Mann et al 2007 is a new RegEM version, replacing the RegEM calculations of Rutherford et al 2005. The logic is not entirely self-contained and so I re-visited some of our previous comments on Rutherford et al here here here here . I’m going to reprise two issues today: Collation Errors, a small but amusing defect; and Calibration-Period Standardization, a more serious problem, raised last year by Jean S in this post – an issue evocative of the calibration period standardization error in MBH98. This latter problem has now been acknowledged; Mann and Rutherford have now deleted all source code pertaining to Rutherford et al 2005 in June 2007, nearly a year later. The error is mentioned in Mann et al 2007 – needless to say without mentioning climateaudit.
Collation Errors
First, the smaller point, collation errors. I observed an amusing collation error in Rutherford et al 2005, in which they had inadvertently spliced their instrumental data to the wrong calendar year. On an earlier occasion, we had reported collation errors in the first MBH98 data set to which we had been directed at Mann’s FTP site, which we reported in MBH98. After MM03, the “wrong version” was deleted from Mann’s ftp site and a new MBH98 directory appeared (which has in its turn dematerialized to be replaced by yet another version.) The collation errors observed in the first version did not occur in the later versions and some time ago, I arrived at the conclusion that the PCproxy version that Rutherford had directed us to was a version that he’d developed for his studies (perhaps Rutherford et al 2005) and that it probably hadn’t been a factor in the original MBH. Anyway, Rutherford et al 2005 contained a snark about this topic as follows:
some reported putative “errors” in the Mann et al. (1998) proxy data claimed by McIntyre and McKitrick (2003) are an artifact of (a) the use by these latter authors of an incorrect version of the Mann et al. (1998) proxy indicator dataset
.
Of course why did we use an “incorrect version”? Because they said to use it. I raised the splicing issue with Rutherford and he said that it was before his time. I asked Mann about it and he said that he was too busy to respond, but that Eduardo Zorita hadn’t had any problems replicating his results. 🙂 Anyway, when I went to re-check the code containing the collation error, it’s now been hoovered as well. If you go to the Rutherford et al 2005 SI and follow the link for MultiproxyPC Matlab Code, you go here , where a message states:
UPDATE (June 20, 2007):
Since the original publication of this work, we have revised the method upon discovering a sensitivity to the calibration period.
When, as in most studies, data are standardized over the calibration period, however, the fidelity of the reconstructions is diminished when employing ridge regression in the RegEM procedure as in M05 (in particular, amplitudes are potentially underestimated; see Auxiliary Material, section 2).
[Note: a re-visit on Feb 12, 2009 showed that the above link had been modified some time previously to say only:
UPDATE (June 20, 2007): Since the original publication of this work, we have revised the method upon discovering a sensitivity to the calibration period.
]
Interested parties can obtain the hoovered material here , originally saved by John A for me since I had been blocked from the Rutherford site.
3) Unreported “standardization”
The issue of sensitivity to the calibration period was noted on July 10, 2006, here when Jean S posted the following note, in which he noticed the then unreported short-segment standardization (a huge issue in MM2005) and thought that it was a potential problem (although he merely noted the issue without fully diagnosing it). (UC had noticed another interesting problem):
There is a “standardization” step in Rutherford’s code, which seems to be (to my knowledge) unreported. Here’s a segment of the code (taken from “mbhstepwiselowrecon.m”, but the same is present in all reconstruction codes):
[nrows,ncols]=size(composite);
if i==1% first step standardize everything
means=nanmean(composite(500:560,:));
stdevs=nanstd(composite(500:560,:));
composite=composite-repmat(means,nrows,1);
composite=composite./repmat(stdevs,nrows,1);
save standardlow
else % now just standardize the new pcproxy network
means=nanmean(composite(500:560,1009:1008+nproxies));
stdevs=nanstd(composite(500:560,1009:1008+nproxies));
composite(:,1009:1008+nproxies)=composite(:,1009:1008+nproxies)-repmat(means,nrows,1);
composite(:,1009:1008+nproxies)=composite(:,1009:1008+nproxies)./repmat(stdevs,nrows,1);
end
The above code “standardizes” all proxies (and the surface temperature field) by subtracting the mean of the calibration period (1901-1971) and then divides by the std of the calibration period. I’m not sure whether this has any effect to the final results, but it is definitely also worth checking. If it does not have any effect, why would it be there?
In Mann et al 2007, they say:
When, as in most studies, data are standardized over the calibration period, however, the fidelity of the reconstructions is diminished when employing ridge regression in the RegEM procedure as in M05 (in particular, amplitudes are potentially underestimated; see Auxiliary Material, section 2).
The difference is not illustrated in the article itself, but here is the relevant comparison from the SI, illustrating the impact of calibration period standardization on Rutherford et al 2005 RegEM (using ridge regression) said to be corrected in Mann et al 2007 (using TTLS regression).
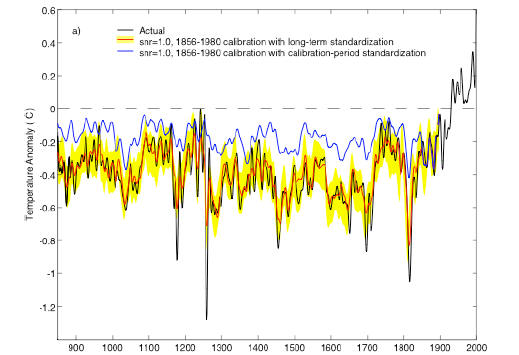
Rutherford et al had cited their code in their Journal of Climate article. In my opinion, Journal of Climate should require them to restore the code even if it was erroneous so that people can inspect what they did.
Stepwise Reconstruction
In Jean S’ note, he observes that the RegEM method is not really designed to deal with stepwise situations. In the MBH PCproxy network where PCs are calculated on several occasions, this poses an interesting conundrum: the PC most dominated by the bristlecones changes position so that bristlecones contribute mainly to the MBH PC2 in the AD1820 network, while they morph over to the PC1 in the earlier networks. What happens in a RegEM situation when PCs change places? It’s not discussed in any of the publications. It seems to me like it would be an issue, although I have no plans to investigate the matter.





28 Comments
Assignment for CA readers 🙂
There was an even bigger issue in Rutherford’s code, which I communicated with Steve (and MarkT) at the time. It was around the Wegman hearings, and we never proceeded with the error. Since the code has now been taken down, and the error does not seem to be there anymore, I think it’s time to let the public know about this.
Since we have an assignment for JEGs hockey stick class, I think it’s only fair to disclose this information as an assignment for all CA readers 🙂 Here we go:
1) What is the center.m function (also here) in the RegEM main function (also here) doing, and why is it essential to the covariance matrix estimation used? Relevant lines of code:
% re-center data and update mean
[X, Mup] = center(X); % re-center data
M = M + Mup; % updated mean vector
% update covariance matrix estimate
C = (X'*X + CovRes)/dofC;
2) Explain what happens if the center.m is “modified” to be as follows:
Rutherford's center2.mfunction [xc, xm] = center(x)
%CENTER Centers data by subtraction of the mean.
%
% [XC, XM] = CENTER(X) centers the data in X by subtraction of the
% mean XM. If X contains NaNs, indicating missing values, the mean
% of X is computed from the available data.
%
% See also NANMEAN, MEAN.
error(nargchk(1,1,nargin)) % check number of input arguments
if ndims(x) > 2, error('X must be vector or 2-D array.'); end
% if x is a vector, make sure it is a row vector
if length(x)==prod(size(x))
x = x(:);
end
[m,n] = size(x);
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Added 5/30/00 by sdr for testing
% Enter interval to calculate the mean over
startyear=1;
endyear=m;
sprintf('%s','start mean year')
sprintf('%5.2f',startyear)
sprintf('%s','end mean year')
sprintf('%5.2f',endyear)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% get mean of x
% if any(any(isnan(x))) % there are missing values in x
xm = nanmean(x(startyear:endyear,:)); % changed 5/30/00 by sdr for testing
% added 6/9 for testing mean
xm =nanmean(xm);
xm =repmat(xm,1,n);
% else % no missing values
% xm = mean(x(startyear:endyear,:));
% end
% remove mean
xc = x - repmat(xm, m, 1);
sprintf('mean removed')
Re: 1 (Jean S)
Okay, I’m a numpty, and by that I mean empty of knowledge of statistics, but I like puzzles which is one of the main reasons I read this site. Its full of maths thats nearly beyond my grasp but with a bit (lot) of work I can actually get my head around most of it and have a grasp of whats going on. The above post is one of the more challenging posts (I don’t speak R). Could you explain (in words of less than 4 syllables) what you are explaining?
Forgive me if I’m being obtuse, my only excuse is that I’ve just come home from celebrating the birth of my friends first daughter. Did you know that his wife wants all the credit when all she’s done is lie on her back for 16 hours whilst he’s had to spend all that time pacing up and down! Some people amaze me
Re #1
You remove the single average value over all years and all data sets? The original removed the all-years average of each data set from itself.
Terry November 22nd, 2007 at 6:45 pm
Looks like matlab (or octave to linux users) code to me.
Jean S. I expect it would be rather difficult to get a valid covariance statistic from two series unless both are centred to the same mean.
Well OK the average of the averaged data series is used, which is not necessarily the same as the average of the entire data set over time and series… so it is even more ill-defined. If you have some numerically higher valued series then they will destroy the centering of any low-valued (numerically) series. Screws up the computation of the X’*X, making the covariance of the high-valued series even change sign against the low-valued. In short, apparently a complete dogs-breakfast results.
Chefen’s (nice to see you here again!) and Jan’s analyses are correct. Congratulations! So my answers to my own assignment:
1) The data is given in mxn matrix (X), where each column corresponds to a (proxy) record and rows correspond to years. The meaning of center.m is to remove the mean of each column (proxy) (i.e., to make each proxy zero mean). Once you’ve done that, you can estimate the covariance matrix by X’*X/NoSamples (‘ denotes transpose in Matlab; CovRes is the code is the regulation parameter which is immaterial here). This is simply to actually calculate the sample covariance matrix. If you don’t make you data zero mean, you have to remove the mean within you smaple covariance calculation.
2) As Chefen correctly observed, the Rutherford’s modified center.m actually removes from the data the mean of the means! Therefore, the columns of X (the proxies) are not themselves zero mean anymore, and one can not estimate the covariance matrix by the formula X’*X/NoSamples. This means that the covariance matrix estimation in Rutherford’s code is completely messed up. As this is one of the crucial parts of the (Reg)EM algorithm, IMO this makes the algorithm completely useless. Hence, the results in Rutherford et al (assuming they actually used the code they published) are rather meaningless.
Ross noticed in the previous post:
So the things are even worse: they didn’t actually use RegEM (whose properties are yet to be established) but they actually used a “modification” of RegEM, which does not even behave like RegEM. My guess is that the short-segment standardization (and later there is also a “standardization” of the final result) and maybe also the low/high-pass splitting were introduced simply because the algorithm was not performing it was expected to due to this “covariance estimation error” (which I believe, is an honest mistake (due to sdr’s terrible coding) and hard to spot). At some point, it seems, they decided to start from the scratch (resulting into the current code).
One more slightly off-topic comment: there’s been some discussion about Mann’s capacity to admit even the most trivial errors. Well, they still have the wrong figure from Rutherford’s paper (the bottom figure is figure 2, should be figure 3 from R05) over RealClimate in the post The missing piece at the Wegman hearing (which was a hilarious read to me as I had just found out the centering mistake). I commented that mistake over here, and even sent them a comment (which, of course, was deleted). If I recall correctly, someone else also sent a comment about this, but obviously with no effect.
Re #6
Hi Jean S. I spent a lot of time recently designing Kalman filters so am thoroughly sick of covariances. But this seemed like a relatively easy quiz. Why he would even put a mean-of-means in for a test is a bit of a puzzler since it is guaranteed to cause nonsense. A quick test with even reasonably similar data series indicates that it totally messes up the covariance. I imagine if the code was used in an actual physical application the mistake would have been found quickly enough, when the aeroplane being tracked suddenly disappeared off the Earth for example.
Chefen (BTW, are you the chefen of the MBH98-attribution fame as I suppose?), of course, the problem should have been observed with any reasonable checking. If I recall correctly from my testing, the error really makes the algorithm behave strangly (convergence problems etc.).
Jean S, yep it is me. Have been exceedingly busy with other things since then, although I did get a giggle out of analyzing the data from that solar paper (Lockwood et al) a few months ago. As you say, the results from using that covariance calculation are totally meaningless without any shadow of a doubt.
#7 Jean S
It was I that also pointed out on RC that that they had used the wrong graph, and my post amazingly made it through. However there was no comment, and no correction, in spite of the fact that it was obviously the wrong graph. It does make you wonder about the inability to concede the smallest error.
Given that Team never makes mistakes, I’d say Wishart was wrong, and this is the right way to compute matrix of sample second-order moments.
James, I recalled it was you, but was not sure. Have they deleted the comment later (I can’t find it)?
Looking at Jean S’s snippet of SDR’s code, I think it is fascinating that as well as the “test” piece of code that calculates the mean-of-means, there is also a “test” piece of code which allows a mean based on a limited sample of the date range.
Now this code has been effectively disabled by hard-wiring the date range from 1 to the size of the matrix, but what kind of “test” would be achieved by investigating another form of incorrect mean removal? It sounds remarkably like the sort of “test” one might conduct with PCA recentring 😉
This doesn’t sound like any form of meaningful testing, it sounds like messing about with the detail of the algorithm to create degrees of freedom that the user might be able to tune results with. If at first you don’t succeed, hack about with the data analysis until your results are significant.
That said, I guess using a shorter date range is typically not going to give a “bad” estimate of a mean (as long as the low frequency terms are not too dominant), I suspect this “test” was disabled as it didn’t give the required tunability?
The above code standardizes all proxies (and the surface temperature field) by subtracting the mean of the calibration period (1901-1971) and then divides by the std of the calibration period.
Just so I ‘get’ it. The mean of each individual proxy subtracted from itself then the result is divided by the standard deviation of that proxy, not the mean and std of the whole set.
Spence, the life is some times stranger than you think 🙂 Actually, the “center”-code I quoted is renamed to center2.m (and the call in the main file(s) is changed accordingly). Now, there actually is also a file called center.m, which is modification of center2.m (or opposite way, don’t know) which is doing exactly what you said: “centering” only to a short segment! That is used before the main loop (where the center2 call is located) in “centering” the initial guesses (remember that Rutherford et al is done in a stepwise manner similar to MBH9X).
I’ve seen my share of bad code, I’ve seen terrible code, but trying to understand SDR’s code was — well — an experience 🙂 And you have to take into consideration that SDR’s code is based on Tapio Schneider’s code, which is reasonably well written and documented!
S_UK, what do they say about one bad apple?
==========================
Jean S
Thank you for your kind remark it means I’m starting to get my head around new areas of statistics which has never been a strong point of mine. I have never in the past put the stats elements in Octave to any use so if you’ll bear with me. I couldn’t actually play with it until I installed the NaN library. Now that I have and tried it out I can see that none of the vectors within the matrix will be likely to be centred unless all the means are exactly the same. That would be unlikely i should think.
And as a service to Climate Audit readers, here is that Rutherford explanation [snip]
[snip]
[snip]
Steve: C’mon, John A, a little more irony.
Steve,
How much irony would you like?
When Ross McKitrick mistakenly assumed that a program required data in degrees instead of radians, this was picked up by an Australian academic, and copied to multiple blogs and right around the internet as “Ross McKitrick not knowing the difference between radians and degrees”.
What Ross in response did was proper and exemplary – he issued a corrigendum, an impact assessment showing the scale of the error to the final result (as it turned out, it had very little effect), and a new corrected paper the very next issue.
Compare that with Scott Rutherford. He has a clear mistake pointed out to him in data collation which any undergrad would get marked down hard on. He admits that this might have an effect on the results but declines to show what the effect of the error is. The Australian says NOTHING about it. Rutherford just deletes the datafiles and the source code to cover his tracks. He doesn’t issue a Corrigendum. He doesn’t issue an impact analysis. His faulty paper remains in the record with no word from the journal or editor that there is anything wrong with it.
And Rutherford carries on regardless.
I do not understand why some academics should get massive deference for mistakes when if a data analyst made such a mistake in the Toronto stock exchange he’d have to consider changing careers.
I like my irony hard and bitter – what about you?
Steve: Stock analysts make mistakes without having to change careers. I agree that the conduct of Rutherford and Mann compares very unfavorably with Ross’.
#14
Or as one associate of mine put it, “They tortured the data until it confessed.”
Chefen, it has long been my position that The Team does nothing accidentally, though they often do not understand the implications of their flawed methods. I did analyze the differences last summer in a very cursory manner and concluded that the intermediate results were similar, but not identical, though I did not dig deep enough to determine where the differences may lie, nor did I analyze the final answers. Since I no longer have the original code (obviously others do, so there’s no issue) due to a computer malfunction (dead drive), I have never finished the work (I’m also overloaded for other reasons).
Btw, I recently finished a Kalman project myself, chefen. 😉
It was unbelievably bad.
Mark
While there are some Matlab people around here, can anyone help me: I’m unable to read the .mat files from Mann’s data archieve. Those files seem to be written with Matlab (Linux?) version 5.0, I’m using Matlab Windows version 6.5. I get an error message saying that the file maybe corrupt (I’ve tried several of those .mat files).
Which directory in particular, or which file in particular? I have 7.4 and they load fine. Shoot me an email…
Mark
Oh, I have winders as well, though MAT files should port from Linux to winders without a problem (I’ve used them both ways).
Mark
Mark, actually with all of them 😦 But send me (I’m not sure what your current address is 🙂 ) keepers.mat in order to narrow down where the problem is.
Jean S
I’ve tried a couple Octave on Imac seems to load them OK. Octave does use it’s own binary format for saving data though it can save it in matlab format. It doesn’t tell what format it is when loading it just does it.
Help for non-statisticians:
http://climateaudit101.wikispot.org/Regularized_expectation_maximization_algorithm
Expectation-maximization is explained at http://en.wikipedia.org/wiki/Expectation-maximization_algorithm
Cheers — Pete Tillman
ClimateAudit 101 team
http://climateaudit101.wikispot.org