The long-awaited (and long overdue) PAGES2K synthesis of 57 high-resolution ocean sediment series (OCEAN2K) was published a couple of weeks ago (see here here). Co-author Michael Evans’ announcement made the results sound like the latest and perhaps most dramatic Hockey Stick yet:
Today, the Earth is warming about 20 times faster than it cooled during the past 1,800 years,” said Michael Evans, second author of the study and an associate professor in the University of Maryland’s Department of Geology and Earth System Science Interdisciplinary Center (ESSIC). “This study truly highlights the profound effects we are having on our climate today.”
A couple of news outlets announced its release with headlines like “1,800 years of global ocean cooling halted by global warming”, but the the event passed unnoticed at realclimate and the newest “Hockey Stick” was somehow omitted from David Appell’s list of bladed objects.
The OCEAN2K Reconstruction
One of the reasons for the strange lack of interest in this newest proxy “Hockey Stick” was that the proxy data didn’t actually show “the climate was warming about 20 times faster than it cooled during the past 1,800 years”. The OCEAN2K reconstruction (see Figure 1 below) had a shape that even David Appell would be hard-pressed to describe as a “Hockey Stick”. It showed a small decrease over the past two millennia with the most recent value having a tiny uptick from its predecessor, but, whatever image one might choose to describe its shape, “Hockey Stick” is not one of them.
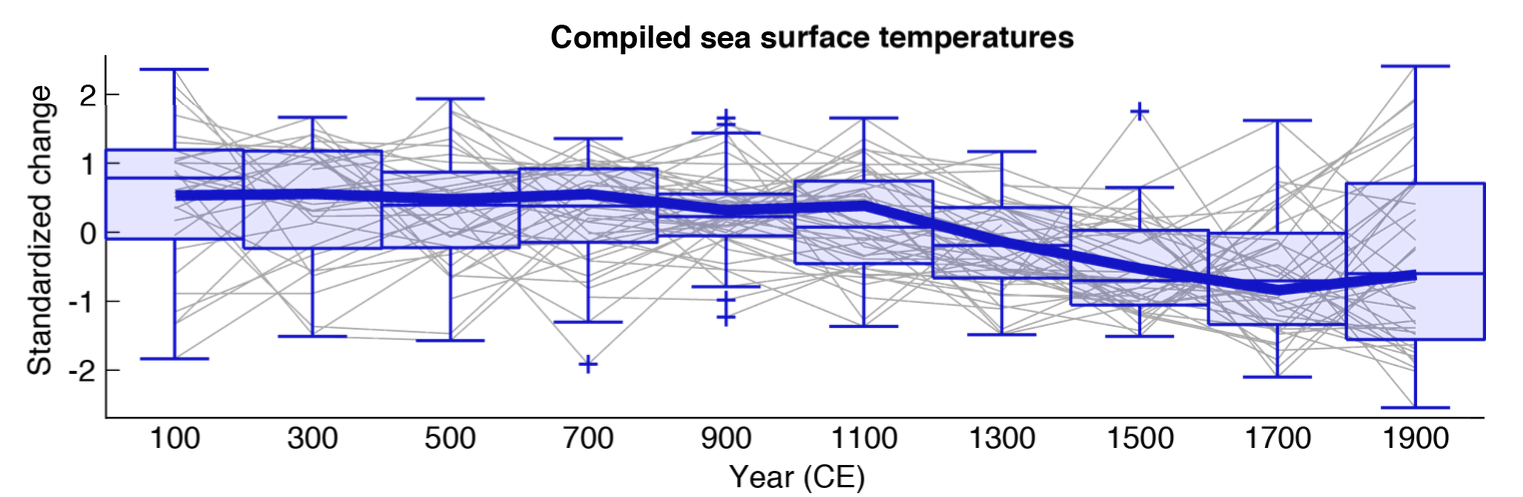
FAQ Figure 1: Results of the global sea surface temperature compilation from Ocean2k: A cooling over the past two millenium was reversed only in the most recent two centuries. Fifty-seven previously published and publicly available marine sea surface temperature reconstructions were combined and compiled into 200-year brackets, represented by the boxes. The thin horizontal lines dividing each box are the median of the values in that box. The thick blue line is the median of these values weighted for differences in the region of the global ocean in which they were found. (More in Figure 2a in the paper and Supplementary Table S13. ) Link
Technical Comments
The authors have done a really commendable job of archiving their data as used, the original locations of digital data and have even archived (much of) the code for their reconstruction.
As you can see from the above diagram, the authors have “binned” the data into 200-year bins – a decision which makes the results rather uninformative on the relation of modern proxy values to proxy values earlier in the millennium. While series with high-resolution through the 20th century are not as common as one would like or expect, there are some (I keep an eye out for them and have written at CA about such series from time to time). Given the seeming purpose of the study, its silence on this topic is more than a little surprising. It also seems improbable that their ex ante strategy was to use 200-year bins, given their uninformativeness on modern-historical comparisons. This has the hallmarks of a “researcher degree of freedom” (in Wagenmakers’ sense) – or more colloquially, data torture. I presume that they must have done a study using much higher-resolution bins: I’ve done my own calculations with 20-year bins and will report on them in a later post.
Second, their money graphic is denominated in SD Units, rather than deg C anomaly, even though all of the 57 series in their database (alkenone, Mg/Ca, foraminifera) are denominated in deg C. This seems to me (and is) a pointless degradation of the data that ought to be avoided. Particularly when they want to be able to express the decline in deg C (as they do in a later table.) To do so, they convert their composite back from SD Units to deg C (anomaly) using a complicated home-made technique. I think that there’s an easy way of accomplishing what they want to do using conventional statistical techniques. I’ll show this in a subsequent post.
In addition to the publication of their paleoclimate series, the article includes a lengthy section on simulation of ocean SSTs using climate models with volcanic forcing. While the model simulations are an interesting topic, it is not the expertise of the people collecting the ocean sediment data and requires different contributors. In my opinion, the publication of a composite of 57 ocean sediment series is itself a large enough and meritorious enterprise to warrant publication on its own and ought to have been done separately (and much more promptly, as discussed below).
David Appell’s Cherrypick
David Appell recently listed 36 supposed “hockey sticks” (though many of these supposed “hockey sticks” had pronounced medieval periods and, in my opinion, were more similar to the variations that Ross and I showed a decade ago. One of his series (Spielhagen et al 2011) is among the OCEAN2K proxies, shown in their original in the next figure (SI Figure 1). In accordance with the overall non-HSness of the composite, individual HS’s are hard to spot, but there is one. See if you can spot it before looking at the answer.
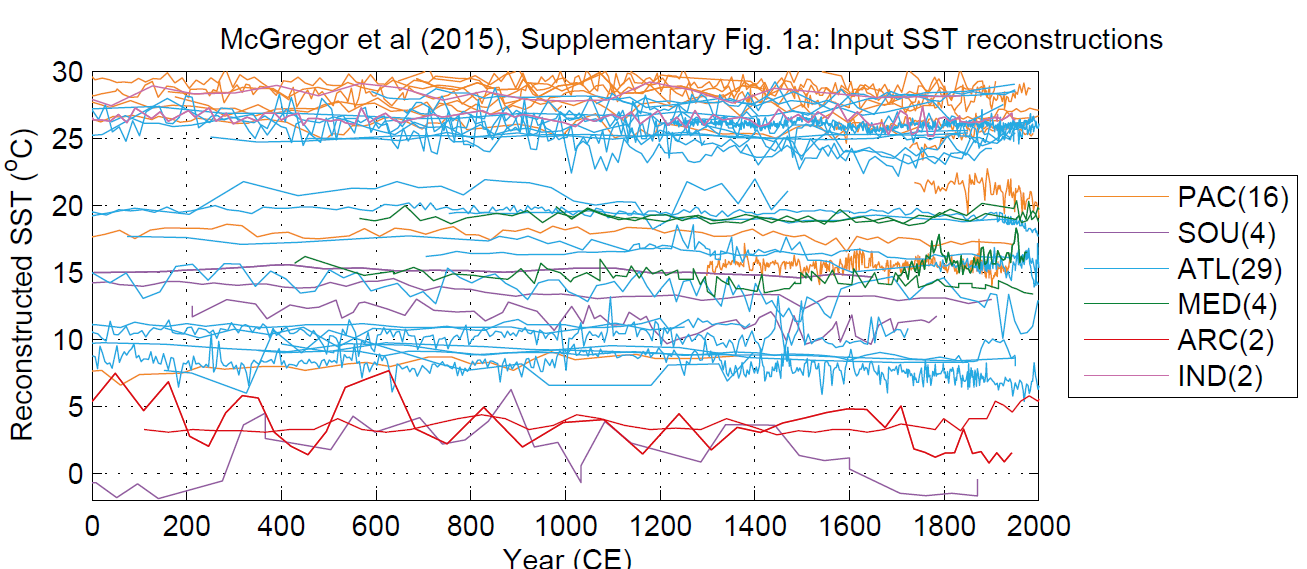
Figure 2. From OCEAN2K Figure S1a. The 57 SST series.
In the next figure, I’ve highlighted the Spielhagen 2011 series listed as one of Appell’s hockey sticks. Only one of the 57 series has a noticeable HS-shape and, by coincidence, no doubt, it is the only SST series from this collection that was cited by Appell.
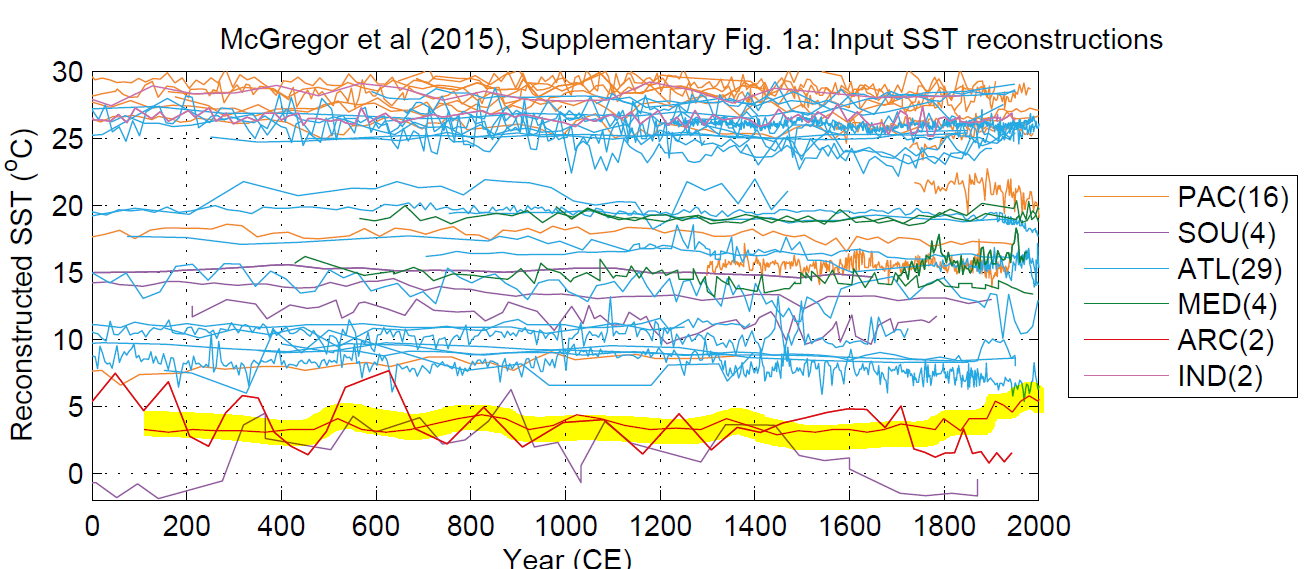
Figure 3. From OCEAN2K Figure S1a. The 57 SST series with the Spielhagen series highlighted.
Among the series that I’ve discussed in the past is lead author McGregor’s offshore Morocco series, which goes down in the 20th century as shown in the highlighted version (solid black) below:
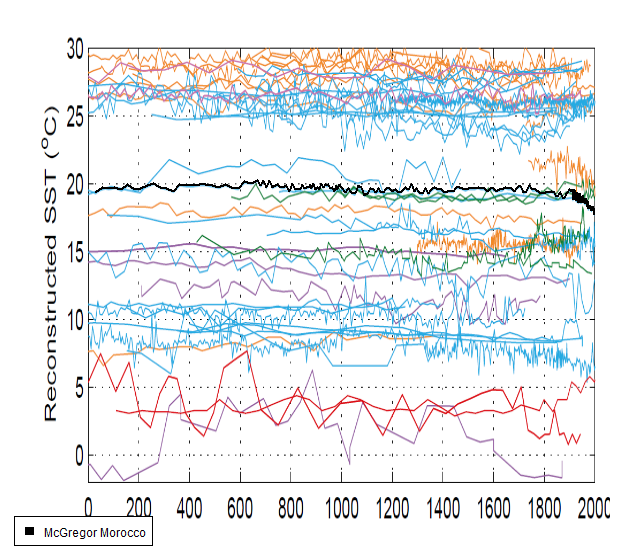
When McGregor originally published this series with decreasing SST, she was able to find a cloud in the silver lining, worrying that increasing strength of “offshore currents may be too strong for fish to swim against”, raising the spectre that scarce resources would have to be diverted to providing swimming lessons to impacted fish. The decrease in SST also had a serious negative impact on multiproxy authors seeking to display hockey sticks. Needless to say, the resourceful authors of Trouet et al 2009 mitigated this adverse impact by turning the data upside down – Cape Ghir below (see here)
The Delay
Another curiosity of the present study is its lengthy delay. The OCEAN2K program had been announced in November 2011, stating their intent to synthesize ocean data in time for AR5 as follows:
We plan to generate two outputs in time for consideration in the IPCC’s Working Group I Fifth assessment report, and contributing to the PAGES2K synthesis planned for 2014. The first goal is a metadatabase (Box 2) of Ocean2k-relevant proxy records and model output from publicly-accessible and citable sources, to be completed in January 2012… The second goal is a synthesis paper, based on the metadatabase, addressing the questions in Box 1, and submitted no later than July 2012.
However, the present publication is more than three years behind schedule. According to the SI of the article, the dataset appears to have been mostly collated on schedule (in 2011-12). The calculation of a composite isn’t very hard, so one wonders why there was such a delay.
I’ve taken an interest in high-resolution ocean data for many years and had noticed the OCEAN2K program. I had wondered about its non-publication and had even written to co-author Michael Evans earlier this year (January), wondering what had happened to it:
I notice that the Ocean2K project did not make a synthesis in time for AR5 as had been planned. PAGES2K hasn’t updated the plans for Ocean2K. Are there any updated plans or was it a project that just didn’t work out.
Evans politely wrote back:
the Ocean2k working group did not feel ready to contribute by the AR5 deadline, nor in time to contribute to the PAGES2K Consortium paper published in 2013 (and recently corrected, I understand, with input from you). We’ve recently updated the Ocean2k webpages at the PAGES website (http://www.pages-igbp.org/workinggroups/ocean2k/) to describe progress and future plans. But I see those updates haven’t yet been applied by the system administrator there. I hope they will be shortly
Had the results been more HS-like, it’s hard to believe that the OCEAN2K authors would not have found a way of publishing them in time for AR5. It seems to me that, since the results were “bad”, the authors seem to have felt little urgency.
In making this criticism, I am influenced by my knowledge of the mining business, where promoters are strongly tempted to delay bad drilling results of a program in progress in the hopes that the program gets salvaged by a later hole. For investors and speculators, delayed publication of exploration results are generally a sign of bad results. Influenced by this perspective, I predicted (somewhat acidly) in 2006 that Lonnie Thompson’s delay in publishing Bona-Churchill results indicated that they would not have the Hockey Stick shape of “Dr Thompson’s Thermometer”. They remain unpublished to this day. At the AGU conference last year, Mosley-Thompson’s abstract stated “The δ18O records from the Bona-Churchill and Mount Logan ice cores from southeast Alaska and southwest Yukon Territory, respectively, do not record this strong warming”, confirming my surmise of many years ago.
I plan to do a couple more posts on this study, which, as noted above, has a pretty exemplary SI, thereby facilitating discussion and analysis.





166 Comments
That spin “warming about 20 times faster than it cooled during the past 1,800 years” is epic.
Suppose temperature is a perfect sinusoid. T = sin(t). Then the “rate it cooled during the past 1,800 years” is zero. Suppose I sample the temperature from say t=-0.01 to 0.01 so that the “average warming rate” is cos 0 = 1.
AAGH AAAUGH it is “warming infinitely faster than it cooled during the past 1,800 years”! Head for the hills!
“warming about 20 times faster than it cooled during the past 1,800 years”
The authors are time travelers. The “past” ends in 1900 a.d. The “1,800 years” is the period 100-1900 a.d.
So what is happening here graphically? Hide the Decline? Withhold the Incline? No-tell the no-cline?
Maybe I’ll start a protest movement: “Recent Years Matter!”
Reading the supp. material I suggest new possible nomenclature: “Binning the decline”
Still can’t see why data was not depicted past end points of 100 and 1900 a.d.
Bins are 200 yrs wide. The first bin covers 0-200 and is centered at 100. The last bin is 1800-2000 and centered at 1900.
MJ: I’m understanding the binning approach, but I do not see yet a necessary informational purpose for not depicting the data of the 57 series (i.e. the faint gray lines organized by region) for the periods 0-100 a.d. and 1900-2000 a.d.
MJ: Furthermore, take a look at SI Section 3 “Binning.” Supp Fig S5 shows the 100-1900 bin center depiction. Yet, “Additional tests were conducted on the 200-year binning methodology.” The tests are two: shifting the bin centers earlier 50 and 100 years. Showing are two lines beginning at–note: with circles–0 a.d. and 50 a.d. There is also the familiar 100-1900 a.d. line. The stated purpose of the tests is to show the different bin centers “are representative of the distribution or ages within each bin.” As the lines look similar, I suppose this is supposedly visually ‘proven.’ I also suppose they are using first century b.c. data to fathom these 0 and 50 a.d. “centers,” but that would only be supposition.
Note the “0…1800 bin centers” line continues a downward trend to 1800, and exhibits the biggest divergence on the graph. Why not extent it to a 1900 “center” since there is more than 200 years of data after 1800 to use?
I sense helpful depictions of 20th century data do not comport with an hs blade, and that is the reason a broad 200 year periodicity is selected.
As far as I can tell, the entire time period 1800-2000, for both the blue composite line and the individual series represented by faint gray lines, is represented by a single dot labelled “1900”.
It does not comport with an hs blade as Steve pointed out in his original post, but the authors haven’t hidden that fact (at least not as dramatically as if they actually cut off data).
I agree with you that they probably made their decisions so as to get as much of a hockey stick as possible, which makes it all the more interesting, because the decision to group the entire 1800-2000 period together into one bin almost certainly smoothed out the end of the graph compared to how it would have looked had they say chosen a 100 year or 50 year time scale. Makes you wonder about earlier periods.
FtM, all the grey lines in the FAQ Fig 1 look like they go from the time centerline of one bin to another. So there are no grey lines to shown from 0-100 or 1900-200. What you see as lines from 100-300, for example, are lines from 100-200 and then 200-300. I haven’t looked at the SI yet, sorry.
But I share your view that the broad 200 year periodicity is selected for post hoc and ah hoc reasons.
Steve says she’s going to show some other time period selections. I’m anxious to see them.
I’d also love to see someone who has broken down the code somewhat turnkey to apply this binning methodology to MBH98 data. If this OCEAN2k is a legitimate way of combining and depicting proxy data for a publishable regional/global reconstruction, how will Mann’s conclusions about 20th century warmth hold-up? Especially when combining the two and weighting for ocean (OCEAN2k) and land (MBH98).
Furthermore, I’d love to see this ocean data reconstructed, if possible (which may or may not require not using the PAGES2k data but the raw data behind the 57 series), using MBH98 methodology and combined with that (with proper weight for ocean vs land, of course). I know that’s asking for probably way too much considering how MBH98 fished for hockey sticks and how Mann was inconsistent in his application of things such as Preisendorfer’s Rule N. Using MBH98 methodology itself is a flaw.
Back in my grad school days, I’d take it on. These days…well, Steve, UC, Hu, etc, are way ahead of me with R-programming and blow me away in stats.
I know that’s asking a whole lot, especially since MBH98’s methodology is so wrong in the first place that it doesn’t really make sense to follow its steps exactly.
Admkoz: “(at least not as dramatically as if they actually cut off data). ”
Depiction-wise, the non-appearance of lines for proxies after 1900 happens to omit many potential end-points. Of the about 37 proxies showing in the figure to reach 1900, only 21 of them have data for the 50 year period of 1951-2000. That is, 16 of the proxies, if the data was depicted, would show terminations in the first half of the 20th century. Besides aesthetics, this raises a question for me how “binning” the “200” year period of 1800-2000 was effectively accomplished.
Steve: I did a 200-year bin by dividing the year by 200, taking the floor and making a factor. This seems to replicate things. Their method looks trivial.
Ralph, welcome to the climate blogs. You’ll learn a lot more on the blogroll (upper left of site) than from news articles, on this topic especially. Anthropogenic global warming (AGW) is very political, and hard facts are few, and hard conclusions fewer yet.
On the items you bring up, I believe the deep ocean is cold mainly due to downwelling of cold, and thus more dense, polar water from summer melts. The oceans unlike the atmosphere are poorly mixed due to the warm, less dense, water wanting to stay on the surface. The exception to this is when evaporation at the surface increases the density to the water, along with some cooling, that makes it downwell. This is thought to be the mechanism of the global thermohaline conveyor, the perhaps most important part being the AMOC, of which the Gulf Stream is part. I believe the consensus is that the glacier have been melting an ocean level rising since the beginning of the modern interglacial period, the Holocene, with the exception of a period between four hundred and two hundred years ago is known as the Little Ice Age (LIA).
I will think you will find nobody in favor of polluting the Earth, only debate on the effects of CO2 in the context of the past, present and future hydrosphere. There is even little debate about the need for alternative energy, only how that comes about, free market, etc… By the way, we are still in the Quaternary Ice Age; just in a geologic pause due to mainly orbital influences, three Milankovitch Cycles. The AMOC flow is important too.
Ralph,
I recall reading a paper that indicated it took 800 to 1,000 years for heat from the surface to penetrate into the abysmal ocean depths.
I don’t think you will find much debunking of man made global warming. Humans have warmed the earth’s surface by changing the earth’s surface, urban heat islands, dumping waste heat from industrial processes and possibly by adding IR absorbing gases to the atmosphere.
I think you might find evidence that this warming is not that unusual or alarming.
Personally I believe climate change is inevitably the norm. Given a choice I would prefer warming because the alternative is terrifying.
I’ve also witnessed similar examples of delays to publishing negative/less-than-hoped for results of Phase II and III clinical trial results in the biopharma world of drug trials in the US.
When the clinical trial conclusions are + for a trial drug, the authors are obviously under a lot of pressure to publish and do so expeditiously. Delays, even of several weeks, are almost sure signs a drug trial has or is failing, and investors should take defensive positions.
How can Michael Evans make such a statement? Presumably his is neither crazy nor stupid. I simply do not understand what is going on with these people.
PhilH
He is just putting the best spin on it that he can.
No he is simply totally committed to the AGW cause.
It will be interesting to see what 20 year ‘bins’ do for these graphs, if as you say they have archived the data honestly.
Looks just like a hockey stick to me; obviously, you’ve never seen a hockey stick that was run over by a steamroller . . .
It looks like a deflated hockey stick.
Get Brady!
It looks like reversion to the mean to me. Which raises the interesting question of what the ‘correct’ temperature for the Earth is…
With archiving and data code released, this looks like good scientific practices, supporting good faith critique of the paper’s presentation, analysis and conclusions. Thus, I think the authors are entitled to spirited debate here on the merits without snark or sarcasm, even regarding the silly press release, which is merely tribute to one’s patrons in today’s academia.
Steve:in all other walks of life, press releases are treated very seriously. Even the smallest public companies are required to ensure accuracy and are required to comply with regulations. The press release is how the results are conveyed to the public. Much of the offensiveness in the field pertains to inflammatory press releases. Why shouldn’t the press release be treated seriously? If it deserves snark, then so be it. Note that I went out of my way to commend the authors on their archive and did not merely flame them for their press release. The delays and seemingly ad hoc methodology also deserve notice.
“Without snark or sarcasm”. Such comments are prompted by hyperbolic descriptions of the study’s conclusions.
If such hyperbole were eschewed, then the negative reaction would be toned down, I expect. See Michael Evans a announcement in the post.
The press release says:
“the profound effects we are having on our climate today.”
This phrasing is a direct statement about anthropogenic effect and deserves close scrutiny, including examination if it is an “executive summary” puffing of the underlying science paper.
“Today.”
Okay. Where is the plotted data after 1900??? Is lack of same 0-100 AD a cutesy symmetry to look serious? The data does not seem to preclude post-1900 information, but if it does not appear to be used in the underlying paper, the implementation of the word “today” is rubbish.
hswiseman says:
The “silly press release” contains the following statement directly from the second author, quoted by Steve above. It is not from the author of the press release. It is from the second author himself, who said:
I would classify this as “both false and misleading”, because from looking at the graph in Figure 1, it is obvious that rather than “warming about 20 times faster than it cooled in the last 1800 years” as he claims, in fact the warming is LESS than the cooling at ANY TIME from 1100 to 1700.
That would be a bad enough misrepresentation, but his statement itself is simply not true. Again from Figure 1 above, from the year 100 to the year 1900, the linear trend of the temperature drop is -0.08 SD per century. Since 1700, from Figure 2, it has been rising by 0.10 SD per century. It is warming about as fast as it cooled overall, not “20 times faster” as the second author speciously claims. And more to the point, it is warming at half the rate that it cooled from 1100 to 1700.
So while we may have a “spirited debate here on the merits”, that kind of totally misleading statement by the study’s second author deserves absolutely nothing but a huge helping of snark and sarcasm. It is a bogus statement, untrue in root and branch, that is clearly nothing but rampant alarmism of the most poisonous kind, the quasi-scientific kind.
How do I know Evans is wrong? I digitized his Figure 1. The data is as follows:
Year, SD
100, 0.55
300, 0.56
500, 0.48
700, 0.55
900, 0.30
1100, 0.39
1300, -0.14
1500, -0.52
1700, -0.82
1900, -0.62
Linear Trend, 100 to 1900, 1800 years, -0.08 SD per century
Linear Trend, 1100-1700, 600 years, -0.20 SD per century
Linear Trend, 1700-1900, 200 years, +0.10 SD per century
In other words, his claim is simply untrue, start to finish, and is totally contradicted by his own graph.
I know of no way to have a “spirited debate on the merits” of such an egregious distortion of the past record. I can’t have a spirited debate on the merits of the statement because for me, it has no merits at all.
But if you think there is a way to have such a “spirited debate on the merits” of a merit-less statement, how about you open the bidding by telling what YOU think the merits of such an obviously slanted and clearly untrue statement might be?
Regards,
w.
Ah Willis, do you not recognise a stitching of the instrumental record onto a proxy reconstruction when you see one? 😉
Willis —
Touche, as usual!
What was the cooling trend from 100 to 1700? It will be a little stronger, since it leaves out the recent warming observation, but perhaps still weaker than -.10 sdu / c.
It is conceivable that coauthor Evans was comparing recent instrumental measures of warming to the proxy rate of cooling from 100 to 1700, but I can’t find any mention of instrumental trends in the paper itself on a quick scan. But if so his statement is still misleading since it purports to be about this new proxy index.
I imagine the “20 times” figure is referencing the last few years (post 1900, and probably 1970-1998), instrumental data, which aren’t shown on the graph.
The modern SST reconstruction is described in the supplement (section 8) as 25-year bins from 1851-2000. See figure S10. Visually, there isn’t much resemblance between the reconstruction (panel b) with its instrumental analog (panel a). The authors write, “Because of the limited number of composited data series within these comparisons, the limited degrees of freedom in the correlations, and the complexities of localized conditions on decadal time scales, these results suggest that these comparisons should be interpreted cautiously.”
Evans’ statement does not seem like a cautious interpretation to me.
“…Thus, I think the authors are entitled to spirited debate here on the merits without snark or sarcasm…”
Did you see the lone co-author contribution “to spirited debate here?” Holy frijoles.
I’ll start the timer – Appell should be by in about 30 minutes or so. Should be maddening as usual.
For financial results bad figures also take longer to add up. I’ve rarely seen delays in announcing good or expected news. I’ve been in the City since late 1976 and done my share of listings.
When David comes it will all be “about the blade”, not the shaft. Its the blade that’s important. Obviously the blade is provided by the GISS temperature data, not by silly proxies. For goodness sake, who ever thought that proxies were important. Don’t be ridiculous! (précis of D. Appell on Bishop Hill)
I look forward to commentary on this business of “SD units”. I have absolutely no statistical background but the idea that you can combine standard deviations of different series and come up with anything meaningful sounds extremely counterintuitive. Maybe I’m wrong.
As Steve noted, pre-standardizing the series is gratuitous data degradation. The calibrated temperatures should have been averaged directly (perhaps weighting according to geographic representation). This is what Craig Loehle did in his 2007 reconstruction, to which I added standard errors in the 2008 Loehle & McCulloch revision online at http://www.econ.ohio-state.edu/jhm/AGW/Loehle/ . This is a much bigger sample (57 series vs Craig’s 18), and probably includes a few of his series. (He included land series as well, so these would of course not be included in the Ocean2K group)
Averaging the temperatures directly would, as in our paper, have the result that some of the series would have much higher standard deviations about the mean than others, rather than equal variances as assumed by the elementary standard error formula. (See the “spaghetti gram” on my webpage above.) My contribution was to compute standard errors for the mean that take this into account. This is not difficult, and I provided the formulas in the 2008 paper for the benefit of other researchers who only know the elementary formula.
Hu,
Would you agree that error calculations must contain bias estimates and are inadequate if only customary estimates of precision are made with a stats pack at the end of a study?
For example,we have credible evidence that Australian temperatures might have a trend over the last 150 years or so, that is half of the official value.
If official data are used in the calibration of Australian parts of Pages 2K (there are few Australian sets), those parts would carry a potential bias that would not appear with the way errors have been estimated.
For this reason and others, it is possible that the whole final series would be contained within the 95% bounds and hence shown nothing of significance.
Geoff —
Stats packages will give the correct answer to whatever answer you ask them. But often researchers ask them the wrong questions. By all means there should be an appropriate measure of precision, and it’s best to check homemade calculations against package results, but just getting an answer from a package doesn’t mean it’s meaningful.
Hu,
I should have made it more clear that my comments above were general and not specific to this Ocean only segment of Pages 2K. A matter of reconciliation of ocean and land temperatures is an old saw from emails with Phil Jones from July 2009.
The distortion from averaging several standardized noisy series is best understood by considering the combination of two series, one of which tracks temperature perfectly, and the other of which is just white noise with no temperature signal at all. If temperature is highly serially correlated (as is the case), the first series can easily have a much bigger standard deviation than the second series, and hence it will receive a much smaller effective weight after averaging the standardized series than the second. The result will be a “reconstruction” that is much too flat — perfect for a hockey stick if instrumental temperatures are then spliced on at the end!
McGregor, Evans, et al express concern on their first page that not standardizing would allow noisy series to have inordinate effect on the results. I sympathize with this now much more than I did back in 2008, since I have thought a lot about the calibration problem since then. The calibrated series probably use what UC calls CCE (Classical Calibration Estimation), which regresses the proxy on temperature in a calibration sample, and then inverts the regression to infer temperature from the proxy outside that sample. Although this (unlike what UC calls ICE — inversely regressing temperature on the proxy and then using that regression directly) is based statistically consistent regression coefficients, it has the drawback that the temperature estimate is the ratio of two approximately normal (exactly elliptical student t) random variables. Such a ratio has infinite absolute first moment, and hence does not obey the Law of Large Numbers when many of them are averaged. In other words, some of them have an inordinate effect on the results!
The simple answer, however, is not to squash the signal and lose the temperature units by standardizing, but rather just to take the median of the individual demeaned series rather than their mean. This is actually more justifiable than the Weighted Least Squares I tried out in the SI to the 2008 L&McC paper, since WLS relies on the consistency of a first-stage unweighted mean estimate. Upper and lower CI bounds can be placed on the median using empirical quantiles selected by means of the binomial distribution. (This may not be in Geoff’s standard statistical packages, but it would make a good Stats 101 homework assignment.)
McGregor et al justify their use of standardization by its routine use in the earlier literature, e.g. Mann et all (2008). ‘Nuff said.
By all means the temperature-calibrated series should be demeaned before combining. If the series vary in length, this should be done for the full reconstruction period for the longest series, and then shorter series should have their means matched to the mean of the longer series over the shorter interval. This isn’t quite what Craig did in his 2007 paper or in the 2008 revision, but only one of the 18 series was substantially shorter than the others, so that I doubt that it much affected the results, however.
On calibration see my page at http://www.econ.ohio-state.edu/jhm/AGW/Thompson6/ . Despite the infinite absolute first moment of the CCE estimator, it can be given a Bayesian interpretation that allows compact confidence intervals to be computed, based on the ratio-of-two-normals (or of two Student t’s) distribution.
“not standardizing would allow noisy series to have inordinate effect on the results”
If you already know what is “noise” and you already know what series you don’t want to have “inordinate effect”, then you already know the answer you’re looking for and are reasoning backward.
admkoz —
“If you already know what is ‘noise’ and you already know what series you don’t want to have ‘inordinate effect’, then you already know the answer you’re looking for and are reasoning backward.”
So long as each series has already been validly calibrated to temperature (as is assumed to be the case here), standardizing creates no bias toward giving a flat reconstruction.
However, if the series have not been calibrated to temperature (as in Lonnie Thompson’s 2003 6-ice-core index or 2006 7-core index), and may vary in the strength of their temperature signal (as appears to be the case with Thompson’s data), pre-standardizing by the series’ standard deviations will have the effect of giving undue influence to ones that are all noise and no signal, and hence will tend to give an artificially flat index. If that’s what you’re looking for, then your conclusions are indeed circular.
If the amplitude of temperature change is different e.g. tropics and extratropics and the changes are in different directions, then standardizing by SD will change composite as well.
“Such a ratio has infinite absolute first moment, and hence does not obey the Law of Large Numbers when many of them are averaged. In other words, some of them have an inordinate effect on the results!”
Distribution of a ratio when the denominator has a range overlapping zero. As in v=x/y, where x is rate now and y rate during the past 1,800 years.
“Averaging the temperatures directly would [mean] some of the series would have much higher standard deviations [..] than others[..].”
I mean, SHOULDN’T that be the case? Unless temperature has somehow varied by roughly the same amount everywhere on Earth, which seems fairly implausible to put it mildly?
Sounds like a standard application of climate data splicing techniques. Low-resolution historical proxy data spliced with high-resolution recent surface measurements.
In addition, it would seem that the strength of the finding that volcanic eruptions produced a centuries-long cooling trend is contingent on the accuracy of the modeled natural variability of global climate — which I understand is not impressively robust.
Thanks to Dr. Leduc’s web page, I was able to access a non-paywalled copy of the McGregor, et al, paper. Interesting reading.
While discussing volcanic forcing as a potential source of cooling trends, the paper makes the point that:
Of course, volcanic influences (particularly large ones) trigger relatively sudden, transient responses in the climate system that exist below the resolution scale of the paper’s 200-year bins. The paper’s slope of the cooling [Fig. 2(a)] deduced from temperature proxies is produced by effectively smoothing annual T slopes through the binning/averaging of limited data points.
When one considers that delta-T slopes from the early instrumental period are just as steep as recent warming slopes, it is entirely plausible (indeed, a physics-based certainty) that short-term slopes for delta-T over the past 2000 years exist that would display a magnitude similar to recent warming trends.
Therefore, IMO the statement by Dr. McGregor that the Earth is currently warming about 20 times faster than it cooled is unsupported by either the methodology or the results of this paper.
Correction to the above: The statement was made by Evans, not McGregor.
Steve says
“Had the results been more HS-like, it’s hard to believe that the OCEAN2K authors would not have found a way of publishing them in time for AR5. It seems to me that, since the results were “bad”, the authors seem to have felt little urgency.”
##
It’s a fair conclusion that had a magnificent HS been produced, this study would have been published years ago. I wonder what finally prodded the author into publishing this abysmal failure, as it must seem in the eyes of hockey stick devotees.
One wonders at the rank hyperbole of Michael Evans and whether he thought that such would compensate for the shortcoming of the curve. Poor fellow, all his hopes dashed.
I’ve understood that our current land-based measurement of global temperature is flawed and that the ocean temperature is a far better method of measuring whether the planet is heating or cooling. Looking at their Fig 1 doesn’t the implication of results of the global sea surface temperature compilation from Ocean2k suggest claims made repeatedly over the past decade that 20xx was the “warmest year ever” are now suspect?
“…20xx was the “warmest year ever” are now suspect?”
One must pay close attention to the wording of NOAA and NASA press releases invisible disclaimers as if one is considering an advertisement for “a limited offering of the recent release of the rarest coins ever.”
Ever in NOAA and NASA terminology means since thermometer records (or 13/1000 of the Holocene, 6/100,000 of the Quaternary and 5/100,000,000 of time since life on Earth).
They thought he was sleeping with the fishes but he was fact checking McGregor et al 2015.
The problem is near solution. The Atlantic Trawler’s Association have volunteered to rescue the impacted fish with their purse-nets, dependent of course, on the appropriate subsidy being paid them by government. The Minister of Fish Rescue says that he is very much taken with the idea, as long as the Ministry does not have to subsidize the drying and salting of the rescued fish.
To paraphrase Kevin Costner’s wife in Field of Dreams,”What’s it got to do with football?”
“..whatever image one might choose to describe its shape, “Hockey Stick” is not one of them.”
I choose to describe it as a ski jump on the beginner’s hill. (Keeping with the winter sports theme.)
I’m thinking spatula, though some were ladle-like.
Hockey stick lying on its side with the blade’s curve just barely visible.
McIntyre (above) “Only one of the 57 series has a noticeable HS-shape and, by coincidence, no doubt, it is the only SST series from this collection that was cited by Appell.”
It seems to me that the 57 series are “reconstructions” of sea surface temperature over the last 2000 years. How is that possible? Really? The sea surface temperature of large sections of sea in the distant past.
These are said to be derived from “proxy data”. They measured some other thing and assumed that this other thing was associated with sea surface temperature to within a fraction of a degree. How does one prove that association, eliminate all of the known confounding factors, and bound the unknown ones? Are those proxies reliable compared to today’s measurements, to within a fraction of a degree?
57 series, all proxies of the same thing, the average sea surface temperature in some location or in different locations. They don’t match one another. In peasant terminology, they should all squiggle in about he same ways, or have the same slopes after some amount of smoothing. They don’t seem to, by my eye. So, after running complicated statistical alterations, themselves prone to error and artifact, I don’t believe the results.
57 series which don’t match, all proxies of the same thing, mutually disprove the reliability of one another and the reconstructions. Am I an uninformed peasant?
Andrew,
Welcome to the world of climate science, the paleoclimate reconstruction division, unreconstructed.
Bang on target there Andrew.
The paleo reconstructors are well-aware of this, one of the Climategate emails noted this (IIRC) that all “Skeptics” had to do, was point out how much variation there was and it’d pretty well kill off their little industry.
It’s not quite that bad since the 57 series are from different parts of the ocean.
In the SI, the authors state:
The reconstructions were selected
from the Ocean2k metadatabase (http://www.pages-igbp.org/workinggroups/ocean2k/data)
They go on to provide the 7 criteria for selecting 57 datasets from this metadatabase.
It would have been nice if they had listed the datasets that did NOT make the cut. Even nicer if they gave the reason for each database being deselected. But they did not.
So I thought I would look at the complete set of datasets, just to get an idea of the universe from which they selected, but the link resulted in a 404 “Not found” error message.
I suppose further work would run it down, but at that point I thought I better scrub down the outdoor furniture as suggested by the wife.
Please let us know if you achieve any results in this most commendable endeavor.
Yes, very commendable. I hope she’s duly appreciative.
==============
He could say “Sorry, honey, I got a 404 on the outdoor furniture.”
And we will all be duly appreciative. Maybe.
Reblogged this on 4timesayear's Blog.
Appell has our paper listed as a HS. he even said our instrument record was a proxy record.
Stick appeaser.
When I told Appell the hockey stick was about the behaviour of temperatures in paleo times, he accused me of lying and told me the stick was about 20th century temperatures.
He then corrected himself, saying it was about temperatures whenever it goes back to – apparently he couldn’t remember. Never has his eye off the ball, our David.
I emailed him a comment by RGB@duke, and he threatened to “report me to the police for harassment”
Glad to see you back on the trail of the lonesome pine:-)
I suppose you mus be deflated with all that work you have carried out on footballs?
The guy got off ?
Sorry slightly ot
It doesn’t even occur to them, does it, that they better hope this reversal of 1800 years of cooling is predominantly natural. If man has reversed that sort of trend, we’ve used a pitifully inadequate method to sustain it. The Little Ice Age was the coldest depths of the Holocene, and we’re at half-precession.
If the rebound is natural, we have a chance of avoiding, for longer, the cliff at the end of the Holocene.
====================
Steve: let’s not coatrack this larger issue.
Okay, I’ll get me reconstructed hat. Thanks for not zamboni’ing my large pile of issue.
=====
I’ve often written that it would be amazingly cool to see historic global temperatures. After so many hours spent, to actually know what the Earth climate had done hundreds and thousands of years ago would be a dream come true. I still look at the noisy lines on the graph with hope that some piece of history will show itself. The average of the lines is smooth enough that it appears to be a signal but alas, with the various problems in the data it just isn’t something we can conclude about.
These data simply don’t appear to be very strongly related to temperature. It is somewhat interesting to see a higher temp in history with so little uptick in recent years, but only because so many proxies take on that shape – boreholes for instance. I can’t convince myself that temperature is the cause of any of them.
There is only one proxy that has a demonstrated relationship to temperature: d18O. It works very well in ice cores and foram deposits but is tricky when applied to cave deposits or corals. None of the other proxies have such a well demonstrated relation to temperature.
For a reliable charting of the climate history of the Holocene, see ice core d18O reconstructions. These tell an entirely different tale than what the ideologues are trying to peddle with their dubious proxies.
mpainter
Can you post a plot that shows ice core proxie reconstructions, or provide a link?
Thank you
Richard
Sorry, no link. I have seen the d18O paleoclimate reconstructions often my visits to climate blogs. This is true science, originating over fifty years ago, very well understood, precise, definite; at least in ice cores and ocean sediments (forams).
All of your Pleistocene reconstructions are by d18O (ice cores). The paleoclimate of the whole of the Tertiary has been reconstructed from sediments (forams)
There is really no need for any other temperature proxy, but the ideologues hate it like the plague because it utterly refutes the message that they try to push with their tree rings, etc.
However, cave deposits and coral d18O are tricky due to other variables. Our host, Steve McIntyre, performed a tree ring study using d18O, an original! That study was several years ago and you can locate in the archives.
mpainter: Thank you
So….an appell picks cherries and produces a lemon?
Steve
“While series with high-resolution through the 20th century are not as common as one would like or expect, there are some…. I’ve done my own calculations with 20-year bins and will report on them in a later post.”
I have followed your past posts on this and look forward to the upcoming post. What wait do you give to Oppo et al 2009 and Rosehthal et al 2013?
The Rosenthal paper provides evidence that the cores, I believe from the Pacific Warm Pool, represents the intermediate waters of the entire pacific. Does this relate to the SST?
What is gained, in the Ocean2K Reconstruction, by combining all series in one plot? Are not the locations of each series extremely important, some locations more relative to the global SST than other locations?
Steve: Ocean2K say that they do not include thermocline estimates. Thus, Rosenthal 2013, which uses thermocline forams, is not included. Whether it really represents intermediate waters of the entire PAcific is not necessarily graven in stone.
Thank you Steve
I agree with mpainter and wonder why the ice core studies show such a different result than some of the other proxies.
The Antarctic ice core studies of PAGES 2K showed a warmer period from 141 AD to 1250AD than temps today. There was also a 30 year warmer spike from 1671 to 1700 as well.
The real reason for the 57 varieties (from Wikipedia):
Heinz 57 is a shortened form of a historical advertising slogan “57 Varieties” by the H. J. Heinz Company located in Pittsburgh, Pennsylvania. It has come to mean anything that is made from a large number of parts or origins. It was developed from the marketing campaign that told consumers about the numerous products available from the Heinz company…
The first product to be promoted under the new “57 varieties” slogan was prepared horseradish. By 1940, the term “Heinz 57” had become so synonymous with the company the name was used to market a steak sauce.
Oooh, that’s gonna sting …
As usual, Steve, your insights and research far outpace that of the original authors … and with your two successful predictions about Pages2K and the Bona-Churchill results, you’ve made more successful predictions of the future than all the alarmists put together.
Thanks as always for your outstanding blog,
w.
Yes, I loved that gentle sarcasm too. And it’s great to see ClimateAudit getting back to climate, rather than weather on a football field. Still, having read the Financial Post article I can see why those statistical inferences intrigued SM.
Rich.
Not to mention the CAGW-caused increased wind velocity, too strong for birds to fly. Thankfully, the Federal agency for teaching birds to fly around windmills is fully staffed and will only need an increased budget to cover this extra task. We’ll need a whole new agency to make sure no fish is left behind.
Why does all this teaching of fish to swim and birds to fly remind me of the Chinese Government and their work with “Lucky” – their captive panda that they tried to reintroduce to the wild? Supposedly, they taught him how to “howl and bite” etc. so he could survive back in the wild.
The result?
Wild pandas killed him.
BTW Dr Roy Spencer has posted the August results for UAH V 6. August is up 0.1c from July.
http://www.drroyspencer.com/2015/09/uah-v6-0-global-temperature-update-for-aug-2015-0-28-c/
Data bins of 200 years! I, too, eagerly await Steve’s contribution to this study with his smaller data bins. I also would be curious about any post 1900 data.
Blasphemous thought: global SST anomalies are more determined by rate of meridional ocean overturning circulation than by air temperature, by an order of magnitude.
The blasphemous thought sounds like common sense to me. How far beyond the pail can one get?
pail. ++
Although the Phys.org press release quotes Evans in the third person, it was provided to them by UMd, Evans’ university, so it wouldn’t be at all surprising if he write it himself.
Nor would it surprise anyone. The name is Michael Evans. He is Associate Professor at the University of Maryland’s Department of Geology and Earth System Science Interdisplinary Center. In short, that institution has “binned” geology with the AGW crowd. Horrid.
In Section 7 of the SI, the authors explain how they tested for significance of bin-to-bin changes:
“We estimated the bin-to-bin change in standardized temperature (dT) as the median of all possible 2-point slopes calculable from the available values in the nth and (n-1)th bins
(Supplementary Table S13). The Wilcoxon signed rank test was used to test the null
hypothesis that the median slope dT was equal to zero, and the z-statistic approximation for large sample sizes was used (Davis, 2002).”
Thus, for example, in bin 1100 they have 45 observations and in bin 1300 they have 49. This makes at most 45 series on which they have observed the change, and on which they can reasonably use the Wilcoxon signed rank test to test for median change = 0. Instead, they construct 45 x 49 = 2205 unmatched pairs of observations, and pretend that these are 2205 independent paired observations of changes. In fact, they’re not independent, and generally not even matched. They have therefore grossly inflated the nominal sample size and hence their z-scores.
It might still be that some of the bin-to-bin changes are significant, but they haven’t shown that.
They have enough series, some of which are close together, that spatial correlation that violates the test’s assumption that pairs are drawn independently may be of concern. However, this is a much more subtle problem than their inflation of the sample sizes by duplication of data.
The test also assumes that the unspecified distribution of changes is symmetric about its median of 0, even though this is rarely stated explicitly. When symmetry is present, this makes the signed rank test more powerful than a simple signs test. However, it’s not an unreasonable assumption in the present instance.
The absurdity of the z-scores in SI section 7 and SI table S13 should have been a clue to the reviewers for Nature Geoscience, if not to the authors, that something was amiss with their calculations: For the change in temperature between 1100 and 1300, they report a z-score of -14.80, which implies a 2-tailed p-value (the probability of a type I error) of 1.47e-49. Such certainty can never be obtained from noisy data like this.
The spaghetti of FAQ Fig 1 is ridiculous. I have a hard time believing the error envelope wouldn’t include the entirety of the bins.
Posted Sep 4, 2015 at 10:57 AM and still no response from the bad appel … this must be a record somewhere in the world.
Contrary to my earlier comments above, at
https://climateaudit.org/2015/09/04/the-ocean2k-hockey-stick/#comment-763048 ,
it occurs to me now that it would be quite easy to recover the temperature units from their composite of the standardized series: They have divided each series x_i by its standard deviation sd_i, and then have taken the average of these n series. The coefficient on each x_i is therefore 1/(n sd_i). Since these coefficients don’t add to 1, this is not a weighted average, and the resulting series no longer has temperature units. However, if the resulting composite is simply multiplied by n / sum(1/sd_i), then it is a weighted average, and the temperature units are restored, without re-calibration!
In fact, under the assumption of this exercise that each temperature-calibrated series consists of a common global temperature plus a variable amount of noise, this weighted average is in fact a move in the direction of the theoretically optimal Weighted Least Squares, rather than in the opposite direction as I had feared: the variance of each series will be the variance of the common signal, plus the variance of its noise, so that the procedure will in fact give less weight to the worst series.
However, any average, weighted or unweighted, runs up against the problem I mentioned in my earlier comment, that Classical Calibration Estimates (UC’s CCE) are the ratio of two normal random variables, and hence have infinite absolute first moments, and so may not obey a Law of Large Numbers. A median-based estimator might therefore be more appropriate. A median analogue of WLS would be the following: Take the equally weighted median of all the series at each point in time. Compute the Mean Absolute Deviation (MAD) across time of each series from the common medians. Then assign Importance Weights (as in Monte Carlo importance sampling) to each series proportional to 1/MAD_i, and scaled to sum to 1. Then take the weighted median of the series, using these importance weights in place of 1/n. Use the signs test, appropriately modified for the weighting, to construct a confidence interval or, if you are willing to assume symmetry, the Wilcoxon signed rank test.
“it occurs to me now that it would be quite easy to recover the temperature units from their composite of the standardized series”
Wow, Hu, it’s GREAT, you’re a GENIUS. FYI next time, instead of re-multiplying by n / sum(1/sd_i), just click on the articles’ links provided everywhere to get the °C numbers – or perhaps you just enjoy the idea that the other idiots think that you’re smart, in such a case just go ahead with your little equations.
Nice ! Another [snip- coauthor] heard from…
I see a list of URLs of the temperature-calibrated input proxies in the SI, but no link to the composite reconstruction in dC values. Perhaps you can point us to the page and paragraph?
PS Ed — Leduc is one of the co-authors of the McGregor, Evans et al study.
“Leduc is one of the co-authors of the McGregor, Evans et al study.” I’m sorry to hear that. He has done a real good job as presenting himself as a partisan rather than a scientist.
Hu, I got that, but based on the snark, my opinion stands. Sucks to have to polish turds like this because “consensus” doesn’t Guillaume ?
Is it possible that the comment is not actually from Guillaume Leduc but from a troll using his name to stir the pot?
I half expected the last sentence to continue with “In such a case just go ahead with your little equations. I don’t want to talk to you no more, you empty headed animal food trough wiper. I fart in your general direction. Your mother was a hamster and your father smelt of elderberries.”
Dear Dr Leduc,
while the members of your team may be knowledgeable about foraminifera, none of the authors, to my knowledge, are experienced statisticians. In my opinion, the paper makes a number of dubious methodological choices, not least of which are various decisions to degrade data, including the decision to bin in 200 year periods and standardize this data – a topic on which I plan to post.
I don’t know whether you fully understand the degree of data degradationm but here’s what you did to six high-resolution (some better than 10-year) series. Two series (Pahnke) were NA-ed out as only in one bin. Four series were in two bins and all were set at +- sqrt(2)/2, as shown below extracted from your archive. This data degradation is really stupid. (Also note that the Pahnke data has data for two bins as well, but was incorrectly transcribed in your dataset – though this clerical error is not material to the results.)
You might also be sure that your facts are right before being quite so chippy.
I have looked closely at the SI to the article and it does not include the reconstructions as re-scaled from SD Units to deg C nor is such calculation shown in the source code, which ends with the calculation of Figure 2. Please note that Hu’s interest here was in the reconstruction, as he (and I) recognize that the authors have commendably archived their data as used.
Is what they did really to make well over half the cells read “NaN”? Or is that just on my screen?
Admkoz —
It’s normal for missing data to be coded as NaN (Not a Number), since a blank might be misinterpreted as a zero. Programs like Matlab and R will recognize this, and even have functions that will take averages, etc, of only the non-NaN values. Some of the proxy series have no data in several of the bins, and hence will be coded NaN there. It will be interesting to see what they did with a proxy that had data for only half a bin — is it the average of the available data, or is it NaN since it is incomplete? It will be doubly interesting to learn where these sqrt(2)/2’s came from!!
That was quite a polite response to a horrible and unprofessional drive-by snark from a co-author. As usual, your behavior is commendable, Steve (even though it had been directed at Hu and not you personally).
I have examined the links to the names of the fifteen authors and their fields of study are climatology, paleoclimatology, oceanography, earth science, geochemistry, biology, etc. Not one has any mathematical or statistical expertise. I doubt that it occurred to any that their study would wind up being dissected at Climate Audit.
Hu McCullough : The problem I have is, I think, an issue of calibration. The author regularly posts things that make the study look like something I would describe as “laughably wrong”. He then uses a descriptor such as “data degradation”. I am left wondering whether I have misunderstood or whether it’s just Canadian understatement.
Steve, that 0.7071 catch is a beaut example of what I have been rabbiting about over at Judith’s.
My contention is that people working with numbers can gain a ‘feel’ for them that sometimes says ‘Hello, there’s a number I know, better look into this’
I suspect there are many numbers people who have in their minds a set of numbers useful for work, better than looking them up. Examples:
sin 30 = 0.5 sin 60 = 0.8660 tan 45 = 1
pi = 3.141592653
Main Fibonacci series 1, 1, 2, 3, 5, 8, 13, 21 etc (found in the patterns of seed growth in flowers)
sqrt 2 = 1.4142 sqrt 3 = 1.7221 sqt 0.5 = 0.70710678 = 0.5*sqrt 2
A solid correlation coefficient is greater than 0.8
speed of light in vacuum = 299,792,458 m/sec ….. and so on, depending a little on your discipline
Australians use toilet paper at a velocity over 1,500 km/hr, faster than the speed of sound
Normal body temperature is around 38 deg C
Rust On Your Gear Box Is Vile, for colours of the rainbow
For chemists,
LIttle BEryl Bates Cries Nightly Over Freddy
NAughty Maggie ALan SIngs Poor Sappy CLod — to remember the start of the periodic table
Gas constant R is 0.082057 L atm mol^-1K^-1
and so on.
Those who lack the ‘feel’ for numbers are prone to carry too many (or too few) places of significance, and might well miss that 0.7071 figure, which casts a whole new significance on the data.
Am I being led by my mind into a realm of foolishness, or do others do this too?
Geoff
Geoff,
I live walking distance from http://www.sparcsf.org/ and many others.
So I’m with you.
Guillaume Leduc, given as CNRS ( Centre National de la Recherche Scientifique), France. Area of study: Paleoclimatology, Paleooceanography. Seems to have a good command of English. Listed as forth of fifteen (I think) authors of the Oceans 2K study.
Guillaume, congratulations on getting your study published. I wonder if you would share with us the reasons for the lengthy interval before publication. My guess would be the choosing of a methodology for treating and presenting the data and the lengthy conferences that this process would entail. Is this correct?
Sing a song of sixpence,
The pie is full of lies.
Break the breaded crust whence
Out swarm all the flies.
The Duke is in his counting house,
His servant piles it high.
He scurries so, the tim’rous mouse;
The Masque of Paris nigh.
===================
I am not a statistician and have no experience with statistics and am more than happy to be shown to be wrong, but I just don’t get how it is at all valid to average together the standard deviations of different series and then attempt to convert that back to deg C.
Obviously, if you take two random series, with two totally different standard deviations, and you graph those series separately, it would make sense to graph them in SD units if you are trying to show how much they changed.
But I just don’t get how anything meaningful happens when you combine those two in “SD units”. One series could have a standard deviation that is 100 times the other series. That smaller series could go up by 10 standard deviations and it would be utterly meaningless in terms of the combined system. It would be interesting in terms of the smaller series itself, but nothing of relevance for the overall system necessarily happened.
My salary plods along with a very low standard deviation, while my minuscule stock holdings jump all over the place in value. However, the stocks could go up 10 times more than they usually do without me being more than 1% richer for the year. I’d love to be able to convert the “SD units” back to dollars and conclude that I was 1000% richer but sadly that does not work.
Makes me wonder what Mann’s reconstructions (such as http://www.ncdc.noaa.gov/paleo/pubs/mann2003b/mann2003b.html) would look like “binned” – especially under a methodology which is not mining for hockey sticks.
Seems at first-glance that such a global land+ocean reconstruction would devastate most of his notable conclusions, especially considering how much weight the oceans should get compared to land.
Oh that they were binned.
“Second, their money graphic is denominated in SD Units, rather than deg C anomaly, even though all of the 57 series in their database (alkenone, Mg/Ca, foraminifera) are denominated in deg C. This seems to me (and is) a pointless degradation of the data that ought to be avoided. Particularly when they want to be able to express the decline in deg C (as they do in a later table.) To do so, they convert their composite back from SD Units to deg C (anomaly) using a complicated home-made technique. I think that there’s an easy way of accomplishing what they want to do using conventional statistical techniques. I’ll show this in a subsequent post.”
According to a post here from a supposed co-author, the easy way to do it is to “just click on the articles’ links provided everywhere to get the deg C numbers.”
Which is great for the individual series but not the composite reconstruction.
Until about 3 months ago I was a lifelong true believer in CAGW, then I found this Blog and have been researching both sides since. I am astounded at what passes for science in the Alarmist camp and am now convinced that there is NO dependable Alarmist research, that is, there is so much bias that I can’t trust any of it. This is a tragedy because we are wasting money and effort that should be used to study the Whole climate system. There Will be huge volcanoes or other apocalyptic events (as seen on the “used to be about Science Channel”) for which we will need that information to.
That was by way of introduction as I am a first time poster. The comment I wanted to make about this thread is that looking at graphs of Milankovic cycles there appears to be some mechanism that makes temperatures fall relatively slowly during a cooling period and each cooling ends with a much more rapid warming. It’s obvious looking at the +/-100,000 year cycles but seems to be true at all scales. Does this process have a name? If this is a genuine phenomenon, then we should be expecting rapid warming now as we come out of the LIA, even 20 times faster than we cooled. It seems that we should anticipate a hockey stick under natural forcing. Then proof of AGW would require some sort of Super Hockey Stick. In other words, the alarmist not only need to demonstrate a hockey stick but that is steeper than all other natural hockey sticks.
Or am I drinking out of the toilet?
John:
Nice to have you joining the discussion. Let me make a quick observation – Steve likes to keep his posts narrowly tailored to the subject of the post. Your question would probably receive more responses at one of the more generalist skeptic blogs.
Can’t speak to your source of hydration…
Respect for the Porcelain Empress, embraced oft’ of Sunday Morning Coming Down.
==============
John A. Hunter
The process is called stadial-interstadial transition, or most commonly abrupt warming. As you have noticed it takes place at the end of glacial stages and during Dasgaard-Oeschger cycles. You should not worry about them taking place during the Holocene, as it is way too warm and there is no nearly as much ice as it is required for this abrupt changes to take place. It has been shown that they require sea levels to be below -45 m. present levels and above -90 m to take place. See “Amplitude variations of 1470-year climate oscillations during the last 100,000 years linked to fluctuations of continental ice mass.”
Michael Schulz, Wolfgang H. Berger, Michael Sarnthein, and Pieter M. Grootes
GEOPHYSICAL RESEARCH LETTERS, VOL. 26, NO. 22, PAGES 3385-3388, 1999
These abrupt warming events of 8-10°C in a few decades are very likely to be the product of the rapid elimination of extensive permanent sea ice over the Nordic sea and vertical disturbance of sea layers with warm subsurface waters coming to the surface and venting great amounts of heat suddenly to the atmosphere. This model is rapidly gaining acceptance over the old AMOC perturbations model of Broecke.
There is zero chance of this type of abrupt warming taking place today as there is no nearly enough sea ice cover to eliminate and there is no subsurface warm water stratified to mix.
Hi Steve
this paper may be of interest but is only focussed on N. Atlantic
Click to access Cunninghametal2013.pdf
Rob
ah finally, the jackson pollock graphs are back ! (what was this deflated business about?)
I take offense btw that David Appell wouldnt be find able to call any random plot a hockey stick
Regarding the missing appellation, give the guy a break, it was Labour Day.
What a minute why would a strident defender of Climate Change Catastrophe Panic and Northern De-icing Panic be unavailable on Labour Day?
Academics who have grown up in Fortran tend to write scripts in Matlab (or R) that look like transliterations of Fortran.
Here’s a (turnkey) script in R for calculating the (degraded) SD composite of their Figure 2A. I’ll vary this when I discuss results without degradation to SD units and 200-year bins.
In addition to the calculation of the composite, it retrieves their result, which is embedded in a Matlab-workspace, and shows that the result in my more logical script matches their inelegant result.
##FUNCTIONS ############### library(XLConnect) library("R.matlab") library(reshape2) bin=function(A,scale=F,center=T){ work1= with(A, tapply(sst,list(period,id) ,mean)) work1=scale(work1,center=center,scale=scale) work=melt(work1,id.vars=c("period","id","sst")) names(work)=c("period","id","sst") work$ocean=info$ocean[match(work$id,info$id)] work=work[!is.na(work$sst),] work$id=factor(work$id) work$ocean=factor(work$ocean) return(work) } ext=function(x) c(x,x[length(x)]) #TARGET RECONSTRUCTIONS OF FIGURE 2A #######################################333 loc="ftp://ftp.ncdc.noaa.gov/pub/data/paleo/pages2k/Ocean2kLR2015.zip" download.file(loc,"d:/temp/temp.zip",mode="wb") handle=unz("d:/temp/temp.zip","Ocean2kLR2015/composites_shipped/compositework.mat","rb") cwork=readMat(handle) close(handle) #INFO SUMMARY ############### loc="http://www.climateaudit.info/data/multiproxy/ocean2k/info_ocean2k.csv" info=read.csv(loc) w=c(arc=.034,atl=.183,ind=.113,med=.008, pac=.384,sou=.278) #weights ##PROXY DATA ############### #setwd("d:/climate/data/multiproxy/ocean2k") #wb=loadWorkbook("Ocean2kLR2015sst.xlsx") loc="ftp://ftp.ncdc.noaa.gov/pub/data/paleo/pages2k/Ocean2kLR2015sst.xlsx" dest="d:/temp/temp.dat" download.file(loc,dest,mode="wb") wb=loadWorkbook(dest) K=57 O=NULL for(i in 1:57) { work=readWorksheet(wb,sheet=4,startRow=1,startCol=2*i-1,endCol=2*i,colTypes=rep("numeric",2)) names(work)=c("year","sst") work=work[!is.na(work$sst),] work$id=info$id[i] O=rbind(O,work) } O$ocean=info$ocean[match(O$id,info$id)] O=O[O$year>0&O$year<=2000,] M=200 O$period= factor( M*floor((O$year-1)/M)+M/2) O200=O Bin=Bin200= bin(O200,center=T,scale=F) Bin200scale= bin(O200,center=T,scale=T) P=Bin200scale P=P[!is.na(P$sst),] P$id=factor(P$id) #two NA-ed out=with(P,tapply(sst,list(period,ocean),mean,na.rm=T)) emulation=apply(out,1,function(x) weighted.mean(x,w,na.rm=T )) X=cbind(emu=emulation,archive=rev(cwork$wavemn)) cor(X) #0.9999759 range(X[,1]-X[,2]) #[1] -0.003437707 0.005643450Steve, thanks as always for posting your code. I can’t tell you how much I’ve learned from working with your scripts.
Now if only the mainstream climate scientists would do the same, posting code and data AS USED in their study.
Regards,
w.
Thanks.
Sometimes the hardest part of the scripts is dealing with compressed files. Reader “Nicholas” gave me some scripts for dealing with binary objects some years ago and I regularly rely on them both directly and indirectly. I did something new in today’s script and wonder at not thinking of this earlier. I’ve had trouble reading within unz handles. In today’s script, I used the parameter “rb” (readbinary) rather than “r” and it worked like a champ. This can be used for many other situations.
Ocean2K authors, like Mann, speak Matlab with a heavy Fortran accent. Good R programmers use tapply,apply,sapply,… rather than do-loops.
whenever one sees a comment like:
“% now loop over the chronology for each dataseries individually:”, one knows that it can be done simpler. And simpler usually exposes the underlying structure more clearly.
Here’s something odd. According to Ocean2K, the temperature of the Pacific Ocean in the periods 1600-1800 and 1800-2000 was exactly -1/sqrt(2).

who would have guessed that an ocean temperature would be an important mathematical constant?
Figured out how they got to a mathematical constant, something that one sure doesn’t expect after spending lots of money to collect samples.
Under the scaling system of Ocean2K, series with values in only two bins, when standardized, give values of +- 1/sqrt(2) – regardless of values, as long as they are unequal. This is a huge degradation of data, obviously.
In the PAcific Ocean, there are two such series, Goni2006_BC-43 and Gutierrez2011_B0406, one of which is positive in the 1800-2000 bin and negative in the 1600-1800 bin, while the other is the opposite, thus giving a value of -1/sqrt(2) in each period as well as a value of +1/sqrt(2) in each period.
By coincidence, the value of -1/sqrt(2) is the median in each bin, though from a different series in each case.
That’s how you get to a mathematical constant as an ocean temperature.
My guess (so much more fun than working)
Series of two values x1, x2
Mean = (x1 + x2) / 2
Stdev = sqrt (sum squares (xn – mean) / n) = sqrt ( (x1 – mean) ^ 2 + (x2 – mean) ^2) / sqrt 2
= sqrt ((x2-x1)^2) / sqrt 2
= abs(x2 – x1) / sqrt 2
So, if each column is “scaled” as # of standard deviations from the mean, then
x1 – mean = x1 – (x1 + x2) /2 = (x1 – x2) /2. Divide by the standard deviation then you get +- 1/sqrt(2).
This statement hasn’t been peer reviewed, but if my half-baked, lunchtime reverse engineering is correct, it kinda implies to me that the entire exercise is wholly meaningless. You could add up 500 series and all you would find out is how many of them “went up” versus “went down”.
A much more subtle issue is that it is not valid to calculate anything based on the “mean” of series of differing lengths. Obviously, series that go back to the MWP are going to have higher “means” than series starting in the LIA, which says absolutely nothing about the temperature of the ocean.
Steve: see https://climateaudit.org/2015/09/04/the-ocean2k-hockey-stick/#comment-763127
Actually I blew it. Missed a factor of two. They must have used stdev = sum squares/(n-1) where n = 2 so the factor of n-1 goes away.
Then sum squares = 2 (x1-x2)^2 / 4 = (x1-x2)^2 / 2 so stdev = abs (x1-x2) / sqrt 2 like I said. Rest of calculation is the same and I will now stop shooting off my pen without more consideration.
Sigh one more thing.
Are you saying that the way they got to their final value for each bin was by lining up all the series and taking the median?
I guess what I was trying to do is guess what the scaling system used in Ocean2K actually is.
It might be instructive to feed some values for temperature in, run that method, and see what it comes up with.
Hmmm…maybe you’ve found Trenberth’s missing heat. Quick, before someone like Gavin’s Mystery Man takes credit for it!
You have to give them credit for getting these figures to 8 decimal places. Very impressive…
How about “wet noodle”
it makes for an interesting question to the warmish “savants”, why their expensive experimental data returns sqrt(2) as measurement samples.
Could we not have obtained that with a calculator, instead of sending ships out on taxpayers’ expense???
Noone seems to have commented on Figure S11 in the supplement. From it, we learn that according to two climate models (CSIRO Mk3L and LOVECLIM), the effect of GHG from 1600-1800 was to reduce SST noticeably, despite a change in GHG forcing (Figure S4) of only around -0.1 Wm-2. Oddly, the models’ results are not shown for the most recent bi-century (1801-2000).
Steve —
Thanks for pointing out where the sqrt(2)/2 values come from, above at
https://climateaudit.org/2015/09/04/the-ocean2k-hockey-stick/#comment-763127 . Evidently similar values for the Pacific basin arose because the medians (which were used for the regional reconstructions) happened to fall on one of these values.
However, I believe that these short series still contribute validly to the change in the reconstruction, and therefore to the reconstruction itself, so long as the composite is converted back to dD by the “little equation” (to use Leduc’s phrase) I proposed above at
https://climateaudit.org/2015/09/04/the-ocean2k-hockey-stick/#comment-763075 .
My real concern about these short series, however, is they should not be standardized to average to zero over their own period as in the McGregor et al paper. Rather, their temperature should be standardized to have the same average as the centered dC composite of all longer series. Failure to do so will flatten the reconstruction if they happen to fall in a cold period (like the LIA as your examples do) or in a warm period (like the controversial MWP).
I pointed this out above, at
https://climateaudit.org/2015/09/04/the-ocean2k-hockey-stick/#comment-763048 :
“By all means the temperature-calibrated series should be demeaned before combining. If the series vary in length, this should be done for the full reconstruction period for the longest series, and then shorter series should have their means matched to the mean of the longer series over the shorter interval. This isn’t quite what Craig did in his 2007 paper or in the 2008 revision, but only one of the 18 series was substantially shorter than the others, so that I doubt that it much affected the results, however.”
Craig’s one significantly short series was the Calvo Norwegian sea series, but even it ran through 3/4 of his 2000 period, and so how it was centered did not greatly affect the results. The McGregor et al study uses it (it shows up in the above graphs as ending circa 1495), but also several shorter series like the ones you show, so that at most 49 of the 57 series are active at any point in time. On Craig’s data, see my SI webpage at http://www.econ.ohio-state.edu/jhm/AGW/Loehle/ . (I see now that my SI table on the data has a typo indicating that Calvo ends in 1945 rather than 1495!) Craig’s criterion that each series have at least 20 dated points during the period 1-2000 eliminated the shorter series that were available at the time.
Correctly standardizing the means of the short series will eliminate the glaring sqrt(2)/2 values, even if the series are further divided by their own standard deviation, and will still allow them to contribute to the local rate of change of the composite. The resulting series will not quite have mean zero, but there would be no harm in recentering it after all the short series are added in.
That I can see, their technique entirely destroys all information to be gleaned from these series in two bins, except for the single bit of information as to whether it was colder or warmer. I don’t see that multiplying by anything is going to change that. Recentering might, but your second sentence seems to imply that even without that something valid is happening.
A concrete example would help the layman. Suppose an earth consisting of 5 equal regions. For each of these 5 regions, we have a single series, with two values.
1: 10.0, 9.5
2: 10.0, 9.5
3. 10.0, 9.5
4. 10.0, 9.5
5. 10.0, 52.0
I believe that any normal person would say that the “composite” temperature was
10.0, 18.0.
Now let us see what Ocean2K’s method would yield. First, we ‘standardize’ the series. As Steve showed this means converting all values to +-1/sqrt2 based solely on whether the series increased or decreased.
1: 1/sqrt2, -1/sqrt2
2: 1/sqrt2, -1/sqrt2
3: 1/sqrt2, -1/sqrt2
4: 1/sqrt2, -1/sqrt2
5: -1/sqrt2, 1/sqrt2
Now we calculate a “composite”. It would appear that this means nothing more than taking the median of the above values. I find this almost impossible to believe, but suppose we do. The composite is then
1/sqrt2, -1/sqrt2
The “little equation”: Multiply by n / sum(1/sd_i) = about 0.1
1/10sqrt2, -1/10sqrt2
or basically
0.071, -0.071
This is wholly worthless. Goes the wrong direction, and the magnitude is off by a factor of 100.
If I’m wrong, I’d appreciate knowing where I made a misstep.
Steve: only a few series are reduced to two boxes. If there are 10 boxes, there is enough content that it’s not so silly.
Most of the series have more than two boxes. It’s a coincidence that the median in these networks falls on values that come from two-box series.
I showed this to illustrate data degradation using their method.
On the other hand, all they are doing is measuring a sort of average. This is a pretty simple procedure and even you do stupid stuff, you can still end up with something. The overall structure of the composite – blurred as it is – does exist in the data and is not an artifact of a stupid method.
Understood. I was responding to the comment above which stated “However, I believe that these short series still contribute validly to the change in the reconstruction, and therefore to the reconstruction itself”. It seems to me that a series in two bins contributes nothing of value whatsoever and in fact subtracts validity.
admkoz —
Thanks for your comment.
Centering each series on 0, your data becomes:
1. +.25, -.25 dC
2. +.25, -.25
3. +.25, -.25
4. +.25, -.25
5. -21.00, 21.00
The equally weighted average of these is
-4.00, +4.00
The standard deviations of the centered series are:
1 to 4 : .25 sqrt(2).
5: 21 sqrt(2).
As Steve and you point out, the standardized data becomes, in standard deviation units,
1. to 4.: +1/sqrt(2), -1/sqrt(2) sdu
5.: -1/sqrt(2), +1/sqrt(2)
The average of these is
.6/sqrt(2), -.6/sqrt(2) sdu (not 1/sqrt(2) as in your comment), or
+.424, -.424 sdu
The factor n/sum(1/sd_i) is 0.44063, so that my “little equation” converts these sdus to the following temperature values:
+.187, -.187 dC
My point is that this is a weighted average of the original data, with weights proportional to 1/sd_i of
1. to 4.: 0.24926
5.: 0.00296
These sum to 1 to within rounding error and hence return an answer that has the dC units of the data.
Thus taking a composite of standardized series is somewhat like (but not equivalent to) Weighted Least Squares (WLS). WLS weights each observation inversely to its variance, not standard deviation, of the errors about the (first stage) estimated mean of the series, not of the data about zero. WLS has a theoretical justification as giving the minimum variance estimate of the mean (given the true variance of the various errors), whereas the present paper’s composite of standardized series method is entirely ad hoc. But in many cases the two may give somewhat similar results.
The first iteration of WLS computes the errors about the equally weighted mean:
1 to 4: 4.25, -4.25
5: -17, +17
The variances of these are
1. to 4: 4.25^2 x 2
5: 17^2 x 2
Weights inversely proportional to these variances and normalized to sum to 1 are:
1 to 4: 0.24616
5: 0.01538
The first iteration WLS estimate of the means is
1 to 4: -0.07682, +0.07682 dC
Usually WLS quits here, but it could be iterated to convergence. This will give even less weight to observation 5, since the variance of the first 4 is much less around this estimate than around the original estimate.
A big drawback of WLS is that we don’t really know the true variances of the errors, only estimates of them. And here, with only two observations, each variance estimate has only one degree of freedom. A chi-squared distribution with only 1 DOF has its mode at 0 and is even more sharply declining than an exponential distribution (which is chi-squared 2). Hence there is a big danger that we are getting very low estimates of one or more of the variances, and hence giving that observation (or observations) undue weight. It might therefore be prudent to disregard low variance estimates, i.e. to downweight observations whose variance estimates are above say the median, but to treat all the others as if they had the median variance rather than their own estimated variance.
I really appreciate your response. I realize that it is not the most fun thing in the world to re-explain this kind of thing.
OK, so I should have started off by centering everything at 0. OK.
Anyway the reason I chose the average of -1/sqrt2 was because according to Steve they ended up saying that -1/sqrt2 was the “temperature of the Pacific” because “by coincidence that was the median value”. So I took the median value. The mean is what you said. I also miscalculated the scaling factor but since you can’t edit comments it stayed. Using the mean we get your answer.
So the final value ends up like you said
+0.187, -0.187 dc
Which is, I hope we’re agreed, an entirely false representation of the original data. It goes in the wrong direction and the magnitude is non-close.
So if all they had were series in two bins, their composite would be wholly worthless. Of course they don’t have that.
As you point out this is because the series with small variances end up weighted far more heavily than the one with a large variance. You seem to think this is legitimate. I don’t get why. Obviously my example here is extreme but all that means is that in less extreme cases the distortion is less absurdly extreme. When people are claiming they know the temperature of the past to within tenths of a degree, but are actually engaging in this level of subjective decision making as to which data to disregard, something is wrong.
Seems to me this is a pretty large “researcher degree of freedom”, that in extreme cases like the two bin example here completely destroys the data.
admkoz:
“So the final value [converting the standardized series average back to dC with my formula] ends up like you said
+0.187, -0.187 dC
Which is, I hope we’re agreed, an entirely false representation of the original data. It goes in the wrong direction and the magnitude is non-close.”
No, I don’t agree that this is any worse (or better) than the alternatives I considered: the unweighted average of
-4, +4 dC ,
or the (1 iteration) WLS average of
-.077, +0.0.77 dC.
In fact, given that the composite of standard scores does sort of weight the apparently high-variance series less than the low-variance series, it’s not as cockamamie as it first appears to be, and could even be a move in the right direction, relative to the unweighted average.
However, it’s completely futile to try to estimate 7 parameters (2 means and 5 variances) from only 10 observations. Clearly these series do not all have equal variance about the global temperature signal, so we can’t just assume 1 common variance to evaluate the unweighted average.
Under the circumstances, the median of the raw temperature series of
+.25, -.25 dC
looks least unappealing, but then not much of a confidence interval can be drawn about it: Using the signs test, we can say at the 90% confidence level that the true median for e.g. the first period’s temperature (relative to average = 0) is between the highest and lowest observation, i.e. -21 to +.25 dC, but a 95% CI is unbounded in both directions. The Wilcoxon signed rank-sum test (used incorrectly by McGregor, Evans, Leduc et al in their SI) could give a tighter CI for the median, if we were willing to assume symmetry, but your hypothetical data is anything but symmetric. It is, incidentally, pretty meaningless to take the median of standardized scores, as McGregor do for their oceanic indices in the SI.
Anyway, thanks for forcing me to think more about this — I had originally overlooked the fact that the composite standardized score weights inversely by a standard error, whereas the theoretically efficient WLS weights inversely by a variance!
The equally-weighed average has less variance than any other average, only if the variances of the observations are equal. If, as is often the case with this kind of data, the different series have different variances (and we either know these variances up to a constant or can estimate them with high precision), WLS provides the lowest variance estimate of the mean.
BTW, Steve, I seem to recall that there was an accepted acronym for the composite of standardized scores often used in climate studies, but unfortunately the acronym link in the left column is no longer active. Do you recall what it is?
PS: I’m still trying to get ahold of John Davis’s 2002 Statistics and Data Analysis for Geology, which McGregor et al referenced for their Wilcoxon test, to see if there was some ambiguity in how it was explained there that could explain their creative interpretation of it.
Hu –
The former contents of the acronym link are available here.
Were you thinking of CVM — Composite plus variance matching — as in Juckes et al.(2007)?
Harold —
Yes, the acronym I was thinking of was CVM. Thanks!
Hu: Thanks for your response.
To be clear, I believe that a normal person looking at this sample dataset would say the average anomaly was:
-4 deg c, +4 deg c
and you are stating that you don’t agree that
0.187 deg C, – 0.187 deg C
is a completely invalid representation of the data. This arises from arbitrarily weighting one dataset 100 times as lightly as the rest. It seems obvious to me that I could feed almost anything I wanted into that and achieve as big a discrepancy as I wanted between what any normal person would say and what this algorithm would produce.
I spent a long time puzzling over how such a disconnect could exist. To me it seems clear that any procedure that leads to the latter outcome is wholly invalid. To you (and you obviously have an actual background in statistics, which I don’t) it apparently isn’t.
Ultimately I came up with what I think the problem is.
The algorithms and approaches you’re describing are for regression, correct? That is, they assume you have 5 datasets that roughly represent the same thing, and you’re trying to tease out an approximate guesstimate as to the correct value based on those 5. In that case, you could use algorithms that tend to reject outliers because, if you have 5 values that you have reason to believe roughly represent the same thing, you figure that if one is radically different than the other four, it is less likely to be correct.
But the problem as I described it is not that problem. I said there was an earth with 5 SEPARATE regions. The 5 series are NOT approximations of the same thing, but 5 totally different entities. It is no more valid to calculate an average of these series by rejecting outliers than it would be to calculate the average change in the Dow Jones over the last ten years by disregarding the “outlier” 2008. You’re just being asked to mush them together and come out with something we can call the “temperature of the Earth”. And I see no justification, in doing that, for weighting some of them 100 times as strongly as others.
admkoz —
If indeed all 5 observations are accurate measures of the temperature in each of 5 equal-area regions, then the best estimate of average temperature anomaly is the equal-weighted average of the 5 anomalies, or -4dC, +4dC, as you advocate.
I implicitly had in mind the (to me) more realistic problem of proxies that only measure their own local temperature with considerable noise that varies from proxy to proxy.
An area-weighted average of regional averages of noisy proxies would be ideal, but that would require an awful lot of data in order to make it feasible.
Thanks for your feedback!
Michael Evans asked me to post the following:
Dear Mr. Wallace,
Thanks for your interest in Ocean2k. We apologize for the broken link. The correct link to the paleodata metadatabase is: http://www.pages-igbp.org/ini/wg/ocean2k/data
The redirect from the URL given in McGregor et al (2015) was restored yesterday, so that link should also again work for you: http://www.pages-igbp.org/workinggroups/ocean2k/data
I just tried both links successfully.
Sincerely,
Mike Evans
(for the Ocean2k Working Group)
BTW, Craig, the old link to your own data file, at http://www.ncasi.org/Downloads/Download.ashx?id=996 , is no longer active. Is there a new version? If you no longer have access to ncasi, perhaps Steve could host it here. Else I could upload it to my SI webpage.
Exactly my first thought on seeing that graph. I look forward to seeing a more detailed resolution shows.
At least they have archived the data. So enquiring minds can dig further and apply a more rigorous approach.
They are to be commended for that. It’s taken a long time to get this far.
Has anyone looked at this study of Australian climate during the Holocene? I’m very much in the layman camp so I hope others find the time to have a look at this study.
Sorry I’ll try that link again.
http://www.researchgate.net/publication/236177734_Cross-continent_comparison_of_high-resolution_Holocene_climate_records_from_southern_Australia_-_Deciphering_the_impacts_of_far-field_teleconnections
And this Calvo et al study shows a decline in temp over southern Australia for the last 7,000 years and a drop in rainfall.
Click to access 12.pdf
snip – blog policy discourages coat-racked comments that have nothing to do with the thread
Disregard the pesky lines between the points, ignore the axes and treat the points as if they were just pixels comprising part of an image: to me what they’ve done is pixelated the data into 10 big blue boxes. Now that I just have the boxes to look at, to me that’s not very informative.
But I do wonder if applying modern image processing techniques to the data en mass could help in its analysis.
My two cents as a layman.
My impression is that they were trying to make the non-HS as obscure as possible.
Yeah, it’s all about image.
Steve, If you sketch out what you would like to see as a trial of image processing, I shall have a try as I have a history of manipulation (of photo images, detecting them as a Judge).
Geoff
Steve, Thank you for the service you are providing with CA. I am encouraged to see at least one of the paper’s authors commented, albeit not seemingly sincerely (or responsively). I hope my following comment is cogent and not stepping too far back.
Imagine Ocean2K was a combination clinical study for a drug candidate. And imagine you were a drug regulatory panel member. Would careless errors or systematic flaws in the statistical analysis give you pause, not only about the conclusions of the analysis, but also about trusting the data? I would have pause.
If this were a court case where lives were on the line would you accept this expert testimony into evidence? I wouldn’t.
Yet, clearly, lives are the line with the specter of CAGW and the pretext for the expenditures of untold wealth. One would hope more author’s respond seriously and soberly.
Reblogged this on brickwalls2.
What were the seas thinking rising from 900-1500 while they were cooling?
“What were the seas thinking rising from 900-1500”
Whereas thermal expansion caused sea level rise is directly correlated with global mean temp, glacial melting is only correlated with the mean temp at the poles. Thus there is a small chance both reconstructions are not wrong.
The 1100-1500 segment, if correct in both, could only be explained by an anomalous polar-warming-caused glacial melt while all other oceans were cooling. Unfortunately, for the Pages2K their arctic ocean study shows no 900-1500 warm spell. It could still be and Antarctic warm spell but the cause would be a mystery. Good catch.
Please do not discuss the Kemp et al squiggle as though it means anything. It’s just the Mann et al 2008 network in a different costume.
Hi Steve, sorry that I mentioned it after going back to Kemp-related threads. My intent was just to show that seemingly contradictory results get published without apparent questioning, provided that they are on the “right side” of things.
10 Trackbacks
[…] In his latest post McIntyre welcomes the publication of “Robust global ocean cooling trend for the pre-industrial Common Era”. So should we all. […]
[…] Full post […]
[…] https://climateaudit.org/2015/09/04/the-ocean2k-hockey-stick/#more-21349 […]
[…] Read it all here: https://climateaudit.org/2015/09/04/the-ocean2k-hockey-stick/#more-21349 […]
[…] at Climate Audit, Steve McIntyre is doing his usual superb job deconstructing bad science. In this case he is […]
[…] The Ocean2K “Hockey Stick” […]
[…] The Ocean2K “Hockey Stick” […]
[…] on David Appell’s blog) seems to be highlighting that the recent Ocean2K reconstruction does not have a blade. Well, the data appears to end in 1900 and the paper title is Robust global ocean cooling trend for […]
[…] at Climate Audit, Steve McIntyre is doing his usual superb job deconstructing bad science. In this case he is […]
[…] « The Ocean2K “Hockey Stick” […]