Anders Moberg sent a courteous response on the Lauritzen issue mentioned in More Moberg and Brandon Whitcher sent some comments on end effects in waveslim. Update Sep 7-8: I’ve been blown off totally so far by Moberg and Lauritzen in trying to obtain the digital data underlying the discrepant graphs.
Moberg said that he used a pers. comm. version of a series from Lauritzen which ended in 1938. He agreed that Figure 11 of the Lauritzen article ended in the 19th century. He referred me to Lauritzen for particulars on the differing versions (which I’ve done.) He also referred me to Lauritzen for the differing version. I think that he should provide the version that he used and have re-submitted this request. So the issue is not between differing digitizations, but between different versions. It will be interesting to see what the explanation is and how robust the results are to differing versions of this series.
I also asked Moberg about the identifications of two bristlecone series used in Moberg et al [2005], identified as Methuselah Walk and White Mountain Master and whether these were ca535 and ca506 respsectively and to confirm that Indian Garden was nv515. Since ca535 and ca506 are both from the same site (ca506 is also Methesulah Walk, but is from an earlier study ending in 1962), I asked why he used the same site twice (acknowledging that this wouldn’t affect results very much). Moberg said that he was aware that the series were from the same site, but thought that the studies used different trees.
I also asked for a digital version of the Indigirka series, which I’ve been unable to locate. Moberg explained that somebody he knew got it from someone else and that he can’t give me a copy. He referred me to the guy who gave him the series. That’s one of the problems with paleoclimate. You try to work through a study. Then some of the data is tied up, so you always end up picking up and putting down files. AGU has a data citation policy (which they don’t enforce in paleocliamte) discouraging the use of grey versions and not permitting it to be "cited". Authros get around this by citing the print versions. Then you get into situations like Lauritzen where the cited print version differs from the grey version. This happens all the time with Mann and Jones. I know most of the different versions now (and to check). Anyway I’ve written away for the Indigirka series and, if I get nowhere with anybody, will write to Nature. My current prediction: 6 months from now, I will not have the Indigirka series from anybody.
Lastly, Brandon Whitcher, the author of the waveslim package and a wavelet expert, wrote back about end effects. Whitcher said that one of the assumptions of wavelet (and Fourier) analysis was that the underlying process was periodic and that the waveslim package had an option in which the end data could be reflected. In a follow-up comment, Greg F. pointed out that Moberg had padded his series with 350 years of data equal to the mean of the last 50 years of data (front and back). Mats Holmstrom pointed out that Moberg’s wavelet method is nothing more than a lowpass filter, a point with which I obviously agree. Thus, one can check alternative methods which may be less problematic with end effects. Intuitively, if one is trying to draw conclusions about the relationship of the closing values of a series to values elsewhere, a methodology which is tricky on end effects would seem like a poor choice.
I have some other work that I have to do for a couple of days, but I’ve found the feedback for this, shall we say, online seminar on Moberg to be very helpful.
Update (10.48 EDT): More updates from your on-the-beat reporter. Moberg says that he doesn’t have either of the two series (Inidigirka or Lauritzen) requested, that I should ask the Russian coauthors, who do have the data. I asked him to ask them for me, which he agreed to do.
Lauritzen said that, according to his recollection, Figure 11 showed the 5-year running mean, while he sent the full original dataset to Moberg. I wrote back to Lauritzen asking for the data as provided to Moberg. He has now refused saying "These are unpublished data, and they come with co-authorship." I would have thought that Lauritzen et al [1999] and/or Moberg et al [2005] constituted publication, but, hey… [snide comment self-deleted]. What a goofy system these guys have. Now I’m going to have grind Nature about this. It’s not as though I’m just looking for non-archived stuff – I was trying to see how Moberg worked and got stuck at this point.
Also I don’t think that this explains it. Now I’m wondering about what the differences between the two datasets really is – it looks to me like the step-version in Lauritzen Figure 11 corresponds to the Nature version.
First, Lauritzen Figure 10 has a legend denoting a series as the 5-year running mean. I’ve shown below as Figure 1, a blown-up excerpt from this Figure showing the Figure in question.
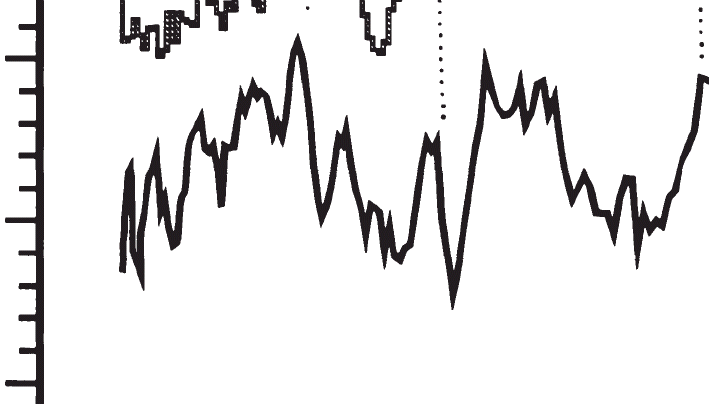
Figure 1. Blown Up Excerpt from Lauritzen et al 1999 Figure 10, labelled 5 year running mean.
Now if we look at Lauritzen Figure 11, we see two versions – the line version visually corresponds to the 5-year running mean version of Lauritzen Figure 10, if you allow for scale dilations. So we can identify the linear version of Figure 11 as the 5-year running mean (even though there is no legend in Figure 11 explicitly saying this.)
Figure 2. Lauritzen Figure 11. The linear version is the 5-year running mean. The step-version is a more "original" version.
Now let’s look at the Nature representation of this series, which I’ve flipped and dilated to more or less match the Lauritzen figures. It sure looks to me like the Nature series matches the step-version of Lauritzen Figure 11, if you do line connections instead of steps. (I’ve tweaked the graphics in my editor so that everything is lined up and this is clearer than online where I’ve not figured out how to line up and tweak the picture sizes. I may resample the graphics a little later.)
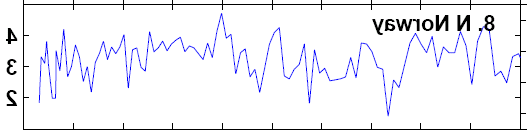
Figure 3. Flipped version from Moberg et al [Nature 2005] Supplementary Figure 1.
That said, I don’t see how 5-year running mean answer from Lauritzen is responsive to the problem of the 1938 end of the Moberg data set.





10 Comments
That is an incorrect citation. (Use of the pers comm series versus printed one). It’s two different data sets. Maybe even two completely different studies.
I’m not sure if this is being picayune (someone who is an editor of a refereed journal can weigh in), but it may be worthy of a correction.
I have to give Moberg credit for the courteous response. (That is how everyone should be regardless of if their work is being picked apart…unfortunately many practicing scientists are not.)
If we in the mining business offered these explanations for missing data……………
Steve,
It seems to me that the proxy data effectively are individual signal sources (temperature, CO2, etc.) mixing together in various sensors. There is a method called ICA which is very good at separation in cases such as these. ICA uses PCA as a start. I don’t think anyone in paleoclimatology has used this technique although it’s been around for some time and seems to be most applicable. ICA doesn’t seem to have the same problems as wavelet transforms albeit it has its own primarily in the assumption that the signal sources are independent, which I believe they may be in this case.
There is an R version of this method in package fastICA. Since no one seems to have used this on tree ring data, applying this would be wandering a bit from audit to original work. Are you aware of anyone who has done this?
This post may be somewhat OT here. I tried to just e-mail you but when I clicked on the “contact us” under “pages” I got what appeared to be a random page.
Dav, Peterson did some work applying factor analysis to ITRDB data. He found that the bristlecones were a distinct group. PCA is regarded by ecologists as a data exploration techique; even biased PCA can be used for data exploration – for example, if you want to mine for hockeysticks, Mann’s biased PCA is useful for that. But once you’ve noticed the problem with the bristlecones, you can’t just ignore it.
The problem is ultimately whether there is useful information about temperature in the ITRDB tree ring dataset which can be extracted through unsupervised techniques. The average correlation to gridcell temperature of the 70 sites in the AD1400 network is minus 0.08; they have an average correlation to precipitation of 0.29 and the bristlecones have correlations to CO2 levels of over 0.4.
For all of Mann’s savaging of the handling of precipitation-related proxies in Soon and Baliunas, it’s pretty ironic that his own reconstruction, to the extent that it reconstructs anything, probably reconstructs southwestern US precipitation.
Steve
RE 5
May statistical knowledge is pretty basic. But what do you mean by “The average correlation” The average of a perfect positive and a perfect negative correlation is zero. So an average of 0.08 could mean all of the correlations were very good, but some were positive and some negative, therefore cancelling each other, I am sure that is not what you mean.
Paul, I’ll post up a histogram some time soon. By any way of looking at it, the relationships to temperature of the “proxies” were poor.
If you have set the directionality “as expected”, then averaging positive and negative correlation is a bad thing. IOW if half of the time, there is a trend of smaller ring size with inc temp and half of larger ring size with inc temp. That sort of response means that you shouldn’t assume (for all trees) that inc ring size scales linearly with temp (for reconstruction).
Of course, you might have some super fancy shmancy multiple regression where you show what types of trees give what effect or how to remove effects of rain or other confounding variables (but need some extra input data or features to allow that.) But then you need to apply that same transform on the historical data.
0.08 seems low indeed but I’m cautioned by a study that I did for amusement once. I computed the correlation between the speeds of various race and the final positions. I got a correlation of 0.05. This seemed patently absurd and in fact it was. The problem was that I should have at least used the deltas from the maximum speed of each race instead of the actual speeds. The correlation then jumped to 0.97.
The moral is: a low correlation coefficient doesn’t always mean little correlation. It may instead mean that more work may be required. A small correlation of temperature to growth seems unlikely. How then would one account for seasonal variations? I’m not saying any error or mishandling occurred but the result seems to run contrary to expectation. That makes it interesting. 🙂
Dav, the majority of series in the AD1500 North American tree ring network are more closely related to precipitation than to temperature. Hence the higher mean correlation of these sites to precipitation than to temperature. Many of the sites are in the arid southwest. Bristlecones compete with sagebrush for goodness sake – there’s a really nice picture in an old botanical publication where you can see a geological structure between dolomites and sandstone by the vegetation – sagebrush on the sandstone, bristlecones on the dolomite, a nice vertical divide. The mean correlation to gridcell temperature of the bristlecones is 0.01. And yet these are supposed be the key arbiters of climate history. Come on…