predictions of the future, and decisions are made based on these flimsy extrapolations.
Paolo M #102: No, if there model has poor skill they may only need to revise their estimate of the parameters. If the model is falsified by the data (i.e. the
data are in[word that cannot be uttered] with the data, then their approach is fundamentally wrong and they needd to go back to the drawing board. Douglass et al tried to establish the latter, but used flawed statistical test (does nobody want to comment on #71?). Santer demonstrate that they don’t need to go back to the drawing board, but they do not show that the models exhibit great skill (and nobody has been able to give a quote when challenged that demonstrates that they claim to have done so).
Would it be better if I had said
because that is basically what I meant.
anna v: Try reading the works of Jaynes, RT Cox and Jeffreys, especially the distinction between a credible interval and a confidence interval.
Alan Wilkinson (#93),
Degrees of freedom are a measure of the amount of information upon which an estimate of the uncertainty (i.e variability) is based. Since the estimates of the variability are calculated from extra information available for each model (but not used in the approach taken Santer et al.), the degrees of freedom are increased. When there is a reduction in the uncertainty of the statistic, the power of the test (i.e the ability of the test to correctly find differences when they do exist) is higher.
Alan Wilkinson (#93),
This isn’t a case of “matching reality better”. The weights are determined, not by how close the values are to the observed temperature, but purely by how “uncertain” a model is in estimating the actual trend. If, as in the assumptions of the null hypothesis, each model produces an unbiased estimator of the actual trend, then we should put heavier emphasis on those estimates that are more likely to be closer. The math simply calculates the best choice of weights to use given the variability information.
Alan also asked
That is an excellent question which you will notice that beaker didn’t answer. It is evidently clear from the first set of tests done by Santer that the models do NOT produce results which are equally variable. So the population of model estimates is not a homogeneous set of equally good (or bad) estimates which could be represented with a simple normal distribution. Beaker’s statement in beaker (#99)t that “The 2 x sd test establsihes whether the observations lie within the variability of the models” is basically hogwash under the circumstances.
I will ask beaker some simpler questions. Why would I choose to ignore the extra variability information that is included in the other parts of the study? Given that the “population” of models results has a mixture distribution, what is the exact statistical meaning of the “standard deviation of the ensemble” (not the formula for calculating it, but the parameter that it represents)? What is the significance level of the “test” – why would 2 SDs be a meaningful quantity in this context? What is the power of the test (the ability of the test to reject “inc******ent” ensembles)? Genuine statistical tests will have answers provided to these questions before they are used.
I wish to refer readers to Karoly et al 2003 , an article cited in the CCSP 1.1 report discussed in Douglass et al, in the only usage in that report of the term “inconsistent with” – though the term “consistent with” is frequently used.
Karoly et al 2003 provide the following interesting operational definition of “consistent with”:
This falls between the Douglass usage and the Santer usage and may offer a way of advancing beyond what seems like a pointless philosophical debate. Instead of calculating trends for every individual run (as Santer), they average out runs for a given model creating an ensemble for each model, as a practical way of averaging out Nino impact on trends. If you look at Santer Figure 1, the Karoly approach would use the ensemble mean from this model.
Second, here’s an excerpt from the money figure in Karoly et al 2003. Error bars are shown here on the models (as in Douglass, except that they are shown for individual models, rather than the “model gestalt”), but not on the observations (also as in Douglass).
Karoly Fig. 3. Trends in North American mean temperature from anthropogenically forced (GS, open symbols) and natural externally forced (NAT, solid symbols) model simulations and observations during 1900–1949, 1950–1999, and 1900–1999. The error bars on the model trends are the 90% confidence interval for the ensemble-mean trend, estimated by resampling the respective long control model simulations and allowing for the number of members in each ensemble (16). The error bars about zero at the location of the observed trends are the uncertainties in the trend estimates due to natural internal climate variability, as simulated by the models. They are the 90% confidence intervals for a single realization, estimated using the control simulations from the ECHAM4, HadCM2, and PCM models (16)
From this sort of diagram, which has a similar logic to the Douglass diagram, they conclude:
As I mentioned in my head post, I thought that the wide Santer-style error bars on trends would be a two-edged sword, as it seemed to me that if this were not an industry standard, consistent application of the standard would overturn some other results.
Having said that, there’s also something that feels a bit off to me in the Santer error bar calculations, tho I can’t quite formalize it yet. In looking at the Karoly ensemble averaging, they try to get rid of “Nino noise” in their trend calculation. A very large element of the “uncertainty” in the AR1=modeled trends is allowing for the theoretical possibility that we were in a prolonged Nina phase in 1997-1999 (which we know to be untrue on other grounds) but which the AR1 likelihood method doesn’t know. But merely allowing for Nina-style “noise” as a possibility in the late 1990s – a possibility known to be false – hugely widens the Santer error bars. I think that there might be a good case for deducting a Nino effect from the observational record prior to trend calculation – something that would greatly reduce the AR1-type noise. I’m not sure exactly how to do this, but something like this was done in Thompson et al (Nature 2008 on SST) and maybe that could be applied.
The other line of progress from working at a model ensemble mean scale is that, until a coherent definition of what a “gestalt” model really means is advanced, maybe it’s more useful to examine models one by one. USing ensemble-means from individual models seems practical in this context.
Beaker #104
Well, I went to Wikipedia:
and:
Note that “a posterior probability interval”. This means we go to the year 2100 and look at the data and check whether the “projection” was good or not, i.e. within the credible interval. After we have destroyed western civilization.
The modelers, because like God, can run the models to the future, confuse reality with virtual reality, and think that the “a posterior probability interval”( credibility interval, instead of confidence interval), derived from models is a real measure of what nature holds for us.
In my modeling experience we computed the likelihood function of fitting data to models and gave results in chi2per degree of freedom. This, as the quote from AR4 I have given in #96 above says, has not been done for these models. Rather the feelings of the modelers were consulted.
b What are we talking about? Is this science?
Roman M #105: Alan Wilkinson asks:
The standard deviation is the square root of the variance. The variance is the expected difference between a sample drawn from the distribution and the mean, and hence it and the standard deviation is a measure of the variability of the population. This is true regardless of the form of the distribution. The important element here that I was emphasising in my original answer is that the standard error measures variability and that the standard error does not.
Now, to answer the question more directly, for a Gaussian distribution, approx 95% of samples will lie within two standard deviations of the mean. For another symmetric distribution the proportion of samples lying within two standard deviations of the mean will be different, but this only changes the significance level of the test, it doesn’t make it any less meaningful. However in practice, a Gaussian approximation to the true distribtion is adopted for mathematical convenience. This is a footling consideration compared to the huge unstated difference in significance level you get from using the two standard error, how many of the models lie within two standard errors of the mean?
Of course you can get better estimates, you can weight models if you like, I have no problem with that, but the objection is a rather minor one in the Douglass-v-Santer SE-v-SD comparison.
you ask:
I think you will find I discussed this in an earlier thread, yes the population does have the form of a mixture distribution.
By the way, Douglass et al. ignored a significant part of the variance by using the standard deviation of the average of the runs for each model, i.e. they ignore a large part of the stochastic variation, thereby making the error bars narrower than they actually are.
Essentially it is a measure of the variability of the models comprising the ensmeble (duh!). The composition of the ensemble expresses an implicit (and possibly unintentional) prior over the beliefs of the modelling community regading the plausibility of the models. Of course this prior could be adjusted by weighting.
Becuase there is a (possibly implicit) assumption that the distribution (represnting a subjective Bayesian prior) is approximately Gaussian. This is a very common thing to do – the definition of a frequentists is “someone who knows what to assume to be Gaussian” ;o)
Exactly the same as the standard frequentist test to see if an observation can be regarded as a sample from a Gaussian approximation to a distribution (which happens to coincide exactly with the Bayesian equivalent).
Re: beaker (#108),
Thank you for the elementary statistics lesson, but for future reference, you can safely assume that after 44 years of graduate study and career of teaching this stuff at every level and to diverse groups, I might have learned something about statistics. My questions were not looking for arm-waving answers, but rather a consideration of a more technical nature regarding whether the assumptions “implicit” in the Santer H2 analysis were in fact appropriate. The disregard for the validity of assumptions and the failure to take them into account and adjust for them are usually an indicator of a lack of understanding of the overall picture.
You didn’t answer whether you thought that the ensemble did qualify, but I assume that you are saying that you think that then that in fact a simple Gaussian is appropriate AND that the 2 SD bounds will be appropriate. Does it not seem to you that, given the radically different variabilities of the various models, the actual distribution is going to be considerably different and the actual significance level will typically NOT be 5%. Did you even consider that factor? By the way, I failed to understand what you meant to say in the “footling” sentence.
It is indeed, but you might have thought that I would know that. I guess I didn’t make myself clear enough. In this case, the expected value of the sample variance is equal to the average of the variances of the individual variances of the models. Do you not think that when you are evaluating the performance of a given model, it would be more to the point to use the model’s SD rather than the square root of the average of all the model variabilities? With a statistician in the mix of the authors, it seems that a naïve approach such as the simple one used could have been replaced by a technically improved one.
“What is the power” means “how likely is the test to pick up the situation when the ensemble is ‘inc******ent”. Without consideration of the power of a test, the test is basically just arm waving. I am somewhat unclear how the “test” works. Do I just reject those observations which fall outside and not the ones inside? Maybe, I only reject the ensemble when all of the observations are inside? Something in between? What must an ensemble look like to be rejected? What parameters of the ensemble is the power a function of? A genuine statistical test would have a context within which these questions could be theoretically answered. I was looking for a hint in that direction … or is that not a consideration for the test?
As an aside, (in a purely nonjudgemental way), I usually write my longer posts in a word processor which corrects my spelling and mistypes). It makes them look cleaner and more readable. Also, if you type a : or ; followed immediately by ) , the website converts it into a smiley, wink, or whatever. ;o) doesn’t work.
Steve #106: I’ll read the Karoly paper when I have time, but from what you say I think the Karoly paper is perhaps more in need of an audit than Santer et al. I can’t see how you can tell if a trend is outside natural climate variations by looking at the uncertainty regarding the mean.
The appropriate test for whether something is [word I can’t used] or [another word I can’t use] depends on what is being claimed. If it is claimed that the mean is an estimate of x then the standard error test is fine. However, if the claim is that x is within the uncertainty of a prediction with error bars (as is the case with an ensemble), then the SD test is appropriate. Of course the mean is still likely to be the best point estimate of x, but that is only part of the prediction.
At the moment I am re-reading “confidence intervals vs Bayesian intervals” by E.T. Jaynes, which I strongly recommend. It contains a beautiful example where following frequentist best practice you end up with a confidence interval guaranteed not to contain the true value (and explains why)!
This is a long argument about what appears to be nothing.
snip – Paul, you’re venting too much. As an editorial policy, I much prefer to deal with small issues in the hope that some solid ground can be identified.
O.K., how about this:
A sample of 10,000 men from a particular city have their heights measured for a medical study on (say) the effects of diet. The mean of this sample is found to be 5’10 (1.778m) with a standard deviation of four inches (0.1016m). Assuming heights are normally distributed, we now have a model of the heights of the men from this city. As 95% of the population can be found within 2 standard deviations of the mean, this gives us a confidence interval of 5’2 to 6’6.
We later revisit this city and measure the height of the first man we run into (let’s call him “Gerald”), who happens to be 6’2″ tall. According to the +- 2sd test, Gerald is with two standard deviations of the mean and so we conclude that our observation is consistent with the model.
We now measure the next man we run into (“Rupert”), who happens to be 7’2 tall. He lies outside two standard deviations of the mean, and so we say that “Rupert” is inconsistent with out model, he is an observation that can only be explained by our model with very low probability.
All happy so far? Lets look at the SE test. The standard error of the mean of our original sample is sd/sqrt(10,000) = 0.04″ (0.001016m). Lets apply the SE test:
Gerald: Gerald is way outside 2 standard errors of the mean, so he is inconsistent with out model.
Rupert: Rupert is a huge distance outside 2 standard errors, so he also is inconsistent with the model.
We now measure “Sydney”, who at 1.78435m tall is a whopping 1/4″ above average height. He is also a little over two standard errors of the mean outside the mean, so even he is inconsistent with the test.
Now answer me this, is the model reasonable? Is it reasonable to view Rupert (or Gerald) as being “inconsistent” with the model?
Can anyone provide a common-sense justification for Rupert to be in anyway “inconsistent” with the Gaussian model from mens heights?
Re: beaker (#111),
Noticed this one after I made the previous post. Your example does not mirror the test. In an effort to produce an extreme example, you have confused things.
The parallel between the example and the models is:
Sample of 10000 == observed temperature data.
SE = .04 == standard error of the temperatures.
Rupert = model ensemble of size 1.
Thus, to test the ensemble, we would use a SE = population SD / 1 = 4” and not reject him. If in fact, both of the first two men are combined to form the ensemble, then the Douglas version of the test would calculate their average height = 6’8” and the SD = 8.49 with the SE of the mean = 6. If these are a random sample, they are still within 2 SEs and would not be rejected by the Douglas test(although they are not very likely to be from a population with mean 5’10” and SD = 4).
Sydney certainly would not be rejected by himself and could very well bring the other two in and make them look shorter if he is brought into the ensemble.
beaker, I’m not sure what word you’re avoiding?
Also I’d be interested in what you think about the effect of Nino-type “noise” on trend estimation if you have prior information on the Nino index – the issue in the latter part of my post.
The Santer confidence intervals on trend (and, for that matter, the confidence intervals in my figures shown above) assume that you don’t know anything about the actual Nino index. If you have a prior estimate of Nino (as we do), why wouldn’t you utilize that knowledge?
The residuals in the model runs are largely Nino-Nina events. Apply this to the observations. If the observational record were incorrect by underestimating the trend through AR1 error structure – the case of most interest to Santer – then your residuals have to tie in to the Nino-Nina index. If the trend is underestimated, there has to be a prolonged Nina-type event in the late 1990s. That’s not correct on other grounds. So they are not using all the relevant information – which should bother you as a Bayesian (or for any number of other reasons).
When you think about it from this perspective, it makes a more precise identification of the issues. The “real” problem in all of this is that there are still unresolved differences between the UAH and RSS records. Until this is resolved, there is an observational uncertainty – which is one of the options in Douglass et al.
Oops, that should be “Sydney” instead of “Rupert” for the last two lines of my previous post (obviously)
Steve #122: “consistent” and “inconsistent”, just trying to retain some levity in the discussion.
You would have to ask a modeller for a definitive answer, but my understanding is that while it would be possible to add the known ENSO forcing, we can’t predict ENSO into the future, so the projections of future climate can’t benefit from them. This means that if you included ENSO forcing in the hindcasts used for verification/validation you would get an unduly optimistic estimate of the real uncertainty of the future projections.
I’m afraid I don’t follow your third point. If you mean that a lot of the variability in the model runs is due to variations in their simulated ENSO, then that is probably true. This is why I say the ensemble mean is not expected to match the observed trend exactly even if the models were perfect. They don’t have access to the ENSO information, and there is no reason to expect the ENSO we have actually observed is necessarily “average” (especially 1998!).
In my opinion the whole point of Santer et al was to highlight the fact that both the models and the observational data are subject to uncertainties that are currently so large that we can say little for certain about tropical trends. Work need to be done both on the models (which have substantial irreducible uncertainty) and in analysis of the data.
Douglass et al. seems to me to assign almost all of the “inconsistency” to the models (for instance by not including datasets that are closer to the models, thereby unintentionally downplaying the uncertainty in the observations and amplifying the differences). I expect this is the result of subconcious bias, the data men blame the models, you would perhaps expect the modellers to blame the observations (remember they are only estimates of real world quantities, not the quantities themselves!).
RomanM: It would help if you would post questions one at a time rather than long posts asking many questions discussing different aspects of a topic as this makes giving a straight answer rather difficult (especially if some of the questions are based on assumptions about my position that are not justified).
For instance
In which case my answer would be “I don’t know without investigating the data, which I haven’t done, however such approximations are very common in statistical analysis, so it is not inherently unreasonable”.
BTW: My “footling” comment was basically saying that the difference in the significance level arising from a deviation from the Gaussian approximation is almost
certain to be tiny compared to the difference arising from using the SE instead of the SD. This means that questioning the validity of the Gaussian approximation is a bit like re-arranging the deck chairs on the Titanic.
#115. You missed my point re Nino, I’m afraid. Here I wasn’t talking about models but about observations. There are major issues between UAH and RSS but that’s not what’s being measured in the Santer AR1 error bounds. IF the true “trend” was much larger than the observed MSU trend due to an odd draw in the “AR1” residuals, this could only happen through a huge closing Nina, whereas we had a huge closing Nino in the 1979-99 record of Santer. An AR1 residual model is not using the available information intelligently. I think that it would make sense to de-Nino the observed record according to our best information on the one hand and to follow Karoly be trying to average out Nino noise through model ensembles (at a minimum.) But the operations are distinct.
Re: Steve McIntyre (#118),
One of the reasons I would like to have the data I was looking for earlier was to try some ideas of bringing in the ENSO index when estimating the observed temperature trends. A simple starting point is to simply regress the temperature on the index and the year. It may turn out that it doesn’t change things much and perhaps some other function (exponential?) might work better. IMHO, This line of analysis is worth a try. One possible end result could be a reduction in the autocorrelation of the residuals producing an increase is the “adjusted” degrees of freedom and narrower error bars on the observed values.
It does indeed seem to be a clash between Bayesianism and frequentism. Most of us are probably used to having enough trustworthy data to test our models but climate science consists largely of best guesses based on sparse, adjusted data. So a Bayesian approach is really their only option. Though the idea that a bunch of inadequate models when combined can make an adequate ensemble is probably unique to the climate arena…A frequentist collection of Bayesian models perhaps. This is the bizarre idea that Douglass et al. were challenging.
Now I once wrote a Bayesian control model for a chemical plant (with much trepidation) and it worked fine but then I wasn’t just guessing the rules or weights – they came from interviewing experienced operators. And the system still of course needed extensive testing. When a bad system would cause an explosion you don’t hear blather about phony confidence intervals. In real life a model is either right or wrong. When it’s wrong you try to fix it. If you can’t then it’s useless. It really is that simple!
Douglass said on the previous thread that he wished he hadn’t even mentioned statistics and he was right. All you really need to do is eyeball the graphs and use your gray matter. Using statistics just brings out the black-is-white brigade. The main problem with climate modeling (and their defenders) is the lack of accountability. They can make up any phony, illogical story to cover their inadequacy and it’s accepted thanks to an overdose of political correctness among their superiors.
This is a side issue, and not entirely relevant to the debate at hand. Steve, feel free to snip if you feel this is a distraction.
A quick question for you Beaker. I have a data set which contains data points that are independent, identically distributed random variables which have a student’s t distribution with two degrees of freedom. Student’s t is symmetric so meets your criteria. From theory, what percentage of points lie within two standard deviations? In what way is this “meaningful”?
FWIW, this isn’t a big deal in the general discussion at hand. More a reminder that aspects of statistics – particularly gaussian assumptions – need to be carefully considered and not hand-waved or treated glibly. On the wider issue, IMHO Roger Pielke has it right with comment #50.
RRomanM #116:
The sample of 10,000 men represents the distribution of temperature trends that are considered plausible by the modelling community (obviously if a model produces that trend value it must be considered plausible). The individual named men represent estimates of the observed trend (I chose not to complicate matters by incorporating that our knowledge of the true trend is uncertain). What do we achieve by the sd test? We find out whether the observed climate fits within the range of outcomes that the modellers are predicting. If the observed trend is outside the interval, we can be fairly sure the models are fundamentally wrong.
Now lets perform the test the other way round. Now we are asking the question “is there a statistically significant difference between the ensemble mean and the observed trend”. However, we know a-priori that there is almost certain to be a difference between the ensemble mean and the observed trend [if you understand the sources of uncertainty resulting in the variability of the ensemble, you will understand why], even if the model is theoretically ideal. Therefore all your test tells us is whether or not the ensemble is large enough to be statistically confident of a question to which we already know the answer!
A question, why should it be more difficult for the ensemble to pass the test as more and more models are added, even if the mean and standard deviation of the ensemble remains the same (and hence has exactly the same skill at predicting the observed trend)?
I would agree with Steve M that some of what is being discussed here has more of philosophical tone in that the statistical comparison method of choice has lots to do with how one is viewing the model output. The inter model and inter observed results and average model to average observed results are rather easy to comprehend visually, but how one understands the model to observed comparison has lots, in my mind, to do with the consideration that the comparison of differences of temperature trends, troposphere to surface, can remove spurious effects that are in both trends and that without an attempt to put ones hands around quantifying the chaotic content of a single rendition of a climate response, the model result uncertainties are essentially boundless. On that note, I would like to suggest that we discuss what Ross McKitrick proposed in at Re: Ross McKitrick (#74), .
Can we agree that McKitrick’s proposed method is valid? I like it because it makes full use of all the available data of temperature trends by altitude. Would it be proper to statistically compare the models and observed results at a selected altitude and ignore the other altitudes where differences are dramatically larger. I realize that the UAH and RSS sources of MSU data look at 2 or 3 integrated altitudes, but the radio sondes look, as the model do, at incremental altitudes. It would be of interest to compare within the observed methods of measurement also.
In the Santer et al. (2008) paper, as do many papers by this group of authors on this topic, the authors point to the average ratios of observed global tropospheric to surface temperatures trends agreeing (better) with the global ratios from models. This is where I have a problem with averages and I suspect also those who pointed to problem of the bigger differences between model and observed results in the tropics in the first place. One can say that on average that a difference between any pair of results are small or statistically insignificant over the entire altitude spectrum but, that in and of itself, can be very misleading.
A final question that I have on the RICH treatment of the radio sonde measurements as it appears in the Santer et al. (2008) paper. From an excerpt from a link in an earlier review of these treatments in thread introduced by Steve M, I got the impression that the RICH treatment used model results for making adjustments. Does anyone here have any more detailed information that might clear up this matter?
JamesG:
Yes, unfortunately he expressed his claim in a way in which, in the context of a statistical test, was much stronger than the point he presumably intended to make, i.e. that the observations refute the models rather than that the models don’t have great skill (although the SEPP press release suggests the actually meant the former). Unfortiunately if you do use statistics, you need to get the test right and express the interpretation with great case. However that is science.
I fully agree there, an appeal to common sense is much better than inacurate use of statistics. If you include all of the datasets (as in Santer et al.) you can see that the estimates of the observed trend are also so uncertain that no unequivocal conclusions can be drawn in either direction at the current time. Hopefully the uncertainties in the observational data will be resolved and we will have a clearer picture.
Re: beaker (#123),
It’s a pity that Mann and his cohorts don’t follow that rule.
beaker, you say:
For example, I suspect that the range of trends considered plausible by the modeling community “net of ENSO” is much narrower than the range of model-sample trends with ENSO in. The trouble with analogies is that they don’t necessarily capture all the relevant issues. If they did, then no one would still be arguing. I don’t see how your analogy incorporates the ENSO problem in any way, let alone any relevant way.
Steve, can you tell me where to get the tropical temperature data which you generate in the script at the start of this thread? The problem in the script you posted is the line
source(“d:/climate/scripts/spaghetti/tropics.txt”)
which presumable references a drive on your machine. I couldn’t locate a similar file on the script directory of the web site. Thanks.
Kenneth Fritsch #122:
Yes absolutely, I would argue that any interpretation that suggests the observed trend can be expected to lie within two standard errors of the mean, but it should be within two standard deviations. To do so, I will use a thought experiment (if it was good enough for Einstein, it is good enough for me!). Say we could travel to parallel universes, and in each we find a duplicate Earth that is identical to ours in every respect but one. While they all share identical physics and forcings (including anthropogenic), they all varied in the initial conditions, and so there is stochastic variation in the trends you would observe on different duplicates due to chaotic features such as (but not restricted to) ENSO.
Now, you could have no better model of our Earth’s climate than one of these duplicate Earths, they are effectively GCMs with infinite temporal and spatial resolution. The only way we could improve on this is to initialise the dupicate Earths with the same initial conditions as ours, however this is impossible as we failed to measure the initial conditions on our Earth with infinite precision.
We can’t expect the trend on any of the duplicate Earths to be identical to that on ours, due to the stochastic variation, the odds against it are literally astronomical. So the next best thing to do is to make an ensemble of duplicate Earths and take the mean. This is exactly what climate modellers do here with their inferior GCMs, for exactly the same reason.
So can we expect the trend on our Earth to exactly match the ensemble mean? Following a frequentist approach, our Earth is statistically interchangable with any of the duplicates in the ensemble. This means that the probability that the trend on our Earth matches the ensemble mean is the same as the expected proportion of the members of the ensemble having a trend that matches the ensemble mean, i.e. pretty much zero!
As we know, even if the model ensemble is perfect, to expect a difference between the observed trend and the ensemble mean, why test for one?
Re: beaker (#126),
Beaker we have had this discussion before.
You have to tell me about what happens in your experiment if one is using the difference or ratio of troposhere to surface temperature trends in the tropics. You appear to be concentrating on a rendition of climate that would have no cancelling properties.
That single rendition of climate in your experiment that has an unknown content due to starting conditions (chaotic content?) has to be capable of estimation at some level or the models individual and ensemble results would never be able to predict/project a single rendition of the climate. If it can be estimated it can be subtracted/added to the ensemble mean and the statistical analysis proceeds from there.
If one takes a ratio or difference of troposhere and surface trends as described above, the occurence of a major ENSO event would have an effect only if it were realized significantly different at the surface and in the troposphere in the tropics.
Steve #124: the “ENSO” problem is exactly why the ensemble mean should not be expected to match the observed trend exactly. The best the modellers can possibly do is estimate the distribution of trends you would observe on a population of Earths with different realisations of chaotic phenomena like ENSO. That is why the correct test is to see if the observed trend is consitent with a sample from that distribution.
#127. beaker, you continue to completely miss my point. I understand the point you’re making and it is not responsive to mine. Please try to assume that I am not missing the obvious. Could you try re-reading my previous point.
#monthly Uploaded to
…data/spaghetti/tropics.tab
The master script is at
http://data.climateaudit.org/scripts/spaghetti/tropics.txt
but it downloads some very large gridcell files (180 MB from GISS to calculate their tropical average.)
Steve #124:
i’ll try any go through your comment in more detail so we can identify where the miscommunication arises.
That is certainly true, however I don’t think the model archive was constructed
with this application in mind. If they re-ran the models with “ENSO forcing” there would indeed be a lower degree of uncertainty, but how much lower I wouldn’t dare guess.
Perhaps you could explain exactly what the ENSO problem is. It is true that both Douglass et al. and Santer et al. are using model runs that don’t take advantage of information about ENSO etc, but if they did anything else they would run the risk of being criticised for using GCMs in a manner that was unrepresentative of normal operation. However I suspect the real reason was simply convenient,
the model archive is already there.
Sorry Steve, I have no idea what is obvious to me and not to others and vice-versa, however it is hard for me not to assume that something fundamental is being missed if people can’t see that the SE test is unreasonable given that (a) the test statistic demonstrably doesn’t measure what Douglass et al. say it measures [#71] and (b) we know that there will be a difference between the observed trend and the ensemble mean, yet Douglass et al. test for it anyway and think it is of interest when they find it.
Steve: For the 5th time or so, I’m not talking about the models here but the observations. For a high-trend “true” model to exist concurrent with observations, the 1990s would have had to be La Nina. IF we know on other grounds that 1998 was not a Nina, then the Santer error bars are smaller. And I’d appreciate it if you recognized that I’m talking about Santer here and not Douglass. So why drag in an extraneous bit of editorializing?
Steve #124:
i’ll try any go through your comment in more detail so we can identify where the miscommunication arises.
I think I misread that. The uncertainty in the range of trends considered plausible will be larger with models that don’t include the observed ENSO as a forcing. ENSO is a source of variation, so if the models and the real world have the
same realisation, they will have more similar trends.
In other words, if they included ENSO forcing, the standard deviation of the ensemble would be smaller than those plotted in Santer et al.
Steve: NO, that’s not what I meant. ENSO is not a “forcing”. It would be produced by the model as an output and for short 21-year periods like the truncated Santer-Schmidt example, the phase affects trends. In short periods, this accounts for a noticeable portion of potential “reported” trends. But the inherent trend variability in the models stretched out over a long enough period to even out the ENSOs would have be less.
#132-133. you’re fixating on one point in Douglass. I said in the head thread that I agreed with criticisms of the procedure in which a bare trend is compared to models without allowing for the CI of the observed trend (as is done in Douglass and, appears to have been done in Karoly as well – though that doesn’t appear to have aroused the ire of the Santer 17.)
It’s just that I’m not convinced that Santer’s solved the problem either. Alternately, if this is now the industry standard, I don’t see how Karoly’s results can survive. But I think that the problem is how Santer is handling uncertainty. I’m feeling my way through the question and am not making any proclamations tho.
My sense is that there is a real discrepancy between the UAH observations and the models, as Douglass et al claim, tho their arguments don’t show that yet. However, I don’t think that this proves that the models are wrong as it’s quite possible that the RSS interpretations are correct as opposed to the UAH interpretations – I think that that is the real battleground issue.
I think that the Douglass group might be able to get to a solid statistical discrepancy that is more solid by (1) the inclusion of more recent data – they used out to 2004, while Santer and Gavin Schmidt et shamelessly deleted observations after 1999 – I find this mindboggling; (2)incorporating NINO knowledge in the estimate of the observed trend. The Santer procedure seems goofier and goofier the more I think about it, tho I don’t have a recipe just yet.
My guess is that (1) by itself will throw the H2 hypothesis offside.
Steve #134:
The problem I am fixating on is nothing to do with the lack of a CI on the observed trend.
There may be some subtle point in Karoly that excuses them, not having read it I can’t give a definitive opinion, but I think I can see why it didn’t get so much attention!
I agree, however I interpreted Santer et al. as saying that we can’t tell anything at the moment due to the uncertainties invovled, so I wouldn’t claim they had given a definitive answer to anything. As to the methodology, I’m sure it could be refined and will be.
If you mean accounting for all sources of uncertainty, I certainly hope so. The last thing we need in this area is people making strong claims and asserting more certainty than is justified.
There will always be some difference, whether it is significant depends on how large the discrepancy is in relation to the standard deviation of the imaginary population of trend from duplicate Earths in parallel universes, which would be the source of some debate!
Being an objective Bayesian my prior distributes wrongness fairly evenly accross the models and the data, I am not in a position to know where the problems truely lie.
I would advocate a min-max approach (as in chess), by making the strongest argument that your oponent can’t refute (e.g. choose the observations that minimise the discrepancy if you want to argue the models have no skill). If you can’t make a claim on that basis, you are generally better off not making it in the long run.
Beaker #135
In answer to Steve’s:
You reply.
You throw with great ease these imaginary parallel earths.
These imaginary paths have a meaning only if by a minimization/maximization method ( as with path integrals or Action) a specific path is picked out as the most probable with an error band. Otherwise you are just stating in fancy words what to skeptics is obvious from the beginning, that there is no meaning in this ensemble of probable worlds except as a science fiction game.
By the acknowledgment of AR4 ( my #96 above) no such method has been demonstrated or developed yet. The error bands given are artist’s impressions.
I would like to give a link to Leif Svalgaard’s compilation of albedo values, http://www.leif.org/research/albedo.png . We see there that the albedo has large variations. This, for models which assume constant albedo, as far as I know, around .31 or so, such large percentage changes will enter as systematic errors, moving the whole path in units much larger than the .2 C effect per decade claimed, demonstrating the nonsense of the ensemble method.
Kenneth Fritsch #136:
If you use a quantity of interest that is less sensitive to the stochastic variation you would get a commensurate decrease in the variability of model runs for
a given model. However for the real (non-ideal) GCM ensemble you would still have other sources of variability due to uncertainty in the physics (why there are different models) and stochastic variability due to lack of resolution etc.
I can only comment on the statistics, not the quantity of interest the climatologists chose to use. However, even if the cancellation were perfect, the standard deviation would still be the correct statistic, but the error bars would be smaller for a real GCM ensemble and would disappear entirely for the ideal parallel universe thoughe experiment ensemble.
That is exactly the point I am making, the ensemble fundamentally can’t predict a particular realisation of the climate as the information regarding the required initialisation is unavailable. The best that the modellers can do is to predict the distribution of values for all plausible realisations and claim that the true value for the realisation we actually observe can be viewed as a sample from that distribution (hence the sd test is appropriate).
If it could be accurately estimated, we could theoretically have accurate long range weather forecasts, sadly it just can’t be done.
I can’t comment on what is a valid quantity for climatologists to use, but any quantity less strongly affected by all forms of stochastic variability (of which ENSO is only one) would probably give a clearer picture of any model-data discrepancy.
A longer window would also help (am I getting closer to understanding your point Steve?). If you could subtract the effects of ENSO from the observed trend and the effects of the synthetic realisations of ENSO from the model runs, then that probably would reduce the uncertainty somewhat. However, I think this would raise more criticisms than it would address. I have seen examples of temperature time series where the effects of ENSO were removed by regression. It seemed fine for making a qualitative point (e.g. that the peak in 1998 was probably ENSO), but I wouldn’t trust the method quantitatively.
Steve: Karoly et al 2003 attempt to remove trend effects arising from random inter-period ENSO phasing by making one-model ensembles e.g. an ensemble of CSM3 runs. I’ve tried to re-visit this issue below with a men in hats analogy.
Beaker
“Being an objective Bayesian my prior distributes wrongness fairly evenly across the models and the data, I am not in a position to know where the problems truly lie.”
Therein lies your problem – lack of experience. As a Bayesian you should know the value of experience. If you were a computer modeler you’d know that it is very much more likely that the models are wrong. Data is the correctness test for the model theory. They should match within a certain percent error if the model is to be considered valid (eg 5% error in most finite element models). If there is doubt with the data source then we seek an independent set – which is exactly what Douglass et al. did. The more data, the merrier for validation purposes – preferably raw data.
You endlessly repeat your distaste for the Douglass et al. statistical test. Fine, we heard you. But a proposal to substitute a test which encourages the use of even poorer models is utterly illogical to the rest of us. Do you accept that at least?
James G #139:
I was agreeing with Steve, who said
i.e. that the models are not neccessarily wrong, but that the disparity could be due to the uncertainty in the data. I was suggesting that the answer is that they are probably both wrong to varying degrees and that work was needed in both areas. You seem to be treating the observational datasets as ground truth. They are not, they are uncertain estimates of the true trend, nothing more.
As a Bayesian I do indeed know the value of experience. However I also am aware of the danger of having a prior that us unduly confident before looking at the data! ;o)
No, the sd test doesn’t encourage the use of even poorer models (a) as I have endlessly repeated “consistency does not imply skill” so passing the sd test is not encouraging anything and (b) the size of the error bars gives a better criticism of the models than an inappropriate and unssupported claim of inconsistency based on a misinterpretation of the prediction given by an ensemble. Lastly, you choose the test according to the question you want to ask, not according to the result you want.
“the models are not neccessarily wrong, but that the disparity could be due to the uncertainty in the data”
Intrinsically then you accept – as most modelers would – that it is far more likely that the models are wrong than the data.
“You seem to be treating the observational datasets as ground truth.They are not, they are uncertain estimates of the true trend, nothing more.”
No they are not estimates, they are instrumental measurements whose uncertainty is usually scientifically determined by finding the normal distribution. If there is a bias suspected then we search for independent corroboration and if two separate sets of observations agree then that it is usually a pretty good indicator of the truth. We don’t usually assume that the data is wrong because the models disagree. That is putting the cart before the horse. Without a test against data there is no validation of the models. Conversely we cannot validate data against the models. That would be nonsensical yet it is what some scientists have been suggesting – another reason to suspect confirmation bias.
As for Bayesian priors you’d need to ask some computer modelers yourself. You’ll find it very difficult to find anyone who suggests that models are more likely to be correct than data. A possibility does not become a probability.
If I was testing the models then I’d test each individual model against the data spread and reject poor models. However the IPCC, with very little justification, use an ensemble of poor models with the gross assumption that it is useful. Hence Douglass et al. combined the models only because that is what the IPCC do. Their test was necessarily ad-hoc but whether it is a test of skill or consistency is pure semantics. In the modeling game we talk about tests as determining “fitness for purpose”. Of course the argument that 20 bad models can make a good model is so odd it should really be rejected so that then we might concentrate on which of the models appears to be best. One of them actually does seem to be ok – the Russian one I believe.
Lastly, we usually only choose a test to see if the model matches reality. That is the only question to be asked and the only result desired and that is what Douglass et al. tried to do but Santer et al. did not attempt.
Re: JamesG (#142),
Good post. The points you make are well stated. I also agree strongly with the following:
Clearly this is the proper route to take. However, I suggest that it hasn’t happened, not for scientific reasons, but for political ones. It is not likely that the IPCC or the modelling community would wish to admit overtly that any particular models (created by some of their own colleagues) do a poor job and should be scrapped. Although the Santer paper seems to make individual comparisons with the measured temperature data, there does not appear to be any information given as to which (if any models) did not perform as expected. Treating the models as an ensemble (without including useful available information on the performance of individual models) will shield the poor ones from scrutiny and have the side effect of creating a large ensemble of GCMs that the public will believe are all capable of predicting the future climate.
James G: The “instrumental measurements” most certainly are not in agreement. If they were you would get the same trend from the various products, however as shown in the diagram in Santer et al. they don’t.
#142. The ongoing dispute between UAH and RSS is because the “data” is itself highly modeled. There isn’t any argument over the “raw” data; the problem is that the satellite temperature series are stitched together from different instruments on different satellites, that allowance has to be made for diurnal heating, drift, things like that. There is a statistical aspect to the satellite stitch that would be interesting to look at. So, yes, there is a valid reason under which an honest disagreement an arise over which temperature series is better.
One of the Santer coauthors (who asked to remain anonymous) sent me a cordial email and said that their original submission contained a Douglass analysis through 2004 as a sensitivity study and that “as the main thrust of the paper was not impacted by this choice it was removed as part of the review process”, that the 1979-99 was “a choice forced by the availability of model results, an availability over which we have no control until the next set of runs is archived in support of AR5”.
He/she went on to say that “our results held for 1979-2004 with a slight increase in rejection of H1. H2 could still not be rejected for all observatonal estimates. So, no H2 is not dependent on choice of apples-apples period or Douglass time period” and further observed that extension to 2008 with its big Nina might well be a cherry of the opposite persuasion.
In this instance, I would submit that a “review process” which required the removal of 1979-2004 results with a direct comparison to Douglass et al was a process that lowered the quality of the paper. A third party confronted by the failure of Santer et al to provide an apples-to-apples period comparison can and should question that failure. IMO the authors should have resisted this singularly perverse reviewer request.
As to the constraint supposedly placed by 1979-99 runs, a couple of observations. It is bizarre to say the least that there isn’t a population of runs going to 2009 or 2019 on a consistent basis. I thought that that was what modelers did (but it’s not an area that I’ve investigated.) If there are no runs to 2009 on a consistent basis, there should be, AR5 or not. Also, updating runs is something that should not be tied to articles in an academic journal. It’s an operating activity and a technical report would suffice.
Also I don’t understand what relevant changes in forcing occurred in the 2000s that would make the trends for 1979-99 unusable for 1979-2004 or even 1979-2008 calculations. Santer et al said that the unavailability of results was the “reason”; it’s just that, all things considered, I don’t find the reason convincing on its face, tho I don’t preclude the possibility of being persuaded by a more thorough explanation.
As I noted above, I’m interested in directly verifying the H2 calculations. I asked the coauthor for digital versions of the runs as used so that I can verify the calculations for myself.
Re: Steve McIntyre (#145),
A welcome sign of hope. Long live cordiality.
============================
#111. beaker, I don’t think that anyone disagrees with the specifics of this example. So let’s stipulate it. The problem with analogies is always whether they’ve captured all the relevant aspects. So let me submit a variation.
Instead of measuring the height of men in your study directly, let’s say that we are only able to measure their height wearing hats of between 0.5 cm and 500 cm in height. We have a distribution of the gross height of men in hats.
If we only know the height of the man in a hat, then there is an uncertainty interval attached to his “net” height depending on the distribution of hats and hat sizes. Let’s say that we conclude that this uncertainty has a standard deviation of 6″.
Applying this to your example:
We’re on the same page. Now here’s where I’m trying to clarify things in my own mind.
Let’s go back to Rupert. We have a measurement of Rupert in a hat at 9’2″ (outside 2 sd’s.) Let’s suppose that analyst Grover observes (1) that the 95% uncertainty in Rupert’s true height is 2 times the hat standard deviation of 6″= 1 foot; (2) if you add this uncertainty to the population standard deviation, Rupert is no longer outside the 2 s.d. test.
As I interpret this sort of example (and I’m thinking out loud here, not making findings), Grover is double counting an uncertainty aspect. If your population is men in hats, then you have an exact measurement of Rupert in a hat and Grover’s invocation of the uncertainty in Rupert;s true height is not relevant to the problem at hand.
Alternatively, if you approach things from a “true” height perspective and place appropriate error bars on Rupert’s “true” height, then you have to compare that to a relevant distribution of “true” heights which, in this case, has a smaller standard deviation than the distribution of “gross” heights.
But, in this particular example, Grover is not entitled to conclude that Rupert is not outside the 95% distribution interval.
Over to you, beaker.
PS. One last thing about priors. Let’s suppose that when we measured Rupert’s height in a hat someone made a qualitative observation that he was not wearing a “tall” hat”. Let’s suppose that Grover continued to argue that Rupert might have been wearing a “tall” hat and might still fall within 2 sd’s. Grover’s Bayesian friend, Beaker, would presumably try to apply the qualitative information about the tall hat.
Steve #134. Your point 2 about incorporating NINO knowledge in the estimate of the observed trend. I assume this means that some of the models incorporate NINO and others do not. If NINO is a significant variable, models lacking NINO should be excluded before conducting statistical tests.
So we would have a subset of models that include NINO and a subset that do not include NINO. We could knock NINO out of the observations to get adjusted observations lacking NINO and run tests on each subset of models, one subset with the raw observations and one subset with the adjusted observations.
Regarding the tests: Could we just treat model results as proxies for samples drawn from the same population as the observations? In effect, that’s what the modelers claim. We would need to know for each model: Could these results have been drawn from the same population as the observations or adjusted observations? An obvious difficulty is autocorrelation in both models and observations.
Once we have subsets of models that could have been drawn from the same population as the observations or adjusted observations, we could proceed to compare trends. I don’t see why we would include any models that appear not to have been drawn from the population represented by the observations.
Except for autocorrelation, I don’t see why the statistical methodology is an issue. Am I missing something? Is the issue the methodology of comparing trend in the model results with trend in the observations?
[Convention allows us to treat statistics of the observations as population statistics. The concept of many imaginary Earths, while not necessary is the usual way of explaining the convention to undergraduates.]
Steve: once again, and I made this point above, “Nino” is not a forcing. In model terms, Nino’s turn up as random events and their phasing in 21-year runs introduces a variability in trend estimates. That’s fine. My only point here is that we know that 1998 was a huge Nino. You’re mixing up a point about the observed record with models.
Steve #146: I think in hindsight my analogy was way too cryptic, many thanks for your persistence. I had intended the inital sample of mens heights to represent a sample of the modellers opinions regarding the trend, as expressed by the model runs. However we know the trends exactly from the model runs themselves, so there is no uncertainty about them. The complication of hats suggest we are talking at cross-purposes.
Now that I can see where the confusion arises perhaps I can make a less tenuous analogy to see if that clarifies things?
Consider sampling the subjective opinions of 100 climate modellers about their view on the best point estimate for the sensitivity of the climate to a doubling of CO2. We find we get a mean of 2.2 degrees with a standard deviation of 1 degree. If we assumed that our sample is representative of the community as a whole and that the distribution can be modelled by a Gaussian, we could reasonably conclude, with 95% confidence, that it is the view of the climate modelling community that the true value lies between 0.2degrees and 4.2 degrees with a most probable value of 2.2 degrees.
Now suppose we had an oracle that could tell us the true value exactly. If it gave a value of 1.9 degrees then that would obviously be consistent with our common sense expectations given our Gaussian model. Using the SD test, we find that 1.9 is within the condifidence interval of 2 standard deviations (0.2 to 4.2 degrees), so we conclude the true value is consistent with the model. Using the SE test, we find that the confidence interval is 2.0 – 2.4 degrees (as SE = SD/sqrt(100) = 0.1 degrees). According to the SE test, the observation is inconsistent with the range of plausible values given by our model. Common sense suggests that is clearly unreasonable. The reason is that the uncertainty of opinion about the climate sensitivity is represented by the standard deviation. The standard error only tells us the confidence in estimating the population mean from the sample.
This example relates to the current issue as follows. The oracle represents theestimates of the tropical trends based on the observational data. In reality the observational datsets are subject to considerable uncertainty, however I have ignored this as it is entirely peripheral to the issue of SD-v-SE. The climate modellers point estimates of the climate sensitivity map onto the output of the models, noting that the models implicitly represent the consequences of the modellers assumptions regarding the climate. The stochastic variability of the models, represented by having multiple runs, is an added complication that I have also ignored for clarity as it is also not central to the SD-v-SE issue.
Now this analogy ignores several factors that could easily be included, but the important issue is that we should be testing for a sample (which is not known exactly) from a distribution, not testing for a difference between means.
Re: beaker (#148),
I don’t know about anybody else, but this analogy did it for me. I’m not going to try to paraphrase or anything, but I now think I understand why you think Douglass et al. used the wrong test and I agree with you.
Re: DeWitt Payne (#154),
DeWitt, don’t buy a used AGW from this man. 😉
Suppose his oracle was just fibbing and my oracle who tells the truth tells us that the correct value is a measly .3 degrees and hardly worth worrying about. He looks at his 100 opinions and says, “Yes that’s consistent with the view of the climate modelling community”. So, I say, “OK, let’s get more opinions”, and I get 1000 more. But, lo and behold, because the sample is representative of the population, the mean is still 2.2 and the standard deviation is again 1. Now I apply the beaker test and, surprise, surprise, the value .3 is still consistent with the view of the climate modelling community. In fact, every representative sample of any size will always give results which are “consistent” with each value in the range .2 to 4.2.
Beaker’s consistency test is nothing more than calculating an interval with endpoints that are the 2.5th %-ile and the 97.5th %-ile of the climate modeller population and declaring that the set of values in that range are somehow “consistent” with the population. What does it tell me about the correct value in a practical situation. Zilch! Regardless of how much information I collect, I won’t be able to eliminate any of the numbers in the aforesaid interval. A sample of 10 gives a result which is as good as those a sample of 10000. This is statistics?
He would however explicitly state (mathematically) how he interpreted the qualitative information about the hat and would be willing and able to discuss the consequences. Poor frequentist Grover on the other hand can’t use the information at all, which reduces his chance of getting the right answer. ;o)
Steve McIntyre: #145
October 19th, 2008 at 8:07 am
I am amazed, considering that the models project to the year 2100!!
Or does this mean that the new data have not been assimilated in the parametrization yet?
#148. Can we finish with the height analogy before we change analogies? Do we have common ground on men in hats?
I’m not really familiar with Bayesian vocabulary which wasn’t an issue when I took statistics courses. On the other hand, my statistics prof in 3rd and 4th year was D.A.S. Fraser who seems to have had a Bayesian approach in his publications and may have inhaled some of it. We spent a lot of time on transformation groups in our courses, not that I remember exactly why.
Steve #152: am I right in thinking that the height of the hat represents the effect of ENSO on the tropical trend? If so, the problem is that we have no way of estimating the variance of this using observations (as we have only one realisation) and we can’t estimate it accurately from the models either as they contain sources of stochastic variation other than ENSO (unless you have a portal to parallel universes ;o).
I don’t think I understand this part:
The standard deviation of mens net heights is the standard deviation of mens heights wearing hats minus the standard deviation of the hats. However you would then have to see if Rupert without his hat would be within two standard deviations of the mean of men without hats [which we have yet to infer from the sample – but it will be lower] not the mean of men with hats. I can’t see any double counting in that case.
Having said which if the s.d. of the hats is 6″ and the s.d. of the population is 6″ doesn’t that imply that the variability is all in the hats and everyone is the same height?
D.A.S. Fraser sounds like like he exhales Bayesianism pretty well if he taught you about transformation groups. Did he talk about MaxEnt a lot as well?
Re: beaker (#153),
A naive question: wouldn’t the SD_net_height be the square root of the difference of the squares of the SD_height_in_hats and SD_hats? Or am I missing something obvious?
Beaker
Of course you choose the test according to the question.
I think even those who know very little about statistics know it perfectly reasonable to ask a large variety of quesiions. For example, one could ask any of the following questions:
0) Is the best estmimat of “something” based on the average of one models (say FGOALs), treated as a single value, consistent with the data?
1) Is the best estimate of “Something” based on the average of all models used by the IPCC and treated as a single value, consistent with the data?
2) When we consider the standard error in the best “Someting” based on the average of all models, is this consistent with the data?
3) Given the spread of all models and model runs, is would best estimate based on the data be an “outlier”? (This treats the data as just another model run.)
We can ask even more questions. Each question requires a different test. Yet, given your discussions on this thread, it appears you favor only one test. This suggests you think only one question may be asked.
I think that is odd.
However, if you want to explain why the question you ask is “the” on an only question anyone anywhere should consider, I’d advise you do so. Then people might understand why you prefer the test you favor. Otherwise, you seem to be insisting on the test without explaining why it answer “the right” question.
De Witt Payne #154:
At last someone sees my point! I wish I had thought of that example near the start of the last thread ;o)
Lucia #155
(i) The SD test and the SE test are the two important tests to discuss as it is the major difference between Douglass et al. and Santer et al.
(ii) The question was chosen by Douglass et al., not me, I am just commenting on the vaidity of their test to answer the question they pose “are the observed trends consistent with the model trends”. The SD test actually answers that question, the SE test doesn’t, for the reasons set out in #148.
(iii) Douglass et al make a very big claim, namely that the observations are inconsistent with the models or the models can’t be reconciled with the data. This effectively means that the data falify the models. A claim such as that reqires the justification provided by the correct test for that question.
(iv) Douglass et al claim the SE measures something that it doesn’t, namely the model variability. This hints quite strongly that it is the wrong test, see #71.
(v) Does the SE test answer an interesting question? No, because as I establish in #126 an ensemble of theoretically ideal models is almost guaranteed to fail the SE test, so how can it tell you anything of interest about an ensemble of imperfect models? We know a-priori that the ensemble mean is not exactly the same as the observed trend, so why test to see if a difference exists?
Of course there are other questions you could ask. The question asked by Douglass is a very good one and deserves a good answer. Santer et al. provide a better answer as theirs is based on a test that is actually capable of answering it.
beaker, what does any of this have to do with what Santer calls their H2 case?
beaker, Steve M. asked a reasonable question above:
To which you replied:
I’ll take that as a no.
The problem that I have is with the underlying assumption. This assumption states that the average of a group of models is more skillful that a single model. Or as the IPCC TAR put it:
Parsing this, it says:
1) IF the models represent “plausible solutions to the governing equations”, and
2) IF the natural variation is symmetrically distributed about the mean and thus averages out, and
3) IF the model errors are distributed symmetrically about the mean and thus average out,
THEN the mean of the model results will be better than the result from a particular model.
I see absolutely no reason to believe that those three assumptions are generally true. This of course means that there are errors inherent in each of the assumptions.
Now, I don’t know how to calculate an error bar on that particular mean. We can easily figure out the standard error of the mean, it’s the standard deviation over the square root of N. As a number of people have pointed out, as N gets large, this gets small.
But the statistical errors are not the only errors in play. We have errors in the three assumptions above. How big are the results of those errors? We don’t know. Can we assume that the three error terms are zero? Absolutely not.
This is one of the many reasons that I say that model results are not evidence for anything. They can give us insights into physical processes. They can give us best guesses. They can give us forecasts. But they cannot give us evidence. And in fact, because of the problems above, they cannot even give us error bars. All they can do is show us the best guesses of the individuals who built the models as filtered through any inherent model errors. The spread of these guesses is by no means an estimate of the error in the models.
I look at this through the other end of the telescope, and start with the observations rather than the models. I would take each of the different observational datasets, and put error bars on them. Any individual model result that falls outside all of those error bars can be said to be inconsistent with the observations.
And if most of the models are outside all of those error bars, then we can assume that one or more of the three assumptions listed above are not true in that particular case for that particular group of models … my vote goes to assumption #1, but YMMV …
Best to all,
w.
PS – the whole construct laid out in the IPCC TAR seems like it begs the question of model reliability. The IPCC says that if the models are right, the model mean will be better than any given model … well, d’oh, that’s a no-brainer, but until we know if the models are right, it’s no help at all.
#160. That would be my interpretation as well. It would also be the viewpoint (I believe) of Lanzante 2005, one of two relevant citations by Santer et al 2008.
Beaker–
(i) You seem to have changed the question Douglas asked. In comments above, john Christy ,an author of Douglas describes the question they ask this way:
Your rewording drops the idea of the “best estimate”.
So, it appears your conclusion that SD must be used is in parge based on changing the question that is asked.
(ii) You then proceed to try to explain why the question that was asked by both Douglass and Santer is, supposedly, uninteresting. Your explanation is unconvincing.
In your discussion of #126 you explain why we can’t compare the best estimate from the models to a single observed trend without an estimate of the observational uncertainty due to stochastic variability.
Of course we should not do that. We need to account for the observational uncertainty arising from the stochastic variabiilty of the earth’s climate system.
Douglas ought not to have neglected that uncertainty; Santer attempts to correct that issue. (They also do a number of other modifications.)
So, in fact your #126 fails to prove uninterestint the question: “Is the best estimate of a single model (or groups of models) consistent with data”.
Here is why comparing the best estimate from the models to the range consistent with observed data is interesting:
In principle, if we run a single model 10000….000 times, and it’s correct, it’s best estimate averaged over all 10000….000 realizations, should fall within the uncertainty of the observation. This is true provided that “uncertainty in the observation” is some uncertainty based on the stochastic variability for the earth’s temperature trends. (That’s what Santer tries to do.)
If the model average does not fall inside the range consistent with data, then the ‘best estimate’ from the model must be biased. This would true even if that model has some amazingly large standard deviation (possibly due to outrageous “weather noise”) that encompasses the observation. To do this comparison, ideally we use the SE — not SD– for the models but we must also include uncertainty for the observations.
If we collect 20,000,….,000 individual models with different parameterizations, and which have 20,000,….,000 different individual best estimates, one would be interested in knowing if the average over the 20,000,….,000 models is consistent with observations. One might expect thataverage should fall within the range of the uncertainty in the observations.
We can ask that question. Once again, when doing the test, we use the SE, not SD, of models. Nothing perverse happens provided we include the uncertainty due to stochastic variability in the observations.
Santer tries to answer the question about consistency between the best estimate of models and the observations. There is nothing perverse in the question. They use SE not SD for the models; the use of SE for models is appropriate given the question both Douglas and Santer actually ask.
Willis Eschenbach:
October 19th, 2008 at 7:43 pm
I agree with you, but I would add for the uncertainty in your
I would add a clause, “plausible solutions to the whole time interval of projections”.
This because even if the solutions of the coupled differential equations are plausible for the interval they are being fitted for, they still are linear approximations ( mostly through use of averages) to highly non linear real solutions. This means that extrapolations will inevitably fail after a certain number of steppings through time. We are aware of this when the GCM are used for weather reporting, where they fail after a few days ( time intervals of 20 minutes?)and are just becoming aware with the divergence of IPCC projections from temperature data in the new century.
I apologise for a naive question, but I do not understand the philosophy of ensembles of model runs at all.
So my question is, is an ensemble of runs for a single model supposed to converge towards either a “true” temperature/time slope or a “true” temperature vs time line as the period the run covers increases? If not, what is the usefulness of the ensemble?
Likewise, but more so, what of an ensemble of runs from different models?
I cannot see any point in debating statistics of variability of models that merely represent imaginary data generated by arbitrary assumptions.
Re: Alan Wilkinson (#164),
I give it a start/try:
The assumtion is that there is an universal physics machine that will produce our observable climate (change) if only we could be sure about all details of how we need to interconnect that machine and providing it with the true observed initial conditions to start with.
So basically there’s two sets of parameters: One that turns the machine into a model and one that makes this model perform a certain run.
However there are uncertainties about how this machine should be interconnected properly (how climate really ‘works’) and there are uncertainties about the proper initial conditions. These uncertainties are accounted for by generating some slightly different sets of interconnection (t.i. models) and some slightly different sets for initial conditions (t.i. runs).
It is believed that if we would exhaustively use all possible sets of models and initial conditions (according to their probability to be ‘true’) this would generate a continuous climate probability distribution. This distribution would completely reflect the results of our best knowledge of how climate really works and our uncertainties with respect to that. As for the starting conditions, it’s a similar affair.
Then if the model universe’s mean matches real world observations within their uncertainty bounds it is assumed that our assumtions (sets) are probably correct and unbiased.
However such an exhaustive test is an impossible thing to conduct. That’s why this universe of models and runs (the parent distribution) is probed by drawing a (representative? random?) sample of models and runs.
With a limited probe like ours there is some uncertainty about wether the sample will reflect the parent distribution’s characteristics correctly. That’s where the standard error comes into play.
If we continue to draw samples of size n from the parent distribution then we would find the parent distribution mean to be within the sample mean +/- 1 SE about 68% of all times (or within sample mean +/- 2SE about 95% of all times). Thus for just one sample taken (as is the case with our set of models here) we would expect a 95% chance that the parent distribution mean lies within the sample mean +/- 2 SE.
That’s basically what Douglass tested: The probability that our best estimate of how the climate machine works is unbiased.
The main difference to the SD test proposed by some ist that the SD test will check wether the results of combined bias and uncertainty are flexible enough to probably contain the ‘true’ climate machine too.
Re: Wolfgang Flamme (#185),
Sorry I’m very late replying to this, but I have seen no good reason to believe that the n samples from the parent model distribution are random or unbiased and therefore there is no sound basis for computing any kind of confidence measures from this sampling of model outputs.
Mornin all!
Steve #158:
Point 3 of section 4.2 (top of first column on page 8) in Santer et al.:
Willis Eschenbach #159:
This issue has been discussed this before
Note that it says that the ensmeble mean is a better estimate of “the FORCED climate change of the real system” not simply “the observed climate change of the real system”. The difference between the observed climate and the FORCED climate is the result of chaotic variability due to the initial conditions that CANNOT be predicted, even in theory, nevermind practice.
In a frequentist sense the ensemble mean gives us the best estimator of the observed climate change on a random sample from an imaginary population of Earths that vary only in their initial conditions. That is not the same thing as the best estimator of the observed climate change for this particular Earth. This is one of the less satisfactory features of frequentist statistics, people often interpret them as if they were Bayesian, and this can lead to misunderstandings.
Kusigrosz #160 and Steve #161: Sorry, brain fade I expect! The point I was making was that you seemed to be making an inference about net heights and then testing it against a distribution of gross heights. I don’t understand how the hats map on to the ensemble/observations problem, which is making it difficult to see the point you are making.
Lucia #162:
One observation, you say that Santer et al use SE not SD for the models. That is not true. See point 3 of section 4.2 (top of first column on page 8) in Santer et al.
I don’t think you undestand the point of #126. The observational uncertainty due to stochastic variability that make the test of the IPCC claim difficult is nothing to do with the uncertainty in estimating the true trend for our particular Earth. It is the variability in the true trend in the population of Earths assumeb by frequentist statistics. It doesn’t go away even if there is no measurement/estimation uncertainty. It has nothing to do with the spread of the spagetti plot of Radiosonde and other estimates.
Three questions for you:
(i) Can you come up with a better model than an infinite ensemble of Earths in parallel universed discussed in #126?
(ii) Would the infinite ensemble of parallel universe Earths pass the SE test?
(iii) Why is it reasonable that the best ensmeble possible in theory fails the SE test?
Alan Wilkinson #164: The basic idea is discussed in #126. They key point that seems to be confusing people is that the ensemble mean is not intended to be the observed trend for the Earth on which we live, it is the average trend for an imaginary population of Earths with different realisations of the inherent chaotic variations.
The reason for the statistics is to determine whether the arbitrary assumptions are false (“the data are inconsistent with the model”) or to see if the models survive and encounter with the data (“the data are consistent with the model”). Note if they survive, it does not imply that the models were skillfull. Indeed Gavin Schmidt made a comment on RealClimate that implies that Santer et al. is not intended to show that the models have skill (a point I have been making), and that such a test is not currently feasible as the data are not in suffuciently good shape. (see comment #143 of “Tropical tropospheric trends again (again)”).
Re: beaker (#165),
Surely the corollary of this is that only model runs that produce trends within the CI of the S.E. of the observed data and whose data points fall within the CI of the observed data can then be considered valid forecasters of climate change?
All other predictions which may include that of the ensemble mean(s) [either of individual models or ensembles of models] can then be ruled inconsistent with the observations. The question then becomes whether the IPCC forecasts are then consistent with this subset of runs which are validated as consistent with the observed data.
Beaker #126
I went back to it because of this parallel earth discussion.
Let me translate this in my field, high energy physics. We have been running monte carlo models since the year 1 of models. You are saying, if the Higgs exists, if we run enough monte carlo models and take the mean, we will surely be close to the mass these LHC experiments are running for. So why do them?
But the Higgs comes from symmetry breaking, and how the symmetry is broken cannot be foreseen from the initial conditions, ( which last is the basis of what chaos means actually for the climate models).
Let me give you a simple example. Think of a parabolic mound and a ball sitting on the top. It is in a metastable state. The slightest change will make it roll down the side, in a random 360 degree direction. Your statement is like saying that by taking the mean of all possible directions , we can tell which direction the ball will fall when something changes.
Well, they are testing for it continually over in the AGW literature.
Re: anna v (#166),
I like the remark about the broken symmetry because , indeed , that is a hep equivalent of the climate physics .
There are many things fundamentally wrong with the Beaker’s “duplicate Earth” model and it doesn’t really answer anything .
Let’s mention only the more important flaws .
.
1) It postulates that the climate variability is due to the variability of the initial conditions . It is not . An equivalent of phase change (chaotic bifurcation or symmetry breaking) is a cause of variability too .
.
2) It postulates (even if I am not sure that Beaker is aware of that) that all initial conditions are equiprobable . They are not . The set of possible initial conditions is rather constrained and there is no reason that all be equiprobable .
.
3) The set of “duplicate Earths” contains a rather horrible infinity of Earths .
That’s why [our Earth (1) / Number of Duplicate Earths (infinity) = 0] what Beaker apparently interprets as that the probability to find our Earth among the duplicate Earths is 0 . Yet as all the duplicate Earths necessarily lie in the chaotic attractor for the climate , the probability that we find one exactly identical to our Earth if we look long enough (actually an eternity) is always 1 . So there is always exactly 1 duplicate Earth that will exactly reproduce our Earth at any time during it’s 5 billion years past and any X billion years future . The problem is that it is not possible to say today what this future will be even if we hold an infinity of Earths looking like our Earth .
This statement is technically called the shadowing lemma in the dynamical system theory .
Statistics don’t help and doing an “average of the duplicate Earths” would be about the stupidest thing to do .
.
4) At least the duplicate Earths have the advantage to have exactly the same physics inside . So we can be at least confident that even if we can’t predict anything or find any meaningful stochastic behaviour , it is not because there are different laws . This condition is of course not at all fulfilled by the models because they have NOT the same physics inside . That’s why there would not be ONE set of duplicate Earths but N sets , N being the number of models . From those N models most or all would generate really moronic duplicate Earth sets if we had the possibility to look at them all .
Obviously making an average of moronic sets gives a moronic set what might be interesting for an artist but certainly not for a scientist .
And the reason for averaging is certainly not because the real Earth at a particular time (now) can be found with a probability of 1 among the infinity of Earths in a moronic set .
.
So the “duplicate Earth theory” is only good to show why it is physically wrong and why its real life equivalent , the model averaging is worse , e.g not even wrong .
From p. 8 of the Santer et al publication (bold mine):
This is the crux of the matter. It is all about comparing the multi-model mean trend to other estimates. In order for all of the calculations in the paper to make any scientific sense, it is necessary to state the (tacit) assumptions of the Santer analysis:
1. We must have some sort of population of models (more specifically, model trends) from which a sample of models has been selected. This population has a mean µ (multi-model mean trend) and standard deviation σSDMod. The observed models are a simple random sample from this population so that the sample mean ModAv has a sampling distribution with the same mean µ as the population and standard error given by σSEMod.
2. There exists an actual trend T whose value must appear as a parameter of the model population. If not, then there is no way that the models can provide any information about the actual trend. By calculating the sample mean, the authors are tacitly assuming that in fact µ = T, since otherwise, the value of the sample mean would have an undefined relationship with T and any interpretation of ModAv would be baseless.
3. The observed temperature trend t has a distribution with mean T and standard error σSETemp (which is not necessarily related in any way with σSDMod).
Now, the appropriate analysis depends on the meaning of the phrase “a single observed trend”
If the phrase means “a single observed trend of a model selected from the population”, then in fact, Santer would be correct. The standard error of the single observed model trend is the same as the standard deviation of the population (assuming no other information is available about that model other than that it was selected from the model population). Thus to compare the difference in trend estimates of the single run and the ensemble average, the appropriate error term would be +/- 2 SEDiff (where SEDiff = sqrt(σSDMod^2 + σSEMod^2 ) . This is somewhat larger than the +/- 2 σSDMod of the beaker-gavin “test”, but reduces to their bound for large ensembles with the multi-model trend deemed “consistent” with the single observed run if the bound is not exceeded..
However, if the phrase means “a single observed trend of observed temperatures”, then the previous “test” does not apply. The observed temperature (whether a perfect estimate of T or with uncertainty) is not a model run nor does it necessarily have the same standard error as a single model run. In order to see if the value of T estimated by the observed temperatures differs from the estimate obtained using the ensemble mean, the correct bound is given by SEDiff = sqrt(σSETemp^2 + σSEMod^2 ) . This is exactly the statistic used by Santer when comparing single runs to the temperature records in the H1 tests. In that case, σSEMod is replaced (more appropriately) by the internally estimated SE of the individual model and not influenced by other unrelated models. When the temperature estimate is exact, SEDiff becomes equal to σSEMod, the test deemed “invalid” by beaker.
The error made Santer and supporters is simply that they are treating the observed temperature sequence as if it was just another model run with an uncertainty level that is calculated from the models and not from the observed data where it properly should be.
anna v #166: Sorry, I am not sufficiently familiar with the way monte carlo methods are used in high energy physics to know whether it is a reasonable analogy.
As for the parabolic mound example, it is obviously specious as the inherrent symmetry means that the mean direction is meaningless a-priori. Indeed, if you perform an infinite number of trials, you will have a uniform distribution and the mean is then defined completely by the experimenters arbitrarily chosen point of reference.
Here is a more reasonable analogy: Pick an apple at random from a barrel and weigh it. Can we accurately infer the weight of that particular apple by taking a sample from the remaining apples in the barrel? No of course not, we can only estimate the average weight of the apples in the barrel. Is there any reason for the weight of the first apple to lie within two standard errors of the sample mean (think what happens in the limit of an infinite sample)?
Relating this to the parallel Earths ideal GCM ensemble of my thought experiment. The first apple is the true tropical trend on the real Earth, the sample of apples represent the model runs obtained from the tropical trends on the parallel Earths. Even by using GCMs with infinite temporal and spatial resolution and with perfect implementation of the physics, the ensemble mean will not exactly match the observed trend, so why test for something we already know is false – even if the model ensemble achieves exactly what the IPCC claim?
RomanM #167:
No, the uncertainty applied to the observed trend is based on the variance of the observational estimates, not the models. Note about half way down the first column of page 8, where Santer et al. say
Re: beaker (#168)
You are indeed correct and Santer et al. does not make the error that of treating the problem as described in the first part of my post (#167) . I stand corrected, It is still clear, however, from the quote taken from the paper that Santer uses the phrase “consistent with” in referring to a relationship between two values – nothing more. In fact, lucia (#172) hits it right on when she says:
I would claim that Santer may be somewhat disingenuous in the approach to H2 by refusing to include the information about the variability of the models which is available (and used) in the analysis of H1. You don’t have to calculate a weighted average as discussed in my comment (#88) to make improvements. The estimate of σSEMod = standard error of the ensemble mean can be easily replaced, in equation (12) of the paper, by an estimate which uses the excluded information. A little math:
Var(Model trend Average) = Var( Σt_k /n ) = Σ Var(t_k) /n^2 = (average of the model variances)/n
where t_k is the estimated trend of model k, and Var stands for variance. It is my suspicion that the average of the model variances could be smaller than the current value used in equation 12: s{b_m}^2 because of the extra information taken into account. This could conceivably have some effect on the results in table III of the paper. How much (if any)? Can’t tell because the data isn’t included in the SI. A further comparison not done by the authors is to average the four observed temperature trends before making the comparison to the ensemble mean.
If you’re going to throw together the numbers from a bunch of models/codes/applications it seems to me that you should apply some kind of selection criteria to the candidates.
What are the measurable technical evaluation criteria and associated objective success metrics for inclusion of a candidate into the bunch?
Absence such selection criteria, what is to prevent all the chosen models/codes/applications from simply being wrong?
I think there is no such testing in place. Instead, it seems that if you’ve calculated you’re in.
UC: There is a vast amount of material available on the relative merits of frequentist versus Bayesian statistics, the paper by Jaynes I mentioned earlier is particularly relevant to this point. The distinction between a confidence interval and a credible interval is in the interpretation of the interval (often the size of the interval is identical via both frequentist and Bayesian methods). If you interpret the interval as meaning “with 95% confidence, the true value lies within the interval” the interpretation is only correct if it is a credible interval. If you mean “if I repeated the experiment a large number of times I would the find the true value will lie in 95% of those the intervals” then it should be a frequentist confidence interval.
Note that the frequentist interpretation DOES NOT mean that we are 95% sure that the true value lies in the confidence interval using the particular set of data we actually have. Indeed Jaynes gives an example where we can be 100% sure that the true value is NOT in the confidence interval using information contained in the sample!
romanM
Partly wrong. In sections 5.1.1 and 5.1.2, Santer estimates the uncertainty for the observed trend based on the residuals to the linear fit for the observations. They assume AR(1), just as I did in my first posts and as Steve shows above in the AR(1) curves.
Santer does dispaly the SD’s in figure 6, but the computations to determine consistency all appear to use SE’s.
As for the of what you say, I agree. 🙂
So, despite the fact that Gavin and Beaker appear to promote the use of SD’s, the Gavin attached his name to a paper that uses a test that relies on SE. Where Santer differs with Douglas is not the SD/SE issue beaker is on about (and which Gavin has insisted is “the only way” in comments at my blog); the main difference between Santer and Douglass is to include estimate of the uncertainty in the observations, which you call σSETemp. Once again, this is an “SE”, not an “SD”.
beaker: #171
Well, for me the model ensemble, what with the large uncertainties in the parameters used and the linear approximations of nonlinear solutions is very close to my metastable example.The direction is not meaningless if the ball falls in a pond if going one way or rolls down another incline on another.
But if it is inherently wrong, how can it predict for us the end of the world as we know it?
Why test? test for that word in the quote above, the definition of “exactly” (quotes mine). How much is “exactly”
Are you saying that GCMs are unfalsifiable, because their output will be inherently off the data?
Unfalsifiable models are religions and not scientific theories.
Following a comment made by Gavin Schmidt on Real Climate, apparently Douglass et al. used used observational trends from Jan 1979- Dec 2004 and model trends from 1979-1999, i.e. the same period as used by Santer et al. This is contained in section 3.1 on page 4 of Douglass et al. Unless I am missing something, this means that Douglass et al. did not perform a like-for-like comparison.
The concerns about the 1998 El-Nino suggest this inconguity potenitally introduces a significant bias in favour of rejection by any test, nevermind the SE test which requires an exact match to guarantee acceptance!
Beaker–
Santer says what you claim in point 3. However they are specificslly commenting on the use of equation (11). When the supply their modified equation (12), you will note that it still contains SE as define din equation (10). They do not replace SE (for the models) used by Douglas with SD for the models. Going from (10) — used by Douglass– to (12)– which they use– they replace SE(for the models) with sqrt(SE_models^2+ SE_observation*2).
So, their objection is not to an “SE” per se, it is to the use of the SE_models alone when we need to include the SE_observation in the correct treatments.
What Santer does simply does not support your promotion of SD to replace SE. They do what I said above: Include the uncertainty due to observations.
Lucia #172:
Santer et al. do NOT use the SE test, see the top of the first column of page 8.
anna v #173:
Setting hyperbole aside for one moment, it is not inherently wrong. The population mean is still the best point estimate of a single random sample in the least-squares sense. It is just that the uncertainty of that estimate is the standard deviation not the standard error of the mean.
My definition of the idea that two things are exactly equal is that the difference between them is precisely zero (in the sense that 2+2 is exactly 4). If you
have an infinite ensemble (which would be the ideal) it would fail the SE test unless there was an exact match in that sense.
No, if we can show that the true tropical trend lies outside the 2 standard deviations of the mean (interpreting it as a credible interval) we have falsified the models with 95% confidence. If the uncertainty of the observational data were smaller, we wouldn’t be that far away from falsifying the models.
As I have REPEATEDLY said, consistency doesn’t imply skill. Models can be useless for a variety of reasons. Being inconsistent with the observations is an absolutely damning reason. Being uncertain is another way.
However, statistical decision theory gives a sound means for decision making under uncertainty, so whether they are too uncertain depends on the effect it has on the decisions.
I think James G (#142) nailed it. Absent evidence that the observational data is wrong, the obervational data needs to be considered the “true” value (within the uncertainty limits imposed by measurement and estimation errors.) Therefore, the question should be “is the model output consistent with the observational data?” not “Is the data consistent with the models?”
Just for amusement, google “Santer 2008” or “santer climate”
#171,
IMO tolerance interval would be better term for model variability and that IPCC Ch02 example. Or maybe we need a new term for interval that is based on range of model simulation results.
Lucia #175:
I see your point, however I think it is more likely to be an error in the manuscript rather than an error in the experiments. Otherwise in Figure 5b both tests would have the undesirable dependence on N that is not there for d_1^* (note if you use the SD in place of SE then n_m disappears from (12) entirely).
Looks to me that they may orginally have developed their final test incrementally and there was an error when the paper was shortened. Seems the most likely explanation to me, given that it comes so shortly after an unequivocal rejection of the SE, and the discussion on RC!
Steve #178:
8)
Re: beaker (#181),
I have no idea where you get the theory that equtaion (12) contains a typo.
A) Santer does not use the SE test in the way that Douglas uses it. Douglas uses SE in equation 11 in Santer
B) Santer uses euqation 12 which contains SE, but not used the way Douglas uses it. They use euqtiona 12. Note the quantity 1/n s(<(bm)>)^2 inside question 12 is the square of SE.
That is, Santer replaces SE used in Douglas with sqrt( SE^2 + SE_obs^2)
So, they use SE not SD.
Now you suggest this is a typo. Oddly though, the typo is a persistent one, and even more oddly, the describe the meaning of SE^2 in words, saying the quantity in equation (12) is “a standard estimate for the variance in the mean.” Those words correspond to SE^2. The equation corresponds to SE^2. They repeat the use of SE^2 in equation 13. Santer then cites others who are clearly using SE.
So: Based on the equations, and the words, Santer is using SE, not SD.
They do show the SD in figure 6, but their tests use SE.
They are not using S
Tom Vonk #179:
No, that is the chance that our Earth has a tropical trend that is exactly the same as the mean tropical trend over the population of parallel Earths (i.e. virtually zero). I could hardly make that point any clearer when I wrote:
The SE test tells us something we should already know: the models are not reality, the map is not the territory. The SD test is nearly as uninteresting: the uncertainty of the model outputs seems to be large enough to include current observations. The question is skill. Does any individual model or some combination of models have sufficient skill to be useful? Can any model have sufficient skill? What is sufficient skill? Neither Santer nor Douglass address these questions as far as I can tell.
Thank you Dewitt.
Lots of wasted bandwidth over several threads avoiding the important questions.
DeWitt Payne #183: I agree with all that apart from one point. The SD test is interesting if the models don’t pass it (back to the drawing board climate modeller types!), it doesn’t say a great deal that they passed. See this comment from Gavin Schmidt
Re: beaker (#186),
Indeed.
Wolfgang Flamme:
Yes, you could put it that way. However, as I have already shown, we know a-priori that the models are biased in this sense, so why test for bias? The fact that there is a bias doesn’t mean the models aren’t usefull (for instance most statisticians are happy with the idea of ridge-regression which deliberately introduces bias). It is the size of the bias that matters and the Douglass test doesn’t say anything about that.
I’d say a reasonable interpretation of “consistent” in this case would be that we can be confident that the climate machine is capable of generating the observed climate, i.e. the observed climate isn’t an outlier in the distribution of model runs.
Lubos Motl has some interesting comments on the models here.
I think this discussion continues to slid over some points that never seem to be addressed which in my view are:
When the ratio/differences of tropospheric and surface temperature trends in the tropics are compared how much of the “single rendition of climate content” and/or the ENSO effects are cancelled out? That question was not answered to any detailed satisfaction by Beaker (or anyone else here).
Beakers point on the use of SEM versus Stdev seems almost to take a position that SEM would never be the proper statistic to compare averages from a population. It is standard practice (in statistical text books) to use SEM for comparison when 2 (or more) average values can be derived from a population. If indeed the models have a central tendency as Santer et al. (2008) must concede or why use an average (with a Stdev) to look for differences, and if we have no non canceling “single rendition of climate content” then I could see no objection to comparing the averages of the model and observation results using the SEM.
If there exists a non canceling “single rendition of the climate content” (SRCC) it must be capable of being estimated or models could never be considered capable of projecting future climates because one would have an ensemble average minus the observed results plus the SRCC which is boundless. Therefore if one makes all these assumptions (in favor of the models) one would compare the model averages (MA) and the observed averages (OA) using the SEM by comparing the difference OA – MA – SRCC or MA + SRCC – OA.
On the other hand, if the SRCC is not capable of being estimated and/or the model average has no meaning in the usual sense of an average, then we have a situation where the model ensemble really produces nothing to compare to the real world.
What does switching from an ensemble of model results to individual model results for comparisons do under the above assumptions? With an assumed canceling of SRCC and ENSO like effects by differencing or ratioing the tropospheric to surface temperature trends in the tropics, we could proceed with a statistical analysis as suggested by Ross McKitrick above, whereby we use all the model and observed data and compare results over the entire altitude range. If we assume that the SRCC and ENSO effects do not cancel, but are capable of being estimated than we can proceed with a similar approach as above with reasonable SRCC and ENSO adjustments. If SRCC and ENSO are not capable of being estimated than we cannot use the individual model results for real world comparisons any more than we could use the model ensemble results as argued above.
I think that Douglass et al. (2007) made a first effort attempt to use the assumptions (as they saw them) of the IPCC to make a comparison between model and observed results. I think that Santer et al. (2008) in attempting to spin the uncertainties arising from their assumptions about both the model and observed results (by adding newer adjustments to old results) into inferring that their interpretation brings the model and observed results more inline with one another is a major blunder.
Re: Kenneth Fritsch (#190),
But we’re not comparing two samples from the same population. We’re comparing one item from a population with the estimated population mean of a completely different population to see if the two populations are comparable. But even if they were from the same population, the SE test is too stringent.
Say you have an arbitrarily large barrel of apples whose individual weights are iid. Take one apple and weigh it with arbitrarily high precision and accuracy (1 ng, e.g.). Now take an arbitrarily large number of apples from the barrel, weigh them to the same precision and accuracy and calculate a mean, standard deviation and standard error of the mean. You can always make the sample size large enough that the probability that the weight of the individual apple will fall within the 95% confidence limits of the standard error of the mean is vanishingly small. But 19 times out of twenty, the selected apple will fall within the 95% standard deviation confidence limits independent of the sample size used to determine the sample mean and standard deviation.
Comparing model results with a single realization of the climate is worse because you’re not even comparing an apple with other apples. You’re comparing an apple (and you only have one) to a set of things you synthesized in the lab that you think might be like apples. And you don’t and can’t (I think) even know if your apple is representative of all apples. Passing an SE test under those circumstances would be both interesting and near miraculous.
Re: DeWitt Payne (#197),
DeWitt, the observed average is an estimate of the true average and not just one apple from the barrel. It is the target much as that value is determined when one determines the in-control process mean and then uses an average of several samples and SEM to determine if the process is within an agreed upon limit from the mean of the process.
If the observed were considered just another apple in the barrel like just another model result than one should go back to Karl et al. and not even use averages and stdev but look at the single rendition of the climate (or its estimate) and compare it to the range of model results. Of course, a model outlier or two will always keep the the single climate rendition within the range and that was the weakness that I saw Douglass argue about the Karl approach. Using the stdev will also allow outliers considerable leverage in keeping the observed result within the 2 stdev limits of the model results.
In the apple barrel experiment one would compare the sample average with the true average of the barrel which would have been obtained by counting the apples going in and weighing the net apple weight of the barrel. The sample average would tell us about the uniformity of the apple distribution in barrel perhaps. And on average 1 time out 20 we could reject the hypothesis that we a “good” sample of apples at the p = 0.05 level when indeed we did, but that is life in statistical world that applies with all sampling of this sort
Re: Kenneth Fritsch (#207),
That wasn’t my point, although I don’t blame you for missing it as my example wasn’t as clear as I would have liked, not to mention that I changed my mind about what my point was. After thinking some more and re-reading Santer et al., I still think that test used by Douglass et al. was wrong, but not for the same reason as beaker. It’s not that Douglass used the standard error of the mean of the model trends rather than the standard deviation, but the failure to include the variance of the observed trend in calculating the confidence interval for the test. The Santer paper’s confidence interval seems more reasonable because they do calculate the combined standard error. Of course the confidence interval of the observed trend is quite large and includes zero, which doesn’t help the warmer’s case, but that’s another story.
I could try to explain it in apple barrel terms, but I’m sure everyone is bored to tears by now of questionable analogies. I also agree with Steve McIntyre and think lucia is reading Santer et al. correctly and beaker isn’t.
Re: DeWitt Payne (#212),
So we could provisionally conclude that both Douglass and Santer have used SE tests on the model’s side. And the methology differs in that Douglass didn’t take into account uncertainties in observational data while Santer did.
So at first glance it looks like Santer’s method is more authoritative than Douglass’. However for this to be true we need to be sure that uncertainties in observational data haven’t already been accounted for as uncertainties on the model’s side.
Now with all that tweaking and parameter fitting that went into these models, with all the efforts that went into them to make them match actual observational data and variance as good as possible, can we safely conclude that observational uncertainties haven’t found their way into the model world already?
I really don’t think so. Not a single one model is purely drawing board. They’ve all been exhaustively checked against observational data, re-versioned, improved, corrected. Innumerable models and sub-models that may have looked nice on the drawing board must have been scrapped or reworked because they just wouldn’t comply with what was observed, already including all plausible uncertainties in these observations. These model stars are the survivors of a rigorous competition to match observations as closely as possible without violating physical plausibility. At least such influence is a reasonable thing to assume.
(That is why I’m more with the Douglass method – we shouldn’t account for observational uncertainties twice)
Besides, it is proposed that we can conduct an objective test to see wether the models closely match the observations the models were designed to match closely. Well, I wouldn’t be too surprised if the models would perform greatly passing this test. But as it turns out they are close to failure. So with some mild sarcasm I conclude that it’s likely the restriction to use plausible physics that obstructs the model’s performance.
Re: DeWitt Payne (#212),
So, the H0: cannot be rejected. And if you take long memory into account, the same applies to surface data for much longer period. Santer’s 17 seems to dodge long memory, sample is too short and temperature data has too high temporal autocorrelation (!)
cannot be rejected. And if you take long memory into account, the same applies to surface data for much longer period. Santer’s 17 seems to dodge long memory, sample is too short and temperature data has too high temporal autocorrelation (!)
Re: DeWitt Payne (#212),
DeWitt, calculating and using the variance of the observed results to make the comparisonwith the model results has been covered rather extensively in previous Douglass et al. (2007) threads.
I think we are starting to repeat ourselves and in that vain, I continue to vote for the McKitrick approach in comparing the observed and model results. It gets around the concept of the model ensemble having a meaningful average in the context of how the models are constructed and uses all the available data i.e., the entire altitude range.
I could, I think, as a layperson, conjure up a simple nonparametric test whereby I look at the probability of the model results laying above and below the observed results.
Re: Kenneth Fritsch (#223),
Yes, but for some reason it didn’t sink in until recently. Sometimes repetition is necessary. Sometimes you have to hit the mule with a two by four more than once to get his attention.
re 186: beaker here is gavins comment
[Response: Well, since that wasn’t the aim, we are doing ok. What is needed to show that models have skill are comparisons to data that is a) well characterised, and b) with a large signal to noise ratio. Both elements conspicuously absent in the tropical tropospheric trends, but abundant in the 20th Century global mean surface anomaly, or in the stratospheric cooling, or the Arctic amplification or the response to Pinatubo, or the increase in water vapour, or the enhancement of the Antarctic polar vortex etc. Please see the IPCC report for more detailed assessment of these issues. – gavin]
Now I want you to note this. Gavin says that the GCMS Show SKILL in comparisions such as “the response tp Pinatuba” What this means is that GCMs that represent Volcanic forcing are more skillfull than those that don’t. However, Santer utilizes a range of models, some that utilize volcanic forcing and some that dont. Quite simply, when proving the skill of GCM the AGW crowd utilize only those models that represent Volcanic forcing, but when they want to show that the models are not inconsistent with tropospherical trends they include models that are known to be less skillfull. That should strike you as odd.
Steven Mosher #191:
Read the comment again, Gavin clearly does not state in that comment (he may well do elsewhere) that the GCMs have SKILL in those areas. Instead he merely says the observations available in those areas are well characterised and have sufficiently high signal to noise ratio for testing the skill of a GCM to be feasible.
The reason I mentioned Gavin’s comment is that it makes it clear that he at least does not claim that Santer et al. demonstrate that the models have skill in predicting the tropical trends and indeed the uncertainty in the observations make it impossible to establish skill at the current time. It appears that he at least understands what a scientist means by “consistent”.
Beaker–
Other plausible explanations why Santer uses SE even though Gavin has posted that the SD is the only right way (as he did in comments at my blog):
1) A number of the other co-authors disagree with Gavin’s idea about SD.
2) The peer reviewers disagree with Gavin.
3) Knowing many statisticians and climatologists disagree with Gavin’s arguments, the authors collectively worried that the peer reviewers would disagree with Gavin, and knew they could convince the SE test is meaningful. They judged the SE test sufficient to show their case.
4) Someone is planning a breakthrough paper suggesting this nifty SD technique.
5) Other.
Santer uses SE not SD.
Lucia #192:
Other than the reasons I gave previously, I have published and reviewed enough papers to know that busy authors can make mistakes when revising papers in response to reviewers comments (especially when told to shorten the derivations). I’m sure having seventeen authors is likely to make this worse rather than better. Fortunately Mrs Beaker is an excellent proof reader, which I find invaluable.
Secondly, I prefer to adopt a variant of Hanlon’s razor and opt an interpretation that reflects on the purported perpetrator of a mistake in the best light I can find, whether it is Santer et al. or Douglass et al.
Lucia #194:
O.K., how do you explain the lack of dependence on n_m in the performance of the revised test, shown in figure 5b, given that the test statistic is explicitly dependent on n_m?
Beaker–
I have also published and reviewed peer papers and am aware that typos happen. But your desire to assume there is a typo in equation (12) conflicts with the text of the article!
What’s to explain? That’s precisely what to expect A paird t-test is done correctly. By definition the false rejection rate is supposed to be independent of the number of samples– that’s true even in the simple undergraduate text book example where the number of samples is something like “widgets”!
Out of curiosity, what do you expect that graph to look like if (12) is applied exactly as written?
Anyway, I invite you to go ahead and run some monte carlo yourself. You’ll see that if you interpret (12) exactly as written, and generate synthetic data with identical trends and AR(1) noise for the observations, you’ll reproduce that figure.
You might also cast your eyes to the caption for figure 5b. Notice these words:
So, the authors are, in words, reinforcing that the difference between 11 and 12 is the inclusion of the uncertainty in the observed trend. (Not replacing SE with SD.)
Time after time, their words reinforce the notion that the difference bewteen 12 and 11 is not substituting SD for SE but adding the uncertainty associated wtih observations.
I don’t see how you are applying this. You attribute more blunders to authors than I do!
* I attribute fewer mistakes to Santer than you. Nothing about my interpretation suggests Santer made any mistake at all. For your theory to be correct, Santer has to contain typos.
* I either attribute fewer errors to Douglas than you do, or we attribute the same number of errors. lf my interpretation is correct, Douglas’s only error is to neglect the uncertainty in the observed trend. In your interpretation, Douglas used SE where SD was required. It’s not clear to me if it bothers you they neglected the uncertainty. But at most I attriute 1 mistake to Douglas; you attribute at 1 or 2.
So, if you are going to use this razor, you need to switch over to my interpretation!
OK, let’s get this straight: Santer et al use SE in their paper. Douglass et al use SE in their paper. So this whole discussion on SE versus SD has been on a false assumption. So I have slowly plodded my addled brain through discussions on shady men with top hats, fictitious AGW surveys for sale, and a mysterious barrel of apples for no earthly reason.
Beaker, you owe me three hours of my weekend and the cost of an expensive present to placate my wife.
lark #200:
good point!
Beaker pictured earlier today ;o)
RomanM– I was planning to look at the issue you mention to see if other ways of doing the comparison between models and data are more efficient. (That is, less prone to false negatives.)
Beaker– I asked Gavin about the typo. His answer should trump our argument.
Lucia #202:
Whether it is a typo or something more substantial, it would be interesting to find out, given that it contradicts an emphatic paragraph earlier in the column.
I wonder if the subscripts have been swapped, so it is the SE of the models and SD of the observations rather than the other way round.
I would have asked Doug Nychka, given that it is a purely statstical matter.
beaker–
I wrote Gavin because I have his email address. I’m fairly confident Gavin will be sufficiently familiar with the paper to be able to answer himself. However, if he doesn’t he’ll have Nychka’s email! 🙂
I’d be surprised if Gavin doesn’t read this blog – he has indirectly responded to postings here (without naming the blog of course) in the past. Plus from #145, we know that at least one of the coauthors has been following this discussion. Why don’t they just eliminate our suspense and post a comment?
There’s an ongoing refusal to comment here with any substance in an attempt to marginalize Steve’s contributions to the field. In other words, if they post with substance, or reference Steve’s work, they ultimately acknowledge his contributions.
Mark
Re: Mark T. (#206),
Of course they do. Citations are the primary currency of scientific status in the world of research.
Re: Pat Keating (#210), ??? One type of comment that does elicit a bit of snark from Steve (tounge-in-cheek, of course) is the fact that the RC crew make adjustments without ever pointing out that they originated here. Even when the work is not Steve’s, they refuse to acknowledge that the blog was the source.
Or were you being sarcastic? 🙂
Mark
A CA reader has identified an error in the above graphic. I’ve added a note to the Figure captions observing that the red line showing 0.28 is incorrectly located. The multi-model mean is 0.215; the figure of 0.28 appears in Santer et al Figure 1, but is the ensemble mean for the MRI model only.
I agree with Lucia’s interpretation here. An additional argument in favor of Lucia’s interpretation (as opposed to beaker’s implausible misprint hypothesis) is that Lanzante 2005 – about the only statistical citation – argues in favor of a “Pythagorean”-type sum of the equ (12) type.
The CI is made substantially narrower by including data up to 2008, instead of deleting post-1999 data. I’ve worked out some distributions which I’ll show tomorrow.
I dont know much beaker. But I know this. Santer et al used a variety of models. Some represented historical Volcanic forcing, others did not. How important is this forcing to having a more accurate model?
I dont know. Lets see what Santer says:
Santer et al. 2001
Santer, B.D., T.M.L. Wigley, C. Doutriaux, J.S. Boyle, J.E. Hansen, P.D. Jones, G.A. Meehl, E. Roeckner, S. Sengupta, and K.E. Taylor, 2001: Accounting for the effects of volcanoes and ENSO in comparisons of modeled and observed temperature trends. J. Geophys. Res., 106, 28033-28059, doi:10.1029/2000JD000189.
Several previous studies have attempted to remove the effects of explosive volcanic eruptions and El ño-Southern Oscillation (ENSO) variability from time series of globally averaged surface and tropospheric temperatures. Such work has largely ignored the nonzero correlation between volcanic signals and ENSO. Here we account for this collinearity using an iterative procedure. We remove estimated volcano and ENSO signals from the observed global mean temperature data, and then calculate trends over 1979-1999 in the residuals. Residual trends are sensitive to the choice of index used for ENSO effects and to uncertainties in key volcanic parameters. Despite these sensitivities, residual surace and lower tropospheric (2LT) trends are almost always larger than trends in the raw observational data. After removal of volcano and ENSO effects, the differential warming btween the surface and lower tropospher is generally reduced. These results suggest that the net effect of volcanoes and ENSO over 1979-1999 was to reduce globally averaged surface and tropospheric temperatures and cool the troposphere by more than the surface.
{ prepare for the money quote}
ENSO and incomplete volcanic forcing effects can hamper reliable assessment of the true correspondence between modeled and observed trends.
In the second part of our study, we remove these effects from model data and compare simulated and observed trends. Residual temperature trends are not significantly different at the surface. In the lower troposphere the statistical significance of trend differences depends on the experiment considered, the choice of ENSO index, and the volcanic signal decay time. The simulated difference between surface and tropospheric warming rates is significantly smaller than observed in 51 out of 54 cases considered. We also examine multiple realizations of model experiments with relatively complete estimates of natural and antropogenic forcing. ENSO and volcanic effects are not removed from these integrations. As in the case of residual trends, model and observed raw trends are in good agreement at the surface but differ significantly in terms of the trend differential between the surafce and lower tropopshere. Observed and simulated lower tropospheric trends are not significantly different in 17 out of 24 cases. Our study highlights the large uncertainties inherent in removing volcano and ENSO effects from atmospheric temperature data. It shows that statistical removal of these effects improves the correspondence between modeled and observed trends over the satellite era. Accounting for volcanoes and ENSO cannot fully explain the observed warming of the surface relative to the lower troposphere, or why this differential warming is not reproduced in the model simulations considered here.”
So, Santer 2001 says that incomplete volcanic forcing effects can hamper reliable assement of true correspondence of models with data. BUT in 2008 where his goal is to show that models and data are not inconsistent, he uses a mix of models: some with volcanic forcing and some that have no volcanic forcing whatsoever.
If you dont see the problem with thi, there is not much more I can say.
One last comment on this thread for the time being. It ocurred to me that there is a valid way to used the SE test, which is to compare the ensemble mean with an estimate of the forced component of the tropical tend rather than directly with the observed trend. To do this you would need to estimate the variability of the observed trend due to the initial conditions/stochastic variability. You could estimate this using the variability of model runs, however I find that a slightly circular argument, but not actually incorrect per se. This would be fair as it would be testing a claim that the modellers actually might make (that the ensemble mean, at least with ideal models, is an unbiased estimator of the forced trend), so it is a like for like comparison.
This doesn’t mean that the SE test in Douglass is in any way correct as they compare the ensemble mean with the observed trend directly. As I keep saying, you need to match the test to the claim involved.
However, testing to see if the best estimate of the observed trend lies in the SD of the models, which would give pretty much the same result with a much clearer justification.
TTFN
Beaker–
As you know, I asked Gavin if there is a typo in equation 12. So far the answer is
Evidence for your typo theory appears weak. But who knows? Maybe when Gavin checks, he will discover that the 1/n in equation (12) was a typo. If so, the authors will presumably issue an erratum.
It’s worth nothing that in the limit that observations are perfect, Santer’s 12 as written becomes the Douglas method. In the limit of an infinite number of model runs, Santer’s 12 means we compare the model average as a single number to the uncertainty bounds for the observation.
This is reasonable. If models replicate the true earth trend on avearge and modelers actually ran their models 100…..000….000 times, then the model average must fall inside the range consistent with observations.
Thanks to a CA reader, I’ve corrected the constant to 2,8 in the above equation. I’ve added the following sentences:
Since nobody has done this yet on this thread, I’m reproducing Sanders et al Figure 6:
There are two issues that make comparing the variation of the model outputs to the measured data sets difficult to assess in any meaningful way.
First the distribution of the temperature output of the models (for a given elevation) is provably not a Gaussian: For any given climate model, you can’t get an arbitrary temperature trend at a given altitude by varying the model parameters, given the constraint that you must match the correct temperature trend on the surface. And the ensemble of models all making current physics assumptions will produce a finite range of temperature output regardless of how you tweak the individual models:
If you had a range of temperature gradients at a given elevation (e.g., 0.0-0.4C/decade at 500 hPa), this distribution tells you nothing as to whether a model exists that could produce a value outside of that range (e.g., –0.15C/decade, the observed value) at that elevation. All you can conclude is that none of the models could reproduce that trend, and if all model variations have been tried, that either there is a problem with the models, or a problem with the data.
Thus, at its core, Sanders—or any other analysis that talks of means and standard deviations—that tries to assign uncertainties to excursions from the mean value of the ensemble of current models—is fundamentally flawed.
Secondly, the distributions of temperature outputs of he models are highly correlated: If a given model produces a temperature T1 at elevation z, it can not produce any arbitrary value T2 within the range of observed model variations at elevation z + delta z. Put another way, if you varying the parameters of a given climate model while constraining it with the surface measurements, once you pick a set of parameters so that your model gives the value T1 at z, the values that it can produce at z + delta z are highly constrained, and generally fall within a very narrow range relative to the total range of output of the models. Simply because you have one model that produces a near zero trend at e.g., 500 Pa, doesn’t mean that a model exists that reproduces the minimum of the envelope of models (the left-hand side of the gray envelope in Sanders et al Fig 6).
Fundamentally treating model output as if it were “data” and applying normal-distribution statistics to it is simply an inappropriate thing to do. The “correct” classical statistical approach is to look at the data (plus its uncertainty), then optimize the model parameters to minimize the difference-squared between the model and data, given the measurement uncertainties. You can then make a statement (e.g., using chi-square statistics) on how good a job a particular model can do in reproducing the observations.
Thus if you have a distribution of models, all failing to reproduce the data, the correct conclusion is not that a (not yet realized) realization of this distribution of models could actually be consistent with the observed data, but rather that all of the models fail to reproduce the data.
The straightforward implication of that is we probably need to add new physics to the climate models to explain the observed stratospheric temperature trends.
Re: Carrick (#221),
I did post this figure early in the thread at the link below. I think my rendition is easier to read.
Re: Kenneth Fritsch (#79),
Re: Carrick (#221), In support of Carrick’s point, we can consider the set of models as candidate companies bidding for a technical job. The question is, do they meet the specs? Testing one by one, they all fail (or not). We don’t say that the variance of the bidders is such that we can not reject the possiblity that a bidder exists who would pass. But that seems to be what Beaker wants.
Some of my meanderings into log-likelihood may not have been necessary.
I think that I’m now able to more or less replicate the Santer significance tests on their face – and applied the same method inclusive of 2008 data.
Notwithstanding the statement of the Santer coauthor that the deletion of post-1999 doesn’t “matter”, this appears not to be the case. Merely applying Santer’s own test as set out in Table III using the additional information up to 2008 (which is mainly relevant in narrowing the CIs), it appears that their results for the H2 hypothesis no longer hold in respect of UAH.
As I’ve noted before, I think that much of the sound and fury in Santer v Douglass is a distraction from the data issue – whether RSS or UAH are more accurate, a matter that Tamino has recently posted on. (I don’t plan to visit this issue for a while as I need to get back to proxies.)
Re: Steve McIntyre (#224),
Regarding the relative accuracy and consistency of the RSS and UAH datasets, I presume you are aware of Douglass and Christy’s discussion and conclusion on the matter (in favour of UAH) here (Appendix A):
Click to access 0809.0581.pdf
Kenneth Fritsch:
Sorry… I managed to miss that one.
I still think the bigger issue is whether an ensemble of deterministic model outputs, varying only due to slightly different physics assumptions, should ever be treated as if they were normally distributed.
I would say the correct answer is they should not.
Craig, that’s a good analogy.
If none of the bids meet the specs, you reject them and send a letter explaining how all of the bids failed in meeting the specs to all bidders. You don’t go through some contorted logic to explain to your boss that some aggregate of the various bids aren’t that far away from the original specifications. (Try this and see whether it works.)
In this case, the clear fact is the particular set of physical assumptions made by any of the known models do not reproduce the observed experimental data. But it seems completely obvious that some choice of physical assumptions would be able to do so—one hardly needs to perform a jimmied-up statistical analysis to come to that conclusion!
What is it that that Sanders is really saying? That in spite of the fact that none of the models can reproduce observations, they are so all-over-the-place that somehow in ensemble they become consistent?
That deserves a hearty “what the ______”.
I’m not sure these guys know how to apply the scientific process at all, if this is an example of their “finer work”.
Re: Carrick (#230),
I agree. I have read both papers and have a number of issues:
1) The use of autocorrelation to the real world signal is incorrect. The real world signal clearly has structure, how much will be determined by averaging measured data. The use of autocorrelation artifically inflates ‘confidence intervals’ (Santer et al term) and it means you are imposing a linear trend on the data which is not correct without some stated assumptions.
2) The fact that models cannot match ENSO variations even to some degree says to me the models are not good enough. Using Santer’s increased CIs (which appears reasonable expect no sqrt(N-1) demoninator in eqn 9) the paper even shows how you can get an anomaly of around 0.5 ± 0.5 (i.e. 100% error). This paper should have been a critique on efficacy of models.
3) Douglas et al does not average out the ENSO oscillations (some only have single runs) so he should be using autocorrelation for consistency (even though this is a wrong method to use)
4) The statement that y0 = phi0 + noise in the real world is incorrect (see 2). You CANNOT assume that ENSO is random. This is what is measured. THEORY MUST FIT FACTS
5) In general the skill of a model is how well it predicts more than one property. For example in plasma modelling using Particle-In-Cell (PIC) codes which are not dissimilar to GCMs, if you get a good agreement with electron temperature but number density and plasma potential are way out the model is declared to have a problem. Why? Because enough is known about plasma interactions that you have an idea of the parameter set and bounds to be used.
All these papers show is that it appears that people in the Climate community are trying to make facts fit their theories. They have already settled on a ‘consensus’ about the assumptions and the results. Douglas et al and Santer et al are not addressing the fundamental assumptions and methods about how much skill models have in representing measured data and how much parameter variation is needed to achieve this. This is much deeper problem
See post at blog Niche Modeling for account of how Ben Santer has grudgingly begun to acknowledge some reality, while failing to cite prior contributions of critical authors from CA etc.:
2 Trackbacks
[…] Climate Audit? It’s discussed in several threads related to “Santer17″. (See 1, 2 etc.) Are you wondering what it all […]
[…] project of auditing climate research papers, Steve McIntryre wrote a measured analysis: “Santer et al 2008“, 16 October 2008. He then sent the following request (see here for full details of this […]