What is the standard deviation (variance) of an autocorrelated series? Sounds like an easy question, but it isn’t. This issue turns out to affect the spurious regression problem, so I’m posting up a short note on the problem. These issues are well-known in econometrics, where they have led to “heteroskedastic-autocorrelation consistent” estimators. There’s an interesting discussion in Percival [1993], who’s involved in climate, who says:
the effect of not knowning the process mean can be rather large: whereas s is an unbiased estimator of à?à’ when µ is known, the commonly used s can severely underestimate à?à’ when µ is unknown.
Percival gives an example where small-sample methods are biased by a factor of 100!
The caption to Figure 2 of Percival [1993] reports that the variance of an autoregressive process with à?à=0.997 is 166.9. This can be derived as follows.
An autoregressive process is defined by:
(1) y[t] = à?à * y[t-1]+ àŽàⳠ[t], where àŽàⳠis the error-generating process (“innovations”) with mean 0, assumed independent with standrd deviation à?à’[àŽàⴝ.
Then the value at time t can be represented in terms of the innovations as follows:
(2) y[t] = àŽà⡠(à?à^j ) * àŽàⴛt-j], where j=0:à⣃ ’ à
⼍
The variance of y[t] is generated by the inner product as follows:
(3) var (y[t]) = < àŽà⡠(à?à^j ) * àŽàⴛt-j], àŽà⡠(à?à^j ) * àŽàⴛt-j]>
= àŽà⡠(à?à^2j) < àŽàⴛt-j], àŽàⴛt-j]>
= à?à’[àŽàⴝ^2 * àŽà⡠(à?à^2j)
= à?à’[e]^2/ (1- à?à^2)
Percival illustrates the very serious finite sample problems of variance estimation in autoregressive processes when you don’t know the true mean as follows in connection with his Figure 2 (s being the estimate of the standard deviation and à?à’ being the true standard deviation of the process (notation slightly different for typology reasons):
For sample size N = 10, we have E{sà’¹”¬➲/à?à’^2} = 0.01; i.e., the sample variance is biased by a factor of 100. The two thin vertical lines enclose one such sample of 10 points, for which s^2= 0.7 (well below à?à’^2 = 166.9). If we sweep across the time series plotted above and compute s^2 for all possible 991 subseries of size 10, we find that s^2 varies from 0.1 to 17.1 and has an average value of 1.8 (again well below the true variance). On the other hand, if we compute s^2 based upon the known process mean of zero, we find that s^2 varies from 0.6 to 764.0 and has an average value of 184.1, which is rather close to à?à’^2= 166.9.
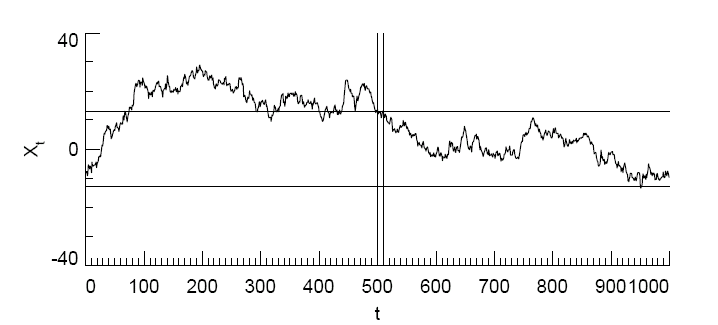
Percival [1993] Figure 2. The jagged curve shows a portion of size 1000 of a realization from the stationary zero mean AR(1) process X[t] = 0.997X[tà⣃ ’ ”¬’¢1] + àŽàⴛt], where àŽàⴛt] is a white noise process with zero mean and unit variance. The variance of X[t] is à?à’^2 = 166.9, and the two thin horizontal lines mark ±à?à’ = ±12.9.
Percival reports a short theorem stating that the situation can get arbitrarily bad, as follows:
For every sample size N à⣃¢’¬°à⣠1 and every àŽàⳠ> 0, there exists a stationary process such that E{sà’¹”¬➲/à?à’^2} < àŽàⳠ.
I’m going to come back to these issues when I discuss why “scaling” autoregressive processes in a short calibration period (as recently argued by Hockey Team members Briffa and Esper) does not avoid the need to examine statistical issues and is thereby not a magic bullet. You can also picture why a certain amount of care needs to be taken if you are standardizing by dividing by calibration-period standard deviation or even calculating correlations (which include standard deviation terms). Simply transposing techniques from independent samples can be a dangerous recipe.
Reference:
D. B. Percival (1993), `Three Curious Properties of the Sample Variance and Autocovariance for Stationary Processes with Unknown Mean,’ The American Statistician, 47, no. 4, pp. 274-6. http://faculty.washington.edu/dbp/PDFFILES/three-curiosities.pdf





3 Comments
Typo: The estimator symbols, s^’0 and s^0, got left out of your first Percival quote.
I always become suspicious when complex statistical techniques are needed to extract “facts” from data that on first examination are rather uniformative – almost as if the a theory was proposed and the data then massaged to support the theory.
As for your initial question, I just wonder whether these issues arise because statistics are being extended to problems that can’t be subject to this type of analysis in the first place.
Your forthcoming explanation should be interesting.
damn, just read your bio. You are a stud. First in class in pure maths. Squash world champion. Chavez coup experiencer. Sheesh.