Rutherford et al 2005 (the et al being half the Hockey Team: Mann, Bradley, Hughes, Briffa, Jones, Osborn) is a re-statement of the MBH98 network (flawed PCs and all) and the Briffa et al 2001 network using RegEM. I haven’t figured out exactly what the properties of the RegEM method are as compared to other multivariate methods, but that’s a story for another day. This is the article where they first put forward the idea that the verification r2 is a "flawed" statistic.
While one could seek to estimate verification skill with the square of the Pearson correlation measure (r2), this metric can be misleading when, as is the case in paleoclimate reconstructions of past centuries, changes are likely in mean or variance outside the calibration period. To aid the reader in interpreting the verification diagnostics, and to illustrate the shortcomings of r2 as a diagnostic of reconstructive skill, we provide some synthetic examples that show three possible reconstructions of a series and the RE, CE, and r2 scores for each (supplementary material available online at http://fox.rwu.edu/~rutherfo/supplements/jclim2003a)
In our discussion of verification statistics, we’ve not argued that a verification r2 is sufficient for model success, only that it’s necessary. So their illustration has nothing to do with any actual argument that we’ve ever made. But, hey, they’re the Hockey Team. Their illustration of the above paragraph showed the following "synthetic" example where there is high verification r2 with poor model behavior.

Figure 1. verifexample.pdf top panel from Rutherford et al 2005 SI
It seems hard to imagine a real-world model where you would actually get an r2 of 1 and lose track of the mean level so badly. Actual statisticians (as opposed to “I am not a statistician” statisticians) use other methods to test for situations like this – a Durbin-Watson statistic would have picked up this sort of situation effortlessly. There’s no real need for the Hockey Team to re-invent time series statistics. If they think that they’ve proved something about the r2 statistic, they should submit it to a real statisticl journal and not just push it by Andrew Weaver at Journal of Climate. It’s embarrassing that the Journal of Climate, which has published much sophisticated and interesting material in the past, should, under Andrew Weaver’s watch, publish such a juvenile sketch.
However, for today’s little irony, they really didn’t need to invent a synthetic example. I’ll rotate this example, just to get your eye in (although the comparison I’m about to give is pretty obvious). Here you see a case where the divergence is upwards.
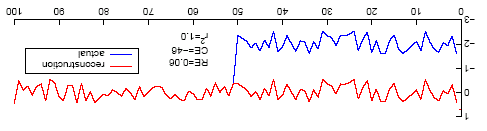
Figure 1 rotated 180 degrees
Now here is Figure xx from Rutherford et al, showing one of their reconstructions which has MXD data in it and the resultant "divergence problem". There seems to be some high-frequency coherence which would help the r2 (but the r2 is not JUST a high-frequency statistic as the diverging trend will penalize the r2 statistic.) A Durbin-Watson statistic would pick up the divergence effortlessly – or simply looking at the plot wouldn’t do any harm. So Rutherford, Mann et al. didn’t need to invent a synthetic example, they could have just used their own reconstruction with MXD data.

Figure 3. From Rutherford et al 2005.
If the point of their synthetic example was to say that such cases are flawed, then surely they had an obvious example right at hand. They could have said – here’s the MXD data, it demonstrates what happens with flawed models.
But this is the Hockey Team, so they handle it differently. Remember the Briffa MXD reconstruction, which had the same divergence problem. They truncated it in 1960 and snipped off the embarrassing bits at the end. This was done for the first time in IPCC TAR (I reported this last May: you had to blow up the graphic to see the truncation). In the article cited by IPCC (Briffa 2000), there was no truncation. It occurred in print in a later article (Briffa et al JGR 2001, not cited in TAR).
Rutherford has archived a number of reconstructions from this article both at his website (where I’m blocked) and at WDCP. If you examine them, you’ll see that he’s done the same trick. The digital data is truncated. None of the series contain digital data for the series illustrated above with the closing downtrend; they are all truncated, nearly all of them to 1960.
Has an MXD-based reconstruction shown any ability to measure warm periods? Who knows? They sure haven’t provided any evidence so far.
Now let’s suppose hypothetically that IPCC 4 AR had a spaghetti graph and that both the Briffa et al 2001 reconstructions and a Rutherford et al 2005 reconstruction were in it. Do you suppose that they would show the entire series, complete with "divergence" in the late 20th century? Or do you suppose that they would obtain "consensus", so to speak, by censoring the post-1960 values of these series so that the reconstructions all appear to go up in the late 20th century? A hypothetical question, of course.





13 Comments
Steve, your posting is very hard to follow (not from difficult technical material but from gaps in the explication). You don’t even reference the actual article, but I think I’ve tracked it down.
Realclimate has a pdf of the submitted paper: http://www.realclimate.org/RuthetalJClim2004.pdf
1. I’m looking at the 3 panel figure in the SI and the whole thing makes a little more sense, now. I think I still have some basic gaps in my understanding of what periods of observation are and how the statistical measures are computed (normalized variables). Not clear what the purple part is for or the significance of the perfect match in that part.
2. It’s not just my ignorance, though. You tend to write a bit cryptically. Almost as if talking to self. The Mannian explanation is not perfectly explicative either (but better in terms of communication, only–like your science better). Like they have the purple lines on their graph and you have red. And like they try to explain the point all the way out.
3. I saw the part of that paper where they take a dig at you for not doing stepwise PCs.
4. I think the issue of the “desirability of annual resolution series” of tree rings (mentioned again in the paper, what puffers they are…) and then their cake and eat it too wrt low frequency effects is somehow related to these charts with the big jumps in mean (essentially a low frequency signal no)?
I didn’t think that the point of this post would be very hard to pick up.
The stepwise stuff pisses me off. It’s not like this is a method used anywhere except in Mann-world; it’s not mentioned in their article and they refused to provide particulars. They’ve pissed off Zorita as well by playing gotcha with failing to exactly replicate unknowable methodologies, where the issue ends up being completely different. It was a tempest in a teapot because the actual PC effect had nothing to do with stepwise. But they spin disinformation like promoters.
In our NAture submissions and in MM05 (it wasn’t really an issue in MM03), we had stepwise. They knew that, but then went back to an earlier article – WITHOUT discussing the later articles. I complained to Andrew Weaver in Jan last year prior to publication of Rutherford – saying that “full true and plain disclosure” meant that it was dishonest for them to discuss the old article without disclosing and discussing PC issues that they knew about. I had a bit of a row with Weaver, but got nowhere.
Yeah, they are scoundrels. I agree with Weaver that they don’t need to bring the PC stuff in, but also think that the throwaway criticism of you should have been pruned. (It’s just a driveby, it doesn’t even feed their story.)
1. How about the issue of annual data and low frequency signals wrt mean changing?
2. Could you explain please what goes on in the purple part of the figures where the match is exact and the other parts? How do these periods connect to what we’ve heard of in terms of verification, calibration periods (and then that period that is outside of either)?
3. Clarifying question. When you or Mann talk about rsq, what is it you mean? of what data to what model?
4. the 3 variables that he lists in the examples, are they over the 0-100 period or over the 0-50 period? And what is going on with normalization or standardization (if anything) in the comparisons?
I only have access to the RC pdf. Is the as-published paper different (if you know)?
Where is the section that discusses rsq in the text of the paper? I skimmed paper and could not find it, but it is long.
Steve, the side bar covers the figure xx portion of interest (btw, at least according to the preprint, that is the top panel of Figure 4). However, I’m looking at the preprint now.
Boy that paper is hilarious. They even use scare quotes around *correction*, when they say “McIntyre and McKitrick (2003) in support of their putative ‘correction’ to the…”
Steve: That’s redundant. Shouldn’t use both scare quotes and the word putative. It’s redundant. Almost like a double negative. Poor writing.
I’m going through that whole thing right now. skimming it doesn’t do it justice. Trying to figure out what it is all about. Is it a validation of RegEM methods? Is it a counterattack on MM03?
I’m not done with the reading, but the one snippet where they talk about how well RegEM matches MBH98 is bizarre. Yeah if it’s completely independant that’s specatular. but what about the much easier inference that it essentially does the same thing as MBH98? How do they square this particular closeness of two methods with the spectacular differences in the Buerger and Cubash paper for 64 model examples?
It’s a mess. Just can’t read any further. So bloated and self-congratulatory. It’s gross. The anti-Burger and Cubasch.
r2 is just a measure of fit to any model.
In their RegEM calculations, they usd the MBH98 proxy network AFTER PC calculations. They have a multivariate method after the PC calculations, which is a form of partial least squares, although they don;t know it. See my posts on the Linear Algebra of MBH.
The MBH98 multivariate method ends up giving weights to the proxies which overweights the bristlecones enabling them to dominate, since there is no overall signal in the rest of the proxies. I presume that RegEM gives similar weights to the bristlecones, since the answer is so similar. Is RegEM “right”? There are lots of texts on multivariate methods, I’ve been re-reading them lately. If I saw RegEM written up in a real statistics text with a discussion of its properties, then you could begin to think about what’s involved.
The RegEM thing is typical Mannian. You have an obtuse description of a method that is unused in the general statistical world, although there is a third party reference by Tapio Schneider, who doesn’t seem to be in the Hockey Team locker room. But you don’t see this in Draper and Smith or usual texts. In this case they have provided code so there’s a chance of wading through and seeing what they are actually doing.
When I finally sorted out the linear algebra of the MBH98 multivariate method,it boiled down to a method which one could see described in chemometrics – although Mann doesn’t know it, and about which some properties are known. That’s one of the things that I’m working on off air.
It’s possible that worrying through the algebra of RegEM might lead to some other reduction to a known method. Also sometimes the methods “converge” a little since the proxies are almost orthogonal in some systems.
At the end of the day, the RegEM is just assigning weights to the proxies. If there’s a temperature signal in temperature-sensitive proxies, you should be able to get it with an average.
I know that rsq measures how much the data points vary from the line in a best fit analysis.
What is the 0 to 50 and 50 to 100 in their Figure 4 (3 panel drawing of which you show one panel). I mean in terms of verification, calibration and uninstrumented?
Over what period do they do rsq? In figure 4?
What does it mean to do rsq during the uninstrumented period? And what is the data? Or the curve that varies from best fit model?
I don’t see how the rsq stays at one given how far apart the curves are. Is this a result of just doing the analysis over a limited part of the period (0-50) versus over the whole thing?
In the NAS thread Lubo commented on the Solar study found at:
http://www.tmgnow.com/repository/solar/lassen1.html
RealClimate quoted the following paper as a comment on it indicating that there are errors in the last 15 years.
Click to access damon&laut_2004.pdf
It sounds like the divergence problem being discussed here. Has anyone looked at both studies?