Mann connoisseurs eagerly await any offerings from the Maestro and, just as the Christmas season typically brings a new potboiler from John Grisham, so Christmas 2007 has brought us a new offering from the Maestro, this time on hurricanes. Readers will not disappointed.
The season brings us two closely related papers: Sabbatelli and Mann (JGR 2007) and Mann and Sabbatelli (GRL, 2007). The first paper purports to establish a relationship between Atlantic cyclones and independent variables: Main Development Region SST, Nino 3.4 SST and NAO. The second paper applies the relationship from the first place to estimate cyclone “undercounts” in the pre-reconnaissance period, settling on a modest undercount estimate of 1.2 storms/year.
Mann and Sabbatelli 2007 refers to an SI (doi:10.1029/2007GL03178) but there is no such SI as of today at ftp://ftp.agu.org/apend/gl/2007GL031781. Data versions are available at http://www.meteo.psu.edu/~mann/TC_GRL07/ without commentary. Separate files for each component of the regression can be identified.
The file TCcounts.dat has four columns with the year in column 1. Column 2 matches Hurdat basin counts for 1870-2006; column 3 adds an undercount of 1.2 for 1943 and while column 4 adds an undercount of 3.
The nino.dat file also has 4 nino variations that are highly correlated. I could not locate an explanation of the difference between the different versions. It is said to be:
The Nino3.4 index was taken from the Kaplan et al. [1998] data set and updated with subsequent values available through NCEP. The
However, I was unable to identify in matching version in a couple of potential Nino 3.4 data sets listed below and temporarily gave up in frustration. (AGU has a policy requiring authors to identify replicable url’s, but the policy is not applied to the Team.)
- http://www.cdc.noaa.gov/Pressure/Timeseries/Data/nino34.long.data
- http://www.cgd.ucar.edu/cas/catalog/climind/Nino_3_3.4_indices.html
- ftp://ftp.cgd.ucar.edu/pub/CAS/TNI_N34/N34.ASCII
I had more luck identifying a provenance for the NAO data. Sabbatelli and Mann stated:
The boreal winter (DJFM) NAO index was taken from Jones et al. [1997], updated with more recent values from the University of East Anglia/CRU.
There is a data set at NOAA http://www.cdc.noaa.gov/Pressure/Timeseries/Data/nao.dat which exactly matches the CRU version http://www.cru.uea.ac.uk/ftpdata/nao.dat during their common coverage. Updated values are listed at http://www.cru.uea.ac.uk/~timo/projpages/nao_update.htm. Sabatelli and Mann stated that the winter indices are assigned to the December year.
the 1997/1998 El Nino and winter 1997/1998 NAO value were assigned the year 1997
I cross-checked this manually and confirmed that, for example, the 1997 value in Mann’s nao.dat (0.8000) matched the 1997-98 CRU value (+0.80).
I first made a data frame in which all series were assigned to the same year as the Mann data i.e. the row with the year 1997 contained the NAO for winter 1997-1998 etc. Sabbatelli and Mann says:
For simplicity, the “year” was defined to apply to the preceding storm season for both indices (e.g., the 1997/1998 El Nino and winter 1997/1998 NAO value were assigned the year 1997).
You have to watch a bit carefully here, because it turns out that Mann regresses the storm count against the following Nino and NAO indices not the predecessor. Mann justifies this with the tricky phrase:
However, we do find a statistically significant lagged correlation relating the Nino3.4 index to the MDR SST series for the following year’s storm season, consistent with the observation elsewhere [Trenberth and Shea, 2006] that ENSO events influence tropical Atlantic SST in the following summer.
If you’re not watching carefully, you’d assume that preceding winter’s climate data would be used to predict tropical cyclone counts rather than the following winter’s data. But you’d be wrong, as I’ll show shortly. Now for the purposes of estimating past tropical cyclone levels, as Mann and Sabattli try to do, this is not necessarily the end of the world. If there’s a relationship between 2006 cyclone counts and 2006-2007 Nino 3.4 and 2006-2007 NAO, one can utilize this for past estimates. But the causality relationship is certainly not what one expects and this surely warrants a little discussion.
I did both ordinary linear regressions and poisson regressions. The relative performance in different cases was virtually identical and I found it a little bit more convenient to do simple linear regressions as the diagnostics in R are a bit more elaborate. I got an r2 of 0.4647 using this model, which corresponds to Mann statement:
The statistical model captures a substantial fraction R2 = 50% (i.e., half) of the total annual variance in TC counts
I thought that it was very nice of Mann to provide an interpretation to climate scientists of the difficult % statistic. I’m sure that the explanation that 50% was in fact the same thing as one-half will be welcomed by his readers.
If you do the same calculation for the lagged NAO and Nino indices (or for the lead indices by one more year), the r2 declines to the 0.32-0.33 range in both cases. So the reported relationship is definitely with the following winter’s Nino and NAO indices. The assignment of the 1997-1998 Nino to 1997 was not just for “simplicity”, but to improve the stats. It’s hard to imagine that they didn’t also do calculations using the preceding season indices, discarding these calculations when they didn’t work as well. This sort of data snooping needs to be reflected in confidence estimates, but isn’t done here.
Early. Late and Middle Models
Mann and Sabbatelli 2007 report on two alternative calibrations of the model used for verification: one on the period 1870-1938 and the other for the period 1939-2006. They report that the r2 declined only slightly to 43%. (Speaking of which, didn’t Mann say somewhere that calculating r2 statistics would be a “foolish and incorrect thing to do”. Such merriment from the prankster.)
In the R-implementation of Poisson regression, the r2 statistic is not reported (and I didn’t, at this time, bother calculating it.) Since the linear regression moved in parallel with the poisson regression, I compared information using linear regression – recognizing that a more precise match would calculate the r2 using poisson regression. I got similar results, only a very slight decrease in r2.
Now here’s the interesting bit. Just for fun, I re-calibrated the model using a calibration period 1946-1992 and then 1930-1992. The r2 declined to about 0.2. So the model is not nearly as stable as advertised.
Following Mann’s method with 1930-1992 calibration (although using linear rather than Poisson regression – I could retool this with Poisson regression, but it won’t make anything other than a microscopic difference and it will take extra time not required for the point), I then compared the estimated count to the actual count below. In the calibration period, you can see a plausible fit. However after the calibration period in 1993-2006, you see that there are more storms than predicted using the “middle” calibration and prior to the calibration period, amore substantial; undercount. Given the low r2, I wouldn’t put a whole lot of weight on these results, but they are definitely inconsistent with the advertised results in Mann and Sabbatelli.
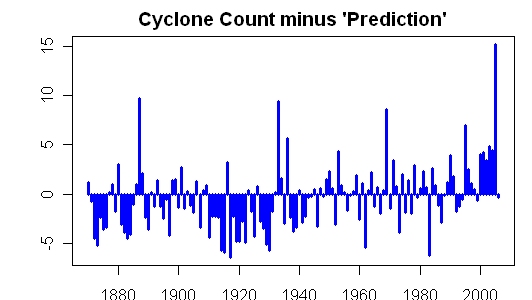
In any event, the performance of their model degrades substantially when the middle portion is used for calibration. Did they bother doing this elementary check and failed to report the results? Or did they omit this obvious check? Neither is a very good answer. This particular check was not very hard to do. I’ve probably spent about 5 hours on this study, much of which was consumed with attempts to verify data given the inadequate data provenance. If a reviewer was spending a few hours on the review of a paper like this, you’d think that they’d try an analysis like this and have got similar results.
So when you’re appraising exactly what you’re getting from a review, you need to bear in mind that the reviewer has merely expressed his opinions on the paper based on a read of the paper and that even minimal due diligence has probably not been carried out.
References:
Mann, Sabatelli et al 2007. http://www.meteo.psu.edu/~mann/shared/articles/MSN-GRL07.pdf
Sabbatelli, T.A., Mann, M.E., The Influence of Climate State Variables on Atlantic Tropical Cyclone Occurrence Rates, J. Geophys. Res., 112, D17114, doi: 10.1029/2007JD008385, 2007.





73 Comments
I read this awfully fast, but are you are saying that the hurricanes affect the El Nino events? So we could predict ENSO from Atlantic hurricane data? Or is this forward telecommunication?
You have to admire their wordsmithing anyway.
Steve: I’m not taking any position on the topic; I’m merely reporting what they did. They regressed this year’s Atlantic storm count against the coming winter Nino and NAO. On this basis, yes, they imply that they can predict ENSO from Atlantic hurricane count. However as I observe with the middle calibration, any relationships in this study are probably fortuitous to a considerable degree.
And they call the wind La Nina.
====================
Who cares about predicting ENSO. Do Atlantic hurricanes predict what the price of gold is going to do next year?
Steve: For that you need a “more sophisticated” model using bristlecone chronologies as well.
To any economist, all of this has a horrible feel of déjà vu about it, expressed eloquently enough by Ross McKitrick in comment 3. Years ago, a fairly unscrupulous econmetrician friend of mine used to spend hours adjusting leads and lags (mostly lags) with the result that he could always generate models that “explained” brilliantly within sample, but immediately fell apart when challenged to forecast anything.
If you have the time and inclination, it might be fun to mine the data further. If the experience of my friend is anything to go by, there is a set of lags in there somewhere that will produce a higher R2 than 0.5.
out of curiousity because I don’t have regular access to an academic library, what was their conclusion?
Probably had a senior moment, and thought he was writing an RC post.
Steve, there’s a Supplementary Information file on Mann’s website now.
Steve: It was there before. It’s the reported (and permanent) GRL archive that’s missing. Mann’s archives are not permanent; he has deleted inconvenient archives e.g. Rutherford 2005.
Can’t wait to see the gymnastics used to estimate the hurricane undercounts of earlier years. Will it depend on rural lights?
A few comments (items for further research):
1. Why did they pick the NAO boreal winter (DJFM) when standard hurricane season runs from Jun 1 – Nov 30? They should have used “summer” (ASON), which would have kept it closer to the season, and in the same year. Or with further research, even used the Jun/Nov period.
2. Someone could check their stats against the ACE listings.
3. If I’m not mistaken there are three or four areas in the Nino/Nina zone. How does it stack up against the others?
I still say the only reason they’re doing this is to set a “floor”, so that they can report later “this year exceeded our predicted amount”.
Or now since they’ve set a reconstruction (the “stick”) they can now comment on the increase (the “blade).
Don’t know if this helps, but this listing (teleconnection indices) lists the whole series (monthly, going back to 1950):
North Atlantic Oscillation (NAO)
East Atlantic Pattern (EA)
West Pacific Pattern (WP)
EastPacific/ North Pacific Pattern (EP/NP)
Pacific/ North American Pattern (PNA)
East Atlantic/West Russia Pattern (EA/WR)
Scandinavia Pattern (SCA)
Tropical/ Northern Hemisphere Pattern (TNH)
Polar/ Eurasia Pattern (POL)
Pacific Transition Pattern (PT)
ftp://ftp.cpc.ncep.noaa.gov/wd52dg/data/indices/tele_index.nh
And I was right: there are Nino4, Nino3.4, Nino3, and Nino1+2 areas plotted. Again, why use just the 3.4 plot?
This is beginning to sound like a “sophisticated” example of the Texas Sharpshooter Fallacy.
#10. I’ve looked through a variety of data sets without success at matching. I’d much prefer it if you or someone else could confirm a match as opposed to simply listing more things for me to go through.
Hit the wrong key.
The Nino listings, (monthly, from 1872 – present) are here:
http://www.cdc.noaa.gov/Pressure/Timeseries/Nino3/
http://www.cdc.noaa.gov/Pressure/Timeseries/Nino34/
http://www.cdc.noaa.gov/Pressure/Timeseries/Nino4/
So it seems that the standard hurricane season could have been used. So now someone can re-check the robustness of Mann’s calculations, using different time periods of the year, and different Nino areas.
SteveM:
Sorry, just commenting as to why they would use the time periods they did, when the entire year was available.
Mann is now resorting to more crude data torture techniques, as he is emboldened by his reviewer’s unwillingness to examine his work in any meaningful way.
If this continues, he might make the mistake of doing something really crude, such as taking a simple mean. 😉
MrPete, this is precisely why I ask my question at RC. It is clear these are post-hoc human inventions; empirical characterizations of patterns observed over a given, limited time and space. So, are these teleconnections spatially stable and temporally persistent, and if so, over what time scales? And to what extent are GCMs being tuned to structurally unstable fluid flows? I have never gotten a satisfactory answer from anyone. I get the sense that the statistical behavior of these flows is glossed over and/or ignored. No one cares about the ergodicity assumption.
Great – do I detect a hurricane hockey stick?
Re #10/#11/#16
If I understand Sadlov’s hypothesis (underlying his regular reports on synoptic weather forecast failure) – it is that long-range forecasters do not have the skill they think they do. If there is no predictability in the time domain, perhaps there is no predictability in the ensemble domain. Non-interchangeability of time-series and ensembles implies non-ergodic flow, implies … what, exactly, for the GCM tunings?
The tie-in to the post is that M&S appear to be trying to predict ENSO (#3) based on past correlations – a subject that JEG is also pursuing. Is this a fool’s game? Like the texas sharpshooter?
Thanks, much, Steve M, for the effort expended in the sensitivity testing of the data selection that went into the 2007 Mann and Sabbatelli TC Poisson model. I was most curious about that sensitivity and also struck by the use of indexes from future years. I hope your analysis here piques the interests sufficiently to lead to further sensitivity analyses. It also reinforces my view of some climate scientists who seem to data snoop the data without apparent recriminations for failures to explain what was done and the potential statistical repercussions.
RE: #18 – Yes.
RE: Mann et al – As I predicted, the obsession with TC count (as opposed to ACE, or other more objective measures) has concluded in yet another purported “leading indicator” of a “killer AGW” scenario. This is why I have been challenging the count padders and calling them out this year. Count padders, to be fair, are not all necessarily part of “the Team.” Some of them are rather innocently caught up in hysteria, in PR campaigns (aimed at getting more visibility for their orgs, via increased media exposure), etc. But nonetheless, count padders, at best, unwittingly serve the “cause” of making the case for a “killer” future scenario.
I personally see nothing at all in Mann and Sabbatelli that is remotely insightful or scientifically useful. Non-statisticians like Mann should stop trying to screw up climate science with bad statistics and stick to something he’s good at (probably grant applications).
The most significant result on hurricanes this year was Linsay (2007) which rocked my world.
Press releases/coverage:
http://live.psu.edu/story/27428
http://www.sciencedaily.com/releases/2007/11/071126090229.htm
http://blogs.usatoday.com/weather/2007/11/simmering-debat.html
I would add that it was important to the Team that this year’s count, which, as early as June, was obviously not going to match the forecasted 14 or 15 if only real TCs were counted, needed to be inflated as much as possible without straining the credibility factor pertinent to the average boob tube zombie. They knew they’d be in negative territory with the predicted minus actual figure. They were in damage control mode, trying to get predicted minus actual as close to zero as possible. The goal would have been, don’t undo the “results” of 2000 – 2005. Now, they may have put their feet in it. Conventional logic would say that next year ends up being a smokin’ year for TCs, due to La Nina. I say, don’t bet on it, everything changes when PDO flips and AMO quiets down. So, by using up a lot of wiggle room this year in terms of naming and claiming, if the next few years are flops, they cannot pad much more than they did this year without raising undue suspicion.
you can snip #5, I see their conclusion in their press release.
not surprising.
I suspect now, The Team will attempt to remove from the record the paleoclimate data that indicates that TCs come in regular on and off cycles. plus ca change.
it’s very interesting that I see a hockey stick in that data too. very,very interesting.
#20/23 I don’t think any of the ‘count padders’ on The Team work for TPC and HRD, but they may have to deal with edicts from NOAA.
Kaplan’s monthly Nino data:
http://iridl.ldeo.columbia.edu/SOURCES/.Indices/.nino/
It looks like the 4 columns in Mann’s file is Nino 1&2, Nino 3, Nino 3.4 and Nino 4.
Steve: Did you check? I don’t think that they match.
Wasn’t the press release linked here the other day Mann and Sabbatelli (GRL, 2007)? It had to do with cane undercounts. But the press release acted as if the modeling was calibrated for 1945-present, not 1939-present.
Steve,
The storm counts for 1911, 1912, 1913 are short a total of five. Should be 6,7,6 according to this Hurdat best tracks file last revised May 2007. Link
They say the Hurdat Re-analysis Project is now complete through 1914. Maybe using an older file?
The logic can be shown at its most basic by the old doctor story.
The doctor would tell pregnant women the gender of the child to be born. He would then make a show of writing it up on his calandar near the forecast birth date. When born, if the child had the gender as spoken, he was accurate. If the new mother said, “But you told me it would be a boy” the old doctor would look up the calendar and show that he had written “girl”. Method – he simply said one gender and wrote the opposite on his calendar.
This prepared him to be r^2=100% (fully) correct in all future cases of prediction.
Oh yeah. 22 of the storms 1968 and later are subtropicals. None prior to that.
D’oh! Forgot again.
The visible link http://www.meteo.psu.edu/~mann/TC_GRL07/ in your post takes you to the CRU instead of Mann’s page. Might want to correct it.
The following warning popped up upon my access of the NOAA FTP site. Since I need to get my bar ticket punched every year, I decided to forgo this bit of info. In this age of creeping totalitarianism, I would rather avoid having my name on another government list, particularly one that might brand me as “curious” about the climate.
**WARNING**WARNING**WARNING**
220-This is a United States (Agency) computer system, which may be accessed
220-and used only for official Government business by authorized personnel.
220-Unauthorized access or use of this computer system may subject violators
220-to criminal, civil, and/or administrative action.
220-All information on this computer system may be intercepted, recorded,
220-read, copied, and disclosed by and to authorized personnel for official
220-purposes, including criminal investigations. Access or use of this
220-computer system by any person whether authorized or unauthorized,
220-constitutes consent to these terms.
220- **WARNING**WARNING**WARNING**
220-******************************************************************
220- **NOTICE**NOTICE**NOTICE**NOTICE**NOTICE**NOTICE**
220-This server is not considered operational. It is only supported
220-Monday thru Friday between 0700 and 1600 EST.
220-Report any problems to ncep.helpdesk@noaa.gov.
220-The NWS ftp server (tgftp.nws.noaa.gov) is the most reliable
220-source for operational data. That server is supported on a 24×7
220-basis. Please report any problems accessing that server to the
220-OOS Tech Control at toc.nwstg@noaa.gov or 301-713-0902.
220- **NOTICE**NOTICE**NOTICE**NOTICE**NOTICE**NOTICE**
220-*****************************************************************
220
Standard CYA govment website lingo
Here’s something interesting. In a news release last week, Mann href=”http://www.physorg.com/news115288117.html”>announced his 2007 “predictions” after the season:
However, as I understand his model, he requires the NAO and Nino 3.4 for the upcoming winter in order for his model to work. Anyone have ideas on what he did?
Would hate to speculate what he might have done. But …
Extrapolate NAO and Nino 3.4 by one year and feed into model? (But extrapolate how? As with Timonen’s Scots pine proxy?)
Steve, I think you got it wrong. The Nino 3.4 index in 1997 is predictive of storm count in 1998. Besides, if you look at the results it is clear that SST in the MDR is the main driver and that NAO and Nino 3.4 are modulators. BTW, this season was affected by wind shear in west of the MDR which prevented many storms which formed (or tried to form) from becoming major hurricanes. Since the M&S model only claims to predict named storms it seems as though they nailed it pretty well.
Why don’t you read the cited Trenberth paper?
Steve: I’ve checked and double-checked. I’m talking about the Mann statistical model. I’ve verified that the 1997 NAO figure in his data is the 1997-1998 NAO. And that he can only get his r2 if he uses the 1997-1998 winter NAO and Nino as regressors for the 1997 hurricane season. You may not think that that makes sense, but that’s what he did.
They state:
If you want to check the collation of NAO, here’s what people can do. Mann’s data is at http://www.meteo.psu.edu/~mann/TC_GRL07/nao.dat
125 1994 2.4375
126 1995 -2.3225
127 1996 0.1750
128 1997 0.8000
129 1998 0.9825
130 1999 1.8475
131 2000 -0.5000
132 2001 0.7900
133 2002 0.3975
134 2003 -0.2025
135 2004 -0.1125
136 2005 -0.8200
137 2006 2.4300
Source information is at http://www.cdc.noaa.gov/Pressure/Timeseries/Data/nao.dat which states:
Winter (DJFM) NAO index
Year Index
1994/5 +2.44
1995/6 -2.32
1996/7 +0.18
1997/8 +0.80
1998/9 +0.98
1999/2000 +1.85
2000/1 -0.50
2001/2 +0.79
2002/3 +0.40
2003/4 -0.20
2004/5 -0.11
2005/6 -0.82
2006/7 +1.83
So Mann’s 1997 figure is the 1997-1998.
Here’s code to collate Mann’s data into a data frame plus create a lag for NAO and Nino:
Here is a regression using the following winter information:
This yields an R2 of 0.46:
Now if you do the same regression using the preceding winter (the lag variables here) as follows:
one gets a degradation of regression performance to values noticeably less than reported:
As far as I can tell, there’s no way that MAnn can get the claimed r2 using the preceding winter – only the following winter. HEnce the prediciton problem.
As noted before, there is also a very large model degreadation if the middle period 1930-1992 is used for calibration:
This yields results:
So there are real problems with this puppy.
I have not read the paper yet. Are you sure he’s using lm()?
Re #35 The key 2007 wind shear plots are here , here and here . The lower the wind shear, the more favorable the condition. These plots indicate that wind shear was an overall favorable factor, not an unfavorable one, in 2007.
Most likely the 2007 season was a dud because of anomalously stable (and likely dry) air.
I think that somehow the “Atlantic dipole” factors into all of this and may be a bigger player than MDR SST. Here’s a plot of dipole versus ACE (a better measure of Atlantic activity than storm count). The dipole, which contrasts North Atlantic and South Atlantic SST, is a measure of thermohaline activity.
David,
I did not look at the windshear plots, I just judged it from looking at the sat photos of developing storms. It was pretty obvious that as they moved into the Western Atlantic that most developing storms were ripped apart by upper level winds. However, the 2007 season was not that much of a dud — with 14 named storms (BTW, the Sabatelli & Mann model predicted 15 +- 4) — many of the storms which should have developed into major hurricanes simply sheared apart before they reached the Windward Islands. Whether it was dry air or bad juju I don’t really know, however Mann, Sabatelli and Neu was just looking at named storm undercounts and not ACE. The undercount issue is interesting as the number of threads on CA devoted to it indicates, the paper under discussion seems to validate other work and provides a model with reasonable predictive power, no matter what Steve claims.
I also wonder what the various “count inflation” posts have to do with reality. Storms are classified by the NHC (you know, Landsea?) so even if a storm starts out as an extra tropical cyclone, once it becomes a warm core storm (you know, a tropical cyclone?) with the necessary wind speeds it should be classified as a TC. Mann, Emanuel, Webster, Curry and Holland do not get much of a say in what is classified as a TC; that is left up to the guys at the NHC.
It is also interesting that Steve does not understand the complex relationships which El Nino (the Nino 3.4 index which seems to be the best diagnostic) has with local climatic effects. Many of the effects of El Nino do lag, read “El Nino in History” by Cesar N. Caviedes for a very through analysis of the effects of El Nino and the diagnostics that climatolgists use to detect ENSO events in the past.
This is quite clearly a massive advance in climate science.
All we need to do to forecast hurricanes in 2008 is forecast ENSO in 2009…oh…
Re#40 Hello JMS. I’ve only scanned the paper to-date so I can’t say anything one way or the other on its methodology. Maybe this weekend.
The year 2007 saw 13 named tropical cyclones (the first named system lacked a warm core and was not tropical). The “institutional” forecasts (midpoints) were:
UK Met – 11
IWIC – 13
Accuweather – 14
IWIC – 14
Mann – 15
National Hurricane Center – 15
TSR – 16
Gray/Klotzbach – 17
“Climatology” (average of last 12 years, since entering active phase) – 14
“Climatology” (last 60 years) – 10
Mann (and the rest of us) would have done better by simply forecasting “recent climatology”.
ENSO and Atlantic hurricane activity are related though it’s not as big a factor as is often thought.
My recollection is that March-May are something of a “foggy window” through which it is hard to see the tropical conditions, like ENSO, in the months after May. There are what’s called “skill” statistics that reflect this barrier. It’s as if some elements of the tropical climate are random (or at least beyond our knowledge) which get decided for the next 12 months around April. There’s a fair amount of persistence from May thru February and then the atmosphere “reshuffles the deck” around April and applies that reshuffle to the next 12 months. Sorry for the poor analogies.
Personally, I think the NHC uses its available tools to call it as they see it on individual systems, and are not attempting to inflate storm counts. The problem is that their tools get better and better, so more swirls get classified as tropical cyclones.
#38. He’s using poisson regression. I’ve done poisson regression using glm () which doesn’t give r2 as a stat unfortunately. I could write a little routine to add this statr to thie fit (And will do so if we discuss this more), but the lm fits and poisson fits had similar properties as contrasts. So the degradation in the lm fit will be matched by a degradation in the poisson fit. I guess I’d better add an r2 function to the glm fit.
#40. You say:
I made no comment on the effect of El Nino or lack of effect whatever in any of these comments. I am merely trying to report the statistical properties of the Mann model – where, as so often, one has to try to decode obscure wordings. One is always speculating to some extent as to what Mann did or didn’t do in any article, but here my present view is that he used the following winter’s Nino 3.4 index as a predictor for cyclone count.
#42, You say:
A couple of years ago, I was in a Japanese restaurant and they had a large long rectangular tank with water on the top and colored sands of some type on the bottom which was moved up and down on each end like a teeter totter. As the tank moved up on one end, there was eventually a type of “avalanche”, re-arranging the sand in new patterns as it went from one end to the other with swirls in the water, sometime coming after the center of gravity seemed like it should have shifted already.
IT struck me at the time, without being able to formulate it, that the change from northern summer to northern winter to northern summer has an element of surge to it. Summer seems to come from the south and both seasons linger.
Steve,
No they don’t match. The files at the link in #25 are monthly data, Mann’s file is yearly data. However, it looks to me like this is the data Mann could have used to create his file. Assuming column 3 is Nino 3.4 (and that this is the one he used in the regression) I’ve tried to find a match between data at the link and Mann’s data. Using the file at “Extended”, “Nino 3.4” that goes from January 1856 to December 1991 I get an R2=1.00 correlation by taking the average of Jan/Feb/Mar of each year and applying it to the previous year (So the average of JFM of 1871 is 1870’s Nino 3.4 index). The correlation is y=x-0.0328. When I try this with Nino12, Nino3 and Nino4 files, I can’t get it to match the data in Mann’s file.
Unfortunately this changes after the 1991 data and I can’t find a match for the NCEP data at the link from 1991 to 2007. Go figure.
I made an error above. The “Extended” files go all the way to October 2007 and the correlation holds true through the entire time period.
Does this mean the this year / next year bit cancels out, and the forecast is based on the earlier Nino data?
#47. No this is what was already observed with the NAO data. Mann puts winter 1997-1998 results in his 1997 row. At this point, it’s just housekeeping. But it also seems that he then does the regression using this alignment of data – thus using next winter’s NAO and Nino to “predict” this year’s hurricane count.
As I mentioned before, for reconstructions, this is not the end of the world, but the causality is odd as, in Granger causality terms, it suggests that this year’s Atlantic cyclones have greater predictive value for Nino 3.4 than the reverse – which suggests an odd sort of causality undiscussed in the literature and which would contradict Mann’s claim to have predicted 2007 counts using this method.
But hey, this is Mann and at this point, I wouldn’t bet 10 cents that we’ve been able to sort out exactly what he did yet. What was it that JEG said about being able to follow the Methods in an article as a criterion for publication? Remind me again.
#46. That’s progress. Can you figure out the other columns?
Here’s a game one could play:
My 2007 hurricane forecast was skillful, therefore
The model that produced it is correct, therefore
I am a credible authority, therefore
My doomsday warming scenarios are believable.
But the logic does not follow. Is the hope that people won’t notice? The pea under the thimble.
1. Correlation is not causation, and Mann admits he’s “not a statistician”. Does he know the true epistemological cost of fishing for correlations with red noise processes? [History says ‘no’, and it’s not clear that he’s learned from past mistakes.] Does he pay the price (in terms of reducing his degrees of freedom)? Does he reduce the strength of his conclusions accordingly?
2. As #42 suggests, credibility comes only with skill in predicting unlikely events, which 2007 was not; it was the most mundane possible outcome.
3. The hurricane question is a quantitative one: how many additional storms per year do you expect under X amount of additional warming? Whether the answer is 1% or 100% makes a big difference whether I pay any attention at all to this model. Why not answer the obvious question? Why obfuscate? It’s analysis vs. alarmism, and the choice, too often, is alarmism.
4. Obfuscationists have zero credibility.
5. Alarmists have negative credibility.
Steve M, you are so forgetful. The word is: PSEUDO-SCIENCE.
No, not at all. I’ve tried all the Nino 12, 3 and 4 files and different combinations of seasons and can’t figure it out.
Also, column 3 is actually DJF, not JFM as stated above.
RE 51. 1 for the money 2 for the show: Suedo Science:
#35,
The 2007 season had 6 marginal storms that only fit the definition of TS by briefly having sustained winds of 40Kts. The central pressures of these storms were too high. In past decades, both central pressure as well as sustained winds were used.
Now let’s see if the number of named storms or the number less the six marginal ones do a better job of predicting this winter’s Nino and NAO. LOL.
RE: #42 – We therefore shall have to agree to disagree. I think count padding and bogus classification of what, 20 years ago, even with maximal available data, would not have been deemed named storms, is indeed happening. I believe there has been a subtle and perhaps even sub conscious lowering of the bar for naming. That’s in addition to the understandable “detection” improvements.
RE: #54 – Also, in the past, it was far less common to name mid latitude features that “went tropical” or other questionable features resulting from voritical combinations of mid latitude and tropical features. There was an element of conservatism and subjective judgment applied. That is sadly lacking today. Some of it may derive from some of the preparation and response debacles in the US since the 1980s. Political damage control. Some of it may be something worse.
Looked at the abstract for the 1st paper by S&M. I see they used peak(whatever that means) SST(ASO) in the MDR as part of establishing a relationship with total storms for each year. Doesn’t seem to make much sense to me to compare a three month temperature for a part of the basin with yearly data for the entire basin.
During their 1870-2004 data period 1200 storms occurred. Of those, 981 were active at some point during Aug-Oct. Of the 981 only 333 ever formed in or entered the MDR. Why use a data set with more than 70% of the data coming from outside the area and time of the temperature value? Seems more appropriate to confine the observations by time and place.
So I worked up the figures for just the MDR. Used the monthly SST at each observed time and track location Aug-Oct to create a mean temperature for each year. May not mean much, but I doubt what they did with the SST means much either. Don’t know what use they’re making of ENSO and NAO and I’m not going to purchase the article to find out. So I won’t do anything with that. Here’s what I came up with for anomalies. The choppiness is due to 16 years not having any data during the Aug-Oct period. Mostly in first half of the period.
Here’s a map of the track data. Link
Dividing the data at 1938-39 gives the distribution below. Only 0.1c temperature increase while ACE per track is 20% higher in the first half. Although the ACE per storm is 6% higher in the second half.
1st half 2nd half
SST 27.61 27.74
tracks 1142 2321
mdr ace 360.86 599.38
ace per track 0.32 0.26
storms 130 203
ace per storm 2.78 2.95
Final note then I’ll shut up for a while. It’s one thing the “name for safety’s sake” in the case of a feature that actually has a chance of becoming something more than a “storm” or “Cat 1” equivalent. It is quite another thing to name a questionable feature that will never amount to anything and will curve out somewhere between Bermuda and the Azores or diffuse due to shear and / or dry air. This is where the credibility factor is lacking. If I did not see such behavior, I never would have raised this issue in the first place.
More pea & thimble tricks.
Except that HSs are not well-described by a ¦Ñ=0.32 red noise process (or even a ¦Ñ=0.71 process for that matter), and the HS bcp signal is not representative of patterns in the other proxies in the network. So assuming that the network-wide ¦Ñ=0.32 estimate applies to each member of the network (or the one member that is driving AGW) is incorrect.
Always keep your eye on the sample statistic and the torqued-up population-level inference. It’s tough with all those words.
See how they “move on”?
http://www.chron.com/disp/story.mpl/front/5337583.html
Whatever it takes to get a hockey stick, that’s what you say, right Judith?
The thing is, if they really wanted to compare historical numbers, they would talk to the guys who were responsible for the policies at those times, instead of dismissing them out of hand as old cranks.
From my link above.
Yorick.. have you seen Dr Slop, Uncle Toby and Tristram?
Expect everyone to guess low next year. It gives a better action line.
Rock paper scissors
The issue has move Beyond public information to public indoctrination.
GUESS LOW for 2008! and blame the excess on AGW. GUESS really low and say
that AGW has effed up our understanding, we are in uncharted waters.
Guessing high and being wrong has no political force. Guess low, Blaming
c02 for your missed putt…..Is genius. C02 is warmng the climate and confounding our ability
to predict disaster. it’s a doubly disasterous disaster.
Sorry Steve, but no, I haven’t. I am not sure where you are going with that line, but fire away. It sure beats “Alas poor Yorick”.
yorick, uncle toby dr. slop and tristram are all characters in a book.
#61,
From all of the evidence that I have seen, historical instruments, while not as accurate as today, were still pretty darn accurate.
The idea that 200 hundred years ago, instruments routinely mismeasured windspeed on the order of multiple knots, is utterly ridiculous.
Additionally, from the data that Anthony Watts has been gathering, it might be safe to claim that back then, they took better care of their instruments as well.
Yeagh, Tristram Shandy, I assume, but what is your point?
Comment on guessing low.
For 2008 guess the actual average of the last five years. Keep doing that and your error should be pretty low over time.
Then you can say your longer term record is very good.
#67. I also think the observations, instruments, and logs of 200 years ago are pretty good. I believe the issue is the presence of ships to observe storms. Sailing ships and fishing avoided unproductive routes and areas. That left large areas of ocean empty. That meant many small and short duration storms were undetected. I suspect ships were even more cautious about routes during the peak storm months.
I’m confused a bit… but did Mann just show that:
1) If he took the batch as a whole, we can reject the hypothesis that the distribution is poisson. (Figure 2.a: Note, y axis shows as many as 40 samples in some bins.)
2) If he breaks it into two batches with half as much data each, it still reject the null hypothesis. (Figures 2. b & c: note, y axis shows only 20 samples in some bins.)
But
3) if we split it into even smaller bits, we can no longer reject the null hypothesis?
Is there some way to calculate beta errors on this? Is this really just an exercise in increasing beta error until we have a test that more likely to give the wrong answer than the right one?
I can’t do numbers in my head, but, given the logic for making a conclusion, I wish the reviewers had required Mann to include some estimate of beta errors.
After all, the logical argument may rest on beta error.
Also, why didn’t they make him repeat with similar binning for pre/post aircraft sampling. Can the reader tell whether one might not get just a change in the poisson distributions based on that sort of binning?
Re: #70
I am looking at the Mann data and analysis as we speak and plan to do some sensitivty analyses. I agree that the total data does not fit a Poisson distribution nor does the data for Easy to Detect storms fit one even through that distribution has little or no trend.
Mann divides the data by classifying favorable and unfavorable using the variables SST (which I judge is confounded with changing detection capabilities and is effectively detrended using Easy to Detect storm counts) and nino 3.4 index. He reports some p values for the chi square test that give reasonably good confidence the distribution is Poisson for the classifacation -SST/+nino, the unfavorable condition, and the classification +SST/+nino or -SST/-nino, the nuetral condition. The p value for the chi square test for the classification +SST/-nino, the positive condition is 0.27 and while one cannot reject the null hypothesis that the distribution is a Poisson distribution (normally one uses p less than 0.05 for a rejection level) the beta error here would be considerably larger. In an attempt to get around this issue Mann looks at the average p value for all three cases or at least the favorable and unfavorable cases and implies a rule of thumb guide line that an acceptable average value for p is 0.50.
Willis E. in a much earlier thread detrended the storm count time series and removed the cyclical component. He graphed it and I did a chi square test on the adjusted time series and calculated a p value of approxiametly 0.9 — which I consider a very good fit.
I want to remove the cyclical component from the Easy Detection storms counts and do a chi square test on the result. I think it is important to note that in the Willis E analysis nothing is presented a prior as a parameter. It simply shows that a detrended count series with a cyclical component removed fits a Poisson distribution very well.
I will also use Mann’s classifications for nino 3.4 and calculate the p values for a goodness of fit test for my Easy Detection storm counts series.
I have done essentially what I described I intended to do in my preceding post. I used the Mann nino 3.4 index to divide the Easy Detect storms counts (using the David Smith criteria as described previously) into 2 categories depending on whether nino 3.4 was positive or negative for the months of DecJanFeb following the storm season. Under those conditions I calculated the following p for the chi square goodness of fit test for a Poisson distribution:
Nino 3.4 index was negative: p = 0.40
Nino 3.4 index was positive: p = 0.92
I think these results demonstrate that one can obtain similar results to those determined by Mann without using SST when the process is applied to Easy Detect storms. Following further on this line of thinking offers evidence that the variable SST with its trend increasing with time can easily be confounded with improvements over time in storm detection capabilities.
Since Manns use of the nino 3.4 index for the months following the storm season seemed rather an unphysical connection without some explanation, I looked at the differences that would result in the using the same months for categorizing the storms counts for the following season (as opposed to the preceding one as Mann evidently did). Those results for the goodness of fit test for a Poisson distribution were as follows:
Nino 3.4 index was negative: p = 0.01
Nino 3.4 index was positive: p = 0.90
It is interesting to note a couple relationships here. Firstly the Easy Detect storm counts for the years with a DJF nino 3.4 index that is positive yields a very good fit to a Poisson distribution whether applied to the following or preceding storm season. Secondly, when the nino 3.4 index is negative, the fit to a Poisson distribution becomes significantly less probable for the storm count years preceding the DJF indexed months and, when the negative DJF nino 3.4 indexed months precede the storm count years, one can reject the null hypothesis that the distribution fits a Poisson one at the 0.05 level.
I did one more analysis by removing the cyclical component from the Easy Detect storm count series (1860-2007) using the Willis E derived cycle for the Total count series of a sin wave with a peak-to-peak amplitude of 3.2 and a period of 58.8 years. I would caution that this procedure removed a cyclical component based on the Total count series and not the Easy Detect series and should be redone using the Easy Detect series. Removing the described cyclical component increased the p value for a chi square fit for a Poisson distribution from 0.01 to 0.59.
I have received an update of the Easy Detect storms that was not applied to this analysis. It does not appear that the changes will change the above result significantly, but for completeness I will repeat the calculations with the update and report any differences.
Here’s something:
Click to access bams_hurricanes.pdf
Again, Held et al.