We have a new article from the Mannian school, this time involving supposedly “independent” NAS panelist, Doug Nychka, and geologist Caspar Ammann, who is very enthusiastic about calculating covariances using Mannian proxies. The lead author is a statistician, Bo Li. The article purports to use MBH99 proxies and says
we do not critically evaluate these proxies but simply apply them as the best available set at the time of 1999
They then proceed to use what appears to be Mann’s PC1, plus no less than 4 different time series from Quelccaya (Core 1 dO18 and accumulation, Core 2 dO18 and accumulation) with each different core remarkably and mysteriously teleconnecting in different ways with “climate reconstruction fields” such that mere covariances are interpreted as having physical meaning.) But more on the statistics on another occasion. The article concludes by saying:
The authors thank Dr. Michael Mann for providing the proxy data.
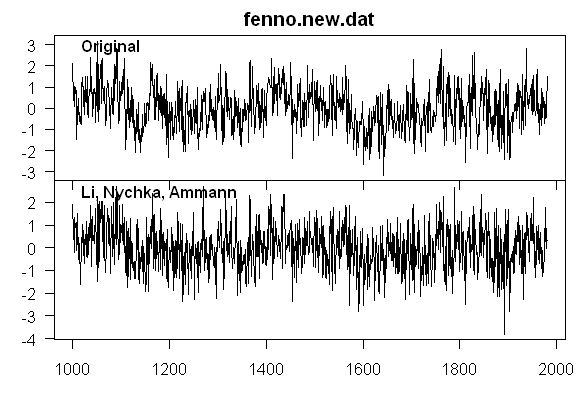
Jean S observed that the proxy series do not match the MBH versions that he had. I checked this as well. The figure below compares MBH99 Quelccaya Core 2 accumulation (with its characteristic pattern that Hans Erren figured out a few years ago) and the Quelccaya Core 2 version used by Li et al. The two proxy series are clearly not the same; the correlation is 0.70. Correlations of about this value are typical. It’s hard to say what Mann has done this time. I checked the a.c.f’s of a couple of versions to see if Mann had given them smoothed versions, but, in the examples that I looked at, the new series did not have additional autocorrelation. The correlation of the original version to the new version was consistently about 0.70 for all of the series – which is close to the square root of 1/2 – but why? All these proxies could have been obtained from WDCP so I don’t know why they didn’t use original data. Pretty mysterious.

Here’s another example:
UPDATE: The above surmise that noise was added to the data has proved correct. Bo Li has confirmed that noise was added to the proxies and that they archived a sample of synthetic data and did use original proxies. She has accordingly corrected the description of the data sets on her webpage to “synthetic” instrumental and “synthetic” proxy and responded cordially, apologizing for any inconvenience. This resolves the proxy issue, which was an odd one. When I get a chance, I’ll look at the statistics.
The data sets that I posted on my website are not the real Northern Hemisphere temperature and the MBH99 proxies. They are generated by adding white noise with unit variance to the standardized real data. The pseudo data sets on my website only serve as a toy example to try the R code that I used in my paper. However, the results in Li et al. (Tellus, in press) are based on the real data instead of the pseudo data. I am sorry that I did not explain very clearly what the data set on my webpage is and also sorry for the confusion that I brought to you as a consequence. I have modified my webpage to make the point more explicitly.
In our paper, we looked at the residuals in calibration (14 proxies against not PC1 of instrumental, but full N-Hem average) and found that there is enough serial correlation that an AR2 process is warranted to represent the “noise”. Then, the approach was to simulate a set of ensembles that fulfill the criterion during calibration so that the explained variance is the same but that the noise is different (using that AR2). Then, because we wanted to establish a method to study the maximum decadal values, we then simulated all series. Simulating time-evolving series was necessary because we have serial correlation, and thus decadal maxima can be computed. The goal was not to be producing the best reconstruction that is currently possible, but to demonstrate a way of how one could go and address the decadal max question. This question was not well addressed in the NRC report, and thus this work is a followup as collaboration between stats and geoscience to show how one could better answer the significance question for the old MBH99 framework.





70 Comments
Here’s a script to do these calculations. Be careful with quotation marks as they copy funny out of WordPress.
I’ve sent the following inquiry to Doug Nychka:
These guys just don’t know when to “move on.”
Pardon my ignorance, but I’m wondering what the heck that weird repeating pattern is on the left side of the “original” series.
Art.
Mark
I’m no statistician, but something visual immediately hits me: the “original” graph has a striking visual curve/pattern.
From 1000 to about 1500, all the highs and lows are clearly fitted to a man-made curve. Nothing random, noisy or natural about it.
What causes that?
I had the same question Ian, but had written it off as a display artifact. Anybody know what is creating that pattern?
Hans Erren has an explanation on his website. What happens is that the ice layers get compressed and are measured to only 1 digit. Then they assume that the compression is exponential yielding the results shown in the top panel through a re-expansion.
But let’s not get too caught up in this issue but focus on what Mannis doing. I’ve added another example to avoid this distraction.
Ian:
That pattern really jumps out, like a repeating signal of some sort. It must have a mathematical form. It looks like the same set of data repeated but displaced to the left and shifted up slightly. “Weird” is exactly right.
Hans’ explanation is at: http://home.casema.nl/errenwijlens/co2/quelccaya.htm
Not to sidetrack this too much, but after reading Hans’ correspondence from Thompson, it seems like there is an opening for acquiring the elusive quelcayya dataset in his response. If his claim is that he cannot provide the data because it is not in electronic form, surely it would be simple for him to fax the handwritten pages to somebody? Or to xerox and snail mail them? I am sure we could find a way to get the handwritten form into electronic form pretty easily.
0.7? Perhaps they have been partying with another group of scientists….
http://www.telegraph.co.uk/news/main.jhtml?xml=/news/2007/08/25/nwiggle125.xml
Hans’ explanation was crystal clear – a model for those describing their adjustments and modifications to the original data. Pity we do not see similar clarity from certain other quarters.
In Hans’ explanation the input data is a cyclical accumulation between 0.5 and 2.5- does this represent a seasonal change i.e the regular seasonal cycle? Therefore, has Mann removed this seasonal signal to produce his result?
No, the cyclical data was artificial test data conmstructed by me, without any climatological implications.
… and besides that, it is annual accumulation data, so the seasonal effects are integrated over the annual accumulation anyway.
If the pattern has disappeared, maybe the rounding step that caused the pattern has disappeared? (Feel free to call this a naive question, it well could be.)
Then Li et al. would have original Thompson data, that Mann also didn’t have, and Thompson never made publically available simply because he didn’t have it! (see my pers. comm.).
As the used compaction formula is not mentioned in TMBK1985 nor at the NOAA archive, Lonnie Thompson was asked for the original core log data. After a reminder he responded as follows on 10 March 2004:
Would that be from the authors or their legal counsel?
Geez! I hope I’m not somehow paying for this mindless rehash of useless data!
#17 – that’s not it, because ALL the MBH proxies are changed in their new costume.
#19. NOt that Bona-Churchill core have been reported. AS I’ve mentioned before, I predicted a ong time ago that the delay in Bona-Churchill results is because they aren’t “good” – I predict that dO18 goes down in the 20th century. It’s not a risky prediction since dO18 at Mount Logan went down a lot – of course, this is due ot changes in regional wind circulation, but if it went the other way,. Thompson would interpret it as evidence of GW.
>> What happens is that the ice layers get compressed and are measured to only 1 digit. Then they assume that the compression is exponential
If you all had read every detail in this paper by one of the world’s foremost experts on ice cores, you wouldn’t be so surprised by what looks like faked data.
For example, based on this underlying assumption, the experts expected the B 17 planes to be at a 12 meter depth. I saw the documentary, they actually found the planes nearly 80 meters down. I urge you again to look at figure 3 very closely.
But “lets not get too caught up in this issue” because…
Re: #19
Probably just my sensitivity but does not this statement by Thompson encapsulate the tendency that we have seen before in climate science to hurry through a study in sloppy fashion then move on — and in this case move on from a “move on”. It seems they feel they need to get the word out and eventually they will get it right or maybe at least in a form that can be replicated.
The pattern in the “Original” first graph between 1000 and 1400 is clearly a result of some very brutal rounding: only a few values are a priori allowed for each year. But why aren’t the lines with the allowed values simply horizontal? There is some superimposed parabolically decreasing trend, and moreover the distance between the allowed values gets smaller as you go to the future.
I find this kind of rounding very strange. It might have a small effect on temperature averages but it brutally influences the counting of temperature variations, especially the very high-frequency ones. One could understand this rounding if they had digital thermometers with 1 digit in the year 1200. But the actual numbers are clearly obtained differently and should be continuous. Clearly, the error margins are huge but what’s the point of allowing 3-5 different temperatures only?
#27
The lines won’t be horizontal if a graph is showing growth rates in an index level with brutal rounding.
Thus, for example, consider an index set to 100 in 2007 and rounded to one decimal place. The growth rate calculated form that index will show the pattern you observe. (Although that is not exactly what is happening here, it is a very common occurrence.)
Re: Lonnie Thompson’s statement that:
Perhaps he is unaware that most new copiers produce very nice PDFs from hand written logs.
Lubos:
RTFR!
http://home.casema.nl/errenwijlens/co2/quelccaya.htm
The “parabolic effect” is caused by the ice compaction.
An unbiassed sampling strategy is essential to any statistical paper. It must be based on quantitative methodology that could be reproduced by another, which also enables future out-of-sample data to be added in.
The behind-closed-doors selection of these proxies simply renders any statistical significance as worthless, because it enables cherry picking. But then, the team like cherry pie, and it seems the newest team member has a taste for it as well.
The versioning issues are just farcical. How many different temperature reconstructions can you achieve by swapping out different versions of different proxies? This would be a useful indicator of how much uncertainty is introduced by versioning issues alone.
Postscript to #31:
Credit to Bo Li at least for making his data and methods more visible, and credit to Steve McIntyre for shaming them into behaving more like scientists; this should enable more efficient analysis of the work, which can only help to advance our understanding of historical temperature reconstructions.
After playing a while with the Li proxies, and performing various tests, here’s my GUESS how the proxies were obtained. I’m not saying this makes any sense nor I’m not guessing who did this (if it was done). UC and others should try to prove me wrong 🙂
It’s simple as this:
take MBH99 proxies, standardize them to zero mean and unit variance, and then add standard Gaussian N(0,1) white noise!
#30
That was back in 2004. Have there been any studies since on how to mitigate this effect in the reconstructions?
Jean S, perhaps a completely dumb idea, but what would their other “proxy” data source — the temp record — look like if the same procedure were applied? (Standardize to zero mean and unit variance, and add standard Gaussian N(0,1) white noise.)
My gut-level confusion about their process is that they have some proxies with the desired shape; they convert to 1000 years of noisy low-variance “data”, which they then “whip into shape” presumably by fitting to a temperature record… and they assume that all of this is reasonably accurate information. Take the numbers you want to come out, hide them behind noise door #2, mix, analyze, and *poof* what a surprise.
It just feels like linking assumption to assumption to create a tissue of presumption.
[If so, who has a good calculator puzzle that might be appropriately similar if simplified, in a fun way? I’m thinking of things like the old “pick any three-digit number; enter it twice into your calculator (e.g. 123123); divide by eleven; divide by your original number; divide by thirteen. The answer is… seven! Wow….]
If the data was never put in electronic format, then how did they ever generate the charts?
Are they saying that all of their calculations were done by hand, and then the graphs drawn by hand???
#35. Thompson won’t disclose sample data. This was one excuse at that time. But there are many posts here at about attempts to get at Thompson’s data (prominently used in Inconvenient Truth) and Thompson just denies access. Most recently, Ralph Cicerone of NAS explicitly endorsed Thompson’s denial of data access.
I received a cordial reply from Nychka who asked Bo Li to identify the source of the proxies as he had “assumed that it was Mike’s original 14 proxies.” On the query about MBH confidence intervals, he said:
I replied that MBH98 confidence intervals were calculated on the calibration period but MBH99 procedures were something to do with the spectrum of the residuals. I also observed that, if MBH98 CIs had been calculated on verification period errors, they would obviously have been the same size as natural variation since the verification r21 was approximately 0.
Nychka was one of two statisticians on the NAS panel investigating MBH and other surface reconstructions.
I think that you may be right about this. The range of the standard deviations of the “new” version is about 1.4 which would make sense as the sum of two near-orthogonal N(0,1) series – for most of you, this is just a version of the Pythagorean Theorem.
I’ve posted here on a number of occasions that you can get results like MBH with one spurious regression plus white noise. It would be amusing if Nychka was inadvertently moving acceptance of this viewpoint along.
Steve,
I wasn’t attempting to comment on the whole issue of data access, I’m just poking fun at the latest excuse.
Color me gobsmacked. This is the data that he is using as an input for his study, and he never bothered to check to see if the data was any good?
#32
residuals are not autocorrelated, they do not correlate with each other, do not correlate with original data.. Seems that you are right. Heh, if residuals are pseudo-random values from Matlab (or whatever software) , and someone forgot the randn(‘state’,sum(100*clock)) -command.. Oh dear 😉
Why are the points along the X-axis points, rather than bars? It is quite clear that there is much error in the time base the further back in time we go. It is also quite clear that the further back in time we go the more the data along the y-axis is smoothed, naturally. Each sample from the core contains more decades of signal when the ice is compressed, than when it is less compressed.
It would be quite easy to workout what the actual error range is, just from ice compression, using a simulation. The further back you go, the bigger the pixels are.
The “original” graph has blurred my vision after looking at it for too long. I`m not kidding….everything looks fuzzy now.
So that`s their evil plot….to cause epileptic seisures in the heretics !!
There seems to be rnorm command here http://www.image.ucar.edu/~boli/hockeystick/uncertainty.R . Maybe proxyexample.dat is just an example of bootstrap process, not the original..
Re # 36 Steve
I wrote to Ralph Cicerone as you suggested and have not had an answer. I saw one other similar Cicerone letter answered elsewhere in CA and it was just evasive. Has anyone had any luck?
My USA friends advise me not to annoy any important USA person with an Italian-sounding surname. I’m still trying to work out why. I would not believe that people with Italian surnames are deficient in intelligence. I just bed it down to a racist statement or a statement about race-horse heads in bed.
Change of topic. For those not familiar with correlation coefficients, would it be instructive to show some scattergrams with various r? As a mining man too, we seldom placed much weight on r below 0.9, even 0.95, depending on the purpose of the calculation. When people talk about r of 0.7 or less I stop reading.
Second last topic: Can an authority direct us to a quantitative paper on the estimation of age in ice cores from stable oxygen isotopes? I cannot understand how a qualitative description of a partitioning weather effect suddenly turns into a quantitative numerical estimate. Besides, fluid inclusion studies in rock minerals are subjected by responsible authors to all sorts of caveats and enjoy low acceptance of reliability.
[Steve: snip ]
Geoff.
Re #37, and building on #41’s reaction…
With all due respect to Nychka for his cordial and helpful reply… They call this kind of ignorance regarding their own data and methods climate science?
I wish I could say I’m surprised but the same kind of ‘good enough for getting published’ partial knowledge of data and methods is not uncommon in my own field of political science either.
UC – worthwhile thought, but it doesn’t look like that’s the case from her script. This particular data set seems to be read in on the same basis as instrumental data. So this example seems to be embedded.
BTW the statistical analysis completely evades the topic of spurious regression – a topic which seems to be incomprehensible to climate scientists. They all need to take a course in stock markets and random walk to get a better sense of how you can trick yourself.
Steve, can you run her script with the original MBH99 proxies as an input (my R skills are still a bit rusty)?
So he admits that he was intentionally using Mannian PCs processed from the bristlecones … hmmm.
Steve McIntyre August 30th, 2007 at 5:34 am
For the electronicers among us. Adding two noise sources increases the noise 3 dB. A 3 dB power change is an increase of 1.41 in noise current and noise voltage into a constant load. i.e. the power doubles.
Re: M. Simon August 30th, 2007 at 8:02 am :
It should be two equal noise sources of course.
#49. Their excuse: “the best available set at the time of 1999”. The problems with the bristlecones were already known in 1999. The bristlecones gave an answer that they wanted; they were already known to be flawed, so they were obviously not the “best available” even then.
The eigenvalues from a PC decomposition of scaled versions of the 14 proxies are:
37.08555 34.26219 33.46126 32.76277 32.57690 32.23882 31.74980 30.92965 30.27287 29.66433 29.16858 28.13424 27.54338 26.73989
which is completely consistent with red noise and no common signal.
#34 Mr Pete
Hadn’t seen that one but I guess it is (10^3 + 1)(X*10^2 +Y*10^1 +Z*10^0), where (7*11*13) = (10^3 + 1)
Hans.. that was some genius work on your part
That’s one thing that bugs me about so many in the climate change community.
There willingness to work with data that is known to be bad, as long as it’s “the best that is available”.
Such an attitude is acceptable when you are doing a research project and are just trying to get a basic understanding of the phenomena in question.
However these same “scientists” will then turn around and tell us that their understanding of how the atmosphere is very high (based on what, bad data?)
and that their models are sufficient to justify overturning the world’s economy. Still based on data that many of them admit is deeply flawed.
Re:#47 “BTW the statistical analysis completely evades the topic of spurious regression – a topic which seems to be incomprehensible to climate scientists. They all need to take a course in stock markets and random walk to get a better sense of how you can trick yourself.”
Unfortunately, climate scientists are not the only ones unable to grasp this concept. Over the years, I’ve come across a number of statisticians who don’t understand it either. I once saw a neural network model built to predict regions where a competitor was likely to target a compan’s prime customers. What it actually did was very nicely report the areas that the competitor ALREADY HAD targeted.
The above surmise that noise was added to the data has proved correct. Bo Li has confirmed that noise was added to the proxies and that they archived a sample of synthetic data and did use original proxies. She has accordingly corrected the description of the data sets on her webpage to “synthetic” instrumental and “synthetic” proxy and responded cordially, apologizing for any inconvenience. I’ve edited the post accordingly. This resolves the proxy issue, which was an odd one. When I get a chance, I’ll look at the statistics.
Dr. Li:
There’s something here that bugs me. I think I successfully replicated the Figure 1 (calibration residuals) , see
my http://signals.auditblogs.com/files/2007/08/res.png
original http://signals.auditblogs.com/files/2007/08/res_org.png
Two problems:
1) these are ICE residuals. Gaussian i.i.d prior just doesn’t work for climate reconstructions, how many times I have to repeat that? 🙂
2) These residuals are highly correlated with temperature (r=0.67). How does the statistical model Eq (1) explain that??
Note that temperature is updated:
It would be easier to replicate the results if the original data would be on the web page instead of those noisy ones.
But I’ll stop criticizing now, I find the paper interesting, and I will try to understand what was done.
Yes, especially if they write in the paper
There is only one example in the paper: the one with the supposedly original proxies. Also the figure code supposedly creates the images in the paper; how can you reproduce those if you don’t have the original data? Unless, of course, the added noise does not really matter.
Li:
Yes, and this is the reason why the results are presented in conferences in this fashion (my bold):
I suppose that due to the lack of space they omitted the info that their results are based on 14 harshly criticized proxies (sufficient spatial coverage, bristelecones, Mannian PCA, Thompson’s Quelccaya, etc.).
I also find it extremely interesting that the paper cites (twice) the Shumway and Stoffer (2006) book. The same book argues that the global temperature series is a random walk… Dr. Li, please re-read especially the pages 57-63 although I recommend studing the whole book in detail.
re #59 (UC):
1) Well, it is hard to tell if it should be called classical or inverse. That is, they still haven’t figured out that the problem under study is known in statistics as (multivariate) calibration. Their model (eq (1)) is misspecified: I wonder if, statisticians, Li and Nychka have ever wondered why in the regression model the variables on the left (usually denoted by Y) are called dependent/response variables and the ones on the right (X) are independent/explanatory variables. For useful references, see, e.g., here.
2) Don’t be too harsh, UC 🙂 That would actually amount to testing the validity of the model. I see some positive signs here: they implicitly admit that MBH99 is a terrible overfit (p.4 “For example, MBH98 and MBH99 applied essentially an OLS to fit the linear model”, and on the next page they notice that even the GLS fit is an overfit).
I found a pdf of what appears to be a presentation on Bo Li’s website. Is there also a paper somewhere? Or is the pdf it (at least for now)?
Although I need to study these results to be more specific, my first reaction of what is up on the website is that Bo Li has made a critical error than many young statistcians make: they don’t ask enough questions before diving into the mathematics. As a result, we’re left with many of the same fundamental flaws M&M exposed in the original hockey stick, but covered up with more complicated mathematics.
Jean
If I understood it right, we have two approaches in statistical calibration
a) CCE (classical calibration estimator (Williams 69)) , indirect regression (Sundberg 99), inverse regression (Juckes 06) and
b) ICE (inverse calibration estimator (Krutchkoff 67)), direct regression (Sundberg 99)
Residuals from Li et al. Fig 1. are obtained using b) for sure. That’s the one that assumes that very special prior for the temperature. And as those residuals are correlated with temperature, that AR(2) noise model is partly based on temperature autocorrelation! But I’m walking on thin ice here, as I haven’t had time to comprehend the full paper 😉
Li et al uses only 14 proxies:
As ICE (b in the post #64) was the correct method to replicate Figure 1, (and R-code indicates that ICE it is) I tried the same method with AD1820 network. There’s 112 proxies, so overfitting (if present) should be more visible with this network (compared to AD1000). Here’s the result, 1850-1859 as a verification period:
Larger figure in here .
Li:
If I got it correctly, for AD1820 step, the variance of observed prediction error is 300 times the predicted error.. Compare to the one they obtained with AD1000 step
Quite interesting, Wahl and Ammann would probably deem #65 reconstruction unreliable, and they would have to remove proxies to obtain acceptable RE.
#66: Yes, that applies directly to MBH99, that’s why I said they admit that MBH99 is a terrible overfit. But notice that the inflation factor 1.3 is not directly for ICE (with AD1000 step), it’s for their model where they allow AR(2) for the noise (GLS fitting).
#64: If you have time, run their code to obtain the true residuals. Then plot the residuals against the fitted temperature values. I would be surprised if there is no pattern.
In any case, IMO trying to work with MBH99 AD1000 proxies is waste of time: garbage in garbage out.
Silly me, used sample variance of calibration residuals directly, and forgot degrees of freedom. Inflation is 50, not 300 (without AR(2) GLS fit).
#67
They should state it a bit more explicitly, it would save time 😉
Was not aware of this thread. May I bump it and suggest it is relevant to confidence testing in Loehle (2007).
Actually, it makes sense to have both threads, this one for “MBH proxies” used in Li et al, and the other one for Li et al 2007 methodology independent of the proxy issues.
One Trackback
[…] 8/29/07 CA thread MBH Proxies in Bo Li et al has already discussed certain data issues in depth, but the 11/18/07 general discussion Li et al […]