Getting methodological information from Esper is a bit like dealing with Mann, a lot like dealing with Mann. It really makes me wonder whether there might be some clunker like Mann’s PC methodology lurking in Esper’s closet. Like Mann, instead of providing a comprehensive methodological desscription ideally with code as in econometrics journals, Esper would rather provide non-responsive answers. Right now, I have two outstanding methodological questions – one that I’ve been asking for a while: how he operationally allocates tree populations into “linear” and “nonlinear” trees; the other rose out of disclosure in February and March – not all trees were used from a site, so how did he decide which trees to use an which trees not to use.
Here were the questions that were put to Esper via Science:
a) In 4 cases (Athabaska, Jaemtland, Quebec, Zhaschiviersk), Esper’s site chronology says that not all of the data in the data set is used. This is not mentioned in the original article. What is the basis for de-selection of individual cores?
b) Esper et al. [2002] do not provide a clear and operational definition distinguishing “linear” and “nonlinear” trees. As previously requested, could you please provide an operational definition of what they did, preferably with source code showing any differences in methodology.
Here is Esper’s non-responsive answer:
As described, in some of the sites we did not use all data. We did not remove single measurements, but clusters of series that had either significantly differing growth rates or differing age-related shapes, indicating that these trees represent a different population, and that combining these data in a single RCS run will result in a biased chronology. By the way, we excluded other sites because growth was too rapid, for example.
The split into linear and non-linear ring width series is shown in a supplementary figure accompanying the Science paper. The methods of this widely accepted, approach are described in the paper cited below and in the Science paper. It is possible to make this an operational approach, for example, by fitting growth curves to the single measurement series (e.g. straight line and negative exponential fits) and group the data accordingly. We didn’t do this in the Science paper, but rather investigated the data with respect to the meta information (i.e. for a particular site; data from living trees, and clusters of sub-fossil data), which I believe is a much stronger approach. This, however, requires experience with dendrochronological samplings and chronology development: Esper J, Cook ER, Krusic PJ, Peters K, Schweingruber FH (2003) Tests of the RCS method for preserving low-frequency variability in long tree-ring chronologies. Tree-Ring Research 59, 81-98.
First, consider Esper’s statement: “As described, in some of the sites we did not use all data.” I challenge anyone to locate any “description” or even hint in the four corners of Esper et al 2002 that they did not use all the data, let alone any reason for why they did not use all the data. There is no “description” or even hint in Esper et al 2002 that all the data was not used. The admission came only in response to my parsing through data that took nearly two years to get.
Esper now says that cores were de-selected to avoid a “biased chronology” and cited Esper et al 2003 as a suppposed authority for the procedure. However an examination of Esper et al 2003 provides no such authority. In fact, the closest thing in Esper et al 2003 to such a statement is the following, which I’ve quoted before:
Before venturing into the subject of sample depth and chronology quality, we state from the beginning, “more is always better”. However as we mentioned earlier on the subject of biological growth populations, this does not mean that one could not improve a chronology by reducing the number of series used if the purpose of removing samples is to enhance a desired signal. The ability to pick and choose which samples to use is an advantage unique to dendroclimatology.
Here Esper is talking about removing data to “enhance a desired signal”. Excuse me – that doesn’t sound like a way of avoiding a “biased chronology”; it sounds like a recipe for making biased chronologies – biased towards a “desired signal”. I think that readers are entitled to a better explanation of what Esper is doing.
As to the distinction between linear and nonlinear trees, it is simply not described in either publication. I challenge any of the people who usually disagree with me (Peter Hearnden, Steve Bloom, John Hunter) to read Esper et al 2003 and locate for me where this publication distinguishes between linear and nonlinear trees. The figure in the SI cited by Esper simply shows the number of “linear” and “nonlinear” trees. It does not explain how the distinction is made.
So how did Esper distinguish between linear and nonlinear trees? What effect does this classification have? An obvious question: if he didn’t make this distinction, does it affect relative MWP-modern levels? Did Esper exclude data to “enhance a desired signal”? If so, what was the “desired signal”? In fact, I’m not sure that these particular issues necessarily affect Esper’s results, but right now it’s impossible to replicate his calculations until one knows how these things were done. For all we know, maybe he used Mannian principal components.
There’s a little edge to Esper’s calculations because he has a high MWP as shown below.
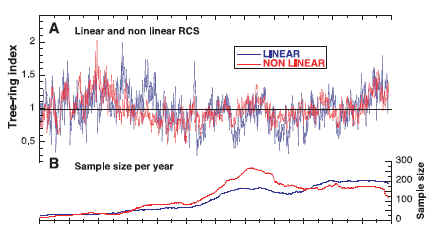
The main reason why his MWP is high relative to usual Hockey Team fare is that he used the updated Polar Urals data (see my discussions of Briffa) which had elevated MWP values. This is the only Hockey Team study with updated Polar Urals data. Once Briffa realized the updated Polar Urals data set had a high MWP, he substituted the nearby Yamal data set which has a pronounced HS-shape and called it “Polar Urals”. The substituted data was quickly incorporated into subsequent HS studies – Mann and Jones 2003, Osborn and Brifa 2006, D’Arrigo et al 2006, etc.





{kind=link}
19 Comments
I can’t see any possible way Esper can defend his particular form of cherry picking. Some of these “scientists” have absolutely no clue about the scientific method. Where the hell did they get their training/education, anyway? They are bastardizing dendrochronology, and you would think some of the dendro people would be castigating them, too. I am actually having a hard time believing what I’m reading here; it is so far out of line. It is simply disgusting.
Blimey. You’ve quoted this before, and I had always assumed it was an off the cuff comment he made in some informal context.
I hadn’t realised it was in writing, in a peer-reviewed paper.
I do hope Rep. Boehlert’s statistics team is paying attention.
Might there be some kinds of selection that may be quite valid for chronological purposes, while being quite invalid for climatological purposes?
If so, avoiding a “biased chronology” may produce a biased climatology.
“As described, in some of the sites we did not use all data. We did not remove single measurements, but clusters of series that had either significantly differing growth rates or differing age-related shapes, indicating that these trees represent a different population, and that combining these data in a single RCS run will result in a biased chronology. By the way, we excluded other sites because growth was too rapid, for example.”
What an entertaining paragraph. The first two sentences are a kerfuffle, intellectual mumbo jumbo, wordy mish-mash. Translated the paragraph reads, “we excluded sites because growth was too slow or too rapid for our purposes.” The terseness of the last sentence reads like a comedic punchline subverting the pretentiousness of the first two, all the more funny because the writer isn’t conscious of the humor.
Thanks for sharing.
#4, the quoted paragraph, and in Steve’s description, amount to no more than a way of saying a qualitative judgment was made about which trees followed temperature. Some, ala the porridge of Goldilocks and the Three Bears, were too fast, others too slow, and the published ones were ‘just right.’
‘Just right’ conceivably meant those trees that produced rings that tracked the modern instrumental temperature record. The unspoken presumption then is, as usual, that having proved themselves with the modern record, those same trees therefore accurately tracked temperature into the indeterminate past. Again conceivably, then, there was curve-matching done with cores from fossil trees, in that some of them produced rings that tracked the cores from the ‘just right’ living trees in the years of overlap. Such fossil trees having thus proved themselves against the accurate trackers, also were taken to accurately track temperature even further into the indeterminate past.
One could see producing a tree ring series “tracking” temperature as far back into the past as one can find fossil trees. It all seems superficially reasonable, except for the unspoken presumption that the growth of certain trees, for some reason linear with temperature now, were linear with temperature throughout their entire lives. Likewise those fossil trees that proved linearly congruent with the living ones. Once linear, always linear — the sine qua non of dendroclimatological science.
It’s pseudo-science with a kind of statistical rigor pasted onto its surface; rather like astrologers who, using Newton’s mechanics to produce ever-more-precise charts, go on to argue the subtleties of polynomial corrections to the intractable three-body problem.
Steve M., if you hadn’t come along and taken an interest, all this might have escaped notice for decades. I’ll say it again: You deserve an enormous vote of thanks.
And let me add this: If it’s true that, “Once Briffa realized the updated Polar Urals data set had a high MWP, he substituted the nearby Yamal data set which has a pronounced HS-shape and called it “Polar Urals”. The substituted data was quickly incorporated into subsequent HS studies – Mann and Jones 2003, Osborn and Brifa 2006, D’Arrigo et al 2006, etc.“, then we have active conscious [snip]
I’ve posted this here before. But I like and want to remember it as well as pass it on.
Mark Twain on extrapolation
http://www.lhup.edu/~dsimanek/twain.htm
Interestingly I couldn’t find it with a search of “mark Twain” Extrapolation
Anyways. Says a lot about expectancy of trees ability to predict today to accurately predicting the past.
Oh another good one from Twain. Bit insulting, but it’s Twain, second only to Shakespere
“Scientists have odious manners, except when you prop up their theory; then
you can borrow money from them.” –Mark Twain
Who blows the whistle? Who calls the cops?
#8 -To answer, Steve McIntyre and Ross McKitrick.
I see no reason why that observation should not be included in a critical paper written for a wide readership, if it can be definitively shown that a “Polar Urals” was used by subsequent authors when in fact the data were “Yamal.” Likewise, if the non-Polar-Urals “Polar Urals” data set consistently shows up in HS studies only after Briffa tendentiously incorporated it then a good inferential case of fakery is made.
Given Esper’s description of data-choosing, it’s possible that the choice of Yamal over the revised Polar Urals was made because the former did a better job of tracking the modern instrumental record. Obviously, I don’t know whether that is true, but it seems like a possibility to me. If that were indeed the case, then the use of ‘Polar-Urals-Yamal’ instead of the revised Polar Urals could be the outcome of creeping self-delusion (i.e., it’s a more T-competent data set) rather than a conscious effort to defraud. A choice between innocent incompetence and connivance is not very attractive for anyone, but in the case of the former it is only professional standing that would be impacted rather than personal integrity. I would hope for that to be the case.
Innocent incompetence doesn’t fully explain why Yamal should be called “Polar Urals,” however, unless no one except Briffa actually looked at the raw data
Who are the cops?
I wish you hadn’t mentioned cops. We have problems with cops in Toronto as in many other places. One of my sons got stomped in the head by bouncers in front of witnesses and could have been killed. He had internal fractures in his skull. The cops were flagged down within 10 seconds. They didn’t take the names of the bouncers and didn’t talk to witnesses. One witness, an American accountant, was so upset that he insisted on making a statement. He gave his card to my son’s grilfriend. I talked to him the next day when I realized how serious the injuries were.
Later I found out that the police did not even open an incident report on the assault. Then they said that they couldn’t locate any witnesses. They said that they couldn’t locate the witness statement from the American accountant. At the start, I had no reason to think that anything untoward was going on, but after a while, it was too weird. So I called the accountant and got a description of the detective and asked the Division to locate him. The cops got enraged at me for doing that and threatened to charge me with obstruction of justice. Like I’m easily intimidated.
I filed a formal complaint and got stonewalled. I appealed to review boards. Even with evidence that a witness statement had been destroyed, no one seemed to care. It’s almost like climate science.
I did find the name of the plainclothes detective through the complaint process. It was front page news in Toronto in 2004 when this very detective was charged for corruption some 4 years after my complaint.
Steve: I had the same sort of problem with the police in Tacoma, Washington a number of years ago. My son was nearly killed by a gang. There were witnesses who agreed to testify, but the police did nothing. I believe they were afraid of the gang. A lawyer warned us that we would be harassed by the police if we tried to pursue the matter any further. Sadly, there’s a lot of this kind of thing in the world.
Wildy off topic.
I don’t know about the legal system in Canada, but I assume at this level it is simlar to the U.S. in that it’s all derived from English common law. But once you run into that kind of a thing what you want to do is go over their heads. You go to a court, or a higher court, and apply for a writ of mandamus.
Of course that’s gonna cost you money (legal fees).
And I don’t say it will get anything done, for the most part it’s probably a waste of time, but between that and a press conference you might get some movement.
Wish I had the cash, I would do so to the INS myself.
I could have pursued, but the cop was arrested and there are inquiries going on so there wouldn’t be much point. A judge was appointed who I’ve literally known all my life as he was one of my father’s oldest friends. There was a change of municipal government in Toronto and the police chief got replaced. One of our close friends became civilian chair of the Polic Services Board, although that didn’t have a lot of stroke against the police. If I weren’t busy with other things, I might have pursued it. I also wanted my son to get on with things and not get involved with litigation. It’s fine for me because I understand it, but it’s easy to get eaten up by it.
In this case, it was the back story that was interesting and intrigued me and sounded like a Ross MacDonald novel. The detective’s father had formerly been a police chief in Toronto. He had resigned about 6 months after a strange inquiry – the Junger Inquiry- about 14 years ago. The son’s name turned up tangentially as being connected with a male prostitution ring being run by the police. In that case, the police had destroyed evidence in their deal with Junger. The policeman who was responsible for investigating my complaint was mentioned in the Junger Inquiry and was disciplined in it. It’s easy to picture circumstances where a reputable father got involved in a mess of his son’s making and then walked the plank. I once sat at lunch with a book agent and for some reason got into this story. If I knew how to write fiction, it would make a great Ross MacDonald type novel.
Sad when you can’t trust the cops.
But if that kind of thing interests you Steve M, Might I recomend a book “The Brothers Bulger” By Howie Carr. Howie is a local newspaper/radio/ex-TV guy.
You wan’t to talk strange.
Whitey was the Brother of Billy, Whitey was high up in the local organized Crime ring, and Billy was high up in the State legislature. And they pretty blatantly took care of each-other.
Stand up to the Politician and the Mobster gives you a warning. Go after the Mobster and the Pol gives you a warning.
Ties in with law enforcement too. There are more than a few local cops and FBI types in Jail or fired for their involvement.
The only reason Whitey is on the run instead of jail is that the local FBI office gave Whitey a call when they were on the way to arrest him. At least one FBI agent is in jail for whacking a guy for Whitey.
Maybe the IPCC can help you.
Seriously, this sort of thing is all too common and it seems the only difference between the good and bad guys is that one side has badges. In the US the “Policeman’s Bill of Rights” gags the release of information and a lot of stuff stays hidden. OTH, victim’s advocacy groups always play the conspiracy card in the media and make the authorities even more closed-mouth.
#16. I don’t agree with that. There are a lot of differences between the cops and the gangs. However, they protect their own and their code all too often seems to include the toleration of bad apples.
Here’s an obvious comparison to climate scientists. No climate scientist or learned institution objected when Mann said that he would not be “intimidated” into disclosing his algorithm, but there was outrage from the learned instituions when civilians from the Barton Committee asked for the information. As someone who’s pushed at both systems, I don’t see a speck of difference in the behavior of the institutions on this class of issue – in both cases, “guilds” set highest priority on protecting their own. It’s humna nature. But the interest of the National Academy of Sciences in dealing with this type of issue is approximately as serious as that of the Toronto Police in dealing with a rogue cop – none.
The only way this problem will get addressed is by people like Steve hammering away. A lot of publicity helps. That is also why some bad cops get charged.
Correction to #18 – “people like Steve McIntyre”
One Trackback
[…] – Esper et al 2003- […]