Here’s a pretty little graph that I think that you’re going to see more of. One is using the Wahl-Ammann variation of MBH methodology applied to MBH data; the others are from low-order red noise. 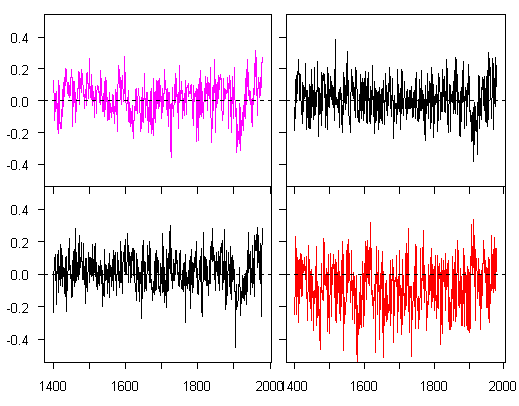
Pink – no PC reconstruction from WA without strip-bark and Gaspé; black – from low-order red noise.
I worked this up to illustrate a point in the no-PC part of Wahl and Ammann, but it bears a little commentary separately. You may recall jae trying to wrap his mind around overfitting and bender getting frustrated with him. If it makes either of them happier, MBH – WA variation – is a wonderful example of overfitting that may illustrate the point for jae, who might then undertake to explain the problems to Ammann and Wahl.
The pink graphic is the no PC reconstruction from WA without strip-bark and Gaspé, resulting in a network of 70+ series (down from the 95 in their Scenario 2 due to the strip-bark sites.) If you did a multiple linear regression of NH temperature against 70+ series with little mutual relationsip in a calibration period of length 79, I think that you’d agree that it was overfitting. So what would a reconstruction look like from such a process? I haven’t illustrated that here (I’ll do that now that I think of it), but it would look a lot like the above graphic.
Here I’ve used PLS (partial least squares) rather than OLS- see my linear algebra posts as to the proof that MBH regression can be reduced to partial least squares. OLS multiplies the partial least squares coefficients by 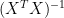
All the reconstructions have high r2 (greater than 0.5) in the calibration period, and ~0 verification r2. This would be enough for non-climate scientists to conclude that there was overfitting.
Another distinctive feature of overfitting is the characteristic downward notch at the start of the calibration period – this is worth paying close attention to in the WA diagrams where it’s all too visible.
In the red noise and non-bristlecone cases, the reconstruction reverts to close to zero fairly quickly. If you re-insert bristlecones or HS-shaped series, their impact is to change the shaft location to more and more negative, while preserving the general geometry. I’ve been alking about the interrelation of spurious regression and overfitting for some time without illustrating it as clearly as I’d like. Fortunately, the Wahl and Ammann variation has introduced overfitting on such a colossal scale that it’s easy to show the effect.
I doubt that anyone in our lifetimes will ever again see elementary overfitting on the scale of Wahl and Ammann.





28 Comments
Sorry, why ?
Actually it’s overfitting against a trend. The target trend segment is more or less centered in the calibration period and is fitted fairly well. But because there’s no actual relationship the “prediction” reverts to noise around 0.
Steve,
I really thinks its time that you told Wahl and Ammann about the highly correlated and well established relationship between Anglican marriages and mortality rate (George Yule)and that they should seek advice from David Hendry on the well established relationship between UK inflation rate and rainfall in the 70s.
Thanks to Skog, I’ve recently been keeping an eye out on the the variation in sunspot activity as I know thanks to his work that this correlates well with introvenous drug use which based on reports from the MSM is currently on the increase. In fact, thinking about it just now I guess this puts introvenous drug users in the frame for causing all this bloody global warming?
KevinUK
Re: Partial Least Squares
“OLS multiplies the partial least squares coefficients by (X’ X)^(-1).” Is partial least squares then just X’Y?
#4. Yes. In the MBH case where he only has one reconstructed PC, the NH reconstruction boils down to
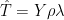 where Y is the matrix of standardized proxies, rho the correlations to the temperature PC1 and lambda an empirical constant.
where Y is the matrix of standardized proxies, rho the correlations to the temperature PC1 and lambda an empirical constant.
By using principal components, the 14th century step does a partial least squares regression on 22 predictors; in the non-PC case, he uses 95 predictors. If the proxies were orthogonal, PLS and OLS would be thesame. However, you can see why it’s prone to overfitting.
The amazing thing is that NO ONE in the climate community understands the PLS structure of MBH; Burger and Cubasch were close but didn;t get there (even though it was posted up on CA already.)
I’m not sure the point behind the partial least squares observation because the principle components are orthogonal. Therefore doing a partial least squares against the principle components is the same as doing normal least squares against the principle components.
#6. In the Wahl and Ammann variation, there are no principal components.
In MBH itself, principal components are only done on some of the data. So only 3 of 22 series in the AD1400 network are PC series; 31 of 112 in the AD1820 nbetwork. There’s little rhyme or reason to it all.
Also the PC series are in blocks.
Having said that, in the MBH98 network, the proxies are surprisingly close to being orthogonal (which should be alarming to hopes that they contain a “signal”) – multicollinearity is good not bad in this context. As it gets closer to being orthogonal, it gets closer to being an OLS regression on between 22 and 112 predictors in a calibraiton period of legnth 79. Overfitting anyonbe?
1. For anyone who doesn’t know what “orthogonal” means (I realize most will) – it means “related”. i.e. The individual “proxies” are barely related to one another.
2. This is a killer point, Steve M. One you won’t hear the team repeat often, or underline in their conclusions. How can the proxies be statistically independent of one another if what they are are “proxies” for a single, supposedly global signal?
#7 Steve, I’m looking at MBH98 and I see him discussing various networks of proxies and associated principle components but when he plots the data we only see the result of one choice of proxies (The one that goes back the furthest in time). Additionally the plots of the principle components looks weird. Wouldn’t normally we expect them to have equally distributed variances? The ones I see all start at different points in time. Should of this been a red flag?
BTW I’ve got a question about a test for overfitting in this sort of multivariate context – in the red noise situations, the std dev of hte reconstruction in the calibraiton period is about 0.15 and in the reconstructed period is about .09 – a ratio of about 60%. This is very consistent in these examples and it’s exactly the ratio in MBH.
It make sense that if you artificially align noise in a calibraiton period that the variance would attenuate out-of-sample. If there is no variance attenuation in the underlying signals, a test for change in variance seeems like a pretty good test for overfitting.
Make’s sense to me Steve. I’ll have to think about it some more though. It is my bedtime.
# 10
which suggests to me that the mob know exactly what goes on, but hide in the shadows when CA, for example, shines a spotlight on them.
We do a BrEx and get pilloried.
They do it and we still get pilloried.
BTW there’s a wonderful quote in Wahl and Ammann in which they say that because of the close fit between the reconstruction and instrumental temperature, that it’s therefore valid to extend the reconstruction past the proxy period with instrumental temperatures. Because they don’t understand the Mannian regression method, they seem blissfully unaware of how the overfitting works.
If you have 1-2 (or more) synthetic HS-shaped series to the above networks, you get HS reconstructions and regularly get high RE statistics (which is what we pointed out in Reply to Huybers, and in further details in the climateaudit post Reply to Huybers #2 – but at the time I hadn’t fully realized the connection of Mannian regression to partial least squares and it does not articulate the point.)
Sorry for the repost but I originally meant to post this in this thread. I think it is much more relavent here as it addresses the point about the orthoganality of the proxies.
The following was moved from:
http://www.climateaudit.org/?p=796#comment-44648
I was thinking about the orthogonally of the proxies and my first thought was it is probably a precipitation index. Precipitation indexes can be related to cloud cover which play a big part in warming. Of course low clouds cause cooling and high clouds cause warming so precipitation is not directly related to warming. I then recall one of Robert’s posts,
http://www.climateaudit.org/?p=796#comment-44086
and I then wonder if maybe Mann took care to select the worst of the tree proxies. I am not sure if Robert was saying the MWP and LIA was in most tree data or not. Regardless tree proxies supposedly best for high frequency information so if low frequency proxies are first used to identify the low frequency model and then if the low frequency part of the signal is removed by an inverse filter (similar to differencing think arima) then maybe trees will provide a more robust method of identifying the high frequency part of the signal.
Anyway, we may be able to use trees to get low frequency information but we have better ways of doing it. I think tree proxies should only be used were they better proxies are not available. This seems to imply that they should only be used to reconstruct the high frequency part of the signal.
For some reason, this proxy-temperature relation is amazingly hard to understand (can’t figure out what MBH98 assumptions mean). Anyway, one can work by guessing. Let’s guess that proxy record (p) and nearby local temperature record (T) are related (location i at year t) (that is, skip the teleconnections):
where is the scale factor, b is the bias term, and n is the noise term. Using this model, and assuming that the noise term can be neglected, it is easy to show that standardized proxies equal standardized local temperatures. So, running MBH algorithm with arbitrarily chosen (well, far apart) local standardized temperature records should be equal to running it with corresponding proxies. It would be interesting to see how this ‘noise-free’ reconstruction behaves when compared to proxy reconstruction. Of course, the comparison would be possible only for the long-instrumental period.
is the scale factor, b is the bias term, and n is the noise term. Using this model, and assuming that the noise term can be neglected, it is easy to show that standardized proxies equal standardized local temperatures. So, running MBH algorithm with arbitrarily chosen (well, far apart) local standardized temperature records should be equal to running it with corresponding proxies. It would be interesting to see how this ‘noise-free’ reconstruction behaves when compared to proxy reconstruction. Of course, the comparison would be possible only for the long-instrumental period.
If the proxies are proxies only for global signal, and local temps do not matter, then there should be some physical explanation of the teleconnections. References?
#15 if you can show you temperature curve fits the tree ring proxies used by Mann well then that is awesome. As for tellaconnection that is of course hand waving. I don’t think it is impossible for proxies with no apparent correlation to local temperature to act as global temperature indicators. However, it does seem like an unreasonable starting point without as you said some sound theoretical explanation of why this should work.
Actually though, thinking of tellaconections, if it is a principle that works then it should be much more effective if it is used to find a fit to grid cell temperatures first and then if the fits for grid cell temperatures are used to find a fit for global temperatures. So instead of applying Mann’s method to global temperate we can see the best fit to a singe grid cell using his global network of proxies.
If we repeat this exercise for each grid cell we should have a much better idea of how telleconected the proxies actually are.
About teleconnection: I don’t recall if this has been pointed out earlier, but although MBH9X is a NH reconstruction, it uses several SH proxies … including 7 tree-ring PCs obtained from proxies around 40S (listed in Corrigendum as ITRDB-SOUTH AMERICA,ITRDB-AUSTRALIA/NEW ZEALAND)!
#17
I’ve been wondering why the ‘NH’-term in MBH99 title.. Plotted the locations here
#16
Global temperature is the average of grid cell temperatures, right? So, without teleconnections, it would make more sense to try to fit proxy nearest grid cell, one by one. That would be quite easy using the equation in #15.
I’m trying to compress my MBH99 confusion to one single question, at the time it would be something like:
‘If you could replace the 12 proxies by 12 thermometers, would the results be more accurate?’
#19 The obvious answer is of course…..well at least if you use proper weighting.
The fact that he used southern hemisphere proxies is interesting. I am not sure why Mann used grid points as I don’t recall any fit to the local grid points. I personally would abandon grid points completely.
We are trying to construct the northern hemisphere mean which is an interregnal of the temperature over the northern hemisphere divided by the surface area of the northern hemisphere. Had man first fit the temperature proxies to the grid points and then averaged them he would of used a Crude Reman Sum to estimate the northern hemisphere temperatures.
Numeric integration works by dividing up the integral into regions small enough that we can approximate the integral of these regions with integrals of functions with analytic solutions. Thus the proper approach to the problem would be to identify an iterperolation function between the proxies and the temperature over the space we wish to integrate. If we wish to be crude we could divide the global up into triangular planes with vertices at the location of the proxies. If we wish to be advanced we could consider the topology of the earth in our interpolating function and sum up over much smaller regions then allowed by our proxies. If we wish to be even more advanced we could consider the uncertainty in our interpolation and perhaps use this to adjust the weighting in our average of surface temperatures.
Anyway getting back to proxies it is unlikely that proxies in the southern hemisphere provide much useful information in determining northern hemisphere temperatures. Thus for numerical reasons it would be unlikely we would use them when constructing an interpolation function for a region of the northern hemisphere. The only reason I see to include them would be to remove an unwanted common mode signal.
#19
#20
1) Define proper weighting
2) Remeber that MBH99 2-sigma is 0.5 C. You have to do better than that.
Long instrumental data would be useful in testing, but I couldn’t find the data (CA old topic here )
re #22: Central England Temperature. See also (for a comparision) Armagh Observatory Temperature.
This might be also useful: Northern Sweden temperature series (1802-2002), there exist also two long series by A. Moberg & co (Uppsala 1722-1998, Stockholm 1756-1998) but I don’t know if they are publicly available. The Haparanda (Haaparanta in Finnish), 66N (!!!) 24E, series is very interesting, see the location from a map! It should be a useful reference to any northern Scandinavian proxy.
#22 (UC) for proper weighting the proxies should be weighted approximately by the percentage of the geographic area they cover. Some adjustments could be made because some proxies are more accurate then others. However, the weighting should be know where near as unbalanced as it was for Bristle Cones in MBH98.
#23-24
Thanks! We need more, I tried 3 station average (your links + Calgary, no cherry picking 🙂 ). Reconstruction error 2-sigma for 1901-2002 is about 1.1 C. Need to find how many stations needed until we get down to 0.5 C.
#25
But thermometers are equally accurate, so only area-weighting is needed.
UC, I am not sure if you can get 2 sigma of 1.1 C for a simple average of temperatures because doesn’t the temperature very by about 20 degrees at least depending on the location.
Randomly picking temperature stations shouldn’t you get a one sigma error about?
20/sqrt(3)= 11.5470 degrees
However if we frame the problem as an estimation problem of T_global as
T1-E[T1- T_global]=T_global
…
Tn-E[Tn- T_global]=T_global
I would suggest computing E[Tn- T_global] from satellite data. The term should be computed assuming E[Tn- T_global] is ergodic.
http://www.ualberta.ca/~cdeutsch/images/Lec03-StatModels.pdf#search=%22ergodic%20statistics%22
That is sum{ Tn(i)- T_global(i), i=1…oo}= E[Tn- T_global].
We could even use satellite estimates to get an initial estimate of the noise covariance.
Let
Y=
[T1-E[T1- T_global]-T_global]
[…]
[Tn-E[Tn- T_global] -T_globa]
Then the noise covariance is
E[y y^T]
Again we assume the noise is ergodic and the initial estimate of the noise can be used for weighted least mean squares estimate of the global mean temperature.
#27
I used Temperature Anomaly approach, i.e. comparing to 1951-1980 mean. The graph is here. Clearly 3 is not enough, but is 12?