One bit of housekeeping that I want to tidy up before more NAS postings: a couple of months ago, Eduardo Zorita kindly sent me comprehensive data from ECHO-G, on which, unfortunately, I’ve so far not been able to spend as much time on so far as I would have liked. So much to do, so little time. Included in the package were supporting calculations for their Comment on MM05 in which they stated:
Our results, derived in the artificial world of an extended historical climate simulation, indicate therefore that the AHS [Artificial Hockey Stick] does not have a significant impact but leads only to very minor deviations. We suggest, however, that this biased centering should be in future avoided as it may unnecessarily compromise the final result.
Obviously this is a different conclusion than we reached and I’ve been anxious to reconcile the different findings. Eduardo and I already exchanged code on our replication of Mannian PCs and I’ve confirmed that the key aspects coincide (although Eduardo did not use detrended standard devations in Mannian PC calculations).
As shown below, I’ve determined that the the AHS has no effect on Eduardo’s results, not because of the climate model, but because the PC series are essentially identical when pseudoproxies are constructed with white noise under both Mannian and conventional PCs (either correlation or covariance). I would submit that the implication of this is: if a network consists of a signal plus white noise, then the PC1 is similar under different methods. This defines a test for whether the network consists of a signal plus white noise, and does not prove that the differing methods have no impact on a Mannian network.
Von Storch and Zorita 2005 reported that they constructed pseudoproxies based on mixing white noise with gridcell temperatures generated by a climate model. In the run erik167 sent to me, the proportion of white noise appears to be 50%, as the correlation of pseudoproxies to gridcell temperature is around 0.7, at the upper end of the range in Jones and Mann 2004 cited by VZ (0.3-0.7). While the erik167 run was at the higher correlation range, VZ report that results are similar within the range and I expect that to be so. As we pointed out in our Reply to VZ, this is not an accurate value range for actual MBH98 tree ring proxies, where the correlations to gridcell temperature are around 0, although many proxies have correlations to precipitation around 0.4 and some have correlations to CO2 levels as high as 0.7.
VZ carried out PC analysis on three different "regions", two of which are illustrated below. The figures below show the PC1 using Eduardo’s implementation of the Mannian method (AHS) and the correlation PC1 (the covariance PC1 is nearly identical), as well as the difference. Note that Region 1 had more proxies (55 to 9) and the difference between results is less, although it is tiny in both cases.For pseudoproxies constructed from gridcell temperatures with 50% white noise, the PC1 from the AHS calculation is virtually identical to the PC1 from the normal calculation.
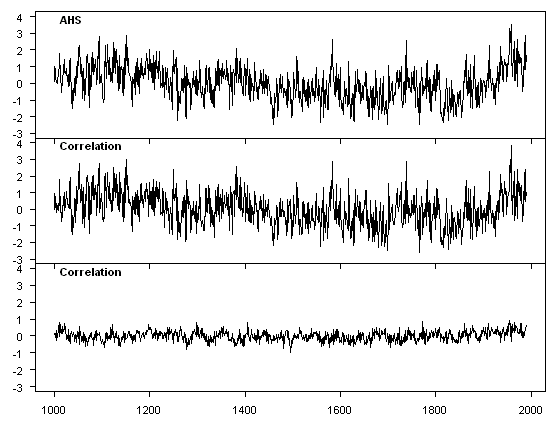
PC1 from VZ Region 3 – AHS and correlation PC, with difference. Legend of bottom panel is incorrect.
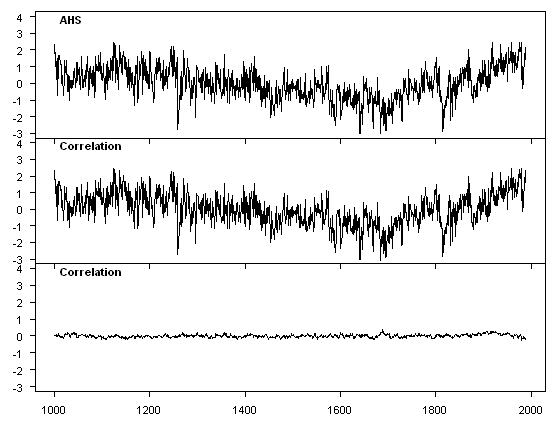
PC1 from VZ Region 1 – AHS and correlation PC with difference (legend of bottom panel is incorrect)
Now compare this to the North American tree ring network, illustrated below, showing the Mannian, covariance and correlation PC1. Regardless of the position of what one takes on which, if any, of these series is "right", the PC1s are obviously different and substantially so.
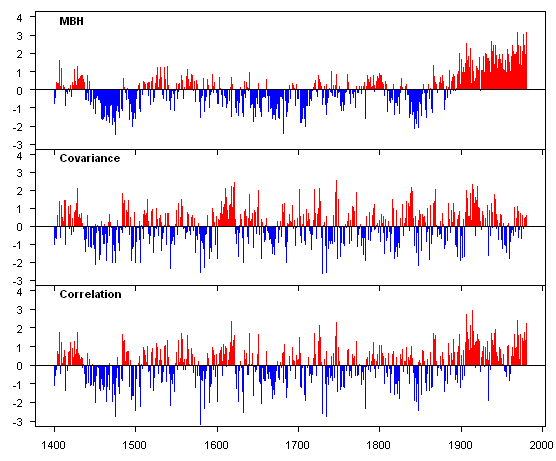
PC1 from MBH98 North American Network – Mannian, covariance and correlation.
Using two PCs from this network as in MBH98, these different results have a substantial impact on an MBH98-type reconstruction (although again their regression methodology is itself not neccessarily "right" a priori.) This is simply an empirical result. In our 2005 E&E article, we summarized a variety of results, including that the reconstruction using correlation PCs was intermediate between reconstructions using covariance PCs and Mannian PCs.
Notice the constrasting situation with the VZ network. In the VZ network, the Mannian PC1 and the correlation PC1 are essentially identical. Thus, there can only be negligible difference in the final reconstruction obtained by carrying these series into the regression module. The reason for the seeming lack of impact of the AHS effect is not that the climate model washes out differences in the PC series; it’s that there was simply no difference in the PC series.
Now let’s re-examine the conclusion of von Storch and Zorita 2005, cited by the NAS Panel:
Our results, derived in the artificial world of an extended historical climate simulation, indicate therefore that the AHS does not have a significant impact but leads only to very minor deviations. We suggest, however, that this biased centering should be in future avoided as it may unnecessarily compromise the final result.
Let’s be perfectly clear on what VZ have and haven’t shown: all they’ve proved here is that in a sufficiently "tame" network, and a network constructed from a signal plus white noise is about as "tame" as you get, Mannian PC methodology and conventional PCs give almost exactly the same answer. We agree with this and have always agreed with this. This has nothing to do with climate models; it’s simply to do with "tame" networks. This was the position that we proposed in our Reply to VZ and, in my opinion, the correctness of the position in our Reply is proven by the near identity of the PC series in the two VZ versions.
However, there’s something very interesting in this that we did not raise in our Reply and, oddly enough, it relates more closely to their dispute with Wahl, Ammann and Ritson than to their exchange with us. Ritson at realclimate has argued that North American tree ring proxies can be construed as having white noise.
However, if the MBH North American tree ring network consisted of signal plus white noise (or low order red noise), then the above results show that Mannian PC methods and conventional PC methods applied to the North American network should produce almost indistinguishable results. But they don’t. Ergo, the MBH North American tree ring proxies do NOT consist of a signal plus white noise in the 50-75% range. This doesn’t say what they are – however, it says something about what they aren’t. I would surmise that low-order red noise (say AR1 of 0.5 and lower) would yield identical results.
There is a further point. It almost seems to be a characteristic of "tame" networks that you "get" fairly similar results regardless of what you do. You see this point made from time to time in multivariate statistical literature (especially chemometrics) – that one gets fairly similar results using various methods.
On the other hand, if the network doesn’t contain a common signal, then different methods can produce quite different results and I’m not convinced that much purpose is served by trying to decide which one is "right". I’m inclined to think that the lack of consistency in the results is the take-home message and, if you can’t get consistent results using somewhat similar methods, then you probably have to abandom the attempt to extract a "signal" from that data set and go back to improving the data. I’m going to do a post in the next few days on what happens with very noisy data sets, drawn from what will seem like a quite unexpected source.





28 Comments
a. Glad to see in your initial graphs that the comparison is AHS to correlation matrix (since comparing to covariance would be combining the AHS debate with the correlation versus covariance choice).
b. Slight nit: In multi-colored panels, the relevant comparison is AHS to correlation. If you gotta retain covariance, might be best to alternate the last 2 panes so that the progression is logically away from AHS: AHS, AHS avec one change, AHS avec two changes.
c.
Seems like an easy thing to see. Was there ever any doubt of this? Did you or someone at some time think the issue had to do with differences in the rest of the reconstruction rather then differences in the PCs? Would think that if the recons are being done properly (identically) from case to case, that any difference has to be a result of the PCs. Although agreed, there could be some damping (dilution) from the PC2 or the non-PCs.
d. The point about Ritson is interesting, although would be wary of stating it with mathematical certainty until so proven. (Did VZ covers all the types of “white noise plus signal” possible for instance.)
e. To understand the issue, maybe you should just generalize and have a computer program run some different examples (vary the AR coefficients, the amount of noise, the type of signal etc.) and then record some relevant output parameter (something numeric like correlation between AHS and correlation matrix examples). You would then have a factor space that maps how AHS interacts with type of signal.
What is it MATHEMATICALLY about the “signal” (or in essence grid cell temp based) proxies that make them behave differently from tree ring proxies in AHS? The vector algebra doesn’t care where the shapes came from. It just churns on shapes. So “signal” is a bit of a misnomer. Need to describe this more in terms of characteristic shape and then make the argument that temps follow a different characteristic shape then tree rings. Perhaps the issue has to do with intercorrelation of the high frequency data in the different data sets? Maybe grid cells track closer to each other then tree rings on an annual basis? I donno. But it must be something that can be expressed mathematically rather then wrt source.
In the end it comes back to Zoritas adroit comment that if you are going to complain about how a method interacts with bad apples, you need to mathematically describe what an apple is (and it has nothing to do with it being contaminated or bad or whatever, has to do with it’s shape…it might well be that bad things can give it a shape…but the vector algebra doesn’t know that. The mattresses just churn on shapes.
And after you’ve described it, you (or he) need to examine the posited interaction of method with data.
TCO, when you talk about supposedly “combining” debates, please recall that in our 2005 EE article, we specifically said that reconstruction results using correlation PCs were about halfway between covariance PCs and Mannian PCs. Everyone seems to forget that we set out this result.
I think that it’s also unfair to talk about “combining” issues. Remember that MBH said that they merely said that they used “conventional” PC methods. They did not SAY that they used Mannian PCs with de-centering and division by the detrended standard deviation. In MM03, we did “conventional” PC analysis using the algorithm default (covariance) which is consistent with authorities like Preisendorfer and Rencher (who were Huybers; authorities) and also North 1982. There was nothing unreasonable about doing so.
So when we came to reconcile MM03 and MBH results in MM05 (EE), we were able to isolate the difference as resulting primarily from two issues: the undocumented and IMHO unjustified Gaspe extrapolation in MBH98 and the difference between “conventional” covariance PC results and Mannian PC results. Yes, there are two (actually) three tweaks to Mannian PCs: 1- de-centering; 2- division by standard deviation; 3 – division by detrended standard deviation (which has the effect of further enhancing the weight of trending series).
The only one of these steps that is relevant to “bias” is the de-centering. The division by standard deviation has an empirical impact because of the bristlecones have low standard deviations, but that’s specific to this network and not germane to bias in a mathematical sense.
The NAS panel has issued a comment on this matter effectively endorsing our position in Reply to Huybers that there is no a priori “right” method (as Huybers seems to imply in favor of correlation PCs) but that any method would have to be established on scientific grounds. I’m going to do a post on this.
#3. Without necessarily being able to define a “bad apple”, one can surely agree that tech stock prices inserted into a dendro network are “bad apples” as climate proxies. Nonetheless, in MBH methodology, the tech stock prices are viewed as “significant” and imprint the reconstruction.
On number 5: the math cares about the shape, Steve. It really does. It has no way to know that you put something laughable in there. And that tech stock thing kinda baffles me what you think it proves. First, obviously, you must have stretched the period to make it match. And it’s the shape that matters. That it was tech stocks versus blue chips versus coyote sightings versus seaweed tree rings is irrelevant. Maybe it touches a vein for you or hits some PR point, but I’d really prefer that you had just used a stylized shape. Back to my point of mixing one HS with 9 straight lines (or something analagous…iow looking at shape as an issue.)
What is the nature of nature? Wow this has to be one of the most challenging posts I have read. Do you really want to get in to the dirty details of all the methods? It seems you are proving from the methods at arm’s length that nature is not signal+white noise. You could just plot them up on a log-log aggregation plot to show that.
Wouldn’t a better approach be like this:
1. Describe the nature of the noise in the series as best as you can.
2. Use simulation of that noise to establish benchmarks for statistics and expected results.
3. Pass the real data through the system and see how it differs from the noise.
I realize that point 1 is an issue, which is why I think it is the real issue. So I agree with TCO in #3. Agree with the point about tame networks. Great post. Go where the wild ones are.
On number 4:
a. I’m aware that you referred to correlation/covariance choice in EE. You said it before. I haven’t forgotten it. Give me some credit. My point was that what you did right there, doesn’t excuse doing it wrong in other places. You still haven’t addressed that, but just repeat what you did in the EE article. No matter how many times you mention what you did in the EE article, it won’t excuse the problem (either a logic flaw or deception) in other places or even in future posts.
b. I’m completely aware that you did the best you could in MM03 to emulate MBH given a poor description of methods. Furthermore, I think the poor description of methods is a failing of MBH that should be called out and something that should be fixed there and in many other science papers. No argument. (I think somehow, you are conflating a defend yourself issue from 2003 of having made a mistake) with the need to clearly differentiate multiple changes in a method.
c. The comment about the three tweaks is new and additive. What goes on with the division by detrended standard deviation? He divides twice? Or this is a qualification of the type of SD that is used? And does “detrended” mean “using SD from 20th century” or something else (what)? Nexttolastly does Huybers explanation/equation call out the use of detrended SD? What I especially liked about his comment was the very clear equation and explication to show what goes on wrt Mann off-centering and correlation/covariance (standard deviation dividing). In addition to aspiring to BC logical precision, would be good to aspire to H communication skills. 🙂
d. I agree with the NAS that the decision of correlation versus covariance has to be established based on the situation. I figured that out from common sense and then googling to see that my common sense was backed up. Unfortunately I think your reply was overly argumentative and muddied the issue by citing all the reasons for covariance as a good choice rather then just being from on high fair in examination. My impression from H in any case is not a strong one of arguing in favor of correlation or averages even, but a suggestive one. However, the really USEFUL thing about H comment was to clarify that not all of the impact in your comparison of methods comes from the universally reviled off-centering. That you had mixed a different change in at the same time. I think if you step back and try to look at it more dispassionately instead of defensively, that you will see this. And you also wont’ have to make arguments about units and the like…that you must see are argumentative and defensive rather than insightful and fair.
I think it is also interesting to think about what happens with the overall PCA given the different transforms. How does the second PC (or other retained PCs) look? In addition, would want to know if Preisendorfer’s n changes with the methods and then what implications this has. IOW either with “same number from cased to case” or with “Preisendorfer’s n from case to case”, how do things compare with the various test alterations of Mann’s method? Interesting to look at the amalgam of retained PCs from the different cases.
On a purely observational note: it looks like the AHS method gives you a PC1 that is much less “snaky” (like a longer period sine wave) then the correlation matrix. I wonder if this signifies something.
Ordinary PC methods introduce a spurious increase in "low frequency" variance. I’ve never seen this mentioned in print, although I may have mentioned it on the blog in the past. I’ve experimented with red noise networks and the increase seems to be to enhance about 2-3 waves. It will flip red noise series to match. So there are problems with ordinary PC methods as well. This is your snake appearance, which is good spotting on your part. It’s easy to say that all these things should be disentangled, but sometimes there’s not much information on it. I’ve corresponded with Huybers about this effect, which intrigued him as he’s not seen any discussion of it, but it seems like something that someone must have reported on before.
Yes, it’s interesting. If we take all the PCs, we get the average no? But obviously the first one will have significant differences from the average. I guess in some sense then PC1 is spurious. But I’m not sure that spurious is the right concept. More that PCA is not appopriate to transform a datga set for MBH work (when you discard the lower PCs).
A suggestion.
It seems to me from what you have said, that there are three steps to the Mannian computation of the data. Perhaps another approach would be to isolate each step in the Mannian programme, output the numbers, and see at what stage the “exageretion” is occurring.
Mann apparently used a Fortran programme, and I would imagine that if you have access to the source code it would be possible to chop the different sections and reintroduce them sequentially. I imagine that the code is not very sophisticated, if it is only following three main steps, and also as I believe Mann is not a Fortran programmer.
At some stage I would expect strange results similar to Manns to be produced. This would identify the area of the programme at fault.
As TCO points out, computer programs don’t care whos numbers they are, they just follow instructions.
Isolating the faulty instruction may be the way to go.
PS There are some very clever PhD Computer Science students, who could probably knock that off in an afternoon, and would appreciate their name in lights, and another line on their cv.
Leaving aside the risks of performing PCA on time series data in the first place, having used PCA myself for 25 years, I’m a bit surprised that any Fortran programming was necessary. A number of tried and true statistical packages have been available for years which can easily perform PCA (e.g., SAS, SPSS).
– Kevin
Look, Mann’s PC methods have been replicated. The only step that rally matters to the bias is the decentering. The only reason that correlation versus covariance makes any difference is that the bristlecones have lower OLS standard deviations and especially lower detrended standard deviations calculated than the other tree ring series. But if you calculate the scale using other plausible measures of scale ( see Reply to Huybers – and that point, TCO, is not simply being argumentative, I’ve posted lots here on problems with OLS standard deviations e.g. Tukey), then the results change again.
I think that all the germane permutations and combinations have been identified. The differing results from perms and combinations come from differing weights of bristlecones and the $64 issue is whether they are a valid proxy. The NAS Panel says that they should be avoided. I think that that’s the end of the story.
Sorry to be dense, but if all the permutations have been carried out, why is it that random numbers put into the Mannomatic consistently apparently produce a hockey stick?
17. Random red noise with some persistence will produce a HS. But if the underlying series are antipersistent (as in a Stahle network) you won’t get a HS. In the North American network without the bristlecoens, you don’t get a HS. Even with persistence, you don’t ALWAYS get a HS, just consistently.
Re #12
I believe I looked at the code sometime. It’s a mess. One of the reasons it’s a mess is that it calculates matrix inverses from scratch, so to speak. Fortran is a low level language and you have to build it all up from the bottom. I typically used Gauss when I wanted to do some complicated statistics. It, for example, has a pre-programed matrix inverse in it (it’s actually a language designed for dealing with matricies). Even higher level statistics packages like SAS mean you don’t even have to worry about inv(X’X)(X’Y).
You have to be careful what you call the Mannomatic and what you mean when you say “produce”. Still waiting for the simple description of how much hockey stick index changes in the reconstruction based on correcting the off-centering.
The thing to understand is that the calibration interval is fixed to the 20th century instrumental temperature which is essentially a HS blade. So the Mannomatic will think that only those “proxies” containing a temperature rise in that period are good proxies and will give them a high weighing. Since this rise is primarily the recovery from the LIA you’d expect that going backward we’d have higher temperatures. (Regression to the mean and all that.) So our fixed points are a highish temperature at the beginning, a low temperature in the 1800s and a highish temperature today. Take a bunch of Proxies, some of which have those three points and random noise in between and what do you get when you combine them; weighing those with the 3 magic points highly?– A hockey stick. That’s MBH98 in a nutshell. The off-center PC thingee primarily results in the shaft being smoother (no prominent MWP or LIA) whereas a regular PC allows more of the other features in the proxies to show up.
#19. TCO, look at the EE 2005 article for chrissake. Read section 3. For the Nth time, the result using correlation PCs is about halfway between the result using covariance PCs and MBH. That’s one of many results reported there.
I looked at it. You cited it. I said I looked at it. Give me some credit. Don’t be a Mike Mann for goshsake. EE was ok. Your other remarks and such, not always fine. And even in EE, a better explanation would be in order, that points out that correlation matrix is one change of method from Mann, covariance is two changes.
Steve,
I essentially agree, as you state in your posting, that a white noise error model for the real proxies is too tame, and methods should be shown to be robust by testing them with more complex error models. The MBH methodology has a number of “dangerous” aspects and the decentered pc-calculation is just one them. My hunch is, however, that the main aspect contributing to the hocke-stick shape is the overfitting in a calibration period with a strong trend. This would also mine data for strong trends in the calibration period.
24.
Eduardo, I take the fundamental point of von Storch et al 2004 as being that it’s essential to benchmark these multivariate methods to see how they work. It’s amazing that such an observation would cause controversy. And even if one is concerned with a network being too “tame”, if one doesn’t understand what happens in a tame network, how can one possibly understand what happens in a wild network?
I’ve been trying to spend time understanding exactly what happens in a "tame" network by experimenting with the erik167 network using different multivariate methods. The more time that I spend at it, the more foolish the hyper-ventilating of Wahl et al and Rahmsdorff seems. HAving said that, I think that there is some useful additional perspective from examining the coefficients resulting from the different methods (obtained in the MBH case by unpacking the algebra) . I’ll probably have a post up in a day or two.
Zorrie:
I think we’ve talked about the danger from the calibration period before. The thing that I don’t understand is how to do it right or at least to assess what one is doing. To exlain:
I want to pick proxies that work as thermometers. Temp has gone up last century. So I pick proxies that have gone up last century. Then I look at what happens in the out years and see that tha result is much less varaible (shaft of the hockey stick). But how do I know that this is from a relevant thermometer and not just because proxies in general average out to zero and I just picked the few that had nice blades (to match recent temp increase) but that in past they average out to no impact. (Since they are not really that accurate a thermometer). How can I tell mathematically my likelihood of doing one or the other?
TCO,
this is related to the trending/detrending problem. If I test my statistical method on the interannual variations, where I have much more degrees of freedom, I can in theory test the skill more robustly than just focusing on the 20th century trend, which is essentially just 1 degree of freedom. The problem even with detrended calibration, as Steve has explained elsewhere, is that the predictor network has 112 predictors, diminishing in time. I think that this guarantees overfitting.
Good point on the interannular thing.
Re#20 and others,thanks for the clarification and guidance.
Thinking about what you say, it seems to me that there should be no need to calibrate in this way. Surely if a proxy is proven to be good in relation to temperature, it should be included, and if not, then it should be discarded.
It seems that the PC1 Bristlecones, which are known not to be a good proxy for temperature in general, just happen to fit for the 20th century.
The other PC’s which by your given definition (because they do not match the calibration), are not such good proxies for 20th century temperatures should also be discarded for prior periods.
Then we are left with no reliable tree based proxy.