I’m not sure that there’s a huge demand for more linear algebra on MBH98, but here’s the rest of the proof that the NH temperature index in an MBH98-type calculation is simply a linear combination of proxies and, when only one temperature PC is reconstructed, the weights are proportional to the correlation between each proxy and the temperature PC1.
Re-scaling of Reconstructed Temperature PCs
After the calculation of RPCs, Mann re-scaled the variance of each RPC in the calibration period to the variance of the “observed”‘? RPC. This step is not described in MBH98 itself and was not replicated in our emulation for MM05b. There, purely for reasons of expediency, we re-scaled the variance of our emulated NH reconstruction to the variance of the MBH reconstruction. The impact on cross-verification statistics for the 15th century of the two methods is negligible -as the cross-validation R2, RE and CE all coincide within 1%. The method is also one that is not written in stone. Bürger and Cubasch describe it as a “flavor”‘? among various reconstruction alternatives.
The existence of this step in MBH98 has also eluded other observers. For example, Von Storch et al [2004] postulated that the lesser low-frequency range of MBH relative to other reconstructions [e.g. Esper et al, 2002] was due to MBH regression procedures without subsequent “parching”‘? (i.e. re-scaling) of the series. The step was seemingly only introduced by Ammann and Wahl at the penultimate stage of their analysis. Their code includes an annotation dated April 2005 providing for re-scaling of the RPCs as described here, which presumably had been absent in their earlier code. The rescaling step is definitely observable in the MBH98 source code archived in summer 2005.
This step can be expressed in linear algebra terms as follows:
19) 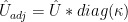

In our algorithm, we have calculated the two standard deviations, which is a slight departure from a purely linear analysis as the term 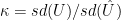
Calculation of NH Temperature Index
The RPCs are estimates of the temperature PC series, which were originally obtained from a PC decomposition of 1082 gridcell series (after division by their standard deviation and their area weight). The next MBH98 step is to take the vector of eigenvalues àŽⲠand the matrix of eigenvectors V from the original temperature PC decomposition (using Neofs principal components) and re-combine then to estimate the gridcell temperatures (after division by standard deviation and area-weighting):
20)

Next, the division by gridcell standard deviation and area weighting prior to the PC calculation are reversed by multiplying by gridcell standard deviations and the reciprocal of the area weighting (gridcell cosine latitudes in MBH98, although this should have been their square root) as follows:
21) 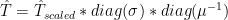
where 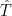
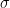
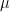

22)
![\tau = \hat{T} [,index] *\mu [index] * ( \sum \mu [index])^{-1}](https://s0.wp.com/latex.php?latex=%5Ctau+%3D+%5Chat%7BT%7D+%5B%2Cindex%5D+%2A%5Cmu+%5Bindex%5D+%2A+%28+%5Csum+%5Cmu+%5Bindex%5D%29%5E%7B-1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
where
Weighting of the RPCs
There are some useful simplifications that can be obtained from the linear algebra here. First, I show that the calculation of the temperature index
23)
![\tau = \hat{T} [,index] *diag( \mu [index]) * ( \sum \mu [index])^{-1}](https://s0.wp.com/latex.php?latex=%5Ctau+%3D+%5Chat%7BT%7D+%5B%2Cindex%5D+%2Adiag%28+%5Cmu+%5Bindex%5D%29+%2A+%28+%5Csum+%5Cmu+%5Bindex%5D%29%5E%7B-1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
![= (\hat{T}_{scaled} * diag (\sigma) * diag (\mu)^{-1})[,index] * diag (\mu [index]) *](https://s0.wp.com/latex.php?latex=%3D+%28%5Chat%7BT%7D_%7Bscaled%7D+%2A+diag+%28%5Csigma%29+%2A+diag+%28%5Cmu%29%5E%7B-1%7D%29%5B%2Cindex%5D+%2A+diag+%28%5Cmu+%5Bindex%5D%29+%2A+&bg=ffffff&fg=000&s=0&c=20201002)
![( \sum \mu [index]) ^{-1}](https://s0.wp.com/latex.php?latex=%28+%5Csum+%5Cmu+%5Bindex%5D%29+%5E%7B-1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
![= (\hat{T}_{scaled} [,index] * \sigma[index]* ( \sum \mu [index])^{-1}](https://s0.wp.com/latex.php?latex=%3D+%28%5Chat%7BT%7D_%7Bscaled%7D+%5B%2Cindex%5D+%2A+%5Csigma%5Bindex%5D%2A+%28+%5Csum+%5Cmu+%5Bindex%5D%29%5E%7B-1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
![= (\hat{U}_{adj} * diag(\delta) * V^T) [,index] * \sigma[,index]* ( \sum \mu [index])^{-1}](https://s0.wp.com/latex.php?latex=%3D+%28%5Chat%7BU%7D_%7Badj%7D+%2A+diag%28%5Cdelta%29+%2A+V%5ET%29+%5B%2Cindex%5D+%2A+%5Csigma%5B%2Cindex%5D%2A+%28+%5Csum+%5Cmu+%5Bindex%5D%29%5E%7B-1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
![= (\hat{U} * diag(\kappa)* diag(\delta) * V^T) [,index] * \sigma[,index]* ( \sum \mu [index])^{-1}](https://s0.wp.com/latex.php?latex=%3D+%28%5Chat%7BU%7D+%2A+diag%28%5Ckappa%29%2A+diag%28%5Cdelta%29+%2A+V%5ET%29+%5B%2Cindex%5D+%2A+%5Csigma%5B%2Cindex%5D%2A+%28+%5Csum+%5Cmu+%5Bindex%5D%29%5E%7B-1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
It can be readily seen then that:
24) 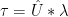
where 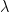
25)
![\lambda= (diag(\kappa)* diag(\delta) * V^T) [,index] * \sigma[,index] *( \sum \mu [index])^{-1}](https://s0.wp.com/latex.php?latex=%5Clambda%3D+%28diag%28%5Ckappa%29%2A+diag%28%5Cdelta%29+%2A+V%5ET%29+%5B%2Cindex%5D+%2A+%5Csigma%5B%2Cindex%5D+%2A%28+%5Csum+%5Cmu+%5Bindex%5D%29%5E%7B-1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
This weighting can be readily calculated as a function of the selection of Neofs eigenvectors and the logical vector of gridcells, thereby quickly yielding either a NH temperature index or a temperature index for an individual gridcell. The key point here is that, up to the very slight linearization of the re-scaling step, the temperature index is a linear combination of the RPCs.
Collecting the Terms
There is an even further simplification possible. Let’s recall that the RPCs can be calculated in 2 lines:
![G = (U^T * U)^{-1} *U^T *Y[503:581,]](https://s0.wp.com/latex.php?latex=G+%3D+%28U%5ET+%2A+U%29%5E%7B-1%7D+%2AU%5ET+%2AY%5B503%3A581%2C%5D+&bg=ffffff&fg=000&s=0&c=20201002)

We can now express the final NH temperature index in terms of the original proxies as follows:
26) 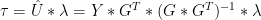
where
27) 
28)
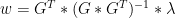
In the one-TPC situation (of AD1400 and AD1000), this reduces to (replacing matrices in capitals with vectors in Greek lower case (including
29)
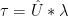

That is, the NH temperature reconstruction is a linear combination of the individual proxies, each weighted by their correlation to the temperature PC1.
I’ll post some more on this situation on some other occasion, but, for now, if the proxies are all orthogonal (and the inter-proxy correlation of most of the 15th century proxies is so low that this is surprisingly close to being the case for the major block of the proxies), then the coefficients would be identical to those from multiple correlation. With some inter-proxy correlation, this multivariate method gives coefficients that differ from those of multiple linear correlation. However, when one starts to think about this odd methodology in statistical terms, I think that it’s helpful to start with known results arising from multiple regression.
In the 15th century case, this boils down to an operation like multiple regression with 79 observations against 22 variables. In the AD1820 case, there are 112 variables. If you add autocorrelation into the mix, the “effective” number of observations is reduced from 79 to some lower number – Moberg et al. estimate 6 in not dissimilar circumstances and then recoil from the implications. You can start to see why you can get some pretty high calibration R2 values and why estimation of confidence intervals based on calibration residuals is fraught with problems.
We are starting to see an infectious spread of this aspect of MBH98 methodology in multiproxy studies in the guise of correlation-weighted reconstructions (see Mann and Jones, 2003; Mann, Rutherford, Ammann and Wahl, 2005). I’ll re-visit this on another occasion.





15 Comments
Let’s see. I’ll engineer a proxy goodness test which “rewards” certain proxies based on the goal to create a Hocky Stick shape. How might I do that? I now recoil from that very thought …..
Hey, you just keep changing the statistical methods, until you get the curve you want!
There are lies, damned lies and statistics.
#1. You use principal components with short segment centering: it mines for hockey stick shaped series and flips them so that they match. Wait a minute, they already did that.
#4
A double whammy??
Steve, yes, there certainly is such demand, even if it takes a while to get around to absorbing it properly. Getting this down and available is very worthwhile.
Re: “MBH Calibration-Estimation Procedure” and “More Linear Algebra”
There is a story about Albert Einstein whose subplot might pertain here. Einstein was invited to tea party at Princeton, the hostess of which was naturally thrilled by the honored guest and asking Einstein if we would speak on relativity theory.
Without any hesitation Einstein rose to his feet and told a story. He said he was reminded of a walk he one day had with his blind friend. The day was hot and he turned to the blind friend and said, “I wish I had a glass of milk.”
“Glass,” replied the blind friend, “I know what that is. But what do you mean by milk?”
“Why, milk is a white fluid,” explained Einstein.
“Now fluid, I know what that is,” said the blind man. “but what is white?”
“Oh, white is the color of a swan’s feathers.”
“Feathers, now I know what they are, but what is a swan?”
“A swan is a bird with a crooked neck.”
“Neck, I know what that is, but what do you mean by crooked?”
At this point Einstein said he lost his patience. He seized his blind friend’s arm and pulled it straight. “There, now your arm is straight,” he said. Then he bent the blind friend’s arm at the elbow. “Now it is crooked.”
“Ah,” said the blind friend. “Now I know what milk is.”
Well reconstruction ain’t relativity, but now we know what “milk” is.
Steve, I was hoping in this post that you would shed some light on MBH98 “skillfully resolving” methodology in chosing the RPC to keep in their NH temperature reconstruction. Phil
#8. I’ve never figured out quite what they did. There’s nothing in their source code released last summer about it. Ammann and Wahl didn’t replicate it either. It’s one more loose end.
Steve, normally the PCs in a PCA type analysis are columns of a unitary matrix, so the PCs (columns of the unitary matrix) are orthonormal to each. In mbh98, they use monthly data and than average to get yearly PC’s, such that the resulting PC1-16 (from website) are almost orthogonal but not quite. In Zorita et al JC may 2003 which has been referenced by Mann as supporting his reconstruction, they proceed directly to annual PCs by doing a svd on the standardize yearly T matrix resulting in orthonormal PCs. It is interesting to look at your above equations and treat the retained U’s as orthonormal. G becomes G ”€ ‘? UT *Y[503:581,] and substituting G into the à…⪬ and dropping [503:581,] to simplify and for clarity. Gives the following
à…⪠”€ ‘? Y * YT *U *( UT*Y*YT*U)-1
Now if the inverse exists and keeping in mind U columns are orthonormal, than with modest effort one can show that UT*à…⪠= à…⫔*à…⪠= Identity_matrix and à…⪭U = 0_matrix, so one can say that U=à…⪠or one can get exact reconstruction RPCs during the calibration period. Now in order for the inverse to exists the column space of the proxys have to span the column space of the retained U’s. So any arbritrary proxy set (including women skirt length) that provides an inverse can provide exact reconstruction and small residuals and error bounds. The NH temperature errors during calibration are based only on the number of retained U’s and have nothing to do with the proxies themselves expect for the inverse requirement. So now all mhb98 needs is to manage some statistical significance during the verification period. Hope this analysis sheds some light. Phil
#10. Phil, thanks for the comment. I’ll have to think about it. I’m pressed on the NAS presentation right now and even the Briffa stuff that I’m posting up now is linked to that; could you refresh this comment in about 14 days if I forget. Cheers, Steve
I got time, let me try. Hey kids, where’s the abacus?
=======================================================
I can’t archive my work, and God only knows where the decimal point is, but I think that’ll do it.
=====================================================================
Steve, I know you’re busy but let me summarize what you probably already understand. During the calibration period, the proxies are regressed against the retained PC(almost) orthogonal vector basis set to obtain a G matrix that will be used for reconstruction during the verification period and further back in time. Normally the PC are orthonormal and it would be possible to exactly reconstruct the retained PC during the calibration period given conditions necessary for the inverse to exist. The point I want to make here was that it is easy to get very good RE and residuals during the calibration period.
MBH98 uses essential your equation 29) à?’€ž= à…⪠* àŽ» to obtain NH temperature both during the calibration and verification periods and back to 1400 AD. The problem with equation 24) is that the lambdas are only valid during the calibration phase. Martin Ringo post is pointing at this fact. SVD decomposition is not additive if one appends a matrix to another matrix to add more records. What I mean by this is that if you one does takes the svd of the standardized gridcell T matrix from 1854 to 1980 (assuming all gridcells available or filled in by a RegEm procedure) than the last 79 elements of that PC1 (even with scaling) will not be equal to the PC1 of mbh98 calibration period, nor will be the lambdas in equation 24).
This really begs the obvious question of why didn’t mbh98 “skillfully resolve” or regress the proxies directly onto the NH or global temperature series, as it would make obvious the gain factor associated with each proxy such as the bristlecones or Gaspe.
Note in my #10 post, instead of “retained U’s” it should be “retained PCs used to form U”
Phil – the trouble with MBH is that there are so many statistical horror stories than it makes a rather sick beauty contest. I apologize for not fully going through the temperature PC issues right now, but I will. One aspect that I’m going to write up a little bit more at some point is the massive overfitting in the calibration phase.
If you look at the equations, the calibration period for the 22 15th century proxies is no more than a representation of Neofs series of length 79 against 22 proxies. The representation is not quite a multiple linear regression, but since many of the proxies are fairly uncorrelated, viewing the operation as something like a multiple linear regression is not too far off. Since the target PC1 especially is very autorcorrelated and the “effective” length of the series is much less – certainly no more than 22: so there is overfitting of massive proportions and most of the covariance relationships are insignificant. It’s even worse with 112 proxies in the later steps.
But you also have one classic spurious regression. But MBH doesn’t fail a Durbin-Watson statistic (although the other multiproxy studies all do). The reason why it doesn’t fail a Durbin-Watson statistic is because of all the overfitting, which ruins the DW diagnostic.
One Trackback
[…] The final RPC includes a re-scaling step described in the following post on this topic here. […]