I will go approximately 50-50 for a while on posting statistical and non-statistical notes. Today’s another statistical note. It’s a bit technical, but some of the statistical findings from econometrics on autocorrelated series are highly applicable to climate and, while there is occasional citation of econometric literature in climate articles and occasional forays by econometricians into climate, the diffusion seems very incomplete at present, with climate scientists often using quite (in my opinion) naive and inadequate techniques. So I’m trying to bring some statistical findings on the impact of autocorrelation to the attention of people interested in climate series.
I’m learning some of this as I go, so I’m just a one-eyed man here. Some references have been sent to me on earlier notes and I’ll comment on most of them a little later, after I get review a couple more papers. I’m also going to return to the specific examples of spurious significance cited in our GRL article – the extraordinarily high RE statistics from simulated PC1s combined with insignificant R2 statistics.
One of the reasons for discussing Granger-Newbold and Phillips is to show their approach to "spurious" regression statistics (here t-statistics and F-statistics) and why other statistics need to be considered to ensure that there is no mis-specification in the model. In the case of our MBH98 critique, we argue that it is the RE statistic that is spurious and that the R2 statistic, in this case, provides a cross-check. In the examples below, it is the t- and R2 statistics that are spurious and the DW statistic is a cross-check. The point is the need for care and due diligence, rather than magic bullets. Perhaps the discussion of Phillips and other texts on spurious signifiance will also illuminate the approach that we used in our GRL article and why we discuss "spurious significance"
Phillips has a remarkable series of articles on spurious regression – see a listing here – , a few of which are listed below. One of them deals directly with the issue of trends versus random walks in time series analysis “€œ an issue that I was wondering about in connection with the satellite series.
Phillips [1986] commences with a discussion of Granger and Newbold [1974], commenting that their simulations gave “dramatic demonstration”‘? of the “failure of conventional test procedures”‘?. Phillips summarizes Granger and Newbold as having shown that many time series of interest can be represented by ARIMA-type processes and are often near random walks; and that regressions between such time series frequently have high R2 statistics, combined with highly autocorrelated residuals, indicated by very low DW statistics – a situation which we’ve seen in some important climate series and (I suspect) prevalent in many others not discussed so far.
Phillips points out that no one explained “what exactly goes wrong”‘? with the conventional tests. He then introduced a very high level of mathematical sophistication to the analysis of what, until then, had been a pretty low-brow problem, demonstrating an “asymptotic theory”‘? expressed in terms of “functionals of Wiener processes”‘?, “weak convergence in probability measure”‘?, “functional central limit theorems”‘?. The entire procedure appears really remarkable to me, not just because of the mathematical sophistication, but because the mathematical tools used here seem to come from out of the blue. Who would have thought to discuss humdrum and humorous problems, like regressions of South African wine sales against Honduran birth rates, in terms of martingale convergence?
The results are summarized in his Theorem 1 here, which is not quite as hard to read as it looks, if you set aside the various integrals of Wiener processes as just being a complicated non-standard but calculable distributions and don’t worry about them further for now. Phillips’ Theorem 1 says of regression between random walks:
1) the regression estimate of the slope coefficient 
2) the regression estimate of the intercept 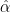
3) the regression R2 does not converge to 0, but has a random distribution as 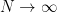
4) the t-statistics for both
5) thus, based on a nominal critical value of 1.96 for the t-statistic, the t-test is biased towards showing that a relationship is statistically significant, when it isn’t (rejection of the null hypothesis of no relationship). Phillips observed that the Granger and Newbold recommended a benchmark of 11.2 (rather than 1.96); Phillips pointed out that the benchmark of 11.2 had no meaning, but simply represented the asymptotic distribution in simulations where N=50, which in this case was 1.96*sqrt(N) with N=50 “a rather neat confirmation”.
6) the Box-Pierce Q-statistic diverges with N (not sqrt(N)) as
7) the Durbin-Watson statistic “converges in probability” to 0.
The issue is not just that the t-statistic doesn’t work in 1 out of 20 cases: the problem is that, as N goes up, the t-statistic gets so that it nearly always doesn’t work (on the side of showing significance where none exists.) The problem isn’t limited to the t-statistic, but applies to many other common statistics. The one ray of light in this is the Durbin-Watson statistic. Phillips observes that “all of these results differ from the conventional theory of regression with stationary processes”. He stated that, when the “correct asympototic theory” is used, there are no surprises in the Granger-Newbold results.
This theory applies to random walks (unit root) processes and a vast literature has developed on testing for unit roots. Phillips pointed out the usual asymptotic theory still works when x and y are generated by independent stable autoregressive processes (i.e. à?’?<1), in which case the estimates for àŽ⯠and àŽⰠconverge in probability to 0. However, most calibration periods in paleoclimate are relatively short, e.g. MBH of 79 years. If “low-frequency”‘? effects are sought by averaging or smoothing, the effective calibration period can be reduced much further (even by an order of magnitude). While "near-integrated processes" (AR1 coefficient >0.9) work out OK as N => ‘ˆž, it turns out their finite-sample properties have many characteristics in common with random walks (unit roots).
Most of my interest is in finite sample situations and so I’ve looked more at what happens to “near-integrated”‘? series (i.e. à?’? near to 1), rather than the unit root literature. As a result of the recent discussion of satellite temperatures, I’ve also looked more at the issue of trends versus random walks and will get to both of them.
REFERENCES:
Phillips, P. [1986], Understanding Spurious Regressions in Econometrics. Journal of Econometrics, 33, 1986 [30pp] http://cowles.econ.yale.edu/P/cp/p06b/p0667.pdf
Phillips, P. [1988], Regression Theory for Near-Integrated Time Series. Econometrica, 56(5), 1988, http://cowles.econ.yale.edu/P/cp/p07a/p0711.pdf
Phillips, P. and J.Y. Park, [1988], Statistical Inference in Regressions with Integrated Processes: Part 1. Econometric Theory, 4. http://cowles.econ.yale.edu/P/cp/p07a/p0715.pdf
Phillips, P. and J.Y. Park, [1989], Statistical Inference in Regressions with Integrated Processes: Part 2. Econometric Theory, 5, 1989 http://cowles.econ.yale.edu/P/cp/p07a/p0722.pdf
Steven N. Durlauf and P. Phillips [1988], Trends Versus Random Walks in Time Series Analysis. Econometrica, 56(6) http://cowles.econ.yale.edu/P/cp/p07a/p0744.p
Phillips, P. [1998], New Tools for Understanding Spurious Regressions. Econometrica, 66(6), 1998 http://cowles.econ.yale.edu/P/cp/p09b/p0966.pdf





14 Comments
1. Your recent technical published criticism did not have any of this DW or ARIMA criticism. Are you exploring these avenues to end up publishing another one? Or is this just canoodling? Are there examples in econometrics or other stats-heavy disciplines like sociology of people publishing DW criticisms? FYI: I’ve never published (or heard of) DW. And I did some simple regressions as part of solid state chemistry.
2. Ever read Stan Lieberson, MAKING IT COUNT? Comments?
In econometrics it is de rigeur to test for integration (or near integration). DW stats are a sign that something is wrong after the fact. The problems of integration and near integration are so well known in econometrics that you test your series beforehand to avoid the problem. Thus, Dickey-Fuller or Phillips-Perron test statistics are almost always calculated – if you have a problem you do a proper regression that accounts for the integration (that is test for and account for cointegration) or you don’t publish. 20-30 years ago when this was first emerging there might have been some criticisms of work that had spurious regression problems and DW stats might be mentioned, but these days they won’t pass muster (or peer review). Reporting DW stats is also relatively common because autocorrelation in residuals is such a common problem with economic time series. Calculating Durbin-Watson stats is generally taught as part of a first or second year undergraduate econometrics course – problems of integration may wait until graduate level depending on your institution.
As Steve has noted previously – statistical techniques in other disciplines seem relatively primitive compared to econometrics. A significant reason for this is that many other disciplines are experimental – if you have a problem you get better data. Because economics is not really experimental you can’t do that. Instead you need to get a better statistical technique to deal with the data you have. Paleoclimatology has the same non-experimental problem as economics but they don’t seem to have compensated by improving their statistical techniques to the same extent.
My question remains however as to whether improper work is being done in experimental science: in signal processing, in semiconductor physics, in crystallography. Anywhere regressions are done. Because we definitely don’t learn the DW test.
Crystallography etc. don’t have the same problem with autocorrelated series. I’m wondering whether learning (identical independent) i.i.d. statistics is almost worse than not knowing anything. It makes people think that they know stuff which is not actually true in time series situations.
One of the things that I requested from Mann in Nov 2003 was his digital version of the 15th century reconstruction so I could calculate a DW statistic. This gets tied up in a long story about his submission to Climatic Change in 2004 which was rejected (although he cites in Jones and Mann 2004). Anyway even with the Barton stuff, we still don’t have Mann’s actual 15th century reconstruction. The Wahl-Ammann emulation is the same as mine and there are puzzling differences in the early portion. They don’t necessarily “matter” for whether it’s a hockey stick or not, but they sure could matter for calculating DW statistics. I’ve never figured out any validity to either Nature or NSF refusing to require Mann to produce output from which a DW statistic could be calculated for the 15th century proxies. Even Barton hasn’t got this.
So chemists don’t need ARIMA or DW. COOL! I can’t keep track of p and f and t tests as it is. Damn corporate six sigma crap!
Oh…and what about manufacturing consultants? Do they need to know DW?
And can you just include “run order” as a variable in the multiple regression from the DOE? Does that take care of autocorellation (I had never heard that term, concept before here…still not sure what it is.)
TCO,
You may not need DW etc but general advice is that you should be aware of the assumptions implicit in any regression or statistical technique you are running and be wary of situations where these might be violated. In whatever you are doing you should think about potential problems with your data and how these interact with the assumptions required for OLS (or whatever) to be correct. A common problem in econometrics is that the errors in a regression are not iid but are autocorrelated. I don’t know what common problems in crystalography, chemistry or manufacturing consulting are but they are undoubtedly there – identify what they are and make sure you are accounting for them. In general – a little knowledge is a dangerous thing.
TCO,
try this link
http://66.102.9.104/search?q=cache:wntz5IzG0cYJ:www.sussex.ac.uk/Units/economics/qm1/lectures/auto.doc+autocorrelation+time+OR+series+OR+econometrics+OR+simple+%22problem+of+autocorrelation+%22&hl=en
John S, did you see Benestad’s article at realclimate applying iid to climate series? His articles from which he draws do the same thing. It’s hard to comment on stuff like this without being acid.
Steve,
I saw the article. My take is that they reached a solid but completely unremarkable conclusion – you can not treat temperature as a random draw from an iid distribution. He doesn’t account for any process that might drive temperature or lead to even cyclical variability (or, alternatively, they conclude that there is some process leading to fluctuations in temperature). That is, he concludes confidently (and I agree with him) that T(t) = e(t) is not a correct model for temperature (where e(t) represents draws from an iid distribution). But the universe of possibilities outside that is still rather large so it doesn’t get us a long way.
Is the issue of run order, the same as the idea of autocorrelation? Should people doing manufacturing analysis use DW? Do they?
boompity
Steve, could you please send me a [blank or not] email? 🙂
Best, VS
Ah, forget it, found your e-mail address already 🙂