I showed a little while ago the impact of the Polar Urals update on the Briffa 2000 reconstruction – using it instead of the Yamal substitution resulted in an MWP index higher than the 20th century.
Today I’ve done the same calculation for Jones et al 1998, this time substituting the Polar Urals update using additional 1998 information (from Esper et al 2002) for the earlier Briffa version. I’d more or less surmised this, but the beauty of using the Esper version is that I don’t have to argue or justify my RCS calculation, since Esper’s already done it.
With the Polar Urals update, the 20th century Jones et al 1998 index is no longer higher in the 20th century than the MWP. This is from merely replacing one series with an update used in a later multiproxy study.
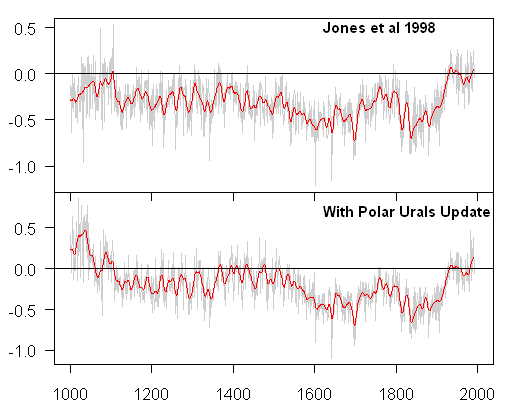
Top – Archived version; bottom – with updated Polar Urals version using my emulation of Jones et al 1998 methods.
The medieval portion of D’Arrigo et al uses almost the same roster as Briffa 2000 (all but one series.) Although they had no access to the Yamal data, as discussed before, they substituted the Yamal series for the Polar Urals update (which they calculated.) So it will almost certainly follow the same pattern as Briffa 2000 where the Polar Urals update has a similar effect relative to the Yamal substitution.
Esper et al (obviously) used the Polar Urals update and still claimed higher modern levels (although he had the warmest MWP). How did this happen? Just speculating for now, but Esper used TWO foxtail series. At this point, I have no idea how Esper got to his final answer. I’m going to average the sites (I’m trying to decide what to do about the missing Mongolia data – this is the sort of stuff that stalls analysis).
What do you want to bet that he needs both foxtail series to drag down MWP values? I’m going to check that soon. You can see why it was such a fight getting data from Esper. He’s probably more aware than anyone that he’s had to use two foxtail series to offset the Polar Urals update and probably knew long before me where I’m going to get to once I get into his data.
So you can see where I’m going with this. I’m going to test the impact of the Polar Urals Update and the bristlecones on all the "other " studies. There are many problems, but this will be a nice unifying theme that one can reduce to a journal soundbite. For the Team, the problem with the lack of "independence" of the various studies is that the entire corpus becomes vulnerable to a problem in one of the common series.
Leaving Moberg aside (which stands or falls on different issues), if IPCC were hypothetically assigning likelihood to whether the modern or MWP periods are warmer based on this sort of data, essentially they are taking an opinion on whether the Polar Urals Update or the Yamal Substitution is a more accurate thermometers – an issue on which there has been precisely ZERO discussion in the specialist literature.
The Yamal Substitution was accomplished sub rosa by Briffa, without any exposition of the issues. I don’t see how IPCC can take any view on relative MWP-modern warmth without an informed view on the Yamal substitution.





29 Comments
Indeed. I don’t think they realize this problem, either.
I think the obvious take-away from this is: Given the immense impact a single proxy can make in the results of a temperature reconstruction, the entire science of using proxies to determine past climate history is not only questionable, but likely false.
I think, too, that this is explained by local temperature phenomena. Use one proxy that was a result of a different trend than another proxy, and your results are going to vary wildly, much the same as local climate varies wildly.
Mark
Its a wrap! Though I don’t see how taking out options on which one is right would help work out which one is right. Perhaps you have in mind the IPCC setting up a market prediction system, and trading options on proxies. It could be listed along with the Kyoto carbon trading scheme.
Exciting stuff. As a long time follower of this site I was starting to lose track with the many different studies audited and wondered what others have expressed before: why isn’t Steve getting this stuff into a paper? There’s plenty of material you’ve delivered.
I’m seeing the bigger picture now. This is a potential slam-dunk.
If I read the graph correctly, the red line for the Update is well outside the confidence intervals of the original near the beginning.
This should be no surprise, but for how many reasons? one, two …?
Thinking about it, has my vote for your best post yet.
#4. Given that the two series have essentially identical values in the calibration period, they have the same “confidence intervals”. Since they are mutually exclusive, that is a reductio ad absurdum of the original confidence intervals (which are absurd anyway).
#4:
Correct me if I’m wrong, but I don’t think those are confidence intervals. I think those are year-by-year estimated values.
This could be written up using the Berger and Cubash framework. Results depend on a number of different choices. It is not obvious which choice is correct in each case. Choosing various combinations of the choices produces a spaghetti graph with substantial variability.
I would also throw in variations on which proxies are included.
#the red line in both graphs is just a smooth. Should have said that, but I often show graphs with light gray annual and red smooths.
I don’t really see this going the same way as Burger and Cubasch. B-C is a good paper and pointed to more issues, but it’s really limited to studies using certain kinds of multivariate methods. The variations introduced here do not arise from trivial variations of METHOD using the same data set, but from variations in the DATA set from biased picking or flawed data in small subsets. This does not lead to a bewildering variety of results, because Jones 98 uses a simple average plus re-scaling, which has quite different properties than an MBH multivariate method. But you don’t need to have a bewilidering variety of results to demonstrate the non-robustness of the result.
There’s still a lot to do on the multivariate front but the issues are different. I think that, for example, VZ have not explained the attenuation properties of the MBH method very well and B-C have not explained the non-robustness properties very well. Both articles are really more phenomenonological (as were our articles); all are necessary preliminaries, but the final explanation of the phenomena has not been achieved yet. Framing the question in this way is half the battle, but I’m working through the other half.
Has anyone tried to estimate the parameters of 1000-1400 temperature error distribution with a theoretical assumption that all the proxies are as accurate as thermometers? Would the 2-sigma level of yearly temperature errors be less than 1 C?
Ist das Ulrich Cubasch heir, der wer schreibt uber “uc”? Ich habe ihre diktat sehr gern. Es gefellt mir. Sie sollen ein Pries greigen.
#10 UC related to your comment, what I thought would be an interesting experiment would be to use 22 (chose the number) grid cells to estimate nh or global temperature. Using your favorite method to calibrate, calculate the error from the nh temperature calculated from all the grid cells and the reconstructed nh temperature estimate during the verification period. Randomly select 22 new grid cells temperature series available in the cal and verification periods and repeat above. Do this 1000 times so that one obtains a robust histogram of the error for each of the verification years. Now you can obtain your best possible error bounds for the reconstruction. A reconstruction from proxies with errors will only be worse.
Couldn’t you just characterize the distribution function (s.d., skew, etc.) and then do some sort of actual calculation of expected results rather then running the 1000 experiments? I’m definitely not a stats jock, but I would think I’ve heard of “standard error of the mean” and such. Does this really require monte carlo approach?
#13. If you knew what the distributions were. Ever seen any discussion of the distributions of gridcell time series by the Team or anyone else. Didn’t think so.
#12. I think that Zorita et al 2003 did something like that. I’ll check some time.
14. (Don’t get enraged, Socratic dialogue is my way…) If we have the data to do a monte carlo sampling experiment, don’t we have the data to express a distribution? (Segue) does the data in and of itself express a distribution or does one need a functional expression into some analytic approximation (some math equation) to do what I talked about? IOW, is a monte carlo experiment required or can one do this analytically? IOW characterize what one would get in the limit of infinite monte carlo trials?
#15. When I was 19 or 20, I could do tricky integrations and get analytic results. I’ve forgotten all the little tricks. For these studies, even if you figure out one part of the distribution, you end up doing convolutions of difficult distributions. It’s usually simpler to do a Monte Carlo which does a sort of empirical integral. If it’s something real interesting, maybe it’s worthwhile trying to figure out the analytic expression.
Of course, if you’re at realclimate, you just state that everything is i.i.d. gaussian and that “simmplifies” things.
I guess my point is that the DATA IS THE DISTRIBUTION. If you have the data to do the monte carlo from, can you instead of running a bunch of sample means from within it, someone crunch some function on it that will tell you what the distribution of means will be. I’m not asking the question critically, but in all humility. Well, not that much humility. I know I’m stupid on the mechanics of the field, but I trust my instincts on general problem-solving even in areas where I don’t know the specifics. At work, I lots of time have to ask questions and steer people in directions who know more about the specifics than I do, but who can benefit from the critical question on methods.
Actually as I think about it, subsampling from a set is just a probability and statistics problem. In a simple sense, it’s a bridge or poker problem. Just a bunch of permutations (or is it combinations…can never remember which is which) from within a larger set. Now I don’t know if the practical computational issues make a brute force calculation unfeasable.
#14
Steve,
No, we did not work with observations. Something on this line
was done by Mann and Rutherford, GRL (2002= and Rutherford et al, J. Climate, 2003. Both with the RegEM method
eduardo
#11:
à?⭠à?⾃ ?Ⳡà‘’€šà?°à?⻃ ?⿃ ?ⷠà?〃 ?°à‘€à?ⶃ ?⾃ ‘Å’. à?⭠à?⾃ ?Ⳡà‘’?à?»à?⹃ ‘ˆà?⻃ ?⿃ ?⺠à‘’?à?⹃ ?»à?ⶃ ?⻠à?Ⱐà?⾃ ?ⶃ ?⽃ ?ⶃ ‘’€ à?⻃ ?⿃ ?⺬ à‘€à‘Æ’à‘’?à‘’?à?⻃ ?⿃ ?⺠à?ⶠà‘’€žà‘€à?°à?⾃ ‘’€ à‘Æ’à?⸃ ?⻃ ?⿃ ?⺬ à‘’€šà?°à?⸠à‘’€¡à‘’€šà?⼠à?〃 ‘€à?ⶃ ?ⵃ ?»à?°à?ⴃ ?°à‘Ž à?⿃ ‘’?à‘’€šà?°à?⾃ ?⿃ ?ⳃ ?⹃ ‘’€šà‘Å’à‘’?à‘’? à?⾃ ?° à?°à?⾃ ?ⴃ ?»à?⹃ ?⺃ ‘’?à?⻃ ?⿃ ?⺮
🙂
Re: #21
Yes, English would be preferable. Besides TCO’s german is atrocious.
Ist das Gothische schrift?
re #22 No, it’s Russian.
re #19, thanks Eduardo, I will check it out
#12
That would be one way to get an estimate. I was thinking about an oversimplified model: if the sd of annual averages of one temp station is 2 C, you need an average of 70 stations to get sd of 0.25 C, assuming that there is no correlation between the stations. If there is a positive correlation, more stations are needed (negative correlation between annual station averages would be interesting to see). Only way to get down to 0.25 C with fewer stations is to apply a dynamic model, but that’s another problem. We can’t predict the temperature of next year very well, implies that we don’t have exact dynamic model.
Re #25 What you are suggesting is fine for i.i.d. temperature time series but the grid cell temperatures are time and spatial correlated.
I think that variation of a series from year to year is different then variation from station to station.
# 26,27
Positive spatial correlation just makes things worse, I guess (can’t get rid of variability by averaging). Positive temporal correlation means that there must be low-frequency variation in the temperatures, not helping either. i.i.d process with annual deviation of 0.15 C would be easier to reconstruct (in RMSE sense) with noisy observations than a positively correlated process with 0.15 C sd driving noise – the former has lower variability. Random constant process would be the easiest to reconstruct, but that’s apparently not very good model for annual global temperature. Maybe this is getting silly, I’ll read the refs in #19 before continuing..
Ok,
1) If we know beforehand that there are no large variations in global temp during 1000-1860, we don’t need to reconstruct those temperatures. 1860-1900 average will do.
2) If there are large variations, with a sparse network of thermometers we would be unable to reconstruct the temperatures completely. This is due to the measurement noise that increases when the number of stations decreases. Averaging would help, but long averaging periods would average the high-freq signal components out as well. And we don’t know the frequency distribution of the temperature in the absence of human-CO2 (at this stage we can’t use the results of MBH99, the uncertainty levels would be a function of the results).
3) From this viewpoint, a good way to test the reconstuction would be to find a verification period with a strong, rapid increase or decrease in the temperature. Such as 1980-2005. If the verification period does not contain rapid variations, there is no penalty for taking a too strong average of the measurements.
One Trackback
[…] But I, for one, find these little cherry picking exercises increasingly absurd. So why isn’t the Polar Urals update used?For that matter, why isn’t the Indigirka River chronology used? Could its elevated MWP be […]