A CA reader, John Goetz, has written in with a mind-numbing puzzle related to Waldo in Bagdarin, Siberia, where Waldo appears to have experienced an adjustment unusual even by the standards of NASA chiropractors.
This is still fairly preliminary so keep that in mind. John G tried to replicate a really simple step in the NASA calculation: the combination of different series at the same station; and encountered problems. He initially experimented with Erbogacen station and more recently with the Bagdarin station. I’ve posted up a data set showing the three source versions (dset-0) and the combined version (dset=1) at http://data.climateaudit.org/data/giss/bagdarin.dat.
The three Bagdarin versions (222305540000, 222305540001 and 222305540002) do not appear to be from different stations as their values are identical for many periods. The first series goes from March 1938 to April 1990; the second series from Jan 1951 to December 1990 and the third version from Jan 1987 to Apr 2007 (and probably has been updated). During the period of overlap of all 3 series from 1987 to 1990, every value is identical. For the period from May 1980 to 1987, all the values of the first two versions are identical. During the period from Jan 1951 to 1980, the first two versions diverged substantially with the difference having a standard deviation of 1.14 deg C .
If I were trying to combine these records, my instinct would be that the exact identity of the series in their overlaps indicates (1) that they are all versions of the same thing; (2) there is no basis for preferring version 1 or version 2 where they differ; so I’d be inclined to simply average the available values of the three versions.
The graphic below shows the differences between the NASA-combined version and the individual series and the average. The first thing that you notice is the opposite noisiness of the first two series in the 1960s; the standard deviation of the differences is 1.14 deg C – which is not a small amount if one has no reason to prefer one series to the other. If you look at the bottom panel, you can see that the two versions are averaged in some way – fair enough.
The second thing that you can see (which is what caught John’s interest) is the downward displacement of all versions prior to 1990. The amount of the displacement is about 0.3 deg C – an amount which should “matter” even to Hansen and Gavin Schmidt. John G has looked at many alternatives to try to explain the displacement. Below I outline what adjustment appears to have taken place, although developing a rational basis by which the adjustment was done is not easy and I have so far been unable to discern policy: warning, it’s very weird.

Here’s what I’ve noticed about the data (posted up here)
1) After Jan 1991, when there is only one version (version 2), the GISS-combined is exactly equal to that version.
2) For December 1990 and earlier, Hansen subtracts 0.1 deg C from version 2, 0.2 deg C from version 1 and 0.3 deg C from version 0.
If I average the data so adjusted, I get the NASA-combined version up to rounding of 0.05 deg C. Why these particular values are chosen is a mystery to say the least. Version 1 runs on average a little warmer than version 0 where they diverge ( and they are identical after 1980). So why version 0 is adjusted down more than version 1 is hard to figure out.
Why is version 2 adjusted down prior to 1990 and not after? Again it’s hard to figure out. I’m wondering whether there isn’t another problem in splicing versions as with the USHCN data. One big version of Hansen’s data was put together for Hansen and Lebedeff 1987 and the next publication was Hansen et al 1999 – maybe different versions got involved. But that’s just a guess. It could be almost anything.
Here’s what Hansen et al 1999 said that they were doing – a statement which NASA spokesman Gavin Schmidt says is adequate to replicate their results and anything further would be spoon feeding :
Two records are combined as shown in Figure 2, if they have a period of overlap. The mean difference or bias between the two records during their period of overlap (dT) is used to adjust one record before the two are averaged, leading to identification of this way for combining records as the “bias” method (HL87) or, alternatively, as the “reference station” method [Peterson et al., 1998b].
The adjustment is useful even with records for nominally the same location, as indicated by the latitude and longitude, because they may differ in the height or surroundings of the thermometer, in their method of calculating daily mean temperature, or in other ways that influence monthly mean temperature. Although the two records to be combined are shown as being distinct in Figure 2, in the majority of cases the overlapping portions of the two records are identical, representing the same measurements that have made their way into more than one data set.
A third record for the same location, if it exists, is then combined with the mean of the first two records in the same way, with all records present for a given year contributing equally to the mean temperature for that year (HL87). This process is continued until all stations with overlap at a given location are employed. If there are additional stations without overlap, these are also combined, without adjustment, provided that the gap between records is no more than 10 years and the mean temperatures for the nearest five year periods of the two records differ by less than one standard deviation. Stations with larger gaps are treated as separate records.
I’ve tried to replicate this verbiage in a couple of different ways to see if it yielded the NASA-combined series and got nothing near their result. It would be interesting to check their source code and see how they get this adjustment, that’s for sure.
Are there similar problems in other series? I haven’t evaluated this yet. John G said that he had first noticed the combining problem at another Russian station (Erbogacen), so there appear to be at least two stations with this type of problem. In this case, the error, if it is an error, imparts a bias increasing recent values relative to older values. If the problem is more widespread, is there a systemic bias (as we found with the USHCN data) or does it cancel out? Questions for another day. (Note: I just did the same calculation for Erbogacen and there again seems to be a downward bias, but not as much as Bagdarin. )
Hansen cites the fact that Phil Jones gets somewhat similar results as evidence of the validity of his calculations. In fairness to Hansen, while they have not archived code, they have archived enough data versions to at least get a foothold on what they are doing. In contrast, Phil Jones at CRU maintains lockdown anti-terrorist security on his data versions and has even refused FOI requests for his data. None of these sorts of analyses are possible on CRU data, which may or may not have problems of its own.





79 Comments
Whiskey! Tango! Foxtrot!
“Charlie Fox” describes this one.
Is Waldo on the staff of the Ministry of Truth?
The “combining sources at same location” process at GISS can do some odd things.
See, for example, a graph of the Capetown Five
plus, in cyan, the GISS combined. For most of the 1960s and 1970s, the
combined is outside the range of the others.
Thus far I have really only looked at Erbogacen and Bagdarin. Tonight’s job is to see if I can find other stations with a similar problem, because I have all-but given up on replicating the bias result GISS gets. I have tried injecting a number of what seem to be obvious programming errors and the closest I got was when I biased the “accumulated reference” and averaged it with the third station from the location, rather than the other way around, but the result was still not as close as I would like to see. I have tried using applying the bias method on the stations in different orders, but to no avail (HL87 notes that the order stations are combined influences the final result).
I will note that I started with Erbogacen purely by mistake. I was intrigued by some things I had read in the blogosphere about economic incentives Siberian station operators might have had to report lower-than measured temperatures in order to receive a higher fuel allocation from the central government. So I went to GISS and clicked on the middle of Siberia, got Erbocacen, and looked at the graph. Sure enough, it visually appeared that the period from early 1950 to late 1980 “dipped” below the period on either side. Initial readings of some books I bought on Siberian history indicated this would have been a period of such fuel allocations (I’m not done reading, so there is still much to learn).
Before jumping to conclusions, however, I thought it might be a good idea to see if I could at least replicate the bias method on the station. Unfortunately, this station combines seven separate records, so I realized I needed to start with something simpler. That is how I selected Bagdarin.
I do still have a couple ideas as to how the records might be combined – alternative interpretations of HL87, if you will – but I am not hopeful I will hit that nail on the head.
By the way, the thing that may not be entirely clear here if you do a quick read is that (loosely speaking) the combined record prior to 1990 is colder than what the stations actually measured. After 1990 the combined record is equal to what the station measured.
#5. John if you subtract 0.1 from seris 2, 0.2 from series 1 and 0.3 from series 0, you get the GISS-combined for Bagdarin. Of course, figuring out the basis of these numbers is a mystery.
So is the lower one adjusted up or the upper one adjusted down by the mean difference in each iteration of the combination process? Maybe Waldo plays Twister during lunch breaks.
#7. Steve…That was a good catch, but you’re right, there must be some basis. I don’t think that algorithm works for Erbogacen.
One thing I noticed in the graph I emailed you is that the points where the slope changes for each station appears to correspond to a discontinuity in the station’s record (a 999.9 entry). This leads me to believe that separate dTs are calculated for the small, individual periods of overlap between two station records, rather than one dT for the total overlap.
Example: Station A has a record from 1/1930 through 12/1990 and station B has a record from 1/1950 through 12/1980, but is missing a data point for 5/1963. The way I read HL87, one dT would be calculated for the entire overlap period of 1/1950 through 12/1980. However, it is possible two dTs are calculated: one for 1/1950 through 4/1963 and another for 6/1963 through 12/1980.
I tried that approach and initially got slightly better but similar results – until I injected the error described in #5 where I bias the reference instead of the station to be included. In that case the results were a lot closer to GISS from beginning to end. The thing I have left to try is to decide what to do with the discontinuities and the period of non-overlap when injecting the error. Right now I don’t do anything.
I don’t want to assume there are multiple programming errors in a seemingly simple algorithm – something much simpler must be going on.
ok – I’m convinced the ground station global temperature record is meaningless. Now what?
I opened this image in Photoshop and flipped series2 and superimposed it on series1 Graphically the two are nearly identical – with series 2 upside-down and slipped down 0.5 on the left-hand scale. Could it be they put the graph-paper role in upside-down? No doubt, I am probably stating the obvious here.
Steve:
If that is what they did, it is no wonder they are not willing to share their code. I sketched out the impact of the changes and it looks like you add a slight but hockey shaped adjustment to whatever the underlying trend is!! Is that correct?
PeterS:
I see what you mean. They could have only done that once, right?
#11. there’s nothing surprising about that. there are only two series which are more or less averaged, so the deltas from the average should be mirror images. Not an issue.
Re#8, if the bias is warm, then the warmer record is adjusted downward. If the bias is a cold one, then the colder record is adjusted upward. But how someone can take two overlapping and diverging records and determine a which one is biased solely based on those two records is beyond me. Maybe Peterson 1998b explains this better. It sure sounds goofy regardless.
#11: It looks like they are taking two datasets that are very similar, inverting one and summing. This would just be a filter to find the real differences.
#16. They’ve done nothing of the sort. AS I said on a couple of occasions now, they just averaged the data after making the stated subtraction from each column. The issue is not the averaging – that’s fine – it’s how one gets to the delta for each column.
Could you post the graphs of the individual stations? This may help people (myself included) sort out what is going on with your ‘differences’ graphs.
Re#17, mebbe so, but that’s not how the process is described.
“… mean difference or bias between the two records during their period of overlap (dT) is used to adjust one record before the two are averaged…”
Maybe I’m wrong, but I don’t think that the method described in Hansen et al. 1999 is deterministic.
To see a simple example, imagine 3 records for a site. One from 1900 to 1930 with all measurements at 12, one from 1920 to 1980 with all measurements at 11 and one from 1970 to 2000 with all measurements at 10.
If I’m following their description, I could get 10, 11 or 12 as my result for that combined data, depending on my choice of reference sets.
Here’s an example of how I think it would give back 12…
Step 1 – Take mean difference between 1970-2000 and 1920-1980. [1 degree]
Step 2 – Use that to adjust 1970-2000. [now both sets show 11 degrees]
Step 3 – Average them. [combined set shows 11 degrees, weighting is gone]
Repeating the process with 1900-1930 as the reference set gives back 12 degrees. I hope they’re using a “fair” method for selecting the reference set.
Re #15 … “determine which one is biased”
Well that’s simple, since we know global warming is happening, obviously we choose to adjust which ever series will show more recent warming.
sigh
How about the first two versions contain data from results of the calculation of the standard temperature minus the observed temperature? Only for large periods of time the data in the spreadsheet columns was reversed. That is why parts seem to be a mirror image. Minus becomes plus, and plus became minus.
The third version is a partial continuation of how the first chart would have looked if continued.
The average is some average of the first two, but it is meaningless because only one of the first two charts had the differences worked out correctly.
Finally, if either chart one or two is purporting to be a result of correct difference calculation, the obviously there must be something “very wrong”, as the spikes are way off the scale of any reasonable measurement of temperature anomaly.
Shoot me now.
PS the changes/adjustments on average seem to make the present seem warmer.
What a surprise.
#17 The first two graphs sure look like inverted data of each other – I’m not sure what I’m looking at. I think you need to clarify the labels of the graphs to what is being subtracted – something like dataset xxx – yyy and average of xxx, yyy,zzz etc.
#17: When you invert a dataset, it’s origin will then be at the opposite side of y=0, in this case it looks to be around 0.3. When you then sum the two, it puts it at origin. You then have to subtract 0.3 to get back to the original base line.
The real issue is where that step comes from around 1990.
The monthly graph using GHCN v2 data and simply averaging all available values by month is available at http://www.unur.com/climate/ghcn-v2/222/30554.html
When I look at that graph, I notice that the GHCN adjustments are basically increasing the mean temperature in warm months and decreasing the mean in cold months.
If you compare peak-to-peak and trough-to-trough, that graph paints a rather different picture than the GISS graph (annual averages) shows:
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=222305540002&data_set=0&num_neighbors=1
— Sinan
Ross McKitrick sent me an older version of Russian GISS data. The current combined Bagdarin version either matched the older version or was 0.1 deg C lower as shown below.
I’ve marked the 1990 breakpoint.
The difference here is just rounding, but the distribution of changes is not random. In every case where there is a difference, the present version is rounded lower in the current version for values before 1990 than for the older version. I wonder how they accomplished this. No wonder why they don’t want to show their source code.
These guys don’t leave anything on the table, it seems. While this particular adjustment may not “matter” in the big scheme, it sure looks damning.
Re: 27
If the input data came from the GHCN, note that all temperatures are entered as integers in that data set (so 212 means 21.2 degrees Celsius).
My guess is, they did some intermediate math which involved floating values and an implicit conversion to an integer which caused in values being truncated rather than being rounded properly.
I am also guessing this sort of bug may have affected more than one series.
The change in 1990 could have happened as a result of a different program being used for data after that time (with the prior data not being run through the new program).
This is all speculation, of course.
— Sinan
Ok, I got it all to work out in Excel (yes, sorry I’m an Excel guy). Here is how it is done.
Baseline assumption: Most recent data is most likely to be correct so no adjustments to the 222305540002 data set.
Now, we can work backwards from here.
The average values for the 222305540002 during the overlap with 222305540001 (date ranges 1987 to 1990.917) gives -3.9067. The same time overlap average for 222305540001 gives -4.3660. The average of these averages rounded to 2 decimal places is 0.23. This is the amount later subtracted from the 222305540001 series.
Now do the same comparison as described above for the overlap of 222305540002 and 222305540000 (date ranges 1987 to 1990.25). The average of the averages rounded to 2 decimal places is 0.26. Also, do a comparison as described above for the overlap of 222305540001 and 222305540000 (date ranges 1951 to 1990.25). The average of the averages rounded to 2 decimal places is 0.04. Now add the two adjustments and you get 0.26 + 0.04 = 0.3. This is amount to be subtracted from the 222305540000 series.
So now we have:
222305540002 – no changes to temperatures
222305540001 – subtract 0.23 from temperatures
222305540000 – subtract 0.3 from temperatures
With these three new ‘adjusted’ series, average the temperatures for each date entry and round to 1 decimal place. BINGO!! At least according to Excel my averages were EXACTLY the same as the Combined column provided in the bagdarin.dat file.
Oh, hopefully my description is adequate. If not I can attempt to explain further.
Re: 29
I am confused about a couple of things:
average(-3.9067, -4.3660) = -4.13635
Did you mean:
Calculate average for Series 2 over the overlap period with Series 1. We have
Calculate average for Series 1 over the same period. We have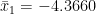
Then,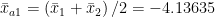
The adjustment amount is then
Is this description correct?
— Sinan
I had the same question as Sinan, so I won’t repeat. I am wondering about combining the series 0 data. In that case, do you take the overlap period for just the 0th series and the 2nd series, or the period of overlap between the 0th series and the combination of series 1 and series 2?
If it is the former, then there is still a problem. A number of stations have many series and some do not overlap the latest series.
Other than that, this is a good catch thus far.
It just so happens that (x1 – x2)/2 also gives you 0.22965, so maybe he subtracted on accident?
Damek – I think I understand what you are describing and will try to implement your algorithm. However, I am a slow programmer so you may read this before I finish. Please try your method on the following stations: Cara, Kalakan, and Erbogacen. If your method works please let us all know.
You are right, my description was incorrect, I should have said “The DIFFERENCE of these averages rounded to 2 decimal places is ((-3.9067) – (-4.3660))/2 = 0.23”. Or as you have written it Xa1 = (X2 – X1)/2.
Darnek
Were you looking at the month by month data or annual? I have not finished looking yet but there is a whole bnch of fiddling that need to be done in order to first estimate the missing data and then match the months. I assume Steve was talkingmonth by month adjustments.
Damek, I cannot duplicate your results when comparing 222305540001 and 222305540000. In this case I get -0.0279 instead of 0.04. I can duplicate your other results. So we are off by the sign and 2x.
I’m working on a longer explanation including describing that issue (sign and value). I made a mistake in my first post and it should have been a 0.03. More to come.
John G and Damek,
I just did the same calculation in Excel and got the exact same results as John. Perhaps we are both interpreting your instructions incorrectly. Regardless we are only talking a few hundreths of a degree.
What is fascinating is the cause of the 0.23 and 0.26 numbers. In the 1987 to 1990 the data is exactly the same between the three sets with the exception of some missing data points in set 1 and set 2. These missing data points are the entire cause for the discrepancy in temperature averages in this time period (i.e. the 0.23 and 0.26). Since this data appears to have pretty obviously come from the same source during this time, the data should be the same across all three sets for the missing points (either the same data value or missing in all three sets).
I’m still trying to wrap my brain around this appears to say that GISS is trying to normalize all three sets of data based on the overlapping periods from 1987 to 1990. Despite the fact that the ONLY cause of the difference during this period is the inconsistant missing data points. This really seems bogus.
Re#17: Steve McIntyre,
Is it really that easy though? Why should there be several records for a “single” location? Something must have happened to make it desirable to end one record and start another. If the reasons why there are separate concurrent records are not factored into the compilation then they are just fooling themselfs.
This is not acceptable and illustrates again the value of Anthony et al’s work.
I corrected an error on my Series 0 adjustment as shown below but it didn’t change the results at all. Also read the end to see what could be considered two errors in direction adjustment.
Well, I didn’t do anything fancy with the numbers. I just imported the .dat file right into Excel. Then for the overlap areas I just did =AVERAGE(XX:YY) leaving in the ‘NA’ entries since they don’t get counted for the average function in Excel. Also, this means that you are going to have different total number of data points averaged for each of the overlap series. This definitely gives the correct results for these series, but it does need to be checked against other locations.
Series 1 Adjustment
So for the Series 2 / Series 1 overlap, Series 2 has 45 entries between 1987 and 1990.917 (inclusive) and 3 additional entries are ‘NA’. The average of these 45 entries in Series 2 is -3.9067. Series 1 has 47 entries in this same date range and has 1 additional entry as ‘NA’. The average of these 47 entries in Series 1 is -4.3660. So for this overlap ‘calibration’ range, the average difference is ((-3.9067) – (-4.3660))/2 = 0.23 (rounded to 2 decimal places). This average difference of 0.23 is later subtracted from the entire set of Series 1 entries from beginning to end (dates 1951 to 1990.917).
Series 0 Adjustments Part 1
For the Series 0 adjustment, you must take all other series that overlap it and that end later to find your total adjustment. For the Series 2 / Series 0 overlap, Series 2 has 37 entries between 1987 and 1990.25 (inclusive) and 3 additional entries are ‘NA’. The average of these 37 entries in Series 2 is -5.3514. Series 0 has 40 entries in this same date range and has 0 additional entries as ‘NA’. The average of these 40 entries in Series 0 is -5.8750. So for this overlap ‘calibration’ range, the average difference is ((-5.3514) – (-5.8750))/2 = 0.26 (rounded to 2 decimal places). This average difference of 0.26 is later subtracted from the entire set of Series 0 entries from beginning to end (dates 1938.167 to 1990.25).
Series 0 Adjustments Part 2
For the Series 1 / Series 0 overlap, Series 1 has 464 entries between 1951 and 1990.25 (inclusive) and 8 additional entries are ‘NA’. The average of these 464 entries in Series 1 is -6.7595. Series 0 has 470 entries in this same date range and has 2 additional entries as ‘NA’. The average of these 470 entries in Series 0 is -6.7036. So for this overlap ‘calibration’ range, the average difference is ((-6.7036) – (-6.7595))/2 = 0.03 (rounded to 2 decimal places). This average difference of 0.03 is later subtracted from the entire set of Series 0 entries from beginning to end (dates 1938.167 to 1990.25).
Apply the adjustments
Series 2 – No adjustments
Series 1 – Subtract 0.23 for all Series 1 entries (1951 to 1990.917). All ‘NA’ entries are ignored.
Series 0 – Subtract the total adjustments 0.26 + .03 = 0.29 for all Series 0 entries (1938.167 to 1990.25). All ‘NA’ entries are ignored.
Average the series
For each individual row, using the adjusted temperature series, average the available entries. If there are three entries on a row, then average all three. If there are only two entries on the row, only average the two. If there is a single entry on a row then that is your ‘average’ temperature for that row. Ignore all ‘NA’ entries. Round the average for each row to one decimal place. This result gives an identical match to the ‘combined’ column in the .dat file.
Potential errors
If this is the correct method, then there are two glaring bias errors that are being implemented.
1) Incorrect direction adjustment – Notice that on the Series 2 / Series 1 overlap comparison, Series 1 has a colder average than Series 2. Yet using this method we SUBTRACT the average difference from SERIES 1 making it even colder than it was before (and a greater increase in the average difference). If the purpose of this adjustment is to REDUCE the average difference between the series, it has failed terribly and in fact made it worse.
2) Average difference is always used to cool the older series – If you had a sharp eye (or do the calculations yourself like John Goetz), you would have noticed I swapped the order of the series averages in the Series 0 Adjustments Part 2. Instead of ((-6.7595) – (-6.7036))/2 = -0.03 I wrote it as ((-6.7036) – (-6.7595))/2 = 0.03. This is the opposite order from the first two adjustment calculations. This serves the purpose to ensure that the adjustment result is a positive number and that the adjustment from Part 1 and Part 2 make a larger total adjustment. If we had taken the (what I consider correct) result of -0.03 for the Part 2 adjustment, we would have only had a 0.23 total adjustment for Series 0. This ‘incorrect’ calculation was to make sure we matched the numbers in the ‘combined’ column. If the calculation is always supposed to be (Newer Series – Older Series)/2 however, I feel that the supplied ‘combined’ column is in error.
It’s getting late and I’m not going to get to proof read this much. Please point out anything that doesn’t make sense and I’ll follow it up with another post.
Oh, and when I’m talking about “Potential Errors”, I’m not talking about my calculations. My calculations give the exact results as the ‘Combined’ column. The errors I’m talking about would have been perpetrated by those that originally created this data.
The only way to know if this was a one time error or not is to try this method on other locations.
If my assumptions are correct and these are real errors, then the actual series should be adjusted like this:
Series 2 – No adjustments
Series 1 – ADD 0.23 for all Series 1 entries (1951 to 1990.917). All NA entries are ignored.
Series 0 – ADD the total adjustments 0.26 + (-0.03) = 0.23 for all Series 0 entries (1938.167 to 1990.25). All NA entries are ignored.
This so the differences between the incorrect and correct data (assuming my assumptions are right):
Series 2 – No differences
Series 1 – Lower by 0.46 for the entire series.
Series 0 – Lower by 0.46 for the entire series.
#40
Need to think about what you wrote but I agree with your potential error #1, seems like the sign is inverted.
I mentioned earlier that the missing data was the only cause of the average temperature differences between the overlapping period of the three sets (1987-1990). Turns out that’s not quite true. There is a very incongruent -26.5 deg in dataset 0 for 1989.00. Data sets 1 and 2 have -21.5 for the same date. All the other values agree across the sets except for the missing points. That apparently bad data point and the missing data points are the cause of the 0.23 and 0.26 values.
Just an interested comment here, but try this in mineral exploration reporting.
🙂
#40 Jeff…I have noticed similar things in other series and commented on it elsewhere in this blog. Steve commented:
GHCN uses a quality control program that tries to kick out errors like the one you describe by looking for values that fall way outside the norm for that particular month. This is described in Peterson, T.C., R. Vose, R. Schmoyer, and V. Razuvaev, Global historical climatology network (GHCN) quality control of monthly temperature data, Int. J. Climatol., 18, 1169-1179, 1998c.
The error you describe flew under the radar because the value made sense for that month. Unfortunately, the method used to combine the stations and the brevity of the overlap period serve to magnify the impact of this particular error.
I think the recording error is a separate topic though. I am still scratching my head over the methodology used to combine stations.
#40 Damek, I see that taking the absolute value does the trick, but I am having trouble accepting this is the way Hansen does the combining because it is very different than what is described in his papers. The algorithm he describes is simple enough that I have trouble believing there are multiple serious programming errors. Have you tried your method on the other stations I listed? Start with Cara and Kalakan, as they have only three records apiece, like Bagdarin.
I would be glad to if there is a .dat file available for Cara and Kalakan. I’m not sure where to pull that information together myself.
Great work gentlemen, true auditing at its best. One comment Steve, you might consider at some point in the near future a thread to compare the relative merits (contrast and compare) between R and Excel for this type of analysis, and other types of analysis, since many of us (me included) can audit faster using Excel.
I know many of you around here feel Excel is considered passé, but many of us are more dexterous in Excel, R is after all, another language for us to learn. There have been some rudimentary discussions of R buried in threads on other topics (ex. one of the Juckes threads, when he could not figure out how to download from your dataset), but the discussion never stated precisely why R is superior to Excel other than opinion. Statistics are statistics in either R or Excel (yes?, no?).
I was thinking that maybe a tutorial of some type on R and have those more familiar help those who are not. If more or us were familiar with R, the code you often include in your threads would be for one thing intelligible, and hopefully more threads like this one with more contributors.
Damek above uses Excel, but it seems to me the exception than the rule.
Just a thought, anyone else feel this idea has merit.
Ian
RE #46
I had noticed that the absolute value would do the trick. I assumed we would want to know the sign of the adjustment so we could ‘correctly adjust’ the mean difference of the non-reference station. Unless you know ahead of time what direction the ‘bias’ is on the non-reference station, you would have to keep the sign on the difference to make sure you correct in the right direction. However, if you just take the absolute value of the difference and always subtract it from the older series, this seems like purposeful biasing of the older records to colder temperatures and is almost scandalous.
I am a bit of an outsider here and have not read (HL87) or [Peterson et al., 1998b] and probably will not unless push comes to shove. So I do not know the full methodology as it is being described in those references. I’m just an engineer that happens to use Excel quite a bit, reads this blog and enjoys a good mathematical puzzle. If I have stumbled upon their methodology, then being an outsider with a simplistic view on averaging numbers was a huge help.
🙂
Version zero looks like the “inverse” of version 1.
Back on my post #42 I made a minor mistake but it is corrected in bold below:
This comes from the series being lowered by 0.29 when it probably should have been increased by 0.23. I mistakenly used 0.23 for the increase and decrease on post #42.
Ian:
If Excel is doing what you need, I wouldn’t worry about switching to another language (Excel is a graphically based language of course). Over time, you can adopt what Steve does, and learn enough to piddle with his scripts to get them to do what you need, without the requirement of becoming a wizard at R. Again, the only time I would consider learning a new language is when the one I am using isn’t doing everything that I need it to do.
Damek…I implemented your algorithm in VBasic and tried it on both Cara and Kalakan. Unfortunately I cannot get those stations to match. Cara’s three records overlap each other almost entirely, so I tried all possible station orderings, and the closest match was 2 / 1 / 0, but it was not exact. Kalakan’s record and adjustments are similar to Bagdarin’s, and while an ordering of 2 / 1 / 0 gets me close, the difference on record 0 is still about 0.1 degrees.
By the way, I am not using the .dat files. I am simply importing the .txt files I downloaded from GISS.
#52. I don’t disagree. I hadn’t done any programming for over 30 years and had only done a small amount in university. Of course, I’d used Excel extensively in business-type analyses. I abandoned it when I was trying to do tree ring principal components. There was a simple routine in R which could do the calculation in one line. Also the tree ring data sets were so large that they swamped Excel, whereas R did this effortlessly.
I found – and this is my personal experience – that there were almost instantaneous dividends in my ability to do calculations. I’m not approaching this from a techie point of view, but from a practical point of view.
I loved being able to download data directly from the internet into a working matrix.
While I hadn’t done programming for many years, I’d learned linear algebra well when I was young and thought in terms of functions and data matrices etc., all of which are important to using R well and helped me get going.
There is an unbelievably vast library of packages that do almost anything under the sun as well.
But I promise you that you can get up to doing whatever you can do in Excel almost instantaneously.
You can write data back and forth by saving Excel files in tab-separated formats. I continue to use Excel occasionally for editing messy data. For example, if I copy a table from a pdf file and there’s quite a bit of manual work to make it readable.
I’ve put up a corresponding file for Cara – see the new thread for a link. I’ll add in one for Kalakan in a few minutes.
Kalakan is up as …/data/giss/22230469000.dat
Kalakan is weird as well. There are 3 versions. The NASA-combined is equal to the ongoing version while it exists (after 1987). The other 2 versions have equal overlaps and during the period of overlap all versions are word for word identical.
Nonetheless Hansen subtracts 0.1 deg C from the two older versions creating a completely artificial step of 0.1 deg C.
Hansen was so insistent that 0.1 deg C “doesn’t matter” but seems to try to catch a little edge for the house whenever he can.
I think Steve is exactly correct and the corrections are far simpler in form, though without any obvious rationale. I translated the array data into month by month vector and lined up the four different series: March 1938 to April 1990 is Series 222305540000 (http://data.giss.nasa.gov/work/gistemp/STATIONS//tmp.222305540000.0.1/station.txt). January 1951 through Dec 1990 is series 222305540001 (http://data.giss.nasa.gov/work/gistemp/STATIONS//tmp.222305540001.0.1/station.txt). January 87 through August 2007 is series 222305540002 (http://data.giss.nasa.gov/work/gistemp/STATIONS//tmp.222305540002.0.1/station.txt). The combined and the combined and homogeneity adjusted series for 1938 to 2007 appear to be identical series and are also referred to as series 222305540002 but we will simply refer to it as the C&A Series (http://data.giss.nasa.gov/work/gistemp/STATIONS//tmp.222305540002.2.1/station.txt )
I did it in Excel so it took a little time.
The apparent rules are:
1. For February 1938 though Dec 1950, C&A series is obtained by subtracting 0.3 from series 222305540000
2. For January 1951 through December 1986, C&A series is obtained by subtracting 0.3 from the average of series 222305540000 and series 222305540001 and rounding up
3. For January 1987 through April 1990, C&A series is obtained by subtracting 0.2 from series 222305540002 OR where series 222305540002 was incomplete subtracting 0.3 from the average of series 222305540000 and series 222305540001 and rounding up
4. For May 1990 through December 1990 C&A series is obtained by subtracting 0.1 from series 222305540002
5. For January 1991 through August 2007 there is no adjustment
There are a few places where missing data and rounding rules do not apply, but the above rules apply to all by 10 of over 800 months of data.
Other approaches may lead to different overall series wide adjustments but the rules I laid out above (or some minor variant of them) are obviously readily programmed. Now “why” is a completely different and at this point unanswerable question.
Bernie, now the trick (which has frustrated me thus far) is translating these rules into a program that works on other stations. The other two I have fiddled with are Cara and Kalakan. I can’t find one algorithm that makes all three work.
Didn’t Gavin tell us that all of this was already explained in exhaustive detail? Was Gavin joshing us?
#60. John G,
Kalakan is particularly simple in that the values overlapping with the recent ongoing version are identical. And the deduction from the two earlier versions is both 0.1 deg C.
Given that the overlap values are identical, I can’t conceive of any plausible rule that would result in a deduction from the other two versions.
It’s mystifying.
John:
Did you lay the data out month by month? Since these rules are clearly driven by start and end dates and overlaps, each station may have been treated differently. The rules for Bagdarin are systematic but arbitrary. Perhaps they treated each station the same way, like the Soviet form of governance – systematic but arbitrary!!
I will try to look at the Cara and Kalakan data tonight.
Steve Mc, if you want the Excel file let me know. This time I appended the links to data sources.
Looking at intermediate calculations from the raw data just causes confusion. The trends for some months are up while others are down in a couple of cases I looked at to date. Things like that don’t cause a panic like shouting “Fire”. 😉
It sounds like they obtain a multiple overlap average by pair-wise averaging. This is just wrong.
T(mean) = (T1 + T2 + T3)/3 = T1/3 + T2/3 + T3/3
Their way would be:
T(mean) = ((T1 + T2)/2 + T3)/2 = T1/4 + T2/4 + T3/2.
RE: 54
Be careful using Excel with calculations involving small fractions. There eventually become resolution issues that introduce errors. For work with integers, it seems to be fine.
I see one of the inhomogeneities in your Bagdarin differences chart is circa the same time (just post 1965) as “The Great Olenek Mistake”
Warwick, where did you get the gridded maps you used on your site?
The homemade maps are from a good mate who has MapInfo.
I’m cross-posting this information from the Waldo Slices Salami thread.
It seems that the difference of averages is taken for only the most recent 30 years of overlapping data. If there less than 30 years overlap, uses as much as possible. But if there is more than 30 years of overlap, use only the most recent 30 years. I went back to my Bagdarin calculations and made this adjustment for the average difference for the 222305540001 and 222305540000 series comparison. After making the change my calculated average temperatures still matched the ‘combined’ column.
#70. OK, but can you get this to work for any other station? How do you get Kalakan to work?
I apologize if I have missed it, but where can I find the Kalakan data?
Go to http://data.climateaudit.org/data/giss/ It’s one of the two numbered series; Cara is the other.
Thanks Warwick. I’m wanting to make maps of every grid there is and do some up/down anomaly percentage numbers on all the grids on Earth for both land and sea, so I need to chop up 5×5 and 2×2 plots and it’s too tedious in Google Earth. I’ll check out the MapInfo Pro v9 eval. They have a tutorial on their site.
Using my method on Kalakan, I overshoot the average difference for adjusting the first column. I calculate an average difference of 0.2205. Actually, half this amount (0.1103) is exactly what you need to match the calculated averages to the ‘combined’ column. Since the average differences between columns 1 & 3 and 2 & 3 are practically zero (looks like a scribal error for the only different temp in 1987.333 in the overlapping range) they aren’t being adjusted before the final average of the columns. I’ve tried several date ranges for comparing columns 1 & 2 and can get the 0.11 I’m looking for, but so far nothing lines up with to allow Cara and Bagdarin to work with the same methodology.
#75. Damek, I don’t think that Kalakan is possible to adjust using your type of adjustment since the values are equal in overlapping periods. I think that there’s a screw up and that we’ll just have t wait and see what it is.
I have been staring at the Cara data and cannot see any pattern in the adjustments. On the other hand I am not sure why there are three series covering the same dates in the same location.
#77. One more time -these are differnet scribal versions. One might come from the Smithsonian records, another from the WWR records, another from Russia or something like that.
Think of different people copying down the Dow Jones Index manually, introducing little errors. Scholars deal with this sort of thing all the time with rare literature.
#78 Steve, not to add to your pile of things to do, but you know R and I am new to VBasic, so we know who can produce results much more rapidly…
I was going to compare the daily Cara station data downloaded from the following two sites:
The GSN repository at ftp://ftp.ncdc.noaa.gov/pub/data/ghcn/daily/gsn
and the Russian repository at ftp://ftp.meteo.ru/okldata
Unfortunately, the formats of the two files are so different that the vbasic programming effort to compare them was starting to get out of hand. Do you have programs already in place that will compare the two, or perhaps a Perl script that will reformat one to match the other?
I did look at the two files and noticed they are basically identical where they overlap, but the station record from the Russian site extends into 2005 whereas GSN goes to the present. So, I was hoping to figure out just how identical the two sites are.
Other questions popped into my mind:
– The GSN and Russian records are for a “single station” whereas GISS combines three records. So, which GISS record (combined or station) most closely matches GSN and Russia? Why does GISS have three records but the other two have one?
– Who is the ultimate source of the record? GISS, GSN, Russia, ….?
– GISS stops at 1990. What happens if we add in the post 1990 record from GSN or Russia?
– The Russian data contains something called “Mid” – this value is almost always different from the average of Tmin and Tmax. I wonder: where did it come from? How does it and the average compare with the other station records?
So, do you have anything canned that can put one or the other into a format that is identical to the other so that I can then do some simple analysis, or am I asking you to add to your plate?
Steve: A script to read the Russian meteo data is a little tricky. I put one up with some other collation functions – look at http://data.climateaudit.org/scripts/station