When one looks at the plots of the various Juckes proxies against gridcell temperature, the possibility of spurious regression must come to mind.
“Spurious regression” has been discussed on this blog from time to time and tries to provide a statistical framework for seemingly high correlations between unrelated series – things like Honduran births and Australian wine exports. The original article on the topic by Yule in 1928 observed a correlation of something like 0.97 between alcoholism and Church of England marriages. A prominent econometrician (Hendry) observed in the early 1980s that rainfall provided an excellent statistical explanation of inflation in an interesting article “Econometrics – Alchemy or Science?” (url).
The same question – Alchemy or Science? – is surely applicable to proxymetrics. In 1974, Granger and Newbold, the former a Nobel Prize winning economist, wrote an influential article on Spurious Regression, posted up here, which I discussed last year here.
Granger and Newbold observed that, although the classic spurious regressions (see Spurious #1) had very high correlation (r2 statistics), they had very low (under 1.5) Durbin-Watson (DW) statistics. (The DW statistic measures autocorrelation in the residuals.)
Granger and Newbold:
It is very common to see reported in applied econometric literature time series regression equations with an apparently high degree of fit, as measured by the coefficient of multiple correlation R2 or the corrected coefficient R2, but with an extremely low value for the Durbin-Watson statistic. We find it very curious that whereas virtually every textbook on econometric methodology contains explicit warnings of the dangers of autocorrelated errors, this phenomenon crops up so frequently in well-respected applied work. Numerous examples could be cited, but doubtless the reader has met sufficient cases to accept our point. It would, for example, be easy to quote published equations for which R2 = 0.997 and the Durbin-Watson statistic (d) is 0.53. The most extreme example we have met is an equation for which R2 = 0.99 and d = 0.093.,,
Granger and Newbold found that regressions between random walks consistently had “statistically significant” F-statistics (or equivalent statistically significant correlation r statistics) – they didn’t mention whether they were “99.98% significant”, but some would have been. Granger and Newbold suggested that the Durbin-Watson (DW) statistic did a good job of identifying problems. They didn’t argue that a failed DW statistic was a necessary condition of a spurious condition, but they certainly argued that a failed DW statistic was sufficient for a failed model.
Granger and Newbold:
It has been well known for some time now that if one performs a regression and finds the residual series is strongly autocorrelated, then there are serious problems in interpreting the coefficients of the equation. Despite this, many papers still appear with equations having such symptoms and these equations are presented as though they have some worth. It is possible that earlier warnings have been stated insufficiently strongly. From our own studies we would conclude that if a regression equation relating economic variables is found to have strongly autocorrelated residuals, equivalent to a low Durbin-Watson value, the only conclusion that can be reached is that the equation is mis-specified, whatever the value of R^2 observed. …
It is not our intention in this paper to go deeply into the problem of how one should estimate equations in econometrics, but rather to point out the difficulties involved. In our opinion the econometrician can no longer ignore the time series properties of the variables with which he is concerned – except at his peril. The fact that many economic “Ålevels’ are near random walks or integrated processes means that considerable care has to be taken in specifying one’s equations… One cannot propose universal rules about how to analyse a group of time series as it is virtually always possible to find examples that could occur for which the rule would not apply.
Let us now visit the residuals of Juckes’ Union reconstruction. Here is a plot of residuals between the Union reconstruction and the archived instrumental temperature.
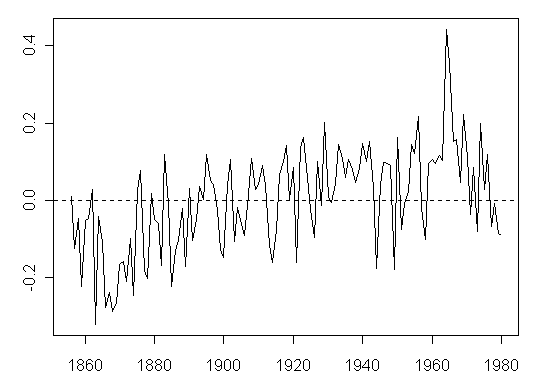
Figure 1. Residuals from Juckes “Union” reconstruction and archived instrumental temperature.
Plotting of residuals is a standard operation in applied statistics. A simple inspection of the plot strongly suggests the possibility of autocorrelated errors. A Durbin-Watson test (which is a very elementary test) returns a value of 1.09 far below the required minimum of 1.5. The p-value for autocorrelated residuals is 1.018e-07 – less than one in a millll-yun.
Following Granger and Newbold, the following can be asserted of the supposed relationship between temperature and the Juckes Union reconstruction:
“the only conclusion that can be reached is that the equation is mis-specified, whatever the value of R^2 observed”
If you do an elementary arima fit on the residuals, one gets highly significant ARMA(1,1) coefficients relative to the standard errors of the estimates:
Coefficients:
ar1 ma1 intercept
0.9505 -0.7545 -0.0104
s.e. 0.0406 0.0941 0.0440
It is difficult (rather impossible) to contemplate an undergraduate econometrics student presenting a univariate relationship between two variables, with correlation between the only statistical test being performed. It is impossible to contemplate a student failing to carry out a Durbin-Watson (or equivalent) test. It is hard to imagine the response of statistical reviewers to a team of professors presenting an econometrics paper based on a single univariate equation with a Durbin-Watson statistic of 1.09. (It is taking all my will-power to avoid making a snarky comment.)
Now think about the reviewing by paleoclimatologists at Climates of the Past. No one has raised this topic. I suppose that either I or someone else will wander over to CPD and make this and other observations – but it would be nice to see some adequate reviewing within the discipline.





41 Comments
Here’s a nice quote from Hendry 1980:
Sound like anything we’re talking about?
I had been meaning to ask Jukes whether Union and temperature cointegrated as a basic test that they hadn’t shown a spurious relationship. Looking at these residuals I think the answer is clear. The two series are not cointegrated because the residuals look to be strongly I(1). (Precisely, it looks like you can not reject H0 that the residuals are I(1) using an ADF or similar test). It is a basic point that you can make with reference to lots of econometric literature without worrying about the potential ambiguity of a DW statistic (although the DW statistic tells you essentially the same thing, the formal DF tests aren’t structured around the DW statistic).
The simple point is – temperature is I(1) (I’m assuming this from inspection), Union is I(1) (similarly by inspection), unless the residuals are I(0) there is no basis for claiming a meaningful relationship between the two.
I’m sure you’ve got it in your reference list but classic references for this for those that are interested would be:
Engle, Robert F & Granger, Clive W J, 1987. “Co-integration and Error Correction: Representation, Estimation, and Testing,” Econometrica, Econometric Society, vol. 55(2), pages 251-76, March. (JSTOR link here – but full test restricted to JSTOR subscribers.)
James MacKinnon, 1990. “Critical Values for Cointegration Tests,” University of California at San Diego, Economics Working Paper Series 90-4, Department of Economics, UC San Diego. (Available here. Warning 6.4MB download.)
John S, thank you for your most puzzling post above. Questions:
What are I(1) and I(0)?
What is the ADF test?
What is meant by “Union and temperature cointegrated”?
Many thanks,
w.
I(1) and I(0) refer to order of integraion. (See this brief Wikipedia link for a sketch of the idea – also called having a unit root.) The term shares an etymology with the mathematical concept of integration. The easiest way to make an integrated series (I(1)) is to sum up or integrate another (stationary) series.
An I(0) process is a stationary process. An I(1) process is stationary once you difference it (delta X=X(t)-X(t-1)). An I(2) process would require you to difference it twice for it to be stationary, and so on. For example, a random walk or an AR process with an autoregressive parameter of 1 is I(1).
For example, the rate of economic growth is I(0) while the level of GDP is I(1). I(2) series are relatively rare in economics but there are some people who believe that the price level is I(2) while inflation is I(1) – most people believe that the price level is I(1) and inflation is I(0) although it may have mean shifts or breaks. Other less economic data: population is I(1).
An ADF test is an Augmented Dickey Fuller test.
The whole econometric literature on spurious regressions boils down to dealing with integrated series properly. If you have two trending series (I(1) series) then you will get high r-squareds and the like even though there is no real relationship. In order to test whether there is the possibility of a meaningful relationship you require that the trends in the two series are actually common across the series. This is known as testing for cointegration – that is, two integrated series actually share the same stochastic trend.
I think I used the abbreviations and whatnot without explanation because explaining it if you don’t already know the terms is the work of a good statistics or econometrics course – which I wouldn’t presume to be able to provide.
A Primer on Co-integration by Dickey et al.
Definition of I(1), Augmented Dickey-Fuller Test (ADF)
My impression is that statisticians working in climate science often seem wedded to frequency domain time-series methods, and I was curious if anyone had any thoughts about that.
#7. I agree with your comment about frequency-domain. At the NAS panel, both Bloomfield and Nychka were frequency-domain guys,
#5.
John S, my impression is that there are other animals in the spurious regression zoo besides two I(1) processes – although this is the type case. You can get spurious regression between fractionally-differenced processes. In any case, the Team should have carried out a pretty nuanced statistical analysis, as opposed to merely providing one statistic.
Steve,
all the references are interesting, but I am a bit confused by this contribution. As far as I understand it, CVM is not a regression method in which regression coeeficients are estimated through minimization of some funtion, so I am not sure whether the DW test finds application here.
I would agree that the variance matching step could be affected by the co-integrated nature of the series, but this is a different question.
Or can CVM be reformulated as a regression method?
After taking the average of the scaled proxies, the re-scaling procedure can be shown to be a constrained regression in which the variance of the estimator is constrained to be equal to the variance of the target.
However, quite independently of this, many techniques for analyzing statistical significance transpose quite readily. Just saying that something is “CVM” rather than “regression” doesn’t negate the responsibility to analyse the residuals.
BTW Eduardo, I wasn’t able to replicate the exact Union reconstruction from archived proxies anyway – perhaps there’s something in the Python code but the code is so poorly documented that it would take a long time to sort out – and the sd of the archived instrumental target for 1856-1980 doesn’t quite match the sd of the Union reconstruction. DO you have any hints?
#8
There are other animals at the zoo – but the initial motivation and driving force was integrated series, which economics has so many of. Along the way techniques for a much wider class of pathologies were undoubtedly covered. So perhaps you could rephrase my comment somewhat for perfect accuracy but I think the gist is still accurate.
Re #9:
Eduardo, two series don’t have to be a ‘regression’ product for you to test them for cointegration (or any other desirable statistical property). Cointegration is really just another property of the data like correlation. It’s just that cointegration is applicable when the series you are dealing with have stochastic trends. So cointegration isn’t a different issue – it’s just a different test of the data. (As you observe, the variance matching would be heavily influenced by the presence of non-stationary series in just the same way that OLS is with non-stationary series – testing for cointegration between the series is one way to check if it has been fatally affected.)
But more generally, what do you mean by ‘regression’? There are many estimators available and you need to test their outputs regardless of the methods used to obtain them. Thus, minimising the squared deviations of residuals is one very popular technique for constructing linear estimators, but it has no special status (at least because of that). You can also maximise the likelihood function, match the moments (GMM rather than just variance matching) or any other variation you care to speak of. OLS is popular because it has a number of nice properties – being the best linear unbiased estimator is a major part of that.
#10 Steve, I have never programmed in python and I do not have the proxy data, so unfortunately I cannot help you in this. I have not located the link to the data archive you mention in other post.
In my comment I was trying to clarify things, mostly for myself. I was not stating that the analysis of the residuals is not important. For instance, if the spectrum of the residuals is clearly red, the CVM estimation should have wider confidence intervals.
#11 John, perhaps my previous post was unclear, sorry for that. I was not trying to mix the concepts of regression and co-integration. I agree that the estimation of the variance ratio may be affected if the two series are integrated processes. This seems to me quite clear, although one should be able to guess how strongly thzey are affected in this case. More interesting would be perhaps how the confidence intervals for this ratio would look like. Assuming simple AR1 processes, Montecarlo experiemnts do indicate that these confidence intervals widen. On the other hand, I am only aware of one application to climatic timeseries of the concepts of cointegration (Kaufmann and Stern, Nature 97). My (honest) question to the econometricians here would be if 100 samples are enough to distinguish between an integrated process or just stationary ARMA process, and even if they could apply such a test to the NHT timeseries.
I mentioned ‘regression’ before, because it was not clear to me whether CVM is a regression method in the sense of minimizing some function to estimate the parameters, as you wrote. In that case, it was not clear to me whether the DW test can be applied to the residuals of CVM.
#12. Eduardo, in Appendix 1, Juckes provides the following “statistical model” for his CVM composite:
That’s a regression model. So a Durbin-Watson test can be applied directly to this model in any event. The rescaling should only be a linear transformation and the autocorrelation properties of the residuals would remain unchanged through re-scaling, also leaving the DW value unchanged.
BTW on the “correction” of the estimate by inflation – this methodology was discussed in von Storch [1999] which sharply criticized this procedure. You really should include some discussion of why you think von Storch [1999] no longer applies.
#12
You can never have enough data. I am not aware of exact statistics but the closer to 1 is your AR parameter, the more data you need to separate the two hypotheses. But the amount of data available to you is typically larger than that available to macro econometricians and with 100 observations or more that would normally be considered ‘enough’ to conduct meaningful inference using these tests.
You will see the paper by Kaufmann, Kauppi and Stock that finds temperature to be an I(1) process. At this stage it appears to be a working paper but it may be submitted for publication somewhere – regardless, there is nothing wrong with their test of the properties of the temperature series and they obtain significant results.
Having reread the Kaufmann et al paper now and spurred by Steve’s presentation of the residuals I think the basic point to be made is pretty simple.
Temperature is non-stationary (Kaufmann, Kauppi and Stock – on further checking it is forthcoming in Climatic Change). Any proxy series that purports to reflect temperature must likewise be non-stationary. Thus, standard statistical techniques that assume stationarity can not be used. A basic requirement for such a proxy series to have any forecasting (actually hindcasting I suppose) ability is that it cointegrate with temperature over the instrumental period.
In economic journals it is a basic test whose failure would lead to almost certain rejection. (If you can tap dance like Gregory Hines there might be arguments you can make to get over it – but they need to be really good.)
#15:
That would be a huge leap, and I’m not sure there is any reason to take it. While it is true that the climate system exhibits long-term excursions from the mean — ice ages; sea level changes that last for millennia; centuries-long periods of drought — it also seems to revisit the same “regimes” again and again. That is how stationary long-memory processes behave; it is not evidence of nonstationarity.
To illustrate the point, you might try generating and looking at synthetic time series — say 1000 years each — from stationary FARIMA (start with (ar=0,d=0.4,ma=0)) and non-stationary ARIMA (say (0,1,0)) models. You will find that you can produce remarkably realistic temperature records using stationary LTP (e.g. FARIMA) or ARMA(ar=0.95,ma=-0.95) models.
At the risk of repetition, I once again recommend taking a look at Koutsoyiannis’s work on long-memory processes (see here).
From a statistical point of view it is not a huge leap. It is generally better to treat near-integrated series using the cointegration techniques to ensure that your inference is not flawed. While the leap may be large philosophically it is still a valid statistical aproach.
But regardless. If you believe that human emissions are leading to global warming and that such warming could be catastrophic you implicitly believe that temperature is non-stationary. Furthermore, as discussed in the Kaufmann et al paper, human emissions are non-stationary as they derive from economic activity which is non-stationary.
#15 John,
thanks for the link. I had downloaded the preprint in May but I did not know that the paper
is forthcoming. Climate Change.. this is interesting.
Surely, the degree of timeseries analysis in climate research has probably not the level of sophistication as in econometrics. You can have a look into “Science” this week and you will see estimating trends and their significance without looking into the residuals whatsoever.
#12 Steve,
ok, CVM being a simple linear re-scaling it can be re-stated as regression with inflation. At the end, the variances should match, and since there is only one free parameter, this parameter should be the same within both ‘views’. I am not sure if the nuisance is important here. I tend to see the CVM method simply a brute-force calibration, and within this “model” the autocorrelation of the residuals would only matter for the estimation of the variance. But I cave in that you can see it in the other way. Anyway, ideally the residuals should be white and trendless, this latter point seems to me to be more important than the autocorrelation. Simple extrapolation would indicate that residuals were larger (negative) in the past, i.e. that the true NHT was cooler than estimated. This is also what one gets with the pseudo-proxies.
#9:
Eduardo, with all the respect, you are not the only one. Most (all?) of these multiproxy reconstructions are in a terrible confusion of two statistical disiplines: estimation theory and regression analysis. Let me quote the relevant definitions (from Wikipedia):
[The following is a very crude explenation, so sorry for all those who are very careful about exact details.]
So in the problem setting in question, your goal is to estimate/predict the temperature of the NH from the indirect measurements (proxies). So the problem itself can be thought as an estimation problem or as a regression problem. If you want to think it as an estimation problem, then you think temperature as a random field over NH and you are estimating its mean. If you want to think it as a regression problem, then the (NH) temperature can be thought either as a random process whose particular sample you try to predict or as a determistic variable.
Now the crucial difference comes from the fact how you handle the known (instrumental) temperature data. In the estimation problem setting, you can not basicly use it once you have defined your model (for proxies). An estimator is a function of your observations (proxies in this case) alone. Thus treating the problem as an estimating problem, you only use your knowledge of the instrumental series to improve your model, but you do not incorporate the instrumental series (a particular sample) into your model. Once you have defined your model, you now define your function of proxies alone (an estimator) that should give you the thing of the interest, an estimate of the temperature given a particular realization of proxies. Now it is easy to check your performance as you can compare your estimate directly to the measured instrumental series.
On the other hand, in the regression problem setting, you define your model to describe the relationship between the temperature and the proxies. Once you have done that you then (use estimation theory to) estimate the parameters of that model with the known values of all variables. Then you use the same model, with estimated parameters, to predict the (out of sample) values of the temperature variable (i.e., the “non-instrumental” part). Now it is crucial to understand that the same values you used for estimating your parameters can not be any more used to check how well your model is behaving. You already fitted you values best you can during that period! Your model may be worthless, but you can still find nice parameters to fit your model and get the error in the instrumental time very low, in essence your are then overfitting/-learning. The simplest way to guard against this is to have a verification period. If the verification period stats are bad while calibration period stats are good, this is usually a clear sign of overfitting happening.
Now all of these multiproxy studies I’ve seen (excluding Mann, he has invented his own terminology), the papers are mainly using estimation theory language, although they clearly use regression analysis setting (and (rather simple) methods). This is a confusion which should be cleared away before anymore spaghetti graphs.
What comes to CVM, it is not an estimation method (so you can safely categorize it as a regression method). The reason is that in CVM you match your reconstruction variance to that of the instrumental series. That is not so “innocent” as it first appears, because you have already “standardised” your proxies to have the same sample variance (and mean) in the very same period. If your proxies were uncorrelated, you could equivalently describe CVM such that you first match the variance (and mean) of the proxies in the calibration period to that of the instrumental series and then take the mean. Anyhow, CVM is not a function of proxies alone as it uses the instrumental series also, and it is not therefore an estimator.
I can think of ways of solving this problem within the estimation theory setting. However, assuming the linear proxy response, I think the solution comes easiest way with the regression methods. In fact, it took me about an hour to derive the “correct” regression model and find its optimal (unbiased) solution from the linearity assumption. However, as I have stated many times earlier, I do not believe in that linearity assumption, so it’s not worth going into details. If you are interested in knowing more (and even if not), I suggest that you have a careful reading of the book I have mentioned here a few times:
Rao & Toutenburg: Linear Models: Least Squares and Alternatives
It contains pretty much everything you need to know about linear models.
As some clarification of my suggestion that it doesn’t matter whether the temperature process is truly non-stationary or whether one merely needs to treat it as such for the purposes of statistical testing I provide a quote from the conclusion of Stephen R. Blough (1992) “The Relationship Between Power and Level for Generic Unit Root Tests in Finite Samples”, Journal of Applied Econometrics, Vol. 7, No. 3. (Jul. – Sep., 1992), pp. 295-308.
So, perhaps I mis-spoke, it is not necessary that temperature be non-stationary, rather, temperature should be treated as if it is non-stationary.
Jean,
How does the variance matching of CVM compare with the Generalised Method of Moments (GMM)? I have not used GMM myself but was wondering if there was a correspondance there and thought you might be well on top of that sort of thing.
#18. Eduardo, can you explain something that has totally baffled Jean S and myself. You say that the autocorrelation of the residuals only matters for the estimation of the variance. MBH99 does something along these lines, inflating the confidence intervals because of autocorrelated residuals. We have both tried diligently to replicate how this increase is supposed to be estimated and have been completely baffled. It’s not a procedure (as far as I know) known to econometrics, which takes the position that the appropriate diagnosis is that the model is mis-specified and confidence intervals cannot be estimated. MBH99 did not provide a reference for this method; I take it that there is some trade technique for the inflation of confidence intervals that has eluded us. Can you give us a reference? Cheers, Steve
#19,
Jean, thank you for your clarification and the reference . I think my confusion is, or was, rather related to the use of the DW statistic in this context. For instance, in OLS one requires that the residuals are not autocorrelated, and therefore a DW test is meaningful to ascertain that the model is not mis-specified. In CVM, it is not completely clear to me, although it would make things easier For instance, if I am estimating the variance ratio of two ar1 processes and I am to use this ratio to predict one of those processes in an out-of-sample period, is it important that the residuals were uncorrelated? I would see that this would affect the estimation of confidence intervals but it would not be a sign of mis-specification, as my model does not assume uncorrelated residuals.
On the other hand, if the residuals indicate that the processes are of different AR order, this would mean a mis-specification.
#21: John S, hmmm, I hadn’t thought about that, but you are right. CVM can be thought that way if you think the sample moments of the temperature T as population moments (which IMHO does not make sense). Then the model is simply and the parameters (vector w and scalars a,c) are obtained from the moment equations:
and the parameters (vector w and scalars a,c) are obtained from the moment equations:


 .
.
Then this is not then even generalized MM, simply MM.
#22
Steve,
I was talking only about simple CVM of two processes, and about the confidence intervals for the estimation of the variance ratio, and not on the confidence intervals for the prediction. perhaps this is the source of confusion (?).
re #23: Eduardo, you are on the right track. When you do your regression in this case, you think temperature as determistic and the rest is stochastic. Then your optimal solution depends from the (auto)correlation structure of your noise. This is the reason why I have been here (in vain) few weeks trying to get the answer from your lead author about the assumed noise structure in your paper. Then there is only one more additional thing to know: (the out of sample) prediction depends additionally only from the correlation structure between the noise in the sample time and the noise in the out-of-sample time (this is a result due Goldberg (1962) if I recall right, don’t have any references here at home). This gives you the final correction term needed for the optimal (unbiased) solution. Of course, if you finally obtain anything reasonable depends if the assumptions you make for your noise are (physically) plausible. But these are all explained much better in the book I referred.
#23
I found a paper that says (my bolds):
Now, I see a lot of problems before I can contribute to this discussion. Either I or you need to take another course on statistics (yes, it is very possible that I am missing something).
But I think these quotes are relevant:
I know that the above refers to OLS, but I think it is a good start before going to CVM.
Quotes from: Durbin and Watson (1950) Testing for Serial Correlation in Least Squares Regression: I, Biometrika, Vol. 37, No 3/4, pp. 409-428
There are relatively well known adjustments for the variance estimates in OLS that are robust to general forms of heteroskedasticity or autocorrelation.
See White, H (1980) “A Heteroskedasticity Consistent Covaraince Matrix Estimator and a Diret Test for Heteroskedasticity”, Econometrica, Vol. 48, No. 4, 817-838.
and
Whitney K. Newey, Kenneth D. West (1987), “A Simple, Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix “, Econometrica, Vol. 55, No. 3 (May, 1987), pp. 703-708.
If you are really worried about it you can do FGLS but for the most part OLS with robust standard errors is generally considered sufficient.
Yes, that is true. If we know the covariance matrix of noise.
Juckes’ reply is now online at CPD. I’ll post up on this separately. In the mean time, here is what I said in my review about this topic and the response of Juckes et al. I commented:
Juckes et al replied as follows:
Wow. Juckes should have Googled that one before replying.
These people can only be described as aggressively stupid.
#31 and #32: SteveM has it right and Juckes is wrong when it comes to the substance of SteveM’s comment, but Juckes does have a point about the Durbin-Watson test. It is usually used to test for autocorrelation in regression residuals rather than for spurious correlation.
I’m not aware of a standard test for spurious correlation.
re: #33
I suppose there’s a technical definition of spurious correlation which would allow a test, but basically the concept shouldn’t allow a test. I.e. if something passes the tests for correlation but can’t have a true correlation for logical reasons, then it must be a spurious correlation.
I think usually when we have what is called spurious correlation we assume that it will disappear when later data comes in. This would imply that you could divide up the available data and look to see if the correlation disappears when hidden data is examined. Except that that would require no cherry-picking. If the data is cherry-picked all you can do is wait for new data.
TAC, is he trying to make a distinction between spurious regression and spurious correlation? My goodness.
I agree that the DW test is “usually” used to test for autocorrelation of residuals, but the interest in autocorrelated residuals was prompted in part by Granger and Newbold 1974, Spurious Regression in Econometrics – linked to a url above – in which the DW test was suggested as a test for spurious regression.
If Juckes is trying to say that the test would apply to a regression, but not to a correlation, then you have to reflect on the underlying geometry. The correlation coefficient is the angle between the vectors in N-space. The regression coefficient between two normalized vectors is equal to the correlation coefficient. Any apparatus from one applies to the other.
Also, as noted in a post above, the variance-matching procedure of CVM is mathematically equivalent to a constrained regression in which the norm of the estimator is equal to the norm of the target. This is very simple mathematics, which does not cease to apply, merely because Juckes ignores it.
SteveM (#35): Is Juckes
That’s how I read it. Sure, it’s irrelevant and unresponsive, but, strictly speaking, it’s not entirely wrong. 😉
re: #36
I’ve read most all of the responses now (not very hard since they’re quite short.) Your remark above about irrelevant and unresponsive is a good summary of all of them. Actually I was tempted to post something even snarkier, but I think I’ll leave it to Steve (or Willis when he’s back and up to speed) if they desire. Let’s just say that it was quite obvious that there is no attempt to actually address the questions put before Dr. Junkes. BTW, I wonder if Dr. Junkes himself actually composed the responses. When he was here he was fairly responsive, if a bit pompous. I wonder if there was a mini-IPCC meeting to make sure that this summary for policy-makers will match the individual positions to be given out later.
Juckes’ coauthor Zorita made no such distinction in a comment last year at CPD where he cited Phillips 1998, which used spurious (nonsense) correlation and spurious regression as the same concept:
This strikes me as one of the most useful threads on the site. Many thanks for all the citations and ULs.
Dave D said:
I don’t think he was responsive then or now.
DaveD (#37): I just re-read SteveM’s comment and Juckes’s (non) replies. I agree with you that in most cases Juckes presents
Under the circumstances, it is curious that he decided to respond at all.