"Standardization" and averaging are operations that are done time after time in paleoclimate studies without much discussion of the underlying distributions. If one browses through recent statistical literature on "robust statistics", one finds much sophisticated analysis of how to handle outliers. The term "robust" is commonly used in paleoclimate, but the term as used in paleoclimate is merely a term of self-approval rather than an application of methods known to Hampel or Huber, to mention two prominent practitioners of robust statistics.
The multiproxy studies covering the MWP are all small-sample populations (4-14 series). Only MBH98, which has other problems, and Briffa et al MXD 2001, have large populations and these both only go back to 1400. Thus robustness becomes a real issue. I’ve previously noted the fantastic non-normality of key Moberg series. I’ve been reading articles on robust statistics from time and time and, in doing so, ran across Tukey 1960 on contaminated distributions. Tukey was one of the pre-eminent statisticians of the last half-century. Tukey 1960 is relatively accessibly written and is still stimulating today.
Tukey interspersed his article with a series of questions, inviting the readers to think about them and then turn the page for the answer. Pretend to do the same.
1. Given two normal populations with the same mean, one having three times the standard deviation of the other, it is proposed to prepare a sequence of mixed populations by adding varying small amounts of the wider normal population to the narrower one, It is well known that in large sample the relative efficiency as a measurement of the scale of the mean deviation as compared with the standard deviation is 88% when the underlying population is normal. As specific amounts of the wider normal population are added to the narrower one, thus defining new classes of distributions of fixed shape, will the relative efficiency for scaling of the mean deviation compared to the standard deviation increase or decrease or stay the same?
The relative increase of the mean deviation will increase.
2. Will the relative efficiency ever reach 100%. In other words will the mean deviation be as good a measure of scale as the standard deviation for any of the contaminated populations obtained by mixing tow normal populations which have the same mean but whose standard deviations are in the ratio 3:1? Never, just reach or reach and go beyond?
For some contaminated populations, the mean deviation will be a better estimate of scale, in large samples, than the standard deviation.
3. What fraction (between 0 and 1) of the wider normal population must be added to the narrower one for the mean deviation to be as good a large-sample measure of scale as the standard deviation?
When just less than 0.008 of the mixed population comes from the wider normal population, the mean deviation has the same large sample precision as the measure of scale as the standard deviation has. (Note: Do not judge an answer which deviates widely from 0.008 harshly. Many distinguished and experienced statisticians have given answers between 0.15 and 0.25).
4. Can I expect to know whether or not the population from which I draw large samples deviate from normality as much as say a contaminated population containing 0.008, 0.02 or 0.05 of the wider normal? If I cannot, what should I do about estimating the scale of an actual population from a large sample?
Tukey’s recommendations should cause great concern to paleoclimatologists accustomed to substracting the mean and dividing by the standard deviation of a calibration period.
“Clearly the second moment which corresponds to the standard deviation is the least safe of all. Its use can only be recommended when àŽàⱠis far less than 0.01 and we are rarely sure of this…
Probably the most promising of the alternatives shown, if substantial àŽàⱠis to be feared, are (i) the mean of exp(-x^2/4) and if àŽàⱠis quite likely to be <0.07 say (ii) the 2%-truncated variance. …
It is hard to imagine a situation where contamination would appear and yet appear in such small amounts as to make the standard deviation either as good as the mean deviation or nearly as good as the 2% truncated standard deviation, at least insofar as variability of scaling goes…
Because of practical questions of computing [this was 1960], we may find averaging exp(-x^2/4) uncomfortable. If so, then the most reasonable solutions for this problem are:
1) the truncated variance and its square root the truncated standard deviation with 2% to 5% of the observations deleted from each tail.
2) the mean deviation.
Since the variance (and its square root the standard deviation) cannot be more than 11% better than the 2-% truncated variance, while it can be 140% worse (for àŽàⱽ0.05), the variance will never be a safe choice.
One of Tukey’s conclusions: Nearly imperceptible non-normalities may make conventional relative efficiencies of estimates of location of scale and location entirely useless…If contamination is a real possibility (and when is it not?), neither the mean nor variance is likely to be a wisely chosen basis for making estimates from a large sample.
Now look at the qqnorm-distributions of (say) Moberg. Here we are far from "nearly imperceptible non-normalities". We have gross non-normality.
A truncated-mean applied to the MBH98 roster would have "thrown out" the MBH98 PC1 from the fifteenth century roster together with one series on the other side and yielded an entirely different result (with a high 15th century.)
In the hands of later writers (e.g. Hampel), one of the objectives of analysis was to identify outliers and then determine on scientific grounds whether they should be included. This would lead to the type of analysis carried out in MM05b, where we considered specialist opinion on the validity of bristlecones as a proxy. The only effort to reclaim bristlecones has come from Rob Wilson in a posting to climateaudit; there is none in the peer-reviewed literature. But regardless, it’s pretty evident that Tukey would have had no truck with a result which could not be replicated with a truncated mean.
Update: Here are qqnorm plots for Moberg previously posted up here
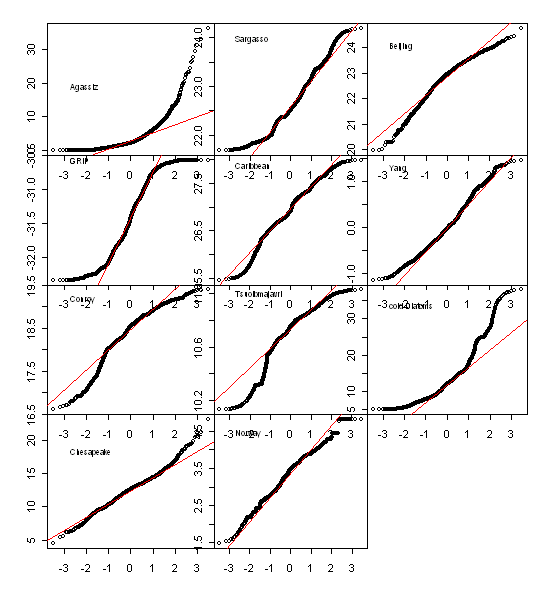
Moberg has a knife-edge difference between MWP and modern levels, precariously balanced so that they “show a profit”. The most important contributors to modern-MWP differences are the Arabian sea diatoms, Agassiz melt and the Yang China composite (imprinted by Thompson’s Dunde series). The first and third are arguably precipitation proxies. The first and second are not calibrated to temperature but raw non-normal series are used. It is inconceivable that any attention was paid here as to compliance with Nature’s statistical policies.
Reference:
Tukey, J. 1960. A survey of sampling from contaminated distributions in I. Olkin et al (eds) Contributions to Probability and Statistics.





63 Comments
1. what is relative efficiency?
2. Is it “as” or “of”?
3. what is the “mean deviation”?
4. (non quoted, italicized): I think you mean relative effeciency not relative increase.
q3 is quite a zinger! Is there an “introduction to robust statistics”-type book that you would recommend for folks not yet comfortable diving into the original papers?
Actualy Tukey 1960 is surprisingly readable. Frank Hampel has a couple of readable papers if you google frank hampel robust statistics. I’ll try to remember to insert URLs.
http://e-collection.ethbib.ethz.ch/show?type=incoll&nr=105'ˆ'€š=text
http://e-collection.ethbib.ethz.ch/show?type=incoll&nr=118
http://e-collection.ethbib.ethz.ch/show?type=incoll&nr=106
What are multiproxy studies if they are not continuously contaminated sampling of the behavior of trees to their local environments?
There’s a gap in the discussion. It’s not JUST my lack of knowledge although that a big part of it. Some of it is Steve citing things and then not spelling them out to implications. I think this will create an issue even with sophisticated stats types. as stats is complicated and as terminology needs to be precise.
Re#1 TCO,
“Efficiency” (in statistical estimation) is the ratio of the minimum achievable variance [footnote 1] of the estimator to the variance of the estimator. Note a statistical estimator (e.g. sample mean, sample standard deviation, regression coefficient) is itself a random variable, and variance in this context is the expected value of the square of that random variable minus its mean. [footnote 2] Also note that this comparison is for unbiased estimators.
“Relative efficiency” is the ratio of variances of two estimators (with the smaller variance in the numerator so “efficiency” can be expressed on a 0-100% scale).
The parameter of concern in the quoted section of Tukey’s article appears to the standard deviation of a random variable Z = (1-U)*X1+U*X2, where X1 is a normal with a variance of V1 and X2 is a normal with a variance of 9*V1 and U is a Bernoulli trial with some low probability of success (Tukey gives a 0.008 probability as an example). Thus the estimator in question is an estimate of the standard deviation of Z, the contaminated variable. The mean deviation is average of the absolute value of the deviations from the sample mean. [footnote 3]
And yes, “relative increase” appears to mean “relative efficiency” since the case cited (the 0.8% contamination) is about the point at which the mean deviation equals the efficiency of the sample standard deviation in estimating the population standard deviation of the contaminated sample.
Finally and with regard to terminology, “robust statistics” is often used as a coverall term for two types of approaches for dealing with the real life deviation from the theoretical model. The first is the more formal use of “robust” to refer to those kinds of statistics that better handle deviations in the assumptions, e.g. non-normal distributions versus normal distribution. The second — called “resistant estimators” — deal with problems of the influence of outliers on the statistical inference. This distinction does not mean that the actual estimators used are different, just that the types of problems for which the robust or resistant estimators are designed to handle have been distinguished.
footnote 1: If you want to find more about the minimum achievable variance of an estimator, look up the Cramer-Rao Inequality (or Rao-Cramer Inequality as I learned it) in a statistics text. With a normal (Gaussian) distribution, the sample variance has an efficiency of (N-1)/N and, hence, is essentially efficient for large N.
footnote 2: Note, not all random variables have a finite variance, e.g. the Cauchy distribution. The kind of estimators associated with climate reconstruction look sufficiently messy (algebraically complicated) that the existence of the expected values of the estimator and its square may not be a trivial matter even assuming underlying normality of the series from which the estimator was composed.
footnote 3: The mean deviation will underestimate the population standard deviation by about 20%. Thus, the unbiased estimator based on the mean deviation is about 1.254 * the mean deviation. Also note that today the median of the absolute deviations from the median (times a factor of 1.483) is a more popular “resistant” estimator of scale. This estimator is considerably less efficient in the Tukey example (38% versus 88%) but because it is based on the median, it resists the influence of outliers or misspecification of the model much more strongly.
Wow. That’s an awesome response, Martin. Makes me want to take down a stats textbook, relearn the stuff I’ve forgotten and learn the stuff that I don’t know. I figured that the discussion had to have something to do with what I remember being called the error of the mean estimate (or something like that) and evidently from your note that it did. Now, I will feel guilty until I read enough to justify your long, helpful comment. What would you recommend as a general text for someone of my ability level?
C’mon TCO, that’s leading with your chin. Here are some texts for someone of at your level. Just teasing.
I got the book from the library that has the Tukey article in it. There are some interesting things in there. The book is a 1960 compendium of papers in honor of Hotelling (I did not even know him as a statistician, just from his ice cream/beach game theory ideas from some MBA work). Some other intersting things in the book:
-article by Milton Freidman on very abstract math topic (not FREE TO CHOOSE).
-pre-word by Madow on Hotelling’s life
-pre-word by Neyman on Hotelling’s twin battles with higher mathematicians and with fields of application to get statistics onto a rigorous ground of research and study. The 1960 article points out that the second battle was not over (still isn’t now) and gives that as justification for printing 1940 article by Hotelling on How to Teach Statistics.
-the Hoteling teaching article: says that schools of engineering, medecine, etc. ought to have real statisticians teach the basic courses vice doing them in house. Talks about the dangers of home-grown (in the fields of application) new methods of statistics that are not proven in the mathematical sense and reviewed in the real theoretical stats world. But also says that it’s important for statisticians to have exposure to fields of applicagtion and that advances do come from looking at the problems of particular fields. Very accessible.
-bunch of other papers that are too hard for me.
I wonder what the dangers of not dividing by standard deviation are? I would think that they are considerable. One tree species or location might have signifacantly more sensitivity to temp deltas than another. By following Steve’s advocated policy of “not standardizing” we’ll have worse distortions then if we do standardize.
#10. TCO, this is getting annoying. I have no “policy” on what is an appropriate method to extract a temperature signal from a hodge-podge.
Tree ring chronologies are all “standardized” to common dimensionless units. The issue of dividing by the standard deviation is totally different than the issue of ensuring that the series are in common units. The “conventional” method of principal components – which is what Mann said he did – on series in common units is a covariance PC i.e. not dividiing by the standard deviation. This yields different results than using the correlation PC option. We stated this in our own articles and it continues to piss me off that later commenters proclaim this result as their own, not only not acknowledging our earlier statement to this effect, but reproaching us. PArticularly with Wahl and Ammann who intentionally did this, despite being informed of this and still refusing to change their comments.
The purpose of citing Rencher and Preisendorfer to this effect is that competent statisticians have taken the position that the use of a covariance matrix is the appropriate method.
But I don’t think either method is “right”. I don’t think that there is a “right” method. If someone wants to advocate and prove a method, then god bless them. If Huybers thinks that a correlation matrix can extract something from the Mann mess, then let him prove it. I’m not advocating the one way is better than another.
I haven’t proposed a reconstruction; I haven’t proposed a method of PC analysis. It’s just that plausible methods produce different results. Burger and Cubasch agre entirely with this point and they even considered precisely this issue as one of their flavors.
Steve, (forgive me) I didn’t for the first second think that you were advocating such a policy. I said what I did (tongue in cheek). I wanted to smoke you out and show that you are ambivalent about the choice.
As far as “what is in Rencher or Preisendorfer” or ‘how well Mann described his methodology’, those are legalistic arguments about what was alleged that are far less interesting to me than to you. They are not the subject of my examination.
I also continue to think that it would be more fair to both the discussion and the development of the field if you were to be fair about what circumstances drive use of std deviation division and what argue against it. The plusses and minuses. There is a definite possible drawback of not standardizing in that less sensative (in inches wood/degree) trees will not get their proper weighting. I think. Correct me if this concern is wrong. But I think the “same units” is a bit legalistic rather then thoughtful. If I have RW and RD and get the same order variation versus mean, should I standardize because the “unit” is different? What if I have a cedar that shows 10 times the temp response of a fir tree? And is a mil of firwood really the same unit as a mil of cedarwood, if I write the whole thing out?
That’s fine if all you care about is whether you look good and whether Mann looks bad, but I want to hash over the concepts from an objective CEO standpoint.
Couple contributions to help balance my noise with some signal:
Hotelling panegyric:
Click to access hhotelling.pdf
Article on difficulties in teaching stats to ecologists.
Click to access 3l1_ande.pdf
note many Hotelling-era problems remain the same, also note the implications for misuse of tools). Of interest, I liked the article overall, but didn’t like the author wedging in his hobbyhorse of a new method with what is a generally good article about pedagogy.
1. I wonder how the Tukey work connects to a situation with time series. He seems to be talking about sampling from populations.
2. I thought your insight about dividing by standard deviation for autocorrelated series was interesting.
3. Also I wonder what the meaning of the standard deviation is for a time series with some signal in it.
4. Can’t one just individually calibrate the series in terms of their responsiveness to temp and then divide by the respective factor for each series? (If you have enough data to fit a non-linear response, would need to do a transform of the data for that as well.)
#12. The RW and MXD argument is a debating point. There are only a couple of MXD series in the network – AS STATED IN OUR REPLY – both of which are also represented by RW series. So the network is 98% RW. You shouldn’t twist the method to accommodate the couple of MXD measurements.
As to what’s the “right” method, it wasn’t our job to sort what the “right” method was; that should have been done ahead of time. It’s not the job of a statistical analyst to sort out a “better way”. You can huff and puff all you like that I should have done that or that it would be interesting if I did that, but that’s a completely different job.
Auditing and verification is legalistic. You take what people say they did seriously. Maybe they can “get” an answer some other way. Fine, then present it that other way and that can be examined. Maybe there are problems with that other way.
In studies like Jones et al, the estimate is an average of 3-10 series. Each annual value is some kind of population estimate. From reading Tukey, you can see the problems that arise in merely estimating means within a population., If you add time series autocorrelation in, you can see how it gets more complicated. Now that you’ve read Tukey on mixed distributions and the problems of non-normality, look at the qqnorm-plots in Mo’ Mo’ Moberg. These are a total mess. What’s worse is that the medieval-modern differential in Moberg is DETERMINED by the worst non-normal offenders. This aspect of Moberg is junk.
Did you read what I said? I think you are the one who is debating and also diverting. What if I have two tree rings of different species and sensativities. Are they different units? Is “units” the important thing or mathematical characterisics? I’m not arguing the MXD point of huybers. Don’t flail away at a straw man. I’m making the basic point of when the standardization COULD help. BTW, your failure to at least address and explain it is tendentious.
In addition, I think it would have been much better if you had realized (or explained if you did realize) that your different normalization was a change BOTH in centering and in normalization. With Huybers paper, it was clear as a bell what the differences were. Not even worrying about what is right and wrong. At this point just saying to be clear.
I’m not trying to get you to endorse a method. I’m trying to get you to be fair in discussing the plusses and minuses of alternate techniques.
1. This doesn’t gibe with your comment stating that Huybers needed to address CO2. If you can audit that way, so can he. Actually, I don’t even think he did. I think what he did was disaggregate issues and deal with specific items and be clear in communication when doing so.
2. Step back, chill out, take the long view. For me, what Huybers did was to show an alternate way. When I read his (very clear and well written) paper I can see 4 ways of doing the recon. average, correlation PC, covariance PC, and MannPC
Are you going to get to my Huybers questions? I still want to know how that all played out. If he agrees with your interpretation or if you accept any comments of his or got any insights from the interchange. In particular, I want to know more about this 22 series stuff. Is it a deux ex machina or part of your original calculations that Huybers failed to emulate?
Working through your last para on Jones and Tukey.
In the sense, that there is a selection of series from the overall literature or even the overall world of trees, yes. But the std deviation that we talk about when standardizing is the within series distribution along years. not the within year distrubution of different series.
I agree. To me this is the more interesting comment than the nonnormality worries from contamination. Wonder if standardization is ever used in PCA of time series in econometric data and how this concern for sd being inadeqate handled. I still like my idea to train each series individually and then scale based on that factor.
I lack the ability to interpret them. Just not educated. I can see that the data leaves the line, but don’t have a good feel for how much deviation is allowed. Would prefer a numerical expression of normality deviation even if I knew these concepts/graphs.
Noted. I’d like to stick to discussion of methods for a sec and leave the individual sins for later punishment. I still wonder a bit what SD means when you have a real signal in the data. Certainly if there is real signal, the series won’t be normal. This could still be ok, I guess in the standardization if you had perfect proxies, since you could divide by the range just as easily. What you are trying to do is calibrate for sensativity.
I’m doing some surfing on this whole issue of correlation matrix versus covariance matrix. Unfortunately, I think that you see the discussions of alternate methods too much in terms of defending your choice of method versus analyzing the different possible options. Anyhow, it is clear from reading that correlation matrix usage is not at all unheard of in general time series analysis.
http://www.cas.sc.edu/geog/rslab/Rscc/mod8/exercises/Tsa.html
Please put some text above my last posting. I’m messing up the side bar. This is a really simple explanation that shows that my instincts to examine this issue were in the right diredtions:
http://www.riskglossary.com/link/principal_components.htm
TCO, I don’t know if you’ve been reading too much James Joyce, but your stream of consciousness posting is becoming both irritating and embarassing. It’s like reading “A Young Person’s Guide to PCA” written in the first person, present tense.
You accuse Steve of wandering all over the place and not tying things together. Sheesh.
Could I suggest that the best thing would be if you did a bit of PCA yourself? Most stats packages have it. It’s not difficult to format the data (anything will do, but paleo-climate stuff seems appropriate). You can experiment with standarised and non-standardised data, as well as correlation and covariance matrices. Note that a lot of the proxies come “pre-standarised”.
I think this would enhance your understanding of PCA as an adjunct to reading papers.
Reading the Huybers comment was very helpful.
TCO, can you type up that quote. It’s obviously applicable to Hockey Team studies.
I’ll see what I can find. You should read the article. I got the book from an academic library. I’m sure it is held at UT or that you (or Ross) can get it via ILL.
#25. The U of T library has a copy – that’s how I got the Tukey article. I just thought you might have had the quote handy.
Will look up a quote later tonight, Steve. For now some diffuse signal:
http://links.jstor.org/sici?sici=0003-4851%28194012%2911%3A4%3C457%3ATTOS%3E2.0.CO%3B2-K&size=LARGE
Click to access hhotelling.pdf
http://nobelprize.org/economics/laureates/1976/friedman-autobio.html
Click to access article44.pdf
Click to access KennedyJEconomicSurveys2002.pdf
I will have to look to see how good the quote is. I am paraphrasing.
Could not find a killer quote. Maybe I overemphasized this aspect. His main tenant is a parralel one, that practioner teachers of statistics are not as good as statistics teachers who really understand the material theoretically. Even when teaching practioners. In same manner that the calculus teacher is better if he is a mathematician then if an engineer. Even when teaching engineers.
Here is a cute one (not exactly the point I was trying to make but indicative):
In terms of content (in 1940) he thinks practioner-taught stats does not do enough examination of sampling methods. And spends too much time on central tendancy measures without addressing the key criteria for picking a measure (sampling stability). However he sees the applied departments (the users) as best to teach field specific biases to watch out for. I wonder who should examine sampling bias then? He also sees an important role for statisticians to be consultants to their fellow academics in other departments, thus improving the research stats done, and finding and solving new problems that arise. In addition, while he thinks that statisticians should be grounded in pure theory and advanced math, he also beleives it critical that they have worked in at least one applied field in detail to understand the issues of statistics in practice.
This article is a frigging fun read for those of us who don’t know “mattress theory” (matrices). Lots of philosophy for us who want to think about RC and Steve.
Click to access KennedyJEconomicSurveys2002.pdf
Oh…and James, yeah, it may be annoying that I’m discovering basics in a stream of consiousness. But it’s interesting that my suspicions were upheld by a bit of work and that Steve’s defense of the covariant matrix is rather defensive and onse-sided and tendentious. And that you wouldn’t answer my questions about degree of sensitivity versus “units”, but that checking the literature backed me up…HA! Mutherfukking HA! (I’m drinking.)
Oh…and James stop trying to get me to “do PCA”. That’s like on the Asimov’s board where they want me to write fiction vice criticize it. For me, googling was work. I usually stick to a rather “arch” Socratic style of asking Ross and Steve essay questions…
TCO, I didn’t for a moment imagine that anything I could say would stop you posting in your inimitable style. And to be honest, I guess it’s entertaining enough.
I’m not a statistician as accomplished as Steve, but PCA is something I do know a lot about, as I’ve used it extensively in business applications. That specific knowledge is what got me interested in M&M and the hockeystick in the first place, long before CA was born.
Your enthusiasm is appreciated, but I’m afraid that your musings on PCA indiate that you still have a poor conceptual understanding of the processes. My recommendation that you play with PCA is nothing like your Asimov analogy. I genuinely belive you would achieve a superior understanding of the method.
You are the first person to slap down someone that has an incomplete understanding of an issue, so you should have some sympathy with Steve and especially Ross when you presume some undergraduate “gotcha!”.
I don’t know what you’re talking about in the context of “degree of sensitivity versus “units”, but I understand that you have been drinking.
My gotchas are not related to finding Steve/Ross in a math mistake but to areas where they are being tendentious/misleading in discussion on the issues (even in published work in some cases). If Steve wants to see himself as an advocate, that’s fine. But this is supposed to be an uncensored board and if he is being misleading by being one-sided and selective in points, I will point it out in a heartbeat, because what I care about is truth.
With respect to the sensativity issue, it is dead-on and was not being properly addressed by Steve (and I’m not accusing him of not “knowing it”, am accusing him of being argumentative and misleading in not responding to it, in raising feeble points). He blathers on about units, when he knows perfectly well that “units” is not the key criteria. If the shoe were on the other foot and it were Mann defending “units” thinking, I bet Steve would point out rationally the point made in the material that I quoted:
Ths article about practical versus theoretical statistics (“Sinning in the Basement”) is very fun and interesting.
Click to access KennedyJEconomicSurveys2002.pdf
I think there are some interesting insights when reading this article and thinking about the MBH work. It’s not “dead-on”, but there’s stuff that’s applicable. I would say about 95% of inferences for us end up being anti-MBH. There are few places where MBH could gather a straw of support.
Without recapping the whole article (which I already linked to and noone commented on…sheesh…do I need to get my own blog?), some of the tidbits:
-our friend Tukey raises his head again with some cautionary philosophy
-Overly complex models are indicted and the dangers of overfitting highlighted
-Practical stat problem-solving is much more a domain where errors of method and logic are the problem then not using a sophisticated enough technique. In fact, these continue to be the more important things that people need to think about even with all the education and developments that have been done over the last 100 years.
-Graphical methods and inspection, parsing, looking at, immersing in (data) is emphasized
-The article is rather fun and contrarian in its wording. The main lesson is that the “sins” can really be restated as commandments. In most cases, they are calls to careful problem-solving methods rather than statistics per se.
-One of the two places where MBH can get a gram of support is the chapter on data mining, where the author says that workers need to completely understand the dangers of data mining in a sophisticated way, but then do a little of it now and then.
I’m going to invite Professor Kennedy (“the sinner”) over here to see me mistreat his writing. I want more heavies here to mess with you Steve. Plus, I can’t follow linear algebra so I drag in this philosophy stuff…
I’ve found his email address and his web page and class notes and stuff. I’ve never heard of Simon Fraser University. Trying to figure out where it is, if it is some freshwater cow college or if it is some pink part of the map place.
Damn. My yahoo is misbehaving. Won’t send this email:
Discussing your paper in a blog over here. Not econ field per se, but parallel issue of common sense, not being so, of it easy to make errors in methodology in the real world of problem solving.
http://www.climateaudit.org/?p=671#comment-30720
Dardie: give it a shot to kennedy@sfu.ca?
Wow. This is a really cool list of lectures from 2000. Wonder if they were all as general and interesting as the titles would make you think.
Here is another one from our friend Kennedy: “Eight reasons why real versus nominal interest rates is the most important concept in macroeconomics principles course”. I wonder what his reasons are. My reason is that I’ve seen people make this mistake, VERY OFTEN in NPV DCF calculations. To do those right, you need to do one of two uncomfortable things: either show prices of sold goods and inputs changing over time to reflect inflation or use a WACC that removes the inflation rate component of bond price term structure. Even Pekka Heital messes this up in one case for students (small impact because of minimal inflation rate). Actually, I think using the constant dollars and adjusting the WACC is the easiest thing to do. If you really want to model things of course in your NPV, though you need to show how different factor costs change over time. Some of these can be estimated from futures markets, others with some thought can put in rationales for changes over time that vary by quantity.
This one also looks cool (note it is pre-Enron crash): “The knowledge economy? No! More business as usual”
Simon Fraser University is Canadian in British Columbia.
Remember when people talked about “new” ways to value companies based on growth rather than profitability? Whenever I hear the Team say that you don’t need to look at the r2 statisitc, you just need to look at the RE statistic – it reminds me of promoters saying that you just need to look at growth, you don’t need to look at profitability.
It amazes me how people seem to have a hard time paying attention to more than one statistic from an analysis. In real life, they can effortlessly distinguish between profitability and growth or between height and weight or beween speed and the ability to catch the ball, but presented with the need to look at two statistics, r2 and RE, many climate scientists seem to be like deer caught in the headlights, not knowing what to do.
I think ability to look at more than one factor or to deal thoughtfully with uncertainty is something rare in most managers, even many consultants. I’m not very impressed at all with the sophistication of most on the RC site and even with some of the scientists there. On converse, I expect that Mann and Gavin have the ability to think with sophistication, but the field is politicized (literarally) and in terms of academic fads and they are complicit in it.
Left this off. This was the list of lectures.
http://www.commerce.otago.ac.nz/econ/seminars/2000seminars.html
Although Mann right now on the MBH front is more like someone in litigation who repeats an untrue story often enough that he comes to believe it. It was amazing to see him tell that NAS panel that he’d never calculated the r2 statistic – that would be “foolish and incorrect”. When he was saying it, I’m sure he believed it.
Here is another site for you, Steve.
http://www.hmdc.harvard.edu/micah_altman/socsci.shtml
Have you seen this book? It is by the “sinning” author and supposed to make math shtuff more clear in econometrics.
re: #36
This is where you need a little introspection, TCO. Is there a reason people might not follow a link you post? Possibilities include:
1. Intemperate language on your part making people disinclined to read your messages at all.
2. Just too many messages on your part, making people disinclined to follow your messages at all or in detail.
3. Demonstrated lack of knowledge of subjects under discussion and a tendency to blame others (particularly Steve) for your lack of knowledge causing people to distrust your judgement re citations.
I like option number 2, but maybe we should do some blind testing. BTW, I appreciate your taking my place while I was gone. Now that I’m back, you don’t need to be the conscience.
Here is another interesting link. The projects at bottom look really cool.
I need to blather about it a bit to make sure that I don’t screw up the floating bar again. And I need to post this message to bump down my earlier comment which is screwing up the floater bar.
http://www.amstat.org/publications/jse/v6n3/smith.html
By the way, I forgive the misguided number 3 choosers. They know not what they do.
(This should bump the floater)
More number 2 sinning. Here are some tools that you can use to explain detrending and collinearity to the tree-cutters, Steve.
bar blather
bar blather
http://www.amstat.org/publications/jse/v10n1/kennedy.html
re #49,
You claimed not to know linear algebra, and have in fact not demonstrated any great ability concerning the subject. Now I also have not had a formal course on the subject and consequently avoid discussing the details presented here. But I also don’t post multiple messages telling Steve that he should do this or that; and which require some knowledge of the subject to be valid. You may be the world’s greatest expert on k-level spritz-modules and still not be qualified to talk to Steve about what’s correct in his area of expertise.
Now I do sometimes post on matters which rely on non-technical analysis, but that’s different. For that matter when you attempt to advise Steve about publishing that’s ok except that you go overboard and reach a #2 disconnect.
Dard:
Yeah, I tried to take it easy on him for a while. He said he’d heard it enough from me. Even agreed with parts of it. Didn’t agree with all of it. Had heard it enough, so why should I repeat? So I stopped. But…the flesh is weak! And when I see him proposing doing in Tellus exactly what he did wrong with Nature (Polar Urals). But I will stop. I’m even sick of hearing myself blather about it. And I don’t want to draw his spirits down, by being too tough.
On the “non-technical analysis”: I think I do exactly what you said you do: about making points on logic rather then on technique or math detail. I really do. To the extent that I do wander into technical topics, I think it’s clear that this is a discussion forum and I feel backed up by a few things that I drove from more the logic/questioning standpoint.
On the linear algebra: I don’t know the first thing about it. Have never had a single course in it. So me not showing ability at it is not surprising.
Here’s another interesting paper. It talks about all the ways that a sign in a regression might come out wrong.
bar blather
Click to access oh_no_I_got_the_wrong_sign.pdf
Here’s a sort of interesting stats blog. Pretty readable.
space
space
http://www.stat.columbia.edu/~cook/movabletype/mlm/
here is a book for you Steve
asdf
asdff
http://www.stat.columbia.edu/~cook/movabletype/mlm/
I mean here:
die bar
die bar
John, every other site does not have this problem
die bar
Ok. Here is my assessment of VSO6. We have talked about this paper some on this site, as it is “pro-warmer”. Steve has not addressed it. Sorry, I did not “have the time to be brief”.
Commentary on RBHvS06: Long-term Persistence in Climate and the Detection Problem
Citation: Rybski et al., GRL 33, L06718, 2006
Link : http://w3g.gkss.de/staff/storch/pdf/rybski-etal.2006.pdf
Overview:
This article has gotten interest on the site because of two issues: support for AGW and citing MM03 as a “reconstruction”. Big picture: what the authors do is (1) look at the change in temp over last 100 years (instrument) and compare it to the historic changeability of climate (in proxy reconstructions) to see how “unusual” (in the sense of odds) that the recent warming is and (2) look at “long term persistence” (LTP) within the reconstructions. The discussion, a bit unnecessarily, mixes the two issues (perhaps to make the simple point (1) seem more “technical”). Really they are BOTH interesting issues on their own. The problems of LTP just make for a case where temp rises are more likely than if the data were independent (thus setting a higher bar for “remarkability” of the recent temp increase).
The article is a bit more technically written than needed, but with a little effort, one can get most of the physical insights from the text. I think I got about 85%. This discussion will contain criticism, observations and questions from reading the paper. It is organized in the order of reading the paper (by paragraph number). Some points are minor, some stylistic.
While most of my comments are negative, that does not mean I think the work without merit. I just like to note all the assumptions and things that could influence the result or the interpretation of the result.
[1] (reads like an abstract)
A. 6 reconstructions (Jones98, Mann99, Briffa00, Esper02, “MM03”, and Mo05) were examined.
1. The paper does not explain the selection process: Are these the only 6 reconstructions of the NH temps? Do they use the entire records or chop them to be historic only?
2. Are the reconstructions independent (in method or data?) Could one get a false picture of 6 different samples for this analysis? (think a verbal caveat called for here.)
3. In particular, “MM03” was not intended as a reconstruction (so that selecting it misrepresents the population of reconstructions…all the rest of the samples were at least trying to solve the question of what happened). In that sense, at least there is some Bayesian benefit to looking at several recons. But not with MM03 (the authors don’t stand behind it as an attempt to measure temps). More troubling, MM03 was run as a variant of MBH98 (to test robustness) so it is very much non-independent of MBH in inputs and method.
4. If variants of MBH are of interest to subject to this analysis, it would be good to look at the Burger and Cubasch full factorial of MBH variants as well.
B. There is an implicit assumption (not stated, granted, but not caveated either) that the proxy recons are historical records equivalent to the instrument period (thus allowing the point (1) examination). If the proxies are contaminated by CO2 or cherry-picked then that affects the results. Same issue with the instrumental record (if it is inaccurate)”¢’¬?in particular, the instrumental record is based on ground stations, not on satellite or balloon measurements. That might be fine. But it should be noted.
C. It’s not clear to me why we compare the instrument temp change to the proxy records. Why not compare recent proxy history (last 100 years) to overall proxy records. This type of analysis would better show the unreliability of the proxies (or their divergence from instrument), would bring in the divergence problem and the lack of recent proxy data.
D. (Observation) The paper looks at delta temperatures from midpoint of one averaged temp period to the midpoint of another averaged period. This is where (L, m) come in. This is made more technical sounding than it needs to be.
E. (Minor) Not clear to me why M=30 (averaging period) and L=100 are “climatologically significant”. Certainly sigma ratio = 2.5 is not “climatologically significant”. I think 100 is really significant since it is closely related to the observed recent warming (especially when you have to average across a period, so you’re really looking at 100+15+15=130 years within the delta T. Would rephrase this to be more precise and thoughtful and less “puffy”.
F. The difference between an onset of detection and a “excessive odds versus historic variability (isubc and isubd) is just a feature of the “smoothing” or averaging inherent in the 30 year number. I’m not clear why there is a 14 year difference versus a 15 year difference.
[2] This is a good introductory paragraph.
A. While the paper gives a nice hat tip cite to others who have worked on “attribution and detection problem”, none of the later discussion compares the results obtained to those other papers.
B. Is there going to be a “longer paper”? In theory, letters should be followed up by longer papers that go into more detail. Recently, in the physical sciences, people have started blowing this off. I wonder if climatology/GRL is even worse about this.
[3] This para has a tiny bit more detail on recons selected, but still fails to answer the questions from [1].
A. Also gives a false impression (to the extent of a bad error or a lie) that MM03 is a “time series supposed to describe the historical development of the variable”. (BTW, that sentence is bloated and poorly worded as well as being inaccurate wrt MM03.)
B. The authors fail to say how they obtained the MM03 data (not on file at WDCP). This is poor form, both for future readers, wanting that info, and because they fail to acknowledge or thank MM for providing the info (even knowing that it would be used in a manner per A above that they disagree with.) To the extent that they make it look like MM are failing to archive adequately (when MM03 is like a Burger and Cubasch run)”¢’¬?that is a really nasty, nasty trick.
C. The second half of the paragraph (about LTP) should be its own paragraph. It’s a different subject.
D. The many cited “real” (I don’t like that term btw) climate records with LTP are never directly compared to the obtained results here. We just get a claim that there is similar behavior. Of course in the longer paper, this will all be better described. àⰃ à ➠
[4] This para is more intro and is about both the moving averages and the comparisons. (Overall poor construction of the paper in layout of subjects: excess repetition and lacks a “pyramid” organization of content.)
[5] This para is about Figures 1 (spaghetti graph) and 2a (normal distribution of temperature deviation from the mean).
A. This should be two separate paragraphs.
B. Both figures are very tiny and hard to read.
C. The sphaghetti graph would be better shown in smoothed version.
D. SG has bad background color.
E. 2a is a semilog plot (always look at semilog and log-log suspiciously because a lot of range is compressed) and the normalization by std deviation obscures the difference in range of the curves. In addition, I would like to have a numerical value of some test or percent normality. Not just this visual.
F. Last sentence has a lot of puffery. Just say that the visual confirms normal distribution (or what have you). The Gaussian comment is not needed and the “fully described” is puffery and non-quantitative.
[6] Is about the assessment of LTP in the reconstructions.
A. I could not follow the math. (Just my fault.) I don’t know what the bra ket notation means or what the triple bar equals sign means.
B. I wonder if this is a “vanilla style” of LTP or of explanation of what LTP means. Why aren’t they talking about “redness” or about ARIMA coefficients? At least with ARMA, I have an intuition what the parameters mean (storage effects and the like).
C. Is DFA[2] analysis conventional? (very recent publications). Could we do similar analysis with something more “standard”?
D. (Figure 2b) not clear to me why none of the lines cross. Luck? Significant? Something about how the analysis was done (for graphical purposes)?
E. Significance of the deviations from the line (on log-log). BTW, lines on log-log are very, very easy to get.
[7] Is a comparison of Mo recon to an artificial LTP function.
A. Not clear to me why so much text space (and two of the only readable figures) are dedicated to this essentially didactic point. (nature of LTP).
B. If one wants to make this didactic point (nature of LTP), better done as on Steve’s blog by showing some iid, some ARMA of different types, etc.
C. The Bunde citation sentence seems odd and forced. Is there really something so special about this 2005 paper on heart rates that needs to be compared to these climate records? Wouldn’t it be better to cite a classic, older paper (the Nile hydrology)? And it’s such a throwaway remark that it doesn’t seem to mean much, the way it’s said.
D. The function used to generate 3b is not ARMA and seems overly technical (not sure why we need to look at a 1996 reference instead of a textbook).
[8] This para is about variability in the instrument record.
A. Not clear to me what the author means by use of the word “natural” within the period of instrument time. In the past it seems that he uses this word for “historic times”.
B. I don’t see a graph or a table where the results of this “examination within the instrumental period” is recorded. Confusing para really.
C. Oh wait, I think I get it. They are using Tsubi not for T(instrument), but for T(ith reconstruction)? Confusing. Grr. (If the para is about T(instrument), then figure 2a is missing set of records for the instrument. Actually come to think about it…if we have a hockey stick occurring, how can we possibly have this normal disrtribution at all for any records? Wouldn’t it be skewed normal?
D. Is it a truism that if the overall dataset has normally distributed (from the mean) temperatures than the M, L results will be normally distributed? Not sure I buy that as a truism.
E. “very unreasonable” is puffery. Just say “low”.
[9] Is about the relationship of the standard deviation to the (m, L) parameters. Basically, as you get a larger L (several values shown) or smaller m (two values shown), you get a larger standard deviation. This makes implicit sense. Smaller m means less “smoothing”. Larger L means end points further apart (less correlated).
A. The stuff about “error bars” of the artificial functions is just another proof that the climate records have autocorrelation or can be compared to classic autocorrelation functions.
B. Why are only 4 records looked at?
C. What is the significance of crossings of the error bars. Is there a better (numeric) way to describe goodness of fit?
D. The comment about significantly greater variability in these records then in uncorrelated ones ought to be proven/quantified. I believe them. I just think if they want to make the point, they should prove it.
E. As expected, the “bumpier recons” have higher SD than the smooth ones.
[10] Para is about figure 5a and 5 b.
A. 5a just shows a good view of the instrumental record. Para makes the point (which we grasped earlier) that the (m, L) blabla is just a deltaT on a smoothed graph.
B. 5b, jumps two steps down the explication train by both having the delta T and by dividing it by the SD of the reconstruction(s): for L=20, m=5. The different reconstruction SDs are just scalars, so what you have are six versions of the same curve, just shifted different amounts from the axis.
C. During the instrumental time, there are a couple periods where the (1940ish, 1995ish) where the curves veer over significance limits. The text discusses the likelihood of this happening. (pretty unlikely).
D. It’s not clear to me if this likelihood equates to a per period sense. That is if we have something that is 1/44 likelihood, it means it happens once per 44 years (on average)?
E. As might be expected, given the general warming experienced in last 100ish years, there are no crossings of the significance boundaries in the negative direction. A couple come close. I think some comparison of negative and positive excursions should be made (and it helps the warmer case).
[11] this para is about the same concept but with L=100, m= 30 (incidentally why vary both at same time?) Because the instrumental record is only about 150 years long and we need 130 years of data to start to do this method, the graph doesn’t show much extent of time (1970-1990).
A. The curves start out significant (or near significant) and with time all show some excess of the control limits.
B. The 14 year delta of isubc versus isubd is finally clear here (versus a 15 year delta). The smooths are for 30 record years, thus covering 29 calander years duration. They do 14 ahead and 15 behind. I think it would just be better to do 31 year smooths and keep it symmetrical, but no biggie.
[12] This para just gives the different years where we cross significance thresholds and when detectable, (because of the smooth). The bumpier curves (Mo and Jones) give a later detection limit (it’s just a function of the larger scalar divisor in the SD).
[13] Conclusion para (claims that observed warming is inconsistent with natural variation.
A. This is a reasonable, mathematical expression of the proxy records versus instrument. I think it is better to drill things down into math than to just show spaghetti graphs (I couldn’t for the life of me tell from the spaghetti who’s side it supported). This at least moves it to math.
B. There is a gratuitous comment about the “quality controlled” instrumental data. But the earlier article did not establish the quality level of the instrumental data. I’m not a UHI whiner, but this kind of gratuitous comment in a conclusion is uncalled for. No new facts/points in the conclusion. Just a natural denoument.
C. Similarly it seems gratuitous and forced and even a little political to frame this result in terms of supporting the arguments of several other “detection and attribution” writers rather than to just give own conclusion. And some summary of these earlier results/arguments was never given earlier in the paper. It’s another case of bringing in new stuff in the conclusion (and in this case stuff that one has to go to a cited reference to even use…or just be part of the club and be familiar with those papers).
D. I think the prominent (by having it in conclusion) and almost titillating comment about the similarity of results from MM03 and MBH is a bit nasty. There are a lot of criticisms of MBH by MM that are not captured in this particular analysis of the two “records”. One might get entirely the wrong point from this paper. Also (as discussed before) the reconstructions are closely dependant (given that one was a variation for effect of the other). However, it is interesting that this analysis shows that the prominent hump at 1450 of the MM03 variation may not be so significant from a mathematical standard deviation/confidence interval point of view.
Acknowledgement: (style nit) Rather than “We’d like to thank…” say “We thank…”
One more post to get the bar fixed:
I think this article is interesting for the pure pedadogy field evolution. But for purpose of this debate versus MBH, what is relevant is that it explains why there is no hard core stats help. Applied stats has been “captured” by math. Because the field has evolved in difficulty and the path to advancement has become very abstract theory.
Click to access article44.pdf
bar fixer
bar
re: # 57
Don’t know how many people will wade through this post so I’ll say it was pretty much worthwhile to read through with the original paper pulled up in another window to cross-reference.
BTW the bracket style notation generally means an expectation value. And the triple equal sign almost universally means “defined as.” Both seem to be the case here. IOW it says that C a function of s which is equal to the expected correlation value of the data filtered through an s sized window is defined to be….
Sounds like you have attended ToastMasters. The local club my wife and I attend have a wooden numeral 2 on a chain and anyone who says “I would like to…” has to wear it until someone else errs or the meeting ends.
Nice post, TCO.
It seems to me that the paper is premised on the idea that the paleo-reconstructions adequately represent the historical variability of temperature. This is the key point that you make here:
“4.B. There is an implicit assumption (not stated, granted, but not caveated either) that the proxy recons are historical records equivalent to the instrument period (thus allowing the point (1) examination). If the proxies are contaminated by CO2 or cherry-picked then that affects the results.”
We could add in the ubiquity of certain proxies (with characteristically low millenial scale variability) in the selected reconstructions, a point you allude to earlier.
I think Steve has done enough to seriously challenge such an assumption.
If that assumption dosn’t hold, couldn’t you turn the whole hypothesis upside down, and ask “does the variability of the paleo-reconstructions match the instrumental record”. From the same results the answer is “no”, can we conclude that the paleo-reconstructions understimate historical variability? No, but then only if we assume that the instrumental record might be influenced by AGW.
Seems to me that the paper gets us nowhere.
It gets us to a little intermediate somewhere. Instead of looking at spaghetti graphs (a graphic that has always been confusing at least to me), they are stating their case numerically. That’s the first thing. I also think that implicit in the 100 year thing (especially for the comparison to Moberg) is some some numerical capture of what the warmers talk about when they say that the recent rise is dramatic not only for the amount but for the speed. Yes, if the reconstructions suck, then the paper rests on tissue paper. But, if they are good, the paper moves things from the graphical to the numeric.