realclimate today has a post How Red are My Proxies? which is so weird it’s worthy of Rasmus. (Note: see lsubsequent comment here). They discuss the autocorrelation properties of North American tree ring proxies, something about which I know a lot. They say:
Using data from the North American network of seventy sets of tree rings extending from 1400 to 1980 you obtain an actual one-year AR1 mean autocorrelation factor with a value close to 0.15 (the exact number depends on the proxy series and time period chosen but is always less than about 0.3).
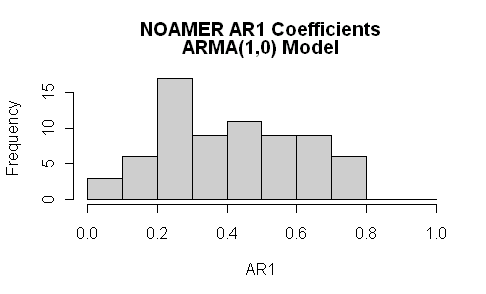
They are nuts. Here’s a histogram of the AR1 coefficients of the 70-series MBH98 tree ring network which we archived in a readable table in connection with our GRL paper. I’ve included a short R script here to calculate AR1 coefficients. The mean autocorrelation was not 0.15, but was 0.4. Out of 70 AR1 coefficients, only three were less than 0.15 and the mean was 0.4. The range of values was from 0.03 to 0.79. Tellingly, the highest AR1 coefficents all belonged to bristlecones.
But it’s even worse than that. If you model the series as ARMA(1,1), the AR1 coefficients increase dramatically with high negative (and nearly always) statistically significant MA1 coefficients. Many of the AR1 coefficients now become close to 1- random walk levels, especially the bristlecones. The statistical properties of this type of series – high AR1 and negative MA1 – are trickier than people think. I’ve posted up notes on them by Ai Deng for example.

I have no idea how realclimate got their results. Their whole post looks completely goofy to me.
The other salient point – and we included this histogram in our Reply to Von Storch discussed , is that the tree ring series in this network have virtually no correlation to gridcell temperature; many of correlations to precipitation and of course the bristlecones have a correlation to CO2 levels.






40 Comments
I’m only vaguely knowledgeable enough to know what you are talking about with the auto-correlation statistics, but the last graph really speaks for itself. I’ve seen it before but I guess I forgot its significance. Even Blind Freddy could see that any meta-analysis of these proxies which doesn’t have any way of telling one signal from another, would be far more likely to extract precip. than anything else given those correlations.
And here I thought they had moved on.
From the RC post:
Looks like they are finally really worried about the autocorrelation problem.
Steve: then perhaps Von Storch should have used red noise with an AR1 coefficient of 0.4, rather than 0.7?
“Devestating” (and to think …. the warmers love to use the term triumphalism). Right …
Steve,
How interesting. It is also known that if you model LTP (long-term persistence, say with 0.3
RE: #3. I think they are also worried about the slight correlation with precip. Bristlecones correlating with precip would, I believe, “bring back” the MWP. It would also further focus attention on the seemingly “odd” behavior which has been experienced on the US West Coast, which seems to call into question the GCMs most in vogue at present.
#6 got truncated by an errant “less than” symbol. The post was supposed to say:
Steve:
How interesting! It is also known that if you model LTP (long-term persistence, say with d between 0.3 and 0.5) series as ARMA(1,1), the AR1 coefficients increase dramatically with high negative (and nearly always) statistically significant MA1 coefficients. Many of the AR1 coefficients now become close to 1.
You can test this in R by loading the fracdiff package and entering the command:
arima(x=fracdiff.sim(n=1000,d=.3,ar=0,ma=0)$series,order=c(1,0,1))
How can this be?
So what are they correlated to that gives them such a large weight in the reconstruction — to global temperature? If so, this alone would obviously disqualify the entire study, which makes me think I have missed something.
re #9,
No, it’s true that the claim seems to be that bristlecones can intuit global temperatures even though they can’t follow grid-cell temperatures. Now it is possible that there could be a linkage between say global temperatures and precipitation and that could be reflected in ring widths, but if so it’d require them to admit the the bristlecones are precipitation proxies first and foremost and the team definitely doesn’t want to admit that. So they just talk about this magic low-frequency signal which must be maintained at all costs.
I checked the paper the RealClimate post links to, and it estimates an AR1 coefficient of .15 based on data from 1400 – 1880.
Does that explain the difference? Is the bristlecone “blade” in the twentieth century that makes the autocorrelation coefficient so high in your calculations?
Looking at the paper RealClimate linked to raised some more questions. I submitted the following post to RealClimate hoping to be educated a little bit.
Perhaps your results are different because you are using a standard autocorrelation estimate. If so, which is the appropriate estimate, i.e., what does the Von Storch model actually assume?
The von Storch-Zorita approach to all of this doesn’t make a whole lot of sense either. I’ve spent quite a bit of time the last week or two pondering this dispute. Their main point is simple: if you mix a signal with high-frequency white noise and then rescale to match the amplitude of the signal, you lose amplitude in the signal. Because white noise is orthogonal to the signal, the underlying algebra is just the Pythagorean Theorem. So in that sense, it’s almost trivially true and using a climate model to provide empirical evidence of the Pythagorean Theorem seems a little longwinded. Equally it seems a little foolhardy for realclimate to argue that the Pythagorean Theorem is wrong.
Underneath it all is a fairly intriguing issue though which I’m mulling over presenting as a publication.
Submitted another comment over at RealClimate:
Terry, maybe you can figure out what Ritson actually did. If you look at the url of my R script, that has the data that he probably used. I supplied scripts to Ritson while I was working on our GRL article. I remember him getting all ballistic at one point. He asked what would happen if you added a fixed amount to the front part of the series. I did an experiment adding to the early portion of non-bristlecones (this is reported in our E&E article). The Mannian method flips all the series over and produces a colder estimate for the 15th century. You make 50 series “warmer” and the estimate gets “colder”. Ritson accused me of manually flipping the series over and comparing it to Rathergate. It’s amusing to see him teamed up with Wahl and Ammann and posting at realclimate.
Re #9: Terry, you haven’t missed something. The ‘correlation’ can be opportunistic correlation to any pattern in the temperature principal components (which they call ‘Instrumental Training Patterns’), which may be a weighted average of temperatures from anywhere on the planet. As for the local temperature, here is Section 5.3 of our E&E paper from last year.
==============================
5.3 Lack of a linear response to temperature in “key” proxies
In McIntyre and McKitrick [2004b], in our criticism of bristlecone pines as an arbiter of world climate, we pointed out (as above) that a linear response to temperature had not been established for these sites (as seemingly required by MBH98). Mann et al.[2004b] replied that:
We doubt the authors really believe the idea of a temperature proxy exhibiting no relationship to local temperature makes much sense. It is instructive to compare this response to the policy articulated in Jones and Mann [2004], which states:
Jones and Mann [2004] do consider “climate field reconstructions” (CFRs), which appear to be similar to “instrumental training patterns” of MBH98. In this case, Jones and Mann [2004] argue that the CFRs should be shown to be similar to some aspect of local climate during some part of the year. This would seem to invite opportunistic use of either precipitation or temperature as a climate indicator, something for which they reproached Soon et al. [2003]. But perhaps most telling is the comment of MBH98 co-author Hughes in Hughes and Funkhouser [2003], who did not attribute the bristlecone pine growth to an “instrumental training pattern”, but stated that their anomalous 20th century growth rate is a “mystery”.
==============================
Gaia taunted the bristlecones to get some cojones.
===============================
I’m trying to understand what Ritson actually computed. It is not the autocorrelation (ACF); it is not the partial autocorrelation (PACF). But might it be some kind of novel backwards PACF, where the contribution of variability associated with high-lag correlations to a shorter-lag correlation is effectively subtracted from the shorter-lag correlation? It is common to do this sort of adjustment to deal with deterministic sources of variability like seasonality. However, we are not dealing with a deterministic source of variability, so in any case I am not sure how to interpret the NBPACF statistic.
#18. It looks like he calculated the AR1 on the first-differences of the data. Terry has asked about this at realclimate and Mann has denied it. However, if you read Ritson, it’s pretty clear that that’w what he’s done. I’ll do a quick run and see what happens with AR1 on first differences. What a bunch of goofs.
You’re kidding. That would be the first difference of the first differences.
#20. Ar1 on first differences yields many high negative values. Ritson’s calculation is a formula based on the assumption that the first differences are AR1. It’s pretty goofy. I’ll make a new post on this.
Re #19: First differences? That’s cool. I take it as a sign of progress. Last December there was that hullabaloo about non-zero values of d (as in ARIMA(p,d,q)), so seeing d=1 — first differencing — is good news indeed. Of course, my sense is that Mother Nature prefers d in the 0.3 to 0.5 range, but at least we now we have a pair of bookends.
#22. Except that with first differences, a random walk has a Ritson-autocorrelation of 0. This is realclimate – you have to watch the pea under the thimble at all times. I’ve done another post on this.
Terry’s got me in stiches. Excellent! Scientifically brilliant, while at the same time, entertaining in terms of subtle dashing to pieces of some absolute …. bull#$%s
Steve, just a note to say I’ve audited your work (using the same data, but doing it in Excel). My results agree exactly with yours, viz:
Average__________________0.41
Std. Dev._________________0.19
Max______________________0.79
Min______________________0.03
Skew_____________________0.2
Kurtosis_________________-0.91
Normality (Jarque-Bera)___2.86
They claim the autocorrelation is “always less than 0.3”. In fact, 64%!! have a lag-1 autocorrelation greater than 0.3 … go figure. Have you written to ask them what’s going on?
w.
more from RC
#11 & #12, I guess I am confused like Terry. In Ritson’s paper, the third equation down, it appears that the proxy data is differenced Y(j)=X(j)-X(j-1) ??? Phil
[Response: We’re checking with David Ritson for confirmation. However, the average raw lag-one autocorrelation coefficient for the full set of 112 (unprocessed) predictors used by MBH98 is rho=0.28 with a standard error of 0.03; if the 20th century is not included owing to the argument that the natural autocorrelation structure is contaminated by the anthropogenic trend, the value is lower, rho=0.245 +/-0.03. In either case, the inflation factor is minimal compared to what is assumed by Von Storch. -mike]
[Response:(update) David Ritson confirms that the procedure in question is exactly as specified in the linked attachment and is designed to find, within specified approximations, the AR1 coefficient that describes the proxy associated random-noise. As mentioned above, we ourselves independently find an AR1 coefficient (for the combined noise+signal) between 0.25 and 0.30 for the MBH98 network, close to the Ritson value and qualitatively lower than the value used by von Storch. –mike]
RealClimate had been pretty good about responding to reasonable questions on this one.
So far, there has been some partial reconciliation with Steve’s calculations. Including the 1880 to 1980 data increases their estimate from .15 to .30.
I posted another question that may further reconcile things.
Terry, they don’t know what weights they assign and have said that it cannot be calculated. You can and I have.
AS to the effect of one HS series in a system of white noise, take a look at http://www.climateaudit.org/?p=370 down the page which illustrates that one series is enough to bias their methods.
I’ll try to post up in the next day or two a graphic illustrating what’s wrong with the entire premise here.
Sounds like there might be a minor research opportunity here.
It could go something like this:
This paper provides a method for estimating the AR1 coefficient of the noise in the Von Storch analysis and applies that model to the data used in MBH98 to obtain an estimated AR1 coefficient of xx%. Inputting this estimate into the Von Storch model results in an estimated [blah blah] of yy%.
Estimate the average AR1 over the entire time period (footnote: I do not truncate the data to avoid concerns about data mining) using weights proportional to the importance of the series in the MBH98 reconstruction.
Explain the weighting scheme, include an intuitive justification for the weighting along the lines of my comment above, provide a rigorous mathematical derivation of the weighting scheme.
Footnote thanking RealClimate for suggesting this approach to the problem.
RE: #29. You’ve got your abstract. Looks like a really nice opportunity.
30:
It’s a research proposal, not an abstract.
Until you do the work, you don’t get to write an abstract.
D
I always write my abstract first. It helps to scope the paper.
re: #30
I think you need to tell the Hockey Team and the other warmers that fact.
32:
So you know your results before you collect data? Impressive study design!
But, to break with this site’s implicit rules, I’ll admit to being overly nitpicky on the importance of semantics here. I’m sure you mean you write a ‘research proposal’ to scope the paper.
Best,
D
RE: #34. Of course the results are not known. So, at this juncture, the statement is of the approach and the overall scope. The one liner (and that is all it should be) is put in at the end. A few other mods are possible. Why are you nit picking? Ad hominem again?
Don’t argue with DanO. He is not up on complicated subjects. He is a good liberal and strong biker and is our
tree coring bitchdata-gatherer, for when we get funding.You write:
Out of 70 AR1 coefficients, only three were less than 0.15 and the mean was 0.4. The range of values was from 0.3 to 0.79
This is trivially inconsistent (if the bottom of the range is 0.3, there can’t be any values below 0.15). What did you intend to write?
Good catch. My guess is he meant the range of values was from 0.03 to 0.79. The graph shows one value between 0.00 and 0.10, and two between 0.10 and 0.20, consistent with his stateent that three were less than 0.15 (presumably two were between 0.10 and 0.15 and the other was 0.03).
OK, now that I look at that, I realize my last comment was wrong, I was looking at the wrong graph. The second graph, the ARMA(1,1) Model, shows a range starting at 0.3, but his comment about 0.3 to 0.79 was before the ARMA(1,0) Model graph. Now I’m thinking the sentence should have been in the following paragraph. But, I’ll shut up now and let Mr. McIntyre sort it out…
#40. If you look at the script here, http://data.climateaudit.org/scripts/rednoise.realclimate.txt, I try to include cited values at the script line where they are calculated. The 0.3 – now changed – is a typo for 0.03 (as seen in the script.)