Jablonowski and Williamson is here. Judith’s review follows.
The paper is very solid and well done; I don’t have any criticisms at all, so I will focus my comments on the implications of this for climate modelling. The ppt file is the more broadly useful document for those that don’t want to delve into the details but are interested in the motivation, punch line, etc.
This paper addresses the need for a standard suite of idealized test cases to evaluate the numerical solution to the dynamical core equations (essentially the Navier Stokes equation) on a sphere. Each modelling group runs through a variety tests to assess the fidelity of their numerical solutions. These include running idealized cases and comparing with an analytical solution, comparing with a very high resolution numerical solution, and testing the integral constraints (e.g. make sure the model isn’t losing mass). There aren’t any standard test cases used by atmospheric modelers. This paper argues that there should be, and further argues that there is much to be learned by using multiple models to establish the high-resolution reference solutions. They are not the first group to argue for this: the Working Group on Numerical Experimentation (WNGNE) of the World Climate Research Programme (WCRP) (has its roots in the World Meteorological Organization and the UN) has been (sort of) trying to do something like this for several decades. Maybe with leadership from Jablonski, this can happen.
The Jablonski and Williamson paper poses two such tests: steady state test case and evolution of a baroclinic wave. They consider 4 different dynamic cores, including finite volume, spectral, semi-lagrangian, and icosahedral finite difference. The main points are:
1) there is uncertainty in high resolution reference solutions, largely owing to the fact that a chaotic system is being simulation. Reference solutions from multiple models define a range of uncertainty that is the target for coarser resolution simulations.
2) In terms of resolution for the baroclinic wave simulation, they found that 26 vertical levels was adequate at a horizontal resolution of about 120 km. At resolutions coarser than 250 km, the simulations weren’t able to capture the characteristics of the growing wave.
So what do we conclude from this? Numerical Weather prediction models really need resolution below 125 km (note NCEP and ECMWF have horiz resolution at about 55 km). Climate models with resolution 250 km can reproduce the characteristics of growing baroclinic waves. Coarser climate models are not simulating baroclinic waves, and are accomplishing their transports by larger scale circulations. I did a quick search to see if I could find info on the resolution of the climate models used in IPCC, but didn’t find it. Many are in the 100-200 km resolution range. NASA GISS is about 500 km.Owing to computer resource limitations, each modeling group has to make tradeoffs between horiz/vertical resolution, fidelity of physical parameterizations, and the number of ensemble members. The resolution issue is more complicated than the dynamical core issue, largely because of clouds (finer resolution buys you much better clouds). Does this mean that the solutions to climate models are uncertain? Of course. The IPCC and climate modelers don’t claim otherwise. Are they totally useless and bogus because they don’t match tests such as jablonski/Williamson with fidelity? Not at all. They capture the large scale thermal contrasts associated latitudinal solar variations and land/ocean contrasts; this is what drives the general circulation of the atmosphere.
Taking this back to the issue of hurricanes (the topic of this thread). Even at 125 km resolution, you are capturing only the biggest hurricanes, and at coarser resolutions, you aren’t capturing them at all. Nevertheless, the coarse resolution simulations capture the first order characteristics of the planetary circulation and temperature distribution. This suggests that hurricanes probably aren’t of first order importance to the climate system (the impacts are of first order importance socioeconomically). A dynamical system with 10**7-10**9 degrees of freedom can adjust itself to accomplish the unresolved transports, in the case of hurricanes probably by a more intense Hadley cell.





290 Comments
I’m confused is the above Judith’s review or is her review contained in the link. Anyway, good summary. I applaud the work which Jablonski and Williamson, is doing to establish a rigorous set of standardized tests for global circulation models.
In terms of global warming though most of the energy transfer is through radiation. While it is important to establish reliable GCM it is equal if not more important to make sure that these models are well integrated with realistic radiative transfer models which provide good agreement with the in going and outgoing radiative fluxes at the atmosphere.
Perhaps such considerations are beyond the scope of Jablonski but I hope that if these models are used to make predictions about future global mean temperatures then a further set of standardized tests will be considered.
John,
A link to the Jablonski’s paper appears in “references” on the page SteveM linked. You can find additional papers by Jablonski here
http://initforthegold.blogspot.com/2007/12/why-is-climate-modeling-stuck.html
“There aren’t any standard test cases used by atmospheric modelers.”
I find this utterly astonishing! You mean no one has bothered to apply various GCMs to reference solutions until now? And we’re talking about just the dynamical cores here…
There is also another related issue that I believe plagues many of the numerical models. How do you prove that the algorithms expressed in the computer code are actually solving the equations they purport to be solving? That is, has anyone done a software audit on these codes? Many organizations, like NASA GISS, provide little to no documentation of the algorithms, even though the code itself is provided. For those who are interested, take a look at Model E for instance at the GISS website. What equations are used for the dynamical core? Are they implemented correctly? Has any stability analysis be performed on the discrete equations? What are the stability limits? How do changes in parametric models (e.g. ocean, ice, tracers, radiation, precipitation models) and initial conditions affect the stability? I could go on…
Yet, these are the numerical models that are being used to advise policy makers on future climate. I think it is high time we demand the same kind of software verification and validation for climate models in particular that we demand for codes used in, say, the nuclear industry.
#3 and #4:
Having spent fifteen years writing software in the nuclear industry, I have an appreciation for the issues associated with doing V&V on complex software. I’ve also been involved in several code re-engineering projects.
Referring to the discussion concerning GCM models underway in Steven Mosher’s link, it would be a most interesting (and expensive) experiment to take one of the older GCM models running in procedural language, construct a requirements document and a code design document for the GCM under current V&V practices, and then re-code it using a more modern object-oriented language.
Would the two incarnations of the same GCM model produce identical results starting out with identical initial parameters?
My guess is, not the first time around doing the re-coding, and probably not even the second time around.
Prof Garth Partridge held several eminent positions in Australia, latterly CEO of the Antarctic CRC. So we can assume he is quotable, at least to provoke discussion. Quote –
Is this just one of a set of limits to calculation that inherently restrict the utility of modelling? It takes my mind back to Mandelbrot’s fractal images, where you mined deeper and deeper to get different patterns, seemingly without limit.
Is there a worthwhile payback for the work Judith Curry proposes, or is it merely another demonstration that too many people drew inferences from models before they were ready? Will they ever be ready in the sense that they can be? Meanwhile, what of policy formulation……
I was tasked with reproducing a statistical package on Unisys computer to replace existing one on a IBM mainframe that the company was getting rid off. This was an important tool to the company that had been in use for many years and was implemented on a statistical software package. Mathematician that I am, I went back to the original statistical equations to implement my solution in a structured programming fashion. After careful testing, we ran a parallel test of the two systems and found a serious discrepancy. Since my program was the new kid on the block, I went and did a careful analysis of the system and could not find any software errors. We then went back to the original coding in the statistical package and found an error in the original code.
One problem I have found in many of the organizations that I worked for is that they forget that when you work with packages such as SAS, SPSS, EXCEL etc. and are constructing in them data. relationships and formulas you are still programming and minor errors that have significant implications. I have had to correct many spreadsheets that were used in producing reports for higher management of organizations for large manufacturing firms, state and federal government agencies.
Hey lucia,
I took your advice and looked at one of Jablonowski papers and it looks pretty advanced. I hope to read them some day but I think I need to read some more background material first. Her work looks pretty cool though. Apparently the grid cell resolution can be adapted as needed in localized regions to better model more major items of energy transfer like hurricane’s when needed. I also found interesting the discussion of the pole problem and how this can be eliminated by using by using a grid which is composed of equal sized triangles. Such a grid almost reminds me of a sockerball even though the shape is different.
#4: “There aren’t any standard test cases used by atmospheric modelers. I find this utterly astonishing!”
I don’t think this should be so astonishing, though you might want to be astonished by some other stuff. (And if my discussion of the other stuff is insufficiently close to the original topic, it’s OK with me if some moderator-type person deletes all but the next two paragraphs.)
I did some undergraduate research, and my Ph. D., in simulations of biomolecules. There are some standard sorts of checks that people tried to do — e.g., compare to the atomic positions found by experimentalists in really-well-studied macromolecules. But even with complete scientific integrity there can be vexing practical obstacles to making satisfactory “standard test case” choices. For example, the stuff which is known most clearly can be annoyingly far from the regime which is of the most practical interest. For the proteins-in-solution problem which motivated my work as an undergraduate programmer, the experimentalists had very good results for protein crystals, but they have to impose pretty weird harsh conditions (like extreme salt concentrations) to get them to crystallize, and what we care about much more in practice is how proteins behave in milder environments more like the insides of living organisms.
I am generally underimpressed by the climate science folk — e.g., yesterday I was idly wondering whether a page like http://www.realclimate.org/index.php?p=11 would look more like Darwinism or Lysenkoism to someone who doesn’t already have my cynical view. And I generally support some common criticisms of modelling, like Steve McIntyre’s remarks somewhere about how blurring the distinction between measured and modelled/extrapolated results is a well-recognized sin in mining-related advocacy and should be here too. But I don’t think you should necessarily be shocked at the lack of standard test cases.
One less-standard criticism you might want to be shocked at, or at least very seriously disturbed by, is lack of attention to other kinds of verification of predictive power. It is weird for me, coming from molecular modeling (and a general interest in the history of science), to see people paying so much attention to matching a very small number of observations given the large number of parameters in the model. It is particularly weird because I currently have _The Minimum Description Length Principle_ checked out from the local university library (for my own machine-learning reasons, not for policy advocacy reasons). In my experience, when scientists have a theory which they believe to have a lot of predictive power and only a few obvious numbers of practical importance to test it against, they look intensely for less obvious practically unimportant observations to test it against. These numbers may not come up in, e.g., testimony before Congress, since they may be honest-to-goodness very hard to present in a few pretty pictures. But they come up all the time in more technical discussions.
E.g., in molecular modelling, people got very interested in higher-dimensional nuclear magnetic resonance data. Such NMR doesn’t naturally give the same kind of pretty every-atom-in-its-fixed-place pictures as X-ray crystallography, but it gives a great volume of weird detailed little constraints and correlations which could be cross-checked against a model. And even if what eeveryone cared about in practice was some simple high-level summary like the function of a protein (e.g., something like the O2 affinity of hemoglobin), nobody would present a new model with hundreds of parameters and focus only on its fit to a few-parameter curve of bound O2 vs. partial pressure of O2. If you can’t find datasets with very large numbers of degrees of freedom to compare against (like higher dimensional NMR, or various other kinds of spectroscopy) caution is in order. And if the modeller isn’t terribly interested in finding such datasets, perhaps great caution is in order.
Without knowing much specific about climate models, coming from chemical modelling I’d expect two general things of them. First, they’d regularly refer to at least one huge family of checkable things about regional distributions and correlations and so forth, rather larger than “the number of adjustable parameters” (a vague concept, but one which can be made more precise, as e.g. in the book I mentioned) in their models. Second, if they’re confident their models are precise enough to pick out interesting nonobvious phenomena (e.g., famously, that the net temperature response to C02 concentration is considerably higher than the first-order effect) then even if the mechanism doesn’t leave clear footprints in the current experimental datasets, it should be leave footprints in some imaginable experimental datasets that the climate folk are now passionately longing to measure (I dunno: nocturnal concentration fluctuations of an ionized derivative of CO2 over the Arctic and Antarctic). I don’t absolutely know that these things don’t exist, but I’ve spent some hours surfing RealClimate without noticing any hints that they do. (And if molecular modelling had been subject to the same level of informed controversy as climate modelling, I’d’ve expected that a few hours surfing the RealBiomolecule site would have given many such hints.)
I’d be reassured to see climate modellers hammering on how detailed interesting regularities in experimental data (existing or wished-for) are explained or predicted by their model: something like the (honestly exasperated) way biologists refer to all the megabytes of detail revealed by DNA sequencing and other molecular biology which just keeps matching the constraints of Darwin’s model. So far, that honestly exasperated attitude hasn’t come through as strongly as I’d like.:-| I don’t expect the climate scientists to be angels: I’ve followed the creationism dispute for decades, and honest competent biologists are not immune to the temptation to be exasperated at distractions like their critics’ funding not coming from the holy NSF and their critics’ almighty credentials not being biology degrees. But biologists seldom get so fascinated by distractions that they forget to refer to fundamentals like the enormous volume of detailed regularities in nature that the consensus model matches.
For my Ph.D. thesis I developed a model of a grazing ecosystem in Pascal. It ran beautifully, but one curious bug was that when I simulated adding cows to the range, it stopped raining. Pretty realistic, a rancher would say, but really due to utilizing dynamic arrays of unequal length, so the added item stomped on some of the memory. I would say my code from 1981 was much better structured and documented than Model E etc. Sad but true.
Craig, I had days like that.
However, I am not so sure that the GCM modelers would see that as a problem. 🙂
Geoff–
If you are asking whether there is payback in doing standard tests or codes and/or models in climate science, yet. In principle, yes there is worthwhile payback for the work Judy supports and many, including Jablonski also support. Even though all flows affected by turbulence large amounts of apparent randomness, there are various different ways modelers try to account for the average effects of the random fluctuations in the flow. (That is: the mean fluxes associated with eddies, which result in transport.)
These different methods of accounting for these effects work to greater or lesser extents. So, even in the regions where flows include random effects, test to see which formulations work. It’s always having tests so modelers can compare how well the different models are doing or, baring that, to make sure modelers know for certain that the different models disagree.
In fact, the tests are particularly important when the models disagree. Seeing this quite vividly does three things
1) it reminds modelers that the models may not be capturing reality, this helps remind people that results my not be quantitatively accurate,
2) it motivates improvements and
3) Helps people be more realistic about what the codes really can do. (Though, it actually helps only a little. )
Scott–
It’s pretty obvious GCMs haven’t been subjected to the V&V imposed on codes used for Nuclear applications. When I was at PNNL, codes used for tank safety work has to pass strict V&V which meant certain types of documents existed and were publically available. Modelers could not use off the shelf codes like Fluent etc. because those private companies– which did their own V&V (sometimes internally) didn’t do this in away that satisfied the paperwork requirements for nuclear and clean up applications. Everyone had to write lots of what academics call “grey literature” discussing all theory and v&v tests. This went through internal peer review, external peer review, and programmatic reviews that are entirely different from the peer review process at journals.
Anyway, I understand what you are talking about and recognize the various reasons why it’s needed. (And if it existed, it would greatly benefit the whole climate wars debate.)
That sais, I have to ask you: Other than as a personal hobby, why in the world would anyone spend the money to replicate an old code in object oriented language? Wouldn’t it be wiser to simply press for V&V of work going forward, and admit that the past work wasn’t subject to V&V at that standard? The standards could include adopting standard tests, of the sort Judy and Jablonski are describing, running the tests, and documenting the results in those horribly boring Laboratory reports so that third parties can read the results. (The alternative leaves them wondering if the tests were run, or what, the precise results where after they were run. )
As a tax payer, the second course– requiring some standard V&V and documenting, is what I’d vastly prefer! I don’t give a hoot if the code is object oriented.
re #6,
Geoff,
I think I am mostly agreeing with lucia here but I say it differently. The payback is in learning what we don’t know about climate. The models will never have predictive power.
As an aside, I’ll note that PNNL does outstanding and highly effective V&V work on their software projects — as long as the customer makes a point to ask for it.
In many cases, the codeheads are like engineers in that they always think they have a better set of technical solutions than the ones that currently exist. As an engineer, I am generally sympathetic to such arguments, except where the replacement technical solution is clearly an excuse to spend money, rather than to improve the product.
In my case, the systems we re-coded were targeted for elimination because the IBM mainframes they resided on were targeted for elimination. We were given a date on which the mainframes would be shut down, and we met that date.
Did we spend the money wisely? Well, when we eliminated the IBM mainframes — a decision driven by the “Everything IBM is more expensive” IT management paradigm of the 1990s — we also eliminated our disciplined IT management support infrastructure, and so V&V and a strong systems management approach took a vacation for quite a while. It is only recently making a comeback.
I concur that the money is best spent implementing a decent and appropriate V&V program for the existing GCM code base. This is a very necessary first step for the interested public to understand how the codes actually work. If the codeheads get their way, the resources will go into the low-level code design and code construction effort, not into the very important and very necessary upstream process of identifying and documenting the scientific requirements basis on which the codes are built.
The January 5, 2008 edition of “New Scientist” contains a report on the work described in the paper found at http://www.arxiv.org/abs/0712.1187 . The research concens the effect of the effect of using tools like Mathematica of the physics reasoning skills of students. There are two stage in this. The first is to use physics to develop a strategy to solve a problem. The second is to code it. What the researchers found is that it was the physics that was deprecated in this endeavor . Coding took on paramount importance. One set of students who chose an incorrect strategy to solve a problem in quantum theory repeatedly re-coded the incorrect physics strategy in an effort to correct their mistake.
The final quote from the “New Scientist” story is perhaps illuminating.
One example of this is to take the simulation as reality and believe that perform experiments on it are representative of reality.
Reality check, my statement about no standardized tests to evaluate codes for dynamical cores in atmospheric models has been misinterpreted.
First, each modelling group does its own testing, my statement did not imply that people weren’t testing the dynamic cores, but that there were no standardized tests, and the jablonski paper points out the advantage of using high resolution simulations from multiple models to establish the reference simulation.
Model thermodynamics are compared by creating single column versions of the climate model, just looking at what goes on in a single vertical grid cell. Different single column models are compared with each other and with observations. Certain physical parameterizations are tested in stand alone model. Radiative transfer codes are being evaluated very thoroughly in the context of the ICCRM program (not exactly sure what the acronym is, but it is a radiative transfer model intercomparison program organized by the World CLimate Research Programme (WCRP) that has been underway for several decades.) Codes are compared with line-by-line radiative transfer models that are carefully evaluated against high resolution spectral measurements made by the DOE Atmospheric Radiation Measurement Program. The boundary layer parameterizations are evaluated against reference large eddy simulations and field observations, under the auspices of another WCRP program. and so on.
Back to the dynamical core evaluation. In the 70’s and 80’s, much effort was put into investigating the accuracy and stability of these solutions. Alot of kinks were worked out back then, and more robust and efficient solution algorithms were obtained. The dynamical cores haven’t change much in the last few decades, with the exception of increasing use of semi-lagrangian and lagrangian methods. People at the main modeling centers are starting to work on new numerical solutions for the dynamical core, and hence the rationale for the new call for standardized evaluation cases.
Climate model simulations in all their complexity are extensively intercompared (the so called AMIP and CMIP intercomparisons) with each other and with observations. However, when discrepancies arise (and they always do), you can’t tell where the problems are. Hence the need for more emphasis on breaking the code into parts and evaluating against reference solutions or relatively simple observational case studies.
The bottom line is that I think the U.S. climate models that are been run at resolution 250 km or higher almost certainly have robust dynamical solutions (the real problems are with things like the convective parameterization). I am not quite sure how to interpret results of coarser resolution simulations (such as NASA GISS and many paleo simulations), this should really be evaluated better.
I didn’t find contact info for the page
http://www-personal.umich.edu/~cjablono/dycore_test_suite.html
If you know them, someone, please tell them they’ve got a typo:
“… packages on the sphere if highly desirable. …”
———————–
“Opposition is true friendship”
— William Blake, Proverbs of Hell
Hi Judith,
“The bottom line is that I think the U.S. climate models that are been run at resolution 250 km or higher almost certainly have robust dynamical solutions (the real problems are with things like the convective parameterization).”
Do you have a paper which provides documented proof of the foregoing statement? And what do you mean by “robust”?
Thanks,
Frank K.
Judy–
I agree with you that V&V is done in climate science. But, I’m in the position of knowing climate science V&V is not done quite the way it’s done in nuclear or safety work. (In some sense: thank heavens! In another sense: climate science could improve.) 🙂
But, when I say the codes aren’t generally subject to the type of V&V in nuclear applications, they generally aren’t. My husband Jim worked on ARM. (You also did a project with Sheba, right?) I’ve worked on a range of projects; he has. We both know the range of what is done.
I’m tempted to write more, but I can’t figure out how quickly compare and contrast and also explain that
a)climate science could benefit from more formal V&V procedures but
b)it should adopt the full nuclear safety V&V requirements.
The main benefit of the more formal V&V than typical of academic peer review is not scientific: it’s to communicate with technically competent non-climate scientists who must make up their minds before casting ballots during elections. I think some of the violent disagreements over V&V here and at RC come from each side not understanding what formal V&V is for.
The reason to avoid full nuclear safety requirements would be clear if you read how amazingly detailed they could be. The most formal V&V requirements are reasonable when a single mistake in a single application can cause an accident that kills someone. They aren’t quote so necessary when the results of a study will simply add to a body of literature that helps us gain understanding about science but does not lead to any particular decision immediately. Some of the V&V demands I read are too extreme– but it is regrettable that more formal V&V was not adopted by climate modelers.
But, in some sense, that’s in the past. What would be nice is if these methods of testing were adopted and some program began encouraging or requiring some formal methods of documenting the V&V for codes.
Yikes. Serious typo alert!
b)it should not adopt the full nuclear safety V&V requirements.
Judith, it is the lack of standardized tests to evaluate the cores that concerns most people here.
lucia,
If climate models are to be used to learn what it is we don’t know about climte, then I agree with you vis a vis V&V.
If climate models are going to be used as the justification for restructuring the entire world’s economy, then nuclear/avionic levels of V&V are the absolute minimum that I am going to demand.
The climateers can’t have it both ways.
Judith,
If the cores have been validated, then the modelers should have no trouble providing the documentation to prove it.
If they can’t provide the documentation, why should the rest of us just take them at their word?
Lucia: #19: I would not expect that full nuclear-grade V&V be applied to the GCMs. Something less is needed for these models.
What I would expect instead is that the scientific knowledge and the scientific concepts which form the design basis of the GCM’s expected operational behavior be documented in such a way such that: a) the science itself is understandable to both the programmers and to the general scientific community; and b) the behavior of each code module can be traced back through all of its predecessor design criteria to the requirements which spawned those expected behaviors; and c) the documentation is written at all design levels so as to be objectively verifiable and testable relative to the criteria stated in the predecessor design requirements.
Now, whether or not the scientific basis itself, as written in the design criteria documentation, is “valid” scientific criteria is a different question from a purely QA/QC perspective. That is something that a formalized V&V process for the GCM’s could never be expected to verify all by itself. (Otherwise there would never be consensus on what the design basis criteria should be.) That part is in the hands of the GCM modeling community to decide, and is a matter of how they choose to approach their professional responsibilities.
As interested customers for their work, we need to know the actual design basis criteria on which the GCM’s are operating, and whether or not the basis criteria is being successfully implemented from a purely QA/QC standpoint. One can then argue about whether or not the design basis criteria itself is appropriate.
Recognize too that arguing the fundamental design basis after the fact is not the best approach from an idealized Requirements Management perspective. However, the GCM’s already exist, so the cart is already before the horse, so to speak. Idealism will not change this reality.
Interesting discussion on V&V. The problem, in a nutshell, is that there’s never enough money to do the science right, but there’s unlimited money to react to the science that wasn’t done right. We’re missing a step in the process. The way the UN and most of the world is doing it, is according to the following formulation:
1. Survey the science.
3. Act.
What’s missing is:
2: Review the science with a fine toothed comb. The V&V, or what Steve calls the “engineering report” should be done done between steps 1 and 3. If they don’t have the money to do this, they have no business enforcing the unfunded mandate implied in #3.
I’d like to think that this was a colossal accident, but the charter of the IPCC specifically forbids them from conducting original research. That means they CANNOT influence the process of the research. It’s almost as if they designed a system that specifically forbids quality control.
When you are already getting the answer that you want, why risk going through quality control?
Re V&V, probably the model with the best documentation is ECMWF (which is the same dynamical core and mostly the same parameterizations of ECHAM climate model). Here is the link to the full archive of their technical notes. Read all this and let me know if you have confidence in the model.
http://www.ecmwf.int/publications/
specifically, the technical memos and technical reports
RE 10. ha.!!!! you wrote in pascal you wascal. I loved that
language.
RE 17. HANK! Googlemaster! you find them and you contact them.
It’s in the white pages.
27, I still use Pascal for the little chips:
http://www.mikroe.com/en/compilers/mikropascal/dspic/
RE 16.
Easy question Dr. Curry. If GCMs are used to asses, base, craft, create, change, construe, delimit,
determine, establish, finesse, form, guage, influence, invalidate, inform, judge, juggle,limit, maintain,
manage…… public policy, you will agree that they should pass a standard test and actually graduate.
No GCM left behind!
I have a comment “awaiting moderation”. for some documentation on what goes into the atmospheric part of a climate model (specifically ECMWF, which forms the atmospheric core of ECHAM climate model), go to http://www.ecmwf.int/publications/
specifically, the technical memos and technical reports. After reading all these (going back to about 1980), tell me whether or not you have confidence in the model.
Maybe not but I would wager that most of these models haven’t even been verified. If I read J. Curry’s assessment right, that is what is being proposed a standardized set of cases that begins to touch on the subject of verification. Validation is years away….which leads me to ask: How can anybody depend on these things for any type of conclusion at all? If I used a sim that wasn’t V&V’ed to help evaluation/design the devices I’m involved with, my head would be metaphorically taken off at the shoulders. Guess that’s the difference between engineers that have to actually make something work and researchers whose work is confined to bickering back and forth in journals.
nuance, objectify, persuade, quantify, reify, substantiate, translate, ululate, verify, wring, xonerate, yahoo, oh Hell, I give up.
===================================================
#31
This one caught my eye. Ahhhh. The Cooley-Tukey FFT.
How is the model performing at prediction?
Britton Stephens, et al, “Weak Northern and Strong Tropical Land Carbon Uptake from Vertical Profiles of Atmospheric CO2”, Science, June, 2007, points out some rather significant inconsistancies in current models. If the uncertainies in CO2 sources and sinks are as large as 25 – 75%, it seems that many GCMs are of very limited value. Stephens makes the case for increased spatial and temporal resolution. Atmospheric and oceanic stratification is recognized but dynamic production and transport models are inadequate (I realize that NCAR has a “…horse in the race!)
Jaye– I’m an engineer. There have always been engineers who use codes and software that don’t go through formal V&V. There always will be. It depends what they are doing and how it’s being applied.
V&V is rarely emphasized on exploratory research.
Judy — “After reading all these (going back to about 1980), tell me whether or not you have confidence in the model.”
With regard to the skeptics screaming for V&V you posed an irrelevant question. The question should be: “Tell me whether this is V&V?”
Alas. While the things you point to are interesting, and show that good work is done in weather prediction, it does not resemble any sort of formal V&V. Some I saw would fulfill part of Verification. I saw absolutely nothing that would remotely fulfill validation in any formal way. The validation is stuff you would have expected all those people to do, but would normally find boring to read. If it were in those documents, you’d consider the material filler. If you put it in a peer reviewed article, the peers would either reject your manuscript or tell you to take out the filler.
But, unfortunately, this validation is important when things switch to guiding policy. One reason this is important is simple: a sizeable fraction of skeptics are unconvinced because they want to see this stuff in black and white. They know the are required to provide it when they need to convince regulators. They didn’t make up those rules — they know skeptics won’t just take their word they did the validation if they didn’t document it. (They know some people won’t do the Validation and they know sometimes things go wrong do to lack of validation.)
The people who will not feel confident without V&V need to see V&V documents. An infinite number of good science documents won’t make them feel confident.
For those of you taking potshots at the models, going to the ECMWF site (#32) is a must, even if you just read the titles of the tech notes. This will give you an idea of what goes into these models and how they are evaluated. Rejecting the models because of the lack of a standardized set of tests is irrational.
Scott-in-WA has some sense of the reality of climate modelling. You will really need to crank up the activity in the tip jar to pay for the development and implementation of standardized tests for each element of a climate model. In the best of all worlds, would this be done? yes. But actually figuring out how to do this for such a complex numerical system is no easy task, and then getting people to agree on what tests to actually use is probably hopeless, and finding resources to fund such an activity is a fantasy. Unfortunate, but this is reality.
#34
Boy do I need to review my matrix algebra texts
re 37. Judy judy judy.
“For those of you taking potshots at the models, going to the ECMWF site (#32) is a must, even if you just read the titles of the tech notes. This will give you an idea of what goes into these models and how they are evaluated. Rejecting the models because of the lack of a standardized set of tests is irrational.”
1. I have slogged through almost the entire 100K lines of ModelE. Now I am I starting On the MIT GCM which
is much easier. So, Some of us have earned our potshots. In walking through ModelE I found nothing to reccommend it.
No test cases. No test suites. No test drivers. No unit test. No standardized test. At one point gavin
directed me to a site of “test data”. I found errata exposing monumentaly stupid programing blunders that
your worst GT undergraduate programing student wouldnt commit to a daily build after an all night bender
Worse, when I requested access to the IPCC data, I was denied. Private citizens cannot get access to this data
. You want to talk about irrational. Irrational is this: no spec. no coding standard. no test plan. No verification.
No validation. No manual. No documentation. No public access. no accountability.
I’ll link some climate modelers in a bit saying essentially the same thing. you can potshot them
“Scott-in-WA has some sense of the reality of climate modelling. You will really need to crank up the activity in the tip jar to pay for the development and implementation of standardized tests for each element of a climate model.”
I ran cocomo which nasa uses to estimate a total rewrite of ModelE. With a full V&V its less than 10Million
dollars. It is the responsibility of program manangers within nasa to make the appropriate
budget requests. The problem is they dont value transparency and openness and testing and accountablity.
Ask the guys on challenger. opps they are dead. pity that. The explosion was pretty however.
Re: #36
Would not the people charged with running these models want to validate them in some formal manner regardless of what potential skeptics might say or want? Or would they argue that validation is a waste of time like an unfortunate TV network news reader did a few years ago.
I agree that anyone slogging through a GCM code is entitled to make potshots. But there is a WORLD of difference between the ECMWF model and the NASA GISS model. I encourage you to look at the documentation of what is regarded to be the best atmospheric model in the world. ECMWF puts NASA and NOAA to shame.
A model of the complexity of global models is never going to be perfect. What can we learn from an imperfect climate model? I refer you to a paper by Leonard Smith, who is somewhat of a guru in the field dynamical systems, their simulation, and applications to atmospheric models
http://www2.maths.ox.ac.uk/~lenny/PNAS.ps
Ken Fritsch
Competent responsible people running these models would validate things. The question is the level of formality. If an unfortunate newscaster suggested validating itself is a waste of time, that unfortunate newscaster possibly doesn’t understand what’s can go wrong when coding.
To give an example:
Supposed, for some reason, I write a subroutine that to calculate
T= T(o) exp(-t/tau) in excel.
After I write it, I might want to validate and do that several ways. One might be to enter time in one column of a cell, enter various the formula in a cell, passing both time and tau. Then I might plot.
That’s sort of a validation.
So, do I do this informally: I just do this routinely and look?
Or do I do this formally at the thermo-nuclear level which involves:
a) I print the chart out,
b) I print the data out.
c) I write a 4 page document discussing the equation, and printing out the VBS macro in excel.
d) Format the docunett nicely so a human can read it.
e) Hand the document to a competent individual with at least a BS who will read it and check that my formula correctly calculate the intended value. The other engineer is required to pick a few values and calculate, and attach his results.
f) Have then initial this, put it in a file, which will later be stored by the Richland Field office of DOE.
g) Have the field office guy come by and pass his geiger counter over the files before storage. (Not making this up. It has nothing to do with V&V. Evidently, radioactive stuff once ended up in storage.)
h) maybe, depending on the project, have this be subjected to additional reviews.
a-f is the thermo nuclear validation and verification. My simply checking is informal.
I’ve obviously picked a simple example involving software and I’m describing extremes. (It’s also unlikely that one equation by itself would go through V&V on in isolation.That would only be V&V’d if that two line macro were used in something else. The whole thing gets v&v’s collectively.)
That said, sometimes just me checking my work is enough. Other times, the thermo-nuclear V&V is required.
Climate science falls in between. In many cases (particularly many documented in the efforts Judy pointed to) the proper level is closer to the informal method. The researcher checks.
For actual GCMs, now that it’s apolitical issue, something more formal is required.
The thermo-nuclear V&V would be overkill.
Argonne National Lab actually has guidelines, and the “thermo-nuclear” V&V would not apply to GCM’s.
#41 — “I agree that anyone slogging through a GCM code is entitled to make potshots.”
Sufficient, but not necessary. Anyone who can appreciate the model errors documented in the 4AR Chapter 8 and Chapter 8 Supplemental, which show that GCMs not only make large intrinsic errors when tested against observables but also that different high-resolution GCMs can make large-scale errors of the opposite sign when tested against the very same observable, is entitled to make potshots. These GCMs all presumably include the analogous physics and are parameterized with best-guess estimates. Nevertheless, the error residuals vary from GCM to GCM, often wildly. This is hardly cause for confidence in prediction.
#43, I wonder at what point they really start to fail? Do they start to fail when they start doing ideological things like putting in too much positive water vapor feedback and then trying to fix the model by adding aerosols that aren’t really there.
I think as far as basic circulation goes we should understand the physics enough to produce reasonably accurate models given that much more energy is transfered trough radiation then trough convection.
Thank you, Dr. Curry, for your participation and for the link to Dr. Smith’s paper. Googling Smith I also found “Confidence, Uncertainty, and Decision-Support Relevance in Climate Predictions,” co-authored by Smith. The heart of its scientific conclusion is:
the tone of which somewhat contradicts his politically necessary concluding paragraph,
Especially because of the possibility of catastrophic climate change honest assessments of uncertainty are important. “We don’t know but scary possibilities exist” is very different from the claim that we “know” that we only have ten years left to “save the planet.” It seems that while Smith is certainly concerned, that Smith’s view of “Accurate communication of the information we have” may differ from the communications of the IPCC and Hansen. This sentence, in particular,
Seems like a very polite way to flat-out contradict IPCC statements of probabilities.
I’m late to this party and have not read all the responses. But, haven’t the models already been tested and shown to be way off target? The SH is not heating as “required” by the models. The troposphere is not heating faster than the surface as the models suggest. The models have not tracked temperatures since the 80’s, especially during the last 9 years. How can anyone support these things with a straight face?
#46, I think they may be trying to be too accurate. In my opinion it is much better to get a smooth fit with lots of error but zero bias, then to obtain an accurate fit by over fitting the data with too many unknown and unmeasured parameters. I confess I don’t know enough about climate models to know that they are over fitting the data in this way, but the runs I’ve seen suggest to me that the responses are not smooth enough given the amount of error.
Hansen goes beyond the IPCC. The IPCC is much more conservative. Personally I agree with Smith’s interpretation, we have not done the full analysis of model uncertainty. But again the IPCC is pretty conservative, it states that the range from its scenario simulations are “likely”, implying > 66% (and therefore that there is 24% probability that the temperature change will be outside the range. So I don’t think the IPCC is inconsistent with what Smith is saying, but some of what Hansen says is.
#48, Judith doesn’t that go against the claim that the science is settled? It is my understanding that the policy summaries are anything but conservative.
RE:42
Looks like A-F is just verification.
Mosher is right. The sort of code that potentially influences trillions of dollars of public spending should be developed to a standard that is much better than the Level 1 amateurish stuff I see from most academics. Requirements, design, coding standards, documentation, peer review, unit/integration test, etc and at least verification should be the minimum standard for this type of project. Making policy decisions based on code that does not reflect that sort of pedigree is foolish.
1. If all this is just exploratory research then it should not be used in any to guide policy.
2. If I were writing the models I would at least make sure they were verified via testing. Especially if I were writing papers on that used the model results…anything less would be sloppy. Plenty of good testing tools out there some free, CppUnit comes to mind. Use’em they are free. I wouldn’t promote past a work space branch without passing unit tests.
Back to my question, which wasn’t answered…
“The bottom line is that I think the U.S. climate models that are been run at resolution 250 km or higher almost certainly have robust dynamical solutions (the real problems are with things like the convective parameterization).”
Again, is there a report or paper which provides proof of the foregoing statement? And what is meant here by “robust”?
The reason I ask these questions is that I am convinced that there is a fundamental limit to the predictability of the dynamical “core” equations (continuity, momentum, energy) due to the ** nonlinearity ** of the system. Depending on what is meant by “robust”, I would venture that modern schemes for integrating the dynamical core equations in climate models are no more “robust” than in those in the NWP codes. That is, of course, if you believe that climate prediction is an initial value problem (as I do).
I looked through the archive of technical papers and reports at http://www.ecmwf.int/publications/, but didn’t find anything to support Judith’s claim above. Perhaps she can provide a mathematical proof of this herself to settle this once and for all.
Finally, are we being too hard on the climate modelers? After all, CFDers like myself can publish papers on esoteric topics like numerical prediction of steam droplet nucleation, and no one asks us for stability proofs or verification studies. Then again, most engineering CFD analyses are not used to construct apocalyptic fantasies such as the infamous “Climate Change and Trace Gases” by Hansen et al.
Click to access 2007_Hansen_etal_2.pdf
If we are to submit to the will of the IPCC and make the costly changes to our society and economy recommended in the policy documents, I believe it is not asking too much for rigorous validation and verification of the software upon which these policy recommendations are based.
All this is a very nice sophisticated discussion about testing the models but in my opinion ignores the much more fundamental issue – the data base for the model construction. Surface data is totally inadequate in space and time for almost every part of the Earth. There is almost no upper air data of any consequence. There is talk of testing one column, but which one. I doubt there is one with adequate data in all dimensions even in the 250 km scale grid.
The GCMs are not going away and will eventually act as the recognized formal basis for justifying many trillions of dollars in anti-GHG measures. So these discussions concerning GCM software V&V issues are far from being an academic exercise in software V&V theory.
Implementation of a successful V&V philosophy for the GCMs implies that a full lifecycle approach must be taken in developing and managing the GCM software and its employment while in production operation. Elements of the full life cycle approach include a Conceptual Design Document, a Functional Requirements Document, a Detailed Design Document, Code Construction documentation, a V&V Testing Document including unit tests and all-up integration testing, Production Implementation documents, Ongoing Software Maintenance and Enhancement documents, and Code & Documentation Configuration Management.
If a successful V&V program is ever to be established for the GCMs, then there has to be a precise, foundational decision made as to how that V&V program will be defined and structured for GCM software applications, and as to how the V&V program will be applied in actual practice in terms of integrating specific software V&V activities with the other software lifecycle processes as listed above.
As a starting point in bringing some kind of order to this rather chaotic V&V discussion, let’s define some basic terms. Verification and Validation (V&V) can be thought of as two related fundamental questions: “Did you build the right thing?” and “Did you build the thing right?”
For the GCM’s, the question of “Did you build the right thing?” has to do with whether or not the design basis assumptions for the software are appropriately chosen so as to achieve the desired functional utility of that software. For GCMs, these design basis assumptions might include first-principle physical equations, assumed IR spectral behavior of gases, fluid dynamics principles, thermodynamic principles, and more technically-complex assumptions concerning the behavior of clouds, aerosols, non-C02 greenhouse gases, etc. etc. One also has to precisely define just what the “functional utility” of the GCM software is expected to be. Is it to be a simulation of actual physical reality? Is it to have predictive capabilities? These further questions are all part of the fundamental question “Did you build the right thing?” All of this information must be documented in their appropriate places within the GCM design documentation, otherwise there is no practical basis for implementing a successful V&V approach.
The second fundamental question of “Did you build the thing right?” has to do with whether or not the software properly implements the design basis assumptions and the specified software functionality, as these are described within the software design documents. I see no alternative but that the mathematical equations as implemented in the GCM software must be unit tested to ensure they are properly doing their calculations. I see no alternative but to design tests which indicate that the sub-module interactions are operating as designed. I see no alternative but to design load tests that give some indication of the software’s behavioral stability on the hardware platforms it actually resides on. I see no alternative but to devise all-up tests that evaluate the software’s overall ability to fulfill its design basis criteria, as that criteria is described throughout the design documentation.
Generally, in the world of nuclear-grade software, the twin questions of “Did you build the right thing?” and “Did you build the thing right?” both have equal levels of applicability as they affect a Pass/Fail evaluation decision.
But is this so for the GCMs?
In nuclear, we usually know fairly well what the question “Did you build the right thing?” means for any given technical situation, and so managing uncertainty in the design basis requirements is a fairly straightforward process. The GCMs are a very different story, in that managing uncertainty in the design basis is a much more difficult and contentious process—a process which will always be difficult and contentious because of the inherent uncertainty of the climate science on which the CGMs rest.
This implies that climate science uncertainties which affect the GCMs design and operation must also be documented as a formal part of creating the design basis criteria against which the V&V processes will operate. Such uncertainties might well include the issue that surface data might be totally inadequate in space and time for almost every part of the Earth, and that there is little upper air data of any consequence.
I just read the Dr. Syun-Ichi Akasofu paper that is up on ICECAP website. In it he states “we asked the IPCC arctic group (consisting of 14 sub-groups headedby V. Kattsov) to “hindcast” geographic distribution of the temperature change during the last half of the last century.” The result: “We were surprised at the difference between the two diagrams in Figure 11b. If both were reasonably accurate, they should look alike. Ideally, the pattern of change modeled by the GCMs should be identical or very similar to the pattern seen in the measured data. We assumed that the present GCMs would reproduce the observed pattern with at least reasonable fidelity. However, we found that there was no resemblance at all, even qualitatively.” I would have presumed the IPCC would have used their best GCM.
He then goes on to give two examples of how to use “GCM results to identify natural changes of unknown causes.” That was a nice twist.
Doesn’t fill you with a warm fuzzy feeling about GCMs.
#56
Do you have a link? More context is needed.
#55
All very nice but in answer to your questions “Did you build the right thing?” “Did you build the thing right?” I would have to say you can’t build anything if you don’t have the building material, in this case data. The only way I can see GCMs achieving any hope of validity is if a concentrated program is begun right now to develop a complete global network of data collection with adequate samples in each grid box to establish a reasonable measure of the weather dynamics. Then after 30 years you might have sufficient statistically significant data to be able to construct a model. This is not going to happen, indeed, the trend is to close stations – there are less stations now than in 1960. Just as an example of the problems consider that the entire continent of Africa does not have enough stations to meet the minimum density requirements for measuring precipitation as set out by the World Meteorological Organization (WMO). This leaves a massive hole in knowledge about the dynamics of the Hadley cell and the transport of latent heat to warm higher latitudes. The GCM program is a complete waste of time and money yet the output is being used to impose massive energy and economic policies for the entire world. Let’s get some meaningful data first.
#49 — A 95% physically accurate climate model couldn’t predict 20 years on. One that’s 66% accurate couldn’t predict two years on. But the conservative IPCC extends its predictions out a century. It’s all so wildly improbable that it’s no wonder no one pays attention. It’s too embarrassing. And so objective nonsense is discussed with sonorous gravity.
Building current GCMs with the presently available data is simply building the wrong thing with hopelessly defective data. The people who persist in attempts to force such square pegs into round holes are not unlike the people and organizations responsible for constructing a certain infamously empty and useless hotel in Pyongyang. The solution is simple, unless getting a truthful answer is not the genuine intent and objective. Secure data which is verified to be qualitatively and quantitatively adequate for the intended tasks. Publicly archive the data and methodologies in publicly verifiable and obtainable formats. Exclude from consideration as evidence any papers which fail to meet minimum standards required for public disclosure and verification of data and methodologies. If the IPCC and/or other organizations fail to meet minimum standards for public application of the scientific method, organize new organizations who will meet such standards and replace the organizations and people who refuse to do so.
Re # 43 lucia
What you write often strikes a chord with me, perhaps because we both have nuclear safety backgrounds and a better idea of the consquences of error.
Three matters concern me, as I’m sure they do you. First, there is a paucity of reliable data upon which to build any framework for testing, V&V or even simple proof of physics and chemistry. Like others above, I suspect a cell size of well under 200 km will be needed, maybe even smaller to allow an extrapolation to a limiting case (like the missing exponent in how long is the coastline of Britain, Mandelbrot). In the non-temporal case of mineral resource work we used weighted search ellipsoids in the tens of meters range.
Second, the danger in providing a standard set of tests that all models can pass is that all models will be tweaked to pass the test. Maybe urban myth, but whem Chairman Mao decreed there were too many rats in China, he ordered each person to take a rat tail to a repository every week for a payment. In a short times, farms had sprung up to breed rats to take to the repository. Even now there are data comparison projects between GCM modellers to see how close they are to each other. The real question is, how close are you to truth? Look at this set of numbers for Australia’s CSIRO model performance compared with the average of 22 models (data for temp change at various altitudes, espressed as millidegreees C per decade).
Aust. Mean of 22 GCMs.
163 156
213 198
174 166
181 177
199 191
204 203
226 227
271 272
Then the figures start to diverge a little more.
307 314
200 320
255 307
166 268
53 78
See how close the models can be?
Third worry is that modellers full of confidence after passing tests will be more insistent that they are right and push the political cart. Not much we can do about that.
I’m all for improving the quality of data, but the numerous instances of wrong data even reported in CA would make an aircraft unsafe to fly and a nuclear reactor a good place to keep at a distance. I keep repeating that the scientific method is in places and at times being used in the wrong sequence; and that failure is a high probability because of this. There have to be more microexperiments to put better estimates on variables and shapes to equations.
lucia,
The difference between doing your validation informally, and doing it formally, lies in how easy it is to convince others that you did it.
If I trust you, then probably your word is good enough. To date, none of the GCM modelers have earned our trust. Indeed, many have done things that scream that they can not be trusted.
I would also like to see a rigorous justification for every parameterization put into the models.
The statement “it works when I set it this way” doesn’t cut it.
#49: Dr. Curry says
Isn’t there a typo here? Shouldn’t the two percentages add up to 100?
#50 The IPCC never said the science was “settled”. Their main conclusions are:
Most (implying >50%) of the warming in the latter half of the 20th century can very likely (>90%) be attributed to anthropogenic burning of fossil fuels.
Re the climate model simulations, the state
It is very likely (>90%) that there will be more warming in the 21st century than in the 20th century.
The ranges they give for the climate model temperature increases in the scenario are ascribed as likely (>66%)
When people say “the debate is over”, etc., this is not the IPCC saying this. the debate is over in terms of whether humans are contributing to climate change. the magnitude of the contribution, and what that means for the future of course has uncertainty
I encourage you to (re)read the IPCC summary for policy makers:http://www.ipcc.ch/pdf/assessment-report/ar4/syr/ar4_syr_spm.pdf
It is really a conservative document.
Dr. Ball, based upon your own understanding of how the GCMs are constructed, would it be accurate to say that the models—as a matter of necessity—internally generate their own “observational” data as a substitute for the observational data which is not currently being collected from natural climate processes?
Several points re model V&V
First, no one has any idea how to do V&V on a model of the complexity of a climate model. Individual elements are tested against theory and more complete (e.g. higher resolution models). The model thermodyamics (e.g. clouds, radiation) are tested in single column mode. And the overall simulations are evaluated against observations and other models. There is no single bullet “test”. The documentation provided by ECMWF builds confidence in what goes into each layer of model improvement, how it is tested, etc.
Second, one of the main points made by the Leonard Smith paper, is that you have to make some tradeoffs depending on what you are trying to accomplish with the model. Is it better to spend your time and resources on V&V of an old model, or work to make the models better? Smith comes down on the side of running large ensembles to assess the model uncertainty (this was part of the philosophy behind climateprediction.net)
Third, climate model simulations of the 21st century climate are not intended as forecasts. They are intended to be scenario simulations, illustrating the response of the climate system to a range of different emission scenarios, with all other factors (like volcanoes, solar, landcover) remaining the same (although some models are starting to put in interactive vegetation).
So climate models are much more complex than other models being discussed here, and their projections are not being used for deterministic decision making by major policy makers. They are used to indicate the range of potential risk from climate change.
Dr. Curry #65,
I agree with part of your statement, i.e. humans are contributing to climate change. Yes but so are termites, pine beetles, codfish, cows, pigs and every other living thing on this planet. What the models can’t do, let alone get near magnitude, is get the sign right. If computing sophistication was at today’s level back in the 70’s, GCM’s would focus on human caused cooling through aerosols and such. It was getting colder. Models would have predicted continued cooling. They are bent after the fact to match what already happened.
“So climate models are much more complex than other models being discussed here,”
Oh really? Have you ever looked at a code developed for nuclear industry applications!?
“and their projections are not being used for deterministic decision making by major policy makers.”
Oh really? Please show us the scientific proof of AGW, which is the basis of the IPCC policy recommendations, that does not involve any modeling…
And, while you’re at it, please prove/justify your statement below…if you can’t that’s OK.
“The bottom line is that I think the U.S. climate models that are been run at resolution 250 km or higher almost certainly have robust dynamical solutions (the real problems are with things like the convective parameterization).”
ICRCCM
Also, the more recent I3RC
Re: above
Is potential risk the same thing as risk? What is deterministic decision making? Is that the same thing as decision making? How do I know what factors are, or are not, being used for deterministic decision making by major policy makers? How does Dr. Curry?
If a simulation is the same thing as a projection but different from a forecast, is a simulation falsifiable? If so, how is that different from being a forecast? If not, why bother troubling ourselves with their results?
Sign me confused.
re: #68
and
Both of these statements are not quite correct. Especially, the first V in V&V, meaning Verification, can be successfully carried out for any piece of software no matter how complex the physical phenomena and processes modeled. In its most simple application, the coding can most certainly be Verified. That is, the coding can be shown to correspond to the mathematics and logic that were specified to be implemented into the code. In its second application, Verification that the numerical solution methods do in fact lead to solutions of the continuous equations, is also possible. More difficult, but not impossible. Of course either or both of these Verification activities might lead to the conclusion that the null hypothesis, correctness, is shown to be false. Then the problems must be fixed.
It is extremely depressing to see someone in the climate-change community trying to argue that Verification of computer software is basically an impossible task. That does not favorably reflect on the attitude of the community relative to usefulness of its software products. In many engineering and scientific disciplines such an outlook would lead to immediate dismissal of all calculational results presented by the community.
Climate models are not the be-all and end-all of complexity of modeled physical phenomena and processes. They are not the ultimate and creme-la-creme of state-of-the-art mathematical modeling. The natural evolution of all modeling and computer codes is toward more and more complete descriptions of, and fidelity to, the underlaying physical phenomena and processes. Consider a supersonic aircraft releasing external stores while executing a complex flight pattern with the objective that the stores must be placed within an effective distance of their targets.
The second V, meaning Validation is another, and somewhat more difficult, problem. But to say ‘no one has any idea’ is to underestimate the extent of the work and associated successes that have been achieved in problems of equal, and sometimes greater, complexity.
And, finally
” … and their projections are not being used for deterministic decision making by major policy makers.”
ok, put a statement that significantly qualifies the usefulness of Chapters 8, 10, and 11 in the WGI IPCC reports. Or eliminate these completely. Based on my present understanding of the attitude of the climate change community relative to V&V and SQA of its software, the latter seems to be the most scientifically sound decision.
Bender:
Here are two links: The first is to ICECAP. The second is to the Dr. Syun-Ichi Akasofu message and to his paper Both have a link to the PDF. I suggest to everyone here to read it (and the article and it’s plead).
http://icecap.us/index.php
http://thenewamerican.com/node/6973#SlideFrame_1
It directly addresses the problem of how much of the 0.6C 20th century temperature raise is due to man (0.1 Deg C) and how much to natural variability (0.5 Deg C). Dr. Syun-Ichi Akasofu admits it is not rigorous but says his findings indicate a need for more study in this vein. It uses GMCs in the way mentioned in #56. My very rough interpretation of the “twist” (see #56) is this.
GMCs assume that CO2 is the diver for change. Test them against reality and the difference is the change natural variability causes.
Also at ICECAP they have the latest January RSS January 2008 data. I have downloaded and graphed both the RSS and UAH data. If you make the graphs bar graphs and compare (I printed them and scotched taped them together in the order North pole (top), Northern Ext, Tropics, Southern Ext, South Pole [bottom]) you will see see something that does not relate the the CO2 hypothesis very well. Also you will see something interesting in the northern latitudes which relates to the Arctic 1920 to 1965 temperature “bump” and the present raise in Artic temperatures in Dr. Syun-Ichi Akasofu paper.
Steve – I hope this doesn’tviolate the thread.
Dan Hughes–
You are correct that Verification can always be done. This has absolutely nothing to do with complexity.
You are also correct that Validation is complex confusing part. But, strangely,though Judy says V&V is impossible, she also points with pride to those aspects of validation that are done. Validation is what peer review journals appreciate; verification is not. It’s boring, boring, boring, boring from the point of view of science.
I think Judy’s incorrect impression that formal V&V is somehow impossible for GCM’s may stem partly from the fact that some posts in this thread convey the idea that that formal validation requires pre-specified procedures imposed on all. It doesn’t.
Validation provides quite a bit of flexibility, permitting specialists to decide what is validation in the context of the needs of a project.
Given their application, validation documents for GCMs would certainly be longer and more detailed than the peer review documents or the reports Judy is pointing to. You don’t get to send readers on too many goose chases pointing to bits of theory scattered all over the place; you re-capitulate a lot, while still citing where the originalsource. Re-iterating places information right there in front of decision makers and that, not novelty, is key in a validation document.
You can’t fail to document key bits simply because peer review journals don’t care about that bit or would tell you that bit is already published in another document. There are plenty of other ways to publish: laboratories have laboratory reports. Some universities have University Reports with document numbers. UofI has numbered documents for university reports. So do a number of other universities– I know because I’ve gotten them occasionally. I know I have one from Stanford. Judy will recognize that these documents are often considered “grey literature”. With regard to tenure decisions, it often doesn’t count.)
Judy suggested that GCM’s aren’t used for guiding policy– a point many dispute. This is a nebulous areas because it depends on point of view.
With regard to the funding agencies goal (NASA for example) the justification for the GCM’s in not to drive policy. So, when the scientists fill out any little checklists (as we would do at a national lab), they can simply say the goal of the work is not to drive policy, doesn’t impact safety etc. The work is exploratory from the point of view of the funding agency. This cuts out a lot of work, lets the scientist do the fun science stuff. And, technically, from the point of view of the person paying for the work, is even true.
(I fill out forms of this nature all the time. If I were working on a GCM, and my funding agency didn’t plan to directly guide policy, I’d check that it doesn’t drive policy. Because the question implies “directly drive policy”. NASA doesn’t decide how to responde to climate change, so the work doesn’t drive policy from their point of view. )
But, the reality is that, unlike a project to further develop string theory, GCM results will ultimately be used to drive policy. They are being used that way now; some scientists are putting together documents advocating political decisions. (I don’t have a problem with this, provided they say they are doing this and they don’t modify their results to promote their advocacy. But the appearance can be bad.)
But, from the point of view of funding this is an indirect effect.
In any case, because the reality is these are used in policy discussions, as a practical, political matter, the system enforcing V&V on projects that would benefit from them breaks down.
We end up in the situation we are in: the public (aka voter) aren’t provided proof of verification. And, though scientists are more interested in documenting validation than verification, members of the public are often very, very very strongly swayed by lack of formal written validation in black and white.
As someone above said: It’s a matter of trust. When I did things for nuclear work, the individual clients always trusted me personally to check things. Had they not, they wouldn’t have given me a task. But the system, and the American public, who don’t know me from Adam, didn’t leave verification to trust. I had to sign seal and deliver certain documents.
In some projects, verification must be formalized, and provided on paper, in black and white with signatures. I say this as a person who loathes paper work. But climate science has gotten to the point where task which is loathsome to people who are fascinated by physics, not paper work, must be done.
OK so I took my time and looked at that ECMWF that’s supposed to be the 8th marvel of the world .
After having looked at the titles of all the documents accessible on line , I selected the Radiation Transfer that I know well .
More precisely “The technical memorandum 539 . Recent Advances in Radiation Transfer Parameters .”
I took a stance of an independent expert charged to audit this piece of document .
I must say that the result was depressive – it has all the flaws that have already been mentioned in this thread .
Specifically the part that should consist to compare the new McRad (new model) prediction to reality with a precise description of the experimental detail and data treatment is completely missing .
1)
They want to introduce a random cloud generator .
Besides the generic method consisting to compare the model vs model runs (which would consist to compare error to error if the models were inadequate) there is a weak attempt at comparing runs with reality .
So here with cloudiness and CERES is mentionned in that respect .
However the CERES equatorial satelite doesn’t work and the other 2 are at polar orbits what means that you get readings always at the same time of the day .
A question forces itself upon us – what kind of data did they use ? What kind of “cloudiness” did they extract from CERES ? How did they (re)treat it ?
Shouldn’t that be at least mentionned in a document that recommends nothing less than to redo the biggest part of a radiative model ?
Well it is not .
The argument for the “cloud generator” is weak and is supposed to be supported by one work mentionned as reference .
This question being central , something better than only a reference should be in the report .
2)
They also want to model aerosols .
Here is mentionned Modis Channel – same satellites as CERES , same remarks .
Yet Modis on top of the above caveat gives neither vertical distribution of aerosols nor their nature .
So what is it used for , what data treatment , what period ?
That is not mentioned either .
On the other hand valuable time and space is wasted on an anecdote showing a Modis picture of a sand plume coming from Sahara to Europe and a chart of a simulation .
There is a qualitative agreement between both .
Of course it doesn’t impress anybody because already the Romans knew 2000 years ago that when the wind was coming from the south and the weather was fine , sand from Sahara could come to Europe .
They didn’t need satellites and multimillion computers .
So also on this topic no adequate argument is made about why the skill of the new model should represent the reality better .
No attempt is made on justifying the statistics used .
For example what time averaging is relevant and what bias there may be ?
3)
Of course Hitran is used .
Therefore collisionnaly induced emissions/absorptions (and no it is neither 0 nor negligible) are ignored because they are not in Hitran . I already noticed that people use Hitran like a magical word – if you say Hitran , you access to the Nirvana of infinite accuracy and the world where “the radiative transfer is a settled science” .
Well it is not in the famous details where the devil is .
Also CFCs are mentionned .
We know about everything about their radiative properties but we know very little about their distribution and have practically no past data .
4)
The list of references and charts is almost as long as the text and that is never a good sign .
Conclusion after 2 hours of reading the document .
It is neither V nor V .
The way in which the document is presented doesn’t seek to present the reader with a logical argumentation structure , doesn’t separate the essential from secondary , doesn’t explain and structure experimental data and its treatment when applicable .
In short the reader is either supposed to be one of the 19 people (yes they wrote about 1 page per person) who wrote the report or to have unlimited faith in the 19 people .
The reader can neither validate the recommendation presented (the use of a new model) nor can he even in principle redo/verify any part or statement in the report .
If I was charged with a real audit of this document (or generally with other documents made by those 19 people) I would add :
– the above doesn’t mean that the 19 people don’t know what they do . They probably do .
– the above is not an exhausting analysis . Many more flaws , defaults and methodological errors would probably be appear after a thorough examination
– an advice on 1 document doesn’t represent a synthesis on all documents . There may be others of a much better quality
– but … between us , if you ask me , they are really sloppy
Hi,
V & V is perhaps possible to ensure there are no bugs in GCMs (but probably not easy because of the nonlinearities). But I guess Judith refers to the validation of GCMs with observations in order to see if the physics and the parameterisations are correct. This is another topic and not a trivial exercise. How should you do that when there are chaos/internal variability and incomplete observations?
#70 Frank (and others using the nuclear analogy)
I have never seen a code developed for the nuclear industry. But…
A climate model could easily be more complex than a code developed for the nuclear industry because climate covers far more phenomena in a greater parameter space.
What is the appropriate measure of “complexity”? I would say a climate model will be more complex because a decent nuclear reactor will be comprised of easily unit-testable components whereas the climate comprises too many closely coupled phenomena with too complex a relationship.
A climate model comprising a number of well-validated components will not meet all your requirements (correctly predicting all the climatology at all spatial and temporal scales), and it’s difficult to predict which ones will be hard or easy to meet. You do set minimum standards for validation though.
gb–
The goal of V&V is not to prove something is absolutely correct. The difficulty you describe is shared by all codes involving transport phenomena. It’s most certainly present in codes involving thermal-hydraulics for nuclear applications.
If the modelers said their goal was to predict averaged behavior in a particular range of circumstances, then all that would be required is to compare the predictions to averaged behavior in those circumstances.
In the event this could not be done adequately, or there were deficiencies in the fidelity of the predicitons, the validations documents call these out very explicitly so that users would know better than to expect the models to describe something they can’t describe.
In contrast, weaknesses are often skirted in peer review documents, where the goal is to describe new things we can do not reitterate the fact that we still can’t do some things well.
Models & codes don’t have to be proven perfect to be validated. However, their strengths ,weaknesses and limitations need to be stated explicitly and unequivocably.
If these validation models existed for GCM’s, skeptics would be able to find the paragraph where modelers describe what models can’t do and what you should not expect from them! (Once again: no one likes to write these things. It’s no fun to explain what your model can’t do!)
75,
Not just nebulous, but Dr. Schmidt is schizophrenic on that point, saying in one context that GCMs aren’t the kingpin of the case for action, and then saying in another context that attribution comes from models. You gotta think about that for a while.
Oh, and Lucia, #75 is an excellent summary of the problem that basically puts flesh on what I said in #25. Somewhere between “let’s survey the literature and report the state of the science” and “let’s do something radical”, they left a step out. I’m not saying necessarily that the scientific community has the responsibility to perform that step; it’s up to the political leadership to make that decision. I do, however, fault certain scientists for a) failing to communicate to the political leadership that this step is necessary, and b) in many cases outright denying that it’s either necessary or even possible.
I think that’s the heart of the whole dispute here. And yes, I agree that it can be done, and anybody who claims that it can’t just doesn’t want to be burdened with the task of doing it, or the task of learning something new.
re: #78
There are two different subjects in these sentences. The first subject is ‘unit-testable components’ and the second is ‘many closely coupled phenomena …’. The objectives of modeling are the phenomena and processes in both cases, not the components. A straight piece of pipe, a very simple component, can easily involve inherently complex physical phenomena and processes going on inside; single-phase turbulent flow is just one example.
Compare apples to apples.
I am getting very little sense that most of you have any understanding of the complexity of climate models. How to treat the unresolved degrees of freedom in any model is a huge challenge; in the case of climate models this includes things like clouds, and is at the heart of the so called parameterization problem.
The issue that concerns many of you is not technically V&V but whether or not the models are “perfect” enough to prescribe policy. The models are not perfect and are not being used to prescribe policy. They are being used in the assessment of risk that we are facing from global warming. Susann on other threads has described how policy making actually works
Re V&V, here is an interesting overview on the subject.
Click to access 016.PDF
there are many different components and ways to do this. I suggest that the V&V discussion be framed in the context of the validation techniques listed in this document. In the case of the ECMWF model, the V&V is very clear (read the technical notes, memos). If i had time, i could go through each of the ways of validating a model, then refer back to the relevant technical memos and notes.
#82 Dan
The link between components and the controls put on them should be simple enough that the resulting phenomena and processes remain within tolerance and remain predictable – that’s the link between the apples and the oranges. If you can’t design it that way, then you don’t build it (I hope). If you don’t build it, you don’t have to model it.
#79 lucia
For the model I’m working on (not at the science end), initial tests involve a few dozen diagnostics. A comparison is made between the model, its predecessor and observations. For each diagnostic the new model comes out as green if it is better than its predecessor or if it is within observational constraints, and red otherwise. More greens = happier scientists. But yes, the diagnostics reflect things that are hard to get right and therefore show up things the model can’t do.
Models are the source of the scary scenarios that predict large increases in temperature. There is no other source for these projections.
The claim that models don’t influence policy decisions fails the laugh test.
#67
The short answer to the question,” …would it be accurate to say that the models—as a matter of necessity—internally generate their own “observational” data as a substitute for the observational data which is not currently being collected from natural climate processes?” is yes.
Not only are there many surface rectangles with no stations at all, but large areas such as the oceans, deserts, forests and polar regions have one or two stations at most. Look at the GHCN map of stations here: Some argue you need as few as 50 to 100 stations to determine a global average temperature, but that is not the objective of the models that strive to simulate interactions between each rectangle. Anyone who has studied microclimates knows how much temperature can vary in short distances in many parts of the world. I think a bigger problem is the surface measurement is not the surface measurement at all it is the measurement of conditions at the hight of the Stevenson screen. Again studies of the difference in conditions, especially temperature between the actual surface and the Screen surface is markedly different. I recall research at an Ohio micro-station found the difference in maximum frost free season length between the actual surface and the Screen Level was 90 days. The layer below the Screen level contains the interface between the surface and the atmosphere and is a variable but thin zone known as the Boundary Layer. In this layer most dynamic interactions that determine the nature of the atmosphere occur yet that is not what we are measuring. It is also not what the models are using. As i have mentioned above the Stevenson Screen level the paucity of data is far worse.
The IPCC claims are delusional here. There are so many uncertainties, ranging from the projections to the credibility of models, to assign 90% probability just to 21st century warming – let alone 21st century warming exceeding 20th century – is massively overstating certainty and is not compatible with the claim of being a conservative document. It is a narrow document, yes, an advocacy document, yes – but conservative, no.
The claim above is akin to me producing a model to predict the future of mankind, projecting forward that humans will evolve to be taller in the 21st century, and the rate of change will increase compared to the 20th century, with 90% certainty. If I were to make such I claim, I personally hope my boss would fire me and encourage me to become a mime.
The only reason the IPCC can get away with it is that by the time the extent of the delusion becomes apparent, everyone involved will have “moved on”.
Footnote: I quickly checked the SPM for context and note that Dr Curry left out an assumption in the above quote that GHG emissions continue (at least) at present rates. I do not think this assumption affects my position on the statement.
i just did an interesting exercise, google the the three words (no quotes)
ECMWF model validation (18,000 hits)
ECMWF model verification (10,400 hits)
reproduce this exercise, cruise the titles of the first few pages of hits, and you will get some sense of the complexity of this challenge and the huge amount of work that has been done on this issue.
I can’t get the link function to work. Simply go to Wikipedia under GHCN Temperature Stations.
re: #83
I hope we don’t have to get into that whole I’m qualified and understand but you’re not and don’t discussion. From what I read here there is a great deal of understanding, in depth, of the complexity of both the physical phenomena and processes, the mathematical problems associated with both the continuous and discrete equations, numerical solution methods for the latter, and designing, developing, building, testing, and applying computer software that has all this stuff in it.
One major aspect that I’m having problems dealing with is the apparent lack of application of fundamental processes and procedures to these problems by the owners of the products.
I will venture to say that all real-world problems of interest include all aspects of the climate-change problem. Otherwise we would leave them to the academy for playing around with.
Dan,
Can you clarify this statement, not sure what you mean
“One major aspect that I’m having problems dealing with is the apparent lack of application of fundamental processes and procedures to these problems by the owners of the products.”
One of the interesting things about this thread is having people that are familiar with models from other fields discuss these issues. I appreciate your statement
“From what I read here there is a great deal of understanding, in depth, of the complexity of both the physical phenomena and processes, the mathematical problems associated with both the continuous and discrete equations, numerical solution methods for the latter, and designing, developing, building, testing, and applying computer software that has all this stuff in it.”
I am dismayed by some of the comments by people who are ready to reject the models based upon something that seems ” fishy” without having any real understanding.
The reason i am spending time on this thread is that I would like to see people with some technical background (and possibly even some modeling experience in another field) develop an improved understanding of the credibility of climate models, and their outstanding issues. Lets face it, some climate models are a lot more credible than others, having higher resolution, more advanced physical treatments, better numerics, and a more extensive V&V process. I put the ECMWF modelling system out there as the one that is generally regarded to score the highest in this regard (this does not necessarily mean that a climate model with the ecmwf atmosphere will provide the “best” prediction on century time scales, that is a whole different issue).
I’m getting very little sense that you understand the verification process. I’m betting that there exists no piece of code that cannot be verified, unless you have some sort of non-deterministic behavior because of flaws in the code…which in itself would cause the verification test to fail.
Frankly, its just too bad that these things are seen as “too complicated” to verify. Its a burden that the modelers have to bear or their results will always mean little to nothing. Boeing, Airbus, Lockheed, etc write much larger OFP’s (Operational Flight Program) that go into the flight computing systems of various civilian and military aircraft. This type of code has the added complexity of having real time and safety requirements that generally go beyond, in terms of sheer complexity, plain old non-realtime, non-embedded simulations and models. These guys manage to do a fairly good job of doing V&V, almost infinitely better than anything coming out of the climate community. Now I know the budgets/development environments are different but that still doesn’t relieve the burden of at least verification from any climate model used to shape even 1 dollar of policy. Its okay with me that models that have not gone through some sort of semi-rigorous V&V effort are used to bicker back and forth in arcane journals. When these things are portrayed as good enough to bend policy without publicly available V&V documentation, then I call BS on the whole process.
There’s an obvious cultural divide here. Here’s the rhetorical question to consider: how many dead astronauts would be strewn over the oceans, space, and the moon, if the core part of NASA did business like GISS?
92,
That’s the key point. I don’t see the modeling community even asking for the resources to do it the best way possible. I see them rationalizing why they don’t need to.
All,
I am writing a comprehensive review of this manuscript that is quite different from Judith’s review. But might I suggest that you go to the site mentioned at the beginning and look in the downloadable pdf file
in the first reference at the following items.
Figure 2.2 on page 9 shows contour plots of the perturbation of the steady state zonal flow (not shown in published manuscript). Note that the perturbation is quite large scale, but also quite small in magnitude (1 m/s as compared to ~40 m/s in the jet maximum of the steady state zonal flow solution). This perturbation, as small as it is, suffices to destroy the numerical accuracy of the dynamical cores within a matter of days. Also note that observational errors in the winds are at least this order of magnitude and that the inaccurate parameterizations in a climate model can easily lead to errors in the winds of this magnitude.
Even more of interest is the discussion of the sensitivity of the dynamical cores to different hyperviscosity coefficients beginning on page 38
(and there are other forms of spectral and damping included in the EUL model). (This is a point I have emphasized over and over.) This section was not included in the published manuscript for obvious reasons.
Jerry
#76 Tom Vonk writes:
Tom when you say that collision induced emission and absorption is ignored in Hitran, I’m left to wonder how Hitran decides what frequency the absorbed radiation is re-emitted at? Does Hitran simply use a plank distribution to determine the amount of emitted radiation and if so how does the model determine the temperature? Tom do you have any numerical comparisons available to show how good or bad an approximation this is?
Steve, please feel to interject if you think we should move model discussions which don’t have to do with the dynamic core to another thread.
I recall a recent Mars probe that exploded because one group was using English measurements and another group was using metric.
Thanks for an interesting thread. This focus directly on the issue that first caught my interest of climate science – the challenge and uncertainty of numerical modelling. I’m not a climate scientist myself but have spent quite some time with numerical simulation, both developing simulators and using simulation models, for multiphase pipe flow and reservoir simulations, also coupling such models. Since Judith asked for experiences from other fields it struck me that advanced history-matching and upscaling technologies used in number crunching reservoir simulation may be of interest for climate modellers.
Judy:
Yes. Some people are arguing about whether or not the GCM’s are perfect. Other people really are discussing the V&V. These are entirely separate issues.
GCM’s can’t be perfect. The people asking for that will never be convinced by a GCM. But that’s probably only a very small fraction.
GCM’s are complex and so more difficult to validate than models describing simpler things.
However, neither complexity nor the impossibility of perfection interferes with the “do-ability” of a V&V! The goal of V&V is absolutely not to create a perfect model, and complexity is simply not a problem.
If you can write a code, you can do a V&V. Complexity doesn’t actually affect form Verification very much; it only means one requires longer document because there are more modules to test. If a model is approximate and has difficulties (like GCM’s), or the results are difficult to interpret, that is reflected in the narratives and figures contained in the Validation document. All the caveats you describe here would be included in the validation document in written from where third parties could read the caveats. That’s a purpose of the validation.
But with regard to this:
No. It’s nto at all clear in those notes and memos.
I suspect the V&V for ECMWF may well be very clearly stated somewhere. In so far as a model is used for weather prediction broadcast to the public, and it’s predictions have a direct impact on public safety, funding and regulatory agencies probably do require V&V for any model.
That said:, there are zillions of links at the site you point to. I’ve clicked on 20 or so links to reports and memos and skimmed. They look like good reports. They look like decent science. Unfortunately, with regard to the discussion going on in this thread, absolutely nothing I clicked remotely resembles a Verification. A small fraction of documents contain snippets that would belong in validations, but those would be stupendously incomplete as validations.
Could you point to an individual link that you think looks like a verification?
If you could point to a specific one, this get us all on the same page. Otherwise, right now , it looks like everyone is talking past each other.
Meanwhile– Dan, or Tom Vonk, could you supply Judy with examples of formal verification documents? (I know this is difficult since most are only available in the grey literature and they are generally a set of documents. At that, they represent such a small fraction of the grey literature that you need to know a named party did one. But if either of you was involved in one, then that might help Judy understand.)
(FWIW, in some ways, I’m agnostic on this isue. I frankly don’t give a hoot whether GCM’s are verified or validated because I don’t base any of my judgment about AGW on the results of GCM’s. I rely on simpler energy balance models supported by temperature trends, and some physical arguments. I think the balance of the evidence points toward warming caused by human activity.
Nevertheless, if documents describing formal validation and verification of GCM’s do exist (and I’m betting Quatloos they don’t,) it would be useful to the never ending discussion if someone could identify those specific documents.
Identifying alternative documents of the sort that appear in academic journals and incorrectly calling them V&V just won’t do for people who now what V&V is and want to see V&V. (It’s a bit like giving someone chocolate ice cream when they want chocolate fudge and saying “See, I gave you chocolate! And anyway, ice cream is better than fudge– you should want fudge!” Ice cream is tasty, but the customer wants fudge.)
Only bringing the V&V to table can bring this bitter arguments about whether or not V&V has been done.
This is a fascinating thread.
As for Dr. Curry’s call for modeling from other fields—I do work with a transportation travel demand model. Not sure if it’s close to the GCMs in concept, but I’d be happy to explain more if asked via email. Keep in mind I’m not a programmer, I am just being trained as a user for a pilot program to bring it back to my state.
My eventual goal, if they let me, is to learn the programming portion of it as well.
I’d also have to say that from what I’ve learned here in the past several months about GCMs, Dr. Curry’s review is more then fair.
A standard suite of idealized test cases is, incidentially, what we use in our travel demand model.
94
That’s mostly because they are either glorified hackers or just one of the rabble of grad students punching out code for their profs. Its been my experience that these grad students have a decent grasp of the science but are woefully lacking on the coding side. Now, when you iterate this process over hundreds of grad students for 10’s of years what sort of pasta does the process produce?
“I am dismayed by some of the comments by people who are ready to reject the models based upon something that seems ” fishy” without having any real understanding.”
I have spent over twenty years in my academic and professional careers in the computational fluid dynamics field, and have written several codes and examined many others.
What is fishy to me is that someone knowledgeable such as yourself would throw around statements like
“The bottom line is that I think the U.S. climate models that are been run at resolution 250 km or higher almost certainly have robust dynamical solutions (the real problems are with things like the convective parameterization).”
and then provide no justification. So be it. I believe this statement to be generally false (though it depends on what is meant by “robust” and what time scales are considered).
Having looked at several of the climate models (source code and documentation), they are indeed very impressive creations. And I’m sure there are many thousands of hours collectively tied up in their development by highly competent researchers. To me, the use of semi-lagrangian and lagrangian schemes for convection is interesting, as are the spectral core solvers. But in the end, they really are no different than most of the academic, commercial, and government CFD codes I’ve seen and used.
All,
The best way to obtain the manuscript I mentioned above is to do a google
search on NCAR Tech Notes and then on Jablonowski. The tech note is more
complete in its presentation and has the amusing details mentioned.
Now the interesting question is why were these rather revealing discussions
removed from the final published manuscript.
Jerry
Frank K (#102),
I am so glad that you picked out the serious flaw in Judith’s comments
that followed her “review” so that I was not forced to do so. 🙂
Jerry
Lucia, the sheer complexity of the V&V for these models is pointed out in #88. V&V for any complex model is a complex process, as pointed out in the paper that I linked to in # 83 http://www.informs-cs.org/wsc98papers/016.PDF
This paper says there are 3 different categories of V&V:
1) that done by the modelling team
2) independent verification done by an independent team (very costly and time consuming for what is actually obtained)
3) scoring model. while the article says this is infrequently used in practice, no so for atmospheric models used in weather mode (e.g. ECMWF). I will get to specific references for scoring later in the message
The recommendations for validation made by Sargent (the author) are:
1) assessing the conceptual validity of the model
2) computer model verification
3) necessary data is available for building the model
Recommendations for verification are:
1) comparison to other models
2) degenerate tests
3) event validity
4) extreme event validity
5) extreme condition tests
6) “face” validity tests
7) fixed value tests
8) historical data validation
9) internal validity (stochastic runs)
10) multistage validation
11) parameter variability-sensitivity analysis
12) predictive validation
13) traces
14) turing tests (i didn’t know what this is so googled ECWMF turing test, and i got 150 hits)
All of these kinds of tests have been done for the ECMWF model. But a reminder, you are doing V&V on the dynamic core, the bottom boundary conditions (like orography), each individual parameterization (e.g. radiative transfer, convection, boundary layer, clouds, etc), and in the case of coupled models the ocean module, the sea ice module, the land process module, the aerosol module (and in future the ice sheet module), in stand alone mode as well as when coupled in the climate model.
The key issue of interest here (at least on the threads re verification of NASA GISS climate model simulations) is predictive verification. The ECMWF atmospheric module is evaluated every day in numerical weather prediction mode, and also each month for the seasonal forecasts. Evaluating on climate change time scales can’t effectively be done because we only have crude climate model simulations from the 1980’s and the more sophisticated coupled models really came in the mid 1990’s. So we are talking about a 10 year period for “verification”, and these projections make no pretense at simulating things like volcanic eruptions. So the IPCC 4th assessment report simulations can be verified say in 2030, and by then we will have much better models. so in many ways climate modelling has unique verification challenges since the model development time is much faster than the time scale of what is actually being modelled. Also, the extreme event validity is very difficult one for climate models because even in the paleo record we don’t have an exact analogue for what we might be looking at in 100 years. however, simulation of a broad range of paleoclimates (and verification against whatever paleo data is available, given all the uncertainties, can help here.
To Jae or whoever said something about climate scientists not asking for money to do this, there are incredible efforts undertaking by administrators from NCAR, NOAA, NASA and DOE to try to get more funding for this, not to mention from our professional societies, and many individual scientists. The funding for all this is peanuts (when you see big numbers being spend on climate research, most of those funds go for satellite systems, then some for computer hardware, and other observing systems, not much for actual scientific research and modelling). I probably get 10 requests a year either from the AMS or NCAR/UCAR to engage in a letter writing campaign to congress members. We conduct lots of congressional briefings that highlight the need for more resources. It seems to be more important to fight wars in Iraq, send people to Mars, etc. Don’t blame the climate scientists for this one.
I
There is a simple method used by numerical analysts to test that a numerical approximation of a time dependent PDE is working correctly.
One only need choose a reasonably realistic time dependent analytic solution, insert it into the PDE to obtain forcing terms that ensure the test solution is a solution of the forced system, and then see if the numerical errors behave correctly as the mesh size is reduced, e.g.
the errors in a second order finite difference scheme should reduce by a factor of four when the mesh is halved.
This will reveal all sorts of boundary treatment mistakes, unphysically large dissipation, and coding errors. Of course some scientists might
not want to know that these problems are impacting the solution.
For an example of this technique, see the Browning, Hack, and Swarztrauber
manuscript (details provided on request).
Jerry
Judith Curry,
Have you ever coded an NWP, climate model, or any numerical model?
Jerry
Right there you are confusing verification for validation. Verification has nothing to do with what is being modelled.
Also, 98 is ancient in terms of software process think.
105,
Rightly or wrongly, the official mouthpiece for the climate establishment (at least to the public and the media) is Realclimate. I haven’t heard them beating the drum for more funding for better quality control; as far as they’re concerned, further research is pointless, since the “science is settled”. You can’t simultaneously claim that the science is settled, and then say that we should be spending more on research.
If there are basic mathematical problems with the unforced continuum PDE system, convergence tests of the numerical approximations of the unforced dynamical system will reveal those problems. Thus we need to stick to the issue of dynamical cores on this thread and not get into the more complicated questions of errors in the parameterizations (forcing).
If the dynamical cores do not provide accurate numerical solutions for
simple tests, then adding forcing is not going to help and in fact will
just be a tuning exercise and not science.
The points mentioned in the technical note on the NCAR site should be
read and discussed. These point to very serious errors in the dynamical
cores that cannot be overcome.
I am working on a thorough review of the Jablonowski manuscript that will discuss these and other points.
Jerry
re: way back up at #91 I was asked a question.
Although it has been discussed many times and in several places it will be easier for me to list the things I would expect to see for any production-grade software the results from which might impact the health and safety of the public. My list, by the way, is very likely one of the shorter lists you would get if you ask others.
Some requirements that must be met for software to be released for production use are:
Requirement I: Documentation
Adequate documentation must exist that:
1. Describes the theory and assumptions made in developing all mathematical models and analytical and numerical solution methods for the code.
2. Describes the code structure, logic, structure and overall execution procedures.
3. Describes in detail how to use the code.
4. Describes how to install the code on a user’s computer system.
Requirement II: Verification
The code must be verified to assure:
1. The coding is correct with respect to the code specification document.
2. The numerical solution methods are consistent, stable, and convergent.
3. The code is correctly solving the equation set of the models.
4. The MES and MMS methodologies demonstrate expected theoretical performance.
Requirement III: Validation
The code must be validated to perform the analysis required of it by:
1. Comparison of code predictions with relevant experimental data.
2. Comparison of code results with results from other approved calculational techniques.
3. Assuring that code results are consistent with the physical phenomena of interest.
Requirement IV: Qualification
The code must be demonstrated to be qualified for use in its intended applications areas by:
1. Demonstrating that the software and its users can correctly and accurately apply the software to analyses for which it is designed.
2. Providing users with sufficient guidance and training for use of the code and its output.
Requirement V: Quality Assurance
The production-level versions of the software must be maintained under approved quality assurance procedures.
These requirements will usually be met by the availability of the following documentation:
(1) A theory manual in which the derivations of each and every equation, continuous and discrete, are given in sufficient detail that the final equations for the models can be obtained by independent interests. The equations should be developed down to the version tat is actually coded.
(2) A computer code manual in which the code is described in sufficient detail that independent outside interests can understand the source code.
(3) A user’s manual that describes how to develop the input for the code, perform the calculations and understand the results form the calculations.
(4) A manual or reports in which the Verification and Validation of the basic functions of the software and example applications are given.
(5) Additional manuals or reports in which the models and methods, software and user are demonstrated to be qualified for application to analyses of the intended application areas.
(6) An approved and audited Software Quality Assurance Plan for the production-grade version of the software that assures the quality status of the software is maintained..
Other reports and papers can be used to supplement the above documentation.
Additional details are available in this document.
And I suggest that anyone serious about V&V and SQA for scientific and engineering software get Pat Roache’s book and go to http://www.osti.gov, then to Information Bridge and do a Basic Search for Oberkampf. From those hits you can easily taylor more specific searches. May of the hits will have reports available for downloading.
Basically I see a huge disconnect between what I read in the WGI IPCC reports and the true status of the models/methods/codes.
Tom Vonk (76): If you quote “radiative transfer is a settled science” there’s some someone who actually said that in this context, right? Could you give the reference? If you don’t see the importance of having the precise reference, look at http://www.realclimate.org/index.php/archives/2004/12/myths-vs-fact-regarding-the-hockey-stick/ . Would you agree that mike@RC would seem to be some weighted average of clueless and sinister if he didn’t have an actual op-ed reference that literally contains his Myth #0, that evidence for modern human influence on climate rests entirely upon the “Hockey Stick” Reconstruction of Northern Hemisphere mean temperatures indicating anomalous late 20th century warmth?
Sadly, given the level of the debate, mike@RC might actually have read such an op-ed, and you might actually have seen someone making your quoted claim. But even then, if you’re going to use the quote, a citation would be a lot more constructive. Or at least non-destructive: responsible venting rather than what looks almost like an irresponsible slur. You’re putting a sufficiently bogus claim in the mouth of some opponent that even in this debased debate it’s not obvious to me that such a dumb opponent exists. (Exists in any meaningful way, anyway: anonymous trolling is hard to interpret sometimes.)
(speaking of venting: At that realclimate page, the comments make it look as though no one wants to ask mike@RC for a reference to some op-ed that actually claimed that particular odd-sounding and easy-to-refute thing. It seems hard to read that page without being awestruck by the implied editorial practices.)
Judith Curry,
You have provided your “review” of the Jablonowski manuscript. Do not go off on some tangent about V&V for climate models that has no bearing on dynamical core testing. It is trivial to test a dynamical core for the
issues that need to be brought to light and the Jablonowski Tech Note
is very close to providing that information.
Jerry
Some people seem to think my statements re climate model complexity is a copout, so I will try to address this. The best documented climate model is the NCAR CCSM, http://www.ccsm.ucar.edu. You can download the code and read the documentation at http://www.ccsm.ucar.edu/models/ccsm3.0/. My reasons for thinking that climate models are among the most complex, if not THE most complex models out there are:
1) In meetings between Georgia Tech and IBM for us to possibly purchase a Blue Gene (hugely big fast computer), discussions around the kinds of codes that need this kind of computing power are climate models, bioinformatics (dna type simulations), and complex fluid flow simulations. while bioinformatics and fluid flow calculations require lots of computer power, the codes aren’t nearly as complex as climate models.
2) the number of degrees of freedom in climate models is almost certainly more than any other model (after all, were doing the whole earth here).
3) the nonlinearities in the system and coupling of different systems
4) the sheer scales that are involved, and the need for subgrid parameterizations of many different processes
I would appreciate any comments from big modelers (e.g. Lucia) regarding how the NCAR climate model stacks up in terms of overall complexity (not just number of lines of code or length or run time or amount of storage).
re: #99
lucia, all the reviews that I have work on were conducted under formal SQA procedures. As such all the paper work, and I do mean all, was considered to be controlled SQA documents. After signoff it was collected and stored as per the SQA plan. Later when I would ask for copies I would be told that the documents were controlled. I could get controlled copies, but these have to be returned or destroyed.
So, in summary, I might be able to get some grey (but closer to black) documents to you but then I would have to … .
Judith Curry: Thank you for general helpfulness and courtesy in this trying environment, and for general on-point-ness, and specifically for the references to the Technical Reports and Technical Memos.
I’m sure I’ll learn something just from undirected stumbling around among them. But, in case you (or anyone else knowledgeable, that works too) feel like giving extra hints, I’m particularly curious about two things…
First, I’m interested in the general outline of the kinds of parameters and procedures used to tune the models. In particular, trying to understand how important the historical hockey stick fit is as constraint determining low-uncertainty high-feedback CO2 temperature response behavior. I grant in advance that it might be impossible to give a usefully honest summary in a few pages, like the classification of finite groups or something. Or, if it exists somewhere in some prominent place (TAR?) and I just haven’t read it yet, my apologies in advance for not doing a better job of getting up to speed. (This is in a sense my less-strawman version of Myth #0: I find myself wondering what all the fuss is about…)
Second, I’m interested in things quantifying the detailed predictive power the models have demonstrated. As you might guess from my earlier remarks, I’d probably be especially delighted with something with a learning-as-compression aesthetic, letting me count how many kilobytes of confusion go away when we look at the world this way, but traditional statistical significance conventions are OK too.
All,
For those that do not know my background, before I obtained my advanced
degree, I coded a fourth order accurate hydrostatic dynamical core
in a week (including out of memory buffering). This has become even more trivial with the advent of enormous amounts of memory.
Jerry
Lucia: you wrote “FWIW, in some ways, I’m agnostic on this isue. I frankly don’t give a hoot whether GCM’s are verified or validated because I don’t base any of my judgment about AGW on the results of GCM’s.”
I myself do give a hoot. Lemme try to justify why.
There’s a very substantial difference in expected impact and rational policy response if CO2 forcing is only as large as you’d get from first principles “simpler energy balance models.” And unless something like the hockey stick is known with high confidence, it’s hard to know what fraction of the temperature trend assign to CO2, and then “supported by temperature trends” becomes a very iffy argument.
How very substantial is the difference in economic impact? The models seem to be saying that temperature response is amplified twofold or threefold from a trivial first-order result, right? Any detailed estimate of economic impact from climate change is a ridiculously vexed question, of course. (Imagine estimating an economic impact over the 20th century given the knowledge of someone in 1900. Good luck.) But on very general principles I’d expect that to the extent that change is a problem in and of itself, we should think of it as at least a second-order effect, with little important first-order effect. So the twofold or threefold feedback turns into half or a whole order of magnitude economic impact.
(Conversely if net economic impact had a substantial first order term, change would tend not to be a problem in and of itself, one direction of change would be net bad and the other would be net good, and we’d be highly motivated to artificially drag the earth’s temperature at least some amount in whatever the net good direction was.)
#112 Dan, at least for the NCAR CCSM and ECMWF models, I would say the the documentation that I have referred to meets your Quality Assurance requirement. WIth the exception of the NCAR CCSM, the other climate models (e.g. GFDL, NASA GISS) are run only by the modelling team at those institutions, and hence the qualification issue isn’t all that relevant. For the NCAR CCSM (a community climate model), there is extensive documentation on how to actually use the models, and NCAR offers classes, user support, etc. All of the models are verified against observational data, but in a model with 10**9 degrees of freedom, it is not always clear how to interpret these verifications, and what elements of the solution are actually important in terms of the objectives of the simulation. Documentation for all of the models exists (clearly for the NCAR and ECMWF models); some documentation is much better than others, and for those models that are run in house only, the documentation may not be especially simple for independent validators to try to sort through.
So where do you specifically see, say the NCAR and ECMWF modes falling short in terms of V&V? The main problem that i discern is that some of you expect independent verification without having to work very hard at it (again, those of you slogging through the nasa giss code are exempt from this criticism).
Judith Curry (#120),
And what about Dave Williamson’s tests that show that the CAM3 deviates from reality in a few days?
Jerry
Judith Curry,
You are a master at avoiding the main issues. This comes as no surprise,
but I await your assessment of the NCAR Tech note section missing from
the Jablonowski manuscript. I am beginning to doubt if you even understand the implications. Lucia can jump in here at any point and tell us about the problems when using unphysically large dissipation.
Jerry
Argh.
Jaye,
What observational data. There is barely enough large scale observational data to interpolate to a model grid in an accurate way. The only way the NWP models kind of stay on track over the US and Europe is thru the insertion of new observational data into a model every 6-12 hours (see Sylvie Gravel’s manuscript on another thread).
Jerry
Jaye,
Given the inaccuracy of the large scale observational data and the sensitivity of jets to small magnitude (1 m/s) large scale perturbations (Jablonowski manuscript), what does this say about NWP model forecasts?
Jerry
Gerald,
I just wish she would stop confusing the two V’s.
Jaye,
She got off the main topic of this thread in order to avoid the real
mathematical issues with the dynamicaal cores that cannot be solved. Actually I doubt if she knows that much about numerical models. It is just a smoke screen to avoid her lack of knowledge in this area and the fact that she wrote a “review” about a manuscript that she does not fully understand.
Jerry
William, you raise important issues.
First re “tuning” of the models. There are certain fundamental physical constants, these are of course not tuned. There is external forcing (e.g. solar input, volcanoes) which is specified in historical simulations to the best of our knowledge based upon observations. The only real wiggle room in the external forcing is aerosols. This is handled differently by different modelling groups: some specify aerosol properties for purposes only of the radiative transfer calculations. Other models have aerosols that also interact with cloud processes, and a few have more interactive aerosols (NASA GISS is a leader in the sophistication of aerosol module). We have had good satellite observations of aerosols for the past decade or so, but it is a challenge to deal with historical aerosol loading. The IPCC 4th Assessment Report, Physical Basis, section 2.4, summarizes these issues. There is another category of “tuning” that occurs in the context of subgridscale parameterizations to deal with unresolved degrees of freedom in the model; this includes clouds for example.
I am going to provide a specific example of parameterization tuning in the context of sea ice albedo (surface reflectivity), which is an example that I have been directly involve in (for a scientific reference, see my paper http://curry.eas.gatech.edu/currydoc/Curry_JGR106b.pdf (lucia, a paper from sheba). During the summertime sea ice melt, after the surface snow has melted off, the albedo of melting ice is complicated by the presence of melt ponds and depends on the areal coverage and depth distribution of the melt ponds. Current sea ice modules don’t explicitly model melt ponds, so they parameterize in some way the melting ice albedo, the simplest parameterization being setting the melting ice albedo to be constant. Now the constant is broadly constrained by observations, but could range from 0.3 to 0.56. How does a modeler select which value to use? Well there are a few other tunable parameters in sea ice models as well, so sensitivity tests are done across the plausible range of values, compared with observations, and then the parameters are selected. By the way, I have been arguing for an explicit melt pond parameterization in sea ice models, but a few years ago the NCAR climate modelers told me they didn’t want to use my parameterization since it would make the sea ice melt too quickly (maybe they would have predicted the meltoff in 2007 with my parameterization!) The next planned incarnation of NCAR’s sea ice model includes a number of upgrades, including melt ponds! the upshot of this is that the current albedo in NCAR’s model makes it too insensitive to melting, making it melt too slowly. The challenge with such tuning within parameterizations is that the fit best to the current climate, and not necessarily to future climate. Hence there are ongoing efforts to increase the sophistication of the parameterizations so fewer “tunings” are needed. The bottom line is that in a model with order 10**9 degrees of freedom, there are really very few tuning knobs, and while aspects of the model can be sensitive to an individual tuning, there is no way you can tune these models to give the observed space/time variability of so many different variables.
Re predictive power. In terms of the core atmospheric model at ECMWF, this shows good predictive power on the weather time scale out to a week or so, and on the seasonal time scale. The atmospheric core of other climate models is not evaluated in weather/seasonal modes. The climate models are evaluated in hindcast mode, comparing them with observations over the 20th century. they are also evaluated in paleoclimate simulations. The Eocene (5 million years ago) is a useful one since it had high CO2. paleoclimate simulations haven’t focused on the last 1000 years, and hockey stick type reconstructions are not input into the model in any way, nor have they been used much in terms of model evaluation.
Dan Hughes– Can you provide us examples of full V&V software, so we can see these for other codes? I think it’s only fair to show what these are as you describe in 112?
Judy– Thanks for the specific link. It really saves me and the whole peanut gallery time.
What the V&V propoentns are howling to see is examples an of : “2) computer model verification”. done formally. What is required is dicussed in section 6 of http://www.informs-cs.org/wsc98papers/016.PDF What the also want to see is the formal, published documents that show this was done. That’s what I’m not seeing anywhere in the list of links you provided. Dan is also describing this is bullet 2 of comment 112. (FWIW, there is much, much more validation out there than verification. Sargent’s paper also discusses validation more. All scientist will say validation is more important. Scientifically it is. But, that may not be so politically.)
Obviously, Sargents document saying this should be done is not an document that contains a formal verification.( It is unlikely such a document would be presented at a conference. They are boring and exceed page restrictions. ) But at least this shows that verification is discussed in climate science.
Yes, formal verification and validation is costly. Horribly costly. Is it worth the money? Depends.
The only time I did formal verification is for *nuclear safety work* and even then only when the relationship between safety and my specific results was very direct. As in: the person who hired me to do an analysis did so specifically to decide whether or not to have a guy suit up in a rad suit, enter the hot area and do something dangerous. And dangerous means: experiments on radioactive equipment that might contain a combustible mix of hydrogen and oxygen and explode as a result of the experiment. All the formal *verification* paper work ended up in files in the archives at the Richland Field Office. If I wanted to find these for you, I’d need to remember the title of the program and then file a Freedom of Information request using very specific language.
The verification steps made an otherwise simple analysis costly. Was it worth the money? In the nuclear case, to prevent an horrible accident, it was costly. (Besides, it was a legal requirement!)
Is the cost of documenting a formal vefication worth it for GCM’s?
The reason I say some sort of document would be advisable is neither technical nor scientific. FWIW, I believe the GCM modelers do verification. They just don’t write a big costly document, or maintain archives in NASA’s equivalient of the Richland Field office Archives.
The reason documentaiton is adisable is entirely political. Documentation would permit with third parties (particulary skeptics) need to be convinced. For scientists or researchers assessing a theory, validation is what counts. For doubters both count, and verification is important.
Much of the case for AGW is presented to the public based on these models. A certain fraction of the public will feel uneasy until such time as someone can say: “Here. This document shows the verification of the GISS Model E”. Then, we need each major groups writing GCM’s to write these documents for their codes. And for the skeptics, it really, honestly has to be a formal published verification as discussed in on page 125, section 6 of http://www.informs-cs.org/wsc98papers/016.PDF . Validation won’t do.
If you read Sargent’s seciton 8, you’ll see he says just what I’m saying:
It’s the lack of formal documentation that is causing a political problem.
Steve McIntyre,
Please ask Judith to stay on the topic of dynamical cores and quit raising smokescreens to avoid the topic.
Thank you.
Jery
Jerry and Jae, a few points of clarification. I did not bring up V&V, Lucia did. It seems to be a topic that people are interested in. This paper was originally mentioned on the hurricane thread, i tried to make my review relevant to issues that people have been discussing on CA like climate modelling and hurricanes. My Ph.D. was in geophysical fluid dynamics at the University of Chicago (about 25 years ago). I am not currently active in fluid dynamics modelling, my most recent exercise was LES modelling of the stable boundary layer (about 7 years ago now). I do not run climate models myself, but am actively contributing to the development of parameterizations for clouds, sea ice, boundary layer, radiative transfer, and ocean surface fluxes. Am I the last word in fluid dynamics or climate modelling? not at all. But I am making an effort to communicate to this group to address some fundamental questions that people have about climate models and to what extent we can have confidence in them.
Jerry, once you write your review, I will critique the substance of it. I see several flaws already in the reasoning of your previous post advertising your forthcoming review, so this could be interesting.
I will repeat the following statement. If the unforced dynamical system
cannot be accurately approximated, then the forcing terms (parameterizations) are not physical and the associated parameters must be adjusted to compensate for the unphysically large dissipation
Jerry
Judith,
I await your comments on the NCAR Tech Note Section.
Are you claiming that one need not accurately approximate the basic dynamical system in order to obtain physically correct solutions?
Please cite a mathematical reference that contains a proof of this
assertion.
Nonlinear cascade is serious business.
Jerry
I think I’ll wait and see how this thread evolves a little before I continue to add to the confusion.
But, Verification of the coding and numerical solution methods must precede Validation calculations. Calculations without Verification don’t count as Validation.
Thank you Judith for you productive additions to these discussions.
As an intelligent (modestly) engineer, machinist and fairly old man, one main point comes to mind. First, I would like to thank, on behalf of all the other lurkers, all of you for a very interesting and somewhat enlightening discussion. The main thing that comes out of all of this, here and in other threads, is that these various climate models and their scenarios, forecasts or predictions, or whatever you want to call them, are the basis for a major push to totally dislocate the world economy. I think that I can safely say, on behalf of many people, that I would very much like to see some rigour and demonstrated accuracy in these various model outputs before my life is turned upside down.
One suggestion that has been made many times, but, as far as I know, never really demonstrated is prediction from these models. Many of them hindcast, but how many of them have been subjected to the test of being fed data from, say, 1960, and then producing an accurate representation of subsequent history. I could even go along with feeding in known variations such as Pinatubo, etc. That and proper verification and validation. Surely, the possible dislocation of the world economy is worth at least a nuclear style justification as well as complete openness with data and code.
Worried.
Free the code.
Gerald, your comments are lacking in clarity and even apparent relevance to the paper. The term “nonlinear cascade” is not even mentioned in the paper, the only possible related issue seems to be the different ways in which the models cut off the high frequency waves. So unless you actually do some work, including writing something that is readable and clear, i am certainly not going to waste time responding to this. Frankly it seems to me that you have misinterpreted this paper and are reading things into it that are not there.
Jaye wrote “If I used a sim that wasn’t V&V’ed to help evaluation/design the devices I’m involved with, my head would be metaphorically taken off at the shoulders.”
And if someone tried to promote an officer of an insufficiently noble family in 1234 AD, his head might end up *literally* removed. And it was easy to find people who claimed this was because high performance in the military was important and the noble-born were literally better. Perhaps they sincerely welcomed actual chances to demonstrate this by competing directly against the pushy low-born types, dunno. (Do we have any good proxies for that?) But even if they were sincere, in hindsight it appears that aristocratically-managed organizations seldom thrived in direct competition with less-dogmatic ones.
While history doesn’t always repeat itself, still it’s a curious coincidence that a dogmatic bureaucratic approach to engineering software quality thrives in fields where central authority prevents pushy strivers from embarrassing more formally-controlled projects by superior performance.
“Guess that’s the difference between engineers that have to actually make something work and researchers whose work is confined to bickering back and forth in journals.”
Oh, puhleeze. Quite literally, if you’re so smart, why aren’t you rich? Pick any field where big money swings on software functionality and where your way isn’t mandated by law. Especially, pick a field where big money famously swings on unregulated model functionality: security and commodity trading decisions. (Also, perhaps, geological model functionality, but I’m not one of the people here who knows anything about that.) Is it so obvious that your approach to modelling is so qualitatively superior over the irresponsibly wrong ideas? So obvious that all reasonable people with an engineering background can see it? So they won’t mistake your “difference” opinion above for mad arrogant delusion, but recognize it as simple reality? Then duh, there are thousands of seriously wealthy potential backers with solid engineering backgrounds. Start a quant hedge fund (or perhaps oilfield services company?) devoted to taking advantage of superverified doubleplusgood software engineering methodology for its models, and kick some serious ass!
If you are sincere, I doubt the convinced backers exist, but in case your scolding is more persuasive in person, maybe your fund can come into existence, and then just maybe I can hear about it and somehow synthesize a modest short position before you’re eaten alive. The existing trading ecosystem is full of savages who do things like hacking together their models out of uncertified scripts in half-assed underspecified languages. That’s not a best practice I’d recommend, but neither is it enough of an overwhelming disadvantage to justify your contempt for university-grade models.
Possibly, however, you’re completely insincere and know full well that all your potential backers know full well that your approach is not a particularly competitive way to “make something work”. In that case, you’ll have time on your hands to keep posting here, and I hope you’ll stop being so dogmatic about the overwhelming superiority of nuclear-medicine-on-the-space-shuttle software engineering practices for building useful models to drive big-money decisions.
It is possible to argue that climate decisions would be best made by software designed and constructed by heavy bureaucratic machinery like that used for manned spaceflight. It might even be fairly easy to argue that position, given that governments have a lot of trouble managing more flexible approaches. But even for governments it’s not a completely obvious position. Not everyone is more impressed by Ariane software than ocaml software. And in the modelling problem domain, you don’t need to pick one software package to control your very expensive explosive device for a very brief period of time. You can follow the usual academic approach of letting a number of teams and their software fight it out continuously.
I think Steve McIntyre’s record-keeping and repeatability and reporting priorities are so fundamentally appropriate for policy-relevant models that dogmatism might well be appropriate. Your priorities are not nonsense, but they are not as fundamentally appropriate as that.
RE#129: Lucia, I can give you an example of a code that has had “full V&V” for its use on the Yucca Mountain Project (high-level radioactive waste repository).
FEHM is a finite-element heat- and mass-transfer code that simulates non-isothermal, multiphase, multi-component flow and solute transport in porous media.
To look at the V&V documents for this code, go to the public Licensing Support Network site (http://www.lsnnet.gov/) and search on “FEHM and Verification and Validation”.
I got 66,485 document hits. I guess they take V&V seriously at Yucca Mountain.
#66 — Judith wrote: “I encourage you to (re)read the IPCC summary for policy “makers:http://www.ipcc.ch/pdf/assessment-report/ar4/syr/ar4_syr_spm.pdf
“It is really a conservative document.”
You all really should read it. But not in isolation. Compare the certainties it oozes with the GCM errors reported in Chapter 8 Supplemental.
You’ll quickly discover that the IPCC Summary for Policymakers is a luridly tendentious misrepresentation of the science. There is no scientific basis for any of the specified probabilities. Figure SPM-5, and Technical Summary Figures TS-22 and TS-26 present numerical standard deviations as though they are valid physical reliability limits. Even technically trained people tend to overlook that as numerical uncertainties they convey no physical information.
And in Figure TS-6, bottom, the 90% uncertainty limits in the global average surface temperature of about (+/-)0.1 C prior to 1940, lessening to about (+/-)0.05 C after 1940 amount to a lie.
Conservative, my foot.
re: #129: Lucia, the codes for which I was a part of the V&V and SQA are not in the public domain. Even the code manual documents are not available to the general public. And as I mentioned before, the V&V and SQA documents were never in the public domain. The owners of these codes paid for the development and especially paid for the V&Vd versions. If you want the codes you got to help the owners recover some of these costs.
140, a different part of my anatomy came to mind.
.
Population is a terrific source of heat and amateur radio signals are a powerful greenhouse electromagnetic field.
Re: 130
“But I am making an effort to communicate to this group to address some fundamental questions that people have about climate models and to what extent we can have confidence in them.”
Regarding confidence in climate models:
“Global and regional climate models have not demonstrated skill at predicting regional and local climate change and variability on multi-decadal time scales.”
http://climatesci.org/2007/09/02/summary-conclusions-of-climate-science/
Dan Hughes– Thanks for the answer. I totally understand (and had missed your previous response). These things are generally not publicly available– and that of course is a question one might have vis. GCMs. Do they not exist? Or are they just difficult to find.
Luckily, George Crews knows where we can find a trove of examples! I went to the Yucca mountain link he provided, Search the LSN Document Collection, entered “verifiation” and found several documents, that include the utterly boring (as required of a verification) SCALE-YMP Software Verification Report for OSF1_V5, ORNL OCRW-SQA-010, Rev. 1 and SOFTWARE INDEPENDENT VERIFICATION AND VALIDATION REPORT FAR VERSION 1.1 (C)
These seem like a near top level verification document, along with cd attachments, and references to other sub verifications. I think comparing these examples to the much more intersting (to me) documents Judy linked will clarify the huge difference between validation (which can look more like what Judy linked) and verification.
@William Newman– I totally understand why you give a hoot about this. It’s an entirely rational thing to worry about. All I mean is this doesn’t happen to be the nail I tend to pound when worrying about whether something is proven to my satisfaction.
What I’m trying to communicate to both skeptics and advocates is that this step is standard, it is considered important by third parties trying to make up their minds. So, if these documents exist for GCMs, its in the interest of those who advocate for political action to dredged them up or told skeptics where to find them.
Of course, the verification documents may not exist because these GCM research programs weren’t perceived as existing to drive policy by the funding agencies. (Yet, as a political reality, they do act that way.)
Judith Curry: Thank you for the information, I appreciate it.
“hockey stick type reconstructions are not input into the model in any way, nor have they been used much in terms of model evaluation.”
Yes, I didn’t really expect the hockey stick data would be explicitly input either into the model or into the evaluation. (Among other things, I had the impression that people aren’t interested in its error bars in the way one would expect if it were explicit input.) I’m not even sure how best to express my curiosity about how the hockey stick might be an implicit input, but in case anyone might have a suggestion, I’ll try.
(If I am painfully reinventing the early steps of some well-known line of analysis, or talking about something which is too far from the thread topic, someone please let me know. Or if it’s just incomprehensible, sorry, maybe someday I’ll learn more standard R-ish stats jargon instead of my pidgin of quantum mechanics, Monte Carlo, and machine learning.)
As long as the hockey stick reconstruction is very compelling, it’s natural for modelers to prefer a model which doesn’t make big spontaneous excursions: evidently in the absence of CO2 forcing the Earth doesn’t make big decades-long and centuries-long excursions, so models don’t need to either, and probably shouldn’t. And while in the evaluation procedure you described, there’s no explicit minimal-spontaneous-excursions constraint, there does seems to be an implicit minimal-spontaneous-excursion constraint. Models which do make big excursions will tend to lose, because when a butterfly flaps its wings, the model can have only a small chance to fit 20th-century CO2-forced behavior even when historical CO2 forcing is replayed. Models which don’t make big excursions (can) win (given any overfit to the historical record) because they don’t bounce around so unpredictably on every damned run, so they can fit the historical record more closely. And that implicit bias is a tame problem, not high on the list of all the other annoying approximations which must be made for a tractable simulation, because the hockey stick shows experimentally that any instability must be fairly mild compared to the forced excursion you are fitting to. Even if you don’t quantify it, the proxy reconstruction informs you qualitatively that if a bunch of runs of the model from 1000AD to 1900AD don’t find big excursions, that’s likely a feature not a bug.
Conversely, though, let’s say hypothetically speaking that the hockey stick was found dead tomorrow. (Don’t have any idea how, hope Steve M. has an alibi.) I’m under the impression that its immediate replacement wouldn’t be a new clean historical global temperature curve suitable for pretty graphs. Instead, maybe it’d be a lot of general uncertainty, and various difficult-to-plot proxy constraints (e.g., “in Arrow Valley, rainfall and average temperature never moved more than 38% off this 2-dimensional curve in (rain,T) space”), and perhaps a few clear fluctuation constraints (e.g., freezing the Thames), and some suggestive fluctuation constraints (like from proxies that can easily be weighted to look like the MWP). To paraphrase into English, loosely one statistical implication of the fluctuation constraints might be “a realistic model should sometimes wander pretty dramatically even without being forced by CO2 fluctuations.” (I’m encountering difficulty trying to talk about butterfly wings in English, there’s probably some better way to express it.)
With historical climate constraints like that, any implicit bias toward models with small excursions starts to look perverse, perverse enough that it might be more natural to find some way to evaluate a model based not only on its ability to reliably follow 20th century forced behavior, but also to have a tendency toward big un-hockey-stick-like bounces when CO2 is flat for a millennium. (The temperature hockey stick dead, long live the CO2 hockey stick!) I’m not sure how best to express that as a quantitative statistical constraint: perhaps favoring models which have spontaneous excursion properties under which historical temperature anomalies weren’t 14-sigma events? But I don’t think I need to figure out how to express it quantitatively to suggest that it’s an evaluation criterion which could be explicitly in tension with any small-excursion constraint.
(And of course, all that’s just tentative — the kind of thing I’d like to get a handle on from poking around in a model evaluation, not anything I confidently predict I’ll find once I actually see the details.)
William, This is my take on it, note i am not a paleo-oceanographer or paleoclimate modeler. the reason the period of the last 1000 years isn’t much of a priority in terms of paleo simulations is that you need some specified change to external forcing (solar, atmospheric composition) or bottom boundary conditions (like continents moving around) to get a simulation that is different from present. We can simulate the “blade” of the stick during the last 100 years (CO2 increase), but there is no particular change to external forcing in the earlier period that we know about. The medieval warm period and little ice age (whther they are local or global phenomena) are believed to be associated with thermohaline circulations in the atlantic; correct simulation of such long term internal oscillations in an ocean basin requires long term simulations for the ocean for which we don’t really have any observational constraints. So this is why there is probably not much to be learned from such a simulation. Coupled climate model simulations for a period of about 10,000 years would be probably needed to capture these kinds of circulations ( I am just speculating here). Interesting for sure, vut the scientific payoff for using all this computer time doesn’t seem to be too high in the absence of observations of the ocean circulation during this period with which to compare the simulations.
Judith Curry (#137),
Good try. The manuscript is all about the nonlinear cascade of vorticity to smaller scales of motion that are unresolvable without numerical damping gimmicks, e.g. you might look a bit closer at Figure 8. Note that the plots of the very small magnitude (1 m/s), large scale perturbation are
not included in the published manuscript and one must go to the NCAR Tech Note to see those plots (page 9). Then one can quickly understands how a small wind error in a hydrostatic model, observationally induced or inaccurate forcing induced, will cause very different results in a very short period of time (on the order of days, not years).
And if one reads the Tech Note section on “Sensitivity to the Diffusion
Coefficient” that was mysteriously deleted from the published manuscript, one can also begin to see the impact of incorrect dissipation coefficients
on a solution (also see Polvani’s disaster discussed in the published manuscript).
Note that a hint of these problems can be seen in Table 1 of the published manuscript if one is familiar with the gimmicks that are used.
[snip – c’mon, Jerry]
Jerry
William,
How do you know I’m not rich?
You assume too much. There is quite a bit of difference between, process for process sake, and designing code with care and professionalism. If you were truly in the business you would know the difference…thereby sparing us from several hundred words worth of inane prattling.
To quote Hans Solo: “I must’ve hit it pretty close to the mark to get her all riled up like that, huh kid?” So I’m guess you are close to the spaghetti making processes at NASA or else where.
All,
I have asked that the comments on this thread be kept to the issue
of dynamical cores. If you want to dicuss other issues, please go to the general thread or ask Steve M to start a new thread on the subject you wish to discuss, e.g. V&V.Please keep unrelated questions on other issues (such as forced atmospheric models or full climate models) off of this thread so that this manuscript can be used to illuminate the serious and unresolvable problems with numerical approximations of the unforced dynamical systems.
Once this discussion is complete, I think the other issues will become clear. Thank you.
Jerry
Jerry
Are there any good web resources to help guide novices through the theory in global climate model. I’d expect something along the lines of a summary table giving the models, in one column, the continuous equations in another column, the discrete equations in another column and the coordinate system used.
I’d also like like links to the derivations for both the continuations equations and how the discrete equations are derived from the continonus equations. Maybe the models are too complex for such a simple summary table but it would be nice if possible.
I know it sounds rather rudimentary but not everyone that is interested in GCM have studied computational fluid mechanics.
John (#151),
I can write down the continuum unforced equations of motion in a few lines of calculus. In textual terms they are
the equation of mass conservation (density rho), the 3 momentum equations for the velocity (u,v,w), and the pressure equation. In vector notation they are deceivingly simple. But the range of motions that can be described by the system, especially with forcing, is hard to imagine. I need to know more about your interests and level of education to provide you
pertinent references. If others wish, I will write down the unforced equations so that the above manuscript can be understood in more detail as we go along. I would then be able to reference specific terms during the discussion of the manuscript.
Jerry
Tony (#136)
Agreed.
Tony (#136)
Agreed.
Jerry
Dan Hughes (#134),
I think that the wait will be worth it. 🙂
Jerry
Vector form is fine but all the models must pick a coordinate system. I’m currently reading “Tensors Differential Forms, and Variational Principles, by David Lovelock and Hanno Rund” so hopefully I’ll be very good and changing coordinates systems soon. I’m only on chapter 2 though.
I’m also reading, “Mathematical Physics by Donald H. Menzel” I’m on section 13. I actually have a physics degree but unfortunately undergraduate students don’t tend to have the math skills to properly learn classical physics. It’s also been a while so I need a refresher.
Not totally relevant to this topic but I studied electrical engineering after my physics degree. Anyway, you don’t need to explain the math, I just need to see the algebra and have all the assumptions clearly stated. Steve has a forum which he created where basic physics can be discussed:
http://www.climateaudit.org/phpBB3/viewforum.php?f=4&st=0&sk=t&sd=d&start=0
Also if you have a link which derives something then linking to the derivation is more then sufficient. Now you told me the three equations that should be applied. I could go Google them and learn the derivation but it wouldn’t be obvious to me how to apply them or solve them.
Now it wouldn’t be fair for me to ask you to write an entire text, so listing the equations and links to the derivations and the names of the methods used to solve these equations in GCMs would be a good starting point. Expect a lot of questions. 😉
There is some math though that I might need help with. I understand that often the special functions are used for the solutions / parameterizations. I’m weak in special functions and can’t remember if the solutions are Bessel functions are not.
I have never applied the method of separations of variables to a system of partial differential equations and do not know what other analytical methods there are to solve partial differential equations.
I also know nothing about applying laganandre or Hamiltonian (if possible) methods to partial differential equations. I’m curious if there are analogous methods to Rung Kutta for partial differential equations. I don’t know how well partial differential equations solvers deal with various numeric problems like stiff systems or chaos.
Also in terms of mathematics I noticed that some coordinate systems used an equal sized triangle sized grid. This strikes me as a kind of fractal geometry. I’m curious as to weather it is possible to express the continuous equations in some kind of fractal geometry or is this triangle grid system only used in an ad hoc discrete fashion.
An analogy.
Before they became popular, I investigated the concept of the “call centre” and recommended firmly against involvement.
There were two broad groups of people, those who designed and made the product and those who answered questions about it.
Those who answered questions were trained in people communication skills. They had a brief written manual about FAQs and a default of calling a supervisor who worked from the same manual.
Those who designed and built the product (one example was a PC) marched to a different drum. They worked with data and science and math and stats and knew things like the properties of semiconductors, heat flows, electronic circuitry etc etc. But they were never let near the telephone to answer the public’s questions.
Climate science is a bit like this. The public face knows very little about the science and the scientists know very little about how their work will be represented.
One can introduce quality control measures of various types. For example, a considerable effort went into solving the magnitude of pi to a million places. It can be stipulated that this value of pi be used as a standard and that any model which cannot beack-engineer to it fails.
There is intellectual satisfaction in the pi exercise and there is in coming up with a GCM that accounts precisely for every problem that can be thrown at it. But, for what purpose? Make the grid cells as small as computers will handle and you still have large input errors in representing surface albedo, temperature at screen height, sea surface roughness and a myriad of other variables. So it will not be possible to gain the parallel intellectual satisfaction of solving for pi to a million places. Why try?
Whatever answers come out of GCMs, no matter the standard of computing and quality control and lagrangian mathematics and progress in solutions to Navier-Stokes, we are left with fundamental fact that the wrong question was asked.
Instead of postulating “Can we model global climate” we first should have thought “How many angels can dance on the head of a pin?”
If the models are too complicated to be tested adequately, then they are too complicated to produce useable results.
William, #138:
Are you honestly dismissing V&V as just another means for keeping down the masses?
This facet of the modeling problem adds yet another nuanced connotation to the term Virtual Reality.
As far as V&V issues are generally concerned, I believe it was the Car Guys, both graduates of MIT if I remember correctly, who dryly observed that you can be ISO 9000 certified and yet still build a Yugo.
J.Curry wrote # 83
J.Curry wrote # 105
That is exactly what I did and I provided you in this thread with a free review of a very recent ECMWF Technical Memorandum 539 Recent Advances in Radiation Transfer Parameters .
It is true that I would need probably 1 week to audit it really but that would not be so much considering that 19 people were necessary to write this memo .
Incidentally I notice that there is no scarcity of ressources when 19 people sign a report of this quality .
I suggest that 2 of them be specifically dedicated to insure that the recommendations quoted in thread # 105 are followed by effects .
Even after only a 2-3 hours study it appears that items 3) , 4) , 8.) and 12) are severely mishandled in this ECMWF Technical Memorandum .
I suggest that the Memorandum be rejected in its present form and a serious predictive and historical validation takes place with explicit disclosure of experimental data used , its validity and representativity and its (re)treatement takes place .
Farther I suggest that while model to model comparisons may have a limited use , they can’t replace the quantitative studies concerning prediction skills . The use of such comparisons should be strictly restricted to statistics related to calculated parameters and only under the condition that the relevance of such statistics has been proven beyond any
reasonnable doubt .
Lastly I suggest that teams refrain from anecdotical evidence (like f.ex the Sahara sand plume) whose relevance to the topic is not quantified .
I have done this (small) work in my free time for free , the subject is not of extreme complexity , so I trust that there is enough time available in a team of 19 people active full time to comply with the above recommendations .
Jerry # 111
I am fully with you in that and I indeed agree that everybody would save much time and money by focusing only on the relevance , sensitivity and convergence of the dynamical core .
These issues have been largely discussed here in the “Exponential divergence thread” , Dan Hughes has an extremely interesting blog on those issues too and it appears clearly that this very basic issue is unresolved .
We may have minor divergences about the Chaos theory and its relevance to the problem but substantially we share the same concern 🙂
However I am not sure that a board discussion is a very efficient way to treat that kind of problems .
#158, or if the developer barely knows how to debug the system today, it’s too complicated for anyone else (including the developer one year later) to keep bug-free.
If so many people here know what’s wrong with the climate models, why aren’t they out there fixing them???
Wouldn’t THAT be the scientific thing to do? Jerry- why didn’t you do this while you were at NOAA?
Much of the discussions around here seem like a whole lot of finger pointing and name calling where not many people are actually stepping up to the plate. (other than SteveMc or Judy Curry…)
The NCAR CCSM has a very complete writeup on their dynamical core
http://www.ccsm.ucar.edu/models/atm-cam/docs/description/
Go to Chapter 3. I suggest starting with section 3.1.3, which describes the original continuous equations.
For purposes of discussion, i suggest we focus on this model since it is well documented, and also included in the Jablonski paper
163:
This is an audit site, not a “fix it” site. If you could provide a few $million, some of these folks might be enticed to really fix them (if possible). And I think this site is pointing out flaws that will aid in “fixing” them.
Re the issue of “fixing” climate models. There are definitely things to improve, most notably in the treatments of aerosols, clouds, ice sheets (the parameterization part of the problem). The dynamical cores of the atmospheric part of the models are sound in terms of providing validated, verified, and useful solutions of weather systems including baroclinic waves. Perfect? Optimally efficient in terms of numerics and computational speed? Almost certainly not. By focusing here on the dynamical core of the atmospheric part of the model, this is not even close to the place where a big concerted effort is needed.
One of the best groups of fluid dynamicists in the world is arguably at Los Alamos National Laboratory. About 10 years ago, they were looking to redirect some of this brain power into climate modelling. After looking at the various elements of the climate models, they judged that there was little to do with the dynamical core of the atmospheric model (that it was quite mature and performing quite well), although there were issues with the parameterizations of convection and the atmospheric boundary layer. Hence they have focused their efforts on the ocean and sea ice models (and a new focus area is ice sheet modelling). Note, the LANL group collaborates closely with the NCAR group and NCAR is using their ocean (POP) and sea ice (CICE) models. Information on this group can be found at the LANL COSIM website http://climate.lanl.gov/
Now maybe Gerald is smarter than all the people at LANL and ECMWF, or even just has a plain good idea about something that is wrong or an idea for fixing it (I certainly can’t find evidence of this in his publication record, but i have an open mind). So far, all I’ve heard are innuendoes.
Jimmy,
How can we fix the code, when the modelers don’t release the code?
Regardless, do you always take the position that unless someone is willing to take the time and effort to fix something, they aren’t allowed to criticize it?
Can I safely assume that you never criticize politicians, since you haven’t run for office yourself?
#165. The money is there. It is called NSF. Or NASA. Or another funding agency if you’re European.
I’m saying people should “walk the walk”, not just “talk the talk”.
MarkW wrote “Are you honestly dismissing V&V as just another means for keeping down the masses?”
I’m saying that pushing any detail of heavyweight policy as obviously *the* way to do modelling for decision making tends to sound like dogma to me. If you believe as revealed truth that V&V (e.g. vs. sleazy V or some newfangled V&V&V) is *The* Right Way to get decision-making data out of models, I’m usually skeptical.
My principled reason for skepticism is that it doesn’t seem to be utterly dominant in fields where models of their own free choice drive people to make big decisions with their own money. (for modelling: finance, and perhaps drug discovery and mineral wildcatting too. for software in general: any number of products)
My bad attitude, what you paraphrase as “way to keep down the masses,” is in part from experiences like working as a contractor at Nortel ca. 1998 (and using telecom standards, and doing some standards work at the IETF),. The old-line telecom folk (whose attitudes concerning the right way to get quality sometimes sounded like Jaye’s) ran into the IETF, Unix, and so forth; interesting times. And my “eaten alive” image could be taken to apply to that in hindsight.
My literally keep-down-the-masses analogy was partly just driven by the whimsical tie to Jaye’s image of decapitation. But there was a cliche among old cynics at Nortel that “our customers’ core competence is lobbying.” So it’s not entirely whimsy: I’m predisposed to notice when people who are self-righteous about their superior procedures happen to be protected by law from any competition by pushy upstarts with ostensibly inferior procedures.
I’m basically fine with formality and process which is common to IETF working groups, the OpenSSH project, Linux, ocaml, and any number of invisible commercial projects. Once tricky projects involve dozens of people, the successful ones tend to have some things in common. But the consensus set of good practices truly common across “engineers that have to actually make something work” does not have all the details that Jaye is calling for. And good sense and integrity and ability are even more important than procedure. And when I see someone fixating on some bureaucratic detail which is not in the intersection of sets of policies of the projects I mentioned, I take it as evidence of lack of good sense, lack of integrity, lack of ability, or all three.
I’m not dogmatically opposed to heavier process than that. I’m dimly aware that historically a surprisingly large amount of bureaucracy was needed to get interchangeable parts working, for example. But I want to see processes and bureaucracies justify themselves by eating the competition alive (not so many non-interchangeable parts used today…), not by appealing to voters’ and legislators’ intuition that ordnung muss sein.
Jaye: I am an independent software developer. I don’t have any active organizational affiliation unless you count a free software project that I started years ago and still nominally control. Not even an employer: I’m taking a flyer by working for myself on a search-related problem, which is likely too hard for me, but with a potential payoff which seems to make the expectation value worth it.
“If you were truly in the business you would know the difference.” Yeah? I’m not in the businesses I mentioned in my post. But one of the sizable bodies of university-based code that I’ve worked on is driving many dollars worth of decisions at a successful airline-ticket search/optimization website today, and I think that qualifies me for an opinion about your original rhetoric about “engineers that have to actually make something work.”
If I write off my current project and go back to contracting, I might end up in something related to finance, but I’ve never worked in anything related to finance. I chose that because there is a well-known niche there where qualitatively better modelling would tend to be all you need to make a ton of money, and I can’t think of a comparably clean example in fields closer to my work experience.
To the extent that you “hit close to the mark” (my words might be “struck a nerve”) it’s partly because of general common sense (the years have exhausted most of my patience with quality claims from process bigots, language bigots, and funding-source bigots who have the One True Way but weirdly never get around to dominating quality-sensitive fields like finance or compilers), and partly because of experiences like contracting at Nortel, above.
Some may be puzzled by Jerry’s discussion of the importance of ‘Figure 2.2 on page 9’ and the contents of page 38 in the document that Judith reviewed. Many of us downloaded and read the document and are aware that it is only 33 pages long ad contains no figures on page 9. (Moreover, the adjacent figures on page 8 do not match Jerry’s description.)
It appears that when Jerry jumped into the hurricane thread to request Judy review
Jablonowski, C. and D. Williamson, 2006.
A baroclinic instability test case for atmospheric model dynamical cores.
Q. J R. Meteorol. Soc,
132, pp 2943-2975.
Jerry did not wish Judy to review the article he cited ( click for pdf). He wished her to review a different longer manuscript, of the same title. If I am not mistaken, that manuscript is available at NCAR Technotes at UCAR. ( Click here, for the pdf.)
Evidently, Jerry intends to review this second document; his review will focus on the material the author’s (Jablonowki and Williamson) ommitted from the journal article Jerry asked Judy to review. Consequently, I think we can anticipate that Jerry’s interpretation of the other, longer paper, may differ from Judy’s.
William,
You believe that code shouldn’t be tested to prove that it does what’s advertised? That’s all V&V is.
William,
Would you mind letting us know the name of the company that employees you. I want to let purchasing know that they should never, ever, buy code from your company. If you don’t think testing is important, I don’t want anything you produce.
re: # 115
Judith,
General
A desire for bigger, faster hardware is not necessarily a valid measure of inherent complexity. Bigger, faster hardware can be driven by the need to increase spatial and temporal resolution, for example. And as Judith notes, the scales of these for the GCMs are enormous. Higher fidelity relative to resolution of multi-scale phenomena and the interactions of these will also generally demand more compute power. Poor coding practices can also lead to the need for more power in attempts to simply power through all the operations required (give me a bigger hammer). Legacy software will generally have tons o’ poor coding and as the desire to get more info out of an application naturally evolves brute force is one way to overcome these. On a personal level, I simply like to have, and drool over, bigger hammers in my computing environment.
Complexity
I would say that a more likely measure of complexity of the software is the number of interactions/interconnections that occur between the data structures. Typical examples of this are physical situations that involve several important coupled physical phenomena and processes. Fluid flows, conduction, power production processes, the response of structures to temperature gradients and fluid forces, different kinds of engineered hardware of various degrees of geometric complexity, and others. The parameterizations, I think engineers generally call these the heat and mass transfer coefficients and friction factor correlations, might need to cover wide ranges of possible fluid and structure-interface conditions. The equations of state for the fluids in the system might also need to cover wide ranges of thermodynamic states.
Each one of these separately would not necessarily require large LOC counts (some might) and the coding should be easy to follow, if good coding practices are set and followed. But if two of these are coupled, fluid flow and conduction, for example, the data structures for each must know the data structure of the other (or carefully selected parts of each). And if three or more are coupled, fluid flow, conduction, and structure response to these, the number of interfaces of course increases and each data structure must know about at least some parts of the other data structures. Additionally, the fluid flow itself might be inherently complex. Transient compressible flows of mixtures of fluids, for example, are notoriously complex in the physical domain. Couple this flow to conduction and you’re got yourself a real hard problem. A control system, a flight control system in an airplane for example, needs to know about almost all the other systems in addition to the state of the plane relative to the fluid through which it is moving. Control systems in engineered process plants must interface with all the pieces parts as well as the working fluid. A model of such a system would have a data structure that interfaces with almost all other data structures. And so it goes.
What I’m trying to say, and maybe not too successfully, it is the coupling of the data structures as dictated by the physical situation that can lead to complex codes. The coupling in the physical domain leads naturally to coupling in the code domain. Absolute conservation of mass, momentum, and energy requires that the physical coupling at the interfaces be evaluated consistently and at the same time levels in each of the coupled systems.
For a comprehensive GCM I can count oceans, land, atmosphere, ice, biological processes, organic and inorganic chemical processes, human-made sources and other effects, radiative energy transport, conduction and convective heat transfer, phase change, clouds and aerosols, as some of the important system components, phenomena, and processes. The fluid flows are 3-dimensional and turbulent. There are probably more. This list is getting quite long, but I don’t know that any single GCM has yet included all of these.
Legacy software, which generally evolves from simple one-objective model/method/code/application is especially deficient in handling data structures and especially interfaces between data structures. Parts get tacked onto the previously existing pieces and the thing grows up to be a really big and ugly thing. Tacking on leads to really bad code primarily because the original code did not plan for coupling to other data structures. I have seen some really scary code.
Problem Size
As for the degrees of freedom, I don’t know what today’s CFD codes are running at, but I’ll bet it’s a huge number. Simulation of transient, compressible single-phase turbulent flows around the complete airframe of an Airbus 380 has got to need lots o’ nodes. Almost any problem can be made into a Grand Challenge grade problem as the need for higher temporal and spatial resolution is factored in along the software-evolution trajectory.
Nonlinearity doesn’t count. All interesting and actual real-world problems are nonlinear. The universe is nonlinear.
But none of this negates any of the requirements for V&V and SQA relative to applications that involve decisions about public policy. Equally important, as the models and codes evolve to greater degrees of complexity, the higher the payoff relative to maintaining the integrity of the entire software development cycle and the ultimate usability and maintainability of the products.
The only data point that I have is the NASA/GISS ModelE/ModelE1. These are built with about 100,000 LOC. That’s not many.
Judy– 115:
First: I agree that climate models are very complex. They may be the most complex codes around or they may not. (I don’t know; I am entirely ignorant about the complexity of codes to model DNA or those that do ab initio computations in chemistry.) The UCAR site is interesting, contains lots of information I would like to read. Anyone who looks at that material knows climate models are complex.
That said: Only a tiny number of people are disputing that climate models are complex. I think a larger number are saying that complexity is not particularly relevant to the issue of whether or not formal V&V could be accomplished.
I am know for a fact it doesn’t impact verification much. (I admit it complicates validation.)
I’m not a big time modeler. When I did research and development, I did focused on experiment and simple closed form, pen and paper analyses. My peer reveiwed articles fall in those areas. I’m familiar with V&V because I worked closely with modelers on safety projects associated with Hanford clean up. I know that formal V&V is different from what you are describing and linking because I had to watch formal V&V in action. (It is a horrible sight to behold. Sorry Dan.)
I think a lot of cross talk is happening because various people are mixing up: a) informal verification with formal verification, b) informal validation with formal validation, c) verification with validation and finally, d) the whole V&V process with proving a code really is accurate and to what degree.
For the most part, you seem to be focusing on the actual level of accuracy; some others are focusing on the formality of the process. (The level of formality does affect their willingness to believe codes are accurate, and that makes conversation even more confusing.)
I’m just trying to explain the word use is different, and as a result the arguments and counter arguments aren’t really meshing because people are sometimes arguing about different things.
#173 Dan
I agree with everything you say about complexity. I am in the process of helping to build a model with all the components you describe. Common data structures can be a nightmare when bringing together components developed by different institutions (eg. the CICE model mentioned by Judith, the NEMO ocean developed in France, the chemistry and land surface schemes developed by the academic community etc.).
Looking at the paper lucia mentioned, most aspects of V&V are done here though it all has different names – eg “Event validity” is done by comparing model’s internal variability with observed variability.
One area of weakness is some of the verification tests – it is difficult to do unit tests when interfaces are complex and diverse, so we require that an updated component must include backwards compatibility such that new versions of the full model can produce bit-identical results to the old. Components also produce increment diagnostics (the per-timestep change it makes to the main model fields) that can be examined. So here, validation and verification are a little blurred.
On the other hand we’ve lived with our current model for over a decade with hundreds of developers and users poring over every result. The system we have “works” (the model is also used for short-range forecasts) even if we are looking constantly to improve it. In 98% of testing and use, the GHGs are set constant. My inability to produce V&V documentation in the standard demanded here does not reflect a lack of V&V.
I’ve had a brief look at modelE, and I have to say “my” model is significantly more readable, so I hope people don’t think it is a typical example (sorry RC folk!).
re: NCAR CCSM, ECMWF, and NASA/GISS ModelE/ModelE1
Judith has several references to codes and documentation other than NASA/GISS ModelE/ModelE1.
First I have tried to break the ModelE habit more than once. But having time invested it’s kind of hard to do. Based on the discussions here I think I can make the break now and focus on other codes.
As a rough example of what an Independent Verification exercise might look like consider the following. For what ever the reasons, Judith’s organization has given me a Grant, for sinful amounts of money, to check the SQA status of parts of the ECMWF model and code. We have decided that the momentum balance for the vertical direction is a critical aspect of the model and its applications. Possibly because we know that there is more than one approximation used for this equation, and some of these have bad properties.
Here’s an outline of some of what I need to see in order to satisfy the SQA Plan for the code.
1. The derivation down to the exact final form of the continuous equation for the vertical direction momentum balance as used in the model.
2. The exact and final form of the discrete approximation of the continuous equation. All time and spatial locations, and sizes of the discrete increments, also documented.
3. The numerical solution method used for the discrete equation. For this case the method is very likely a part of a method that solves all the momentum balance equations.
4. Demonstration that the numerical solution method used to solve the discrete approximations are consistent, stable, and convergence. Including effects of discrete approximations for the BCs.
5. Demonstration that the actual working order of the solution method(s) is in agreement with the theoretical order. Including the effects of any stopping criteria, and grid refinement effects. Ideally these demonstrations will include all the parameterizations that a part of the vertical momentum equation model.
6. Documentation of how the discrete approximations and solution method(s) fit into the actual code.
7. The routine(s) and data structure(s) that are used in the code to obtain the solution of the equation. These will be used to check that all the stuff in 1 thru 6 has actually been implemented as specified by the documentation.
For each of the above I will have objective technical evaluation criteria and associated success metrics to show that the requirements have been met, or not.
I’ve constructed this from memory as I type, so it very likely is not complete.
Here’s a test. Can anyone point me to document(s) that contain the information that is needed to complete this checklist for the ECMWF model/code.
Thank you again Judith for your constructive additions to these discussions. I’ve got some coupled radiation-convection-conduction finite-difference equations to look at.
re: NCAR CCSM, ECMWF, and NASA/GISS ModelE/ModelE1
Judith has several references to codes and documentation other than NASA/GISS ModelE/ModelE1.
First I have tried to break the ModelE habit more than once. But having time invested it’s kind of hard to do. Based on the discussions here I think I can make the break now and focus on other codes.
As a rough example of what an Independent Verification exercise might look like consider the following. For what ever the reasons, Judith’s organization has given me a Grant, for sinful amounts of money, to check the SQA status of parts of the ECMWF model and code. We have decided that the momentum balance for the vertical direction is a critical aspect of the model and its applications. Possibly because we know that there is more than one approximation used for this equation, and some of these have bad properties.
Here’s an outline of some of what I need to see in order to satisfy the SQA Plan for the code.
1. The derivation down to the exact final form of the continuous equation for the vertical direction momentum balance as used in the model.
2. The exact and final form of the discrete approximation of the continuous equation. All time and spatial locations, and sizes of the discrete increments, also documented.
3. The numerical solution method used for the discrete equation. For this case the method is very likely a part of a method that solves all the momentum balance equations.
4. Demonstration that the numerical solution method used to solve the discrete approximations are consistent, stable, and convergence. Including effects of discrete approximations for the BCs.
5. Demonstration that the actual working order of the solution method(s) is in agreement with the theoretical order. Including the effects of any stopping criteria, and grid refinement effects. Ideally these demonstrations will include all the parameterizations that a part of the vertical momentum equation model.
6. Documentation of how the discrete approximations and solution method(s) fit into the actual code.
7. The routine(s) and data structure(s) that are used in the code to obtain the solution of the equation. These will be used to check that all the stuff in 1 thru 6 has actually been implemented as specified by the documentation.
For each of the above I will have objective technical evaluation criteria and associated success metrics to show that the requirements have been met, or not.
I’ve constructed this from memory as I type, so it very likely is not complete.
Here’s a test. Can anyone point me to document(s) that contain the information that is needed to complete this checklist for the ECMWF model/code.
Thank you again Judith for your constructive additions to these discussions. I’ve got some coupled radiation-convection-conduction finite-difference equations to look at.
oops. sorry, don’t know how that happened. snip away SteveM.
And thank your Steve for providing this place.
Code complexity? This is a common excuse used by lazy people to argue against a variety of
things.. 1. the junk compiles so the compiler understood
it. 2. the junk executes so the NAND gate understood it.
Bottomline: It compiles. Bottom line: sheffers stroke.
If you want to measure “code complexity” there are many measures.
start here:
http://www.sei.cmu.edu/str/descriptions/halstead.html#1227444
And theoretically, this is what we mean when we talk about complexity.
http://en.wikipedia.org/wiki/Kolmogorov_complexity
I am intrigued by the argument that historic temperature reconstructions play no part in the proof if human causation of recent warming. In 2006 the BBC Climate Chaos programme gave a very different impression. Joanna Haigh was shown giving a presentation to Paul Rose of a climate model. When I asked what it was she emailed “The model is an energy balance model as described by Crowley and Lowery. Full GCMs produce similar results for global averages.”
She started with a temperature reconstruction presumably from Crowley that was pretty flat to 1850 and then shows how the model matches all the wiggles to 1850.
Next the instrumental temperatures are added and the model is shown to undershoot
and finally adding in CO2 and of course a few aerosols, and hey presto it all fits
I asked what happens if she if used Esper 02 or Moberg 05 instead of C&L but got no reply?
This whole argument is so familiar. When I was a pup, I was arguing the “it can’t be done” side. Then my boss hit me over the head with a 2×4. Now I understand that it can be done.
Of course a half dozen calls in the middle of the night to come to the plant and reboot the system may have also had something to do with seeing the light.
“You believe that code shouldn’t be tested to prove that it does what’s advertised?”
Is that a reasonable reading of my position? (Actually, I *don’t* believe the “prove” part; good luck with that. But I assume you mean something like the usual “show [probably, mostly]” that’s used for testing nontrivial systems in practice.)
If the argument was really between the sensible engineers asking things like “you don’t think you need to test your model code?!” and the zany academics responding “lalalala, testing? we have verified that the computer falls at about 10 meters per second per second,” then I’d be on your side. Testing is important, and tossing the computer out the window is not a relevant way to test. As long as you keep connecting back to things that are sound ground priorities, like testing, relevant testing, comprehensive testing, or usefully archived testing, I’m happy.
I criticized “if I used a sim that wasn’t V&V’ed to help evaluation/design the devices I’m involved with, my head would be metaphorically taken off at the shoulders.” If I had thought that was equivalent to “if I used a sim that wasn’t tested,” then I would’ve gently criticized Jaye for using obfuscatory jargon “V&V” when English has a perfectly good ordinary word “test” that means precisely the same thing. Instead, he was using it in a discussion where clearly the code in question is tested, just maybe not tested enough, and definitely not tested using his traditional standards. And instead of focusing on some fundamental “enough,” he goes off on his traditional standards. Read post 33 again — there’s no reasonable way to just substitute “test” for “V&V” there. It’s means something like “that particular constellation of testing procedures/traditions/priorities/distinctions/etc. which is called V&V in my world.” (And that’s the world of “engineers that have to actually make something work” as opposed to “researchers whose work is confined to bickering back and forth in journals,” check!) So I tore into him for confusing the fundamental importance of things like reliability (and related things like testing) with the particulars of a family of bureaucratic procedures. (and for the particular tradition of respecting bad philosophers/engineers and not respecting good plumbers/scientists)
“Would you mind letting us know the name of the company that employees you. I want to let purchasing know that they should never, ever, buy code from your company.”
I don’t think I’ve ever been *employed* making code you can currently buy, or even products or services you can currently buy. I’ve been employed on things like pilot projects and internal projects and troubleshooting, not products you can avoid. But I was *involved* *in* a service you can buy, the aforementioned airline-ticket connection.
A research group at CMU developed an optimizing compiler CMUCL, and freed the code when the funding ran out. Various volunteers worked on it off and on for a decade or so. I reengineered part of the compiler, and its development and release process, to start the project at sbcl.sf.net. The company ITA chose to use first CMUCL, then SBCL to build the deployed version of their airline ticket search engine. And Orbitz (along with, I believe, several other sites) uses that search engine as their backend to solve the customer/ticket/schedule constraint/search problem. ITA has hired some of the other programmers from the SBCL project, but I’ve never been employed by any of the companies involved. I think ITA and Orbitz have a pretty good record of matching customers and tickets, and I’m very impressed by the people they chose to hire, so I’d recommend them to anyone who isn’t too hung up on the need for “V&V” as opposed to mere “testing” and “reliability” and “correctness” and so forth. (And I hope my display of temper doesn’t mean this confession costs them customers. Come on folks, the thing is the reliable economical airline tickets, pay no attention to the savage of OrbitZ behind the curtain.)
“If you don’t think testing is important, I don’t want anything you produce.” If you are too irate to read carefully, I hope you take several deep breaths before you go back to producing something I might end up using. And if someone says “responsible organizations use C&A” and in the same post refers to “certified by three line managers” and “approved by a bilingual external auditor” and gets criticized for it, and you come back with “if you don’t believe in decisions being made by qualified people,” I think it’s up to you to demonstrate the equivalence between the phrase “three line managers and a bilingual external auditor” and the phrase “qualified people.”
Three reasons I try to focus on fundamentals instead of falling head over heels in love with one particular formalistic procedure related to the fundamentals… (1) I did a lot of work with QM, and thrice (old quantum mechanics, then Heisenberg vs. Schroedinger, then Feynman vs. Schwinger vs. Tomonaga) the field went through confused situations where disagreed-upon things turned out to be fundamentally the same. (2) I have written a lot of Monte Carlo code and random algorithms, and there are some odd limitations on testing such code, which can make for an irritatingly poor fit to testing formalisms which were specified without MC in mind. (3) This policy debate is full of people stubbornly fetishizing procedural things like “peer reviewed” as if they trump fundamental things like “archived” and “disclosed” and “written by an author who acknowledges errors after they are pointed out” and “clear” and “technically correct.”
Dan,
Verification for 2006/2007 ECMWF forecasts is at
Click to access tm547.pdf
The model is proprietary to the EU, so the code is not publicly available (it is heavily scrutinized within the EU, and there is much documentation that is not publicly accessible).
The Technical Notes in an aggregate sense constitute the documentation that is publicly available
If I were going to audit a model, i would do the NCAR CCSM, far and away the one with best documentation and cleanest code (at least on ocean and ice part).
@William Newman–
Yep to what you are saying.
The reason what I post often sounds in disagreement with Judy is simply that I’m pointing out what she is saying is done is not what some of the others are asking for. Lots of good engineering work is done writing codes that are not formally V&V’d in the sense people here are asking.
That doesn’t mean the work is poor, no one’s head comes off for doing this.
Nevertheless, the people who say they won’t believe a complex code without formal V&V they could be shown are probably telling us the truth about themselves: They won’t.
That doesn’t mean other people won’t believe the codes. It doesn’t even mean one groups has better or worse standards: it just means people weigh evidence differently. (That’s why we have 12 people on juries, right?)
When Steve Milesworthy says:
I believe him. That’s actually ok by me. If he had it, I personally would not read it and it wouldn’t affect my assessment of the codes. But it would make a difference to others. I recognize that.
Going forward, it appears Steve Milesworthy understands what some skeptics are asking for . It appears he is heading some sort of task to improve documentation. I hope it provides the public the sorts of detail that are never available in peer reviewed journal articles because they have page limits, and limit themselves to including only the novel portions of work and also edit out details not necessary to illustrate the main most important point in the article. I hope the task documents the V&V more formally so that those who need to that to feel comfortable with model predictions.
We won’t know the results of his task until documents begin to be available, but it sounds like the correct path to me.
Dan,
Re: #173
I share many of your views but didn’t understand your comment near the end that “Nonlinearity doesn’t count. All …” It seems to me that nonlinearity makes “all the difference in the world.”
JC says:
Rejecting the models because of the lack of a standardized set of tests is irrational.
And accepting them without tests is just as irrational. I’d say that puts the models into Schroedinger Cat territory. Neither alive nor dead. i.e. not useful for policy. Maybe even not useful for climate science.
John (#156),
The most common coordinate system used on the sphere for hydrostatic models is the spherical coordinate system in the horizontal direction and a normalized pressure type of coordinate, e.g. p/p_s (p is pressure and p_s is surface pressure), in the vertical direction. This choice of the vertical coordinate has much to do with historical development.
There are many others, e.g. stereographic coordinates. But to understand the problems with the continuum system, Cartesian coordinates are sufficient and I wouldn’t spend tons of time on learning coordinate transformations at this point just for this purpose.
Jerry
I meant that nonlinearity doesn’t count anything special relative to climate science because every problem of interest is nonlinear.
There is another model for verification, of course. It’s called open source. It didn’t take long for the world to find the famous excel bug that Microsoft’s V&V never found. Turning the code loose to 1000 fiddlers will find the problems in short order.
However, the same people who are resisting V&V are also resisting open archiving. Funny how that works.
Tom (#161),
Yes we are in agreement. You are not the problem. Notice how Judith always wiggles out of any very specific question and tries to dilute the topic with tangential issues. This is very typical for scientists that are more into wordsmithing and not quantitative science.
Jerry
lucia (#190).
Well you almost got it right. I actually jumped into two different threads
with the same comment to ensure that Judith Curry and Roger Pielke Jr. saw the comment. I asked them if they were interested in reviewing the published version (QJRMS) of the Jablonowski manuscript because Judith spouted the standard line about the need for more resolution that is
complete nonsense for reasons that are becoming apparent. Judith’s review is exactly what I expected give her source of funding and ties to the meteorological community. After thoroughly reviewing the manuscript,
I noticed that the plots of the perturbation were stated not to be in the published manuscript (QJRMS), but in the NCAR Tech Note series. When I went to that Tech Note (how to access the Tech Note is discussed in comment #103 above), I found the missing plots. But even more of interest the missing section 5.3 on “Sensitivity to the diffusion coefficients”. I was
fully aware of the changes of the diffusion coefficient of the unphysical hyperviscosity as the resolution is reduced that can be seen in the published manuscript (QJRMS) in Table 1 and the vorticity cascade in Figure 9. These were exactly why I wanted the general reader to be able to see this manuscript. The serendipity of finding the missing section in the NCAR Tech Note will just make the discussion easier to understand for the general reader. I also think that the fact that the missing section was not published is very telling.
Jerry
Lucia writes “Nevertheless, the people who say they won’t believe a complex code without formal V&V they could be shown are probably telling us the truth about themselves: They won’t.”
Yes. And there are more arguments than that in favor of the kind of V&V under discussion, and plenty of valid rebuttals to specific objections to V&V, and many of the pro-V&V posts, including yours, seem valid.
I can oppose a particular argument in the spirit of a certain statistician (Invalid Argument + Possibly Correct Conclusion = Bad Logic) without necessarily hating the conclusion. And even if I doubt regulated-engineering V&V practices are globally optimal, it would be an invalid argument for me to conclude from that that for climate problems they can never be an improvement over what’s being done.
Jerry– Will you ever get around to posting your review of J&W and explaining what you think is significant? Particularly in the materials that were omitted in the version you asked Judy, Roger Jr. and Roger Jr. to review?
It’s find to tell us you think the fact those bits were omitted is signifcant, but it might be more useful if you told people why you think it’s significant. The most common reason material in a long tech note is omitted from the journal article is that it is judged to be less important by the authors.
William– Quite honestly, I think we agree, not only on things you say, but more generally. Better regulated formal V&V practices would benefit this area and make the results of GCM’s more convincing to many. At the same time, the fact that V&V does not meet the standards of many engineers doesn’t mean the GCM’s just spew forth drivel.
Just for clarification, I hope that I have stated that my primary concern is that all software the results of which might impact public health and safety must meet, by Federal Law in some (all?) cases, certain standards of Independent V&V and SQA.
If this is not a correct statement, let me know. But I do not recall seeing anyone disagree with it.
I also think that ‘spew forth drivel’ are your words, lucia. I don’t recall seeing them either.
Dr. Curry, just to illustrate that it isn’t just Rush Limbaugh getting into the amateur climate expert game:
http://www.businessandmedia.org/articles/2008/20080206170159.aspx
Oops, wrong thread.
#166, Judtih, thanks for the link, unfortunately the equations they start with don’t look like something recognizable to people not in the field. Instead of starting with something like stokes equations they give you a reference:
http://www.ccsm.ucar.edu/models/atm-cam/docs/description/node48.html#simmons81
As to where to look up the derivation.
Excuse me but will you kindly stop using my post as a red herring. You inferred lots of motive behind my post that isn’t true. For me V&V means that the various classes do what they advertise and that the code as a whole adequately mimics the device’s behavior in field tests. Just what are my “traditional standards”? In the spirit of keeping this discussion to the actual content of the posts, why don’t you stop inventing motives, processes and techniques on my behalf? Hmmm…
Hmmmm…..This link:
http://www.cptec.inpe.br/eta/produtos/eta/Docs/wmo2.doc
may tell me how to go from the equations mentioned by Gerald Browning (post #152)
http://www.climateaudit.org/?p=2696#comment-208514
to the continuous equations used in the climate models. It will be tomorrows reading for me.
I read through the above link:
http://www.cptec.inpe.br/eta/produtos/eta/Docs/wmo2.doc
and thought it might be helpful. I discovered at the end that the document was the eta limited model which is frictionless adiabatic motion. I was disappointed because I’m sure that GCM models would not use such an idealistic model given that the greenhouse effect is highly dependent upon radiative energy exchange and as a consequence friction is most certainly important. Alas, maybe though I will recognize some similarities between this model and others.
RE 196. you’ll never knit in my factory.
Larry, are you an embedded type?
If so, drop Anthony Watts an email and tell him to cough up my email. reference this
post in your mail so he knows I’m cool with it.
RE 184. Milesworthy is a good egg, most steves are.
RE 183. Thanks Dr. Curry. I already like what I see there.
RE 183. Hey Dan Hughes. Dr. Curry mentioned NCAR CCSM. I like what I see.
When you look at the working groups the ONLY POSITION without a Liason
is…………………………………..
Software engineering.
http://www.ccsm.ucar.edu/working_groups/
Now, we have been tackling this thing from the wrong perspective.
Figger a way to get on this global warming gravy train. The software I’ve
seen is retarded. We both know that better code can often beat better iron. Saving instructions
in a GCM MAY VERY WELL SAVE THE PLANET! why let the chipheads get the dollars.
I’m thinking of a consulting group. snappy climate science name will come to mind.
like “carbon neutral code”
We’ll make billions.
RE 183. Hey Dan Hughes. Dr. Curry mentioned NCAR CCSM. I like what I see.
When you look at the working groups the ONLY POSITION without a Liason
is…………………………………..
Software engineering.
http://www.ccsm.ucar.edu/working_groups/
Now, we have been tackling this thing from the wrong perspective.
Figger a way to get on this global warming gravy train. The software I’ve
seen is retarded. We both know that better code can often beat better iron. Saving instructions
in a GCM MAY VERY WELL SAVE THE PLANET! why let the chipheads get the dollars.
I’m thinking of a consulting group. snappy climate science name will come to mind.
like “carbon neutral code”
We’ll make billions.
I’ve posted some of the theory that I was able to find for GCM models here:
http://www.climateaudit.org/phpBB3/viewtopic.php?f=4&t=99
and here:
http://www.climateaudit.org/phpBB3/viewtopic.php?f=4&t=100
as I seem to be the only one interested in the theory who doesn’t understand it.
John, I am googling “introduction to climate modeling”, not finding much. Here are a few things that should be of some use (i found these via google, didn’t look at them too closely)
http://www.climateprediction.net/science/model-intro.php
http://www.carleton.edu/departments/geol/DaveSTELLA/climate/climate_modeling_1.htm
http://www.atmos.washington.edu/honors_220/model/model_instructions.html
Some books:
A Climate Modeling Primer by Henderson-Sellers and McGuffie
Fundamentals of Atmospheric Modelling by Mark Jacobsen
re 207.. Check the MITGCM. You will lots of documentation. just google mitgcm
All,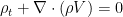
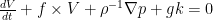


Here are the inviscid equations of motion so that I can discuss them by name.
Cont:
Momentum:
Pressure:
Total:
The above equations are all that one needs to understand dynamical cores
and the problems discussed in the Exponential Growth in Physical Systems thread. In the former case I will discuss the impact of unphysically large and nonstandard dissipation forms.
This example is to provide the general reader with a basic feeling for the
problem. Consider two identical earths, one with air and one with molasses
as the fluids in the respective atmospheres. Clearly it would take a much larger amount of heating (forcing) to drive a hurricane in the molasses atmosphere than in the air atmosphere. This is because of the much larger viscosity (dissipation) of molasses.
Jerry
# 210
Jerry, viscosity and dissipation are not the same. A different viscosity does not have to imply a different dissipation. Two models with different viscosities can have the same mean dissipation.
gb (#211),
Here we go with the smokescreen. If both air and molasses are described by the viscous NS equations, the only difference is in the size of the dissipation coefficient. Call it what you want. But the standard type
of dissipation for the viscous NS equations is not spectral chopping (dealiasing), hyperviscosity, or a sponge layer near the top of the model atmosphere as used in the Eulerian dynamical core. Note that a dynamical core is not suppose to use any form of dissipation (explicit or implicit), but clearly they are present in one (or more) forms in the dynamical cores for reasons that will be discussed in detail.
Trying to create a hurricane in molasses would require quite
different forcing than in air. That is the essential point for the general reader and I note that you did not dispute that point.
I find it amusing that I am willing to write down the inviscid equations in 3 lines while Judith just cites complicated documentation that is completely unnecessary to read in order to understand the basic continuum problems with NWP or climate models. Could it be that by doing so she is confusing the reader with unnecessary trivia?
Jerry
All,
Let me discuss a few mathematical properties of the inviscid equations.
There are five equations in the system (the continuity equation,
the three momentum equations, and the pressure equation).
Then there are 5 different motions associated with the system, e.g. two sound waves, two inertial/gravity waves, and an advective type of motion.
These motions can be seen by linearizing the system about a given state and computing the associated frequencies of motion (after Fourier transforming the system in space).
Now meteorologists like to linearize about simple states such as one that is at rest. This makes the ensuing computation of the frequencies easier, but is extremely misleading. In this case the system is hyperbolic, i.e. all of the frequencies are real (or all of the eigenvalues are purely imaginary).
However, if one linearizes about a more realistic state, one finds that the frequencies are not all real (Browning and Kreiss reference available on request). In the case of the hydrostatic system,
the complex frequencies lead to ill posedness (exponential growth that is unbounded in any small time period). This has been shown to occur in the numerical examples on the Exponential Growth in Physical Systems #1 thread (comments 165 and 166). In the nonhydrostatic system, the complex frequencies lead to bounded (but extremely fast) exponential growth. This type of growth will destroy the numerical accuracy of any numerical method in a matter of hours.
Jerry
All,
Before I proceed with the discussion, are there questions I can answer
with respect to the equations of motion (e.g. more thorough definition of symbols), the discussion of the simple molasses versus air example,
or the discussion of the frequency determination. Clearly I have left out many details, but I want to get to the main issues without obscuring the reasoning with trivia.
I will add dissipative terms at the appropriate time when discussing the nonlinear cascade of vorticity.
Jerry
I have a couple of quick questions:
1) Are there four equations or five?
2) Can you give me a quick peek or preview of what you intend to show/prove?
Thanks in advance.
Mike B (215),
There are five time dependent equations: the continuity equation (1), the momentum equations for the velocity V=(u,v,w)(3), and the pressure equation (1). The continuity equation and the pressure equation can be combined to form a potential temperature (entropy like) equation that does not involve the divergence. This simplifies the matrix computations for the frequencies
and the prescription of lateral boundary conditions for an initial/boundary value problem.
Note that the hydrostatic system neglects the total derivative of the vertical velocity w and this is what causes all of the mathematical problems, i.e. the ill posedness of the initial value problem and
the initial boundary value problem.
I will restate where I am heading. If numerical methods cannot accurately
compute the solution of the basic dynamical system (so called dynamical
cores) either because of ill posedness, fast exponential growth, or inadequate resolution to properly resolve the rapid nonlinear
cascade of the vertical component of vorticity (requires unphysically large dissipation to overcome), then adding necessarily unphysical parameterizations to overcome these deficiencies cannot lead to a correct physical solution as the resolution is reduced.
Jerry
Thank you Gerald Browning,
for your posts. I look forward to further insight. About a week ago I tried to summarize what I could find on line here:
http://www.climateaudit.org/phpBB3/viewtopic.php?f=4&t=99
I’m sure you will take me while past my feeble attempts:
I think what is important is not so much that the model can predict weather. What is important is that it gets the ensemble average of heat transport correct. My biggest area of concern is that they compute temperature in a way to yield stable results. I don’t know enough about how temperature is computed in the model to know if this is the case. I do know though that purely adiabatic equations are at best metastable which means without considering the energy exchange in and out of the system the energy in the system will drift.
John (#217),
If the model cannot accurately compute the real spatial spectrum
due to the real nonlinear cascade, then it must necessarily use forcings that are not physically accurate to overcome that deficiency and produce a spectrum that looks correct, but is not based on the correct physical balances. Thus neither the dynamical cascade nor the forcings are accurate and the entire modeling process is doubtful. On the Exponential Growth in Physical Systems thread I provided a simple example of how one can compute any desired solution by rigging the forcing appropriately, even with the wrong system of equations or the incorrect, unphysically large dissipation. These examples should be very disturbing, especially in light of Sylvie Gravel’s manuscript showing that the forcing had little to do with the accuracy of a global NWP model in the first few days. Williamson et al. essentially duplicated this result for the NCAR atmospheric model that is a component of the NCAR climate model. And for longer runs, the correct cascade is crucial. The models are not physically accurate and will not be with increasing resolution for reasons above,
i.e. lack of convergence due to ill posedness (hydrostatic system), fast exponential growth (nonhydrostatic system), and incorrect cascade.
Jerry
John (#217),
One additional point. Look carefully at the plots of the vorticity in the Jablonowski manuscipt to see how quickly the vorticity cascades down to smaller scales when the steady solution is perturbed by a very small in magnitude perturbation. And note that although the features appear to be small on the plots, they are in fact quite large, i.e. well over 100 km in lateral dimensions, i.e. the models have not even resolved any
mesoscale features let alone fronts or hurricanes.
Jerry
Obviously Stokes equations haven’t yet been solved. I can’t help wonder if there is some kind of fractal approximation to take into account turbulence on all scales.
Judith says: “The issue that concerns many of you is not technically V&V but whether or not the models are “perfect” enough to prescribe policy. The models are not perfect and are not being used to prescribe policy. They are being used in the assessment of risk that we are facing from global warming”
It is just basic adequacy we seek. The recent external verification tests by Douglass, Christy et al. showed that the models get the basic theory wrong and are thus inadequate. The climate community response amounted to saying “the large uncertainties in the models overlap the probable uncertainties in the observations.” In other words the models are actually worse than you thought. The only two tests that I’ve seen the climate modeling camp boast about have been the Pinatubo volcano test, and the Hadley “take away AGW and you can’t model 20th century temperature” test. The former modeled short-term, natural cooling, not AGW warming, and the latter was very obvious circular reasoning which became redundant when Hadley later admitted their natural variability assumptions were wrong anyway. One must presume that all the other internal tests are even worse than these flag-wavers. So are they good enough for risk assessment? The answer is clearly no, and nobody should pretend otherwise!
Gerald: Since Wunsch and Seager tell us the main driver for the winds and hence the ocean currents is the actual rotation of the earth then maybe we should have angular momentum in that equation list, otherwise is there much point?
I’d be happy if the output of the models could be recognizeable as something akin to reality.
JamesG #221
We are dealing with fluids here .
The N-S equations are technically field equations solving for the velocity field by writing F=ma , energy conserved , mass conserved .
There is nothing that “rotates” and the field is fully defined when you know the velocity components for every point and every time .
If you look at a flowing river , you see that rotating pseudo structures are not conserved – they appear , dosappear and change all the time .
They are only transient large scale manifestations of the velocity field .
However as the local spiral like structures are common , it is interesting to consider closed field lines .
Gerry already mentioned vorticity , it will appear when he’ll talk about it .
Tom
I respect your opinion but I’m not sure what you think you proved. Are Wunsch and Seager wrong, or did I misunderstand them? Are the principal air and sea currents largely caused by the rotation of the earth or not? The NS equations can be formulated in spherical coordinates if we like so there isn’t the restriction you imply. Rotational effects can be consistent too – have you never seen a Von Karmann vortex street? – not that it matters because vorticity is a red herring. If you are not going to emulate the major known fluid currents of the earth you may as well not bother with Navier-Stokes at all: it’s only useful when it emulates reality and reality emulation is what we want. I want to know will happen in Bangladesh, the Antarctic, the Arctic, Europe etc. Random, unforced fluid movements get us absolutely nowhere.
#223, Don’t take my word for it but I think that that in most GCM models that the rotation of the earth is approximated by a coriolis term that is latitude independent.
MikeB, to expand slightly on Dr. Browning’s reply to you: Dr. Browning wrote four equations but the second equation is standing in for three momentum equations — one for each dimension. The fourth equation is simply the definition of the total (material) derivative used in the other equations. [To see where it somes from, use the chain rule to write out the time-derivative of velocity.]
The momentum equations are basically f=ma expanded to the particular case. You can see a term for the time-rate of change in velocity, a term for coriolis acceleration (involving the cross-product between velocity and earth’s angular velocity), a term for the acceleration due to a pressure gradient, and a term due to gravity’s acceleration. If Dr. Browning were allowing for viscosity, the momentum equations would be more complicated.
The hydrostatic system of which Dr. Browning speaks is a simplification of the momentum equation in the vertical direction in which everything is neglected except the pressure gradient and gravity.
(I apologize in advance, as a layperson, if I am confused about anything here, and would appreciate correction. It helps me to be explicit so that I can follow the discussion.)
John (#225),
That is correct. The f in the momentum equations is the Coriolos force.
In most models only the vertical term of f is included. On the largest scales, f plays a very important role. But as one moves to smaller scales of motion the Coriolis terms play less and less of a role.
Jerry
Neil Haven (#226),
Perfect (bang on). 🙂
Jerry
John (#220),
Actually the two dimensional incompressible ( viscous) Navier-Stokes equations have been solved numerically and the numerical solutions shown to converge if the minimum scale of motion is resolved. The estimates of the minimal scale for a fixed kinematic viscosity are very complicated but have been shown to be very accurate. In two dimensions, no additional assumptions are needed to obtain the minimal scale estimate. But in three dimensions one must assume that the velocity is bounded. Then the
estimates also apply there. I can supply appropriate mathematical references for the estimates. But you might want to look at the Math. Comp.
article by Heinz and me that shows that an incorrect type (hyperviscosity
or spectral chopping ) or size will lead to very different results.
Jerry
All,
For different scales of motion, a fluid can have very different
behavior. In fluid dynamics, the equations of motion are scaled according to the properties of the motion of interest. To see how this is done, I refer you to our 2002 JAS manuscript (specific reference available on request) as the article on the frequency computation is not as readily available. The scaling simply introduces a new set of variables that
indicate the sizes of the independent and dependent variables for the motion of interest. Then it is easier to mathematically determine
the behavior of the motion. The JAS article shows how that behavior changes as one proceeds from the largest scale of motion in the atmosphere (~ 1000 km) to the next smaller scale of motion (~ 100 km). The behavior for the two scales of motion is very different. On the largest scale the notion is in approximate hydrostatic and geostrophic balance ( horizontal pressure gradient balances Coriolis term) , but on the smaller scale the total heating becomes dominant and balanced motion is very different. The latter type of balance also is dominant near the equator for all scales of motion.
Jerry
James G (#224),
There is a mathematical theorem that states that if we can solve the homogeneous (unforced) system of equations, then we can solve the forced version. At this point we are not discussing any forcing terms other than
the gravitation term. After linearization about a general state of motion,
that term will appear as a large undifferentiated term. Its importance in the frequency computation has been discussed above. Given that there are serious problems with the unforced (except for gravitation) system,
there is no reason to discuss other physical forcings – they will not
help the situation. That is why we are discussing only the inviscid system and dynamical cores at this point.
Jerry
Gerald Browning, do you by chance have any plans to write a textbook on this stuff? Or do you know of any text that cover a good amount of the important results from your papers?
John (#232),
Actually Heinz Kreiss proposed that we write a book containing info from many of the manuscripts I have cited. But a book is a considerable amount of work with little career gain (except for ego) when you are under pressure to produce manuscripts. 🙂
Heinz does have a book on the Navier-Stokes equations that I highly recommend, but you will have to wade thru some mathematics.
And everyone can just call me Jerry. 🙂
Jerry
John and others,
If you are really interested in all the basics I can recommend the book by Vallis ‘Atmospheric and oceanic fluid dynamics’ Cambridge University Press. It presents a thorough derivation of all the equations of state including thermo, and explains the effects of rotation and stratification and at what scalses these are important. It also explains the physics behind the atmospheric and oceanic dynamics and ciculations.
Gerald, I don’t have much time to write here at the moment, but you seem to be misleading the readers regarding viscosity. By comparing molasses to air in terms of molecular vlsocosity, this simply is not relevant. The molecular viscosity of air simply is not relevant in modelling of the atmosphere beyond a scale of order meters. Stable and accurate solutions to the Navier Stokes equations for large scale atmospheric flows are obtained by filtering sound waves (the hydrostatic assumption) and filtering high frequency unresolved gravity waves. These solutions converge generally to the solutions of higher resolution models (nonhydrostatic, including more of the higher frequency gravidty waves). The unresolved degrees of freedom (e.g. subgrid cascade of energy, momentum) are addressed through parameterization of the subgrid motions. Such solutions are highly robust for large-scale atmospheric circulations that are of relevance to climate modelling. The success of numerical weather prediction at predicting say the 500 hpa height field on the time scale of the lifetime of a baroclinic wave (nominally 4-7 days) is a testimony to the credibility of these solutions
You are also neglecting to consider the chaotic nature of any solutions to these equations, and the need for an ensemble of solutions for any kind of comparison, evaluation, etc.
Lets focus down in scale, say to a large eddy simulation model, with resolution of say 2 m. Even such models have parameterizations of the subgrid motions. I have addressed this issue specifically in a paper on the LES of the stable boundary layer.
Click to access Kosovic_JAS57.pdf
Are you really prepared to say that all gas phase fluid dynamics modelling (in aerospace, mechanical engineering, physics, geoscience, etc and in all their applications) is incorrect?
Re Judy in 235
And, in terms of Jerry’s complaint about ‘unphysical viscosity’, these parameterizations often look like ‘viscosity’ because, to a large degree, the action of the small scales is diffusive.
This issue has arisen on past threads and Jerry has been asked by me, and others, to quantify the ‘false’ (or possibly parameterized) viscosity used in these weather models, so those familiar with numerical modeling can form an impression of whether or not the magnitude used is actually unphysical or just represents an approximation abhorrent to Jerry.
Judy: I’m ready to say DNS is correct. 🙂
Everything else is approximate. Of course, the degree of approximation in many LES codes may be so small as to be of no physical significance. In other models in use, it can be sufficiently large to matter quite a bit.
I’ve never quite figured out where climate models fall in the spectrum of models. The narratives decribing parameterizations in papers discussing climate models themselves don’t seem to suggest LES like parameterization, as the parameterization does not depend on the computational grid size of the length scale of the turbulent like motions. (However, the fact that I haven’t found narratives discussing this in detail could be my lapse. I’ve only read a few of the papers.)
So, if you could elaborate a bit more on the issues of
a) are climate modles LES like? (vs. Reynolds average like) and
b) what magnitude of turbulent diffusivities are introduced in the dynamical core region of the model, and how do those compare with estimates for kinematic based on scalings like u’*l’, where u’ gives a scale of the turbulent fluctuations and l’ is some sort of integral scale.
I’d welcome this! (I know this would take a while– but I’d be interested.)
Lucia, I agree that we accept DNS as an accurate solution. LES, with appropriate subgrid parameterization, is consistent with DNS (Kosovic published some J. Fluid Mech papers on this). Turbulent diffusivities used in atmospheric dynamical cores are parameterized based on LES simulations. The point is the parameterization for turbulent diffusivity in a large-scale (global) atmospheric model does not dominate the solution at all, as evidenced by sensitivity studies to different treatments of the diffusivity. The sensitivity of climate models to this issue wrapped up in boundary layer cloud issue, but the issue is the cloud part not the turbulent diffusivity part. I will try to get some more specifics later this weekend if i have time.
Judy– I’m aware LES with appropriate subgrid parameterizations agree with DNS in all relevant ways. 🙂
The discussion of the sensitivity to the parameterization is what I’m looking for, and of course also just information of how large that happens to be. (BTW: Some of my questions have to do with where I know others are driving. However, that trip inevitably seems to end at a cliff. Based on what you are writing so far, I think your may be willing to drive to a bridge, which will permit me to learn the information I’m hoping to learn.)
Sorry to be such a stickler, but I want to make absolutely sure I understand what you’re saying, particularly in the highlighted portion . Are you saying that viscocity is not relevant because of the way the model accounts for it? Or are you saying that in the real world, the viscocity of air is not relevant? Or have I missed the point entirely?
Mike B:
In flows of this type, the parameterization of the mean effect of subgrid motions introduced a diffusive type term. The simplest form looks exactly like Newtonian viscosity– but contains a turbulent viscosity. The turbulent viscosity is so much larger than the viscosity of air that one can neglect the real viscosity. (It’s in the round off error of any estiamte of turbulent viscosity in many problems.)
So, the uncertainty in the ‘turbulent’ viscosity, which is estimated based on properties of the flow solution matter more.
In general, there can be difficulties associated with using a turbulent viscosity. These are often highlighted in comments by Tom Vonk.
I’m asking Judy questions to figure out if, in any particular case the difficulties both Tom V and Gerry B bring up are hypothetical or of practical importance to climate modeling. As distinct from weather forecasting. The problems are related, but not identical.
(P.S. The last bit is actually for Judy’s benefit, as I think it may help her formulate answerd in ways that are likely to provide answers to questions I have. It is often difficult to state these precisely in comment threads.)
Thanks Lucia, I think I’m following…
But then to get at the crux of Judy’s complaint about Jerry’s air/molasses comment, is the turbulent viscocity independent of the fluid?
Mike B. Often, the turbulent viscosity is more or less indepedant of the fluid viscosity itself.
I’ve read Jerry’s argument before. The difficulty is that I haven’t seen him get beyond mere claims that the viscosity used in some particular model, is the equivalent of molasses. One way to back that such a claim is to
a) provide numerical values of viscosities used by someone somewhere, in a particular situation.
b) provide a scaling argument comparing the ‘turbulent viscosity’ used in the model to the magnitude one might expect in a real flow. (This can be estimated based some characteristics of the real flow– for example the magnitude of the turbulent kinetic energy and an integral length scale in the real flow. The TKE could diffuse in from the boundary layer or be created by the gravity waves etc. Judy has mentioned some of the forms in her comment.)
The aim of the turbulent viscosity is to get the correct dissipation rate of of turbulent kiinetic energy. If the small scales are not resolved this energy will not be dissipated and accumulate. You need then to introduce a subgrid model, or turbulent viscosity.
Dr. Curry,
Surely it would seem, a priori, that since climate modeling treats a different regime of fluid dynamics modeling than these you mention — with different assumptions, scales, and approximations — it is quite possible that there are problems with certain types of climate models without invalidating ‘all gas phase fluid dynamics modelling’. Or do you understand Jerry to be arguing that all subgrid parameterization is incorrect?
Not entirely clear i’m interpreting correctly all the questions. Yes, the Navier-Stokes equations when applied to the atmosphere are Reynolds averaged. the “turbulent viscosity” depends on the scales of motions that are not resolved by the model, this is where the molasses analogy breaks down. I’m having a hard time figuring out what Gerald’s issue is, it isn’t making much sense to me. The general modelling techniques used in the atmospheric dynamical core, and the treatment of unresolved degrees of freedom are fairly standard as a general approach across many different applications of fluid dynamics. for example, i think Gerald also complained about the treatment of the upper boundary. Well, the main point is that the upper boundary is far away from the region of interest, and the wave damping at the upper boundary is designed so as not to have any spurious boundary effects contaminate the interior of the solution that is the region of interest.
The complicated issue associated with the so called turbulent viscosity is tied up in the interplay with the convective and cloudy boundary layer parameterizations. These are a small deal for baroclinic waves, but more important in climate simulations. This is the parameterization part of the problem, that is the key issue to worry about, not the dynamical core.
I found a good ppt from ecmwf that explains things pretty well
Click to access PA_Beljaars0.pdf
The NCAR model documentation gives a good description of their treatment of “turbulent diffusivity”
http://www.ccsm.ucar.edu/models/atm-cam/docs/description/
go to section 4.11
@Judy–
The figure on page 5 gives characteristic time and length scales for some general features. That’s pretty good for SWAGing magnitude of “turbulent viscosity” (though not perfect, and we could all argue.)
Turbulent kinematic viscosities scale as ~ ν ~u’L’ or L’^2/T’ where u is a characteristic velocity, L is an integral time scale (usually) and T’ is an integral time scale (usually). (I say usually, because these estimates are for RANS where one doesn’t usually resolve any turublence.)
Based on the figure, and my guestimate, the turbulent kinematic viscosity for only small scales would be a least
ν ~ L’^2/T’ ~ (10 m)^2/ 100s = 1 m^2/s.
This is 10^5 times as large as the kinematic viscosity of air, and in fact, near the values for molasses.
So, in this regard, a parameterization that uses a turbulent viscosity near that of molasses could not be called unphysical on that basis. (I’m always willing to see flaws in models and parameterizations, but this isn’t one.)
Lucia, the molasses/air analogy is a bad one, we are talking about totally different reynolds numbers. Turbulence and chaos dominates in the atmosphere, while molasses is dominated by viscosity. In the atmosphere, this is determined by the flow and not the material.
Judy–
And there I was just saying Jerry’s concern that they set ν to the value of molasses is just fine and you contradict me. Shoulda been Jerry!
Flow of molasses in the kitchen at engineering length scales is dominated by viscosity. Consequenty, there will be no turbulence or turbulent viscosity.
But, at if the length scale were as given in that power point presentation, flow of Molasses would be turbulent. What matters is the Reynolds number ~ UL/ν Even with a kinematic viscosity of molasses, the flow with the U and L in that figure would be fully turbulent!
Jerry has been claiming the modelers set turbulent ν (as a parameterization) to values appropriate for molasses, not air. What I’m saying is, while the molecular viscosity of air is nowhere near the of molecular viscosity, based on that scaling the turbulent viscosity in the flows described in that figure are very high. They happen to be as large as the molecular kinematic viscosity of molasses. (This magniude of turbulent diffisivity doesn’t supress the turbulence or make the flow laminar. Turbulent diffusivity cant do that. It just describes the magnitude of parameterization. It just means there is one heck of a lot of turbulent diffusivity for momentum.)
It is my understandiIt is my understanding that the velocity due to turbulence is a consequence of the bulk flow of air while viscosity is due to the molecular flow of air. The amount of turbulence depends on the Reynolds number which depends on the viscosity. Therefore these turbulent kinematic viscosities are not independent of the fluid.
I have no problem with parameterize these turbulent viscosities if they can be shown to be realistic. It should be clear that since these viscosities depend on the length scale. Therefore in areas of higher turbulence, near the ground or near a hurricane that these viscosities should be higher then they should be in calm areas high in the atmosphere.
If these turbulent viscosities can be modeled well empirically then to me it would seem acceptable. I would however, like a more fundamental way of capturing the dependence of this viscosity on turbulence and that is why I thought fractal geometry might be relevant.
http://www.me.jhu.edu/~meneveau/pubs-fractals.html
http://www.climateaudit.org/phpBB3/viewtopic.php?f=4&t=112
Another concern is if the bulk flow of air effectively increases the turbulence does it also effectively increase the conduction? That is how much energy is exchanged by turbulent flows which are two small for the model to capture? Do the models effectively capture this energy exchange.
I have a feeling that I am going to need to read texts suggested by both Jerry and Judith to decide how significant the concerns mentioned by Jerry are.
Lucia, we agree 🙂
Lucia,
I just picked a fight for you over at Atmoz. I promised that you would unclown the boys
who had beclowned themselves. Sorry.
Oh yes. I named Lumpy! not Sadlov. people always confuse us. I’ll forgive you.
Well here comes the nonsense. The molasses versus air example is to say that the forcing when using an unphysically large viscosity or other unphysically large numerical damping is not physical, but an ad hoc tuning mechanism (not science) to try to make the spatial spectrum look realistic when in fact the dynamics and physics are both incorrect. That the forcings are wrong have been shown by both Sylvie Gravel (Canadian operational global NWP model) and Dave Williamson (NCAR atmospheric component of NCAR climate model). The former reference is available on this site and the latter available on request (or see Pat Frank’s manuscript that will appear in March in Skeptic).
One only need look at the changes in the hyperviscosity coefficients in the manuscript (Table 1) to see that the hyperviscosity (unphysical) is reduced as the mesh size is reduced. That is because the real vorticity cascades to higher and higher spatial wave numbers (smaller spatial features) that cannot be resolved at lower resolutions. Thus the hyperviscosity is larger at lower resolutions in order to keep the smaller scales of vorticity that appear in the higher resolutions from forming. And as I have stated very clearly, the smallest features shown in the plots are still well over 100 km in extent, i.e. no mesoscale feature (storms), fronts, hurricanes, etc. are resolved.
I guess the ladies are saying that this part of the spectrum is not important to weather or climate. And if the models try to resolve these features, the ill posedness and fast exponential growth will appear.
Now what is not stated very clearly in the manuscript is that there is another even larger form of spatial spectrum alteration going on in the Eulerian model called dealiasing. This essentially zeroes out the highest spatial wave numbers and reduces the resolution of the model even further. The amusing thing here is that the Eulerian model did better with a simpler form of spatial spectrum chopping although it has always been said that the quadratic dealising is best. Keep on tuning. In the Math. Comp. article by Heinz and me (reference available on request), once the minimal scale (smallest scale feature of vorticity) is properly resolved by a numerical model, the correct Navier-Stokes dissipation form (second order derivatives) can be used and produces the correct spatial spectrum, i.e. the numerical solutions converge. Note that in this manuscript we proved that hyperviscosity will not produce the correct spatial spectrum and neither will chopping.
And there is even one more form of dissipation in the Eulerian model near the top of the model atmosphere (second order derivatives) called a sponge layer. This leads to a discontinuity in the approximation of the equations of motion and is suppose to reduce reflections of vertically propagating gravity waves. But the coefficient of this diffusion operator is not
reduced as the mesh is refined. And there is no discussion of how information can enter from above the top of the model lid (unphysical) over long periods of time. Here I guess the ladies are saying that info is not important to climate.
Jerry
Judy– I thought we’d agree on this. 🙂
steve moscher: So you were the one who sicked that nearly incoherent commenter on me. I think I’ve been accused of not liking approximations. Clearly, news of “Lumpy” has not gotten out! Off to unthreaded!
Steve Mosher #252
Which post was that in (or maybe you can provide a link). I saw your response about the GISS adjustments. Is that the one you mean? It looked a little rabble-rousing, but I didn’t see any fight being picked.
That site doesn’t seem to have a list of recent comments. (Probably because it doesn’t seem to get many).
OK. I see it now here.
As Lucia says, grist for Unthreaded.
Yes. DNS gives the right answer. We all know this. It’s been shown by others in a variety or flows. You did not run the first case.
Of cousre they don’t. So?
All,
I think the correct statement is that when a numerical model cannot resolve the small scales of motion in the real solution, one must add some form
of damping to prevent those scales from forming in the model.
There have been many forms used, but little or no proof that they
will provide the real solution. For example, it has been shown mathematically (and demonstrated numerically) that the minimal scales for the regular NS second order diffusion operator are quite different than the sclaes for fourth order hyperviscosity (see Math. Comp. article).
Jerry
lucia,
As an engineer that lives off of numerical models, your responses are exactly what I would expect. The Math. Comp. article contains a mathematical proof, not just another model run. And as you now agree that
hyperviscosity produces a different spatial spectrum that is not what the standard NS equations prescribe, I have to assume that you also agree that the spatial spectrum of a climate model in wrong so the forcing is not physical.
Jerry
Jerry
Jerry, so you are saying the the hyper viscosity is incorrectly parameterized?
On fortunately one of my previous comments is awaiting moderation:
http://www.climateaudit.org/?p=2696#comment-212501
but I would like to know if they also parameterize the effective increase in conduction which is due to unmodeled convective flows.
John,
Do not be misled or side tracked. The issues can be understood from the simple equations I gave and an appropriate discussion of the gimmicks that are used in the dynamical core manuscript on this thread. The rest
is minor in comparison to these issues.
Jerry
John,
I am saying that if one uses something other than the true second order
derivative dissipation form prescribed by the NS system, then one will obtain a different spatial spectrum. The dissipation operator
removes enstrophy incorrectly, but the spatial spectrum can be altered to look more realistic by pumping in energy in a nonphysical manner. This is the main point.
Jerry
Gerald, you are swatting at gnats here. for any conceivable application of a global atmospheric model, say for weather forecasting or climate sensitivity experiments, the issues you raise are irrelevant. These models, even when run at quite low resolution, provide credible solutions in terms of comparing with higher resolutions simulations and verification with observations. Can more efficient, exact solutions to the dynamical core be configured? I hope so and expect so. Do these little gnats get in the way of weather prediction or climate sensitivity studies? not at all. If you want to critique these models and sow doubt about their results, you need to do much better than this.
John, regarding the treatment of unresolved convective transport, see for example the documentation for the NCAR climate model
http://www.ccsm.ucar.edu/models/atm-cam/docs/description/
see sections 4.1 and 4.2
Gerry,
My main work in fluids is as an experimentalist not a modeler. I told Judy this earlier in the thread. But, in fluid dynamics research these days, experimentalist generally need to be attentive of the state of modeling because certain types of measurements of are particular importance to modelers who need to find decent parameterizations.
Many things are done in engineering and science with no formal mathematical proof models. Every one knows that after the engineers figured out things and came up with models for boundary layers, the mathematicians howled. Meanwhile, the scientists jumped right in and used it in there studies (where it worked quite well, thank you very much.) Then 70 years or so later, some mathematician to came up with formal mathematical proof that boundary layer theory was ‘true’ in a mathematical sense.
Do you really think complaining about lack of formal mathematical proof is going to stop people from modeling?
Re the upper boundary condition for the atmosphere (I couldn’t quickly find this discussed in the ncar documentation), the standard method is described in the Rasch paper (which unfortunately isn’t available online), but you get a sense from the abstract:
Toward atmospheres without tops – Absorbing upper boundary conditions for numerical models
RASCH, PHILIPJ
Royal Meteorological Society, Quarterly Journal. Vol. 112, pp. 1195-1218. Oct. 1986
The appropriate upper boundary condition (UBC) formulation for the dynamical equations used in atmospheric physics is discussed in terms of both theoretical and computational aspects. The previous work on the UBC formulation is reviewed in the context of a linear mid-latitude primitive equation (PE) model. A new technique for constructing the UBC is introduced. The technique depends upon the existence of analytic solutions to simplifications to the equations of motion. These analytic solutions are used to construct the exact radiation UBCs (often used in tidal theory and studies of the upper atmosphere) which are non-local in time and space. Approximate UBCs, which are local in time, are formed through rational approximations to the exact radiation UBCs. The technique is demonstrated to be effective for both Rossby and gravity modes. The UBC is tested for computational problems initially in the linear PE model, and subsequently in a forced, damped nonlinear quasi-geostrophic model. (Author)
This is a robust method for a fluid without an upper boundary. Further, the “upper boundary” is tens of kilometers away from the region of interest for a climate model, and no, this upper boundary treatment does not degrade the solution in the interior and near the lower boundary
#245
Are you conceding that there are problems with the dynamical core, but that those problems are small relative to other problems with the models?
What criteria do you use to evaluate the models? Is there a standard set of criteria?
I gots all my quatloos riding on this thing.
If I decide both Jerry and Judy are all wet do I get to keep my quatloos? 😉
Judith Curry,
Please explain to me the mathematical difference between an inflow and outflow open boundary in terms of characteristics.
Once you have understood and can explain that mathematical concept, then tell me that the upper boundary sponge layer has no impact on a weather or climate model.
BTW we saw an impact quite clearly in the Canadian NWP model even in a few days.
[snip – SM: Jerry, please observe blog rules about personal comments]
Judith Curry,
Please compute the frequencies for the system I gave above linearized
about a general state or at least read the article in the book mentioned many times before on this site. (I am willing to cite it again if you want).
How about a mathematical proof (or at least convergent numerical solutions) to lend some credibility to your statements. It is very clear that the “review” you did of the Jablonowski manuscript is typical of how many articles get in print.
If you knew anything about the details of the manuscript, you would have asked the pertinent scientific questions that I have raised and you continue to skirt.
Jerry
lucia,
As I have shown and stated many times before, one can add
appropriate forcing terms to any time dependent system to obtain the solution one wants. That does not mean the dynamic or physics of the solution is correct. I assume you still did not read the example
I asked you to read on the Exponential Growth in Physical Systems thread
that showed this.
And the error in the boundary layer approximation in the Canadian model
destroyed the forecast in a matter of hours. Oops.
Jerry
All,
Now that it has been revealed how to carefully interpret some of the results in the Jablonowski QJRMS article, I ask that you read the missing section in the NCAR Tech Note series about the sensitivity of the solutions to different coefficients of the hyperviscosity to further support my arguments. As I have clearly stated, this problem can be seen without the missing section, but that section will help to clarify the discussion about too large of dissipation impacting the accuracy of the numerical solution
and the subsequent need for unphysical forcing to “adjust”
the spectrum.
Jerry
re 268. As bookie of all CA quatloos, you can rest assured that your initial bet shall be
returned in the event of mutual self destruction by the contestants, minus of course my vig.
Every system has friction. Thank you for playing.
Where the heck is Bender?
There are times when this argument reminds me of John Candy Mud wrestling girls in the
movie Stripes.
Jerry–
Once again, so?
You need to learn to
a) state your actual point,
b) to the support it and
c) make sure the point you are wishing to make and the argument to support that specific are contained in a single comment. (Or, should you ever write a post, in the post itself.)
The elliptic statements, though they may touch on some truths, are pointless as no one knows how to connect them to any argument or claim of interest.
Hey, the vig is the cost of doing business.
Seriously, if this were a WWE match, I’d consider disqualifying both Judy and Jerry. Judy for running around the ring and failing to engage, and Jerry for axe-grinding in his corner between rounds.
Right now, this looks like the CA equivalent of Ali vs Inoki.
Gerald, please get over yourself. my credentials are nontrivial in this area, but I don’t tout them (trust me, i’m no lady), rather i try to make coherent arguments and provide references and explanations. I am pretty much through on this thread, i don’t see it going anywhere. In the unfortunate absence of bender, i leave it to people to decide what if anything they have learned here and who they learned it from.
FWLIW, you were ahead on my card. That’s bad news for me, since I had all my quatloos on the Math Guy.
Do I have to shut up now?
I’ve learned I need to do more reading to decide the winner:
Judith mentioned:
A Climate Modeling Primer by Henderson-Sellers and McGuffie
Fundamentals of Atmospheric Modelling by Mark Jacobsen
Jerry mentioned some book by Heinz but I didn’t get a title
GB mentioned:
Vallis ‘Atmospheric and oceanic fluid dynamics’ Cambridge University Press. By Geoffrey K. Vallis
I hope that one of these texts address the concerns of Jerry and if not I hope that one of them will at least take me far enough to toughly understand the papers which address Jerry’s concerns.
The irony is bender made me the ref on this! 🙂
re 281. That was evil bender trying to remove you from the fight. He’s no dummy.
Some day we’ll chat about mixing things with vastly different viscosities.
Mike B.
She floats like a butterly but stings like a hornet. Lucky I had side bets.
A book ever avid knitter stocks on her shelf. . .
hmmm preview doesn’t show image?
Lucia, you must see the connection between knitting and N-S
Judith Curry,
please answer the very specific mathematical questions I asked you ….
1) Compute the frequencies or read our reference on the computation of frequencies for a realistic atmospheric state.
2) What is the impact of those complex frequencies on the hydrostatic and nonhydrostatic continuum equations.
3) What is the impact of those complex frequencies on a numerical model of the atmosphere.
2) Clearly state the impact of an incorrect spatial spectrum due to incorrect dissipative operators on the tuning that is required to make the spatial spectrum appear realistic.
3) The atmosphere receives information from above any artificial lid in a numerical model. How is that info transmitted when the numerical model has an artificial boundary at a predetermined height, i.e. there is no flow of information from above the artificial lid.
4) The equations of motion change nature at higher altitudes, e.g. they change to the plasma equations. Is this change taken into account.
…
Jerry
SM- Jerry, please be more moderate in your tone.
Lucia,
A referee is not required when the facts are presented openly.
I await your answers to the specific questions that you said I did not
state specifically ( only all thru this thread and the Exponential Growth in Physical Systems threads).
Jerry
All,
I have made my case quite clear. If one reads my comments and looks at the QJRMS manuscript as I have indicated, one can see there are serious problems with the continuum equations and their numerical approximations. (dynamical cores). No amount of wordsmithing can overcome these problems.
I will come back to this thread to answer a few more questions. But the mathematical analysis of the frequencies, the demonstrations of the
problems with the continuum systems using convergent numerical solutions
on the Exponential thread, and the dynamical core manuscript itself
should make the issues very clear.
Jerry
John (#280),
The book is
Initial-Boundary Value Problems and the Navier-Stokes Equations
Heinz-Otto Kreiss and Jens Lorenz
Academic Press
Note that the credentials of Professor Kreiss are well known in both the theoretical study of PDE’s and in numerical analysis. It was my privilege to have him as a mentor.
Jerry
#227 Jerry, required or If you have any references I would appreciate you posting them so that in the future when hopefully I have more background on this stuff I can better investigate your concerns.
Let’s have a little time out on this. I’ll re-open the thread in a few days.
One Trackback
[…] regards to what is anti-science, here is a quiz. Read blog thread A and blog thread B. Which thread is […]