I’ve noticed that even Hansen’s rounding seems to give a little edge to modern values relative to older values. It’s not a big effect, but Hansen doesn’t seem to like to leave any scraps on the table. Cara, Siberia has 3 versions – all of which appear to be the same station; all 3 versions cover more or less the same period (Data here ) and, in this particular case, the values only go to 1990.
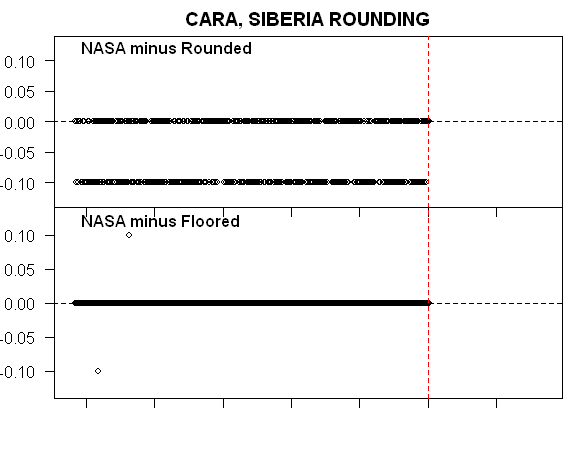
As a first step, it seemed to make sense to take a simple average of the data (first 3 columns of data at link) and compare it to the Hansen combined version (4th column). The Hansen combined more or less matched the rounded average up to 0.1 deg C, but the differences were not random: Hansen was always lower as shown in the first panel. In the second panel, I’ve pretty much matched Hansen by doing the following:
1) calculate the average rounding to 2 digits; 2) multiply by 10, take the floor and then divide by 10.
Typically, this sort of situation only affects pre-1990 data. GHCN made a major collection effort around 1990. In this particular case, the data hasn’t been updated after 1990. IT’s not that this station necessarily ceased measuring temperatures (as often thought); it’s may be that GHCN (and thus NASA and CRU) merely haven’t updated it since 1990. GHCN says that it updates rural stations only “irregularly” and, as it happens, the “irregular” schedule apparently hasn’t included any updates since 1990 for large areas of the world – so NASA are CRU are “forced” to rely for more recent readings primarily on the WMO airport system, which presumably is more urban-biased than the historical network. For these later readings, multiple scribal versions do not arise and “Hansen rounding” doesn’t come into play. A small effect to be sure, but Waldo is voracious and seemingly no scrap is too small.





97 Comments
id0=”22230372000″; title0=”CARA, SIBERIA ROUNDING”
combine=read.table(file.path(“http://data.climateaudit.org/data/giss”,paste(id0,”dat”,sep=”.”)),header=TRUE, sep=”\t”)
combine=ts(combine[,2:ncol(combine)],start=c(combine[1,1],1),freq=12)
average0=round(apply(combine,1,mean,na.rm=TRUE),1)
average1=round(apply(combine,1,mean,na.rm=TRUE),2)
average2=floor(10*average1)/10
nf=layout(array(1:2,dim=c(2,1)),heights=c(1.1,1.3))
par(mar=c(0,3,2,1));ylim0=c(-.13,.13); M1=min(c(time(combine)))
plot(c(time(combine)),combine[,4]-average0,type=”p”,xlab=””,ylab=””,axes=FALSE,col=”black”,ylim=ylim0,xlim=c(M1,2007))
axis(side=1,labels=FALSE);axis(side=2,las=1);box();abline(h=0,lty=2)
abline(v=1990,col=”red”,lty=2)
text(M1,.12,paste(“NASA minus Rounded”),font=2,pos=4)
title(main=title0)
par(mar=c(3,3,0,1));
plot(c(time(combine)),combine[,4]-average2,type=”p”,xlab=””,ylab=””,axes=FALSE,col=”black”,ylim=ylim0,xlim=c(M1,2007))
axis(side=1,labels=FALSE);axis(side=2,las=1);box();abline(h=0,lty=2)
abline(v=1990,col=”red”,lty=2)
text(M1,.12,paste(“NASA minus Floored”),font=2,pos=4)
THAT IS JUST STUPID!
Sorry for shouting but this is an intolerable mistake. If you have seen Office Space, you will recognize this method as the scam the characters pulled off: salami slicing.
— Sinan
From THE SPECIAL STATUS OF COMPUTER ETHICS:
— Sinan
Forgive me but I need a translator. Are you saying that the result has been shaved to reduce it so that future results look even more impressive in comparison? btw as a Software Engineer I’m not sure what the purpose of floor(10*average1)/10 actually is. Why not use round (or ceil!)?
Re: 4
ceilis just as inappropriate asfloor.— Sinan
#4. Ay, there’s the rub. Of course, any normal calculation would use a rounded average. The floor calculation is an attempt to replicate Hansen’s actual results. In this case, the floor function reduces data values slightly (0.1 deg C for some percentage of the values) when there are multiple versions (i.e. before 1990). It’s a little bias increasing post-1990 results relative to pre-1990 results. Not a big bias, but it seems to be at work here. It may be embedded a little differently than I’ve replicated it here, but, however HAnsen implemented it, it has the effect of giving an edge to the house.
Sinan, I’ve adopted your title for the post.
Here’s some information on the effects of different rounding methods: http://support.microsoft.com/kb/196652
Re: 7
Very nice, although I can’t really take credit for the phrase 🙂
— Sinan
If you inspect the Kalakan data http://data.climateaudit.org/data/giss22230469000.dat , in the early portions, the Hansen combined total is simply 0.1 deg C lower even when there’s no rounding involved. It looks like rounding’s involved but maybe it’s elsewhere. I wonder what the hell their source code looks like. I think that it looks like FOI time.
Re: 10
I still suspect an implicit conversion from float to int somewhere in the code.
— Sinan
So walk us through this — if for any given rural site, there are significant chance that recent collection has *not* been done, then a significant proportion of sites will be left out of the data. It seems that it would then follow that the more recent the date to the current time, the greater the proportion of remote/rural sites left out of the available data.
Without adjustments, it would seem a near guarantee of a hockey stick for any given time’s available data, no?
So this is “Office Space” NASA edition. Are we full circle? The original purpose of the Office Space SW engineers was to fix Y2K bugs! 🙂
n this particular case, the values only go to 1990.
Re: 12
It seems that it would then follow that the more recent the date to the current time, the greater the proportion of remote/rural sites left out of the available data.
That seems to be the case. I noticed earlier that there were only 11 stations in Canada with data for 2006 in GHCN. All eleven seem to be airports (some on islands):
http://www.climateaudit.org/?p=1958#comment-130531
In a follow-up comment, I gave links to the graphs of those stations (on my web site). The graph pages also have links to Google maps and GISS graphs for the stations with data for 2006.
http://www.climateaudit.org/?p=1958#comment-131398
— Sinan
#5
Indeed, so unless it’s just a plain error, you would be consciously choosing floor for a reason other than the integrity of the result ;).
#6 – does this mean the 1930s inch up another fraction in the world rankings?
This looks like an old programmer trick to truncate a number to a given number of digits after the decimal point. To three digits you’d do
double num = 1.153395; // original number which would print as written
num = num * 1000.0; // shift it three places
int val = (int)num; // cast the result to integer truncating the shifted number
num = (double)val; // cast it back to double
num = num/1000.0; // shift it back three places
// num will print as 1.153
To round it you’d have to add .0005 to this number before the shift. Bet they forgot to do that step.
Floored division:
http://www.forth.com/forth/fph-2-2.html
Re: 17
That would yield incorrect results in all cases, though, would it?
— Sinan
Re: 19
Sorry, I meant:
— Sinan
FOI ‘R US
1.153395 can not be represented exactly in floating point binary.
Re 20
True, but it It biases the answers down. Actually I didn’t give a good example because that one (1.153395) would have given the answer with correct rounding (rounded down). If I’d used 1.153695, it would have given 1.153 the same as 1.153395, not rounding up to 1.154. Without adding in the .0005 it winds up truncating the answer not rounding.
Well, I’ve tried the various patches proposed for Bagdarin to Kalakna and Cara and nothing works. I’ve sent the following letter to Hansen and Ruedy:
Add 0.01 to the first column.
Subtract 0.2 from the second.
Add 0.01 to the third.
If you now average the resultant values you get the combined figure.
As to where the +0.01, -0.2, +0.01 figures come from I have no idea.
We coders recognize that trick. To truncate to two decimal places: multiply by 100.0, cast to an integer, then divide by 100.0 (converting the number back to a real). This does not round. One would need to add 0.005 first in order to round.
I thought scientists desire precision though. Why would one purposefully get rid of it?
My guess is that the reason that they don’t want to show their code is because of exactly whatever’s going on here.
It does not matter what method they use as long as they were consistant. While most people would assume that a rounding function was used, if a floor function was used, then that is fine as long as it is used for all data sets. Of course, if you use a method other than rounding, then that should be documented. — John M Reynolds
Please excuse what may be a stupid question but, wouldn’t any failure to update rural
stations with the same frequency as non-rural stations in the post-1990s period have
the potential to produce a spurious trend if a different “station mix” existed prior
to the 1990s?
I just looked at some stations in India and the averaging there seems to be OK. Maybe there are patches all over the place with some calculations being done separately for Russia; it seems inconceivable, but so do all the other explanations.
In some programming languages, including any of Microsoft’s .Net languages, the round function by default rounds towards zero (ie floor when +ve, ceil when -ve). This has caused problems in my own code when I assumed that rounding would work properly.
#28. In theory, but you only have multiple versioning before 1990. After 1990, you have a single series. So the bias, slight as it is and assuming that we’ve diagnosed it, applies only to pre-1990 series and imparts a slight warming bias to recent years.
RE: #3 – the film “Entrapment” comes to mind.
Re #26
Sometimes reals get you in trouble because you don’t have infinite precision.
Here’s a trivial example.
float piFloat = (float)PI;
double piDoub = (double)PI;
double should_be_zero = piDoub/piFloat – 1.0; // the divide gives you a small residual since the two values aren’t really equal (the float has less precision)
If you then multiply the result by a very large number you a non zero answer. As Simon mentions in #18 depending on the algorithms implemented can also vary from machine to machine or language to language.
Re #24
I can just imagine the faces of those in the receiving end when they read this email. “What now?!”
Then everybody will start running around with much flapping of hands, just like headless chickens …
Start running around like headless chickens???
I’ve been getting the impression that they have been performing that act for several years now.
I wonder if this truncating is not due to Fortran variable declaration where you can (must ?) give the number of decimals for a float variable (I’m no specialist in Fortran, just vague memories from my Fortran courses years ago).
In looking at the Bagdarin data I noticed that in some instances they constructed values where they had missing data in order to come up with annual temperatures. A number of these were bizarre to say the least in that there was no way to find a simple rule as to what they had done. In the analysis I did for Bagdarin I only reported the rules for month by month adjustements not for seasonal or annual data points. In many instances this is where additional adjustments can enter into
the data series.
For example, The March 1990 data is missing in this data series . The Apr and May 1990 monthly average are -2.4 and 9.1 and the seasonal (M-A-M) average is -2.1. This means that they have inserted an average temperature for March, 1990 of (3*-2.1)- (-2.4) – (9.1) or -13.0. It is totally unclear where this number came from but it is needed to generate the annual temperature. The March temperature in the other Bagdarin series that overlap this period and the ones used in the final compilation are -5.3! Now the final reconciled series simply includes a -0.3 adjustment, but one has to wonder how these numbers are being derived. Remember these are the numbers that are supposedly being charted on the raw data graphs.
With the number of “adjustments” Steve and others are finding (and their seemingly arbitrary nature), I’m almost convinced that these researchers use the “Adjustment Dartboard” (available at all fine scientific supply stores).
As someone who routinely handles and post-processes large quantities of data for a living, I know first-hand mistakes are made without any ulterior motive (except maybe to get out of the office on time). What is very disturbing is that the noted inconsistancies all seem to go in the same direction. The hockey stick, the NYC Central Park UHI correction, the GISS Y2K error, rounding issues, homogenity corrections that spread around microsite/UHI biases instead of removing them – all either cool the past or warm the present. The only example I can recall that went the other direction was the UAH orbital decay error, which was promptly acknowledged and corrected.
Perhaps this is the result of internal auditing that only checks data that doesn’t meet preconceived notion (i.e. they know it getting warmer so processed data that says otherwise must be in error) and isn’t intentional. With all the funding at stake it’s getting harder and harder to believe that.
I would think that this would perform an implicit round, though I cannot guarantee that. All modern CPUs have built-in round, ceil, and floor functions and typically their behaviors are configurable (though you may have to operate at the assembly level). The standard C math library, libc, checks to see if the primitive exists, and uses that instead of the IEEE754 variant that is written into the library. I believe it is not much different with Fortran, though again, I cannot guarantee this since I only did a little work with Fortran during my optimization phase a year or so ago.
Mark
#41. I agree that there’s a bias in what’s detected. Had the Y2K or NYC errors gone the other way, I think that they’d have more likely to notice it.
Re #32,
There are some multiple versions after 1990
mostly prior to 1994. However, those that continue into the late 1990s, and
the 2000s, would be actual multiple stations, not multiple versions of single
stations.
#39 The “data series” link in the post doesn’t appear to work.
http://data.giss.nasa.gov/work/gistemp/STATIONS//tmp.222305540002.2.1/station.txt
I do hope Waldo hasn’t taken his data home so no-one else can play.
#45. GISS links expire.
The data in the GHCN are expressed as integers corresponding to temperature in degrees Celsius in tenths of a degree. That is, 212 is actually 21.2 degrees Celsius.
If one leaves the data that way and carries all operations using integers, there is no risk of loss of precision or overflow or underflow (assuming 32-bit signed integers).
Then, one can do a one of conversion to a decimal and round the result to one decimal digit. Works fine.
I suspect, whatever the NASA guys has written is similar to the following C program:
#include <stdio.h>
#define ARRAY_SIZE(x) (sizeof(x)/sizeof(x[0]))
int celsius_i[] = {
432, 121, 212, -13, -141, 222, 67, 99, 101, 12, 1, -169
};
int main(void) {
size_t z;
float avg_f;
int avg_i;
float celsius_f[ ARRAY_SIZE( celsius_i ) ];
float sum = 0.0;
for ( z = 0; z < ARRAY_SIZE( celsius_i ) ; ++z ) {
celsius_f[ z ] = celsius_i[ z ] / 10.0;
}
for ( z = 0; z < ARRAY_SIZE( celsius_i ) ; ++z ) {
sum += celsius_f[ z ];
}
avg_f = sum / ARRAY_SIZE( celsius_i );
avg_i = (int) ( avg_f * 10.0 );
avg_f = avg_i / 10.0;
printf( "%.1f\n", avg_f );
return 0;
}
C:\Temp> gcc -Wall n.c -o n.exe
C:\Temp> n
7.8
whereas the correct result should be 7.9.
— Sinan
Your text tells me you divide X by Y.
I want to see how you do that in code.
I believe I have mentioned this before.
RE 43.
Best example is Crater lake NPS HQ. The entire series is deleted by hansen ( 2001) for no
discernable reason. Its homogeneus with surrounding stations. Its just colder. ( altitude of
station and massive snowfall I suspect)
I’ve asked Gavin for the stations used to kick Crater Lake off the Island and I got SQUADUSCH.
( ok, I don’t ask nice like you do)
I find it difficult to believe that NASA scientists would be using C, but I suppose anything is possible.
One would think that scientists, particularly NASA scientists, would have the whole precision thing “down pat” by now. I can understand the desire create datasets with the same precision as the original datasets, however one has to take into account that errors propagate and get amplified. (Then again, we are talking about an organization that sends multi-million dollar satellites into space with code that unwittingly and unsuccessfully mixes metric and English measurement.)
Re 50
We should be so lucky that they’re using C. DIdn’t someone say the codes in FORTRAN? I wonder what version?
50 & 51
They are using Fortran but Fortran makes me want to puke. My example is an illustration. I never made the claim that they were using C.
Sinan
MarkR
Sorry about that. I didn’t know the links expired – that explains why I have to use the basic link and click
through.
Which reminds me that if anyone has a macro or function that turns Excel arrays/matrices into a vector that would help. I am sure there is a faster way to do it but I simply can’t find it.
ModelE is F90..i think
I’ve never seen a line of NASA C code. ( shudders) the fortran with
giant common blocks was bad enough. Imagine if you passed gavin a pointer?
He’d poke his eye out, execute garbage and publish the output.
Re #53 bernie
What do you mean exactly ?
#53 bernie No probs.
Sorry I don’t have more time to completely fill everyone in on the details, but my method for Bagdarin does work for this station IF you use the overlap period from 1960 to 1989.917 to get your average differences.
Average of dates 1960 to 1989.917 (inclusive)
Column 1: -7.8656
Column 2: -7.6662
Column 3: -7.8917
Once the averages for that period are calculated, subtract the average difference between the first and third columns (-7.8917 – -7.8656)/2 from the third column for the entire series.
Then for the second column, subtract the averaged difference between the first and second column (-7.6662 – -7.8656)/2 from the second column for the entire series. Also, ADD the averaged difference between the second and third column (-7.8917 – -7.6662)/2 to the second column for the entire series.
After averaging these adjusted series and rounding to 1 decimal place, there are only 4 data points that differ from the ‘combined’ column and they are only off by 0.1.
I’m running out of time to play with these, so if I made a mistake post it but I might not get back to it until Tuesday.
Some places used to use Ada and Fortran, but everyone probably uses Fortran now.
What version, who knows.
Re: 50
Here is the thing: GHCN temperatures are integers in tenths Celsius. So, in calculating a sum, I would only use integers. Then, calculating the average involves a single floating point operation (as opposed to 24 – 12 for converting measurements from tenths Celsius to Celsius, 11 for adding them up, one for division).
The calculated average would also be in tenths Celsius. I would carry out all operations in tenths Celsius. When it came to the point where I wanted to display results, I would just divide the result by ten and print with with one decimal digit precision.
Looking at ftp://data.giss.nasa.gov/pub/gistemp/download/SBBX_to_1x1.f they seem to have a preference for storing and processing temperatures as floating point values.
I have a feeling they have not read Goldberg
— Sinan
I think even a lot of computer folks don’t know that you can have binary numbers like .0110 for 1/6
Re: 59
I forgot: In their gridded data sets, temperatures are stored in the internal binary representation of floating point values as I found out when I was trying to produce the one-and-only known animation of month-to-month temperature anomalies using their data (sadly, the animation is now incorrect due to Steve’s discovery of errors in GISS processing).
http://www.unur.com/climate/giss-1880-2006.html
— Sinan
fFreddy
GISS data comes in a matrix with essentially the months as the columns and the years in the rows. To line up and compare different multiple series for the same site, I needed to create a single column for each series with all the months for all the years in a single column. I found code to do it MATLAB but that is not my poison and I am just starting R.
I can do it relatively quickly using simple copy and paste commands but I think something more elegant
probably exists.
Uh, actually, in binary each point on the right side of the decimal is a power of 2 just like on the left, i.e. 1/2 = 0.1, 1/4 = 0.01, 1/8 = 0.001, etc. 1/6 would then be the infinite series 0.001010101…
Mark
#62. This sort of thing is very easy in R and I do it ALL the time.
Let’s say that x is one time series and y is another, both annual.
Then do something like this
It joins things without you having to keep track of the exact number of rows and columns.
For GISS data, if you start with a matrix X with year,jan,feb,,,, then you do this:
It transposes the matrix; c makes it into a vector columnwise which is why you need to transform it first; freq=12 shows the ts that it’s monthly.
Collation of the GISS global series from their archive is annoying because they have a variety of oddball formats and clutter. HOwever here’s a way of doing it:
If you want to use in Excel, you can export it from R by:
This gives a tab-separated file that Excel recognizes.
You have to watch quotation-marks when you copy out of WordPress.
Steve:
Thanks, I will try it out.
Bernie
#57 Damek – Do you have thoughts on what the rule is that would have us select the period of 1960 to 1989.917 for this station (when the overlap period is longer) and a different set of overlap periods for Bagdarin? The rule for Bagdarin is somewhat clear, but the one for Cara seems arbitrary.
You caught it too quick. 🙂 I was hoping it would take longer. 😀
No, seriously, I buggered that one up. I forgot about 0 and 1 and hadn’t had seen that to correct it. (as in it goes 4/1 2/1 1/1 0 1/2 1/4 etc)
Silly me, just doing the inverse of 6.
I prefer to use the base in the number, so it’s not confusing, and not mix the fractions and binereals:
.12 = .510
.012 = .2510
.0012 = .12510
.00012 = .062510
.000012 = .0312510
But that’s cool, I never realized 1/6 is a repeating alternating 012 after the first .02 I only thought it out to .1562510 but it seems correct.
Dang I haven’t done this in a while.
(Oh, don’t try to do this binereals to decimals or vice versa in Windows sci calc kiddies, it won’t work btw) (Yes I made that word up and don’t know if it’s a real one.)
Quick, what’s 210!!! And 220!!! 🙂
Dang, preview showed all my sub and /sub tags as working, and stripped them out when it posted it. Grrrrr.
That should be .1 base 2 = .5 base 10 not .12 and .510 etc.
The .012 is .1 base 2, .02 is .0 base 2 and .15625 base 10 etc As in after the first .0 in binary, it repeats as 01 in base two etc.
And the last bits are totally hosed, supposed to be 2 to the 10th and 2 to the 20th.
RE: 66
Yes, I believe the rule is to just use the most recent 30 years of overlap when calculating the average difference. If there aren’t 30 years, then use the most overlap available. I went back to Bagdarin, adjusted the average difference for just the last 30 years on the older two columns (222305540001 and 222305540000), and I still got an exact match to the ‘combined’ column for the entire series.
Base 3? That would be 12 in base 10, followed by 15 in base 10. 🙂
Oh, I see your follow up, hehe.
Steve M., reading that, I’m glad I’m a Matlab user. Oh so simple to use…
Mark
Base 3? That would be 21 in base 10, followed by 24 in base 10. 🙂
Oh, I see your follow up, hehe.
Steve M., reading that, I’m glad I’m a Matlab user. Oh so simple to use…
Mark
Oops, hit stop after I realized the error in my first, but it took anyway. The second is the corrected one, though totally immaterial to any discussion and nothing but fun anyway. 🙂
Mark
#71. The difficulty is not with R; it’s with Hansen’s crappy formating. I challenge you to do any better with Matlab. Matlab and R are a lot the same and I doubt that Matlab can do it any better. There might be an easier way in R, but this was one-off and it worked and I can do this quickly.
Steve, your #71 is referencing Darnek in #69 perhaps?
Mark, well, I did a little work in Matlab a long while ago, but nothing much at all just graphing. I’m actually doing those conversions in my head. (Well, I had to write down .03125 and .125 before I added them. Looking at it now, no I don’t know why.)
But if that was base 3, yep, 2 9s and 1 or 2 3s is 21 or 24 decimal 🙂 lol That’s why I messed up the .0110, I did it too fast and didn’t go into thinking mode! 😀 I’m usually pretty good at factoring by 2s. Let me see, what is it, right and left shift logical and circular, isn’t it? I haven’t done any assembly/machine in quite a while.
If only we had 16 fingers. bin oct and hex are our friends.
I don’t know why, but it’s interesting to me that 2 to the 10th is 1024. I wish I didn’t have to put up with 10 to the 3rd being 1000. 10 to the 2nd would be much more elegant.
What’s even more interesting is how it goes; 2 10th is a K, to the 20th is an M, to the 30th is a G, to the 40th is a T… I don’t remember the next one. Maybe I’ll make one up, a KT? Or maybe K*T Or 2 20th + 2 20th + 2 10th….
Sort of like Waldo Slicin’ the Salami. I prefer Bratwurst myself. But there ya go.
Re #62 bernie
Paste the following code (between the hash lines) into a module on your workbook
################
Option Explicit
Public Sub TableToColumn()
Dim RwIx%, RwNo%, ClIx%, ClNo%
Dim FrmRg As Range, ToRg As Range
Set FrmRg = Selection.Areas(1)
Set ToRg = Selection.Areas(2)
RwNo% = FrmRg.Rows.Count
ClNo% = FrmRg.Columns.Count
For RwIx% = 1 To RwNo%
For ClIx% = 1 To ClNo%
ToRg.Value = FrmRg(RwIx%, ClIx%).Value
Set ToRg = ToRg.Offset(1, 0)
Next
Next
End Sub
#####################
Usage :
Select the table of Giss data
Hold down Ctrl key, click on first cell of target column
Run the macro
Hope this helps.
bernie, I don’t know your level of experience – if this is not clear, say so, and I’ll explain in more detail.
Oh, that wasn’t what I was trying to imply. I mean “so much simpler to understand,” but I’m biased because I’ve been using Matlab since the late 80s (William Tranter, my first signal processing professor, was a Mathworks consultant at the time IIRC). R totally loses me not unlike LaTex. Sorry ’bout that. 🙂
I spent the better part of 2005 and 2006 optimizing C and assembly routines on a MIPS based machine, even digging in to libm and the compiler, gcc, optimizations (I incorrectly referred to the math library as libc earlier). Ugh.
Mark
I’m talking inputing op codes in hex into an i 8080a or doing assembly for a tms 9900! Or doing some stuff with the 68000 or 80186. Ugh, MIPS. Might as well start talking about PDPs. 😀
Let us not talk PDPs.
I never programmed one of those.
Re: 8080 – I still remember C3h. What is required to make Hansen, Mann, et. al. C3h?
Mark T.August 31st, 2007 at 5:23 pm,
I had to write some drivers for a Linux variant to get the debugger for a new processor to work. C internals are some very ugly s***. Stack frames ugh. And optimizing your compiler has got to be tough. Lots and lots of trying to find the correspondence between the input source and the assembly language produced.
When ever I wrote C for demanding applications there was alway the question of what was the compiler actually going to do. C was never a good fit to real time.
steven mosher August 31st, 2007 at 12:33 pm,
As I commented in another thread in response to your question “how to do x/y”. I have done that in binary. It is a most difficult question and implementation dependent. Also truncation errors. Because decimal fractions do not map well into binary floating point. This is true no matter what wrapper is put around it (FORTRAN, LISP, Basic, etc.). Best is to convert every thing to integers (provided you have enough) and renormalize at the end of the calculation. Like any true FORTHer would.
Floating point is a crutch for programmers who do not wish to think through the problem. The noise propagates and multiplies. Very small from one multiplication. A chain of 300 can ruin your result.
The problem with doing everything in integers is that each problem is a new one.
Nothing wrong either way, as long as you understand the limitations.
re 78. Simon.
I had drinks with Maddog last night
http://en.wikipedia.org/wiki/Jon_Hall_(programmer)
we toasted to many old things we shared. New things too.
Floats are a crutch.
But the uber high-end DSPs use floats. I think they have a good reason.
Larry,
An awful lot of DSP was done with integer arithmetic.
A lot depends on how much the result of your last calculation influences your next one. If the function converges. No problem. If not – look out.
Even non-convergence is not a problem in some feedback systems. The feedback tends to anneal out the errors. Although they will add noise to the system.
With static calculations (no feedback) you have nothing helping you and each multiplication tends to multiply the errors. As does each addition or subtraction (where a number is not fully represented in floating point).
Filters are different from control systems.
If I was doing an IIR filter – feedback – I’d prefer integer arithmetic. That is because due to the feedback you wind up reprocessing the noise over and over.
For FIR filters – no feedback – floats would just add calculation and rounding noise at each stage but the noise merely propagates instead of multiplying due to feedback.
But I’m kind of fussy that way. I tend to prefer systems that don’t add noise to my signal. Or add the minimum.
Re #77
Having debugged machines in octal with punch paper tape for input and no operating system I feel your pain. I get puzzled looks from programmers when I mention KSR-33 teletypes (one of our I/O devices).
Remember that C was written to support the development of the operating system for PDPs (no I’m not talking about RSX) which is where the i++ came from (increment register).
fFreddy
Many, many thanks. I hope generating it was not too much of a chore. You would think there would be a standard function in Excel.
I don’t do a lot with Macros, but I just got this one running and it works well. It should make extracting the data a lot easier. Though I am still stumped on the Cara data. It will keep me busy until I master R – which I can see will take a little while.
Rounding is a very contentious issue, and a lot of care is needed. Stepwise rounding (e.g. rounding to the 1000th, then to the 100th, then to the tenth) in itself creates a problem because it puts the breakpoint at 0.445 rather than 0.500 – just bad practice to do this. Floor puts the breakpoint at 0.999, and ceil at 0.001. Bearing in mind we are looking for trends of a tenth of a degree, these differences are far from trivial.
There are occasions when floor is appropriate – when comparing stopwatch times from a 1/100th stopwatch and a 1/10th stopwatch, you should always “floor” the 1/100th stopwatch, because 1/10th stopwatches “tick over” at 0.09 by design. But for thermometer readings, I would assume a straight round to the required precision is most appropriate.
This is interesting.
I’ve looked at more examples. Whatever’s going on is more than simple slicing: there are a few examples with upward slicing. While I can’t put a firm handle on it, I’ve looked at about 100 plots and would say that there are definitely more negative slices. Sometimes the displacement is more than 0.1 deg C. This is very annoying.
There are all sorts of weird variations. Changsha has 2 series that cover virtually the identical period and it doesn’t come up to date. The combined is about 0.2 deg C cooler than the average or any conceivable variation.
In other cases, the combined is bang on to the average. There’s no rhyme or reason that I can discern.
I can’t believe that this crap can meet any sort of NASA specifications.
OK, I’ve replicated a Hansen combining of two series in a case with two series only: Changsha, where the station values. I don’t vouch for whether this works anywhere else.
Changsha has two versions with one having only a few more values. The longer series was chosen first pace Hansen. The delta between the two versions over all available values was calculated ( 0.4169249) and rounded to one digit (0.4). The average was calculated. Then the average was multiplied by 10, 0.499999 added to the average, the floor taken and then it was divided by 10. If you add 0.5 (equal to 0.05 in the unadjusted), you don’t get the slicing.
There was NO difference between this value and the dset=1 combined value for Changsha. I’ll experiment with other stations with only 2 columns. It looks to me like this method ends up giving some extra points to the house, but I’m still experimenting. Here’s the code. AS usual, watch out for quotation marks in WordPress versions.
Re: 88
Most likely, they did not intend to add 0.499999. Accumulated floating point errors can have manifest themselves in that way. The fact that they are using single precision floats does not help but one can run into this kind of thing with doubles as well.
— Sinan
Well.
Do not let these guys near any Navier-Stokes equations. DOH!
Cara, Siberia
There are 604 months that overlap all three series and the combined column, which 604 months average:
Col. 1 (Series 2): -7.63
Col. 2 (not named): -7.39
Col. 3 (not named): -7.62
combined: -7.61
In the case of multiple series for a given station, Hansen, et. al. supposedly claim that each series is weighted equally, but that does not appear to be the case when comparing these 606 months (i.e. apples to apples).
Giving equal weight to each series average should result in a combined average for these 604 months of -7.55, a difference of 0.06 degrees C or about 0.1 degree F for the entire series. While this might seem small, it appears to be a consistent difference over 604 months or about 50 years.
You can EXACTLY duplicate hansens combined figure by doing the following.
1. Convert to Kelvin by adding 273.2 to each series.
2. Apply deltas to series 2 and 3 (see below for deltas)
3. Average the monthly values.
4. Round to nearest 1/10th degree.
5. Convert to Celsius by subtracting 273.2
You now have hansens combined figure.
Valid deltas for the 2nd and 3rd series are:
-0.17 and +0.01
-0.18 and +0.01
-0.19 and +0.01
-0.18 and +0.02
-0.19 and +0.02
-0.19 and +0.03
If you try this and get any different values to hansens combined figure could you please include just one of the differences so I can verify your results.
re: #92
But would/should 273.15 be rounded up to 273.2 for such calculations? I think should not; don’t know about would.
Re 25:
This is consistent with the treatment of the single value (2nd column) for October, 1941 of -3.7: the “combined” value is -3.9. Obviously, something other than rounding has been applied here.
Compare A to B, combine to form AB. Compare AB to C, combine to form ABC. Repeat until you run out of records.
If you don’t do it this way, you’re doing it wrong.
Terry #92 I’m looking at your step 2.
Terry.
I don’t think they would do a conversion to Kelvin.
The input data from the US would ALL be in Fahrenheit. For early records the data would be
INTEGER F.
For the ROW input data would be Centigrade INT.
So, I’d think the first step is a Fahrenheit to Centigrade Conversion for the US sites.
for ROW no conversion is necessary.
This is 1987. I bet the station data is read into a 2D array of 16bit int
Column 1 is year. Column 2 is 12ths in int. col 3 starts the data
speculation.
#92 Terry: I have confirmed your calculations. In addition, the following values also replicate exactly:
-0.20 and +0.01
-0.20 and +0.02
-0.20 and +0.03
In addition, when rounding the deltas to the nearest tenth of a degree, all of the valid adjustments resolve to -0.2 and 0.0. When rounding the averages in my #91, they are: -7.6, -7.4 and -7.6, so it looks like the warmest series was “adjusted” by -0.2 and then the three were averaged using the method you describe.
Hansen, says (from the excerpt in Hansen’s Bias Method):
In the case of Cara, the highlighted part of the quote above does not seem to be true, as the warmest series appears to be biased down to the mean of the other two, colder series. So all records do NOT “contribute equally“
#97
Glad you spotted that Phil, my little perl script had a problem rounding one particular value and so rejected those deltas. Fixed it now.
Cheers