The US CRN (Climate Reference Network) appears to be a generally well-designed network for measuring 21st century temperatures. Its mission statement includes an undertaking to make its results available online. Here as with GISS and the metadata, system designers have provided webpages – in a format that may be interesting for very casual users, but a nightmare for serious data processing. People interested in monthly data are apparently expected to cut and post innumerable monthly data sets.
I’ve written a short read function to scrape monthly CRN results by individual station at http://climateaudit.info/scripts/station/read.uscrn.txt . This uses the style of Nicholas’ function to scrape information from GISS.
You can look up station IDs either at http://mi3.ncdc.noaa.gov/mi3report/MISC/CRN-STATIONS.TXT (outdated but ASCII readable) or http://www.ncdc.noaa.gov/app/isis/stationlist?networkid=1 (up-to-date but inconvenient for searching. I’ve scraped a more usable form of this as well).
Because of the crummy CRN interface, you have to individually download every month to extract the monthly data. So it ends up taking a fairly long time to extract the tiny amount of data of interest. (I’ve written to Karl suggesting that they provide a sensible ASCII-based archive).
Here’s an example (also showing a download of GHCN daily data for Detroit Lakes for comparison) and comparing the Goodridge MN CRN site and the Detroit Lakes MN USHCN site, yielding the figure below:
source(“http://climateaudit.info/scripts/station/read.uscrn.txt”
goodridge=read.uscrn(id=1039) #Goodridge MNsource(“http://climateaudit.info/scripts/station/read.ghcnd.txt”
detroit=read.ghcnd(usid=212142) #DEtroit LAkesplot(c(time(Y)),Y[,4],type=”l”,ylab=”deg C”)
lines(c(time(X$monthly)), X$monthly[,”ushcn.area”],col=”red”)
lines(floor(detroit$time/100)+(detroit$time%%100 -1)/12,detroit$tmean,col=”red”)
lines(floor(detroit$time/100)+(detroit$time%%100 -1)/12,detroit$tmean,col=”red”)combine=ts.union(ts(detroit,start=c(floor(detroit$time[1]/100),detroit$time[1]%%100),freq=12),goodridge)
nf=layout(array(1:2,dim=c(2,1)),heights=c(1.1,1.3))
par(mar=c(0,4,2,1))
plot(c(time(combine)),combine[,10],type=”l”,ylab=”deg C”,xlim=c(2002,2008.3),xlab=””,axes=FALSE)
lines(c(time(combine)),combine[,6],col=”red”)
legend(2007.2,-10,fill=1:2,legend=c(“Goodridge CRN”,”Detroit L USHCN”),cex=.7)
axis(side=1,labels=FALSE);axis(side=2,las=1);box();abline(h=0,lty=2)
title(main=”Comparing CRN and USHCN in Minnesota”)
par(mar=c(3,4,0,1))
plot( c(time(combine)),combine[,6]-combine[,10],ylim=c(0,3.75),xlim=c(2002,2008),type=”l”,ylab=”Deg C”,xlab=””)
points(c(time(combine)),combine[,6]-combine[,10],pch=19,cex=.8)
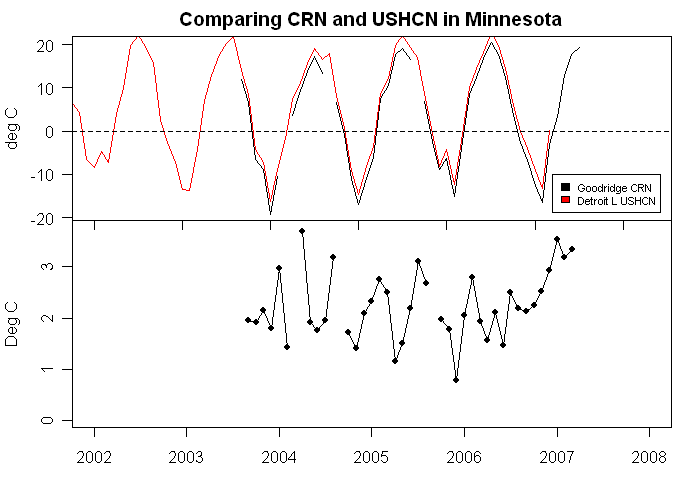
Figure 1. Top – Detroit Lakes MN data from GHCN daily and Goodridge MN CRN data (both as average of max and min); bottom – Detroit Lakes minus Goodridge MN
BTW the NOAA robots.txt file – not that I agree that this is relevant to acquiring temperature data from a site that is supposed to provide temperature data – does not disallow access to the crn/ directory and subdirectories.





10 Comments
I hope you let them know what you’re doing before running the robot and also have a time delay. Legalistic arguments about what they explicitly disallowed in the robots text would be a waste of all’s time…
Steve I also found a download page with a CVS file and text file and text version of the data.
However, you have to download the whole mess. Also it not clear how current it is.
FYI
Here is the url. Hidden cleverly under Misc.
So frm the MAIN, select programs.. then downloads.. then Miscellaneous.
or go there like so:
ftp://ftp.ncdc.noaa.gov/pub/data/uscrn/download/
you’ll find a data directry a bit dwn the page
other stuff is here. I’m kinda busy otherwise I would start scouting through it
ftp://ftp.ncdc.noaa.gov/pub/data/uscrn/download/
I’ve dwnloaded this but havent looked yet. SO your Milage may vary
Why are there so many data discontinuities in the CRN data? Was some of the data “trial” I wonder?
RE 3.
I’m researching that. I was also looking at how the 3 sensors at one location recorded differences.
ALSO, Beware of Tmean Tave issues. Did you knw ModelE reports out Tave? and the correlates to histrical
Tmean?
Not a huge deal but anther one of thse things
( ps the ‘o’ on my keyboard is cutting out..)
Will they consider it a cyberattack and block access? Seriously ….
TCO, bringing up the DDoS handwaving again, why don’t you give it a rest. There’s not enough of a load any of this will do to make it matter. Unless their systems are as underpowered as the others were.
No matter if it’s a robot or a script. Doesn’t matter. I say script. Whatever. That’s why Steve already checked, in case.
BOT. Interesting that the data matches so closely, is it adjusted already I take it?
Am I correct that if it’s raw, that it being shown by Steve here, together, compared to the other station, and they are so similar, that would tend to disprove the claim anyone’s trying to invalidate the USHCN or any other such nonsense?
Looks good. Some minor style hints for the R code, which you may or may not find useful:
1) Consider adding some white space to your statements, it can make them easier to read. For example, instead of
you could write
My eye passes over this and distinguishes the variables being assigned from the expressions which compute the values more easily.
2) While your indentation style is consistent – which is all that’s necessary, really – personally I find this style to be easier to read and less likely to lead to errors. Rather than (abbreviated)
I prefer this:
The advantage is that all the elements within a { … } block are at the same level, and the start statement/block end are at the same level. Thus I find my eye is drawn to the contents of the block and treats it as a unit more easily.
3) I try to give my variables longer and more descrive names than, say, “fred” or “test”. I realize this means more typing and more verbose code, but it makes it easier to remember/understand what they are used for.
4) I also try to avoid putting multiple statements on one line, even though it’s perfectly legal, simply to make it harder to miss a statement which is at the end of another when reading the code. Again I realize this makes the file longer vertically, but I feel it’s generally worth it.
Don’t take this as criticism, the most important thing about style is that it is consistent and doesn’t obfuscate the program structure. However, my style has evolved over time in order to make my life easier, so perhaps you will find you can adjust your style similarly to make it easier for yourself and others too.
Oh, also,
5) I’d avoid re-using a variable (e.g. N) – it can be OK in a small program but can get confusing in a larger one. (“Which value does N have at this point in the program again?”)
6) Code which is heavy in parentheses can be hard to read (you can tell I’m not a LISP programmer…), strategically placed spaces can make it easier to see which parentheses match. For example, instead of
you could do
That’s not necessarily the best way to do it, but by putting spaces around the important nested elements you can avoid having to count parentheses. It’s even better if you have an editor which highlights matching group elements (parentheses, brackets, braces, etc.), but not everybody does.
Thanks, Nicholas. If you can think of a better way to scrape data, I’m all ears.
I got an email from a reader pointing out the ftp location. There’s no shortage of data here and this would probably be a terrific file for some applications.
ftp://ftp.ncdc.noaa.gov/pub/data/uscrn/products/hourly01/
But it looks to me like each hour has its own file for the past 3 years and that every station is represented in each hour file. So you have to read all the data on everything to get the monthly average for one station. I think that the scraping is easier.
Perhaps it’s easier… it may well be less of a load on their servers, and ultimately (if you want all the data) faster to fetch the hourly files and then read them all in in one go.
I guess it depends on what you are trying to do. If you just want to look at one station, reading the hourly data for all stations is probably silly. If you’re trying to do a meta-analysis, it may make sense.
I get the feeling that data is designed so that you can “keep up to date” by downloading a new hourly file every hour, and then you will always have all station data fresh within an hour.
I can’t really see anything wrong with how you have programmed it; if you make the changes I suggest, it will work exactly the same. It just might be easier for others to see what you are doing and modify it to suit, and the same goes for you yourself a few months down the track if you decide to revisit it and are no longer familiar with the code. That happens to me all the time, but I deal with quite a large amount of code.