I’ve been reading through some articles on altitudinal reconstructions by Rob Wilson and other Luckman students. The studies all follow a similar strategy as Wilson et al 2007 – principal components analysis; truncation to eigenvalues 
Today I’m going to work through the linear algebra of the multivariate method used in Wilson et al 2007 and similar studies. It appears to me that the Varimax rotation doesn’t actually do anything and is cancelled out.
I’m not 100% of the algebra below; maybe UC or Jean S or someone else can check this. Also if anyone has any references in a real statistics book (not by climate scientists) to the effect of combining regression with varimax principal components, I’d be interested.
First, denote the network of tree ring chronologies as the matrix 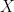
(1) 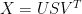
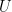
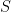

(1a)

since V is orthogonal and S diagonal. Denote the truncation to the k principal components with eigenvalues GT 1 by 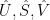




(2)

The inverse regression of temperature 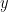
(3)

with the reconstruction 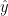
(4)

By simple linear regression algebra, we have:
(5)

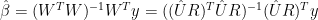
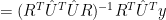
From (1a) we have the following expansion for
(6)
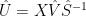
From (5), we therefore have:
(7)
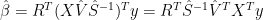
From (4) we therefore can express the reconstruction
(8)

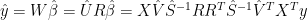

where 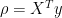


Since the varimax rotation operator
In my post a year ago on VZ pseudoproxies, if tree ring proxies are believed to be signal plus low-order noise (I don’t necessarily believe that, but it’s presumed in many analyses), then any rotations that result in negative coefficients result in overfitting. With the information available in these studies and the absence of any archived measurement or chronology information, it is impossible to assess the severity of the problem. My guess is that there’s some overfitting and the claimed r2 statistics are exaggerated, but that a simple average of the proxies or a simple allowance for regional weighting will probably yield results that are generically similar in appearance; I’d expect the greatest differences to be in the 20th century portion.
Update:
I mentioned in a post a year ago experiments with a VZ pseudoproxy network, which I construe as being a very “tame” network in that the noise is prescribed as white or low-order red and there is no contamination of the network by totally mis-specified series. A year ago, von Storch and Zorita were embroiled in a dispute with the team over the impact of different methodologies on attenuation of low-frequency variance. The VZ observation about low-frequency attenuation was 100% correct as far as it went, but the debate got sidetracked by an irrelevant distraction thrown up by the Team about whether trended or de-trended calibration was used. If one examined the linear algebra of that calibraiton (along the lines of the discussion above), one can see how idle the Team’s purported rebuttal was.
In developing my own view of the matter, I prepared the following two graphics, which I think is a very nice illustration of the impact of various multivariate methods on a tame network. The first graphic shows the effect of several different multivariate methods on a reconstruction – numerous other multivariate methods could be developed. The comparison between OLS and Averaging is intriguing – the calibration fit of OLS is highest, but it has the worst performance in recovering low-frequency information. Mannian regression (which I’ve shown is equivalent to Partial Least Squares regression through following the linear algebra) is in between the two. Principal components (either correlation or covariance) applied to a “tame” network does quite well (but is obviously vulnerable to breakdown with contamination as I’ve discussed elsewhere.) But I’d like you to look at the 2nd figure.

Figure 1. Reconstruction from VZ pseudoproxies using several multivariate methods.
This figure shows the coefficients of the different methods. People should recognize that, beneath the skin, “regression coefficients”, “eigenvectors”, “empirical orthogonal functions” etc all boil down eventually to producing a vector of weights. Here I plotted the vector of weights in a controlled network under the different schemes. The OLS coefficients are the most diverse . In this controlled network, the variation in coefficients is entirely adventitious. The introduction of negative coefficients through the OLS mechanics is particularly pernicious as this flips the signal over and works against any recovery of the signal.

Figure 2. Weights from different multivariate methods from VZ pseudiproxies.
If you think that something is a temperature proxy, at a minimum, you need to use a multivariate method that can’t result in negative coefficients. An advantage of simple CVM methods is that they avoid the introduction of negative coefficients. In the particular case of Rob’s network, without the data being archived, I can’t tell whether the coefficient distribution looks more like an OLS distribution or are balanced. Going towards OLS distributions of coefficients will increase calibration r2 but, in a controlled pseudoproxy system, these seeming gains are illusory and it is the same in a real network.





36 Comments
Steve:
Just a thought. A Varimax rotation maximizes the distances between the PCs and allows for an easier definition of the factors. But this presupposes predefined component variables. I still am not sure that the factor analysis as actually conducted in tree ring studies doesn’t simply cluster sites or tree series together and that ex post factor scores are correlated against temperatures and the ones with the best correlation with temperature is called the temperature signal. One question is what do the other factors represent? Unless you can define these other factors, it is hard for me to figure out how you get to define the one you were hunting for.
Again the way I use this tool is to use it to confirm or discover the most efficient way of compressing data. Once a factor is defined then you use the items that are weighted most heavily on a factor to create a scale. But the scale has to be coherent – it cannot be be simply empirically derived. Otherwise all you can do is use factor scores for something that has no conceptual content.
Perhaps other statisticians/pyschometricians can chime in because this type of factor analysis is extremely common in survey research where you have a 100 or so questions and you want to isolate patterns of results.
Try this:
Click to access pcr.pdf
Principal components regression with data chosen components and related methods (with Dan Nettleton, Technometrics, 45, 70-79, 2003. Contains an example on QTL identification.)
I’ve not read it myself, yet, but the abstract and keywords look promising.
bernie, my point here is that the rotation matrix R in the varimax rotation appears to be cancelled out in the regression phase – so whatever the original motive for the varimax rotation, the weights that are finally assigned to the individual sites appear to be the same, whether or not the varimax rotation is done prior to the linear regression. I’m not 100% sure of my linear algebra (although it’s pretty reliable.) Given that varimax rotation is a rotation within a subspace, one can see a geometric argument why regression onto the subspace wouldn’t be affected, although I’ve only worked through the linear algebra. The geometric argument using projections might be very concise and slick; they usually are.
One other thing that you have to keep an eye on the tree ring regressions as compared to what one expects in regressions in conventional statistics is that everything is an inverse regression i.e. you’re not regressing tree rings on their cause – temperature -, you’re regressing temperatures on their presumed effect, tree rings. It’s more like signal processing. IF there’s a “signal”, the series will be multicollinear – something that’s not wanted in regressions, but desirable in signal processing. You really have to keep your eye on the ball.
Steve:
I am beyond my current pay grade – 30 years ago things might have been different. I think I get your point, but it makes me think that what they are still doing is the equivalent of a cluster analysis and hence your finding that the regression solution is driven by a single atypical cluster of tree rings. But I best stop, because I am going on intuition and my linear algebra is much too rusty. Perhaps there is someone out there who can better explain the distinction between a typical factor analysis that looks at the common themes among variables (tree ring characteristics) and a cluster analysis that looks at common themes among respondents (tree ring series) and regression analysis – they certainly are all highly interrelated. Hopefully my musings are not a total distraction.
#4. No, that’s not my point. My point is that the authors of these studies forget that the PCs can be expressed in terms of the original proxies; and that weights assigned to the original series are independent of the varimax rotation – that says nothing about whether the weights are concentrted or not.
Bernie:
This a point that’s bothered me before. Mann argues that using correct centering the “climate signal” simply moves from PC1 to PC4, so as long as you include four or five PCs in the regression stage, everything is tickety-boo. Ignoring the point that this “climate signal” is no longer the “dominant pattern”, what the hell are PCs 1-3 (which now explain most of the variance)?
BTW, I think you’re going up the wrong path talking about cluster analysis. That’s something completely different. Mann’s method doesn’t “cluster” proxies, it assigns weights, and the process can be explained as linear algebra.
#6. we’re not talking about Mann’s method here, but about PC as applied by Rob Wilson and other Luckman students, where centering isn’t an issue. This isn’t a post exposing a huge bias like Mannian PCs, it’s just an exposition showing a subtler sort of overfitting. It’s impossible to scope the impact without access to the data.
What’s in the PC1, PC2 are species that are believed to be precipitation proxies, PSME, that sort of thing. I suspect that there are probably almost NO temperature proxies in the MBH98 North American network (except a few double-counted Jacoby sites) if one applied the criteria that the angry dendroclimatologists have insisted are applicable to Meko’s white spruce.
Steve,
Steve, that seems to me exactly right. There is a perfect relationship between the original proxies and the PCs. This remains true after rotation, except that it is no longer reversible (you can’t exactly reproduce the original variable from the PCs, as generally not all the PCs are rotated.)
Steve et al.
Let’s forget maths and interpret what the PCs mean in a real world sense:
In Wilson and Luckman (2003):
Two independent reconstructions developed:
REG – A PC regression based reconstruction using 12 RW and 5 MXD chronologies. This reconstruction was spatially representative for Interior British Columbia, but restricted in length (1845-1997). In hindsight, I should have used a nesting approach to extend the reconstruction.
IBC – A reconstruction derived from averaging the three longest RW and two longest MXD chronologies not used in REG. Final reconstruction 1600-1991 (outer date restricted due to the use of Hart’s Pass).
REG
Four PCs were identified.
PC1 = the signal from the MXD data
PC2 = the main mode of variance in the RW data
PC3 = an intriguing mode of variance in the RW data that was hypothesised in Wilson and Luckman (2002) to reflect long term influences of night-time temperatures. This is likely not the final word on these sites and this ‘mode’ of variability. Alas, I have never had time to return to this, although Don Youngblut has some very interesting hypothesises using his whitebark pine data from the same region.
PC4 = A spatially non-homogenous PC with greater loadings in the west. This PC score correlates with the PDO and may reflect the influence of the North Pacific on tree-growth in the region – possibly through precipitation effects.
ONLY PCs 1 and 2 were used for the REG reconstruction.
The IBC reconstruction utilised mean series of the RW (equivalent to PC2 in REG) and MXD (equivalent to PC1 in REG) long chronologies.
BOTH reconstructions explain 53% of the temperature variance. They correlate with each over the 1845-1991 period at 0.92.
I am sure you can argue to the cows come home that the REG reconstruction ar2 has be inflated due to overfitting, but you cannot say that about IBC.
And by the way – the Luckman and Wilson (2005) reconstruction, also derived using simple averaging (no PC regression), explains 53% of the temperature variance as well. This also compares very favourably with the BC reconstructions.
Finally – the BC data will be archived to NOAA when / if my AGU presentation is published. Don’t flatter yourself that you ‘encouraged’ me to do this. I have sat on these data purposely as I had not finished with them.
—————————
One final comment on Wilson et al. (2007).
In this situation, the study region is climatological heterogeneous, although this is hard to quantify due to the sparseness of climate data (as discussed in the paper). PCA was the perfect method to identify the regional groupings within the TR data that reflect the geography (or spatial signal) of the data.
PS – all the information above is clearly expressed in the papers.
Why should I really repeat it here?
Rob, #9. Your comment said
A general issue is that before doing any statistical analysis, you must first have a model of the data. So, what are the assumptions in your data model? How have you justified them? How robust are your model calculations when the data does not exactly match those assumptions (as almost certainly happens)? Additionally, what are the confidence/likelihood intervals for the calculated quantities?
Those questions are vital. Without good answers, numbers such as given in your quote have little meaning. Doing reliable precise statistics can be really difficult. But the questions need to be addressed.
Rob, jeez, you’ve got a thin skin sometimes. I specifically said that a simple average would yield something that was “generically similar” to your reconstruction so that people wouldn’t think that this was a MBH situation.
You say as though you’re reproaching me:
I think that you’re saying the same thing – except that I’d suggest that any claimed r2 due to your multivariate methodology over and above what you got with a simple average was due to overfitting. At this point, my recommendation would be to to use simple averaging or simple regional weights in your reconstructions – a recommendation also made by the NAS Panel. Any seeming statistical gains from the more complicated multivariate processes are likely to be illusory without a more sophisticated justification that neither of us can provide right now.
You say:
I studied math – why can’t I write about math? What I wrote here is very elementary – otherwise I couldn’t have written it. I think that the point here is interesting intellectually and may illustrate something interesting about the combination of varimax rotated PCs and regression – which is why I asked for a statistical reference for this combination of techniques.
As to your suggestion that we focus on what the “PCs mean in a real world sense”? That’s exactly what I was doing. I was observing that the PC methodology simply resulted in weights for the underlying proxies. I’m not sure that much “real world” significance can be placed on the PCs as stable things, that’s not a line of argument that, in your shoes, I’d take.
I think that your reaction to this post should be: (1) hmmm, let me think about why I’m using varimax rotated PCs or PCs at all; (2) it looks like I’ve been lucky enough that the method, even if questionable in my circumstances, may not have had a big impact on results.
However, as you say, don’t shoot the messenger. If you want someone to pat you on the head, go to realclimate.
Why – it’s the whole point of this thread, and it’s the basis (obviously) for any calculations.
Worth a follow-up publication, perhaps?
That’s irrelevant to the point of this particular post as the same linear algebra applies to any particular step.
Calling Dr. Mathew Witten …. doubt he’ll see this, but you never know … who is he? …. a really good Linear Algebra dude. Would be a hoot to get him on this thread.
Rob writes:
Rob please accept this Amicus curiae
Your field might consider instituting something like this:
and
Certainly your field would benefit from a formal collaboration with statisticians and I’m sure they would be very interested in your problems.
— Pete
Steve,
I also think that in general the varimax rotation- and indeed
any linear rotation- will not affect the final reconstruction, but in my opinion the critical step is the truncation. In many applications, the subspace used for the rotation is spanned by the eigenvectors with eigenvalue greater than one: this, however, assumes that the original data are standarized to unit variance, and this is just an option, as it has been alread commented in ca. With non-standarized data, it is much more difficult to justify a particular truncation.
In a second step, the goal of varimax rotation is to identify meaningful patterns- in some subjective sense- , which are then use for the regression.
What I do not like of varimax rotation is that this second step depends on another subjective decision, namely whether to use standarized PCs or not – here I mean something differnt from standarized data: as the amplitude and sign of the eigenvectors and corresponding PCs are not defined a priori, one could perform a varimax rotation in which the PCs are, for instance, standarized to unit variance and the eigenvectors are scaled to carry the physical units, or the opposite, or even something in-between. The resulting varimax-rotated vectors would look different and one may be lead to apply a different truncation, depending on the subjective judgement whether a certain vector is physically reasonable or not.
I think its is safer just to perform a standard PC analysis, and perhaps truncate by looking at gaps in the eigenvalue spectrum. The rule of just keeping eigenvalues greater than one may also be misleading, as PCs with close eigenvalues, say 0.9 and 1.1, may be in essence part of the same proper subspace.
My skin is fine – it is just that you keep highlighting my papers and readers might get the wrong impression that there is a problem with them.
Rob, I’ve written about lots of papers. You emphasize the need to be attentive to the exact location of the site being presented as a temperature proxy. When I look for updated studies of upper treeline sites in North America, it’s remarkable (and I hadn’t realized this) the work of you and your associates constitutes the bulk of recent work. Tell you what – if you give me some references to studies not involving you that you believe to be good studies of dendro temperature proxies, I’d actually prefer to look at them rather than yours.
In terms of the studies using varimax PCs and regression, I think that this multivariate method is statistically interesting, I think that it’s a bit od a “problem”, although, as I’ve said, almost certainly not a fatal problem and probably not a very serious problem, as similar results can be obtained using a preferable method. If you had archived your chronologies, I could have quickly assessed the materiality of using this particular multivariate method, but you haven’t, so I couldn’t. I guessed as to the effect; I suspect that my guess is a good guess, but it’s still a guess.
Your decision on archiving should not be based on whether you think that it would or would not give me satisfaction. I hoped that your reaction would be – “I hadn’t really thought about it, but now that’s it brought to my attention, I’d be delighted to archive the results.” If people are now not archiving that they might otherwise have archived simply to spite me, that’s very immature and I’m sure that you’re resisting any such temptation. Again, this particular instance shows the value of having the data available when the article is read; also the value of a SI which provides the ITRDB id codes in a text file. If that information were available, I could replicate the network, do the calculations and assess the situation in under an hour.
I’m going to do a post up relating this discussion back to a post I did last year on VZ pseudoproxies which should illustrate a bit more clearly what I’m thinking about.
#17. Hi, Eduardo, long time, no chat. We missed you here. I’m going to comment on this topic in light of the experiments that I did with the VZ pseudoproxies, which illustrated things for me.
Witten:
http://forums.wolfram.com/mathgroup/archive/1993/Feb/msg00035.html
The dude definitely knows jack about both Linear Algebra and computer modelling. In his case, he’s applied his maths to neuroscience. This sort of experience would be an intersting thing to bring into the dendro debate.
I’ve updated this post to show some analysis on coefficient distributions from last year’s analysis of VZ pseudoproxies (an interesting analysis to re-read) and perhaps illustrate better the nature of my concern about the methodology that Rob used and also why it is not ideal, but not necessarily “fatal”.
Steve, I’m not qualified for climatological PCA, but I’m trying to learn it. Quick comments :
Matrix X, each column is a moment in time? In some references principal components are columns of V (U or V – time in rows or columns). I think it is better to define rather than let the reader figure it out. Sizes of matrices (mxn or mxm) would be useful as well.
Eq 2. hat for U, Eq 3., no hat for beta (?) Eq 6. is not a direct result from Eq 1, but I guess it is easy to show that Eq. 6 holds.
Rotation is done before or after the truncation?
Is Richman (1986) and Jolliffe’s comments to that paper available online somewhere?
Some comments:
1) A classic statistics reference to these kind of things is:
G. Seber: Multivariate Observations, Wiley, 1984.
2) Steve’s analysis is correct: any rotation does not affect the final result. However, this follows directly from the (LS) regression used and the actual “PC part” is irrelevant. This is easy to see: simply substitute eqs (2) and (5) into eq. (4); the rest is immaterial to the point. The result does not necessarily hold for other type (e.g. least absolute) regressions.
3) Something about terminology. Varimax is ultimately linked to Factor Analysis (FA) and not so much to PCA. Seber (p. 215)
Maybe in the next edition he could substitute “climate” for “behavioral”. 😉
The key difference is that in PCA there are no underlying assumptions whereas in FA there is the assumption of the linear model (and usually normally distributed errors). A quote for Rob (#9) from Seber (p. 235):
I would say that if one assumes the linear model, there are much better ways of doing the “signal extraction” than FA (with or without post rotation), e.g., Kalman smoothering (filtering), Independent component analysis (ICA),… In fact, I think some (nonlinear) extension of Kalman procedure (e.g. extended, unscented, particle filtering…) might be something appropriate for these type of studies.
4) Re: #6 (James Lane) and #17 (Eduardo Zorita):
One should be extremely careful on what purpose PCA/FA etc is performed. If one is performing FA/PCA/ICA etc. as in Wilson et al 2007 (I suppose), the purpose is to extract signals. That is, one tries to find (linear) combinations of the original data to find out new signals (factors) that represent (are) something. In this case it is essential to be able to link each one of the signals to something, e.g., (local, “global”) temperature, precipitation whatever. Otherwise the procedure does not make too much sense.
On the other hand, PCA can be used for dimension reduction as I think in MBH was the (stated) idea. Then the idea is to find a (much) lower dimensional representation for the original data. Now, individual PCs do not necessarily represent a meaningful signal but are rather combinations of the “urderlying signals” and the idea is simply that the (few) PCs describe (most of) the original data, i.e., we try to summarize data. In this case it is rather clear that covariance (not correlation) matrix should be used (unlike W&A are implying, and a point TCO never seemed to get). Furthermore, in this case there exists some meaningful (and nowadays rather standard) criteria (Akaike, MDL, BIC etc) for selecting the number of PCs needed.
5) Also, once more thing as this still seems to be unclear for many people: there is no point of talking about the actual procedure (“non-central PCA”) used in MBH in the context of PCA/FA: it is a completely different ball game. Talking about, e.g., how to apply known PC selection procedures in “Mannian PCA” is like using American Football rules to analyse a Champions League game.
ICA requires independence of “sources,” however, which is certainly not true w.r.t. ring-widths. Temp and CO2 are certainly correlated, if not causal one way or another, which rules out independence in either case and they’re both potential ring-width “signals.” These methods also require fairly stationary statistics over the estimation period…
Correct, Jean?
Mark
re #25: Correct, Mark. That’s why I didn’t propose it for these dendro studies; I just gave an example what might be more useful than varimax FA if the linear model is assumed. Also handling nonlinear response, as I believe tree-rings have, are rather poorly handled with current ICA techniques although there exist some approaches. Non-stationarity is also an issue for ICA although I’ve been told some people have some recent results on that direction. Unscented Kalman filter would be my number one candidate if I had to work with that data.
My stationarity issue is regarding the mixing matrix, primarily (well, the combination of signals from mixing). One cannot differentiate changing mixing vs. changing signals using any form of standard component analysis. Heck, even in the comm world we use differential encoding on the bits because there’s no distinction between a +/-1 data bit and a +/-1 channel sign.
Mark
Which is, btw, an online (adaptively tracking) method of signal extraction. 🙂
Some form of Kalman filter is what I’m probably going to implement in my current radar problem. We’re only worried about detection at the moment, however, so I haven’t looked into it. I spent a little time researching the KF and EKF a few years ago, but never paid much attention to the UKF (more complex than I needed at the time).
Mark
re #28: Sorry, I should have been careful with my wordings when dealing with you 😉 Unscented Kalman smoother would be my first candidate. See, e.g., here:
http://www.cse.ogi.edu/PacSoft/projects/sec/wan01b.ps
#24. Jean S, thanks for looking at this. I thought that my (8) was just the substitution into (4). Here’s another interesting perspective on this. If you express the OLS “rotation matrix”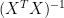 in svd decomposition of (1), one trivially obtains the expression
in svd decomposition of (1), one trivially obtains the expression 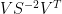 which is structurally quite similar to
which is structurally quite similar to 
The equation is simply:
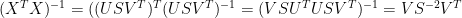
So the more eigenvalues are retained the close the reconstruction approximates an OLS reconstruction – and the more low-frequency variation is lost.
Gotcha.
I remember taking the detection theory class a few years ago (Van Trees, DEM Vol. 1) and, as I recall, there’s a problem at the end of Chapter 4 that was a back-door introduction to the standard KF. I had already taken a class that introduced it years earlier, but we worked the problem and Ziemer asked “do you know what you just solved?” We were clueless. After he told us, I asked “all this does is find the time varying mean, right?” Yup… I was just glad to be done with that class anyway as it was tough.
Mark
I’ve just spotted this thread and do not have the time to comment in depth or respond to other posts. I’m a bit surprised that rotation, of which varimax is just one kind, is news. I believe William Kaiser developed it around 1955 when he was doing his dissertation. In cross sectional data settings, rotation is nearly always performed in both PCA and FA. This is because the PC’c without rotation are often uninterpretable. With the eigenvalue=1 cutoff the total variance explained in a PC regression will not change but the PC scores before and after rotation will not be the same and interpretion of the regression results will not be the same. I assume Wilson’s intent was to generate PC scores comprised of closely related proxies for use in the regression. Nothing novel or controversial about the procedure except that both PCA and OLS regression are inappropriate for time-series data in the first place, as I and others have pointed out numerous times. Got to run.
#32. It’s not that it’s “news”. I’m just collecting and reporting information on the habits and customs of this little sub-culture of dendroclimatologists, their technologies, their war cries, their statistical methods, how they do things. It’s like being an anthropologist. Of course, the people in the sub-culture think that they are superior to outsiders, but anthropologists are used to this sort of behavior even in primitive tribes.
Thanks Steve, easier to follow now. Yet, I’m not sure what PCA actually does (and why it is used) in climate reconstructions. ..plain and simple guy.. Illustrative examples like this
http://www.uwlax.edu/faculty/will/svd/compression/index.html
would help a lot. And those relevant papers should be made freely available for everyone. Something IPCC should do instead of having press conferences on monthly basis..
Steve, your derivation suggests that you assumed that two sets of PC’s were calculated. One set which spanned the calibration period 1899-1985 were the beta vector was calculated. The beta vector is then used on the PC’s that span the total length of the proxy set to calculate the temperature reconstruction? Now Rob didn’t correct you, nor could I tell after reading Wilson et. al 2007.
Are the authors not allowed to put equations in these papers? I find verbal descriptions of algorithms not very helpful. Just complaining.
Steve,
I think I see a mistake in your algebra. dim(X) = (n,m). The idea of truncation is that only a few of the eigenvalues and corresponding eigenvectors are preserved. In the matrix algebra, this means that the inner sums are truncated, but not the outer dimensions. Therefore dim(Vhattranspose) = (k,m) or dim(Vhat) = (m,k), not (k,k).
The next point I am not 100% sure about, but here goes. I think the rotation matrix R has dim( R ) = (m,m). Remember that the eigenvectors get rotated in such a way that they stay orthogonal. That means that two eigenvectors, multipled and summed across all values of m, are zero for 2 different values of k, the eigenvalue and eigenvector index. The only way this can hold is if dim( R ) = (m,m).
The reason I am not 100% sure is because I have not yet found a paper where these things are written down mathematically. I agree with some of the previous comments, that a mathematically detailed description has the best chance of being unambiguous. Like it or not, the computer IS doing math. If we don’t understand these things mathematically, then we don’t understand what the computer is doing. I applaud you for trying to bring math to the discussion.