I never quite got to presenting an attempt to replicate Moberg before. Here’s a try. I’m still a long way off from being able to replicate his results. It is so infuriating to have to try to do such an amount of detective work prior to even atempting any analysis. I presume that has been Hockey Team strategy all along and, only the most intrepid and persistent, can even come close. I’ve provided a collation of Moberg’s data here together with a script showing my present emulation. The script is not very pretty and I’ll try to tidy it at some point when I return to this. I’ve also done a comparison of the archived Moberg reconstruction to actual CRU data with interesting results.
You may recall that I was on my way to trying to replicate Moberg when I ran into lack of data problems with a couple of series. Moberg wouldn’t provide the data – there also seem to be some question about the Lauritzen verion used. Rather than stew about it, I filed a Materials Complaint with Nature and to their credit, Nature has dealt with it. It seems that Moberg used data without permission, hence the problem. He’s going to have to publish a Corrigendum, after which he is supposedly going to provide the data. In the mean time, I’ve plodded along trying to replicate his results with the data versions that I have (although the discrepancies in the Lauritzen versions may be material.) Once again, it’s ridiculous that there’s no source code, making it a bit of a guessing game. Here are some preliminary results.
Figure 1 shows my emulation of Moberg as compared with the archived version, then the residuals. In this case, I’ve done the emulation using a discrete wavelet transform (DWT) rather than a continuous wavelet transform (CWT) which Moberg used, since (1) I’m used to working with the DWT; (2) I figure that any valid result should not be sensitive to the difference between the DWT and CWT; (3) Moberg did not justify a use of CWT in preference to DWT. This might account for the differences but you never know. I’ve posted up my code for this reconstruction. Any bright ideas would be welcome. The maximum difference between my emulation and Moberg’s archived version is 1.15 and the 95% confidence interval has a width of 1.18. By contrast, Moberg stated that the jack-knife confidence interval for this reconstruction was 0.23 standardized units. His confidence interval calculation is really hokey.
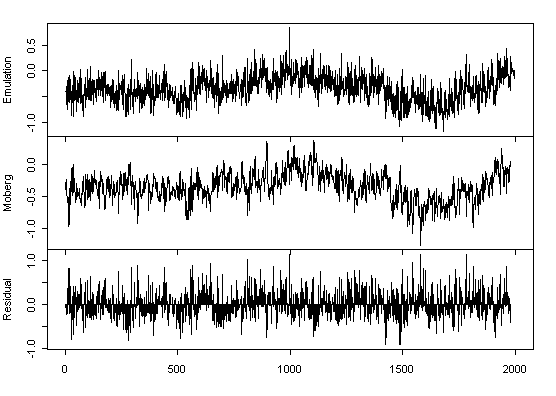
Figure 1. Top -emulation of Moberg; middle – archived Moberg; bottom – residuals.
Next is a figure showing the Moberg reconstruction against the CRU series (top panel) and residuals (bottom panel). Moberg is a coauthor of one of the Jones’ CRU temperature collations (Moberg and Jones [2003].) The red lines in the bottom panel show the supposed "confidence intervals" of Moberg (the CI of the reconstruction in standardized units scaled to temperature using Moberg’s factor), which do not appear to bear any relationship whatever to residuals to actual CRU data. Moberg’s SI includes a description of how the confidence intervals are calculated. I wish that – just for once – the Hockey Team would involve an actual statistician in their calculation of confidence intervals rather than their typical concoctions. I’ll spend a little time on this, but, unfortunately, it always takes a while to decode Hockey Team shenanigans.
Below I’ve done a simple plot of the archived Moberg reconstruction against the actual CRU dataset being modeled. You’d think that Moberg and his crowd would have done something as simple as plotting the residuals against the confidence interval. Look at the autocorrelation of the residuals.

Figure 2: top – Moberg reconstruction vs CRU; bottom; residuals with "confidence intervals" in red.
Moberg does not present elementary statistics on the residuals. For example, the Durbin-Watson statistic is 0.6 – a value in the spurious regression range. It is unacceptable for the hockey Team to simply ignore this. See my discussion of Granger and Newbold [1974] who said over 30 years ago:
It is very common to see reported in applied econometric literature time series regression equations with an apparently high degree of fit, as measured by the coefficient of multiple correlation R2 or the corrected coefficient R2, but with an extremely low value for the Durbin-Watson statistic. We find it very curious that whereas virtually every textbook on econometric methodology contains explicit warnings of the dangers of autocorrelated errors, this phenomenon crops up so frequently in well-respected applied work. Numerous examples could be cited, but doubtless the reader has met sufficient cases to accept our point. It would, for example, be easy to quote published equations for which R2 = 0.997 and the Durbin-Watson statistic (d) is 0.53.
I’ve re-read Moberg’s discussion of Confidence Intervals and it makes me ill. And to think that Dano slags me as an "amateur".
Update: Doug Hoyt inquired as to the residuals from my emulation of Moberg. Here’s something curious: my emulation has better performance than Moberg’s original result in the various statistics that I’ve examined so far (and I’ve not been exhaustive). The igure below shows the same as Figure 2 for my emulation.

Figure 2: top – Emulation of Moberg reconstruction vs CRU; bottom; residuals with "confidence intervals" in red.
The correlation of the emulation to CRU is 0.42 ( Moberg – 0.30), and the match is obviously better if you compare the two graphs. The Durbin-Watson is still in the red zone at 1.36 (below 1.5 is in the red zone), but is less bad than the DW for the archived version which is a ghastly 0.6. So riddle me this: why is Moberg’s reconstruction using a CWT "right" as opposed to a reconstruction using a DWT?





25 Comments
Re: being an “amateur”.
I think that doing the work purely because of your interest in the subject makes “amateur” quite a complimentary term in your case.
Re: Moberg Corrigendum
If it’s just a question of data attribution, what will the Corrigendum contain? Just a correct attribution for the data? Or do you expect a correction of a scientific nature?
From what I understand Moberg isn’t a “hockey team member”. He’s very neutral in the debate about temperature reconstructions. Went to a paleo-climate conference here in Sweden a few weeks ago where he talked about modelling and reconstructing temperature varibility for the past millenium. My impression was that he didn’t want to point out anthropogenic emissions as the culprit in present day climate. He also questioned the validity of MBH98 since both GCM-studies (if they are trustworthy is another question) and other temperature reconstructions show much more variability.
Re #2, rather too subtle a distinction for most contributors here to get it I think Daniel. ‘He does recons therefore he is a member of the hockey stick team and a bad man’ is the simplistic line being pedalled here.
Steve,
What happens if Moberg fails to get permission for the datasets he used?
1. You will need to do the CWT to take it anywhere. (Is it that hard?)
2. What you have now is publishable. You would need to be upfront about the lack of all the data and such. But it’s publishable as is. (and what’s the likelihood that adding a couple series will drive the residuals down much? Unlikely, no?)
3. I still worry about your publishing strategy. You seem to think that everything needs to be perfect. Or that what you do here is some form of publication. You could publish the above and it would be “imperfect” in that you lack the exact Moberg method (not adeqautely provided in text and code not provided) and the exact data. However, if you are upfront about it, who cares. If the best that they can do is come back with “you couldn’t play the guessing game”, then that points something out to the field also.
Looking at the residuals, only 36/103 measurements fall within the confidence limits. What does this mean?
Actually, John, I have a question here. Earlier Steve says "Moberg stated that the jack-knife confidence interval for this reconstruction was 0.23 standardized units." But this is clearly not the confidence interval in the 2nd graph, unless there’s been some transformation or the vertical scale isn’t ‘standardized units. So what is being shown?
Steve: The Moberg confidence interval was stated for the graph in standardized units. The scaling factor into the temperature reconstruction is 0.59 so I multiplied 0.23 by 0.59. I presume that the confidence interval refers to the entire interval and not the half-interval so the 0.23 *0.59 is distributed half above the line and half below the line.
What do the residuals look like for the “Moberg Emulation” and CRU? Are they red noise also?
What does the “jackknife” mean?
No article could be published in an economics journal with a DW of 0.6. This has been true for over 25 years, as I can personally attest. Steve, you should have something prominently on this website that states what questionable elements of the hockey team’s “reconstructions” are still unanswered. One is the bristlecones; one is the autocorrelation problem; one is the lack of “cross-validation” to temperature records. What have I left out? Anyway, as long as these are unanswered, many will consider the hockey team’s work as inconclusive.
On another note, the defenders of IPCC and AGW are backing away from the climate reconstructions and saying that they are not necessary because we have so much evidence of the “effects” of GW today. But if it is possible that we are only returning to an “average” temperature from the little ice age, then the only way to prove AGW is by doing climate reconstructions. You cannot prove AGW by pointing to melting glaciers unless you show that these effects are unprecedented.
John, Here’s a quote from Granger and Newbold [1974] which I posted up previously:
It’s frustrating to see the Hockey Team ignore elementary autocorrelation considerations. I’m going to add this back to the head post.
Re #7: Doug: I looked at the residuals for my emulation as compared with Moberg’s archived version. Here’s something amusing: it looks like my emulation reproduces the temperature history much better than Moberg’s original !?! The correlation improves from 0.3 to 0.42; the Durbin-Watson statistic improves from a ghastly 0.6 to a still-bad 1.3, but not as horrendous.
I have one major difference in data: I used digitized data for the Lauritzen series so that the cold end point is in the 1860s, rather than the 1930s as in Moberg’s chart – which looks like a goof somewhere: hence the fuss about providing data leading to the Materials Complaint.
I guess this means that I don’t need to worry about trying to replicate the CWT version, since I’ve already out-performed Moberg. I guess that I can focus a bit on the impact of the non-normal and peculiar series e.g. the coldwater diatoms of Oman, by which upwelling cold water is the essential to Moberg’s conclusion of a warm 20th century relative to the MWP. I’m closer to making this comparison than I thought.
Re #19: the “jack-knife” is a calculation of results leaving out one proxy. The citation is Efron and I haven’t checked to see exactly what Efron says. Moberg says that he assumes that the series are i.i.d., when of course they aren’t. Intuitively it seems to me that if you’re taking an average of 11 red noise series and then calculate the results on a leave-one out basis, you’re going to get a spread not dissimilar to the spreads observed in Moberg.
What repulsed me in his discussion of confidence intervals was this: he started with an acknowledgement of autocorrelation, then determined that allowing for autocorrelation meant that there were the equivalent of only 6-8 independent observations in the calibraiton period and this resulted in a very wide confidence interval – such that the reconstruction was useless. So he ignored these results and did the calculation in a way unknown to statistical science outside the locker-room of the Hockey Team. I can’t quite figure out how his calculation of confidence intervals worked, but, when I do, I’ll probably post on it.
Why can’t you get more help from the regular statistician or econostatistician community to repudiate the Team’s methods? Would mean something to have the academic imprimateur involved…
Mr. McIntyre often compares the lack of data backup for climate articles with the field of business and finance, in which a propspectus discloses all relevant information as a matter of government regulation. This brings to mind another arena in which all backup information must be disclosed, and that is the arena of litigation. I don’t know if it will ever come to this, but if there were to be a lawsuit against a member of the hockey team based on some of their results, the discovery process would require them to disgorge all of their data and to demonstrate at time of deposition exactly how they got the results they claim.
Interesting to think about. The Barton committee is being compared to the Spanish Inquisition and the McCarthy hearings. But if even a minor lawsuit were to involve the hockey team’s results, much more disclosure than Barton requested would be demanded.
Re: 15
Mumm,
Excellent point. I made a similar point on RC about the discovery process. If articles by Mann, Jones, et al are referenced by either the defence or the plaintiffs as part of the basis for a lawsuit, the discovery process will be far more persuasive and invasive than any of us could be requesting their data.
My comment on RC was muted, so that it would make it on to the site. It appears that any mention of missing data diverts your posting attempt to RC purgatory. This goes against the RC mantra is that all the data has always been available.
Re # 9 and # 13
To rephrase Steve McIntyre (if he will forgive me) the jackknife is the statistical technique of resampling by running the estimate on subsamples of N-q from a sample of N then averaging the results. It was introduce separately by Quenoulle (sp) and John Tukey 40-50 years ago. It was made popular in Mosteller and Tukey’s 1977 classic “Exploratory Data Analysis,” which is still a good book to read on practical statistics.
A similar technique called “bootstrapping” takes a random subsamples (usually of a given size) from the sample and runs the estimate on each subsample and then averages. Many econometric packages give code (scripts) for automating a bookstrap regression or similar procedures.
Bradley Efron’s (who Steve mentioned) little paperback book “The Jackknife, the Bookstrap and Other Resampling Plans” from the late ’70s or early 80s is clean and elegant introduction by a master.
A question: why does Moberg feel it was necessary to use a jackknife (presumably on the variance?) with his data? The jackknife is not normally used in non-exploratory analysis unless one suspected data irregularities. And reason for using it is probably as interesting as the results. I don’t have the article — did he show the standard confidence interval in comparison?
Martin – Moberg’s SI is online here and includes the jacknife discussion. If you look at the right frame here under multiproxy pdf and follow that link, I’ve posted up the Moberg article for people to look at.
He certainly didn’t identify some obvious data irregulaties. Series 1 and 11 were not calibrated to temperature, are wildly non-normal and are the keys to keeping 20th century temperatures on a par with MWP temperatures. One of the most important Moberg proxies (and very non-normal) is the percentage of coldwater diatoms, an increased amount of cold sea water offshore Oman being held to be correlated with global warming and indeed one of the most essential proxies.
I think that you;ll be pretty amazed at the analysis of confidence intervals in the above URL. I’ll be interested in your thoughts.
Re # 19
Danke for URL. Will read with my turkey (and think of the late great Tukey).
stay awake. I order you
Dear Steve,
it must be a pain to go through the data used by authors who don’t quite co-operate, regardless of their other attitudes.
But I also think that Moberg is not a member of the hockey team. He is just a climate scientist, so it just happens that he had to co-author with Mann, Jones, and others. But that does not mean that his approaches and conclusions are equal.
Incidentally, the Moberg graph itself does not really seem to show any visible anthropogenic influence, I think.
Happy Thanksgiving
Lubos
re:2
Moberg used the Keigwin’96 (Sargasso) proxy; he’s banned from the HT!
Re#13 “Re #19: the “jack-knife” is a calculation of results leaving out one proxy. The citation is Efron and I haven’t checked to see exactly what Efron says. Moberg says that he assumes that the series are i.i.d., when of course they aren’t. Intuitively it seems to me that if you’re taking an average of 11 red noise series and then calculate the results on a leave-one out basis,…”
What strikes me is that, going by past modus operandi. The Hockey Team could leave out any set apart from the Bristlecone, and still get the results they wanted.
Now Moberg says he can leave out any one proxy and still be robust.
Looking at his graphs More on Moburg it appears that numbers 1 and 11 are very similar (HockeyStickish), and just leaving out one of them would still leave the other, to perform the same task as the Bristlecones did for Mann et al.
Therefor a good test would be to see if the results were robust leaving out any 2 Proxies, but particularly No’s 1 and 11.
How is averaging subsampled populations expected to differ from just looking at all the data straight up? I mean what is the tendancy of this? To reduce outliers (extreme values)? And if we do this, how do we know it’s proper?