Subsequent to MM05 (GRL), the issue of covariance and correlation PCs as applied to the North American tree ring network was considered in Huybers [2005], our Reply to Huybers [2005] and the NAS Panel. It was also discussed in the rejected Ammann and Wahl submission to GRL. Juckes did not even cite the discussion on this topic in Huybers or the NAS Panel, but does cite Wahl and Ammann’s Climatic Change submission.
The story so far
Just to review the bidding, contrary to what one might think in reading Juckes, there are no actual differences between the parties in the values of the different series. There is a difference in terminology – I’ve referred to covariance and correlation PCs; instead of using these terms, Juckes uses the terms "centered " (cen) and "standardized" (std). The term "standardization" is also used in dendroclimatology to describe the process of making tree ring chronologies, so I think that the terms covariance and correlation PCs are more precise.
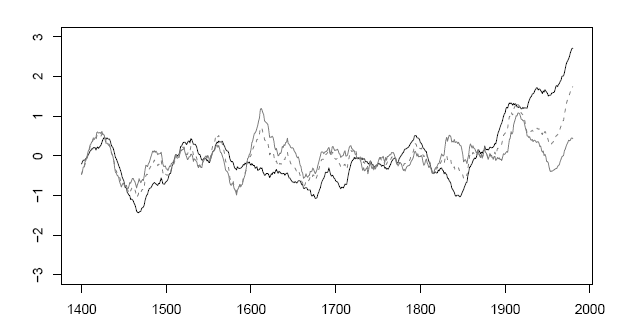
Here is Figure 3 from our GRL article, which compared the MBH98 PC1 for the NOAMER network with the covariance PC1 (which is what we had used in MM03 as the most plausible interpretation of "conventional" PC methodology in a network denominated in common dimensionaless units.)
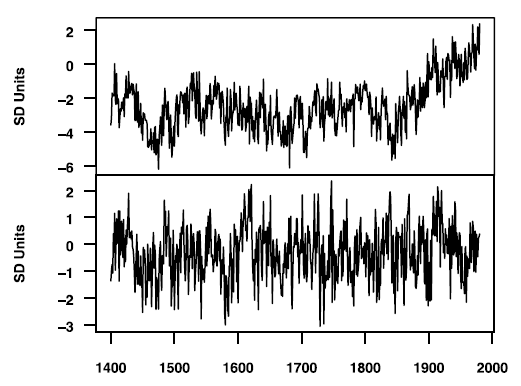
MM05 (GRL). Figure 3. PC1 for AD1400 North American Tree Ring Network. Top: Result with MBH98 data transformation; Bottom: recalculated on the same data without MBH98 data transformation. Both standardized to 1902–1980 period.
We’ve provided many supporting references for this interpretation – Overland and Preisendorfer 1982; Rencher 1992, 1995, 2002; North et al 1982. No one has ever provided an external statistical reference supporting the primary use of correlation PCs in this context. It’s not that we advocate covariance PCs as a way of making sense of the dog’s breakfast of tree ring chronologies; it’s just that that’s what an innocent reader of MBH98 would assume that they did based on their description of their methodology – just as an innocent reader would have assumed that when they said that they considered verification r2 values, the innocent reader would have assumed that the verification r2 values were significantly greater than 0. As we said in our Reply to Huybers, we neither endorse or oppose PCs as a sensible way of approaching the problem – the onus was on the original authors to prove the methodology. There’s been endless discussion of covariance versus correlation PCs. For now, I’ve excerpted the figure merely to show what we actually published.
Next here is a figure produced from the PCs archived at the MITRIE SI, plotted in the same way. Obviously the MBH series match, as does the covariance PC1 and the CEN version at MITRIE. I’ve added in the correlation PC1 in the same format.
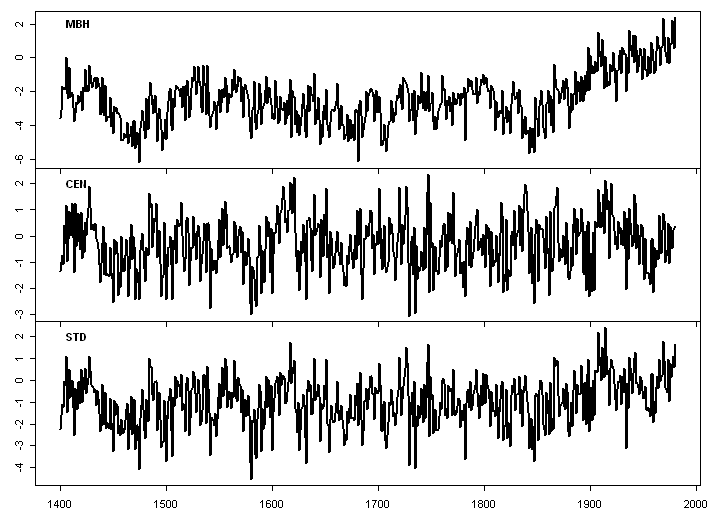
From Juckes archive. Series 16 mppc01_itrdb_namer_1400_mbh_01, 24 (mppc01_itrdb_namer_1400_cen_01), 22 mppc01_itrdb_namer_1400_std_01. Standardized to 1902-1980 as in MM05a Figure 3
Next, here is an excerpt from Figure 1 in our Reply to Huybers, showing covariance and correlation PC1s. Again, you can see that the series precisely match to Juckes’ versions, although you’d never know it from all the huffing and puffing. " Calculating standard deviations in autocorrelated series has some subtleties and just for fun, we also illustrated a PC1 calculated from chronologies standardized with autocorrelation-consistent standard deviations – which by chance produced something rather like the covariance PC1.
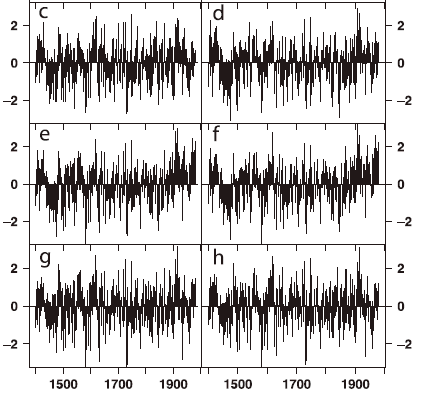
Reply to Huybers Figure 1 Excerpt. MBH98 North American AD1400 network. (c) Covariance PC1; (d) mean of all 212 series. (e) Correlation PC1; (f) mean of 70 full-length series. (g) Autocorrelation-consistent correlation PC1; (h) correlation PC1 with bristlecone pines censored.
In our Reply to Huybers, we discussed the various PC1s and observed:
The differences among these PC series can be traced to differing weights for bristlecones… Bristlecone impact can be seen directly by comparing the MBH98 PC1 (Figure 1a), which is weighted almost entirely from bristlecones, with an unreported PC1 from Mann’s FTP site (Figure 1b), which Mann obtained by applying MBH98 PC methodology while excluding 20 bristlecone sites (ftp://holocene.evsc.virginia.edu/pub/MBH98/TREE/ITRDB/NOAMER/BACKTO_1400-CENSORED/pc01.out). Given the tendency of the MBH98 method to yield hockey stick shaped PC1s (MM05), it is remarkable that this PC1 does not have a hockey stick shape. The correlation PC1 without bristlecones (Figure 1g) is virtually identical, showing that the actual PC method has little impact in this case once the bristlecones are removed.
This is a completely simple point and yet no one on the Team wants to discuss it. If there’s a problem with the bristlecones, then it makes no sense to say that a methodology that increases the weight of the bristlecones is the "right" method.
A Puzzle in the Juckes SI Figure
Now here’s a problem where I’m stumped and which illustrates why source code is a good idea. I’ve spent a lot of time trying to figure out this graphic. I know this material inside-out and I can’t figure it out. It’s a total waste of time when I could sort it out in a few minutes with properly annotated code. Here’s the figure:

Juckes SI Fig. 1. Proxy principal components: the rst principal component of the North American ITRDB network of Mann et al., 1998. (1) Using the normalisation as in Mann et al. 1998, (2) as (1), but using full variance for normalisation rather than detrended variance, (3) normalised and centred on the whole series, (4) centred only (5) as archived by MBH1998. 21-year running means.
Here’s my attempt to replicate the Figure using archived Mitrie PCs (mbh, mbhx, std, cen and the archived MBH98 PC1). The smoothing is a 21-year running average with end-point extrapolation (this is not disclosed but is used in the code in their MM05b Figure 2 Comment). Although the legend says that the PC1s have been "normalised", the series are obviously not centered on 0. I guess they are scaled on some subperiod, but I haven’t been able to figure it out. The worst thing is that I don’t see anything that corresponds to the covariance PC1. Juckes "cen" series ends higher than the covariance PC1.
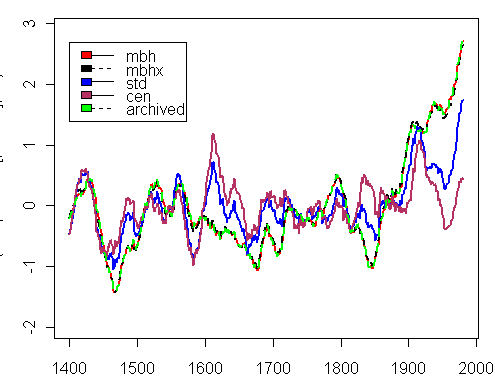
Emulation of Juckes SI Figure 1. All PC1s scaled on 1400-1980 period.
The odd thing is that Figure 3 in the Juckes Comment on MM05b Figure 2 seems to match my emulation. Here it is with its legend:
Comment Figure 3: As figure 2, but using a 21 year block average instead of Gaussian smoothing. Figure 2: As figure 1, but using the grey curve is generated using the “princomp” function instead of the “svd” function, so that the data is automatically centred. Also shown is the PC generated when the data is also standardised (grey dashed curve). As in figure 1, the PCs have been smoothed with a Gaussian weighting. Here the curves have also been normalised to unit variance. All these curves have, by construction, zero mean (prior to smoothing).
If anyone can figure it out, I’d appreciate it. I’ve tried 1856-1980 scaling and 1902-1980 scaling and neither seemed to work. I’ve archived the 6 relevant PC1 s here http://data.climateaudit.org/data/mitrie/mitrie.pcs.txt and a short script to produce my emulation figure at http://data.climateaudit.org/scripts/mitrie/si.figure1.rtf





81 Comments
Or perhaps you could ask the author?
“Normalisation” in the legend refers to normalisation of the data fed into the PC algorithm — this is obviously unclear when the legend is taken in isolation, thanks for pointing that out.
Its true that the PCs in Juckes et al. SI are not normalised — do you think the change in plotting affects the interpretation (the same question could be asked of your revised figure posted here http://www.climateaudit.org/?p=880, comment 83)?
Good morning Stephen,
I’m afraid I’ve been unable to replicate many of your McIntyre and McKitrick (2005, Energy and Enviroment) calculations because I can’t find the input data required by your code. I’d be grateful if you could tell me where to find the files referred to in ee2005.backup.txt as:
c:/climate/data/tree/northamerica.details.tab
c:/climate/data/mann/proxy4.tab
c:/climate/data/mann/proxy.tab
c:/climate/data/MBH99/hockeysticks.tab
In asking for the data I am not implying there is any obligation on your part to supply it.
#1. OK, Martin, you seem to have smoothed and re-scaled the archived PC series in some fashion to go from the archived figures to your SI Figure 1. Can you please explain what was the smoothing and re-scaling that you did?
In particular, what did you do to the CEN series to make it look like it does in Figure 4?
#3 and other posts on this blog (too many to quote here)
Martin would you not agree that unlike over at Climate of the Past and with similar proxy reconstruction papers published in Science/Nature, your paper is getting a good grilling (proper independent peer review) over here at CA? Perhaps you should recommend CA to some of your fellow paleoclimatologists as their papers would/will be better for it? I also hope that you will also acknowledge that despite opinions to the contrary previously expressed by your fellow HT colleagues that Steve M is most definitely an expert in this field.
May I suggest that you tell all your colleagues that if they are sincere about the need for and importance of truly independent peer review, particularly when their work plays a role in determining policy on climate change that they should seek comments on their work not on web sites like Climate of the Past or through private emails to fellow co-workers in the same narrow field but rather on blogs like CA.
KevinUK
I’ve made slight edits to the backup scripts to deal with these issues. proxy.tab is just the object proxy.MBH already loaded. proxy4.tab was a collation containing the sheenjek River chronology (ak033) used in MM03; I’ve modified the script to read in ak033 directly. hockeysticks.tab is just the R version of the table archived at GRL; I’ve modified the script to read this in. The details tab is just a collation of WDCP material.
#4 It’s a nice idea, but the problem with CA is that the signal-to-noise ratio is very poor and that the level of personal hostility directed towards climate scientists is often very high. Read some recent comments by people like John A and ask yourself if you would want to bother wading through such abuse when you could just submit to an open journal like Climates of the Past and do the refereeing in a perfectly acceptable manner that way? To his credit, McIntyre sometimes tries to control himself, but a sneering, hectoring tone often creeps through and it doesn’t exactly help his cause. Refereeing should be about matters of fact, not personal animosity.
I’m sure the US Hockey Team is out there somewhere, crying, “We’ve moved on.” I can’t quite hear it, but I know it’s out there somewhere.
Re #6
I must have missed this. Can you give me a recent example of “such abuse”?
#6 To take it a step further then, what ought to be the criteria/rules for an audit website that would be biased only toward advancing the accuracy of the science? I see benefit to the free-for-all on blogs like CA even though the noise often overwhelms the signal. However, useful audits must be more professional than school-yard name-calling. Is the wiki- concept under the guidance of moderators who understand their function and know their boundaries workable? Should moderators have to prove their worth through nomination and confirmation? Should there be a “professional” association of data and analysis “auditors”? Clearly, peer review has flaws that could be addressed by an independent examination of research.
Steve, perhaps there should be a new thread to solicit suggestions for the governing rules that make the process a bit more formal and “respectable”.
Look, I don’t say that blogs are a substitute for refereeing. The signal-to-noise is an issue especially for people that are strangers to the discussion. I can’t absorb all the posts and comments. So I wouldn’t expect a journal editor to wade through the posts to see what he thought. In a way, there’s a need for collations of some of these discussions.
However, I think that Juckes should wade through and participate in these discussions. There’s obviously a much more substantive discussion of his papers going on here than any referee will ever do. An author should desire substantive refereeing and discussion and he’s got an opportunity for that here. Whether he takes advantage of the opportunity is a different issue.
What’s amazing about academic refereeing (to me) is how trivial the refereeing is. I’ve hardly seen any referee reports that couldn’t have been written while watching TV.
As to tone, in threads that are about technical papers, I see little evidence of an unreasonable tone to the comments, although some people get excited in the general threads.
As to my tone, in this particular case, Juckes has made many disparaging remarks about us.
#6, Nick
“but the problem with CA is that the signal-to-noise ratio is very poor”. Well that’s most likely because the main subject of this blog is proxy reconstructions which also have a very poor (some of us think virtually non-existent signal) signal-to-noise ratio. Would you care to recommended other web sites/blogs where in your opinion the signal-to-noise ratio is high? I wager you’ll be hard pressed to find any other web sites/blogs where the quality of auditing (done largely bu Steve, Willis, bender, jean S etc is better than it is here at CA.
Now given what has occurred in the past in regard to the HS, climate change alarmism etc it is understandable that any climatologists who venture onto this blog are bound to be asked questions about their previous work and statements in the MSM. In particular they are bound to be asked to justify some of their claims as has been the case recently during Isaac Held’s and Judith Curry’s visits to this blog. As Martin Juckes is hopefully now finding out there can be pluses as well as negatives. Any scientist worth his/her salt will encourage criticism of their work. If their work is sound then they should be confident enough to defend it against rigourous review.
It is in the nature of discussion forums/blogs and politicised subjects like climate change that such dialogues will on occasions become heated. Provided discussions do not descend into lowest common denominator ad hominem attacks then heated debates are a plus in my opinion and not a negative as you suggest.
KevinUK
#3: OK it is also true that the axes label is incomplete: it should be “normalised then smoothed”. I think what you have plotted above is smoothed then normalised? Smoothing in the manuscript and supplementary material is without padding, resulting in shorter time series, smoothing in the comment on McIntyre and McKitrick (2005, EE) uses padding as used by McIntyre and McKitrick to maintain record length.
#5: Thanks, looks as though you’ve answered my questions there.
#4: There was a lot of agression in the first couple of days, which might have been influenced by the “Potential academic misconduct” banner Stephen used to start the discussion. I’m glad that the final editorial decisions will be taken by a slightly more impartial group of people. The level of agression appears to have died down a little, which is obviously a good thing. Another problem, from my perspective, is the number of different threads started up on closely related topics, so that people get indignant about questions being unanswered when the answer is just on a different page. I reckon the structured approach of CP is essential if the decision making process is going to be transparent. This site certainly reaches a broader audience, which is a good thing as far as the present topic is concerned.
#12. #e. Look, my primary concern is what you did. How hard is it to simply say what you did in SI Figure 1. If you don’t want to provide code, I can’t make you, but then:
a) what series did you use for the 5 series shown – could you provide reference id’s back to: mitrie_new_proxy_pcs_1400_v01.nc? In particular, which series is the basis of the plot shown as CEN?
b) the PC series in Figure 1 are not centered on the 1400-1980 period. What period are they centered on?
c)Did you use the same period to re-normalize the PC series? If not, what period did you use?
The plot that I did above is normalized then smoothed (as shown in the little reference script.)
#12, Martin
Thank you for your reasonable reply to #4. Do you agree with my question, namely that you are getting far more and better feedback on you paper on CA than you are ever likely to get on CotP? Does this say something about the whole peer review process of scientific papers and not just those on paleoclimatology? I think it does. Much as the usefulness of blogs (and wikis) are currently denegrated by the media and some scientists, I think in the fullness of time they will become a standard tool in the whole peer review process. In that respect, I think Steve M is a trail-blazer.
As a slight aside, I’m an ex-UKAEA employee who has visited and on occasions worked at the Harwell site (as you do?). As an ex-nuclear scientist I had to develop a pretty thick skin. I know what it’s like to turn up for work to find an angry crowd of protestors outside you office with plackards. It was a much hairier experience than being criticised on this blog I can tell you. Nonetheless thank you for having a thick skin in regard to this blog and please keep visiting and contributing to the debate. A final (polite)request? Please remove that unjustified critiscism of Steve M from your paper. If/when you do, we will all think better of you for it.
KevinUK
PS What do you think of the Diamond Light facility?
#8 Can you give me a recent example of “such abuse”? – John A
How about your comment in the thread “Potential Academic Misconduct by the Euro Team”, where in response to McIntyre’s post you wrote “I guess there are only so many lies you can take, Steve?”? Here you are directly accusing Dr Juckes and colleagues of lying. I would call that abuse. There are other similar examples.
A good rule is to say nothing on the internet that you would not say to someone in person. Now it may well be that you spend your days going around calling people you meet liars and worse to their faces, but I hope that is not so. People who behave like that are often not very happy in life.
Dr Juckes and his colleagues work in a fascinating and important area of science. I believe they are genuinely motivated by the desire to learn about the world and to do good work. I would do them the courtesy of taking that as my starting assumption in dealing with them. Maybe you should too.
RE: #6 – there is not hostility toward Climate Scientists as a class. However, there is disgust for the subculture of those who attempt to be both Climate Scientist as well as hard core political activists using their station to promote radical Green extremism.
Re#15-
What does your rule say about people who post comments on internet sites implying that specific people are unhappy in life? Or do you go around calling people that you meet unhappy to their faces?
Yes, the signal-to-noise ratio can get messy here. On the other hand, the commentary/behavior of a certain climate scientist acting as reviewer was pretty disgusting as discussed on this site in places such as here. I’d say there’s a lot of “noise” in there.
And certain climate scientists themselves have spoken through websites, to peers, or to the media with pretty nasty ad-homs and lies and such about people such as Steve M. According to Steve M’s accounts, some of these people did not make these nasty assertions when they met him in person. Are you suggesting these climate scientists are also “unhappy in life” despite working in “a fascinating and important area of science?”
Re #13: No problem, sorry I missed out two details: the plot in the supplement is made by normalising the uncentred PCs (this only affects “MBH”, “MBHX”, and “Archived”) whereas your code centres first and then normalises. I’ve checked doing it this way round in my code and I’m fairly sure that it explains the difference in amplitude of variation in the plots. As in the manuscript, plots are centred on the calibration period — because the proxies should be centred in this way before input into the regression algorithm.
Re #14: Certainly more, not sure about better. The focus here is, understandably, concentrated on issues that have exercised Stephen in the past and left other aspects of the paper untouched. But that doesn’t mean it isn’t a valuable exercise.
Concerning Harwell, we are next door at the Rutherford Appleton Lab. Diamond Light looks great from the outside and by all accounts lives up to appearances on the inside, though I haven’t been in.
re #17
And, indeed, that was and is Steve M.’s reason for beginning this blog in the first place since he was unable to respond to such things directly because of being blocked from posting on the offending blog.
I’ve been posting on political, religious and scientific blogs (and their forerunners) since at least 1992 and CA is by far the most polite and has the highest S/N ratio of them all. (Religious sites are often the worst and not solely from the anti-religious side, I’m sad to say).
Re 13#: Sorry, I forgot to post the ids of the series plotted:
mppc01_itrdb_namer_1400_mbh_00
mppc01_itrdb_namer_1400_mbhx_00
mppc01_itrdb_namer_1400_std_00
mppc01_itrdb_namer_1400_cen_00
re: #20 Sigh!
And here I purposely chose not to mention trolls to avoid stirring them up!
RE: #20 – there is a such thing as the honest Left. You know that, right?
Re # 10.
‘What’s amazing about academic refereeing (to me) is how trivial the refereeing is. I’ve hardly seen any referee reports that couldn’t have been written while watching TV.’
That is not my experience and I don’t think it is true in general. True, some of the referee reports are not so valuable but till now at least one or two
of the three reports I receive of a submitted paper are valuable and result
in a significant improvement of the paper. Your sample is probably I bit to small. Furthermore, you forget that the task of a referee is not only to check if the analysis is correct but also to see if the paper is suitable for the journal, if the material is relevant and new, and if simulations or experiments are carried out properly. You need to have a proper background in the relevant research field, otherwise you cannot judge this properly.
Academic refereeing does perhaps not prevent bad publications. But what is a good alternative?
re: #21
Since it now has no reference could you pull that post of mine (#21) and this one as well? Also it would be useful to get rid of Steve S’s post since it now sounds like he’s accusing Martin J of being part of a dishonest left.
Re: #15, Nick
you might want to have a look at this, or this, or this for some “interesting commentary” by Michael Mann. WRT martin Juckes, you can have a look at this to see “…papers by McIntyre and McKittrick,… which have little credibility in the scientific literature…”.
I have to say I am a little bit surprised; if someone published a comment about you in the open literature, and that comment was (publically verifiable as) untrue, and defamatory; what would you do ?
I find it difficult to relate to your portrayal of climate scientists as saints. Some people “are genuinely motivated by the desire to learn about the world and to do good work“, but whatever their motives, that is no excuse for when they behave disgracefully. You may wish to read up on some of the really rather surprising behaviour of climate scientists that is documented on this site.
yours
per
re 23 on academic refereeing
Tim Berners-Lee’s first paper on the web was submited to the Hypertext conference. It was rejected. The next Hypertext conference was dedicated to the web.
Other developers of signficant technologies have posted reviews suggesting rejection of their papers on their office doors. In my own case, I have received reviews which caused me to wonder if the referee had read the paper or not. They were reviewing something quite different than I submitted
Nick
I should also be clear that there is a lot of background here. The fundamentals of scientific process is that data and methods are fully described, so that other people can verify results.
Steve has been working on this since 2003, and has seen many examples of people who point blank refuse to provide details of the methods or the data in their published papers. Some people even boast about the fact that they censor original data.
I would characterise behaviour like this as poor, and inimical to the scientific agenda; but I have not had to deal with this as the central issue of my science. If steve is occasionally annoyed, I can tell you that there are several years of archives, and some of the behaviour that is lovingly documented is simply amazing. You could have a look at this; it would be almost impossible to guess that the excoriating criticism of M&M2003 was shortly to be followed by MBH releasing a corrigendum in nature which accepted that there were errors in their original publication.
yours
per
Re #15
I said that there were only so many lies that Steve could take, and Steve has been on the receiving end of quite a few blatent lies by Hockey team members.
I’m sure there are quite a few examples of me calling ’em as I see ’em, but unless I’m making a habit of accusing people who haven’t made misrepresentations of facts, then I’m afraid I can’t see your point.
But I have said those things in real life. I have called people liars to their faces when I have incontrovertible evidence of their intent to deceive.
More importantly, why should I accord such people some sort of special dispensation to not tell the truth that I expect from anyone else? Does Climate Science have its own "Get Out of Scrutiny" card that I’ve been unaware of?
Oh please, give it a rest. My starting assumption is that everyone, including scientists, can shade the truth for varying reasons. I assume a neutral position, hearing what they have to say, and verifying things I’m not sure are correct. I’ve checked quite a few of Steve McIntyre’s statements and he’s checked some of mine and yet we trust each other the better for it.
"I believe they are genuinely motivated by the desire to learn about the world and to do good work."
Aren’t we all? I’m motivated by the same desire every day. Does this make me or Steve any more or less trustworthy in what we say? Should people take a neutral, positive or negative aspect to anything Steve says? I take a fairly neutral stance on most things that people tell me unless I can verify some of it.
I think the real reason is that I refuse to hold scientists in general and climate scientists in particular with some sort of transcendental awe, even though I respect and greatly treasure the achievements of science and the scientific method.
I’ve just had a couple of scientists twit me over something I’ve written which criticized them, and yet they’ve managed to not take a direct hit to the ego. Somehow, life goes on.
My reading of science history is that there are many scientists who were great in one field but hopeless and out of their depth in another, yet expected just as much acceptance of their authority regardless.
My reading of climate science is that there is a star system, and there are some monster egos as well. It’s quite like baseball in lots of ways.
Hi,
I have been following the Hockeystick saga from the beginning with great enthusiasm, and continued eavesdropping on both CA and RC to get all the naughty details. It’s been fun, and now I think its time to use my overly powerful ability to abstract and shed a few words of wisdom.
First, if we disregard all the slinging of badly disguised academic euphemisms of profanity I think it is fairly obvious that we can summarize what has happened over the years since the EE-article as follows: 1) climate science had and still has a fairly low standard of auditing and quality control. 2) SteveM (and RossM), coming from industry where research actually has life and death consequences for companies, injected a highly needed wakeup-call avout the very lax state of affairs in climate science. 3) This resulted in the equivalent of being thrown directly from little league to National Hockey League, resulting in many scientists fighting desperately to hide their previous inadequacies. 4) After the dust has settled the result is that climate science is moving forward, the hockey teams are slowly learning to play fair. Data and code are far more available than previously and this is surely improving the productivity of quality control.
Prior to the global warming scare there wasn’t really any need for intense auditing. Why? because the results really didn’t matter that much. Most of the time the work being done was honest and crafty, and peer review weeded out the worst. So what if a little error crept in every now and then? It might take a few years but eventually the scientific process gradually weeds them out. That all changed when global warming became a multi-trillion problem. When literally trillions of dollars are on the line, auditing and quality control becomes an absolute must. Little league is simply not good enough for this kind of challenge. All of a sudden the fate of trillions of dollars were in the hands of a lax peer review process, so-so statistical expertise and a thoroughly out of date set of proxy data. That’s just not acceptable, and this is precisely what SteveM and other climate auditers have made us all painfully aware of. You do NOT make life and death decisions on the toss of a coin.
But enough about the past, where do we go from here to improve the state of the science? I’ve been thinking about this quite a bit and have identified a couple of very serious issues that seem to be hampering productivity: data availability and code/procedure availability. It is simply horrible that it takes months and even years of nagging to get hold of data and code. That’s not acceptable. How do we solve this? As in so many other places the answer in my view is private property.
What stops scientists from giving up their data and code is primarily the fact that they’ve put a hell of a lot of work into it, only to see it being used by others without compensation. By creating an international system of intellectual property rights for scientific data we solve three problems in one: 1) data becomes available to everyone, 2) it now PAYS to do really good science and make data available and 3) funding becomes disentangled from special interests, like the industry or the government. Good research becomes funded by everyone who uses it, including opponents and critics.
But what kind of intellectual property are we talking about here? Clearly it cannot be patents or copyright because both of these put too strict terms on usage. With patents and copyright you can actually refuse people you don’t like to use the data. Clearly that defies the whole purpose. If you make a public claim about something being true then obviously people need to be able to verify those claims, otherwise you are producing fiction, not science. So I propose a new kind of intellectual property that pertains to claims of truth.
This new property type should have conceptual elements from both copyright (pertaining to data) and patents (pertaining to method). The new property should to secure attribution and monetary compensation, but not generally to limit usage. In fact, in order to obtain such a property protection one must make the data/methods available according to some agreed upon standard. This means: openly available repositories, well-defined standards for data sets and scripts/code/processing/methods.
Ultimately this should totally reshape the peer review process and scientific publishing. By writing a scientific paper as not just a verbal recipee for others to meticulously reconstruct by hand but as an automated press-a-button-to-reproduce-the-results electronic document, the productivity of peer review and auditing is increased by orders of magnitude. Obviously this will dramatically improve the quality of the scientific process and will raise the bar for what is considered good science.
Martin Jukes, so refreshing to see you here. Much better than the offhanded comment “…The code used by MM2005 [the GRL article] is not, at the time of writing, available, ….” Is this really so hard?
I look forward to much more of your input, if it does not unduly interfere with your important work. Do you have any recommendations of other blogs or web sites that you feel do a particularly good job of critically discussing the “science” of Climate Science.
Like many others here, I am a layman who does not deny there has been warming, but is agnostic regarding AGW and wish only to learn. I am particularly interested in the level of certainty with which claims can be made. This is particularly true because as a taxpayer, Sir Nicholas Stern and others seem to be sending me rather large bills. Thank you.
Re#29
They ARE compensated for their work. My profs back in the day didn’t get paid $75k for just teaching a few classes per week – they got paid for the research results.
Now maybe climate science is a poor example, so take a nuclear physics researcher. When he/she gets to use university facilities, university funding, etc, to come up with something groundbreaking, is it really his/her property? And what if the university is a public state university?
If scientists want to keep their data and code private, maybe they should fund all of their research themselves.
And it’s not like climate scientists are finding cold fusion or the cure for cancer. Their data and code is typically relatively basic programming stuff. It’s not like Dr. A is going to take Dr. B’s code and sell it overseas or something as a software product. It’s just there for duplication and auditing.
re 29: Sounds like ASCAP for scientists.
This is really quite brilliant. A graduate student could be paid well to “Bring the proxies up to date!!”
#18. Martin, the reason why I’ve tried to get code from people is simply because it’s impossible to read people’s minds. Here are more missing details – this is on just one diagram and this still doesn’t work.
Here’s your SI Figure 1.
Here’s what I’ve got based on what you’ve said so far, the best that I can understand it. First dividing all series by the standard deviation during tghe period 1400-1980; then centering all series by their mean in the period 1856-1980.
I’ve posted up my script for this diagram here – scroll to the end. Feel free to annotate the script to show how you got your diagram. The real mystery is that none of the series in your diagram have a similar shape to the archived "CEN" series – and all the scaling and centering in the world isn’t going to change this.
Here’s my guess as to what you’ve done and it’s only a guess:
1. What you’ve labeled as the CEN series looks like it’s actually the STD series.
2. What you’ve labeled as the STD series looks like the MBH series.
3. You don’t actually show a version of the CEN series, which lacks an uptick of the type shown by all the series in Figure 1. What you’ve labeled as the mbh/archived series also looks like it might be the MBH series scaled differently than in (2), but this is just a guess.
Re #30: I’m afraid I can’t help you on which blogs to read. For the basics of global warming I’d recommend reading “Atmosphere, Climate & Change”, by Thomas Graedel and Paul Crutzen.
Dr. Juckes,
Just a note to say that I am very glad to see you here working to clarify your methods to Steve, code or no code. You can imagine how time-consuming it would be for an auditor to try to re-create these reconstructions with no formalized recipe for the reconstruction method. It’s absolutely daunting.
Your participation here is not only helpful, it serves to illustrate the broader need for us to work together to figure out what’s going into these recon soups that are being served up on a near monthly basis. The public has a right to know the science behind the policies that affect them, and academics have an obligation to disclose that science. Those academics who don’t share this view should get themselves out of the policy arena and off of the public purse.
Again, thanks very much for your co-operation.
Try normalising by the rms.
#36. Martin, this is getting very annoying. I said that I divided by the standard deviation over the period 1400-1980. You said to try “normalising by the rms”. I am baffled as to how this makes any difference. Wikipedia for example says: “The standard deviation is the root mean square (RMS) deviation of the values from their arithmetic mean.” Dividing by the standard deviation is, as far as I’m concerned, “normalising by the rms”.
Also this has nothing to do with the seeming mis-labeling of the series in your graphic. None of the series in your graphic has a closing endpoint lower than the peak around 1600 in some series. While in the CEN series, the closing point is below the peak around 1600. This feature is not going to change with scaling and centering. Similarly if you compare the appearance of the series, the statements below seem to be correct. Please comment.
Your wikipedia definition of standard deviation is correct. Rms is not the same as rms deviation from the mean. Try normalising by the rms. The graphs are not mislabelled, you’re just having trouble with the normalisation.
In your paper, you refer to series as being "normalised to unit variance (standardised)". If I’m having trouble with the normalization – and I know this stuff inside-out – what the hell do you expect ordinary readers to do? Can you provide me with a reference describing your "normalising by the rms" procedure so that I can try to replicate what you did? I’m tired of guessing.
better yet, why don’t you archive the frigging code? You’ve been funded to do that and now you’re playing these stupid games.
#39. OK, folks http://www.ece.unb.ca/tervo/ee2791/vrms.htm discusses rms in the context of voltage. This is integral of the squared signal divided by the length of the period. So if you have de-centered methods – which Juckes is trying for some absurd reason to salvage – you get a different normalization factor. I don’t think that this is going to cure SI Figure 1, but I’ll give it a go.
How the hell anyone would ever know that this is what he did – if it’s what he did- baffles me. It’s taken how many posts and responses to winkle this info out?
Perhaps part of the problem here is that what one group considers standard lexicon the other considers insider jargon. I see this all the time in my work when equally credible but distinct scientific cultures occasionally collide.
Dr. Juckes, please recognize that Steve M, though not an insider, is very competent if the language is clear.
I know it is hard for each of you to be patient with the other, but let’s try to separate the personal stuff from the professional, and focus on getting the recipe correctly transcribed. The sooner we’re on the same page, the sooner we can get to the real interesting part of experimenting with different recon soup seasonings to get different flavors.
#41. bender, whatever its merits, I’ve never seen the use of “rms normalization” in multiproxy studies and its use is not mentioned. But be that as it may, I’ve figured out SI Figure 1 and posted separately. It’s a total cock-up.
re: #40
Huh? What would a rectified voltage have to do with a climate proxy? We’re not trying to calculate power used or anything similar. We want to see if temperatures are rising or falling. Further, let’s say we have the following data points: 1, 1, 2, 5, 1. then sqt(sum (x^2))= about 2.53 compared to an pure average of 2.00 That’s fine if you want to emphasize the high points, but then it all depends on what you’re using as your 0 point. If you add one to all five pieces of data, do the RMS and then subtract one you get 2.37. So how is this supposed to work if you don’t set something like the mean to compare things to?
BTW, forgive me if the above just reveals my deficiencies in matters statistical.
Re #32: James, you’ve totally got it.
Re #31: Michael, see #32. 🙂 You’re absolutely right that technically professors are paid to do this stuff, but technically the government is paid (via taxes) to provide welfare services in a social democracy, and you can see how well that works. The point is: the whole system is rotten because all universities are government funded and all professors receive all the salaries in advance and have no incentives to go the extra mile. In a privately funded system based on private property there is tremendous economic incentive in addition to the scientific. And I’m not just talking about the professors here, but also the universities and research centers, which are equally part of the problem. Some universities might want to pay their professors, say, $40K + revenues from publications and results. The university could have a standard fee of e.g. 25% ownership in the publications to fund their own basic operations, and higher fees for the usage of special, expensive research equipment. In this way all the parties have an incentive to do a good job.
Funding for basic research would then become part of the general funding of universities. Universities should ideally not receive a dime from governments but rather get all their income from attending students and from private sponsors. Private sponsoring could be done in two ways: 1) a low cost sponsorship in which the university retains all/most rights to the results and publish them openly in the repository system discussed in #29. 2) a high cost sponsorship where the results are not published but remain the priviliged information of the private sponsor. 1 is the preferred model for general claims of truth, 2 is the preferred model for technology.
Of course, I’m getting ahead of myself here now. All of this is not needed to implement the core idea, namely a system of property rights for truth claims.
Glad you got there in the end Stephen, though I’m surprised you couldn’t decipher the wikipedia definition.
Martin, now that you’ve made Steve jump through all of your hoops to finally be able to reconstruct your SI Figure 1 … I certainly invite you to comment on the manifold problems that Steve has identified in the SI Figure 1 here.
Also, now that we have clearly established that both Indigirka and the Sargasso Sea proxies fit your criteria (they must extend from 1000 to 1980), I trust that you will amend your study to include them. You said the only reason they were not used was that they didn’t fit the criteria … but they do. In addition, they make a significant difference in the outcome, and thus cannot be ignored.
Finally, you have never answered the question of why you chose the particular versions of Polar Urals and Tornetraesk.
Because you left out proxies that fit your criteria, and have chosen proxies without a priori rules, at present, your study is merely an ad hoc collection of proxies, without statistical significance. You have cherry picked your proxies, which is not science, just an exercise in promoting your point of view. However, you do have a chance to right the ship before it sails …
I look forward to your answering the questions about your SI Figure 1. And finally, I commend you for your participation here. In a few days, we’ve found more errors than a year of reviewers might find. Rather than cut and run, you have hung in and discussed some of the issues.
w.
PS – You should just cut the reference to the data issues with Steve M. out of your paper. I say this because it will at least disguise the fact that you have still not commented on the egregious, ugly, and repeated data and methodology concealment done by Briffa, Moberg, and Esper … or you could put something in the paper about their very serious scientific infractions. In any case, the issue will not go away, and you’re not on the side of the angels in the position you have staked out. You need to consider your options carefully. At present, there is no blot on your reputation … but if you continue to try to bust Steve without cause, while ignoring your co-authors’ problems, your reputation will take a severe blow.
This web site gets about a million hits per month, lots and lots of people are following your story. If you don’t deal with these problems, lots of your friends (and enemies) will read about it. Is that really the outcome you are looking for?
Re #45:
Prof. Juckes, like Dave in #43, I am surprised that one uses a waveform standardisation instead of a simple standardisation by dividing with one standard deviation. If all series are supposed to be linearly correlated with temperature, why should one use something that is related to waveforms?
It doesn’t matter much for the actual comparison (except for the amplitude differences), more important is the unanswered question of Steve that the series themselves are mislabeled…
See #38: the graphs are not mislabelled.
The normalisation has nothing to do with waveforms, this was a gratuitous diversion introduced by Stephen. RMS is an abbreviation for root-mean-square, that is the square root of the mean of the squares of a series. This is different from the standard deviation which is, as Stephen’s quote from wikipedia makes clear, the rms of the departure from the mean. As standard deviation and rms are different quantities, Stephen’s statement that he regards normalising by one as equivalent to normalising by the other is very strange.
Martin,
I’m not fully up to speed on this so I might have made a mistake but if you consider the following two procedures:
Proc 1:
* Centre series (subtract mean)
* Normalise by RMS
* Decentre series (subtract mean of limited period)
* Apply PCA
Proc 2:
* Decentre series (subtract mean of limited period)
* Normalise by RMS
* Apply PCA
As you can see, Proc 1 is equivalent to normalising by the standard deviation. I assume this is the misunderstanding Steve made. To be fair to Steve, you weren’t really clear enough in your description of the process (you should have made it more clear exactly where the normalisation takes place). This is why provision of code saves a huge amount of time and effort in the long run (in spite of the additional time required to do this).
You may argue that you would describe Proc 1 differently to Proc 2 but then Proc 1 seems to have a clearer physical meaning than Proc 2 (I am struggling to see the physical meaning of the temperature power density related to an arbitrary mean period myself), so a reader may well naturally think of Proc 1 first.
Steve,
How about using Prof. TAPIO SCHNEIDER’s code for filling in of missing values in a dataset by using the EM algorithm (Expectation Maximization). Tapio had informed me that his codes is used by Prof. Michael Mann. His paper and his Matlab codes can be downloaded from here:
“Analysis of incomplete datasets: Estimation of mean values and covariance matrices and imputation of missing values”
http://www.gps.caltech.edu/~tapio/imputation/
You have a nerve, Juckes!
I’ve examined your qualifications and I’ve examined Steve M’s qualifications.
You come in here taking a lecturer’s tone with a man who could tie you up in statistical knots before you’d even put your shoes on in the morning.
You have a choice: gain some humility or prepare to be the new Mannomatic.
Your arrogance is breathtaking. Your self-assurance, misplaced.
I indicated to you in another post that you should be very certain that your study was robust, because Steve and Ross were not good people to goad. You replied that you certainly hoped it [your study] was robust.
Trouble is, it looks increasingly like your study is a “Mannomatic, with fries”.
Your proxies are Mann’s. Esper’s, Hergl’s, Moberg’s are all, basically, Mann’s.
Should Mann fall, they all fall – including you, because you have done nothing, as I understand it, other than re-work the same data/proxies used in prior studies.
If Mann falls, you fall.
You think you’re smart, pinging Steve on minor coding/archiving issues.
Can’t see the forest for the trees, Martin – Steve did his best to archive accurately, but made the odd mistake. Your good pals – Mann, Esper, Jones, et al – pulled a complete Oracle of Delphi number [this is what my data says…but you can’t see my data, nevertheless, you must believe!].
Honestly, I’d love to have you in the dock – I’d tear you to shreds within the first minute. It’s a shame that scientific forums don’t take a lead from legal ones.
What original work did you do? You re-worked old data sets.
What does your work add to human knowledge? The knowledge that, if you re-work the same data sets (with minor variations), you get the same results.
If Steve and Ross cannot get access to the original data and methodologies, but you can create a study based on that same data and methods, how did you do it?
Did you have access to their actual methods and data, or did you just trust that they did it all correctly? [Do you know something that prestigious journals do not? ie. The Hockey Team’s data and methods?]
As you didn’t archive the Mannomatic 98, nor other similar, undisclosed studies/methods, we assume that you did just that – assumed. Scientific method? Or Voodoo?
I could go on, but this post is far too long.
Mann is discredited in the eyes of serious scientists – if not for his publications which re-write history, then certainly because he refuses to release the data on which they are based. In every field of endeavour, other than climate science, that equals laughing stock.
In short, Martin, if your study fundamentally relies upon Mann (which it undoubtedly does), it inherits Mann’s failings.
Mann, flawed = Juckes, flawed.
#45. MArtin, in deference to your concerns about trying to wade through a number of threads, I’ve collated issues onto the thread Juckes Omnibus and invite you to reply there to any specific issues so that your responses are in one place. If you wish to comment on individual threads, you are of course welcome.
I’m sorry but that’s just rude.
#51 you hit the nail on the head. And we have come to the conclusion that all of these climate scientists actually believed nobody would ever check their work in any detail. That’s why they behave so STRANGE when it is checked in detail.
Juckes never mentioned dividing uncentered series by their rms in his article. I’ve never run into this procedure in any proxy article. Juckes does it for uncentered series in a step where even Mann standardized by dividing by the standard deviation. How anyone was supposed to decode this from the article baffles me. And yes, I agree – for Juckes to put on airs, after playing this little game, is pretty annoying.
However, the next part of the story is why Juckes introduced rms normalization. Juckes gave no explanation or rationalization of this. I’ll try to figure that out.
In the context of Burger and Cubasch 2005, does the “new” normalisation process represent a further 32 flavours (NB: not 64*2, because the new process should have no effect on the centred case)?
If so, there is a question for Martin Juckes:
Do you have a substantive reason as to why this normalisation process should intrinsically improve the robustness of the MBH method? If not, surely fixing the already broken 64 flavours should be the priority before adding another 32?
RE: the RMS.
http://planetmath.org/encyclopedia/RmsError2.html
So the RMS of a sample is equal to the sq. root of the variance?
#56 Following your link it appears that they are only the same if the sample on which they are based contains no bias.
Sample standard deviation s is
but as an error measure this is not a fair one, because it removes the sample mean. That’s why rms,
is commonly used with measurement errors, i.e. for rmse =measurement-true value. I don’t know why rms should be used for normalisation, but maybe we’ll find out.
=measurement-true value. I don’t know why rms should be used for normalisation, but maybe we’ll find out.
Just to note my comment #55 is irrelevant, I had originally thought the normalisation was being applied prior to the PCA to produce the PC1, rather than just rescale it for plotting purposes.
When plotting temperature anomaly, the mean bias error is not relevant because the use of anomaly (vice absolute temperature) eliminates the mean. One could argue that when cross-comparing two temperature anomalies, the uncertainty on where to place them on the Y-axis relative to each other implies that there is a mean bias discrepency between the plots (if only Hansen considered this, eh?); however, that in itself is no justification for rescaling by the RMS, the only relevance I can think of would be a reason to incorporate such a term into the confidence limits when cross-comparing two series.
re: #58
But how do you decide what the “true value” is? In climate we’re not dealing with some area of science where we can calculate a true value from theory which we then compare with the measured results.
Surely they’re not saying that we can use the instrumental record as a “true value” which can’t be questioned, are they?
re: #57 – the actual bias is indeed a mix of factors. However, the term “unbiased estimator” is related to whether the expectation over all sample space equals the parameter in question. It’s why the standard deviation of a sample given by the 1/(N-1)^(0.5) factor is unbiased whereas the 1/N^(0.5) version is biased.
Just to add: there may be some confusion here between biased estimators and bias occurring in measurement. Biased estimators will be inaccurate regardless of the accuracy of the measuring device.
re #58
Yeh – that’s the RMS. I guess the example I gave is the RMSerror. Which is the same as s.d. Is this what was meant?
#60
Yes, at least the reference data should be clearly more accurate than the measurements. Maybe
http://www.cru.uea.ac.uk/cru/data/temperature/HadCRUT3_accepted.pdf figure 12 gives some idea whether this condition is satisfied or not.
re: #64
Thanks for the link. How can they figure the sea temperatures are more accurately known than the land temperatures? And the dismissal of urbanization just won’t fly. Their figure is .0055 deg C per decade or .055 degree last century. I think they just came up with the method to get the results they wanted. Admittedly this figure was for the whole globe which includes a lot of ocean and uninhabited land, but I suspect there are other effects, such as lower error bars which come from their uniform treatment of urban heating.
#64
Scafetta and West (2006b)
Compare and contrast with Brohan, paper in #64, who has published a lot with Jones of the Hockey Team. Wegman was correct about the network. The paper in #64 is an attempt to rule out “urban heat island”, and error from any increase in temperature, increasing the odds of CO2 alone being responsible.
#66
Since you mention Scafetta, I recommend reading his work, which is highly interesting. See his web page where you can find PDF’s of his papers.
He comes from the field of nonlinear physics, developing tools to analyze chaotic time series. That’s how he became interested first in the sun’s turbulence behavior, and then on its effect on our climate. Not coming from the climate science community, he has a fresh approach to those problems that makes a lot of sense, and goes much further than the usual linear correlation analysis we see all the time. Here’s from his web site:
#66 A fresh approach as you say
Link
RE: #68 – This is precisely the sort of thing I had been wondering about vis a vis solar cycles / variation as a forcing with potential significant knock on effects.
Re #68
While I am a fan of the solar-climate connection, far more influencive than what is currently implied in climate models, I disagree with the total CO2 increase as result of higher temperatures.
The ice core correlation between CO2 and temperature is ~10 ppmv/K, one-way. That means that a change in temperature of ~1 K (like the MWP-LIA transition) removes about 10 ppmv from the atmosphere (as smoothed in ice cores, real short-time variations may be larger). The LIA-current temperature increased again with ~1 K, thus should have given a change of ~10 ppmv extra. In reality the high accumulation ice cores (like Law Dome – inclusion at ~60 years) show a continuous increasing CO2 change of ~70 ppmv since the start of the industrial period. Thus only 10 ppmv of the 70+ ppmv may be the result of the increased temperature. The discussion that started in september between me and Richard Courtney is not yet settled, but is going on in private, with him and the other authors of their book with the same point of view.
Basic is that, in my opinion, no other explanation is possible than that the increase of CO2 in the atmosphere is caused by humans, if one takes into account that
1. CO2 levels increase in the atmosphere and the upper ocean layer.
2. The 13C/12C composition in the atmosphere and the upper ocean layer decreases (fossil fuel contains more 12C).
3. Ocean layer 13C/12C composition is higher than in the atmosphere (the d13C change in the oceans lags the atmosphere).
4. O2/N2 ratio in the atmosphere decreases, but less than expected from fossil fuel burning (part is replaced by increasing biogenic CO2 uptake).
points 3 and 4 are opposite to ocean degasing and increased biosphere decay…
But that doesn’t undermine the role of the sun in this debate. No matter the amount of CO2 in the atmosphere, the direct influence of it is limited (less than 1 K for a CO2 doubling, including water vapor feedback, any extra increase is computed from problematic feedbacks – like clouds), while the sun’s influence is directly small, but due to interaction with clouds (no matter the exact mechanism) and stratospheric waves, it is fortified, especially on longer time scales…
#68 and 69
This is what I meant recently when I found out that the so-called “water vapour feedback” is not a feedback to CO2 per se, but to a change in the radiative budget, whatever its cause. If, say, less clouds are formed due to less cosmic rays, this change in albedo will warm the surface just like an increase in GHG, and will be amplified the same way by an increase in evaporation and water vapor. So a solar forcing can get the same amplification as a GHG one.
Another point that is very relevant to what Steve is doing: Scafetta’s analysis uses a temperature reconstruction for the past millenium (Moberg 2005). In fact, a lot of analysis use such reconstructions to estimate the relative forcings. This is precisely where a bad reconstruction (àƒ➠la hockey stick) can lead you astray, because it will cause you to understimate the solar forcing (which is, after all, the main pre-industrial forcing). So it’s not true that the HS is irrelevant because the attribution studies have proven that only GHG’s can be responsible for the late 20th century warming. If a well done reconstruction would result in a warmer-than-today’s MWP, Scafetta’s analysis would give an even larger value for the solar forcing, and a correspondingly lower value for GHG.
The same is true if the temperature record is affected by UHI or land-use change. Even a 0.1 degC difference could change the proportion of solar vs GHG.
Finally, Scafetta can spot some nonlinearities, for example frequency response, but won’t catch others like threshold effects that can change the climate regime. Since the Sun has been unusually active towards the end of the 20th century, it might also have been responsible for a shift in the climate regime, maybe in conjunction with increased GHG’s.
#70 Ferdinand,
I agree that the evidence for an increase in CO2 due to warming is so far inconclusive, although a 10 ppmv is not negligible either. Furthermore, I don’t think we’ve seen the last word on pre-industrial CO2 concentrations (e.g. deLaat’s work).
What puzzles me with CO2 is not so much the build up, but the uptake. About half of the surplus “anthropogenic” CO2 is uptaken either in the oceans or on land. In fact, I haven’t seen a convincing explanation for this, just handwaving arguments. But, why 50%? Why not 0% or 100%? Will the uptake increase or decrease in the future? I think it’s crucial that we undertand this point. What’s your take on that?
re: #72
A couple of points. First while warmers make much of supposed acidification of the oceans, the fact is that the level of CO2 either as dissolved gas or bicarbonate or carbonate (mostly as shells as carbonate is pretty insoluble) will continue to increase. And the ocean currents will typically move a constant volume of ocean water to deeper levels yearly. This means that an increasing amount of CO2 will be moved to deeper waters. Though the fact is as I’ve mentioned before that we actually get more CO2 in the rising waters than in the falling waters at present. So what is happening is that the increase in CO2 from deep waters is decreasing relative to rising waters. But we’re close to the break even point so it could well be that there will be net movement of CO2 to deep waters before long.
In any case there is a constant flow of CO2 via shells and dead bodies directly to deep waters and this is likely to also increase both because there will be more net production in the surface waters as there is more CO2 in the waters and because if we continue to deplete fisheries more primary producers will die and rain down before being eaten. So we’re likely to have a continued uptake by the oceans roughly proportional to the total concentration of CO2 in the atmosphere.
On land the situation is more complex and humans are even more in the picture as a lot depends on the storage in forests which are subject to logging, burning, insect infestations, etc.
Finally, more CO2 in the atmosphere will increase the weathering affects on carbonate rocks which in turn will increase CO2 flow into the oceans. This isn’t gigantic, but it’s increasing and needs to be taken into consideration.
Re #71/72
Francois, as there is a temperature dependent dynamic equilibrium between CO2 levels in air and water, the net in/outflow depends on temperature (long term average ~10 ppmv/K) and the difference in concentrations between air and ocean surface. In formula:
Fout = f(T)*(Cair-Csink(T)) + constants
(this is Fick’s law modulated by temperature)
Csink(T) is observed in ice cores (10ppmv/K)
f(T) is Ahlbeck’s CO2 thermometer.
As the concentration in the atmosphere increases, the equilibrium is shifting towards more absorption, but of course not 0% or 100%, somewhere in between. With a pulse emission, the absorption would decrease in time, until a new equilibrium is reached, but as there is a more or less linear increase in emissions, the result is a more or less linear increase in atmospheric concentrations and in increasing absorption by the ocean’s surface layer.
But as Csink (the concentration in the ocean’s surface layer) increases too, if the emissions remain constant, the % absorbed will diminish in time. Thus even with future constant emissions at some level, the atmospheric levels will increase and more will remain in the atmosphere as the ocean’s CO2 concentration increases.
Of course, this is not the complete story, as there is buffering in the upper layer and exchange with the deep layers of the oceans. The latter is a slow process (~1500 years overturning rate via the THC), about the first, we have already used about 1/3rd to halve of the buffer capacity (according to different sources).
For biogenic uptake/release, the equilibrium is more difficult to follow: the increase in temperature at one side increases (old) vegetation decay (and less optimal temperature/precipitation will reduce uptake in some parts of the world), while at the other side more CO2 (and more optimal temperature/precipitation for other parts of the world) will increase uptake. The net result in the past decade seems to be more uptake (the “greening” earth), which may be deduced from less O2 decrease than calculated from burning fossil fuel and land use change (both use oxygen, while uptake releases oxygen).
The problem which confuses many people is that the amount of CO2 (and oxygen) largely varies during a year, due to seasonal changes, and even from year to year. And the seasonal in/out flows are much larger than the changes in CO2/O2 due to human emissions. Nevertheless, the trends in CO2, d13C and dO2 over decade(s) are quite clear…
Some rough carbon cycle graphs can be found here and here.
Back to the original discussion (the carbon cycle is an interesting item, but a quite different topic!):
Steve M, have you read the article by Esper, Frank, Wilson and Briffa:
Effect of scaling and regression on reconstructed temperature amplitude for the past millennium? Seems interesting, as indeed the difference in amplitude is important for the attribution of solar vs. other forcings…
Re Ferdinand Carbon Cycle
What do you think abiut this theory:
Link
I think maybe the use of ice core data from the recent past to support CO2 measurement is still open to question.
Link
As far as I know, all recent ice core data has been “age adjusted” to a greater or lessed extent.
I just don’t think that there is enough certainty about how CO2 behaves, and can be measured in recent ice core.
Germany mainland enough?
more data:
http://gaw.kishou.go.jp/wdcgg/data.html
Re #77:
As Hans already provided, seasonal changes are much higher as measured on land based stations, especially when located in areas with a lot of forests. Further, the seasonal variation diminishes southward and is virtually absent at the South Pole. And there is a lag of 6-12 months between the average (yearly) concentrations between the NH and SH. This points to the NH as main source.
And it is a typical example of confusion between seasonal/yearly variations and a multiyear trend, caused by some continuous (in this case increasing) source. The seasonal variations (which is one independent variable) in the above example are up to 60 ppmv (6 ppmv for Mauna Loa), the yearly variations (around the trend) are about 1 ppmv (depends on the difference between uptake and release in oceans and biosphere, another natural variable, but partly depending on the first one), while the trend is only 2 ppmv per year (but mainly caused by a third non-natural independent variable). Despite that, the trend over 30 years is equal to much larger than the seasonal variations and 60 times higher than the variations in yearly average.
Last but not least, 13C trends are declining everywhere, but again with a lead of a year (to several years) in the NH against the SH, and with a lead of the atmosphere vs. the upper ocean layer. This again points to fossil fuel burning (which is 13C poor) mainly in the NH. Ocean degasing can’t provide the extra 12C, as the surface as well as the deep ocean is far more 13C rich than the atmosphere. Biogenic decay is 12C rich too, but that can’t be the source, as this should deplete oxygen faster than measured, while oxygen is depleted less fast than expected from fossil fuel use (+ land use change) alone…
For the second part, that still is under discussion, as several of the high spikes of CO2 (e.g. around 1940) are not visible in independent measurements of stomata index data. Further, I like to see some independent view/comment on the data from Prof. Jaworowski. It seems to me that many of the data are quite old, while most ice core measurements are from more recent times, when better treatment (relaxation) of the ice cores may give a difference…
See further a lot of comment on this topic at CA #820
Re#78 and #79 So the sawtooth appears in both inland locations and island ones like Mauna Loa (I looked at several more).
My question is why the sawtooth, as the local conditions are very different? CO2 can’t be absorbed and released by the sea in central Germany, and can’t be absorbed by plant life on desolate island locations, so where is it going to and from? Even Mt. Waliguan, China, which probably has no vegetation, and certainly has no sea, but it has a sawtooth.
Re #80:
MarkR, sorry for the delay in reply (have a few very busy days…), as you could see, the largest differences are in forested areas, but also near tundra’s. And mainly in the NH. That is caused by biomass decay (autumn to spring) and biomass growth (spring to autumn). While this happens, the CO2 richer (or poorer) air travels around in the main wind direction, which in general is West to East and from the equator to the poles. But at the same time it is mixed to some degree with air that is less affected by CO2 changes (thus smoothed). And over the oceans, CO2 is exchanged between air and ocean surface (which again smooths the changes). The travel time of air over each hemisphere is a matter of weeks, that makes that the effect of the seasons is seen everywhere, but most at places with the largest changes…
As the exchange between NH and SH air masses is more limited, one will see some delay in trends and far less variation of CO2 levels in the SH, which is further counteracted by the (smaller, because of less land) seasonal variations there, which are in opposite direction.
One Trackback
[…] (Juckes and the NOAMER PC1) […]