It’s interesting to see what’s been changed between the Second Draft and AR4 as it went out the door, and compare that to comments. von Storch et al 2004 argued that the low-frequency variance of reconstructions wsa under-estimated, a point with which I agree (although it’s a different point about whether these reconstructions are biased by proxy selection and Mannian methods.
von Storch et al 2004 was not mentioned in the First Draft. The Second Draft included the following language:
Recent work using pseudo-proxy networks extracted from GCM simulations of global climate during the last millennium indicate that a number of the NH temperature reconstructions may not fully represent variance on time scales longer than those represented in the calibration period (Burger and Cubasch, 2005; von Storch and Zorita, 2005; Burger et al., 2006). If true, this would represent a bias, as distinct from the random error represented by published reconstruction uncertainty ranges. At present, the extent of any such biases, in specific reconstructions and as indicated by pseudo proxy studies, is uncertain. It is certainly model dependent (with regard to the choice of statistical regression model and to the choice of climate model simulation used to provide the pseudo proxies).
It is not likely that any bias would be as large as the factor of 2 suggested by von Storch et al., (2004) with regard to the reconstruction by Mann et al., (1998), as discussed by Burger and Cubash (2005) and Wahl and Ritson (accepted).
However, the bias will depend on the degree to which past climate departs from the range of temperatures encompassed within the calibration period data (Mann et al., 2005a; Osborn and Briffa, 2006) and on the proportions of temperature variability occurring on short and long time scales (Osborn and Briffa, 2004).
As an AR4 reviewer, I commented on their estimate of the size of the bias as follows:
You don’t have evidence to say that the bias is “likely” not as large. The matter is in controversy. I’ve read all the articles closely, am very familiar with the literature and the arguments and I think that the comment by Wahl et al is completely beside the point.
What did AR4 do? Strangely they deleted the citation to Bürger et al 2006, an excellent article. They cited Bürger and Cubasch 2005 only as supposed authority for the MBH variance underestimate not being as high as indicated in von Storch et al 2004, a very curious application of this article and they upgraded the certainty estimate of this opinion from it being “not likely” that the bias was as high as 2, to being “very likely” that it wasn’t.
Using pseudo-proxy networks extracted from GCM simulations of global climate for the last millennium, von Storch et al. (2004) suggested that temperature reconstructions may not fully represent variance on long time scales. This would represent a bias, as distinct from the random error represented by published reconstruction uncertainty ranges. At present, the extent of any such biases in specific reconstructions and as indicated by pseudo-proxy studies is uncertain (being dependent on the choice of statistical regression model and climate model simulation used to provide the pseudo-proxies).
It is very unlikely, however, that any bias would be as large as the factor of two suggested by von Storch et al. (2004) with regard to the reconstruction by Mann et al. (1998), as discussed by Burger and Cubash (2005) and Wahl et al. (2006).
However, the bias will depend on the degree to which past climate departs from the range of temperatures encompassed within the calibration period data (Mann et al., 2005b; Osborn and Briffa, 2006) and on the proportions of temperature variability occurring on short and long time scales (Osborn and Briffa, 2004).
So much for them paying attention to my comment. In this particular case, this wasn’t an issue where I had a horse in the race. I was familiar with the issues and had commented on them. It’s not as though there are dozens of other people who understood exactly what was involved and most of them were parties to the dispute. I don’t think that the citations (Bürger and Cubasch; Wahl et al) are adequate to support a claim of “likely” and to apply them for a claim of “very likely” adds insult to injury. I wonder what their authority was for making this change in confidence assessment.





78 Comments
I think it is very likely that the AR4 is more of a political document than a scientific document.
It’s my view that most of these threads that Steve M has initiated in recent days on AR4 have consistently shown the political spin that the IPCC authors have put on the underlying climate science. The selling that is done does not make the underlying science less reliable by itself, but certainly makes one more skeptical of the completeness of the review process and presentation of the spectrum of views on the subject matter.
My question and concern is this:
How much of this spin is originating from scientists and how much from the political administrators? If scientists have become this good at spinning facts and without the aid and instruction from real politicians, I have some major concerns.
Here’s another interesting change:
Second order draft 6-29:
“Wahl and Ammann (accepted) demonstrated that this was due to the omission by McIntyre and McKitrick of several proxy series used by Mann et al. (1998). Wahl and Ammann (accepted) were able to reproduce the original reconstruction closely when all records were included”
Just published page 446:
“McIntyre and McKitrick (2003) reported that they were unable to replicate the results of Mann et al. (1998). Wahl and Ammann (2007) showed that this was a consequence of differences in the way McIntyre and McKitrick (2003) had implemented the method of Mann et al. (1998) and that the original reconstruction could be closely duplicated using the original proxy data.”
I wonder why?
The W&A paper is still listed in the references as “in press”. Is it still not published?
This just goes to show, once more, that the IPCC process is flawed in terms of providing an objective assessment of the state of science. The reason it is so is that there are no independent editors to ensure balance. The authors ARE the editors, something you never see in any other scientific publication. So the authors chose to take into account or not the reviewers comments. Worse, the authors have themselves published in the field, so the chapters will necessarily reflect THEIR view. Whenever there is a controversy, you can be sure that only one side will be presented positively. It is clear from those excerpts that the authors make value judgments on the published papers. In other words, some are deemed more valid than others. So, under cover of objectivity, the IPCC process is really one where the authors present one view of the state of the science. Choice of lead authors determines the outcome.
For example, to come back to the solar question, the role of the sun is still presented as minor in 4AR, despite the more than 50 papers published in the area since TAR. But guess what, the authors of those papers were not lead authors. So there is no room for their point of view. Those are all peer-reviewed papers, but somehow, someone has made a value judgment that all those results meant nothing, or were not credible enough.
The IPCC reports are only good as informative documents. They are just very long review papers. But the moment value judgments are made w/r to what research is good and what isn’t, then any claim of objectivity is obviously lost. It may be inevitable, but then it should be presented as such (ie. as one viewpoint), not as the scientific truth about climate.
How about running a diff of the AR4 development process?
I think their objectivity is feigned at best. Only those untrained are fooled, which accounts for the majority of policy makers as well as the public at large.
Mark
#4 Francois wrote:
Well, they do discuss some of this new literature on solar forcing, but dismiss it as being “controversial.” Which only demonstrates the hypocrisy of it all, for the same can be said about most of what is included!
For what it’s worth I’ve posted a specific change from the Second Draft to the final report on model prediction accuracy. You can find it at:
http://planetgore.nationalreview.com/post/?q=OTk3ZjYyNmU1YTI3NzUwZTQxZGEyNTdhNTI4ZmZkZTE=
Jim Manzi
re #1-4, 6, 7
from the IPCC website: http://www.ipcc.ch/about/about.htm
“The role of the IPCC is to assess on a comprehensive, objective, open and transparent basis the scientific, technical and socio-economic information relevant to understanding the scientific basis of risk of human-induced climate change, its potential impacts and options for adaptation and mitigation.”
My grading of the IPCC’s success at fulfilling their role in AR4, in language that only an authentic climate scientist could love:
comprehensive: unlikely
objective: extremely unlikely
open and transparent: very unlikely
Now that I have released my grading summary on IPCC AR4, I reserve the right to revise the underlying data behind the full grading analysis. So it will match my summary of course.
Re #8 That *is* a good observation, Jim. That’s Pat Frank’s bugaboo. And mine. Propagation of errors through a GCM calculation is now not just ignored, but swept under the rug. You know what would happen if an engineer did that? Now you see why Jimy Dudhia doesn’t like the topic of exponential growth in physical systems.
Uncertainty deniers.
I agree, somewhat out of context. But in fact here they say
And the counterexample kindly asked for way back in #7,8 of this post is still pending.
#11
Too much equations for me, let’s try to simplify: the topic is linear calibration, and we have known true values (x, temperatures) and responses y (proxies). In statistical literature, if we use regression of y on x, E(y|x), we’ll have classical calibration estimator (CCE), and the opposite case is inverse calibration estimator (ICE). From this picture you’ll see that using ICE, reconstructed temperatures are closer to mean value than by using CCE (see dashed lines). Note that mathematically the selection should be straightforward:
(Kendall’s Advanced Theory of Statistics, Vol 2A)
To me, it seems that in the proxy-temperature case, the model is not clearly stated. And I think that comparing the sample variance of reference data and reconstruction in the calibration period is not the essential part; a good model, autocorrelation of residuals and correlation of residuals and temperature are more interesting. See e.g. example in here . In the case A, the reconstruction ‘amplifies’ the variance, but I still think that it is better than case B. (Like many others, I’m here to learn, pl. keep that in mind)
#12: The v. Storch et al. argument is clearly stated in the paper:
and it’s all about calibration statistics. Statistics with independent data are a whole different issue (though of course important).
The problem is that v. Storch et al.’s damping argument applies to 1-dim direct regression but MBH98 use (m,n)-dim inverse regression. vS’s argument easily extends to the (m,1)-dim case (via the multiple correlation coefficient) but not to inverse regression for which variance is amplified. While that amplification is trivial for the 1-dim case it can also be extended to the (m,n)-dim case as applied by MBH98 (counterexample?).
Hence, if variance is systematically reduced it is not the regression-type method (apart from the detrending that was applied), perhaps some external factor in the independent data such as overfitting.
So again, where is the counterexample? – I’m patient.
Isn’t it true that the larger the swings of past temperature,
the larger the response of climate to forcings, and thus a
bitter pill for skeptics?
Re#14: Another obvious interpretation is that the larger the swings of past temperature, the larger the natural forcings. This would also imply that the current state of climate is not “unprecedented” and could be explained by natural variation. Thus a bitter pill for alarmists.
#14 tony…
it is not a simple matter of “skeptics” vs “alarmists”. as scientists, a certain attention to detail, and a willingness to have one’s work viewed critically, and to provide the means for replication, that allow for the scientific method to even exist. as steve m and others have pointed out, showing the hockey stick (etc.) is garbage DOES NOT disprove AGW. it just shows we really do not know. perhaps, if climatologists who perform statistical studies would actually consult statistics expertts, there work might pass muster, or survive an audit.
“Isn’t it true that the larger the swings of past temperature,
the larger the response of climate to forcings, and thus a
bitter pill for skeptics?”
Hmm…your rhetorical style makes me skeptical.
How about these,
“Isn’t it true we should subject the IPCC science and findings with skepticism since they are guided and managed by non-scientists, mostly political operatives, an unprecendented event in scale in the history of this planet?”
#13
Thanks for your response. Takes some time for me to go through this.. If I have understood it right, climate term ‘inverse regression’ is classical calibration, and ‘direct regression’ is inverse calibration, makes this a bit confusing. Krutchkoff was first, right? 😉
I do. If it lead to some sort of failure and was ferreted out he would be fired. But this is academics, so they don’t actually have to make something work.
..and in this Matlab code , INV refers to classical calibration, wrote it before read those relevant papers in Technometrics. Anyway, the code shows that local calibration works better than any of those the quick and dirty multivariate calibration methods..
Naaahh… he wouldn’t be fired. I’ve seen a total of ONE engineer fired for incompetence, and the underlying cause was actually a personal issue between the manager and the engineer (I almost resigned over the debacle as it was unjustified and poorly timed). I’ve also seen outright fraudulent behavior by engineers that did not result in firing.
That said, such engineers, those caught being incompetent, fraudulent or guilty of hiding adverse results, rarely get listened to. Nobody forgets the guy that did the dirty deed. Such engineers usually have to go somewhere else lest they be relegated to “assistant” work. He shouldn’t count on ever getting a raise, either, should he decide to stick it out (like a fool). Reputation is everything in the generally small communities in which engineering folk circle about.
Mark
Yup. Bender’s point stands either way. Such behavior is not tolerated.
Mark
Wow, that’s an interesting way to use Cubasch Burger, indeed. See
Click to access b%FCrger.cubasch.grl.2005.pdf
Given that the last 1/2 sentence of the abstract is “it is not clear how these methods can be salvaged to be robust” (read also [21], the end of paper), any usage of this paper to support the Mann-like methods is bizarre, to say the very least.
#11
In the linked paper you write
but, to me, those equations look quite similar to Brown’s controlled multivariate calibration estimator (natural generalized least squares estimator, set gamma = I, page 350 in Prediction diagnostics and updating in multivariate calibration , Biometrika (1989), 76, 2, pp. 349-61 ). Brown uses interesting inconsistency diagnostic, using your notation take a statistic
where z is proxy vector at year k ( out of calibration period). That is, test how well the model reconstructs proxy record by using the reconstructed temperatures. Someone who knows how to play with MBH98 should try this (well, probably it is done somewhere already)
#25. UC,
This terminology is not very apt because it doesn’t connect with any known statistical terminology. The Mannian multivariate method, as I posted last year and as you confirmed with MBH99, is weighting by partial correlation coefficients which is equivalent to Partial Least Squares regression. The term “inverse regression” as used by climate scientists should be discontinued since it is poorly defined and inverse calibration already has a different definition,
BTW let’s move this discussion back to the original thread. Gerd, you’re quite right that I didn’t follow up on this. I’ll try to re-open the file.
This comment by the IPCC (“it is not likely..”) is indeed strange, since there are very few studies that have analyzed the influence of different factors on the bias. One of those factors, is for instance, the amount and character (red or something more complex) of non-climatic noise in the proxies, and I think it is quite sure to say that nobody knows very well how this noise really looks like. This is just an issue which several groups are working on and the outcome of which is completely open.
I really cannot see the reason for including this unjustified comment in a “consensus” document, but to support the HS.
By the way, this effect is present, under all reasonable assumptions of noise, in all linear methods to reconstruct the NHT that I am aware of. In the recent meeting of the European Geophysical Society in Vienna, there were at least three presentations showing this effect in pseudreconstructions in different methods and different climate simulations (with pseudo-proxies), and the bias can be indeed easily be a factor of two
eduardo
I know what is going on, but I won’t tell. Brown’s articles are a bit awkward to read, but they are very informative when you get used to the notation 😉
#26
That’s where the problem is. Statisticians have studied these issues for decades, climate scientists invent same methods again, and begin to wonder why we have biases in Inverse Calibration Estimator output and specially, why we have biases in (multivariate) Classical Calibration Estimator output. Back to the ’60s.
#3, DavidH,
Well why? Because as you noticed, Mann and the rest of the ‘team’ when defending the Hockey Stick, they faced three main allegations.
1) Provide data for reproduction
2) “Avoid” bristlecones and foxtails
3) Statistical issues
The answer for 1 is ignore request and when not possible, lie that it is already available or that there is a good reason why they didn’t provide it or cannot (“The dog ate it”). The answer for 3 is easy because hardly anyone understands the issues one can talk and talk for hours or pages why you are still right.
The asnwer for 2 is bad, as this is such a simple issue everybody can understand it. So far the tactics have been ignore the whole issue and don’t mention it. Hence the change from draft to final.
#3
To my opinion Wahl & Ammann (2007/accepted/in press) appears to be this one
Has anyone tried the r-code yet?
#31. We know about this version and have discussed it before. I posted about their code almost 2 years ago. With one slight modificaiton to our code, I reconciled to my results to 9 decimal places. Their claim that their emulation had done anything that we had not already done was dishonest. Both emulations are somewhat different than the limited available information about the MBH98 AD1400 step. They attributed this to their different weighting system. Two problems – this is not the reason for the difference and they presumably knew this. Second it is ridiculous to benchmark their emulation using different weights and then attribute discrepancies to the differing weights. You benchmark using the same weights. I said this as a reviewer. But the editor did not require Wahl and Ammann to do so for reasons that are inexplicable to me. The puzzle is that this article isn’t actually printed yet. It is the ONLY article in AR4 chapter 6 that is not in print.
I am waiting with great curiosity to see how they handle the rejected Ammann and Wahl, which they rely on, when it gets into print. Do they leave the claim that Ammann and Wahl is under review over a year after it’s been rejected? Do they rework the article to argue for the points rejected by GRL? Do they simply delete the citation and drive on without support for the points where they previously cited Ammann and Wahl? None of the alternatives are particularly appetizing. They should have immediately amended the article, but they presumably had to twist arms to get it accepted by the end of February 2006. Tangled webs.
You’all might want to check out what http://rabett.blogspot.com/2007/05/it-writes-itself-ethon-after-sharing.html had to say about this.
JMS, for heavens sake, the link to Eli’s site contains the very excerpt from the AR4 report that is under discussion (and is quoted in the top post), with a “ha-ha” added at the end.
If you’d like to make a substantive comment, why don’t you explain to us how Burger & Cusbash refute Von Storch and support MBH, as asserted in AR4 (both above and at Eli’s site)?
My learning experience continues.. Question:
In Zorita05
and in vS04
But for permutation matrix A,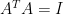 , and thus we get the same LS solution for all permutations of time-indexed data. What is the theoretical justification for above sentences?
, and thus we get the same LS solution for all permutations of time-indexed data. What is the theoretical justification for above sentences?
(Zorita05: Methodical aspects of reconstructing non-local historical temperatures, E. Zorita, H. von Storch)
The difference between low-frequency and high-frequency is not a permutation of the time ordering; it lies in the changing link of the underlying physical processes with timescale. To illustrate this with an example of economics – in which I am not an expert, but perhaps you are, so correct me if I am wrong: Variations in salaries may be anticorrelated in the short term with share prices, since they dent the companies’ surplus; on the long-term they may be positively correlated, since they increase purchase power. The problem occurs when one calibrates a regression model between both using high-frequency variations and extrapolate to low-frequency variations to predict one of them.
In our case, there may be a small correlation between tree-growth and T because many other factors act at high-frequencies (the noise). It may, however happen that on the long-term, T is indeed driving tree-growth. A statistical model calibrated at high-frequencies will tend to underestimate the variations in T.
The solution perhaps: calibrate with filtered data, but then the degrees of freedom is much reduced, so that the regression is very uncertain.
#36
Thanks for your response! Slowly starting to understand.. With vS04 data, did you observe that residuals (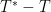 ) are negatively correlated with T? Just like in MBH99 AD1000 step ?
) are negatively correlated with T? Just like in MBH99 AD1000 step ?
Hmmmm.. If I take a sequence of white noise, it has (on the average) a flat spectrum. If I sort that sequence, most of the energy goes to the low-frequency side. Permutation changes the spectrum.
Now, in vS04, your reconstruction is obtained using
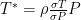
and all operations are invariant to permutations. Thus, I found this sentence a bit strange:
Well, the sentence is actually true, this is what happens. But shouldn’t the alarm bells ring loud at this stage? Something wrong with the model / chosen estimator? But the model can’t be wrong, as you simulate it.
Your solution is inverse calibration estimator (ICE), (direct regression in many references). It works well when Ti and Pi are samples from joint normal distribution. The other option is to go with CCE, in that case we don’t need to model T stochastically. With ICE there is a underlying assumption that statistical properties of T remain the same outside the calibration period. In climate reconstruction case this assumption is silly, with this assumption we state that temperatures are always normal (no AGW then). And if you apply ICE to red T series, you’ll note that residuals become negatively correlated with T.
So, univariate ICE clearly underestimates the simulated low-frequency temperatures. It is easy to find out that so does multivariate ICE. And it seems to me that also multivariate CCE underestimates. But who said that multivariate CCE is ML estimator ? And guess why we haven’t seen univariate CCE..
I think it is time to open the Stochastic Processes and Filtering Theory book.
#38
I am not sure that I understand what you mean by
Well, the sentence is actually true, this is what happens. But shouldn’t the alarm bells ring loud at this stage? Something wrong with the model / chosen estimator? But the model can’t be wrong, as you simulate it.
What we do is to apply the MBH estimator to simulated data. These data stem from a climate model simulation -with some modification to include noise (please clarify if you are referring to a climate model or to a statistical model, they have nothing to do with each other). In this climate simulation we have perfect knowledge of the predictand at all times.
The conclusion is indeed that the estimator is wrong – or more accurately- that the estimator can be wrong. This happens also without the proxy prepocessing by PCA and all other aspects that M&M have raised regarding the MBH reconstructions. And it happens, by the way, to other estimators, not only MBH.
Sorry, I was thinking aloud. In general, if you select an estimator, it should be optimal in some sense. And with Monte Carlo simulations it is easy to verify that it works that way. If it doesn’t, then consult nearest statistician. He or she knows what is going on.
So, after all MBH estimator is ICE, nearest grid-cell vs. proxy? I don’t have enough math muscles to figure out what MBH estimator actually is.. Steve and Jean S have tried to explain to me, without success 😉 But AD1000 step is a linear combination of proxies, year by year (i.e. my comment on permutations applies to that case as well).
I’d try something else then (think out of the box : ). Or do you mean that it happens to all estimators?
#25,26
That’s a good observation. Actually, when I first studied the MBH method I remember to have run across this paper, which gives a very nice overview of the topic. But my focus was then on variance issues, so I must have forgotten it.
So now we have a name: MBH use multivariate calibration.
Actually I don’t care so much about names. But ‘calibration’ in this sense means instrumental calibration, which is perhaps not the most central part of statistics. There are other terms (“errors in variables”, “data least squares”,…) for the same or similar things. On the other hand, “multivariate calibration” is often used synonymously with (direct) multivariate regression.
The MBH method, however, (excluding their subsequent variance matching) is definitely not partial least squares regression, despite Steve’s sporadic attempts to frame it that way. While in fact the 1-dim versions (x n-dim, y 1-dim) are both built from the cross covariance matrix and differ only by a scaling – but where is variance inflation in PLSR? – they are completely different in higher dimensions. This applies to the later MBH steps and fully to v. Storch et al. 2004.
#41. Gerd, I don;t think that “multivariate calibration” is a helpful term here. In my prior notes on the topic (which worked through the algebra), I showed the difference between the multiple-D and 1-D cases. The 1-PC case which governs the controversial steps of AD1400 and AD1000, is the linear algebraic equivalent to Partial Least Squares regression (with variance matching which is one of the common PLS scaling options). In more than one dimension, the MBH algebra has a weird rotation. However, despite the algebra, it is closely approximated by the one-PC case. The variance inflation in multiple dimensions is a type of piecewise PLS. I really should write this up as an article.
you definitely should. Then it’s falsifiable. 😉
#41
And CA readers are well aware of that paper
http://www.climateaudit.org/?p=1531#comment-107775
🙂
I’d focus on Brown’s inconsistency diagnostic, it sounds interesting.
I think calibration is a good term for proxy reconstructions, multivariate calibration takes training data Y at values X to construct a relationship between Y and X. This is used in future to estimate a new fixed but unknown X corresponding to the observed Y. Just replace Y with P and X with T. As we have multivariate ‘€”term, both T and P can be vectors for given year.
variance matching, variance of calibration residuals, upper bounded error levels .. I think Steve should write that paper. BTW, are the theorems of logic and mathematics falsifiable or not ? 🙂
Well, by definition a “theorem” is falsifiable. In the broader sense of “proposition” or “claim”, most are, but some aren’t (being undecidable). I guess Steve would manage to make his theorems on PLSR undecidable. 🙂
I have always wanted to falsify Pythagoras’ theorem. I just don’t know how to do it.
Look here, it’s easy.
ok, ok, back to business. I have an exam question, anyone can answer.
a) We have a random vector x (N x 1), which is zero mean and its covariance is P. You observe
where H is known matrix and v zero mean measurement noise, covariance matrix of v is R, v is independent of x. Find a matrix K
where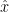 is BLUE of x.
is BLUE of x.
b) Assume both P and R are diagonal, ,
,  , and H is scalar. Show that K is diagonal, and that diagonal elements are equal to
, and H is scalar. Show that K is diagonal, and that diagonal elements are equal to  , the same term you’ll find from vS04. What kind of implicit assumption there is in the estimator of vS04 ?
, the same term you’ll find from vS04. What kind of implicit assumption there is in the estimator of vS04 ?
Re # 44,45,46,47 – **BTW, are the theorems of logic and mathematics falsifiable or not ?**
I think you are confusing “Thorem” and “Theory”.
A “Theory” is falsifiable. In science, a theory is a mathematical description, a logical explanation, or a proven model of the manner of interaction of a set of natural phenomena, capable of predicting future occurrences or observations of the same kind, and capable of being tested through experiment or otherwise falsified through empirical observation.
A “Theorem” is a statement that can be demonstrated to be true by accepted mathematical operations and arguments. In general, a theorem is an embodiment of some general principle that makes it part of a larger theory. The process of showing a theorem to be correct is called a proof.
No answers yet to 48 … Hint 1: google Kalman Gain
Re #48, UC too easy, found this on page 12 of my optimal estimation book.
Gaussian noise assumption with k = P*H’*(H*P*H’ + R)^-1 , but can H be a scalar?
Re #48, reverse engineering suggests that v is the scalar and H is nx1 and more formally x ~ N(0,sigma_x^2*I) and v ~ N(0,sigma_r^2) where N stands for gaussian distributed. Is the implicit assumption in vs04 that the x elements are uncorrelated since you get the same answer with a diagonal covariance matrix P?
Re #52 oops H is 1xn
#51
Getting closer 😉
(H can be scalar, and Gaussian assumption comes to play if you want to drop L from BLUE. )
What do you know about x before seeing the observations? If you know nothing P must be very large.
Re #54, I agree that the gaussian assumption lets one drop the L from BLUE and one doesn’t need the gaussian assumption for BlUE. If H is a scalar than x, R, P, and K are scalars so you confused me when you talked about diagonals for K, P, and R and I assumed that H was at least 1xN. I have assumed that x is a state to be estimated not a proxy of record length N, predicated on your discussions in Re #50 and 54
Answering your question Re #54 “What do you know about x (scalar) before seeing the observations?” Given your problem statement of Re #48 than the expected value of x is zero with variance sigma_x^2.
Your statement from Re #54 “If you know nothing P must be very large.”
Suggests to me that you are thinking not of the problem statement in Re #48,
but of the Kalman filter state estimation problem with dynamics were the
state error covariance matrix is large with no observations taken.
Normally this matrix is initialized with large values to get the states to converge quickly.
Uh, H being scalar does not necessarily make R and P scalar as well…
For a scalar H, you can rewrite it such that H = hI (i.e. scalar matrix), where I is the identity and h is the actual scalar value. Then, for real matrices:
z = H*x + v: [Nx1] = [NxN]*[Nx1] + [Nx1] which is the same as
z = h*x + v: [Nx1] = scalar*[Nx1] + [Nx1]
P = E{(x-m_x)*(x-m_x)’} = E{x*x’ – x*m_x’ – m_x*x’ + m_x*m_x’} = E{x*x’}: [NxN] = [NxN]
R = E{v*v’}: [NxN] = [NxN]
If the random variables in x are uncorrelated, then P is a diagonal matrix with the variances of each element of x along the diagonal, though they are not necessarily the same (in part a). The same goes for v and R. Part b then, I assume, says the elements of x and v are uncorrelated with equal variances, in which case P and R become scalar matrices, though x, z and v are still [Nx1] vectors.
The optimal Kalman gain is, as you mention, K = P*H’*(H*P*H’ + R)^-1, where P in this is given by P_k/k-1 (i.e. P at state time k given P at state time k-1). Assuming this is correct (rusty on my Kalman), then with H = h scalar,
K = h*P*(h^2*P + R)^-1 = h*sigma_x^2 * (h^2*sigma_x^2*I + sigma_v^2*I)^-1
= h*sigma_x^2 * 1/(h^2*sigma_x^2 + sigma_v^2) * I
which shows that K is diagonal…
Since H is scalar and x, v are zero mean, z is as well, therefore
sigma_z^2 = E{(z-m_z)*(z-m_z)’} = E{z*z’} = E{(h*x + v)*(h*x + v)’} = E{h^2*x*x’ + h*x*v’ + h*v*x’ + v*v’}
= h^2 * E{x*x’} + 0 + 0 + E{v*v’} = (h^2*sigma_x^2 + sigma_v^2)*I
and then
K = (h*sigma_x^2 / sigma_z^2)*I
rho = E{(x-m_x)*(z-m_z)’}/(sigma_x*sigma_z) = E{x*(h*x+v)’}/(sigma_x*sigma_z)
= E{h*x*x’ + x*v’}/(sigma_x*sigma_z) = E{h*x*x’ + 0}/(sigma_x*sigma_z) = h*E{x*x’}/(sigma_x*sigma_z)
= h*sigma_x^2/(sigma_x*sigma_z) = h*sigma_x/sigma_z
and
K = rho * sigma_x/sigma_z * I
Phew! At the moment, I’m not sure what the implicit assumption is. Probably that some of the matrices are invertible, though by definition in part b, (h^2*P + R) is invertible.
Mark
Oh, wait, I think I made the implicit assumption in the above mess (sorry, I don’t know LaTex)… Since I have not read vs04, I’ll assume it is the “elements of x are uncorrelated with each other” assumption. If they are not, the off diagonal elements of P will be non-zero, and the above derivation does not work.
Mark
Re #56, Mark T, I considered H = hI with h a scalar as you did, but now H isn’t a
scalar anymore. Seems strange UC would have specified H that way, but his
comments seem to indicate that perhaps you have interpreted H correctly.
Normally in kalman filter state estimators with dynamics and multiple measurements then the P in the Kalman filter gain is actually the apriori error Covariance matrix.
It doesn’t matter since a matrix multiplied by a scalar is the same thing as a matrix multiplied by a scalar matrix.
i.e. h*I = H, z = H*x is identical to z = h*x (scalar times a matrix is a scaled matrix).
That’s what I was showing in the first few lines.
Oh, I left off a few identity matrices in the rho calculation. Also, the standard Kalman only works for linear relationships.
Mark
I like this blog 😉 Mark T, that’s correct derivation. Now, in vS04 estimator (which is ICE), calibration period data is used to obtain estimates of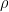 and sigmas. If the calibration is perfect (sample
and sigmas. If the calibration is perfect (sample 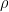 equals
equals 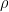 etc) we’ll get the estimator derived in here. Here’s the assumption, divided to two parts:
etc) we’ll get the estimator derived in here. Here’s the assumption, divided to two parts:
1) sample variance of calibration period data represents variance of past temperatures
2) temperature is i.i.d
From vS04 Fig 2A you’ll see that assumption 1) does not hold. Now, is it a big surprise then that the estimator ‘loses variance’ ? ( now please list all reconstructions where ICE is used ).
Phil:
Yes, but in climate reconstruction case we don’t need recursive filter. Thus we can use this version, where all measurements are used at once. This is very convenient form, it can be used to show how flawed the Briffa-Osborn adjustment procedure is, or to see what optimal smoothers do near the end-points..
1) my friend stationarity, without any justification.
2) do you mean noise in the temperature response is i.i.d.?
In this context, what would x represent, btw?
Oh, I never intended to solve your exam question. I started by trying to explain to Phil why the term “scalar” allowed matrix representations to hold. I just happened to “see” the answer so I kept typing. I’ll have to solve a tracking problem, likely with some simple Kalman filter, in my radar design effort shortly. As a result, this refresher is a benefit! 🙂
Mark
I find it funny, people trying to reconstruct past using this assumption. Even more funny with divergence problem.
x is temperature (global or local, doesn’t matter much here). Don’t hesitate to take it as a random variable. Actually, ICE origins are in sampling from normal population, not in stochastic processes. But now we have showed that it can be derived using one-step-Kalman filter.
Careful with large bearing errors 😉
The dendros think uniformity == stationarity. Two totally unrelated concepts. Rob Wilson’s comment in the other thread that he can be quoted stating tree-rings are good proxies for temperature fails merely through the divergence problem. That we have no idea what was happening with the other forcers, temperature included, pre-recorded history doesn’t seem to phase folks like him. This doesn’t even get into the linearity issue.
I assumed x was temp. Then they’re saying that each of the temps is i.i.d. w.r.t. to each other, right? That’s a difficult assumption. Also, temp ain’t the only forcer for plant/tree growth. In fact, two of the three likely largest are temp and CO2 (moisture is probably the largest), which are correlated not only by hypothesis (that’s the whole debate at least), but fact. That’s a big 10-duh.
We’re not a true tracker due to a 5 degree (minimum) beam width so the “track” will be pretty much grid-cell centroids only. We’ll need to convince the customer of this reality at some point, hehe.
Mark
I located a copy of vs04 last night which helps explain some of UC comments. What is interesting is that vs04 doesn’t cover the error variance for T*. For UC #48 problem, the error covariance is Px/z = (P^-1 + H’*(R^-1)*H)^-1 or Px/z = P – P*H’*((H*P*H’+ R)^-1)*H*P. Translating to vs04 notation, we have Variance(T-T*) = (1-rho^2)*Variance(T). Vs04 suggest rhos of between .4 and .7 but from what I have seen is high. For a rho of .4 than the error covariance is .84*Variance(T) which isn’t much of an estimate.
Even though the weight of the dead horse is burdensome, I still think it is incorrect to call H a scalar.
Re #63 Conclusion sentence from peer reviewed paper “The 1000 year temperature reconstruction demonstrates that the 20th century temperature rise is unprecedented, yet we calculated most of our sample temperature variances during the 20th century and assumed stationarity.”
Assumed stationarity… I’m curious what their justification is.
Oh, dead horse or not, from wiki:
In other words, matrices obey scalar multiplication rules (I removed the LaTex because it was broken). I think the point of UC’s example, and apparently that used by vs04, is that there is a single transformation (linear of course) that relates temperature to tree-ring width. I.e. width = h*temp + noise, for all trees. It is quite amazing though I must assume that the breakdown is an intentional simplification (I hope, at least).
Mark
Re #65, Mark, I am arguing the correctness of calling H a scalar in Re #48 problem statement, not a mathematical equivalence. Normally, one sees this type of problem statement in the textbooks as, z = Hx + v were x is nx1 vector, z is px1 vector, v is px1 and H is nxp matrix. With P nxn and R pxp. Would you consider H as a scalar?
Now let p=n which is what UC was considering. Now H is nxn and let’s consider the special case in vs04 where H = a*I_nxn. One can multiply any vector or matrix by H as long as it has n rows. Similarly, a vector or matrix can multipy H if they have n columns. Since H is a special case, we can skip the matrix multiply and multipy every element of the matrix or vector by a as you have shown in Re#65. What about adding H to another nxn matrix, no problem. What about adding a (from a*Inxn), a scalar to the same nxn matrix. Does that give the same results as adding H nxn?
If we substitute a scalar for H nxn, we can multiply or add to any size matrix and the matrix additive properties aren’t valid. Mark I hope you understand my argument.
I gotcha. I think what UC was getting at was not that H _should_ be a scalar, but the problem formulation in vs04 _is_ a scalar. I completely agree that generally H is not simply a scalar as in this simplified problem since that would be completely unrealistic in any process model.
I was wondering why you didn’t seem to understand, particularly given that you seem to understand the problem… you understood too well, and I just wasn’t quite getting what it was you were trying to say. My bad.
Mark
Re #66 oops H is pxn
In the contrived example, H is never added, only multiplied, so there’s no issue. Yes, however, if we were to treat H as purely a scalar, it could not be directly added anywhere (without assuming it was a “scalar matrix,” or H = h*I).
Mark
Re #69, Mark, did you get a chance to turn the crank on the error covariance term in Re #64?
As far as your radar problem, there are 100’s of papers in the IEEE and AIAA journals about this issue. All peer reviewed, some good, some bad, and some ugly. I have hard copies on 5-10 articles myself. Good luck
H is in the measurement model, not in the process model, and IMO scalar H wouldn’t be unrealistic.
That’s correct. In the derivation of optimal K you don’t need such operation.
Phil B., your error covariance term looks correct to me. Remember, the paper we are talking about is Science, not Technometrics or Biometrika , no one checks equations in Science … 🙂 They are worried about sample variance of the reconstruction in the calibration period , not the error covariance you just computed.
Fortunately, I’m clued in on this overall problem. I’ve been doing radar for 12 years now, just not to the level that this project requires. We (two on the signal processing) are designing from the ground up a type of system that’s never been done before. Oddly, the hardest part is the geometry involved with three bodies in motion (independently). I have to admit, however, I’ve read more books on radar in the last three months than I ever have in my life.
Nope. Maybe later…
Oops. I suppose it depends upon how you view the problem for H. I was seeing it more as H being what controlled actual temperatures to create tree-rings, i.e. tree-ring width is only a scalar multiplied by temp in this example, which is unrealistic I think. That would differ per tree, over time, etc., and then you’d have to add in the other forcers as well, yadda, yadda.
Mark
Re #72, UC thanks for confirming. The take home point is, as the correlation coefficient drops, the gain on the proxy drops and the error covariance rapidly reaches the original variance of the temperature record. Makes for a good hockeystick shape (okay, maybe a dental pick). The RegEm appproach of Mann and Rutherford performs similarly, only with a multivariable approach and a few more math twists.
And remember variance adjustment , when R gets higher, they scale reconstruction down, so that sample variance of the reconstruction won’t change. Same implicit assumption there. Sad.
Now, check latest mike’s comment
🙂 They don’t know how that figure was generated..
Mark T and others, it is non-causal filter with data extrapolation, see Mann’s paper
Click to access MannGRL04.pdf
It uses filtfilt. It is true that optimal smoothing should be applied for reconstructions, but remember that these people don’t talk to mainstream statisticians. Read mike’s paper and you’ll get the idea.
Re #76, matlab’s documentation for filtfilt states that their algorithm uses a reflected copy of the data at the endpoints. Not clear to me how this provides “minimum slope” at the end.
UC, I assume you meant for this to be in the other thread?
They should reference the same article in the IEEE that MATLAB references for filtfilt:
Gustafsson, F., Determining the initial states in forward-backward filtering, IEEE Transactions on Signal Processing, April 1996, Volume 44, Issue 4, pp.988’€”992.
I only briefly skimmed this paper, though perhaps I should take a little deeper look.
Mark
Oddly enough, I’ve got an estimate of Mann08’s reduction in variance at approximately 3 times by CPS.