Rob Wilson wrote in today pointing out that D’Arrigo et al 2006 had obtained a correlation to gridcell temperature of 0.58 for the Jacoby Mongolia site chronology, working from original data and not relying on hand-me-down data from Mann and Jones. This is actually higher than the 0.25 reported by Mann and Jones for annual correlation, which, regardless of whatever is the "correct" answer, is a disquieting difference for a simple calculation between a gridcell temperature series and a tree ring site chronology – a calculation which should reconcile exactly.
However, it turned out that this correlation was not to the actual gridcell containing the Sol Dav site (48N, 98E) but to the northeast contiguous gridcell 100-105E, containing Irkutsk, Russia. So this rises an interesting question about the effect of "picking" from 9 candidate gridcells, as the results vary dramatically from gridcell to gridcell.
Secondly, although Jacoby has not archived an RCS chronology (or any other chronology for the extended Sol Dav collection archived in July 2004 and published in GRL 2001), he did archive a chronology for the shorter collection published previously, which I’ve considered here. I’ve also done my own RCS calculation (which is very trivial mathematically) – so we’ve got three tree ring chronologies to compare against 9 gridcells. I’ll show these correlations for the 1881-1997 (although all 9 contiguous gridcells are only really represented in the 1936-1997 period) and then show details for the northeast gridcell and central gridcell.
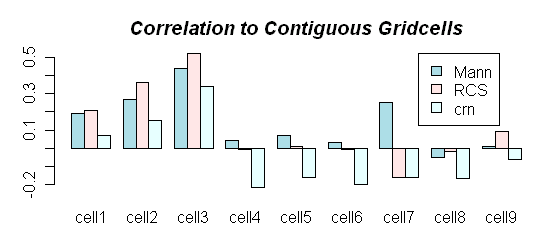
Figure 1. Barplot showing correlations of Site Chronologies to Gridcells 1881-1997
As you can see, one can derive a correlation exceeding 0.5 between the RCS chronology and the northeast gridcell (more or less as reported in D’Arrigo et al.) However, the seeming significance of this relationship must surely be qualified by the negligible correlations of the RCS and crn chronologies to the other 8 contiguous gridcells, includinga negative correlation for the actual gridcell (5). Ths possibility of a spurious correlation to the northeast gridcell must be considered.
Next here are some details of the gridcell series from the northeast gridcell and the actual gridcell (top and middle panels.) The bottom panel shows the Mann-Jones archived chronology as compared to the Jacoby archived mong003 short chronology (which was actually used in MBH98 and presumably familiar to Mann) and in Briffa 2000 (and familiar to Jones coauthor Briffa).
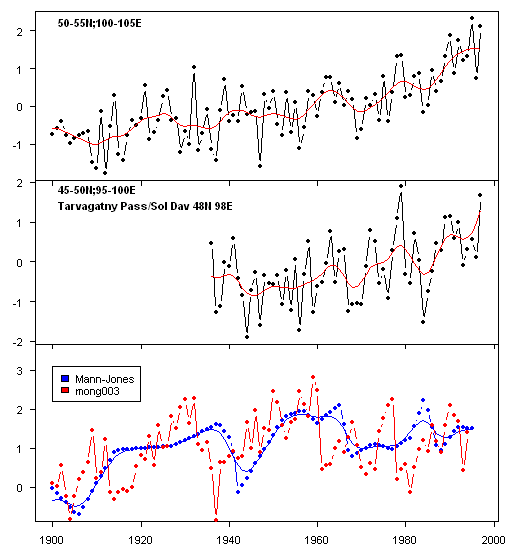
Figure 2. Top gridcell 50-55N, 100-105E; middle gridcell 45-50N, 95-100E; Bottom – Mann and Jones chronology compared to mong003.crn
The deficiencies in Mann’s scanning process are evident here as the entire Mann and Jones chronology appears a couple of years out. The RCS chronology (not shown here) tracks the crn chronology reasonably but has additional upward drift. The "decadaly smoothed" chronology has a correlation of 0.53 to the northeast gridcell and -0.17 to the actual gridcell. So the gridcell selection "matters". Now the northeast gridcell is available for a longer period. However if the 1936-1997 common period is used, the relationships are about the same – a correlation to the northeast gridcell and negligible correlation to the actual gridcell.
Some Time Series Properties
Before venturing into thinking about regression significance, it is prudent to examine the ARMA character of the series. Millennial climate scientists have got into (in my opinion) a very bad habit of using AR1 models as a benchmark, when the series are nearly always strongly ARMA(1,1) or probably some very high form or persistence.
Gridcell 50-55N 100-105E has very high and highly significant ARMA(1,1) coefficients : AR1 0.9817 (se- 0.0175) and MA1 -0.8032 (se – 0.0527). The actual gridcell has similar properties. This series has an AR1 coefficient almost equal to that of a random walk and, in econometric terms, is almost integrated. With the high MA1 coefficient, it is a combination that is "almost white almost integrated" – which poses difficult significance tests. I’ve commented on this from time to time – see comments on Vogelsang, Deng on Ferson etc. The AR1 coefficient in a mis=specified AR1 model is only 0.50, giving a false idea of the degree of persistencei n a mis-specified model.
The DW statistic is valid only for AR1 errors and is not sensitive to ARMA(1,1) as here. However, even here the DW statistic for the relationship between the RCS chronology (my version) and the northeast gridcell is 0.67 – which is well below the 1.5 minimum. Rob Wilson has reported a much different value.
Irkutsk
Hockey talk always leads to interesting little by-ways. Rob mentioned Irkutsk; this is located at 52.3N, 104.3E in the contiguous northeast gridcell. This turns out to be a site studied by Warwick Hughes here. Warwick’s website show the figure below, with a bewildering variety of station data, leading to a very different outcome than the HAdCRU gridcell.
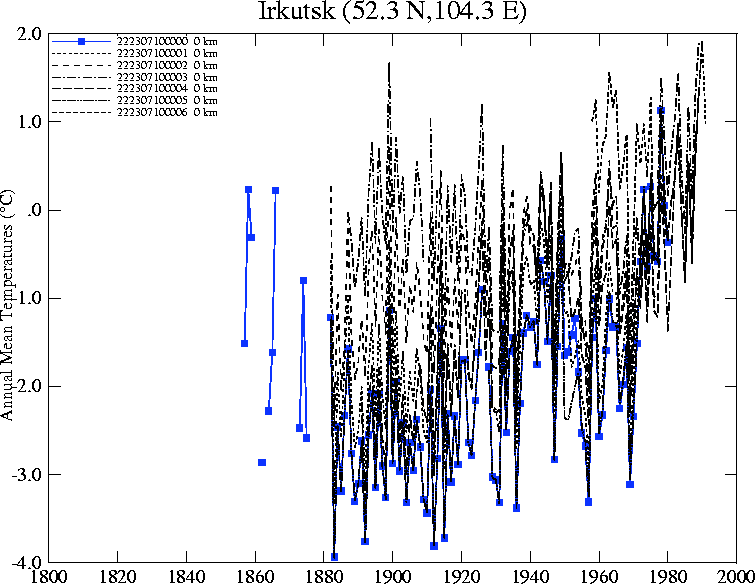
Figure 3. Irkutsk variations from Warwick Hughes





20 Comments
Is there a map available which shows where the Jacoby Mongolia site is with reference to the 9 gridcells in question and also Irkutsk and any other cities of significance? I mean, if the Jacoby site is in the NE part of the center gridcell and Irkutsk is in the SW part of the NE gridcell, it might be quite a sensible result. If it isn’t then I’d assume it’s either spurious or some sort of similarity of conditions in the two areas. E.g. both are at about 5000m on the lee side (with respect to prevailing winds) of a mountain chain with a large lake south of the site.
Dave, Google Earth is always fun, and gives you elevation along with lat/long. With it, you can see that Irkutsk, while roughly centered E/W in its cell, is near the N side, and sits astride a river (dammed at the S end of the city) roughly 40 miles N of where it flows out of a large lake. Elevations are in the 1200-1800 foot range.
By contrast, the Mongolia site has no major river/lake nearby, and seems to be in the midst of harsh mountains, with elevations in the 8-9000 foot range.
Twins separated at birth?
Sorry, should have noted that the lake near Irkutsk is not a trivial one, being Lake Baikal.
Irkutsk increased its population ten-fold in the 20th century, http://www.library.uu.nl/wesp/populstat/Europe/russiat.htm. Its UHI increased by at least 2C due to this (my estimate from temperature data in the region). Since CRU does not correct for the increase in UHI, much of the claimed warming in the Irkutsk grid cell is really urban warming.
#4. Before I became known, I was interested in UHI. It struck me that if the effect increased as log(pop) as hypothesized by Oke originally, then the SIZE of the cities was less relevant than their growth rates to the UHI effect. I asked Jones for the data for his NAture study on UHI and he said it was on a diskette somewhere, he didn’t know where. That’s before I was wise to the ways of the Team and I didn’t pursue the matter. Maybe someone else could inquire again.
It is isn’t just size related. I did studies of Winnipeg in 1972 intrigued by Chandler’s studies (1952) of the climate of London. Winnipeg was a good site because there was virtually no topographic effect and no other significant urban interference. It is important to know the location of the weather station relative to the city because the dome of warm air that is the UHI adiabat is shifted by the wind. Some cities will show significantly different effects depending on the location of the weather station.
Steve: I share your opinion that
Even a quick glance at time-domain plots of temperature (and proxy temperature) records reveals enough short and long-term persistence to rule out iid (“white noise”), AR1, and MA1 error structures (does anyone seriously argue otherwise?). But I’ve also noticed that, among the immense population of alternative time series structures, you usually mention ARMA(1,1); I’m curious as to why. Is this because you think ARMA(1,1) best represents the physics? Because ARMA(1,1) is the simplest stationary model that can reproduce statistical features you’ve observed in temperature time-series? Because you prefer the mathematical form of ARMA(1,1)? Something else?
#7. For now, all I’m saying is that it’s much less bad. I’m impressed by Demetris Koutsoyannis view of scaling, but I haven’t mastered how to simulate noise using his methods – another thing to do. (That’s a priority!) I’ve noticed that ARMA(1,1) coefficients are massively significant in both coefficients in temperature series. In terms of physical meaning, Demetris has observed that is you take an average of AR1 series and then do time series analysis on them, the averages are ARMA(1,1). So even if the monthly or daily series are AR1, the averages willbe ARMA(1,1). There’s no physical reason why the annual series should be AR1 if the monthly series aren’t.
In terms of autocorrelation functions, ARMA(1,1) with high AR1 and high negaive MA1 also reproduce some of the main features much better than AR1. Again ARMA(1,1) leads into some difficult statistical areas, which I have not mastered, but have mentioned – see notes on Deng 2005, one on Vogelsang. What happens is that the AR1 coefficient in an ARMA(1,1) model can be close to a random walk; while the high negative MA1 coefficient makes it look white -hence the term "almost integrated almost white" used in some time series analysis.
For your purposes think "almost random walk almost white" – sounds contradictory doesn’t it. It’s hell on wheels for many statistical tests by good statisticians, but just ignored by the Team.
#8 Thank you for the quick reply. Like you, I find the structure of the noise very intriguing. It seems consistent across many data sets and scales, suggesting — as Koutsoyiannis discusses — some deeper explanation and possibly a promising path forward. My sense is that we are going to need something to replace the “hockey stick” approach, and whatever it is will have to take Mother Nature’s time-series structure into account. However, I realize this may not be a primary interest of yours right now.
Although this is off-topic, I would add that your audit reports on the “hockey stick” continue to amaze me. They convinced me long ago that the “hockey stick” research is flawed in multiple, interesting, ways (my rough tally is that there are substantial questions related to errors in the data, bias in the sampling, and uncertainty in how proxies correspond to climate. In addition, the statistical methods are opaque and biased toward specific outcomes, the statistics — even the simplest statistics like correlations — are not always computed correctly, and when computed correctly statistical results are not always interpreted correctly; etc.; etc.; etc.). It makes for interesting reading, and I continue to look forward to the next chapter.
In any case, thanks again for the reply.
Is “TAC” Tom Crowley?
No that’s TJ. Could it be Cubasch? No…he’s Ulrich. Oh well…
#9. Take a look at Peter Huybers’ new article at his website looking at variability across a continuum of scales. Huybers is thoughtful and bright. Some time I’ll try to post a teaser on the article.
Steve, the terms “woop” and “rat” were meant affectionately. Take a look at his bio on that site and you’ll understand. Or he will anyhow. And yes, it is a bit funandgamesy but I got that big book on Hotelling from the library and sitting next to me, so let me have a little sugar with the medecine. (I’m still trying to figure out the right way to mix in snark about a certain December football game into the mix…)
I’m reading the Huybers article now. Interesting seeing him making some points about skill versus significance and degrees of freedom wrt low frequency calibration. Glad to see someone is publishing…;)
Pretty interesting article. Haven’t put it under the TCO microsceop yet, but looks decent.
#12 Thanks for the Huybers preprint. I will read it, but, based on the number of equations (0; that’s about average given GRL’s 4-page limit), that I likely won’t understand it until I’ve also read the background articles.
I don’t think people should write letters so much. They should write papers. Letters should be restricted to very small points and breaking news. Everything else should be a paper.
#16 I may have been a bit hasty with my thanks [;-)]. Huybers’s manuscript reports some interesting findings, but I’m not sure I learned that much about his methods. In particular, it would not be easy to reproduce his results from the manuscript. For example, the reference to multitaper methods [Percival and Walden, 1993 — incidentally, it is missing in the bibliography, though it is well known] does not adequately explain the estimation of “coherence” (my memory is that there are questions about how you define the taper, though I haven’t looked at this in a while). Presumably there are background documents that lay out the mathematics, but they aren’t cited. While I don’t have reason to think anything was done wrong, when you have complicated variability (in this case due to both process and measurement error) in both the response and predictor variables, things get tricky (generally speaking, linear models are not appropriate in such cases without simplifying assumptions). PCA in theory can avoid some of these problems, and it may be an appropriate tool in this situation, though I don’t know for sure. I’d like to see the arguments laid out formally.
Here is the sort of thing I have in mind: Assume — because of process physics — that the ring width or density at site i is functionally related to temperature, T, at the site. However, we cannot employ T or W because we don’t know them. Instead, we invert the function and insert our “best” estimates:
In any case, it is an interesting manuscript presenting interesting results on an interesting topic.
Thanks Steve for recalling my USSR gridcell pages re Irkutsk. My Figure 3 that you show is only there to demonstrate the seven widely varying GHCN data versions available for Irkutsk. The GHCN preferences are indicated by the last digit in their series names, hence 0 is their first choice, 1 their second choice etc.
Readers might like to ponder why the GHCN tean would have opted for the strongest warming version post 1880 as their first choice when they must know Irkutsk is a fair sized city.
But back to my subject.
I hope readers found my link “Lake Baikal Region” to the page below presenting station trends for the Irkutsk gridcell and the neighbour to the east containing the significant sized city of Ulan Ude.
http://www.warwickhughes.com/climate/baikal.htm
So few stations that the full horror of the Jones et al cosmic mistake is clearly visible.
So, do I take it that tree ring trends from nearby Mongolia are being generated that agree with the urban warming trends in these gridcells ? What a hoot.
I wonder if there are trees in downtown Irkutsk that are old enough to study ?
But how to make a reconstruction from tree rings when both observed climate data and tree ring series contain linear trends? Some guy suggests whitening both series and then correlate.