Here’s a first attempt at applying the techniques of Brown and Sundberg 1987 to MBH99. The results shown here are very experimental, as I’m learning the techniques, but the results appear very intriguing and to hold some possibility for linking temperature reconstructions to known statistical methodologies – something that seems more scientifically useful than “PR Challenges” and such indulgences. Ammann and the rest of the Team are lucky to be able to mainline grants from NOAA, NSF etc for such foolishness.
One of the strengths of Brown’s approach is to provide some tools for analyzing inconsistency between proxies. This has been an issue that we’ve discussed here on an empirical basis on many occasions. Let’s suppose that you have a situation where your “proxies” are somewhat coherent in the instrumental period (say 1856 on), but are inconsistent in their earlier history – a possibility that can hardly be dismissed out of hand. And you can analyze your data in the instrumental period till you’re blue in the face – you can call part of it “calibration” and part of it “verification”, but it still won’t prove anything about potential inconsistency in earlier periods. You have to have some way of measuring and analyzing potential inconsistency in the earlier periods – even if you don’t have instrumental information to calibrate against.
Brown’s “Inconsistency R” (which I’ll call Inconsistency Rb” here) to try to avoid confusion with 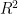
In my opinion, this is a very dramatic graph and should give pause even to the PR consultants and challengers hired by NOAA and NSF. There is obviously a very dramatic decrease in the Inconsistency Rb statistic in the instrumental period and particularly in the calibration period. This is a vivid quantification of something that we’ve observed empirically on many occasions. This change begs for an explanation, to say the least. This graphic raises two different and important questions: 1) what accounts for the change in inconsistency R statistic during the instrumental period relative to the pre-instrumental period? 2) what do the very high inconsistency R values in the pre-instrumental period imply for confidence intervals?
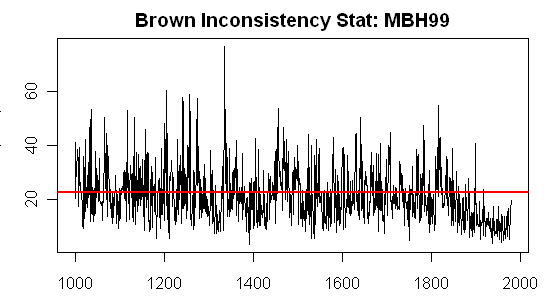
Figure 1. Brown’s Inconsistency Rb Statistic for MBH99 Network (14 series).
For the first question, the change in Inconsistency Rb levels from the pre-instrumental to instrumental period, one hypothetical explanation would be that the changes in the instrumental period are “unprecedented” and that this has occasioned unprecedented coherence in the proxies. An alternative explanation is that the “proxies” aren’t really proxies in the sense of being connected to temperature by a relationship and that the reduced inconsistency in the calibration period is an artifact of cherrypicking, not necessarily by any one individual, but by the industry.
Interesting as this question may be (and I don’t want a whole lot of piling on and venting about this issue which has been amply discussed), I think that we can circumvent such discussions by looking at the 2nd question: the calculation of likelihood-based confidence intervals in the period where there is a high Inconsistency R statistic.
High levels of the Inconsistency R statistic mean that the information from the “proxies” is so inconsistent that the 95% confidence interval is so wide as to be uninformative. The graphic below shows a plot in the style of Brown and Sundberg 1987 showing likelihood based 95% confidence intervals for three years, selected to show different Inconsistency Rb statistic levels.
The highest value of Inconsistency Rb was in 1133, where the Inconsistency stat exceeds 50. The “proxies” are very inconsistent and a likelihood-based confidence calculation from the MBH proxies tells us only that there is a 95% chance that the temperature (in anomaly deg C basis 1902-1980) was between -20 deg C and 20 deg C., a result that seems highly plausible, but uninformative. By comparison, the MBH99 confidence interval (the basis of which remains unknown despite considerable effort to figure it out by UC, Jean S and myself) was 0.96 deg C.
The year 1404 had an Inconsistency R of 26.6, slightly above the 95% chi-squared value for inconsistency. The Brown-style confidence interval was 2.2 deg C, as compared to MBH99 CI of 0.98 deg C (again using an unknown method) and an MBH98 CI of 0.59 deg C (based on calibration period residuals).

The graphic below compares confidence intervals calculated in the Brown-Sundberg 1987 style to those reported in MBH99 (red) and MBH98 (green). Note the similarity in shape between the CI widths here and the Inconsistency Rb statistic (a similarity which is more pronounced between the log(CI) and the Inconsistency statistic, which are related.

Calculation of the Inconsistency R Statistic
The underlying assumption for these calculations if that there is a statistical relationship between proxies (Y) and temperature (X) can be modelled. Yeah, yeah, I know all the arguments about tree rings (of all people in the world, I don’t need readers to remind me that these relationships are precarious), but mathematically one can carry out calculations as if there was a relationship – just as one does in mathematics arguments even if one’s objective is to show a contradiction. The model is simply:
(1) 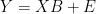
What’s important here is that the model is from cause (X-temperature) to effect (Y – tree rings etc), something that is not always observed in Team methodologies and that there are residuals from this model for each proxy providing a lot of information about the model that is not used by the Team (“thrown away” perhaps).
The matrix of regression coefficients 

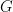
(2)
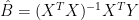
This fit in the calibration period yields a matrix of calibration period residuals 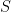

(3)

He then calculates the garden variety GLS estimate (as follows where y is a vector representing proxy values in one year):
(4)

This yields a vector of GLS-estimated proxy values 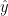
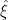
(5)
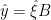
and defines the inconsistency R (a scalar) from the residuals:
(6)

UC has consistently emphasized the similarity of MBH methodology to “Classical Calibration” other than its idiosyncratic ignoring of the residual matrix and its ultimately arbitrary re-scaling of series to make them “fit” – a procedure that is then said in climate literature to be “correct”, although the only authority for the “correctness” of the procedure would be appear to be Mann himself, a nuance which doesn’t appear to “matter” to IPCC – and UC has been very consistent in objecting to this procedure.
What’s important for readers here about this statistic is that it’s relevant to the temperature reconstruction issues discussed here and that a statistical authority has derived a distribution for this statistic and has used it to consider problems not dissimilar to ones that interest us. For example, Brown and Sundberg ponder questions like whether the calibration model is still applicable in the prediction period, or whether, heaven forbid, new data and new measurements are needed.
In this case, the MBH Inconsistency statistics are in the red zone from the early 19th century to earlier periods, suggesting that this particular network (the AD1000 network) is not usable prior to the early 19th century. The reason why the MBH results are unstable to seemingly slight methodological variations (e.g. Bürger and Cubasch) is because the individual series are inconsistent. Any PR Challenge analyses which purport to replicate “real world” proxy behavior of MBH type have to have this sort of inconsistency, something that is not done in standard climate pseudoproxy studies, where the mere addition of standard amounts of white or low order red noise, still leaves data that would be “consistent” according to this statistic.
Oh, and what do the “reconstructions” themselves look like done this way? The figure below shows the maximum likelihood reconstruction (black), confidence intervals (light grey) together with the CRU NH instrumental red and the MBH reconstruction (here an emulation of the AD1000 network using the WA variation (green), the WA variation being separately benchmarked to be 100% file-compatible with Wahl and Ammann in the AD1400 network).
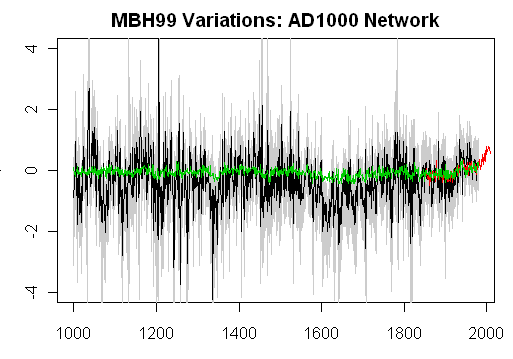
A closing comment about continuing to use MBH networks for statistical analysis. It is very common in statistical literature to use rather archaic but familiar data sets to benchmark and compare methods. The paint data of Brown 1982 has no intrinsic interest, but has been considered in a number of subsequent multivariate studies. This sort of thing is very common in statistics, where one specifically doesn’t want to introduce “novel” methods without benchmarking them somehow. So there’s a valid reason to study the MBH network in the same sense; it has the added advantage of not being a particularly consistent data set and so it’s a good way to study weird statistical effects that are hard to study with sensible data.
Aside from that, as we’ve observed, the MBH98-99 data set continues in active use -used without modification in Rutherford et al 2005 and Mann et al 2007 without changing a comma, no concession whatever to the incorrect PC1 calculations or even the rain in Maine. So there hasn’t been a whole lot of “moving on” in the Mann camp anyway. And as we shall see, it’s baack, brassy as ever, in the most recent U.S. CCSP report, which I’ll discuss in a forthcoming post.





34 Comments
Steve, a clear and straightforward presentation. However, it might be a good idea to clarify that S is a (square) matrix which consists of sums of products of the residuals and not the matrix of the residuals themselves. With regard to explanations of why the proxies might not behave well in this test:
If the reconstruction is to work properly and give valid results, it is an implicit assumption that the relationships between the proxies and the “temperature signal” be the same in the entire period under consideration. If this is not the case, then the reconstruction is basically a bunch of numbers with no relation to reality. I have always found it surprising that in most of the reconstructions no effort was expended to check the proxies for agreement in the out-of-calibration time period. Even simply looking at the correlation structure of the proxies could possibly indicate possible problems. But I guess they probably do these checks, find no problems, and just forget to report those results…
Steve
Thank you for the very heavy lifting. It implies that every number coming out of the IPCC needs review, a daunting undertaking at best. I especially liked that after very precise calculations the numbers are then ‘fit’ to the requirements.
Terry
##APPLY BROWN AND SUNDBERG METHODS TO MBH99 DATA
#see http://www.climateaudit.org/?p=3379
##DOWNLOAD MBH DATA
source(“http://data.climateaudit.org/scripts/utilities.txt”)
source(“http://data.climateaudit.org/scripts/mbh/functions.mbh.v08.txt”)
url=”http://data.climateaudit.org/scripts”
method=”online”
source(file.path(url,”spaghetti/CRU3.nh.txt”))
tsp(cru.nh)# annual 1850 2008
cru.nh=cru.nh-mean(cru.nh[(1902:1980)-1849])
source(file.path(url,”spaghetti/sparse.txt”))
tsp(sparse) #[1] 1854 1993 1
source(file.path(url,”spaghetti/mbh99_proxy.txt”))
tsp(proxy) #tsp(proxy)[1] 1000 1980 1
#this is collated from WDCP archive and includes the “unfixed” PC1
pc1=proxy[,3]
pc1f=read.table(“http://data.climateaudit.org/data/mbh99/BACKTO_1000-FIXED/pc1-fixed.dat”)
dim(pc1f) #[1] 981 4
proxy[,3]=pc1f[,2] #replaces the “unfixed” PC1 with the “fixed” PC1
proxy=extend.persist(proxy) #extends an incomplete series to 1980
download.file(“http://data.climateaudit.org/data/mbh98/pc.tab”,”temp.dat”,mode=”wb”);load(“temp.dat”)
tsp(pc) # 1902 1993
#get reconstruction data: note this is spliced
if(method==”offline”) MBH99=read.table(“d:/climate/data/mbh99/MBH99.txt”,header=TRUE) else {url< -"ftp://ftp.ncdc.noaa.gov/pub/data/paleo/contributions_by_author/mann1999/recons/nhem-recon.dat"
MBH99<-read.table(url) }#this goes to 1980
MBH99.1) testl=unlist(optimize(h,c(test$maximum-30,test$maximum,Z=Zcentered[i,]),tol=0.001,maximum=FALSE));testl
testu=unlist(optimize(h,c(test$maximum,test$maximum+5),tol=0.001));testu
if(testu[“objective”]>.1) testu=unlist(optimize(h,c(test$maximum+30,test$maximum,Z=Zcentered[i,]),tol=0.001,maximum=FALSE));testu
fig2.stat[i,]=c( testl[1],testu[1])
plot(xx,gx(xx,Z),type=”l”,ylim=ylim0,xlim=xlim0,ylab=””,xaxs=”i”)
abline(h=c0[i],lty=2)
if(i==1) mtext(side=2,line=2,”Log Likelihood (2.14)”,cex=.8,font=2)
if(i==2) mtext(side=3,line=.5,”MBH99 Selected Years: Brown 1987 Style”,font=2)
text(-10,0,font=2,pos=4, paste(999+case[i]))
text(-10,-2,font=2,pos=4,paste(“R=”,round(Profile$stat$R[case[i]],1),sep=” “))
lines(xy.coords( rep(test$maximum,2),c(-100,test$objective)),col=2,lty=3)
}
###########
##3. CONFIDENCE INTERVAL COMPARISONS
####MBH99 EMULATION
#use script at scripts/mbh99/emulation.v08
#reconstruction is in emulation2$series (“fixed”) and emulation1$series (original)
#2 sigma confidence MNH98.ci; MBH99.ci
url=”ftp://ftp.ncdc.noaa.gov/pub/data/paleo/contributions_by_author/mann1999/recons/nhem-standerr-labeled.dat”
MBH99.ci=read.table(url,skip=1);dim(MBH99.ci) #2 sigma is column 3 tp 1901
MBH99.ci=2*MBH99.ci[,3] #plus/minus 2 signa
url=”ftp://ftp.ncdc.noaa.gov/pub/data/paleo/paleocean/by_contributor/mann1998/mannnhem.dat”
MBH98.ci=read.table(url,skip=1);dim(MBH99.ci) #2 sigma is column 3 tp 1901
MBH98.ci=MBH98.ci[1:581,6]-MBH98.ci[1:581,7]
stat=Profile$stat
plot(1000:1980,stat$ciu-stat$cil,type=”l”,ylim=c(0,5))
title(“MBH99: Confidence Intervals”)
#these look like R
lines(1000:1901,MBH99.ci,col=2)
lines(1400:1980,MBH98.ci,col=3)
#http://www.climateaudit.org/wp-content/uploads/2008/08/brown_15.gif
############
#4. RECONSTRUCTION VERSIONS
#################
layout(1)
plot(1000:1980,stat$mle,type=”l”,lty=1,ylim=c(-4,4),col=”white”)
polygon(xy.coords(c(1000:1980,1980:1000), c(stat$ciu,rev(stat$cil))),col=”grey80″,border=”grey80″)
lines(1000:1980,stat$mle,lty=1)
lines(c(time(cru.nh)),cru.nh,col=2)
lines(1000:1980,emulation2$series,col=3)
title(“MBH99 Variations: AD1000 Network”)
#Docs/…/statistics/brown_16.gif
Steve,
Is there any meaning in the wiggles in the likelihood reconstructions which seem to show a MWP and LIA if you draw a line through their centers? It seems odd if it was a coincidence.
Steve: These are Mann proxies and any results are pretty much meaningless.
Re #4
For comparison why not run the same test on the Loehle reconstruction, the data is all to hand?
Steve: My priority is to examine studies in IPCC reports and I have quite a few other studies to examine prior to Loehle. I’ve provided a script and tools for others in case their priorities are different.
Graph says 1403 and the text references 1404.
I think I understand that you have found an efficient and seemingly non controversial means to point to a major flaw in how these temperature reconstructions are interpreted. Having done that, you will get no discussion or replies at your blog from those who are, or at least should be the most interested. That seems to leave you with the options of publishing your work or
given sufficient pause by those who should be most interested, maybe an invite to the PR challenge process to explain your analysis is not out of the question – Steve M challenges the PR challenge.
Thanks for the commentary in the code it helps the unwashed follow the flow.
Can you clarify the definition of the ‘Inconsistency R’ statistic in layman’s terms? Is it essentially a measure of dissimilarity on a 0 – 100 % scale? Some of us are deeply interested, but struggle with the math.
Steve: This is a summarization of the issues in as congenial a style as I can muster. Don’t ask me to make analogies to something else.
Steve,
WRT your comment
When considering stats treatment of past proxy data, are there certain types of numbers that are excluded or require special treatment? It’s too simple to ask if they have to be real, positive, unbounded, smoothly varying etc. To purposely mix metaphors despite your warning, you could have a paint climate proxy, with colour saturation the dependent variable. If the paint is composed initially of a mix of several hues, some hues might go up and down the saturation curve quickly, some slowly and some might be persistent through the whole period. Some hues might lose their ability to change saturation. So the sensitivity of the proxy would alter with time and might even plateau. Would you not get into trouble if these hue changes were insignificant in the calibration period but (unknown to anyone) quite significant in the longer period under study? How close do you think you are to exhausting statistics for teasing out the last drop from the available climate proxy numbers? I’m fascinated by the depth of the work, I admire how diligently you are proceeding.
Phil. when you want to get the puck otta your end of the ice, its a good thing
to keep your head up before you get forechecked.
Steve: That’s something that the Team needs to remember when they issue PR Challenges.
#5
Steve must like Phil. (as he said he did) That’s the nicest way I’ve seen anyone say ‘I gave you a way to recreate it, do it yourself if you care about it, otherwise shut up.’
Won’t they answer that whatever recent change they see, including the reduced inconsistency, is evidence of an unprecedented human influences? 😉 The whole statistical character of the proxies and they correlations could have changed, with the CO2 emissions.
I wouldn’t buy it – and it may be useless to preach to the converted – but as I understood the psychology of those people, they will view any difference between the past and the 20th century as evidence supporting cataclysm. Well, the recent global warming is very consistent, if it has a lot inconsistency, they will say. 😉
Sorry, I was just testing that I could avoid the faulty spam filter in this way – it works – so there are some typos I didn’t have time to correct. What I meant was:
Won’t they answer that whatever recent change they see, including the reduced inconsistency, is evidence of unprecedented human influences? 😉 The whole statistical character of the proxies and their correlations could have changed, with the CO2 emissions.
I wouldn’t buy it – and it may be useless to preach to the converted – but as I understood the psychology of those people, they will view any difference between the past and the 20th century as evidence supporting cataclysm. Well, the recent global warming is very consistent, if it has a low inconsistency, they will say. 😉
Steve: I have no idea why the spam filter is cross-eyed with you and I apologize.
re 10. PR challenge is just an attempt at iceing
Re: #14
Unfortunately the cake is collapsing as the ice it!
James,
Mosher is referring to hockey not cakes. The reference to puck and forechecking in #10 should have been a dead giveaway.
#8 Gary
Since this material involves multivariate statistics, you can appreciate that the explanation is not going to be completely simple. The statistic R given by Steve Mc is basically the square of something called the Mahalanobis distance which measures how far an observed value of a multivariate random variable is from the centre (mean) of a multivariate distribution with a given correlation structure. It is similar to a statistic used in the Hotelling T-squared test (a generalization of a simple t-test) for testing means of multivariate normal distributions. The calibration period proxies are used to estimate the correlation structure and then the out-of-calibration proxies for each year are compared to see how they differ from this structure. The advantage is that one can evaluate the probability that the proxies in a given year will be some specific distance away from the distribution structure defined in the calibration process.
An (as simple as it can get) exposition of the Mahalanobis distance can be found on Wiki at http://en.wikipedia.org/wiki/Mahalanobis_distance.
Phil #5
Loehle reconstruction is made from calibrated proxies. It would be foolish and incorrect to calibrate again. To keep temperatures as temperatures, you’d need to set B as row vector of ones (*). Consistency check would be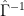 -norm of proxy minus reconstruction for each year (?).
-norm of proxy minus reconstruction for each year (?).
*) would then be averaging vector, reconstruction with S=I assumption would be unweighed average of calibrated proxies.
would then be averaging vector, reconstruction with S=I assumption would be unweighed average of calibrated proxies.
#8, 17. In fairness to Gary, there is some illustration of the point in simpler terms that may be feasible. I don’t want to get pressed too hard on the analogy but I think that it illustrates in a way, the sort of statistic that’s involved here.
If you take the square of a variable with a N(0,1) distribution, that has a well-defined distribution (chi-squared with df=1). If you sum n of them, you get a chi-squared distribution with df=n.
In a sense, Brown’s Inconsistency R “standardizes” the residuals and then compares their sum of squares to a chi-squared distribution.
“Standardization” is something that we’ve talked about endlessly at this blog and thinking about Gary’s question has made me think a bit more both about what Brown is doing and paleoclimate standardization steps that fly under the radar.
Consider the matrix , the inverse of the residual sum of square matrix. If you limit yourself to thinking about the diagonal of the matrix (which is not a bad idea to think about this in order to get a feel for what’s going on), in effect, this standardizes everything by dividing by the standard deviation in the calibration period. Remember that, in Brown’s method, you don’t “standardize” sub rosa outside the statistical process. You carry it out within the process because these estimates also have an error distribution which are an important part of the estimation process.
, the inverse of the residual sum of square matrix. If you limit yourself to thinking about the diagonal of the matrix (which is not a bad idea to think about this in order to get a feel for what’s going on), in effect, this standardizes everything by dividing by the standard deviation in the calibration period. Remember that, in Brown’s method, you don’t “standardize” sub rosa outside the statistical process. You carry it out within the process because these estimates also have an error distribution which are an important part of the estimation process.
Boiling it down and assuming that everything has been “standardized” somehow, you then calculate the sum of squares of the q proxy residuals year-by-year on the basis that your estimate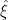 is correct. If the observed value doesn’t outperform the sum of squares of q N(0,1) random variables, then your prediction isn’t accomplishing very much.
is correct. If the observed value doesn’t outperform the sum of squares of q N(0,1) random variables, then your prediction isn’t accomplishing very much.
I think that this sort of philosophy can be applied to calculate inconsistency statistics for non-standard estimators such as MBH or CVM.
Gary # 8, Here is my statistical layman’s take on this. Maybe Steve or RomanM can confirm or refute my take. We have 14 proxy records over time and one temperature record over the instrumental period. We assume a nice linear relation ship between the temperature, X, and each of the proxy’s Y in the calibration period. Steve’s equation 2 yields 14 equations that represent the relationship of each proxy to the temperature in the calibration period. The matrix, gamma, is a measure of how good each proxy relationship is.
Now say we want to estimate the temperature in a year for which we only have the 14 proxy measurements. We use a maximum likelihood estimate that is a weighted average of the temperature implied by each of the 14 proxy relationships and where the weights are proportional to the “goodness” of each proxy relationship in the calibration period. This is Steve’s equation 4 and it gives an estimate zeta_hat of the temperature. If this is a good estimate and if the proxy relationships are robust over time, then we should be able to use these to make a good estimate of the proxy measurements in this given year. These are the y_hat in equation 5. If the set of 14 y_hats are much different than the actual ys, then there is reason to question the robustness of the proxy relationships. Rb is a measure of of how much the y_hat values differ from the y values relative to the implicit differences embodied in the proxy relationships during the calibration period. Brown and Sundberg were able to quantify what a “large” value of Rb is.
Put simply the Mahalanobis distance is roughly the distance between a sample point x and the mean of the distribution normalized by the std deviation. So that the idea of “closeness” between x and the distribution takes into account the spread of the distribution. The intent is that we have a very different situation if x = 1, m = 0, and sd = 1000 than if x = 1, m = 0 and sd = .00001. The odds are much better that x is “in” the distribution in the first case and “outside” in the latter.
Well there you go, as congenial an explanation as there is. Knowing a thing in layman’s terms is knowing a thing.
I believe this a is a proper metric in a metric space whose elements are real valued probability densities (at least?).
Lubos — I can’t find any postings from you in the last 24+ hours that got spam-trapped. Are you having trouble with the “captcha” checker? If you will simply make your posting and answer the captcha challenge, it will either go through on its own, or we will pull it out of the spam trap.
[Readers may be interested to know that CA receives as many as a dozen spam comments a minute… fortunately most of them are easily auto-detected. Further spam discussion to unthreaded please 😉 ]
Re #18
That’s why I suggested it as an appropriate comparison, even though independently calibrated surely they could still be inconsistent?
It would also give us some idea of the range of the statistic for climate reconstructions, is a value of ~20 typical or a statistical outlier?
Comparing with another study which uses the same proxies wouldn’t seem to be as informative.
Phil, at a chisquared value of 22 with the degrees of freedom here, we’re simply talking about the upper end of what you’d expect merely from white noise. My guess is that unless you have an Inconsistency R of about 5 or so, you’re going to have very uninformative confidence intervals.
I’d encourage you to try to spend a little more time understanding exactly what is being measured here. Also, because Loehle (and Moberg) used some very smoothed data versions, there are some issues involved in transposing the methods that need to be thought through fairly carefully before jumping to any conclusions. I think that it’s more orderly to work through the recons that purport to have annual resolution, see what they look like from different perspectives, before worrying too much about Loehle.
Phil,
I realize the semantic implications of my choice of analogy can be considered pejorative, but that isn’t my intention.
If someone claims the sky is falling, do you spend all your time investigating the validity of the claims that the sky isn’t falling? I hope not, because disproving their claims says nothing about whether the sky is falling or not. Believing otherwise would be the false dichotomy fallacy. The data and models of the AGW proponents need to be subject to at least the same level of skepticism and scrutiny as the FDA applies to a potential blockbuster new drug application.
#17, #20, let me try to add something from engineering viewpoint;
Assume that calibration was perfect, i.e. and
and 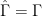 . Now, in the prediction phase we have to estimate
. Now, in the prediction phase we have to estimate 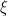 in the normal regression model
in the normal regression model
where is normally distributed,
is normally distributed,  and
and 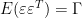 . Under these assumptions it can be shown that the quadratic form of residual vector
. Under these assumptions it can be shown that the quadratic form of residual vector  ,
,
is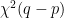 distributed. Thus, when having multiple observations, we can test whether observations agree with the statistical model, without knowing the true
distributed. Thus, when having multiple observations, we can test whether observations agree with the statistical model, without knowing the true 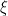 .
.
Only difference between R and W is that in the former (calibration), we have only estimates of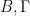 . Thus, R is asymptotically (
. Thus, R is asymptotically (  )
) 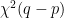 distributed.
distributed.
Re #24
I can appreciate the concern regarding the smoothing issues and how that might impact on the method.
I’m not worrying about Loehle rather my way of approach is different that yours, Steve, faced with a group of recons and applying a new analytical technique I’d pick the two most different ones first to see what the range of values is likely to be. Your approach is more orderly, just two different ways to skin the same cat.
Re #25
DeWitt I’ve no idea what you’re referring to here?
Phil,
You asked why not audit Loehle? I answered. The priority is to investigate the data and methods used by the IPCC, because they are the ones who claim there is a problem (the sky is falling) and we must do something about it. The false dichotomy is that if the skeptics do not have a valid alternative theory for the recent temperature change, then the AGW theory must be correct.
Re #28
I certainly did not, I said: “For comparison why not run the same test on the Loehle reconstruction”
As I have pointed out since it would be a comparison of two reconstructions with different philosophies (e.g. dendro vs non-dendro) and it would be interesting to see if this consistency analysis would pick up a significant difference, also comparing with recons which contain the same proxies wouldn’t seem to tell us much.
Steve pointed out that the use of smoothing and non-annual data might be a problem: “Also, because Loehle (and Moberg) used some very smoothed data versions, there are some issues involved in transposing the methods that need to be thought through fairly carefully before jumping to any conclusions.”, which is a valid concern. As for auditing Loehle that has already been done on here and errors were found and a corrected version produced. If the use of the data by IPCC is an important consideration then compare with Moberg with similar logic (but also subject to Steve’s reservations).
Wordsmithing.
Mark
Phil. #29
After that SEM versus SD debacle (Why don’t you use the same easy to pass method everyone else does rather than one that’s hard to pass?) I don’t see what use it is to delve into a study that clearly shows once you remove the material that gives you a certain signal, the signal goes away. 😀
Seriously, it might be interesting, but unless the IPCC relies upon it for policy, what’s the point of taking time away from investigating the things it relies upon?
Gary (#8) asks,
Let me try — Suppose you have 3 proxies (different tree ring series or whatever) that give reconstructed temperature anomalies for some year in the past of -.5, -1.0, and -1.5 dC, respectively, each with error bars (2 sigma) of plus or minus 1.0 dC. These average to -1.0 dC, with a somewhat reduced composite error bar of about 0.6 dC. In this case, each proxy’s reading is within its error bar of the average, so there is probably no inconsistency problem. Brown’s R-stat more rigorously combines the three discrepancies into a single chi-square distributed statistic that takes into account any differences in precisions and correlations of the different proxy measures.
But now suppose that instead the three proxies gave readings of +1.0, -1.0, and -3.0 dC, each still with an error bar of 1.0 dC. They still average out to -1.0 dC, with the same composite error bar of 0.6dC. However, something must be wrong with the assumption that these are measuring the same global temperature, since two the readings are 4 standard errors from the average. Brown’s statistic would surely register an inconsistency in this case.
Of course, any statistic should give a false rejection of the null (here that the proxies are all measuring the same global temperature anomaly) p percent of the time, where p is the test size used. Steve’s Figure 1 above has a red line at the 95% critical value of the appropriate chi-squre distribution, corresponding to a test size of p = 5%, I believe. Outside the calibration period (where the fit has to be good, by construction), it looks to me like maybe 40% of the readings are above the line, which is far more than one would expect by chance if the proxies really were consistent.
Steve — what is the actual fraction of pre-calibration values that lie above the line?
Inconsistency of proxies during the reconstruction period could be caused by cherry picking of proxies during the calibration period. If say 100 proxies were examined for correlation to instrumental temperature, just by chance 5 or so would appear to be significant at the 5% test size (loosely called the “95% significance level”), even if none had any real value as a proxy. If the three “best” proxies were then singled out and used, their computed standard errors would give a misleadingly small confidence interval for the historical reconstruction. However, there would be a very good chance that they would flunk Brown’s R-stat test.
Phil. (#5) also asked if the test could be applied to Craig Loehle’s reconstruction. (See http://www.econ.ohio-state.edu/jhm/AGW/Loehle/. However, he did not calibrate his data from scratch as assumed by Brown, but rather just took published local temperature reconstructions that had already been calibrated by their various authors, and then averaged them together. A few of these series did have published error estimates, but my understanding is that not all of them did. Accordingly, the standard errors I provided for the corrected estimates in the 2008 Loehle and McCulloch paper are based entirely on the deviations of the individual proxies from their average, which basically assumes that the individual proxies are consistent. In any event, any published errors would be only for the precision of the estimate of local temperature, and would not include the also important deviation of local temperature from the global average. Since Brown’s statistic does not take this additional source of error into account, it is possible that it would reject that the various proxies are all measuring the same temperature anomaly, but only because local temperature anomalies naturally differ at any point in time.
Someone also asked why the statistic looks so good in the calibration period. As noted above, this is true by construction, since the estimated coefficients and standard errors were computed from this data, and therefore must be consistent with it. It is only out of the calibration period that the statistic starts to tell us something we didn’t already know.
Brown’s R-stat in a sense provides a “verification” check on the calibration, but one that does not require withholding instrumental observations as is often done in this literature.
(Sorry I’ve been away from the group for so long — I’ve been traveling and have had time-consuming day-job and other responsibilities.)
Steve,
can you explain why the correlations between proxies and the temperature in nhem-raw.dat are very poor in the period 1902 to 1980 for proxies 2, 5, 7, 12, 13, and 14?
mike:
No, no, just trying to clarify. So, from this text
http://www.eastangliaemails.com/emails.php?eid=355&filename=1062527448.txt
I can infer that I was quite close with http://www.climateaudit.org/?p=647#comment-103560 , but now we can hopefully figure it out exactly. Or do we need to, as the main post above shows how to really do it ? ( And all the millennial reconstructions published so far need to be corrected? )