The question today is: how does Hansen calculate quarterly and annual averages when there are missing values? It’s not obvious.
The issue arose in the previous puzzle in trying to calculate Hansen’s adjustment prior to combining scribal versions. Essentially what happens as reported in the prior post is that when there is a missing value, Hansen estimates the missing value (without doing the obvious thing and uses the available reading from a different version.) His estimates typically differ a lot from the actual value. He then says – aha, there is a bias between these versions and adjusts everything down.
As noted, Praha Dec 1986 is missing from one version and is 1.4 deg C in another version. Hansen then estimates the missing value at -3.6 deg C, a value of no less than 5 deg C lower than the actual value. There are 48 months in common, so he then concludes that the average bias is -0.1 deg C and adjusts all early Praha values down by 0.1 deg C. It sounds pretty absurd when written down. The methodology is not reported in the publications that NASA spokesman Gavin Schmidt has said to contain a comprehensive description of calculations.
Today’s puzzle: how did Hansen estimate Dec 1986 temperatures at Praha at -5 deg C (and other similar estimates)?





126 Comments
Without looking at the actual data, perhaps a starting point would be the infamous nanmean() Matlab script as used in Rutherford and Mann, 2006? I may have a copy of that somewhere around.
Mark
I am guessing that to solve the next puzzle we need to look at seasonal or annual averages.
I think a clue can be found when looking at scribal record number 2 for Bagdarin:
YEAR JAN FEB MAR APR MAY JUN JUL AUG SEP OCT NOV DEC D-J-F M-A-M J-J-A S-O-N ANN
2007 -25.3 -21.3 -16.9 -0.4 999.9 12.9 16.4 999.9 999.9 999.9 999.9 999.9 -24.83 -3.75 14.18 999.9 -4.97
This begs the question, how is an annual average calculated for 2007 when May, August, September, October, and November are missing (December will be used for 2008).
For one thing, it tells us our algorithm only needs to look backward in time, not forward, which is a big help.
Steve and John (#189):
I would suggest that the quarterly and yearly entries in these series are scribal and not calculated. That would explain how you could have averages over missing data or even different averages over the same data (i.e. scribal error for the average). If true, than at least some of the missing monthly data could be recovered from the averages.
#189. Doesn’t the 1991 SON for PRaha contradict the view that it is only backward looking? All lead-in values are identical, unless there’s a long backward look.
It certainly appears that Hansen’s bias is doubled before he uses it. A demonstration. Compare these two charts:
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=425725520000&data_set=0&num_neighbors=1
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=425725520000&data_set=1&num_neighbors=1
You will notice that in the area of overlap the combined version is lower than either original. That’s because the bias is doubled. This is common in combined records.
For further demonstration simply combine this record yourself. Use floating point and round at output time. Calculate the bias in a straightforward fashion and double it.
This works for every 2-record station I have tried, as long as there are no months in the overlap period that are present in one record but absent in the other.
The situation where there are mismatched months in the overlap period is a special case that you guys have apparently solved.
If anyone tries this and gets a different result, please let me know. Start with Grand Island and then pick one I haven’t tried.
Correction to #192. I just realized the half-dozen records I have combined this way had no missing months during the overlap period. Every single month was present on both sides. Next I’ll checking to see if it makes a difference if some months are absent in both series.
#191 Steve McIntyre…Are you looking across records or at a single record. I am looking at one record independent of the others, and I see very different lead-in values. However, your point is well-taken, as the value of 94 for SON doesn’t make sense given the previous years on record 2.
Maybe we should look for three “boundary conditions”:
1) The last year of record has many missing monthly values, but the annual average has been calculated. (Bagdarin)
2) The first year of record has many missing monthly values, but the annual average has been calculated.
3) A middle year of the record has many missing monthly values, but the annual average has been calculated. In this case, one or more adjacent years – forward and backward – should be missing.
My hypothesis is that these boundary conditions skew the algorithm enough to tease it out of hiding.
#194. There are a lot of these calculations so we should be able to reverse engineer it. I’ll put htis in a ne wthread.
Candidate for boundary condition #1:
Birao record 0, year 1987.
Candidate for boundary condition #2:
Yalinga record 2, year 1987…in fact, maybe this should be the poster child?
Candidate for boundary condition #3:
N’Dele record 1, years 1974-75…Not perfect, but maybe usable.
One has to love those African stations.
For condition #3:
Dire Dawa record 1, 1967
oooh found THE ONE:
Neghelli, only record, 1955
For this station, the previous years annual average and the following two years are not calculated. However, the annual average for 1955 is calculated even though five of the twelve months are missing (OK, four of twelve, or one-third, given the annuals are calculated Dec – Nov). Solve that one and we should be well on our way.
My assumptions:
Probably no programming errors, or at worst one.
The algorithm, once found, is not bizzare (it may not be sound, but it probably is not bizarre).
Rounding issues probably affect the result.
The code was created in the mid-80s or earlier and has not been changed think like a programmer from back then, probably using Fortran 77.
With all the talk of rounding errors and integer arithmetic, it would be pretty easy to unintentionally introduce an integer conversion via Fortran’s implicit variable typing by a naive translation or simple oversight. This could catch the unwary or hurried programmer and would only take one oversight to cause subtle problems. As any FORTRAN programmer should remember:
“The type of any constant, variable or array used in a FORTRAN program must be specified either implicitly or explicitly. In implicit typing, all constants, variables and arrays beginning with the letters I, J, K, L, M, or N are automatically taken to be of type INTEGER.”
More subtle problems could come from implicit typing on parameters to functions. ftnchek could check Fortran source for such errors, but no source. And even with source, the compiler used and the libraries called upon might be necessary to reconstruct the configuration of code run at the time 😦
param-implicit-type:
Implicit typing of a parameter by the data type of the value assigned. This warning can only occur if implicit parameter typing has been turned on by the -source=param-implicit-type option, or if the PARAMETER statement is of the nonstandard form without parentheses. If this option is turned on, then any instances where implicit parameter typing occurs will be warned about. If you want to be warned only in those instances where the implicit data type differs from the default type, use -portability=param-implicit-type instead. According to the Fortran 77 standard, the data type of a parameter is given by the same rules as for a variable, and if necessary a type conversion is done when the value is assigned.
John Goetz and Steve,
I’m looking at Yenbo. Here is raw and then combined.
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=223404390002&data_set=0&num_neighbors=1
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=223404390002&data_set=1&num_neighbors=1
Get the monthly data and look at the seasonal averages for the period 1992 through 2007. There are variations in the seasonal averages even though the monthly data for that period is an exact match.
Here is a situation where different estimates are arrived at even though nearby data is unchanged. If you can figure out what triggers that you may have your answer.
Follow-up to Post #11. Any effort on the Fortran conjectures offered in #11 should be spent on first two paras. Upon further review, I’d retract the third and fourth paras of the ideas to consider for Fortran errors — implicit typing errors coming from Fortran PARAMETER *statements* seems an unlikely source of problems — and integer precision (byte count) probably isn’t a likely problem either given the tenths.
OTOH, whatever the programming language, details surrounding the overall build and configuration of the software and the system it ran on might still be a final obstacle to recreating Hansen’s process, even if “source code” is released.
My suggestion:
He uses the average temperature for December based on years around 1987.
Followup on #12
The J-J-A period for 1988 for Yenbo is:
32.7 in record 0
32.5 in record 2
32.6 in combined
There are no monthly values that differ over the entire record. There is no bias applied in this combination. The only difference between these three records is that they cover different periods. How that affects the estimate for June is a mystery worth solving.
RE11 I agree with Mikes first two paragraphs; the requirements that FORTRAN puts on the programmer to always specify exactly what type of number you are dealing with lends itself to simple errors of omission in many many places. I used to program in FORTRAN back in the punched card era, and I found it to be maddeningly dense at times.
With Steve and John doing reverse engineering to try to make sense of these things, and then find places where no sense is made at all, it points to programming errors, plus some SWAG in initail decisions, IMHO.
The problem with FORTRAN is that if you screw up or omit a declaration on choosing Integer or Floating Point at the right place, the program can still run and produce a result. If the result fits your “expectation” or is within reasonable bounds, often the error can be overlooked. I had this happen to me once in doing a simple calculation on beam loading for a mechanical engineering class. In one step I went from floating point to integer accidentally and then back to floating point again, truncating the decimal places in the mistake but then seeing an end result with decimal places didn’t trigger any worries.
When I turned in the program, I got a near failing grade because the mistake made the answer way off where it should have been, but being new to this, I had no frame of reference as to what the answer “should” have been. The same thing can happen with adjustments. If you don’t “know” what to expect or a SWAG was used in applying offsets, you have no real reference for an outcome.
FORTRAN programming is not easy to catch these kinds of mistakes in. And since GISS Model E is still FORTRAN based codes, its a safe bet that the input data adjustments to GISS datasets are too.
Many programmers have moved well beyond FORTRAN because of such issues, using more modern and flexible languages. GISS is stuck with FORTRAN legacy than spans years and possibly dozens of programmers. Finding errors in such legacy spaghetti code is almost a certainty.
All the more reason to “Free The Code”!
Further on #15
The estimated temp for June 88 in Yenbo record 0 is 32.5 degrees. That estimate is higher than any June in that entire record. WTF?
Examples of GISS Fortran code to on which to practice one’s forensic skills:
ftp://data.giss.nasa.gov/pub/gistemp/download/sbbx2nc.f
ftp://data.giss.nasa.gov/pub/gistemp/download/SBBX_to_1x1.f
#15 KDT said:
The J-J-A period for 1988 for Yenbo is:
32.7 in record 0
32.5 in record 2
32.6 in combined
This may be further evidence that the averages are scribal and are averaged/adjusted just like any other data point. The combined value for 1998 JJA for Jenbo is the average of records 0 and 2. The actual values for JJA in 1998 are:
999.9 32.5 33.1, the latter 2 of which average 32.8.
#19, That relationship may be coincidence. Yenbo seems consistently hot in the summer.
One last oddball before bed. Omaha, record 0, Dec 89 is estimated at 1.2 degrees. Record 2 recorded temp is -8.1, over 9 degrees lower. And 1.3 is the record high for December. Nutty.
That estimate is so out of line it sticks out like a sore thumb in these charts.
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=425725530000&data_set=0&num_neighbors=1
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=425725530000&data_set=1&num_neighbors=1
One last thing, it occurred to me that batch processing all of the raw, combined, and homogenized records could give you a rather large database of estimates. Many would have actual temps to compare to. Get an idea of the big picture.
I remember the problem now with reals and integers: It was a big hassle. C protects you somewhat but Fortran doesn’t. The standard practice of using implicit i-n for integers and all other letters as real used to help in spotting these problems but standard practice clearly wasn’t used in the code listed above and even a cursory glance identifies some potential problems there. It looks like typical student code.
eg1 : The classic error of using the loop integer as a real number in an interpolation. A specific conversion is needed with most compilers or the right hand part may become an integer. The lhs is real despite beginning with l.
do 5020 J = 1, jm
lat(J) = fsouth + (J – 1.) * flatres
5020 continue
do 5040 I = 1, im
lon(I) = fwest + (I – 1.) * flonres
5040 continue
do 5060 iyy = 1, iyrs
iyr = iyrx + iyy
do 5060 imm = 1, 12
imoff = (iyy-1)*12 + imm
time(imoff) = iyr * 100 + imm
eg2 : the second part of the equations will likely always be an integer but the first part is real.
js = 1.5 + ((lats + 9000) * jm) / (18000)
jn = 0.5 + ((latn + 9000) * jm) / (18000)
iw = 1.5 + ((lonw + 18000) * im) / (36000)
ie = 0.5 + ((lone + 18000) * im) / (36000)
These truncations may have been intended but it’s still sloppy coding. Since we’re talking about tenths of a degree, truncation error is important.
Folks, just to keep things focused, this puzzle is to determine how Hansen calculates quarterly and annual averages when there are missing monthly values. This is independent of the previous problem, which was to determine how multiple scribal versions were combined.
Yenbo seems to have a missing version. The last digit of the IDs skips over the digit 1. Maybe some data manipulation was done with a version not accessible online. It also appears the combined version ID may be related to the raw version with the most complete years of data. Not necessarily the longest history.
Raw versions
223404390000 1967-1991 has 13 years with ANN computed.
223404390002 1987-2007 has 21 years with ANN computed.
Combined
223404390002 1967-2007
Mr. D,
Here is a link to a paper by Christopher Monckton which details how Satellite temperature trend observations of different layers of the troposphere do not match expected GCM expected trends.
Greenhouse Warming? What Greenhouse Warming?
I calculated the imputed values for missing months when there is one missing month in the Neghelli version 0 quarterly estimates. The imputed values were not necessarily equal for a given month. So the estimate is not as simple as filling in an average for the month.
What I notice is that (for 1955) the missing months are not back-calculate from the quarterly estimates, and neither is the DJF quarterly estimate back-calculated from the annual estimate. This leads me to believe that the quarterly estimates are calculated first from the available monthly data (two or three months), and then the annual estimate is calculated from the quarterly data, assuming 3 or 4 quarters are then available. So, there must be enough information available given two months of data to calculate the quarterly. Perhaps some sort of average or weighted average for each month in a given quarter?
Steve & John:
I am not sure I follow. Which versions of the data are you looking at? Can you give an example?
I’m working with dset=0 examples only right now.
I see the train has finally arrived at this station:
http://www.climateaudit.org/?p=2018#comment-133380
I’ll wait for you here:
http://www.climateaudit.org/?p=2018#comment-133887
I’ll be at the bar.
Approaches.
Imput a value for DEC to preserve Annual Means
Imput a value to preserve a trend in Annual means
Imput a value from the means of the Season
Imput the mean of all Decembers ( This doesnt work)
Imput the mean of Jan ( assuming some kinda one off error… this doesnt work)
Infill DEC using a linear regression
Infill DEC using some kinda markov model
Make stuff up
#30. Touche. You were 100% correct in identifying this as an issue; in fairness, I was then working on a different section of the fishing line and, as you say, we’ve now got to this point. You could be right that he uses a model to infill data. That would be too funny.
Anyway I’ve sent the following email to Hansen and Ruedy. So that if they aren’t going to answer, there will have been at least one inquiry.
Looking at Data Set 0 from Neghelli for 1986 and 1987:
1985 20.4 21.1 20.6 19.3 18.9 17.1 17.2 17.7 19.2 19.3 18.7 19.4 {20.4} {19.6} {17.3} {19.1} 19.11
1986 19.7 20.6 21.0 18.9 999.9 999.9 999.9 18.0 19.3 19.2 19.6 19.9 {19.9} {19.4} {999.9} {19.4} 19.11
It would be an awfully strange algorithm that can calculate an annual average of 19.11 (in bold) for the year 1986 from quarterlies (in brackets) that are all greater or from the monthly averages. However, the yearly average for 1985 (in bold) is exactly 19.11. If the record was being copied by human, it is easy to see how this could have been either entered or transcribed in error (i.e. entering the 1985 annual average twice). Per #20, it could be another coincidence, but the math so far is awfully weird for a computer algorithm. It may be my failing, but I am having a great deal of trouble spotting other patterns. Just a suggestion.
Steve, thank you. I love your blog. I’ve been a lurker here for ages. This puzzle finally got me involved. Sometimes I’m a wise-ass. If I hang around you’ll have to tolerate me, I can’t help myself.
#30 KDT
The train left a while ago 🙂
http://www.climateaudit.org/?p=1956#comment-130421
#35 John, you are indeed the man who asks the right questions.
Ah, but KDT…I filed it away until later…see
http://www.climateaudit.org/?p=2018#comment-133551
😉
Steve:
Sorry if I am being desnse about this.
I am looking at the raw Neghelli ‘0’ 1955: There are a total of 4 months with missing data. Jan,Feb,May, Aug. This means that three of the seasonal numbers are constructed: DJF, MAM, and JJA with the ANN being also constructed. This means that Hansen et al must have set 2 Seasonal and 1 Annual estimate to generate the Seasonal and Annual numbers that appear in the Raw and Adjusted (I can see no differences between the Raw and After Homogeneity Adjustment). When you say “The imputed values were not necessarily equal for a given month.”, I am not sure I know to what you are comparing the imputed values.
YEAR 1955
DEC(54) 22.2
JAN 999.9
FEB 999.9
MAR 24.4
APR 21.9
MAY 21.5 Monthly imputed value from MAM Seasonal
JUN 19.1
JUL 18.6
AUG 19.3 Monthly imputed value from JJA Seasonal
SEP 20.8
OCT 19.9
NOV 20.8
D-J-F 22.02 Seasonal Imputed Values from ANN
M-A-M 22.6
J-J-A 19
S-O-N 20.5
ANN 21.03
KDT
SteveMc is fairly tolerant of Wise asses, its the dumb asses for which he has no patience.
Welcome aboard. If you need an intervention, let me suggest WiseAssAnonymous.
#38 Bernie
Since Hansen does not bother filling in imputed values, I don’t believe he uses them.
I think instead he has a method for filling in MAM and JJA when one month is missing, and then because he has MAM, JJA, and SON he is able to use the same method for filling in the annual with DJF missing.
Guess (please check):
I think there is some kind of anomaly method going on here. In a slightly different context it is discussed in Hansen et al (1999)/Section 4.3. So what you need is a reference temperature for each month (which gives also reference seasonal and annual averages). Substracting the references gives you the anomality. Now if a month is missing from a seasonal average, you simply average the available two anomalies and add it to the reference seasonal average to get the seasonal average in celcius. The same way annual average is obtained if a seasonal average is missing: take the mean of the available seasonal anomalies and add to the reference annual average.
I don’t have access right now to my own laptop, so I can not check the above guess: if it holds, then if in one station data, there are two or more missing values in the same month, then the difference between the seasonal average and the mean of the corresponding two available monthly values should be a constant (over the years with missing values).
Please someone check if the above holds. If it does, then we can start thinking how the reference numbers are calculated…
#41 Jean
I have been thinking something similar. Hansen consistently refers to the 30 year period of 1951 through 1980 as his reference…
Hi, in December 1986 we made a school trip to the National Technical Museum in Prague. 😉 There were quite many airplanes around etc. but it was also the first time I saw a hologram, an impressive one with the Soviet bear, the icon of the 1980 Moscow olympic games. It wasn’t freezing. I suppose Prof Hansen made the trip as well and because it was cold to him, he said it was -5 C. Correct? 😉
Here is an approach to think about. I tried on Neghilli (year 1955) and it worked. I will need to program it and try it on more data points, but that won’t happen until evening.
Remember I am using Excel and loading the .txt file downloaded from GISS.
1) Look at only the years from 1951 through 1980 inclusive. For Neghilli that limits us to 1954 through 1980.
1a) Remember to also delete any quarterly and annual value that was estimated, because these are what we need to estimate ourselves. For example, delete the MAM, JJA, and annual data for 1955. Make sure you do it for all years.
2) Calculate the average for each month, quarter, and the annual average (average down the columns).
3) For MAM, we need to estimate the missing May value. Do this by
3a) Subtract the March average from March actual to get March delta.
3b) Subtract the April average from April actual to get April delta.
3c) Get May delta by averaging April and March delta
3d) Add May delta to May average to get May estimate
Make sure all deltas are rounded to 1 decimal place.
Now MAM is calculated by averaging March and April actuals with May estimate.
Repeat for JJA
Follow a similar approach for the annual record, but use the actual for SON and the estimates for MAM and JJA to create and estimate for DJF.
As I said, it worked for the first row. I am not sure for the next row down if I leave all the new quarterly estimates in or not, because they obviously affect the average.
#43. In Version 0, there were reported monthly averages for Dec 1986-Feb 1987 of -0.8, -6.7, -0.8, from which Hansen calculated a DJF quarterly average for Version 0 of -2.0.
In Version 1, the Dec 1986 measurement was unavailable. From this available Version 1 readings for Jan and Feb 1987 of -6.7 and -0.8 (as above), using a presently unknown algorithm, Hansen calculated the version 1 DJF average to be -3.7 deg C – which yields an imputed Dec 1986 value of -5.0 deg C: fully 5 deg C lower than the value reported in another source (which yields completely identical values for all other common months.)
Because Hansen’s estimate differs from the actual value, Hansen then concludes that version 0 is biased relative to version 1, even though every other value is identical where they coincide. He calculates this “bias” and then adjusts all early Praha readings down by 0.1 deg C, thus creating a slight spurious increase in Praha temperatures from the mid-1980s on.
It’s not just Praha. His entire data set is corrupted by this new error.
Now, even though it is slightly off-topic for this thread, I would like to draw attention to my post #5. This is not idle speculation. Grand Island is uncomplicated by missing months. No estimates are required. You can look at the charts and guess what Hansen’s result should be: an average of the two. And you can see that his result is wrong. The shorter record is biased too much, resulting in an average lower than the original two.
The bias just so happens to be twice what it should be.
I have observed this in every case I have checked, more than a dozen so far. All combinations uncomplicated by missing months (so far) show an obviously wrong result, and it’s obviously wrong by 2X.
If confirmed, this is a serious error. Unless that’s what Hansen wanted to happen. I don’t think so.
I don’t think this is a programming bug. I think it is an error in logic. Maybe he thought, “I’m going to divide this by two when I take the average, so I’d better double it.” Maybe. I don’t know.
But that’s getting ahead of myself. First I’d like somebody to check my work. Or tell me if this is old news.
Many thanks in advance.
John:
I had arrived at the same conclusion and the same process and fitted the right number for 1961. I think you cracked it.
Well done.
Just want to give Steve a big thanks for doing all this work.
#46, 47. I checked this for the entire data set (and will post up an algorithm after I play squash). Up to rounding, this worked for all the values in this series. So this looks like what he did.
It might also explain why old values get adjusted slightly after they’re in the clubhouse if the reference averages change for the old numbers.
After we get this ironed out, let’s look at KDT’s Grand Island problem which he’s been patient about. But I’d like to iron this out first.
#49 Steve, I’ll wait patiently.
May I suggest Yenbo as a good test for your current problem. It is peculiar. See #12 and especially #15.
Jean your insights at 41 about anomalies were critical in getting this solved. Kudos to you. Now the question is what, if any, inherent issues are there with this approach. It seems to me that apart from playing havoc with any eforts to calculate confidence intervals ( a seasonal datum based on 67% of the data or an annual datum based on 50% of the data are treated exactly the same as datum with 100% of the data) , this procedure will tend to amplify any deviations from the 30 year norm and that any general warming trend will in turn get amplified because I assume that there are more missing records earlier in the history of a station than more recently. This obviously needs to be more formally worked out – which is currently beynd me.
One final aside before we leave Neghelli. It is listed as a rural site – but is reported to have a population in 2006 of 43,000 and about 12,000 in 1984.
#44 John: What values did you get for May, August, and DJF?
Sorry, been away.
I got the following estimates:
May: 21.6
Aug: 19.3
DJF: 22.1
Per #51 bernie, I too need to stop and think about the implications. Remember, we started by examining the process of simply combining scribal versions of the records. The method used to do this was far afield of what I expected, to say the least.
Hansen’s method of estimating missing values from the average of anomalies from adjacent months seems valid. However, it does give demonstrably-odd values when applied to “stations” that are really just scribal variations. (There should be a new step in the algorithm prior to merging station data: scribal variations should be identified and merged).
The reverse-engineering done here has been impressive, and has turned up some issues with the Hansen algorithm. It will however be difficult to quantify the effect of these issues. Perhaps a forward-engineering effort to create a new open-source program for processing station data should be considered.
I am interested in pursuing the forward-engineering route. If all of the necessary data is available, the code should not be overly difficult. (What was a large problem in 1987 is much smaller now). That brings me to my questions:
Does this seem like a good idea?
Is the necessary data available in a well-formatted archive?
#54 John V.
The data is available and in a well formatted archive. Steve can probably provide a link to his script that scrapes out the station data from the GISS ftp archive. I typically go to http://data.giss.nasa.gov/gistemp/
and download .txt files station-by-station. It is tedious, but I don’t look at lots of stuff at once.
If I were combining individual station records I would have done so month-by-month, averaging during the overlap periods. The first program I wrote to combine records did this, which is why I noticed Hansen’s combined record as being different.
I don’t think I agree with the process of estimating values prior to combining records…
John V, as you say, another “common-sense” step is required, wherein scribal differences are dealt with before the station-merging algorithms are brought to bear. This seems obvious to me.
I am getting the feeling (and this could be just my own selection bias from reading this site too much lately) that a lot of climate science has ‘lazy’ scholarship. By that, I mean that they use computer algorithms where simple human effort would be a lot more effective and accurate. Maybe it’s a funding issue: there isn’t enough money to hire enough grad students to trawl through all the temperature records applying human judgement to them, just like it would be too expensive to pay people to photo-document all the USHCN surface temperature stations.
#56 John Goetz:
I realize that there is a website where individual .txt files can be downloaded. A full archive of all .txt files (or similar) will be required to really tackle the forward-engineering problem. With over 6000 stations listed, it is not trivial to collect all of the data. I would prefer to focus on the program itself.
Does anyone have a full (or at least substantial) archive?
Steve McIntyre said…
I calculated the imputed values for missing months when there is one missing month in the Neghelli version 0 quarterly estimates.
I haven’t been able to contribute something for this thread, since I am busy trying to post my messages at RealClimate, although they kept deleting some of them, but here is a good paper & matlab codes that the author used for missing data imputation.
“Analysis of incomplete datasets: Estimation of mean values and covariance matrices and imputation of missing values”
http://www.gps.caltech.edu/~tapio/imputation/
I think that the above codes would be useful.
#58 John V.
Right, I was just mentioning I use the well formatted .txt files. Instead of doing that, you can try modifying / using the script that Steve wrote to scrape out the station data from the GISS ftp archive. I just don’t know where on the site it is, so when Steve gets back perhaps he can point you to it.
If I remember correctly about the FTP site, they have some shell programs that might be for automating the FTP process.
Also, if you use a web browser to get in you should be able to drag and drop everything.
Or get something like Filezilla or ftp commander.
John V
Steve may well have scraped the files but the toughest issue is that there are multiple versions of files for the same “defined” site and to go with the consolidated version is a bit of a leap of faith. Some of these sites have moved numerous times under the same “location”. Many have misleading designations as rural, suburban and urban.
Just as Anthony Watts put together a program to catalogue all sites perhaps it is time to scrub the data from one manageable
geographic area (My vote is for all cells/stations above 60N) and generate estimates for these cells. This latitude should reduce the number of stations and large scale UHI effects. It is also meant to contain the most sensitive locations for AGW. We will be left with local micro-climate effects. Thoughts?
There is still a mystery to be solved. A key piece of this crossword is incomplete.
Note that the method I defined requires one use averages from 1951 to 1980, inclusive.
What happens if a station record does not include data from that period?
I believe the same process is being used, but where the averages used to calculate the deltas come from is unknown to me. This is a serious issue that remains open, as many scribal versions start in 1987 or later.
Falafulu Fisi says:
These are the infamous nanmean(), nanstd(), etc. functions used, and modified, by Rutherford and Mann in their regularized EM paper, 2006. These merely compute the mean of the existing data, then backfill said mean into the missing values (essentially).
Mark
These are the infamous nanmean(), nanstd(), etc. functions used, and modified, by Rutherford and Mann in their regularized EM paper, 2006. These merely compute the mean of the existing data, then backfill said mean into the missing values (essentially).
Mark
Related issue arises when there is (a) a large amount of missing data for those years (b) the record starts say in 1965.
#58 John V
Believe it or not Microsoft list lots of free software, including a page of time saving software:
http://www.windowsmarketplace.com/category.aspx?bcatid=845&tabid=1
There’s a lot to choose form, but WebRipper looks good. Point it at a directory, and it will download everything. GISS will love it (not).
I’ve scraped all the data from GISS and also have convenient functions to scrape individual stations. I’ve learned a little bit about the structure of the data as we’ve been doing this and my scrape of the dset=1 is better organized than my scrape of the dset=0 data. I’ll organize my scripts tomorrow = tonight I’m watching Federer- Roddick.
As to scraping, I received an interesting email from someone from GISS about 10 days ago. He was doing some work on the data and was interested in using my scraped data as otherwise he would have to scrape the data himself (which took him, like me, about a day.) I just about fell over with astonishment.
Like others, I strongly disagree with this in the case of scribal variations. IN Hansen’s hands, this procedure corrupts the data base. Whether it introduces a bias is a different issue. As Gavin Schmidt observed of the Y2K error, it was not obvious a priori that it would increase U.S. trends, as opposed to being simply random, but it did. My gut feel here, without having waded through all the data to prove it, is that, like the seemingly “unbiased” Y2K error, this error will also introduce a bias – probably not a large bias, but it would not surprise me if it ended up introducing a bias as high as 0.1 deg C in the global number. It could also be negligible. Hansen should be the one to do the analysis as to the impact of this particular error and I’m sure that they will eventually. He’s not Michael Mann.
Everyone participating here is doing real hero’s work. Keep it up.
John V in #54 states
This is just plain wrong and bad science. By doing this Hansen is substituting the output of an algorithm, i.e., a model, for data from the physical world. Whatever alternative data analysis you come up with has to live with the data gaps.
How are missing data treated in other forms of time series analysis? Is this “in-filling” actually necessary to do what Hansen wants to do, i.e., create a single multi-year index of surface temperatures.
Re: #71
I think each missing data item must be treated as a variable whose upper and lower values describe the limits of possible variability. Doing so would at least describe the emperically known upper and lower limits for the average/s.
Re: #44
Steve sent me an email saying he did not think that 1951-1980 matters for this algorithm, that Hansen calculates means on available data. I agree. I’ve been playing around with station data that falls outside the 1951-1980 period and find I get consistently within 4 or 5 tenths of the GISS values if I average across all available data for the record (using same bias or anomaly approach suggested by Jean S in 41 and detailed by me in 44). Getting that close is pretty good, but still outside the rounding error, so some slight refinement is still going on. Hopefully either Federer or Roddick can describe the refinement.
Here is an interesting talk on floating point:
Click to access KahanTalk.pdf
— Sinan
#69 (Steve McIntyre), #70 (Paul Linsay):
I should have clarified my statement re the validity of “averaging anomalies”. If you accept that there is a need to estimate missing values, then estimating by averaging the anomalies of adjacent months is a valid way to do it. The more I think about it, the more I realize that’s a pretty big “if”.
#62 (bernie):
I like the idea of starting with stations above 60 degrees North. It’s a reasonable subset for testing a new program.
#67 (MarkR):
I will look into anonymous FTP access and/or a WebRipper-style program for downloading all of the data files.
—–
I am going to spend a little time researching and determining what I can offer towards a new toolkit for processing raw station data. I will post again when I have a plan.
John G:
Conceptually I agree, but the question is what gets you closer. Certainly replacing missing values with the mean of the available values is a pretty standard approach and is an option in a number of statistical packages where listwise elimination of cases with missing values can dramatically shrink your sample. Hence my question about how other fields address the missing value issue.
I just checked Negele (sic!) and Steve is correct. Kind of obvious and standard, at least in the type of analysis I do. There is greater precision when missing data is replaced by the average of the available data. Obviously a bigger sample is needed to verify. Steve will have programmed something to check the precision for all the missing values by morning probably. I have to work tomorrow, so I’m to bed.
If there was no other info, perhaps. But it makes no sense when you have another scribal version which contains the actual value.
Also to use this calculation to estimate a “bias” over all the values is insanity. If you went to the bother of estimating the “bias” using mixed effects, the “bias” between scribal versions is zero – as one intuitively knows. Hansen’s method simply corrupts the data base,
#69 Topic: Filling in missing values
I would agree with Steve that filling in missing values could corrupt the data base. Slightly different algorithms, by varying which adjacent months are used to reconstruct data, may yield surprisingly different reconstructed values. I had a senior moment reconstructing Steve’s algorithm and interpolated instead of using the adjacent months used for the quarterly averages. I used April and June for the reconstruction instead of March and April. This small change, which could be argued is just as “valid” a method as Hansen’s, resulted in a difference of over 1 degree C in the estimate for May:
John Goetz: May 1955 Neghelli estimate – 21.6
Interpolation May 1955 estimate – 20.5
RE #78 Aaack: another senior moment: John’s algorithm. My apologies John.
#78.I don’t agree with the nuance here: it’s not so much that the fills themselves corrupt the data base, but that Hansen takes the difference between the fill in one version and the actual value in another version as evidence of bias and that he uses this calculated bias to adjust data. The method is so nonsensical that it’s difficult for parties to comprehend what he’s done.
Re: #76
Yes, replacing missing values with the mean of the available values is a pretty standard approach…. whenever you are conducting a subjective analysis of the information in lieu of an objective summary. But the preparation of a subjective analysis before or entirely without an objective summary produces opinion and not empirically based scientific evidence. It amounts to putting the cart before the horse and then entirely getting rid of the horse. To give credit where it is due, subjective analyses can prove useful when they are instrumental in guiding researchers to valid objective evidence, but they are much worse than useless when their subjectivity results in guiding researchers away from valid objective evidence. In any case, subjective analyses, no matter how pseudo-scientific they appear to be in their mathematical interpretations, are still nothing more than subjective opinions which may or may not correspond with objective reality.
Rather than report a subjective opinion of what the missing value/s are in a time series, it is essential for the actual observed values to be reported in order for there to be a valid application of the scientific method. When a value is missing from the observation record, report the fact it is missing. When you must prepare a report which summarizes the mean value of the time series which has one or more missing values, report the objective reality. This can and must be done by reporting the actual uncertainty which exists in the mean value of the time series. The uncertainty in the case of a surface air temperature will almost always be no greater than the historical known high value and no lower than the historical known low value, unless the preceding and receding values where at or near to the historical extremes. When extremes are in evidence, their values and trends can be reported as measures of uncertainty. Report the actual observations and the known range of historical values as variables for the missing value. Doing so represents the actual observations, and the subsequent subjective analyses and adjustment models may then be prepared and debated on the basis of the original empirical observations which include what is actually known and not known about measured values of the uncertainties. In any event, it is essential for the validity of the observational data to keep actual observations of measured values and observed uncertainties strictly separate from each other and strictly separate from the following analyses which attempt to subjectively interpret the meanings of the observed values.
Yes, I agree completely. Treating scribal variations as independent records to be compared and adjusted is a major mistake. They should be identified as scribal and their values should be merged.
I was going to qualify my original comment further, but it has already taken up too much time and space…
#80 Steve: Is it possible that Hansen is not aware of this error? In the thread titled Hansen’s “Bias Method”, you quoted him:
(my emphasis)
Below I’m going to show why figuring out the Hansen method for interpolating the missing month is like a quest in search of the Holy Grail. You think it should be possible, but Hansen and crew seem to have lost the map.
Looked at raw data for Tarko-Sale.
Mar Apr May MAM
v1 -15.4 -12.4 -2.6 -10.1
v2 N/A -12.4 -2.6 -10.9
Hansen and crew have interpolated v2 March at about -17.7, off 2.3 degrees for the month. Not even in the same ballpark as the ver1. The method below came within .4 degrees, but it’s possible I didn’t go back the the proper number of years.
My method is to take the three month period that straddles the missing month and go back in time to try and establish some sort of an average slope to fill in the data. What the proper number of years should be is another question. What do you do with missing data if you come across it while going back?
I generally get quite close. On the money quite often. Haven’t spent much time investigating the rounding problem since it seems their agorithm doesn’t do very well anyway. How can you figure out the rounding if their algorithm does a poor job?
Here is the way I’ve been doing it. The method might not be right, but it may be close. Food for thought anyway.
I went back 10 years starting 1977. All data was present. Grabbed the sum total for the months Feb. Mar. Apr. and deducted Mar from the total.
total Mar. Feb. and Apr.
-484.4 – -149.9 = -334.5
Found the percentage of the 3 month period belonging to March.
-149.9 / -334.5 = 0.44813154
sum(Feb Apr 1978) = 35.9
multiply by March percentage history.
-35.9 * .44 = -15.796 my March estimate .4 off from the actual figure
Sum(Mar Apr May) -15.8 + -12.4 + -2.6 = -30.8
-30.8 / 3 = -10.26666667 my MAM estimate
Off .2 from v1 while their algorithm was off .8 degrees.
Here’s Tarko-Sale for another year, 1988 where all three versions overlap.
It can be seen that they do the interpolation totally by algorithm. They don’t import the missing month from any other version even if they have it. Like they do once again in this case. All data identical except for what’s missing yet they still get three different seasonal means. At least this time they kept it within 1 degree anyway.
JUN JUL AUG JJL
v1 9.8 15.1 13 12.6
v2 9.8 N/A 13 13.2
v3 9.8 N/A 13 13
I don’t see much hope for anyone figuring out their method.
Should have said those top figures for v1 v2 are for 1978.
Steve, I disagree with your figure for the missing value, but aside from that here’s how I think he does it.
In his description he mentions Peterson et al 1998 and this paper details a method of “filling in the blanks” called the “First difference method”. I don’t have a copy of the paper but you can find a brief description of the method here about half way down
Basically what he does is take the months either side of missing values and calculate the average difference between them and the corresponding months next year. This is then used as a delta for adjusting Dec 1986 based on Dec 1987.
Here’s the values and calculations
Nov 1986 – Nov 1987 = 5 – 4.9 = 0.1
Jan 1987 – Jan 1988 = -6.7 – 2.6 = -9.3
(0.1 + -9.3)/2 = -4.6
Dec 1987 + -4.6 = 1.8 – 4.6 = -2.8
The result is a Nov 1986 value of -2.8 and hence a delta of 0.06
Correction to #86
Should read “and hence a delta of -0.06” which rounds nicely to -0.1
Bob:
Well, I think I have it 🙂 It is as I suggested in #41. The reference temperatures for the months are the means of available values and the seasonal averages are calculated first. The annual mean is then calculated with the same method but from seasonal averages which include the ones infilled in the first step. For seasonal averages there can be one missing month, and for the annual average there can be one missing seasonal average.
I’ve tried it for several stations, and I’m able to exactly reproduce the seasonal averages. The annual averages I’m able to reproduce up to 0.01 degree (some rounding thing?). Here’s my Matlab code (inputs are original GISS station files with headers clipped off):
-------------------------------clip here -----------------------------
clear all;
%original=load('301875960000.txt');
%original=load('301875960002.txt');
%original=load('30187596000c.txt');
%original=load('613262310000.txt');
%original=load('613262310001.txt');
%original=load('61326231000c.txt');
%original=load('61111520000.dat');
%original=load('61111520001.dat');
original=load('6111152000c.dat');
original(original==999.9)=NaN;
[r,c]=size(original);
a=zeros(r,c)*NaN;
a(:,1:13)=original(:,1:13);
ka=nanmean(a(:,2:13));
anomal=a(:,2:13)-repmat(ka,r,1);
% DJF
a(2:end,14)=mean([a(1:end-1,13) a(2:end,2:3)],2);
season=[NaN anomal(1,1:2); anomal(1:end-1,12) anomal(2:end,1:2)];
I=sum(isnan(season),2)==1;
a(I,14)=nanmean(season(I,:)')'+repmat(mean(ka([1:2 12])),sum(I),1);
% MAM
a(:,15)=mean(a(:,4:6),2);
season=anomal(:,3:5);
I=sum(isnan(season),2)==1;
a(I,15)=nanmean(season(I,:)')'+repmat(mean(ka(3:5)),sum(I),1);
% JJA
a(:,16)=mean(a(:,7:9),2);
season=anomal(:,6:8);
I=sum(isnan(season),2)==1;
a(I,16)=nanmean(season(I,:)')'+repmat(mean(ka(6:8)),sum(I),1);
% SON
a(:,17)=mean(a(:,10:12),2);
season=anomal(:,9:11);
I=sum(isnan(season),2)==1;
a(I,17)=nanmean(season(I,:)')'+repmat(mean(ka(9:11)),sum(I),1);
% Annual
a(:,18)=mean(a(:,14:17),2);
kaa=nanmean(a(:,14:17));
season=a(:,14:17)-repmat(kaa(1:4),r,1);
I=sum(isnan(season),2)==1;
a(I,18)=nanmean(season(I,:)')'+repmat(mean(kaa),sum(I),1);
% round
a(:,14:17)=round([a(:,14:17)]*10)/10;
a(:,18)=round([a(:,18)]*100)/100;
% check the results:
a(:,14:18)-original(:,14:18)
-------------------------------clip here -----------------------------
Have fun!
Thanks, JEan S. I’ve been busy doing the same thing in R. I’ve uploaded the scripts to read GISS data and to do the seasonal averages at http://data.climateaudit.org/scripts/station/read.giss.txt .
You can access these simply in R using the following (And WATCH the quotation marks out of WordPress – you may need to change them!)
#88 Jean S.
Nice 🙂
RE: 87
At this point there is no need to round to -0.1. If you apply the -0.06 adjustment to the entire first series you still get the same answers as the combined column once you average. If you round to -0.1 then you then have to deal with some rounding issues to get all of the averages to match. For Praha any adjustment to the first series between -0.06 and -0.095 will get you the combined column answers without having to deal with weird rounding issues. The question is how to get the adjustment to be in this range and it sounds like we have several possible methods for that. I like that you have used the Peterson reference to get the averages (and adjustments) as that feels more like would have been done.
I’ve seen this same issues on several other threads where it is suggested to round to the tenths and then apply only to the non-overlap part of the series. In those cases I also noticed that using an adjustment rounded to the hundredths applied to the whole series would eliminate the need for odd ball rounding methods.
#91. I think that you’re probably right about this.
RE#86, from your link:
One would think a “Central Difference Method” would truly “maximize the use of available station records.”
I see the GHCN has tossed it out the First Difference Method for 5×5 gridded data http://lwf.ncdc.noaa.gov/oa/climate/research/ghcn/ghcngrid.html because of “serious” random errors it introduces. But hey, at least the errors are random and therefore theoretically equal in both directions.
“…These datasets were created from station data using the Anomaly Method, a method that uses station averages during a specified base period (1961-1990 in this case) from which the monthly/seasonal/annual departures can be calculated. Prior to March 25, 2005 the First Difference Method (Peterson et al. 1998) was used in producing the Mean Temperature grid, and prior to February 24, 2004, the FD Method was used in producing the Maximum and Minimum Temperature grids. Due to recent efforts to restructure the GHCN station data by removing duplicates (see Peterson et al. 1997 for a discussion of duplicates), it became possible to develop grids for all temperature data sets using the Anomaly Method. The Anomaly Method can be considered to be superior to the FD Method when calculating gridbox size averages. The FD Method has been found to introduce random errors that increase with the number of time gaps in the data and with decreasing number of stations (Free et al. 2004). While the FD Method works well for large-scale means, these issues become serious on 5X5 degree scales…”
#86, #87
I think you can ignore my method as is doesn’t transfer to other datasets.
I do think Hansen is using some form of “first difference” method and the key to solving this problem is the Jan 1987 temperature. This looks to be a lot lower than normal January temperatures and for that reason has biased the calculation of Decembers value.
Perhaps, he calculates the the average for January and November and bases his December value on how much they vary from the norm.
Anyway, must go and earn some money now so I might try playing around with this again tomorrow.
#94: Yes, it does not (tried it already yesterday). But did you find something wrong with #88, or is there another reason to ignore it?
I have to admire you puzzle solvers. This has been a most interesting exercise to follow. Thanks, and congratulations. I am not a mathematician, statistian or programmer, so can’t contribute, but can follow. While I don’t have any positive feelings about Hansen, you may be being too hard on him.
As I understand where you are now, it is dealing with European sites where there are at least two historic time series of records covering different time periods but with an overlap. The particular sites you are dealing with have the same values in both series where there are values for the same month in the overlap period. Clearly, where there is a value for a given month in only one series, then, the value for the same month in the other series should be just copied. However Hansen has used an algorithm to estimate the missing month (or season), with a high probability of getting a wrong value, which seems silly. However, consider that there are over 6000 sites world wide, and it is very unlikely that they want to inspect the records for every site. For single series with missing months they need a method of estimating the missing months, and would logically create an algorithm to do that. It seems logical then that they would simply use that algorithm to fill in missing records in any series, before calculating variances, to automate the job as much as possible. Sure, they could have written a program that inspects overlapping series for commonality before applying algorithms to estimate missing data, but that is probably not something you would think of a priori. So what has been done is less than correct, and less than optimum for accuracy, but may be simpler for efficiency.
As for adjustments seeming to selectively run in the direction of a warming bias, that too is understandable. Most human beings suffer from reenforcement bias, and scientists frequently moreso than ordinary people. Since they know a priori that there is warming, they will accept any algorithm that results in a warming bias without question, but will likely examine, and if necessary, correct one that has a cooling bias. It may not be the best science, but it is human nature, even for scientists, even for Gavin’s scientists. Murray
Something like this could be how the erroneous Hansen method (which on its face, like the Y2K error, doesn’t imply a bias) could, in practice, cause a bias.
The start of the data versions that continue to the present day seem to come from one source which begins in Jan 1987 for a vast number of stations and is not random. Dec 1986 is therefore “missing” from the DJF quarter and is estimated from the Jan-Feb values. If there was a systemic difference between DEc 1986 anomalies and Jan-Feb anomalies over a large number of stations, this could yield a bias and this is where I expect any impact of the erroneous method to be felt.
I’d be more sympathetic if his attitude was: here’s our code; if there are problems with it, we want to be the first to know. Instead of that, they stonewalled.
As it turns out, there was enough available data versions that we seem to be able to sort out some of their methods (but no thanks to them). This may get harder in later stages.
However, to give them their due, they are much better than Phil Jones, who’s avoided giving out any data versions, even the identity of the stations – making it harder to get a toehold on his methods.
#87: This “meteorological start year”-bug (or is it a feature?) has a “side effect” that it may introduce a bias even when two series are exactly the same in the overlap (same values, same missing months)! In general, this Hansen combination methodology seems to include a nagging “feature”: the future values will affect previous values in the combined series.
Sorry, the reference was #97 (Steve).
Re: #68
Is there a need to establish a program to scrape the data from the GISS pages? If so, I can probably help there.
Richard
An interesting observation about Hansen’s bias method.
LongSeries has 100 months in the overlap period, they sum 650.
CombSeries has 100 months in the overlap period, they sum 700.
This example series has a bad result. Consider
LongSeries – 100 months – 650
ShortSeries – 100 months – 550
ShortSeries is 1 degree per month cooler. To bias it, add 1 degree per month, or 100 degrees total. Now, you have two series with the same sum.
When you average two series with the same sum, the resulting series will also have the same sum. If it differs significantly (num_months * 0.05 works) you have a BUG. Because you can’t get different sums without one.
Now, note that it doesn’t matter what’s going on with the ShortSeries. It need not have 100 months of data to demonstrate the error. It don’t matter what happened, the result is wrong.
This relationship holds as long as the number of records in the reference series during the overlap is the same as the number of records in the combined series during the overlap(LongSeries == CombSeries). This relationship is a necessary result of Hansen’s method of combining records. If these sums aren’t even close, it is undeniable evidence of a mistake.
I’d suggest that you don’t have to know what his mistake was, as long as you can show that it was made. Free the damn code already.
Does anyone have a sense of how missing data varies overtime and within the year? With respect to the latter, Negele has most missing data in Juneyet least in July and November. Presumably we are looking at monthly data constructed from daily data. Are similar processes in play for assembling a “complete” monthly record?
I don’t know if this will help or that I will get it. I have an FOIA to GISS for the raw data in Hansen etal 1999. It is supposed to be the raw data supplied and any data that it was compared/combined with. It is supposed to be the raw data Hansen used. I am due a reply shortly.
I think the effect of this algorithm on the record can be seen by looking at it mathematically:
The quarterly temperature T for any given quarter q is
where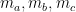 are the months in the quarter (in no particular order) and n is the year. So if one of the three months
are the months in the quarter (in no particular order) and n is the year. So if one of the three months  is missing:
is missing:
where N is all years of the record. Continuing:
where
Substituting:
And finally substituting for the seasonal temperature:
As you can see, the estimated seasonal average becomes very heavily influenced by the average of not just the missing month, but also the existing months. The existing monthly values end up having one half the influence they would otherwise have if the missing month were present. By extension, this effect would extend to the yearly average when it is calculated from the seasonal averages.
Hopefully I got the equations and latex correct.
Looking at it another way, the seasonal average becomes based 2/3 on the seasonal average over the entire station record, and based 1/3 on the measurements of the other two months. It almost seems that the following would be better:
So now consider the implication on Hansen’s bias method (Sunday’s crossword). Recall that he wrote:
What we found from the previous puzzle is that he may not actually use the entire period of overlap, because what he actually does is use only the annual values from the complete years of overlap, so if there is overlap that extends into a prior or subsequent year but does not produce an annual average, the data is disregarded.
What we also found is that some of those annual values are estimated, which was the purpose of this puzzle. We do not yet know the extent of the estimation, but when it exists it has an interesting effect. In those cases, the periods of overlap are now influenced by the entire record. It is left as an exercise to determine / quantify the extent of that influence!
John:
What impact will these adjustments have on data that has an existing trend? If there is no trend, then I do not see a problem except for being a fundamentally poor practice.
#108 Bernie
I believe trend is unimportant, because averages are being used. one can’t determine a trend from a single average. As Steve M. has pointed out, the issue is corruption of the data. That corruption will probably introduce a bias that was not there.
#109. Just looking back at Bagdarin in light of what we’ve learned. Many of the guesses in the Waldo in Bagdarin Thread are now superceded. The early portion of the Bagdarin record shows that Version 0 (Starting in 1938) was adjusted down by 0.3 deg C relative to Version 2 continuing to the present, although they are scribal variations in the overlap period. At the time, we weren’t looking for single-digit adjustments, but it is clearly evident by comparing 1938 values for Version 0 and dset=1. Hypotheses of adjustments such as 0.23 deg C have been overtaken by the near certainty that he does single-digit adjustments.
The 0.3 deg C step at Bagdarin is introduced in the mid-1980s – so the Hansen scribal-variation error can cause substantial errors in individual stations. I’ll bet that the Siberian data versions are very similar in their date structures and this we may see the Bagdarin step in multiple stations. Time will tell.
Jean,
Good job working it out and thanks for posting the code although it won’t be of much use to me. No matlab skills and too far along in life to be interested enough to learn. Only semi-literate statistical skills.:)
I’ll reread your description until I have a good handle on it.
Looking at the adjustments made due to missing data, I have zero confidence in their method. It seems they’ll be continually re-adjusting older records as more years are added. Makes no sense to me. The historic records are what they are and should be left as such. Any infill of permanently unknown data should be done carefully and only once.
Seems what they’re doing would make any relationship to older dewpoint/humidity data of questionable use. Maybe they’ll come up with a new algorithm to compensate.:)
Side note. I was looking at Bangor, Maine and noticed they have a same location dataset they don’t use in calculating the combined file. There is no direct link to it. I only noticed it because it is shown in the upper corner of the graphic you get with the link accessible raw files. The ID is 425726190010. Paste the ID into the search page and you can access it. Or by making it display a list of stations near Bangor. It seems to be a fairly full set and would add another twenty years of history if it were in use. Very curious. Maybe they didn’t like the slope.:)
#101. I have a program which does this. Thanks for the offer.
If it’s FTP, you can drag and drop folders through a web browser connection or use Filezilla.
#113. No, it’s not FTP. It requires scraping from webpages. This was discussed last May. It takes many hours to scrape net 8 MB of data.
#114: I have been searching for alternate methods of obtaining the raw data and found the GHCN archive, which is available as a single .tar.gz via FTP. It contains daily station data (min temp, max temp, precipitation) for all stations in GHCN. It’s roughly 1GB, but took only about 2 hours to download.
I assume that the daily GHCN data is averaged to create GISS dset=0 monthly data (minus the USHCN corrections). I will attempt to confirm myself, but was hoping to get some direction from the community first. In particular:
– Is there a reference for USHCN corrections?
– How should I combine min and max temp to get average temp? (Is a daily average adequate?)
My plan is to re-create GISS dset=0 from the daily GHCN data. By starting with the daily records I can keep track of error bounds on the monthly averages.
The next step will be combining station data to create dset=1. Alternatively, station data could be combined directly from the daily records instead of the monthly averages.
The final step of creating dset=2 is a long way off, so I have not yet thought about it much.
Of course, all code will be provided to the community for review and suggestions.
Thanks in advance for any help or feedback.
#98
To say Hansen “stonewalled” is very fair. It is clearly an understatement. Hansen has worked long and hard to earn the treatment he is receiving. Free the code!
THe USHCN corrections only apply to the 1221 USHCN stations. If you stick with non-US stations. It’s not an issue. The UShcn adjustments are a hornet’s nest that I’ve not ventured into yet, but the station history adjustment looks especially problematic.
You’ve downloaded daily data. There is a much smaller monthly GHCN collation, which has different versions. Ive posted up relevant links at http://www.climateaudit.org/?page_id=1686
Thanks for the link. I will probably use the daily data as my primary data source, but the monthly data will be useful for checking the code.
I hope that an open temperature analysis library will be useful as a starting point for more analysis. As Steve has said elsewhere, there are other problems (such as limited station meta-data and quality control) — but robust analysis code can’t hurt.
The GHCN daily data is also in indivdual files by station. You can collect using a function here http://data.climateaudit.org/scripts/stations/read.ghcnd.txt
#115 John, Could you post the link where you found the daily records? Thanks.
#120: Phil, all of the GHCN data is available via FTP at this base address:
ftp://ftp.ncdc.noaa.gov/pub/data/ghcn
The daily records are in the daily folder.
The raw data used by GISS is in the v2 folder.
FYI, these links (and *many* more) are available on Steve’s Station Data page.
For completeness, here is the derivation of annual temperature when a quarterly value is missing:
The annual temperature T for any given year n is
where are the quarters in the year (in no particular order). So if one of the four quarters
are the quarters in the year (in no particular order). So if one of the four quarters  is missing:
is missing:
where N is all years of the record. Continuing:
where
Substituting:

And finally substituting for the annual temperature:
In this case, a missing quarterly value means that the annual average will be 50% based on quarterly averages instead of 25%, as one would intuitively expect.
In this case, a missing quarterly value means that the annual average will be 50% based on quarterly averages instead of 25%, as one would intuitively expect.
Argh…it works in the Latex equation editor.
Here is the raw latex:
{T}_{q,n} = \frac{1}{4}{\overline{T}}_{{q}_{a},N} + \frac{1}{12}{\overline{T}}_{{q}_{b},N} + \frac{1}{12}{\overline{T}}_{{q}_{c},N} + \frac{1}{12}{\overline{T}}_{{q}_{d},N} + \frac{1}{6}{T}_{{q}_{b},n} + \frac{1}{6}{T}_{{q}_{c},n} + \frac{1}{6}{T}_{{q}_{d},n}
Basically, take one-fourth of the current quarter average, add to it one-twelfth of each of the other three quarter averages, and add to that one sixth of the other three quarter actuals.
Steve: it looks like the formula was too long. just insert an end tex and re-start tex and it will patch.
John V,
Some caveats:
The GHCN daily files include many locations not included in the
GHCN (V2 monthly) files, and vice versa.
In GHCN V2, when monthly max/min data are present, the raw mean numbers
are almost always (max+min)/2.
The station numbers in GHCN daily are not the same as the station numbers
in GHCN V2.
re 125.
JerryB… A while back we chatted about the rounding rules for daily data since the data
was ints.
Tmean = (tmax+tmin)/2
What was your thinking on this.. I’m loathe to search the threads..
RE #126
steven,
I posted an attempt to express Terry’s point in a different way, but I
avoided posting my views on the subject.
Someone, perhaps Jean S, posted a link to http://www.diycalculator.com/popup-m-round.shtml
which offers some thoughts on rounding. I like the idea of “bankers rounding”
but I would not like the overhead it would require.
Practically, for temperature data I would be inclined to keep the numbers in hundredths,
or thousandths, to reduce the effects of rounding errors with minimal computational overhead.