One of the Kevins has drawn Appendix A “Statistical Issues Regarding Trends” in the recent USCCSP report "Temperature Trends in the Lower Atmosphere" to my attention. The appendix is coauthored by the omnipresent Wigley.
Kevin writes:
It’s quite amazing and, from where I sit professionally, very disturbing. Re-inventing long-established methods (sometimes getting it wrong), strange terminology, blatant errors of omission and commission (MBH have lots of company) etc. all point to a divorce between the climate science community and the mainstream statistical community, as Wegman noted…
Even if there were no potential human cost to not doing things properly, I must say it irks me to see folks doing things that would land me in the street…and becoming celebrities in the process to boot!
Aside from the juvenile tone, what is wrong with it? As a start, the handling of autocorrelation. Readers of this site – or readers of Koutsoyannis or David Stockwell – know that AR1 is not a suitable model for a climate series null process.
I don’t mean to imply that there’s some great gotcha staring everyone in the face. It’s just that it’s a very bad piece of work. I don’t have time to fully discuss it, but perhaps others will.
Update: Against my better judgement, I’ve spend some time looking at the references for their AR1 autocorrelation model. Santer et al (Science 2000) discusses autocrrelation issues as follows in the legend to Figure 1:
Confidence intervals are adjusted to account for temporal autocorrelation in the data (21).
Footnote 21 says:
The method for assessing statistical signiàÆà ⽣ance of trends and trend differences is described by B. D. Santer et al. ( J. Geophys. Res., in press). It involves the standard parametric test of the null hypothesis of zero trend, modiàÆà ⽥d to account for lag-1 autocorrelation of the regression residuals [see J. M. Mitchell Jr. et al., Climatic Change, World Meteorological Organization Tech. Note 79 ( World Meteorological Organization, Geneva, 1966)]. The adjustments for autocorrelation effects are made both in computation of the standard error and in indexing of the critical t value.
Santer et al (JGR in press) turns up in JGR 105. It describes the AR1 saying:
The model that we use here is simple and has considerable empirical justification based on results from extensive stochastic simulations (D. Nychka et al., manuscript in preparation, 2000).
I have been unable to locate any publication Nychka et al,… which fits the bill. If there was no subsequent publication, this is academic check kiting worthy of Ammann and Wahl. They acknowldged Nychka as a consultant in Wahl and Ammann 2006. Perhaps that was one of the things that they consulted Nychka on. More to the point, surely Santer et al could have located some third party statistical reference.
Update(Aug 21):
Santer et al (JGR 2000) state:
There are various ways of accounting for temporal autocorrelation in e(t) [see, e.g., Wigley and Jones, 1981; Bloomfield and Nychka, 1992; Wilks, 1995; Ebisuzaki, 1997; Bretherton et al., 1999]. The simplest way [Bartlett, 1935; Mitchell et al., 1966] uses an effective sample size
based on
, the lag-1 autocorrelation coefficient of e(t):
By substituting the estimated effective sample size n_eff for n in (4), one obtains “adjusted” estimates of the standard deviation of regression residuals and hence of the standard error and t ratio.
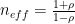
Bartlett is a famous statistician, although 1935 was early in his career, and one would like to see a more up-to-date statistical authority. Bartlett 1935 does not support the citation and arguably says the opposite:
First, there is no objection to our using the usual statistical tests as a preliminary measure. If coefficients are quite insignificant on these tests, there does not seem to be much point considering them further. Secondly, it a correlation coefficient appears significant, the extent to which the necessary conditions for a valid test appear to be fulfilled in the problem under consideration should be clearly stated. It should be noted that the complete independence of observations of one series is sufficient for a test to be valid… If neither series is random, no valid test can be recommended for it is not likely that the dependence of the observations can be specified in any satisfactory statistical way.
So I guess the authority for this procedure is a WMO technical report.





457 Comments
I’ll read it tonight. Deep in the throes of BSS/ICA research at the moment. 🙂
Mark
I must be missing something here. I’ve referenced this paper several times on this site, and Steve M. was the first one to point it out. Why will the folks gasp?
w.
Willis, I didn’t convey the right impression and I’ve edited this as follows:
Mr. Nychka seems to figure deeply in climate proxy reconstructions, doesn’t he. First he seems to advise everyone on the statistical methods to use, and then he sits on the committee judging whether everyone is using the right statistical methods. There seems to be a different sort of autocorrelation at work here.
I met Nychka in Washington and he seemed like a pretty pleasant guy but decent guys don’t always make good decisions. It was ridiculous that someone who had advised on Wahl and Ammann should be one of the two consulting statisticians on the NAS panel. Plus one of Nuchka’s most cited papers is by, ahem, Bloomfield and Nychka – Bloomfield being the other consulting statistician.
After Mann’s presentation, I criticized the NAS panel for not following up on verification statistics with Mann. Mann told them that he hadn’t calculated the verification r2 statistic – that wold be a “silly and incorrect” thing to do, when he obviously had calculated it and it wasn’t a “silly and incorrect” thing to do. Nychka and Bloomfield as the statisticians had no business letting that comment pass, since maybe the non-statisticians didn’t know that.
Nychka came up to me afterwards and said that just because no one had spoken out on this matter didn’t mean that they didn’t notice it. Well, they might as well not have noticed it. And if Bloomfield noticed this, how could he justify his comments at the press conference. As I said, Nychka seemed pleasant in the encounter and I’m sure that he’d be a good guy to go skiing with or hiking with, but zero courage in this instance.
More fundamentally, he should have had better judgement than to place himself in this situation. I objected formally to him being on the panel during the comment period but didn’t have any acknowledgement. I asked Cicerone about this and he said that they got lots of suggestions and couldn’t accomodate them all. I wonder. How many people do you really think went to the trouble of commenting to NAS on the panel formation. I’d be surprised if anyone other than me did.
Nychka is a very nice guy, and very competent, IMO. I think everyone’s pretty nervous about what this all means, Steve. You’re right – good judgement and courage are in scarce supply. I think a lot of people are looking around at the other newer methods that are being used (like RegEM) trying to figure out how flawed they are in extrapolative reconstruction. Lots of backroom talking since Wegman. But once a consensus starts to emerge, separate camps may start to form. Because this stuff is so complicated (and it’s the summer, and everyone’s busy, etc.) no one seems to be running from the main camp just yet. But it could start to happen this fall.
As with a fragile economy, I think no one really wishes to see the bubble pop. I think what’s hoped for is a calm, deflationary adjustment process where no one gets hurt too badly and no one is scapegoated needlessly.
#5 — I commented to the panel beforehand specifically on the choice of Mr. Nychka, and recommended independent statisticians. You’re always looking for the best from people, Steve, but when there are so many ad hoc excuses for why the right thing was not done, and the trend seems so uniformly in one direction, then there is either a widespread delusion or else people are opting for a pre-conceived conclusion. Tendentiousness is rife when righteousness is the driver.
It’s not courage that is missing. In science, and presumably in both econometrics and your mining prospectives, it’s possible to make the argument with objective evidences. That is, the evidence speaks for itself — the correct judgment is not a matter of opinion or personal insistence — and therefore no onus should fall on the person making the argument. If such onus does fall, then it is immediately clear — because of the indisputable objectivity of the argument — that the blame is entirely unfair. The person blamed can readily show personal innocence. The accusers then have the option of either acceding to the argument or of openly engaging in a star-chamber proceeding. That is, their prejudice becomes openly declared. Not many scientists will opt for that (as opposed to politicians or clerics).
It takes less courage to make an objective refutational argument in science than to engage an opinionated polemic, therefore. In climate science, and especially proxy reconstructions, the objective refutational argument exists and has been publicly made. It’s not courage these people lack; they lack some sort of integrity because the effect of what they’re doing is to stack the deck. The dishonesty may be non-conscious but the odor of fish is persistent.
#7 — Someone needs to be scapegoated needfully. Tim Ball hasn’t been fooled by the trends in climate science. Neither have Roger Pielke Sr., or Richard Lindzen, or John Christy, or many others. It becomes a central and very important question as to why so many have willingly stampeded.
In my view, it’s that these people have injected their politics into their science; their science has become pathological because of that infection. In my further view, it comes down to personal arrogance; a claim of precocious knowledge. A personality flaw writ large, if you will.
8: Talk about an ad hom… That is one of the most eloquent ones I’ve read…
#6. Jean S has written me offline with some delicious details on RegEM as implemented by Rutherford and Mann. ANyone want to bet that don’t have some weird undisclosed and unjustifiable biasing step in the program? Didn’t think so. You’ll have to wait until Jean S returns from holidays though.
I did a quick note on trends last summer pointing out that virtually all temperature series were ARMA(1,1) rather than AR1 and modeled this way typically had very high AR1 coefficients, generally above 0.9! Demetris Koutsoyannis has obaserved that taking averages of AR1 series results in ARMA(1,1) series so monthly averaging or annual averaging would change the properties. I did some back of the envelope calculations (and I’m not especially familiar with the topic and do not warrant these calculations):
If you browse through the posts from last August in this category, there are some threads re4levant to this Appendix. IMHO my quick notes compare quite favorably with the accumulated wisdom of these IPCC lunimaries and collective wisdom of the USCCSP program.
#10 — In climate science, specifically proxy climate reconstructions, the refutation has been made and published, and supported by independent review, JMS. Where is the ad hom?
Actually, I had assumed PF in #8 was criticizing a process, not a person. JMS, aren’t you being a little quick with your accusations of late?
Re #12 ARMA processes
I’m not sure if I should post here or in that ARMA thread, so I’ll start here, and take it there if necessary. I’m not surprised temperatures are ARMA(1,1) – but I was very surprised to see that the MA1 coefficients in your global temperature plot were universally (-)! (I’m so used to working on trend-free tree-ring series, where MA(1) is almost always (+).) What is your interpretation of the (-) MA(1)? My wild guess is that it is an artifact of annual framing bias (?). Or possibly that the MA(1) (and more importantly, the AR(1)) coefficient is heavily biased because of the trend in the data. That would explain an AR(1)=0.9. ARMA models should be fit to detrended data, as stationarity is a critical assumption. What happens to the coefficients when you use ARIMA(1,1,1) to take out the trend?
bender, I haven’t studied this in detail. But on tree ring chronologies, my recollection is that a lot of them are ARMA(1,1) with negative coefficients. Actually I’m certain of this – remember my post on Ritson in May 2006 where his goofy Ritsonian formula for autocorrelation was OK for a process that actually was AR1, but was hugely off the mark for ARMA(1,1). realclimate had a thread which they cut off after about 15 posts when we started making fun of them.
Deng 2005 has an interesting take on ARMA(1,1) series discussing a class of noise with high AR1 and negative MA1 that is “almost integrated almost white” that is resistant to some common statistical tests. He cites some hard papers by Perron.
I forget whether I checked ARMA(1,1,1); I probably did, it’s the sort of thing I do and it probably wasn’t significant or else I’d have followed it. ARMA(1,1) is really a very strong feature and it’s amazing that such a simple observation has eluded so many observers.
Demetris Koutsoyannis’ take is different and more subtle and I’ve been meaning for months to try to master his ideas – he thinks that the climate series are red on multiple scales – which is a simple, elegant and unexploited stochastic model.
The trouble with climate is that every stone you turn over, there’s an interesting problem that would take a year to exhaust, but you can find a new stone every few days.
Steve has pointed out a problem with the methodology in MBH98/99. That is a given. Whether or not it makes a difference is something which has not been proved. I tend to lean in the “no difference” direction, as you can probably tell. The BCP issue has to do with proxy selection and is not necessarily a methodological issue. I will, for the sake of things, assume that Malcolm Hughes knows something about dedro studies. You would be well advised not to post stuff like this:
That is an an ad hom against an entire field and one which is made constantly here. As the NRC pointed out there are many lines of evidence pointing to an anthropogenic cause for recent warming — personally I think that the best evidence is the “fingerprint” evidence now that the satellite data has been sorted out. this might be the best summary of the evidence I have seen anywhere. Read it and think.
Well, we;ve not said that the MBH problems are “simply” the incorrect PC method although the PC method is important and its effects are pernicious. The flawed method interacts with flawed proxies. In this case, the NAS panel caught the nuance correctly.
The NAS panel said that bristlecones should be avoided in temperature rconstructions. Hughes has not stood up and said one word about bristlecones in the past 2 years. His other articles (e.g. Biondi et al 1999) said that bristlecones were not a reliable temperature proxy in the 20th century. No wonder he isn’t saying a peep.
The method interacts with the proxies. The incorrect method isolated and promoted a minor effect. Mann described it as the “dominant component of variance”. Mann now tries to argue that you MUST include a PC4 in a reconstruction, but there’s no mathematical rule saying that it’s a good idea to include a PC4 from a tree ring network.
Plus consider Mann’s robustness claim – that his reconstruction was robust to the presence/absence of all dendro indicators (Mann et al 2000) when that claim was known to be false.
#17 “this might be the best summary of the evidence I have seen anywhere.”
It’s wrong here: “Basic theory links these two trends.” Basic theory does not link specific surface temperatures with CO2 levels, because there is no predictive theory of climate. The effect of CO2 on surface temperatures could well be attenuated by negative fedbacks. No one knows whether this is the case, or not. That SciAm even makes the claim is prima facie evidence for the tendentiousness I noted in #8, because anyone who fairly reads the literature on GCMs can’t fail to conclude they are unable to predict climate, and thus unable to predict the effect of CO2.
And frankly, JMS, that you could read MM03/05 and come away thinking the methodological errors ‘don’t matter,’ is yet more evidence of the will to believe.
I might add that “fingerprint” evidence in the absence of any over-riding theory is no evidence at all. Absent a falsifiable and predictive theory, anyone can put any interpretation they like on the fingerprint.
Re #14: Oh, I don’t know, maybe his use of the term “these people” would be a clue to his having referenced person(s) rather than just a process? Then there were the various negative qualities he proceeded to ascribe to “these people.”
JMS, I used to have a problem whenever I saw this stuff, but more and more I take the philosophical approach, the philosophy being that it’s important for visiting scientists, journalists and curious members of the public to see it.
Thank you, Pat. Keep up the good work.
Re #16
ARIMA on the Briffa temperatures for foxtail area 1894-1996
1. ARIMA(1,0,1)
Coefficients:
ar1 ma1 intercept
0.86 -0.73 -0.15
s.e. 0.18 0.24 0.10
sigma^2 estimated as 0.2580: log likelihood = -76.44, aic = 160.87
Supports what you say: AR(1)>>0, MA(1)
2. Linear trend regression
Coefficients:
param Estim. S.Err. t value Pr(>|t|)
intrcpt -8.840 3.293 -2.70 0.0085 **
t i m e 0.004 0.0017 2.63 0.0099 **
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ‘ 1
Residual standard error: 0.5108 on 101 degrees of freedom
Multiple R-Squared: 0.06412, Adjusted R-squared: 0.05485
F-statistic: 6.92 on 1 and 101 DF, p-value: 0.00986
As I say, there is a weak, but significant upward trend.
3. ARIMA(1,1,1)
Coefficients:
ar1 ma1
0.0799 -0.9000
s.e. 0.1234 0.0752
sigma^2 estimated as 0.265: log likelihood = -77.76, aic = 161.52
The AR(1) has dropped to insignificant because the trend has been removed by the I(1) term. But, as you say, the MA(1) term remains strongly (-). I suspect this is a result of framing bias. i.e. A year is defined arbitrarily as 12 months, always with the same start and end dates, but sometiimes winters/springs start soon and sometimes they start late. That the time-frame is fixed while the seasons are free to slide leads to (-) MA(1). If you let the framing window slide from year to year, the (-)MA(1) would probably disappear.
Mr Bloom, there’s a post over at RC for you. #3. Thx.
Steve, since you are so sure of your conclusions why don’t you do a recon like the one I suggested. Take the two major recommendations of the NRC panel (use correct centering and avoid strip-bark BCP samples) and show us what happens. BTW, it was only the strip-bark forms which the NRC said should be avoided, so you can probably use most of the foxtails.
You make your claims and they are answered. Most of the answers seem to fall in the “so what?” category; if the methods you advocate are followed, there is little or no difference in the final recon (outside of getting rid of the NOAMER data and Gaspe). You seem to know enough about the data and the methods to do your own work, so why not? Are you afraid that it might show a hockey stick?
JMS: Patience, friend. Patience.
JMS, check #22. Thx.
Re#19
What a bunch of non sensical babble. Yes basic theory does link CO2 and temperature. I suspect you don’t where a blanket to bed at night because from your logic there’s no predictive theory that it will keep you warm.
Re # 17
JMS that is an excellent article.
Once again these guys are arguing twigs in the mist of a burning forest. These guys could come a long a factual sentence….”.The temperature trends of the lower atmsophere are consistent with modeled predictions”……and focus on the mis-spelling of the word atmosphere as if a spelling error precludes the truth of the sentence. That’s pretty much what you do when you’ve got nothing. Along with attack the messengers as you’ve already pointed out.
Re #19
Wow! Here is a person who just doesn’t want to believe. Giving up all rationality to hold onto his position. I’ve seen stomping screaming temper tantrum throwing 2 year olds that were more rational. Sad!!
To answer the central question opening this thread:
maybe what they are doing are calculating the effective degrees of freedom by using the “effective sample size” as prescribed in Eq. 9 on p. 135 of Appendix A? It’s hard to say. Blind alleys.
Bloom, JMS, what do you say? Should one be forced to speculate like this as to the methods used to calculate confidence intervals? Or should the methods be clear, so that the experiments are repeatable by independent investigators? Say … what method do you guys use when you do your reconstructions?
gbalella,
Glad you’re here. Did you find the Nychka et al. reference yet? No? Could you have a look? Related: JMS and Bloom would like to see another BCP temperature reconstruction. Would you be willing to help them out? Thx. You’re a gem.
Re #29: Trees are difficult for global climate trends (although goood for regional information). I much prefer ice cores for global trends, with ocean sediment cores (much more on the way, soon) in second place. Regarding reconstructions, I’ll show you mine if you show me yours. 🙂
That’s a deal, sir. But since you’re probably way ahead of me … could you please answer the questions in #29, while I catch up to you? Or maybe help locate the Nychka et al. reference? Or answer #3 at RC. Thx. You’re a gem too.
Steve M,
Presumably you’ve scanned through Nychka’s publication list in search of the missing reference?
Based on Nychka’s papers on neural networks [1] and estimation of missing climate data [2] I would suspect he would be well aware of any frailties in algorithms such as RegEM.
[1] Nychka, D. and O’Connell, M. (1996). Neural Networks in Applied Statistics – Discussion. Technometrics, 38, 218-220.
[2] Johns, C. Nychka, D. Kittel, T., Daly, C. (2003). Infilling Sparse Records of Precipitation Fields. Journal of the American Statistical Association, 98, 796-806.
#26 — Tell you what, gbalella, if you post a link to a journal article that includes the parameter uncertainties propagated through a GCM calculation, showing error bars less than or equal to the predicted temperature, I’ll change my mind about “basic theory” and admit here that I was wrong, and that you and JMS are right.
If you can’t do that, then you accept ownership of the “nonsensical babble.”
#20 — Steve B., your stretch to make an ad hom accusation shows much more about your extremist sensitivities than anything about me. And that you, who so regularly here attempted character assassination by pejorative reference to occupation, should claim injury on the strength of a trumped up insult evokes only a cynical regard.
I am, here, a “visiting scientist,” by the way.
Re #32: Regarding #29, I think your energies would be far better spent doing original research.
Regarding #3 at RC, what’s your point? Do you think the data being presented that way was inappropriate for the simplified analysis it supported? Would seeing the noise make the long-term trend go away?
Regarding Nychka, you may want to check the NCAR site. I notice they produce quite a few technical papers that don’t end up in peer-reviewed publications.
Re #35: Of course you’re entitled to your opinions, Pat. But just out of curioisity, where in #20 did I claim injury? I thought I said I had become quite happy with your efforts.
RE #33: You got there first. No such papers that I can see.
#37 — Show you have more than opinions, Steve B., by posting a link to the parameter uncertainties propagated through a GCM. Contrasting your brash challenge with lines 1&2 in #20 merely provides more “negative qualities” grist for the cynical mill.
Re #39: Pat, this stuff is to an extent beyond me, but have a look at this and this. Bear in mind that there are some who might consider the consequences of 3C to be a little on the disastrous side. Er, what brash challenge?
Re 17, JMS, thanks for the posting where you say:
Well, I read it and thought, and my thought was “They didn’t do their homework, it contains all kinds of errors”. In no particular order, some of their errors are:
1) Neither their first nor their second piece of “evidence” for AGW shows anything about AGW. Yes, the earth has been warming for about 300 years, and yes, the CO2 levels have been rising for about 150 years, with a significant rise in the last 50 years. Neither of these facts prove anything at all about whether humans are affecting the climate.
2) They wildly overestimate the effect of increased radiative forcing on global temperature. There is an excellent paper (CO2-induced global warming: a skeptic’s view of potential climate change, Climate Research Vol. 10: 69–82, 1998, Sherwood B. Idso, available at http://www.int-res.com/articles/cr/10//c010p069.pdf#search=%22%22a%20skeptic's%20view%20of%22%20idso%22) that lists ten separate natural experiments that clearly establish that the sensitivity of the temperature to a change of forcing is on the order of 0.1°C per watt, or about 0.3 – 0.4° for a doubling of CO2. (Please, don’t anyone post yet another ad hominem attack on the Idsos. If you don’t agree with any of the ten natural experiments he cites, let me know which one and why; otherwise, don’t bother writing. I don’t give a damn what your opinion of the Idsos may be … I do care whether his claims make sense.)
Your reference claims, with absolutely no citation, that “According to the geologic record, 1 W/sq m should lead to about half a degree Celsius of warming — which matches the observed increase.” While “according to the geologic record” sounds impressive and lends an air of accuracy to their claim, it means … absolutely nothing.
Actually, the evidence (not computer modeling, but evidence) cited above shows that 1 W/sq m of increased forcing should lead to about a tenth of a degree of warming, far smaller than the observed temperature increase. This is why they have had to invoke a totally unsubstantiated “positive feedback” to get their models to agree even roughly with reality. Do you really think that they would have invoked the unproven “positive water vapor feedback” if the theoretical warming from CO2 actually matched the observed increase as your source claims?
Finally, they ignore several other problems with the GHG explanation of temperature increase. One is that the earth warmed considerably from 1700 to 1945. One of the periods of greatest warming was from about 1915 to 1945, well before the large modern increase in CO2. None of this can be ascribed to GHGs, and thus it must be due to other natural factors.
And then, after WWII, when CO2 started increasing radically, the earth … cooled down. That’s hard to explain with CO2. It is usually papered over with claims that it was “masked” by aerosols, but this claim fails under examination, because the aerosols are present mostly in the Northern Hemisphere, while the cooling was worldwide. All of these difficulties are ignored by your “best summary”.
Next, there is another problem, which is the inadequacy of the ground station data. According to the HadCRUT3 figures, the temperature increase over the last century is 0.6°, with a minimum error of +/- 0.2°C (2 std dev, and ignoring UHI as well as inherent station inaccuracy). Since the contribution of CO2 to this temperature increase is estimated to be on the order of 0.1°C, our data is not adequate to say anything about whether CO2 is involved or not.
Finally, the existence of the large temperature swings which predate the increase in CO2 means that there are correspondingly large drivers and/or feedbacks in the climate system which created such swings. Your “best summary” simply dismisses these unknown factors out of hand, saying “Natural factors, such as variations in the sun’s output, have been too small to account for the observed temperature increase.”
But, although everyone agrees that the 1915-1945 temperature rise was not due to rising CO2, no one knows what natural factors led to that temperature increase … so how can your reference possibly say that natural factors have been too small to explain the recent rise, a rise which is smaller than the 1915-1945 rise?
Overall, your reference is a very crude attempt to pin a simplistic explanation on a very complex subject. The climate system is a driven, resonant, chaotic, multi-stable, optimally turbulent, constructal, terawatt scale heat engine with a host of known and unknown drivers and feedbacks. It contains five imperfectly understood major subsystems (atmosphere, lithosphere, ocean, cryosphere, and biosphere), each of which interacts both with itself and with all of the other subsystems. We are discovering new drivers and feedbacks all the time.
Your reference cites, and depends heavily upon, various computer model results. Climate is the most complex system that humans have ever attempted to model, and we have only been modeling it for a very short time. Given the general knowledge that the system is so complex that computers cannot predict next weeks weather, people’s childish faith in hundred year computer climate forecasts is … well, it’s a touching reminder that we have not escaped the thought processes that led us to imagine thunderbolts as coming from Zeus. Humans long for the certainty of explanations, even at the expense of rationality or logic.
And given the complexity of the system and our imperfect understanding of it, anyone who makes foolish claims like “Natural factors … have been too small to account for the observed temperature increase” is suffering from terminal hubris. We are nowhere near being able to make such statements.
w.
#40 — Steve B., your first “this” says: “Climate sensitivity has been subjectively estimated to be likely to lie in the range of 1.5-4.5 C…(bolding added),” and “… we show how it is possible to greatly reduce this uncertainty by using Bayes’ Theorem.” Bayes’ theorem is a sophisticated mode of guessing.
Your second “this” is titled, “An overview of probabilistic climate prediction” in which the author admits to lack of knowledge concerning the response of the atmosphere to CO2 (“… partly because I am no expert on the subject …“). I’m glad to see you citing an honest man.
These are supposed to be predictive?
Come on, Steve B. You evince nothing but certainty for your position. Let’s have the projected temperature error obtained by propagating the parameter uncertainties through a GCM. GCMs are, after all, the best physical representation of the atmosphere we have. If they are trustworthy, let’s have the true error limits. If they’re not, then no amount of Bayesian analysis, or any other sort of empirical estimator, is going to tell us anything definitive about future climates. Oh, and if GCM projections are not trustworthy, then you have no “A” ground to stand on as regards GW.
“Er, what brash challenge?“? Oh, innocent you.
#23. You asked to see the impact of the NAS Panel recommendations on the MBH reconstruction. I’ve done this already in two different presentations.
One of their recommendations was to use averages instead of principal components. I did this with the astonishing results reported here.
BTW it’s nowhere been shown that PC applied to tree ring networks produces temperature proxies. But leaving that aside, I presented a graph to the House Energy and Commerce Committee – 2nd presentation – showing the effect of correct centering leaving out Graybill’s strip-bark samples. Graybill collected a couple (perhaps a few) foxtail sites and said that all of his sites were selected for strip-bark. So one cannot reasonably leave Graybill’s foxtail sites in – and, of course, the whole MBH methodology becomes even more absurd if it stands or falls on a couple of Graybill foxtail sites.
One can see the impact of Graybill’s sampling practices by comparing Graybill’s Niwot Ridge sample to that of Woodhouse from what can be no more than a km away. Graybill’s are completely different. In fact, there’s a pressing need to verify exactly what Graybill did to ensure that independent samplers can replicate his results.
Re #36
Bloom:
You’re telling me you can’t see the point? Answer the questions, and I’ll tell you the point.
Regarding your remark on the other post that temperature measurements are not subject to sampling error. You obviously don’t now what sampling error is. If temperatures are not subject to sampling error then there is no such thing as a global mean temperature field.
Now, be a gem, and go track down the Nychka paper for me?
Bloom, THIS is you’re “sort of” answer referred to in the Katrina thread? I thought you were saying you’d answered over at RC.
You say you’re interested in the AGW-hurricane link. Then why is it so hard to answer a simple question about the statistical implications of summing observations across five-year windows, rather than analysing the data as annual observations?
Hurricane frequency is a parameter that is not subject to sampling error? Bloom, you’re a good debater, but you have a lot to learn about statistical dynamics.
Go look at Judith Curry’s Fig. 1 after reading this post, and then tell me again you don’t see the point. It’s staring you in the face. Open your eyes.
#42 seems like a reasonable request:
Who wouldn’t want to see that?
Re #32
So now you’re asking CA to NOT produce a reconstruction?
You know what I think? I think you fear the truth. You fear the truth because you can not anticipate it. And you can not anticipate it because you have no understanding of statistics.
bender, I re-read some of my posts from last summer on some gridcells with odd ARMA(1,1) coefficients here here here.
Obtaining and mapping ARMA(1,1) coefficients is actually a rather near quality control procedure for the gridcell results. It sure picked out a lot of wonky results like a champ. I liked the African gridcell where the CRU values were out by an order of magnitude every Januray. When you see examples like that, you wonder what their vaunted quality control procedures really are. I spotted that in the first hour or so that I played with the data. If their QC procedures can’t pick up
Re #41
Posts like this really get you thinking.
Re#41:
I’ve been beating this drum a lot lately. All the info I can find (along with common sense) suggests anthropogenic aerosol emissions and GHG emissions went hand-in-hand, at least into the 1970s. It makes no sense that aerosols would wait until the 1940s to suddenly start masking GHG warming – it should have been there all along.
I think you need to brush up on what an ad-hominem means. Ad-hominem is NOT simply criticism or personal insult. Yes, criticism, and sometimes insult, are regularly made here, and there is so much to criticize. Ad-hominem is using said personal insult to refute an argument, which is not being done. Learn your terminology before making such claims. You personally enjoy the appeal to authority (actually in reverse), so logic claims are obviously not YOUR forte.
Mark
Michael Mann already did this experiment without the bristlecones, JMS. Pay attention, this information is located in the CENSORED directory folks like you continually refuse to admit “makes a difference.” Sans HS, btw.
Until a linear relationship between any tree-ring and temperature can be discerned, all tree-rings represent flawed data. This is assumption #2 in MBH98, btw. Also, there is a problem with using trees to represent global temperatures in the face of lacking correlations to local temperatures AND, trees only grow about 4-5 months per year. Hardly a “yearly” proxy.
You keep asking for a “study” that is, inevitably, flawed. Garbage in, garbage out.
Mark
#48 about surface temperatures: there can be random error and systematic error. Random error has no effect on the mean temperature if the sample is large enough. It seems to me that about the only or the main possible cause of systematic error is UHI or similar effect. Both Pielke Sr. and John Christy have shown how you don’t need to have a weather station in the middle of a city to have a significant UHI effect. Now the UHI effect is only positive, or at least I haven’t seen any example of a negative systematic effect. The conclusion to be drawn from that simple line of reasoning is that the surface temperature record is most probably overestimated. Thus the trend is really an upper limit to what the actual trend is. To me it’s very likely that you could easily shove off 0.1C from last century’s warming. In any case, that would make the surface temps more in line with MSU data.
Maybe someone can comment on that paper, linking temperature to CO2, but CO2 is really a spatial proxy for human activity (e.g. industrial). Sounds like an interesting hypothesis.
Dear Francois #53,
the paper you linked is now probably up-to-date because Christy et al. have recently found an imperfection in their satellite measurements and calculations.
On the other hand, one of the previous climate audit articles was about some discrepancies in the surface measurements that point to UHI, indeed.
Best
Lubos
now -> not
Re #41
Willis, that Idso paper you refer to is almost never cited in the literature. What do you make of that?
Are there any benchmarks for the acceptance of GCMs? For example, I would credit any GCM which could predict El Nino/La Nina events 10 years in advance with 75% accuracy.
Re 56, bender, I don’t know why the Idso paper is rarely cited … other than that it blows the entire AGW claim out of the water. If you have read it, you know it is a very solid and very interesting piece of work.
It is not alone in the field, either. Climate sensitivity of the Earth to solar irradiance, Douglass, D.H. and Clader, B.D. 2002., Geophysical Research Letters 29: 10.1029/2002GL015345 came to almost exactly the same conclusion as the Idso paper, that the climate sensitivity (k) for the lower troposphere was 0.11° +/- 0.02°C per additional watt of forcing.
The authors also showed that their studies of several other temperature records came to the same result. These included the Parker (1997) radiosonde temperatures (k = 0.13), Jones et al. (2001) surface air temperatures (k = 0.09), and Hansen et al. (1987) surface air temperatures (k=0.11)
Douglass and Clader also said that White et al. (1999) calculated k as being 0.10° +/- 0.02°C for the upper ocean 1955-1994, and Lean and Rind (1998) calculated k = 0.12° +/- 0.02°C for the surface temperatures of the period 1610-1800.
All of these estimates of k are much lower than the IPCC value, which is stated as mean 3.5°C, high 5.1°C, low 2.0°C for a doubling of CO2. Since the IPCC value for a doubling of CO2 is 3.7 watts/m2, the mean IPCC value for “k” is very close to 1. (Curiously, this is twice the value given in the reference which JSR cited in #17 above. Why? … dunno, because the only reference given for their figure is, curiously, the “geological record” … say what?)
Why the discrepancy between the IPCC value and the others? The main reason is that all of the above estimates (Idsos, Douglass and Clader, White, and Lean and Rind) are experimental, real world measurements. The IPCC values, on the other hand, comes from computer models … I leave it to the reader whether to believe:
a) the ten “natural experiments” of Idso, the four analyses of Douglass and Clader, the analysis of White, and the analysis of Lean and Rind, all of which give a result very close to k = 0.1°C/watt-m2, or
b) the computer models of the IPCC, which give a figure ten times as large.
w.
REFERENCES:
Hansen, J. and Lebedeff, S. 1987. Global trends of measured surface air temperature. Journal of Geophysical Research 92: 13,345-13,372.
IPCC Climate Sensitivity http://www.grida.no/climate/ipcc_tar/wg1/355.htm
Jones, P.D., Parker, D.E., Osborn, T.J. and Briffa, K.R. 2001. Global and hemispheric temperature anomalies — land and marine instrumental records. In: Trends: A Compendium of Data on Global Change, Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory, U.S. Department of Energy, Oak Ridge, TN.
Lean, J. and Rind, D. 1998. Climate forcing by changing solar radiation. Journal of Climate 11: 3069-3094.
Parker, D.E., Gordon, M., Cullum, D.P.N., Sexton, D.M.H., Folland, C.K. and Rayner, N. 1997. A new global gridded radiosonde temperature data base and recent temperature trends. Geophysical Research Letters 24: 1499-1502.
White, W.B., Lean, J., Cayan, D.R. and Dettinger, M.D. 1997. Response of global upper ocean temperature to changing solar irradiance. Journal of Geophysical Research 102: 3255-3266.
Moving back to the Wigley paper, I have a couple questions:
1) Is the adjustment of “N” which Wigley proposes for AR(1) autocorrelation correct?
2) Is that same adjustment appropriate for ARMA(1,1) type processes? If not, how are these adjusted?
w.
Re #58: Real-world empirical estimates are always interesting. Thanks for the additional refs.
Re #59: Will have a closer look at 1 & 2 and get back to you.
I just read “Appendix A: Statistical Issues Regarding Trends,” and I don’t quite know what to make of it. In one sense I am sympathetic with Mr. Wigley, the principal author, because now-and-then I have to explain statistical issues to policy makers, and there is a no truly satisfactory way to do this. The trouble is that policy makers — administrators, legislators and their aides — just don’t have the time to understand the analytical principles, be they statistics or whatever. The “Temperature Trends in the Lower Atmosphere” is addressed to Congress and, as such, is meant for the legislatives aides (usually junior), agency sub-subalterns, and general policy wonks on the broader topic — climate change. As a whole that group is more likely to consider autoregressive behavior as a psychological aliment than a statistical framework and to say, “Oh, a statistical appendix: these guys must know their stuff.”
As I read the Appendix I was irritated by the formally of the piece given the audience, and given the formally I would have expected a little more precision: “statistic” is poorly defined although not misleading, but Mean Square Error is simply incorrect (the difference is vis-àÆà➭vis the population parameter not some estimate, and it is usually not used with respect to observations but rather to the estimates themselves such as in a Monte Carlo experiment.) Why Wigley couldn’t use “squared residual” (fewer words and precise) baffles me. And then there is the little gem about the variance of the sum or difference of two random variables. What happened to the covariance term? Lastly there is the whole discussion of using difference between two series to reduce the confidence intervals. Think for a second: what happens when you subtract a negative trend series form positive trend series? What should we expect of from the difference? A bigger positive trend, right? What does that tell use about the significance of either of the two original trends? Not much.
But my sympathy with the difficulty and my irritation with definitions and algebra are minor. The purpose of the Appendix is to present issues regarding the statistical analysis of trends, and in this it is, if not completely, largely misleading. Trends are problematic. Trend hunters should come to field with a large bag of humility. And if one hasn’t the time or inclination for econometrics texts — and if you do, I have a couple hundred econometric texts I could offer at a discount — one should at least recall the epistemological message of that English economist and sometime econometrician Sir Alexander Cairncross:
A trend is a trend is a trend,
But the question is, will it bend?
Will it alter its course
Through some unforeseen force
And come to a premature end?
Mr. Wigley did neither. Steve McIntyre has introduced the readers of these pages to the “spurious significance” problem of regressing [Granger and Newbold, 1974, Journal of Econometrics] a highly autocorrelated correlated variable on another such when there is no underlying relationship. When there is an important underlying relationship, the “spurious” part of the problem can disappear. In either case the tests of the residuals — such as the Durbin-Watson statistic which Steve has also introduced in these pages — will indicate the existence of problems. [Footnote for those who care: for temperature trend estimation, bounding or testing, I think that you need to use something like Engel’s ARCH LM test (“autoregressive conditional heteroskedastic” Lagrange Multiplier), which is based on the regression of the squared residuals on the lagged squared residuals, for as many lags you want to include, and which the test statistic equal to the sample size times the R-squared is approximately a Chi-square. So if you R guys can’t find it in the R packages — though I bet it or the GARCH version is there somewhere — it is real easy to write your own function. The larger and larger array of tests of the residuals come the continuing study of how to determine whether or not the regression residuals reflect the assumptions that underlie the model, usually white noise innovations.]
The Appendix is disturbingly misleading because it treats the serially correlation problem facially. It shows a bit of the problem of estimating and testing for a trend and then leaves the impression that these have been accounted for. A year ago Steve introduced his readers to a paper by Timothy Vogelsang that proposes a test of trends over a broad range of ARIMA models. [Footnote for those interested in the bottom line: Fomby and Vogelsang used Vogelsang’s test on a bunch of global and hemispheric temperature series and concluded, in amore readable paper, that there was a significant warming trend: Fomby, T and T. Vogelsang, “Tests of Common Deterministic Trend Slopes Applied to Quarterly Global Temperature Data.”] There is no indication in the Appendix of a recognition of the type of problem Vogelsang [and Cajels, E and M. Watson, “Estimating Deterministic Trends in the Presence of Serially Correlated Errors,” 1997, “Review of Economics and Statistics] addressed. Rather the Appendix gives the indication that with its ad hoc significance adjustment for first order autocorrelation all the problems disappear.
[The Appendix says:
“This dependence is referred to as “temporal autocorrelation’ or “serial correlation.’ When data are auto-correlated (i.e., when successive values are not independent of each other), many statistics behave as if the sample size was less than the number of data points, n.”
For any of standard test statistics there is a sample size adjustment that will give the correct significance. For a given regression there is a single adjustment factor depending on rho and n. However, the necessary adjustment is will almost always be difference for one coefficients t-stat versus another and similarly for Wald tests of linear combinations of coefficients. Thus, how does one know a priori which adjustment is correct? I am a great believer in ad hoc adjustments — it and dumb luck are what keep one alive in combat — but significance adjustment in the Appendix is bit too much for me.]
OK suppose Wigley et al are allergic to econometricians — an understandable aliment. However, Messrs. Durbin and Watson published there original paper in Biometrika in 1950, which is probably early enough to have reached the authors. They run their trend estimation on the Hadley monthlies (coincident with the MSU series: Dec 1978 to present), and they get a D-W stat of around 0.5. For time series data, that spells big trouble, spurious significance, or whatever you want to call. [It does NOT spell bias. Serial correlation produces underestimates of the standard errors on the coefficients, but estimates themselves are not biased from the serial correlation.] Suppose they tried estimating with an AR1 term. The D-W test is out of the big-trouble zone and the trend estimate is roughly the same. So they quit? Now if they had paid any attention to their statistical package they would have found a further test. The ARCH LM would be nice, but the Breusch-Godfrey test (from a regression of residuals on exogenous plus lagged (2 or more lags) residuals, which is a standard in the linear model testing of R/S-Plus and SAS and presumably in appropriate module of Matlab) would tell them there was still trouble. When it comes to trends, Sir Alex was a very wise man. Wigley et al would then have continued with, say, an ARMA(1, 1) with trend … ARMA(3,3) and maybe more. Somewhere along the line they would have said “How about taking first differences? The linear trend is just the constant term of the first difference.” And when they did that, they would have been somewhat surprised to now find that there significant trend has become insignificant. Trends are problematic, as I said.
That little exercise — from naàÆà⮶e OLS to AR1 to more involved ARMA models to first differencing or just jumping to the last part ala the suggestions of Box and Jenkins — doesn’t require a Ph.D. in statistics or econometrics. But it does require skimming a few text books or maybe googling serial correlation on the Web along with reading some of the documentation of the software they were using. And it would seem that if one is going to write about the “Statistical Issues Regarding Trends,” that one ought to know a little something about it.
Well said, Martin Ringo. I think your assessment provides some support for the idea that the fields of cliamte science and statistics have been too much divorced from one another for far too long.
Re 41
Willis …you seem to have left out their whole argument on fingerprinting analysis. A bit disingenuous I’d say.
re 58:
My take is that the climate system (being a closed loop amplifier) acts as a low pass filter, i.e. high frequencies have a lower gain than low frequencies
The high frequency validation is Pinatubo (0.15 K/Wm-2) and annual response to solar irradiation (Hoyt 0.18 K/Wm-2)
The midrange observations points to 0.282 K/Wm-2, (The “no feedback” value, as found using Modtran)
Note that Mann and Bradley as coauthors of Waple use 0.3 K/Wm-2 [!]
Ice age sensitivity already is approaching the horizontal asymptotic value:
Hansen 0.750 K/Wm-2
The low frequency response is in the Eocene using 5000 ppm and a temperature difference of 11 degrees
Eocene forcing is 5.35*ln(5000/370) = 13.9 W/m-2 (stretching Myhre a bit here)
Therefore equilibrium sensitivity has a maximum value of 11/13.9 = 0.789 K/W-2 or 2.89 K/2XCO2
So in a summary graph:
see also
http://www.ukweatherworld.co.uk/forumold/forums/thread-view.asp?tid=25003&start=1
Click to access waple2002.pdf
oops:
So in a summary graph:
Re #44/5: Bender, I don’t think I ever said anything to imply that temperature wouldn’t have a sampling error. Regarding TCs, I still can’t figure out what you mean when you talk about sampling error relative to the use of pentads in Figure 1 in the BAMS article. If you had said the use of pentads makes the record appear less noisy, of course it does, but the pentads still wouldn’t be hiding any sort of sampling error. I take sampling error to imply that the sample is not a sufficiently accurate reflection of the entire population, and in this case since the sample was all hurricanes, that would imply that something is missing. If it is missing, it would affect both an annualized graph and the pentad graph, so again how is it *the use of pentads as such* is hiding something? In any case, as I noted, there is a missing data controversy, but the article goes on to address that issue directly.
Re # 41
Ewwwee darn…nice estimate Willis but in case you an Idso missed it the earth has already warmed by 0.8C (2X Idso’s estimate) and we haven’t even doubled the effective CO2 concentration. And you actually believe that is an “excellent paper”??
So Gballela that 0.8C (In actuality for the 20th century it was 0.6C) was entirely from CO2
I think you missed Willis’ point completely, and you ignore any possibility of Natural variability.
I believe Willis’ point was in identifying how much was a result of CO2, the rest being from other causes.
IMHO Douglas and clader mage an elegant breakdown of the contributers to tropospheric temperature:
Enso
Volcanics
sun
“unknown linear trend”
figure 2 from:
Douglass, D.H. and B.D Clader, 2002, Climate sensitivity of the earth to solar irradiance, Geophys. Res Lett. vol 29, no. 16, 10.1029/2002GL015345
Re #66
Bloom: “There is no sampling error as such.”
Please clarify.
Bloom, You do not understand statistics. Would you like to learn? Or would you prefer to play games with you pretending to know what you are talking about?
Re: #41 ff.
Willis, great summary. I have given copies of Idso’s 1998 paper to lots of people. I think it’s one of the most innovative climate papers I’ve seen, based on the idea that, rather than using numerical models, we can test the Earth’s climate system’s response to various stimuli — as Idso says, “I decided to see if I could learn something about [climate science] from the natural experiments provided by the special meteorological situations I was investigating.” There was an amazing consistency in the experiments, showing temperature increases on the order of 0.4C for a 2X CO2 scenario.
Idso’s been wrongly characterized as an AGW denier. He’s not — he’s an AGW “minimalist.” His co2science.org website is also the best source of journal article reviews I’ve seen.
Re # 68
So based on that paper, assuming a modern 0.8 C increase in temperatures, there must have been a net positive forcing of 8 watts that caused the temperature change. And apparently we can’t find what that forcing is as the Sun only contributed ~ 0.5 watt, GHG contributed ~2.0 watt. So some mysterious unknown forcing of about 5.5 watts has occured and we have NO idea what it is? Maybe it’s invisible pink flying elephhants……maybe it’s hiding with the WMD’s…maybe its just the power of persusion on susceptble minds…who knows?
Maybe you need to find what it is before you start blaming it completely on CO2, maybe your solar forcings are off.
Regardless you haven’t made the case for it being 100% CO2.
Your thoughts on the complexity of the climte (giving input to only two factors) is very simplistic.
Re 63, gballela, thanks for your question about their “fingerprint analysis”. You say:
I did not comment on it because it had so many logical errors I couldn’t follow it. I agree with you that their “fingerprint analysis” is a bit disingenuous, actually more than a bit. However, let me take a crack at it:
They say, for example:
This does not make sense, either from the point of view of the data or the logic. Regarding the data, there are so many misrepresentations in this I don’t know where to start, so I’ll list them as I come to them. The lower troposphere records (either MSU or RSS, take your pick) show no significant warming in the Southern Hemisphere since 1979. The high latitudes have not warmed more than the lower ones. Antarctica has not warmed at all. Alaska and Canada warmed in 1976 as a result of the PDO, and it is definitely disingenuous to claim that this was a sign of GHG warming. There is no “arctic amplification” as claimed by the GHG enthusiasts, see Polyakov et al. And while the land has warmed more than the ocean since the 1970’s as they state, this was also true during two-thirds of the ~150 year HadCRUT3 record, so it is not anomalous as they claim. In short, their “facts” are simply not true.
And regarding the logic, while greenhouse gases would have the effect of causing a greater temperature rise in the Northern Hemisphere, so would any natural forcing which changed the forcing equally worldwide. Thus, it is not evidence for anything.
The same logical error is present in the “temporal distribution fingerprint”. Although reduced day-night differences and warmer nights would be expected from GHGs, they are also a sign of UHI. As it is well known that UHI is not accounted for in the temperature records, again this “fingerprint” proves nothing.
Thus, to call these things “fingerprints” is an error in itself. A fingerprint is unique to a single individual. These patterns could be the result of a variety of causes. They call them “fingerprints” precisely to disguise this fact, to convince the credulous that there is no other possible explanation. This is not science … this is false advertising.
Finally, as I remarked above, some of their “fingerprints” depend on the climate models. If you believe the climate models, I can only recommend that you compare their hindcast results to reality. I have done so, and the results were hilarious — many of the models hindcast month-to-month swings of temperature that have never occurred in recorded history.
This is one of the most amazing things to me about the whole climate discussion. People who are very aware that computers can’t predict next weeks weather simultaneously believe that computers can predict next century’s climate … how can that possibly be?
w.
PS – having claimed (above) that more warming is to be expected in the Northern Hemisphere from GHGs than in the Southern, they go on to say “Per unit area, the northern seas have warmed less than the southern ones, which makes sense if greenhouse gases have caused an overall warming trend, offset by sulfate aerosols in the northern climes where they are concentrated.”
Talk about wanting to eat your cake and have it too. When it suits them, they claim the GHGs preferentially heat the Northern Hemisphere more than the Southern … until they need the opposite, when suddenly it makes sense that the GHGs preferentially heat the Southern Hemisphere …
I’d call that as disingenuous as you can get …
Re #71: I think you’re just dodging now, Bender. To show you’re not, let’s consider this in terms of a concrete example:
Year 1 has five storms, year 2 has eight, year 3 has six, year 4 has five, and year 5 has six. Graph that, then add them up to make a single point on a pentad graph (thirty storms for the five years). Now, where exactly is the potential *sample error* between the two representations?
Re 73, gbalella, thank you for commenting:
Umm … not sure where you’re getting your numbers, some citations would be in order, as they disagree with the accepted figures, viz:
First, the increase in temperature over the last century is at most 0.6°C, +/- 0.2°C (HadCRUT3 data, 1900-1999, no adjustment for UHI). This is also the figure accepted by the IPCC.
Second, the increase due to the change in solar forcing (TSI and solar magnetic) over the last century is estimated to be ~ 0.4 – 0.5°C (see Celestial Climate Driver: A Perspective from Four Billion Years of the Carbon Cycle, JàÆà⠮ Veizer, Geoscience Canada, 2005 Volume 32 Number 1, March 2005)
Third, the temperature increase due to CO2 over the last century (from 296 ppm to 370 ppm), using a sensitivity of 0.1°C/watt-m2 and a forcing from doubling of 3.7 w/m2, is about 0.1°C.
These numbers all agree quite well, within the limits of error. Part of the problem, of course, is that these error bars are quite wide. In addition, the error bars typically only include the statistical error, and ignore the measurement error. Thus, the situation is more uncertain than it generally is reported to be.
w.
PS – it does not help the credibility of your arguments to rave on about invisible pink flying elephants and WMDs …
Re #75: So there hasn’t hasn’t been any temp increase to speak of, eh? But, e.g., the GRACE results for Greenland and the Antarctic would be explained by…?
Also, could you give me a cite for those RSS results showing no warming over Antarctica?
Sample error is in the frequency estimate, Steve B., and bender clearly stated “frequency estimate”. Bender is correct, you need to brush up a bit.
Mark
Steve B: I think you are actually learning something here. You seem to have have dropped the supercilious, looking-down-the-nose arrogance (for now?) I sure wish I knew why you spend so much time here with the terrible skeptics.
#73 gbalella;
Oh, but we do have a candidate for some of those 5.5W/sqm: cosmic radiation -> aerosols -> clouds; clouds are indeed the 800-pound gorilla in the climate-mist.
Until recently the link between cosmic rays and cloud formation, were pure speculations (albeit a very good one), but an initial experiment performed by Henrik Svensmark, Jens Olaf Pepke Pedersen, Nigel Marsh, Martin Enghoff and Ulrik I. Uggerhàƒⷪ at Danish National Space Centre, using one 8 cubic meter reaction chamber, has indeed confirmed that the ionisation of the atmosphere inflict on the formation of aerosols, and thereby clouds.
The mechanism has become so plausible that CERN is going to spend 20 mill.$ on a more advanced experiment, named CLOUD, in order to not only confirm the mechanism but also to estimate an effect. In Copenhagen the cosmic radiation were simulated using a radioactive source, but the CLOUD experiment will use particle accelerators instead.
If the CLOUD experiment turns out positive (depending on view), consensus could very well swap around: CO2 is going to have the role the sun has today and visa versa, and rest assure that the fight for the public opinion is going to get bloody. Mann & Co. is not going down without a fight, mostly because they have invested all their authority in scaring and ridiculing everyone who dared questioning consensus. Only…this time around they’re going to wrestle top-notch physicists at a top-notch institution.
Michael Hansen.
PS: and thanks for that little WMD-wisecrack, gbalella. Just like Ray Pierrehumbert, Gavin Smith, William Connolly, and Rasmus Benestad, you try, and you try, and you try, to conceal your true colours, but it’s just so damned hard with those big activist-hearts pumping away. Quite revealing, actually.
Re Idso:
I came across this at Idso’s site I believe he is referencing a theory by Rudiman that says humans have caused warming since 8000 B.C. and thus have prevented an ice age:
“Hence, even if the IPCC is correct in their analysis of climate sensitivity and we are wrong in suggesting the sensitivity they calculate is way too large, the bottom line for the preservation of civilization and much of the biosphere is that governments ought not interfere with the normal progression of fossil fuel usage, for without more CO2 in the atmosphere, we could shortly resume the downward spiral to full-fledged ice-age conditions. Ought we not be doubly careful, therefore, as the United States indeed is, in not rushing forward to implement the Kyoto Protocol or anything like it?ï〢½ We certainly think so.”
So Idso says he could be wrong on his estimate of CO2’s forcing. But that’s not the interesting part. The interesting part is that Idso claims, if he is wrong then he will pick another theory rather than accept the consensus view. I hate to question someone’s principles, but this smacks of results-oriented thinking, and does not give me much confidence in his objectivity. The obsession in a scientific analysis with policy issues is another problem.
Re:#82
Gabe, the way I read that quote is as follows: If Idso is wrong on climate sensitivity, and the sensitivity number is higher, that means that the climate effect of human activities (including those of the past) has been greater. Given a greater effect of human activities, one needs to analyze the sum total of that effect, which may turn out to include delaying/preventing an ice age. He then argues that we should be extra careful before mandating policies that might reverse a delay/prevention of an ice age.
Seems pretty clear that he says if he’s wrong he’ll accept the “consensus view” of a larger climate sensitivity. He’s just pointing out that not all the implications of a larger sensitivity value have been sorted out, and that it would be prudent to delay action until those are better understood, for fear of (e.g.) accidentally reverting to an ice age.
If you want to see what Ruddiman actually says check out this. We have a major climate conference going on here in town this weekend which is the reason for the article. Given my experience with the Idso’s site I have my doubts. The articles which I have read there invariably point to Idso written summaries of papers, without even links to the abstracts.
Gabe: Why don’t you provide a better analysis of what’s going on? NOBODY KNOWS (from a scientific perspective). If you can show me that the MWP was cooler than today, I might have a reason to believe that CO2 is a problem. I’m still not convinced, OK? They may be making wine in higher latitudes, soon, just like the old days…
Well, he’s certainly not being “doubly careful” if he’s wrong and Ruddiman is too. He seems to be bending over backwards to find an argument for the status quo.
Bloom: dodge! Ha! You would know.
Bloom, let’s start simple, and progress at a speed you can handle. “Hurricane frequency” is a random variable, yes or no?
Re #79: Um, nothing about frequency estimates in either thread, from Bender or anyone else. But maybe you could explain using the example I gave.
Re # 77
1st…the warming during the measured instrumental period is about 0.8 C
2nd.. selective references that are not backed up by the literature found in the most prestigious journals is worthless….as was the original Idso article
3rd…tautological argument based on a false unproven premise.
P.S. The point was that the Idso paper is as credible as pink flying elephants…invisible ones at that.
Re #88: Oops, didn’t refresh before I sent that. But please just cut to the chase. I’m sure a short paragraph will suffice.
bender said:
Hate to be so obnoxious, but can’t you read, Steve B.? Hurricane frequency is the parameter he is talking about estimating, because it is, as noted, a random variable (for which we only have about 50 years of relatively accurate information). And sorry, but it is not a complete population sample as bender is implying.
Mark
These are fundamental concepts… I’m curious why you expect us to lecture you on first semester college statistics?
Mark
Re 90
gbalella said
“the warming during the measured instrumental period is about 0.8 C”
Not in my book, the warming since 1970 is about as much as the cooling from the late 30s to the 70s.
The instruments have been affected by “urban heat” which is now included in most readings, as a result the rate of global temperature increase is slowing down.
There is absolutely no credible evidence that we are approaching the mythical “tipping point”.
The Earth has been as warm before, and will get a good deal cooler within the next 20 or so years.
The might be the end of AGW.
It appears, however that some “climatologists” have the idea that such cooling could be an effect of AGW.
Re 78, Steve Bloom, you’re up to your usual, misquoting what I said. You say:
I did not say that there hasn’t been any temperature increase to speak of, so I have nothing to explain about the GRACE results. I said nothing about RSS results showing no warming over Antarctica, so I don’t owe you a citation.
Why did I say nothing about RSS results for Antarctica? Because there is no RSS data for Antarctica, data south of 70° south is not produced by RSS. Do your homework.
Steve, go away, please. You are neither asking serious questions nor contributing anything to the discussion.
w.
Re 90: gbalella, you say:
1) I made it abundantly clear that I was speaking of the temperature rise 1900-1999. You gave no dates for your claim.
2) I cited the Idso paper, which was published in Climate Research, along with two other papers that were published in the Journal of Climate and the Journal of Geophysical Research. I invited comments on the substance of the papers, and asked that ad hominem arguments not be advanced.
In response, you don’t say one damned word about the substance, but you whine about the the Journals that the papers were published in. Get real, come back when you’re ready to discuss the substance. If you think there are errors in any of the Idso natural experiments or the other papers, tell us what they are … otherwise, you’re wasting our time. Your claim that an idea is worthless unless it is published in some “prestigious” journal that gballela personally approves of is a pathetic sick joke. Forget where it was published, forget who wrote it, and think about the ideas and conclusions!!!
3. I have given you 10 natural experiments and three peer reviewed studies that establish my premise. There is no way to “prove” these papers are correct — like any other scientific claim, they can not be proved, they can only be disproved. If you think one or more are incorrect, the onus is on you to disprove it. To date you have not even started to do that.
Re pink elephants, it reminds me of the old joke … “How many legs does a cow have, if you consider its tail to be a leg?”
…
“Four, because calling a tail a leg means nothing, it doesn’t change the fact that it is a tail.”
In the same way, gbalella calling a paper “as credible as pink flying elephants” means nothing. If you can find something wrong with the papers I have quoted, bring it on … otherwise, you’re just calling a tail a leg.
w.
Re #95: Testy, testy. Are you concerned about having another episode like the one over at Warwick’s a while back regarding your Coolwire 13 sea ice article? I’ll see if I can make the time. (Did Warwick ever correct your sea ice data set error, BTW?)
You wrote (in #75): “The lower troposphere records (either MSU or RSS, take your pick) show no significant warming in the Southern Hemisphere since 1979. The high latitudes have not warmed more than the lower ones. Antarctica has not warmed at all.” Where exactly in that did you stop referring to MSU (I assume you mean UAH) and RSS? I’m well aware that RSS doesn’t cover Antarctica.
In addition to saying there had been no warming of Antarctica, you went on to imply very limited warming of the Arctic (“no Arctic amplification”). My response was that something seems to be melting both Antarctica and Greenland. What do you think that might be?
re #97: Hey Steve B! Love your work. Still working on the explanation as to why the Summary for Policymakers for TAR was so VERY different from the supporting documentation? Looks like an egregious example of propagandising to me, but maybe I am missing something?
End justifies the means? OK to lie if it is addressing a greater good?
Re Hurricanes:
“The data further refute recent claims that the rapid increase in non-normalized damages are due to climatic changes (cf. Changnon et al. 1997 )……Indeed, a climate signal is present in the normalized data, and this is of decreased impacts in recent decades.”
Normalized Hurricane Damages in the United States: 1925–95
Roger A. Pielke Jr
link
Steve Bloom.
Volcanic action is certainly responsible for meltng on the Antarctic Peninsula.I theorise that melting of the rest of Antarctica is illusory since winter sea ice around the Antarctic is expanding year on year.
As to the Arctic, it must have melted similarly in the past because it was warmer in the late 1930’s than in the late 1990’s.
Oldham Sceptic’s of analysis of Nansens 1896? voyage indicates that it must have been similar in temperature then, as it is now.
I read somewhere that a mediaeval map demonstrates that someone sailed along the North East passage during the MWP.It took a Soviet Nuclear powered Ice Breaker to do that in the 1960’s.
How can you still assert that today’s temperatures are the warmest in 1000 years and that the 1960s were warmer than the MWP?
#85: “Why don’t you provide a better analysis of what’s going on?”
Oh, I can’t. I was just pointing out a logical inconsistency and an appearence of bias. It’s fun.
Re# 41
Do you really think this is an accurate statement you made?
Re #89
Bloom, you are a lousy student, and that was your last dodge. Because you are so unreasonable, I will give it to you straight.
Hurricane frequency over any interval is a random variable subject to sampling error. Using a five-year window lessens that sampling error, and in so doing improves the optics on the hurricane trend statistics, which Judith Curry, laughably, does not report in her Fig 1. This allows her, like you, to dodge the complexity of statistics & confidence intervals, and to argue black-and-white, when the issue is really shades of gray. If the statistics were calculated on annual hurricane frequency the statistics would drop in significance, and she would be forced to draw in the trend line, the confidence intervals, and to report the regression statistics and reveal the uncertainty in her inference of a trend. And that would make her argument seem less certain.
The reason this is significant is not because of inferences about hurricane frequency over time. As I say at RC, I’m confident that changing the time-frame to one year rather than five will not completely erode statistical significance. It is because we’ve seen this pattern of behavior before. This is exactly what the reconstructionists and IPCC have been arguing in regard to “uncprecedented” 20th c. warming trend. Sure, you pretend those reconstructions are error-free and it’s a no-brainer. But when you see the width of those confidence envelopes – a mile wide during the MWP – then you realize what a pile of crap that argument is.
And I’ll tell you this too. Choice of a five-year window is suspicious. Why not three? Why not seven? Is this yet another instance of cherry-picking/model-overfit?
Her regression trend analysis should have a degree of freedom chopped off of it to account for that little cherry.
Bloom, the only dodge available for you at this point is to take issue with my choice of words, or to twist around what I’ve said, trying to discredit me. Don’t bother. My argument is rock solid, so you’ll only make a spectacle of yourself.
And yes I’m testy, testy. Professor bender is fed up with student Bloom.
Re 96
Willis,
About Idso’s first experiment he states;
How in the heck is this measurement any measure of climate sensitivity when it in NO ways includes feedback effect? Plan and simple it is NOT a measure of climate sensitivity and most of his “experiments” are similarly flawed.
You might want to look at a real piece of science, in a real journal, estimating real climate sensitivity using empiric evidence not models.
Re: #92:
Correct. The number of hurricanes realized over any given interval is just one sample realization from the ensemble population of hurricanes that could have been produced in alternative stochastic realizations. Hurricane frequency (or count over an interval) is thus subject to sampling error because if the chaotic turbulent weather system were to replay itself, it would likely produce a different number of hurricanes despite similar conditions.
[Note: A time-series analysis across (say 1-year or 5-year) intervals makes the assumption that the “populations” (=ensemble means) being sampled in each interval are the same.]
I think this is maybe what Bloom does not understand. Which is not too suprising, as it is a foreign concept to most of those not used to making inferences about the time-series behavior of stchastic dynamic systems. But it is a pity when someone is so afraid to display their ignorance that it impedes their learning. And these are the people who seek to influence global climate policy?
#102 gbalella
You haven’t provided an explaination for the problems brought up in the statement you quoted with that graph. Where’s the temp data?
Re #104
What’s this – a warmer claiming that refuting one element of an argument refutes the whole argument? I thought we agreed that skeptics have to look at the whole body of GW evidence, not just one piece of it. A sixth example of the AGW double-standard. Keep going, gbalella, there are nine more experiments to refute.
gbalella, are you seriously suggesting that when he measures the ACTUAL greenhouse effect, somehow his measurement “misses” the feedbacks?
If the feedbacks have no effect.. there are no feedbacks, or they cancel out. If they do have an effect, then they affect the temperature, which is what he’s measuring. So it’s impossible for his measurement to NOT include feedbacks.
That really does take the cake. How you could miss that astounds me.
If you made the argument that some of his experiments don’t include LONG-TERM feedbacks, that I could understand. Both others of his experiments are based on longer terms, yet they agree with the shorter term measurements, which tends to support the hypothesis that any long-term feedbacks are net neutral.
By the way, when ones thinks one has found an astoundingly fundamental flaw in something someone much smarter and more knowledgeable than one’s self wrote, I find it’s generally a good idea to assume that it’s one’s self who is making the fundamental mistake and carefully go through the logic before shooting one’s mouth off.
Unfortunately, this blog seems to have been troll-infested of late. I used to enjoy reading the comments here. There was some occasional drivel, but I ignored it or skipped over it. Now that the comments on this blog are >=50% rubbish, it’s getting a bit ridiculous. If I wanted to read ignorant ramblings of ill-informed trouble makers there are plenty of other web sites I could go to. What’s worst is the trouble-makers make fools of themselves every time they write something, yet they keep coming back for more. Guys, none of us are impressed with your logic-free comments. Please do us a favour and either say something intelligent, or get lost?
Jab, dodge, exit. Jab, dodge, exit. If these ADD trolls would sit still and listen they might learn why it is that their arguments rest upon a very shaky foundation. But they would rather go down swinging.
You are mistaken bender, students have a desire to learn. Bloom does not.
Mark
“By the way, when ones thinks one has found an astoundingly fundamental flaw in something someone much smarter and more knowledgeable than one’s self wrote, I find it’s generally a good idea to assume that it’s one’s self who is making the fundamental mistake and carefully go through the logic before shooting one’s mouth off.”
So basically you’re saying “Trust us, you idiot. We’re smarter than you.” But there are other people smarter than me who have the backing of peer review and journals like Science and Nature. If Idso’s arguments are so fundamentally correct, then I must assume that most other scientists are stupid or biased. But anyone can be stupid or biased. It could just as well be you, for all us idiots know. And do you have backup? Just asking.
“If I wanted to read ignorant ramblings of ill-informed trouble makers there are plenty of other web sites I could go to.”
I feel the same way, alas. I guess you’re smarter than me. Golly, smugness, attitude and hubris do not seem to be very persuasive.
Cheers.
Re#41
“And then, after WWII, when CO2 started increasing radically, the earth … cooled down.”
Could debris from the destruction during WWII explain this.
I would have thought that the destruction by fire and explosion of many major cities, in Europe and the Far East, would have an effect similar to a Volcanic eruption.
Re 104, gbalella, you astound me. You abuse me for my choice of journals, then quote a study from one of the very same journals, Journal of Climate, that I had referenced … IT’S THE SAME JOURNAL I CITED, DUMMY!
In any case, you claim that
Unfortunately, your claim is not true. The paper says, for example, that:
Didn’t you read the paper? Their value IS calculated using model results, and not even a complex model, a simple model. Another model related problem comes from this statement:
Oh, good. They neglect internal variability of the ocean because one climate model doesn’t show much internal variability … that makes perfect sense.
Well, unlike you, I read the paper, and I had some problems with it. In addition to the use of the models when they claimed in the abstract that theirs was an “observational result”, a major problem was the method whereby the value of k was calculated. To use their words, k was calculated by:
where à⣃ ’ ”¬⟔ is surface temperature change of the ocean, Q is radiative forcing, and F is heat flux into the ocean.
Now as any reader of this site should know, yourself included, this is not a reasonable assumption, and in fact it is a very dangerous assumption. I would place absolutely no credence in this result until they are able to demonstrate, rather than merely assume, that these variables are in fact normally distributed.
Finally, what were their results? Well, they don’t really have results. They end up with a range of probabilities that goes from the floor to the ceiling. All in all, a pretty information-free paper.
w.
PS – I was highly amused by their estimate of the difference in global temperature between the periods 1861-1900, and 1957-1994
I laughed out loud when I read this, a two sigma error of 3 HUNDRETHS OF A DEGREE for 19th century observations? Get real. Plus, haven’t these folk heard about significant digits? In any case, I went back to the Folland et al. (2001) paper to see if these numbers had any relation to reality. Folland et al. don’t give figures for those exact periods, so I don’t know how these folks got their answer, but in any case, the only estimates in Folland et al. are for the uncertainties in the trend, viz:
Global trend from 1861 – 2000 0.61°C +/- 0.16°
NH trend, 1861 – 2000 0.64°C +/- 0.26°
SH trend, 1861 – 2000 0.51°C +/- 0.14°
Well, that looks very suspect already. The number of observing stations in the Southern Hemisphere is way, way less than the Northern … how can the error possibly be smaller? But I digress, the rest of the Folland et al. numbers are
Global trend from 1901 – 2000 0.57°C +/- 0.17°
NH trend, 1901 – 2000 0.64°C +/- 0.22°
SH trend, 1901 – 2000 0.48°C +/- 0.15°
Again very suspect. Why would the error in the more recent global trend, when we have more and better measurements, be greater than the error in the longer trend, where the number of data points in the early record is so much smaller? But I digress …
My main point here is that the paper you cited, gbalella, is claiming a two sigma error of 0.033°C, three hundredths of a degree, for the difference in the temperature of the globe between the late 1800’s and the late 1900’s … do you really think that this is possible?
I can assure you that it is not. The latest Jones et al. data (HadCRUT3) lists the uncertainty (2 SD) of the current temperature, not the fifty year average temperature but a single month, as +/- 0.158°C. The uncertainty of the temperature in 1861, on the other hand, is given as +/- 0.30°C. With those large uncertainties, the idea that the error in the difference between the calculated average temperatures of the late 1800s and the late 1900s could be three hundredths of a degree is a joke. The error in the current month’s temperature is five times that large.
Let me recommend a new, innovative technique to you, gbalella, to use in place of your current method, which seems to consist of just reading the abstract of a paper, and judging it by whether the journal is “prestigious”:
1) Read the whole paper.
2) Think about it critically. I mean, really think about it. Examine the premises. Look at the numbers to see if they seem reasonable. Consider the methods used. Follow the logic. Dissect the conclusion, to see if they follow from the premises.
3) Report back with your findings.
w.
Just a small note why are we writing ARMA(1,1,1) and not ARMA(1,2). I checked wikipedia and they used the latter notation which is what I thought would be standard. In the first notation it is not clear to me which coefficients belong to the auto regressive part and which to the moving average part. Or in the first notation is one of the inputs for the direct feed though term?
http://en.wikipedia.org/wiki/Autoregressive_moving_average
Re 112, Gabe, thanks for your comment where you say:
Clearly, you didn’t read what he said. He said nothing like your papaphrase.
He’s not saying “trust us.” He’s saying, be careful when you think you’ve found some astounding fundamental flaw, and make very sure that it’s not you making a mistake before shooting your mouth off.
For a perfect example of this fundamental error, see post # 112 …
w.
Re 116 papaphrase = paraphrase, mea culpa …
w.
Re 113, markr, thank you for your interesting question. You say:
While it is possible, as you speculate, that soot and ash from the bombings could have had an effect on the climate, it is not possible that the effect could have continued unabated for thirty years.
w.
Re 97, Steve, you miss the point again as usual. You say:
Episode regarding Coolwire 13? Dude, I think you might have forgotten to take your medications again. I went to your link to see what you were on about, and found a claim by some guy named Steve Bloom that I had made an unspecified error in my Coolwire 13 paper, and a dead link to some extinct web page somewhere … that’s an “episode”?
Regarding where I stopped referring to RSS, it was at the end of the sentence about RSS.
Finally, what is warming the poles? I assume the primary forcing is same thing that has been warming the globe for the last 300 years since the Little Ice Age … (hint: it’s not GHGs)
Recent studies show that during several periods of the Holocene, the Arctic Ocean was completely ice free during the summer (see http://climatesci.atmos.colostate.edu/2006/07/12/open-arctic-ocean-commentary-by-harvey-nichols-professor-of-biology/) … the melting of the poles is a RECURRING NATURAL PHENOMENON, and thus requires no special explanations.
Steve, you’re nit-picking and throwing dust in the air. If you disagree with Polyakov and think there is polar amplification of warming, please cite us chapter and verse. If you think that Idso and the other three papers I discussed above are wrong, cite us chapter and verse. Heck, if you think something is wrong with my Coolwire 13 article, cite us chapter and verse (although, obviously, not on this web site).
Otherwise, as I said above … please go away. You’re only embarassing yourself.
w.
Sorry Willis your Idso article is from, Climate Research, which is schmucky. Mine is from a respectable publication, Journal of Climate, from the AMS (the American Meterological Society).
Re #115
JC, I started this, by writing ARIMA(1,1,1) –
the second “1” indicating removal of first-order linear trend by differencing. The “I”, if I recall, stands for “integrated”.
Oh, okay, that is interesting. So it is essentially a high pass filter. So if the second input was a two would that mean you would take the second divided difference? Of course one slight difference from weighted least means squares is the transformation is not linear it is affine.
Willis,
I did go the hyperbolic route, but I don’t think the hyperbole is far off the intent of his post. And Nicholas’ post was pure hyperbolic drivel, to use his word. If you guys want debate here, then the attitude and hubris from the top down needs to stop or you will be relegated to the darkest corner of the internet along with unspeakable umage archives and Rick Springfield fan sites. If this hasn’t happened already. No wonder the real climate scientists won’t play with you anymore.
I shan’t be back. See what happens when you ask the question:
“Please do us a favour and either say something intelligent, or get lost?”
Getting lost,
Gabe
Let me add a little perspective on “k”, the temperature sensitivity. This is the amount that the earth’s temperature would be expected to change as a result of a 1 watt/square metre change in radiative forcing.
In the simplified situation, where we consider the earth as a black body and neglect losses, we can use the Stefan-Bolzmann equation to determine the temperature change. It turns out that this is 0.18°C for a one w/m2 forcing change, or k = 0.18.
However, as I said, this is neglecting losses. The climate system can be very accurately described as a terawatt scale heat engine. One characteristic of heat engines is that additional heat input inevitably incurs additional losses. Given these unavoidable losses, the figure of k = 0.1°C per w/m2 given by the various studies I listed above seems quite reasonable.
Now the IPCC claims that k has a low value (95% confidence) of 0.54, a mean value of 0.94, and a high value of 1.37. Obviously, the only way that these values could be possible is if there is a very strong net positive feedback. The feedback they posit must be strong enough not only to overcome the inherent losses, but to go beyond that to heat the earth about ten times as much as would reasonably come from the original change in forcing.
This huge theoretical net positive feedback flies in the face of common sense. The climate system has maintained a fairly narrow temperature range for several billion years. During that time we have experienced meteor strikes, worldwide vulcanism, a change in the power of the sun of about 30%, and other major climate disturbances. For the earth to enjoy this kind of stability, negative feedbacks must predominate over positive feedbacks.
Now, the modelers and the IPCC say that their postulated postulated feedback is due to increased water vapor (a greenhouse gas that is otherwise generally ignored by the IPCC). Their argument runs increased water vapor => increased IR absorption => increased temperature. While this makes sense theoretically, a net positive water vapor feedback has never been demonstrated experimentally.
This is because there is a fundamental problem with the water vapor feedback idea. This is that increased water vapor is the center of the main negative feedback system that has kept our climate steady for billions of years. This feedback has a variety of loops. One is:
The next is:
The next is:
The next one is:
The final one is:
All of these act as negative feedbacks, helping to reduce the temperature when it gets too hot, and increase the temperature when it gets too cold. Because of these effects, the world has maintained its temperature over billions of years. Given the existence of these large negative feedbacks, the idea that a one-watt change in forcing will result in a ten times larger change in temperature due to imaginary “positive feedback” simply does not pass the common sense test.
w.
I wrote::
gbalella replied:
I cited four articles. One (Lean and Rind) is from Journal of Climate. It comes to a conclusion which is diametrically opposed to the conclusion of your article in Journal of Climate. Since your gold standard seems to be where an article is published rather than what it says … how do you solve that conundrum? How do you decide which one to believe? Do you see why being published in Journal of Climate is no guarantee of anything? Two articles in Journal of Climate with opposite results, imagine that.
Let me say again, it makes no difference where an article was published. This is a very common logical error, called an “appeal to authority”, with the authority in this case being the journal.
Please, gbalella, I ask of you again — read the articles and think about the ideas. If you are unwilling to do that, then I suggest you take your appeals to authority elsewhere.
w.
Re 123, Gabe, you say:
Gabe, the intent of his post was far from your hyperbole. The intent of his post was to encourage people (myself definitely included) from making fools of themselves by assuming that someone else has made a stupid mistake. Or, as my father used to say “If something seems too good to be true … it probably is.”
I do not understand what you mean by “attitude and hubris from the top down”. Steve M is very restrained in his postings. Some posters, such as Steve Bloom, take a lot of heat for repeating ad hominem arguments and refusing to engage with the facts. Me, I get my butt kicked periodically when I make a mistake. But none of that strikes me as “attitude and hubris”.
However, if a call for intelligent comments drives you away … so be it. Me, I’d prefer that you stay and contribute, but your mileage may vary.
w.
Intrigued by a comment about GRACE satellites and the supposed melting of the Greenland Ice Cap, I took a look at the Science magazine article which claimed the melting.
The most surprising part of the study to me was that in addition to Greenland supposedly losing 70-90 km3 per year from the ice cap, various areas of the open ocean are supposedly losing or gaining mass as well. Around 52N 40 W, an area is measured by GRACE as losing 90 km3/yr. Two other ocean areas showed losses of 40 and 50 km3/yr, while an area around Rekjavik increased in mass by 40 km3/year. (see Supplementary Online Materials for details.)
In addition, Hudson Bay and Scandinavia are shown as gaining 470 and 130 km3 per year, which is explained by the authors as PGR, post glacial rebound.
Now, my questions are:
1. If the historical loss of ice over Hudson Bay and Scandinavia causes a mass increase, why does the supposed loss of ice over Greenland cause a mass decrease?
2. What is the cause of the open ocean changes? These are comparable in size and sign to the Greenland loss, but obviously have nothing to do with ice.
Seems to me like we need more study here, and that the GRACE results might not be ready for prime time …
w.
re 124:
The simplified expression of the forcing of CO2 on temperature is given by Myhre et al.
![dE=\alpha \ln([CO_2]/[CO_2]_{orig})](https://s0.wp.com/latex.php?latex=dE%3D%5Calpha+%5Cln%28%5BCO_2%5D%2F%5BCO_2%5D_%7Borig%7D%29+&bg=ffffff&fg=000&s=0&c=20201002)
 = 5.35
= 5.35
where
http://www.grida.no/climate/ipcc_tar/wg1/222.htm
substituting for CO2 doubling yields:
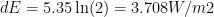
Stefan-Boltzmann:

![dT=\frac{\alpha \ln([CO_2]/[CO_2]_{orig})}{4\sigma T^3}](https://s0.wp.com/latex.php?latex=dT%3D%5Cfrac%7B%5Calpha+%5Cln%28%5BCO_2%5D%2F%5BCO_2%5D_%7Borig%7D%29%7D%7B4%5Csigma+T%5E3%7D+&bg=ffffff&fg=000&s=0&c=20201002)
using the derivative of Stefan-Boltzmann:
substitution gets:
This is the equation without all feedbacks.
Substituting a doubling CO2 level
and substituting T= 15 °C = 288.15K:
dT=5.35ln2/(4*5.6705E-08*(288.15^3))
or
dT=0.6833 °C for a doubling of CO2
Sensitivity is then dT/DE = 0.6833/3.708 = 0.18426 K/Wm-2
However:
If the average emission temperature for the earth (-18 °C) is used:
T= -18 °C = 255.15K
dT=5.35ln2/(4*5.6705E-08*(255.15^3))
or
dT=0.9843 °C for a doubling of CO2, this agrees with modtran calculations.
Sensitivity is then dT/DE = 0.9843/3.708 = 0.265429 K/Wm-2
Willis, Please explain why you use T= 15 °C to calculate the Stefan-Boltzmann sensitivity.
I think I found what Willis omitted:
The complete Stefan-Boltzmann reads:

 is emissivity
is emissivity
where
present day emissivity is 0.6293 (37% of infrared is absorbed)
so, in the 15 °C case, emissivity should be included:
dT=5.35ln2/(4*0.6293*5.6705E-08*(288.15^3))
or
dT=1.0859 °C for a doubling of CO2
Sensitivity is then dT/DE = 1.0859/3.708 = 0.2928 K/Wm-2
This site:
http://hypertextbook.com/facts/2005/JudyTang.shtml
Says the average temperature of the earth is 15 degrees Celsius. I am not sure if we should use average temperature. I think instead it would be better to average the fourth power of the temperature (in Kelvin) and then take the forth root as that as I think that temperature measure would be closer to what is predicted by the black body model.
As a side note a voltage measured by taking the average of the voltage squared and then taking the square root is called the rms voltage. So by analogy should we call the temperature obtained by taking the average of the forth power and then taking the forth root the rms voltage or is that comfusing. How about the 4th_rms temperature. Or in terms of norm
http://mathworld.wolfram.com/Norm.html
we can call it the p4 norm temperature.
#128 looks like one of those glossed over sections of the IPCC that actually has good science. This section I think probably wouldn’t get referenced much on real climate.
Great posts by Willis in this thread.
Particularly the negative feedback analysis of water vapour and clouds. Water vapour is the key to this whole global warming debate. The global warmers will never give up until their models are shown to be wrong and the feedbacks of water vapour have to be the area where they are most wrong. When it is shown that water vapour is not a positive feedback, they will subtly give up and factual temperature reconstructions and analysis will take over and we will finally see what is actually happening in the climate.
The Grace satellite gravity anomalies is also good since it points out that these measurements cannot be relied on. Greenland loses gravity could be the result of the opposite effect (increasing ice mass causing land deformation) if Hudson Bay is increasing due to rebound.
Re #99: MarkR, you cannot simultaneously claim to be interested in the science if you make claims for out-of-date papers without checking to see of there has been more recent work. So that 1997 study was through 1995 and there’ve been ten seasons since then? Google Scholar would be your friend if you gave it a chnace.
Good posts, Willis. And I agree: I hope Gabe C stays too. I don’t mean to get all uppity about statistics. But when people like Bloom go on with their drivel & dodge, I’m really not sure how to put them in their proper place. Which, I assure you, is quite low. Bloom is a good debater, ususally has a good grasp of the more basic facts, but doesn’t understand much at all about inferences in the case of stochastic dynamic time-series. And I assure you, this is a debate about significance levels and confidence intervals. (No offense intended, by the way, Bloom. You have much good company. I just wish you were a better student.)
So Willis I’m waiting for your reply to Hans…..thanks Hans.
He lives on the other side of the world. Give him some time.
RE #41 – Willis: You put out a challenge with your Idso article so let me reply by saying that his Natural Experiment number 6 gives an answer which he claims is identical to his other experiments. But his other experiments include feedbacks where as this one is based the greenhouse effect on Venus and Mars. There is no reason to expect that the feedbacks for the other planets is the same as for earth – if there is a feedback at all. This seems like a significant error.
Regards,
John Cross
Re #125
Poor Willis, you can’t seem to get anything right.
We were talking about the Idso paper which is from a different journal then the one I cited.
Next you changed the subject to the Lean/Rind 1999 paper. You were right that this paper IS published in a respectable journal but sorely wrong of their conclusions when you said;
From their paper ( page 3084);
a. Equilibrium simulations
Although the climate system response to radiative
forcing likely depends on the strength, history, geographical
distribution, and attitudinal localization of the
specific forcing, these relationships are poorly quanti-
fied.
such that an equilibrium temperature change DT 5 kDF (8C)
results from a radiative forcing of DF (W m22).
(Wigley and Raper
1990) and a larger temperature change in the range 0.17
to 0.578C is estimated for the speculated longer-term
irradiance change of 0.24% (DS 5 3.3 W m22) from
the seventeenth century to the present. Consistent with
this an equilibrium simulation by the Goddard Institute
for Space Studies (GISS) general circulation model
(Hansen et al. 1983)”¢’¬?whose sensitivity is in the range
0.78–18C per W m22″¢’¬?estimates a global surface temperature
decrease of 0.478C for a 0.25% solar irradiance
decrease (Rind and Overpeck 1993). ………..
OOPS wrong again Willis.
Here is the link to the Lean/Rind paper that Willis apparently didn’t read.
Re 137
Gonna change the basic laws of Physics is he?
Re 124
Oh Willis come on now!
I don’t know what the exact numbers are but the total GHG effect including CO2, water vapor and others warms the planet by some 33C. Of that something like 9C is from CO2 and most of the rest, say 24C, is from water vapor.
Now Willis made up is own little feedbacks thinking he’s a lot more accurate then the Hadley computer and said;
Willis??? Did you notice what was in EACH of your little feedback loops?? UMMM….HUUUHH??? I wish I knew how to color the text because if I could each time you wrote “INCREASING WATER VAPOR” it would be in large red bold face fonts.
You are ignoring the primary effect of INCREASED WATER VAPOR and only crediting its secondary effect and ASSUMING the secondary effect is ALL that matters.
Tell me Willis how does water vapor contribute 24 C warming to the GHG effect and then in your little “models it suddenly goes away???UMMM HUHH?? UMMM?
Based on your water vapor feedbacks the Earth should be 24 C cooler then it is.
This is why GCM models are important Willis and why people like yourself can get hurt when they try to pretend they are a human supercomputer GCM droid-bots.
No, that’s not what I’m saying at all. Did you read the post I was responding to?
gbalella read the first few lines of a post by Idso, someone much smarter than me, and apparently him too, at least in the Climate field. He then pointed out what he thought was an astoundingly simple error which made the entire thing completely invalid.
Now, don’t you think Idso or someone else during the review process would have noticed if it was such a simple error, and at least written a reply to the journal pointing out why the study is totally invalid?
Of course thanks to people like Mann, Bradley and Hughes, we can no longer trust what scientists tell us or what we read in journals. Idso is not infallible and there may well be problems in his study. In fact, I personally can think of several, and John Cross has pointed out of them out a few comments ago. That’s the kind of constructive and intelligent comment that is worthy of discussion. Idso may even made have a very simple error too. But, (a) gbalella provided not supporting evidence or explanation for his extraordinary claim and (b) it seems to me to be prima facae false, at least without any qualifications.
Mr. McIntyre has done a lot of work and double-checking to make sure he has indeed found a problem with MBH98/99/etc. before he criticises them. gballella, on the other hand, just sees something he doesn’t like and shoots his mouth off.
Now if you could point me to where one of these other smart scientists has refuted Idso’s experiments, I’d love to see it. As I said I can think of several problems with his study worthy of discussion. Here’s one to kick it off:
Idso’s various experiments occur on a number of rather different time scales. Some measure temperature changes in response to radiation fluctuations on the order of hours, others days, others months. Yet they all arrive at roughly the same figure. This suggests that any long-term feedbacks are net neutral, because otherwise the figures derived from longer term changes in radiation (e.g. seasonal) would be affected by longer term feedbacks and those measured over the course of hours would not, giving different figures. How do we account for this? Could there be no non-neutral long term feedbacks? Seems unlikely to me.
Another problem I noticed is that the various phenomena that he is measuring the effects of – e.g. dust or solar incidence changes – do not behave quite the same as CO2. For one thing, dust exists in a much smaller slice of the atmosphere than CO2, so it will cause heating differently at different layers, and solar incidence changes affect how much energy enters the top of the atmosphere, not how much reaches the bottom. Those would likely give at least a slightly different result, surely.
See how easy it is to criticise a paper on its scientific basis? Why can’t we discuss the actual science more often?
Re #133: Well, Jeff, check out this. Dr. Dessler might even be willing to answer some of your questions.
Re #127:
1) Follow the citations in the article. See here.
2) Changes in salinity and currents. There are lots of papers on this.
The statement that the greenhouse effect warms the planet by some 33 degrees Celsius has always bothered me. Does anyone have a source that derives this? Maybe it is true but I remember doing basic black body calculations years ago I got results to within a few degrees of what the average temperature of the earth is. I can’t help but wonder if the significance of the greenhouse effect is highly over played on earth.
gbalella, thanks for actually talking about the ideas rather than where they were published. The quotes you have given are all Lean and Rinds statements of the sensitivities “k” used in climate models. We are in agreement about those figures. For actual experimental data, check out figure 16 in the paper. This figure shows that from 1610 to the present, for each 1 watt change in the sun’s output, the summer temperature changed by ~ 0.125°.
Steve Bloom, regarding the water feedback loops, yes, increasing water vapor is in each of the feedback loops. Your point is? … You seem to believe there is some problem with water vapor adding some 24°C or so to the temperature and then reaching equilibrium … what’s the problem with that? This behaviour is actually quite common in heat engines, where a change in say the efficiency of a radiator will increase the output by a certain amount, and then reach a new equilibrium beyond which it will not go.
For a more relevant example, there appears to be a limit on the temperature of the tropical oceans of about 30°C. Why? Because as the water temperature rises, more and more of the incoming radiation is converted to latent heat through evaporation, and less and less into sensibile heat. In addition, the latent heat in the increased evaporation is concentrated in clouds, where it is transported vertically up to ~ 6,000 metres of elevation, far above most of the GHGs, and then radiated directly into space.
When the water vapor condenses into clouds, the clouds shade the area below them, cooling the ocean. The cooled vapor falls as rain, which also cools the ocean below, and the dry air sinks and circulates to take up moisture again. Thus, although there is more water vapor in the air, it is concentrated into a small wet area surrounded by large area of dry air, and it is moved in such a way that it does not always warm the surface, but instead often acts to cool the surface.
Part of the problem that people have in understanding these processes is that they are accustomed to thinking about CO2 or methane, which are well mixed in the atmosphere and don’t change state. Water vapor is very different from other GHGs. It is concentrated, at times in very wet patches and very dry patches, often within a few hundred feet of each other. In addition, it changes state, almost always in a way that acts to cool the earth (rain, snow, hail, dew, frost, clouds, etc.). Thus, increasing water vapor does not always act to warm the earth in any straightforward way.
Regardless of the exact details, however, the fact remains that there is a practical limit on the heating of the tropical oceans, a situation which you seem to think is impossible.
w.
#147 I don’t completely buy your ocean explanation. It sounds very logical and well thought out but if the tropical ocean is kept at a constant temperature by increased evaporation shouldn’t this result in more storms. How come we don’t see evidence of more storms in periods of warmer temperatures.
Re 128 – 129, Hans, thank you for your clear analysis. You are looking at the average emission temperature of the earth as a whole, including the atmosphere, which as you point out is about 235 w/m2, or about -19°C.
However, the sensitivity question is not how much the entire planetary system temperature would change from a 1 watt change in forcing, but how much the surface temperature would change. To calculate this, we have to use the surface temperature, which is about 390 w/m2, or about +15°C. Remember that the forcing is an additional downward radiation directed at the surface, and we are interested in the change at the surface, not at the top of the atmosphere.
The emissivity of the earth’s surface is quite different from the emissivity of the entire planet including the atmosphere and clouds, which as you point out is about 0.63. I used a black body approximation to the earth’s emissivity, that is, an emissivity of 1.
This is actually a good approximation, as the emissivity of the ocean is usually stated as 0.98, well vegetated land is about the same, and bare land about 0.90 – 0.98 depending on the exact wavelength.
For more accuracy, a so-called “gray-body emissivity” of 0.98 is often used as the average planet-wide surface emissivity. However, at the accuracy level I am discussing, the blackbody approximation is quite adequate, leading to an error of only 2%.
All the best to you, thanks for the question,
w.
Re 148, John Creighton, thanks for an interesting question. You say:
Having lived for many years on various islands in the tropical ocean, I can assure you that the hotter it gets, the more storms (usually called “squalls”) there are. This can be seen most clearly on a daily basis. In the morning, the ocean can be bare of clouds. As the day heats up, individual, widely separated squalls start to form. By the afternoon, if it is warm enough, they will form into “squall lines”, which are long rows of individual cumulonimbus squalls, separated by long aerial canyons of clear, dry descending air.
These persist until late afternoon, when, as the solar input drops, the squalls gradually begin to dissipate, and generally vanish around sunset. So you are quite correct, the warmer the ocean, the more the squalls.
Another curiosity about the heating of the tropical ocean is that the warm water doesn’t mix downwards much. Instead, it forms a thin warm layer on the surface during the day, because it is lighter than the colder water below. At times, I have swum in such a layer where when I stroke with my arms, they go down into perceptibly colder water. The fact that the sun is only heating this warm layer is part of the reason that the temperature is limited to around 30°C.
During the night, of course, the surface layer radiates the day’s heat away. There is less water vapor in the air at night (due to less evaporation), so there is less greenhouse effect, and the surface cools quickly. As fast as it cools, however, it sinks, bringing warmer water to the surface to continue to cool … the intricacies of the water cycle on this marvelous planet are endless. The idea that there is some obvious equation like “more water vapor = more greenhouse warming” is absurdly simplistic.
w.
Re #147
And Willis if you look to the units in the y-axis of fig 16 they are in Solar Total Irradiance (STI). Then read the paragraph below the figure (the one I quoted above) and you’ll see the formula to convert that to incident radiation (forcing at the surface). Basically 1 watt/m^2 STI = 0.175 W/M^2 forcing at the surface.
Which gives you a sensitivity of 0.71C per W/M^2. Which means about 2.8C warming for a doubling of CO2….Hummm looks familiar. But certainly not anything familiar to at least the last 5,000 years of the Holocene.
gbalella
How much energy does it take to evaporate water to yield water vapour?
That energy will either warm the air or be lost to uoter space.
How does this energy compare with the amount of energy due to greenhouse warming. It appears that this energy of evaporation is orders of magnitude greater than the radiative greenhouse effect If a small fraction of it warmed the air,it would reduce the warming due to CO2 to zilch.
Re #144: Bloom cites Dessler (appeal to authority). Dessler attempts to discredit Lindzen (ad hominem), pointing out he’s, suspiciously, the only one to get a paper published that argues for negative feedback in water vapour. It is fair to describe Bloom’s argument against negative water vapour feedback as an indirect ad hom.
I’m glad to see the question of water vapour feedback is now being addressed in a substantive way in this thread, thanks largely to Willis’ posts and some relevant responses.
Dessler is free to jump in at any point.
Re: #76
Bloom, your example is 5,8,6,5,6 for the number of storms in five successive years. The mean is 6.0, and the standard deviation is 1.22. If you accept that hurricane occurrence is the part product of a chaotic/random process, then you understand that you could have gotten a different set of hurricane numbers if you “replayed” the earth’s climate a second time, with identical initial conditions. Thus each of the 5 observations is a sample from a hypothetical population of hurricanes that could have been realized (but weren’t). If the hurricane-generating processes are stationary, then the principle of ergodicity allows you to conclude that the mean and standard deviation of those five samples applies to each of the samples. If you plot the annual numbers you get some sense for how noisy the process is. Integrating over increasingly large time-frames reduces that noise, by the central limit thereom (assuming the process remains stationary).
If you plot the data based on “pentads”, the result is going to look less noisy than if you used the annual counts. If you compute your regression trend line based on “pentads”, the result is going to look more significant than if you used the annual counts. Judth Curry does not report the statistics of her category 4+5 hurricane occurence trend line because she ‘doesn’t need to’. She ‘doesn’t need to’ because by integrating across pentads she’s deflated the sampling error on her observations to the point where the trend line has little high-frequency variation in it.
The question is: why did she analyze her data this way, in pentads? It looks suspicious because it allows her to get past peer-review despite leaving out the statistics and the confidence intervals on the regression parameters. It looks like there’s no uncertainty on her trend line (which she doesn’t actually draw in her figure!) … and there is. The question is, how big is this uncertainty? But you look at her paper, and the average reader would never think to ask the question … because the data are presented in a way that suppresses skepticism.
I want to know if this is done intentionally. JMS, for example, is deeply concerned about “intellectual honesty” in climate science. He needs to know the answer to this question.
My point, however, is not about Judith Curry or hurricanes. I mean to ask a broader question. Is there a systematic tendency to suppress uncertainty estimates in documents fed to policy people? Given the desire and effort to formulate a consensus view where there is none, I think this may be the case. (Many of the sources you cite, such as the James Annan blog, agree that there is little or no consensus on the most critical details affecting the magnitude of the CO2 sensitivity coefficient.)
Got it?
bender knows stats and I’m very happy that he’s on the case.
Re #59:
I think that no one knows if it is actually “correct”. But it is a correction method that is widely used, albeit somewhat unquestioningly.
That is a good question. I think not. I think the MA(1) term adds a second order to the autocorrelation structure. I do not think that corrections have been proposed for higher-order AR processes. Obviously the closer the MA(1) term is to zero, the more reasonable the correction. So magnitude matters.
Willis, the question that needs to be answered – and I’m sure the answer is “out there” – is why the MA(1) term is always (-). I’ve asked here if it’s because of framing bias, but I haven’t gotten any feedback yet on that. This matters because framing bias can be corrected, in which case the series could be reconstituted as an AR(1) process. i.e. We need to know if that MA(1)functional or just arithemtical. I can’t answer that because I’m not a climatologist.
Dan, I know enough to get by. But to put it in perspective, I’m very, very far below a guy like Wegman. I am a statistics user, not an innovator. It’s important to know where you sit, otherwise the users get to thinking they’re innovators. (And we’ve all seen the product of that kind of hubris.)
If you accept that 33 C warming is due to the greenhouse effect and the greenhouse downward radiation is 148 W/m2, then you get a climate sensitivity of 0.22 C/W/m2.
Why should the next anthropogenic W/m2 have a sensitivity 3 or 4 times larger than a natural W/m2?
In addition to #114:
The same HadCM3 model significantly ignores any natural cycle (10-100 years), like short-to-long solar cycles, in ocean heat content. See figure S1 of the supporting on-line material of the study by Barnett ea.. Ocean heat content is the major accumulating factor for the radiation balance & resulting climate of the earth…
124: Willis, that was a great post. I will take Idso’s natural experiments and tthese type of analyses anytime over complex computer models, especially when there is no way to check the models.
Incidently, I agree that much of the stability of our climate is due the the unique and “magic” nature of the water molecule. It can be a positive or negative feedback, depending on what is necessary to moderate the climate. Hurray for the Blue Planet!
RE 160 & 161
LOL
RE: #64 – My own inclination is also to view this from a standpoint of filter theory. All them danged geophysics courses and tensors must have gone to me ‘ead!
RE: #80 – Living here in the SF-Oak-SJ metroplex, I am sure Bloom has run into quite a few sci/eng types. Although he was probably a psych major, he may be secretly attracted to sci and eng (and math).
164: Yeah, he’s attracted, because it is his job with the Sierra Club to keep this AGW “crisis” alive. He is apparently not interested in learning anything, just blabbering to make sure some of the visitors here are sufficiently confused and don’t learn anything, either. I’ll bet most, if not all, of the other trolls here (gballea, muirgeo, etc.) are also active members of environmental activist organizations–not just folks that want to learn something.
gballea and muirgeo are one and the same.
153:
Dessler attempts to discredit Lindzen (ad hominem), pointing out he’s, suspiciously, the only one to get a paper published that argues for negative feedback in water vapour.
No.
1. The point is that his is the only argument for a – feedback, and it hasn’t withstood peer review. One of my assertions is the [snip ad hominem] have no testable hypotheses of their own, so they atomistically quibble to stay in play; this is evidence of my assertion.
BTW, note how a commenter below 153 believes that there is a – feedback despite there being no evidence for such.
2. For some reason , most [snip ad hominem] I see on comment threads use ad hom incorrectly. Or not, depending upon the need for rhetorical advantage to maintain viability of worldview.
Anyway, Dessler said:
Hardly ad hom, as Andrew explains why the argument is invalid, rather than ignoring Lindzen’s argument and attacking Lindzen without addressing the argument (_that_ is ad hom).
IOW, if you want to be taken seriously outside of this website, you have to drop the bad habits enumerated above.
HTH,
D
[Dano, if you want be taken seriously at all, drop the Lambertisms]
Dano,
You have quoted Dessler selectively, leaving out the ad hom (a phrase whose defintion I understand perfectly well, thank you). Shall I reproduce it for you, or can we agree you’re wrong, and move on?
Re #167
Here, Dano, is what Dessler wrote:
Ha ha. Dessler is clearly attempting to discredit Lindzen by pointing out that he’s a special case, an outlier that is easily dismissed, given the consensus that exists when he’s excluded. This is a rhetorical trick, designed to bias the reader’s judgement before heading into the more substantive discussion that follows:
The criticism is legitimate, and this is the section from which Dano cites. My point is that this legitimate discussion is prefaced by an ad hom attack. Why?
Is this an egregious ad hom? No, no more so that JMS’s accusation in #8.
Dano/JMS: if you want to set the standard, you’ve got to live by it. Dessler uses both ad hom and legitimate means to make his case. But it’s the ad hom, as a rhetorical device, that is most effective in the public arena.
JMS, what do you make of the “intellectual dishonesty” factor here?
re 128, Doug Hoyt, thanks for your most interesting analysis and question, where you say:
An excellent point. However, a more generally accepted figure for the downward radiation is not 148 w/m2, but on the order of 320 w/m2 (see Earth’s Annual Global Mean Energy Budget, J. T. Kiehl and Kevin E. Trenberth, Bulletin of the American Meteorological Society, Vol. 78, No. 2, February 1997, for the most widely used figures).
Since as you point out this causes some 33° of warming, a first-order estimate of the contribution from radiative IR forcing would be on the order of 33°per 320 w/m2. This, of course, is the same number that was found by the Idso paper, about a tenth of a degree per watt.
You pose a fascinating and very important question, which is, if the addition of 320 w/m2 caused a temperature rise of a tenth of a degree per watt, why should one more additional watt, the 321st, cause a temperature change ten times as large. Perhaps Steve Bloom or gbalella can answer that one … I cannot.
w.
Hmmm. I can’t gainsay that but I don’t recall knowing it. OTOH, I was surprised while looking through my old archives to see only muirgeo in the early years and gballea appearing later. I suppose I should check. Certainly both had the same MO; appeal to authority and lack of science knowledge…
Yep. I was able to confirm that on 11/24/2003 his messages switched from MrMuir to George Ballela on my system when he switched from AOL to sbcglobal.net but the underlying name was still muirgeo. I probably knew that at one time but had forgotten.
I have not read all the posts on this thread, and maybe I’m way out in left field. Are you guys discussing just water vapor and not clouds? Surely nobody would deny that clouds can cause negative feedbacks.
Dave
He revealed that here about 3 weeks ago.
One of the posts on one log-in got caught in Karma, so he came in on the other and said something along the lines of “I’ve been banned I see this as a victory” and signed it as the other log in.
Willis,
You are right. I looked at one of my old papers on the subject and found I calculated it to be 325 W/m2, close to your 320 figure. Thanks for pointing that out.
Per the above comments, my comment #158 should be revised to say:
If you accept that 33 C warming is due to the greenhouse effect and the greenhouse downward radiation is 320 W/m2, then you get a climate sensitivity of 0.103 C/W/m2.
Why should the next anthropogenic W/m2 have a sensitivity that is 6 to 10 times larger than a natural W/m2?
RE: “surely nobody would deny that clouds can cause negative feedbacks.”
And to think that there are some folks out there who call US denialists? Harumph!
Re #176: Steve S., what’s the point of comments like that? In fact, there is absolutely no one who denies that clouds can (and do) cause negative feedbacks. Since you participate on RC, I know you have seen information to that effect.
RE: #177 – But also at RC are folks who either greatly downplay or outright deny clouds being negative feedbacks in all cases. They typically argue “H2O is a greenhouse gas, ergo, clouds are a positive feedback….” Granted they are not the site owners, but are probably non scientifically trained posters from the general public.
#167 Come one, Dano, don’t go there…
Bender has practically buried Bloom and various RealClimate proxy-debaters in sharp and on-spot remarks attacking the science, the whole science, and nothing but the science. Surely he can go slightly of the limp on occasion without discrediting the other points being made. The very fact that you try this pathetic attack indicates that he’s getting under your skin. But I guess we should all feel much more comfortable with Jim 10-years-from-tripping-point Hansen, Stephen we-have-to-offer-up-scary-scenarios Schneider, Bob world-could-heat-11-degree-and-we-have-to-keep-politicians-on-track Spicer, Michael they-just-want-to-find-flaws-in-my-work-waaaa-waaaa Mann, Gavin we-have-a-responsibility-to-future-generations Smith, Ray I’m-an-environmentalist Pierrehumbert, William I-censor-the-living-crap-out-of-Wikipedia Connolly
I’ll chose Steve M, bender, Willis, Jean S, and Erren, over that gang any day. Not because they are better scientist — I couldn’t really tell — but because they come out a lot more credible AND polite. Whenever I debate the credibility of climate scientists, I’ll just redirect people to the original correspondence between Mann and McIntyre, and its game, set, and match. No one outside the closed circles of environmentalism comes out unaffected by that correspondence.
At this point in time and space you have the luxury of arrogance because you have the momentum. Fair enough. Use it. Enjoy it. But for a soft landing, you might start reading up on sunspots, Dano. It’s going to be a killer. And your Lindzen-crackpot-Singer-oil-sucking-stooge line of attack isn’t going to work on CERN and their CLOUD experiment.
Michael Hansen
Willis, where did you get your number of 320 from? In your reference I found a number of 342 W/m2, but this is found from the solar radiation (1367 W/m2) divided by 4.
Anyway, unless you are saying that we are heated only by the greenhouse effect then your estimate of greenhouse enhanced downward radiation is by far too large. If you are saying that we are heated only by the greenhosue effect then you must use the value of 290K, not 33.
John
I think Willis did a great job on this thread explaining the possibilities for moderation/cooling of the climate by water vapor/clouds. Just go out in a thunderstorm. What do you feel. Cold! Where did the heat go? To the upper atmosphere and space! What is happening to the surface temperature? Cooling! Now, don’t tell me that the thunderstorm is not getting rid of heat. The more water vapor, the more thunderstorms (as well as other cloud formations which block the sun). It is 5th grade science! That is exactly why there is no “tipping point,” and why life is possible on Earth.
Re #179
I apologize to Dessler if he took offence at my remark, though I’m not sure he would. I apologize to Steve M’s blog for a 3:45am weakness. My only excuse is that dodginess of that order is infuriating. I was trying to stick to the science, but those incessant dodges … Maybe I need to take up yoga … and think happy thoughts, about the little blue planet, magic water …
RE: #181 – Since great inventions tend to mimic grand nature, it is more than a coincidence that “tower” heat sinks (e.g. ones of circular cross section with fins consisting also of circular shapes, with radii larger than the heat sinks’ cores’) are so similar in function to cumulonimbus clouds having extensive vertical development. I’ve seen some of them penetrating the stratosphere.
Re #175
Douglas imagine an atmosphere with no GHG. I believe at – 18C we would have a snow ball Earth.
Tell me how much water vapor you would have to add to the snowball Earth to warm it 33C to its current 15C?
Answer that correctly and you have the answer to why your’s/Idos’s calculation is RUBBISH!
Bloom and gballea
I’ve posted in this thread hoping to elicit a response.
Does the evaporation of water vapour transfer any heat to the air?
Is the historical evidence of the MWP not overwhelming?
How sure are you that the effects of UHI have been eliminated from the Global temperature record when you accept that stations adjacent to populations of up 10000 are unaffected by it,whereas truly rural stations show a much lower temperature increase.For example the temperatures for stations above 70N show no net warming between the late 30s and the present day.Most of these stations are virtually uninhabited
169:
let us atomistically quibble about this over at Andrew’s site, eh?
Best,
D
Re #180, John, thanks as always for your interesting questions. You ask:
John, take a look at Figure 7 in the Trenberth/Kiehl paper. They show “Back Radiation” (that is, downwelling IR radiation from the “greenhouse effect”) as being 324 w/m2.
Remember, this is only a part of the surface energy balance. There are other inputs and outputs as well, so you can’t figure the surface temperature just from the downwelling IR.
Re# 185
Sure there was a MWP. But the trees coming out of the glaciers are 5,000 or more years old.
Steve has a 99% feeling that there are MWP forest buried under the ice….somewhere. Once those are exposed I’ll be a skeptic too. Otherwise looks like its as warm as it has been in not only 1000 years but in 5,000 years or maybe 50,000 years…and STILLLLL warming.
re 146:
Stefan-Boltzmann:
A = radiating surface
 emission factor ( 100% for blackbody)
emission factor ( 100% for blackbody)
 Re-emission factor ( co-albedo 100% for blackbody)
Re-emission factor ( co-albedo 100% for blackbody)
T emissiontemperature in Kelvin
Incoming radiation (earth is flat disk):

 solar constant
solar constant

where
outgoing radiation (earth is sphere)
Energy balance:
or
Substituting:
 =0.7 (co-albedo)
=0.7 (co-albedo)
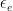 =0.6293 (present day infrared emissivity)
=0.6293 (present day infrared emissivity)
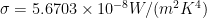
S = 1366 W/m-2
yields
T= 12.942 ºC
yields
T= -18.338 ºC
see also:
http://home.casema.nl/errenwijlens/co2/sb.htm
(modified from http://www.schulphysik.de/solar.html )
met dank aan:
http://www.schulphysik.de/solar.html%5B/quote%5D
Jae, Steve Sadlov:
Thunderstorms are indeed magnificient. The top of the “anvil” that you see at the top of a thunderstorm is actually the level at which buoyant parcels reach equilibrium with the surrounding airmass, which is generally isothermal (in the vertical) at that height (i.e., the tropopause). Some of the higher-end storms will have little “overshooting tops” that can persist (for minutes) above this equilibrium level, but this is usually still within the tropopoause. It is not implausible that a convective element, given enough instability, could make it into the lower stratosphere, but considering the negative lapse rates at that level (i.e., increases in temperature with height), buoyant parcels would run out of energy very quickly. In any case, if you observe the overshooting top phenomenon, just know that you are witnessing an extra-special display of power.
Jae, I am looking for a good diagram of the energy budget of thunderstorms. I have seen them in meteorology textbooks, but all of textbooks are at school. If anyone knows of a good one online, it would certainly be a good tool to use for advancing this discussion. In any case, you say:
It is true that thunderstorms are effective mechanisms for restoring atmospheric stability. That is, they transport the heat from low levels to higher levels, mostly in the troposphere. But to say that the heat went directly into the upper atmosphere and space would be an oversimplification. For one, the cold air is generally drawn down from higher levels by the thunderstorm itself. Secondly, much of the heat that is now missing from the surface was used to energize the thunderstorm itself. Again, an energy budget diagram would be helpful here. I’ll look for one, unless it becomes obvious that nobody cares.
(I notice some tex rendering errors)

Re #178: And they generally get corrected when they say ridiculous things like that, as do you.
A note on negative feedbacks and losses.
The greenhouse effect attempts to further heat the planet beyond the temperature it would have without an atmosphere. If there were no losses, this would result in a very high temperature, far above the current temperature. For a 2 shell greenhouse (the simplest model that can provide enough energy to match the known global energy balance) this would be three times the incoming radiation, or 3 x ~235 w/m2, which is ~705 w/m2 or 63°C (145°F).
Why isn’t the planet that hot? One reason is because the global heat engine we call climate, like all real heat engines, contains losses. None of these losses serve to increase the greenhouse effect, that is thermodynamically impossible.
What are the losses? They fall into three main groups — latent heat losses (through evaporation/condensation), sensible heat losses (by conduction/convection), and hydrometeor losses (from rain, snow, hail, sleet, graupel, etc.).
All of these losses are driven by à⣃ ’ ”¬⟔, the temperature difference between the surface and the upper atmosphere. Without that temperature difference, we would not have any losses. Since the losses are some function of à⣃ ’ ”¬⟔, as the surface temperature increases, so do the losses.
This is why all of the meteorological phenomena, from wind to evaporation to clouds to Hadley cell circulation to hydrometeors and on down the list, cool the earth — because they are parasitic losses to a heat engine, and thus cannot possibly heat the surface. Basic physics, differences in heat (à⣃ ’ ”¬⟔) tend to equalize rather than become more exaggerated.
In fact, the Constructal Law indicates that the system is being driven at something very near its maximum temperature. Natural flow systems, such as the climate heat engine, evolve to maximize the surface of the interface. For a fascinating paper on the subject, see Thermodynamic optimization of global circulation and climate, Adrian Bejan and A. Heitor Reis, Int. J. Energy Res. 2005; 29:303–316, published online in Wiley InterScience (www.interscience.wiley.com). DOI: 10.1002/er.1058
In addition to these losses, however, there is a separate, very powerful feedback system which regulates the amount of incoming solar radiation. This is the albedo feedback, which reflects away solar energy before it ever enters the greenhouse system. Among other things, the albedo is regulated by the amount of snow and clouds, both of which are functions of the amount of water vapor in the air. As an example of the sensitivity of this system, a 1% change in the average planetary albedo is enough to totally cancel out a doubling of CO2.
The net effect of this albedo feedback has to be negative, rather than positive. If it were positive, we would have spiraled long ago into either a frozen or a boiling planet. Since we have not done so, we can conclude that the feedback is negative.
Thus, we have both losses and feedbacks which tend to increase the cooling of the earth when it is hot, and decrease the cooling of the earth when it is cold. This is the reason that, although the theoretical (Stefan-Bolzmann) temperature change from one watt of additional forcing is ~0.18°C, the actual change in the real world must be smaller.
w.
PS – in the longer term, the cloud albedo is also regulated by the solar magnetism/geomagnetism => cosmic ray => cloud formation => changing albedo link. It is this link which is the principal driver of the long term changes in climate. See the October 29, 2005 article regarding the work of Sylvia Duhau at http://www.nuclear.com/environment/climate_policy/default.html for more information on this mechanism.
RE: #190 – No doubt, the mechanical and electrical energy of a thunderstorm help to balance the equation. Net of it is, thunderstorms are nature’s heat sinks, well, at least, are a type of them. Their aspect ratio speaks to their ability to move energy vertically in both directions, thermal energy upward and electrical engergy and mechanical energy bidirectionally. If and only if there is an abnormal amount of warming versus innate levels of expected variation, then I would imagine that the magnitude of these energy flows may also increase abnormally. Does that mean mega hurricanes, superstorms and other fire and brimstone sorts of things? Probably not, as we’re talking about subtle effects integrated over vast volumes.
190:
In any case, if you observe the overshooting top phenomenon, just know that you are witnessing an extra-special display of power.
Indeed. Way back when I was a weatherman, if’n we saw one of these it was immediately reportable, as it was practically guaranteed that any cloud displaying these properties was a hazard to aviation.
Again, an energy budget diagram would be helpful here.
Are you looking for a CAPE diagram/equation, or an optic with, say, a side cutaway view with E at certain points?
Best,
D
Re 190, Kenneth, thank you for your analysis. I look forward to your thunderstorm energy budge.
I agree with you when you say:
It is an oversimplification, but it is also true that thunderstorms greatly increase the IR emissions to space. This can be seen in the IR satellite photos of such storms, where the top of each storm is glowing bright white compared to the surrounding area. This is because the surface heat has been transported (as both latent and sensible heat, as well as heat of condensation) well above the main concentration of GHGs, and thus can emit longwave radiation directly to space.
w.
I just realized that I haven’t thanked bender for answering my questions about the correction of time series statistics for autocorrelation, which was actually the subject of this thread. So, many thanks. I’ll continue to see what I can find on the subject, and perhaps do some monte carlo analyses on ARMA(1,1) random datasets.
w.
Snowball Earth has a surface temperature of -64 C. It absorbs 24 W/m2 of solar radiation at the surface compared to 160 W/m2 at present. The downward IR flux at the surface is about 181 W/m2 in the snowball Earth compared to 320 W/m2 at present. So combined IR and solar absorption at the surface increases by 275 W/m2 and temperature rises about 78 C. So climate sensitivity in that case comes in at about 78/275 = 0.28 C/W/m2 or still much less than IPCC values.
As the temperature rises, one would expect the sensitivity to steadily decrease since gains in absorbed solar radiation from albedo changes disappear, so the value of 0.1 C/W/m2 for present conditions is probably reasonably close to what is happening now.
RE: #196 – Yet another extreme sport (DO…NOT…TRY…THIS…AT…HOME!) – thunderhead soaring! Imagine it, the ultimate thermal!
Passing thought …. looking over the posts on this thread, maybe someday this site will morph into something like “The Virtual International University of Energetics” – 😉
Re #186 Actually, Dano, I would prefer that Bloom not initiate his attacks here, and we just stick to the science. But thanks all the same for the generous invite.
But, hey, Dano, since Bloom has apparently given up on my #3 at RC, maybe you could be a gem and go on over there and help him out with an answer? Or do you accept #154?
Willis,
The “glowing” cloud tops on the IR images are not what you think they are. The bright colors (or bright whites, same thing) indicate colder temperatures associated with the high cloud tops. Independent, high cirrus clouds will often appear very bright too, though there is no convective energy in them. Here is an image scaled with warm=red, cool-blue.
Re #186,
Dano, Dessler asks the wrong questions, as some extra warming may expected from water vapor, but cooling from extra (low level) clouds, depending of the area under consideration. That cloud feedback is one of the weakest points in climate models is proven again and again, as well in the tropics as for the Arctic…
Dano,
Thanks for the skew-T and the eq., though I was thinking of a systematic diagram. E.g., MUCAPE 3000 J/kg at the surface (cinh ~ 0), of which x % goes gets spent on the storm itself, leaving 100-x% for “space” or whatever. I have seen it, maybe in one of Roland Stull’s books, and it is certainly more complex than what I just explained, but it does exist. That last option you gave may be what I’m trying to describe.
Thanks.
199
Steve S – I remember reading a LONG time back (in my teens – a VERY long time – meaning my memory of it or any skeptical analysis while reading it is likely not very reliable) about a military pilot who ejected into a thunderstorm, and was cycled up and down over several tens of thosuands of feet a couple times before he finally fell out of the storm.
re 169 and related:
did a quick search on the Web of Science and found out these statistics:
I should not that in my reply to Willis, the first image gives positive values for bright colors. That is the pixel brightness index, and you need to use their simple equation to get the actual temperature from there.
The second is a temperature scale (C), but it would be nice if they said so and used legible type.
And my last comment should say “note,” rather than “not.” Sors.
re 182, Bender: You don’t find any better magic in this world.
A question: does anyone know if the amount of longwave radiation leaving an area typically decreases at late night?
The reason I ask is that in many areas the overnight temperature is determined by the dew point. At night, as the dewpoint is approached, the sensible temperature stops falling and dew/fog form. The dew/fog slows/stops the earth from radiating heat into space.
If the earth were warmer due to GHGs, then it seems like it would take a little longer at night to approach the dew point, but in the end, we still get to the same temperature.
Agreed, there would be less dew/fog to burn off (absorb heat) in the morning, but dew tends to be absorbed by leaves and I wonder if light fog is easily burned off by much less solar raditaion than the fog blocked that night (a guess). On balance, the late night water vapor effects (dew/fog) may create a sort of reserve of heat removal capacity: a negative feedback mechanism.
Santer et al (JGR 2000) state:
Bartlett is a famous statistician, although 1935 was early in his career, and one would like to see a more up-to-date statistical authority. Bartlett 1935 does not support the citation and arguably says the opposite:
So I guess the authority for this procedure is a WMO technical report.
I find this one always very instructive:
sun in Halpha

and earth in inverse ir

look in both images at the low emitting cool clouds.
Re # 198
Except for the inconvenient fact that we’ve had about a 0.8C increase in measured temperatures with NO evidence for a forcing on the order of 8 W/m2. The real time data from the current experiment we are doing on the Earth kinda supersedes your spurious calculations that can likewise find NO support in the peer reviewed literature.
Where oh where can 8 watts of forcing be hiding?
196:
This [whiteness on IR sat fotos] is because the surface heat has been transported (as both latent and sensible heat, as well as heat of condensation)
No.
If you look at the key for any sat piccie, you can see the brightest white = coolest temps.
Unless you mean all the latent/sensible heat has been transported away and it is now cold [expressed as white on an IR satpic] as a result, then yes. Otherwise, no.
HTH.
———-
201:
maybe you could be a gem and go on over there and help him out with an answer? Or do you accept #154
I take your premise to be the author chose the filter with some purpose in mind. I don’t see how anyone’s contribution but the author’s matters.
HTH.
———-
203:
Dessler asks the wrong questions, as some extra warming may expected from water vapor {etc}
No.
WV influences heat when uncondensed. You’ll also recall that incrd cloud cover warms the surface (Venus being real cloudy-like).
———-
206:
Look at all of these studies of cloud effects.
[/ignore]
Sigh…the topic is WV. WV. WV. Not clouds (which are a subset of WV). Your hint is the search term “water vapor feedback “. The search term was not “clouds”
WV. Not clouds.
HTH.
[ignore]
==========
Best,
D
Re 213, muirgeo, under your other sock puppet name of gbalella, you tried this exact same question earlier, in post #73.
It was answered, clearly and in detail, in posts number 74, 77, and 81. Somehow, you neglected to reply to these …
Asked and answered. Do you find this interesting? You’re destroying your own credibility. Go away.
w.
213: A lot of them are “hiding” in erroneous surface air temperature measurements. But we don’t get to look at how they are derived, do we?
Re # 187
Thanks for your reply Willis (although I take it that my comment on Idso’s paper was not all that interesting 😉 )
I admit that I have no idea where the 320 W/m2 comes from! However I refer you to the text on page 202 where they talk about the 125 W/m2 clear sky greenhouse effect.
Regards,
John
I found the following reference to Nychka et al 2000 (unpublished) here:
210:
does anyone know if the amount of longwave radiation leaving an area typically decreases at late night?
Yes [1.]
Best,
D
214. Err, clouds are feedback to water vapor. You can’t really discuss one without the other in any meaningful way. Also, clouds only DECREASE THE RATE OF COOLING (they don’t cause warming) at night; they cause cooling during the day.
Dano and Kenneth, you are correct. My error on the white showing the most intense infrared emission, as you point out, it does not.
However, my point still stands — thunderstorms shift the emitting regions up high in the atmosphere, above the majority of the GHGs. This allows them to radiate directly to space.
In support of this, take a look at Wisconsin HIRS 6.5 Year Cloud Climatology which says in part:
This is my contention, which I believe to be true, that part of the effect of a thunderstorm is to move heat vertically where it can radiate more easily directly to space.
w.
RE: #221 – Simply put, a thunderstorm is a miniature version of the Hadley Cell, or of a convection cell in a molten or liquid medium. It is vertical heat flow upward and descending cooled air downward. It is nature’s swamp cooler.
I might add, “warmers” like to argue that thunderheads are simply small features that help to “feed” poleward transfer. No doubt, that is partially true, but I also have to concur with Willis that once you have moved the thermal energy up to 40K feet in the atmosphere, there is not much keeping it from getting out entirely. Yes of course the lapse rate reverses in the Stratosphere, but we are talking about miniscule amounts of matter in the column above versus below. Its potential to insulate the thermal energy is not perfect. Therefore, while some of the thermal energy will end up pole ward, not all of it will. Yet another great topic for the budding PhD.
RE #219 Dano, thanks!!! First time I’ve seen that.
What’s the source? It’s be great to find similar plots for other locations.
Re #217, John Cross, my apologies for not answering your question. You say:
which I assume refers to:
As Idso points out,
Since all of those good folks assume that the laws of physics operate the same way on the other planets as on ours, and because it makes sense to me as well, it does not strike me as improbable that the sensitivites would be similar on any planet with a CO2 atmosphere. In any case, it appears from Idso’s calculation that they are similar, so unless you can find a problem with the calculations …
w.
PS – I do not find that he calls the result “identical” to his other results. Having said that, this has always struck me as the weakest of the ten arguments … which doesn’t make it wrong. For more on the subject, see this link.
Re 218, Steve M., many thanks for the research. It appears that the situation is even worse than we thought …
w.
RE 213 “Where is the 8 watts hiding? More accurately you mean 6 watts. It could easily be in unforced variation in cloud cover as reported in a number of papers. Michaels gives a summary at http://www.worldclimatereport.com/index.php/2005/05/10/global-warming-something-new-under-the-sun/
Probably you won’t like the source, but you can always read the original papers. 5.61 W/mw is close to 6 W/m2 and it only covers a few years.
Other possibilities include poor surface temperature measurements, solar forcing, regional land use changes, cosmic rays, etc.
224:
Here.
Best,
D
#61 Use of an AR(1) model to establish trend significance seems inconsistent with what we know about climate variability. For example, Koutsoyiannis (here) argues persuasively that
Along these lines, Cohn and Lins (here), considers the type I and type II error rates for trend tests. It is found that trend tests that fail to consider scaling behavior when it is present will generally overstate trend significance. Moreover, tests that can accommodate the possibility of scaling behavior are almost as powerful as the traditional tests if no scaling behavior is present.
RE 225: Willis:
I think that he calls it pretty close to identical. In method 7 he says:
In regards to the feedbacks, I remain unconvinced. I have not read the NRC reports but I do not think they assume the feedbacks are the same. I believe that the continents on Venus are in different positions and I understand that Martian oceans are smaller than Earth’s.
Goodnight.
John
I think Danoboy protests too much. Tree ring studies are now a proven joke, so he quit defending them. Branching out into fields he knows nothing about, with his characteristic arrogance. He’s now taking the methodology of Bloom, with all the simple little linkies. (ad hom meant) LOL.
John, thanks for your comments in 230. I see that you are unconvinced about the feedbacks. However, that does not change the issue of whether the actual numbers and calculations are correct.
Also, the details of the feedbacks may not be issue. The Constructal Law indicates that all three planets will be in a similar state of optimal turbulence, which may be more important in terms of their reaction to a change in forcing than the details of the actual feedbacks involved.
w.
Re 231, hey, Danàƒⶠactually sent some information in response to a request, with no side comments or anything, I thought that was good … and surprising … so let’s cut some slack here.
w.
Re #201: Actually, Bender, I went back and looked over the whole interchange, but just hadn’t gotten around to writing up the embarrassing (for you) results. For starters, go back and have a look at that first comment you made over at RC. You screwed up at the very start by conflating pentads with a running average. Even I, with no statistics background whatsoever, know better than that. Time to turn in your statistics merit badge, yes?
But just for fun, and thanking you again for your forbearance given my lack of a statistics background, answer me this: Hold up your two hands in front of your face. Count the fingers. Get a couple hundred people together and have them count them, too. Everybody gets ten, right? (Of course we assume your past doesn’t include any birth defects, digital accidents, etc.) Now, as a purely technical exercise, what’s the sample error? This is the same sense in which there is no error in the hurricane count during the peiod of comprehensive satellite coverage. Much like fingers held in front of your face, they’re a little hard to miss.
After your answer, we’ll talk about the TC satellite record as it pertains to Figure 1 in Curry et al.
BTW, I should add that of course I realize that use of pentads or a running average could (and does in this case) hide subtleies in trends. But in the instance under discussion, the difference shown (the large low frequency trend) is so blatant that worrying about a relatively slight statistical uncertainty is pointless. As you admitted at the outset, the difference is so large that the graph isn’t capable of hiding anything meaningful. (Also, to the extent there are higher frequency trends of interest, they’re going to be within individual basins. Lumping things together globally means losing all of that at the outset.)
Note that none the attacks on the Webster et al work are being made on the basis that the representation of the trend is somehow invalid, but instead have entirely to do with whether the hurricanes have been properly counted as to intensity category.
Oh, and regarding your #154:
“If you accept that hurricane occurrence is the part product of a chaotic/random process, then you understand that you could have gotten a different set of hurricane numbers if you “replayed” the earth’s climate a second time, with identical initial conditions.” Well, no, not if what you’re interested in is trends in actual past behavior. But very much yes if you’re interested in hindcasting to validate your hurricane prediction model.
Re #324 Yes, I admit that I made the first part of that post very hastily (never a good idea) and incorrectly described that data manipulation in RC#3 as a moving average. I corrected myself withing 5 minutes however (at CA), you will note. If you’d like to gloat, go ahead. Minor errors don’t bother me when I can catch them before anyone else does. (Changing the phrase doesn’t change the argument in this case.)
If you do not understand in what sense a hurricane count is a sample realization of a stochastic process, then that may explain alot about the problem warmers have in determining whether or not one trend is significantly different from another trend.
Bloom, I don’t want to argue with you. I was just trying to keep you busy with something I thought you needed to understand. If you want to believe that hurricane counts are free of sampling error, you go right ahead.
Tell you what, you get Judith Curry’s raw data, and I’ll produce the correct graph for you, showing you exactly what the problem is with her presentation and analysis. It’s relevant because it’s the same problem with MBH98 that got us into this mess. Some people haven’t learned a thing.
233:
Danàƒⶠactually sent some information in response to a request, with no side comments or anything
In response to customer feedback, occasionally I’m cutting down on side comments for which readers may not understand the context** (still, here, I put them in titles to mouseover on HTML linkies, and I could be doubly insufferable if’n I take the time to look into that latexrender feature). :o)
Best,
D
**Not intended toward David, BTW.
Bloom, the reason the number of fingers on your hand is not subject to sampling error is because you’re only born once, so your sample size is one and there is no underlying stochastic process to sample from in order to obtain multiple realizations. The number of fingers on the human hand in general IS a random variable, but its variance is very low because of strong genetic determinism. The number on a given hand is fixed, which is not at all like stochastic dynamic systems. With hurricane frequency one is trying to make inferences about a trend over time. What would be the comparable inference you would be trying to make in your example? I think your example is nonsensical. I’d be willing to try another one though, if you’re serious about wanting to udnerstand this important concept.
You’re feeding the bears in a national forest, bender. If Bloom were interested in learning, he would.
Mark
Re #238 Maybe you’re right, Mark. It’s just hard for me to imagine. The guy is obviously bright enough to understand it. I can’t tell if he really doesn’t get it, or if he is just trying to play games with me to waste my time. I should just move on.
I just can’t imagine going through life not understanding what sampling error and random variables are. The number of hurricanes in a season is no different from the number of ducks on a pond on a given day or the number of hikers you encounter along a hiking trail. The larger the pond, the longer the trail, the more observations you have and the lower the sampling error. It’s Stats 101 … with a small twist in the repeated measures/time-series context.
Point is: if hurricane frequency is subject to error, then where the heck are Judith Curry’s Fig. 1 regression statistics and error bars? To exclude them is, well, funny (in that RC sort of way). And why did she sum the data over five-year intervals? To improve the optice?
These are fair questions. IMO a reviewer slipped up on this one.
P.S. I make mistakes all the time in my daily work. But thankfully I catch most of them before they go to print. I think making mistakes is one of the best ways to learn. The trick is to admit your mistakes and commit yourself to improvement. I guess that’s the difference between being a good scientist and being a good debater.
Does anyone have a physical explanation for the negative first-order moving-average term that tends to crop up in these temperature time-series? I think this is an important question.
Bender, my first guess would be that in general these series are “anomalies” which have had the monthly averages subtracted from the data … but I haven’t had time to test this hypothesis.
w.
Re #234
Bloom, I recall making another error as well, by the way. When I first started complaining about the Judith Curry Figure 1 (after Sadlov’s announcement) I erroneously started talking about temperature rather than hurricane frequency. This was a reflex reaction, caused by the fact that I had been working alot lately with moving average models of temperature data, and had that phrase stuck in my mind.
Re 227
We observed an overall increase in S (solar radiation at Earth’s surface) from 1983 to 2001 at a rate of 0.16 watts per square meter (0.10%) per year; err uh…Pinker et al
Mr Hoyt you are not even worth my time. What is it about fellas like yourself that you hate the idea of anthropogenic climate change so much that you are capable of making such stuff up and either lying to yourself or others to defend a position with is clearly indefensible….. Jeez…do you actually believe yourself when you say 6 W of energy is hiding in unforced cloud cover variation?….in changes in cosmic radiation?…Really why didn’t you just include invisible flying pink elephants?
Re 241, bender, you asked:
I said:
This turns out to be the case. I just looked at the HadCRUT3 actual monthly temperature averages, 1850-2006. This gave the following statistics:
Coefficients:
_______ar1_____ma1___intercept
_____0.8256___0.7156___14.9545
s.e.___0.0132___0.0121___0.1000
Then I looked at the anomaly record, that is, the same data with the monthly average temperatures removed. The statistics for the anomalies were:
_______ar1_____ma1___intercept
_____ 0.9755___-0.5260___-0.1756
s.e.___0.0059___0.0271___0.0534
Note the negative ma1 term in the anomaly dataset …
w.
I make mistakes myself, regularly. The nice thing about working for a commercial entity, however, is that you often have people checking your work in detail before a mistake has time to really make a difference. I’d estimate I’ve been through peer review nearly 100 times in an 11 year career, plus whatever I went through in school (not much other than my thesis, btw). Peer review in the defense industry, at the technical level, can often be humiliating.
Unfortunately, I now find myself in a situation where the closest thing I have to “peers,” are the folks that understand what ergodic means on this website. Well, here and my advisor, who’s not a slouch by any means. 🙂 Not that I’m dissing anyone here, it’s just that it would be nice to have a colleague or two that can at least pretend (I work with several software/linux engineers, but they don’t have much background in DSP)… Hehe. I guess that just means I have to be extra careful any time I say something as an authority (like an upcoming conference presentation that none of my co-workers will review… sigh).
Mark
You really need to get off your high horse. 0.16 W/sq. meter per year works out to 2.88 W/sq. meter over 18 years from 1983 to 2001 (Hoyt said 2.7, but probably only counted 17 years). He said nothing about “per year” only total… If you paid attention and stopped slinging so much mud, you might not look like such an imbecile when you make such an obvious mistake.
I think you owe Mr. Hoyt a serious apology, not that it will help your credibility any.
Mark
Re 243, gbalella/muirgeo, I don’t understand what you mean. You say:
What is your point here, gb/muir? What do you think Doug Hoyt made up? By my calculations, Pinker et al. said there was an increase of +0.16 w/m2 each year during an 18 year period … which works out to a total increase of 2.88 W/m2, slightly larger than the figure quoted by Mr. Hoyt, who gave a conservative number.
Where is the error here?
w.
PS – I repeat, raving about pink flying elephants only makes you sound like you’re in grade school …
PPS – Let me quote again what Nicholas said above:
If you think Doug Hoyt is wrong, a far better course for you to take would be to say “Doug, aren’t you wrong about the 2.7 w/m2? Seems to me that Pinker et al. said it was only 0.16 w/m2.” Then you wouldn’t look like such an idiot when you turn out to be way off the rails. Me, I’m wrong far more often than I’d like, so I prefer to post my objections in some gentler form … it makes my words that much more palatable when I’m forced to eat them …
Re #242: Yes, mistakes were made.
Re #239: Here’s the data. I understand working with it is a little time-consuming.
Re #248
You mean, like this one?
#232: Willis
When I say I remain unconvinced that means that as far as I can see and in terms of what has been presented to me here Idso’s numbers do not add up! The Constructal hypothesis may apply but that does not change the fact that there is very little water vapor on Mars. Other conversations on this thread are discussing the importance of clouds and thunderstorms. Are you now saying that these aren’t important?
Regards,
John
In terms of the impact of CO2 as a greenhouse gas, we actually have three real-world examples that could be compared, Venus, Earth and Mars.
Venus – CO2 content 98% (no other significant GHGs) – Atmosphere Mass 91 times Earth – Surface Temp. 464 C – Solar Irradiance 2614 w/m2
Earth – CO2 content 0.03% – Surface Temp 15 C – Solar Irradiance 1367 w/m2
Mars – CO2 content 95% (no other significant GHGs)- Atmosphere Mass 0.008 times Earth – Surface Temp. -64 C – Solar Irradiance 589 w/m2
Maybe someone can crunch a few numbers and see how CO2 content compares to temperature in the real world examples we have.
Re #248
Bloom, the ‘mistakes’ were trivial, totally inconsequential to the argument. The questions remain: Why did Curry use pentads? Why did she not publish confidence intervals, trend lines, and regression statistics? Is there a systematic tendency to oversimplify the uncertainty issue in material fed to climate policy makers? I know the answers, my friend. Why don’t you tell me what you think the answers are?
Bloom, that’s a website full of datafiles, not a datafile. Tell me which datafile she used and I’ll have your answer for you in 30 minutes.
bender,
From the context of his messages (which were painful to read), it’s obvious that Steve Bloom was applying the common definition of “error”, as in “to make a mistake”. So he thought that you were claiming that the number of storms for each year was being miscounted or something. He is really talking about measurement accuracy, and did not realize that statisticians have a different meaning for the word “error”. Given this gulf between the two of you on the statistics of time-series analysis, I don’t think you can have a meaningful debate on the subject at hand.
RE: “Everybody gets ten, right?”
Mr. Bloom, you have apparently never been exposed to a Measurement System Analysis (MSA) aka “Gage R & R” before. That may be a seemingly compelling assumption for a simple finger counting exercise. However, let me up the ante a bit. Let us repeat the experiment but a bit differently. Instead of counting fingers, let’s give 100 people a caliper and ask them to measure the width of a metal part. In fact, let’s add the following little twist. We won’t give one caliper for 100 people to share, but instead, each one will have their own caliper. Now, with that in mind, go and google on “Six Sigma” and do a bit of reading on some of those sites. Regards …
bender,
I think you want the two track files at the top of the page, one is for the Pacific and one for the Atlantic. There is a link to a readme file that explains the record formats. I think you just want to pick off the ‘A’ type records since they contain all the information you need. The rest are locations of the storm as it was tracked (record type ‘B’) and the final disposition (landfall info) in record type ‘C’. As far as I can tell you have one ‘A’ type record for each storm, followed by multiple ‘B’ type records, followed by a single ‘C’ type record.
Paul,
I think you are right. But this is why I’m pursuing this so vigorously: I think there are alot of people, not just Bloom – even specialists in the field – who do not understand some basic things about how to make inferences in regards to stochastic dynamics time-series. They do not understand how awfully constraining that damned uncertainty really is.
I apologize if the exchange has been painful. But I think we’re getting somewhere finally. At least now he’s interested in seeing what Judith Curry’s data look like when analysed and presented properly. Let’s do a psychology experiment where I post her graph and my graph side by side, and we get policy people to tell us which of the two they would prefer to act on, the one with uncertainty suppressed (hers), or the one with uncertainty expressed (mine).
The problem is that he’s debating this with an arrogance that presumes bender does not know what he’s talking about. bender has, thoughtfully, attempted to explain the concept, to no avail. Given that these topics almost all revolve around statistical inferences and methods, it should be a given that one not trained would at least debate with a “teach me” attitude rather than a “you’re wrong” attitude. This is one of the fundamental problems in climate science today: those using these statistical methods refuse to understand/learn why they are using them incorrectly and why their conclusions are therefore either suspect, or wrong.
Hehe, the understatement of the century. 🙂
Mark
bender, paul, Mark, SteveS, Willis, etc.: The extremely arrogant attitudes of Bloom and Dano convince me that they do not WANT to learn anything. They are propagandists, not scientists (especially Sierra Club Bloom). You are probably wasting your time arguing with them, if you think you will change them. However, I think your discussions are VERY valuable to many others (me, for sure). I am learning a lot from them.
I agree this is a problem. Perhaps THE problem!
I’m not sure, but I think there’s a certain arrogance factor on the part of people who are smart enough to get the software to run (and they’re pretty smart, mind you), but aren’t smart enough to know when what the software is calculating is meaningless.
I can say this because I’ve been there myself. The difference is that I use Feynman as my reality check. “Have I merely fooled my computer into telling me what I want to hear in order to believe my pet hypothesis? How could I disprove what I’ve just ‘proven’?”
Re #255
Thanks, Paul. Looking at that file I see this is pretty raw stuff. I don’t have time for data pre-processing. Bloom can do penance by assembling the annual time-series for me and posting them. Bloom, that’s a single vector of 31 numbers (2004-1974) of hurricane counts in the Atlantic basin. If you want to get fancy, post three vectors, one each for cat 3/4/5 storms. We’ll do the psychology experiment described in #256 and publish the result as a reply to Curry in BAMS, Bender & Bloom. What do you say?
RE: #258 – jae, I deal with a lot of this in my day job, so it comes fairly naturally. Famous last words “well we qualified 3 of them and they met spec – ship it!”
I can never resist a teaching moment, even with a tough couple of folks like Bloom and Dano.
RE: #260 – it would be of great interest to me to know which storms were at or near a boundary between categories and if so, just how far were they from the boundary, how long were they on which side of the boundary / near it, measured, how, etc.
If you want to be a good propagandist, if you want to save the planet, you need to pay attention when someone who understands something about time-series analysis is talking.
Re #262 – that file pointed to by #248 & #255 seems to have it all. A sensitivity analysis would take very little additional time.
263. LOL. The problem is that these folks are afraid of the truth, since it might damage their egos and their paychecks. I think they are both smart enough to know that you have valid statistical issues; but they do not want to face them head-on. People interested in the truth simply do not act that arrogant.
I’m paying attention to what gets said as best I can. As noted in other posts, I don’t have a lot of “peer” interaction at work so I need outside opinions/comments regarding the basis of my work (I am currently implementing a PCA-based noise reduction method known as the Generalized Sidelobe Canceller using Modified Gram-Schmidt Orthogonalization). The comments in here by the likes of bender, Jean S., Steve M., et. al. are beneficial to my understanding of the other side of the fence (beyond signal processing). Much of this applies to my own needs (career and education), and missing such discussions would be a detriment to my own ability to be a user and/or innovator.
In short, your teachings are not all lost on deaf ears as not everything you (bender) have discussed is part of the standard signal processing view/teachings of statistics and related methods! 🙂
Mark
Re #264
Wow – afraid of the truth?! I’ve heard those kinds of people exist – and I’ve seen them on TV – but I’ve never met any before. What scares ME is ignorance & lies.
221:
This is my contention, which I believe to be true, that part of the effect of a thunderstorm is to move heat vertically where it can radiate more easily directly to space.
Yes.
The issue, however, is whether this transport is greater than the increased forcing from the additional CO2 in the atm. IIRC, there is empirical evidence for increased forcing by CO2 (expressed as an increase in W/m^2 at the sfc). I haven’t seen modeling evidence or data which say that tstms can potentially transport more heat than the increased forcing.
Perhaps, willis, you have read some papers that I have not and can share.
Best,
D
In some instances, I think arrogance is blinding the ability to see that a valid issue(s) has (have) been raised. Whether or not such ideological views lend themselves to being “smart enough to know” is debatable.
I think my evidence of this, btw, is rooted in JMS’ repeated request to Steve M. to do his own reconstruction with an unmodified procedure and “better data.” In science, falsification does not work that way. It is enough that Steve M. has shown the methods (and data) to be flawed. The onus is on the climate community to either a) revise their conclusions or b) prove otherwise. Instead, they simply attack Steve M. and Ross (“those two Canadians” and “those two economists”), do a bunch of hand-waving, and then “move on” (with yet another flawed method using the same flawed data no less).
Mark
This is true, and it has been pointed out several times before in various threads. The alarmists may not understand this, or may be in denial as to where the burden of evidence lies, but I can almost guarantee that the peers of the MBHs of the world very much understand it in exactly this way.
Go ahead, now, Dano, JMS, etc. Say it isn’t so. The fact is, Wegman turned the table. You just don’t know it yet because you’re too far removed from the core.
Danàƒⶬ thanks for your question in 267. You ask:
This is my contention, which I believe to be true, that part of the effect of a thunderstorm is to move heat vertically where it can radiate more easily directly to space.
Yes.
The issue, however, is whether this transport is greater than the increased forcing from the additional CO2 in the atm. IIRC, there is empirical evidence for increased forcing by CO2 (expressed as an increase in W/m^2 at the sfc). I haven’t seen modeling evidence or data which say that tstms can potentially transport more heat than the increased forcing.
Perhaps, willis, you have read some papers that I have not and can share.
Best,
D
Grrr … pushed the wrong button too fast, and couldn’t get it back … more to come …
w.
Yes, it works this way in every other scientific facet of life. My numerous design reviews, btw, have often resulted in simple little questions akin to “why did you do this, wouldn’t this be better?” or “I think this is incorrect, find out for me” which often results in many hours/days of work dedicated to either a) finding proof that I was right in the first place (happens sometimes) or b) a revision in what I had done in the first place (most common). In either case, the onus was on ME to prove one way or another, and without it, the design does not proceed to the next milestone (in a worst case scenario, people lose jobs for failure to comply).
Mark
269:
You just don’t know it yet because you’re too far removed from the core.
It’s enjoyable for me to watch, on this site, how premises are constructed, then how conclusions follow from them, and finally how contagion and dispersal occur. Fascinating, too, the frameworks used and the meanings that arise from them.
Others see this as well, but perhaps they don’t obtain the same enjoyment and fascination from the show that I do.
Best,
D
273: Is it a false premise?
Unfortunately, your “false premise” assertion is false by itself. The flaws in the statistical methods and data have been shown to be true. Nobody has been able to show otherwise and despite pleas from such as yourself, Michael Mann’s assertion that “it doesn’t matter” does not constitute proof of the contrary.
You should read your own words and compare them to reality once in a while.
Mark
re: #274,
What Dano is missing is the ability to introspect. If he did have it, he’d be able to apply what he observes here to what has happened in the climate science world and start to wonder if perhaps his own world-view was subject to the same dynamics.
Now there’s a sense in which what he’s intending as a knock on CA is true and universal. Indeed, I think that’s what Wegman was pointing to in his analysis of the interconnections among the paleoclimate reconstruction community. Of course one thing which Dano misses here is the tendency of the “center”, i.e. Steve M, not to be able to control the community he’s built up except via fairly heavy-handed methods (and I’m not referring to stopping trolling or insult-mongering, but actually getting people to concentrate solely on the particular items Steve is most interested in). Now Steve has kept out thermodynamics and theology fairly well, though I’d be happy to discuss either, but SSTs, UHI, Hurricanes and icecaps have forced their way in to the point Steve has had to start paying attention to them. And I might add that bringing up Wahl’s religious interest isn’t the best way to keep religion out of the threads either.
OH, and for that matter, there were the couple of threads on the theory that the climate system tends to maximize entropy increase, which Steve started, though perhaps for his own purposes rather than to start discussions on thermodynamics.
Re #262: And there we are. There is a very real uncertainty issue (as discussed in the paper), it’s just not the one that bender chooses to focus on. bender also illustrates nicely the assumption made by many of the regulars here that a good understanding of statistical techniques combined with nearly no understanding of the behavior of the physical quantity being measured can allow one to successfully critique the work of those who do have that understanding.
I will repeat that even though Figure 1 from the BAMS study was published nearly a year ago, there has been absolutely no criticism of it (as a means of presenting the low frequency signal that was found) from Chris Landsea, Pat Michaels or anyone else on the other side of the debate. Why? Because they know there is no high frequency information that is obtainable from a global data set of maximum wind speeds that has lost all basin-specific information. (Wouldn’t it even be misleading to purport to directly apply statistical validity tests to data presented in that way? It might be possible to get a result, but could it mean anything?) This is a mode of presenting the data that would be used only if one had found a low frequency signal and wanted to present it in a clear way. Any criticism of the results will need to be basin-specific or storm-specific. Everyone in the hurricane biz understands that perfectly.
Let’s turn this around. Assume that the apparent low frequency signal was much more subtle (remembering that Webster et al found a *doubling* of strong cyclones over the study period). Would the data as presented in Figure 1 be usable? No, and presenting the data on an annual basis wouldn’t fix the problem. To get at a subtle signal, you’d want to go back to look at trends in the individual basins. Even with the apparent large signal, such an analysis would allow one to make sure that there wasn’t some coincidental combination of different basin-specific factors that were somehow combining to make a spurious global signal. In fact, if I were the Webster team that’s the very next thing I would have done!
Re #266: I’m scared by lies too. Remember what they say about statistics taken out of context.
Re #269: bender, I thought you were properly suspicious of global warming alarmists? Why then do you believe anything Wegman has to say?
bender said in #239,
“I just can’t imagine going through life not understanding what sampling error and random variables are.”
As a lurking non-scientist and non-statistician who still finds this site fascinating, I can assure you it is possible to live a fulfilling and happy life not knowing the first thing about either one.:)
Danàƒⶬ thanks for your posting # 267. You ask:
A very interesting question, Danàƒⶬ and one we can answer without consulting a study. Here’s some thoughts on the matter:
1. Everyone agrees that to date, some 340 w/m2 of radiation forcing have raised the earth’s temperature by about 33°C. This gives what I would consider to be the most unassailable evidence that climate has an overall sensitivity of about a tenth of a degree C per watt/m2. By overall I mean the average sensitivity from the time when the earth was a bare ball with no greenhouse effect, to the current atmosphere containing the GHGs such as CO2, methane, water vapor, etc.
2. However, the current sensitivity is likely to be less than that. In a real-world heat engine such as the climate, losses as a percentage of ‘ˆ’€ T always increase with ‘ˆ’€ T. This implies that the current sensitivity must be less than the overall sensitivity, since ‘ˆ’€ T started at zero and is now around 33°C. It also implies that if the earth warms slightly, the sensitivity will decrease commensurately, although this change is likely to be small.
3. Heat losses, such as those in the vertical transport of heat thunderstorms, can never remove more heat than is added. They are parasitic losses driven by ‘ˆ’€ T, and thus cannot exceed the amount of extra added heat.
Therefore, my first conclusions would be:
a) The amount of temperature change from the “increased forcing from the additional CO2” is going to be very small (something less than 0.4W/m2 from a doubling).
b) Part of the reason that it will be that small is because of existing parasitic heat losses, such as those from thunderstorms.
c) To directly answer your question, this thunderstorm heat loss will be less than the added forcing.
Now, a digression here. The amount of “excess” (above pre-industrial levels) carbon sequestered from the atmosphere annually can be estimated very accurately (r^2 = .992) by assuming that the sequestration follows a pattern of exponential decay. It turns out that the globe sequesters about 3.4% of the “excess” (above pre-industrial levels) atmospheric carbon annually. In other words, as we would expect from say Le Chateleir’s Principle, the more “excess” CO2 in the air, the more (absolutely) is sequestered.
A consequence of this which is not generally appreciated is that if emissions stabilize, at some point the amount sequestered will equal the amount emitted, and the atmospheric CO2 level will also stabilize. If, for example, we were magically able to stabilize the emissions at the 2000 rate (about 8.7 GtC, including both fossil and landuse), the atmosphere would stabilize at only about 406 ppm.
A second underappreciated consequence is that, since sequestration increases with increasing atmospheric excess, it will take a long time to get to a doubling of CO2. Using the IPCC “business as usual” assumption that the emissions will continue to increase at about a percent per year, we find that we will reach a doubling of current atmospheric levels (2 x ~380 ppm = ~ 720 ppm) around the year 2160 … but reaching the doubling even that soon is doubtful for a couple reasons.
One is that by then other energy sources will be in play. The other is that the assumption of 1% growth per year is not really business as usual. The emission growth rate peaked in about 1950 at about 4%, and has been dropping steadily ever since. The 1990-2000 average growth in emissions was only 0.6%.
So it is extremely unlikely that the world will see double the current levels of CO2 in the near future. To see a doubling by the year 2100, for example, would require an annual growth in emissions of 1.8% per year, about three times the current growth rate. This kind of large, sustained, long-term exponential growth is extremely unlikely.
How much CO2 warming are we likely to see from this increase in the course of the century? Well, we can put some constraints on it. An unlikely bottom end would be emissions stabilizing at the current rate, or 405 ppm by 2100. An equally unlikely high end would be an increase to a 1% growth in emissions, maintained for the entire century, leading to 540 ppm by 2100. Using a maximum climate sensitivity figure of a tenth of a degree per watt, this gives us 3.7 * log2(405/380) * 0.1 = 0.03°C for the low end estimate, and 3.7 * log2(540/380) * 0.1 = 0.19°C for the high end estimate.
So my final conclusions are:
d) The amount of heating due to increased CO2 forcing over the next century is likely to be less than 0.2°C, an amount too small to be measured with our current crude measuring system.
e) This amount is so small that it would easily be counteracted by the cloud/snow albedo feedback system. Unlike parasitic losses, which can never be greater than the added heat, the cloud/snow albedo feedback system has the potential to set the temperature within a wide range. The expected maximum change in CO2 forcing during this century (see above) is about 2 watts/m2. This could be counteracted entirely by a mere half percent change in the cloud/snow created albedo …
w.
PS – Part of the reason that the CO2 question has attracted so much attention is the terminology used. A change from preindustrial atmospheric CO2 levels (280 parts per million) to the current level (380 ppm) to say my high end 2100 projection (540 ppm) sounds huge. People say “can the atmosphere sustain that load”, and “won’t the sequestration mechanisms break down?”
However, what we are really talking about is going from a preindustrial CO2 level of just above a quarter of one percent of the atmosphere, to the current level, just above a third of a percent, to a projected 2100 high end level just above half a percent …
This represents a possible net change in CO2 levels of a quarter of a percent, an amount which clearly will not change matters much. As an example, to date there is no evidence of any change in the rate of exponential sequestration of CO2 … and why should there be, we’ve only changed A TENTH OF A PERCENT from pre-industrial CO2 levels … man, I’ve never seen so much ink and money spilled over a tenth of a percent of anything …
Interesting:
http://www.ncgia.ucsb.edu/conf/SANTA_FE_CD-ROM/sf_papers/wu_lin/wu_lin.html
277: If you are dealing with uncertainty, you are dealing with statistics. And I don’t think a statistician has to be an expert on the subject matter in order to evaluate the statistics. Look at the mess made by the Team because they didn’t understand the statistics. Ideally, the authors of these studies would team up with statisticians, when uncertainties are so great.
Dano will find devils wherever he chooses to look because he’s using a statistically untenable Mannomatic pattern-matching algorithm with no self-correcting attempt at refutation. Good ideas and bad ideas spread by the same mechanism, Dano.
What are you so afraid of Bloom? Post the hurricane data and I’ll analyse it for you. Then we’ll put it to peer review. Meanwhile … if you could answer my questions, which I won’t bother repeating a fourth time …
Re #278 I don’t doubt it. Give time-series analysis a try though. You don’t know what you’re missing. 🙂
Maybe because they aren’t interested in the bigger problem, which is that pseudo-scientists are feeding oversimplified uncertainty-free pablum to policy makers. If so, I wonder why.
Willis — You’re off by a factor of 10 in your percentages, but correcting that makes your point even stronger. 280 ppm is close to 1/40 of one percent, not 1/4. (Remember that 1% is 10,000 ppm.) So we’re really talking about going from 1/36 of 1% to 1/26 of 1%. Put another way, the 100ppm increase to date is an increase of 1/100 of 1%.
279:
Generally excellent comment sir.
d) The amount of heating due to increased CO2 forcing over the next century is likely to be less than 0.2°C, an amount too small to be measured with our current crude measuring system.
I appreciate the effort, willis, certainly refreshing. The folk who do this for a living disagree; I’m kinda funny this way, but when a pipe in my bathroom breaks, I don’t call a vacuum repairperson, I call a plumber. That is: I go with the guy who does pipes for a living.
However, what we are really talking about is going from a preindustrial CO2 level of just above a quarter of one percent of the atmosphere, to the current level, just above a third of a percent, to a projected 2100 high end level just above half a percent …
This represents a possible net change in CO2 levels of a quarter of a percent, an amount which clearly will not change matters much
Excellent! In our new science, concentrations no longer matter! You’ll have no qualms in upping your child’s dose of, say, Atavan and letting us know what happens. Plz make your data available so we can all audit it.
Best,
D
Re #283.
"Give time-series analysis a try though."
I will if you promise to come out and use my caterpillar dozer to skid some logs.
(Yes, I confess to being a one man carbon de-sequestration machine):O
Re #281: Rah, rah, statisticians.
But maybe I was being too subtle. bender needs to look directly at Webster et al (2005) and Hoyos et al (2006) (for starters) if he wants to critique any statistics in relation to this discussion. And of course now he has the Webster team’s data set.
Re #283.
“Give time-series analysis a try though.”
I will if you promise to come out and use my caterpillar dozer to skid some logs.
(Yes, I confess to being a one man carbon de-sequestration machine, although I do a good bit of dendrochronolgy):O
Re #288
And I thought you were a Congressman! haha.
“man, I’ve never seen so much ink and money spilled over a tenth of a percent of anything … ”
You’ve never done Bill Gates taxes I take it.
Re #254: Steve S., how about instead we ask 100 people to look at the same piece of metal and ask them whether it exists or not? The calipers could be a complimentary gift for participating.
Did you see 285? I would increase any med by .01 % without any qualms.
re 291: you just don’t understand ANY statistics, do you!
Jae, I hope you mean 292, in which case I agree.
If you mean mine, I’d take a 1/0th of a percent of his money and retire tomorow.
I mean 292. Some people just WILL NOT face an issue fair and square. Bloom is an expert at diversion. Good politician, except for his arrogance.
Bloom, call I just call you ‘Dodge’ from now on? This ain’t about hurricane dynamics (though I’m happy to help you analyse any data you want to post). It’s about watered-down science being force-fed to policy makers. Does the bolding help clarify the issue any? Or are you blind to that too?
Interesting discussion at Climate Science:
http://climatesci.atmos.colostate.edu/2006/08/22/real-climate-post-on-weather-and-climate/
Pielke Sr. also linked it into this one at RC:
http://www.realclimate.org/index.php/archives/2006/08/short-and-simple-arguments-for-why-climate-can-be-predicted/
293:
Did you see 285? I would increase any med by .01 % without any qualms.
This is part of what I meant in 273 above.
Plz allow me to use this example to illustrate how the drill goes:
The conc of atm CO2 has increased by ~35%, and ~19%** on the Keeling curve.
So, the rugged new scientist now takes 10mg Ativan (the upper end of the dosage) to allow others to cope with their behavior.
Now, bravely, qualmlessly, the new scientist increases their dosage by 35% to 13mg. Perhaps the brave, qualmless new scientist can keep track of their symptoms and give us the data so we can audit it.
Best,
D
**Not .01%.
OOPS, Dano, I screwed up and you are correct. However, 0.0001 parts of the atmosphere don’t cause too much alarm to me.
Re 279: A couple of comments Willis.
1) As I pointed out to you earlier, the paper claims that the total longwave radiative forcing is 155 W/m2 which includes clouds. If you take out the clouds you get 125 W/m2. This is from the text.
2) Regarding your comments on thunderstorms, while they are important here, do you know the equivalent forcing on Mars so that they would have the same feedback?
Regards,
John
RE: #289 – that’s what I call industrial strength dendro! 😉
300:
However, 0.0001 parts of the atmosphere don’t cause too much alarm to me
Excellent. Then you’ll up your Ativan the equivalent amount in your body without alarm. Let us know how that goes for you.
Best,
D
RE: #292 – You really do not want to learn. Sad.
I realized this also fits in here, a special gift for Steve “I don need no stinking Sigma” Bloom:
“Something fun. Can anyone guess where I found the following?:
“While we can not go back and guess how many storms were missed, or how many higher categories were not detected, we can examine recent seasons and apply early 20th century observational technology to them. Neil Frank did this with the 2005 season (as a casual exercise) and came up with about 19 to 22 named storms, instead of the record setting 28.”
And this is only one aspect of it. Classification is a whole other discussion topic. Etc.
Sigma 101:
Big Y: “Average Hurricane Intensity”
X1: “Annual number of Cat 5”
X2: “Annual number of Cat 4”
X3: “Annual number of Cat 3″
X4” “Annual number of Cat 2”
Etc….
Little x’s: possibly, maximum sustained wind speed, time spent above wind speed x, mileage traveled at Cat Z, etc …..
Take it or leave it. Enlightenment is there for the taking. Or, you could be like the guy who says “ship it!” Whatever …. 😛
Yeah, Dano, if I have a 5 mg tablet and I increase it to 5.0001mg, I would not worry. After all, do you think the amount of Ativan in a 5 mg tablet is within 5 +/- 0.0001 mg? I’ll bet it’s on the order of 5 +/- 0.1 mg, 2 sigma.
308:
if I have a 5 mg tablet and I increase it to 5.0001mg, I would not worry.
Crikey.
You said “0.0001 parts of the atmosphere“. I equated that to medicine dosage, meaning 0.0001 parts of the body. You figger it out.
On second thought, Don’t. Have Sadlov do it for you. Then let us know how that dosage goes for you.
Best,
D
Dano: you know damn well what I meant.
Re # 307: JAE, umm, you realize that according to the analogy this means you have a body mass of 5 mg. I look forward to you elaborating.
Regards,
John
Opps, I see that Dano already pointed this out. Moderator, I won’t take offence if you delete this comment.
John
jae – the “little bitty” argument has got nothing to do with this thread. It’s an argument that I think is particularly weak and I really don’t want it to consume much more bandwidth here.
Sorry, Steve, it’s so tempting to get into these side conversations. No prob. if you delete the comments.
309:
I do, esp. since you took the time to do a 2à?Æ’ on the likelihood of the accuracy of your increase.
—–
312:
I’m personally using it to illustrate part of my point in 273, which is dependent upon your post, so it’s arguably aproposly relevant to the original point. But I understand and I’ll save your bandwidth Steve.
Best,
D
If a method is flawed, no amount of understanding of the underlying data will change that. It still equates to garbage in, garbage out. If one using statistics to analyze data that he knows intimately, yet he implements the statistics incorrectly, exactly how are his conclusions supported? (hint: they aren’t).
Mark
Fascinating:
http://capita.wustl.edu/Asia-FarEast/reports/DustMcarloSim/Dust_Mcarlo_Sim_files/v3_document.htm
Re 286, gosh, DanàÆàⶬ no sooner do I say something nice about you than you start up with ad homs again. You say:
Gee, I’m so surprised to find out that the folks that do this for a living get different answers from mine … I suppose you mean those noted plumbers like Michael Mann, Phil Jones, Gavin Schmidt, James Hansen … this is the problem with the ad hom arguments. The arguments have nothing to do with the data or the conclusions. But what on earth do you do when the good homs get different answers from each other?
Let’s take as an example the statement from your first cited paper, which says “the IPCC includes CO2 growth rates that we contend are unrealistically large.” Now, the IPCC contains “folks who do this for a living”, and the paper was written by “folks who do this for a living”. So your contention, that we should trust the “folks who do this for a living”, leads us nowhere — one of them has to be wrong.
That’s why I advise you to look at the numbers yourself. In fact, the only difference between your first citation and my figures is the climate sensitivity — we both come out with about the same forcing change (which is different from results from the IPCC, who “do this for a living”), of about one watt in the next fifty years.
So, your citation and I disagree about the sensitivity. I’ve given you numbers from Sherwood Idso saying the sensitivity is about 0.1°C per W/m2. I have also added what I think is the best and clearest evidence, which is that some 324 w/m2 of greenhouse radiation has produced a warming of about 33°C. This gives the same sensitivity as obtained by Idso (who also does this for a living) that is to say, one tenth of a degree C.
Your citation, on the other hand, gets its sensitivity, not from evidence, but from a computer model … wow, that’s real convincing …
So, since they disagree … what do YOU think? Is it reasonable that after 324 w/m2 of downwelling IR have made a difference of 0.1°C per W/m2, that the next W/m2 addition will have an effect eight or ten times that large?
(John asked again about where the 324 w/m2 data for downwelling long wave comes from … it comes, as I said before, from Figure 7 of the Kiehl/Trenberth paper, Earth’s Annual Global Mean Energy Budget. As the text states:
Now, all the people I know of who do this for a living agree that the Kiehl/Trenberth energy budget is the best we have, and that their downwelling IR figure of 324 w/m2 is pretty close to the mark. See, for example, Ten-year global distribution of downwelling longwave radiation, K. G. Pavlakis et al., Atmos. Chem. Phys., 4, 127–142, 2004, who say:
The folks who do this for a living also agree on the ~33°C or so warming from the downwelling IR.
So … think about it …
Regarding the change in CO2 of a tenth of a percent, I brought it up to highlight the way that the choice of numbers shapes our perception.
However, having brought it up, the best comparison is not to Ativan, but to the percentage of the major greenhouse gas in the air, water vapor. We don’t even know the average water vapor content of the air to an accuracy of a tenth of a percent. At any given point, the concentration of water vapor goes up and down like crazy. To give you a sense of the turnover, according to NASA (http://earthobservatory.nasa.gov/Library/Water/water_2.html) there’s somewhere on the order of 12,900 cubic km of water vapor in the atmosphere … and about 495,000 cubic km are added to the atmosphere by evaporation every year. More is added than rains out over the oceans, and more rains out than is added over the land. A tenth of a percent change in water vapor is lost in the bookkeeping.
But if you don’t like that example, lets look at the size of the predicted CO2 change in a different way. In the midst of all of the natural climate changes, do you really think the 1 watt/m2 which your paper says (and I agree) may be added over the next 50 years will make any difference at all? The earth’s surface is warmed by a combination of the sun (about 168 W/m2) and downwelling IR (about 324 w/m2), for a total of surface heating of about 492 W/m2 … it’s predicted to increase to 493 watts per m2 over a 50 year period … EVERYONE PANIC!
… we’re talking about a possible change in total downwelling radiation of about a twentieth of a percent over fifty years, folks, no matter what sensitivity you are using. Do you really think, given that the downwelling radiative forcing changes by hundreds of watts/m2 between day and night, that this change of a twentieth of a percent will even be detectable?
w.
PS – you say “Plz make your data available so we can all audit it.” In fact, I have given my data and described my methods to you as I went along, with citations and numbers. So you can start by auditing my figures for downwelling IR (324 w/m2), the heating due to that IR (~33°C), and the resulting sensitivity (~ a tenth of a degree per w/m2).
Please let all of us know the results of your audit, and we can proceed from there. If you can’t find any mistakes in my numbers or my logic, I’d be glad to hear of it.
PPS — Since you have called for this audit, if you do not answer, I’ll assume that you have not found any mistakes but you haven’t got the … … gentility … to admit it.
An interesting scenario appears to be developing. Those of us who have lived on the W. Coast for years know that when a dying typhoon gets entrained in a cold front, strange things can happen. Generally speaking, the early onset of cold, wet weather has been known to occur in similar scenarios. There has also been quite a bit of energy brewing over the Gulf of Alaska all summer long – resulting in a depressing endlessly rainy summer in Anchorage. The Pacific High is under early assault this year. Pielke Sr. reported cooling upper column sea temps. The jet stream is wavy in a manner more typical of early fall. Etc. Just when the main stream media and doomsayers are all wound up about the “great heat wave of 2006” ….. 🙂
http://sat.wrh.noaa.gov/satellite/showsat.php?wfo=mtr&area=west&type=wv&size=28
317: Great post, Willis. It’s gonna be hard for Mr. Dano to dodge that.
The hurricane database for the Atlantic used by Curry et al. is very interesting. It is available as an excel spreadsheet at http://www.aoml.noaa.gov/hrd/hurdat/easytoread-spreadsheetap.xls
The analysis of it is fascinating. My analysis focused on the average power dissipated per year. To me, the number of storms is meaningless. You could have 10 very small storms, or a couple of really big storms. But I was very unhappy with the division of the storms into class 3,4,5, etc. I wanted a continuous measure, rather than a categorical measure. So instead of using the Saffir Simpson scale, I looked at total power dissipated over the storm lifetime.
The spreadsheet gives the storm wind speed for each 6 hour interval of the storm’s life. Since the power in wind is proportional to the cube of the wind speed, I derived an index for the total wind power by cubing each six hour wind speed, and summing the cubed speeds over the life of the storm. This gives a measure of power dissapated. (I divided the power dissipation index by a million for ease of use).
The results were very interesting. Since 1850, while the average has gone up and down a bit, there has been very little change in the power dissipated by Atlantic hurricanes. The validity of the use of power dissipation is supported by an analysis of the distribution of storm strengths. It turns out that this follows a power law very closely, as we would expect.
I append the data for your interest. Note that the power dissipated by the individual hurricanes varies by a factor of 100, showing the shortcoming of the “3, 4, 5” type of categorization.
w.
Year Power Dissipation Index
1851.49 , 5.046
1851.51 , 0.729
1851.53 , 0.216
1851.63 , 25.747
1851.70 , 3.456
1851.79 , 4.199
1852.64 , 35.299
1852.68 , 2.688
1852.69 , 9.31
1852.73 , 21.25
1852.77 , 18.622
1853.60 , 0.216
1853.61 , 0.125
1853.67 , 76.601
1853.69 , 19.28
1853.72 , 0.216
1853.74 , 9.742
1853.74 , 0.216
1853.80 , 10.856
1854.49 , 3.837
1854.65 , 0.343
1854.69 , 25.946
1854.72 , 6.268
1854.80 , 3.354
1855.60 , 1
1855.61 , 6
1855.61 , 0.512
1855.65 , 4.29
1855.71 , 10.944
1856.61 , 19.395
1856.62 , 4.096
1856.64 , 2.376
1856.64 , 0.216
1856.65 , 27.805
1856.72 , 7.366
1857.50 , 1.728
1857.69 , 20.936
1857.73 , 10.24
1857.73 , 13.514
1858.45 , 0.512
1858.60 , 0.512
1858.71 , 7.115
1858.71 , 21.096
1858.73 , 7.54
1858.81 , 12.478
1859.50 , 1
1859.63 , 12
1859.67 , 3.072
1859.70 , 5.482
1859.71 , 5.883
1859.76 , 31.8
1859.79 , 2.867
1859.83 , 15.976
1860.61 , 20.362
1860.65 , 7.65
1860.70 , 0.512
1860.70 , 19.853
1860.72 , 4.362
1860.75 , 8.138
1860.80 , 11.928
1861.52 , 13.7
1861.62 , 8.349
1861.65 , 19.664
1861.71 , 0.512
1861.74 , 2.142
1861.77 , 4.98
1861.77 , 0.216
1861.84 , 3.899
1862.46 , 2.592
1862.63 , 12.187
1862.70 , 27.794
1862.77 , 0.216
1862.79 , 6.238
1862.89 , 4.112
1863.61 , 5.506
1863.63 , 6.482
1863.64 , 13.819
1863.66 , 7.458
1863.69 , 14.186
1863.71 , 3.64
1863.72 , 1.114
1863.74 , 0.773
1863.75 , 2.427
1864.54 , 5.468
1864.57 , 0.343
1864.65 , 12.629
1864.68 , 3.456
1864.81 , 4.622
1865.42 , 0.216
1865.50 , 0.216
1865.64 , 5.59
1865.68 , 32.978
1865.69 , 0.343
1865.74 , 0.512
1865.80 , 15.89
1866.53 , 17.468
1866.62 , 16.227
1866.68 , 6.83
1866.72 , 0.512
1866.73 , 7.854
1866.73 , 60.648
1866.83 , 5.991
1867.47 , 2.86
1867.58 , 18.35
1867.59 , 1
1867.67 , 6.84
1867.69 , 0.216
1867.75 , 6.747
1867.76 , 20.09
1867.77 , 0.125
1867.82 , 11.7
1868.67 , 12.47
1868.75 , 7.999
1868.76 , 12
1868.79 , 8.964
1869.62 , 4
1869.63 , 6.468
1869.66 , 2.048
1869.67 , 2.236
1869.68 , 3.925
1869.69 , 11.857
1869.70 , 24.343
1869.71 , 0.343
1869.75 , 0.216
1869.76 , 5.288
1870.58 , 0.512
1870.67 , 15.43
1870.67 , 3.854
1870.69 , 24.664
1870.71 , 10.362
1870.76 , 31.294
1870.77 , 0.512
1870.78 , 3.072
1870.80 , 11.114
1870.81 , 1
1870.83 , 7.691
1871.42 , 3.214
1871.44 , 1.668
1871.62 , 26.739
1871.63 , 32.144
1871.67 , 16
1871.68 , 6.29
1871.75 , 10.007
1871.78 , 6.872
1872.52 , 2.836
1872.64 , 29.867
1872.69 , 21.168
1872.75 , 10.928
1872.81 , 4.528
1873.42 , 0.777
1873.62 , 42.664
1873.72 , 5.51
1873.73 , 1.955
1873.74 , 33.876
1874.51 , 2.38
1874.59 , 8.042
1874.66 , 17.512
1874.67 , 2.384
1874.69 , 3.456
1874.74 , 7.2
1874.83 , 7.973
1875.63 , 8.192
1875.67 , 18.002
1875.69 , 32.723
1875.73 , 3.028
1875.77 , 11.446
1875.78 , 6.338
1876.69 , 6.77
1876.70 , 14.595
1876.71 , 2.592
1876.75 , 12.919
1876.78 , 27.624
1877.59 , 4.631
1877.71 , 10.189
1877.71 , 13.66
1877.72 , 36.928
1877.73 , 3.728
1877.79 , 5.184
1877.82 , 2.705
1877.91 , 1.864
1878.50 , 1.402
1878.61 , 12.932
1878.64 , 6.77
1878.65 , 14.706
1878.67 , 22.598
1878.70 , 19.434
1878.73 , 82.364
1878.77 , 9.689
1878.77 , 12.3
1878.79 , 25.812
1878.80 , 15.355
1878.90 , 8.216
1879.61 , 5.376
1879.62 , 16.079
1879.64 , 10.478
1879.66 , 17.104
1879.76 , 2.948
1879.77 , 5.722
1879.82 , 6.5
1879.88 , 8.599
1880.47 , 2.054
1880.59 , 32.262
1880.62 , 6.902
1880.65 , 19.876
1880.65 , 19.004
1880.68 , 7.072
1880.69 , 5.744
1880.74 , 42.34
1880.76 , 8.711
1880.78 , 15.492
1880.80 , 3.723
1881.59 , 1.827
1881.61 , 1.358
1881.61 , 18.504
1881.63 , 6.994
1881.64 , 18.179
1881.69 , 10.548
1881.72 , 6.209
1882.65 , 2.56
1882.67 , 26.632
1882.71 , 6.224
1882.72 , 1.932
1882.73 , 8.718
1882.76 , 25.442
1883.63 , 18.222
1883.65 , 34.715
1883.68 , 40.965
1883.81 , 7.52
1884.67 , 7.892
1884.67 , 42.88
1884.69 , 16.509
1884.77 , 21.553
1885.60 , 14.37
1885.64 , 17.325
1885.66 , 1.955
1885.71 , 7.579
1885.72 , 6.67
1885.73 , 6.871
1885.74 , 5.582
1885.78 , 2.8
1886.45 , 3.165625
1886.46 , 11.769875
1886.49 , 10.0065
1886.54 , 15.99575
1886.62 , 31.46325
1886.62 , 50.484375
1886.64 , 15.926
1886.71 , 16.679
1886.73 , 28.224375
1886.77 , 18.29975
1886.78 , 2.29525
1886.81 , 3.728625
1887.37 , 3.506875
1887.38 , 2.6055
1887.45 , 0.790375
1887.55 , 23.662125
1887.58 , 4.556125
1887.62 , 27.3855
1887.63 , 46.332
1887.67 , 12.6435
1887.70 , 35.03775
1887.71 , 5.73825
1887.77 , 1.528125
1887.77 , 1.883375
1887.77 , 20.886125
1887.78 , 4.363125
1887.79 , 10.867375
1887.83 , 9.9345
1887.91 , 8.59125
1887.93 , 7.325375
1887.94 , 3.3685
1888.46 , 2.393375
1888.51 , 1.126125
1888.62 , 26.493625
1888.67 , 29.09825
1888.68 , 2.4185
1888.73 , 3.678875
1888.77 , 8.958375
1888.84 , 4.370625
1888.88 , 33.813
1889.38 , 5.734625
1889.46 , 3.8835
1889.64 , 11.77225
1889.67 , 38.90475
1889.67 , 12.35175
1889.70 , 26.956
1889.70 , 4.188625
1889.75 , 5.0065
1889.76 , 2.91725
1890.41 , 1.099625
1890.63 , 5.524
1890.65 , 32.301
1890.83 , 3.254625
1891.51 , 7.59625
1891.63 , 18.568625
1891.63 , 28.948125
1891.67 , 19.493625
1891.71 , 26.084875
1891.75 , 18.463375
1891.76 , 2.444375
1891.77 , 4.507125
1891.78 , 13.407125
1891.84 , 1.82925
1892.44 , 3.159625
1892.62 , 9.891875
1892.67 , 35.761375
1892.69 , 4.568625
1892.70 , 33.92475
1892.74 , 1.64025
1892.76 , 30.94075
1892.79 , 10.9735
1892.81 , 3.646875
1893.45 , 10.97625
1893.51 , 6.01625
1893.62 , 39.750375
1893.62 , 33.598125
1893.62 , 8.645375
1893.62 , 57.643125
1893.64 , 26.9695
1893.68 , 8.13025
1893.74 , 94.635625
1893.74 , 22.9765
1893.80 , 1.59575
1893.85 , 5.521875
1894.43 , 1.024
1894.60 , 2.330125
1894.67 , 34.75275
1894.72 , 34.78325
1894.75 , 36.82175
1894.78 , 43.133375
1894.81 , 30.752625
1895.62 , 1.771125
1895.64 , 27.106
1895.74 , 6.55125
1895.76 , 1.329375
1895.78 , 44.621625
1895.79 , 0.965875
1896.51 , 9.727375
1896.67 , 51.73825
1896.72 , 32.999875
1896.73 , 27.0385
1896.77 , 14.436625
1896.82 , 41.590625
1896.91 , 1.579375
1897.67 , 31.4425
1897.69 , 7.08975
1897.72 , 4.33225
1897.74 , 1.524125
1897.77 , 8.52875
1897.81 , 7.304125
1898.59 , 1.2645
1898.67 , 3.21025
1898.67 , 5.292
1898.68 , 55.16775
1898.70 , 6.946125
1898.72 , 6.276375
1898.74 , 34.8415
1898.74 , 0.963625
1898.76 , 11.55025
1898.81 , 0.903625
1898.82 , 6.5475
1899.49 , 0.325875
1899.58 , 7.834125
1899.59 , 108.336625
1899.66 , 19.929
1899.67 , 51.395875
1899.76 , 2.914875
1899.78 , 1.549125
1899.82 , 14.164375
1899.85 , 1.75
1900.66 , 36.163375
1900.69 , 30.384
1900.69 , 31.074375
1900.70 , 1.494875
1900.76 , 5.304625
1900.78 , 1.42725
1900.82 , 1.98225
1901.45 , 0.8995
1901.50 , 9.069125
1901.51 , 9.078375
1901.59 , 12.803875
1901.63 , 1.080625
1901.66 , 34.81125
1901.69 , 8.416375
1901.70 , 2.38725
1901.72 , 3.298875
1901.76 , 4.832125
1901.79 , 1.853375
1901.83 , 6.705625
1902.45 , 2.314
1902.47 , 4.357375
1902.71 , 13.3675
1902.76 , 16.81425
1902.84 , 3.95175
1903.56 , 5.682375
1903.60 , 39.031125
1903.69 , 10.003125
1903.70 , 9.713375
1903.72 , 2.7425
1903.74 , 11.979375
1903.75 , 20.314125
1903.76 , 4.544375
1903.81 , 3.136375
1903.88 , 12.406625
1904.44 , 2.761625
1904.69 , 10.51975
1904.78 , 6.102875
1904.80 , 2.053375
1904.83 , 1.865
1905.68 , 1.17475
1905.70 , 2.20425
1905.73 , 2.52025
1905.75 , 24.84075
1905.76 , 2.21025
1906.44 , 2.405625
1906.46 , 15.66475
1906.64 , 2.356125
1906.65 , 84.234125
1906.67 , 20.053375
1906.72 , 21.416375
1906.73 , 11.7445
1906.77 , 34.852375
1906.79 , 1.315375
1906.79 , 1.58625
1906.85 , 3.37825
1907.48 , 3.030875
1907.72 , 1.513375
1907.74 , 0.841
1907.80 , 1.43225
1907.85 , 2.226
1908.18 , 6.30225
1908.40 , 5.844125
1908.57 , 10.86575
1908.58 , 2.4405
1908.67 , 1.238625
1908.69 , 37.668375
1908.71 , 1.6315
1908.72 , 35.305125
1908.79 , 7.413875
1908.80 , 1.130875
1909.46 , 1.53225
1909.49 , 4.91375
1909.49 , 1.813375
1909.54 , 11.63175
1909.60 , 1.155375
1909.64 , 29.68575
1909.66 , 1.12175
1909.70 , 24.409875
1909.73 , 1.743875
1909.77 , 23.644375
1909.86 , 11.022875
1910.65 , 1.604125
1910.65 , 1.1355
1910.68 , 34.65125
1910.73 , 10.262375
1910.77 , 44.94625
1911.59 , 2.010625
1911.61 , 3.97975
1911.65 , 12.81375
1911.67 , 10.372
1911.71 , 3.365875
1911.82 , 2.14875
1912.44 , 7.10125
1912.53 , 1.34875
1912.67 , 1.468625
1912.69 , 6.853625
1912.76 , 8.933125
1912.78 , 11.033375
1912.86 , 25.314125
1913.47 , 4.976
1913.62 , 0.685125
1913.65 , 11.93525
1913.67 , 6.55175
1913.76 , 7.2325
1913.83 , 1.871125
1914.71 , 2.066375
1915.58 , 1.405125
1915.60 , 50.569625
1915.66 , 66.665625
1915.67 , 11.79075
1915.73 , 35.6245
1916.50 , 20.109625
1916.53 , 34.429
1916.53 , 7.68
1916.62 , 32.54325
1916.64 , 5.344
1916.66 , 17.448625
1916.68 , 0.539
1916.69 , 1.722125
1916.71 , 12.331125
1916.71 , 31.4645
1916.76 , 0.954125
1916.77 , 23.574375
1916.78 , 31.68075
1916.86 , 5.2175
1917.60 , 1.6445
1917.67 , 29.83475
1917.72 , 41.67575
1918.59 , 7.001875
1918.64 , 7.31025
1918.65 , 1.40625
1918.67 , 11.459875
1918.69 , 1.576625
1919.51 , 1.60975
1919.67 , 68.712875
1919.86 , 1.270375
1920.69 , 24.195125
1920.71 , 5.203875
1920.72 , 4.094375
1920.74 , 4.602875
1921.46 , 14.862
1921.68 , 3.166875
1921.69 , 38.116125
1921.69 , 2.011625
1921.79 , 3.5345
1921.80 , 37.479375
1922.45 , 1.44275
1922.70 , 81.158
1922.78 , 2.247
1922.79 , 13.02325
1923.67 , 18.195625
1923.73 , 37.597625
1923.78 , 6.83275
1923.79 , 6.890375
1923.79 , 1.5775
1923.79 , 0.866125
1923.82 , 1.164125
1924.47 , 1.076
1924.63 , 42.672125
1924.65 , 29.817875
1924.70 , 6.948875
1924.74 , 1.453
1924.78 , 1.20275
1924.79 , 18.2175
1924.85 , 15.893125
1925.68 , 0.6265
1925.91 , 5.4625
1926.56 , 29.446
1926.58 , 29.624625
1926.64 , 14.448625
1926.67 , 105.85425
1926.69 , 13.40375
1926.70 , 65.567875
1926.70 , 1.7745
1926.72 , 29.64775
1926.76 , 0.490875
1926.79 , 31.807
1926.87 , 1.066875
1927.64 , 34.847375
1927.67 , 14.993625
1927.73 , 4.691625
1927.73 , 25.84325
1927.75 , 1.409125
1927.80 , 0.985
1927.83 , 1.212875
1928.59 , 8.97025
1928.60 , 8.0435
1928.67 , 3.336625
1928.68 , 81.339625
1928.69 , 2.632375
1928.78 , 4.146625
1929.49 , 3.0375
1929.73 , 41.7755
1929.79 , 13.731125
1930.64 , 20.433625
1930.67 , 36.162875
1931.49 , 1.165625
1931.53 , 2.316375
1931.61 , 4.259375
1931.63 , 1.322875
1931.68 , 7.919625
1931.69 , 11.90325
1931.74 , 0.682875
1931.80 , 1.246875
1931.89 , 1.0745
1932.35 , 1.905
1932.62 , 8.970625
1932.65 , 6.547875
1932.67 , 74.877625
1932.69 , 2.619625
1932.72 , 0.66275
1932.74 , 14.502875
1932.77 , 3.199875
1932.77 , 1.4465
1932.83 , 65.20875
1932.84 , 10.97725
1933.37 , 1.5225
1933.49 , 23.781875
1933.54 , 2.164875
1933.56 , 1.263625
1933.57 , 17.7805
1933.62 , 3.827125
1933.63 , 1.15825
1933.63 , 23.901375
1933.65 , 2.478875
1933.65 , 0.810875
1933.66 , 29.805375
1933.67 , 32.601125
1933.69 , 39.33325
1933.69 , 6.722875
1933.71 , 20.37675
1933.74 , 1.070625
1933.74 , 0.682875
1933.75 , 40.8625
1933.82 , 11.013625
1933.82 , 3.6645
1933.87 , 0.490875
1934.41 , 1.382125
1934.43 , 14.791375
1934.56 , 3.20575
1934.64 , 0.66175
1934.65 , 6.351375
1934.68 , 10.69275
1934.71 , 1.718125
1934.75 , 5.42775
1934.75 , 2.3135
1934.80 , 1.229625
1934.89 , 8.522375
1935.63 , 35.147875
1935.66 , 35.801875
1935.67 , 0.609
1935.73 , 36.91575
1935.80 , 12.416875
1935.83 , 11.475625
1936.45 , 1.536
1936.47 , 0.795
1936.49 , 1.95975
1936.57 , 0.481125
1936.57 , 5.889875
1936.59 , 1.972125
1936.60 , 1.450875
1936.62 , 7.319125
1936.64 , 0.86475
1936.66 , 3.089625
1936.66 , 34.607625
1936.69 , 0.298875
1936.69 , 48.62475
1936.69 , 1.20175
1936.72 , 20.262875
1936.77 , 0.4695
1937.58 , 2.36025
1937.59 , 2.739625
1937.65 , 0.256
1937.69 , 13.966125
1937.70 , 22.299375
1937.71 , 1.68475
1937.72 , 21.63625
1937.74 , 1.479625
1937.75 , 1.285875
1938.61 , 1.2835
1938.61 , 12.105
1938.65 , 14.800125
1938.69 , 65.82725
1938.78 , 2.937625
1938.80 , 1.0105
1938.81 , 0.63625
1938.85 , 2.950625
1939.45 , 1.6015
1939.60 , 6.480625
1939.73 , 1.0745
1939.78 , 19.248375
1939.83 , 8.074875
1940.39 , 2.667875
1940.59 , 7.821
1940.60 , 12.11975
1940.67 , 7.550875
1940.69 , 16.092125
1940.72 , 1.795375
1940.80 , 1.1295
1940.82 , 0.50825
1941.70 , 1.5095
1941.71 , 15.89325
1941.72 , 10.865875
1941.73 , 16.821125
1941.76 , 17.285125
1941.79 , 2.152375
1942.63 , 6.03275
1942.64 , 25.70625
1942.65 , 17.239125
1942.71 , 3.027875
1942.72 , 2.31775
1942.74 , 1.102375
1942.75 , 2.142625
1942.78 , 0.556
1942.79 , 2.2455
1942.85 , 8.456
1943.57 , 5.424625
1943.62 , 3.600625
1943.64 , 39.651125
1943.67 , 38.874
1943.70 , 1.650625
1943.71 , 9.902375
1943.74 , 1.683125
1943.75 , 2.949375
1943.78 , 16.988375
1943.80 , 0.845625
1944.54 , 9.824
1944.57 , 3.077875
1944.58 , 5.6075
1944.63 , 21.346125
1944.64 , 2.07225
1944.69 , 0.81925
1944.69 , 32.209875
1944.72 , 5.705375
1944.72 , 11.09575
1944.75 , 0.717625
1944.78 , 26.304375
1945.47 , 11.034875
1945.55 , 1.147875
1945.59 , 1.795375
1945.63 , 2.513375
1945.65 , 22.414125
1945.66 , 1.406
1945.67 , 0.622625
1945.69 , 1.592125
1945.70 , 29.543625
1945.76 , 4.915875
1945.78 , 6.13725
1946.45 , 0.795
1946.51 , 5.870875
1946.65 , 0.298875
1946.70 , 9.1305
1946.76 , 9.9255
1946.83 , 0.752
1947.58 , 0.630375
1947.61 , 10.96475
1947.63 , 8.423375
1947.68 , 103.233
1947.69 , 0.38025
1947.72 , 2.231875
1947.77 , 0.701125
1947.77 , 10.6795
1947.79 , 19.625125
1948.39 , 2.29275
1948.52 , 0.732625
1948.65 , 26.751875
1948.67 , 0.873125
1948.67 , 4.26625
1948.68 , 52.52925
1948.72 , 25.091
1948.76 , 23.8665
1948.86 , 4.242375
1949.64 , 20.92225
1949.65 , 18.254125
1949.67 , 1.278375
1949.67 , 36.049625
1949.67 , 0.927
1949.68 , 2.379
1949.70 , 1.90825
1949.72 , 10.273875
1949.72 , 2.78675
1949.74 , 12.7335
1949.78 , 12.03525
1949.79 , 1.99325
1949.84 , 0.998
1950.62 , 51.186625
1950.64 , 21.637
1950.64 , 33.142625
1950.67 , 122.225375
1950.67 , 20.30125
1950.69 , 42.067375
1950.74 , 20.611375
1950.75 , 1.878
1950.77 , 5.315
1950.78 , 17.842125
1950.79 , 15.12025
1950.80 , 5.3405
1950.80 , 7.729375
1951.37 , 22.601875
1951.59 , 1.77425
1951.62 , 38.329
1951.66 , 13.38075
1951.67 , 63.074125
1951.67 , 25.3025
1951.72 , 1.026
1951.74 , 18.345625
1951.78 , 4.70575
1951.79 , 4.644625
1952.09 , 1.599
1952.63 , 14.990125
1952.67 , 39.471125
1952.73 , 24.861125
1952.74 , 4.043375
1952.77 , 5.136125
1952.80 , 29.463
1953.40 , 6.95375
1953.61 , 11.747625
1953.66 , 1.705125
1953.66 , 45.172
1953.69 , 16.05325
1953.71 , 20.801
1953.71 , 8.093375
1953.73 , 13.464875
1953.76 , 2.98725
1953.76 , 5.583375
1953.76 , 2.359375
1953.77 , 4.363625
1953.90 , 1.315375
1953.94 , 0.49675
1954.48 , 2.266
1954.57 , 0.701625
1954.65 , 19.163875
1954.67 , 6.912375
1954.67 , 29.3185
1954.70 , 1.539
1954.73 , 3.10875
1954.74 , 15.3805
1954.76 , 65.88975
1954.88 , 2.234
1955.00 , 8.56875
1955.58 , 1.764125
1955.59 , 76.606375
1955.60 , 33.2105
1955.64 , 23.339
1955.65 , 1.828625
1955.67 , 19.002375
1955.68 , 2.407375
1955.69 , 30.264
1955.69 , 27.738
1955.72 , 66.39775
1955.78 , 3.284625
1955.79 , 8.748125
1956.45 , 1.076625
1956.57 , 1.72475
1956.61 , 36.993625
1956.68 , 1.846
1956.69 , 2.585125
1956.70 , 1.535625
1956.72 , 6.28725
1956.83 , 19.073375
1957.44 , 3.638625
1957.49 , 12.579
1957.61 , 1.83
1957.67 , 96.584625
1957.69 , 0.53375
1957.71 , 1.099875
1957.72 , 5.273125
1957.81 , 1.341125
1958.46 , 0.570375
1958.61 , 3.359
1958.61 , 52.957375
1958.65 , 24.085875
1958.67 , 13.76075
1958.68 , 7.939375
1958.70 , 1.146125
1958.72 , 29.633625
1958.73 , 22.63825
1958.76 , 13.839125
1959.41 , 1.326875
1959.46 , 2.284375
1959.47 , 3.4725
1959.51 , 3.97375
1959.56 , 3.51925
1959.63 , 0.676
1959.69 , 4.428625
1959.72 , 27.051875
1959.74 , 50.859875
1959.77 , 0.73275
1959.80 , 5.470375
1960.48 , 0.62875
1960.53 , 10.240375
1960.58 , 1.253375
1960.63 , 5.7315
1960.66 , 117.529625
1960.71 , 8.171625
1960.71 , 1.2245
1961.55 , 19.617125
1961.67 , 49.224375
1961.67 , 51.14
1961.68 , 29.848625
1961.69 , 84.521
1961.70 , 0.69
1961.75 , 27.413625
1961.79 , 2.949125
1961.82 , 37.926625
1961.84 , 4.867
1961.85 , 3.871
1962.65 , 6.314
1962.66 , 0.869625
1962.70 , 2.70875
1962.75 , 16.505625
1962.79 , 18.16725
1963.58 , 14.02325
1963.64 , 22.89
1963.69 , 3.081
1963.71 , 2.9025
1963.72 , 4.016625
1963.73 , 7.983625
1963.74 , 79.569375
1963.79 , 28.692625
1963.82 , 0.92425
1964.42 , 2.6505
1964.58 , 1.9895
1964.60 , 0.92625
1964.60 , 1.234
1964.64 , 58.4625
1964.66 , 52.348
1964.68 , 30.810875
1964.68 , 1.06375
1964.70 , 49.961375
1964.74 , 32.3025
1964.77 , 14.427625
1964.85 , 0.85775
1965.45 , 1.385
1965.64 , 7.31825
1965.66 , 73.987375
1965.71 , 22.731375
1965.73 , 1.06625
1965.78 , 7.113
1966.43 , 18.138875
1966.50 , 1.7955
1966.54 , 4.11575
1966.56 , 11.10525
1966.56 , 2.2365
1966.64 , 63.56125
1966.67 , 1.59125
1966.72 , 0.528125
1966.72 , 84.586625
1966.74 , 0.936875
1966.84 , 10.981125
1967.66 , 6.148625
1967.68 , 75.436375
1967.68 , 37.748625
1967.69 , 13.616625
1967.74 , 1.3155
1967.75 , 3.52325
1967.76 , 0.832375
1967.80 , 19.82625
1968.42 , 5.981875
1968.46 , 7.013125
1968.48 , 0.8825
1968.61 , 6.2765
1968.70 , 3.7835
1968.71 , 9.71025
1968.73 , 2.24925
1968.79 , 11.276125
1969.57 , 5.457
1969.61 , 3.064125
1969.62 , 46.315375
1969.62 , 40.31075
1969.65 , 0.9325
1969.66 , 12.32325
1969.68 , 8.222125
1969.71 , 5.585125
1969.72 , 36.53675
1969.72 , 5.284375
1969.73 , 5.294875
1969.75 , 1.408875
1969.75 , 0.758625
1969.77 , 13.87325
1969.80 , 9.858375
1969.83 , 3.01175
1969.83 , 9.245625
1969.89 , 5.529375
1970.38 , 2.706125
1970.55 , 1.837125
1970.58 , 11.016375
1970.62 , 1.5805
1970.63 , 3.0835
1970.69 , 8.073375
1970.70 , 1.835875
1970.74 , 1.614625
1970.78 , 7.039375
1970.80 , 7.314625
1971.51 , 1.687375
1971.59 , 3.418
1971.61 , 5.595875
1971.63 , 1.73475
1971.64 , 2.5155
1971.68 , 20.852
1971.67 , 6.365625
1971.68 , 50.79175
1971.70 , 1.97125
1971.70 , 4.00025
1971.72 , 1.703
1971.80 , 0.974375
1971.87 , 7.91325
1972.40 , 2.41275
1972.46 , 6.753375
1972.64 , 15.558625
1972.66 , 3.927375
1972.68 , 6.105875
1972.72 , 2.303625
1972.84 , 1.3995
1973.50 , 6.90475
1973.58 , 0.540875
1973.63 , 3.645875
1973.65 , 5.345375
1973.67 , 3.695
1973.71 , 17.079125
1973.77 , 7.265125
1973.79 , 8.929125
1974.48 , 0.87225
1974.54 , 1.514
1974.61 , 1.97425
1974.62 , 1.150625
1974.65 , 19.914625
1974.66 , 37.82625
1974.67 , 1.008875
1974.68 , 3.998625
1974.71 , 12.720625
1974.74 , 4.338875
1974.76 , 1.346625
1975.49 , 6.2455
1975.57 , 4.362625
1975.65 , 7.22575
1975.66 , 17.02925
1975.70 , 11.87625
1975.72 , 13.589
1975.73 , 28.74975
1975.82 , 0.937125
1975.94 , 2.022125
1976.39 , 1.34575
1976.58 , 2.01475
1976.60 , 12.91875
1976.63 , 8.774875
1976.63 , 0.73825
1976.64 , 37.8755
1976.66 , 21.146
1976.70 , 0.531625
1976.74 , 13.068875
1976.81 , 3.806375
1977.66 , 20.953
1977.67 , 2.431375
1977.68 , 3.67875
1977.74 , 4.015125
1977.79 , 2.53975
1977.79 , 0.7215
1978.05 , 1.167375
1978.58 , 0.392875
1978.60 , 0.8495
1978.60 , 4.5795
1978.65 , 0.655125
1978.67 , 28.1275
1978.68 , 12.3365
1978.70 , 15.784125
1978.70 , 4.64875
1978.76 , 0.9575
1978.77 , 1.548
1978.83 , 3.99425
1979.47 , 0.983625
1979.52 , 2.400625
1979.54 , 2.074625
1979.65 , 79.90575
1979.67 , 0.67875
1979.66 , 24.6875
1979.68 , 19.740875
1979.71 , 4.097375
1979.81 , 1.509875
1980.58 , 0.13975
1980.62 , 9.4805
1980.64 , 4.631875
1980.68 , 0.61175
1980.68 , 6.39425
1980.68 , 48.628625
1980.67 , 3.498375
1980.72 , 3.8435
1980.75 , 25.2885
1980.85 , 0.159625
1980.90 , 5.682375
1981.35 , 0.780375
1981.50 , 1.767125
1981.59 , 1.385625
1981.60 , 4.934625
1981.67 , 14.93475
1981.67 , 17.0305
1981.69 , 11.54175
1981.70 , 21.83425
1981.72 , 30.060875
1981.83 , 1.047125
1981.84 , 3.830875
1981.87 , 5.54175
1982.42 , 2.112875
1982.47 , 3.248
1982.66 , 5.294
1982.69 , 1.352
1982.70 , 25.670375
1982.75 , 1.5495
1983.62 , 7.724875
1983.65 , 3.063
1983.69 , 3.80425
1983.74 , 2.865125
1984.63 , 1.21775
1984.66 , 1.516
1984.67 , 0.769
1984.67 , 1.244375
1984.69 , 18.9255
1984.71 , 0.651625
1984.71 , 2.900125
1984.71 , 0.718
1984.73 , 5.564125
1984.74 , 2.67175
1984.77 , 22.937125
1984.85 , 13.700125
1984.95 , 15.509125
1985.54 , 2.181
1985.56 , 2.5585
1985.61 , 6.7175
1985.62 , 4.20575
1985.66 , 22.329375
1985.71 , 3.0435
1985.71 , 32.563
1985.72 , 0.92475
1985.77 , 3.71925
1985.82 , 7.811375
1985.87 , 24.6405
1986.43 , 1.48175
1986.48 , 2.971
1986.62 , 8.272125
1986.69 , 1.3585
1986.69 , 26.377
1986.88 , 3.715125
1987.61 , 0.718125
1987.61 , 0.101375
1987.63 , 1.649
1987.68 , 1.460375
1987.69 , 2.867375
1987.72 , 11.856375
1987.77 , 3.12975
1988.60 , 0.496625
1988.61 , 0.8195
1988.64 , 1.533375
1988.67 , 2.332125
1988.67 , 1.083625
1988.69 , 1.34625
1988.69 , 2.713125
1988.69 , 57.856875
1988.72 , 46.686
1988.74 , 0.5415
1988.78 , 31.071
1988.88 , 7.6705
1989.48 , 1.20625
1989.52 , 1.275125
1989.58 , 2.439875
1989.58 , 17.785125
1989.63 , 16.788625
1989.65 , 10.172375
1989.67 , 59.733375
1989.69 , 72.90225
1989.71 , 2.294125
1989.78 , 3.67575
1989.91 , 0.11275
1990.56 , 2.10275
1990.57 , 8.656625
1990.58 , 2.47475
1990.59 , 4.267375
1990.59 , 1.980875
1990.61 , 0.51525
1990.65 , 30.00125
1990.65 , 2.8925
1990.68 , 19.990125
1990.72 , 6.834
1990.76 , 5.434875
1990.77 , 9.971375
1990.77 , 1.27825
1990.79 , 6.20125
1991.50 , 0.257125
1991.63 , 11.129875
1991.68 , 18.498125
1991.69 , 1.467875
1991.69 , 1.67675
1991.79 , 0.680625
1991.82 , 5.675375
1991.83 , 5.13025
1992.31 , 0.902875
1992.63 , 61.623375
1992.71 , 28.610875
1992.72 , 14.113625
1992.73 , 1.946
1992.74 , 2.9455
1992.81 , 7.84875
1993.47 , 0.62125
1993.59 , 2.9625
1993.62 , 0.688875
1993.65 , 1.582875
1993.64 , 27.415875
1993.69 , 7.12525
1993.71 , 4.05925
1993.72 , 2.00875
1994.50 , 1.507
1994.62 , 0.846
1994.63 , 6.560875
1994.69 , 1.2445
1994.72 , 1.332375
1994.84 , 12.55125
1994.86 , 6.857
1995.42 , 5.1435
1995.51 , 2.857375
1995.53 , 6.969125
1995.58 , 0.69275
1995.58 , 7.514625
1995.61 , 37.6795
1995.61 , 1.28525
1995.64 , 26.802
1995.64 , 29.02675
1995.64 , 0.740125
1995.65 , 2.41
1995.66 , 88.481625
1995.70 , 28.23075
1995.74 , 9.80725
1995.74 , 15.5775
1995.76 , 1.849625
1995.77 , 17.67175
1995.80 , 1.629375
1995.82 , 9.740875
1996.46 , 1.574625
1996.51 , 21.520375
1996.57 , 3.59925
1996.64 , 3.501625
1996.64 , 86.114375
1996.65 , 29.227625
1996.65 , 1.732125
1996.67 , 30.48975
1996.73 , 16.093875
1996.76 , 6.2495
1996.78 , 0.42675
1996.79 , 28.09125
1996.87 , 0.30025
1997.42 , 0.160875
1997.50 , 1.027875
1997.53 , 2.095875
1997.54 , 1.049375
1997.54 , 6.511375
1997.67 , 36.73525
1997.76 , 0.983
1997.79 , 0.85
1998.57 , 1.83225
1998.64 , 33.624375
1998.64 , 0.825375
1998.65 , 32.070875
1998.67 , 7.575375
1998.69 , 1.467875
1998.71 , 58.3645
1998.71 , 0.71175
1998.72 , 9.6915
1998.72 , 22.782375
1998.73 , 8.715875
1998.76 , 4.63175
1998.81 , 70.69725
1998.90 , 8.133875
1999.45 , 2.615875
1999.63 , 18.262375
1999.64 , 32.942375
1999.65 , 22.91125
1999.65 , 1.44875
1999.69 , 46.18125
1999.70 , 68.25725
1999.72 , 1.573125
1999.78 , 0.08975
1999.80 , 10.2445
1999.83 , 0.55125
1999.87 , 30.4445
2000.59 , 43.3815
2000.62 , 0.68575
2000.63 , 0.300375
2000.64 , 5.669
2000.67 , 0.539625
2000.69 , 7.893875
2000.71 , 3.695
2000.71 , 3.6695
2000.72 , 43.155125
2000.74 , 7.393375
2000.74 , 16.3355
2000.76 , 2.5195
2000.79 , 7.546
2000.80 , 1.33
2000.82 , 2.98125
2001.43 , 1.9345
2001.59 , 2.097125
2001.62 , 4.471375
2001.64 , 3.40725
2001.67 , 25.478
2001.69 , 19.6365
2001.70 , 9.89925
2001.72 , 10.78125
2001.76 , 14.250375
2001.77 , 0.816
2001.78 , 5.1295
2001.82 , 0.81275
2001.83 , 26.055125
2001.84 , 3.102
2001.90 , 11.147375
2002.54 , 2.28925
2002.59 , 0.401625
2002.60 , 1.1
2002.66 , 2.51225
2002.67 , 1.257625
2002.68 , 1.19575
2002.69 , 6.458875
2002.70 , 1.37775
2002.71 , 23.256625
2002.71 , 0.664625
2002.72 , 13.486625
2002.72 , 21.795625
2003.30 , 3.727125
2003.49 , 0.169375
2003.52 , 8.537
2003.54 , 4.734875
2003.62 , 1.71775
2003.66 , 70.601875
2003.67 , 0.422375
2003.67 , 1.047625
2003.68 , 113.857
2003.73 , 11.294875
2003.74 , 30.32725
2003.74 , 0.170125
2003.78 , 0.7925
2003.79 , 7.085
2003.93 , 3.14875
2003.94 , 1.557375
2004.58 , 14.848375
2004.59 , 2.642375
2004.61 , 14.101875
2004.62 , 15.254625
2004.62 , 0.6135
2004.65 , 73.952875
2004.66 , 3.07425
2004.66 , 1.11975
2004.67 , 131.44075
2004.70 , 28.688125
2004.71 , 46.406
2004.72 , 10.59
2004.77 , 0.711875
2004.78 , 0.79675
2004.90 , 2.412
2005.44 , 2.340125
2005.49 , 0.288875
2005.51 , 2.00375
2005.51 , 29.950375
2005.53 , 54.089125
2005.56 , 5.6055
2005.56 , 0.4385
2005.59 , 6.536375
2005.59 , 14.24375
2005.64 , 0.322875
2005.65 , 34.03125
2005.66 , 0.809875
2005.67 , 20.365125
2005.68 , 7.87275
2005.68 , 17.1475
2005.71 , 5.299
2005.72 , 45.25275
2005.75 , 2.14925
2005.76 , 0.14975
2005.76 , 0.5005
2005.77 , 2.25525
2005.79 , 71.791875
2005.81 , 0.63525
2005.82 , 7.564375
2005.87 , 1.631625
2005.89 , 7.17825
2005.91 , 13.036625
2005.99 , 5.16625
w.
#320 (Willis Eschenbach) That is a very interesting post. If non one else does within the next week or two I might try putting that data trough a low pas filter with a time constant of one year. If any trends look apparent I might try some regression on the data. I am working on something else now though so I’ll let anyone else step up to the plate that wants to. I have bookmarked your post.
RE #318 I’ve checked the Arctic sea ice coverage maps and it appears that 2006 Arctic ice coverage at this point (mid to late August) is a bit higher than in 2005. Coverage along the north shore of Alaska and Bering Sea is definitely greater this year.
It is becoming clear to me, mainly from Willis’ posts, that we currently have plenty of power in the physics realm to know what’s going on. We don’t need all the sophisticated ? proxies and GCMs.
Willis, would you like to post up the spreadsheet so that the calcs can be shown? If so, email it to me and I’ll post it up.
I can do that, Steve, but I’ve removed a number of the formulas because they take a while to calculate.
I also used some special functions to retrieve the information. The spreadsheet looks like this:
Storm NOT NA MED is number 1 of t he year 18 51
********** ** ******** ******** ******* ********** ***
Month D ay Hour Lat. Long. Dir. —-Sp eed—– —–Wi nd—— Pressur e ————Type———–
June 25 0 UTC 28.0N 94.8W — deg — mph — kph 90 150 — mb Hurricane – Category 1
June 25 6 UTC 28.0N 95.4W 270 deg 5 mph 9 kph 90 150 — mb Hurricane – Category 1
June 25 12 UTC 28.0N 96.0W 270 deg 5 mph 9 kph 90 150 — mb Hurricane – Category 1
June 25 18 UTC 28.1N 96.5W 285 deg 4 mph 7 kph 90 150 — mb Hurricane – Category 1
June 26 0 UTC 28.2N 97.0W 285 deg 4 mph 7 kph 80 130 — mb Hurricane – Category 1
June 26 6 UTC 28.3N 97.6W 280 deg 5 mph 9 kph 70 110 — mb Tropical Storm
June 26 12 UTC 28.4N 98.3W 280 deg 6 mph 11 kph 70 110 — mb Tropical Storm
June 26 18 UTC 28.6N 98.9W 290 deg 5 mph 9 kph 60 90 — mb Tropical Storm
June 27 0 UTC 29.0N 99.4W 310 deg 5 mph 9 kph 60 90 — mb Tropical Storm
June 27 6 UTC 29.5N 99.8W 325 deg 6 mph 11 kph 50 70 — mb Tropical Storm
June 27 12 UTC 30.0N 100.0W 340 deg 5 mph 9 kph 50 70 — mb Tropical Storm
June 27 18 UTC 30.5N 100.1W 350 deg 5 mph 9 kph 50 70 — mb Tropical Storm
June 28 0 UTC 31.0N 100.2W 350 deg 5 mph 9 kph 50 70 — mb Tropical Storm
Storm NOT NA MED is number 2 of t he year 18 51
********** ** ******** ******** ******* ********** ***
Month D ay Hour Lat. Long. Dir. —-Sp eed—– —–Wi nd—— Pressur e ————Type———–
July 5 12 UTC 22.2N 97.6W — deg — mph — kph 90 150 — mb Hurricane – Category 1
Etc.
Thus, I had to use some special functions to collect the information for each storm. These are excel functions that I have written.
However, I will rebuild what I can of the erased formulas, annotate it, and send it to you. I’ll mail it to the climateaudit address?
w.
You need to learn R for things like this. Could youpost up the url’s for the data or remind me of the post # if you posted it up already.
BTW I talked to a climate scientist today who said that the upper winds were stronger this year (which stops heat from accumulating and needing vortices to escape if I got the nuance right) and also the SSTs are cooler. You’d that the hurricane people should be chopping their forecasts in half, but right now the unamended Aug 6 forecasts imply that the rest of 2006 will be as active as the corresponding period of 2006. It doesn’t sound like it’s possible. But who will be the first climate scientist to break ranks and chop the forecast in half?
“the unamended Aug 6 forecasts imply that the rest of 2006 will be as active as the corresponding period of 2006. ”
Gee I hope so.
I currently see it like this:
1. There have been temperature swings in the last 2000 years.
2. CO2 levels have been relatively constant for the last 2000 years.
3. The Sun is the source of virtually all our energy.
4. The Sun goes through well defined cycles that affect the Earth’s temperature.
5. Volcanos, small meteors, etc. can effect temperature for relatively short periods of time, but not for hundreds of years running.
5. The Sun, not CO2, is responsible for the temperature swings.
Now, what is WRONG with that logic?
#129 if y=a*b is a or b responsible for y
It doesn’t sit with some political positions.
PS #1 should be changed to
“1. There have been temperature swings in the last X years.”
With X being any amount of years since the formation of the Earth (Mother Earth if you will).
Also works with days, months, minutes, hours, centuries…
You get the point.
Steve, thanks to your prodding, I have learned R and find it extremely useful … but this data came in as an Excel spreadsheet, and required lots of massaging to get at the actual data.
The spreadsheet is located at
http://www.aoml.noaa.gov/hrd/hurdat/easytoread-spreadsheetap.xls
I’ve annotated my version with all of my graphs, calculations, and such, and emailed it to you.
w.
Re #19
No, Bloom is “Dodge”. Dano is “Witchhunter”.
That’s #319.
Re # 317 Willis:
you said:
Just to set the record straight I was not asking about it again. I am sure that you read my post 217, but in case it has slipped your mind let me remind you that in it I agreed with what was said in Figure 7 but gave what I thought was the important section from the text.
In regards to your figures, lets look at it another way. You claim that:
I think we can also agree that the greenhouse effect is about 33C and that blackbody temperature of the earth (with the same albedo) is about 254K.
Now you claim that the 324 is responsible for the 33C increase from the greenhouse effect. Does this mean that the 168 W/m2 is responsible for the 254K blackbody temperature?
Goodnight
John
According to Dano, it must be a false premise somehow.
Mark
Bender, what did you think about my explanation for the negative ma(1) coefficients in post 244?
Re #320: Willis, what you’re doing is along the lines of Emanuel’s work. I don’t think you’re using the same variable, though. Why? If you did use the same variable, it would make the results more strictly comparable.
Willis, you explained how you go from MA1(+) to MA1(-) by focusing on the anomalies in this dataset. The results you get support what you say. But this is what I might call a procedural “explanation”. What I’m looking for is a functional explanation.
But before getting into that, a clarification. It seems you are talking here about monthly data? In my #21 was referring to annual data. So it is not clear we are talking apples & apples. Both series exhibit MA1(-); it may or may not be the same functional cause.
I am typically skeptical of parameters from ARMA models unless they are accompanied by the data. (That way I can judge for myself the degree and pattern of nonstationarity.) I’m curious to know if your time-series give the same visual pattern as the one I analyse in #21 – the “foxtail” annual temperatures of Briffa.
Let me see if I can figure out how to paste in graphs at CA and I’ll show you what my analysis is pointing to.
For any who are curious, Emanuel’s page has links to his data and most of his papers. He discusses various corrections that have been made to the raw data. I’m not sure what differences there are with HURDAT, but I suspect some.
Emanuel’s work is based on an entirely different metric (power dissipation over the life of each storm)) from that of the Webster group (maximum wind speeds, which is the basis for the standard Saffir-Simpson hurricane intensity scale).
Re 338, thanks, Steve. Never having heard of Emanuel, I just looked up his method. Turns out he’s doing the exact same thing, using an index which is the integral of v cubed over the lifetime of the cyclone. Man, I love it when that happens, that I independently develop a method which someone else is using … why am I not using his variable? Because I never heard of him before today …
My results are a bit different from his, though. He found a large increase in the last couple decades, while I show a much smaller increase. In addition, he only showed the data back to 1950. Extending it back another hundred years gives a much more complete picture …
In particular, it shows that there have been two other times in the past, 1850-1890 and 1920-1950, during which an increase of the modern kind occurred. Since he only shows since 1950, he doesn’t show the similar historical times. This is in line with his alarmist title for the study, which is about hurricane power dissipation but is titled as being about hurricane “destructiveness” … seems like that boy has an agenda …
w.
“In particular, it shows that there have been two other times in the past, 1850-1890 and 1920-1950, during which an increase of the modern kind occurred.”
Which is in line with the other literature on the mater.
Destructiveness a more variable metric, as less “destruction” happens when no people are in the area. Fallen trees not a matter for as much concern.
Thanks to Willis for the link to the hurricane spreadsheet. Here is a comparison of what you get from annual data vs. four-year summaries of storm counts (all categories).
Top left graph is much like Judith Curry’s. Below that shows the regression line with moderately high r2=0.55. Top right is the annual time-series. Note r2 is cut in half. Finally, note the high variability in the full dataset.
My point? A policy activist will prefer top left (curry) over top right (bender) any day.
Re #343 Graphic not displaying, but looked ok in preview.
Re #343: Pay attention, bender. Did you make this kind of conflation with the tree ring stuff of which Steve M. speaks so highly? I’m beginning to think probably so.
Re #341: You say *he* has an agenda? *snork* If you were paying any attention whatsoever to events in the larger world, or even if you had read through Emanuel’s site prior to your triumphant bout of spreadsheet analysis, you would have found out that Chris Landsea, the person responsible for the data you’ve been working with, was only able to come up with a minor criticism of Emanuel’s results; see comment and response in Nature. Landsea did threaten that additional work on the data base would prove Emanuel wrong, but he has yet to produce that work (and it is not reflected in HURDAT); this was a year ago, BTW. In any case, we are to believe that in a few hours you spotted something that Landsea didn’t. Well, email him with those results immediately! You could generously offer him second author on the paper.
Re #342: Literature, Sid? Let’s see those citations! There’s lots to the contrary. BTW, do you have idea who Muthuvel Chelliah is, and that he admitted in a very public venue that the NHC/HRC has *nothing* in terms of demonstrating a natural cycle connection to hurricane activity?
Index of atlantic hurricanes 1851-2005:
http://www.weather.unisys.com/hurricane/atlantic/index.html
Current list:
http://www.weather.unisys.com/hurricane/index.html
Steve please post the plots of hurricanes developed by Willis and bender here.
It was very clear that Judith Curry’s paper was using data selection in the EXTREME to criticize the NWS for not declaring global warming responsible for the increase in hurricanes in recent years.
Despite there being an absolutely extensive HURDAT dataset series for hurricanes and tropical storms going back to 1850, she uses 6 pentad (5 year) averages and 2 10-year periods (1945-1955 and 1995-2005) to PROVE? her point that hurricanes are increasing.
Just use/show all the data, Judith.
The reason she didn’t is that HURDAT series shows NATURAL VARIABILITY in hurricanes. We can’t have no NATURAL VARIABILITY if we are going to prove that CO2 is responsible for global warming and hurricanes.
Post the plots and the analysis and put another nail in the coffin of these data selectors. This is a big one.
Re: #345
1. Conflation?
2. If you have a problem with the analysis, why didn’t you say so beforehand?
RE: #320 – Thanks so much. If I can find some time, I might mess around with Star Sigma on these. I really like Power as a measure. I think that looking at the interfaces (and internals) of the troposphere in terms of power or work is a key to developing more effective GCMs.
RE: #329 – CO2 is actually highly variable, not constant. But, to borrow an oft used phrase from the Team, is likely does not matter all that much, in the big picture.
Re:# 340, 341, 346.
Great work Bloom. With one link, you manage to refute Judith Curry and validate Willis’ line of thought. From Emanuel’s site at: http://wind.mit.edu/~emanuel/anthro2.htm
… And further down under Essay, 2. Intensity:
#347
Sure Sierra Club Steve. Just as soon as you post the information to back up your “This is turning into a terrible storm season” information.
You made the comment even though in the Atlantic basin it is below normal, or the opposite of terrible.
So do you have actual information or did you really make it up so you could do a little fear Mongering.
Re #345 The only “problems” I can see with what I’ve done is:
1. lumping all categories of storms
2. using a 4-year window instead of 5-year
The first was a matter of convenience, as I’m currently short for time. If you want the analysis dones a little differently, tell me how, and I’ll do it. The second is because with 32 observations they divide more neatly into 4y windows than 5y.
Shifting these parameters any is not going to change the fact that temporal integration reduces sampling error and improves the optics of the statistics – which was my point at RC #3:
(* Remark not contained in original post.)
People often prefer to only look at the Atlantic basin, which has (was) been up. They fail to notice that the Pacific has been down, so the average has been about the same for some time.
Mark
These storms are fantastic negative feedback mechanisms, I’m thinking. Is this accounted for in the GCMs?
317:
Thank you willis.
Plz learn how to use ad hom. Never did I attack you (the definition of ad hom, frequently malused for tactical purposes). Had I used ad hom tactics, I’d have said something like: x, your conclusions are wrong because you are an y. As I did not do this, ad hom is an inappropriate characterization.
To clarify: I commented (in the Dano character way) on the robustness of your conclusions in the comment above, arising from my point in 273. I did not comment on your character or you directly.
As to your extended comment, you should write that up and submit it. Let us know how that goes. I’m sure the folk in the field would like you to share, as they don’t read this blog, so your contribution would be valuable.
More generally, I’m starting to think all the fantastic science that goes on in these comment threads should be rolled up into a journal. Sales from which can be used to pay for the bandwidth costs (certain commenters would be freeloading, but hey). Just take the comment thread (and delete out certain commenters, of course) and make a journal out of it and compete with Science, Nature, GRL, etc…
Think about it: all the discoveries in this blog’s comment threads can overturn not only climate science, but as soon as the prodigious talents here turn their auditing powers to the real heavy hitters such as medicine – why, all of society will be turned on it’s head!
I think someone should run with this. I really do.
333:
Keep it up. I like the fact that you do this. It makes it easier.
=====
341:
Since he only shows since 1950, he doesn’t show the similar historical times. This is in line with his alarmist title for the study, which is about hurricane power dissipation but is titled as being about hurricane “destructiveness” … seems like that boy has an agenda …
What does the paper say about the 1950 choice, willis?
Best,
D
Hey, Dano:
There’s no need to “overturn climate science.” The science speaks for itself and indicates a lot of uncertainty. Only the media and politically motivated people like you keep saying that there is clear evidence for AGW. Look the hundreds of studies that demonstrate this. (still waiting for your big expose on why this information is “tainted”….)
DanàÆàⶬ thanks for your comment in 358. You indeed used an ad hom by saying that I was not qualified to comment, a “vacuum repairperson” rather than a “plumber”. Doesn’t matter which one I am, DanàÆàⶻ what matters is, am I right or wrong?
I would rather think that the proper comparison would be, if you want to know the estimated cost to repair your plumbing, do you ask a plumber for an estimate to repair it, or an independent appraiser? Me, I’d take the appraiser. Why? Because he has no financial stake in the number he presents. The plumber, on the other hand, has a financial stake in the outcome, so he’s likely to exaggerate the numbers … as we have seen all too often with those noted plumbers such as Michael Mann.
Regarding your comment about publishing, I haven’t noted too many papers that you’ve published based on your claims on this blog, but it’s quite possible I’ve missed them … are there any?
Regarding your claim that the “folk in the field” don’t read this blog, of course you can provide us with a citation or some other evidence that this is true? … Me, I suspect they read it quite often, just as I often read RC, to keep up with what’s going on. I don’t comment on RC (got tired of being censored and ignored), they don’t comment here … which proves nothing about who is reading what. Please provide some evidence for your claim … you do remember evidence, don’t you? It’s those inconvenient facts …
Finally, I had said:
You replied:
Dang, DanàÆàⶬ I give up, I don’t know what he said about the choice. He didn’t mention 1950 at all … please let me know the answer to this question, as despite re-reading the paper, I can’t find anything about the reason for the choice.
w.
360:
Thank you willis. I see your point on what I said in 286 and I apologize.
The intent was to illustrate that I get my science from journals, not blog comments. That didn’t come across and I meant no malintent toward you. Generally I enjoy your comments and the (from what I can tell with necessarily limited information) sincere effort behind them.
I haven’t noted too many papers that you’ve published based on your claims on this blog, but it’s quite possible I’ve missed them … are there any?
No, the Dano character exists to attempt to illustrate/track down climate/ecological mis/malinformation. On this site, the Dano character usu points out gross misinformation when the author of the Dano character has a few moments (this week is a slow week). My papers are in the policy/science interface arena and of course not published under Dano.
Regarding your claim that the “folk in the field” don’t read this blog
Boy, I’ve gotta talk to my editor. S/B ‘folk in the field don’t read this blog’s comment section’.
I don’t know what he said about the choice. He didn’t mention 1950 at all … please let me know the answer to this question, as despite re-reading the paper, I can’t find anything about the reason for the choice.
Yet you impute agenda and alarmism.
Best,
D
Re #347 – **who Muthuvel Chelliah is, and that he admitted in a very public venue that the NHC/HRC has *nothing* in terms of demonstrating a natural cycle connection to hurricane activity? **
Admit or state?? To “admit” to something, it first has to be a fact. However, you are constantly making statements not based on fact.
Re#358,
Since when is being a sarcastic smart ass to someone not an attack?
You clearly implied that since he’s a “vacuum repairperson,” you are dismissing his “plumbing” work and siding with the “plumbers.” You don’t explicitly state that he’s wrong, but we all know you would never choose the wrong side, and since you don’t agree with him…
So you are an expert in the field of philosophy, specializing in logical fallacies? Or are you just a “vacuum repairperson” acting as a “plumber” when it comes to such things?
361: thanks for that post, Dano. Now, I think I finally know where you are coming from. “Policy/science interface,” eh? Here I thought you were a scientist, who knew what he was talking about. Could you possibly be a representative of an environmental activist organization (one of the largest industries in the world, BTW), similar to Brother Bloom? And if so, could you possibly have a financial incentive to push the AGW scare? I sure would not doubt it. But I know that it is OK to have a financial incentive, as long as it isn’t provided by “industry.”
The following thread has evolved (well, maybe a bit of *directed* evolution) in a quite interesting direction, note in particular Mr. Berg’s posts:
http://www.realclimate.org/index.php/archives/2006/08/fact-fiction-and-friction/
Re 361, DanàÆàⶬ thanks for the explanation. I remain confused about one thing:
I had said:
You replied:
Thinking that you had found an explanation in the paper that I had not caught, I re-read the paper without success, and replied:
You responded:
Well … in a word, yes. When Emanuel has 150+ years of data available, and without explanation makes a number of strong statements based on only the last fifty years of data, I do suspect that he has an agenda.
His reasoning may be that the earlier data is poorer than the later … which is true, but is true of virtually all of our climate records. If someone were to make strong statements based on an analysis of only the last 50 years of the HadCRUT3 temperature records, I’d wonder why. Similarly, the ACIA published a graph of Arctic temperatures since 1960, which gave a very distorted view of the arctic temperature variations.
So yes, it does make me suspicious. He may have explained it somewhere in his paper, and I didn’t see it, but if not … wouldn’t anyone be suspicious?
w.
Re#366,
No. When a plumber tells you that you need to replace all the plumbing in your house in order to fix what you think is just a dripping faucet, you shouldn’t be suspicious. To question his conclusions would be to impute agenda and alarmism. Just write a check to cover the costs, recommend the plumber to all of your friends, then anonymously and playfully irritate and scorn any of those who dare to be s(c)eptical. HTH.
366:
Thank you willis.
When I have a question about a paper I’m using, I:
o e-mail the author [to find the information I seek],
o give my name & title [to show I’m not a crank],
o usually give a one-sentence who I studied under [credentials],
o then state my question with an explanation [why I’m e-m’g author].
The author may or may not reply with an explanation. Sometimes I get a 2-3 reply thing going until I understand.
You may want to try this technique. Let me know if you get a reply.
Best,
D
Consider the following scenario. In spite of our best efforts, the idea that “we are past the tipping point” and that “drastic action is needed now” takes hold among the masses and politicians. Geoengineering efforts are kicked off at the same time that a 25% global carbon tax gets put into place to fund them.
Subscenario A: It was a complete overreaction to innate variation. The global economy crashes and the next LIA gets missed until we are in the thick of it. Due to the global economic crisis, the response to the new LIA is pathetic. Famine ensues.
Subscenario B: The geoengineering efforts go too far, plunging the Earth into the next Ice Age.
Subscenario C: There are unintended consequences due to the geoengineering and although it starts to cool the climate, there are many extinctions and chain reaction events resulting in a global disaster of epic proportions.
=======================
And if anyone thinks this is far fetched, those who have spent time at RC know they get seriously discussed by people who ought to know better. Comments?
Thanks, Danàƒⶬ done. We’ll see what he says.
w.
369:
I see Ralph’s has Reynold’s Wrap on sale in the 50ft roll. Looks like you could drive to, say, Willits (or is that a Safeway up there?) and get some and get a nice drive out of it.
Two birds with one stone, I say. Redwoods would be a bonus. Mattole valley thru the redwoods & then the beach – nice and relaxing, take the stress off. Maybe some humpies moving south. I miss that stuff…
Best,
D
RE: #371 – Nice dodge. Pretty uncomfortable topic I see. That’s the thing. You could pretty much turn around the typical “the ole bidness/car companies/Bush are playing with the fate of Earth” and say essentially the same thing about some of the more extreme elements who post at RC. “We must do something now!” – what, pray tell? Just what? Show me the plan!
373:
Not uncomfortable at all, nor a dodge.
Who cares what a few fringe people rant about, and when they do, why would you want to conflate them with the mainstream?
You asked for comments, and in the Dano way I commented on the quality and usefulness of the comment.
Best,
D
370:
Not a problem willis.
Bset,
D
Re #362: So you don’t know who Chelliah is, hmm?
Re #375 – Read my comment again Steve B. I did not say I do not know who Chelliah is – I suggested that you will quote as proof or authority anyone who says what you want to hear. I suggest that there is enough documentation of natural cycles. Again, I repeat, what was stated (in your words “admitted”) was not fact, but more an opinion as you did not produce a peer-reviewed paper. Your problem is that you need a clear conscience to see the golden apparel of the King, hmmm.
Re #376: Ah, so you haven’t seen all the peer-reviewed papers on the other side of the debate. That’s a credibility-stretching quantity of inattentiveness, Gerald, but fair enough: I’ll pull all the links together and post them. Then you can post all the papers on the other side — not the ones that speculate or provide anecdotes, but the ones that actually have *proof*. It shouldn’t take long. In fact, it should take no time at all! 🙂
Re #370: See below from Emanuel’s Q+A, saving Willis some time. The whole Q+A is here.
4.) Q: But aren’t there lots of errors in the hurricane record?
A: Yes, there are. Reliable records of wind speeds in hurricanes over the open ocean go back only to around 1950, when aircraft reconnaissance of hurricanes began over the North Atlantic and western North Pacific; before that, the only good measurements of wind speed were made when hurricanes made landfall or passed over islands or ships with measuring equipment. Unfortunately, methods of measuring or estimating wind speed from aircraft have evolved over time, and these changes were not always well documented. Since about 1980, there are wind estimates for all hurricanes globally, based on satellite images, but these are not as good as aircraft measurements.
5.) Q: Then how can you determine trends with such data?
A: Fortunately, the means of estimating the central surface pressure in hurricanes have remained fairly constant with time. In practice, central pressure is well correlated with maximum wind speed, and therefore can be used to detect changes in the way winds were estimated from pressures. Also, in a large enough sample of events, the wind speeds are well correlated with a quantity call the “potential intensity”, which is a function of the temperature of both the ocean and atmosphere. We have fairly good records of the information needed to calculate potential intensity, and so can compare estimated wind speeds with estimated potential intensity for large enough samples. This is another check on the quality of the wind estimates. Even in the Southern Hemisphere, where there have never been aircraft observations of hurricanes, the satellite-based estimates compare well with estimates of potential intensity.
6.) Q: You say that reliable records of hurricane wind speeds go back only to about 1950, so how can you say that there were not even more intense storms before 1950? How can you assert that the upswing in the last 50 years is a consequence of global warming?
A: We cannot say for sure. What we can say is that everywhere we have looked, the change in hurricane energy consumption follows very closely the change in tropical sea surface temperature. When the sea surface temperature falls, the energy consumption falls, and conversely, when it rises, so too does the energy consumption. Both theory and models of hurricane intensity predict that this should be so as well. In contrast to the hurricane record, the record of tropical ocean temperature is less prone to error and goes back 150 years or so. Moreover, geochemical methods have been developed to infer sea surface temperature from corals and from the shells left behind by micro-organisms that live near the surface; these can be used to estimate sea surface temperature for the past several thousand years. These records strongly suggest that the 0.5 degree centigrade (1 degree Fahrenheit) warming of the tropical oceans we have seen in the past 50 years is unprecedented for perhaps as long as a few thousand years. Scientists who work on these records therefore believe that the recent increase is anthropogenic.
Had to get clear to the end to encounter the bogus logic:
“These records strongly suggest that the 0.5 degree centigrade (1 degree Fahrenheit) warming of the tropical oceans we have seen in the past 50 years is unprecedented for perhaps as long as a few thousand years. Scientists who work on these records therefore believe that the recent increase is anthropogenic.”
So, SST records go back a few thousand years? That’s news to me. Even within the actual record horizon, I’d say the quality of the records would need to be characterized before I’d hang my hat on them. Personally I’d trust no SST records earlier than the onset of automated bouys. It’s always back to that same “unprecedented in X years” thing. That’s what sunk the IPCC.
378:
1950. Measurement type. Huh.
;o)
Best,
D
Re #378 – **Scientists who work on these records therefore believe that the recent increase is anthropogenic.””
“Believe” is not scientific. Is that the type of “proof” you refer to in #377. If you are going to give me links, you can forget about the 30 or 35 year studies by Emmanuel and Curry. Those only give the results you want. And I know you are going to ignore Landsea and Gray, so you will stretch your credibility. I also notice you have been ignoring the thread of Bender’s plot of the number of hurricanes and the discussion.
382:
“Believe” is not scientific.
That’s all you got? It’s a conversation, not an abstract in a journal. Come now. Sheesh.
Best,
D
Re 378, Steve, thanks for the information. However, I fear that I am far from convinced by his arguments.
He says that he started in 1950 because that’s when aircraft reconnaissance started. Before that, hurricane wind speeds were based on data collected by ships. While this is true, in many cases ship-based collection would result in better data (because the ships could record barometric pressure, which the planes could not do until the development of the “drop probes”), and because the ships would spend many hours in a hurricane, where a plane would only be in the hurricane for an hour or so.
In fact, there is no significant change in either the number of reported hurricanes or in the strength of the hurricanes in 1950. I just posted some graphs at Bender’s Plot of Hurricanes, so you can see for yourself — very little difference.
Finally, the idea that we should ignore perfectly good data just because it is less accurate than more modern data flies in the face of all other climate research. No one ignores the pre-1900 HadCRUT3 temperature data just because the error bars are twice as large as for the modern data.
In short, I find his reasoning specious and tortured.
w.
383:
While this is true, in many cases ship-based collection would result in better data (because the ships could record barometric pressure, which the planes could not do until the development of the “drop [sondes])
Ships steering into eyewalls, eh, and making multiple penetrations?
Who knew?
No one ignores the pre-1900 HadCRUT3 temperature data just because the error bars are twice as large as for the modern data.
Yet Warwick Hughes and Daly want to nit-pick over the accuracy of moved stations when making their UHI arguments.
Best,
D
#378. Steve Bloom posted the following from Emanuel’s Q&A:
The NAS Panel did not mention any coral records that say this and I’m sure that would have if they could. Schrag’s presentation said that corals didn’t go back that far. I guess Emanuel’s just pulling our legs – the Team are such pranksters. Steve Bloom, do you mind emailing Emanuel and asking him about the basis for his assertion about corals that you quoted for us.
Re #385: It would be even easier to get you to re-read what he said, only more carefully this time. Note that he referred to both coral and foraminifers as constituting the record. I don’t take the phrasing to mean that the corals go back that far.
Re 384, Dano, thanks for your post. I said:
Your reply:
I fear that you missed my point entirely. Of course we all want the best data, and we know that there is no adjustment in the HadCRUT data for UHI. It is a valid issue (and your description of questioning it as “nit-picking” just reveals your inherently unpleasant attitude.)
Despite that, we all still use the data, because it’s the best we have. I don’t find anyone saying, as Emanuel says, “I’ll just use the recent HadCRUT3 data, thanks, but not the older data”.
w.
Re #387: Willis, Emanuel’s reasoning about not using that earlier data (also see my response on the other thread) is that 1) it’s unreliable (bearing in mind especially the type of data needed to derive PDI), 2) it’s North Atlantic only and so global comparisons using a large data set are not possible, and 3) SST trends were not such during that period that they could have been a major factor in PDI trends. Figuring out what factors did drive PDI then is interesting, but probably very difficult (due to a lack of data on historical wind shear, e.g.) and certainly not relevant to figuring out how future climate change is likely to affect future hurricane activity.
Re 388, Steve, thank you for your comments. I am well aware of Emanuel’s reasoning for throwing out 2/3 of the data. But as I remarked on the other thread:
… perhaps you could point to a climate dataset that doesn’t have problems? … My point is simply that generally we work with the best data we have, which of course is always subject to revision.
What is unusual about Emanuel’s work is that he has picked the data he likes, and thrown out the rest. Perhaps, while you’re finding a problem-free climate dataset, you could also find an example of someone other than Emanuel working with half a dataset …
w.
Reading the FAQs, I’m surprised Emanual isn’t considered a borderline s(k)eptic.
Willis
Before Steve B Gets you your perfect climate data, I was under the assumption he was going to provide a reference to why this storm season is shaping up to be “Terrible”
I’ve got a feeling it’s a combination of models and “gut feelings” by other scare mongerers like him. NOthing based in reality.
Re 390: “Reading the FAQs, I’m surprised Emanual isn’t considered a borderline s(k)eptic.”
Actually, he is, or at least was, a pretty profound AGW skeptic. (Disclosure: He was a college buddy of mine in the 70s.) He delivered the best take-down I have EVER heard of AGW certainty. (I still remember his quip that he was starting a group called the Union of Scientists Concerned about the Union of Concerned Scientists — I think of it every time I see a press release from the UCS.) I noted also that he was very careful not say that AGW was not happening — his point was that there was far too much uncertainty. But that was back in 1990.
Reading some of his more recent stuff, he seems influenced by what he sees as a rapid rise in ocean temperatures, so his thinking may have changed somewhat since then.
I’m puzzled by the criticisms above that he only went back to 1950, because before then the data is far sparser and tougher to relate to modern data. Isn’t one of the main criticisms of the Hockey Team on this website that they are trying to stitch together too many different types of data that cannot necessarily be matched together? Emanuel seems to me to be a much more careful scientist than the Hockey Team, he is stating carefully the limits of his data set and conclusions. Yes, I think the next step is to try (very carefully) to take this data back further, but whoever does this has to be very careful to avoid Hockey-Team-type issues.
Yes and no. Really, the main criticism with the data is that they are trying to stitch together data that does not provide a good indicator of their a-priori conclusions. They could just as well be using the stock market to determine temperatures. The other main criticism is that they don’t know how to use the statistical methods that form the basis nearly every one of these studies.
Mark
383, 387 (389):
Thank you willis.
Do let us know the outcome of your e-m with Emanuel, esp his answer to your assertion that he picked the data he likes. And why he threw out that multiple-penetration ship data.
Best,
D
Danàƒⶬ I wrote Emanuel saying
I just received this from Emanuel:
While he is clearly sincere, this is not convincing.
Regarding your “multiple penetrations” question, sounds kinda kinky, but hey, that’s you. Your reference says nothing about multiple penetrations. It does say that even in the aircraft era, wind speeds continued to be measured by barometric pressure (from ships or planes) in preference to aircraft:
In any case, the existence of better data does not invalidate the older data. The HURDAT reanalysis project has spent thousands of man-hours on perfecting their data. Here’s a description of their method:
And here’s a typical report, this one from 1856:
This is perfectly valid data, and it makes no sense to ignore it. The worst that can happen from using these and other reports of this type is that we would underestimate the strength and number of hurricanes. However, there’s not much sign of that in the data. If you look at my graph of the Hurdat data at Bender’s Plot of Hurricanes, you can see that we have two choices:
a) the underestimation was not very large, or
b) the underestimation was large, and the average number or power of the storms has decreased markedly.
In any case, the data is there and has been subject to far more rigorous examination and correction that the HadCRUT3 temperature database. You can advocate throwing it out if you wish. Me, I’ll use it.
Hey, I just thought of something. There should be some kind of relation between landfalling hurricanes (for which we have better records) and total hurricanes (worse records) for any given year. Let me see if the fraction of recorded landfalling ‘canes has changed, I suspect it has dropped, and we can estimate the size of the underreporting from that … back in a minute … OK, here’s the results:
As you can see, the reported figures drop from about 25% during the majority of the ship era, to about 15% during the modern aircraft and satellite era. A comparable analysis of the relative strengths of the landfalling and non-landfalling hurricanes should allow us to correct the early records with a reasonable degree of accuracy.
My point is simple. The data is there, and it’s good, albeit sparse, data … we should use it. This is particularly true since we know the direction of the error in the data (underestimation). Emanuel even talks in his email about one of the ways it could be done. I have added another here.
w.
Really interesting and intriguing, Willis! You should publish this stuff. Don’t bother sending it to Science or Nature, though…
RE #389,
Is this caveat noted in the paper? Does the removal of this data affect the results (I assume not)?
I could never use data I had “grave reservations” about.
395:
Thank you again willis.
I _am_ kinda kinky, willis, for which my fiancé is often grateful.
But the larger point is that there is a data quality difference between plane and ship; as even when on specific assignment to get data, ships have difficulty surviving penetrating eyewall and thus central BP is often estimated (hence part of the reason for the HURDAT project); I suspect this is the concern. Nonetheless, certainly if you feel the need to want to include that data you mention above, write it up and submit it – Journ Clim or Int J Clim is where I’d send it. IIRC Emanuel in his paper explained the diff between just thinking about landfalling hrcns and total hrcns so there’s more math there.
Best,
D
Re #398,
It was disturbing enough we have to hear from Steve B that Gore is one of the greatest VPs ever – now we have to hear this? It begs the question though: is this kinky one the person behind Dano himself/herself, another facet to the Dano character, or yet another of the multiple personalities? One has to wonder if maybe said fiance is just another personality, or another character.
Certainly. But one could interpret Willis’ graph as suggesting that warming may keep hurricanes out at sea, where large populations of coastal and inland land-lubbers aren’t impacted quite so much.
Willis,
Why not correct the total count of hurricanes using your plot of percentage that are landfalling? You could take the mean percentage for 1958-present (about 15%) and divide that into the smoothed percentage means you show (about 25% in the earlier data) for a multiplication factor about 1.67 on average, for the earlier, with a smaller multiplier for say 1930-1957.
If you do so, I think you will find peaks in hurricanes centered around 1890 and 1935 that have higher counts than now using decadal means.
Looking forward to seeing such a plot.
Re #395: You’re trying to make something out of nothing, Willis.
"(T)he existence of better data does not invalidate the older data." Not as such, I suppose, but it sure could change the conclusions that could be drawn from analyzing it.
"A comparable analysis of the relative strengths of the landfalling and non-landfalling hurricanes should allow us to correct the early records with a reasonable degree of accuracy." I don’t think so. The landfalling record fundamentally lacks enough data points. Even if it were large enough, one would have to be able to deconvolute with some confidence various factors (e.g., trends in the behavior of the Bermuda High) that might influence tracking over a period of time.
But this is your worst nightmare, isn’t it? A long-time confirmed skeptic, the originator of hurricane theory (you knew that, yes?) whose own work predicted we shouldn’t be seeing a detectable signal yet, compelled by his research to revise his views.
Re #396: Or anywhere. But do post the rejection emails, please. But I take that back (a little): Maybe E&E will publish it.
RE: #401 – You definitely do not understand the plot in #395 and just what is its significance, do you? Or, if you do understand it, you simply cannot face it. Pathetic.
RE: the new #401 – referred to the now deleted old #401.
Re #399: "Certainly. But one could interpret Willis’ graph as suggesting that warming may keep hurricanes out at sea, where large populations of coastal and inland land-lubbers aren’t impacted quite so much." It’s just that one would have a hard time imagining that (for the North Atlantic) given the 2004/5 seasons.
?? Because YOU say so?
RE: #404 – because he is either not trained well enough analytically, or, he is, and simply cannot face it. He cannot face the fact that the “baseline” used by hysteria mongers to claim “hurricanes have increased / are increasing” (e.g. pre 1950 or so) is artificially depressed due to the fact that not all hurricanes were counted way back when, and the fact that the past peaks of occurrence therefore are also washed out, data wise.
405:
This is what Emanuel was trying to show. Apparently you disagree. Let us know which journal accepts your manuscript.
Best,
D
405. He is trained well enough. It just fascinates me that an obviously very intelligent person can ALWAYS take the extreme “warmer” side on ALL topics. Never a shred of doubt. That is not scientific, for sure. It is proof of a real agenda and financial compensation. I call it prostitution.
Just a follow-on to my previous comment.
For 1864-2005, there were 244 landfalling hurricanes. If this represents 15% of the total, as recent years suggest, then there were about 1625 hurricanes and tropical storms for 1864-2005. 1199 storms were observed, so it appears that about 400 storms occurred that were never recorded.
Another one deleted! Well, well, John A. *is* up to his old tricks. The mouse will play. It’s irritating to have to ask Steve M. to squelch him as often as seems to be necessary, especially as rhetoric like that used in #405 (“hysteria mongers”) and #407 (“proof of […] financial compensation. I call it prostitution.” — say, isn’t that libel?) seem to be an acceptable baseline around here.
BTW, I say “libel” because I have explicitly told jae that I am not paid to do this stuff (or any of my environmental work), and with occasional minor exceptions don’t even ask for reimbursement for expenses; i.e., I pay to do it.
Bloom, stom whining. We all know those rules arent intended to apply to members of the club – especially Steve’s attack dog co-moderator. They exist to keep the interlopers under control.
410:
Dano is completely banned from RP Sr & RP Jr too. At least I can post here.
Best,
D
Re#403:
So by that logic, it’s justifiable to you when a cold winter or two makes it hard for someone to imagine global warming (either anthropogenic, natural, or both) is real?
It must have been something you said.
413:
It must have been something you said.
Probably.
I don’t think someone liked me enumerating the cherry-picked items from a see-oh-too article that a commenter on RP Sr used to support an argument.
After I submitted that I couldn’t comment any more.
Best,
D
Re #395 Willis,
The underestimation problem is well known which is why some alarmists point to the satellite era (from the 1970s onwards) and the apparent rise there. The only problem is that mutlidecadal oscillations in hurricane frequency are misinterpreted (or misrepresented) as linear increases in activity (and this is on a basin-by-basin basis)
Has _global_ hurricane intensity/frequency increased? No. Some basins (the Atlantic) have recently increased while others are remarkably quiet.
To me, it’s much more likely that increased hurricane frequency/intensity is linked with global cooling events, but the records are simply too sparse on the scale of centuries to make much of a conclusion one way or the other.
It must have had something to do with the way you said it. Usually with maximum sarcasm and minimal argumentation, if your efforts on here are anything to go by.
In any case the Pielkes have become remarkably more skeptical of wild claims made in climate science. I think they’ve realised that another Hockey Stick fiasco could send climatology back to the scientific backwater whence it came.
Wait a minute–I have never said you were affiliated with the Sierra Club. That’s Bloom. I take back my apology.
Bloom – Sierra Club, Green Party, …….. ,
Sr. has always had a more conservative viewpoint (though not really as “skeptical” as he seems now). Jr., however, in my opinion, was almost an alarmist of sorts. Some of his recent statements have been rather grounded.
Mark
#420 Pielke Sr. makes some valid scientific points. We need more like him. Jr. knows nothing about the science (and doesn’t claim to). His views on climate policy are not always easy to follow though. Social scientists can say one thing one day and another thing the next day, and still claim to be consistent…
Re 400, Doug, thanks for your comment. You say:
Well, easier said than done. Come along with me on a journey through the math.
I thought about doing it your way (increase the numbers by some kind of multiplier), but that assumed that the missing hurricanes were proportional to the number of landfalling hurricanes. So first, I thought I’d see if that was true.
To determine that, I took the linear regression of total hurricanes over landfalling hurrincanes for the period since 1951 (where I figured we have the most accurate figures), and compare it to the earlier century (1851 – 1950). To my surprise, I found that the slopes were identical to two significant digits::
1851-1950 T = 1.30 L + 5.4
1951-2005 T = 1.26 L + 9.0
where T = Total hurricanes and L = landfalling hurricanes.
This strongly implied that the chances of missing a hurricane did not depend on the number of landfalling hurricanes.
This left the problem of exactly how to apportion the missing hurricanes. Should they be apportioned based on the number of total hurricanes in a year, figuring if there were more hurricanes in a given year, that more were more likely missed? Or the reverse, figuring that if the numbers were low, it meant that some were missed?
Actually, the slope of the two linear regressions implies that on average we are missing 3.6 hurricanes each year over the earlier period. The best way to apportion the hurricanes, in the absense of any other information, is to add them evenly along the entire period. Kinda bozo, but it has one great advantage, which is it leaves any underlying cycles and standard deviations unaltered. Here are the two records, the original unadjusted version and the one with my adjustments:
Now, before Steve Bloom or DanàÆàⶠmakes some disparaging, sly, nasty remark about my ancestry or my qualifications or my motives or the value of my analysis, let me explain why I do these kinds of analyses. It’s because I don’t trust the plumbers that Steve and DanàÆàⶠput so much stock in, not one bit. I’ve seen too much scamming and bogus statistics and hype and bad mathematics and all kinds of bovine excrement being passed off as science by those jokers. If this were being done by amateurs, it might be understandable, but this is being done by Michael Mann and Phil Jones and Gavin Schmidt and far too many of the stellar luminaries in the field.
So me, I do the math myself. I go back to the original sources and run the numbers myself, draw up the graphs, and come to my own conclusions. That’s one of the beauties of climate science … it’s not rocket science. In this case, my conclusion is, the number of Atlantic hurricanes hasn’t changed much in the last 150 years.
Steve and DanàÆàⶠand a lot of folks seem to think that if some piece of research has been done by somebody with a degree or somebody who does this for a living, and then has been published in some prestigious journal, you don’t have to think about it critically, you can simply believe it.
Me, I take a different tack “¢’¬? I read the research, and I think about it. I don’t pay any attention to who wrote it, or where it was published. I read it and think about it.
Often, I apply the simplest of common sense tests to the data. If we add one watt/m2 to the 490 watts/m2 currently heating the surface, will it make much difference? If 324 watts of downwelling IR have changed the earth’s temperature by 33°, will another watt change it one degree?
In general, I am very suspicious of several things. One is correlations that are too good to be true. Hansen’s “smoking gun” alignment of computer results and ocean temperatures comes to mind, you can read about it here.
Correlations in nature are rarely that good. (I seriously doubt whether Hansen will extend his study for two years, given the recent paper in Nature showing that the ocean has cooled markedly from 2003 to 2005. He’ll just say he’s “moved on” …)
The second is computer models of the climate. I have said it before, but it bears repeating. The climate system is a non-linear, multi-stable, internally and externally driven, resonant, optimally turbulent, constructal terawatt-scale heat engine with a large number of known and unknown drivers and feedbacks. It has five major subsystems (ocean, atmosphere, cryosphere, lithosphere, and biosphere), each of which has feedbacks both within itself and with all the other subsystems. We cannot even successfully model any of the five subsystems. Computer simulation of turbulent systems is in its infancy. The climate is far and away the most complex system that humans have ever tried to model, and we’ve only been at it for a few years. The idea that we can now predict the climate of 100 hears hence is a joke.
The third is results which require sophisticated analysis to tease out a tiny signal which is buried in a mass of noise. The potential for error and either conscious or unconscious manipulation of the results is simply too large to put much trust in any such results.
The fourth is any explanation involving “positive feedback”. The earth’s climate has stayed amazingly stable for a couple billion years. This means that negative feedbacks must predominate.
The final one is consensus, particularly the IPCC consensus. For example, the IPCC blindly accepts the results from all climate models, without even the slightest attempt to find out if each one is any good. This is all too typical of the thought processes, or lack thereof, of the IPCC. The current state of climate science is a scandal. If Phil Jones, Michael Mann, and Gavin Schmidt all agree on something, it’s most likely wrong — see their recent Svalbard nonsence that I have chronicled on this site. The consensus of fools is worthless, and a consensus of savants is not much better.
So, my response to this torrent of bad data and hyped results is, I run the numbers myself, and I think about them. I don’t depend on anyone else “¢’¬? not on a plumber, not on a prestigious journal, not even on Steve M. I know it’s a novel concept, but I highly recommend it. So, Steve Bloom, and DanàÆàⶬ before reaching for your electronic pens … think about this stuff yourself. Don’t listen to anyone, think for yourselves. Don’t both with ad hominem attacks, don’t waste your time being snide and nasty about my work, just think about it …
Radiation heating the earth’s surface is predicted to go from 490 to 491 w/m2 … EVERYONE PANIC!!!
w.
Nice post Willis.
Re #424: Yes, a very nice invention of those storms entirely out of thin air. Willis, I’m a believer in proper skepticism, but that’s hardly a justification for what you did here. Just two points off the top of my head: Observations improved throughout that period such that missed storms would have to be concentrated in the early part of it, and the data problem is probably primarily not missed storms at all but rather underestimeated/overestimated intensity and incomplete track information.
BTW, Lyman et al was in GRL, not Nature. It’s an interesting paper, but if you followed the discussion you will know that there is a problem with the authors’ conclusion that to account for thie observations the freshwater inflow into the oceans must be 6 mm/yr for the last two years (rather than the 2 mm/yr figure inferred from the very recent GRACE data). This would be rather getting very close to abrupt climate change territory if true, and is hardly something in which denialists should take comfort! On the face of it, scientists who commented thought it more likely that there was a problem with the data collection or that warm water is escaping into the deep oceans. Both of those explanations would be far less amazing, but Lyman et al seem convinced it must be freshwater inflow.
I should add that I did not respond to Michael Jankowski’s attempted refutation (in a different thread) of the above reasoning. He had brought up older data to try to show that there must have been comparable freshwater water inflows in the recent past. The short answer is that very recent data (via GRACE just in the last year or so, the ARGO float network in the last two years, and increased accuracy in sea surface altimetry) are vastly more accurate, so we can be much more sure that there’s a real conflict in the numbers.
Re 424, Steve, first you bust me for the “invention” of storms “out of thin air” … then you bust me for not inventing them properly …
The data problem is missed storms as well as intensity and track info, we’ve been through that already, I showed that the ratio of known storms to total storms had changed from about 25% in the early record to about 15% in the later record, clearly indicating missed storms. See post 395, which also refutes your idea that “observations improved throughout that period”. Other than the first decade of the record, the ratio remained around 25% … haven’t you been following this thread?
Finally, yes, there are questions about the Lyman data … my point was simply that Hansen’s paper, showing perfect alignment of sea temperatures and his computer model, was doubtful because it was too good. The Lyman data was only a small part of that, you can ignore my comment entirely, because Hansen’s study was bogus with or without Lyman.
In the future, please engage your brain before speaking up. I requested that you not get all nasty about my calculations, I explained why I do them, I explained that they are a first cut at improving what we all agree is problematic data, data that everyone agrees is missing storms in the early part of the record, and what’s the first thing out of your mouth?
Foul nastiness, accusations of inventing storms …
w.
Re #425: Willis, referring me back to your own prior calculation doesn’t help. But as I re-read tour #395 I did spot this sentence from the HURDAT methodology: “This allows for adjustment of the existing track and intensity estimates as well as occassionally adding a new tropical storm or hurricane to the database that was not previously recognized as being a tropical cyclone.” Note the misspelled word. IOW, they don’t expect to find many. If there was any validity to the adjustment you propose, don’t you think it would have occurred to some hurricane specialist? Also, you make a very big and very unjustified assumption that there was nothing in the past that affected either the proportion of landfalling storms or the records of them.
426: Hey, Dano, a lot of this stuff has already been published in peer-reviewed journals.
Willis – I give up. I already posted a way of looking at your numbers that shows that something is wrong with them and you just ignored it. I gave a reference in the text that disputed your number and you ignored it. This is of course your right, but in that case please don’t use several paragraphs to explain how you examine the science.
John
re: #427
You’ve got me confused. What message of Willis are you complaining about? I just went back and looked at every message you have on this thread and none of them concerns storms, what Willis is discussing lately. You had a lot of messages on IR feedbacks, but unless you mention a message number nobody, including Willis, is able to guess what you’re talking about.
From the Q&A, response to #7:
When this increase in population and wealth is accounted for, there is no discernible trend left in the hurricane damage data…we estimate that it would take at least another 50 years to detect any long-term trend in U.S. landfalling hurricane statistics, so powerful is the role of chance in these numbers.
Maybe his grandkids will be able to “detect” a “discernible trend” of any importance before they die.
RE: “Observations improved throughout that period such that missed storms would have to be concentrated in the early part of it”
And so, based on that, an even better correction factor might be possible. Now, imagining that such a factor would distribute more of the missed storms earlier in the pre 1950 period, think about how the curve would then turn out. Great idea Steve B. Maybe Willis can try it.
I like W’s ability to put things in context.
“Radiation heating the earth’s surface is predicted to go from 490 to 491 w/m2 … EVERYONE PANIC!!!”
Rather than panic I look forward to the world edging ever so slightly toward a tropical climate (mental picture!) away from an artic climate (mental picture!).
Re 431, Steve S., thanks for picking up on this question. You say:
I had considered doing that, but I felt that if I did so, I would be accused of introducing an artificial trend into the data. So I added the storms level all the way across the board, no introduced trend.
However, it is clear that, while for the most part the landfall/total ratio is either about 25% or about 15%, there are two transition periods. The first is at the start of the data, where the ratio is about 40%, and the other is during the transition from the 25% to the 15%.
To weight the additional storms based solely on the L/T ratio, however, would remove other cyclical swings … actually, it could be done, by using a very wide gaussian average to filter out decadal differences, and use that to determine the appropriate amount of additional storms …
Let me think about that one …
w.
Re #431: I never underestimate the power of imagination in AGW denialism, Steve S. But, taking your comment at face value:
“And so, based on that, an even better correction factor might be possible.”
Well, I suppose it might be. But does anyone in the hurricane field think there’s the faintest possibility that it is? Not to my knowledge. Do you have some scientific basis for actually thinking so? By all means let’s hear it.
Why does this make me think about climate models?
Well, per the suggestions by Steve Bloom and Steve Sadlov, here’s the latest adjustments:
Recent measurements have shown that one hurricane in six (14%) of all hurricanes make landfall in the US. This has remained the same for the entire modern period (1960 onwards).
Early observations (1850s) of total hurricanes found only about three times the number of landfalling hurricanes, indicating that about half were missed. This number gradually increased to about four times landfalling, and basically held there until about 1925, when it gradually started to decrease to the modern value.
I have adjusted the number of total hurricanes upwards based on the year to year average value of landfalling/total hurricanes, using a long-period (57 year = +/-3 SD) gaussian average to retain decadal fluctuations.
w.
re 422:
Willis (and doug)
As mentioned earlier the radiative equilibrium concept dictates that earth+atmosphere Top of atmosphere outgouing radiation is in equilibrium with incoming radiation.
Let’s say that
this modtran run pictures the case of present equilibrium. 375 ppm midlatitude summer.
Iout = 279.648 W/m2
Ground T = 294.20 K
Double CO2 to 750 ppm:
this modtran run pictures the case of 750 ppm midlatitude summer.
Iout = 276.791 W / m2
Ground T = 294.20 K
restoring equilibrium:
this modtran run pictures the case of 750 ppm midlatitude summer, with a surface temperature offset of 0.85 degrees.
Iout = 279.648 W/m2
Ground T = 295.05 K
so for a doubling of CO2 a temperature increase of 0.85 degrees is needed to restore radiative equilibrium.
finally, removing all major greenhouse gases (including water vapour and stratospheric ozone) NB this can’t be completely done in this online version as NOx cannot be set to zero:
this modtran run pictures the case of 0 ppm midlatitude summer.
Iout = 371.776 W/m2
Ground T = 294.20 K
Balancing radiation:
this modtran run pictures the case of 0 ppm midlatitude summer, with a surface temperature offset of -21.9 degrees.
Iout = 279.648 W/m2
Ground T = 272.30 K
so climate sensitivity:
zero ghg: 21.9/(371.776-279.648) = 0.23771 K/Wm-2
double CO2: 92.128/(279.648-276.791) = 0.29751 K/Wm-2
Hans, thanks for the calculations. You say:
While this is true, that balance only applies to the whole earth over a period of time, not to one point on the earth at one time (say midlatitude summer, as in your example). Therefore, your calculation, which assumes that balance, is not correct “¢’¬? there is no reason to assume the balance at that one point in time and space.
For the whole earth, the accepted value of the TOA outgoing radiation is about 235 w/m2, not 279 w/m2 as your example shows for the midlatitude summer.
Thus, your calculations are far from correct, and do not give the right answers to the questions that you are asking.
w.
Hans, Modtran only calculates numbers for clear skies, if I recall correctly. The empirical results involve both clear and cloudy skies. This may explain why one gets different answers. Also, negative feedbacks as indicated in Karner’s study, such as increased cloud cover, may depress the climate sensitivity.
are yours any better?
willis you still haven’t explained why the blackbody approximation is valid on a planet with an ghg atmosphere. I think it isn’t, because the lapse rate won’t go steeper, ending up with a radiation deficit, the surface being to cool for radiative equilibrium. Hence the surface will warm up until equilibrium is reestablished.
Re 437, Hans, in your Intensity vs Wavelength plots what are the 300k, 280k, etc lines. I thought they were from Planck equation but the maximums (peaks) don’t seem to match up. Thanks Phil
Re 441, Hans, not sure what your question is. The surface of the planet radiates close to a blackbody, as the emissivity is >0.95. What does a GHG atmosphere have to do with it? Everything radiates, trees, houses, people and planets, with or without an atmosphere. Perhaps I’m misunderstanding what you are asking.
Also, you ask if my calculations are any better … which calculations of mine are you referring to?
Many thanks,
w.
Hans, I’ve been thinking about your statement that the surface is too cool for radiative equilibrium. The reason is, the equilibrium does not involve just radiation. Let me start with the Kiehl/Trenberth energy budget, which most everyone in the field agrees is at least close on the major flows. It is not internally balanced, but let me deal with that later. Here’s the budget:
Now my point here is that the surface is not in radiative equilibrium, but in total equilibrium. It receives radiation from the sun, and from downwelling IR from the “greenhouse effect.” It loses heat through radiation, conduction, evaporation, and hydrometeors. These all balance, so that on average the surface both receives and loses about 490 w/m2.
Now, the whole system is in balance, and in approximate thermal equilibrium. The planet as a whole receives about what it radiates, and the same is true of the atmosphere and the surface. However, this is only on average.
For example, the equator receives much more energy from the sun than it radiates back out into space. It gets rid of the excess by circulating it to the poles. At the poles, on the other hand, the earth radiates much more energy than it receives.
And this is why your calculation doesn’t work “¢’¬? because at any point on earth at any time, there is no balance. It will radiate more than it receives, or less, but the odds of any point being in balance at any moment are almost nil … and if it is in balance, it will go out of balance within minutes as the conditions change.
w.
Re 327 the observations are correct.There are also substantial decreases in both SH m-high latitude SST and stratospheric temperatures.This is expected due to the stage of the solar mimima occuring in march this year.The unpredicted occurence of La Nina and the observation of increased EEP(energetic electron precipitaion).The decreasing SH high latitude pressure gradients etc.
Somewhat higher SH stratospheric temperature changes from 0.5mid to 2k are evident as expected.The increased EEP should see further T decrease of around 5k over the High southern latitudes due to increased ozone depletion of around 30% to 45% in spring due to increased stratospheric cloud and photolysis.
The decreasing SH winter T should bring some intersting results to the Atlantic temperature gradients.
Re 358, Dano, you thought you were mocking when spoke of switching to medicine, but you speak a beautiful truth. I am already there. I published in Energy and Environment in March, and at the same time my anticancer formulation, which I co-invented with two professors from Purdue, has a number of people with throat cancer and prostate cancer in remission. You don’t have to give up your day job to do this, because I drilled a couple of oilwells (as operational director) and ran a company that discovered a zinc deposit (as CEO) in the first half of the year.
Re 445, the solar polar magnetic fields are weak, and the sunspot minimum may not be until 2008.
re 446 No we are at solar mimima,this does not preclude X solar events or enhanced cosmic radiation,indeed we would increased cosmic radiation.
Early correlation would be in the SH after spring sunrise in the Antarctic and observation of increased stratospheric ozone.
Say what?! I missed this laughable retort the first time around.
Bloom, there is a 1963 paper called “Deterministic nonperiodic flow” by Lorenz you may want to read … and understand. Weather, in case you haven’t heard, is a chaotic process. Do you know what that means, or do you need a lesson there too?
Re #448: bender, try to tone down the contempt, OK? As a purely theoretical exercise, I’ll take your word for that. In the real world, our knowledge about the number of hurricanes since 1970 is complete and accurate. As we have discussed (and as did Curry et al at some length), there is uncertainty about the intensity categorization, but that’s a different matter.
To return to my finger analogy, there is some uncertainty prior to the exercise, but after 200 people have independently counted them? In the real world, no.
If you disagree, please go out and find even *one* hurricane specialist who will agree the satellite-era (post-1970) number is uncertain. Good luck with that.
I suppose he’s simply tired of your contempt. I don’t blame him.
Your finger analogy, as has been _repeatedly_ pointed out, is not legitimate. That you continue to harp on it is evidence of not only your contempt, but your unwillingness, or inability, to learn.
Mark
#449 — Steve B., you missed Bender’s point. His point is not that the number of hurricases since 1970 is not well-known.
His point is that if one could scroll Earth back to 1970 and then let it go again, the emergent re-run climate between 1970 to the present would exhibit a different number of hurricanes with a different pattern of annual incidence.
That’s the nature of a chaotic multiple-feedback process. It’s quasi-random with a high dependence on initial conditions, and with multiple underlying quasi-periods that produce unpredictable short-term excursions and occasional jumps to new meta-stable states. All without the need for external forcings, by the way.
Therefore, in terms of climate, the number of hurricanes and their annual tempo is not, and never can be, strictly a measure of some linear climate trend. The 1970-present enumeration of hurricanes should be seen in that light.
Steve Bloom:
Steve B. – look, there’s no reason why anyone should have to explain to you why finger counts as you define them isn’t a stochastic process. Get a high school statistics text and find out why finger counting and hurricane counting are different. Come on back to the discussion after you’ve done that, but otherwise I’d appreciate it if you stayed on the sidelines in such discussions. Sorry about that.
Here’s an pdate to an interesting working paperu by Ai Deng that I discussed once before which discusses testing problems with ARMA(1,1) noise:
#61 (Martin Ringo) :
I agree. Chap 3:
In other words, due to this damned temperature signal, we can’t find the true signal. How can we distinguish natural variability and external drivers? I wouldn’t accept ‘all signals are smooth’-solution. (..signals are smooth, sometimes the signal does not exhibit long-term memory of its phase.. where do these come from?)
Hmmmmm……
“Two climate change sceptics, who believe the dangers of global warming are overstated, have put their money where their mouth is and bet $10,000 that the planet will cool over the next decade.
The Russian solar physicists Galina Mashnich and Vladimir Bashkirtsev have agreed the wager with a British climate expert, James Annan.
The pair, based in Irkutsk, at the Institute of Solar-Terrestrial Physics, believe that global temperatures are driven more by changes in the sun’s activity than by the emission of greenhouse gases. They say the Earth warms and cools in response to changes in the number and size of sunspots. Most mainstream scientists dismiss the idea, but as the sun is expected to enter a less active phase over the next few decades the Russian duo are confident they will see a drop in global temperatures.” (The Guardian)
This first happened a year ago.
I wonder whose figures are they going to consider as being the deciding authority.