I hope that you are following the lively discussion about Burger and Cubasch at Climates of the Past here , where Mann aka Anonymous Referee #2 is carrying on in a quite extraodinary way. I’ll probably try to weigh in over there at some point. The dialogue has exploded fairly quickly and I’ve collated some of the discussion in the post here.
First of all, I’m glad that the question of RE significance has been picked up. We raised the issue of spurious RE significance in our GRL article, but the only discussion of it so far has been Huybers 2005 and Wahl and Ammann (in their rejected GRL submission) both of which were critical and sought to restore the old benchmark of 0. Bürger and Cubasch, together with the Zorita review, are the second discussion to appreciate that there is a real issue with RE significance.
The first, interestingly, was the NAS Panel, which stated:
Regarding metrics used in the validation step in the reconstruction exercise, two issues have been raised (McIntyre and McKitrick 2003, 2005a,b). One is that the choice of “significance level” for the reduction of error (RE) validation statistic is not appropriate. The other is that different statistics, specifically the coefficient of efficiency (CE) and the squared correlation (r2), should have been used (the various validation statistics are discussed in Chapter 9). Some of these criticisms are more relevant than others, but taken together, they are an important aspect of a more general finding of this committee, which is that uncertainties of the published reconstructions have been underestimated. Methods for evaluation of uncertainties are discussed in Chapter 9.
I think that there are two separable issues in the Burger and Cubasch paper which you have to pay attention to –
1) the impact of a spurious regression on RE statistics;
2) the impact of calibration/verification period on RE statistics.
Zorita Comment
Before I comment on Bürger and Cubasch, I’m going to quote from Eduardo Zorita’s posted review in which he cites discussions of “spurious regression” from Phillips 1998 and Granger and Newbold 1974 (previously discussed on this blog). “Spurious” in this context is not merely a term of disapproval e.g. Mann’s generic use of the term “spurious criticism”, but a technical term to refer to high statistical values for unrelated series. Zorita provides a length quote from Phillips as follows:
Spurious regression, or nonsense correlation as they were originally called, have a long history in statistics, dating back at least to Yule (1926).Textbooks and the literature of statistics and econometrics abound with interesting examples, many of them quite humorous. One is the high correlation between the number of ordained ministers and the rate of alcoholism in Britain in the nineteenth century. Another is that of Yule (1926), reporting a correlation of 0.95 between the proportion of Church of England marriages to all marriages and the mortality rate of the period 1866-1911. Yet another is the econometric example of alchemy reported by Henry(1980) between the price level and cumulative rainfall in the UK. The latter “relation” proved resilient to many econometric diagnostic test and was humorously advanced by its author as a new theory of inflation. With so many well known examples like these, the pitfalls of regression and correlation studies are now common knowledge even to nonspecialists. The situation is especially difficult in cases where the data are trending- as indeed they are in the examples above- because third factors that drive the trends come into play in the behavior of the regression, although these factors may not be at all evident in the data.’ Phillips (1998).
Eduardo goes on to say:
Phillips is alluding at the possibility that correlations between timeseries may arise just because a third factor is driving the trend in both timeseries. Is this possible in paleo-climatological applications? I think it is very well possible. For instance, a proxy indicator sensitive to rainfall, nutrients or other environmental factors may exhibit a trend that can be erroneously interpreted as an indication of temperature trend. A regression analysis between a proxy and temperature that oversees this possibility takes the risk of not properly estimating regression parameters. If the validation of the regression model is performed in periods where this trend is continued, a high, but perhaps spurious, validation skill is likely to be the answer, specially when using measures of skill that do not hedge against such risks.
Without directly saying so, the issue posed by Eduardo here, in a Mannian context, is whether the calibrated relationship between the North American PC1 (bristlecones) and the NH temperature PC1, which has a positive correlation even though there is negligible correlation to gridcell temperature, is simply a result of two trends – increased temperature and CO2 or other fertilization, or whether it is a bona fide relationship.
Spurious RE Examples
As an exercise, I located digital versions of the data used in the original Yule (1926) article – Church of England marriages and mortality per 1000. I fitted the relationship in a calibration period and ended up with an RE statistic of 0.97.
Bürger and Cubasch report a very high RE statistic for the “nonsense” relationship betwen the number of reporting gridcells and NH temperature.
I’m quite confident that most “classical” spurious regressions will have high RE statistics. I think that one can prove that this particular statistic has negligible power against common unrelated trends. We showed examples of spurious RE statistics in MM05a and Reply to Huybers, but both sets of examples were framed in MBH contexts and, in retrospect, the argument would have benefited by simply showing “spurious” RE statistics in garden variety contexts of “classical” spurious regressions.
In their abstract, they say:
This setting is characterized by very few degrees of freedom and leaves the regression susceptible to nonsense predictors.
Note that they do not say that the regression is necessarily contaminated by nonsense predictors, merely that it is susceptible. As you’ll see below, Mann, in one of his usual debating tricks, shifts from one to the other, in replying to this. In their running text, they go on to say:
The scores are estimated from strongly autocorrelated (trended) time series in the instrumental period, along with a special partitioning into calibration and validation samples. This setting is characterized by a rather limited number of degrees of freedom. It is easy to see that calibrating a model in one end of a trended series and validating it in the other yields fairly high RE values, no matter how well other variability (such as annual) is reproduced…
Obviously, I agree with the last sentence. It seems that this point, while “easy to see” for Gerd and me, is not widely accepted and, as noted above, showing RE statistics for some classic nonsense regressors like the Yule 1926 example will be worthwhile to illustrate the pitfalls of relying exclusively on this measure. They go on:
The problem is that few degrees of freedom are easily adjusted in a regression. Therefore, the described feature will occur with any trended series, be it synthetic or natural (trends are ubiquituous): regressing it on NHT using that special calibration/validation partition returns a high RE. McIntyre and McKitrick, 2005b demonstrate this with suitably filtered red noise series. We picked as a nonsense NHT regressor the annual number of available grid points and, in fact, were rewarded with an RE of almost 50% (see below)!
Their citation here is a bit wonky, as the citation seems to be to our E&E article, whereas the topic was discussed in our GRL article and our Reply to Huybers (not cited here, although perhaps intended in McIntyre and McKitrick 2005c, not listed in the references). In our article, we tried to show that spurious RE statistics could be expected to arise under Mannian methods, adding these example to the traditional ones. However, these red noise examples were not intended as a universal inventory of all possible situations – merely an example and a highly pertinent example.
David Stockwell’s experiments are also relevant here. There are a variety of situations under which spurious RE statistics can arise and it’s long overdue for climate scientists relying on this measure to understand its properties. B and C go on:
If even such nonsense models score that high the reported 51% of validation RE of MBH98 are not very meaningful. The low CE and R2 values moreover point to a weakness in predicting the shorter time scales. Therefore, the reconstruction skill needs a re-assessment, also on the background of the McIntyre and McKitrick, 2005b claim that it is not even significantly nonzero.
The nonsense predictor mentioned above (number of available grid points) scores RE=46% (and CE=à⣃ ’ ”¬’¢23%), which is more than any of the flavors ever approaches in the 100 random samples. And it is not unlikely that other nonsense predictors score even higher. On this background, the originally reported 51% of verification RE are hardly significant. This has already been claimed by McIntyre and McKitrick (2005b) in a slightly different context. In addition to that study, we have derived more stable estimates of verifiable scores for a whole series of model variants, the optimum of which (1120) scoring with RE=25%±7% (90% confidence).
I haven’t quite figured out how they attribute a RE of 0.25 to MBH. It looks like it arises from various permutations and combinations of methods applied to the MBH network. However, if the network itself contains spurious regressors (bristlecones), none of the choices are really applicable. Their point is more that the calibration/verification period selection of MBH yields an exceptionally high RE statistic relative to random sampling – still a worthwhile point. In their conclusion, they point out that the confidence intervals obtainable from an RE of 0.25 leave an amplitude error of 
Mann’s reply to this (his “review”) depends on Mann et al 2005 (J Clim 2005 available at his website) and Mann et al 2006 unpublished. (Isn’t amazing how often the Team’s supposed refutation of a point is in the still unpublished article?)
Mann:
Let us next consider the erroneous discussion by the authors of statistical significance of verification scores. The authors state the following:The nonsense predictor mentioned above (number of available grid points) scores RE=46% (and CE=-23%), which is more than any of the flavors ever approaches in the 100 random samples. And it is not unlikely that other nonsense predictors score even higher. On this background, the originally reported 57% of verification are hardly significant. This has already been claimed by McIntyre and McKitrick 2005b in a slightly different context.
There are several problems here. First, the authors’ statistical significance estimates are meaningless, ass they are based on random permutations of subjective “flavors” that are simply erroneous in the context of the correctly implemented RegEM procedure, as detailed in section “1” above. Mann et al (2005) provide a true rigorous significance estimation procedure and their code is available as supplementary information to that paper.
Let’s pause here for a minute. First, the high RE results from nonsense predictors and the proposed B-C statistic of 0.25 are different issues. If you can get a high RE statistic from unrelated information, then the RE statistic by itself does not ensure that the model is meaningful. End of story. As to Mann’s statement that “Mann et al 2005 provide a true rigorous significance estimation procedure”, I am unable to locate this calculation in the publication – maybe someone else can locate it for me. Mann describes the “true rigorous significance estimation procedure” as follows:
The procedure is based on the null hypothesis of AR(1) red noise predictions over the validation interval, using the variance and lag-one autocorrelation coefficient of the actual NH series over the calibration interval to provide surrogate AR(1) red noise reconstructions. From the ensemble of surrogates, a null distribution for RE and CE is developed. In other words, the appropriate significance estimation procedure requires the use appropriate AR(1) red noise surrogates against which the performance of the correct RegEM procedure as implemented by Schneider (2001)/Rutherford et al (2005)/Mann et al (2005) can be diagnosed.
This hardly deals with the nonsense predictor problem. The question is whether a proxy (as arguably bristlecones) are affected by an unrelated trend or by long persistence. Low AR1-coefficient red noise behaves a lot like white noise in that the effects attenuate quickly (“short memory”). The Mannian null test is irrelevant. The null test described here was described in MBH98 (not in Mann et al 2005 as far as I can tell).
Mann goes on:
Instead, Burger and Cubasch have simply analyzed the sensitivity of the procedure to the introduction of subjective, and erroneous alterations. Their results are consequently statistically meaningless. This view was recently endorsed by the U.S. National Academy of Sciences in their report “Surface Temperature Reconstructions for the Last 2000 Years” which specifically took note of the inappropriateness of the putative significance estimation procedures used by Cubasch and collaborators in their recent work.
This last sentence appears to me to be a complete fabrication (and is repeated in his Second Reply). I’ve searched the NAS Panel report (Cubasch) and found no reference that remotely supports this claim. If anything, the NAS quote highlighted at the beginning endorsed the view exactly opposite to what Mann espouses here.
Mann goes on:
Burger and Cubasch (2005) attempt to bolster their claims based on a reference to claims by “McIntyre and McKitrick (2005b)”, published in a social science journal “Energy and Environment” that is not even in the ISI database. McIntyre and McKitrick made essentially the same claim in a 2005 GRL article. Huybers (2005), in a comment on that article, demonstrated that McIntyre and McKitrick’s unusually high claimed thresholds for significant were purely an artifact of an error in their time series standardization. Huybers (2005), after correcting the mistake by McIntyre and McKitrick, verified the original RE significance thresholds indicated by Mann et al (1998). It is extremely surprising that Burger and Cubasch appear unaware of all of this.
Now Huybers 2005 demonstrated nothing of the sort. There was no “error” in our time series standardization. Our simulations reported in MM05a used a regression fit (which was in keeping with what was known about MBH methods at the time) and did not include a re-scaling step identified by Bürger and Cubasch as a methodological “flavor”. However, they showed the existence of spurious RE statistics in an MBH-type context. In our Reply to Huybers, ignored here by Mann, we responded fully to Huybers by showing an identical effect with re-scaling in the context of a network of 22 noisy proxies. It’s too bad, in my opinion, that B and C did not discuss Reply to Huybers in more detail as it’s still ahead of the curve.
More Mann:
Finally we come to “nonsense variables” argument made by Burger and Cubasch. Their basic argument here appears to be that CFR methods such as those used by Mann et al (1998), Rutherford et al (2005) and dozens of other groups of climate and paleoclimate researchers, are somehow prone to statistical overfitting in the presence of trends, which leads to the calibration of false relationships between predictors and predictand. So their above claim can be restated as follows: calibration using CFR methods such as Rutherford et al (2005) and multiproxy networks with the attributes (e.g. spatial locations and signal-vs-noise characteristics) similar to those of the proxy network used by Rutherford et al (2005) will produce unreliable reconstructions if the calibration period includes a substantial trend. They believe that such conditions will necessarily lead to the selection of “nonsense predictors” in reconstructing past variations from the available predictor network.
I warned at the start of the post that we’d see the usual Mannian debating trick. B-C said that the Mannian method was “susceptible” to nonsense regressors, a view that I share. Watch the pea under the thimble. Mann re-states this as being “necessarily” and then tries to show a situation where the problem doesn’t occur – thereby supposedly refuting the original claim.
The real “nonsense” however is associated with their claim, which has already been tested and falsified by Mann et al (2005). Burger and Cubasch (2005) cite and discuss this paper, yet they appear unfamiliar with its key conclusions. Mann et al (2005) tested the RegEM CFR method using synthetic “pseudoproxy” proxy datasets derived from a 1150 year forced simulation of the NCAR CSM1.4 coupled model, with SNR values even lower (SNR=0.25 or “94% noise”) than Burger and Cubasch estimate for the actual Mann et al (1998)/Rutherford et al (2005) proxy data network. Mann et al (2005) demonstrate that even at these very low SNR values, and calibrating over precisely the same interval (1856-1980) as Rutherford et al (2005) (over which the model contains an even greater warming trend than the actual surface temperature observations), a highly skillful and unbiased reconstruction of the prior history of the model surface temperature field (and NH mean series) is produced. In other words, the RegEM CFR method applied to multiproxy networks that are even “noisier” than Burger and Cubasch estimate for the actual Mann et al (1998)/Rutherford et al (2005) proxy network, and calibrated over intervals in which the surface temperature field exhibits even greater trends than in the actual data, yields faithful long-term reconstructions of the past climate history (this can be confirmed in the model, because the 1000 year evolution of the temperature field prior to the calibration interval is precisely known).
Certainly, if the method were–as Burger and Cubasch claim–prone to using “nonsense predictors” when applied to multiproxy network with the signal-to-noise attributes of the Rutherford et al (2005) proxy network, and calibrating over intervals with trends similar to those in the actual observations, there would be at least some hint of this in tests using networks with even lower signal-to-noise ratios, and calibrated over intervals with even larger trends? But there is no such evidence at all in the experiments detailed by Mann et al (2005).
In their Reply to Mann, B and C will point out that Mann et al 2005 deals with pseudoproxies in a tame network (using my terminology here).
11.”Mann et al., 2005″. – The rev. tries to disprove our conclusions citing Mann et al., 2005. That study nicely demonstrates a successful reconstruction of a simulated climate history from sufficiently many pseudoproxies (104, representing the AD 1780 network), which obviously cannot contain any nonsense predictors and which has never been questioned by us. Our focus was on the AD 1400 network with 22 real proxies.
I’ll show below some actual results from Mann et al 2005 to confirm the validity of this reply.
Mann’s Second Comment
This time, Mann relies on the unpublished Mann et al 2006. I presume that this will be published in Hockey Team house organ Journal of Climate.
11. This is especially disappointing. Based on the above, the authors appear to have gotten little at all out of their reading of Mann et al (2005). Morevoer, Mann et al (2006) have already dispelled the specious claim that the findings for the AD 1400 sparse network are any different for those for the full network. They are not. Moreover, what can the authors possibly mean by “non-sense” predictors if not predictors that are composed entirely or almost entirely of noise. At SNR=0.25, for which Mann et al (2005) show a skillful reconstruction is still produced, the pseudoproxies are composed of 94% noise by variance. In more recent work Mann et al (2006) have shown this is true even if the noise is substantially more ‘red’ than is supported for actual proxy records. Mann et al (2006) show that the performance for a fixed SNR=0.4 (86% noise by variance) are very similiar that for a multiproxy data set with the same average SNR (0.4), but for which the SNR for individual pseudoproxies ranges from SNR=0.1 to SNR=0.7. Would BC try to seriously argue now that pseudoproxies with SNR=0.1 (essentially, entirely composed of noise) are not ‘nonsense predictors’ by their definition. Lets think a bit about what the real “nonsense” is here.
It really is frustrating wading through these debates. A series with SNR of 0.1 (with white noise) is not “essentially, entirely composed of noise”. It actually doesn’t take all that many series for the noise to cancel out and to recover the signal. The spurious regression problem is the problem of an unrelated trending series. Arguing from high white noise situation is totally irrelevant.
Mann et al 2005
If you actually go to Mann et al 2005 to see how it supposedly supports the claims here, you’ll not find much that actually supports any of the claims. The context is a “tame network” like the one that I discussed in connection with the VZ pseudoproxies a little while ago. Like VZ erik167, they constructed pseudoproxies from gridcells information from a GCM mixed with equal amounts of white noise – a “tame” network. Most of the article is about “CPS” methods i.e. averaging scaled versions of the series. If you know that the proxies all have equal amounts of white noise, this system works pretty well and is probably as good as you can get. Here’s the description of their setup in Mann et al 2005:
We investigate here both the CFR and CPS approaches, using networks of synthetic pseudoproxy data (see Mann and Rutherford 2002) constructed to have attributes similar to actual proxy networks used in past CFR and CPS studies, respectively. The pseudoproxy data are derived from a simulation of the climate of the past millennium (A.D. 850–1999) using the National Center for Atmospheric Research (NCAR) Climate System Model (CSM) version 1.4 coupled ocean–atmosphere modelPseudoproxy time series (see supplementary Fig. 1 at http://dx.doi.org/10.1175/jcli3564.s1) were formed through summing each grid box annual mean temperature series with a realization of white noise (a reasonable assumption for representing observational error”¢’¬?the effects of the noise “color” were investigated by Mann and Rutherford 2002), allowing for various relative amplitudes of noise variance (expressed as a signal-to-noise ratio (SNR) of amplitudes; see Mann and Rutherford 2002). Experiments with SNR 1.0 were performed for all three networks. For the first network (A), experiments were performed for four different values of SNR: 0.25, 0.5, 1.0, and infinite i.e., no added noise).
A SNR ratio of 1 appears to be exactly the same as the VZ erik167 network that I’ve experimented on. In any of these pseudoproxy networks – if you’re adding equal amounts of white noise – you can usually get your signal back using simple averages. From the above networks, they calculated RE, r2 and CE results:
We calculated the reduction of error (RE) reconstruction skill diagnostics during both the calibration period and an independent, precalibration “verification” period (see, e.g., Cook et al. 1994; Rutherford et al. 2005, and references therein). We also calculated alternative coefficient of efficiency (CE) and squared Pearson correlation (r2) verification skill metrics. While RE is considered a superior metric for evaluating statistical reconstruction skill (see Rutherford et al. 2005), verification RE values tend to be enhanced in these particular experiments as a result of the unusually large pre-twentieth-century mean temperature changes that occur in the model output and are captured by the reconstructions.These mean changes are larger than those observed in the actual instrumental data. We therefore also used a highly conservative estimate of unresolved variance provided by 1- r2 (along with the more conventional 1- RE) to estimate statistical uncertainties as conservatively as possible.
It’s interesting to actually look at the table of results. For the MBH98 network (here they use 104 locations), the RE score is very high for all 5 cases (as are the CE and verification r2 scores). Given that the issue with MBH is negligible verification r2 and CE scores, this hardly proves the point that is supposedly being made.
All I can determine from this article is that if you have a tame network, you usually get a decent reconstruction. Also note the apples and oranges comparison for the MBH method – for the simple average, they use 12 pseudoproxies, while for MBH98 they use 104 pseudoproxies. Obviously 104 pseudoproxies will do better with white noise. I don’t see any results here for 12 pseudoproxies using MBH methods. Another odd point, they don’t report calibration RE results saying they are “not available in RegEM”. I don’t understand that at all. I presume that the values will be about 0.99999, but you could still report it.
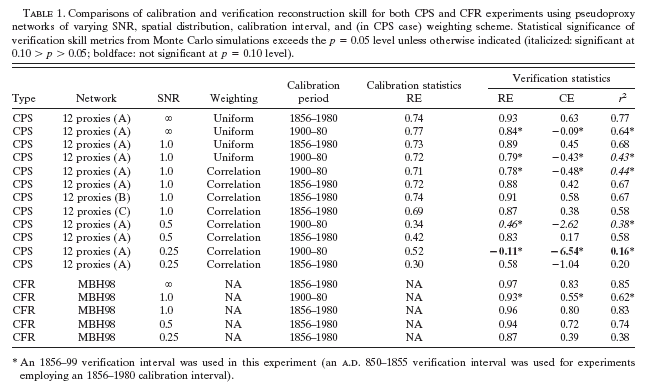
From Mann et al 2005.
Mann, M. E., Rutherford, S., Wahl, E., and Ammann, C.: Testing the Fidelity of Methods Used in Proxy-Based Reconstructions of Past Climate, J. Climate, 18, 4097–4107, 2005.
Mann, M.E. et al, Robustness of proxy-based climate field reconstruction methods, 2006 (accepted).





147 Comments
Mann:
I’ll give Mann full marks for being consistent. To obviously lie like that is the mark of desperation – and obviously the only people who check this are contrarians.
He’s not going to last that much longer before his keyboard starts spontaneously shuffling. Mann is very, very used to having the RC criticism firewall in front of him when he speaks ex cathedra and very unused to have people come back with clear criticism.
As the blood pressure rises so the number of spurious citations rises, in the hope of burying the hapless checker and allowing AR2 to “move on”.
Thanks Steve for wading into (and through) this rather intricate series of arguments. I have read the relevant articles once, and haven’t had the time to work through the logic to the point that I could form a reliable reply. But it seems to me that Mann et.al. have gone out on a very long conjunctive limb. Lets count the things they need to work all at once.
The temperature needs to trend, as detrending doesn’t work. The RE needs to be used, and other stats don’t work. The errors need to be AR just so, or it doesn’t work. RegEM needs to work, as MBH98 doesn’t.
There are probably a few more too.
I think BC point out how long this limb is, but doen’t lop it off. I don’t think bringing up hemlines or something else helps as they are too distant from the problem at hand. From what I gather the simulations assume all the proxy signals are driven by temperature, but as you say, some like bristlecones must be spurious, but we don’t know how many. That they don’t even correlate with local temperatures is worrying. Add that proportion to the ones that are spurious then easily 50% of series could have no relationship to temperature. Then you would get the hockeystick easily.
Anyway, I was thinking of trying to get RegEM running with Octave, a free Matlab interpreter. Has anyone had any success with this?
David, did you read Reviewer #3’s comments. Mann’s comments weren’t really frustrating because they were so transparent. #3’s are frustrating because he mixes some valid points about style with points where he goes completely off the mark. I don’t think he understands the idea of spurious regression at all. I’m trying to collect spurious regression data example to do a bunch of RE calculations. I think that both B-C and ourselves are stating a bit too much in the middle of the argument and have to go back and show actual RE statistics on really really simple examples that are comprehensible to freshmen.
I’m not sure that it is fair to say that “H wanted to revise the RE bar to zero”. I thought your explanation of the whole affair was that he did find a relevant mistake in your calc, that changed where the bar was and that you then found a SECOND mistake (for both you and H) which changed the bar back. BTW, that whole sorta thing bothers me a bit…
Yes I just read the #3 after I wrote my comment. It is hard to find a substantive criticism in it. BC is kind of written in code, but I think adequate. Mann is just bluster. But something like this has a higher hurdle.
I think you are right about starting at the middle. This is why I lost interest in the non-linearity argument as to make it would presume that proxies are correlated in some way with temperature anyway. You seem to be showing that they don’t even get to first base, i.e. correlation with local temperatures, so why bother with second.
One thing to do would be to simulate temperatures and proxies with a big V say instead of the 1850-2000 trend, and reconstruct with RegEM. Presumably in this case the calibration mean should equal the verification mean, and CE=RE. Then I assume the validation stats would be zero, but RegEM would still get the right answer under their conditions. Which would show circularity. Just guessing.
Agreed on the “easy to see” issue. BC make too many offhand comments like that, that are not supported. I’m not disagreeing with them. Just making the point that if they want to CORRECT a science field that doesn’t “see it so easy”, then they need to lay it out in their paper. Otherwise, what the heck are they doing?
Dave,
I use Scilab on occasion. A brief rundown on the Matlab look alikes can be found here
The .25 and root (100-RE) seems confusing. And I’m not sure why that means that the MWP thing can’t be solved. But I still need to dive back into the morass of that BC article.
1 I think Anonymous Referee #3 is cribbing from TCO’s criticism of the paper. See posting S173. All this stuff about “it’s not clear” etc. Either that or Mann and TCO are stylistically similar. (Or perhaps they’re drinking the same beverage? Only joking.)
2 Looking at the Table 1 above, am I correct in thinking that all the correlation and verification tests fail for the calibration period 1900-1980, except when the footnotes show that the calibration period is in fact different. Is that significant?
3 Speaking as a freshman, it seems to me that the Bristlecone Proxies have, practically speaking, zero correlation to temperature after 1850, and the other Proxies have practically speaking, zero correlation to the Hockey Stick graph. What more needs to be said?
Not quite clear to me what resolution of the pea and the thimble is. Yes, he does say nescesarily at one point (btw, I’m intrigued to what extent errors in logic are a result of mind from BC or M and to what respect come from having to write in English vice German), but later on in his discussion he is “fair” and refers to “prone-ness”. The question then becomes, to what extent the test he discussed is adequate to weigh in on this issue of “prone-ness”. What is your take on that issue of content????
Ok. I think your citation and support for BC reply states the belief that Mann’s test was not a good test of “proneness” because the data set was too tame. Why then did Mann argue that this was an especially good data set for this issue of proneness (low snr and all that). Can you show where the misunderstanding between the sides is?
Disregard. Think you answered it as I read on. Sorry for the James Joyce.
Post #3: Yup, I told you so. I told you so. 🙂
Post #5: Yes, stylized shapes is the way to go. I told you so. I told you so. 🙂
#4. TCO. You’re looking for “mistakes” when that’s not what’s involved.
There was no “mistake” in our original calculations. The results are correct as far as they go. Maybe they didn’t go far enough, which people after the fact could see, but there was no slip in the calculations.
We were only trying to show the existence of spurious RE statistics in a relevant context. We did not attempt to consider all possible contexts in a situation when knowledge of the methods was still fluid. (I say this not as an excuse, but that we didn’t try to consider all possible “flavors”).
Having said that, the calculations in Reply to Huybers were much more on point and showed the same effect in a pretty precise context and were a complete reply to Huybers.
Mann and Ammann must surely know this and, for them to ignore this, is a falsification of the record.
Re #7 Thanks for that. My review of Stats packages is posted on my site. Cheers
or “denialist” to use the latest lingo. BTW Steve, have you tried to run RegEM and simulation using the information supplied by Mann et.al. supplement?
I’m fine with that the error came from not knowing the method although it is interesting that you picked a flavor among your choices that ended up making the situation look worse then what we learned it actually was. And isn’t it a second error that you had to do the modified test that you hadn’t done the first time? And it still bugs me. If H keeps finding mistakes in your NPV are you going to keep changing the market size to compensate for the higher cost in the cost model?
I have to say that I am surprised by some of the comments of referee 2.
There is an awful lot of what looks to be rather emotional language. It is sufficient to point out the defects clearly and unambiguously; adjectives are not required, and are likely to undermine the reviewer’s comments.
But the comment on Zorita is exceptional. I am aware that many Journals do not let the author see the reviewers comments directly, because it is not uncommon for a reviewer to say something defamatory. Sentence two appears to me to suggest devious (if not malicious) intent by Zorita, and may be defamatory.
Unfortunately, I cannot really comment on the substance of what the reviewers say. With two referees requiring rejection in categorical terms, I would guess you would have to be able to demonstrate that their criticisms are obviously wrong to get published. If the relevant editor is not seriously fluent in statistical double-speak, they will just count the # of referees that are for rejection.
cheers
per
#17. TCO, you have to stop taking everything Huybers says as the last word.
I would never take a Woop as the last worder. I’m rereading his comment, your reply and the long #2 Huybers post that you did. I don’t take him as the last word. But it is frustrating that he is so much clearer then you.
Mann’s use of a future unpublished work as proof (or disproof) of B&C. Watch the tenses:
I might want to inform Anonymous Referee #2 that the unpublished work John A et al (2007) has shown that Mann is full of crap.
Talking of that last word in #21, a newly released paper by Richard Seager and David S Battisti at (sorry, I don’t know how to make it a link!) has challenged the notion that it is the warm waters of the Gulf Stream that keeps Europe temperatures more mild than they would otherwise be. Quite a fascinating account that ends with the statement:
John replies: It’s quite simple. You select the word you would like to make into a link, click “Link” and type in the URL and click OK. Blockquote works in a similar fashion.
Actually, Bruce, I have a copy of the Royal Meterological Society’s ‘Weather’ magazine with an article that says pretty much the same from April 1993. Well worth a read it is.
The article made sense to me then, and it still does. What we mustn’t run away with is the idea that any mechanism is dismissed, rather it is that the releative contributions of each is different. So, the GS plays a role, so does they way oceans store heat and then give it up over the winter, and the THC etc etc.
Steve,
Zorita’s point concerning a spurious relationship in a time-series is devestating. Just because two variables are highly correlated means very little. They might be related to a third variable when introduced washes out the correlation. He points out that you must not just prove the relationship that you seek; you also must reject alternative explations. This is basic to any science. It is called control.
I recommend that Mann et. al. read Emil Durkheim’s classic work, SUICIDE. It might give them an idea of how to approach alternative explations scientifically and not pejoratively.
JSP
Someone set me straight on what “Mann” is trying to say here. Is it simply that “one Mann’s noise is another man’s signal?” I thought a nonsense predictor was a dataset which had/was a signal in some other field but happened to match a dataset in another field. Yes it’s entirely noise in the new setting, but AFAIK we generally use a more technical definition for noise. If we take him seriously then how do we known any dataset contains a “true” signal? We have to have a decoding mechanism. I can take an article from Encyclopedia Brittanica and convert it to a digital signal and it’s total noise in one setting and perfect signal in another. Is this just 100% obsfucation or does Mann have a legitimate point?
It is 100% obfuscation (combined, of course, with advertising for his own article). A noisy signal is not the same thing as a spurious predictor. The latter looks and behaves like a good signal with very little noise but we know on a priori grounds that it cannot in fact be a good predictor — like Steve’s dot.com stock example.
Dear Dave,
I can also imagine that Mann has some point if understood properly or he can be seriously wrong if properly analyzed, but it does not seem that they ever want to analyze these notions carefully. You’re very right that the question whether something is noise or not depends on details. In the transfer of binary data, random data are such that any reasonable compression mechanism is unable to compress data significantly below the original size in bytes. Of course that the subtlety is in the meaning of “reasonable compression algorithms”. Some algorithms only look at bytes and represent the frequent bytes by shorter sequences. Some other algorithms may be more complex.
The digits 31415926535897932384626…. (I memorized 100 digits) look completely random. Each digit appears 10% of the times. Each pair of digits appears 1% of the time, and so on. In any simple enough criterion you invent, PI will look just like random figures. Yet, if you design an algorithm that computes PI, you can get all the digits from nothing beyond a simple program.
This was about discrete data. For continuous data, there are new subtleties. When we talk about noise, we must know that there are colors of noise. The amplitude of the Fourier component of the function typically depends on the frequency as a power law, and the exponent determines the color. In other words, it reflects the long term persistence of the function. Observationally, some of these exponents seem to be known, some of them are universal, and the existing climate models are not good in reproducing them well. It may very well be true that some features of the resulting data appear for noise of one color but disappear for other colors of the noise.
There is one interpretation that leads me to think that Mann is seriously wrong. It is a basic point of nonsense that nonsense does not have to be random (although it often is); Mann says that nonsense must be random. Nonsense can be meaningful in a different context, but it may be simply irrational to expect any correlation. The prices on the stock market are not nonsense in the world of business. The numbers are not random. There are peaks that represent the collapse after 2000 and the recent recovery, plus the quasi-random walk above it. But you don’t want to insert the Microsoft stock price as a temperature proxy because you a priori expect that results of such a procedure will be nonsensical. Stock market recovery is not the same thing as the recent warming, I think.
M&M have been showing that the Mannian methods tend to pick the hockey stick even from random data. But it is even easier if you invent some nonsensical proxies – like some particular stocks – that have some “signals” in it which are however not temperature signals. The stock prices are nonsensical probably according to everyone. The bristlecones are most likely not temperature proxies either, at least many of them. And Kilimanjaro glacier is shrinking because of drought, not heat. Many people know these things but others don’t.
All the best
Lubos
re 22:
They claim that their model runs show that stopping the GS leads to a general cooling on both sides of the Atlantic. I’d be interested in seeing how far inland that effect runs in North America compared to Europe – as they point out, eastern NA is primarily a contintental climate, and europe is much more maritime, and if they are only comparing to immediate coastal temps in NA they are going to get misleading results. Unless I missed it, they don’t address this point in their artile and its concluding rant.
They also say that a GS shutdown causes land temps to drop by an otherwise unquantified “typically less than 3 degrees,’ and subpolar north atlantic cooling by “as much as 8 degrees in some places.” He doens’t specify units that I saw – I’m assuming degrees C.
He later says “Temperatures will not drop to ice-age levels, not even to the levels of the Little Ice Age, the relatively cold period that Europe suffered a few centuries ago.” Ummm, was the LIA more than 3 degrees cooler than present temperatures? The ranges I’ve seen reported for the LIA run from less than 1C up to less than 3C – IOW in the range he is reporting here from his model runs. A cooling of up to 8C in SST in the north atlantic, with accompanying continental cooling of up to 3C, is a very substantial change, certainly into the ragne of the LIA, at least.
And his general point is that the GS transports heat to the entire northern hemisphere, not just Europe, so this would be expected to to influence a much wider area than just Europe.
Note also that if this were to happen, it leaves that un-transported heat in the tropics, causing greater tropical heating – and greater temp differences between the tropics and temperate regions.
This is an intersting result – although it would be good to see the actual results, and not a general description of his model runs. He *does* say that “A slowdown in thermohaline circulation should bring on a cooling tendency of at most a few degrees across the North Atlantic”¢’¬?one that would most likely be overwhelmed by the warming caused by rising concentrations of greenhouse gases. This moderating influence is indeed what the climate models show for the 21st century and what has been stated in reports of the Intergovernmental Panel on Climate Change. ” Which more or less undermines the plaintive question in his concluding rant, “Why hadn’t anyone done that before?”
There is a new post by Zorita, up there.
There’s an amusing further post by Mann, who, if you can imagine, dares to accuse someone else of “introducing an erroneous step into the literature (in an undisclsoed manner)”. What cheek the Mann has.
I don’t see any recent posts by “Mann”. You must be behind the times.
#28: Lee,
Yes I read the article and the results they found fall into the category of “blindingly obvious”. Which probably explains why it was written in a Scientific American type of rag rather than an academic journal. I think it is interesting that they were able to hang a number on it, don’t really know if it was worth a paper or not.
I do suspect that they are wrong about temperature levels in the LIA in Northern Europe. An approximately 3C drop would certainly lead to shorter growing seasons, and I suspect that the effect would be greater in the fall, winter and spring than it would be in the summer since insolation in the summer is probably the dominant factor for temps (for the denialists around here, this is all speculation).
What I disliked most about the article was that they set up a strawman, press interpretations of practitioner’s statements, to knock down. AFAIK no climate scientist actually claims that a shutdown of the thermohaline circulation would lead to an ice age in Europe. At the most they claim that it would lead to a cooling, which is exactly what these guys showed. If the press chooses to put an alarmist spin on this it is partially the fault of the scientists, and this has been a recent hobby horse over at RC.
Re #32
I think they were pointing out that the relative importance of the THC compared to other influences was exaggerated.
They’ve published different articles on this stuff. Real science papers on the simulations (Journal of Royal Meteorolgy Society), popular articles, press releases, notes in Columbia UNiversity organs.
I thought it was great stuff. So, if nobody had the mistaken impression, fine. I don’t buy that, but fine. No harm done.
No, the effect of the GS might have been exaggerated in the press, but no climate scientist worth his salt would claim that there wasn’t an effect of the mP air masses which dominate the Northern European (especially Britain and the Norwegian coast) climate. Nor would any claim that there wasn’t a moderating effect in the Northeast USA from the ocean which is warmed by the GS, thereby moderating the cP air masses which tend to dominate the winter climate in most of the northern tier of states.
Like I said, it is interesting that they put a preliminary number on it, but the results are not suprising or even really that interesting — which is probably why no one did the experiments they did.
John A, the point is that the effects were mostly exaggerated in the press, and AFAIK not in the scientific literature. I’ll cite a popular book as reference, since I have not read any of the specialist literature on this subject, but “Thin Ice” by Mark Bowen has an excellent discussion of exactly this point, a discussion which surprised me because most of my knowledge on this particular subject (slowing or halting of the THC) had come from the press. The article will have served it’s purpose if the press stops shouting about a coming catastrophic change to an ice age in Europe because of a weakening of the GS; this is a point with which I am sure the guys over at RC would agree.
In the end this does not give any real ammunition to deniers, skeptics or contraians, although I am sure that it will become a talking point.
Depends on what they are saing is of less importance.
Yes, maritime influence matters on the west coast of europe – Ive been aware of this since I first started doing ocean sail racing 25 years ago, and read some practical meteorology texts in the process of learning basic ocean tactics. This matters if the primary issue is the difference between NA and Europe. Yes ths is what they present as a major finding in their article, but they go on to say that changes resulting from shutting down the THC are realtivey minor. If by relatively minor, they mean ‘not another major glaciation’ they are right. This is relevant only if they are countering the more extreme and not commonly scientifically accepted scenarios as the target of their paper.
For practiccal climate-change purposes, what matters is the change in climate as a result of a given response to warming. The only numbers they provide from their model runs are north america and europe cooling of 3C, and north atlantic SST cooling of 8C, if the THC is stopped. Those are not small numbers; they are quite substantial numbers.
Lee, I agree with you violently. The numbers are not small, but they are unlikely to lead to a reglaciation of Northern Europe, but they may well lead to economic displacement and perhaps starvation if growing seasons get appreciably shorter (thought I made that point already, but I did not expand on it). This is (for all you denialists out there) NOT GOOD!
BTW, I also started doing sailboat racing about 15 years ago and so have a similar practical meteorolgy background. I do both ocean and bouy, although I now live in Bozeman, Montana, where large bodies of water and fleets of boats are scarce.
The fishing is great however, that is until the rivers dry up and they get closed down by FWP. That now happens almost every year as stream flows get much lower than they used to and as a consequence water temps rise putting excessive stress on the native fish populations. We’ve had a string of warm winters here, too. Haven’t had a cold one since 2001. Last year I never even put on my snow tires, we had rain in January! An exceptionally warm May and June has melted off most of the high mountain snowpack, currently the flow on the Gallatin is 1/3 below normal, but it has been running like this for quite a few years because warm springs and early summer (basically April, May and June) are causing a much faster runoff than in the past.
Is this all due to AGW? It is a standard joke around here, but after 10 years of drought it is starting to seem not so funny.
You know that you all are so keyed up on the GW debate that you miss the larger points wrt characterization of the reasons for the difference in same lattitude temps accross the ocean. The backing up of the reasoning with models and calculations.
Oh…and if none of you scientists on the warmer side had the wrong opinion, fine. We can still correct the mistaken public view.
tco, I discused that. Bu tthe paper spends quite a lot of time disucsin the moere general issue as well,a nd minimizing the potenital imapct of the kinds of temp changes their model runs showed. That deserves specific response.
So, you agree with their results and just don’t agree with the implication that some people didn’t already know this or had been concerned about the converse? At least, this paper nails it down to a definite analysis. Otherwise, the question might be open.
I dont know if I agree with their results – they dont provide much relevant info in that. The results are plausible and consistent with what I think I know, although it woudl be interesting to see how much inland influence on eastern NA their model runs show.
Taking their numbers at face, value, I do NO tagree with their characterizatin fo the relative magnitude of the temp change values they claim.
Did you read the science paper?
Not yet – I’m on vacation. Grin.
Truly, my reading list has gotten *really* long lately, and I’m working on a business plan as my first priority.
There is a new posting (by Joel Guiot) on the commentary at CP. He sticks up for the paper a bit and disagrees with some of the distracting debates of the reviewer #2: 8 years gone by issue, the other studies show warming, etc. I think he does so in a very temperate way. Of course, he is an editor, so he is a bit sticking up for his journal.
He also says the paper is poorly written and unnescesarily hard to interpret by non-participants in the controversy. I agree.
These two stations at Bozeman are 14 kilometers apart.Why does one show warming since 1946 and the other not?
50km away Norris Madison Powerhouse has warmed
Livingston (56km away) appears to be cooler than the late 19th Century
John A,
You ask “Why does one show warming since 1946 and the other not?”.
Perhaps you could help us by telling us where you got the data, how good you think the data is and your reason for the discrepancy (if indeed it is a discrepancy).
#37
Are conditions in Montana approaching the drought of the 1930s?
From here
Can you find some other thread to discuss urban warming effect or thermohaline circulation? These are ongoing issues and hobbyhorses, while the B-C is topical.
LOL, Mann sure talks like a statistician, although he admits he isn’t one!
Steve
You said you were looking for examples of spurious correlation to calculate RE. You mentioned the example of the number of gridpoints versus temperature. Is that data available? It is a great example.
The number of grid points probably is a proxy for urban growth and thus the UHI effect on temperature data.
John Heckman,
See comment 4 in the CRUTEM and HADCRU thread at http://www.climateaudit.org/?p=312#comments
RE: Mann.
What a snake. Seriously, what a slippery, lying, diversionary, frustrating individual.
OK, John A. I’m ready to have a go at your data.
First, the Bozeman station is located on MSU campus and the area to the east and north of it has been developed since the early part of the 20th century. Land to the south has not seen substantial devlopment, although land to the west has been heavily developed over the last 10 years or so. Prevailing winds are from the SW or ENE.
Gallatin Field is an interesting case. The area around it has been growing very rapidly over the last several years and it has become the busiest airport in MT. However it shows only a mild warming (I disagree with your eyeballing of the graph) since 194x when the station was established. What does that say about your UHI?
Livingston is an odd man out here. It is heavily influenced by Chinooks so if conditions in the winter are for some reason favorable to Chinooks it will show a warmer temp. In the winter time, Livingston will often be 10 or 15 degrees warmer than Bozeman, though not always. In this case I think that local geography and orographic weather conditions have more influnce on the annual temp than the increase in CO2.
I looked at several other stations nearby in SW Montana and all of them showed some warming trend — but this is just from doing the squint test.
As far as the question about whether the conditions are as bad as the 30’s? I haven’t really met anyone here who is that old. Most of my friends are of my age, and the oldest folks I talk to are around 60 or so (and most of those have decided to retire here). All I can say is that most of the born and bred and the longtime transplants think this is the worst it has been in their memory.
It says that the weather records have a substantial heat component that is non-climatic. No two ways about it.
Or alternatively, CO2 increase has very little influence on some places (negative correlation) and lots of influence on others (positive correlation). In any case, one of the main theses of this weblog has been spurious correlations between variables that are not connected. Could the movement of a trace gas and “global temperature” be one of them?
BC has a new posting to several of the substantive comments of reviewer #3. My hope is that a rewrite will incorporate many of BC’s comments.
My hope is also that following blithe remarks will be eliminated or justified with a detailed argument:
-referring to climate reconstructions in general vice those studied
-low degrees of freedom (without a number and a discussion)
-“can’t resolve the MWP controversy”
My hope is also that the paper will also go into greater detail on things that the author implies are basic (same population, verification/calibration period–is entire thing really one period, others), but which were still supposedly done improperly by Mann or Rutherford.
I also (since I did not have the perseverance to read through the paper yet) am not clear how important the actual experiments done by the authors are and how important are their observations of methods wrt Mann and Rutherford. Is the numerical experrimentation only applicable to certain noted issues, is it a distraction, is it something thrown in so that the paper looked less purely critical as per se a review. I don’t have any criticism yet of this aspect, just a concern that there might be some issue here.
My hope is also that the paper can be more tightly structured in an executive format vice a “wandering story format” (I realize that the field is prone to this problem). In other words, give me the “so what” at the front. Then show the supports (and supports for supports…in a clear thought heirarchy). Then summarize. Then add any speculations or recommendations for future work.
Bottom line, I should NOT have to read so hard into the paper to tell what is interesting in it. It’s one thing if I can’t follow linearl algebra. It’s another thing entirely if the thing is poorly structured. I may not be smart enough to follow matrix algebra…but I am smart enough and have read a lot of analyses in my life…to tell when a document is well constructed. In addition to sympathy for me, for the general reader, for future readers of archived literature; I think that clear writing will help the authors themselves to have a better understanding of their performed analyses and of what to do next in their investigations.
——————–
P.s.: Sorry for the off-topic distraction from UHI of Montana.
TCO, if you go to a math journal, you wouldn’t be able to get past the first few lines of any article. That doesn’t mean that the article is unclear.
While there are some style defects in B-C, some of the issues that you raise or #3 raises are not germane to, for example, my ability to understand what B-C are saying. If the article is comprehensible to another specialist in the field, then anything above that is “nice to have” and certainly better practice (and something that I’d aspire to), but I don’t see that it’s “need to have” or material to a yes/no publication decision. It justifies another draft but not rejection.
While your style comments are not agenda-driven, I don’t get the same sense about #3, where I get the sense that there is an underlying objective to suppress Mann criticism – just a sense, I can’t prove it.
On the number 3, I don’t know and it’s not so interesting. It’s a second order issue compared to understanding the science. Regardless, if “Tapio” engages meaningfully, he needs to be dealt with on his specific points not in terms of some sort of overall competition/broad argument that is not part of his stated remarks.
Same deal with Huybers. If you really think that comments are designed to embarress you, then you should in your reply deal with the specifics, first. Then note the broader issues and give some sort of Mannian-Nature remark about it not affecting the results, afterwards. But it’s inappropriate to lead with the side issue.
Actually, I think it’s probably best to just deal with the comments phlegmatically. People at RC cackling about or misconstruing comments is a separate issue, to be joined in other venues. However, if you decide you have to pre-emptively defend your honor, make it at the end of the remarks. Don’t let such defense confound the examination of particulars. The reason for having comments and replies is to allow such examination of particulars. Don’t corrupt that.
Steve, I agree that there is a difference between clear written logical discussion and difficult mathematics. BC is guilty of poor writing. I can recognize bad writing even in areas where I’m not a technical expert (e.g. “Hotelling big book where Tukey was in” has generally very GOOD exposition despite my having exactly the fate that you said I would when I tried reading the papers!) On the other side, your GRL powerpoint and poster were POOR. Even with a highly technical audience (e.g. Mann, Huybers), you need to lay things out clearly. It’s a false dillema to say that tough math papers are automatically well (or poorly) written. It’s a 2 by 2 matrix, Steve, of math difficulty and sound organization: tough/poor, tough/good, easy/poor, easy/good.* Hmmm…sorta like flavors! 🙂
I think you want someone from a general applied stats or dendro (with working experience in stats) to be able to at a minimum understand clearly what the areas of controversy are, what level of experimental work has been done to examine it, and what the relevant outside refs are. Even if he can’t follow every particular, there is no reason that he can’t follow this and its valuable for him to do so. Then if he needs to, he can get an expert to help with the math details or can brush himself up.
That you could follow it is asking a bit too much. An audience of one. And you are sometimes cryptic (not in a purely technical manner) but in an absent-minded leaving out a detail manner. I think in many cases you grasp things not purely from math/stats ability (and I respect your muscles here) but from having read so many papers, from having spent so much time looking at the snailshell that is Mannian logic. So, things become second nature to you and you omit things at times.
Bottom line is that to resolve controversies, the snailshell needs to be straightened out! For example, Huybers did a GREAT JOB clarifying that covariance matrix was two degrees of seperation from Mannian matrix and correlation matrix only one. That a test of off-centering (only) should be against the correlation matrix.
It’s not only that you should be extremely clear in exposition, when dealing with technical material, but that one should be extremely clear in exposition when trying to change a mistaken practice in a scientific field. If you want Mann (or a successor of Mann or a reviewer of Mann’s publications) to avoid flawed practics in the future, you need to very clearly show what was wrong in this case. Obviously he did it wrong to start with, clearest possible logic will be needed to change an opinion that the initial practice was correct.
P.s. Yeah, I know you know that I’m not trying to throw monkey wrenches to keep Mann in business. My complaints are not purely about reader/author/future reader benefit of clear thinking though. At times, you’ve dipped into rhetoric that was tendentious.
I want to learn the truth, whether it supports you or Mike, whether it shows a hockey stick or a sine wave, whether it elects Al Gore or George Allen. Feynmann says that a scientist should show his argument and then disclose everything. This applies both to Mike and to you. Whether or not Mike follows it in no way impacts your proper behavior.
This should be in the most clear, explanatory way. No Enron footnotes in 10Ks. No saying that you covered it once properly in a different paper and then that gives you the right to be misleading in other papers and blog posts. (And don’t come back with a pagecount rebuttal, that’s what footnotes are for!)
*I would say that given that a paper is already “tough” in math, it is a bit much to make it “poor” in organization. This will harm the people who are straining to read the paper despite it’s toughness and reduce the useful audience. So one should be especially clear if one is dealing with difficult material, not the opposite. So for instance, physics professors dealing with diffucult material should not have poor pedagogy. If anything they need good pedagogy more than the English teachers! I think it’s actually a subtle form of snobby laziness, to write poorly when the content is difficult. There is always a convenient rebuttal to cover the lapse: When someone cites the poor expositions, just say that the poor sap just lacks the math ability.
57: To clarify my position, I’m in favor of a rewrite, not a yes/no. The rewritten paper, would still need to be reviewed by the reviewers. (And might still be rejected.) Out of sympathy for the reviewers, though, they shouldn’t have to bother to do much review of this draft. It should almost be treated like one of those papers from Japan or China where the editor says, go get this thing written in proper English, before we even try to judge it. (Note: it’s not so bad as that, but that’s the general concept.)
New reply from “Tapio”. I can’t follow the technical points, but the comments on overly broad claims and on poor explication are exactly what I was arguing. This sort of thing is just not professional. BC need to be clear.
Burger & Cubasch (2005, GRL 32) is very good. Aside from the obvious merit of showing the kinds of variability that result from adopting various arbitrary flavors of regression, their description of the “trapping problem” (why extrapolation through time is dangerous (i.e. violates the uniformitarian principle) if it involves extrapolation beyond the calibration domain of validity) is succinct, right on the mark. Their two recommendations made in closing are exactly what the doctor ordered – especially their plea for a “sound mathematical derivation of the model error”.
Makes me wonder exactly what they’re working on at the moment.
I also like that GRL paper a lot, but felt it would have been even better if they had divided the concepts into different papers (methodology full factorial, variability expansion) or went more thoroughly into depth on the variability expansion.
Their most recent CPD paper is very, very poorly scoped. I think they suffer a bit from the tendancy to want to “make a snowball” by wrapping things together.
Burger & Cubasch (2006) is equally good. They resample from proxy P and temperature T datasets to generate a bootstrap calibration of P on T. They show how CE and RE are asymptotically identical, but may differ substantially if you were to select just one iteration.
What I would like to see is how the SE and RE ranges in their Fig. 1 explode even further when P+error, not error-free P, is used for each time point t. P+e would then be a bootstrap sample from P, and the whole thing would be a multi-stage bootstrap process.
My hunch is they’re already working on such a multi-stage bootstrap calibration method. The 2005 and 2006 papers are clearly a methodological set-up for something bigger in the works.
Add in (1) nonlinearity of temperature responses and (2) survivorship bias for information lost from drought-prone non-survivors, and you can imagine the quality of the reconstruction you would get. Wouldn’t that be interesting to see?
There may be some valuable insights in there, but given how poorly the paper is written, it makes it harder to evaluate them. For instance, there are the confusions generated by their claim to discuss the entire field, when it’s just mann papers, by throwaway comments on degrees of freedom which are not supported quantitatively, by the comment on MWP, etc. I’ve read a lot of papers in a lot of fields. It’s really a bit of a mess. Both reviewers 2 and 3 note this. I’ll bet you another steak dinner that Wegman would back me up on the poor quality of the explication…
On the contrary, I think it is very well written. (1) It’s a challenging subject, so no reviewer would be pleased to have to delve into it such detail. (2) It wasn’t written for you personally, it was written for a diverse audience with a short attention span. (3) It seems you want this paper to address something it wasn’t designed to addresss. That’s the reader’s problem, not the writer’s!
“Snowball” by “wrapping things together”? This paper makes a single, simple point. Future papers will likely build from that. Rather than “wrapping”, they are doing a good bit of dissecting. As for the “snowball” – that’s what science is: it builds from a solid nugget to something bigger and fluffier, but at the same time more weighty and hard to dismiss.
If you can’t see its value, you probably haven’t fully understood it. It is relevant to the entire field because it addresses a general problem: how to interpret verification indices in the face of hitherto ignored samping error. It just uses the MBH data to illustrate with a concrete example. Even if the example were not there it would still be a valuable contribution! But then you’d REALLY think it was irrelevant.
Re-read both after reading my comments.
First, the “comments” are not supported quantitatively in part because it would muddy the waters even further. It is also a single brief line that hardly distracts from the central flow of ideas. It’s not clear why you use the plural here.
Second, maybe it is not a “throwaway” comment, but a lead-in to a future paper?
Finally, the problem is that in such cases it is never all that clear what the actual degrees of freedom are. Do you know how many data points it takes to make a hockey-stick? Two slopes, two intercepts – that takes up four degrees of freedom, so you need at least one more observation than that: five. The effective degrees of freedom in analysis dominated by simple shapes may be very low indeed – even if you have a thousand time points! Do you want to open that Pandora’s box in THIS paper? Then dare to do so in your own papers! See for yourself what the reviewers will say.
You’re right in that one could easily do a sensitivity analysis: reduce the number of assumed degrees of freedom and watch the confidence envelope balloon. Not only is that ho-hum to the average academic, it still leaves you wondering what the actual number of degrees of freedom really is.
You don’t seem to understand that academics aren’t interested in exactly the same things you are. They are writing for an audience, not one person. You’ll frustrate yourself less if you accept that these papers need to be read and understood front to back in order to assess their true value to you.
Whether or not the writers have a cool insight is not germane to my point that it is poorly written. We have to address the writing itself to judge that point. Telling me what you think is the central point of the paper is very helpful, but don’t you think the paper should state their central point and then support it? What does it say, that I need you as the translator to extract the value from the paper?
I think in my defense, I had actually gotten a similar impression of their main theme. Read back to my comments in the earlier thread on this paper. My problem was that the paper was so poorly written that it was painful to try to extract insights while sidestepping past unsupported and unexamined gratituous remarks.)
I’ve detailed several specific criticisms of the the writing and you have not engaged on them: New data in a conclusion, use of the word “vary”, claims on number of papers implicated (made when only Mannian work examined and the broader brush inference to toehr work not spelled out explicitly, MWP claim (made, not proven), “low degrees of freedom” not numerically quantified, etc. Do you think I’m wrong? Do you have a different meaning for the word “vary” then I do? 🙂 Do you think I’m right, but despite that the paper is well-written?
I’m not the only one who feels this way about the quality of the writing. See Reviewer 2 and 3 remarks. See Steve’s remarks saying that the paper might need a rewrite. See others in the earlier thread. Also, look at the very low amount of comments examining the author’s basic science points. It is all about FAmigletti and Mann instead. Now sure there can always be a bias towards that. But not having people like Dave D or Armand or JeanS or Stockwell or Martin engaging, to me says that the technical discussion of issues is being inhibitied by poor presentation of the BC thesis.
I have a heck of a lot of experience reading analysis. Have read (thoughtfully) books on how to present technical work. I really do have some ability to judge clear writing. Don’t take my lack of painting ability as an inability to appreciate Monet. It really is a different facility and I’m well aware of the spotty and loquacious quality of my posts. I try harder on papers for publication. But in any case, this is a “do as I say, not as I do” area! 🙂
I’m inclined to be partial to the authors given that I enjoy seeing “Baldie” found wanting and since BC05 was so wonderful and the authors so gracious. If I think the BC06 paper is poor, it’s NOT an issue of someone defending Mike Mann. Actually I want the writing to be better done so that it can actually have an effect in the debate. In addition, as a truth-seeking scientist, I want the writing to be more clear so that I can examine the validity of the criticisms.
Really I think the major issue is that the writers do not scope the work properly. They should state a narrow thesis, then examine and support it. Instead they mix in some overarching claims to make the paper seem more “broad”, but don’t really examine those larger issues usefully. Perhaps if they want to keep the broader inferences, they could retreat from the broad claims within the astract and bulk of the paper and just discuss likely inferences towards the larger picture at the end.
I will finally buckle down and read the paper in toto. I had given up on it, when seeing how bad it was. (I tend to read papers very closely…see my review of detection and attribution paper by von Storch.) I really doubt that I will change my opinion of the writing, but if I do, I will admit it. And I will keep your comments in mind while reading it.
In any case, I will come back to some technical discussion of the paper’s actual findings. So at least we will have that. This will be painful also as I tend to be somewhat painstaking and as I lack math background. But I’m arrogant enough to show ignorance. I’ve been through this with people like Chefen who told me to get lost and learn some math, and then ended up concluding that I and another reader had made a relevant logical criticism of his work.
God, I sound like a twit. What can I say…
re #65:
I must admit, bender, that it gives me a charge to see someone give advice to the blog advisor, TCO, and do it so much better than my past feeble attempts, but I thought also that your comments and particularly that under 2 and 3, here carry over to what TCO sometimes expects from Steve M.
I thought your comment below hit the nail on the head on the B&C paper.
RE Bender #66 (we cross-posted).
1. Sorry, it is multiple throwaway comments that is more relevant than multiplicity of the “degrees of freedom” comment. He does repeat the phrase in the abstract, conclusion and then several times in paras 2 and 3 of 360. But I’m willing to cede you it as a single issue.
2. I DID find it distracting. If it’s not pertinent, don’t use it. If it’s hard to quantify, don’t use it. If it’s useful enough to become a whole ‘nother paper, then tee this up in the later part of the conclusions rather then using the term and not quantifying it. Note: I’m not indicting the guy as a mathematician here. I’m indicting him as an essay writer.
3. WRT “effective degrees of freedom”. Yes, I think this is very interesting and VERY germane to the type of criticism that BC has. Let’s go, Pando! If he is going to use phrases like low degrees of freedom, he ought to quantify them. Otherwise it’s like Mann using the word “rigourous” as puffery rather then science. Heck, your own use of the qualifier “effective” is value-added over BC’s communication.
4. With respect to your fatherly advice about reading academic papers. I’ve got my union card. Have read a lot of papers. Do not think that the paper would be “hurt” in any sense by more effective writing. I think it might even clarify some logic to the writers themselves. I’ve said the same about some of Steve’s writing. This remark comes from a lot of time on the pond and a lot of reading/writing (including on the theory of writing) in many technical fields.
5. Without arguing in detail the purpose of papers (I guess we can if you want to!), I would suggest that you read “Clarity in Technical Reporting”, NASA SP-7100 by S. Katzoff, 1964. I would also welcome you to go to your average quality book store and take down a handful of books on how to write science papers. The value and emphasis put on clear explication will be right in line with my point of view. I am talking the true religion. You are an Aligensian.
6. Now, you are right that reading papers front to back can have a lot of value. In addition, that sometimes it is nescessary to be a bit of a detective to extract information from papers DESPITE poor presentation. But this is not a RATIONALE for justifying poor presentation.
Albigensian. Guess we won’t burn you. And nescessary is a typo. (It’s a law of the internet, that if you criticize writing, your post will have errors.)
Why do people proofread their comments after they’ve posted them?
To save me from typing paragraph after paragraph of true religion from the good book:
Click to access NASA-64-sp7010.pdf
There’s the problem. I disagree with this guide. The principles espoused there are fine for vulgarisations for public consumption (or by management or policy makers, etc.), but insufficient for scientific papers that are supposed to be complete to the point where they can be replicated by trained scientists. As I said before, it is your goals & expectations that are fundamentally incompatible. An audit means having full power to replicate. Which means seemingly endless mathematical details are unavoidable. You want the literature to be something it can’t: complete but simple. You have two choices. 1. Stick to the readable vulgaristions that are inadequate for auditing purposes, and forever be frustrated that they are incomplete. 2. Step it up a notch and listen and learn from the studies that are complete to the point where they can be used in an audit.
I think some of our posts were removed and perhaps one of yours edited. Strange.
In any case, I think I know literature-reading and the literature (of the literature) more then you.
I say again. Is it possible to have an insight or a difficult paper technically and write a poor paper on it?
Ok. I read thrugh the paper. there is some decent info inside there. still think it reads as hmore opaque then needed out of clumisiness. Will discuss the specifc of the actual paper,
This is how the game is played…
http://www.phdcomics.com/comics/archive.php?comicid=581
Pushing TCO’s link out of recent comments, so all of us MS IE users can see the whole page.
Push
Pushing again
And again
One more time
What will it take to get that side-bar fixed? I’ve seen the request maybe a dozen times.
It’s irritating, but I don’t know how to fix it without learning how Word Press works in some detail and I don’t have the time right now; John A seems to be pretty busy right now. So unless someone sends me explicit directions, just keep pushing.
re: #85
I’d think it would be pretty easy for you or John or someone to just create a macro or at a least written proceedure to turn a long link into a proper link. you just need the “A href=” doohickey in the proper brackets and then “Link” or something to indicate there is one and then the close “A” thing. It shouldn’t be that hard for someone who eats “R” for breakfast to figure out a quick way to do it. Of course if we’d all be careful to use the Link button when we’re entering them, it’d save you the clean-up effort, but it’d be quicker to fix them than reading the complaints or writing apologies periodically.
Of course you could just make it a policy to “snip” all long links and make people re-enter them the right way.
Probably more efficient to find someone who already knows Word Press than to ask someone who uses R to try to learn WordPress as well. The return-on-captial-expended would be very low. How hard could it be to have a text pre-processing algortihm (either inside or outside WordPress) that searches all posts for the url identifier “http://…”, checks if is is properly embedded within the “less-than-a href=” link-coding string, and if not, does so, along with an obvious label such as “click here”? I think it would be worthwhile. Last post on the issue. Thanks.
Attn John A
John, do you remember where this plug-in came from ? It might be worth e-mailing the original author to ask if there is any easy fix to this problem (there must be other places that suffer from it). If nothing else, it might be good to flag it up as an issue for a future release.
Ok. I understand the flavors thing. I think I understand the whole paper now. Leaving the writing efficacy stuff aside and moving to the science:
-what I wonder is the whole point of division into verification and calibration. There are a lot of reasons to think that this may not really be “testing” given that we don’t have proof that models are not altered based in performance in both phases. REally performance in the future seems the best test (or versus newly discovered records). I wonder what kind of scores one would get for RE if we just use the whole period?
You calibrate so that you can reconstruct via extrapolation. Once the reconstruction is done, you have no way of knowing of it’s true or not. So forget about that, even though it’s the primary question – the nugget of truth TCO is after.
But there are other questions you can ask, and so papers tend to focus on these … because they can. So why not?
(1) How well do the reconstructed data fit within the calibration period. This is what verification is. And for it to be a fair validation test, you withold half the data, calibrate on that, and verify with the witheld portion. It’s called verification because you’re operating within the “domain of validity”. i.e. you’re interpolating, not extrapolating. This tells you whether your calibration is any good. Some are. Some aren’t. Note there are different ways to “withold”. In the old days you held back an arbitrary sample, and validated with the complement. Nowadays with supercomputers we can do permutation tests, where we randomly resample a subset of the series 1000 times and add up the number of times the verification is acceptably good. Why? Because that gives us an asymptotic estimate rather than a local estimate, which is prone to sampling artifacts.
(2) You can ask how the reconstruction/extrapolation varies depending on the assumptions that go into it; hence the 64 flavors. If they make spaghetti, then people need to decide which flavors give the truest test for the question at hand. If they don’t, then flavor doesn’t matter. The reconstruction has some structural robustness.
(3) You need some idea of the robustness of extrapolation given a priori sparse coverage
of the data network around the globe; hence the need to iteratively withold one or some of the proxies, and re-do the anlysis each time. If all analyses show the same thing, the analysis is robust to sparseness. This step won;t be required when we have global proxy networks. But at the moment that’s a ways off yet.
You are likely to frustrated by all these papers to some degree, TCO, because the thing you really want to know is unknowable. ie. You can’t get a certain reconstruction. You can’t judge its correctness by eye-balling. There’s only one curve to eyeball! All you can hope for is a reconstruction that has small enough uncertainty that it can be accepted as the basis for a policy tool.
How you estimate that uncertainty is a darn good question.
That is what the fight is all about. This is why Nature rejected the Annan communication: he was proposing something so new (Bayesian approach to confidence estimation) that it questioned the whole statistical methodology of paleoclimatological reconstruction. What is an Editor to do when they receive a paper that suggests a whole methodology is bunk, and you don’t have the mental tools to judge it? What else can you do? You pass the buck.
If I had the paper in front of me I’d try to be more specific, but that’s surely enough for now.
I understand the contention about withholding half. I just wonder if it works in practice. If you end up tweaking things anyway after the verification, it’s as if you didn’t really have one. In that case, might as well just mine and take your best shot. Use an Aikake criteria for complexity maybe will help some Bonferoni fallacies. In any case, future results become the acid test.
I’m not aghast that we don’t have perfect understanding. I’m trying to make sure that we understand as much as we can. In some cases, I’m just thinking through things for my own understanding.
Oh, the pdf is available above.
Read the abstract:
i.e. You do a proper job of bootstrap resampling, and your apparent skill is cut in half. This is because the 50% “skill” is an exaggeration caused by sampling artifacts. Random resampling irons out all those artifacts, providing a fairer test.
Ergo MBH credibility has just dropped another notch. What more do you want?
Look at how SE and RE converge under resampling, as predicted by theory. That’s your proof that it works. SE and RE are unequal only when the witholding is done unfairly.
The lesson: use resampling methods to ensure a fairer verification test.
Whether the test is fair enough is another question. As you say, only time will tell.
I got all that. I’m discussing something else.
One of the points in the RE discussion that is staring everyone in the face but which isn’t in print yet is that the RE statistic for the “classical” spurious regressions are huge. For example, in the Yule 1926 comparison of C of E marriages with death rates (if I recall correctly), the RE statistic in a half-and-half reconstruction was 0.9 or so.
The RE statistic simply provides no information as against spurious trends. That’s why you get high RE statistics from various red noise constructs.
But that same literature also shows very high spurious rsq. Plus, lots of your points aren’t in the literature, because you don’t care to publish them.
TCO, I’m trying to be helpful, again, and you’re being incoherent, again.
Let’s play guessing games, then, since you’re “discussing something else” but are not able, as usual, to describe what that something else is.
I’ve thought about for a while and here’s what I think you’re asking: “Why withold any data? Why not use it all? Wouldn’t you get a better calibration?”
Is that your question? If so, I have the answer. If not, I give up.
Re #96. I think anyone who’s trained in time-series analysis knows this, either by training or by intuition. Which is not to say it’s not significant. Significance is contextual. [Many thereoms which are trivial in statistics are non-trivial in ecological contexts. Moran’s thereom is a terrific example. Look how many Nature and Science papers have been published on this since 1992. Yet Yule 1926 would have scoffed at this as intuitively obvious, as it was well known to statisticians of his day.]
So, it may well be something worth weaving into in a paper. As a standalone proposition, though, TCO, this wouldn’t make for very interesting reading. The problem is that you can’t publish tiny tidbits like this on their own, no matter how interesting they are. Publishers want whole stories, not tidbits.
Look at how James Annan’s tidbit was received.
Dude, if you read the whole blog, you will see that we have talked about the nature of the division of the instrument period and BC’s point that if the performance in validation is used to select different models, it’s no longer really a validation. It’s just training.
If everything’s settled, then please don’t bother asking questions such as you just did:
because that gives the impression everything’s not settled.
Apologies for any redundancy. It happens. I’m reading, I’m reading. While you’re at it, tell Lee to read some. At least I read.
Did you notice how the NAS panel made a total pig’s breakfast of Burger and Cubasch, getting this point exactly backwards. As TCO observes, Bürger and Cubasch made the pretty point that MBH-type methods applied to MBH data throw up a bewildering variety of possible results with slight methodological permutations (in effect, substantially generalizing our original observation); and, that, if you use the RE statistic to pick from the Baskin-Robbins selection, it is no longer a verification statistic, but a calibration statistic. If you have enough play in your data to yield a lot of different results, then the choice ceases to have any significance.
Wahl and Ammann 2006 (their statistical consultant – Nychka, who was on the NAS panel despite this conflict and despite an objection to NAS) grudgingly agreed that you could get high 15th century results using MBH-type methods, but argued that you could reject this choice based on RE failure. They did not discuss the BC argument that this is no longer then a verification statistic.
The NAS panel noted up the BC issue but then astonishingly suggested that you could use the RE statistic to select models – the opposite of BC’s observation. Read and weep. Maybe if they had had non-conflicted statisticians, they’d have done better with this sort of thing. (Bloomfield consulted for Briffa and has worked together with Nychka – so out of the entire universe of statisticians, it would be almost impossible to find two more conflicted statisticians.) This doesn’t mean that they didn’t try or that their comments are all poor; there’s much to commend in their sections, especially relative to Team statistical drivel, but Nychka in particular should never have served on this panel.
Re #102, Steve McIntyre
He is also chairing the American Statistical Association’s late seminar on Climate statistics that Dr Wegman is giving, which should be interesting. I hope Wegman has been reading up on stuff here so he can’t be caught out too easily by questions on papers he hasn’t looked at yet.
Ah, but they are the only statisticians with expertise in this field …
Just to be clear, B&C did not prove RE was useless. They proved that (1) it becomes more robust an estimator when the “play in the data” is accounted for, by resampling, instead of dismissed, which is what you effectively do when you do a single, arbitrary witholding-iteration; (2) its magnitude drops by half in the case of these multiproxy data sets. 25% may not be as good as 50%. But it’s not 0% either.
i.e. It’s not RE that’s the problem. It’s the behavior of RE given the kinds of low-frequency noisy signals that exist in multiproxy data.
I have no reason to doubt Nychka’s objectivity. Wegman & Nychka are rational people. Formally trained statisticians. Don’t expect any fireworks between them. What you’ll see, if they’re give enough time, is a meeting of minds as they hash out details beyond comprehension.
#104. bender, although B&C allude to the spurious regression problem, I don’t think that they grasped the nettle correctly and their RE re-sampling deals with a different issue.
They point out that the RE statistic for an MBH-type reconstruction is not stable and the reported value based on calibration 1902-1980, verification 1856-1901 is at the upper end of values based on random sampling of intervals. This is one point, but a different point than the fact that spurious regressions – used in the Granger and Newbold technical sense of "spurious" ("seemingly unrelated regression", not Mann’s use as a synonym for "specious" – yield very high RE statistics. Because they provide an example of a spurious regression – temperature versus number of reporting stations, the difference in nuance is easy to miss. I think that the latter point is the more important. I actually did some experiments noticing the point discussed here by BC some time ago, well before I started the blog, and thought it interesting but a less important point that the ones raised in our article.
Our approach to the RE statistic tried to follow the approach of Phillips or Ferson – showing that the significance benchmark in some situations needed to be much higher. I think that it is too bad that BC did not discuss our approach to the issue both in MM05a and in our Reply to Huybers, which IMHO is still in advance of what they’ve done.
In my opinion, the problem isn’t that the MBH RE should be 0.25 (as opposed to 0.46), the problem is that the RE statistic has negligible power against spurious regressions and, for example, if bristlecone growth is due to fertilization, an RE statistic will not reject a spurious relationship between bristlecones and temperature, any more than it will reject a relationship between 19th century alcoholism and C of E marriages.
I agree that this is a more important point (and still think that there is something a bit artificial and not quite making sense in dividing the instrumental period into verification and calibration). At the end of the day, you have a certain amount of proxy-instrument comparison that you can use to determine what the transfer function is for proxy to temp. And then you have to use that transfer function to estimate previous temps. It’s not news to me that everyone does this division, I’m just not sure what it really buys you in the end). I think the more interesting point comes down to understanding the transfer function in terms of degrees of freedom with autocorrelation issues inserted, etc. Zorita had a really good point that if you just have two increasing trends, that this is a single point of data. You need to look at year to year variance, to detrend, etc.
What happens if you reverse the calibration and verification periods? Or do an even more general test where you take random calibration periods? Wouldn’t you produce a spaghetti graph of reconstructions? If so, it would show that climate reconstructions are not robust.
TCO, please be clear. Are these requests for clarification, or just scrambled musings? Because there are answers to these questions, you know, if you want them.
If, as a general rule, you would prefer to NEVER have answers, let me know and I’ll gladly oblige by ignoring everything you post.
If B&C’s 2^6=64 flavors generates spaghetti, think what would happen if you used a more honest 2^10=1024, or more, flavors. And what would happen if you had individual confidence envelopes on each of those strands of spaghetti? And what if you represented the spaghetti lines as you should, as lines that fade off as they progress backward in time. The individual confidence envelopes would add up to one fat band of an uncertainty lasagna. Think about that graphic.
Now, where would all those flavors come from? (If you like, focus: which would taste best?)
And where would those individual confidence envelopes come from?
Think about it.
Think what the error bars would look like on the estimated sensitivity coefficients in Hegerl et al 2006 Fig 2.
Eyes on the prize.
Let’s say that you were a betting man and wanted to use some proxy to give you the best estimate, should you just use all the calibration time to bet calibrate a proxy? Should you use aikake criteria? Or will you get better results by the division into different sections of time…and what does it really mean? Do you try various models and see how each does with the subsampling method (rejecting those that do poorly on verification)? When you’re done with such a procedure, why not have just used the entire sample to derive a relationship?
You see?! You ARE asking the question I thought you were.
Now we’re getting somewhere. Assuming you want an answer … TCO, the problem here is spurious significance and the related issue of overfitting. You need to protect yourself from that. [Why? Because describing data is easy. Given enough parameters, any dataset can be described completely. What is difficult is getting a parimonious description of the data, i.e. using as few parameters as possible. The number of parameters is limited by the number of effective degrees of freedom which are limited by the number of independent observations. (When the observations are not independent you lose effective degrees of freedom, and thus have less freedom than you think to fit a model.)]
If you were to take your entire dataset and run a calibration with it, the next question a critical guy like you will ask is “Fine, this is a nice description of this particular sample. But how well does the model perform in an out-of-sample test?” “Hmmm”, you say. “I don’t have the money to go and replicate this study, which is what I ought to do. But what I can do is calibrate on one part of the dataset, and then see how well the model describes the subsample of data NOT used to develop the calibration model.” A verification test is that: a measure of “how well” the calibration performs on the ‘independent’ data NOT used in the calibration step. 1/2 is used as the splitting point simply because that way the number of degrees of freedom in the calibration step and the verification step would be equal. You could use any fraction you wanted. Similarly, you could generate your subsample any way you wanted. You could choose early vs. late strings of years, or alternating odd vs. even years, etc.
Here’s the problem. What if the subsample withheld in the verification step is NOT actually independent of the sample used in the calibration step. For example, what if the process is a red noise process, is autocorrelated, is subject to low-frequency trends? (Use whatever terminology you like, statistical independence is the issue.) In that case you have not solved the verification problem, because you have not gone from a within-sample calibration to an out-of-sample verification. i.e. You’re still “within sample”. Or what if the response you’re calibrating is nonstationary (thus violating the uniformitarian principle)?
B&C solved this problem by randomly subsampling ( as opposed to systematic subsampling) & iteratively resampling. Smart. Now your verification statistic converges to its asymptotic expectation, it goes down, and you see just how crappy your calibration model really is.
Now, what you’ve been waiting for – the answer to your question. After the calibration has been verified, why would you use the calibration (based on a witheld sub-sample) to do the out-of-sample extrapolation/reconstruction step?
Good question. I don’t know why anyone would do that. If the calibration is proven to be valid, it would make sense to recalibrate based on the whole dataset and use THAT. Your intuition is right on.
But that’s where B&C are smart. Because they did not do a single subsampling iteration, they effectively used all the data in the calibration, and at the same time avoided the problems of overfitting to a subsampling artifact. (All artifacts are ironed out through the 100 iterations of the random subsampling.) What this means is in their case they don’t need to go back and calibrate on the whole dataset prior to reconstructing; they’ve got it already.
That’s the difference between smart & honest reconstruction vs. the alternative.
…
Now I’m just waiting for you to say “I know all that already. That’s not what I’m asking.”
bender – the trouble with the B-C procedure is that the RE statistic from two unrelated trends – eg. Yule’s example, is still very high even with subsampling no matter how you slice it.
Steve: I think there are multiple issues and we can discuss all of them.
Bender: what are the requirements to ensure that the model is really getting an independant test? Do we have to use it even if the verification shows crappy performance? If we start rejecting models that have crappy performance and keep the one with the best is the verification really an independant test or is it part of the overall calibration (in effect). Finally is the property of a proxy relationship that works well in multiple parts of the sample “better (say in the sense of one that you would put your bets on for prediction in future or past) than one explicitly calibrated over the entire period? Can you do just as well or better (in the sense of having best model of the transfer function) by just calibrating based on the overall instrumental data explicitly perhaps involving some physical insight or aikake criteria (simplicity, degrees of freedom) to ward against over-fitting?
How would a procedure that looks at different models using the RE/CE splitting differ from one using the whole data set right away in terms of the type of result produced? At the start, just how would they differ. After that, which one is a better one to use for outside sample predictions?
Is there anything useful in proving that the transfer function works well in both cold and hot temp regimes (as would be shown by the division at half-way through…I guess you could also do this explicitly with the year to year data as well)?
#112: Correct. High RE values are induced by a) special calibration/validation partitioning as demonstrated in the CP article and b) inflations of the Yule type as touched, but not really demonstrated in the article.
Both a) and b) are somewhat independent consequences of a strong trend.
I assume a bootstrapped nonsense reconstruction will also have RE values around 25%, and the “real” reconstructions have to be judged relative to that.
Gerd, RE statistics from classical nonsense regressions can be very high – the RE statistic for the original Yule series is over 0.9 on a first-last split. It will be very high on random splits.
The real problem with the RE statistic is that it has no power against a spurious trend. This is also the practical issue in MBH with bristlecones and CO2 fertlization.
I think that your issue about different results emerging from different splits is interesting but secondary to this.
But the Yule-type nonsense regressions employ fully nonstationary data with much stronger trends, no? This is not the case for proxies and temperature.
#116. Gerd, the entire premise of AGW is surely that 20th century temperature is nonstationary. Specialists argue that bristlecones have experienced an anonmalous growth pulse -s oudns nonstationary to me.
I provided one example from the spurious correlation literature to show that the RE statistic had no power against the Yule example. My guess and I’ve planned to collect data to show this – is that the RE statistic has no power against pretty much any other example of spurious correlation that you care to name. In my opinion, that’s the big issue in respect to the RE statistic. The point that you’re emphasizing is interesting – and I noticed it myself some time ago – but I think that the other is the more important issue and the one that deserves airing as it affects studies beyond MBH. That’s just my opinion.
Let’s assume that MBH98 fig7-solar is a reconstruction of fig7-co2 data. After standardization, we’ll get RE of 0.47. Better than co2 vs. fig7-nh (0.43) 🙂
#117. But the measured series of proxies and temperature do not exhibit clear unit-root behavior (=instationarity).
Gerd, spurious correlation is a different and broader concept than unit root processes. For example, Yule did not limit nonsense regressions to trends, but to the general problem of seemingly high statistics from unrelated processes. You can get problems in all kinds of ways – which are reasonable to call “spurious correlations” or “nonsense regressions” or such – but not all problems come from unit root processes.
Examples?
Re #112
Agreed. The B&C subsampling doesn’t solve the whole problem of shared trends (=low-frequency variability). But it does solve the somewhat related problem of first-order autocorrelation not linked to trend. I agree it’s a secondary issue in the grand scheme of things. I was merely trying to explain to TCO what the value of subsampling is in general.
Re #2:
That, to me, is unimaginable. My guess is that it’s become a standard practice in the field and that it hasn’t been questioned much because climatologists are used to operating in data-mining/hypothesis-construction mode. If that’s the case, then the standard of evidence being demanded by CA may simply be a shock to their system. Until now they never had to work to convince skeptics.
Heck, I think even I understand spurious regression better than the HT. I can remember my statistics prof talking about an excellent correlation between the number of nylon stockings sold and the incidences of some type of cancer in the US. Probably both functions of a third variable, population growth. Of course, in this case, one could probably use the correlation as a predictor, even though it is spurious. Maybe that’s the philosophy of the HT.
We have quite a few economists who read this blog, but I’ll bet that none of them know that John Maynard Keynes once co-wrote a paper with Yule of spurious regression note. Here’s a comment from Keynes (Ec Jour 1940) on Yule and spurious regression:
Here are another few quotes from this interesting article (which was about Tinbergen’s econometric modeling):
Or againL
Plus ca change….
Steve, re #124. Keynes’s debate with Tinbergen in 1938 on the value of econometrics is famous and would I think be well known to many of the economists on this blog. Robert Skidelsky gives a good review of it in the second volume of his biography of Keynes (pps. 618-20), in the course of which he quotes the extract used by you (about the ‘strange reflection’ that Tinbergen’s work is likely to be ‘the principal activity and raison d’etre of the League of Nations’ in 1939).
Lord Skidelsky is of course a co-author (with Lord Nigel Lawson, David Henderson, Ian Castles, Ross McKitrick and four others – there’s scope for a “social network analysis” there) of a submission to the UK Stern Review which deals trenchantly with the failings of the IPCC.
One of the objections Keynes had to econometrics, relevant to current debates about GCMs, is that it tended to freeze models by filling in figures which ‘one can be quite sure will not apply next time.’ In the course of the debate, Keynes also said of economics that ‘it deals with motives, expectations, psychological uncertainties’, and went on:
‘One has to be constantly on guard against treating the material as constant and homogenous. It is as though the fall of the apple to the ground depended on the apple’s motives, on whether it is worth while falling to the ground, and whether the ground wanted the apple to fall, and on mistaken calculations on the part of the apple as to how far it was from the centre of the earth.’
In the third volume of his acclaimed biography of Keynes, Lord Skidelsky relates that in June 1942, at a time when Keynes was under phenonomenal pressure of war-related activities, he produced a reader’s report on a manuscript by Yule entitled “Statistics of Literary Vocabulary.” Yule had counted up authors’ choice of nouns. To quote Skidelsky again:
‘This is far too narrow a front on which to advance with such large forces”, Keynes declared, but, as always, he found Yule’s work ‘queer, suggestive and original’ (p. 168).
I think I’m starting to understand what is going on. Pl. feel free to refute:
1) Spatial sampling with only 12 locations makes the estimates of Global Temp very noisy.
2) These noisy samples can be cleaned by a simple dynamic model of the ‘normal climate’. The smaller AR1 coefficient the better. Too small AR1 coefficient would lead to divergence problem (1980-present would be a good data set to verify this).
3) RE-statistic does not punish for low AR1 coefficient. But underestimated AR1 would show up in the residuals – in the lowest frequency band. (In this example RE says blue is better than black, DC removed).
MBH99 Figure 2. supports this.
The discussion between Gerd and AR3 seems to have heated up a bit… especially the language in the comment by AR3 on 22nd looks very … hmmm… Teamish to me 🙂
Also the comment by AR2 to other reviewer’s (AR1) comment (!!!!) is so amazing that I want to quote it in full as an example for future scientists and wanna-be-reviewers:
Outright Poisoning the well attack on a fellow reviewer was something I had not seen before… everything seems to be possible in climate science.
#127. Jean S, hope that you’ve had a nice holiday. Nice to hear from you. It’s worthwhile re-stating the comments that Mann aka Reviewer #2 (von Storch has agreed with this identification as well) was responding to:
re #27: Thanks, Steve. Yes, it was nice. I’ve been back over a week now… I’m just so busy that I have had almost no time to visit CA (or anything related). Also, just going through the new threads I missed while off-line took ages…
AR2 took the bait 🙂 Who said science is boring?
B & C have issued a short statement lessons learned in which they decry the focus on irrelevancies, and not on their primary finding:
With a nod to TCO they also note:
Pretty much sums it up… if you can’t argue the science, smack them with technicalities and bury them with irrelevant issues, so you can marginalize the results.
The writing was really atrocious. That they blame this on using a format from a letters journal chaps my ass even more. First, because it has been written about a million times in science editorials what a bad habit letters journals are in terms of getting proper explication. Second, since they did not bother rewriting the paper when they sent it to the new journal which did not have the space restriction! Based on the example of BC, I am very doubtful about “open journal formats”. And it has nothing to do with reviewer 2. It has to do with the laziness of people who write for CPD (if they are like BC).
Re #132
I thought we covered this topic a month ago? Do you recall me disagreeing with you then? Well, that hasn’t changed any.
1. The reviewers mostly missed the mark, as B&C complain in their recent comment (as I believe I explained)
2. The paper was relatively well-written given space constraints (as B&C explain, and as I believe I also pointed out)
Re #127
From my experience “poisoning the well” is relatively common in arguments against reviewers. Sometimes, say in the case of a nonsensical or incomplete review, it is even justified.
I know we covered it. I’m sorry that you still disagree with me. I still do with you. BTW, other reviewers, the original authors, and even Steve agreed with my criticisms.
I’m still blown away that you are against the message of a CLASSIC in how to write technical reports. That NASA pamphlet is the frigging Strunk and White of science writing! It’s not just a TCO thing. Read up on it. It’s probably the fourth best pamphlet in the English language. (If you want to play…guess the other 3…which ones you would choose, and what you think an ogre like me would like.)
[Ignore on]
Re #121
What a “unit root process”?
Re: B&C comment Sept 4:
They should be alarmed. Note, however, that bender discussed this core result in his comments, above.
In #90 I make reference to James Annan’s interesting paper (rejected by Nature) invoking Bayesian statistics. Given that AGWers are starting to argue that ‘classical statistics are irrelevant now that we have Bayesian methods’, I wonder if we shouldn’t be talking more about this issue? It’s not something I know alot about, but I would like to learn.
I should say: I start with a skeptical bias because when I was a graduate student, there was a certain class of student who – in my view – dabbled in Bayesian statistics with the hope that it might absolve them of the responsibility of learning the “real stuff” of time-series analysis. (Actually, many of them were animal ecologists.) Similarly, there was a complementary gang who, it seemed to me, blindly hoped that “chaos theory” would absolve them of the need to do quantitative analysis and make predictions. It was like they wanted to pet the animals, but not actually do the math that would save them.
So let me start with this: does anyone know of anyone in the real world who actually uses Bayesian methods? Or is it as dubious now as it was 15 years ago?
When I finally broke down and read through the poor explication, I found some interesting things in there (basically their point as elucidated in the lessons learned). I think though:
-overly broad in claims of applicability to the field and to MWP (analysis not sufficient or even geared to the overall claims)
-their sucess with early flavor paper went to their head and they bogged the paper down by having the flavor stuff so prominent when the real story in this case was NOT susceptability of recons to alternate methodologies but the basic jackknifing in and of itself on specifically MBH and regEM papers RE/CE.
-some vague and unsupported claims about degrees of freedom, within population etc.
On the technical side, I’m still very puzzled about the validity or importance of splitting the sample and doing a “verification”. That “verification” is still really a part of the overall calibration of the model. I think the true verification comes from prospective (truly out of sample) tests. That’s what the econometrics purists say. In addition, is a model that is more regular to jackknifing really any better then one selected by using the entire instrument period explicitly for calibration (and perhaps monitoring degrees of freedom and aikake criteria and the like to make sure the model is “simple” and therefore hopefully not overfitted.) It would be interesting to see which performed better for an “after sample test” during last 25 years, the MBH variant used by splitting the instrument period into calibration and “verification” (scare quotes on purpose), versus one that just comes from using the entire period for calibration.
And yes, bender you did note the central point on the jacknifing well.
Of course true out-of-sample tests are better. The only reason they’re not often done is because they’re typically prohibitively expensive. I’m sure I said that already.
Maybe you did or didn’t. When I raised the issue, it was because it was something I wanted to discuss or consider. I don’t remember your making that response when I raised the issue. I think you just blew me off. And I still (naively, openly, wonderingly) wonder if there is any benefit to a model created by division of the overall calibration set into “calibration” and “verification”. Would one be just as well off using the entire period and aikake criteria or the like.
I’m honestly curious.
#137 Bender Bayesian statistics are nothing but a way to incorporate prior information into an estimate. If you assume aprori that a curve is a hockey stick then to get otherwise, you need sufficient information (inverse of the covariance matrix) to over come this biased assumption. Of course if you’re initial assumption is no correlation between the proxies and data, then the aprori information provides a useful method to eliminates the over determined aspect of some multi proxi studies. The aprori information can come from either expert knowledge or by a recursive least squares algorithm. On faulty method I could see the hockey stick team trying is using previous studies as aprori information and incorporating a second study as new and supposedly independent information.
Anyway, I think the best use of Bayesian statistics in climate modeling is for the initialization of global climate models. I previously suggested a maximum entropy assumption as the aprori information for initialization global climate model.
The C&B paper was rejected, but the editorial comment is worth a look.
I agree with the rejection. The editors validated my point of view. TCO was right. Bender was wrong.
TCO is ALWAYS right. Argument against him is futile.
Scoreboard.