I’m working on a long note, but probably a short interim note will make some sense. From the point of view of simply advancing our particular take on the MBH98 mess, as between Wahl et al and von Storch et al, there are pros and cons to us for either side being right. So I’d be inclined to say that we don’t have a dog in this particular race and that I can look at it pretty objectively. Right now, for what it’s worth, I’m inclined to think that VZGT have much the stronger position in the current dispute. Given my personal experience with the various parties, this seemed likely at the outset as well.
I’ve taken some time to re-read VZGT 2004 and have a better appreciation for it now than I did before, which I’ll discuss some now and more on a future occasion. The exercise of re-reading has been highly instructive as I think that I’m now getting into a position to pull together the various disparate threads of this small industry of MBH commentary – starting with the MMs, continuing with VZGT04, Bürger and Cubasch 2005, plus all the comments and replies.
For now I just want to present what VZGT actually say, so that there’s at least a blog record of it without going through the poisonous realclimate filter.
Von Storch et al 2004
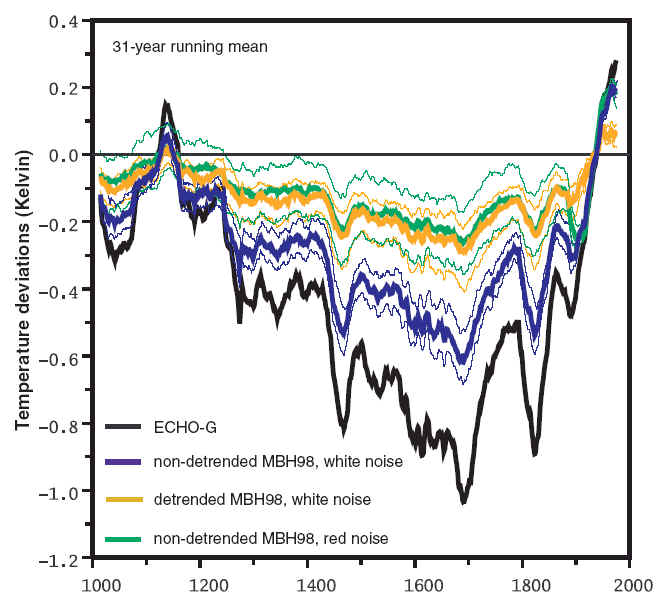
Let’s go back to VZGT [2004]. The figure below is perhaps their key graphic. It showed results from an "MBH98 method" (which in this case involved the use of detrended proxies) using pseudoproxies. Let’s leave aside (for now) the issues of whether detrending is "right" and merely attend to the results under this particular assumption. I’ve blown up the image so that it can be seen clearly as I found the coloring in the original figure at its scale hard to follow. On another occasion, I’m going to try to place the "MBH98 method" within the range of multivariate techniques known to the rest of mankind (for now, grant me that it can be construed as a form of one-stage partial least squares – this follows fairly directly from my posts on MBH Linear Algebra, but I haven’t posted this up).
For now, let’s pretend that VZGT04 presented the graph below as an abstract presentation on the technical limitations of one-stage partial least squares methods with detrended calibration (with no named adversary). Would anyone be surprised that the reconstructions increasingly departed from the target as the proportion of noise in the proxies increased? Of course not. In the context of our empirical studies of actual MBH98 proxies, I’d say that the study left off at much too low a noise level – you need to go to 95% or even 99% or even 100% noise – and/or didn’t adequately explore the impact of contaminated or unrelated proxies. But that doesn’t invalidate the information in the graph below. So despite anything that Wahl et al said or any spin by realclimate, the position in VZGT 2004 Figure 2 below, as far as it goes, seems unassailable to me.

VZGT [2004] Fig. 2 Original Caption. (A) The Northern Hemisphere annual temperature evolution over the last 1000 years. The NH annual temperature simulated by the model ECHO-G and MBH98- reconstructions of this temperature from 105 model gridpoints mimicking the multi-proxy network of MBH98. Increasing amounts of noise have been added to the gridpoint temperatures to mimic the presence of other than temperature signals in the proxies. The corresponding local correlation is also indicated. The 2-sigma uncertainty range (derived as in MBH98 from the variance of the interannual residuals) for the different noise levels is indicated. The reconstruction with ?=0.5 is shown with its 2àƒ—sigma uncertainty range. (B) the spectra of the NH annual temperatures shown in (A).
In partial least squares methodology, there’s a scaling decision that has to be made in each case and I don’t know how VZGT 2004 actually re-scaled the above graphic. There’s a great deal of nonsense being published on scaling and regression by paleoclimate people right now – think of almost any publication by IPCC 4AR Lead Author Briffa – but not the von Storch group. Von Storch [1999] is an illuminating take on this. It’s cited in VZGT04, but it’s easy to miss the citation (I didn’t heed it); I was referred to it by von Storch last year in private correspondence and it’s useful both for understanding what’s involved in re-scaling and may be relevant to what VZGT are doing.
The caveat in von Storch [1999] about re-scaling is that it is not a given that blowing up the variance of a predictor is a "correct" method of matching variance of a predictor to the variance of a target. Von Storch observed that there may be material differences and that it might be more appropriate to add white noise or red noise to the predictor if you want to match variance. Von Storch criticized inflation procedures in Karl [1990] and while he did not mention MBH98, it turns out that MBH98 practiced a similar form of inflation as Karl [1990]. This doesn’t help much in finalizing an interpretation of the above figure and I’ll try to clarify what VZGT did, as I simply don’t know.
We do know (now) what MBH98 did with their PLS estimator – they re-scaled the variance of the PLS estimator of the temperature principal components in the calibration period to the variance of the target series in the calibration period. This re-scaling at the RPC step has been troublesome for people attempting to replicate MBH98 as it was not mentioned in the original text and different guesses as to when and how re-scaling or re-fitting took place can be plausibly made. The matter came up in the Huybers Comment, our Reply to Huybers; there’s a late note in Wahl and Ammann code showing an 11th hour change in how they dealt with this step presumably based on personal feedback from Mann. In any event, the rescaling step in MBH98 methodology is now clear. It should be mentioned that the MBH98 re-scaling procedure is not a law of statistics and is not mentioned in any statistical text. It’s a method used in MBH to deal with an indeterminacy in PLS methods. It’s not "wrong", but neither is it "right". Other methods and other choices could be plausibly argued on an a priori basis. Bürger and Cubasch described this type of decision as a "flavor" and that’s not a bad analogy.
So while I don’t exactly know the provenance of the VZGT 2004 figure, my guess is that you might very well get a result like this for smoothed curves, even with a variance matching exercise. (I’m not 100% sure of this.) As the proportion of noise increases, it gets harder and harder to pick out a signal with PLS or any other method. Think about a limiting case with 100% white noise or 100% red noise. In such circumstances, you can still match variance in the calibration period, you’re not going to recover any information about the "signal". Or consider limiting cases with spurious information (dot.com stock prices) and otherwise white noise. You’ll recognize this line of argument from our work. It’s coming at the situation from the other direction.
Reply to Wahl et al [2006]
Now let’s look at the corresponding figure in the Reply to Wahl et al [2006]. Again, let’s not use the term MBH98 method; let’s continue to use the term one-stage partial least squares with and without detrending, with red noise and white noise. Directionally, the results are the same as before. In the white noise scenario, signal recovery using one-stage PLS without detrending is better than one-stage PLS with detrending. However, with red noise, the results using one-stage PLS are virtually identical with and without detrending. Obviously white noise is very unrealistic assumption not simply in climate series, but especially with tree ring chronologies, which, if nothing else, are reservoirs of red noise. Realclimate huffs and puffs against red noise, but it seems to me that the effect originally described in VZGT 2004 survives unscathed and even to be clarified a little. Again, the results in the Figure below seem unarguable to me.
Update: Apr 30 – Eduardo Zorita confirmed that the data below was re-scaled.
Reply to WRA[2006] Fig. 1. Northern Hemisphere temperature deviations from the 1900 to 1998 mean, simulated and pseudoreconstructed from a network of pseudoproxies and three implementations of the MBH98 reconstruction method (2): with detrended and nondetrended calibration using white-noise pseudoproxies with 75% noise variance; and, additionally, with nondetrended calibration and red-noise pseudoproxies with the same amount of total noise variance, constructed from a AR-1 process with 0.7 1-year autocorrelation. One hundred Monte Carlo realizations of the noise were used to estimate the median and the 5% to 95% range. Two climate models were used, ECHO-G (left) and HadCM3 (right). Scale on the right is half that on the left.
Some Thoughts
So what are Wahl et al and realclimate gloating about? Let’s look closely at what Wahl et al said, this time watching the pea under the thimble. Wahl et al did not disprove any specific result reported by VZGT about one-stage partial least squares methods – just as they have never disproved any specific result that we’ve ever reported. Their comment is usual Hockey Team procedure – isolate some point where parties failed to replicate some poorly disclosed aspect of MBH98 procedure, something which is never mandated as a statistical procedure and shout loudly.
If you think about what VZGT04 are actually doing, surely it is most reasonably construed as setting limits on what performance you can expect from a one-stage partial least squares method – both with perfect pseudoproxies and under noise assumptions (which I view as being inappropriately optimistic). Wahl et al do not show that these performance limits are wrong or incorrectly calculated. They just shout. When I find out exactly what’s going on in the re-scaling step in VZGT, I’ll be in a better position to comment further, but right now I don’t see a problem in relying on these specific VZGT results.
There are other VZGT and VZ assertions that I don’t buy. I think that they are seriously wrong from Zorita et al 2003 on in thinking that you can’t allocate weights to any given proxy and that the MBH one-stage PLS procedure is "robust". I think they really grabbed the wrong end of the stick here and, when they see this, we’ll get to a synthesis.
Back to Wahl et al, who, in effect, claim that the MBH98 reconstruction out-performs the theoretical limits of the partial least squares method. Thus, despite the fantastic noise levels of MBH proxies, the MBH reconstruction supposedly out-performs reconstructions with near-perfect pseudoproxies – and, considering the results in the VZGT Reply, this supposedly happens with and without detrended calibration. How is this possible? What accounts for this remarkable "achievement"?
Answering this takes us into MM world where we deal with the topics that are left out by VZGT and Zorita et al 2003 – the world of flawed proxies, the world of total noise, the world of spurious regression, the world of cherrypicking, failed (and unreported) verification r2 statistics. It takes us into the world of non-robustness, first hinted it in MM03, expanded in MM05 and placed into a broader conext by Bürger and Cubasch. Within a family of high calibration r^2 fits thrown up by various partial least squares (and other plausible methodological) alternatives, you get a wide choice of verification mean. (Also see Briffa et al 2001 for another example of wildly non-robust alternatives). The situation is fraught with temptations to tune on the verification period mean.
If you use the verification period mean to select your model, as B&C astutely point out, you no longer have a statistic left to check against overfitting. (One point here – in the calibration period fit with ultra-high noise MBH proxies, the proxies are close to orthogonal and thus the PLS fit is like a multiple regression of temperature on 22-112 proxies. No wonder you can get good calibration r^2 statistics. This is also why calibration period residuals are totally inappropriate for confidence interval estimation.)
All in all, it’s hard to imagine a worse statistical method.
This covers a lot of ground and I’m going to be tied up for the rest of the week-end. But you can see how one can start pulling together the various strands of MM, VZGT and B-C. Instead of the Wahl et al Comment acting as a vindication of MBH, I predict that it will be a type of catalyst. I think that placing MBH98 regression methods in the context of partial least squares methods will prove to be important in placing this type of work in terms that applied statisticians will understand without having to wade through pages of inflated Mannian, mini-Mannian and Ammannian commentary. Once the applied statistics community understands what’s going on,
and there are signs of interest, that will be the end of the line for MBH98.
I know that they’ve "moved on". But RegEM is another peculiar method, whose statistical properties can’t be read about in a standard statistical text. Mann claims that the similarity of RegEM and MBH98 results shows that MBH is all right. I suspect the exact opposite: the similarity of results using a method with unknown properties to results from a method known to be flawed suggests to me that it has some serious problems as well. No one has ever studied Mann’s application of RegEM to multiproxy reconstructions in a critical way, but doubtless some one will.





60 Comments
I think one problem I see in all this kerfuffle is that you all often don’t go with the killer analysis. And then when there is a debate, people tend to drag in seperate issues than the specific point that is in debate. I mean you can PROVE whether the method mines or not regardless of bristlecones. Bristlecones might be a GREAT PROXY. But you could still prove that the method (the algorithm) was right or wrong. I think the place where things get most confusing and tendentious is in the comments/replies to comments. Also, it bugs me that we have less numerical descriptions of effects. Things like my criticism is of quantity 50% off. Changing from detrended to trended would change the criticism to 45%. I actually sorta see this as both sides (Amman and VZGT and MM and MBH) sinning.
I completely agree that you (MM) are naturally neutral in this exchange because von Storch is on the one hand a co-fighter against poor science and science whose importance is overblown, but on the other hand, he is your competitor in doing the same business. 🙂
So my condolences that our soulmate takes a hit, and congratulations to your increase relatively to the competition. 🙂
I think the whole worrying about alliances and the lot is overblown. If Steve had 10 more real publications out there (he only has one, now), then there would be no question of validity of his insights. He would also push himself more, because his writing would be finished and subject to criticism.
Dear TCO,
I hope that your comments may become a subject to criticism, too. My opinion is that what you’re writing is not true. First of all, it is not true that Steve has one publication. He has at least three, and they are well-known publications available for every scientist who studies the issues via standard channels.
http://scholar.google.com/scholar?q=%22stephen+mcintyre%22
Second, I think that the experience has shown that it is simply not true that that “classically” published papers on climate science are more carefully audited than work published on the blogs.
Incidentally, my guess is that if you write annoying comments like this one (plus the anti-particle-physics on my blog), your inclusion in the Karma trash can was probably not a result of a computer glitch. 😉
Best
Lubos
I’m spending far too much time on this but by it seems fairly straightforward:
Particularly in the case of red-noise and non-detrended calibration. Tellingly, there is not a single mention of red noise in the Wahl note: What they are fighting about is, is the observed trend real or is it red noise?
But von Storch’s requirement is impossible – how can we know that?
But neither do I believe in the significance tests used below as red noise can lead to false significance.
That is why Steve is the one to put the money on here. We cannot know for sure that a proxy response is climate driven or not, and we cannot know for sure that the correlation is not spurious, we can know for sure that 1. a certain percentage of the proxies will be correlated with temperatures entirely due to chance, and 2. these chance proxies can ‘drive the boat’. Whether the 20th century trend is red noise or real is irrelevant to this argument.
Can I ask a dumb question about VZGT(2004) Figure 2?
Just recently Steve was discussing why the confidence limits given in Hegerl et al(2006) appeared to reverse themselves, so that the lower limit become the upperlimit and vice versa. This turned out to be because the confidences limits were calculated after putting in an arbitrary zero anomaly causing the confidences to shrink to zero and reverse sign.
Now with the Figure 2 above, why does it look exactly the same phenomenon?
The confidence intervals here don’t look like they behave in quite the same way as the Hegerl et al(2006) ones.
It could be that in this case, they are shrinking as the date gets closer to the present (more certainty). Because the value also goes up in the 20th century, it appears they shrink when they get closer to 0. However, due to the spaghettiness of the graph it’s hard to tell.
If they’re doing the same thing here as Hegerl I’ll be surprised. That seemed rather nonsensical to me. Hopefully this is a properly calculated +- value rather than a multiplicand.
I don’t see them crossing either, but it’s hard to tell with all the spaghetti. Need to just plot the UCL/LCL for a particular run. The Hegerl thing still amazes me. Did they make that basic of a mistake? Did the mistake occurr in the SI or the regular article? Both wrong for the record, but in the magazine is a lot worse for embaressment and really for the record (SI’s are not really archived for the record in libraries, the way the articles are, SI’s can be amended, etc.)
Given some other discussions going on right now on this blog, can I make a couple points from these graphs? Exclusive of what seems to be Steve’s underlying key issue, which is whether they get the the relative temperatures correct, early and late?
1. The reconstructions (all of them) show an early warm period, then cooling, then warming, which is in temporal rough correspondence with what we know about historical temperatures.
2. The model tracks the reconstructions pretty damned well, although it does overstate magnitudes relative to this record. (I don’t know the model varieties all that well, but I am pretty sure I know that they arent built by looking at tree records and curve fitting to them)
Those seem pretty damned salient points for the larger AGW discussion, and they don’t seem to be often mentioned.
I think you’ve gone a bridge too far, Monty. The recons (just look at a spaghetti graph differ from more classically hockey stick to more curvy ones that show a MWP). For instance compare Moberg and MBH.* I don’t think that they all show the same story. With regard to the models, I don’t know how you can make that statement. Other then the Hegerl paper (which is not complete), where do you get this comparison from? I think many of the models don’t really track the ups and downs we’ve had even during the 20th century (aerosols argument and all that). And they don’t track the regional fluctuations that have occurred during 20th century. But in any case, where are you getting this view from? What article(s) or websites?
*BTW, Steve has been extremely crtical of Moberg despite it having a prominent MWP. It’s still a crappy peice of work.
The larger AGW comment requires magnitude significance, which is extremely salient when discussion statistical variability. Particularly when making the claim that now is warmer than the MWP when a) we can’t calculate the MWP to within 1/2 degree (I wouldn’t be surprised if that number is actually even larger) and b) we can’t even calculate CURRENT temperatures to within a single degree. Further complicate this mess with the fact that we don’t know for sure whether the reconstructions are actually indicated temperature and the house of cards falls.
And yes, these points are mentioned ad nauseum, yet rarely do we see this in the media.
Mark
tco: re 10
The model in this graph in this article tracks the reconstructions in this graph in this article, with the caveats I mentioned.
My main point, really, is in reference to the claims being made elsewhere that there is no (theoretical) basis to the reconstructions at all, and no way to test them.
Mark, re 11. I read a lot of methodological criticisms, some of which seem to be valid ans some of which quite honestly seem to be irritating carping at nits, but I also see a lot of points of correspondence between independent lines of inquiry, and THAT is a strong bit of evidence that the lines of inquiry are at least looking at a real phenomenon, even if they arent exact.
To the extent that the models and the reconstructions are in agreement (and this is just two parts of a much broader puzzle), that lends strength to the validity of each. Not proof, no, but another piece of correspondence. Even with some discord in magnitudes for this particular model adn these particualr reconstructins, it shows the models have gots some of the basics right, and are tracking whatever that reconstruction is tracking. People have been denyign even this, loudly and frequently. Yes, the magnitude issue is important, but magnitudes come from a lot of places, and disparate lines of evidence converge on a range, and at least part of that range is worrisome.
Lee,
“Echo-G” is not a climate model. It is a reconstruction. “Echo-G” is VS’s name for their (imperfect) emulation of the MBH reconstruction method.
from “reply to WRA et al: Fig 1.
“Two climate models were used, ECHO-G (left) and HadCM3 (right). Scale on the right is half that on the left.”
Now that I look again, I see that the figure presented here doesnt have a right scale, nor the HadCM3 data referred to in the legend. WTF?
and from the first figure:
“The NH annual temperature simulated by the model ECHO-G and MBH98- reconstructions of this temperature from 105 model gridpoints mimicking the multi-proxy network of MBH98.”
I’m not (honest) trying to criticize. Just to clarify. I think that most people (and I thought you in your post) when referring to models, mean the predictive physics models or energy balance models (climate prediction models).
Echo-G is just a fancy name for the regression. It’s the VS equivalent of the “Mannomatic”. HADM is (I think) just a compilation of instrumental temp records. I guess these are models in the sense that any excel spreadsheet or even a linear fit of data is a “model”. But they’re NOT climate prediction models.
There are two graphs in figure 1 and Steve only posted ECHO-G.
tco:
I appreciate your attemtps at balance here; I was just confused. Unless they are using the same name for something different, both HaCM3 and Echo-G are coupled climate models
http://luv.dkrz.de/report_2003/report_193.pdf (echo-g)
http://www.metoffice.com/research/hadleycentre/models/HadCM3.html
TCO,
The ECHO-G and HadCM3 are computer models.
Right, so what these graphs are showing is the following (as is my understanding):
* They ran a climate model. We don’t KNOW what the climate was 1000 years ago (that’s the whole POINT of this area of study), so one presumes they have made some kind of educated guess,
* They used that model to create “pseudoproxies”. They are not real proxies. They behave relate to the parameters in the climate model in the way that proxies are thought/assumed to work in the real world.
* They put the pseudoproxies through the same procedures used to calculate what are claimed to be somewhat accurate climate reconstructions when used with real proxies.
* They compared the output of these procedures to the actual data being simulated in the model.
So we have a model presumably based on reconstructions from proxies being used to test methods of reconstructions for proxies. Lee, I’m sorry, but I don’t see how you can use the outcome of that test to show ANYTHING about the real climate. Not only is it circular logic but there are several different stages of large uncertainty along the way. Is the model accurate? Are the input conditions to the model historically correct? Do the pseudoproxies respond to climate like real proxies?
So in conclusion I don’t how the graph has any relationship to real climate, other than being loosely baesd on what’s believe to be a rough estimate of the climate. It’s a vehicle for demonstrating the limits on accuracy of the reconstructions and nothing more.
Nicholas is exactly right. The “Echo-G” squiggly line is the *source* of the pseudoproxies created by VS. Thus the similarity of the “pseudo-reconstructions” to the “Echo-G” line as shown in the figures is simply due to the latter being the source of the former.
VS et al are using these kinds of tests in order to clarify the *sensitivity* of various mathematical reconstruction techniques/procedures to real-world issues, such as varying amounts of noise obscuring a climate signal in climate proxies. The idea is to determine how closely a method will “reconstruct” a sample investigator-created artificial “climate” (Echo-G in this case), using idealized “pseudoproxies” (in effect, not-fully-realistic but well-understood, best-case models of real-world proxies). Any limitations to the method revealed here place a limit on how well the method can work in real-world reconstructions, with less-ideal proxies. The reason for using an investigator-created artificial “climate” is that they need to know the “correct” answer in order to measure how the pseudo-reconstructions differ from that correct answer.
One of VS et al’s main points seems to be that using an MBH-type method for the reconstruction, even in an “ideal” case like their model system, will produce a reconstruction with artificially-low variability around the mean (as shown in the figures, the colored reconstruction lines all have troughs much shallower and peaks much lower than the black “true climate” line). Thus, they are trying to show *theoretically* that, even in a “best-case” scenario, the MBH method underestimates past climate variability, and the more noise in the proxy signals, the more the method underestimates the past climate variability.
In effect, their work says that even if MBH methods are valid for reconstructing past climate, the “true” variability is higher (likely *much* higher) than what the methods report (e.g. warmer MWP, colder LIA, etc).
So, on the one hand, Steve, Ross and others are questioning the validity of the MBH methods, while VS et al are saying that even if they are valid, the “true” past climate was substantially warmer and colder than what MBH methods report.
(at least that’s how I see it)
I guess I was confused on what echo-G was.
I agree. I would suggest it comes down to the calibration of the proxies in the reconstructions. This is done by scaling the proxy so that its variance is equal to the variance of the overlapping instrument record. I believe every reconstruction uses some variant of this method to scale the proxies. In a nutshell, this appears to be a major flaw that VS is attempting to point out. For the sake of argument assume that tree rings can be used as a thermometer. IOW, assume there is a temperature signal buried in the noise of the tree rings. Of course, there is noise in any measurement but it would be reasonable to assume that the noise in the instrument record is going to be somewhat smaller then the noise present in the tree rings. Therefore it seems obvious that the variance in the tree rings should be larger then the variance in the instrumental record. The scaling is in effect going to incorrectly reduce the amplitude of the proxies by making their variance equal to the instrumental record. In the case where the proxies are de-trended, the variance will be reduced relative to the proxies that are not de-trended. The amplitude of the de-trended proxies would therefore be attenuated less then the proxies that are not de-trended. The graphs appear to support this. Does that make sense?
#21. Yes, VZ are saying what is the best that you can hope for with noisy proxies that contain a temperature signal. If this interpretation is correct, then one problem with MBH is that it out-performs in representing the verificaiton mean what the theoretical possibilities are with this type of methodology.
This is a different side of the coin or a different side of a dice to what we were saying, but neither contradicts the other: we said that an MBH system (including the PCs applied to red noise) can very often produce hockey-stick shaped series.
In order to “outperform” what is possible with a temperature signal, you actually NEED a nonclimatic trend. In effect, MBH ability to reconstruct a verification period mean is impossible with valid proxies plus noise but possible with an invalid proxy combined with white noise.
It’s an interesting synthesis.
OK, got it; I was misunderstanding the methodology of this paper. thanks.
An interesting twist here is that as early as May 2005, Science rejected a technical comment on VZGT04 describing exactly the same criticism as Wahl et al, not believing that it “substantially furthers the discussion”. That comment also contained the 32 flavors that went later into our Tellus paper.
But you are the enemy or have made cause with the enemy. WRA are like Mike Mann’s little defenders. They all sit around Real Climate and drink beers together.
I bet they are watching us…RIGHT NOW! 🙂
I’ve done a calculation using MBH98 proxies with and without calibration detrending. There’s not much difference other than in the early 15th century period. In that period, if you use detrended calibration, you get high early values as the weighting of the bristlecones is attenuated. I’m going to put up a got quote for Hampel on robust statistics – Hampel, who’s a god in the world of robust statistics- says that once data is identified as being a “leverage point” then it should be evaluated. Whatever one thinks of the pros or cons of any of the individual arguments, the bristlecones are clearly identified as “leveraged” in Hampel’s sense (and in any intuitive sense). Hampel says that the decision on leveraged points is “non statistical” – you have to go back and examine the data. Sometimes leveraged points bring in new insight; sometime they are outliers that are contaminating the data.
That’s surely what we did – we identified the bristlecones as leveraged – and found that, going back to first principles and surveying the underlying literature, there were serious issues regarding this data and no good reasons why these leverage points should be included on an unsupervised basis.
In our 2005 articles, we tried to get past the idea of whether a method was “right” or “wrong”, but to view the methods in terms of robustness – using the term as it’s used in statistics, rather than in the Mannian sense (among other things, I wish that he wouldn’t use technical statistical terms merely as terms of approbation – “robust” – or disapproval – “spurious”). B&C enlarged on this in their GRL article, referring to our discussion in their GRL article, but probably didn’t express their viewpoint using language of robust statistics as much as I would have liked.
Gerd, in your Science submission, did you cite our articles? Maybe that’s why you got rejected.
Lee, w.r.t. magnitudes: not only imporatant, but they are the basis for the alarmist claims. The magnitudes which may be worrisome on the high end, are based on what seem to be very flawed statistical methods. These same magnitudes are driving policy. They’re the basis for Al Gore’s rants. They’re the basis for the TAR/4AR alarmism. As I said, they aren’t just important, they are central to the whole thesis. This is the worry of most people in here that, yes, maybe there is some warming, but no, it is not significant enough, nor nearly enough within our ability to control, to be spending billions of taxpayer dollars on.
I have some other comments regarding models and reconstructions “tracking,” but I need to think about them a bit more…
Mark
I haven’t looked at the recent VZGT-WRA exchange all that closely, so my comments here are as much queries as assertions.
(1) The WRA argument is that the data should not be de-trended, and VZGT detrended it. Based on the exchange I don’t think it matters immensely in the ECHO-G context, but I’ll bet it does matter in the MBH98 context since it changes the weight on the bristlecones. As to whether the data should be de-trended, VZGT give a sound a priori reason for doing so to avoid conflating nonclimatic trends, and WRA apparently think otherwise, but the matter can be settled on empirical grounds. In a linear regression model, detrending the dependent and independent data prior to the regression is equivalent to using non-detrended data and including a trend in the regression equation, so the decision about its inclusion can be based on a test statistic. If adding a trend changes things, it indicates that the trend captures a component of the proxy data not shared by the temperature data (or vice versa). In other words, if it is significant, it is a signal that should not be assigned to the proxies–meaning the non-detrended option (recommended by WRA) risks spurious attribution of a nonclimatic signal to the proxies. If the issue is CO2 contamination, why not just include CO2 levels in the regression model, or better yet, instead of de-trending, de-‘CO2’ the data.
(2) In the Echo-G model framework there are no problems of degenerate proxies (i.e. bristlecones) dominating the results, unlike the MBH09 context. The issue vS and coauthors have raised is that the least-squares procedure does not preserve the variance of the dependent variable. I know that one proposed ‘solution’ is to rescale the variance, which amounts to an arbitrary change to the model coefficients. But I am puzzled how this can be the solution. The least-squares coefficients optimally predict the conditional mean of the target variable. An arbitrary change to the coefficients might improve the prediction of the conditional variance of the target variable, but at a cost of no longer optimally predicting the conditional mean. (‘Conditional’ just means, given the values of the independent variables)
(3) Our reply to vS&Z last year pointed out the numerous discrepancies between the ECHO-G pseudo-proxy data and the MBH98 proxy data, which made their comment irrelevant for the purpose of assessing the M&M critique of MBH98 data and methods. We conjectured that vS & Z had not actually captured the particular problems of MBH98, and offered a simple statistical test: based on their pseudo-proxy data, if they get a high RE, then they will get a high r2 as well. To show they are simulating the MBH98 problem of spurious significance, they need to get a “high” RE and a zero r2. But we didn’t have access to their model diagnostics, so we had to leave it as a conjecture. Eduardo, if you are reading this, are you able to simulate an outcome with a high RE and a zero r2?
As others have suggested, the magnitude of the warming/cooling and the accuracy with which we can measure them (along with applying them globally) is a large issue.
Also, if you’ll look around the site, you’ll note that there tend to be common proxy datasets as main inputs into the reconstructions, so it makes sense that the reconstructions would produce similar results. The magnitude of the temperature changes, etc, depends on which data sets are used/thrown out and which methodology is applied. And then there are issues with the proxies themselves.
Re:31 Thanks Ross. In reference to your point (1) isn’t it important to point out that the calibration data is virtually a straight line up relative to the noise level. The time period that temperatures have been recorded is so short it creates these ambiguous interpretations: Is it a trend? Is it a cycle? Is it noise?
Look what got posted up at realclimate regarding a VOG comment by Gavin:
This is the nub of the entire problem. I’m amazed that the censors missed this one.
Is that Ross or you in a sock puppet?
#34,35 Wasn’t me.
Not me either. While I obviously agree with the point, it’s expressed a little differently than me.
…than I (would). 🙂
Same problem with Ross’s comment. Predicate nominatives, Profundi.
#65 has prompted two VOG comments. The comment by Gavin originally criticized was:
Gavin’s excuse in the #65 VOG was:
One of the the two then cites a couple of Rutherford et al’s presumably as "fully reasoned and fully caveated expositions".
Now there are many real and interesting statistical issues involved once you raise the possibility of responses varying by scale. But I don’t think that they being to understand what’s involved or, if they do, they’re dissembling.
Now at one time, they claimed that they could obtain results on a year-by-year basis: remember 1998 being the warmest year of the millennium. To launder their previous false claims of valid verificaiton r2 statistics, the Hockey Team needs to argue that they have meaningful reconstructions in "low-frequency" while not having anything meaningful in high-frequency.
But there’s a huge price in goinog from high-frequency to low-frequency claims. You lose degrees of freedom like crazy. If you look closely at the WRA verification claim, they only claim that they can recover the verification period mean – well this has – let me count – 1 degree of freedom. So you can’t have any confidence interval on it.
When they calculate confidence intervals, they use a high-frequency statistic – the sqrt of the sum of residuals in the calibration period divided by the number of measurements without even counting autocorrelation. It doesn’t get any higher frequency than that. So they are sucking and blowing.
If they go for low frequency, they sacrifice confidence intervals. They aer well and truly stuck.
I also have a beef with relying on fellow travellers as authorities for statistical methods. If they want to use a statistical method to do something subtle with low frequencies, then cite a real statistician – find something in a statistical text, don’t cite a couple of Rutherford et al’s. Actually, that’s a big problem with climate science peer reviewing – they don’t use real authorities.
They are going to think that my post on degrees of freedom came from what you just posted, but it didn’t. I guess I’ve heard your arguments before, though.
Oh…and perhaps this is where the frontier of statistics is being expanded. That’s why they cite each other rather than real statisticians. 🙂
I had suggested to one of the more determined MBH98 cheerleaders over on Deltoid that a somewhere like the Journal of Applied Statistics would be a good, independent place to duke out the fine details of verification statistics, spurious regression and detrending. This should enable independent, external statisticians to review the arguments.
I can’t see the hockey team moving outside the comfort zone of their favoured “tame” climate science journals, though.
Gavin’s arguments are pretty weak, all in all. He insists that using the non-detrended case is obvious and leads to better results. This seems to me to beg the question – do any other of the hockey team studies use detrended data; and if so, did these cases yield better or worse verification/validation statistics for it? Anyone got a quick and easy answer to that? (Unfortunately it isn’t a quick and easy question to answer…)
I think it’s a valid comment of WRA that using detrended does not accurately replilcate the mannomatic. The issue of what is wrong with the mannomatic is a side issue really to the problem of replicating it.
re 42:
Gavin actually made a somewhat more detailed and seemingly on point response, tco. He said that using detrended data removes low frequency responses, and given that the low frequency responses are precisely what they are trying to detect, detrending is inappropriate.
Re #43 – Saying it works better in one study (i.e., mannomatic), is inadequate – you need to show it works generally if you want to justify it in an a priori choice sense. And (#44) Gavin doesn’t point out that only stands if you do not have non temperature signal in your data – which is almost inevitable in tree ring data (for instance), which is the point of von Storch’s reply.
Yeah, he did. But to me it is still an incorrect replication of the mannomatic. That point is an argument on the side issue (is the mannomatic correct). And when you get into that, then you have to deal with autocorrelation argument from the other side as well as the common sense response that many hockey team peices of work (including even Mann in parts of MBH) use detrended. So when is it right and when wrong?
Lee, you’re missing the point. First of all, they originally claimed high-frequency ability and the "low frequency" argument is an ad hocery to deal with the failed verification r2 that they withheld.
Second, maybe detrending is appropriate, maybe it isn’t. I don’t want to see Rutherford, Mann et al as the authority for this in a publication after the fact to the problem.
Deal with the inconsistency. How do you think that they calculate their confidence intervals? They calculate high-frequency standard errors. If they want to go low-frequency, they have to go all the way. They talk about their model fitting the verification period mean. OK, but then you don’t have a confidence interval.
They don’t have any idea what they are doing or where the discussion is leading. They’ve tried like crazy to steer things away from this issue. I’ll bet that they cut this off since they are having their heads handed to them.
John adds: I edited this post for some really bad speling.
Steve: I don’t spel badly; I’m pretty much a perfect speller, but I sometimes get lazy about proofing and I make typos.
I’ve collected some info on Hockey Team uses of detrended. It’s pretty funny, because Mann’s submission to Climatic Change in 2004 huffed and puffed that our original emulation of MBH included as a “major technical error” the failure to use detrended standard deviations. I kid you not.
Re #46
Oops just realised it wasn’t obvious – I was referring to Gavins criticisms in the wider context of Burger and Cubasch, and I should have stated as such. It was obvious to me, cause I was thinking about it at the time 🙂
Just don’t spell your major wrong.
Steve said:
I don’t understand. A mean is a summary statistic calculated from a sample, and standard statistics gives a confidence interval for the mean.
Is there something different about this mean?
#51. What I have in mind here is scaling. Let’s say that you start off with a series of 128 (2^7) years long. You have 128 annual measurements; 64 sets of 2-year averages; 32 sets of 4-year averages; 16 sets of 8-year averages; 8 sets of 16-year averages and 4 sets of 32-year averages; and 2- sets of 64-year averages. This is what happends in wavelet scales which pyramid in scales of 2).
Now to make a reconstruction, the argument is that there is a low-frequency relationship without there being a high frequency relationship, as evidenced by say that the 2^5 year scale – but you only have 4 measurements to fit. With the 64-year scale, which is not even centennial, you only have 2 bins. So how do you get any confidence intervals. You might get an r^2 of 100%, but the t-statistic won’t be significant.
In wavelet analysis, where they try to deal with scaling issues systematically, in series of length 128, the confidence intervals by the time you get to the 5th scale are from floor to ceiling.
It’s not whether you’ve calculated the value in the bin accurately, it’s that you’ve only got a very few low-frequency values to establish a relatinoship.
And by the way, the estimation of the mean in autocorreated time series is fraught with problems totally ignored by the Hockey Team – although this is a different issue. Once the data ceases to be “independent”, then the variance of the mean estimate does not decline as 1/n, but at a much lower – and there are quite palusibile circumstances under which Hockey Team methods would underestimate it by an order of magnitude. I’ll post up some references from Hampel, who I’ve been re-reading.
Steve,
Would it not be advantageous to move your filter in one sample steps rather then the length of the filter? For example the 4 year average would be samples 1-4, 2-5, 3-6 …
Steve,
(I see that some of my comments below have already been dealt with during the weekend. Sorry for the possible repetitions..)
I will try to address some of the numerous points that you have pointed to. But before, let me
try to explain a little bit what the pseudo-proxy approach can and cannot achieve. In experimental sciences one cannot really prove a theory, one can only falsify it by performing an experiment in which the theory does not seem to hold. In paleoclimate, obviously we cannot do experiments, so we resort to parallel worlds that could mimic to a certain degree of realism the real world. In the pseudo-proxy approach these parallel worlds are the output of climate models,and this idea has been also applied in other far-away areas of research, for instance to test methods to disentangle the genetic linage of organisms. The draw-back is that we cannot represent the real world that realistically– we cannot grow bristle cone pines inside the computer, so we have to simplify the problem and get something that could look like a dendrochronological -or other proxy, time series. Given en these limitations, your are bound in this approach by two factors: first you can try to be as realistic- or pessimistic if you prefer- as possible, generating artificial “bad apples” and test whatever method you prefer. If the method does not perform well, your study can be always regarded as too pessimistic, and therefore not relevant for the real world: “you have constructed the bad apples to discredit the method”. On the other hand, one has to reach some degree of realism, to avoid a second caveat that is better illustrated with an example. Imagine that you have a marvelous proxy P that shows a correlation of 1 with the Northern hemisphere temperature. In this case, any method, indeed the simplest one T=P, will perform perfectly, but you will not be able to claim that method is right because the starting point was unrealistic. So one has to design, in one hand, proxies that are realistic enough but, on the other hand, that tend to be optimistic, so that at the end of your analysis you can write something like “even in this optimistic scenario, the method….”. Therefore, one cannot test the method in “isolation”: the input data are also important.
The other side of the coin is that if you do not find something very significant, for instance in our response to your GRL paper, in which we did not found a large difference between “normal” pc centering and MBH-PC centering, it can be of course due to the fact that we were too optimistic in our generation of proxies, or due to the fact the differences do not exist. We found that in the world represented by ECHO-G and by our pseudoproxies these differences really were not large. Nothing more, but nothing less. This problem is similar as in statistical testing of hypothesis, and in science in general. Not being able to reject the null-hypothesis, in this case that the differences do not exist, does not mean that you have proven it.
Now, to some particular points:
yes. the PC-variance rescaling is implemented in V06, although I particularly think it is wrong. After finding the optimal (defined in some way) regression parameters, this rescaling shifts their values away from the optimum. Interestingly, there is paper that has not been cited in all this discussion about this point, written quite a few years ago by BàÆà⻲ger in Climate Research 1996 (the same BàÆà⻲ger as in BàÆà⻲ger and Cubasch) in the context of statistical downscaling. Statistical downscaling denotes the methods to estimate regional climate change from the output of global climate models, and technically is a problem similar to that of climate reconstruction – the target this time are the local variables, the predictors the large-scale fields. In this paper the tension between optimal estimation of the mean and variance conservation is clearly illustrated.
-Detrended or non-detrended calibration. This is an well-known issue and to my knowledge it has been considered in the statistical literature under different names: partial correlation, non-stationary regression, regression with serially correlated data.. The first paper seems to have been written by Yule as early as 1926 (“Why do we sometimes get nonsense correlations between timeseries?”), and I read recently one review paper on this topic written by Philips in 2005 (“Challenges of trending timeseries in econometrics”). So the literature must be large. In climate research it is actually very well recognized: this is why, for instance, to calculate the power of the monthly temperatures in Sidney to predict simultaneous monthly temperatures in Toronto you filter out the annual cycle. Otherwise you get a very nice high anticorrelation, which is of course useless. Or you can try to predict the number of births from its correlation with the number of storks, both showing a trend due to urbanization: again a nice, albeit, useless correlation, unless you believe that storks may indeed play a role. Many other examples abound, one particularly nice, indicating a very high (of course spurious) correlation between Northern Hemisphere temperature and West German unemployment, was shown in the NAS panel meeting. To ascertain a real link, you need a certain number of degrees of freedom, and a long-term trend is just one number, which can be arbitrary re-scaled through the calibration step to any other number one pleases. I think this is widely recognized in the analysis of instrumental data, but surprisingly not in paleoclimate.
In case of proxies, you should have to believe that the long-term trends in the proxy are completely due to the impact of its local climate, or to be more accurate, due to the impact of local temperature. This may be, or not, the case as proxies may be affected by many other long-term effects, especially in the 20th century, such as precipitation, nutrients, changes in the amplitude of the annual cycle, biological adaptation, and a long list. Actually, we know that this not just an assumption, since many tree-ring indicators and local temperatures do show a different link before and after approximately 1980, so that there must be a source of non-climatic long-term trends. As this behavior is not really understood, one has to assume that it could have also happened in the past.
This is essentially the rationale for detrending , or alternatively for including random trends in the pseudo-proxies if one relies on non-detrended calibration. Alternatively, if one has a very good knowledge of the proxies and one can rule out these potential sources of trends, then non-detrended calibration should be correct.
Surely, the econometrics literature may offer more sophisticated solutions to this problem,, and we would be well-advised to look more carefully into some of these, more professional, studies.
Ironically, in each one of the three papers submitted in which reconstructions methods are tested (VS04, VS06 and one under revisions), at least one reviewer required to test the method with red-noise pseudo-proxies (or proxies with random trends). In VS06, it was not even in the first draft and was included at request of a reviewer. This is indicative that the problem is recognized by at least some in the paleo community.
All this is however not really essential, since the method also fails even with non-detrended calibration and even with white noise, and in both models (ECHO-G and HadCM3) tested. BàÆà⻲ger, Fast and Cubasch had pointed out this already in January in the Tellus paper, which had been submitted to Science in spring 2005. Science did not consider it relevant enough for publication at that time, although we explicitly recommended it. Now, for some reason (or perhaps by chance) they changed their opinion. In my humble opinion, this paper is, however, better than the Wahl et al comment and actually better than our VS04, since it delves in a much more detail manner into the causes of the failure of many more methods.
Re 52, according to the excellent reference provided by Steve earlier, Statistical Issues Regarding Trends, Tom M.L. Wigley, a reasonable estimate of the reduction in the effective value of N due to autocorrelation is:
N(effective) = N (1-R1) / (1+R1)
where R1 is the lag one autocorrelation. Here’s a table of R1 versus (1-R1) / (1+R1) for some reasonable values of R1
R1 (1-R1) / (1+R1)
0.5 0.33
0.6 0.25
0.7 0.18
0.8 0.11
0.9 0.05
0.95 0.03
As Steve points out in #52, it only takes a lag one autocorreclation of 0.82, which is common in many temperature series, to give a ten-fold reduction in N …
w.
RealClimate Reels From Withering Attacks
May 2, 2006
Bludgeoned by repeated blows coming from even friendly quarters, top scientists lashed back out at Hans von Storch in an article called “A Mistake with Repercussions”.
http://www.realclimate.org/index.php/archives/2006/04/a-correction-with-repercussions/
This counter attack takes places a month before the NAS panel is expected to report possibly embarrassing opinions on scientists associated with RealClimate.
The article seems to hint at being magnanimous by concluding with:
“We hope that after this new correction, the discussion can move on to a more productive level”.
This after repeating some of von Storch’s harsher criticisms of their work:
“in an interview with a leading German news magazine, Von Storch had denounced the work of Mann, Bradley and Hughes as “nonsense” (“Quatsch”). And in a commentary written for the March 2005 German edition of “Technology Review”, Von Storch accused the journal Nature for putting their sales interests above peer review when publishing the Mann et al. 1998 paper. He also called the IPCC “stupid” and “irresponsible” for highlighting the results of Mann et al. in their 2001 report.”
Von Storch is also blamed for getting RealClimate scientists in hot water with the US congress–
They say his research “… furthermore formed a part of the basis for the highly controversial enquiry by a Congressional committee into the work of scientists, which elicited sharp protests last year by the AAAS, the National Academy, the EGU and other organisations”
They even blame him for the US congress shunning the Kyoto treaty:
“it also was raised in the US Senate as a reason for the US not to join the global climate protection efforts”
Actually, the article is presented as an explanation of research which showed von Storch’s research to be in error and argues “the main results of the paper were simply wrong.”
What they fail to report is that their research still has major question marks hanging over it, which are likely to be reported on shortly. They do hint at this by admitting that von Storch is only partly to blame, but at this time do not name other names
Steve:
You might want to tuck the following RealClimate comment away for when the NAS panel’s results are released.
RE #57-
Could be translated as:
[Response: We, the approved climate “scientists”, have stressed repeatedly that single scientists (M&M, Von Storch, etc–these guys are “single” scientists because they don’t use our proxy data in various pie recipies) and single papers (and never mind that the papers are rather devastating to our presentation) are not the things that the public or policy-makers should be paying much attention to (because they represent reality and the current state of science. We’d prefer to think of it as settled so we can advance our agenda). Instead, they should pay attention to the consensus summaries such as are produced by the National Academies or the IPCC where all of the science can be assimilated and put in context (or at least have all of the caveats removed, the language made more inflammatory, and political agenda advanced. In such summaries, it is very clear what everyone (everyone who agrees with us politically, but not those who disagree with us, because they’re quite obviously industry shills and want to see the planet destroyed) agrees on (gravity, the human created rise in CO2, the physics of the greenhouse effect, conservation of energy etc–but never mind that there really isn’t concensus or that the research and data is fatally flawed), what still remains uncertain (aerosols etc.–where etc. really means everything, including the items mentiond as being agreed upon) and what implications these uncertainties may have (but not too uncertain because we have our position to maintain. Just uncertain enough to ensure a substantial increase in funding for “research” to resolve these uncertainties). – gavin]
YOUR ARTICLE WASW INTERESTING , BUT , WAS BOGGED DOWN BY TOO MUCH TECHNICAL DETAIL . YOU COULD HAVE SINPLIFIED THE TERMS FOR THE COMPREHENSION OF THE LAY READER.
Spam