In MM2005a,b,c, we observed that the RE statistic had no theoretical distribution. We noted that MBH had purported to establish a benchmark by simulations using AR1 red noise series with AR1=0.2, yielding a RE benchmark of 0. We originally observed that high RE statistics could be obtained from PC operations on red noise in MM2005a (GRL) simply by doing a regression fit of simulated PC1s on NH temperature. Huybers 2005 criticized these simulations as incompletely emulating MBH procedures, as this simulation did not emulate a re-scaling step used in MBH (but not mentioned in the original article or SI). In our Reply to Huybers, we amended our simulations to include this re-scaling step, but noted that MBH also included the formation of a network of 22 proxies in the AD1400 step and if white noise was inserted as the other 21 proxies, then we once again obtained high (0.54) 99% benchmarks for RE significance. Our Reply fully responded to the Huybers criticism.
Wahl and Ammann/Ammann and Wahl consider this exchange and, as so often in their opus, misrepresent the research record.
Before I discuss these particular misrepresentations, I’d like to observe that, if I were re-doing the exposition of RE benchmarking today, I would discuss RE statistics in the context of classic spurious regression literature, rather than getting involved with tree ring simulations. This is not to say that the simulations are incorrect – but I don’t think that they illuminate the point nearly as well as the classic spurious regressions (which I used in my Georgia Tech presentation.)
The classic spurious regression is in Yule 1926, where he reported a very high correlation between mortality and the proportion of Church of England marriages, shown in the figure below. Another classic spurious regression is Hendry 1980’s model of inflation, in which he used cumulative rainfall to model the UK consumer price index. In both cases, if the data sets are divided into “calibration” and “Verification” subsets, one gets an extremely “significant” RE statistic – well above 0.5. Does this “prove” that there is a valid model connecting these seemingly unrelated data sets? Of course not. It simply means that one cannot blindly rely on a single statistic as “proof” of a statistical relationship.
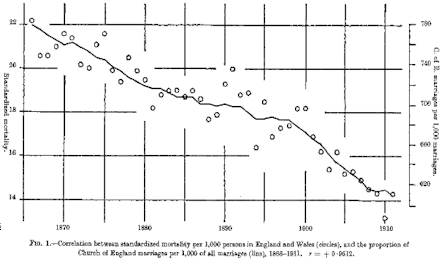
In effect, the RE statistic has negligible power to reject a classic spurious regression.
This seems like a pretty elementary point and I don’t know why it’s so hard for so many climate scientists to grasp in the case of the proxy literature.
Wahl and Ammann/Ammann and Wahl wade blindly into this. They don’t spend any time examining primary literature on bristlecones to prove that Graybill’s chronologies are somehow valid. They don’t discuss the important contrary results from the Ababneh 2006 thesis, although you’d think that they or one of the reviewers would have known of these results.
Instead, they try to resuscitate an RE benchmark of 0, by making several important misrepresentations of both our results and MBH results.
Wahl and Ammann 2007 states (Appendix 1):
When theoretical distributions are not available for this purpose, Monte Carlo experiments with randomly-created data containing no climatic information have been used to generate approximations of the true threshold values (Fritts, 1976; cf. Ammann and Wahl, 2007; Huybers, 2005; MM05a, MM05c—note that the first two references correct problems in implementation and results in MM05a and MM05c).
MM05c is our Reply to Huybers. Obviously Huybers 2005 could not “correct problems in implementation and results in MM05a and MM05c” since MM05c was a reply to Huybers 2005. In fact, in my opinion, MM05c completely superceded Huybers 2005 as it obtained high RE values with re-scaling in the context of an MBH network – a more complete emulation of MBH methods than Huybers 2005. Ammann and Wahl seem almost constitutionally incapable of making accurate statements in respect to our work.
Ammann and Wahl 2007 is later than MM05c. Did it or Wahl and Ammann 2007 “correct” any “errors in implementation” in MM05c?
Wahl and Ammann 2007 Appendix 2 makes the following criticism of our method of simulating synthetic tree ring series:
one byproduct of the approach is that these time series have nearly uniform variances, unlike those of the original proxies, and the PCs derived from them generally have AC structures unlike those of the original proxies’ PCs. Generally, the simulated PCs (we examined PCs 1–5) have significant spurious power on the order of 100 years and approximate harmonics of this period. When the original relative variances are restored to the pseudoproxies before PC extraction, the AC structures of the resultant PCs are much like those of the original proxy PCs.
Here I don’t exactly understand what they did and, as I presently understand this sentence, it doesn’t make much sense in an MBH context. In Mannian PCs (or correlation PCs), the time series are standardized to have uniform standard deviations (and thus variance) in the calibration period (and entire period respectively). So even if the variance of the time series in our network were too uniform (and I haven’t analyzed whether this is so or not as yet, I don’t see how this could affect the downstream calculations for Mannian pseudo-PCs or correlation PCs. I don’t get the relevance of this point even if it were valid.
Later in the paragraph in Apendix 2, they seem to concede this:
Using the AC-correct PC1s in the RE benchmarking algorithm had little effect on the original MM benchmark results, but does significantly improve the realism of the method’s representation of the real-world proxy-PC AC structure.
So if this observation – whatever it is – had “little effect” on the original results, so what?
Even though Ammann and Wahl 2007 acknowledged that MM2005c (Reply to Huybers) contained the most detailed exposition of RE simulation results:
Particularly, MM05c (cf. Huybers 2005) have evaluated the extent to which random red-noise pseudoproxy series can generate spurious verification significance when propagated through the MBH reconstruction algorithm.
Wahl and Ammann 2007 totally failed to consider the methods described in MM05c, instead merely repeating the analysis of Huybers 2005 using a network of one PC1 rather than a network of 22 proxies (a PC1 plus 21 white noise series as in MM05c). They purported to once again get a RE benchmark of 0.0:
When we applied the Huybers’ variance rescaled RE calculation to our AC-correct pseudoproxy PCI s, we generated a 98.5% significance RE benchmark of 0.0.
But note the sleight of hand. MM2005c is mentioned, but they fail to show any defect in the results. They misrepresent the research record by claiming that Huybers 2005 had refuted MM2005c – which was impossible – and then they themselves simply replicate Huybers’ results on a regression network of one series and not a full network of 22 series. Also it’s not as though these matters weren’t raised previously. They were. It’s just that Ammann and Wahl didn’t care.
They also make an important misrepresentation of MBH. Ammann and Wahl 2007 (s4) asserts:
MBH and WA argue for use of the of Reduction of Error (RE) metric as the most appropriate validation measure of the reconstructed Northern Hemisphere temperature within the MBH framework, because of its balance of evaluating both interannual and long-term mean reconstruction performance and its ability thereby to avoid false negative (Type II) errors based on interannual-focused measures (WA; see also below).
In respect to MBH, this claim, as so often in Ammann’s articles about Mann, is completely untrue. MBH did not argue for the use of the RE statistic as the “most appropriate” validation measure “because of its balance of evaluating both interannual and long-term mean construction…”. These issues did not darken the door of MBH. As reported on many occasions, MBH Figure 3 illustrated the verification r2 statistic in the AD1820 step, where they say that it passed. If MBH had reported the failed verification r2 in other steps and attempted to argue a case for preferring the RE statistic as Wahl and Ammann are now doing, then one would have more sympathy for them. But that’s not what they did. They failed to report the failed verification r2 statistic. And now Ammann is simply adding more disinformation to the mix by falsely asserting that MBH had argued for a justification that was nowhere presented in the four corners of MBH.
By discussing these particular misrepresentations, please don’t take that as a complete inventory. It’s hard to pick all the spitballs off the wall and these are merely a couple of them. I’ll discuss more on other occasions.
As I noted elsewhere, I’ve written to Ammann asking him for a statistical reference supporting the statement:
Standard practice in climatology uses the red-noise persistence of the target series (here hemispheric temperature) in the calibration period to establish a null-model threshold for reconstruction skill in the independent verification period, which is the methodology used by MBH in a Monte Carlo framework to establish a verification RE threshold of zero at the > 99% significance level.
So far no support has been provided for this claim.





43 Comments
Steve:
Thank you very much for hammering away at this. I agree with you that the classical spurious regression framework is a better approach but your original simulations also made the point very strongly.
I still can’t get over the fact that these people talk about “98.5% significance”. It is clear to me that they do not understand what a hypothesis test means.
*Sigh*
Sinan
Steve wrote, “It simply means that one cannot blindly rely on a single statistic as “proof” of a statistical relationship.”
Actually, it means that one cannot blindly rely on a single statistic as proof of a *physical* relationship. That’s what Mann was trying to do, namely to import a physical meaning by showing a statistical correlation.
This is an entirely invalid approach to imparting scientific meaning, and constitutes a very basic error in science. Nevertheless proxy thermometry is rife with this error, and in fact relies upon this very error for its entire corpus of claims.
Steve your work on proxies is little short of brilliant, if it is short at all. You should be publishing two papers a year. This blog is great, but it’s too much of a distraction for you. You keep getting bogged down in replying to ‘taminos,’ which is here coined as meaning ‘irritating trivialities, represented as objective but generally of a false and personally insulting nature.‘
When I was an undergraduate, one of our faculty had a habit of doing very difficult experiments to answer some question that interested him. When he got the answer, he was satisfied and stopped there. He never wrote anything up. So, his knowledge wasn’t shared and his work never made it into our human heritage. I consider that a loss. Our loss. Freeman Dyson writes that Richard Feynman was the same way. He had no interest in writing up his foundational work in particle QM until a friend’s wife compassionately locked him into his bedroom.
You need to publish your work properly, Steve. It’ll never make its very necessary impact without entering formal publication. Your work will continue to get pejoratively dismissed as non-peer-reviewed and no more than mere politics. Most people are too lazy to read a challenging report, and so dismissals of your CA analyses will not be critically tested. However, if your work is formally published, that fact alone is enough in the minds of most people to challenge the charge of political content. In other words, formal publication helps keep your critics honest. One might even observe that the taminoing of Steve McIntyre is a deliberate approach to keep you distracted with composing replies, and so unpublished.
It’s three years since GRL2005. You should have had six more papers by now, showing the whys and wherefores of proxy thermometry. You’ve done enough work to easily have had six more papers by now. Your blog entries have certainly taken up no more time than you’d have expended writing six papers between 2005 and now. Even writing those six papers might not have markedly limited your blog entries.
Steve, please write up and publish your work. Peer review will concretize it, taminoizers will be infuriated by it, and proxy thermometry will be greatly improved by it. But mostly, our human heritage of knowledge will be well enriched by it.
Re:3
Pat Frank
My sense is that Steve is comfortable in the “nuts and bolts” role he has assumed through his blog. Writing up papers for peer review [whatever the merits may be in the field of “climate sciences” these days] is not what drives him. By extension, the record is that Steve is reluctant to allow discussions about the “meta level” impacts of the IPCC dogma. Somehow tree rings and proving Mann et.al. wrong over and over again at the micro/nano level is easier to deal with than the very real world consequences of “food for oil”.
Note to editor:
Steve:
Mann et. al. are dead. The entire AGW/ACC story line has moved on into the world of the oh so real “unintended” consequences of the [lest it be forgotten] unproven hypothesis.
If you want CA to repeat as the ” best science blog” next year, you too need to move on into more relevant territory in a hurry.
Re #3, Pat Frank
Pat, thanks for a first-rate post.
Steve, I agree with Pat. Surely you can find collaborators, if the mechanics of academic publishing are disagreeable. The blog is great, but it’s not peer-reviewed publication, and will never have the impact of same.
Best wishes,
Pete Tillman
While I’m very reluctant to suggest to Steve what he should and shouldn’t do, I tend to agree with Pat and Pete. I’d also suggest that first cab off the rank should be a paper on the sensitivity of the various reconstructions to the inclusion/exclusion of certain proxies.
This would be a major contribution to the paleo field and force practitioners to think about and justify their proxy selections.
Speaking as a terrible academic who doesn’t write enough papers :-), it seems to me that the bulk of the writing could be done by a collaborator (say, one of the knowledgeable contributors to this site), leaving only the editorial side to Steve.
What Steve needs is a full-time research assistant.
I remember TCO also said that Steve should publish more about the woes of improper use of statistics instead of relying too much on his blog 😉
In a well thought out post, Pat Frank says (among other excellent points):
The old way was to postulate a possible physical relationship first. These dendros and other climate researchers seem to think the way to do it is backward from this. When did the rules of scientific discovery change? Now, to me, this is the crux of the problem with all this flailing around with these unsupportable ideas. However, this is outside Steve’s interest of correct, supportable and provable statistics, so where do we go to discuss this, and more importantly, how do we bring this failing to the attention of the public?
#2. I did submit a paper with Pielke Jr on an interesting point on hurricanes last year to GRL. It was rejected because one reviewer (Holland, I think) said that the results were all wrong and that the analysis was even “fraudulent” and the other reviewer said that the results were already well-known and well-established in the literature. The editor said that there was a consensus and rejected the paper. Pielke wanted us to resubmit somewhere and perhaps we shall.
I confess that, like the examples you mention, I tend to lose interest in a topic once I’ve figured out what’s going on. I also tend think that the points tend to be sufficiently elementary that authors in the field have an obligation to know these points, aside from whether or not they read CA or whether I publish them somewhere.
I don’t view the blog as a complete enemy to more formal publication. At a minimum, it is a pretty good notebook; for a topic that I want to re-visit for more formal publication, the blog posts are a far better guide than the rough notes that I would otherwise have. On the other hand, after I’ve done a blog post, I tend to lose some of the energy that might otherwise have gone into polishing an academic submission.
I will resolve to submit a few publications this year. (I’ve already got one small accomplishment this year purely through resolve – I’ve lost 22 pounds since Christmas, the first time in my life that my weight’s actually gone down.)
I obviously need to write up the Almagre results. For some reason the lab did not crossdate all the cores, leaving the dating frustratingly incomplete. I’ve forgotten to go back at them and now that I’m reminded, I’ll do this. I need to start making lists. One very intriguing practical point from the Almagre results that I’ve mentioned here, but few people caught the knock-on significance was the very strange behavior of certain strip bark cores which could go on 6-7 sigma excursions for a century before falling back to earth, while a core six inches away did not. I’m trying to figure out how you would create a statistical model for this sort of behavior. It has a practical effect because if you’re making up a site chronology of 20 cores or so, the results will obviously be much affected by whether you’ve got a few of these beasts in the network. Then consider the autocorrelation properties of the result. Now I realize that solving this particular conundrum should not be an obstacle to garden-variety publication of Almagre results, but that’s the sort of rabbit hole that I tend to get into.
I’ve been working on notes showing a representation of MBH and WA reconstructions as a “closed form” algebraic expression – something that both Gerd Burger and Julien Emile-Geay has encouraged. My main point has been very clear for a few years, but there have been nits in the expression that I wanted to iron out before finalizing. This is something finite. It’s more of a technical paper than anything since it then enables the technique to be placed in a broader statistical context.
Ross and I have knocked around the paper suggested in #5. It actually wouldn’t take very long to write. The Ababneh results help this out. I’m trying to get the new Grudd results.
A paper placing reconstructions in a statistical framework would be another useful discussion.
I suppose that we need to reply to Wahl and Ammann. It’s very frustrating since it’s really a sort of long-winded Tamino-type article, full of misrepresentations.
I’m not against academic publication and don’t view the blog as a substitute. Anyway I will resolve to get a few papers done this year. Ross has been pressing me as well.
I’ve picked up on it – and thought about your problem. Those sudden non-stationarities are demonic intrusions (sort of like when the PDO suddenly and unexpectedly goes positive) that are not amenable to statistical modeling. Sometimes (but not always) they are so obvious you could post-hoc detrend them away. But a priori? I do not think it can be done with a known level of reliability. They are a serious problem for which the only solution IMO is tons of replication, so that the jolts effectively sum to white noise. Maybe there is something fruitful to be found in “changepoint analysis”? But this begs the question: how do you process these series under a hypothesis of “rapid climate change” whereupon you expect such “changepoints”.
Of course, whole-stem analysis can help you eliminate these anamolus ripples from a single core. But there are good reasons why that is not possible.
Raise the question in the literature. Put it to experts such as Rob Wilson, Ed Cook.
That sounds like a “scandal” to me.
Michael:
I was thinking about that comment myself. I gather that the “consensus” is the median between “fraudulent” and “well-established”.
Re: #10
I am guessing here, but it appears that most academic publications are confined to rather specific and narrow pieces of a more general research topic and that you are usually attempting to tie together a bigger picture. I am very much a layperson in these matters and have always commented previously that you should follow your own interests in these matters, but I do think your publishing or at least attempts to get published (I would guess that you would have a number of willing potential coauthors) would be a positive pursuit for you and , if you reveal your activities to the blogging audience, the rest of us.
I am sure Ross is every bit the gentleman he appears to be when posting here, but I hope he keeps the pressure on you to publish — maybe we should aid him with some dated posts on this subject from TCO.
Congratulations on the weight lose. I have been there and done that and know what it takes. In fact the recent 5 pounds I put on and attribute to a hard and long Midwestern winter will have to be worked off.
What is the typical lag between a blog post and a journal article? Six months, a year? Are there any non-peer review journals (throw backs to the golden age of physics)?
Here’s another spurious correlation for the files. Apparently scientific productivity is inversely correlated with beer consumption. But a hard drinking scientists, who took umbrage with the findings, showed that r^2
I thought “consensus” was, the majority of “reviewers” voted to reject the paper.
I too find it interesting how the reason’s given are completely contradictory. How could a paper be totally wrong, yet it’s results “well-established”?
Scandal is probably the least perjorative word that I would use.
There’s always the self publishing route. If you can’t get any big name publications to accept it, create a side bar here to post them.
You might work with Pielke and any others who have run afoul of the team to do likewise. Add their papers here, your paper at their sites.
Over time these papers will be picked up.
arrr, my linking skills are lacking
http://life.lithoguru.com/index.php?itemid=119
Excellent review of the review of the review! 😉
One possible suggestion: instead of attempting to swim upstream by trying to publish some of these reviews of Mannian procedures in “climate science” or even mainstream science journals, perhaps it would be worthwhile to submit these types of reviews to a stats journal? I don’t know the stats field and can’t provide a specific suggestion for WHICH journals might be good choices to consider. But, publishing in one of these journals might help facilitate the process of better recognizing/identifying the procedures used by Mann and others in the same light as the Yule and Hendry’s articles. If the journal is a kind of standard, is well recognized by experts in the field of statistics, it can’t readily be attacked by the “Team” for being biased. As a side benefit, it might also help educate budding stats folk. 😀
BTW: congrats on the weight loss!!
Bruce
Steve,
May I add my voice to the chorus recommending that you publish more.
It is ironic that you had one referee report saying the results were wrong and another saying they were well-known! Many authors would complain to the editor about this contradiction (consensus???) and demand another opinion. But if the paper was rejected by GRL, accept that, modify the paper in the light of the comments, and submit to another journal with a slightly lower impact factor (though not as low as E&E!). You could also consider submitting to a journal in a slightly different area, eg statistics. Another thing you can do is put the paper on a preprint archive. It’s interesting to hear you wrote it jointly with Pielke; that’s probably a good idea.
There is indeed a tendency, that we all feel, to lose interest in old work and pursue the new, but this must be resisted – what is old to you is new to others.
If you don’t publish, then other scientists will absorb all your ideas and publish them themselves without crediting you (remember Von Storch and Zorita?)
As you say yourself, some papers would not take you long to write, given what you have already done.
Anyway I’m glad to hear you are planning to submit more papers.
Arxiv.org was set up precisely to avoid long publication delays. The papers are not (yet) peer-reviewed, but at least they are “out there”. The site was initially set up for the experimental particle physics community. It is a small community, and preprints were already being freely circulated between the various groups. Once posted on Arxiv, a manuscript can nevertheless be submitted to a peer-reviewed journal.
Your experience with reviewers is quite typical. I agree that a statistics journal would be a better choice. The blog and the dynamics of the paleoclimate research community will make it difficult to find unbiased reviewers in their journals.
As for your tree ring core samples, welcome to the world of experimental science! It is always more fun to confront the real world, because it’s always full of surprises. My best work (in my view) was made when I had to explain unexpected experimental results.
Glad I struck a resonance. 🙂 I’ll sure look forward to seeing a paper with Ross along the lines James Lane suggested. A reply to Ammann and Whal 2007 would also be a very enjoyable read (not to say polemically useful). I don’t understand Ammann and Wahl anyway. I’ve found that the best way to deal with strong scientific differences is to set up a joint project with experiments that will resolve the issues. Most people end up being relieved to do this, and everyone’s participation means there is no estrangement from the final decision, because everyone has participated in producing it, and no angry feelings at the end. So, Ammann and Wahl’s decision is one equivalent to, ‘I’d rather be angry.’ Very childish.
Bender raised a good point in #7, which got me to thinking. You have become perhaps the most knowledgeable worker in dendrothermometry in the entire world, Steve. Your mathematical acumen shames most of the field. M&MEE03&05, along with GRL05 are publications suitable for a Ph.D. Now you have done your own field work with Pete’s able help. That should result in another paper. Maybe Ross can help with this (or poo-poo it), but it seems to me that you’re in a position to receive a merited Ph.D. in dendroclimatology. Could Ross sponsor you for one? Your thesis chapters would be your published papers. You could make a very creditable defense before the department of the sponsoring institution. It wouldn’t take any more work than you’ve already done.
The University of Guelph doesn’t seem to have an appropriate department, nor the University of Western Ontario. But U. Winnipeg does. They even have a Chair in dendroclimatology.
If you challenged and got a merited Ph.D. (with Ross’ help), Steve, you could be immediately offered a faculty position in dendro science at whatever institution might be arranged. That would free you from material concerns, your publication record already is enough to get a grant, your new university would sponsor your research, and you’d get a graduate student or two to go coring with. How better to spend the next 15 years? Probably pie in the sky, but…
Pat Frank wrote:
Not arguing about the idea, just commenting on typical non-medical school University compensation. 😀
Bruce
Congratulations on the weight loss Steve, but now I feel guilty about the Italian restaurant.
Your experience with GRL reminds me of a true experience I read about some years ago. A frustrated
novelist bought a copy of a novel which had won the National Book Award five years before. He typed
the whole thing out and sent it to five major publishing houses just to see what would happen. It was
rejected, in no uncertain terms, by every publisher.
Paper Journals are on the way out. Now starting an on-line might seem presumtuous, but I think it’s probably the way to go. Sure, whatever way it’s set up initially will probably not be the way things will actually work out eventually, but experiments have to be done to see what works. The only thing I see as vital is an agreement with a funded archive or two which will assure those articles ‘published’ will always be available in the future and in all published states.
I urge Steve to start The Journal of Climate Audit. Costs would be minimal and I expect could be covered by donations. If it sounds like too much work, charge $100 or $200 to submit an article and let someone serve as editor in return for the fees.
27 (Dave): Excellent idea. I just donated my $20US.
Alas, as the evidence with the Pielke paper suggests Steve is too famous to sneak into a peer reviewed journal without the kind of contradictory reviews he has just received. IMHO he is going to have to write a humdinger of an article or find a really big climatology name with whom to co-author. Perhaps one of the more civilzed paleoclimatology guys may step forward.
I am looking forward to when the newest tree-ring paper by Steve and Pete hits the stands. Maybe it could be provided as a low cost download, bypassing the short-sighted and myopic folks at the popular journals that server as gatekeepers.
Or then again, maybe not.
Steve, just a small suggestion, if I may, having looked at various cut stumps, over the years, it is readily apparent that trees are not uniform. Especially, I would imagine with the strip-bark trees. I can easily see that it is sometimes possible to take a straight core, which actually goes through, what might be referred to as a fold in the rings, so that the rings in the sample appear wide where you are almost tangential and when they get narrower, you might actually be going backwards in time. Hard to explain without a sketch, but I hope you get the idea.
Keep up the good work.
Steve: I can picture this quite well from geology.
I agree with Dave (post #27) and MarkW (post #18). If peer-review doesn’t seem to work so well in climate science, let’s fix it. Especially after reading about the tribulations of peer-review in Steve’s recent post “Supplementary Information and Flaccid Peer Reviewing” and its accompanying comments, I am struck that the time is ripe to start an online journal that follows a few basic rules:
1. As much as possible, in an attempt to encourage a review based strictly on the material, the author is to remain anonymous throughout the review process. If the paper’s author can be hidden, it is ok to make the author(s) of the review public. However, where the author cannot reasonably be expected to be anonymous to the reviewer, the editor must find a reviewer who is an arms-length away from the author, and the reviewer remains anonymous in an attempt to encourage an honest review.
2. The reviewer is responsible for a thorough review of ALL material, including data, appendices and supplementary information.
3. All material, including data, appendices and supplementary information, is to be made publicly accessible at publication and remain publicly accessible afterward.
I’m sure I must be missing something. Anybody?
4. Now, here’s the rub: can we pay the reviewers for their time and effort? It’s tough to expect reviewers to put in and get nothing out, no? Well, if we (and I use that to include anybody interested) ever do get this going, I’ll chip in $100 to start and $100 per year. Heck, if we get a thousand or so people, we’re laughing!
Re Steve # 7
Boringly using a geological analogy again, the math situation has something in common with a late, barren dyke cutting an ore deposit and putting a sharp discontinuity into the data stream of analysis results. While one can detect this in the numbers and then confirm it by logging the core, the possibility of confirmation in a dendro analogue is much less obvious, if impossible. Also, it does not seem to lend itself to predictive statistics of a specific nature as there are insufficient other confirmatory factors (like being able to log as well as analyse). It might be a rabbit hole of interest to you, but I’d guess there might not be a solution.
Steve Just a thought about your and Pielke’s paper.
A rose is a rose, by any other name, it is still a rose.
Keep up the good work and keep them honest.
Re:(21) PaulM, “If you don’t publish, then other scientists will absorb all your ideas and publish them themselves without crediting you (remember Von Storch and Zorita?)”
Wouldn’t the clearer example of your complaint be better directed towards the hurricane fellow? Ie. Steve Mc. made a pretty clever hurricane analysis, (one of quite a few), and a limpy. snagged it without giving due credit? I DO remember that one…
10 Steve
I had a similar experience some years ago with a paper on binary arithmetic operations. One reviewer said it was correct but already well-known, and the other said it was wrong (no fraudulence implications, though). I never did go back and resubmit it — too busy at the time.
If I review a paper and it seems known to me, I feel I must cite papers to that effect. If it is wrong, I detail why. If an editor has one reviewer say it is well-known and one say it is wrong, then clearly one of those reviewers is mistaken and the EDITOR needs to get involved and probably get a third review, at least.
I’ve been struggling just to figure out how the arcane “Reduction of Error” statistic RE and “Coefficient of Efficiency” statistic CE are defined, let alone what their critical values are.
MBH98 p. 785 give an equation for what they call the “conventional resolved variance statistic” beta, which appears to be another name for both these things, depending on whether their “ref” period is the calibration or verification period. However, their denominator is clearly wrong, since it is given as the sum of the squared data values in the ref period, rather than the sum of their squared residuals about their average in some period. It makes a big difference which period the average is taken over, so this is not very helpful.
Rutherford et al 2005 (2004 preprint p. 25) give separate equations for RE and CE, which is helpful, making the distinction that in RE the denominator uses the sum of squared deviations about the calibration period mean, while CE uses the sum of squared deviations about the verification period mean. However, they then state that the sums are taken “over the reconstructed values”. The reconstruction period is impossible, since the instrumental values are not known there. They must mean either the calibration period or the verification period,or both together, but which?
Wahl and Ammann (2005) have a lengthy verbal discussion of these statistics in section 2.3 in the text, and their Appendix 1, but don’t bother with any of those pesky equation things. However, between the discussion in the appendix and Rutherford’s equations, I think I see how these are calculated.
Both were evidently proposed by Fritts in his 1976 dendrochonology book as a well-meaning, if atheoretical, attempt to evaluate verification outcomes. They were evidently motivated as extensions of the conventional regression R2 (read R^2) statistic.
If we have a simple regression of some Y observations on a constant and one or more X’s, R2 = 1 – SSR/TSS, where SSR is the sum of squared residuals of the Y’s about their predicted values, and TSS is the total sum of squares, the sum of squared residuals of the Y’s about their average. Note that (absent serial correlation) R2 can be used to compute the standard F test for significance of the slope coefficient(s), and therefore has well-established critical values that depend on the sample size and number of regressors. Evidently the Hockey Team does not deem this test to be worth performing, and instead just look at the ancillary verification statistics instead.
If the regression is just run on a calibration period, and then tested against a verification period, RE and CE can, according to WA, be computed for either the calibration or verification period, so that potentially there are 4 separate statistics here. However, they note that in the calibration period, RE = CE = R2, so that in fact there is no point in even talking about a verification RE or CE — it’s just R2. (This does not necessarily prevent them from referring to R2 as the calibration RE/CE/beta statistic, however.)
In the verification period, RE is, according to their verbal description, computed as
RE = 1 – SSRv/TSSvc,
where SSRv is the sum of squared residuals in the verification period, and TSSvc is the total sum, over the verification period, of squared deviations of the actual values from their mean in the calibration period.
CE, on the other hand, is
CE = 1 – SSRv/TSSvv,
where TSSvv instead uses the sum over the same period of the squared deviations of actual values from their mean in the verification period. They note that since TSSvv %lt; TSSvc, CE %lt; RE, and they have different properties.
I don’t see that either of these is a particularly relevant way to use the verification outcomes to confirm the model. The sum of squared forecast-variance-adjusted forecasting errors, as I mentioned on the “More on Li, Nychka and Amman” thread, seems more promising, and may even have a standard F distribution. But be that as it may, MBH et al are wed to this RE statistic.
There is, however, the further complication that MBH are not looking at regression residuals themselves, but at calibration residuals, in which proxies Y have been regressed on temperature X, and then X backed out of observed values of Y. It turns out that this causes a discrepancy that at first confused me between R2 and r^2.
In an ordinary regression in which the predicted values of Y are found by OLS regression on a constant and X, R2 is simply the square of r, the estimated correlation between Y and X, so that R2 = r^2, and they are one and the same thing. However, if predicted values of X are backed out of a regression of Y on X, this identity no longer holds when R2 is computed from the actual and predicted X values. If we define R2x to be 1 – SSRx/TSSx, where SSRx is the sum of squared residuals of X about its backed-out predicted values, and TSSx is the total sum of squared deviations of X about its mean, we get a different number, because now we are computing TSS from the X’s instead of the Y’s. Unless I am mistaken,
R2x = 1 – (1-R2)/R2 = 2 – 1/R2,
so that R2x $lt; R2. R2x can easily be negative (whenever R2 %lt; .5), goes to minus infinity when R2 goes to 0, and is 1 when R2 = 1.
Since R2 can be backed out of R2x, and then the F-test for zero slopes backed out of R2, R2x could, in principle, be used to construct a valid test for “skill” in the calibration period, though it would be more straightforward to just use R2 or F from the original calibration equation of Y on X.
Likewise, whatever properties RE (and CE) have when computed from the Y-residuals, they will be very different when computed from the backed-out X-residuals. It might be useful in this case to call them REx and CEx.
Viewed in this light, the WA and Rutherford attack on Pearson’s r as a measure of “skill” is simply misguided. The calibration period r^2 = R2 tells us the standard F-test for statistical signficance of the proxies, whether or not MBH stoop to perform this test. Neither r^2 nor R2 purports to be a verification statistic except perhaps in the Team’s idiosyncratic statistics toolbox, which they evidently inherited from Fritts. As a verification statistic, it indeed would be “foolish”, as Mann puts it, to compute r^2. But as a calibration statistic, it would be equally foolish (or should we say innumerate), not to compute it. It is unclear whether WA realize there is a difference between R2x and r^2 in their applications.
(r^2 in the verification period could, of course, be used as a valid test of the statistical significance of a calibration in which the roles of the verification and calibration period were reversed. This would be “2-fold cross-validation” in LNA’s terminology. But even then, r^2 would not equal R2x.)
Wahl and Ammann make no attempt to confirm the MBH98 claim that “any positive value of beta [RE? CE?] is statistically significant at greater than 99% confidence as established from Monte Carlo simulations.” (SI p. 2) They instead pass the buck on to Huybers (2005), whom they claim “determined a 99% significance RE benchmark of 0.0 in verification”. I still haven’t looked at Huybers. WA blast MM for allegedly doing this wrong, but can’t be troubled to do it right themselves.
MBH98 SI gives various “Calibration” and “Verification” values of “beta” and “r^2”, but it is unclear how “beta” relates to what WA refer to as RE and CE, or whether by r^2 they mean R2 or R2x.
Note that “verification skill”, however tested, is not a foolproof safeguard against cherry picking of proxies, since the proxies can just as easily have been cherry picked for the size of their verification statistics as for the size of their calibration statistics. Ultimately what matters is how they were selected, not how big their verification statistics are.
I guess that in MBH9x case this is more complex, as calibration result is further transformed from U-vectors to grid-temperatures and then averaged to NH-mean (
http://www.climateaudit.org/?p=2969#comment-236757 ).
IMO the biggest problem in this monster is possible zeros in matrix B of the applied model
If some column of B is zero vector, corresponding proxy (column of Y) is a non-sense proxy. If some rows of B are zeros, there’s no response at all to corresponding X-vector (TPC in MBH-case). The model still holds, but in calibration we have to eventually invert B, so zeros in B are problematic. This is mentioned in almost all statistical calibration papers.
When Y is a vector, tests for zero rows of B simplify to well-known F-test. Extension of this test to matrix Y can be very likely found from statistical literature. However, in multivariate calibration papers, AFAIK it is always assumed that rows of E are independent, and thus errors are not correlated in time. In later publications of Mann it is assumed that rows of E are as correlated as rows of Y are. And then Mann proceeds with pseudoproxies, climate model realization + noise with non-zero SNR, i.e. possibility of zero B is completely ignored. Does Preisendorfer Rule N takes care of zero Bs? I don’t think so.
RE UC #40, I don’t see that zero columns of B are a big problem, so long as the appropriate F-test has firmly rejected the joint hypothesis that all the elements of B are zero. In the case where X is nX1 (p = 1), and assuming for simplicity that Gamma = I and there is no serial correlation, the CCE estimator of an unobserved x* from observed y* = (y*1, y*2, … y*q) is
x*hat = Sum((y*j-aj) bj)/Sum(bj^2),
where the aj and bj are the OLS estimates from regressing the columns of Y on a constant and X. (Your equation simplifies by leaving out the intercepts, but it’s important in the end not to forget it.) A few insignificant or even actually 0 bj values doesn’t hurt this calculation, since if at least some of the bj’s are nonzero, the denominator is nonzero. But if we can’t reject that the denominator is zero, x*hat is completely meaningless, even though it is computable with probability one.
The near-zero bj’s obviously don’t have much effect on this weighted sum, and so these proxies may as well have been discarded as far as x*hat goes. However, my strong hunch is that discarding them is probably misleading in terms of the appropriately computed confidence interval for x*, through a cherry-picking effect.
A row of B that is zero or jointly insignificantly different from zero is another matter, since it means that the corresponding TPC is unidentified. But IMHO, the TPCs are a waste of time if one is ultimately only interested in global or hemispheric temperature, so I don’t see that anything is lost by just setting p = 1 (where X is nXp). Then the only issue is whether B’s single row is all zeroes.
Either way, the reconstruction step should not be attempted until after it has been established with an F test that B is not all zeroes. “Cross-validation” statistics on the reconstruction are commendable, but completely pointless if the reconstruction was meaningless to start with. MBH & Co err by omitting the important first step of making sure their divisor is not zero before dividing by it! Also, the primary test of “skill” of a proxy network is the F-test on B, not any ancillary cross-validation or “verification” statistics.
While PCA and Preisendorfer’s Rule N do not take care of zero B’s, they may help by reducing q and/or p down to a manageable number, since ideally both of these should be small compared to n before any tests are run that compare the proxies to temperature. If you have a hundred tree ring series from the American SW, say, it wouldn’t hurt to condense these down to their first few PC’s, using Rule N. And even then if you have say 20 such proxies, it is probably useful to do a second round of PCA and Rule N on the full set of proxies (some of which are PCs already), in order to reduce it to just a few “MacroPC’s”! (Or some such catchy term — MetaPCs?). Just passing Rule N does not mean that these are valid temperature proxies, only that they are objectively noteworthy attributes (perhaps identifiable with precipitation, insolation, etc) of the original set, so it is still important to do that F test for their joint significance versus temperature.
I see no harm in discarding contiguous high-order macroPC’s that are collectively insignificant as temperature indicators, so long as the first k are retained for some k. Discarding non-contiguous ones on the basis of their t-tests would have an adverse cherry-picking effect on the apparent significance of the retained ones, but the discipline of considering them in the order of their non-temperature-determined eigenvalues enormously mitigates this effect.
#40, 41. Hu and UC, Preisendorfer’s Rule N has nothing to do with zero B’s. It occurs in the construction of networks used as input in the regression analysis and the zero-B problem exists either way.
I’ve been plugging through univariate calibration equations for the MBH99 proxies using the starting univariate formula of Brown 1982 (which is in chapter 1 of Draper and Smith, Applied Regression Analysis, 1981, which uses a method from Williams, 1959. Unsurprisingly, the MBH99 proxies beautifully illustrate the pathologies.
Relative to the “sparse” NH temperature used in verification, nearly all of the MBH99 proxies are indistinguishable from 0. I observed some time ago that you got as “good” a reconstruction using bristlecones and white noise and this is another perspective on this phenomenon – although a more useful vantage point since it ties this insight into a statistical framework.
There tend to be only a very few proxies that survive first stage calibration testing. When one gets into lower order PCs, I can’t imagine that it’s anything other than a total dog’s breakfast as the entire procedure seems to be mining for any sort of relationship with total disregard for statistical testing.
#41. Note that Wahl and Ammann and (MBH) have heavily relied on the argument that can “get” a HS without using PCs. Their various salvage strategies tend to go from the frying pan into the fire and the criticism will continue to apply to the salvage arguments.
#40 and 41. One of the fundamental themes of Rao’s approach to multivariate normal distributions is that any linear combination of variables is also normal. He uses this strategy to reduce many multivariate problems to univariate problems. Even in cases where more than one temperature PC is reconstructed, the final NH temperature reconstruction is a linear combination of the reconstructed PCs and thus becomes a univariate problem under Rao’s strategy. It would take a bit of work to flesh this out, but I’m 100% sure of the approach.
#41. Hu and UC, in a practical sense, the zero-B proxies have a definite role in MBH tailoring.
My null hypothesis is that MBH has one classic univariate spurious regression, plus 21 or so calibrations against white noise equivalents (all of which would have B=0).
If you do univariate MBH recons with rescaling, the recons tend to overshoot the verification period. If you blend them out with white noise, then you improve the tailored statistics in two ways: 1) you improve the calibration r2 just by having more series and 2) you control the overshoot in the RE statistic. I noticed this overshoot effect in responding to the Huybers Comment. Needless to say, Wahl and Ammann totally ignore this.
So they have a non-null impact on the recons. I’ll try to do a MBH style recon without the “white noise” class of series. My guess is that it will overshoot and be too “cold”.
Peter Huybers (GRL 2005) claims to have confirmed the MBH98 0.0 99% critical value for RE, and argues that MM (GRL 2005) have computed RE wrong.
However, the formula Huybers gives for RE is itself clearly wrong. In his notation, he writes
RE = 1 = Sum(y-x)^2 / Sum(y^2),
where y is instrumental NH temperatures and x is eg the PC1 of proxy records. But as stated, this formula will give different answers if temperature is measured in dC or dF, which is nonsense. (A further problem is that, as in the MBH formula, the terms in the denominator have not been demeaned, but perhaps this is implicit, relative to an unstated reference period.) [Steve: all the series in question have been centered on calibration1902-1980 so I don’t see an issue here.]
But then he states that “Inspection of the MM05 Monte Carlo code (provided as auxiliary material) shows that realizations of x are not adjusted to the variance of the instrumental record during the 1902 to 1980 training interval — a critical step in the procedure. The MM05 code generated realizations of x having roughly a fourth the variance of y, biasing RE realizations toward being too large.”
Adjusting the proxy to have the same variance as temperature during the calibration period would indeed give it the same units as temperature, as if it were a predicted temperature value. However, neither MBH-style simplified CCE estimation (regressing the proxy on temperature and inverting the relationship) nor “direct” or “ICE” regression of temperature on the proxy will made the predicted temperature have the same variance as actual temperature. In the single proxy CCE case, predicted temperature will have a greater variance, by a factor of the R^2 of the regression, while in the “ICE” case predicted temperature will have a smaller variance, by the same factor.
The only estimation procedure in which predicted and actual temperature will end up with the same variance is what I call “Non-Least Squares” (NLS) regression, ie the variance-matching used by Moberg et al (2005). This NLS procedure has no statistical justification whatsoever, but is apparently what Huybers has in mind.
Considerably different values of RE will be obtained, depending on whether the reconstruction is performed by CCE or ICE. Since MBH are using a form of CCE, similarly constructed simulated forecasts should be used to establish critical values, and not ICE (used, eg by Li, Nychka and Ammann).
If anyone is wrong here, it is evidently Huybers.
Huybers also claims that his Figure 2 is “somewhat at odds” with MM’s statement that their PC1 is “very similar to the unweighted mean of all the series”. In his Figure 2, however, all series are plotted with equal mean and variance in the 1902-1980 period. It would seem to me that normalizing them over the entire period 1400-1980 would be more natural for visual comparison.
On his first page, Huybers notes that MBH normalize each series both by subtracting out the 1902-1980 mean, and also by dividing by the standard deviation after detrending, presumably over the same period. He grants that the latter step “seems questionable”, but claims that it “turns out not to influence the results.”
I would think that either step has equal potential for generating hockey sticks all by itself. Even without short-centering, dividing by the standard deviation about a trendline will amplify those series that happen to have a pronounced up- (or down-) trend in the last period, either randomly or because of some spurious factor in the series.
PS: The italics at the end of my post #41 above were supposed to end after “before any tests are run”, so I wasn’t trying to emphasize all this text.
One Trackback
[…] Shea wrote an interesting post today onHere’s a quick excerptSteve Just a thought about your and Pielke’s paper. A rose is a rose, by any other name, it is still a rose. Keep up the good work and keep them honest. […]